
Abstract
Recently, Fast Fourier Transform (FFT) was introduced to study pattern characterization in textiles. Accelerators are a promising platform to accelerate large-scale FFT computation. However, current accelerating FFT only uses the accelerator to compute, but uses a CPU as a mere task controller. Additionally, a specified interface for FFT is built into the China accelerator (CA), which severely restricts FFT parallelization and performance. Hence, we transform four multiplications and six additions into six Fused Multiply Add (FMA) operations, then reduce total float operations by 40%, assisted by FMAs equipped with a Vector Processing Unit (VPE). Moreover, we propose an Interface Adapter (IA) to cater to a specified interface and a Fused Algorithm for Interface Adapter (FAIA) to fully use both the CA and CPU to compute large-scale FFT with coordination. Experimental results validated successful performance.
Keywords
Introduction
The Fast Fourier Transform (FFT) is one of the most widely-used numerical algorithms today in science and engineering domains for advanced textile research, large-scale physics simulations, signal processing, and mechanical responses of materials with complex structures. 1–6 In the field of textiles and clothing, FFT can be used in online textile and clothing quality inspection and it is essential in controlling and updating textile and clothing quality for cotton textile corporations. FFT images can also be used as elements for textile image design for items such as clothing.
Because of color sense with expansion and contraction, the real Fourier transform can automatically generate patterns with fine structure. Based on the FFT with Fused Multiply Add (FMA) for the China accelerator (CA), a clothing image program can automatically generate FFT images. Thus, samples of fashion and textile images using patterns of points and their combinations can be designed efficiently.
Zeman proposed conjugate gradient FFT-based solvers to resolve the linear elastic problem, 7 and Kabel used composite voxels in FFT-based homogenization to consider the interface, which can really improve the local quality of the calculated strain and stress fields; homogeneous reference material should be introduced into FFT-based methods. 8 However, large scientific and engineering computations would spend the majority of execution time on large size FFTs, which require a large amount of computing resources.
Fortunately, accelerators such as General Purpose Graphical Processing Unit (GPGPU),1,2,9–11 Many Integrated Core (MIC), 12 – 14 Digital Signal Processing (DSP),3,4,15– 18 and Field Programmable Gate Array (FPGA)5,6,19–28 have recently proved to be a more promising platform to solve FFT problems, since accelerators have much more parallel computing resources and can often achieve an order of magnitude performance improvement over CPUs.
Efforts have been popularly focused on GPGPU accelerating FFTs such as CUFFT from Nvidia, 29 a GPU-based out-of-card FFT library from Gu et al., 30 FFT implementation based on a GPU cluster, Hybrid GPU/CPU FFT for Large FFT problems,8,9,25,31 and FFT accelerated using MICs.12–14 However, literature has cited the huge computing resources used by accelerators and have barely taken computing complexity and specified restrictions on the size of FFTs into account.
Different from traditional accelerators such as GPGPU and MIC, CA is a self-controlled high-performance accelerator 32 that could be widely used in physics simulations, signal processing, and data compression.
Besides different architecture and programming models from GPGPU and MIC, there is a specified interface on the FFT built into the CA, which severely restricts FFT parallelization and performance. Hence, a customized FFT for the CA is proposed to take full advantage of both the accelerator and the CPU to compute large-scale FFTs with coordination.
Overview of FFT Algorithm
FFT is a fast and efficient algorithm for computing the Discrete Fourier transform (DFT) and the Inverse Discrete Fourier transform (IDFT). FFT algorithms recursively decompose an N-point DFT into several smaller DFTs, and the divide-and-conquer approach reduces the operational complexity of a DFT from O(N2) into O(N log N) by Cooley and Tukey33,34 In this study, we exploit the DFT algorithm for both the symmetry and the periodicity of the complex exponential
Architecture of CA
The CA is a self-controlled high-performance accelerator made by the National University of Defense Technology of China.
As illustrated in Fig. 1, the CA consists of one CPU node, six DSP nodes, one IO node, a GC (Global Cache) partitioned into each node, and four MCUs (Memory Control Units), and all nodes are connected by ring interconnection. Each DSP node is composed of two computing cores, one SubGC (Sub-Global Cache), and sync between GC for synchronization. Each computing core contains 16 VPEs, and every VPE contains three FMAs, and every two SubGCs connect a MCU.
