
Abstract
In this article, we propose StylishGAN, a generative adversarial network that generates a fashion illustration sketch given an actual photo of a human model. The generated stylish sketches not only capture the image style from real photos to hand drawings with a cleaner background, but also adjust model’s body into a perfectly proportioned shape. StylishGAN learns proportional transformation and texture information through a proposed body-shaping attentional module. Furthermore, we introduce a contextual fashionable loss that augments the design details, especially the fabric texture, of the clothing. To implement our method, we prepare a new fashion dataset, namely, StylishU, that consists of 3578 paired photo–sketch images. In each pair, we have one real photo collected from the fashion show and one corresponding illustration sketch created by professional fashion illustrators. Extensive experiments show the performance of our method qualitatively and quantitatively.
Introduction
Fashion illustration is a classical way of fashion communication. Compared with photographs, fashion illustrations are obviously filtered through an individual vision that could obtain more fictional narratives and have more stylish feelings. 1 On one hand, this form of art is costly because it requires skillful drawing techniques with long-time practice. Fashion illustrators can help to better exhibit the designed clothing and have extensive needs from industry, which makes automatically generating fashion illustrations practical and valuable. 2 Thus, it is reasonable to expect that automatically generating the fashion illustrations, which can significantly reduce the cost, would have substantial practical value for the fashion industry.
As shown in Figure 1, designers begin with a sketch of a body figure called a Croquis and build a look on top of it. They typically illustrate clothing on a body figure with exaggerated 9-head proportions. The details of clothing (silhouettes and fabrics) are carefully rendered by using tools such as gouache, marker, and ink. In a word, the requirements for a standard fashion illustration can be summarized as 2 (1) body shape is adjusted to a specific proportion, that is, head-to-body ratio around 9 when in standing position; (2) clothing identities (e.g. design attributes, color, print design) should be the same as those of the source image; and (3) high quality in texture renders a clean background.

Examples of fashion illustration.
To satisfy the above requirements, we transform the real fashion photo into a hand-drawn style while adjusting the body shape to a certain proportion and obtaining the texture information through a new Body-Shaping Attentional Module. According to the definition of the drawing principles of fashion illustration, 3 the fashion sketch is based on the special relation of human body keypoints instead of the full-body shape. We thus adopt the idea of pose transfer-guided person image generation4–6 while using keypoint instead of clothing parsing to represent the geometrical features of body shape. Meanwhile, we introduce an attention mechanism with non-local operation 7 to enhance the model’s ability to select the region of interest (ROI) that needs to be transferred. In addition, apart from the body shape, we introduce a contextual fashionable (coFa) loss, which preserves the edge of the clothing while enhancing the design details. The spatial pixel coordinates and pixel-level Red, Green, Blue (RGB) information are integrated into the image features. To further enhance the details, the Laplacian pyramid is adopted to decompose images into multiple scales. 8 For each output pyramid coefficient, we render a filtered version of the full-resolution image. According to the corresponding local image value from the Gaussian pyramid at the same scale, we build a new Laplacian pyramid from the filtered image and copy the corresponding coefficient to the output pyramid.
In addition, we prepare a new dataset with 3567 paired images, that is, real photos and their corresponding fashion illustration for implementation. The source of the real photo is from catwalk images of various high-fashion brands such as LOEWE, GUCCI, and CHANEL. The ready-to-wear from the “Big Four,” that is, New York, London, Milan, and Paris fashion weeks, would have more design attributes and details to be generated than outfits in our daily life. The illustrations created by different professional fashion illustrators are collected from the Internet.
Extensive experiments demonstrate the advance of StylishGAN qualitatively and quantitatively compared with the state-of-the-art generation methods on the fashion illustration generation. We summarize our main contributions as follows. (1) We propose a fully automatical generative adversial network that can adjust the shape and transfer style while preserving design details of the clothing. (2) We introduce a new coFa loss that augments the details, for example, fabric texture, and reduction of fashion illustrations. (3) We build a fashion illustration dataset, namely StyleU with 3567 pairs of real photos and fashion illustrations. The dataset will be released to favor the academic society.
