
Abstract
We present a multi-task model to perform multiple fashion attribute recognition and retrieval together. Although classical computer vision problems, they still lack good performance in multiple classes. In the fashion domain, the recognition task to capture the attributes of fashion clothing is always challenging, as well as the retrieval task to find similar items of fashion clothing. To handle the first challenge, we built a recognition model to parallelly and independently output a set of labels, each for a pre-defined single attribute notion. To handle the second challenge, we embedded the fashion clothing image into a feature vector, where different subspaces capture different notions of similarities. These two sub-tasks were then connected to be trained jointly in a multi-task learning framework. Their losses were also well aligned, combined, and optimized collectively.
Introduction
Fashion e-commerce has been growing rapidly and significantly with the power of online shopping and social media. With such a growth, fashion visual analysis researchers have made huge progress in fashion recognition,1-5 fashion retrieval,6-12 and fashion recommendation.13-17
Despite advances in recent works, robust fashion recognition or retrieval is still a challenge for several reasons. First, fashion images are generally composed of multiple different fashion items (objects) that vary in styles and viewpoints. Even if one fashion image contains only one fashion item, there still exists various attributes located on different pixel patches. Therefore, it is hard to describe all items through a global representation embedding. Second, with the deform-able nature of fashion items, the wide variety of visual distortions in a fashion image will lead to a hard recognition. Deep learning methods have performed remarkably well in addressing these issues by applying fresher architectures,18,19 attribute modules,2,8,20,21 and attention mechanisms.22-24Other solutions include loss functions selection, similarity metrics building, and network structures refinement, which also play important roles.
In this work, we present a joint deep learning framework to perform both attribute recognition and retrieval tasks in a multi-task manner.
For the attribute recognition task, we notice that some preliminary works1,20,25 rely on hand-crafted features like SIFT 26 and HoG, 27 while others apply deep neural networks to explore the clothing items and attributes. One work describes people's clothing with fine-grained fashion attributes. 20 Another utilizes weekly labelled image-text pairs to discover fashion attributes. 28 One study proposes a multi-task approach to predict multi-attributes, but fails to present satisfactory results since the annotations of training data are poor. 29
Today, we have access to well-labelled public fashion data-sets, among which is a newly released one, FashionAI, 30 which has a great annotation quality of fashion attributes. Although it is single-attribute annotated, we introduced a multi-column recognition network that enables us to perform multi-attributes recognition on this dataset. Usually the final layer of a recognition/classification model is a single-column softmax layer, but we modified it to be several separate multi-column softmax layers. The adoption of this architecture allowed us to have an eye on multiple highest probability scores from different softmax outputs, while each highest score represents the most possible label of a corresponding fashion attribute notion.
For the attribution retrieval task, there have been few works studying multi-attribute fashion retrieval. One approach concatenates hand-crafted features into an embedding vector for each fashion item. 8 A very recent work presents a deep neural network that adopts mixed multi-model embedding to represent all fashion items in image as an outfit item. 7 However, there exists a severe disadvantage among these methods. The learned representation embedding is unin-terpretable, which provides us zero information about why the retrieved fashion items are similar. For many real-world retrieval applications, it is highly necessary for designers, consumers, and businesses to understand in what kind of similarity and on what attribute notion the retrieval work is performed. In other words, an interpretable and partitioned embedding of a fashion item is extremely vital for a practical fashion retrieval system. To address this issue, we introduced a triplet-network-based retrieval model to learn the similarity. This similarity involves multiple fashion attribute notions, and every attribute notion is pre-defined in FashionAI. 30 In this way, users can retrieve the most similar fashion items in a specific and interpretable attribute notion, such as neckline design, collar design, and sleeve length.
To jointly perform these two tasks and to possibly allow one task to benefit from another, as mentioned above, we developed a multi-task training strategy to optimize the model. The joint training strategy refines the network structure and combines the loss function of recognition task and retrieval task. It is intuitive that the combined categorical cross entropy loss from recognition and similarity-based triplet loss from retrieval together will force the representation embedding of fashion items to be highly distinct. We evaluated this assumption that these two tasks may benefit from each other from their respective perspectives, and conducted empirical experiments to demonstrate that the proposed multi-task learning strategy had advantages.
In brief, our work has three main contributions. 1) We present a multi-column recognition network that allows us to recognize multiple attributes of one fashion item even though it is originally single-attribute annotated. 2) We put forward a partitioned feature representation learning model for the retrieval task that enables us to describe the fashion item through interpretable embedding smartly and accordingly. 3) We propose a multi-task learning framework to jointly train the attribute recognition and retrieval tasks together, upgrading the performances of both tasks significantly.
