
Abstract
Data transfer from a host central processing unit (CPU) into an accelerator is a performance bottleneck for applications accelerated by accelerators (such as general purpose digital signal processing (GPDSP), many integrated core (MIC), and general purpose graphics processing unit (GPGPU)). It is complicated and inefficient to transfer non-contiguous data with special respect to strided data. In this work, we present three approaches to transfer strided data for different scenarios: Redundant copy (RC), selective copy (SC), and transfer after transformed (TaT). We propose a space and time efficient method named TaT, in which strided data are transformed on the CPU first and then transferred into the accelerator. We simulated regions-of-interest (ROI) coding and validate proposed techniques. TaT was superior to RC on space efficiency and close to SC on saving space, but better than SC on time waste respectively.
Introduction
In the future, to reflect human body consciousness, realtime control of clothing form and patterns during motion using intelligent clothing research and development with information sensing will play an important role in textile and clothing research. Strided data transfer is expected to be widely used in intelligent textile and clothing design and manufacturing, including advanced textile research, large-scale physics simulations, signal processing, and mechanical responses of materials with complex structures.1–6 This kind of research problem can be tackled using strided data acquired from vision sensors using appearance-based features, which are strongly dependent on visual cues such as color, especially for single steps, and stride sequences. However, stride data sequences analysis often fails to extract quality measurements of an individual's motion patterns owing to problems related to variations in viewpoint, daylight, clothing, and worn accessories, which would require the majority of processing time and require large amounts of computing resources. Hence, how to transfer strided data into an accelerator is proposed in this study.
Accelerators with high computing power have been extended into general purpose computations in recent years,1–6 such as general purpose digital signal processing (GPDSP), many integrated core (MIC), and general purpose graphics processing unit (GPGPU). However, how to make best use of accelerator resources is still a challenge. Most research work is focused on maximizing utilization of accelerator cores by exploiting millions of concurrent threads,7,10–13 while few works are interested in data transfer into accelerators and fewer works have referred to non-contiguous data transfer with special respect to strided data transfer. However, non-contiguous chunks of data, especially for strided data, are widely applied to real-life scenarios, such as regions-of-interest (ROI) coding and critical component of dataset duplication for reliability.
Usually, accelerators, including GPDSP, MIC and GPGPU, are memory-bound architecture, hence, the cost of data transfer could be prohibitively expensive, which often occupies the vast majority of total execution time and severely damages performance of applications.7,8,13,14 Accordingly, we introduce three approaches to data transfer with special respect to strided data transfer for different scenarios. They are (1) redundant copy (RC), which is time efficient to transfer strided data when memory space is large enough, (2) selective copy (SC), which is space efficient, but time inefficient, to transfer strided data because of multiple data transfer calls for non-contiguous data access, and (3) transfer after transformed (TaT), which is a space and time efficient method with cooperation between the host central processing unit (CPU) and accelerators (such as GPDSP, MIC, and GPGPU).
The work is organized as follows. The first section summarizes related works. The second section covers the heterogeneous system and details architecture of the China accelerator (CA) based on GPDSP. The third section introduces methods including RC, SC, and TaT to transfer strided data from CPU into accelerators, and then an evaluation model is presented to decide which method is advisable for the cases in the fourth section. Simulations and experiments are given to validate the above techniques in the fifth section. Finally, the sixth section includes conclusions and discussions, followed by acknowledgements.
Related Works
Scientific computing has gained popularity in recent years using accelerators including GPGPU, MIC, and GPDSP.