Related Work
Image-to-Image Translation
This task that aims to learn a mapping that transforms images within two different domains has recently gained much attention from computer science researchers. It is divided into the supervised setting and unsupervised setting. If the paired data are unavailable, the image could still be translated by sharing latent space9–11 or using cycle consistency assumptions.12,13 Although the previous works, for example, CycleGAN, 12 UNIT, 9 U-GAT-IT, 14 achieved promising performance and could generate diverse results,13,15–17 they are different from our work as we aim to translate all clothing identities, that is, colors, print, attributes, and so on. On the contrary, when we obtain the paired data, the GAN model can be trained in a supervised manner.18–20 Given a reference style image, the style-transfer network creates an output image with the same content as the input but with the style of the reference image.21–24 Our task differs from the above as we only transfer the ROI, that is, the fashion model, to the hand-drawn style without transferring the style on the whole input image with deformation between the source and target shape.
Fashion Image Generation
Many pieces of research have been conducted in fashion image generation.25–28 Similar to the pix2pix, 29 fashion sketches can be transformed into textured fashion items.30,31 Meanwhile, rather than texture transfer, studies also focused on virtual try-on task, that is, conditioned upon new clothing, a desired clothing item can be transferred onto the corresponding region of a person.5,32–37 Han et al. 37 adopted a coarse-to-fine strategy to match the shape of warp clothing and the body shape of the target person, which could preserve detailed texture information. Raj et al. 38 introduced a weakly supervised approach to generate training pairs from a single image via data augmentation to solve the problem of lacking paired data that have the same clothing on different bodies. Very recently, some studies focused on fashion editing or inpainting, which targeted local region translation.27,28,39 Dong et al. 39 enabled editing fashion attributes print design, sleeve length, pant length, and so on. Hsiao et al. 27 proposed a network to minimally adjust the full-body clothing outfit that affected its fashionability. Han et al. 28 could generate the missing part of fashion images. Unlike the above research, our work aims to transfer the fashion image to the hand-drawn style while adjusting the body shape of the original image with a certain ratio.