Related Work
Fashion Retrieval
Fashion retrieval, the task of finding the most similar fashion items in a fashion item query, has drawn great attention recently. Researchers have integrated several deep learning methods to learn visual representations of fashion items and calculate the similarity of these representations to perform retrieval. Learning similarity is one of the applications of metric learning frameworks, among which the triplet network31,32 has proven to be successful in several recent works.7,8,33,34 A triplet is defined as a combination of one anchor sample, one positive sample that shares the same label with the anchor, and one negative sample with a label that is different from the anchor's. The network is trained to minimize the distance between the anchor sample and positive sample, as well as to maximize the distance between the anchor sample and negative samples. By applying a triplet framework, FashionNet 10 augments visual retrieval by using categorical and landmark annotations. One study builds a multi-scale triplet network to learn image similarity. 31 Another proposes a scenario-based triplet weighting approach to address the clothing retrieval problem. 35 Two others achieve success in building a similarity metric with triplet loss.32,36 Nonetheless, several challenges still exist in the triplet network when multiple notions of similarities are involved, especially in the fashion domain where two clothes can be similar in color, but totally dissimilar in style at the same time.
To overcome the single-notion nature of triplet loss, the network was adapted to satisfy with multi-similarities. A multi-task triplet network was used in one study to model the notion of instances in embedding space. 10 Another system learns separate localization-aware heads after shareable layers for each attribute and category. 37 Researchers introduced a memory module and a multi-stage training schedule for similarities measurement of different attributes. 38 Another set of solutions to this problem are derived through some simplified network structures. A modulation module was applied to learn embedding of binary attributes. 39 Subspace embedding was introduced to encode the distinction of various attributes. 40
Yet, to our best knowledge, no previous work has ever taken well-defined fashion design attributes into account when building multi-notion-attribute retrieval models. In this work, we model separate similarity measurements in eight different pre-defined fashion attribute notions within a single system. We capture similarity information for different attributes by disentangling the global embedding of one fashion item and viewing each subspace.
Multi-Task Learning
Compared with solving multiple tasks independently and separately, Multi-Task Learning (MTL) jointly optimizes various tasks to achieve a better global efficiency and performance. A comprehensive survey study is available. 41
In computer vision tasks, one important objective is to learn the features of an image. The features of a single image learned from different tasks might compete with each other in a joint training manner, but several works have proved that in fact it has remarkable efficiency. A multi-task network to jointly perform body-part and joint-point detection was introduced. 42 A multi-linear multi-task method for person-specific facial action prediction was proposed. 43 Other applications in landmark localization, 44 face detection, 45 and pedestrian pose estimation 46 all achieve great success with the power of MTL. Recent work47,48 analyzes the intrinsic relationships between different sub tasks and verifies its benefits. Since MTL has proven its efficacy, we are motivated to apply this technique in our fashion recognition and retrieval model.
Methods
The overall architecture of the proposed network is shown in Fig. 1. For our model, we selected VGG 1649 as the Convolution Neural Network (CNN) backbone, on which we made some modifications on final fully connected layers and built subsequent networks to process recognition and retrieval tasks. We chose this baseline backbone as it has achieved notable performance in various vision tasks and with a reasonable degree of complexity. All layers before the Pool5 layer in VGG 16 were shared. A global average pooling (GAP) layer was subsequently followed to extract feature representation embedding for the input image. We then divided the following networks into two streams. The upper branch was denoted as a multi-column recognition network and the lower branch as an attribute-aware retrieval network. We jointly learned these two tasks by combining two types of losses. One was the cross-entropy classification loss from the recognition model that encourages the learned feature representations to be distinct among other fashion attributes. The other was the similarity distance loss from the retrieval model that encourages the learned feature representations to be close between similar fashion items, while being discriminative from diverse fashion items. We now introduce these two network branches separately.
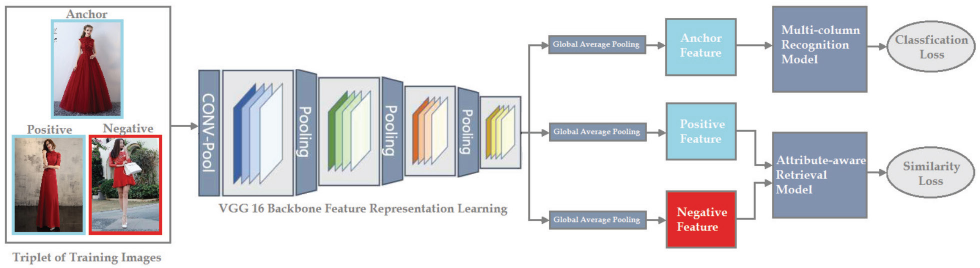
Proposed multi-task learning framework for attribute recognition and retrieval.
