
Abstract
To identify and locate industrial textile defects accurately, this study proposes a textile detection model based on a convolution neural network (CNN) known as Faster R-CNN. First, a textile defect feature map was extracted by ResNet-101 deep convolution network. Faster R-CNN only extracts features from the last layer of the feature map, which leads to a loss of low-level location information. The proposed method adds the feature pyramid network (FPN) to the network architecture to make an independent prediction for each level in the feature extraction stage. The extracted feature map is input into the regional proposal network, among which the overlapping regional proposals are suppressed. The proposed improved Faster R-CNN model with Region Proposal Network (RPN), Soft Non-Maximum Suppression (NMS), and Region of Interest (ROI) Align can achieve a detection accuracy of 98% and an mean of Average Precision (mAP) of 85%, which is more competitive than the state-of-the-art deep learning-based object detection algorithms.
Introduction
The quality of textile products is very important to the apparel industry. Currently, the textile industry heavily relies on manual inspection for textile defect detection. However, manual inspection suffers from several major problems, such as labor fatigue, high manpower cost, and high miss rate, which greatly reduces the working efficiency of the entire production line.
With the rapid development of computer vision, automatic textile defect detection techniques are a promising development for the textile and apparel industry. Up to now, automatic defect detection methods can be classified into two main categories: statistical-based gray level co-occurrence matrix (GLCM) 1 and the local binary patterns (LBP) meth-ods, 2 and filter-based methods, such as Gabor 3 and Sobel 4 filters. However, GLCM and LBP methods cannot extract effective features from textile images due to the diverse categories of textile materials. Therefore, such a statistical-based method can hardly obtain robust features from textile images. For the filter-based methods, it is hard to tune the appropriate parameters of these methods with high-computation complexity. Therefore, the above-mentioned methods can hardly be applied to solve textile defect detection problems.
Recently, deep neural networks have drawn great attention from the research community due to its high performance in various computer vision tasks.5-7 One of these is the convolution neural network (CNN) Faster R-CNN 8 , one of the most accurate neural networks in object detection. Therefore, it has been widely used in different fields of computer vision. For textiles whose foreground and background are not clearly distinguished, it can effectively extract abstract features, having good performance in detecting small scale targets. Compared with the traditional feature extraction method, Faster R-CNN shows more competitive detection accuracy.
Traditional statistical-based methods and filter-based methods are not capable of extracting feasible features from textile images. To address the effective feature extraction problem for textile fabric detection, in this study, an improved method based on Faster R-CNN is proposed to detect defects in textiles. Firstly, the defective features extraction is performed on the whole image by using the ResNet-1019 deep convolution network, and the feature pyramid (FPN) 10 is used for multi-scale mapping. Secondly, the FPN-mapped feature maps will be input to the Region Proposal Network (RPN) to generate the region proposal. By using ROI align and Sof-Non-Maximum Suppression (Soft-NMS) 11 instead of the original Region of Interest (ROI) pooling and NMS 12 of Faster R-CNN, the region proposal can be pooled and suppressed. Finally, the proposed network performs classification and position regression. The contributions of this study include the following three parts.
Anchors Clustering
The
Multi-Scale Training
Using the FPN feature pyramid network to perform multi-scale mapping for each layer feature, FPN can extract more rich position information of low-level features, which will play an important role in small object detection.
Replacing ROI Pooling and NMS with ROI Align and Soft-NMS
By adding ROI Align in Mask R-CNN 13 to the model, the floating-point precision loss caused by the two quantization in the ROI pooling process can be estimated, which is more accurate for the bounding box. When the detection boxes of multiple targets overlap, the use of Soft-NMS non-maximum suppression can effectively reduce the probability that the detection boxes of the real target are deleted by mistake when the overlap occurs, so that the accuracy of the detection result is improved.
