
Abstract
Abstract
Keywords
Introduction
Image super-resolution refers to the process of using low-resolution observed images or multiple image sets to reconstruct high-resolution images with rich detailed features. 1 The super-resolution algorithm improves image visual quality by restoring hidden details and detailed structural features in low-resolution images. In the field of textiles, from the perspective of maintaining the continuity and integrity of fabric graphic patterns, the analysis of fabric structure is a very important part of the textile industry production process, and is the premise of counterfeiting or innovative textile products. Therefore, the research on image super-resolution technology is important to the analysis of low-resolution fabric image texture structures. It also has a wide range of applications in many other fields, such as digital high definition (HD), medical imaging, satellite image analysis, and security detection,2,3 where the super-resolution technology is beneficial to improve the performance of pattern recognition. The high resolution image reconstructed by the super-resolution technology has higher pixel density and richer detail information content, which improves the accuracy of multi-target recognition and judgment in real-life applications.
Generally, we divide existing super-resolution methods into two broad categories: the interpolation-based methods and the learning-based methods. 4 The interpolation-based methods can be further divided into the polynomial interpolation algorithms and the algorithms that use image edge steering for interpolation. 5 The polynomial interpolation algorithms belong to traditional algorithms with the properties of simple and fast including the nearest neighbor interpolation, the bilinear interpolation, and the bicubic interpolation. 6 However, their reconstruction effect of high-frequency detail information is very poor because they only consider pixel and motion information. It tends to generate image blurring edges, ringing, and silver-toothed artifacts in the reconstructed high-resolution image. Sun et al.7,8 successfully preserved the boundary information in the super-resolution image restoration process by exploring the gradient contour prior to the local image structure. This kind of interpolation algorithm with prior information of the natural image could better preserve the structural features of the input observation image, but it is still limited to estimating the unknown pixels in the high-resolution grid using known neighborhoods.9,10 Recently, the edge oriented interpolation methods have been proposed to make up for the shortcomings of traditional interpolation algorithms. Although these methods can preserve the edge structure of the image, they often produce speckle noise or distort the image around the texture regions.
The learning-based super-resolution methods mainly rely on the mapping relationship between the low-resolution image blocks and the high-resolution image blocks in the training set to predict the lost high frequency detail information in the test low-resolution image, 11 so as to realize the super-resolution task. In 2002, Freeman et al. 12 first proposed a single image super-resolution method, namely an instance-based method, which predicts degraded visual information in low-resolution images by learning from the training dataset. The algorithm can recover the high-frequency information of most images with a larger training dataset. However, the algorithm has low computational efficiency and poor anti-interference ability. In 2004, Chang et al. 13 introduced the local linear embedding method and proposed a neighborhood embedding image super-resolution reconstruction algorithm. This algorithm takes a smaller training dataset to represent more image block patterns with low computation and high speed. However, it often leads to overfitting or underfitting and image blurring because the value of the nearest neighbor block is fixed. Yang et al. 14 proposed a super-resolution reconstruction method based on sparse signal representation. By jointly training the high- and low-resolution image block dictionaries, the similarity of real dictionary sparse representations between high- and low-resolution image blocks is enhanced to reconstruct the target high-resolution image.15–17 These methods can fully retain the prior knowledge and reduce the dimension during the training process to improve the computational efficiency. Nevertheless, all of them need an extra and well-constructed image data set to learn the mapping.
Generally, it is difficult to obtain multiple low- and high-resolution images of the same scene simultaneously because of the limitations of complex environments and hardware conditions. At this point, super-resolution technology of multiple images learning encountered a development bottleneck, and more scholars pay attention to the single image resolution technology.18–21 In 2011, Freeman et al. proposed a single image super-resolution framework based on the self-learning theory, which completes the training process only with the feature information of the image itself. This self-learning super-resolution technology improves the image resolution by combining the symbiotic prior information of high- and low-resolution images with high-resolution image blocks containing rich details.22,23 This technology solves the problem of multiple image acquisition difficulties in the same scene, and has become a research hotspot of image super-resolution technology.
In the self-learning framework, similarity matching plays the key role for boosting the image super-resolution effect. 24 However, the existing image blocks similarity measures ignore the two-dimensional structural information and are not robust for some interference. For example, because structural information is corrupted in a super-resolution scene of a textile image with stains, it is difficult for the traditional similarity measure methods of the single image super-resolution framework to accurately find similar low-resolution images of high-resolution images. Thus, this study aims to improve the super-resolution performance of the self-learning framework by introducing a robust image similarity measurement method. Recently, nuclear norm based matrix regression (NMR) analysis has become a popular tool for image recognition, which uses the low-rank to preserve two-dimensional structural information and promote robustness.25,26 In image recognition, the essence of NMR is to measure the similarity of images by regression coefficients. Therefore, using the NMR to address the robustness and the two-dimension structure lost in the traditional self-learning super-resolution is theoretically feasible.
The motivation of this work is to establish a robust matrix regression model based self-learning super-resolution method that fully considers the two-dimensional structure of the image and ensures the robustness of the method on the premise of realizing super-resolution of a single image. Specifically, we substitute the nuclear norm with a non-convex function for characterizing the low-rank structure of the error image block. Based on this characterization, a robust nuclear norm based matrix regression model is introduced and applied to the self-learning framework to realize similarity matching between image blocks, so as to complete super-resolution reconstruction of a single image. In addition, we adopt the alternating direction method of multipliers (ADMM) to optimize our model. We hope that the jointly obtained components, like members with a team spirit, can create synergy through close interaction, and generate higher performance than traditional similarity measures in achieving single image super-resolution.
The contributions of this work are summarized as follows:
We propose an effective super-resolution method for a single image based on the self-learning framework and the robust matrix regression model, which can be applied in the field of textile image super-resolution.
The proposed method not only can preserve the two-dimensional structural information, but also can enhance the robustness of single image super-resolution.
We construct the fabric data set and carry out a large number of experiments on super- resolution reconstruction to prove the effectiveness of our proposed method. Experimental results show the advantages of our method in robustness and the image super-resolution reconstruction effect.
The rest of the paper is organized as follows. We briefly review the single image self-learning super-resolution framework, detail our proposed method, and provide the experimental results, followed by the conclusion.
Self-Learning Framework for Image Super-Resolution
In general, natural images usually contain a lot of visual repetition in different scales, which is called structural similarity. 27 Fig. 1 shows an example of an image with local self-similarity. The image block on the left petal and receptacle root has similarity inside the image rectangle. Although it varies slightly in scale, the image block on the right still shows a high degree of similarity. These features are often used as the prior knowledge to constrain the reconstruction process.28,29 When the image is sub-pixel shifted, a similar image structure appears near the original image block, which indicates that the similarity between the same scale of the image can be used as the theoretical basis for image multi-frame reconstruction. The similarity between different scales of the image constitutes high- and low-resolution training samples, which improves the effective prior knowledge for the sample-based super-resolution reconstruction method. Therefore, self-learning reconstruction without any external training images not only saves time but also generates better results.