Attribute Recognition Network
We introduced an attribute prediction network to infer multiple estimated attributes of a single fashion item. In a supervised setting, we normally need multiple-attribute ground truth annotations to do this job. However, in many scenarios, one fashion item in an image sample is only annotated with one single attribute, and the corresponding recognition task is to exactly predict that single attribute label. We were aware that there are likely various attributes on one fashion item, like color, lapel design, and pattern. In a real recognition dataset, one single fashion item is always annotated with only one attribute label, but it may have multiple copies, and each of them is paired with a distinct label. One fashion item will appear repeatedly several times, such that in each appearance, it pairs with a distinct annotated single attribute label. If an image is associated with four attributes, then that image will appear for four times. To transform this single attribute annotation into a multi-attribute annotation form, we could play a trick by relabeling the fashion item with all attributes notions, keeping its original single-attribute annotation unchanged, and setting the values of the rest new-added attribute notions all as none. In other words, those newly added attribute labels are all set to be zeros in a one-hot encoding situation.
Following this design, we can lead the recognition network adaptable for
multi-attributes. In our experiment, for example, the classical fashion
recognition task may only recognize the sleeve length attribute of a fashion
item, while our modified task is to simultaneously recognize all pre-defined
attributes of this fashion item including sleeve length, skirt length, coat
length, and pant length. Mathematically speaking, for each one fashion item
xa that one image only contains, our network
is proposed to recognize a set of attributes ya that
existed on this item. Attributes recognition is not a binary classification
problem, whether there exists an attribute or not. In reality,
ya has multiple dimensions and each
represents an attribute notion, such as collar design, lapel design, neck
design, and neckline design. For each attribute dimension
So how are we going to design the network? The multi-attribute prediction model is designed in a multi-column style where shallow feature extraction layers are shared, but the final softmax layer for each different attribute dimension is mutually independent. By this design, we could have a broader view on the highest probability scores on each separate softmax function across all attribute dimensions, enabling us to recognize multiple attributes at the same time. As explained before, the VGG 16 CNN builds the shared low-level feature extractor network with its final single-branch fully connected layer replaced by eight parallel multi-branch dense layers, and are followed by softmax activations. The feature embedding of one fashion item will be copied into eight separate vector spaces and rectified to generate the attribute labels ya. As shown in Fig. 2, we can clearly understand that the core idea of multi-column design in Fig. 2b is to recognize the attribute labels separately in each attribute dimension, while the traditional single-column architecture in Fig. 2a combines or mixes all attribute values across various attribute dimensions together. The dashed box in Fig. 2b illustrates the inner structures of the multi-column recognition model in Fig. 1.
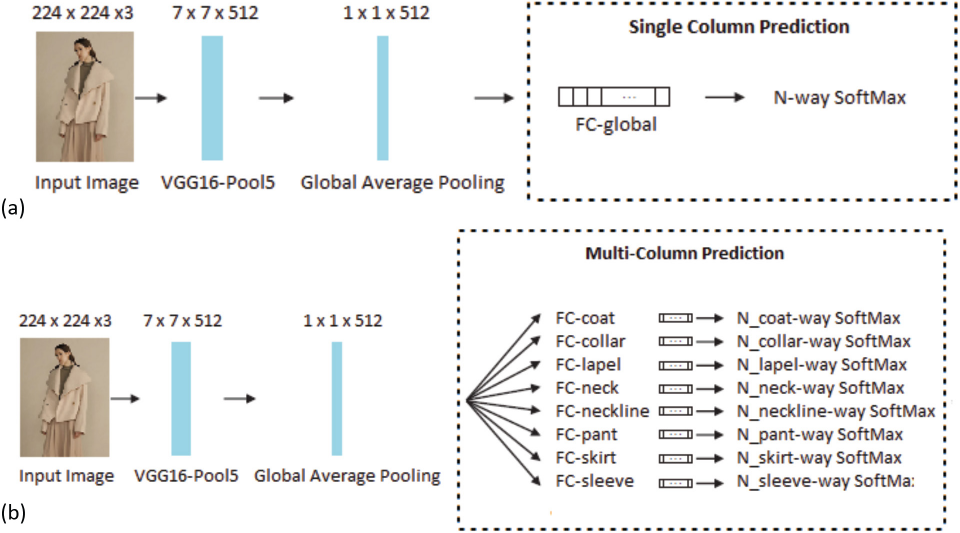
Structures and functions. (a) Single-column structure containing a global softmax function. (b) Multi-column structure containing eight independent softmax functions.
Some may be concerned that relabeling the fashion item with zeros for all originally not annotated attribute dimensions in one-hot label may inevitably cover the truth, when some of these attributes actually exist on that fashion item. It is claimed that, despite not being annotated, these truly existing attribute labels should be relabeled as ones, but not zeros. However, during the training procedure, we noticed that all-zero labels will return a zero loss and no gradients back, hence produce no influence on the trainable parameters. Therefore, we are not concerned if these zeros annotations will harm the classification.