Faster R-CNN
Faster R-CNN is one of the two-stage R-CNN series of object detection networks,13-15,8 which is proposed for the network improvement of Fast R-CNN. 15 R-CNN 14 is a famous object detection technique. It is the earliest two-stage detection network, which uses the selective search algorithm to perform large-scale region proposal extraction on images. It also uses Support Vector Machine (SVM) 16 for classification, which greatly improves the speed of object detection and maintains a high speed recall rate. Therefore, the design of the R-CNN network framework has made a major breakthrough in object detection compared to the traditional object detection method17,18 and opened the upsurge of deep learning object detection. However, R-CNN extracts up to 2000 region proposals each time using a selective search; each region proposal uses CNN to extract features and SVM for classification. Apparently, the efficiency of R-CNN is a big problem, since it repeatedly calculates all the target regions leading to a heavy computational burden for target bounding box extraction. To solve the problems that occur in R-CNN, the Spatial pyramid pooling (SPP) net proposed by He et al. 19 extracts only one convolution feature on the image, and then inputs the extracted region proposals into the fully-connected layer. In this way, SPP net avoids extracting the region proposal multiple time as R-CNN does. Therefore, Fast R-CNN uses CNN to extract features of the entire image instead of extracting each image block multiple times. And in the final convolu-tional layer of R-CNN, an ROI pooling layer (a simplified version of SPP net) was added and combined with multi-task loss. The bounding box regression was directly trained on CNN to develop Fast R-CNN. Because Fast R-CNN does not repeat calculations, it not only maintains the detection performance of R-CNN, but also improves the efficiency of R-CNN. Fast R-CNN still uses the selective search algorithm to find the detection box, which improves the detection speed, but such a speed is still slower than that of the single-stage object detection network. Faster R-CNN proposes to put the RPN candidate area network behind the last convolutional layer and directly train the candidate area, which greatly improves the speed of Fast R-CNN. The RPN network is also the main contribution of Faster R-CNN. As shown in Fig. 1. The essence of the RPN network is a classless object detector based on a sliding window RPN network that takes an arbitrary scale image as input and outputs a series of object proposals.
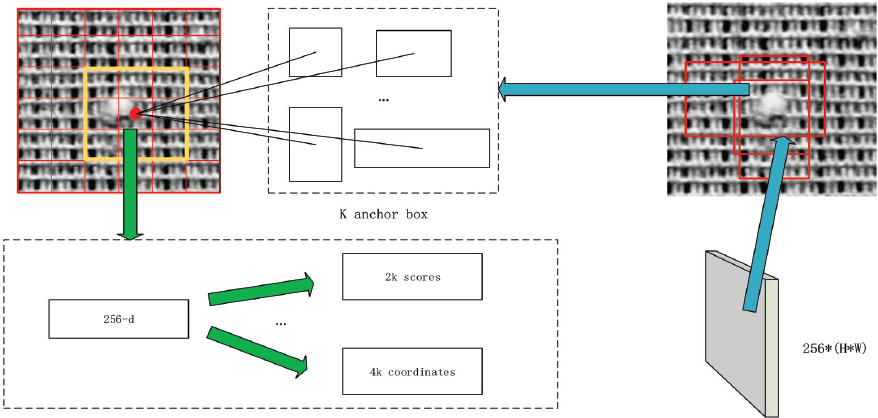
RPN network in Faster R-CNN. 8
Proposed Method
Defect detection of textiles is different from common pedestrian, car, animal, and other object detection. The sample of the textile defect dataset (Tsang, C.; Ngan, H.; Pang, G. Fabric Inspection based on the Elo rating method, Pattern Recognition, 2016, 51(4): 378-394.) has the characteristics that the foreground and background are indistinguishable, and the regression accuracy of the target position is high. 20 It contains some defect targets with large length and width, so we need to improve the original Faster R-CNN to improve its accuracy in detecting textile defects.
In response to the above problems, we have improved the framework of the textile
defect detection model based on Faster R-CNN, as shown in Fig. 2. First, the appropriate samples were
extracted from the textile defect dataset to create a VOC2007 dataset format
suitable for Faster R-CNN training and testing. When clustering the training
samples, we found that the proportion of certain targets was too large, even
reaching a ratio of 5:1, so we changed the anchor rate setting of the native Faster
R-CNN to better ft the length and width of our data samples. However, there were
still some difficult samples existing in the dataset, so data enhancement was used
to augment the dataset, such as adding Gaussian blur and “salt and pepper” noise.
