
Abstract
Image inpainting is a classical yet challenging problem in computer vison with many real-world applications. In this paper, we propose a novel method for inpainting based on Convolutional Neural Network (CNN) and Generative Adversarial Networks (GAN). By analogy with the autoencoder, a new context encoder is proposed to generate the contents of a missing image region conditioned on its surroundings. To improve the stability and efficiency, we also modify the architecture of the context encoder by introducing 1*1 convolution, as well as other improvements. In addition, a multi-scale discriminator combining with GAN is presented. During training, the reconstruction and adversarial losses are used for the global image. To generate more details, we further add a local texture loss for the missing part. Qualitative experiments show that our model performs favorably against classical methods in generating visually plausible inpainting results. Moreover, quantitative experiments substantiate the effectiveness of the proposed method in natural image inpainting.
Introduction
Image inpainting, aiming at filling missing or destroyed parts in images, is a classical low-level vision task with many realistic applications. According to the principle used, inpainting methods can be divided into partial differential and variational method, exemplar-based method, transform-based method, and hybrid image inpainting method. Deep-learning-based image inpainting has been an emerging method in recent years. Benefiting from a large number of hidden layers, Deep Neural Network (DNN) 1 can acquire complex non-linear mapping between data through the training of numerous datasets. When dealing with inpaint-ing of large areas, deep-learning-based method can often achieve the best inpainting effect. It achieves the consistency of the whole picture while maintaining the coherence of the boundary, as shown in Fig. 1.

Recently, considerable progress has been made in applying deep learning to image inpainting. For instance, Zoran et al. 4 firstly proposed an inpainting method by searching and copying similar patches from existing regions. Due to the lack of semantic understanding of images, this method is difficult to generate semantically reasonable results. In recent years, Convolutional Neural Network (CNN)5-7 has greatly improved the performance of tasks such as classification, detection, and segmentation of images.8-10 CNN has been proved to be capable of capturing abstract information of images at high levels, 11 Meanwhile, it has been demonstrated that image features extracted by CNN can be used as part of the objective function,12,13 which makes the generated image more semantically similar to the target image. Combining the CNN with a classical patch matching algorithm, 3 Ren et al. 14 introduced some feature mappings to the Shepard layer to learn semantic features of pictures. This method performs well when it finds the similar patch, yet it is likely to fail if the dataset does not contain enough data to match unknown areas. To address this issue, Vincent et al. 15 designed a denoising auto-encoder that can learn to reconstruct clean signals from damaged inputs. Kingma et al. 16 further proposed a variational autoen-coder (VAE) which can generate images by sampling or interpolation from the potential unit. However, the image generated by VAE is usually blurred since the training target is based on pixel-level Gauss likelihood. To generate more details, Larsen et al. 17 improved VAE by adding a discriminator for adversarial training. This discriminator came from the Generative Adversarial Network 18 and was proved that it could generate more realistic images. After extensive research on GAN,19-23 Pathak et al. 24 proposed the classical Context Encoder for inpainting. A self-encoder was designed to combine semantic features with inpainting, as well as a context discriminator. Yet there were obvious inconsistency between the repaired area and the whole image, and the effect was not ideal at the edge of the repaired area. Focusing on this problem, Iizuka et al. 25 further deployed two discriminators to distinguish the real image from the repaired image. But its training was time-consuming and difficult to converge since the generating network was not improved. For better training and handling arbitrary holes, Liu at al. 26 proposed partial convolution (PConv). To alleviate color discrepancy and blurriness, Contextual Attention (CA)27,28 was suggested, which allows CNN to extract information from regions far from the repair area. To effectively use the attention information, several modules were introduced29,30 based on CA. In 2019, a new model called EdgeConnect 31 was proposed. This model predicted the edge information of the lost part frstly and then used the contour information as a priori guide to repair the image. Motivated by this idea, Xiong et al. 32 further raised the efficiency and proposed the Foreground-aware method. Moreover, to produce multiple and diverse plausible solutions for each masked input, Zheng et al. 33 proposed a pluralistic inpainting module based on VAEs and GAN.
The method proposed in this paper was mainly inspired by the classical Context Encoder. Combining the advantages of CNN and GAN, we propose a novel method for image inpainting. In comparison to the classical methods, our model can generate more convincing inpainting results with better details and efficiency.
To sum up, the main contributions of this research are as follows:
An end-to-end inpainting method for natural images, is proposed, where global and local discriminators are introduced to respectively improve the coherence and details of the image.
