
Abstract
Conversational recommender systems provide users with item recommendations via interactive dialogues. Existing methods using graph neural networks have been proven to be an adequate representation of the learning framework for knowledge graphs. However, the knowledge graph involved in the dialogue context is vast and noisy, especially the noise graph nodes, which restrict the primary node’s aggregation to neighbor nodes. In addition, although the recurrent neural network can encode the local structure of word sequences in a dialogue context, it may still be challenging to remember long-term dependencies. To tackle these problems, we propose a sparse multi-hop conversational recommender model named SMCR, which accurately identifies important edges through matching items, thus reducing the computational complexity of sparse graphs. Specifically, we design a multi-hop attention network to encode dialogue context, which can quickly encode the long dialogue sequences to capture the long-term dependencies. Furthermore, we utilize a variational auto-encoder to learn topic information for capturing syntactic dependencies. Extensive experiments on the travel dialogue dataset show significant improvements in our proposed model over the state-of-the-art methods in evaluating recommendation and dialogue generation.
Introduction
Conversational recommender systems (CRS) have become an emerging research topic, aiming to provide users with high-quality recommendations through natural language conversations [1, 2, 3, 4]. The general idea of such systems is that they support a task-oriented, multi-turn dialogue with their users. Unlike traditional recommender systems, CRS utilizes dialogue data to accomplish recommendation tasks. The CRS usually consists of a dialog component interacting with the user and a recommendation component.
Most existing CRSs focus on natural language processing or semantic-rich search solutions for dialogue systems. Traditionally, the CRS mainly asked users about their preferences over pre-defined slots to provide recommendations [2, 5]. Moreover, some studies [6, 7] use natural language dialogues and user interactions to make recommendations, emphasizing fluent response generation and accurate advice. Recently, a popular trend [6, 8] has been to incorporate knowledge or reinforcement learning into enhanced user models or interaction mechanisms to improve the performance of CRS. For example, the task-oriented dialogue system (e.g., Mem2Seq) uses a memory network based on multi-hop attention to incorporate knowledge and user input [9, 10, 11, 12]. In addition, to meet the needs of multiple topics, the deep conversational recommender in travel (DCR) leverages a graph convolutional network (GCN) to capture the relationships between different venues and the match between the venue and dialog context.
However, these existing methods suffer from two issues. (1) The GCN-based deep conversational recommender model cannot adequately capture space information. Because the conversational recommender system modeled by the graph convolutional network has the same weights, and these weights are assigned to different neighbors in the same order neighborhood, resulting in a huge graph and a lot of noise, which may lead to overfitting of the GCN-based conversational recommendation model. (2) The RNN-based deep conversation recommendation model has long dependency problems generating conversation topics. On this basis, the RNN-based hierarchical recurrent encoder-decoder (HRED) is employed to solve the long dependency problem in natural language processing tasks [6, 13, 14, 15, 16]; however, it is still difficult to capture long dependencies well by concatenating the hidden states of the last steps of each position of a sentence. In particular, when two words in the same sentence are far apart, the model cannot accurately capture the problem of the dependency between the two words, which affects the overall structure of the sentence and is very important to ensure smooth communication between users and agents.
To address these two issues, we observe that sparse graph attention networks [17, 18, 19] can effectively remove edges in a graph unrelated to tasks. The sparse graph attention networks (SGAT) leverage binary masks assigned to every edge to filter out noisy nodes. Moreover, different attention scores solve the limitation of the same weight in the first order. In addition, we also notice that the combination of memory networks and multi-hop attention in the Mem2Seq model reinforces the capability of capturing long-term dependencies. Instead of directly inputting the triples and historical dialogue sequences in the knowledge graph into the encoder, we just use the context as the input of the encoder, which can avoid introducing some noisy information. Graph structure information often contains various types of connections and relationships, while sequence information focuses on the temporal or sequential order of data. The two types of information have different characteristics and may introduce conflicting or irrelevant patterns when combined. This interference of noise information can arise due to the complexity and heterogeneity of the combined data sources. Additionally, the combination of graph structure and sequence information may result in a high feature extraction granularity. Graph structure information provides fine-grained details about the relationships and connections between entities, while sequence information captures the local dependencies within the data. The reason is that embedding vectors are stored in external memory, and query vectors can easily access “memories.” Meanwhile, to learn topic information, we use variational auto-encoders optimized by KL cost annealing [20], and it is effectively solve KL-vanishing problem.