An illustration of the image self-similarity.
The common singular points that improved resolution have singularity-invariant scaling transformations in natural images. Therefore, we can find related sample patches in a very limited set of patches. For each patch in the image, we can find the similar patches of its smoothed version near the same relative coordinates. The Freeman algorithm a classical one based on image self-similarity, which supplements the low-resolution image of the high-frequency patch. In one study, 30 they adopt small scale factors to scale the images, and then load the corresponding high-frequency image into the reconstruction image. The traditional self-learning algorithms usually take the sum of absolute differences (SAD, see Eq. 1) to determine the position of the absolute value difference between the high- and low-resolution images as their similarity matching criterion.
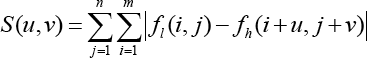
fl and fh represent the gray value of the low-resolution and high-resolution pixels, respectively, and m and n represent the size of the image block. The SAD searches for similar image blocks by matching the minimum gray value of the corresponding pixel points, which ignores the structural characteristics of the entire image. Besides, the method is prone to confusion and inaccurate matching in the condition that the image has more complex textures.
Proposed Method
For boosting the performance of the single image self-learning super-resolution, we introduce an improved similarity measure model with properties of robustness and two-dimensional structure to measure the similarity between image blocks in this section.
Similarity Measure with Matrix Regression
Given a set of n image block matrices D1,…, Dn, ∈ Rp×q and an image block matrix Bi ∈ Rp×q. For ∀i, j, Di ≠ Dj when i ≠ j. Our aim is to find the true nearest neighbors of B i in D. Traditional algorithms accurately calculate each similarity indicator d (B i , D i ) between B i and D i respectively with a variety of defined similarity functions, such as Euclidean distance, Manhattan distance, correlation coefficient, and so forth. Then the nearest neighbors of B i are obtained by sorting them.
Here, we take full use of the matrix regression model to find the nearest image block of high-resolution image block. Specifically, we represent the image blocks in the form of a matrix and use nuclear norm based matrix regression (NMR, see Eq. 2) to preserve the low-rank structure information of the scaled image and enhance the robustness of the similarity degree of the image blocks.
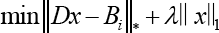
x = (x1,…, xn) represents the linear representation coefficients, which indicate the degree of similarity of the images, 31 and λ donates the regularization parameter, which governs the relative importance between the regularization term and the reconstruction error term.
We take the ADMM algorithm to solve this regularized matrix regression problem. At this point, the model expressed by Eq. 2 can be rewritten as Eq. 3.
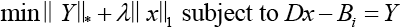
And the augmented Lagrangian function Lμ is defined by Eq. 4.
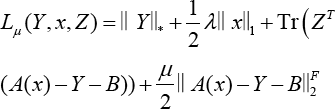
μ > 0 is a penalty parameter, Tr(·) is the trace operator, and Z is the array of Lagrange multipliers.
The ADMM algorithm mainly involves the following iterations (Eqs. 5–7):
Given Y = Yk and
Z = Zk updating
x by
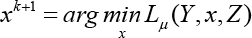
Given x = xk and
Z = Zk updating
Y by
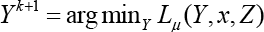
Given x = xk and
Y = Yk updating
Z by
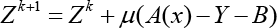
The algorithm we adopted can be interpreted as a two-step iterative strategy for super-resolution. Updating x is the step used to determine the representation coefficient and representation error, while updating Y is actually an error support step used to determine the actual super-resolution fuzzy part. Therefore, the robust matrix regression based on nuclear norm provides a unified framework for integrating error detection and error support into a simple model.
In short, the NMR treats the query image block as a linear combination of the image blocks in the dictionary and determines the nearest neighbor of the query image block by sorting the minimum reconstruction coefficient. This similarity measure model considers both the two-dimensional structure of the image and the robustness for the interference.
Super-Resolution Algorithm
Assume that X h represents a high-resolution image and X l denotes the low-resolution image obtained by the optical quality reduction processing. Then the degradation model can be expressed as Eq. 8.
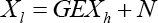
Where G and E denote the down-sampling and blurring operators respectively, and N is the additional noise.
Bevilacqua et al. proposed that it is better to use a small scale scaling factor to iteratively enlarge the high-resolution image, rather than directly magnifying it at once. 32 Therefore, we followed this suggestion and took the small scale scaling factor to iteratively enlarge the low-resolution image in the self-learning Freeman framework. We used the nuclear norm based on the matrix regression model to measure the similarity of image patches, which not only improved the super-resolution quality, but also ran faster. Fig. 2 shows the pipeline of our method.
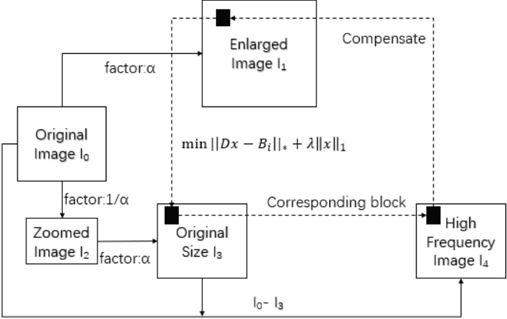
The pipeline of our method.
Self-learning with robust matrix regression

