
Abstract
Recommendation-based dialogue systems aim to capture user preferences via interactive conversations for personalized recommendations. While existing studies focus on modeling user preferences, real-time dialog scenarios face challenges in balancing historical conversation contexts and immediate interests. This study proposes MGIRD, a multi-aspect graph representation approach integrating ordinary graphs and hypergraphs. We use graph structures to model users’ current interests and hypergraphs for historical conversation features, while incorporating historical behaviors in the recommendation module to balance context relevance. A novel item selection mechanism is introduced during dialog generation to naturally integrate recommended items. Experiments on Chinese TG-Redial and English Redial datasets show MGIRD outperforms most state-of-the-art methods in recommendation accuracy and dialog diversity, validating its effectiveness in enhancing recommendation quality and conversational fluency.
Keywords
Introduction
The rapid expansion of smart assistants and e-commerce platforms has led to the widespread adoption of recommendation systems in many areas. These systems are now a key part of our digital lives, making our experiences more personalized and convenient (Gao et al., 2021). The core function of these systems is to predict users’ potential needs and preferences by analyzing historical interaction data between users and products. Recently, due to the swift advancement in the fields of natural language processing (NLP) and the wide application of data mining techniques in the web (Ashraf, 2021), a new methodology has emerged. That is the strategy of adopting NLP techniques and utilizing a large amount of data to train recommender system models to improve the accuracy of the recommender system. This new methodology has gradually become the focus of the research in this field. The essence of this strategy lies in leveraging NLP to conduct an in-depth analysis of text data generated by users, thereby gaining a better understanding of their preferences and needs. Through NLP methods, recommendation systems can detect subtle emotional shifts and specific preferences of users, thus providing more personalized and precise recommendations. Recent research (Chen et al., 2019; Lei et al., 2020a, 2020b; Sun & Zhang, 2018; Wang et al., 2022) has shown that recommendation systems can identify user interests more accurately and effectively through analyzing users’ real-time interaction data. In this context, Recommendation-based Dialogue Systems (also known as conversation recommendation system [CRS]) (Chen et al., 2019; Li et al., 2018, 2022; Liang et al., 2021; Zhou et al., 2020) have emerged. These systems are delineated as a specific genre of task-oriented dialogue systems, with the fundamental goal of discerning user preferences via “dialogues” with real-time interaction data, thereby enabling precise recommendations. This has become an increasingly prominent research trend in recent years. Successful CRS not only have the ability to understand user interests but also possess natural and fluent language generation capabilities to foster natural and enjoyable dialogues with users. A typical case of CRS is shown in Figure 1.
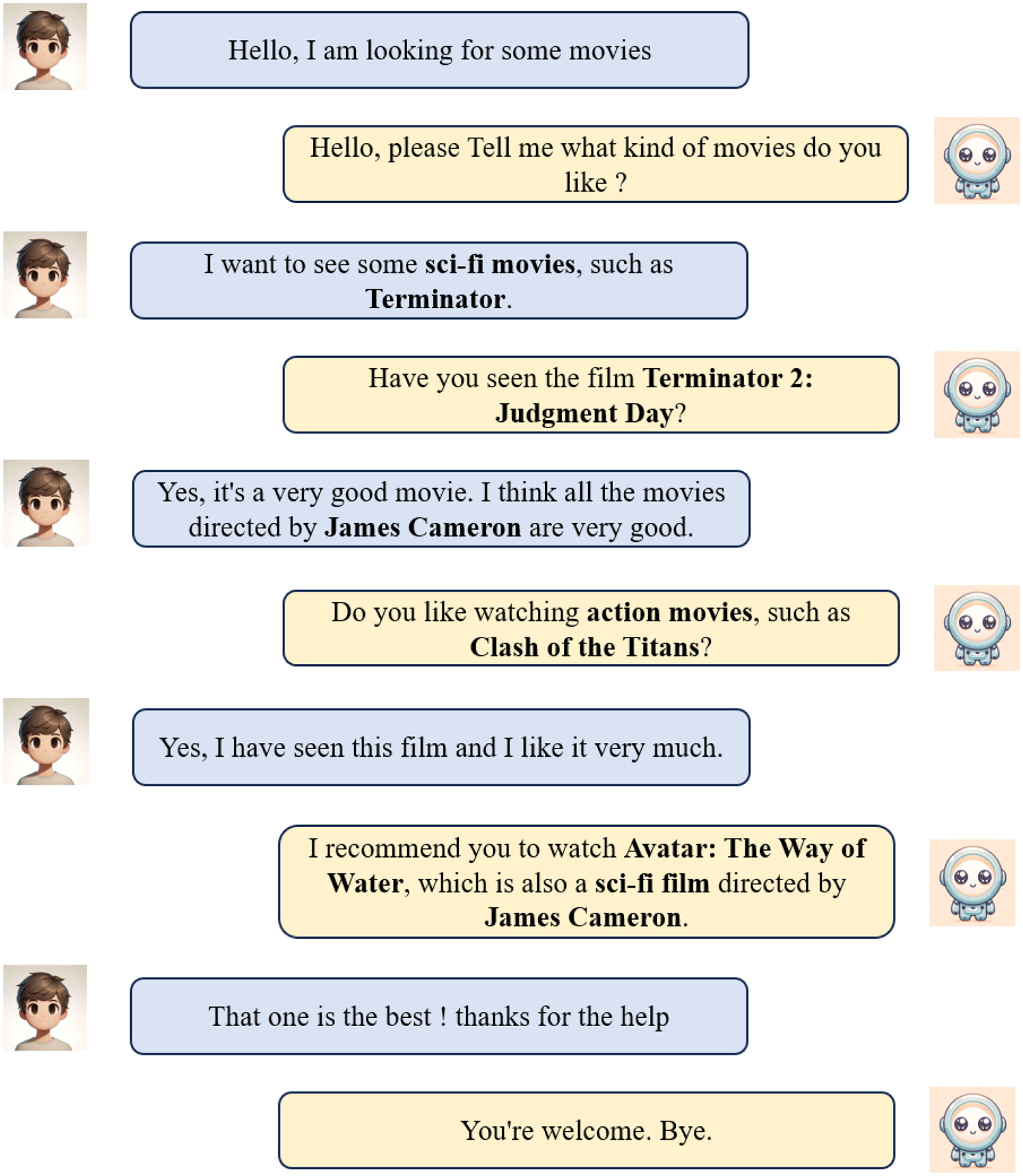
A typical case of conversation recommendation system.
A typical recommendation-based dialogue systems are composed of two core modules: the recommendation module and the dialogue module. The recommendation module focuses on making appropriate recommendations by parsing user preferences from the context of the conversation. Meanwhile, the dialogue module concentrates on generating fluent conversations to enhance the user’s authentic experience. Today, it has been widely deployed across various practical application scenarios, serving either as a standalone system or as an integrated module within large-scale voice assistant platforms, showcasing extensive potential for application.
In the research field of conversational recommendation, accurately capturing user preferences is crucial. Currently, many conversational recommendation systems are focusing on improving their ability to recognize user preferences. Some methods propose utilizing complex encoder structures to enhance natural language understanding capabilities (Li et al., 2018); while others suggest incorporating external information such as knowledge graphs (Chen et al., 2019; Wang et al., 2022; Zhang et al., 2021) and user comments (Lu et al., 2021) to enrich user modeling. While these methods can improve recommendation accuracy to some extent, an excessive focus on current preferences may lead to too much duplication of generated recommendation items and fail to elucidate the reasons for selecting these items when generating responses. In practical recommendation processes, user historical behavioral data holds significant value for more comprehensive user modeling while maintaining alignment with their current interests. Some studies have begun exploring the use of user historical information to enhance user modeling (Li et al., 2022). However, the majority of user historical information follows the characteristic of a “long-tail distribution” (Shang et al., 2023; Zhao et al., 2023), where only a few users have abundant historical data, which is extremely complex and difficult to accurately extract. Additionally, for most users, their historical information is sparse, making it challenging to extract effective information to provide meaningful support for understanding their current interests.