In this paper, we propose a novel model called sparse multi-hop conversational recommender systems (SMCR). SMCR is a neural method that generates natural languages by fusing recommended items through filtered knowledge graphs. We fully take advantage of widely used slots filling techniques to ensure that items are inserted where they are in the sentence. The item recommender selects the appropriate item in the slot, which utilizes enhanced graph attention mechanisms to incorporate external knowledge into the dialogue. Our model is deployed in an end-to-end fashion. The SMCR has both the controllability of traditional slot filling models and the flexibility of neural language models. Besides, Our model cleverly combines the ability of RNNs to quickly deal with sequences and the ability of attention mechanisms to connect different parts of long sequences. The advantage of SMCR is that it can not miss the dependencies of each part of the dialogue under the premise of ensuring the memory of the dialogue content.
To sum up, the major contributions of this work are as follows:
We develop a recommendation model based on sparse graph attention to match items with dialogue context, which can accurately identify important edges, thereby reducing the complexity of graph computing and the interference of noisy nodes. We design a multi hop focus network that can quickly encode long conversation sequences to capture long-term dependencies, and learn topic information through a variable automatic encoder optimized by KL cost annealing. We conduct extensive experiments on a multi-domain wizard dataset to comparatively evaluate, demonstrating that our proposed method outperforms state-of-the-art methods.
Dialogue system
According to different application scenarios, the dialogue system is divided into three types: task-oriented dialogue systems (e.g., Cortana and Siri), chit-chat dialogue systems (e.g., Xiaobing), and question-and-answer dialogue systems (e.g., online store assistants). Traditional dialogue systems are usually based on rules or templates. For example, Weizenbaum et al. [21] developed the Eliza system to simulate psychotherapists’ treatment of people with a mental health conditions. Subsequently, Wallace et al. [22] developed the Alice system based on AIML and XML language to create stimulus-response chatbots. However, these methods rely on a great deal of manual labeling. In order to solve this problem, De et al. [23] designed a multi-party dialogue system based on machine learning and rules, leveraging support vector machines for decision-making. In addition, benefiting from the rapid development of deep learning and natural language technologies, more and more researchers focus on dialogue systems based on deep learning. For example, Dhingra et al. [24] combines reinforcement learning and knowledge graphs to develop a KB-InfoBot model, which is a dialogue agent that provides users with entities from the knowledge base by interactively querying features. Lipton et al. [25] proposed the BBQ network, which uses reinforcement learning for dialogue systems. These studies on dialogue systems can achieve smooth human-computer interaction; nonetheless, we believe that discovering user interests through dialogue and guiding users to complete purchases, subscriptions, and other behaviors has more excellent commercial value. Therefore, it is imperative to construct a dialogue-based recommendation system.
Conversational recommender
With a fast uptake of deep learning in recent years, researchers have become more interested in interactive recommender systems. For example, Christakopoulou et al. [26] proposed a novel view that regards the recommendation as an interactive process. Greco et al. [27] utilized hierarchical reinforcement learning to model the CRS target as a target-specific representation module. Sun et al. [2] proposed a unified framework that integrates the recommendation system and the dialogue system to build an intelligent dialogue recommendation system. Due to the lack of publicly available large-scale dialogue datasets, Li et al. [28] provided a REDIAL dataset containing real-world dialogues. In order to proactively ask questions in the conversation, Zhang et al. [29] introduced not only the system ask-user response (SAUR) paradigm for conversational search and recommendations but also designed a unified implementation framework for product search and recommendations in e-commerce. Although these studies have achieved some success, they only use dialogue information in the model, resulting in a lack of sufficient context to express user preferences. Overall, these models perform poorly on evaluation tasks (i.e., recommendation and dialogue). In order to solve these problems, many researchers focus on knowledge-based conversational recommender systems, which can provide external knowledge to narrow the gap between the dialogue system and the recommendation system for improving the performance of the recommender model.