Dataset Construction
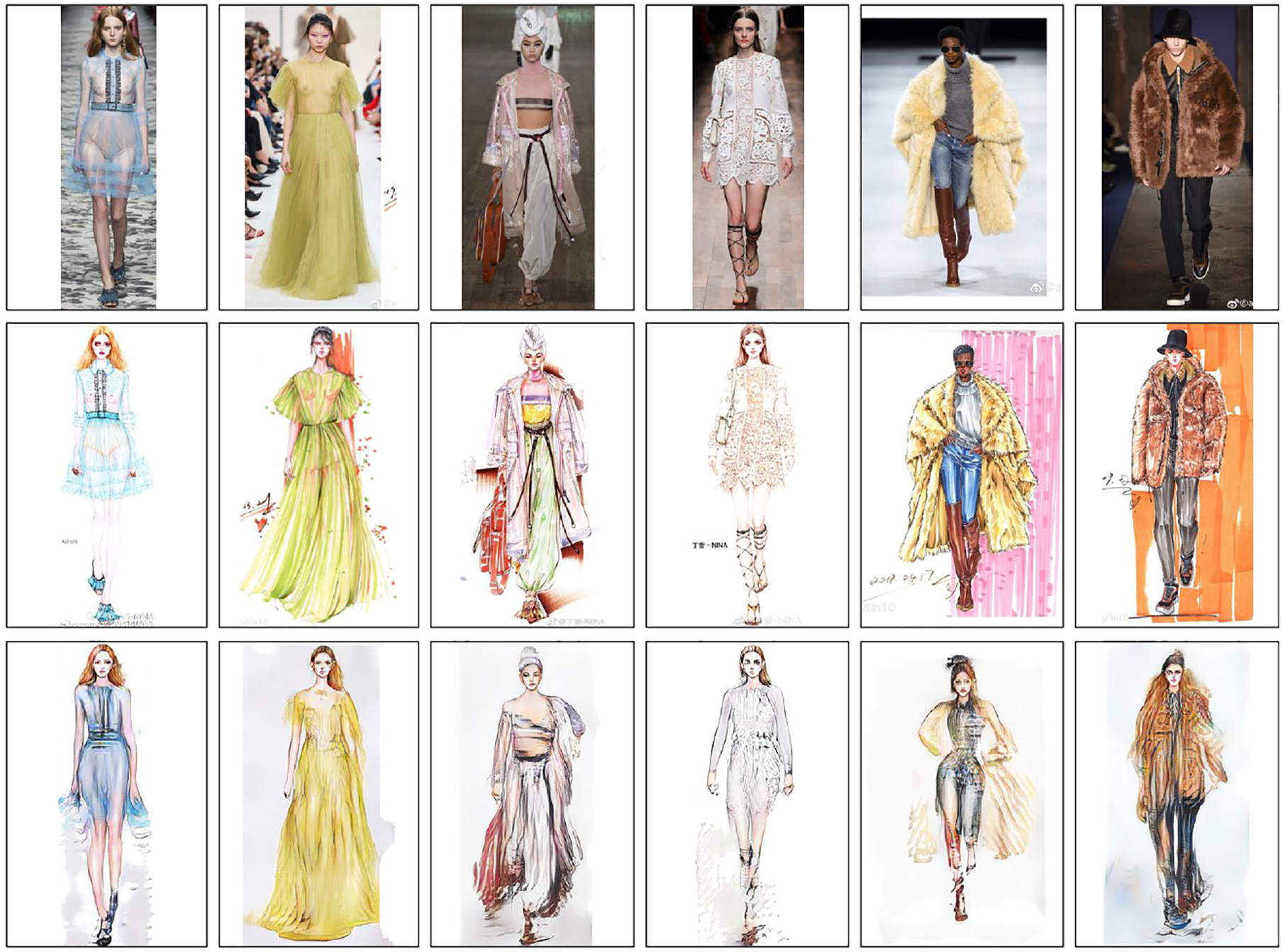
To the best of our knowledge, this is the first work focusing on fashion illustration generation. To implement our approach, we build a dataset, named StylishU, consisting of 3567 paired images. Each paired image include one real photo and its corresponding hand sketch. All real photos were collected from the “Big Four,” that is, New York, London, Milan, and Paris fashion week, which would have more design attributes and details to be generated than the outfits in our daily life. The illustrations are correspondingly produced by different fashion illustrators. (Noted that the duplicate data are automatically removed).
As shown in Figure 2, the images vary in many aspects. First, the styles of illustrations are different as they are created by different illustrators, for example, the last four cases in Figure 2. Second, the background of the real photo is not clean and the hand-created sketch is not always clean. Third, the pose of most images is in front view while the rest of them are in the side view. To retain the original ratio of the fashion model, we pad the image with a white background instead of directly stretching it to a certain size. Finally, the size of all images is 384

Samples in the StyleU dataset.
Methodology
Given a source photo, our task is to translate it into a sketch image with a fashion illustrative style. The image from the domain of real photos is denoted as
Generator
As shown in Figure 3, we have three inputs for the generator, one source image
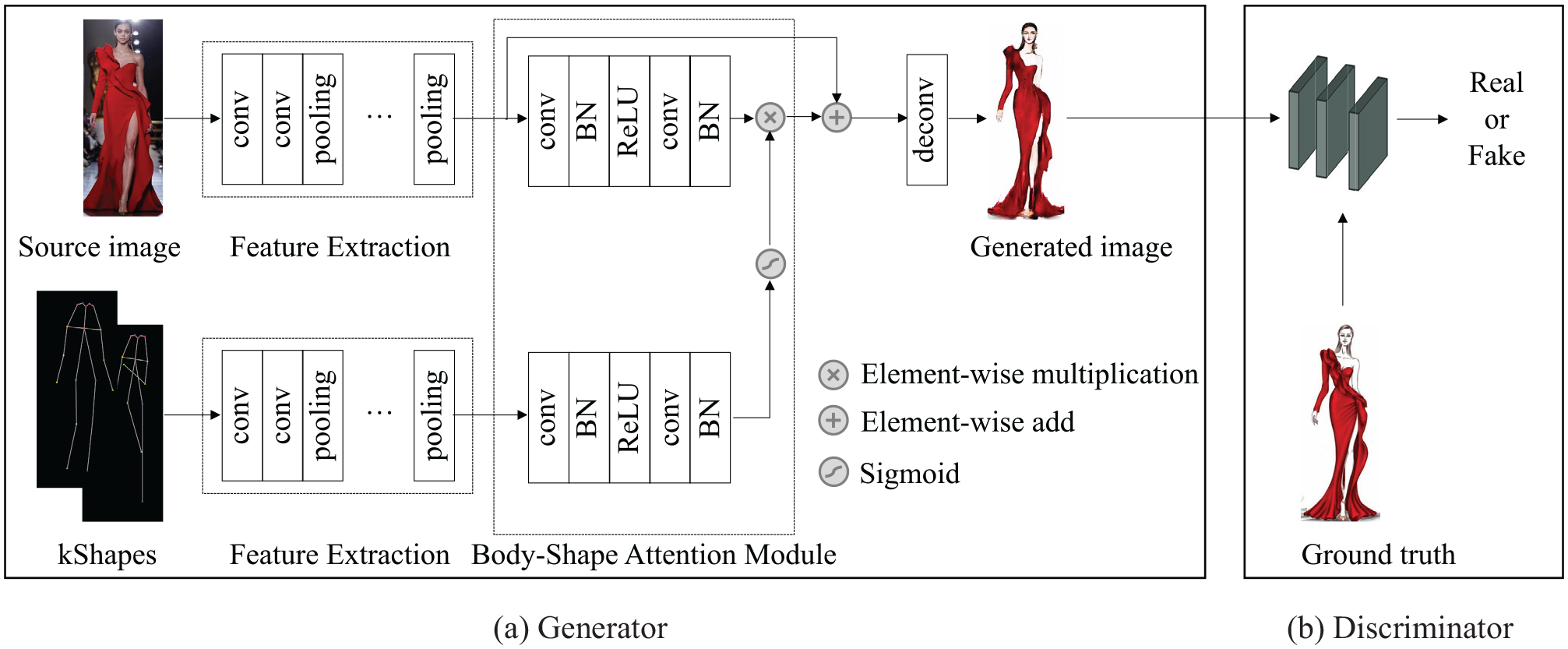
Flowchart for automatically generating fashion illustration.