The goal of our research is to integrate knowledge graphs to strengthen the understanding of users’ current conversation state, and to integrate users’ historical information to enrich user models. Without altering the user’s current preferences, we aim to enhance current user interest modeling through comprehensive integration of relevant historical data. This approach is designed to improve recommendation accuracy and enhance the rationality of responses generated by the dialogue module by effectively combining historical information with the user’s current interests. Inspired by Shang et al. (2023) and Bai et al. (2021), we use the structure of “Hypergraphs” to model the historical activities of users. Then, we extract key features separately from the knowledge graph and historical hypergraphs data to enhance the effectiveness of the recommendation and dialogue. In view of these challenges, we propose a feature learning strategy that integrates user’s multi-faceted graph representation.
Incorporating historical information into the dialogue will help users understand the logic behind recommendation and enhance the interpretability of the recommendation system. Through this method, we can effectively integrate user information and reflect this integration in the content of the dialogue, thus increasing the richness and diversity of the dialogue.
The summarized of our main contributions are as follows:
Our proposed method adopts the strategy of fusing the features of three graphs. This method aims to increase the richness of user features. We propose to enhance users’ current relevant preferences by leveraging historical activity based on hypergraphs structures, and this strategy is used to optimize the “slot filling” link of recommended items in the process of dialogue generation. We tested our model on two real conversation recommendation datasets, and it achieved performance above most current baselines. In addition, through ablation study, we verified that the three graph features are indispensable.
Task Description for Conversation Recommendation System
In recent years, recommendation system gradually became the core function of some of the largest online services in the world (such as Microsoft, Google, Amazon) (Tran et al., 2020), which was widely used in e-commerce, social networks, movies, music, and so on. By analyzing user behavior data and other relevant information, the system scores and ranks candidate options during the dialogue process, identifying products or information that users may find interesting. However, traditional recommendation systems often adopt static models and rely heavily on users’ offline historical data, which may be sparse or contain noise (Gao et al., 2021). At the same time, in some recommendation scenarios, users’ real-time preferences may vary, and the traditional static model can’t adapt to this change, so it can’t quickly capture users’ intentions, which affects the accuracy of recommendation.
With the development of dialogue system, dialogue technology provides a new way to solve the problems faced by traditional recommendation. Recommend fascinating projects and even perform complex tasks by simulating human language interaction (Moradizeyveh, 2022); Conversation recommendation system is the deep integration of dialogue and recommendation system (Lei et al., 2020a). Its purpose is to collect detailed information about users’ preferences through real-time communication with users, and to meet users’ immediate needs according to this information. This method can provide personalized, real-time and coherent recommendation content for users, thus improving the user experience and recommendation effect.
At present, the research on conversation recommendation system is mainly concentrated in two directions: one is attribute-based conversation recommendation system, and the other is generation-based conversation recommendation system. Next, we will introduce these two types of systems in detail.
Attribute-Based Conversation Recommendation System
Attribute-based conversation recommendation system (Deng et al., 2021; Lei et al., 2020b; Sun & Zhang, 2018; Zhang et al., 2018, 2022; Zhao et al., 2023a, 2023b; Zou et al., 2020) evolved from interactive (Guo et al., 2017) and comment-based (Luo et al., 2020) recommendation systems. These systems follow the SAUR (Zhang et al., 2018)(interactive mode of System Asks, User Responses). It is intended to optimize the recommend strategies by continuously asking questions to users and obtaining their feedback. Attribute-based conversation recommendation system aims to reduce the number of conversations required and improve the accuracy of recommendation results. Lei et al. proposed “EAR (Lei et al., 2020a)” proposes to divide the dialog recommendation task into three steps: Estimation-Action-Reflection identifies the basic constructs of such a dialog recommendation system, consisting of an attribute model and a dialog model, and introduces a dialog strategy to control the system’s choice of whether to continue asking questions or recommending. SCPR (Lei et al., 2020b)proposes to model the dialog recommendation task as a path reasoning problem on the knowledge graph, and model the interaction process between the system and users as a path walking process on the graph. Aiming at the issue of users’ multi-interest deviation, Zhang et al. (2022) proposed that comprehensively extracts users’ multiple interests based on multiple-choice questions.
This type of system focuses on improving the efficiency of interactive recommendation and completing the recommendation task in the least number of rounds as far as possible. However, constantly asking questions mechanically may sometimes sacrifice the natural fluency of the dialogue. In addition, because such systems often choose to reply in several preset templates, the query attributes of users are limited, which may have a negative impact on the overall experience of users, thus limiting their application in various dialogue scenarios.
Generation-Based Conversation Recommendation System
Generation-based conversation recommendation system (Chen et al., 2019; Feng et al., 2023; Li et al., 2018, 2023, 2022; Liang et al., 2021; Lu et al., 2021; Ma et al., 2020; Shang et al., 2023; Wang et al., 2022; Zhou et al., 2020, 2022): differing from the former, this kind of system is a special task-based dialogue system. It takes successful recommendation as the final task, and the system independently trains two modules, namely, dialogue and recommendation. By analyzing the current conversation content of users and combining external resources as well as users’ personal information, it is aimed at achieving accurate recommendation through modeling the user’s representation. At the same time, it generates appropriate and informative replies in the dialogue generation module by using an end-to-end framework. With deep learning and language modeling constantly updated, there are constantly new technologies to improve the dialogue understanding and generation ability of this system.
Obtaining a representation of a user’s current interests relies heavily on the context of the conversation, but due to limited conversation data, the system is unable to extract enough information to ensure the accuracy of recommendations. This limitation leads to challenges for recommender systems in accurately capturing user needs and preferences. Therefore, early research usually relied on external data, such as knowledge graphs (Chen et al., 2019; Ren et al., 2023; Zhang et al., 2024, 2021; Zhou et al., 2020). This enabled the system to enrich the content of user preference-related entities and extract the user’s current expression of interest in order to improve the accuracy of the recommendation in the presence of limited data. On this basis, recent research mainly explores other information of users, such as user history, comments (Lu et al., 2021), similar user characteristics (Li et al., 2022) and other dimensions. At the same time, recent research began to pay attention to the dialogue generation module, focusing on how to naturally integrate the recommended content into the reply ? and how to enhance the explanation of dialogue generation (Guo et al., 2023). The goal of this kind of dialogue recommendation system is to simulate an identity similar to that of a “real-world shopping guide,” which can skillfully guide users to the recommendation link on the basis of keeping the dialogue natural and smooth (Zhou et al., 2020).
Our model accurately captures users’ current interest in using graph data representation, and integrates users’ historical information by using hypergraph technology. Thus, it realizes the fusion of several graph features. These features are effectively input into the dialogue generation module to generate answers that are both integrated into the recommended content and maintain natural fluency. In addition, by introducing user information integrated by multiple graph features, our system can introduce other entities related to recommended items in the process of dialogue generation. This not only enrich the dialogue content, but also explain the reason of recommendation, enhancing interpretability.
Description of Method and Structure
In this section, we not only focus on the representation of the current conversation content, but we also cover the features extracted from the user’s historical conversation. Firstly, it focuses on capturing the current interests of users; then, the feature extraction and data enhancement of users’ historical interaction are carried out by applying hypergraph technology; After that, we fuse the historical information identification with entity and word coding feature. Finally, we will describe how to integrate the features of user representation to support the module of movie selection and dialogue generation. The overall structure of the system is shown in Figure 2.
Current User Preference Extractor
In recommendation scenarios, each conversation usually contains only a few questions and answers. There is less data on items that can be related to the user’s interests in the conversation. This leads to the problem of data sparsity in the content of the current conversation. To address this difficulty, Zhou et al. (2020)proposed extracting and integrating information from external knowledge graphs to enhance the feature representation of the current conversation. Following the recommendations of these studies, we employ graph convolutional networks (GCNs) (Kipf & Welling, 2016) and relational graph convolutional networks (R-GCNs) (Schlichtkrull et al., 2018) to extract features of words and entities from two different knowledge graphs, respectively.