Computing unified device architecture (CUDA) from Nvidia was designed to program GPGPU applications with ease. However, it is more expensive to transfer data into CUDA memory.10–17 Therefore, minimizing data transfer is proposed for GPU clusters, 18 and asynchronous transfer is also resorted to in porting FFT into CUDA.11,19–21 But, the above techniques are proposed for contiguous chunks of data transfer and difficult to extend into strided data in practice. Following with GPGPU, Intel MIC, with advantages of CPUs and CPUs could offer implicit mode with offload and explicit mode using symmetric communication interface (SCIF) for data transfer. Unfortunately, achieving high build performance still requires more careful design for data transfer.9,22,23 Hence, both compile and runtime solutions for transferring data into MIC are presented to overlap data transfer between host and accelerator, 16 reduce redundant data transfers, and pack data on demand for transferring into the accelerator, 23 but those solutions have not taken non-contiguous data, with special respect to strided data, into account. It is difficult to effectively employ compile and runtime techniques to non-contiguous data with special respect to strided data. Different from GPGPU and MIC, the CA, based on GPDSP, is a self-controlled high-performance accelerator made by the National University of Defense Technology of China. 18 Although there are some preference optimizations on data transfer in the architectural arrangement, it must be careful and delicate for orchestrating data transfer, especially for non-contiguous data with special respect to strided data. 25
Strided data is one kind of non-contiguous data structure, which is composed of several data strips, in which each data strip is a contiguous data fragment, while there is a space between each data strip, and the space between each data strip is a stride (e.g., there is a 2D array S[5] [5]). Strided data is composed of S[0:4] [0], S[0:4] [2], S[0:4] [4], which are the 1st, the 3rd, and the 5th column of 2D array S [5] [5] and denote a data strip respectively, and there is a space between each data strip—each space or stride is equal to five elements in 2D array S[5][5]. Similarly, with non-contiguous memory accesses using gather/scatter comparing to contiguous memory accesses using load/store, non-contiguous data transfers with special respect to strided data transfers are much more expensive than that of contiguous data transfers. However, non-contiguous data transfers with special respect to strided data transfers are widely applied to real-life scenarios.26,27
To our surprise, there are many more works focused on simultaneous computing threading using computing elements equipped in accelerators than that of data transfer,28–30 and there are fewer works available paying close attention to non-contiguous data transfer with special respect to strided data transfer. Hence, it is challenging to transfer non-contig-uous data with special respect to strided data for improving a heterogenous system equipped with GPGPU, MIC, or GPDSP. Accordingly, three approaches on non-contiguous data transfer (including RC, SC, and TaT) were introduced for non-contiguous data transfers with special respect to strided data transfers to guide data transfer between host and accelerators using peripheral command indicator express (PCIe) with ease and effectively.
Architecture
Modern computers are heterogeneous systems composed of host CPUs and accelerators, especially for supercomputers equipped with GPU and MIC, 31 such as Tianhe-IA and Tianhe-2. The CA based on GPDSP would be equipped for promotion of Tianhe-2. 24 Fig. 1 shows the architecture of a heterogeneous system composed of host CPU and accelerators (GPGPU, MIC, and GPDSP), in which the accelerator is usually used as a co-processor to consume data transferred from the host using PCIe channel on demand.
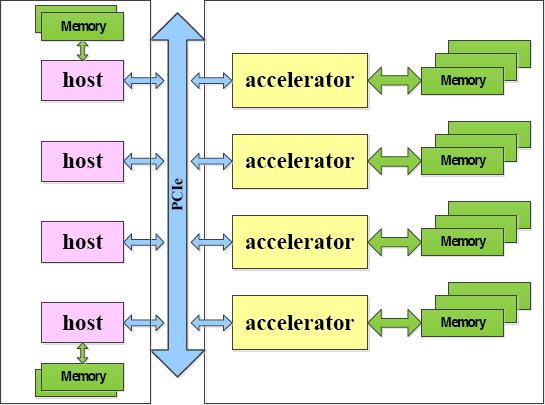
Architecture of heterogeneous system.
Traditionally, data are produced and resided in the host, and processed and accelerated by the accelerator when data are transferred from host into accelerator in a heterogeneous system. As described in Fig. 1, PCIe is the only way for interaction, including communication and data transfer between hosts (CPUs) and accelerators (GPGPU, MIC, and GPDSP).
In the Tianhe-1A supercomputer equipped with CPU and GPU, data transfer between CPU and GPU are overlapped with computation by divide-and-conquer strategy to minimize communication and maximize efficiency of Tianhe-1A, and overlapping data transfer is advisable to contiguous data transfer, but it is difficult and ineffective to extend into strided data in practice.26,27 Similarly, Tianhe-2 is composed of CPU and MIC, and achieves high performance by carefully designing for strided data transfer using the SCIF interface.22,23
Different from Tianhe-IA and Tianhe-2, the CA based on GPDSP is a self-controlled high-performance accelerator, as shown in Fig. 2. There are some preference optimizations on data transfer in the architectural arrangement for the CA.