Ten, feature extraction was performed on the training samples using the ResNet-101
deep convolutional network. To enhance the detection performance to find small
targets, the FPN feature pyramid network was used to perform multi-scale mapping on
each layer in the process of feature extraction, in addition to obtaining high-level
semantic information and low-level accurate location information. Ten, the extracted
features were respectively sent to the RPN network for region proposal generation.
After using RPN to obtain the region proposal, we used ROI align instead of the ROI
pooling to perform the pooling operation, At the same time, Soft-NMS was used
instead of traditional NMS to suppress detection boxes. Finally, the feature was
fully connected, using Softmax Loss and
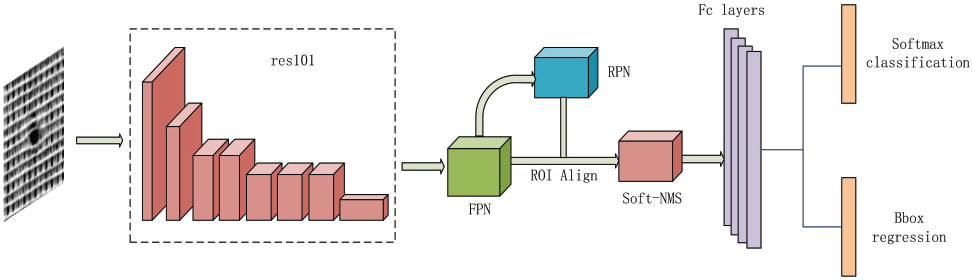
Improved Faster R-CNN model.
Data Enhancement
Our datasets were classified into two categories: normal textiles and defective textiles. For hard-to-recognize samples, we first made a small amount of horizontal and vertical flips. Thus, we added Gaussian blur and “salt and pepper” noise to a portion of the samples to enhance the robustness of the model. But the deep model does not need too many noise samples, otherwise, it will interfere with the true distribution of normal samples. According to the proportion of positive and negative samples, we enhanced about 520 complex samples.
Anchors Clustering
An anchor is a box used to preset the size. In Faster R-CNN,

Samples with a large aspect ratio of the target in defective data.
By clustering anchors, it was found that the length and width of anchors in the training set were mostly between 1:2 and 2:1, and a small number of samples were around 1:4 or 4:1, so we increased the proportion of anchors to (1:4,4:1), where the complete anchor rate value was (0.25,0.5,1,2,4), as shown in Fig. 4.
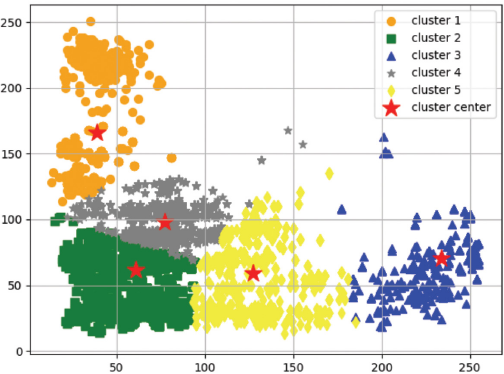
When
FPN
The image pyramid is a traditional multi-level extraction feature method, which changes the scale of the image. The higher the level, the lower the resolution and the smaller the image. By changing the scale of the image to generate different scale features, the use of image pyramids result in increased computational complexity and time overhead. In SPP net, Fast R-CNN and Faster R-CNN only use the last layer of the convolutional network. This strategy is similar to the way that the highest level of the pyramid model is made, but the top-level features ignore some small target information of the low-level features, which sharpens the network's power to detect small targets. However, the stage object detection network Single Shot MultiBox Detector (SSD) 20 adopts multi-scale feature fusion, without upsam-pling; that is, it extracts features from different layers of the neural network for fusion. This structure does not have too many calculations and time overhead, so the pyramid structure can be used to perform small object detection. FPN is a multi-scale object detection algorithm. It uses multi-scale fusion like SSD. First, the bottom-up forward propagation forms a pyramid structure, and then top-down upsampling, the top-level features and the low-level features are feature-fused and horizontally connected (Fig. 5). Faster R-CNN, because it only uses the features of the top layer of the pyramid network, does not perform feature fusion with the semantic information of the bottom layer of the network, thus losing the rich location information of the bottom layer. By using the FPN feature pyramid for object detection, the top-level features can be merged by upsampling and low-level features, and each layer is independently predicted. Since our dataset contains small targets, to improve the accuracy of small flaw detection, we added FPN to the original network model.