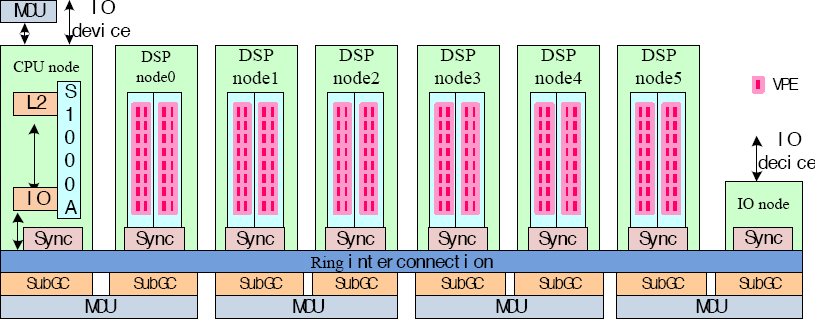
Architecture of China Accelerator (CA).
Details on FMA
As illustrated in Fig. 2, FMA consist of one DFU (Data Fetching Unit), one MMU (Mantissa Multiplication Unit), one FMA (Fused Multiply Add) module, and one normalized unit. Each FMA module is composed of one float MAC (Multiply-Accumulate) unit, one double MAC unit, and one addition unit. Furthermore, each unit is detailed as follows.
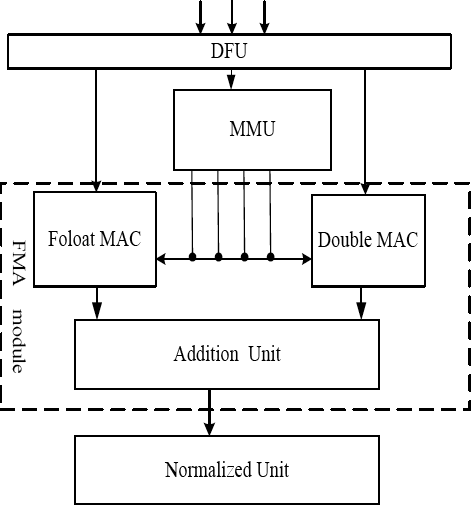
Architecture of FMA.
The DFU would fetch operands and then separate input symbols, exponent and mantissa respectively, and output to MMU. The MMU is used to receive the mantissa of the high and low position multiplication operands, and then four float multipliers would execute the mantissa multiplication in parallel. The FMA is responsible for performing the order shift according to the index of each operand. Finally, the mantissa calculation is performed to get the result of the mantissa and output according to the mantissa operation of the addition number of the added operand and the mantissa operation.
Restrictions on FFT
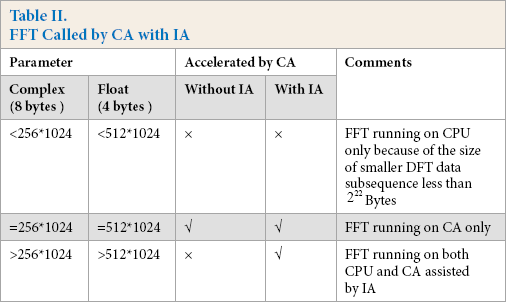
The CA can attain high performance according to the customized FFT kernel with a specified and fixed interface for smaller DFT data subsequence fixed at 2 22 bytes, or 256 x 1024 of complex data, or 512 x 1024 of float data, This would severely damage the flexibility and generality of the FFT ported into the CA, but the customized FFT kernel interface would maximize efficiency of the CA and would attain the expected performance of the FFT in return. Table I lists the details of the customized FFT kernel interface built into the CA according to its architecture and design philosophy.
FFT Kernel Built in CA

As detailed in Table I, only a DFT subsequence fixed with 2 22 bytes (including 256 x 1024 of complex data and 512 x 1024 of float data) would run on the CA and attain the expected performance. However, other smaller DFT subsequences fixed with non-2 22 bytes should not run on the CA because of the customized FFT kernel, damaging flexibility and generality.
However, the specified interface could result in an unfriendly configuration and restrict parallelization for FFT. Accordingly, an Interface Adapter (IA) configured in FAIA is recommended to recognize a friendly configuration for FFT. Furthermore, FAIA would also fully coordinate the CA and the CPU to compute large-scale FFTs.