Next, the information of extracted embedding features from both the source photo image and kShape maps shall be utilized collectively through an attention mechanism, which we define as body-shaping attentional module that is designed to first produce a keypoint attention mask with pixel value ranges from 0 to 1, which indicates the level of importance of each keypoint element pixel. Then the source photo representation embedding and attention mask embedding are multiplied to form an element-wise product. Specifically, we build it by first setting a block of two sequential convolutional layers, which are connected by a batch normalization layer and a ReLU layer in chain between them. Then we input the down-sampled source photo embedding into the defined convolutional block in the upper branch, and input the down-sampled kShape embedding into another identical convolutional block in the lower branch. Two intermediary output embeddings are produced here from these two branches. An element-wise sigmoid function is then adopted to map pixel values of that kShape output feature embedding into a range of
Inspired by Zhu et al., 5 we connect three body-shaping attentional modules in a chain such that the valuable information of embedding is fully exploited. Two output embeddings from the upper/lower branches of the previous module will continue to be the inputs to the upper/lower branches of this module and subsequent ones. It is worth noting that as the source photo embedding gets updated through each module, the kShape embedding should also be updated to synchronize the change in each of them. We achieve this by concatenating kShape embedding and weighted source photo embedding along the axis of depth at the end of each module, equivalently doubling the depth of output embedding from the lower branch. Then from the second module onward, we adjust the lower branch convolutional block to reduce the input feature map depth to half, making the output kShape embedding depths of this subsequent module still equal to those of the first one. Finally, following the standard practice, the decoder generates the output image through some deconvolutional layers with source photo embedding as the input. We discard keypoint embedding after the final convolution block.
Discriminators
The previously mentioned target sketch image
As the training proceeds, we observe that a discriminator with low capacity is insufficient to differentiate real and fake images. Therefore, we build discriminators by adding three residual blocks after two down-sampling convolutions to enhance their capability.