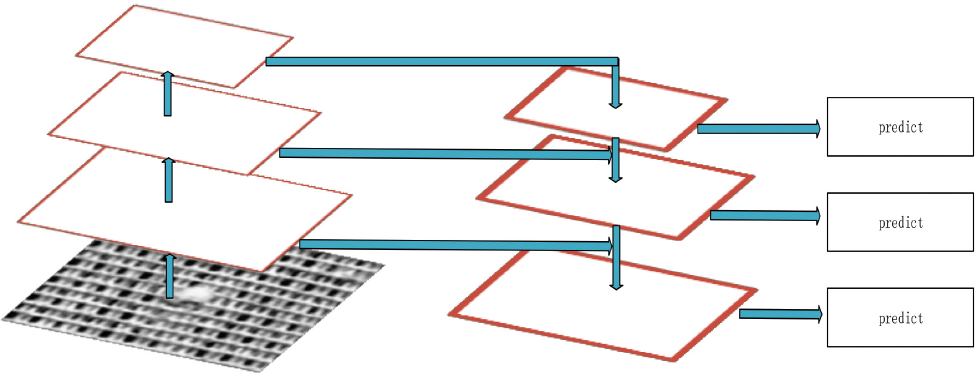
FPN architecture 10
ROI Align
In an existing two-stage object detection framework, such as Fast R-CNN and Faster R-CNN, to classify the target and the bounding box's regression operation, ROI pooling is usually used to map feature maps of different input sizes according to the coordinate position of the feature map. It is translated into a fixed-size output by a block pool, with the idea coming from SPP net. Usually, the position of the preselected box is a floating point number obtained by the model regression. Therefore, in the process of pooling, the position of the candidate bounding box is first quantized from the floating point to an integer, so that the converted candidate area can be equally divided, and each segmentation area is accordingly quantized. Due to the two quantifications, the position of the detection box after ROI pooling will be inaccurate with the position of the RPN return. ROI Align solves this problem. ROI Align is a regional feature aggregation method that was first used in the Mask R-CNN network. It differs from ROI pooling, where the quantization operation is cancelled. It first traverses each candidate region, and performs segmentation operations on the candidate regions. Ten, it calculates a fixed coordinate position for each segmented cell by using bilinear interpolation, and finally performs pooling. Experiments show that the effect of ROI Align on large targets is not obvious, it mainly affects small targets.
Soft-NMS
Using a multi-scale sliding window to detect a target is a widely-used method in the object detection algorithm. Such a detection strategy will generate multiple detection boxes with detection scores. The higher the detection score is, the higher the probability that the box indicates the location of the object would be. Therefore, the main idea of the traditional method is to select the box with the highest detection score as the detection result, while eliminating all the other detection boxes with low detection scores. The extra detection boxes will be eliminated. Non-maximum suppression (NMS) is one of these typical methods and is often used in computer vision for edge detection and target recognition. Therefore, we often use NMS to remove other lower-scoring boxes that overlap with the selected box with the highest detection score. In this case, we normally reset the score of the lower-scoring boxes to 0. However, when two or more targets appear adjacent to each other in the dataset, the detection box of the real target may be suppressed, if the overlap of the two detection boxes is high, which neglects the real target, making the test result a false positive.
To address this problem, Soft-NMS
22
can be used. It improves the
traditional greedy NMS algorithm and sets an attenuation function for adjacent
detection boxes. When the detection boxes of two targets overlap each other,
Soft-NMS will retain the box with the highest detection score, and thus
attenuate the influence of the detection scores of the remaining boxes, namely,
the values of the detection scores of the remaining boxes will be decreased.