Reduction Computations for FFT with FMA
We can also represent N-point DFT X (n) with N/2-point X1 (k) and X2 (k) that have periodicity with N/2. The butterfly computation transforms two complex input points to two complex output points to compute the FFT. The Radix-2 FFT butterfly splits the N-point data sequence into two N/2 point data sequences, for even and odd numbered input samples, respectively, as demonstrated in Fig. 3.
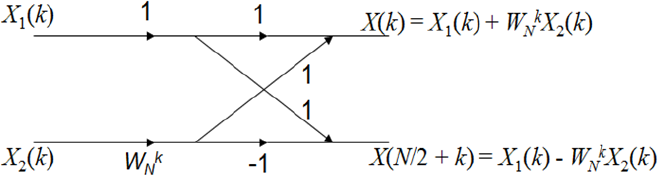
Radix-2 FFT butterfly computation flow.
Each butterfly requires two complex additions and one complex multiplication because W N k X2 (k) occurs twice in the top and bottom halves of the butterfly and could be computed once. In practice, one complex addition would transform into two float additions, and one complex multiplication would transform into four float multiplications and two float additions.
Complexity for Traditional FFT
As illustrated in Fig. 3, the twiddle factor is W N 0 for level one in the butterfly computation, and the twiddle factors W N 0 and W N N/4 for level two, and for level three, twiddle factors are W N 0, W N N/8, W N 2N/8 and W N 3N/8. Similarly, for level M, twiddle factors are W N 0, W N 1 ···and W N (N/2-1).
Theoretically, for N = 2 M point DFT, there are M = log2 N levels of butterfly computation flows, and each level has N/2 butterfly computations, in which each butterfly requires two complex additions and one complex multiplication. Generally, one complex addition would transform into two float additions, and one complex multiplication would transform into four float multiplications and 2 float additions. Accordingly, the maximal FLoat Operation Per Butterfly (FLOPB) is computed as Eq. 1.
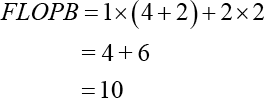
According to Eq. 4, there are four float multiplications and six float additions. Hence, the Total FLOPB (TFLOPB) for N =2 M point DFT is represented as Eq. 2.
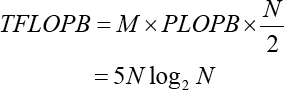
As demonstrated in Eq. 5, the N-point DFT has rather large computations. Generally, there are two ways to solve the large-scale FFT problem. One is accelerating FFT by accelerators such as GPU, MIC, FPGA, and DSP. The other is reducing computing complexity as Cooley and Tukey reducing complexity of a DFF from O(N2) to O(N log N). Cooley and Tukey only pay attention to the mathematical algorithm, but barely take architectural optimization into account.
Reduction Computations Assisted by FMA
For high performance processors, there are hundreds of vector functional units such as MAC, which would assemble independent one multiplication and one addition into one MAC operation and reduce float operation and computation.
Fortunately, when we focus on taking advantage of the architectural properties in the accelerator, especially for the FMA equipped CA, the complexity of a DFT would further reduce to 4N log2 N from 5N log2 N for one Butterfly computation as shown in Eq. 3.

Each butterfly computation could separate into the top half and the bottom half butterfly respectively. Fortunately, each half butterfly contains four float multiplications and four float additions and would be assembled into four FMA operations intuitively. So, therefore there are eight FMA operations per butterfly as demonstrated in Fig. 4.
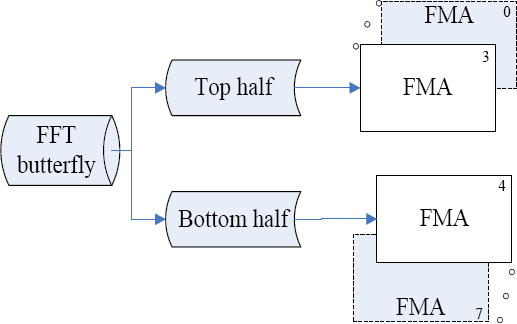
Operations fused with FMA.
Hence, the optimized TFLOPB for N = 2 M point DFT is shown in Eq. 4.