Knowledge-based conversational recommender
Knowledge graphs (KG) are able to represent the structured relationship among entities and have been successfully used in conversational recommender systems. Chen et al. [6] proposed a novel end-to-end framework and introduced knowledge-grounded information about users’ preferences. Moon et al. [30] proposed a DialKG Walker model, which learns the symbolic transitions of dialog contexts as structured traversals over KG and predicts natural entities to introduce given previous dialog contexts via a novel domain-agnostic and attention-based graph path decoder. Liao et al. [13] combined the sequence-to-sequence model with a neural latent topic component and graph convolutional network to recommend in the tourism field. Lei et al. [31] utilized graphs to solve the multi-round dialogue recommendation problem and proposed the conversational path reasoning framework, which synchronizes the conversation with the graph-based path reasoning. This model makes the use of attributes more explicit and greatly improves the interpretability of conversational recommendations. Zhou et al. [8] adopted mutual information maximization to align the word-level and entity-level semantic spaces with bridging a semantic gap between natural language expressions and item-level user preferences.
To sum up, these works utilize the path of the knowledge graph to simulate the dialogue process or leverage the knowledge graph to model the item. However, in the real world, the dialogue has the characteristics of multiple levels, multiple rounds, and multiple topics, and there are complex dependencies between sub-conversations in the dialogue. In addition, there are many items involved in the dialogue, and each item has many attributes, which will add a lot of calculation to the modeling. Therefore, we argue that the graph generated from the dialogue is complex and sparse, resulting in some noise nodes in the process of extracting and aggregating graph information, which does not contribute to the aggregation result. Effectively distinguishing noisy nodes from important nodes will improve aggregation efficiency and save computational space. Based on these assumptions, we develop sparse graph attention to match items with the dialogue context in order to reduce the complexity of graph computing and the interference of noisy nodes. In addition, we design a multi-hop attention network to encode the dialogue context, which can quickly encode the long dialogue sequences to capture the long-term dependencies.
The proposed model: SMCR
In this section, we introduce our proposed conversational recommender method (SMCR), which combines the recommender system and the conversation system. We will illustrate how the encoder based on multi-hop attention maps dialogue information to vectors and how it brings external knowledge to context. The SMCR method consists of two components: a dialogue state tracking module and an SGAT-based recommender module. The detailed structure of the model and a dialogue example is shown in Figs 1 and 2, respectively. Our parameters to learn are organized into three groups. Algorithm 2 presents the training algorithm for our SMCR model. The detailed description of Algorithm 2 is as follows: the conversational recommendation dataset and knowledge graph are used as inputs to the model. In the recommendation branch, firstly, the dialogue dataset is encoded using a multi-hop attention network to obtain the dialogue hidden states. Then, a sparse graph attention network is used to extract the knowledge graph and obtain the graph hidden states. Finally, these two hidden states are passed through a fully connected layer followed by a softmax function to obtain the item probabilities. In the generation branch, similar steps are followed to obtain the hidden states. To differentiate the impact of stop words from non-stop words on the language model, the TopicRNN model is used in conjunction with an RNN decoder to generate word probabilities.