To express the above mentioned method in mathematical form, given a fashion item xa from an image and its corresponding feature representation vector f(xa) learned from the VGG 16 backbone, we define the attribute recognition loss of this image using cross-entropy loss as Eq. 1.
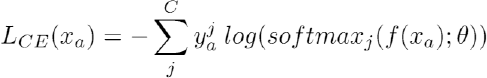
C denotes the total number of attribute types, and
Since the zero label value will only lead to zero loss and hence produce zero effect on gradient backpropagation, the defined sum loss is in fact equivalently valid as its single form in Eq. 2.
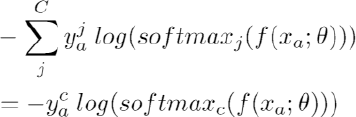
c is the original labelled single attribute dimension. Although this multi-column loss looks exactly the same as the separate single-column loss in form, it still provides a combined information of losses to the shared deep neural layers. The advantage of this multi-column model is also clear, that such architecture greatly avoids features over-fitting, and hence obtains more robust model generalization ability.
Attribute Retrieval Network
Besides attributes inference, we would also like to compare the input image with the rest of the database to process retrieval work. Our goal is to learn a nonlinear feature embedding f(x), which is also used for aforementioned attribute recognition, from an image x into feature space ℝ d such that for a pair of images (x, x) the distance of their embedding represents their similarity. Moreover, we also hope this similarity is attribute-oriented, such that the similarity between example fashion triplet images in Fig. 3 are presented in different notions. This attribute-aware similarity is much more intuitive than general similarity, but many previous works in fashion retrieval have ignored it. Considering performance and efficiency, we chose to build this idea upon the Conditional Similarity Network (CSN), 40 which is briefly reviewed in the following content before describing our modifications.
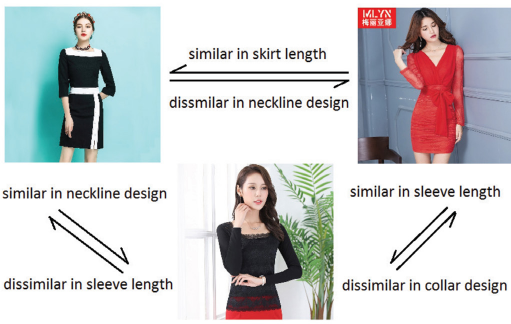
Example illustrating how fashion items can be compared through multiple notions of similarity.
CSN
The CSN model was designed to learn disentangled embedding for different attribute dimensions in a single model. A general representation is first learned as the global feature embedding through shallow layers of neural network. Ten, a trainable mask embedding layer is followed and then learned to isolate a specific part, although it might be a disjoint, of the representation feature embedding when only one specific attribute dimension is taken into account. This network structure allows attribute embedding across all dimensions, shares the same parameters at early stages, and then forces them to be discriminative by learned masking at the final step.
Up to now, we have only discussed the workflow of one fashion item, but similarity comparison is about multi-fashion items. Given two fashion items xi and xj, the similarity of the two corresponding global embedding f(xi) and f(xj) are reflected by the Euclidean distance Dm as Eq. 3.
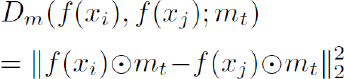
mt is a selected mask embedding for one corresponding attribute dimension t that both xi and xj contain, and ⊙ denotes element-wise multiplication. The original CSN designers 40 trained this similarity network in the popular triplet manner, that one anchor (a) image input, one positive (+) image input, and one negative (-) image input were combined together in a triplet to train jointly. Tree fashion items from three input images within a triplet shall share at least one attribute dimension in which the similarity calculation would make sense, and in our dataset, we labeled each image with only one attribute dimension. Therefore, to simplify notations, in the following expressions we denote ma to replace mt representing the embedding mask of the corresponding attribute type t that are shared among anchor, positive, and negative items. Hence the final triplet loss is defined as in Eq. 4.
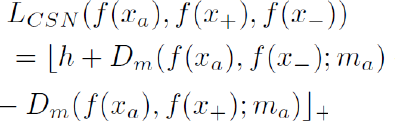
h is a margin value to control the minimum extent of difference between two distances. Furthermore, the general unmasked feature embedding f(∙) is L2 normalized to encourage the regularity in latent embedding space. To encourage sparsity, the mask vector is also L1 normalized.
We integrate these two types of losses as regularization loss in Eq. 5.
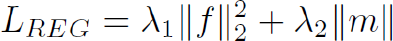
λ1 and λ2 are scalar parameters.
We modified the original CSN model by L2 normalizing the masked feature representation embedding (i.e., f⊙m), as this setting tends to lead a more stable training. According to empirical pre-experiments, we decided to use the inner product as the similarity metric in the replacement of Euclidean distance, since the former metric is more meaningful than the latter in embedding vector space. Moreover, as masks can be viewed as an attention mechanism over the global representation embedding, we followed general attention models that force them to sum to one.