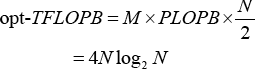
The FMA equipped in the CA is the optimized MAC unit, which would integrate one multiplication and on addition into one FMA. Accordingly, the FMA would assemble four float multiplications and four float additions into four FMAs for both the top and bottom halves. So, eight FMA are sufficient for each butterfly.
Leveraging between CPU and CA
The CA would be used to accelerate the large-scale FFT, however, the size of the DFT subsequence for FFT is specified and fixed at the bytes built into the CA to maximize its efficiency. In other words, the CA would only accept complex or float data, if not, smaller or larger DFTs would not be accelerated or even computed by the CA.
Interface Adapter for FFT
To provide a friendly testing configuration and fully utilize both the CA and CPU to finish large-scale FFT problem with coordination, we use the IA for FFT to cater to specified interface on the FFT built into the CA.
With the assistance of IA, the size of the DFT subsequence for FFT is not only confined to 2 22 bytes, the restrictive conditions for calling the FFT kernel is weaker than that of original interface. Hence, a DFT subsequence with the size of 2 22 bytes or greater than 2 22 bytes both would be scheduled to calling the FFT kernel with IA, while sizes less than 2 22 bytes are ignored by the CA. The comparisons of IA are listed in Table II.
FFT Called by CA with IA
AIA Scheduling Strategy
Generally, to speed up heterogeneous FFT, there are two major classifications of the FFT acceleration.
Static Division
Static Division (SD) has been used in heterogeneous supercomputers equipped with CPU and GPU in TH-1A. 35 FFT should be given priority and would explore optimal DFT subsequence ratio for GPU as shown in Eq. 5.
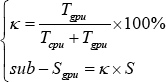
T cpu and T gpu represent computing time for DFT by CPU and GPU, respectively. S is the whole DFT sequence, and sub-S gpu is the portion distributed to GPU acceleration.
Dynamic Schedule
Dynamic Schedule (DS) has also been adopted for TH-2, 36 which would give accelerator, priority and dispatch smaller DFT subsequences into accelerators or CPU, according to the working queue status of CPU and accelerator.
SD is a simple and effective way to accelerate FFT in a heterogeneous system. However, SD should select the optimal ratio based on theoretical peak performance, which is usually not identical to practice. At the same time, there is lack of flexibility because of the advanced decision and non-revision on division ratio. Comparatively, DS has better flexibility than SD, but introduces complicated scheduling algorithms.
Both SD and DS can be adopted to heterogeneous systems, and there are no restrictions on size of the FFT kernel for SD and DS. However, neither SD or DS is suitable for the CA, since it only accepts 256 x 1024 complex or 512 x 1024 float data; if not, the DFT would not even be computed by the CA. Therefore, a Fused Algorithm based on the Interface Adapter (FAIA) would prune the whole FFT sequence into a specified size of the DFT subsequence to cater to the specified interface on the FFT built into the CA. This is demonstrated in Fig. 5a for 1D FFT input data and in Fig. 5b for 2D FFT input data. Furthermore, FAIA would also make full use of the CA and CPU coordination.
As demonstrated in Fig. 5, large-scale FFT should prune the FFT sequence into Sub-SFT size subsequence data inputs for the CA, and non-Sub-SFT size subsequence data would be computed by the CPU. The Sub-SFT and non-Sub-SFT should satisfy Eq. 6.