The proposed SMCR model consists of three components. The left part of the graph is a multi-hop encoder module, which uses a multi-hop attention mechanism to learn historical dialogue information. The upper right part of the graph is the dialogue state tracking module, which is used to capture user dialogue and manage the dialogue state of the system. The lower right part of the graph is an SGAT-based recommender module, which is used to match items and contexts.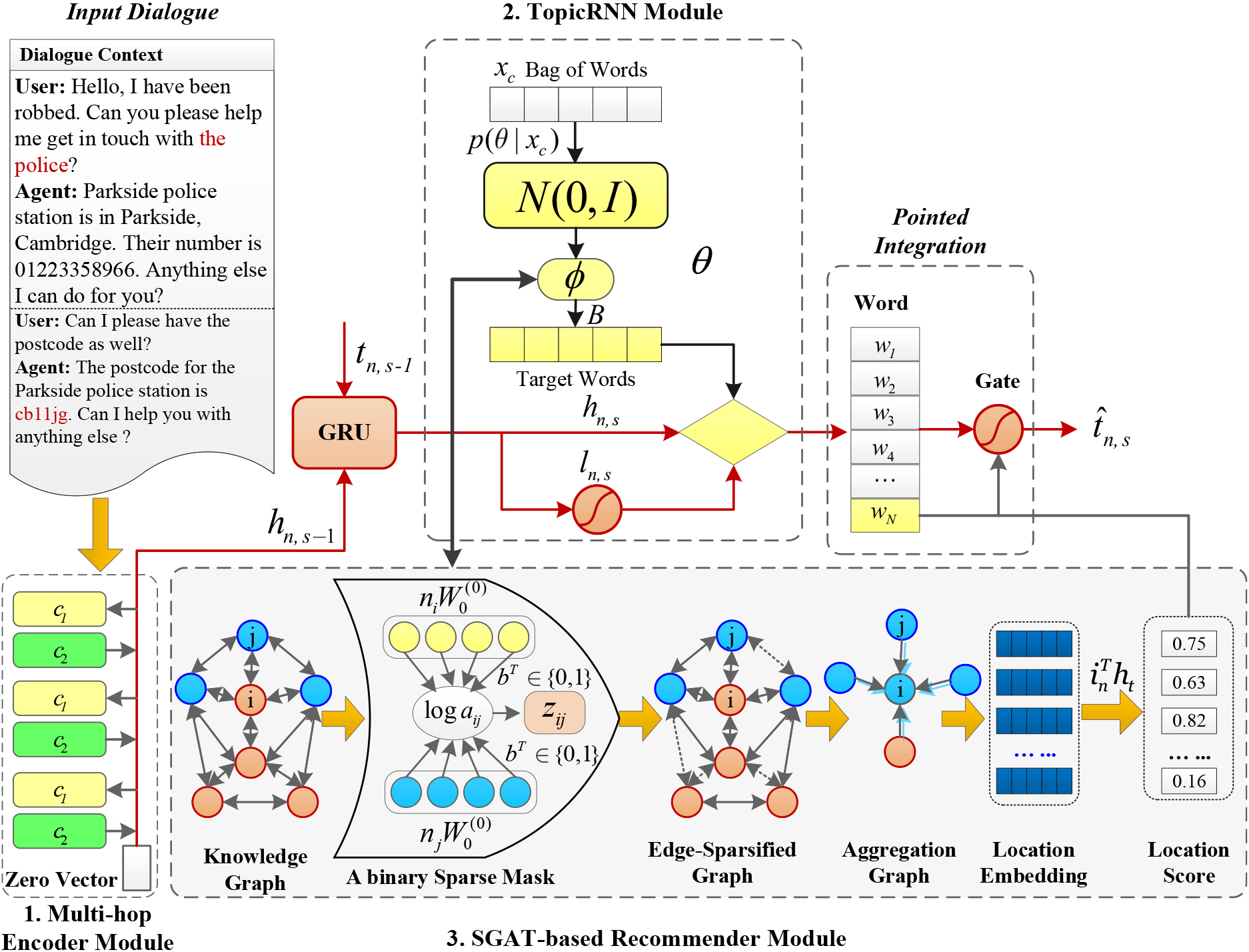
We use hierarchical recurrent encoder-decoder (HRED) to model the dialogue state tracking. First, we use HRED to build an encoder based on sentence-level and word-level RNN to encode the context and words separately; then, we use an LSTM-based or GRU-based decoder.