The complete algorithm of self-learning super-resolution with robust matrix regression is detailed in Algorithm 1.
In terms of our model complexity, given the image size n × n and the size of sub block m × m, the computational complexity of Step 4 is O((n - m)2) is determined by the size n and k, which is the number of iterations of our entire method step. The computational complexity of Step 5 is O(k1n2), which is determined by the matrix multiplication and k1 (the number of iterations to find the similarity image block (ADMM). So, the entire computational complexity of the Algorithm is O(k2(k1n2 + (n - m)2)), where k2 is the number of iterations.
Experiments
In this section, we evaluated the proposed model by several experiments. We first discuss the parameter selection of our model, then demonstrate the super-resolution visual effect in different situations, use objective indicators to evaluate the super-resolution effects of test images in different situations, and finally, we test and compare the efficiency of the proposed algorithm.
To illustrate the effectiveness of the super-resolution algorithm adopted in this study in terms of two-dimensional structure preserving and robustness, we selected the test samples in Fig. 3 as the representative test images. Our experiment mainly showed the super-resolution effect of the images under the influence of illumination and the images with complex texture and complex background. We also selected the natural low-resolution images as the testing images. The bilinear interpolation algorithm and the traditional Freeman algorithm were selected as the comparing methods in our experiment. The magnification was doubled using a combination of small scale factors 3:2 and 4:3. There were no additional high-resolution image data sets in all experiments.