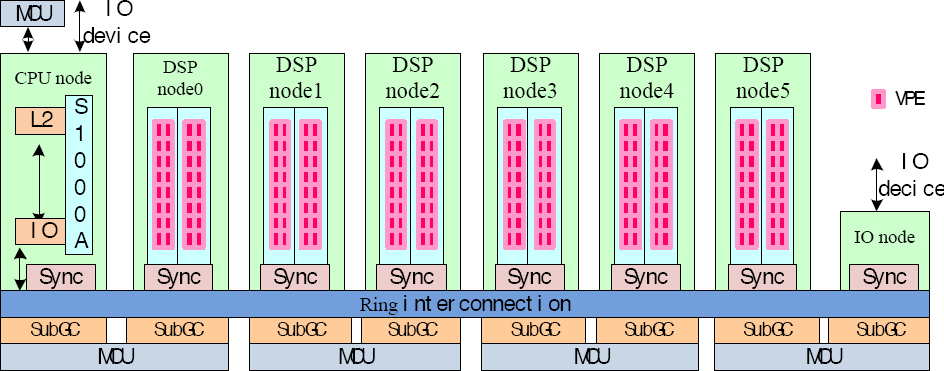
Architecture of China Accelerator (CA).
The CA consists of 1 CPU node, 6 DSP nodes, 1 input/output (IO) node, global cache (GC) partitioned into each node, 4 memory control units (MCUs), and all nodes are connected by ring interconnection (Fig. 2). Each DSP node is composed of 2 computing cores, and 1 sub-global cache (SubGC), and the sync between GC for synchronization are attached to each node including the CPU node, DSP node, and IO node. Each computing core contains 16 vector processing elements (VPEs), and every two SubGCs connect an MCU
To improve data transfer, GC is partitioned and distributed into each node as illustrated in Fig. 2, and there are some other preference optimizations on data transfer in the architectural arrangement for the CA. Although GC partition and architectural optimizations are available data transfer, it also must be careful and delicate to orchestrate data transfer especially for non-contiguous data with special respect to strided data.
Strided Data Transfer
Typically, strided data is an optimized version of vector. Due to practicability, strided data is widely used in global memory access 28 and parallel pile systems. 35 However, data striding would damage access performance, so strided data access operations 34 and runtime support 36 are implemented and proposed to strided data access and transfer.
Usually, data should be loading from host CPU into global memory in accelerators using a specified application programming interface (API) as following, in which Directions are enumeration constants (host to accelerator, accelerator to host).
Take an instance with GPDSP and GPGPU respectively, as listed in Fig. 3. If src is a scalar, above calls are sufficient, but it gets more complicated when src is non-contiguous data access. Since one call to xxxMemcpy only transfers a contiguous chunk of data, xxxMemcpy should be invoked multiple times for a non-contiguous chunk of data with special respect to strided data (e.g., S[*][3:5], where S is a 128 x 128 matrix, the strided data are only from the 3rd column to the 5th column in S to transfer from host to accelerator).

Specified API for data transfer.
Strided data are some sections of a multidimensional array that are widely used in data-intensive applications by accelerators, so strided data are often transferred into accelerator memory from host memory using PCIe in most cases. Therefore, we introduce three approaches for strided data transfer into the accelerator.
Redundant Copy (RC)
Traditionally, redundancy is duplication of critical components of a system with the intention of increasing reliability. However, RC, is duplication of non-DOI (data of interest) in multidimensional arrays other than the strided data we are interested in. The whole multidimensional array is a continuous chunk of data, but strided data, encircled in broken lines, only come in sections of a multidimensional array, which are non-contiguous chunks of data, as in Fig. 4.
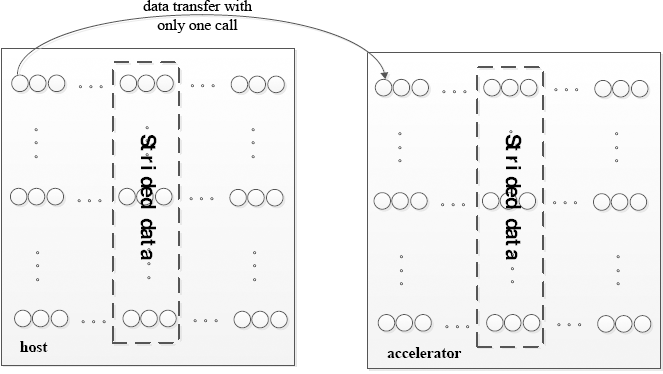
Strided data transfer in RC mode.
To simplify and improve strided data transfer, we could invoke an API call one time to transfer the whole multidimensional array, or we could call mccMemcpy or cudaMemcpy multiple times to transfer strided data. For example, S is a 128 x 128 matrix, but only strided data S[*] [3:5] should transfer from host to accelerator. To simplify, we could transfer the whole S with only one call xxxMemcpy rather than transfer S[*] [3:5] by calling xxxMemcpy 128 times.