Encoding Word-Oriented KG
We select ConceptNet (Speer et al., 2017), a well-recognized knowledge graph, as our word-oriented knowledge base, where semantic facts are stored in the form of triples: word-relationship-word. To mitigate the negative impact of noise on recommendation performance, we extract only words that appear in the corpus and retrieve their related triples in ConceptNet. By applying GCNs, we are able to capture contextual dependencies and potential semantic connections between nodes (i.e., words), thus transforming isolated word embeddings into context-rich representations, ultimately obtaining the current word encoding representation of the user, denoted as

We employ DBpedia (Bizer et al., 2009)(a structured database derived from Wikipedia) as an entity-oriented knowledge graph for entity linking. We systematically identify and collect all mentioned entities from the corpus following the methodology of Chen et al. (2019). Considering the diversity of relationships between entities (e.g., directors, actors, screenwriters, etc.), traditional graph neural networks may not be able to adequately capture the associative properties of these diversities. So we adopt the R-GCN, which can assign different weights to neighboring nodes according to the type of relationship connected to the target node. This ability makes R-GCN useful in dealing with data containing rich types of relationships, especially in entity classification and link prediction, among other tasks, to demonstrate superior performance. The corresponding entity embeddings are obtained using R-GCN denoted as
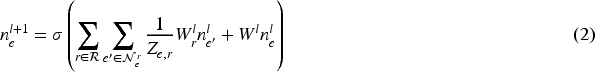
In this step, we perform self-attention transformation separately on the current word and entity representations to identify key information, convert them into the same dimensionality, namely, the current word and entity encodings:




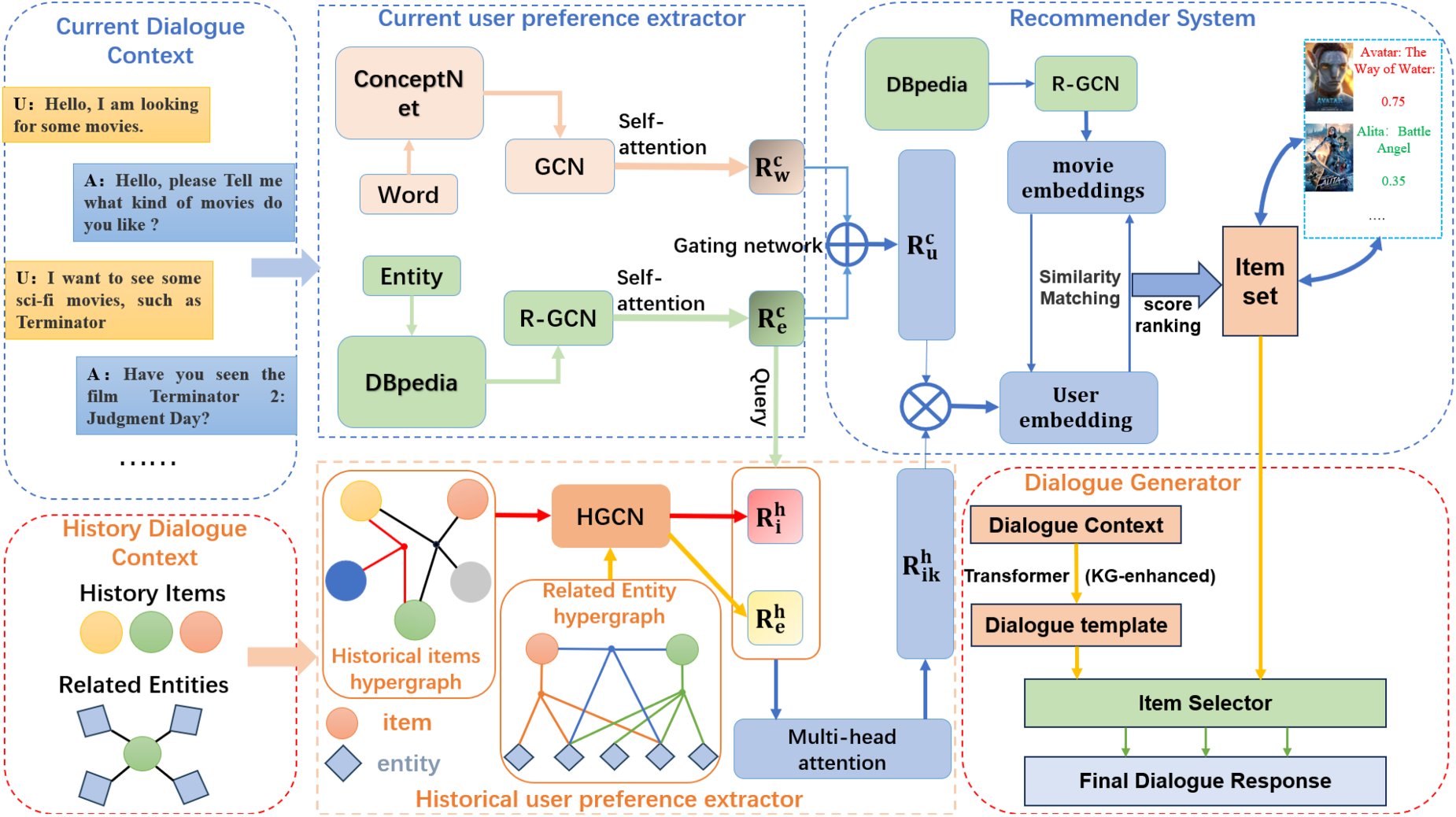
Overall structure diagram: our model (MGIRD) consists of four parts: (a) Current user preference extractor; (b) Historical user preference extractor; (c) Recommender system; (d) Dialogue generator.
Given the difference in interaction frequency between users and the system, with some users engaging frequently while others relatively infrequently, we have decided to utilize a “hypergraph” structure to model historical information.
Hypergraphs have been used in various fields such as social networking (Zhao et al., 2023a), sequence recommendation (Xia et al., 2022), data mining (Alam et al., 2021), and so on, due to their unique ability to deal with “unpaired relationships.” They are particularly suitable for capturing higher-order relationships in data, which is crucial for us in dealing with complex historical information.
Firstly, the “one-side multiple nodes” capability of hypergraphs can integrate multiple entities (Bai et al., 2021; Zhao et al., 2023b), enhancing the connections between them. Additionally, the powerful flexibility of hypergraphs allows the model structure to adjust according to the continuously changing data, for example: when there are new changes in user behavior or dialogue, the hypergraph can adjust the graph structure by adding or deleting nodes and edges.
Construction of Hypergraphs
Following the work done in Shang et al. (2023), we constructed two types of hypergraphs. The build process is shown in Figure 3.