A simplified encoder-decoder pipeline is presented to improve the efficiency and stability. In contrast to the original pipeline, the new context encoder is more effective to extract semantic features.
Experiments on three datasets show that our model performs favorably against the classical inpainting methods. Comprehensive experiments are performed to demonstrate the utility of the improved context encoder.
Related Work
In this section, we present a brief review on the relevant works including convolutional neural network and generative adversarial network.
Convolutional Neural Network
In traditional fully connected neural networks, each neuron is connected with other neurons in the adjacent layers. However, massive parameters among each layer heavily increase the calculation cost, which may lead to over-fitting problems. In the real world, people can infer the content of the whole picture by seeing only few blocks because of the “two-dimensional spatial characteristics” of images. It means the content of a picture can be recognized by extracting the features of this image, which is called convolution. A standard CNN network structure is shown in Fig. 2.
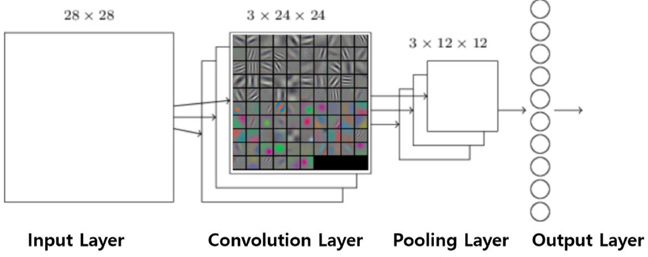
Basic network structure of CNN.
The main ideas of Convolutional Neural Network5-7 are local connection, weight sharing, and down-sampling in pooling layer. Local connection and weight sharing reduce the training complexity and avoid over-fitting problem to a certain extent. At the same time, down-sampling further reduces the number of output parameters, and gives the model the tolerance of slight deformation, which improves the generalization ability of the model.
Generative Adversarial Networks
Generative Adversarial Network (GAN) 18 is a combination of generator G and discriminator D. The discriminator is used to identify whether the generated image is from real world or not. The goal of the generator is to generate realistic images as much as possible to confuse the discriminator.
Principle
The generator mainly generates samples with the same distribution from training data. With the input x and class label y, the joint probability distribution (probability distribution of random vectors with two or more random variables) is estimated in the generator. The discriminator estimates the conditional probability distribution of the sample belonging to a certain class, which means whether the input is real data or fake. The basic network structure of GAN is shown in Fig. 3.
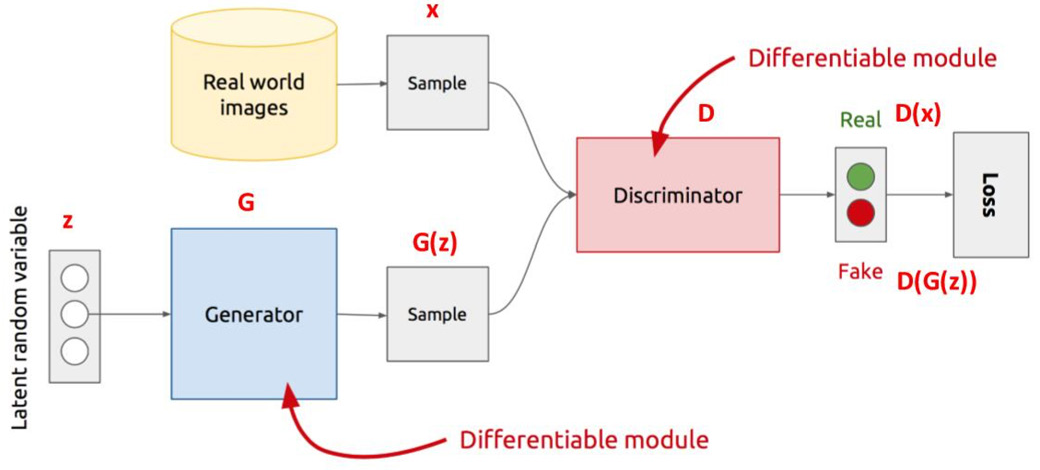
Basic network structure of GAN.
Optimization
The generator needs to generate better pictures to confuse discriminators, while the discriminator needs to improve itself to identify fake pictures from generator. There is an antagonistic relationship between the generator and discriminator. After this rivalry game, both sides will reach a Nash equilibrium. The optimization process of GAN model is a “mini-max two-player game” as shown in Eq. 1.