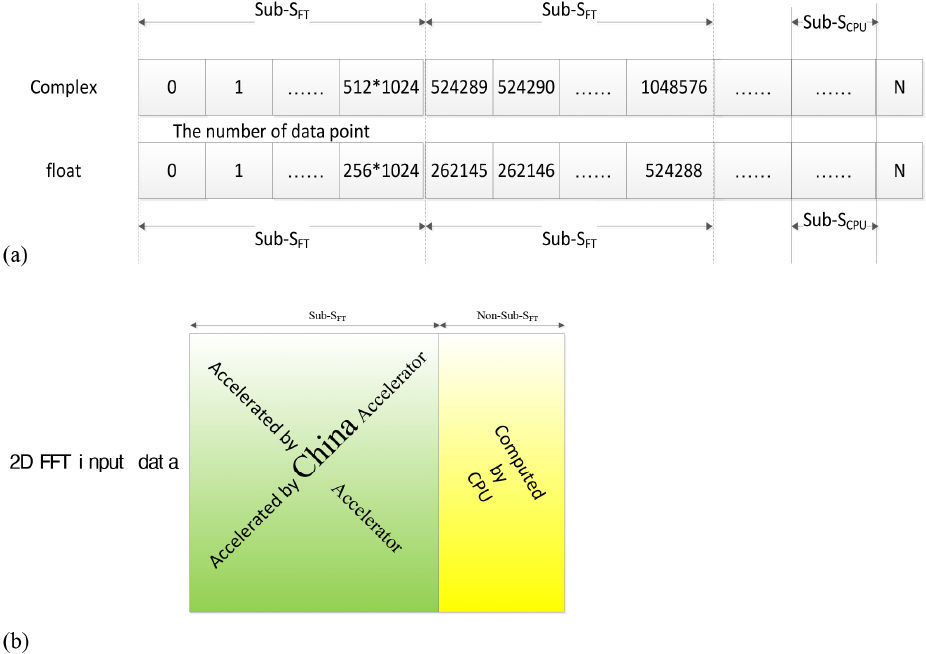
Orchestrating FFT with coordination by using Sub-SFT accelerated by CA and non-Sub-SFT computed by CPU to cater to the specified interface. (a) 1D FFT input data and (b) 2D FFT input data. Only Sub-SFT size dataset is accelerated by the CA, and non-Sub-SFT size dataset would run on the CPU.
S is the size of the N-point FFT sequence, k = 0,1,2…, and w= 0,1,2… Moreover, FAIA is proposed based on integrating DS and SD strategies to fully take advantage of both the CA and CPU coordination to compute the large-scale FFT as listed in Algorithm 1.
Pseudocode on FAIA

As detailed in Algorithm 1, FAIA should distribute a large-scale FFT sequence into smaller DFT subsequences according to the specified interface and architectural parameters, and establish a performance evaluation model to decide the current subsequence to deliver to the CA queue or CPU queue according to queues status.
Practically, FAIA is a static and dynamic balance algorithm based on IA to fully take advantage of the CA and CPU coordination to compute large-scale FFT.
Experiments and Analysis
Testing Heterogeneous System
The testing heterogeneous system was built with an array of CNs (Computing Node), and each CN contains a computing blade, an accelerating board, and peripheral component interconnect express (PCIE) bus, as demonstrated in Fig. 6. In validating the heterogeneous system, the computing blade and accelerating board could be attached and detached on demand. There are four CAs connected with a computing blade using PCIE in an accelerating board, and there are four CPUs in a computing blade interconnected with a high express intranet by an NIO (Network Input and Output) card.
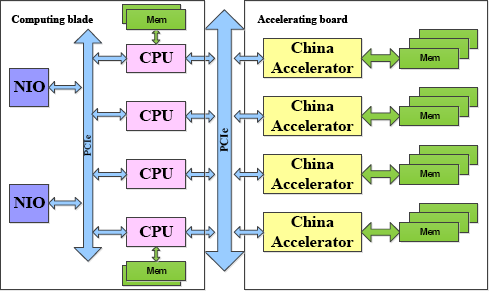
Architecture of the testing node.
Using the testing heterogeneous system, architectural optimizations with FMA and FAIA algorithms with IA were validated. Experimentally, entire validating heterogeneous system was composed of 16 CNs (Fig. 6). Details on the basic experimental environment figuration of CN are listed in Table III.
Details on Testing Environment

IA Testing
The proposed IA would encapsulate the fixed FFT interface into an ordinary one. FFT testing comparisons on IA are listed in Table II. When the FFT input point N is not equal to a complex or float, it is impossible to accelerate FFT using the CA without assistance of IA. When there is no IA, FFT is barely accelerated by the CA because of strong requirements for FFT kernel with fixed interface built into the CA. Fortunately, assisted by the IA, we could test the FFT as usual. The FFT would be accelerated by CA when N is greater than or equal to a complex or float, which are rather weaker requirements for acceleration on the CA than that of the non-IA.
FAIA Validation
The focus of the IA is to cater to the specified interface on FFT built into the CA. But IA is weak in coordinating computing load between CPU and CA. Therefore, we propose an FAIA based on integrating DS and SD strategies to fully take advantage of both CA and CPU to compute large-scale FFT with coordination between them as detailed in Algorithm 1. The performance of FAIA validation is illustrated in Fig. 7.