Joint Formulation for Attribute Recognition and Retrieval
For the final stage of multi-task model training, we used cross-entropy loss for attributes prediction loss and triplet loss for similarity loss together in the form of Eq. 6.
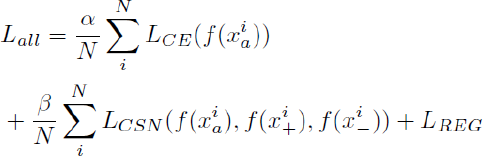
N is the total number of image examples (or fashion items, as
every single image only contains one fashion item).
Experiments
In this section we will introduce dataset, baseline, and model variants, and evaluation protocols as well as training details. We will also present and analyze the experiment results quantitatively and qualitatively.
Datasets and Triplets Building
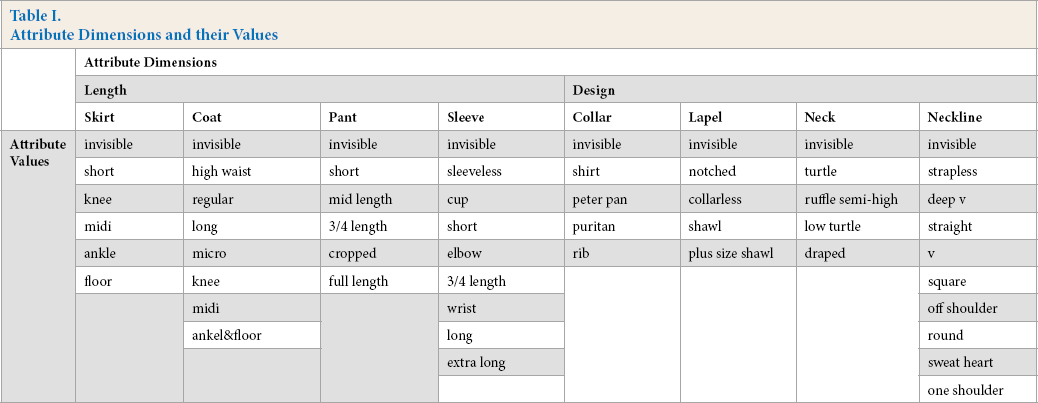
We evaluated our method using a hierarchical fashion dataset, FashionAI. 30 This dataset is a large-scale attribute dataset with manual annotations in high quality that addresses common issues like structured noise, occlusion, uncertain problems, and attribute inconsistency that pervasively exist in other public datasets. There are eight mutually exclusive fashion attribute dimensions across the dataset, and each image containing one fashion item is labelled with one specific attribute value under the corresponding attribute dimension. One image example may appear several times as it contains multiple labels in various fashion attribute dimensions, and each appearance is regarded as one data instance. Full details of all attribute values and their corresponding dimensions are depicted in Table I. The total number of images in the FashionAI dataset is 79,573.
Attribute Dimensions and their Values
Since the original dataset is single-attribute annotated, to perform the retrieval task we needed some additional work to build the triplets ourselves. The triplet datasets were built as follows. We first chose one attribute dimension and only selected images annotated with such attribute dimension from the whole dataset. Then considering each attribute value under this selected attribute dimension, we divided the selected images into two pools: pool1 and pool2. One contained images annotated with the considered attribute value, and the other was composed of the rest of the images that are annotated with other attribute values. The third step was, for each image in pool1, setting it as the anchor image, removing it from pool1, and then randomly sampling another image from the updated pool1 to set as a positive image, but not remove it. At the same time, we also sampled one image without replacement from pool2 to set as a negative image. The sampling procedure did not stop until the last image in pool1 was set as an anchor image in its own triplet, and the triplet dataset in one attribute dimension was completed. The same processes were repeated for the rest of the other seven attribute dimensions. By applying this sampling strategy, we ensured that the total number of triplets was also 79,573, exactly equivalent to the size of the original dataset. During the training, we set the training/validation ratio as 0.7/0.3.
Most importantly, concerns may arise that some images will coexist in different triplets simultaneously. In other words, one image instance could be the anchor image in one triplet but at the same time be the positive and/or negative image in other triplets. We shall point out that according to our triplet building strategy, our objective was to build as many of the triplets as the original single-labelled data to adapt the well-defined multi-task loss. Therefore, the repetitiveness will definitely exist. However, as long as there exists no two identical triplets who shares the exact same anchor, positive, and negative images, the training accuracy will not be harmed or biases weighted. Our sampling strategy ensures this distinctive nature of triplets; they may only share at most two elements with others, but will never be exactly identical. As a result, this concern was relieved.