For non-contiguous chunks of data, especially for strided data, RC could simplify and improve data transfer, but would waste memory space and transfer time. Therefore, SC is proposed to only transfer DoI with special respect to strided data.
Selective Copy (SC)
Formally, there is a general n-dimensional array A of dimension [D1] [D2]… [Dn]. Its section [GB1: GE1] [GB2: GE2]…[GBn : GEn] is allocated in the global memory in the accelerator, and a section [HB1: HE1] [HB2: HE2]… [HBn: HEn] in n-dimensional array B of shape [D1] [D2]…[Dn] that needs to be transferred from the host into the accelerator global memory as shown in Fig. 5. Let p be the index of the innermost dimension of the section to be transferred, whose range is less than the corresponding dimension size of A.
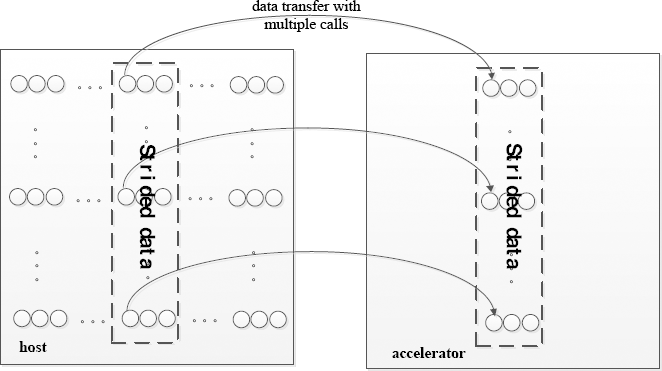
Strided data transfer into global memory in RC mode.
As described in Fig. 5, entire chunks of strided data is non-contiguous, but its subsection [HBp-1: HEp-1] is contiguous. Hence, it gets complicated and inefficient when transferring strided data, because offsets responding to dst and src should be recomputed at first, respectively, and xxxMemcpy would invoke multiple times. But, it is memory efficient, because only strided data would be transferred into accelerator memory.
More formally, i is the loop variable, and stride is a constant over iterations. Offsets of dst offset and src offset responding to dst and src would be computed firstly in Eqs. 1–3.
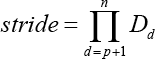
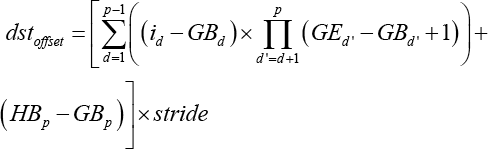
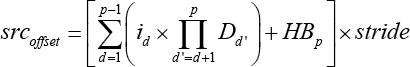
Although SC mode can save memory spaces, strided data transferred using SC would get rather complicated, and should call xxxMemcpy multiple times, which would waste lots of time.
Transfer after Transform (TaT)
Comparing Figs. 4 and 5, it was found that strided data transfer in RC mode is simple but would waste memory space because of redundancy copy for non-DOI data as with special respect to strided data. SC is memory efficient, but time inefficient, to transfer strided data, because SC mode is advisable to transfer DOI, but must call xxxMemcpy multiple times. Accordingly, we propose an alternative method TaT for transferring strided data with cooperation between host and accelerators.
As described in Fig. 6, strided data are recomputed and re-laid out on host at first in TaT mode, and then transferred into accelerators, which should invoke xxxMemcpy only one time. To some extent, TaT would transform non-contiguous chunks of data into continuous data, which could simplify and improve strided data transfer into the accelerator with host cooperation.
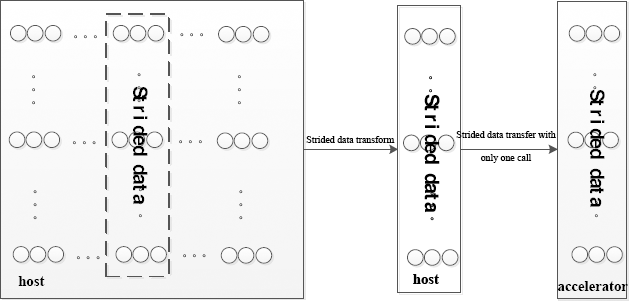
Strided data transfer in TaT modes.
Evaluating Model
There are three modes we introduced and proposed to transfer strided data, and there are both advantages and disadvantages for strided data transfer. So, we present an evaluation model to decide which mode is best for various scenarios and cases.