Training Procedure
To realize the proposed architecture for fashion illustration generation task, as shown in Figure 3, we define the objective of a conditional GAN as follows:
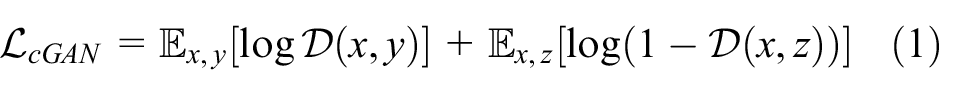
Then, the
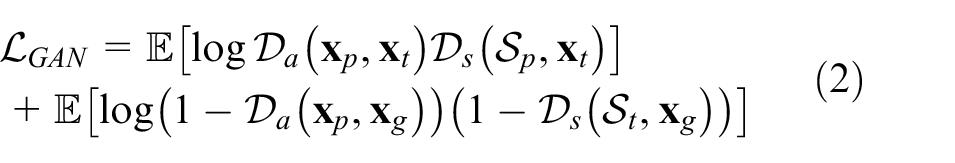
where G aims to minimize this objective and D tries to maximize it, that is,

To ensure the texture rendering of the fabric would be similar to the source image as much as possible and make the appearance of the generated image more natural visually, we take the perceptual loss,
40
noted as
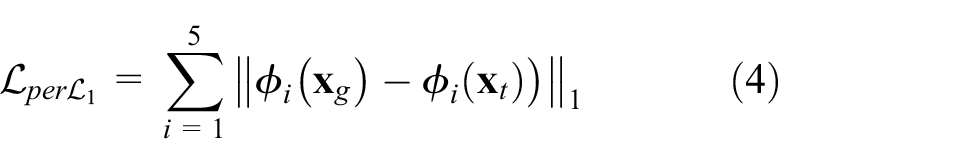
CoFa Loss
To deal with unaligned data pairs, 41 we introduce the CoFa loss (coFa) to further improve the quality of generated images. The original contextual loss (CX) is defined as:
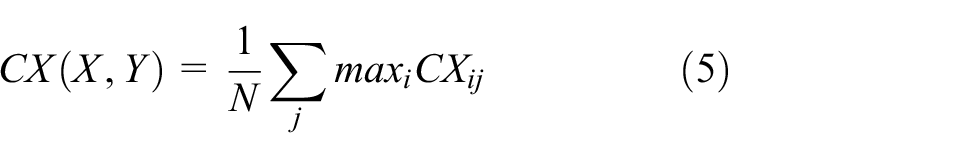
where
Specifically speaking, the generated fashion image focuses more on the following. (1) The overall silhouette is the same in the semantic level, that is, a V-line neckline should be a V-line neckline. However, it is not required to be exactly the same in pixel-level. (2) The texture of fabric needs to be well-rendered on the ROI. (3) The sketch line should be natural but not too solid. Based on these special requirements, we thus consider improving the quality of the generated image from the aspect of image augmentation, that is, preserving the edge of the clothing while enhancing the design details. We integrate the spatial pixel coordinates and pixel-level RGB information into the image features based on the inspiration of the bilateral filter. To further enhance the details, the Laplacian pyramid is adopted to decompose images into multiple scales.
8
For each output pyramid coefficient
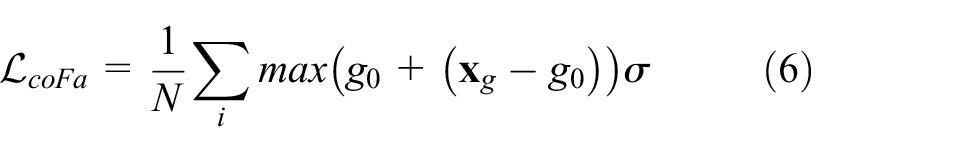
where
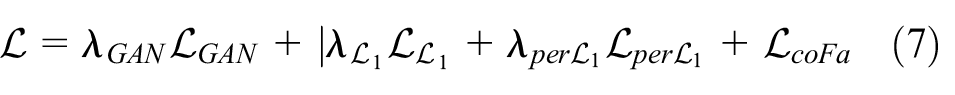
Experiments
In this section, we conduct experiments to demonstrate the effectiveness of the proposed approach. We first describe the baseline model. Then, we show the visual results of our method compared with the state-of-the-art methods and present the analysis. Meanwhile, we demonstrate the importance of each part in our framework with the ablation study. Finally, we discuss some failure cases of the proposed method. We used images from the StyleU dataset to conduct all the experiments in this work. As described in Section 3, the dataset consists of 3567 paired images, that is, real photos and fashion illustrations. Each image is 384
Implementation Details
We use ADAM optimizers
43
in Pytorch framework with
Baseline Model
We compared our method with various models from both image-to-image translation and fashion generation tasks. The mainstream frameworks including Pixel2pixel, 29 CycleGAN, 12 Unsupervised image-to-image Translation (UNIT), 9 and Unsupervised Generative Attential Networks (U-GAT-IT) 14 are adopted. Meanwhile, in terms of fashion generation, we follow the flowchart of CP-VTON. 34 (Noted that we train the baselines using their official implementations.)