Evaluation Protocols
We evaluated our methods in two folds: one was the attribute recognition accuracy, and the other was the attribute retrieval performance. Therefore, we discuss evaluation protocols separately in the following sections.
Attribute Recognition
As each image is annotated with one single attribute label, we considered applying normal classification accuracy, or top-1 classification accuracy, that compares the prediction from highest predicted probability score and the ground-truth label to measure the performance. Some may also suggest application of top-k accuracy, rather than only focusing on the highest probability score. We also calculated the percentage that the classifier predicts the correct class among the top-k probabilities or guesses. In other words, we also examined the second highest or third highest probability score from a softmax function and compared it with the ground-truth. However, since the number of attribute values varied among different attribute dimensions (i.e., five for collar design and nine for sleeve length) according to Table I, it was hard to determine a proper k that worked for all eight attribute dimensions. In view of these concerns, we only applied normal accuracy derived from the results of the highest probability score in softmax functions as the metric method to compare recognition results across all attribute dimensions and comparable models.
Attribute Retrieval
We first evaluated the model's performance on the validation set trough validation accuracy (Acc). For a set of unseen triplet images from the validation set, a successful retrieval happens when the similarity calculated between anchor and positive image is higher than that between anchor and negative image; otherwise it will be viewed as a failure. The percentage of successful retrievals during the whole validation experiment is called validation accuracy. Secondly, although top-k classification accuracy was not applied in the attribute recognition part, it was still considered in the retrieval scenario.
Given a query image, the retrieval model finds the nearest neighbor images from the test gallery of unseen image instances. We reported the recall at k (R@K), which computes the percentage of query images whose top-k retrieved images share the same attribute label with them. If the top-k returned results of a query image contain at least one match, then the retrieval of this query image was viewed as successful; otherwise, it is a bad case. In our experiments, we set the original single attribute annotation as the ground truth, therefore a match existed and only existed when the retrieved image shared the exact same attribute value under the same attribute dimension with the query image. To make the experimental results more convincing, we set k as 5, 10, and 20. We also need to point out that attribute retrieval is a ranking problem that is totally different from the classification problem, so we chose top-k images based on similarity calculation, but not on the soft-max probability score. Therefore, the concerns mentioned previously were relieved. We applied this top-k recall rate across all attribute dimensions and all comparable models.
Baselines and Model Variants
We set baselines and comparable models into two folds and discussed them separately as attribute recognition and attribute retrieval.
Attribute Recognition
Our objective was to investigate the effects on recognition performance of
our model based on two questions:
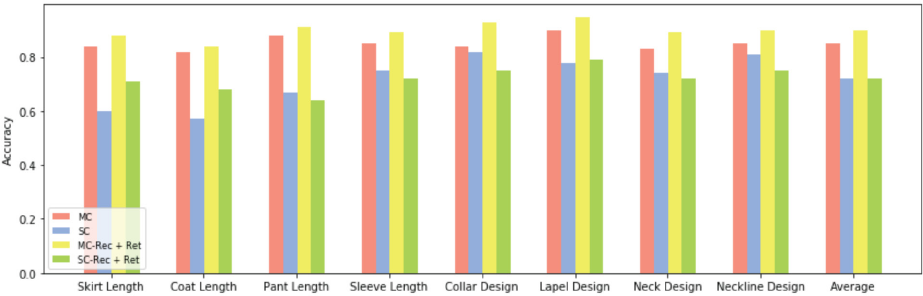
Results comparison among model variants and baselines in recognition task. MC stands for multi-column recognition model, SC stands for single-column recognition model, MC-Rec + Ret stands for the combined multi-column recognition and retrieval model, and SC-Rec + Ret stands for the combined single-column recognition and retrieval model..
Attribute Retrieval
The aim for this task was to verify the retrieval performance of our proposed
model against the other two questions:
Standard Siamese Network (SiaNet), 11 which consists of two symmetric branches that take a pair of image instances that share the exact same label as the inputs and optimizes the model by narrowing the distances between these two image inputs.
Standard Triplet Network (TriNet), 31 which takes three images as the input and uses the margin-based ranking criterion with l2-normalised item embedding as input. We set the same distance calculation function and margin as our settings. TriNet is a category-unaware (or attribute-dimension-unaware) baseline model.
A Set of Attribute Specific Triplet Network (Att-TriNet), which trains triplets separately across different attribute dimensions. The attribute-aware nature of this method is an advantage, but the model complexity and ignorance of relationships between attribute dimensions are apparently disadvantages.
A Set of Attribute Specific Triplet Network + Recognition Network (Att-TriNet + Reg), which is trained in a multi-task learning framework by taking the anchor image of each triplet as the input to an additional recognition network whose architecture is exactly the same as our recognition network
Modified Conditional Similarity Network (new CSN), which models conditional similarity to represent category-aware information. We modified CSN to align with our design described previously. The parameter settings were exactly the same as ours.