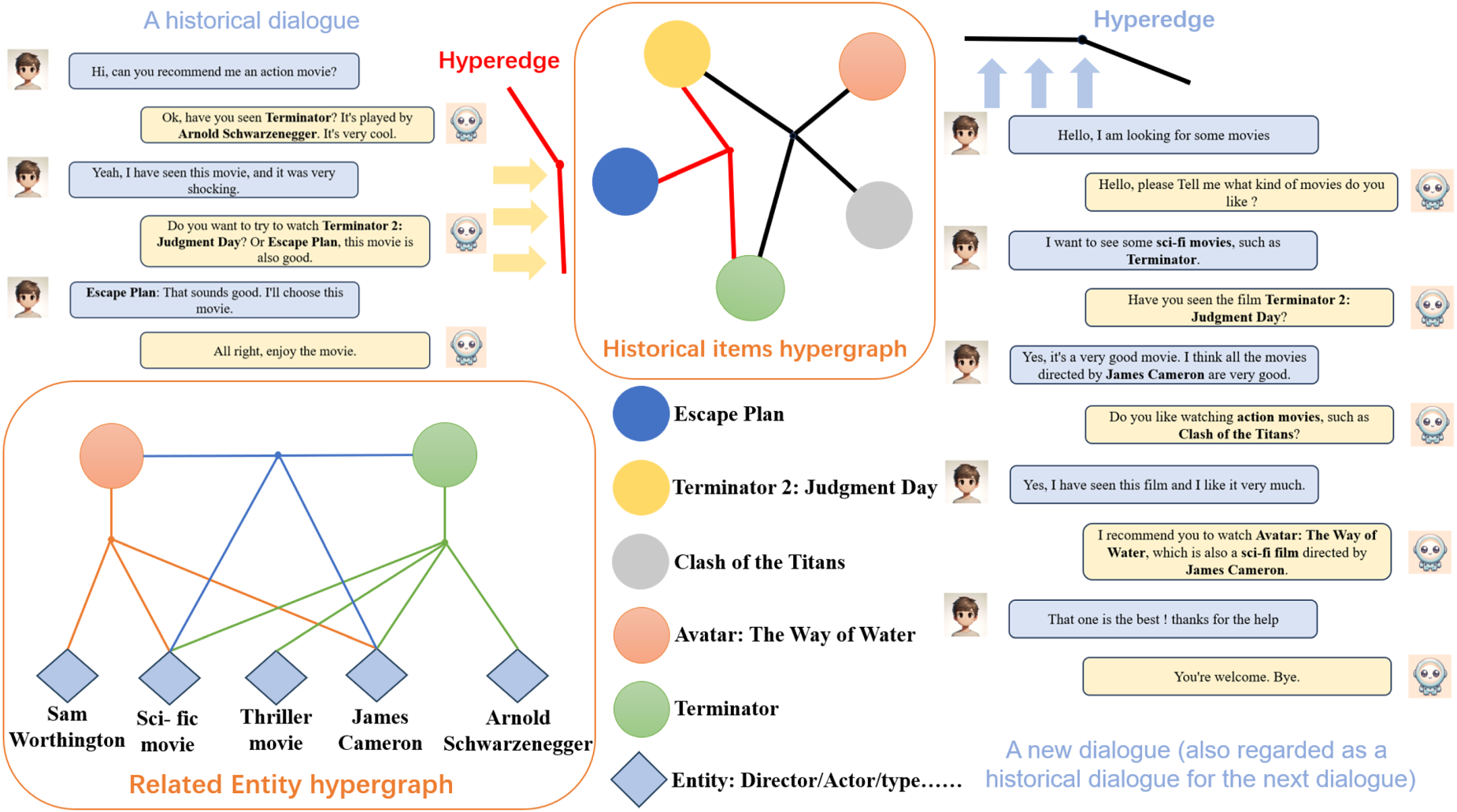
Graph from dialogue to hypergraph structure.
First, we constructed a hypergraph that reflects the history of user interactions. Typically, interactions between a user and the system are centered around specific topics, especially for users with frequent interactions. Certain items may recur multiple times in these interactions, thus providing opportunities to connect different conversations. Specifically, we treat items in the same historical dialog as vertices and represent their connections by constructing hyperedges. This approach allows us to create associations between conversations and items, thus enhancing the relevance of items to each other, regardless of the chronological order.
As shown in Figure 3: take movie recommendation as an example, in one of the history conversations, the user mentions the names of three movies: “Escape Plan,” “Terminator 2,” and “Terminator,” we use this conversation as a hyperedge to connect these three movie nodes. Later, in a new interaction (which should also appear as a history hypergraph in future conversations), the user mentions several other movies. “Terminator 2” and “Terminator” appear again, to which we will assign more weight. Since the two dialog hyperedges are connected to the same node, the other nodes they are connected to will also have some connection to each other.
We have noticed the common phenomenon of “long-tail distribution” in real dialog scenarios, where a few users interact with the system frequently while the majority of users may only interact once or twice. This situation affects the accurate assessment of users’ historical preferences. To solve this problem, we create a knowledge-enhanced hypergraph by merging each item in the history and its N-hop neighbors in the knowledge graph into the hypergraph construction. We chose adjacent nodes because the neighbors of an item usually share similar or related semantic properties with that item. In this way, all hyperedges are interconnected through their shared entities (either items or attributes), ensuring that each hyperedge contains a specific item and multiple related entities, effectively mitigating the problem of sparse historical data.
As shown in the bottom left corner of Figure 3: “Avatar The Way of Water” and “Terminator” are shown as examples, we use a hyperedge to connect them to related entities or properties (e.g., director: James Cameron, star: Arnold Schwarzenegger, movie genre: sci-fi and thriller). When two or more identical nodes are connected to the hyperedge, the connection between the two movies will be increased, and if any one of them matches the user’s interest, the other one will be prioritized in the recommendation.
In this paper, we define the normalized hyperedge convolution layer using the hypergraph neural network (Bai et al., 2021) convolution method as:
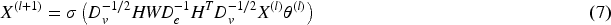
In this description,
From the formula, we can view the operation of this hypergraph convolution as a two-stage process: the first stage aggregates vertex features into hyperedges to form hyperedge features; the second stage refines the aggregated hyperedge features back to vertex features, culminating in the hypergraph convolution formula HCon(


We assign the vertex degree matrix
For the feature extraction of hypergraph representations from historical interactions: we structure a set


After we obtained two forms of historical hypergraph representations:
Specifically, we use the entity encoding obtained via R-GCN from the context entities to perform self-attention operations: the computed values serve as the representation of user historical features and provide a basis for the multi-feature fusion strategy in item recommendation. The formula is as follows:

Using the methods described above, we obtain the item’s word feature representation


Since project recommendations should still be based on the current user’s immediate preferences, we perform matrix operations between the feature representation of the current user and the user’s historical feature representation

We have implemented a strategy with a separately trained recommendation module, using the cross-entropy loss function as the objective function to train the model’s parameters so that its predictions closely align with the actual user behavior.
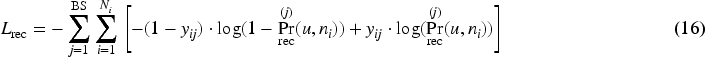
Follow previous work (Liang et al., 2021; Zhou et al., 2020) we divide the dialogue generation into two main operations: first, the response template generator, which creates the basic template and framework for replies; When the recommendation state is not yet achieved, the response template generator engages in casual conversation with the user, generating replies without recommendation items, while also assessing the dialogue’s state to steer its direction. Second, the item selector is responsible for choosing the most suitable recommendation item from a set of options and integrating it into the generated dialogue template. This step-by-step design approach contributes to enhancing the quality and efficiency of replies, making the system more flexible and adaptable to new environments. The structure of the dialogue generation module is shown in Figure 4.