Supposing that
Experiments
Dataset
In this work, we evaluated our model with three datasets. Datasets 1 and 3 were provided by the Institute of Textiles & Clothing, The Hong Kong Polytechnic University. Dataset 2 is an extension of the defective datasets proposed by Hong Kong Baptist University. Dataset 1 contains 1127 positive samples and 1000 negative samples. Because the sample size of dataset 2 was too small, we enhanced the dataset; the images of data-set 2 were reversed horizontally or vertically, and the “salt and pepper” noise was added to a small number of samples. Data-set 2 contains 317 positive samples, while dataset 3 contains 329 positive samples. The sample size of all datasets is 256 * 256 pixels. We divided each data set into training and test sets, and then verified them on Faster R-CNN, Yolov2, and our models. All data samples are shown in Fig. 6.

(a) Positive samples of dataset 1, (b) positive samples of dataset 2, (c) positive samples of dataset 3, and (d) negative samples of dataset 1.
Experimental Results
In the experiment, tensorfow1.8 was used as the deep learning framework, and the training was carried out on a graphics processing unit (GPU) server with Intel core i7-7820 central processing unit (CPU), 62G memory, and one GeForce GTX 1080Ti card. To verify the effectiveness of the proposed method, different models were used to train and test the network. The model based on ResNet-101 iterates 5,000 times and the learning rate was set to 0.001 according to the experiments. Figs. 7–9 show the results of defect detection of datasets 1, 2, and 3 based on the improved model of Faster R-CNN, respectively. Tables I–III show the mean of Average Precision (mAP) values and binary classification recall of the proposed method and other different neural network models on datasets 1, 2, and 3 respectively. Fig. 10 shows the map of the different models. Among the three dataset test results, the best model was our improved method, the worst model was SSD, and the fastest one was Yolov2. Figs. 11–13 are the precision and recall curves of our model based on ResNet-101 backbone network. The performance of our model was the best for dataset 3.

Detection result of dataset 1 on our model.

Detection result of dataset 2 on our model.

Detection result of dataset 3 on our model.
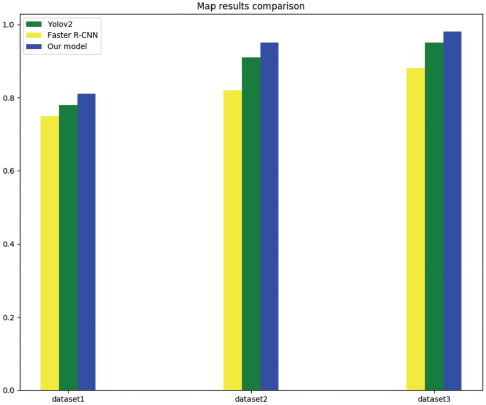
mAP comparison of different methods.
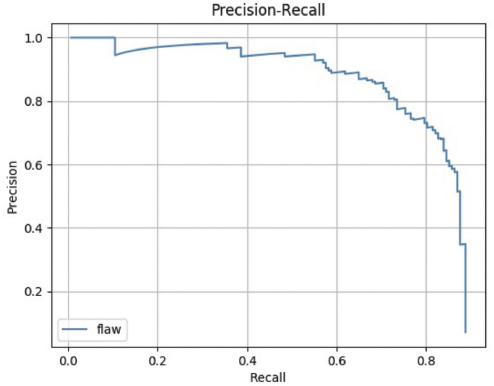
Precision and recall of our method on dataset 1.
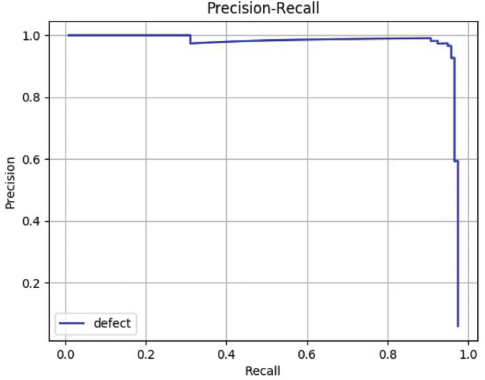
Precision and recall of our method on dataset 2.