Our proposed multi-task learning attribute retrieval and recognition model (MTL Ret + Reg), where we applied multi-column architecture in all recognition settings.
Apart from all the above questions, we also want to answer the ultimate
research question at the end:
Training Details
We used a variant of VGG architecture 49 with 13 layers of 3 by 3 convolutions. The original subsequent fully-connected layers were replaced by a global average pooling layer and a fully-connected layer to produce a representation embedding of the input image. The embedding size was set as 64. All parameters before the global average pooling layer were initialized from pre-trained models on ImageNet, 50 and the rest of the parameters were randomly initialized. The network was trained with a mini-batch size of 32. The Adam optimizer was used, 51 and the initial learning rate was set as 1e– 5 , which was decayed by 0.1 after 100 and 150 epochs. The α, β1 and β2 parameters within Adam were set as, 5e– 5 , 0.1, and 0.001, respectively.
For the combined multi-task model, we set strength balance parameters α and β as 0.3 and 0.7 respectively. For the inner CSN retrieval network, we set the margin parameter h as 0.3, and loss weight parameters λ1 and λ2 as 5e–3 and 5e–4, respectively. In each mini-batch, we sampled triplets uniformly, and for each attribute type, in equal proportions. When learning masks, we initialized the 64-dimensional mask vector using a normal distribution with 0.9 mean and 0.7 variance.
Quantitative Comparison
Attribute Recognition
Fig. 4 shows the accuracy comparison of four model variants. From the results, we made the following observations.
The combined multi-column recognition and retrieval model (MC-Rec + Ret)
achieved the best performance consistently across all eight attribute
dimensions and obtained great improvements over the other methods,
especially in comparison with the combined single-column recognition and
retrieval model (SC-Rec + Ret). While not considering the force from
similarity loss, we also noticed that the multi-column recognition model
(MC) outperformed the single-column model (SC). The higher accuracy
indicates that our proposed model architecture used local feature
information from the corresponding softmax branch, as well as global feature
information among all attribute dimensions from the shared shallow layers.
It also greatly avoided over-fitting in this hierarchical manner of the
recognition. We believe that the results show the advantage of the global
multi-column style over the single-column style (
Between the two multi-column-structure comparable models, we found that, with
the addition of the retrieval branch, MC-Rec + Reg outperformed MC in all
attribute dimensions. The average accuracy also revealed the advantage of
this joint training strategy. However, such an advantage was not apparent
when the recognition task was performed in a single-column style. We believe
that one possible cause of this result was derived from the over-fitting
that exists in the single-column network architecture. Although not obvious,
we concluded that the combined category cross-entropy and triplet similarity
loss present advantages from the average accuracy bar chart
(
Attribute Retrieval
Comparison of the results from all experiment models are presented in Table II. We first explain the attribute-aware metric abbreviated as Attr-Aware that describes the ability of a model to calculate conditional similarity of two fashion objects in a specific attribute dimension. Apparently, CSN and MTL Ret + Reg are designed to achieve this objective. Att-TriNet and Att-TriNet + Reg are by nature trained separately for each group of attribute dimensions, hence are attribute-aware. However, SiaNet and TriNet treat each image sample equivalently and calculate the similarity of images in a global notion that ignored attribute distinctness.
Experimental Model Results
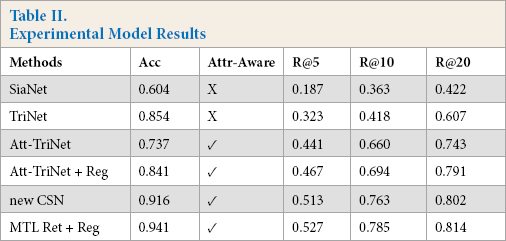
In the view of validation accuracy, the Standard Siamese Network failed to
capture the fine-grained attribute similarity and only reached an accuracy
of 0.604. This is due to its ignorance of opposite relationships between
anchor and negative image instances. Standard Triplet Network, on the other
hand, successfully captured global relationships from both positive and
negative examples within a triplet setting. What is surprising was that the
performance on the validation set of a set of attribute specific triplet
networks was even worse than the Standard Triplet Network. We generally
believe that attribute specific triplet networks greatly improved the
performance over the Standard Siamese/Triplet Network, as it is only
required to learn feature embedding for each well-defined single attribute
notion, and confusions of various attributes normally lead to a bad
performance. However, bad results here tell us it was not a simple
less-workload univariate problem. One possible reason could be under-fitting
as each attribute specific triplet network only deals with a limited number
of training data, and therefore fails to capture more global information. On
the other hand, CSN along with our proposed MTL Ret + Reg achieved the best
validation accuracy. This result means that multiple similarity notions were
well captured by factorizing the global feature representation into separate
semantic subspaces. The combination of the modified CSN retrieval model and
the multi-column retrieval model upgraded the accuracy by nearly 4% more
that CSN itself. This indicates the benefit of multi-task learning that
allowed the model to share information among attributes across all notions
and tasks (
Furthermore, we evaluated the performance of the retrieval task using
top-k recall rate at 5, 10, and 20. We expected a
continuous increase of the recall rate when k climbed from
5 to 20 as the extent of toleration of the evaluation protocol grew. The
results verified our expectations across all model variants. Note that all
results of recall rate were averaged across eight attribute dimensions.