Compared with using Transformer as the backbone of SMCR, The RNN is more sensitive to the timing of sentences, and the memory cost of RNN is much lower than that of Transformer. In addition, the positional encoding of the Transformer has shortcomings. In the processing of utilizing word vectors, word vectors are linearly transformed, and the most semantic information can be preserved. However, it doesn’t work for positional encoding. Therefore, It is unreasonable that the positional encoding is added to the word vector.
A sample dialog between a user and an agent from the dataset. We observe the need for global topic control and knowledge graph to recommend appropriate venue.
Multi-hop Encoder.
It is difficult to deal with the problem of long-term dependence when using RNN-based encoders in dialogue generation modeling. Inspired by the end-to-end memory network [32, 33, 34, 35, 36], we develop a multi-hop attention-based encoder to encode the dialogue context, which is based on the fact that using the attention mechanism in the coding phase helps to deal with long-term dependencies. Besides external memories in memory networks reinforce the persistence of memory. Specifically, we consider a dialogue as a sequence of
where
where the query vector is updated for the next hop by using
TopicRNN Learning.
Although the RNN model can capture the local relationship of the sentence well, it lacks in capturing the dependency relationship of words in a longer-range sequence, while the TopicRNN [37, 38, 39] model can capture the global semantic information in the document well. Since a large part of the long-term dependencies in language derives from semantic coherence, in multiple rounds of multi-topic dialogues, the capture of subtopics will affect the quality of dialogue generation. The generative learning process of the TopicRNN model is described by Algorithm 1.
The detailed description of Algorithm 1 is as follows: Firstly, the user input and context are packaged into a document. Then, a topic vector based on a Gaussian distribution is generated for the document. Next, hidden states for each word in the document are generated. A Bernoulli distribution based on the current word’s hidden state is used to determine whether the word is a stop word. If the current word is a stop word, it is generated from the stop word model; otherwise, it is generated jointly from the stop word model and the topic model.
The output of the decoder is affected by the topic vector
During model inference, the observations are token sequences and stop word indicators. The log marginal likelihood is as follows:
Since direct optimization of Eq. (3) is intractable due to the integral over the continuous latent space. Suppose
Inspired by the neural variational inference framework and the Gaussian reparameterization trick in Variational auto-encoder (VAE), we construct
where
Suppose during training, the one-hot vector for any token
where
[h] : Learning Process of TopicRNN[1] Input the user
SGAT-based Recommender.
Usually, an item has many attributes. For example, when a new visitor queries for a hotel, the hotel has the address, area, network, name, free parking space, etc. It is very suitable for modeling the item by utilizing graph data. When a user sends a request that he wants a Chinese restaurant for dinner, the user clearly provides the system with two constraints like “Chinese” and “restaurant.” Therefore, the system not only accurately captures them but also considers potential constraints such as location and business hours because users are more willing to consider restaurants near the hotel. In order to capture the explicit and latent relationships between these places, we use the sparse graph attention mechanism. Different from the graph convolution network, it can assign different weights to the neighbor nodes of vertexes in the graph and enhance the spatial information of the model. However, in the real world, a graph is large and complex. What’s most important is that the graph is sparse and noisy. Therefore, the graph attention is prone to overfitting if not regularized properly. The SGAT can remove at least 20% of the useless edges from the graph while maintaining high accuracy. In addition, the binary gate in the SGAT model cleverly achieves edge clipping.