Formally, mark the size of the multidimensional array as #volume, the proportion of DoI or strided data taking up the whole multidimensional array is p. And, the available bandwidth for transferring data from host into accelerator is #bandwidth, the time of multiple calling xxxMemcpy is #McallTim and DoI transformed time is #transformTim. So, memory spaces needed on host and accelerators are face-Mem and #hostMem, respectively. Strided data transfer time and total time for data transfer would be #transferTim and #totalTim, respectively, as shown in Eq. 4.

From Eq. 4, we can conclude that SC mode is better than RC mode to transfer DoI as determined by Eq. 5.
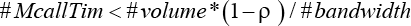
When Eq. 5 is okay, SC mode can save space and time compared with RC mode. Unfortunately, #McallTim would take much larger percentages of the #totalTim in most cases. Fortunately, #transformTim usually is small in most cases. Therefore, TaT is always superior to RC, because there is no redundant copy and no multiple calls to xxxMemcpy. TaT is simpler than SC, because there is no re-computation and location for offsets responding to dst and src in the accelerator, and non-contiguous data access are transformed into contiguous data access by pre-computation with host CPU cooperation.
Experimental Validation and Performance Analysis
Space Efficiency Validation
ROI coding is widely used in 3D meshes 37 and fashion stripe reference material, 38 in which multiple chunks of noncontiguous data as well as strided data would be encoded for various scenarios and cases. In practice, memory space is very critical for 3D meshes and video coding. Given the size of the multidimensional array as #volume, and the percentage of ROI, as well as strided data taking up the whole multidimensional array is ρ, that the space efficiency of RC, SC, and TaT for strided data transfer according to Eqs. 1–4, is shown in Fig. 7.
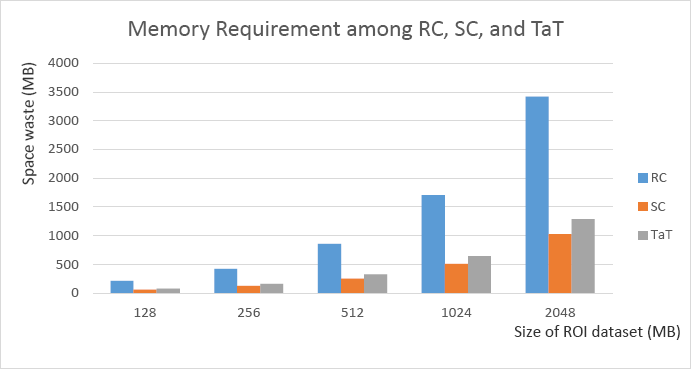
ROI dataset space consumption.
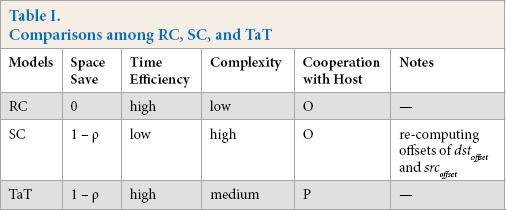
According to Table I, RC was the worst mode for space saving, and both SC and TaT were better than RC on space efficiency, but SC mode must recompute offsets of dst offset and src offset without host cooperation, and then transfer strided data into the accelerators.
Comparisons among RC, SC, and TaT
Time Efficiency Testing
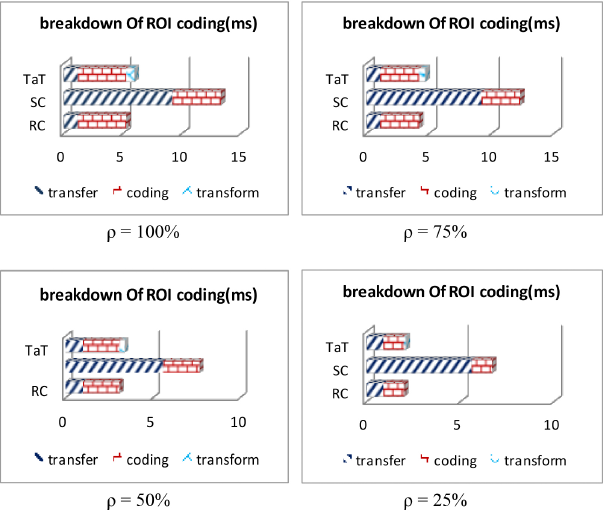
Besides space efficiency, time or latency is rather vital for ROI coding and is often applied to the mealtime system. Therefore, we simulated strided data transfer based on ROI coding and evaluated strided data transfer modes, including RC, SC, and TaT, based on the presented evaluating model in a heterogeneous system equipped with the CA, as illustrated in Fig. 8, in which #volume = 2 MB and ρ = {25%, 50%, 75%, 100%}.