According to the results of the top-5 rate, the significant advantage of the
new CSN, MTL Ret + Reg, and Attr-TriNet, variants over SiaNet and TriNet
again confirms the huge benefits of attribute-aware feature representation
embedding in the retrieval task. Consequently, the proposed MTL Ret + Reg
used in this study achieved the best performance (
Taking a broader view on R10 and R20 results, with the addition of the
recognition network, the retrieval effect will always upgrade a bit across
various levels of recall rate. Att-TriNet + Reg outperformed Att-TriNet and
MTL Ret + Reg outperformed the new CSN (
However, none of the approaches in these experiments achieved a result greater than a 90% retrieval recall rate. One possible cause is that we only considered eight attribute dimensions that were pre-defined in the Fashion AI dataset, ignoring the equally important fashion attributes like pattern, color, subject, and style. We simplified the multi-notions of fashion similarity into eight sections, which may lead to some misunderstandings during the retrieval. Secondly, the size and location of the corresponding region of a specific fashion attribute on an image may vary with those on other images. Retrieval work cannot be guaranteed to achieve a great result. Some recently related works use the information of the fashion keypoint or landmark to direct the similarity calculation. However, our work focused on the partitioning of multiple similarity notions and the benefit from integrating the recognition task.
Lastly, the nature of our proposed multi-task learning framework was to adopt the power of optimization of both categorical cross-entropy loss and similarity distance loss.
This type of network structure and combined loss functions directed the
training procedure providing the information from two diverse perspectives.
While building the shareable feature embedding of a fashion item, the item
was actually analyzed twice: once in the recognition network and once in the
retrieval network. As the objectives of recognition network and retrieval
network were same in building a distinct feature embedding, the two
approaches benefited each other, but not against or deteriorating each
other. The forces from two tasks fully explored intrinsic relationships
between a fashion item and all other instances, illustrating why our model
worked extremely well (
Qualitative Evaluation
Here we present some practical applications of our proposed approach. We predicted a set of multiple attribute labels for a test fashion image. This powerful recognition ability is clearly presented in Fig. 5. Apart from the original annotated single-attribute label, the model tells us all the other relevant multi-attribute labels of the input image. Interestingly, the original single-attribute label for the bottom image in Fig. 5, invisible pant length, was actually a useless annotation. The actual predicted label in the pant length dimension was also “invisible,” but in practice, we concealed any predicted label whose value was “invisible,” and only presented the visible ones.

Some examples of multi-attribute recognition results.
We also presented the power of the attribute-aware retrieval model in real applications. In Fig. 6, we selected three images among the top 10 retrieved results of an image query in two scenarios. The left column required the retrieval work to consider three attribute dimensions—sleeve length, neck design, and skirt length, while the right column required the retrieval to calculate similarity in the attribute dimensions of sleeve length, neckline design, collar design, and neck design.

An example of selected retrieval results through different sets of multi-attribute dimensions.
The retrieval model focused on different fashion concepts, if the various attribute dimensions were required by the user. On the left-hand side of Fig. 6, three attribute dimensions were considered: the targeted fashion concepts were long sleeves, ruffle semi-high collar, and short length. The retrieved results indeed contained these attributes. On the right-hand side, more attribute dimensions we considered, except for skirt length, and hence there were no appearance of skirt items within the returned results. The comparison retrieval was quite vivid and explicit.
We didn't introduce any color-related attribute concept while training the model, therefore the existence of some light blue shirts were only coincidences. Although the training process of retrieval was originally based on a single-attribute dimension, we were still able to perform multi-attribute retrieval work step-by-step in practical applications. For example, if we operated retrieval with three fashion attributes, we first only focused on one retrieval sub-task and considered only one single attribute, outputting some top-ranked results. Ten we completed the second retrieve sub-task for another single attribute only on selected images from the previous outputs. The retrieval data pool was continuously narrowed until the last sub-task was finished.
Conclusion
In this study, we investigated an effective manner of training fashion recognition and retrieval model together in a multitask learning framework. Our empirical results indicated that the proposed training strategy and combination of loss functions led to a consistent improvement on performances of both recognition and retrieval tasks. We also demonstrated the practicality of multi-attribute analysis on the results produced by our model.