The test images.
Parameter Selection
In our proposed algorithm, there were two parameters. The significant parameter mainly used in our experiment was the size of the search window in the entire image I3 and the regularization parameter lambda in the ADMM algorithm of our model. We did a lot of experiments; each experiment only used a single low-resolution image in the test sets.
In our proposed method, there were three parameters: the overrelaxation parameter α value from 1.0 to 1.8, parameter λ value from 0 to 1, and parameter k value from 1 to n (usually we set it as 3). Parameter k was the size of the sub block. A large value of k decreased the precision of the result, while a very small value of k will increase the computation time. Parameter λ is the augmented Lagrangian parameter. Parameter α enlarged the range of computing.
Here, we only provided a guidance for setting them. For many images, parameter α was typically set from 1.0 to 1.8, as a regulator of the result. Parameter λ was the augmented Lagrangian parameter, usually set as 0.01. For most images, k should be properly enlarged to accelerate the process. Next, we set specific values according to the above principles for the different images in the experiment.
Super-Resolution Visual Effects
Here, we mainly evaluate the super-resolution effects of different methods on images in different situations, including images with illumination effect, complex texture, and complex background.
Super-Resolution Effect with Illumination
Our claim is that the robust matrix regression model could boost the performance of the self-learning super-resolution in the presence of some noise, such as illumination. Thus, we firstly evaluated the performance of our proposed method, compared with the bilinear interpolation algorithm and the traditional Freeman algorithm, under the condition of illumination.
In this experiment, we constructed a fabric database and selected fabric images with illumination effects. For fairness, we randomly selected the images and conducted multiple experiments for verification. For the other comparison methods, the solution tools and parameter settings were carried out according to the author's suggestions. We show some effects of image processing with light effects using different super-resolution methods in Fig. 4. Fig. 4a shows the ground truth; Fig. 4b is the super-resolution image obtained by bilinear interpolation, and Figs. 4c and d show the resulting images which were obtained by traditional Freeman algorithm and our method, respectively.

Super-resolution with illumination.
The super-resolution processing visual effect of the proposed method was the most natural and closest to the normal image among all methods (Fig. 4). In addition, our method can effectively eliminate the interference of bad illumination and maintain the clear texture of the image. These demonstrate the robustness of our method under illumination.
Super-Resolution Effect with Structural Keeping
To verify the performance of our method in super-resolution for two-dimensional structure preserving, we constructed the fabric image database and randomly selected fabric images with complex textures. Figs. 5–7 show the results of super-resolution of selected images.

Super-resolution with structural preserving 1.

Super-resolution with structural preserving 2.

Super-resolution with structural preserving 3.
We can see from Fig. 5d that the letters on the fabric pattern were clearer and the textures outside the letters were relatively distinct. Similarly, we can see from Fig. 6 that, compared with other traditional methods, the vertical texture of the fabric image processed by our method was clearer and the two-dimensional structure of the image was better maintained. From the super-resolution effect of Fig. 7, the reconstruction of the bilinear interpolation image was fuzzy. The Freeman algorithm implementation effect of super-resolution was better than the bilinear interpolation, but the printing structure of the fabric image was not good. In contrast, our method kept the structure of the image better and was closer to the real value. In addition, our method performed well for the dot pattern fabric image as well, and was closer to the ground truth.
Super-Resolution Effect with Complex Background
Here we further evaluated our proposed method on natural images with complex backgrounds. Figs. 8 and 9 show the results of the experiment.