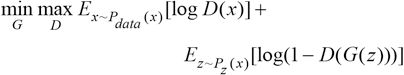
where x represents the image from the sample set, z is a group of random vector coding, which is the input of generator G. G(z) denotes the picture generated by G, D(x) is the probability that D judges whether the sample picture from the data set is true, while D(G(z)) is the probability that D network judges whether the picture generated by G is true.
Method
To achieve reasonable inpainting, three different CNN network models are proposed in this paper, including context encoder, local discriminator, and global discriminator. This section will discuss the structure design of each part, then introduce the loss functions and summarize the overall structure of the model. The detailed architectures of the networks in this work are shown later in the Network Architecture section.
Encoder-Decoder Pipeline
The structure of context encoder is an encoder-decoder pipeline. The first part is a series of down-sampling through convolutions, and the second half basically is an inverse operation of the first half. The context encoder gradually reduces the scale of the image in the encoding process and increases the scale during decoding. These two parts constitute a convolution encoder to output the forecast image of missing parts.
Encoder
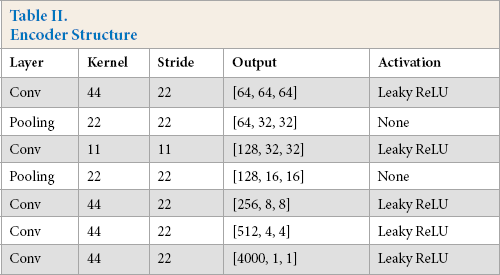
The encoder Enc uses 5-layer convolution and 2-layer pooling, as shown in Fig. 4. It takes a 128×128 partially missing image as the input and extract its features through convolutions. The output is a 1×1×4000 feature map, which is the latent feature representation of this image.
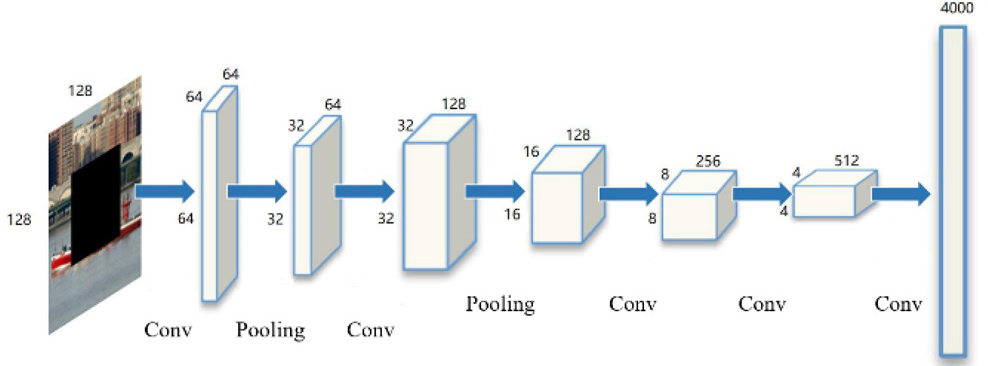
Network structure of Enc.
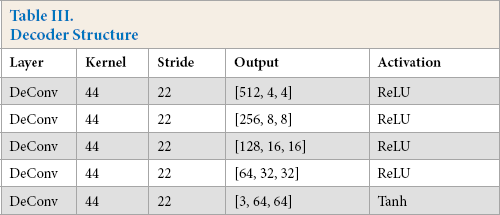
The decoder Dec refers to the generating network part of DCGAN 21 and contains five consecutive transpose convolutions, as shown in Fig. 5. The decoder takes the feature of 4000 layers extracted by the encoder and outputs the missing image with the size of 64×64. The decoder uses transpose convolution for up-sampling. Transpose convolution can restore the input feature map to the original shape with different values, which is the basis of image inpainting.
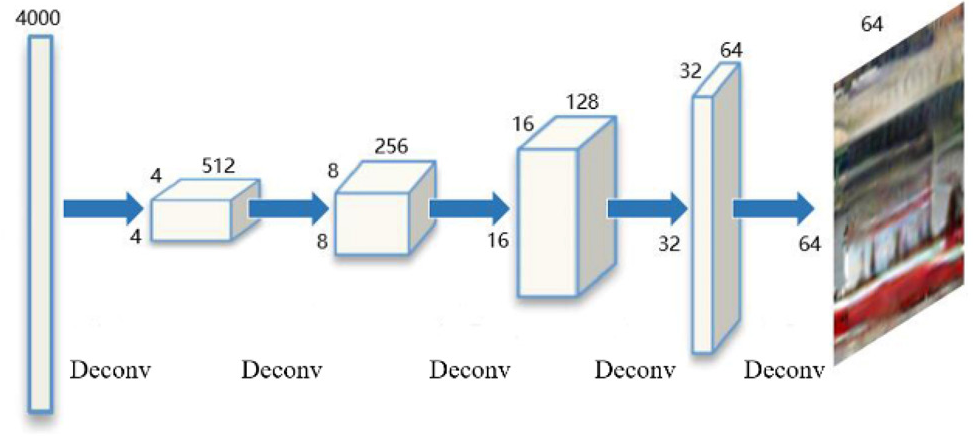
Network structure of Dec.