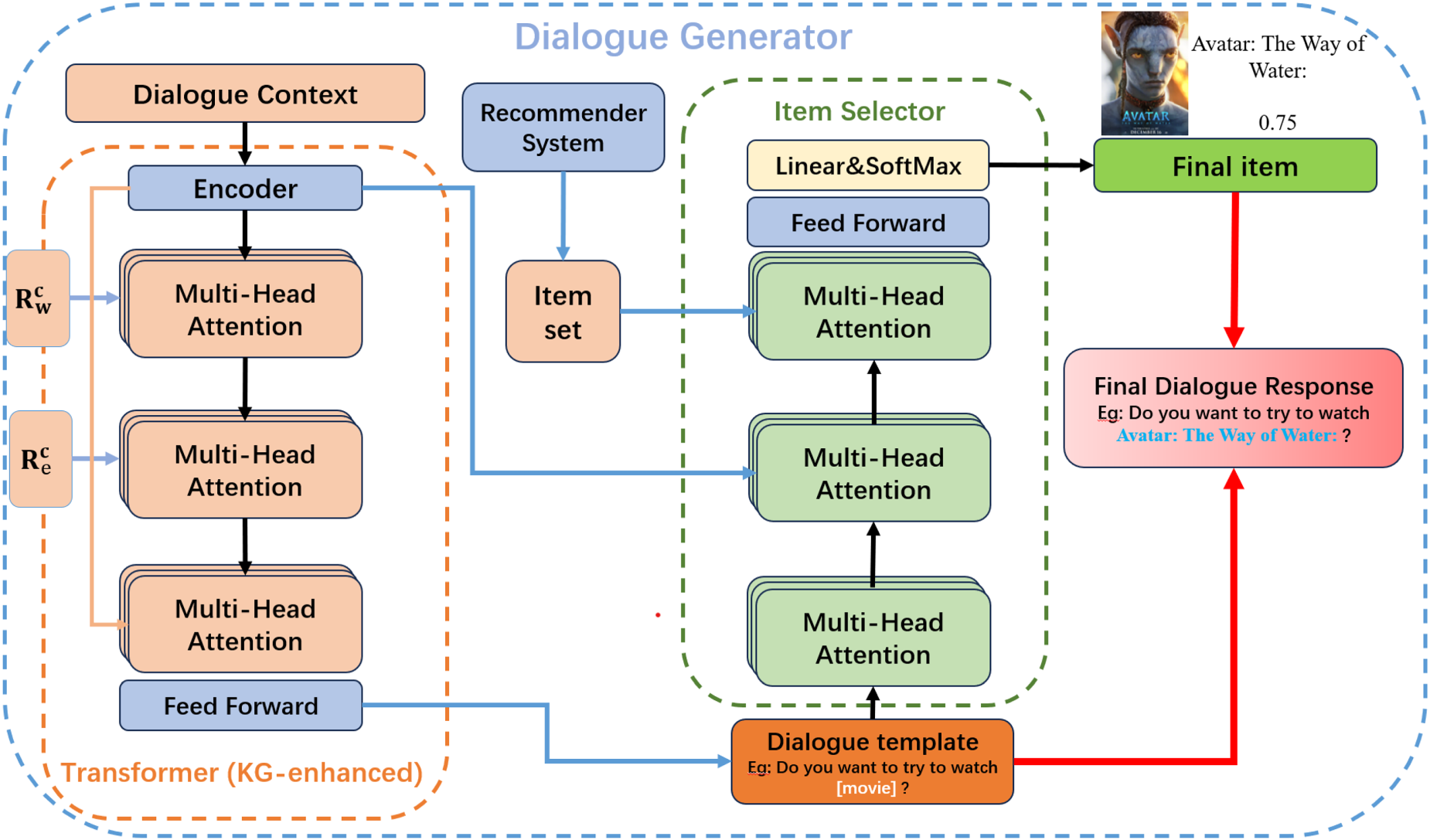
Response generation module.
Unlike traditional fixed reply template generation methods (Deng et al., 2021; Lei et al., 2020b; Sun & Zhang, 2018), we adopt a Transformer network-based approach to generate reply templates, achieving a more natural and realistic dialogue generation effect. Specifically, we use the standard transformer encoder architecture (Vaswani et al., 2017) to encode the current dialogue, and then feed the resulting encoded representation into a KG-enhanced decoder architecture (Wang et al., 2022) for processing. Here, the KG-enhanced decoder can effectively utilize information from the knowledge graph, integrating it during the dialogue generation process to enhance the interpretability of the generated replies. Moreover, following the Liang et al. (2021) method, we add a special

After the previous steps, we have obtained the response template. According to the probability calculation method of the recommendation module, we select candidate items to form the candidate set

To achieve this goal, we first use a KG-enhanced decoder (Zhou et al., 2020) to generate the reply template




Through this approach, we are able to gradually integrate the generated template, dialogue context, and key information from the candidate item set. With the aid of the item selector in the dialogue module. We can ultimately predict the probability distribution of each item in the item set being filled into the dialogue template, subsequently selecting the item with the highest probability for insertion.

Unlike conventional chatbot systems, the goal of a dialogue recommendation system is to integrate recommended items and their associated attributes, entities, or keywords into the generated responses. Therefore, in this specific conversational context, we adopt the method proposed by Liang et al. (2021), training separately for dialogue loss and item slot-filling loss, and combining them. First, we train the loss for the dialogue generation template:
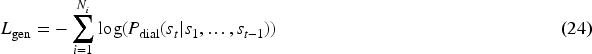


Datasets and Setup
Datasets
We conduct experiments on two widely used datasets in CRS: the ReDial dataset in English and the TG-ReDial dataset in Chinese. The ReDial dataset, collected through crowdsourcing tasks on the Amazon mechanical turk (AMT) platform, aims to obtain high-quality movie recommendation dialogues. This dataset consists of 10,006 dialogues comprising 182,150 sentences. The other dataset, TGRedial, in Chinese, is annotated in a semi-automatic manner with a focus on achieving natural and fluent transitions from non-recommendation scenes to recommendation scenes. It contains 10,000 dialogues with 129,392 sentences. Both datasets are annotated by collecting casual conversations from real humans. Participants are asked to play the roles of either a seeker or a recommender and engage in conversations with each other to achieve the goal of dialogue recommendation. The statistical data for both datasets are shown in Table 1. The data set is divided into training set, verification set and test set according to the ratio of 8:1:1.
Datasets Overview.

Datasets Overview.
In the research domain of CRSs, we focus on two core tasks: recommendation and dialogue generation. To accurately assess the performance of our model and demonstrate its relative advantages, we conducted independent training for each task and compared the results with several landmark CRS models.
Evaluation Metrics
CRS are designed to provide high-quality recommendations through natural and fluid interactions. Therefore, it is crucial to evaluate the performance of dialogue and recommendation tasks separately and to determine the appropriate evaluation metrics for each. We selected the following metrics as key indicators to assess the precision and recall effectiveness of the recommendation system:
For dialogue tasks, we employ the Dist-k metric.
Parameter Settings
Our research work is conducted on a deep learning framework based on PyTorch, using the CRSlab (Zhou et al., 2021) framework as the basis for modifying and extending models. We also performed comparative experiments to verify the effectiveness of our methods. In handling recommendation and dialogue tasks, we set the embedding sizes for knowledge graphs and word tokens at 300 and 128, respectively; to reduce information redundancy due to excessively long dialogue texts, we truncated the lengths of historical and current dialogues to 1024 and 256, respectively; considering the efficiency of the system, we set the number of layers for GCN, R-GCN, and HGCN to 1; we used the Adam optimizer with default parameter configurations; during training, we set the batch sizes for recommendation and dialogue tasks at 128 and 64, respectively; the learning rate was uniformly set at 0.001; gradient clipping was limited to [0, 0.1], and the training dialogue loss weight
Experiment Results of Recommendation Task
Result Analysis
In this subsection, we conducted a series of comparative experiments to verify the performance of MGIRD in recommendation tasks. Table 2 shows the experimental results of different methods on the redial and tg-redial datasets for recommendation tasks.
Comparison of Models on the ReDial and TG-ReDial Datasets.