We formulate an undirected graph
Given such a graph, we generate embeddings of items to calculate the matching score with dialog context. Finally, we get the recommended items. In general, we employ selective multiple-layer convolutional modules to aggregate feature information of first-order neighbor nodes. We get a high representation for an item that contains a great deal of extra information. The purpose is learn how to selectively filter out the nodes that need to participate in the aggregation operation and how to aggregate neighborhood information. We use a binary gate
Where
where
where
We compute normalized attention coefficients through a row-wise normalization of
To reinforce the capacity of the SGAT model, we augment similar multi-head attention as in GAT. Therefore, we define a multi-head SGAT layer as:
where
After introducing the updating rules for node representations are in Eq. (11), the objective function resumes the cross-entropy loss as follows,
where
Integration Mechanism.
Given the dialog context, we can predict the next utterance via the dialogue state tracking component and obtain the recommended item by utilizing the SGAT-based recommender model. We employ an integration mechanism to achieve the above two tasks. Gated Recurrent Unit (GRU) [40, 41, 42] is widely used in end-to-end dialogue systems. In detail, at each decoding step
After obtaining the new hidden state
In one branch, the
In the other branch, the
In order to optimize Eq. (8), we use an inequality in stochastic variational optimization to solve the binary optimization problem of binary mask B. The following inequality holds as follows: given any function
i.e., the minimum of a function is upper bounded by its expectation.
Thus, we can upper bound formula 8 by its expectation:
where we assume
[h] : Learning Process of SMCR[1] Input the conversation recommendation dataset
For the first term, the SGAT selects the Hard Concrete Gradient Estimator to solve
with
The model uses different schemes to optimize binary masks
In this section, we conducted extensive experiments aimed at answering the following research questions:
Experimental settings
Datasets
We conduct experiments in two publicly accessible datasets: MultiWOZ1
Our SMCR algorithm consists of a language generation module and a recommendation module, so we use BLEU score [43, 44], Accuracy, Recall, NDCG, and Perplexity as evaluation metrics to evaluate the performance of our model.
Baselines
The baselines for the experiment are illustrated in the following:
We implement our proposed model SMCR in PyTorch. For the construction of the graph, we utilize a deep graph library (DGL) to add nodes, node features, and edges. We set the embedding and GRU state sizes to 300 and 100, respectively. The reason is that a larger embedding dimension can provide more parameters to represent the semantic features of words, while a smaller state size can reduce computational complexity but may limit the model’s ability to capture long-term dependencies. The number of topics is set to 10, and the stop word frequency is set to 1000. Setting the number of topics to 10 may be to introduce a certain level of topic diversity and coverage in the model. A smaller number of topics may lead to excessive generalization, while a larger number of topics may increase computational complexity. We apply two layers of graph convolutional operations. With multiple layers of graph convolutions, the model can obtain richer contextual information from multiple neighboring nodes. During the training, the dimension of the hidden unit in RNN and the hidden layer of the inference network is set to 64. We exploit the Adam optimizer with a learning rate of 0.001. All baseline models have their hyperparameters set according to the aforementioned values, with slight variations in the learning rate.
Performance of all competitors on the MultiWoz dataset
Performance of all competitors on the MultiWoz dataset
Experiment results and analysis (RQ1)
Table 1 shows the performance of our SMCR method compared with other methods on four evaluation metrics on the MultiWoz dataset. It can be observed that the SMCR method is better than all baselines on the accuracy metrics. Specifically, our SMCR method improves accuracy by 62.6%, 95.0%, 83.5%, and 21.0% compared with HRED, TopicRNN, Mem2Seq and DCR methods, respectively. In the recall metrics, our SMCR method ranked first. It is better than DCR by about 28.5%. Benefiting from the edge-pruning strategy of SGAT, subject-irrelevant edges are excluded from feature aggregation features under the utility of binary gates. Such a mechanism alleviates the obscuring of critical information by noisy information so that more topic-related graph structure information is preserved. Unfortunately, our model does not have an advantage compared with other baseline methods in the BLEU metrics. Although the multi-hop attention mechanism can alleviate long-term dependence to a certain extent, the memory ability of historical dialogue information is still relatively weak. Adding relative and absolute position information to the sequence information will overcome these problems. In the perplexity metrics, we observe a 35.4% performance improvement compared to the state-of-art method (i.e., DCR). The improvement of our SMCR method is more obvious compared to other baselines, i.e., the improvement ratio reached 39.9%, 40.6%, and 41.7% compared with HRED, TopicRNN, and Mem2Seq methods, respectively. The lower the perplexity means that the model knows more about the given historical information.