From Fig. 8, we can conclude that (1) the component of total execution time including transfer time, coding time, and transform time reduced as the reduction of ρ, (2) while data transfer took large percentages of total ROI coding execution time, the strided data transfer should be improved, and (3) TaT was close to RC on time efficiency, and both TaT and RC were much better than SC, which appeared to be the worst mode on time efficiency. That is because in most scenarios, Eq. 6 would come into existence.
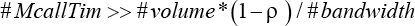
This is the important reason most previous works prefer to RC mode to transfer ROI data at the cost of memory spaces.39–41
To further validate presented modes for strided data transfer, simulation on strided data transfer based on ROI coding accelerated by the CA, CUDA based on Tianhe-1A, and MIC based on Tianhe-2 respectively, was performed as illustrated in Fig. 8, in which #volume = 2 MB, and ρ = 50%.
As demonstrated in Fig. 9, performance of strided data transfer on the CA was better than that of CUDA and MIC. This is because there were some preference optimizations on data transfer in the architectural arrangement for the CA, which is a self-control high-performance accelerator, and lots of architectural details, while there were only external APIs without internal details from CUDA and MIC. We can conclude that TaT was superior to SC and close to RC on time efficiency, similar to what Fig. 8 demonstrated. That is because transform time was generally small for TaT, which was better than RC on space efficiency (Table I).
ROI coding accelerated by CA.
Experimental Analyses
Weighing the advantages and disadvantages in presented models including RC, SC, and TaT (Table I and Figs. 8 and 9), there is a comprehensive comparison among RC, SC, and TaT, as listed in Table I, in which the percentage of ROI, as well as strided data taking up the whole multidimensional array, is ρ.
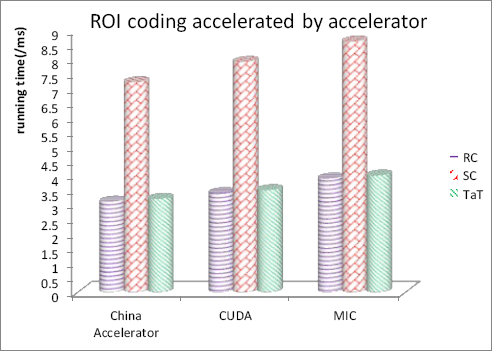
ROI coding accelerated by CA, CUDA, and MIC with different strided data transfer modes under #volume = 2 MB, ρ = 50%.
It was concluded that every model for strided data transfer was advisable depending on the specified scenarios and cases (Table I). RC is simple and time efficient, but space inefficient, so RC is advisable to high mealtime scenarios at the cost of memory. SC is space efficient, but time inefficient, and it is advisable for memory-bound cases. While TaT orchestrates advantages and merits from RC and SC, accordingly, TaT is superior to SC and close to RC for time efficiency and better than RC for space efficiency. Therefore, TaT can extensively be applied to real scenarios and cases for non-contiguous data transfer, with special respect to strided data transfer in heterogeneous system.
Conclusion and Discussion
Data transfer from host CPU into accelerators (GPDSP, GPGPU, and MIC) is a performance bottleneck for applications accelerated by accelerators, especially for strided data transfer. Consequently, we introduced RC and SC for strided data transfer. Both are naive methods to transfer strided data and can be applied to specified scenarios. But they waste memory space and transfer time, respectively. Accordingly, we propose an alternative method, TaT, to strided data transfer, in which strided data are transformed into contiguous chunks of data with host cooperation at first and then transferred into accelerator memory effectively. Although TaT introduces little transformed time, the total time of strided data transfer was reduced remarkably and there was no waste of memory space.
Future work will be on memory optimization such as bank/buffer conflict free and data layout for strided data. Furthermore, memory optimization automation for strided data will also be our focus.
Footnotes
Acknowledgements
This work was partly supported by the National Key Research and Development Program of China Grant No. 2017YFB0202104, partly supported by the National Numerical Wind Tunnel Key Project of China Grant No. NNW2019ZT6-B21 and NNW2019ZT5-A10, and partly supported by the foundation of PDL under Grant No. 6142110180203.