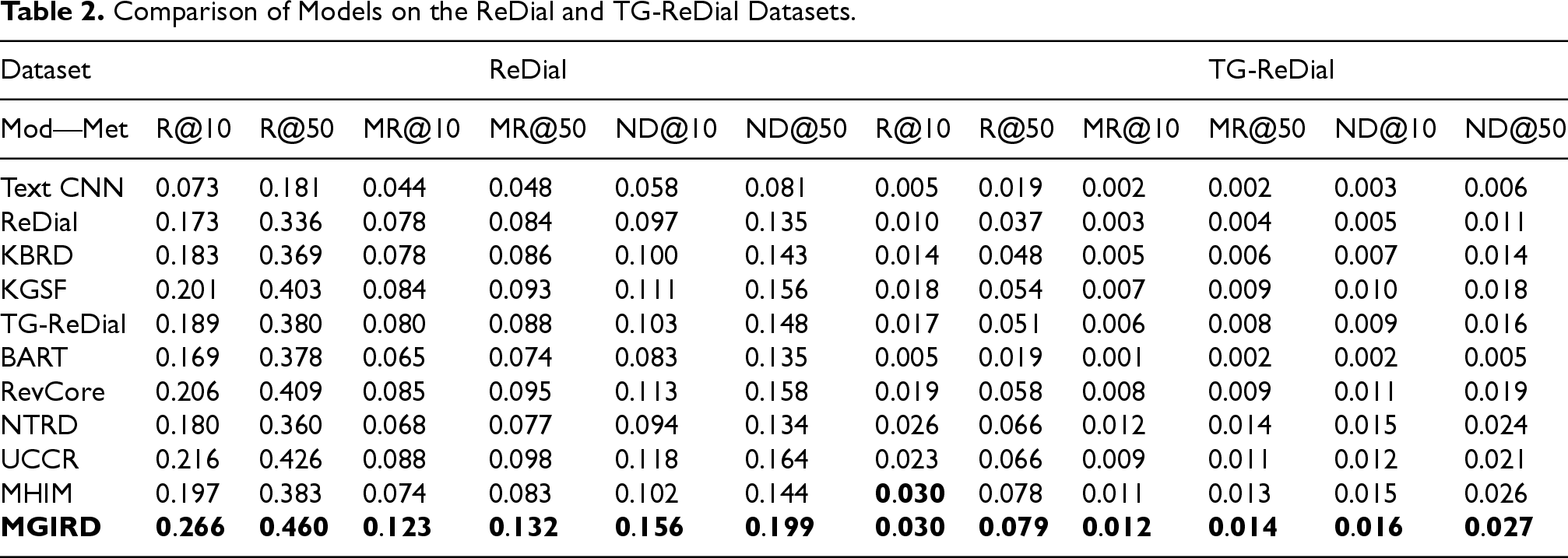
Comparison of Models on the ReDial and TG-ReDial Datasets.
According to the results, we can observe that as a standalone recommendation model, compared to the comprehensive CRS, the performance of the text CNN is significantly worse, reaching only 50% of the average performance. This is mainly because Text CNN cannot capture the user’s immediate interests, while CRS dynamically senses and captures real-time user preference changes through instant dialog interaction mechanisms, thereby improving the accuracy of recommendations.
Furthermore, our results also show that integrating external data contributes to the improvement of recommendation performance. Specifically, incorporating diversified information such as knowledge graphs (Zhou et al., 2020), user reviews Lu et al. (2021), and historical interactions (Li et al., 2022) into the recommendation model can significantly improve the relevance of the recommendation results and enhance the degree of personalization of recommendations. From the R@50 performance metrics of the Redial dataset, these three types of models and our MGIRD exceed 0.4, indicating that a relatively high recall is obtained.
Our method outperforms all other baselines, and MGIRD, by integrating various user features and improving upon these baselines, achieves notable results in recommendation tasks. The experimental results also further validate the superiority of our proposed CRS in facing complex user requirements.
To investigate the contributions of various components to the recommendation task, we conducted ablation experiments on the following three types of graph features: (a) MGIRD w/o Wo: Removing word embeddings extracted from ConceptNet; (b) MGIRD w/o En: Removing entity embeddings extracted from DBpedia; (c) MGIRD w/o Hist: Removing context-aware historical representations constructed and extracted from hypergraphs. The results are shown in the Figure 5 .
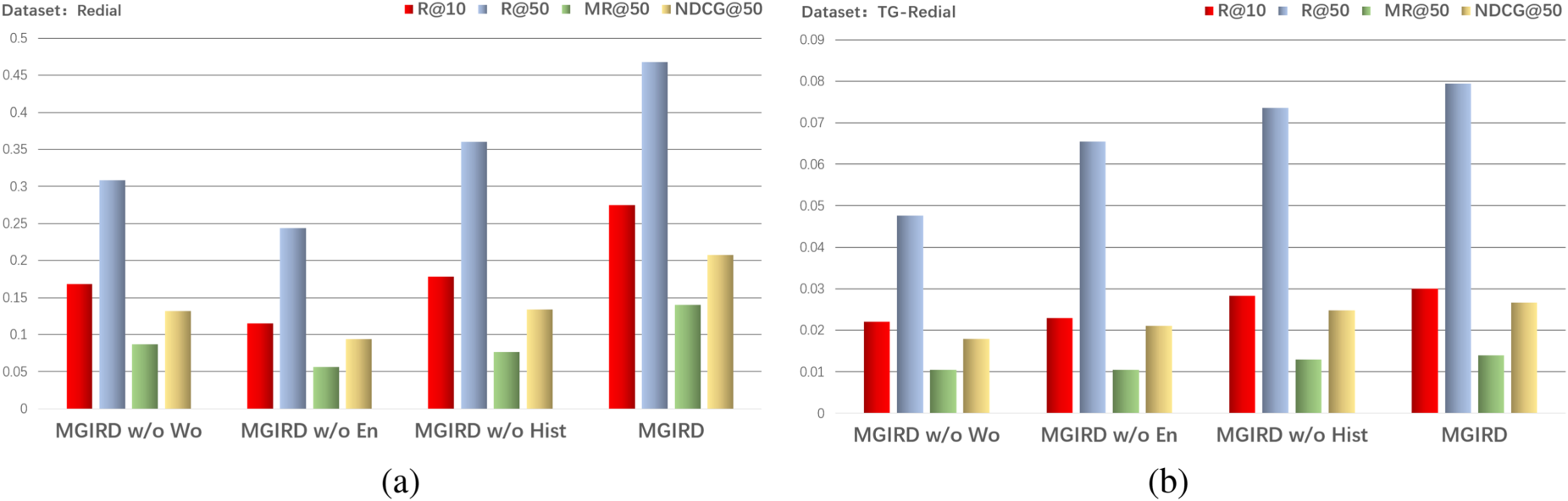
Ablation study results on ReDial and TG-ReDial datasets: (a) ablation study results conducted on ReDial and (b) ablation study results conducted on TG-ReDial.
Based on the experimental results, we note that these three components are indispensable, and removing any one of them results in performance degradation. In particular, the first two features, i.e., the current user’s representation, removing the word and entity representations decreased the performance by more than 20%. This suggests that in a dialog-based recommender system, the user’s primary preferences are captured primarily through the system’s representation of the user’s current interests.
While the user’s history information, although beneficial, contributes less to the overall modeling of the user’s interests compared to the former, and removing it only decreases the performance by about 10%. In addition, on both the English and Chinese datasets, entity representations and word representations of the current user vary in their importance to the system’s understanding of the user’s interests.
In recent years, large language models have demonstrated unprecedented reasoning and generative capabilities, providing new opportunities for the development of powerful CRSs. Several studies have begun to take advantage of the inference capabilities of large models by customizing them through fine-tuning to improve their performance in session recommendation tasks. Here, we decided to compare our approach with the strategy proposed by Feng et al. (2023)(LLMCRS), which divides the conversation recommendation task into four subtasks, namely, subtask detection, model matching, subtask execution, and reply generation, takes the outputs of the first three tasks and the context of the conversation as inputs, and utilizes reinforcement learning driven by CRS performance feedback is utilized to fine-tune the LLM (LLaMA and T5 in this case) and complete response generation. Considering the large number of parameters and high dialog generation capacity of large language models, our comparison will focus on recommendation performance, which is evaluated on the TG-Redial dataset. Table 3 below details the comparison results of recommendation performance:
The Comparison Results with the Large Language Model(TG-ReDial).

The Comparison Results with the Large Language Model(TG-ReDial).
The data presented above show that our method performs well on metrics such as R@50, MR@50, and NDCG@50, but it underperforms compared to LLMCRS in R@10 (LLMCRS: 0.0308; MGIRD: 0.0300). We speculate that this may be because our model was only trained for performance in recommendation systems, without further utilization and training of these candidates within the conversational system.