For now, a new context encoder for extracting context features and predicting the contents of missing areas has been constituted, which is a self-encoder based on convolutional neural network.
Discriminator
According to the work of Pathak et al., 24 if there is only one generator, the resulting image will be quite vague with only a rough outline. To improve the details of the generated images, two adversarial training networks are used as discriminators in this model, focusing on two different aspects: local region and global region. Among them, the global discriminator is to ensure the coherence of the whole picture, while the local discriminator is to improve the details of the repaired region. The specific structures will be discussed respectively in the following sections.
Local Discriminator
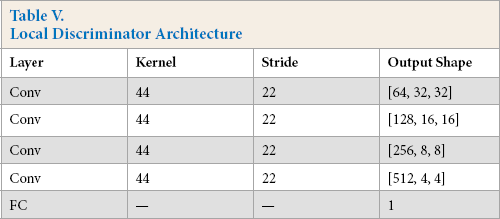
The local discriminator DL contains 5-layer convolution, as shown in Fig. 6. It takes the generated image of context encoder and the real image of the missing region as the inputs, and outputs a Boolean variable to indicate whether the generated image came from the generator or real data. Benefited from this local texture discriminator, the model can generate realistic images with more details.
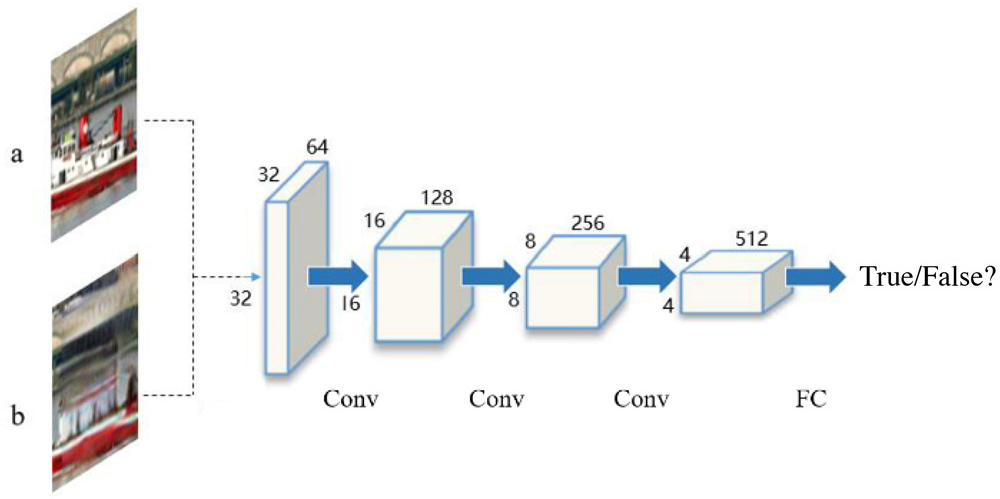
Network structure of DL.
Global Discriminator
Although adversarial constraints are used for the missing part, there are still some shortcomings. On one hand, the local constraints cannot regularize the global structure of the whole image, i.e., the consistency between the generated part and the known content, cannot be guaranteed. On the other hand, since this local constraint only focuses on the missing region, it is difficult to affect the pixels in the existing region during the back propagation. This will cause the discontinuity in the boundary of generated part, which will appear unnatural in the visual sense. To alleviate this problem, Li et al. proposed a new loss called the global adversarial loss. 34 Motivated by this idea, we first complete the inpainting part to the original image and then discriminate whether the completed image is a real sample or predicted one.
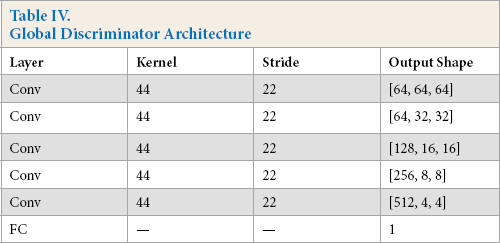
The global discriminator DG uses a network structure like the local discriminator. It takes the real image and the repaired complete image as inputs, and outputs a Boolean variable to indicate if the completed image is from the real dataset. By adding this global discriminator, the model can improve the authenticity of the predicted content, as well as the continuity of pixels in the boundary region. The network structure of global discriminator is shown in Fig. 7.