Qualitative Analysis
The visual results of our method and the baselines for style transfer are shown in Figure 4. We can see that, among the first four baseline image-to-image translation networks, Pixel2pixel produces over-stylish images while the body shape of the fashion model is still consistent with the original photo. Cycle-GAN and U-GAT-IT well reflect the silhouette of the clothing and the body shape of the fashion model to some extent. However, it does not well retain the color and texture of the clothing. UNIT generates more photo-like images and minor changes in the stylish sketch. In addition, we also considered the mainstream fashion generation framework in our task.32–34,37 The inputs in the set of VTON articles include a model image where a model wears a cloth, a target cloth image, a body shape image, a body keypoint image and model face image, that is, more inputs than ours. We present the results of CP-VTON 34 just to show the performance of the current flowchart of fashion generation on the illustration generation task (note that during the implementation, we reduce the global input image channel depth to adjust the difference of inputs).

Overall speaking, unlike StylishGAN, the above baselines either could not adjust the body-shape or faithfully render the design details of the clothing. As shown in the last column of Figure 4, it can be found that the images generated by our approach have high consistency with the source image from the aspect of clothing identities, that is, color, silhouette, neckline design, print design, sleeve design, and so on. On the contrary, the body shape of the generated fashion model is also adjusted to a certain ratio (similar to the ground truth at the second column of Figure 4). Moreover, we can see that the beading and tassel design on the surface of the dress is also well-rendered by the StylishGAN.
Quantitative Analysis
Metrics
It remains a problem to effectively evaluate the appearance and shape consistency of the generated images. Following the general practice, we adopt the inception score (IS) 45 and structure similarity (SSIM) 46 to assess the generated image quality from the two perspectives. However, as discussed in the study by Szegedy et al., 47 the IS metric, which is based on the entropy computed over the classification neurons of an external classifier, is not very suitable in our case. Thus, we further adopted the perceptual study.
Perceptual Study