In this section, we have demonstrated the effectiveness of our proposed approach, and the subsequent table presents a comparison of evaluation metrics against different methods. Notably, LLMCRS and TG-Redial methods utilize additional pre-trained models for dialogue generation, which may introduce unfairness in direct comparisons with other methods; therefore, we did not include them in our comparison. In comparing dialogue performance, we primarily focused on the diversity metrics, such as “dist.” The specific comparison results are shown in Table 4.
Diversity Metrics Comparison Across Models.
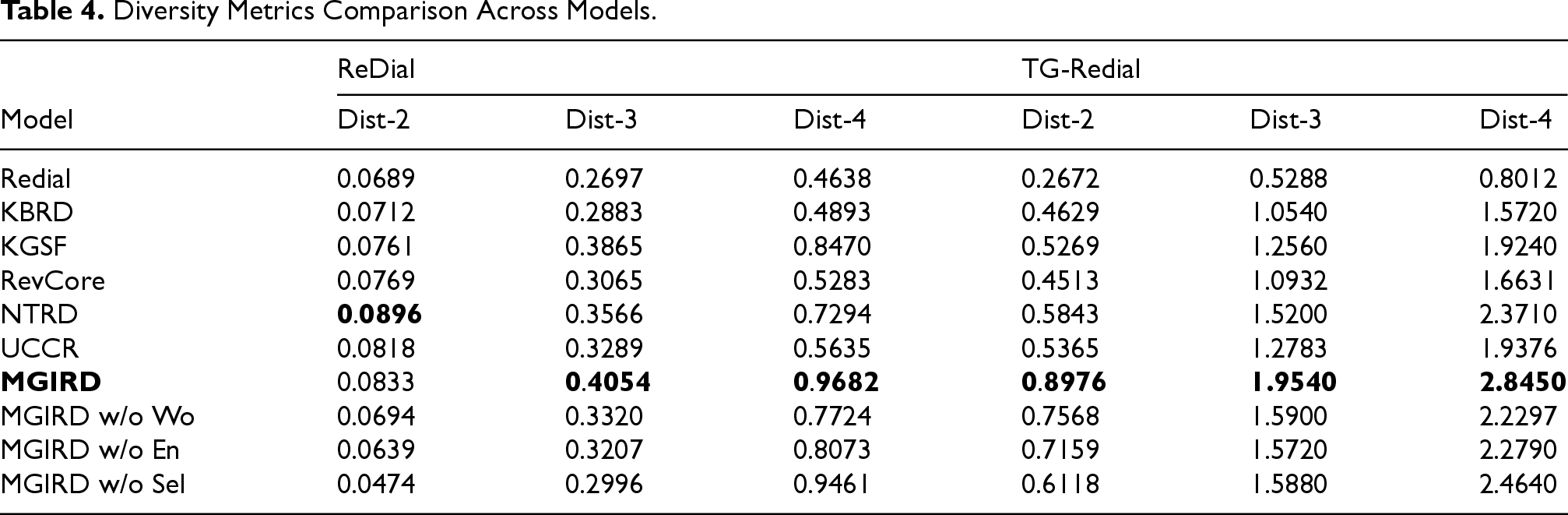
Diversity Metrics Comparison Across Models.
As depicted in Table 4, our approach demonstrates superior performance compared to the majority of other baseline methods across various scenarios.
Our further analysis of the comparison between the different baselines reveals that the Knowledge Graph Enhanced Decoder significantly improves the converter’s ability to understand user conversations in recommendation scenarios. By incorporating rich semantic associations between entities and contextual knowledge into the model, the Knowledge Graph Enhanced Decoder is able to more accurately capture subtle variations in user intent. The experimental results of NTRD also outperform other baselines, especially the “dist-2” metric on the redial dataset reaches 0.0896, which outperforms all baselines. We believe that it may be due to the fact that NTRD skillfully utilizes the multi-attention mechanism to match appropriate recommendation items with conversation content in the item selection process. We believe that it may be due to NTRD’s skillful use of the multi-attention mechanism in the item selection process to match the appropriate recommended items with the dialog content. At the same time, NTRD also adds additional user contextual information to enrich the item slots in each attention layer, thus generating more diverse and richer responses.
Building on these approach, we further infused the integrated user preference information into the decoding process. In the presence of a dialogue template generator, the generated content not only includes movie recommendations but also incorporates casual conversation, thereby expanding the direction of dialogue generation and enhancing the Dist metric of dialogue generation. Experimental results demonstrate that our method can generate responses that are more diverse and aligned with user interests in the dialogue process.
Ablation Study
To explore the role of each component in the conversational task, we conducted an ablation study by removing graph features and the item selector in the generation module.
Specifically, the study included: (a) MGIRD w/o Wo: removing word embeddings extracted from ConceptNet, (b) MGIRD w/o En: removing entity embeddings extracted from Dbpedia, and (c) MGIRD w/o Sel: removing the item selector in the generation module. The results are shown in Table 4.
According to the results of the ablation studies, we found that removing any of the components resulted in performance degradation. This suggests that the multi-aspected graphical representation feature used in the dialog module not only improves the efficiency of the item selector and dialog generation, but also that the item filtering mechanism that we use positively contributes to the dialog generation process by introducing more diverse and content-rich information. The experimental results show that the Dist performance of our method on the Chinese and English datasets is better. It exceeds the current better baseline by about 10%. This suggests that our method can generate more diversified and user-interested responses during the conversation.
Realistic Conversation Recommendation Scenario Analysis
In order to verify the practicality of the method, we conducted an experimental analysis of realistic dialog recommendation scenarios to make it a combination of theory and practice. As shown in Figure 6 below, firstly, the user makes a recommendation request: our method quickly recognizes the keyword “Action Movie” through self-attention computation, which narrows down the space of candidates, and then enhances the information with the entity “Escape Plan” mentioned in the user’s history to generate the candidate “Rambo: First Blood Part II.” After that, we augment the information with the “Escape Plan” entity mentioned in the user’s history, and generate the candidate “Rambo: First Blood Part II,” which is inserted into the reply; after receiving the user’s indication of the right direction, such as “I have already seen it, but I liked it,” we can then add the candidate “Rambo: First Blood Part II” into the reply. Upon receiving a prompt from the user such as “I’ve already seen it, but like it,” which indicates the right direction, the system generates two candidate entities with stronger relevance. Then, the system weights the entity with stronger relevance to the historical information, prioritizes the recommendation of movies related to that entity, and integrates it with the generated dialogue template to generate a satisfactory response.