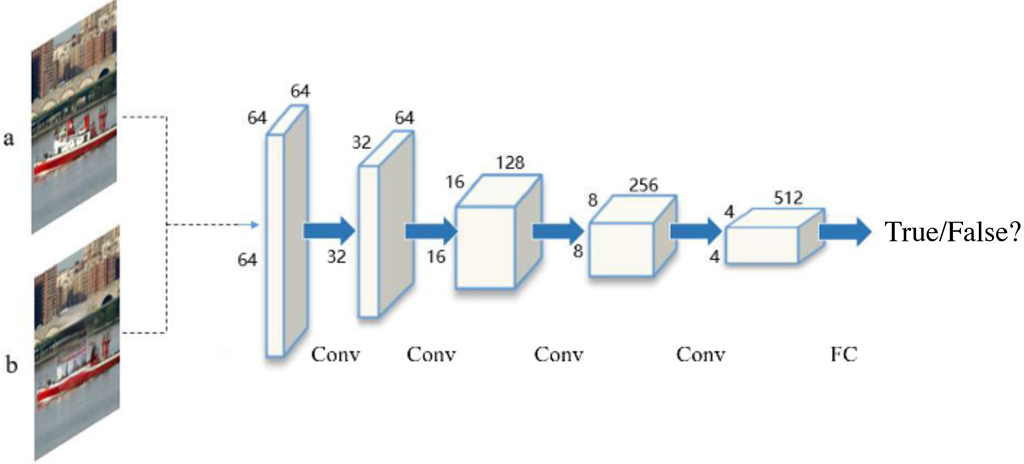
Network structure of DG.
Loss Function
The loss functions in this study contain the following two types: (1) reconstruction loss, which is designed to evaluate the reconstruction effect of the image after inpainting, and (2) adversarial loss, which aims to keep the generated image as realistic as possible. The GAN loss is divided into two parts since there are two different discriminators. The detailed functions will be further introduced in this section.
Reconstruction Loss
Reconstruction loss (Lr) is firstly introduced for the context encoder, which is the L2 distance between the network output and the missing part in the original image. The reconstruction loss (Lr) is mainly used to capture the hidden semantics and ensure the coherence with regards to its surroundings. The reconstruction loss is given by Eq. 2.
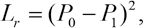
where P0 is the true value of the missing area and P1 is the output of the context encoder.
Adversarial Loss
Since L2 loss tends to smooth out various assumptions, it encourages the context encoder to produce a rough outline of the predicted object, which often fails to capture any high frequency details. In this study, we alleviate this problem by adding local texture loss and global adversarial loss, which are defined by Eqs. 3 and 4.
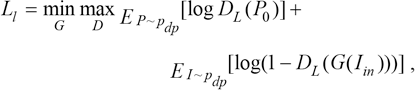

where Pdata and Pmodel represent the distribution of real images and images generated from the model, and Pdp is the distribution of images after preprocessing, which will be further introduced in Data Preprocessing section. G(Iin) represents the predicted picture of the missing area, while I0 and I1 represent the original image from dataset and the completed image after inpainting.
Joint Loss
The overall loss function is defined in Eq. 5.
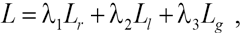
where λ1∼λ3 denote the hyperparameters used to balance losses.
Overall Structure
The general idea of this model is that the context encoder is an hourglass AutoEncoder, 35 and the discriminators are two continuous convolution networks. The context encoder extracts the features of input image through a series of convolutions. Ten it predicts the missing region through decoding and outputs the repaired part of the image. The multi-scale discriminator is used to distinguish whether the prediction is true. The multi-scale discriminator contains two networks, which are respectively used for global and local image training. The overall structure of this model is shown in Fig. 8.