We also conducted the perceptual study from the perspective of fashion. As introduced before, the evaluation standard of fashion illustration focuses on three parts: (1) body-shape adjustment with certain ratio to achieve whole image balance, (2) clothing identities consistency, and (3) quality of texture render. We thus propose three indexes for fashion illustrations:
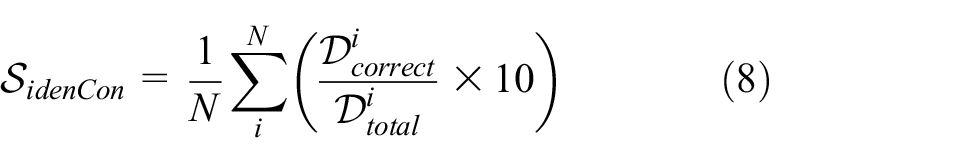
Taking the outfits of the first row in Figure 4 as examples, the design attributes include deep blue (color), plain (print design), A-line in the whole with Mermaid in the bottom (silhouette), sleeveless (sleeve-length), full-length (length of the bottom). Our generated image has the same attribute value in each attribute dimension and thus the design consistency score of this outfit is 10. To automatically compute the design consistency score, it is expected to adopt the model for design attribute recognition.48,49 However, it related to different domain recognition and was highly affected by its accuracy, which is out of the scope of this work. We thus manually calculate the design consistency score (the labeled clothing identities of the test set will be released with the StyleU dataset). In addition, the first and second parts are highly subjective and professional, and are hard to describe in a set of formulations. We thus performed a human perceptual study to evaluate these two parts from the human point of view. Specifically, we invited five experts with majors in fashion to judge the quality of the generated images. The total score is set as 10. To decrease the bias of different judges, we obtained the trimmed mean, that is, the final score is the average of three middle scores (excepting the highest and lowest one). Thus, for
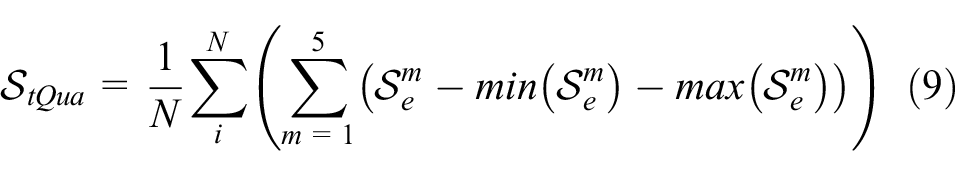
where
Quantitative comparisons are summarized in Table 1 and we make the following observations: (1) Regarding the IS, which indicates image quality, that is, does the image look like a specific object, StylishGAN obtained a relatively higher score compared with the rest of baselines. It demonstrates that our StylishGAN obtains better performance on objective consistency. (2) In terms of SSIM, which is adopted to measure the shape similarity between the source image and the generated image, the StylishGAN achieves the highest similarity. (3) For the remaining indexes, which evaluate the generated images from the fashion perspective, StylishGAN consistently outperforms three of them. In a word, all results indicate the effectiveness of the proposed approach.
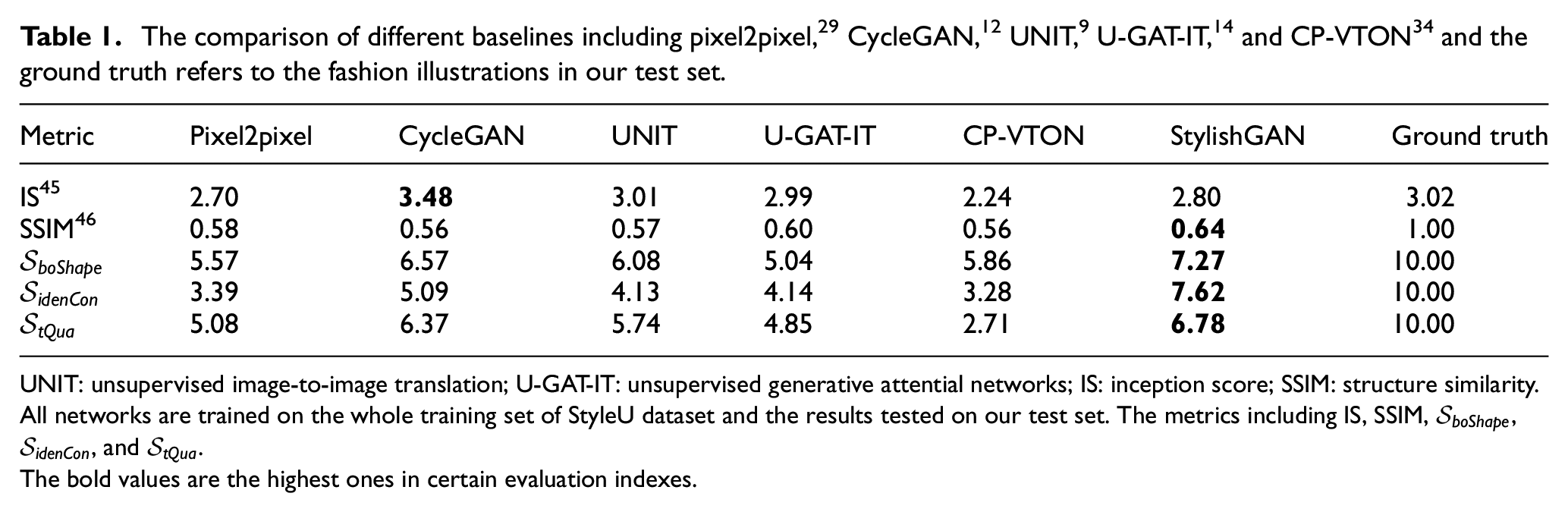
UNIT: unsupervised image-to-image translation; U-GAT-IT: unsupervised generative attential networks; IS: inception score; SSIM: structure similarity.