Table 2 reports the performance of all models on the REDIAL dataset. We can observe that our SMCR method outperforms most models on various evaluation metrics. The metric of accuracy, HRED, TopicRNN, Mem2Seq, DCR and SMCR reach 0.86%, 0.58%, 0.92%, 0.46% and 1.23%, respectively. In particular, in the important recommendation evaluation metrics of recall (the recall refers to recall@1), our SMCR method obtains the best result of 0.0047 among all conversational recommendation models. Compared to the Mem2Seq method, our SMCR method improves by 2.0%, which is a critical metric in CRS, as it means that the top-ranked items can be recommended to users first. Moreover, our SMCR algorithm achieves the highest BLEU and lowest Perplexity compared with all competitors, i.e., lower perplexity values indicate better language model fluency, so it can be concluded that our model achieves very significant results in addressing natural language fluency of generated dialogue.
Performance of all competitors on the REDIAL dataset
Performance of all competitors on the REDIAL dataset
Table 3 reports the performance results of all models in the metric of NDCG@k (i.e.,
Performance of all competitors on the MultiWoz dataset with respect to the different number of NDCG@k
In conclusion, by analyzing the experimental data in Tables 1–3, we summarize the possible reasons why our model is effective. Compared with the DCR method, our SMCR method uses a recommender based on SGAT, which effectively removes edges that are not related to the task; in addition, in the convolution operation, it aggregates more information about neighbour nodes that are associated with the host node. Compared with the encoder based on multi-hop attention, our SMCR method retains more information because the attention mechanism is always interested in the information related to the query vector. What’s more, compared with the traditional RNN model, the multi-hop attention mechanism uses memory to remember historical information and is more stable when processing long sequences. The benefits of separately feeding dialogue text and knowledge graph triples to different models are obvious. A sparse graph neural network is more suitable for feature