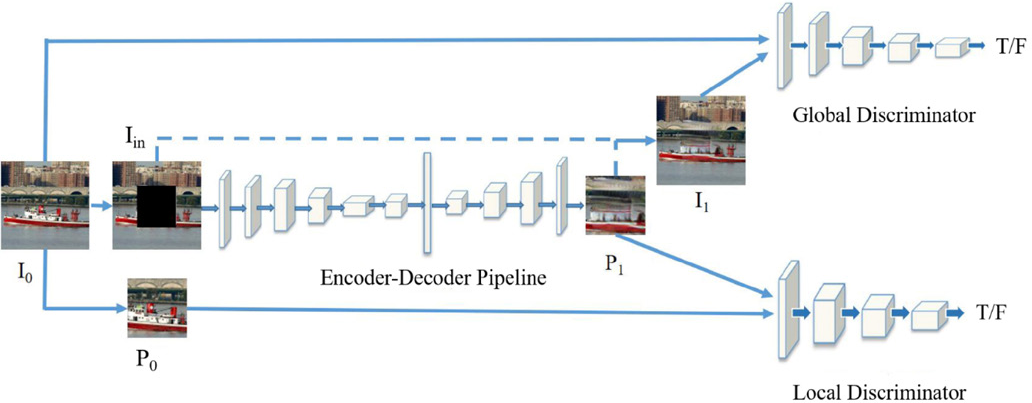
Overall network.
Implementation
Training Strategy
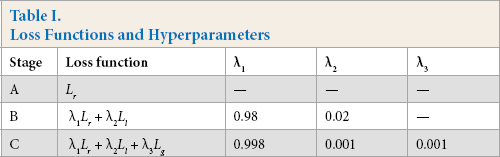
In the beginning, to accelerate calculation, we started training the context encoder and two discriminators at the same time. It turns out that this training strategy may lead to the deviation of training direction and fail to achieve the optimal training. To alleviate this problem, we referred to the Curricu-lumNet 36 training strategy, which gradually increases size and training difficulty of the model. In this work, training procedure is divided into three phases. Firstly, only reconstruction loss (Lr) is used for context encoder to get blurry images. Secondly, the local texture loss (Li) is added to fine-tune the model. Finally, the global adversarial loss (Lg) is deployed to further tuning parameters and optimize the output. In order to stabilize the training process while adding new losses, λ2 and λ3 are supposed to be incremented slightly from 0, which is shown in Table I.
Loss Functions and Hyperparameters
Network Architecture
The detailed architectures of the context encoder are listed in Tables II and III. Among them, the encoder uses five convolution layers, each layer of convolution is followed by BN (Batch Normalization) 37 and Leaky ReLU. The first two layers of convolution are followed by max pooling, which constitutes a normal convolution network. However, the following convolutions are carried out without pooling operations, since the number of features was already small. In order to accelerate the calculation, we skip the rest pooling operations. The decoder contains five layers of transpose convolutions, the first four layers of deconvolutions are followed by ReLU, and the fifth layer is followed by Tanh.
Encoder Structure
Decoder Structure
As shown in Table 2, 1*1 convolution is implemented in the third layer, which was originally proposed in Network in Net-work. 38 It uses fewer parameters than AlexNet 9 and achieves the same effect. Meanwhile the 1*1 convolution core can play a role of cross-channel aggregation, so it can be further used to reduce or increase dimension.
The detailed structures of two discriminators are listed in Tables IV and V. The local discriminator has four convolution layers, followed by a FC (full connection) layer. And the global discriminator shares a similar structure with the former, which consists of five convolution layers and a FC layer. In both two discriminators, each convolution layer is followed by BN and ReLU.
Global Discriminator Architecture
Local Discriminator Architecture
Data Preprocessing
The input of the proposed context encoder is an image with one of its regions “dropped out.” In real world applications, locations and sizes of the missing parts could be various. Focusing on locations, we can simply input the generated region and the “dropped out” part of the real picture to our local discriminator. As for different sizes, the network structure of the local discriminator can be customized according to the size of the hole. In this paper, we trained the model in the most common case: central missing, as shown in Fig. 9. For every original image, a square mask is added in the middle with the size of 64*64, which is half of the total area. In order to assume zero-centered inputs, values in the mask are set to zero. After preprocessing, the dataset becomes (I0, Iin, P0) where I0 and Iin represent the real image and the image with black mask respectively, and P0 is the original picture of the “dropped out” area.

Examples of data preprocessing.
Algorithm
The training process of the inpainting network is represented in Algorithm 1.

Training procedure of our inpainting network.
Training Settings
The model is trained by Adam optimizer 39 (B1 = 0.5; B2 = 0.999), batch size is set to 100, and learning rate is set to 0.0003.
Experiments
The experiment in this study is based on the Pytorch, which is implemented on an Ubuntu 18.04 operating system with Intel (R) CPU i7 8700 @ 3.20 GHz and NVidia RTX 2080Ti-11G GPU graphics processing unit.