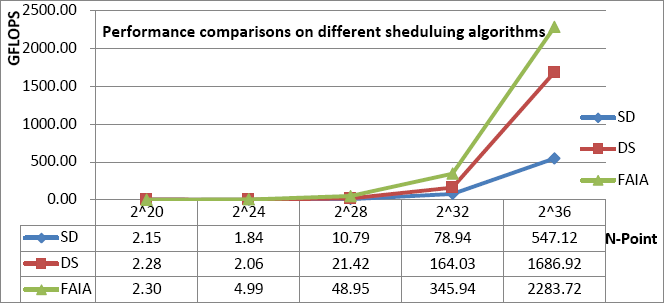
Performance comparisons for FAIA validation.
Performance Improvement with FAIA
To validate the FAIA comprehensively, besides comparisons to SD and DS scheduling strategies, we validated FAIA performance comparisons to the famous six-step algorithm, which is an optimal cache-oblivious algorithm in high performance processors such as GPU, MIC, and other accelerators. Hence, FAIA performance comparisons to famous and optimal six-step algorithms37,38 are also presented in Fig. 8.
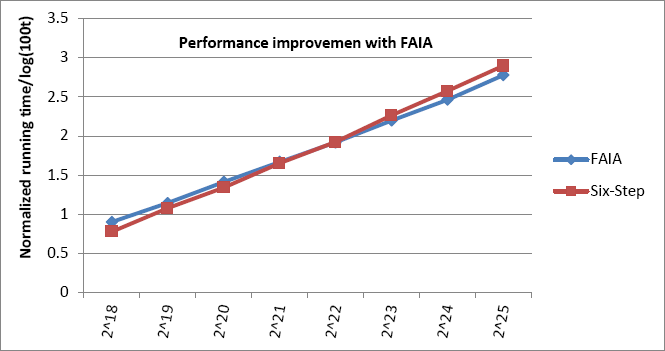
Performance improvement to six-step method.
When the FFT sequence was smaller than 2 20 -point, FAIA performance was slightly inferior to the six-step algorithm. As the size of the FFT sequence increased from 2 20 -point to 2 22 -point, FAIA performance was progressively closer to the six-step algorithm. Furthermore, when the FFT sequence was greater than 2 22 -point, FAIA performance was superior to the six-step algorithm. For smaller DFT subsequences (less than 2 20 bytes), the FFT would run on CPU only without CA acceleration for both the FAIA and the six-step method, and when the FFT sequence was increased to 2 22 point, the FFT subsequence was gradually accelerated by the CA for FAIA, and still ignored by the CA for the six-step algorithm. When the FFT sequence was longer than 222 point, the FFT would run both on CPU and CA with IA for FAIA, and FFT using FAIA would give better performance than that of the six-step without IA.
Conclusions
Although FFT optimizations have been previously reported, in this study, the complexity reduction on DFT by using FMA with IA for the China Accelerator (CA) are detailed.
Assisting with architectural optimizations, the FMA would assemble four float multiplications and four float additions into four FMA operations, which further reduced to 4N log2 N from 5N log2 N for one Butterfly computation.
To provide a friendly testing configuration and fully use both the CA and CPU to complete large-scale FFT problems, an IA was proposed to cater to the specified interface on FFT built into the CA. Furthermore, we proposed a FAIA algorithm based on integrated DS and SD strategies to fully take advantage of both CA and CPU to compute large-scale FFTs with coordination.
Experimental results validated that we successfully achieved a performance of over 2.28 TFlops on 16 nodes of the validating heterogeneous system composed of a CPU and CA (16 nodes, 11.25 TFlops/node, 180 TFlops peak performance) for a 2 36 -point FFT, and FAIA performance was superior to or close to the famous and optimal six-step algorithm for a heterogeneous system composed of the CPU and CA.
Footnotes
Acknowledgements
This work is partly supported by the National Numerical Wind Tunnel Key Project of China Grant No. NNW2019ZT6-B21, partly supported by the Specialized Research Fund for State Key Laboratories of Space Weather, Chinese Academy of Sciences, and partly supported by National Natural Science Foundation of China Grant No. 61602495.