Sensitivity Analysis of Dialogue Parameters
In order to verify the scientific validity and effectiveness of the preset dialog loss weight
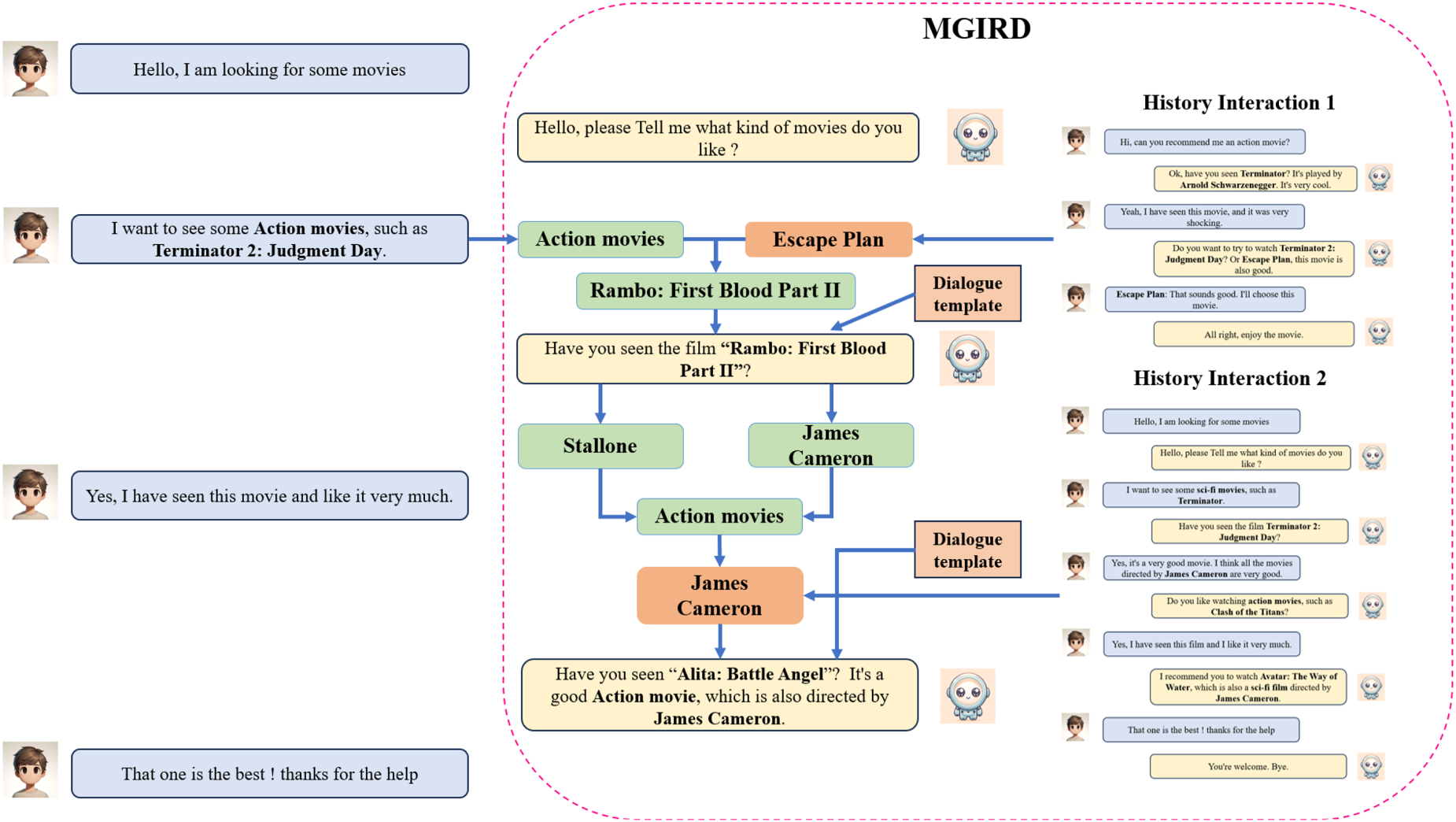
Realistic scenario analysis.
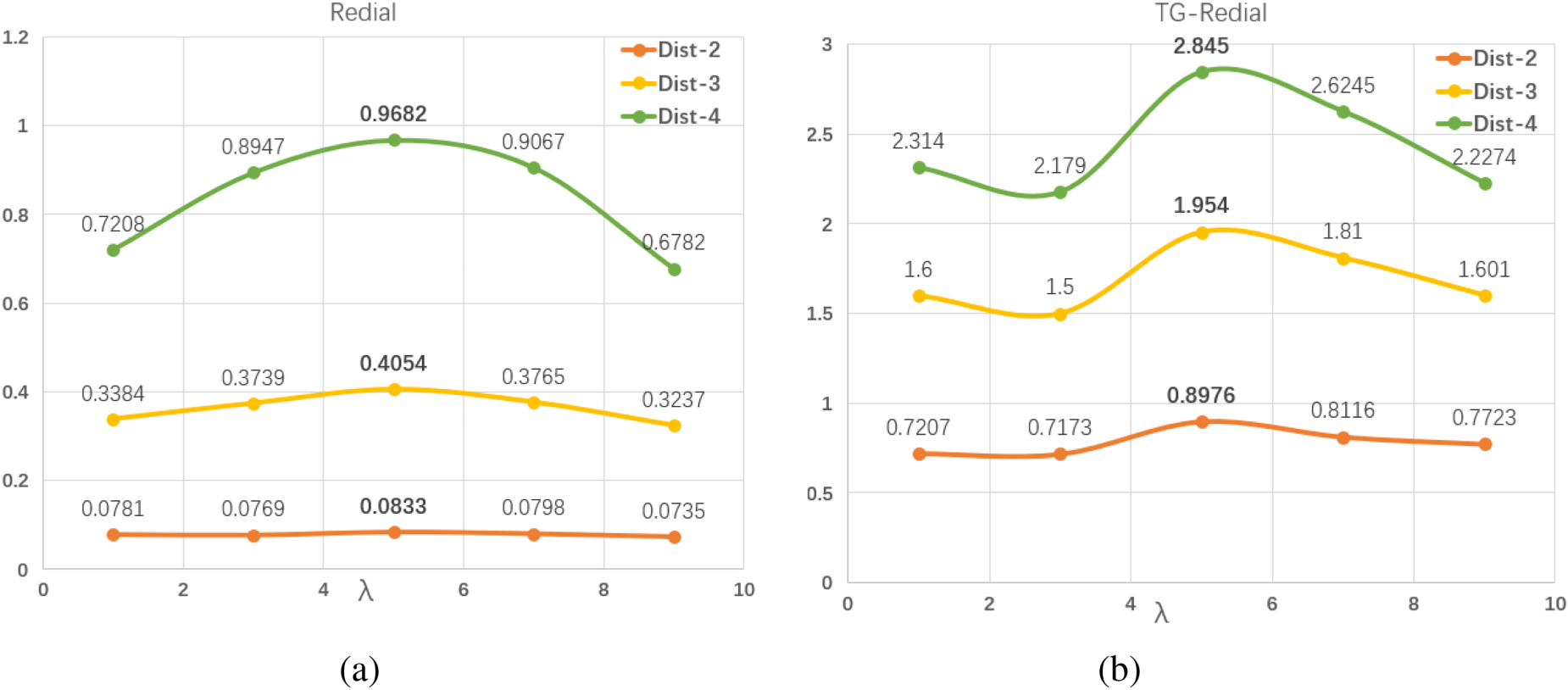
Sensitivity analysis of dialogue parameters on ReDial and TG-ReDial datasets: (a) ReDial and (b) TG-ReDial.
Through parameter sensitivity experiments conducted on both datasets, our parameter settings achieved relatively good performance. Therefore, in our model, we decided to fix the dialog loss weight
This study explores the possibility of integrating multifaceted graphs and hypergraph structures as a way to enhance the representation of user information. First, it conducts graph feature extraction of words and entities from the knowledge graph of entities related to the current conversation using graph convolutional networks, and then integrates historical information about the user by constructing a hypergraph structure. Ultimately, it extracts information from the historical conversations and the entities related to the project to enhance the understanding of the user’s current interests. In the context of the conversation generation phase, we utilize these features to guide conversation template generation and item selection. Extensive experiments on both datasets show the superior performance of our approach compared to other baselines.
At present, there are still many parts of our experiments that can be improved: in the construction of hypergraphs, we give the same weight to all historical information, while ignoring the influence of time factor on the user’s historical representation. For example, the closer the historical information is to the current conversation, the more it affects the user’s current interest, and vice versa, the older the information is, the less it affects the user’s current interest; also some of the user’s interest representations are not only reflected in the historical information, but may also include some other information (e.g., comment information, similar users’ information, etc.). In the future, we plan to explore more comprehensive user information dimensions to generate richer dialog content, while also considering the impact of time factor on the accuracy of historical hypergraph information extraction. In addition, given the rapid development of dialogue models, we hope to optimize the user’s dialogue experience in the future by adopting more advanced dialogue models (including, but not limited to, LLM) to improve the naturalness of the dialogue and the accuracy of the wording.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.