Dataset
Paris StreetView dataset 24 is used for model training and contrast test, which contains 15,000 street photos of Paris, including 14,900 images for training and 100 for test. ILSVRC dataset 40 is a subset of ImageNet, which contains over 1.3 million images of various kinds. In this study, we select 80,000 training images combined with 10,000 validation images as the training set and 10,000 test images to evaluate. DeepFashion dataset 41 is a large-scale clothes database with over 800,000 diverse fashion images. Describable Textures Dataset (DTD) contains 5640 various texture images. 42 LSUN dataset 43 is a large dataset for scene understanding, which contains images of 10 different scenes. In this paper, we use the last three datasets for a series of further experiments on the proposed model.
Qualitative Evaluation
Trough the training of the Paris StreetView dataset, the experimental results are shown in Fig. 10. It is observed that the effect of our model becomes better and better as the training continues, which proves the feasibility of our model for inpainting.

Outputs of the model every 1000 epochs (n).
We compared the test results of the new model with classical PatchMatch method, Context Encoder, and Globally and Locally Consistent Image Completion (GLCIC) methods. In order to compare fairly, these models are trained with the same number of iterations on ImageNet. The experimental results are shown in Fig. 11. It can be seen that the results of PatchMatch method are quite clear, yet the images tend to be wrong in semantic since this method relies heavily on existing blocks. The results of Context Encoder are visually blurry since there is no effective discriminator to improve details. After the same number of iterations, GLCIC method produces less details than ours because its generating network is too complex and time-consuming.

Comparison of repair results of different models.
Quantitative Assessment
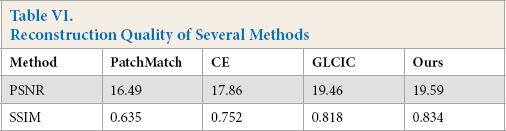
In addition to the visual effects, the performance of image inpainting can also be evaluated in terms of image quality. We compare the reconstructed image with the original image and calculate the peak signal to noise ratio (PSNR) and SSIM, which are two commonly used image quality assessment indicators. The results are listed in Table VI.
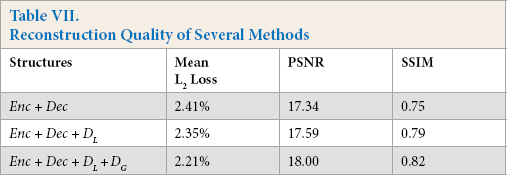
Reconstruction Quality of Several Methods
PSNR (Peak Signal to Noise Ratio) is a full reference indicator which references the image quality. It measures the difference of the pixel value directly. The PSNR unit is dB; the higher the value, the closer the generated image is to the original image. PSNR mainly defines two values, one is mean square error (MSE), and the other is PSNR (Eqs. 6 and 7).
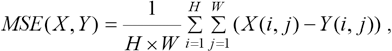
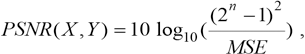
MSE represents the mean square error of the current image X and the reference image Y, H, and W represent the height and width of the image respectively, and n is the number of bits per pixel which is empirically set to 8; that is, the gray level of the pixel is 256.
SSIM is also a kind of full reference index, which measures the gap between the repaired image and the real image. Its value ranges from 0 to 1. The larger the value, the smaller the image distortion, that is, the better the image quality. Its calculation is a little complicated, and its value can better reflect the subjective perception of human eyes. The formula can be written as Eq. 8.
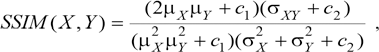
where μ X and μ Y respectively represent the mean values of the images X and Y, σ X and σY represent the standard deviation of images X and Y, σXY represents the covariance of images X and Y, and c1 and c2 are constants, in order to avoid the case where the denominator is 0, usually set C1 = (K1 × L)2, C2 = (K2 × L)2, and C3 = C2/2. Usually, K1 = 0.01, K2 = 0.03, and L = 255.
As can be observed from Table VI, the reconstruction ability of PatchMatch is highly restrictive since the limitation of patch search. Compared with classical Context Encoder (CE) and GLCIC methods, the proposed model can generate better details by using improved encoder and decoder, so as to achieve better reconstruction.
Validation
Compared to the above inpainting methods, we further propose some improvements based on the architecture and training method. In this section, comprehensive verification experiments are deployed to evaluate the effectiveness of these improvements.