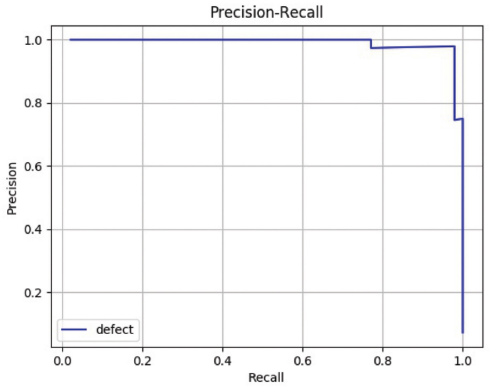
Precision and recall of our method on dataset 3.
mAP and Precision Ratio Comparison of Different Models on Dataset 1
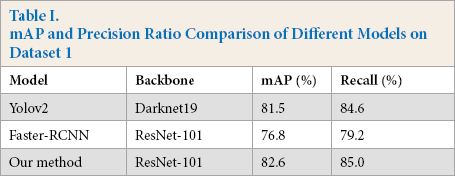
mAP and Precision Ratio Comparison of Different Models on Dataset 2
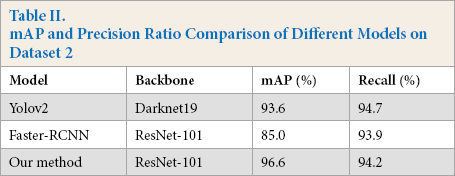
mAP and Precision Ratio Comparison of Different Models on Dataset 3
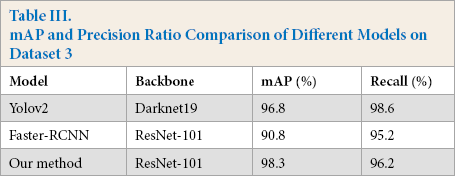
According to the experimental results, we found that using FPN can improve the accuracy of some small defects, but the overall improvement of mAP was not obvious, only about 3%, which was related to the distribution proportion of small target samples in the dataset itself. Changing the anchor setting ratio can effectively enhance the detection of long and narrow targets and make the generated bounding boxes more accurate. Soft-NMS can effectively reduce the loss of the real object detection box in the overlapping area. However, when the detection box overlap is not obvious, the suppression effect of Soft-NMS and NMS was not very different.
Efficiency Analysis
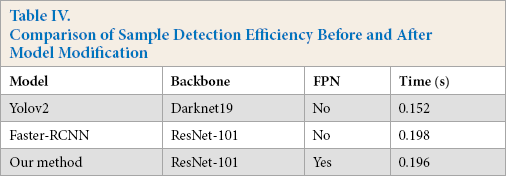
After adding the RPN feature pyramid network, the efficien-cy of our model nearly doubled due to the large reduction of feature dimensions (Table IV). Therefore, adding RPN increased the efficiency of the model.
Comparison of Sample Detection efficiency Before and After Model Modification
Conclusion
We used the improved Faster R-CNN model and the original Faster R-CNN to compare the performance of defect detection. The experimental results show that adding FPN feature pyramid, ROI align, and Soft-NMS into the detection framework effectively improved our mAP value by about 6%, and achieved a high detection precision and recall rate. Our model can detect small defects well, and small defects are often difficult to distinguish for human vision. When the difference between the foreground and background of the textile is not obvious, the detection effect is not observed, and it is not sensitive to the added noise.
This method has proven its effectiveness on multiple data sets. Therefore, our model has good robustness, and it has important significance for actual textile industry production. The use of an object detection network based on in-depth learning had a good effect on textile defect detection. Future work will continue to speed up the model to achieve faster and more accurate detection results.
Footnotes
Acknowledgements
This work was supported in part by the Natural Science Foundation of China under Grant 61703283, in part by the Guangdong Natural Science Foundation under Project 2017A030310067, in part by the Shenzhen Municipal Science and Technology Innovation Council under the Grant JCYJ20190808113411274, in part by the Overseas High-Caliber Professional in Shenzhen under Project 20190629729C, in part by the High-Level Professional in Shenzhen under Project 20190716892H, in part by the Research Foundation for Postdoctor Worked in Shenzhen under Project 707-0001300148, in part by the National Engineering Laboratory for Big Data System Computing Technology, in part by the Guangdong Laboratory of Artificial-Intelligence and Cyber-Economics (SZ), in part by the Shenzhen Institute of Artificial Intelligence and Robotics for Society, in part by the Scientific Research Foundation of Shenzhen University under Project 2019049 and Project 860-000002110328.