Super-resolution with complex background 1.

Super-resolution with complex background 2.
Fig. 8 shows the super-resolution reconstruction of an image with the same foreground and background color. The result of our method was more natural compared to the blurring effect of the bilinear interpolation and the sharpening effect of the traditional Freeman algorithm. In Fig. 9, our proposed method achieved a better overall two-dimensional image effect of super-resolution reconstruction in the case of a complex image background.
Peak Signal-to-Noise Comparison in Super-Resolution
Compared to visual effects, the peak signal-to-noise ratio (PSNR), which directly measures the difference of pixel values, is more commonly used for the quantitative evaluation of super-resolution. The index is calculated between the super-resolution results obtained by different methods and the ground truth. The larger the value, the smaller the distortion.
Assume that the two input images are X and Y
respectively, and the calculation formula is given in Eq. 9.
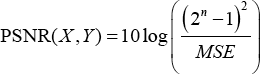
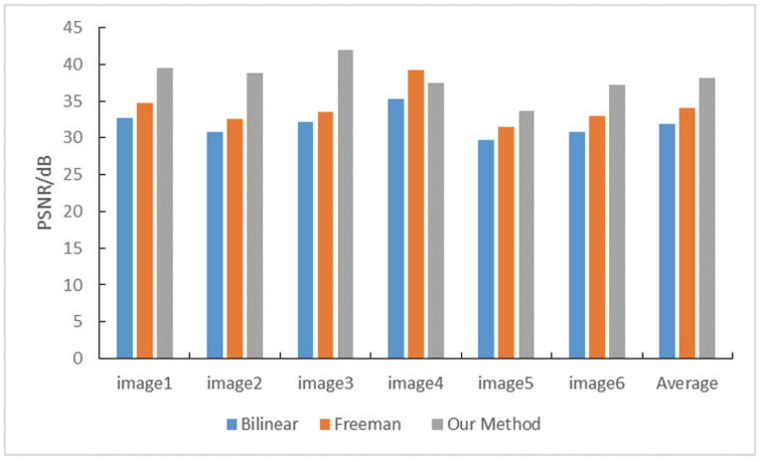
PSNR of the super-resolution images.
Efficiency Comparison in Super-Resolution
In this study, we randomly selected six pictures from the data set to test our algorithm model, as shown in Table I, where the unit of time is seconds. According to Table I, the efficiency of our algorithm was lower than that of bilinear interpolation and Freeman algorithm, but this did not affect the super-resolution effect of the algorithm model in this work. Compared with the operating efficiency, we preferred to consume a little more time to get a better super-resolution effect.
Efficiency Test in Super-Resolution
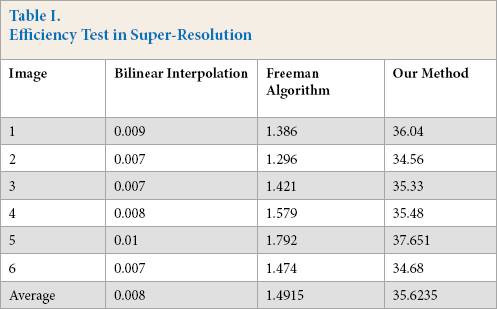
These experimental results provided strong evidence for the motivation of this research. That is, the robust matrix regression model can boost the performance of the self-learning super-resolution in visual robust and super-resolution effects. Although our algorithm was not the most efficient compared with other traditional algorithms, it still had a certain efficiency, and the super-resolution reconstruction effect of our method completely made up for the lack of efficiency.
Conclusion
To improve the robustness and accuracy of single image super-resolution, we introduced robust matrix regression as the similarity measure model among image blocks in the self-learning super-resolution framework. The experimental results show that the robust matrix regression model can significantly improve the performance of the super-resolution effect with illumination variation, structure preserving, and complex background. However, the ADMM algorithm we used in robust matrix regression was slow, and we will focus on improving its computational efficiency in future work.