Local and Global Discriminators
Compared to the original Context Encoder method, we propose a multi-scale discriminator in order to improve the image quality from both global coherence and local texture. To substantiate the utility of the multi-scale discriminator, three comparative experiments are conducted, corresponding to three network structures. For the first experiment, we only deploy the encoder-decoder pipeline. Local and global discriminators are added respectively during the next two experiments. All three experiments were trained separately with Paris StreetView dataset. For each training, loss functions and hyperparameters are set as in Table I.
Fig. 12 shows the experimental results of the proposed multi-scale discriminator. It can be seen that the output (c) is quite fuzzy with few contents. The reason is that the reconstruction loss tends to make the image smoother with no adversarial loss. After adding a local discriminator, the inpainting region (d) becomes clearer, e.g., the wall textures and lamppost have been generated. At last, ben-efited from the multi-scale discriminator, the edges of the missing area (e) are more coherent with more texture. It can be seen that the street light has become more natural.

Experiments on multi-scale discriminator.
Table VII lists the quantitative results of the multi-scale discriminator, which supports the method of using two separate discriminators on different scales.
Reconstruction Quality of Several Methods
Encoder-Decoder
Compared to the GLCIC method, we propose a series of modifications to simplify the encoder-decoder pipeline. In order to verify the effectiveness of these improvements, an image classification experiment is conducted. We separately train the traditional encoder in GLCIC and our improved one with CIFAR-10 dataset. 44 The classification accuracy is recorded in every epoch, as shown in Fig. 13. It can be seen that the proposed new pipeline can achieve convergence faster. Without reducing the accuracy, the improved context encoder tends to be more efficient and stable.
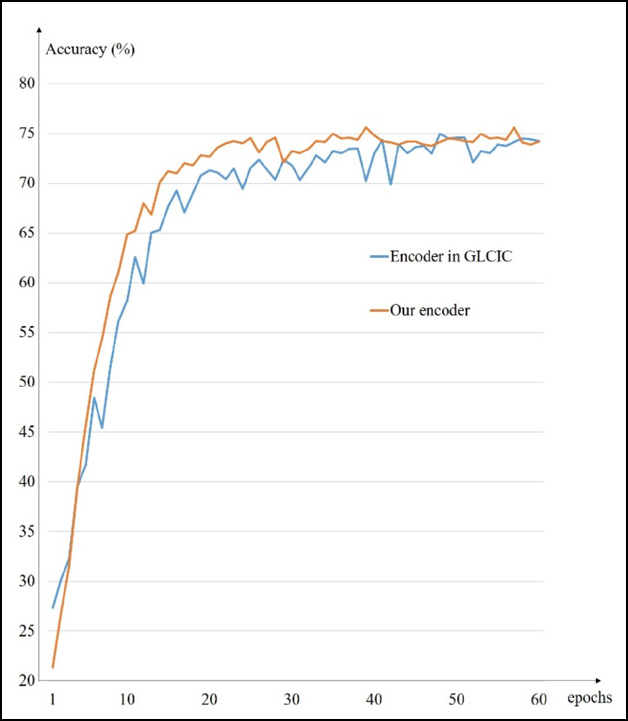
Comparison of two encoder network.
Other Experiments
Inpainting has many practical applications, such as remote sensing. 45 Hence we also conducted experiments on DeepFashion and DTD datasets, which prove that our model has potential applications on the fashion and textile fields. To further evaluate the generalization ability of model, we test on the Lsun dataset with the model well trained by ILSVRC dataset. The experimental results are shown in Figs. 14–16.

Experiment on DeepFashion dataset.

Experiment on DTD.

Further experiment on generalization ability.
Conclusion
This paper proposed a conditional generation model for natural image inpainting. A novel encoder-decoder pipeline is proposed to extract content features and achieve semantic inpainting. Benefited from the simplified generating network, our model is more effective and stable than the classical methods mentioned above. Moreover, a multi-scale discriminator is presented, allowing the model to generate images with better texture and details. Experiments show that the proposed model learns correct semantic features and achieves visually plausible inpainting. Limited by only one local discriminator, our model simply works well for pictures with one region “dropped out.” And based on the convolution principle, this method shows restriction on irregular mask since the discriminator take square images as input. In future work, we will try to repair images with random blocks, and try more effective models to further improve the stability and quality of inpainting.
Footnotes
Acknowledgments
The authors are very indebted to the anonymous referees for their critical comments and suggestions for the improvement of this paper. This work was supported by the grants from the National Natural Science Foundation of China (Nos. 61673396, 61976245) and the Fundamental Research Funds for the Central Universities (18CX02140A).