All networks are trained on the whole training set of StyleU dataset and the results tested on our test set. The metrics including IS, SSIM,
The bold values are the highest ones in certain evaluation indexes.
Ablation Study
To analyze the proposed method in detail, we conducted the ablation study from three aspects: (1) We demonstrated the importance of the coFa loss by the results of removing
Efficacy of the coFa Loss
As shown in Figure 5, it can be found that the coFa loss can effectively augment the details of clothing item and thus improve the visual quality of the generated image. Meanwhile, compared with the last two columns of Figure 5, the sketch line becomes further solid with the increasing weight of the coFa loss. Considering the fluency of the generated fabric, we do not recommend setting the weight of the coFa loss too high in the fashion generation task (

Ablation study: (a) without source images, (b) ground truth, (c) without
Function of Each Module
We present the comparison results without different parts of our framework one by one in Figure 6. It can be found that without

Ablation study: (a) source images, (b) our results, (c) without
Adaptive Weights
Meanwhile, we study the effect of the loss weight under different conditions. The visual results are shown in Figure 7. We can see that when the loss weights are changed, the generated images have some differences. For example, with the decrease of

Abalation study: (a) source images, (b) ground truth, results with different loss weight where
Discussion
Figure 8 presents failure cases of our method. On one hand, as demonstrated before, the proposed framework achieves good performance in most cases, which are expected to deal with the common clothing in our daily life. On the other hand, as stated in the section “Dataset Construction,” that is, the clothing in the StyleU dataset is ready-to-wear with more design attributes, and we found that the proposed method cannot deal with some specific situations. Take the samples of the first two columns in Figure 8, for example. Both of them are made from transparent gauze. Although the generated images are consistent with the source image on the color, the whole silhouette, however, fails to reproduce some design details. Specifically, the Peter Pan collar in the first garment is changed to a round neckline and the round neckline in the second garment is replaced by the off-shoulder. Another case is that when the fabric appearance is texturized and presents a light-weight feeling, the lower saturation of the clothing’s color leads to the poor quality of the generated image. For example, for the white lace dress in the fourth column in Figure 8, the texture of the white dress does not render on the generated image. In addition, as shown in the last two columns in Figure 8, fur clothing is also a difficult category for texture rendering. We conclude that in terms of texture rendering in fashion, (1) clothing made from light and transparent fabric is more difficult compared with solid fabric, (b) the saturation of color has an effect on the texture rendering. The lower the saturation of clothing’s color, the worse the quality of the generated image. (c) A complicated surface of the fabric, for example, fur clothing would increase the difficulty of texture rendering.
Failure cases of our method.
Advantage and Disadvantage
Fashion illustration is the art of communicating fashion ideas in a visual form. As demonstrated in previous sections, StylishGAN has huge advantages in helping design labels or clothing firms to generate fashion illustrations quickly with less cost. This will greatly help them to shorten the process while saving money on hiring fashion illustrators. However, as shown in the last paragraph about the limitation, we can see that StylishGAN has limitations in some specific situations, such as transparent color, complicated textures such as fur, and so on.
Conclusion
We proposed StylishGAN for fashion illustration generation. The body-shaping attentional module was adopted to adjust the body shape of the fashion model and obtain the texture information. A new CoFa loss was introduced to improve the fabric texture rendering. To implement our task, we present a fashion illustration dataset. Through the experiments, we demonstrate the effectiveness of the proposed method. Meanwhile, the newly introduced dataset StyleU with paired images covering two types of domains can well facilitate the task of pixel-level image transfer.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by Laboratory for Artificial Intelligence in Design (Project Code: RP3-1) under InnoHK Research Clusters, Hong Kong.