capture and combining knowledge triples. At the same time, an encoder may be more appropriate for mapping text information with sequence features into high-dimensional feature space. Simply inputting the graph structure information together with the sequence information as combined information into the encoder will lead to the interference of noise information, and the feature extraction granularity is too high.
Ablation study on the MultiWoz dataset
Performance (i.e., Accuracy, Recall, F1 and NDCG@1) of various conversational recommendation methods with respect to the different number of dimensions.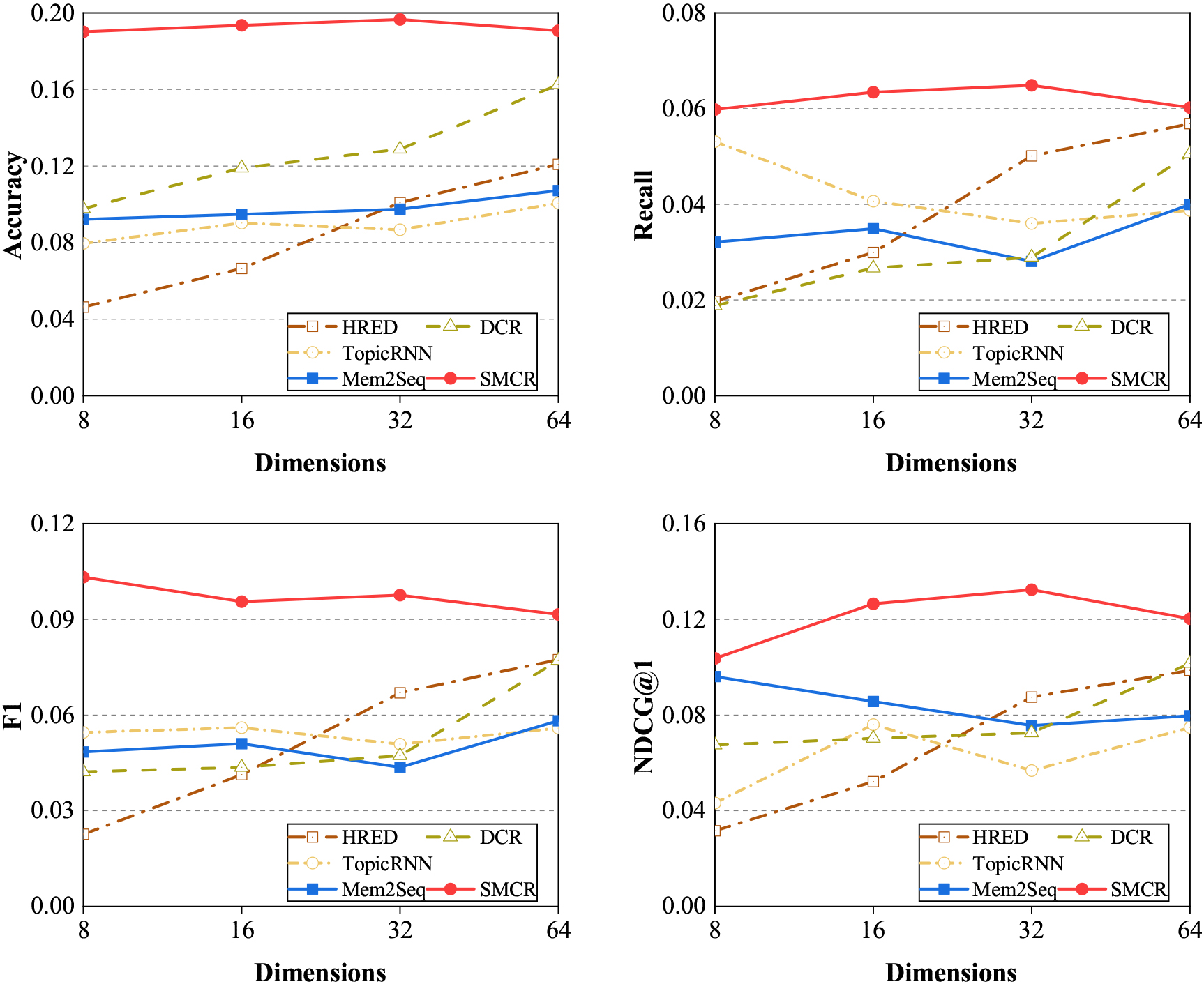
We build an ablation study based on two variants of our complete method to show the contributions of each component to the conversational recommender task: SMCR (-MHA) by removing the multi-hop attention from the dialogue state tracking module, while SMCR (-SGAT) by removing the sparse graph attention network from the recommender module. As shown in Table 4, we can observe that the performance of BLEU and Perplexity degrades after removing the multi-hop attention network. Because the multi-hop attention mechanism utilizes external memory units to store and propagate information. After removing the multi- hop attention network, the proposed model is unable to capture the connection between the current hidden state and the previous hidden state, resulting in a decline in memory ability. Limited information limits the ability of language models, resulting in a decrease in the quality of generated statements. So the semantic information of the sentence is missing. Besides, the sparse graph attention network seems to play an essential role in the recommendation task. One of the possible explanations is that the binary gate in SGAT helps to preserve vital information and remove the noisy information. Therefore, it retains the critical knowledge graph information to the greatest extent possible. In conclusion, Table 4 shows that two components help improve the performance of the conversational recommender system.
Performance (i.e., NDCG@5, NDCG@10, NDCG@15 and NDCG@20) of various conversational recommendation methods with respect to the different number of dimensions.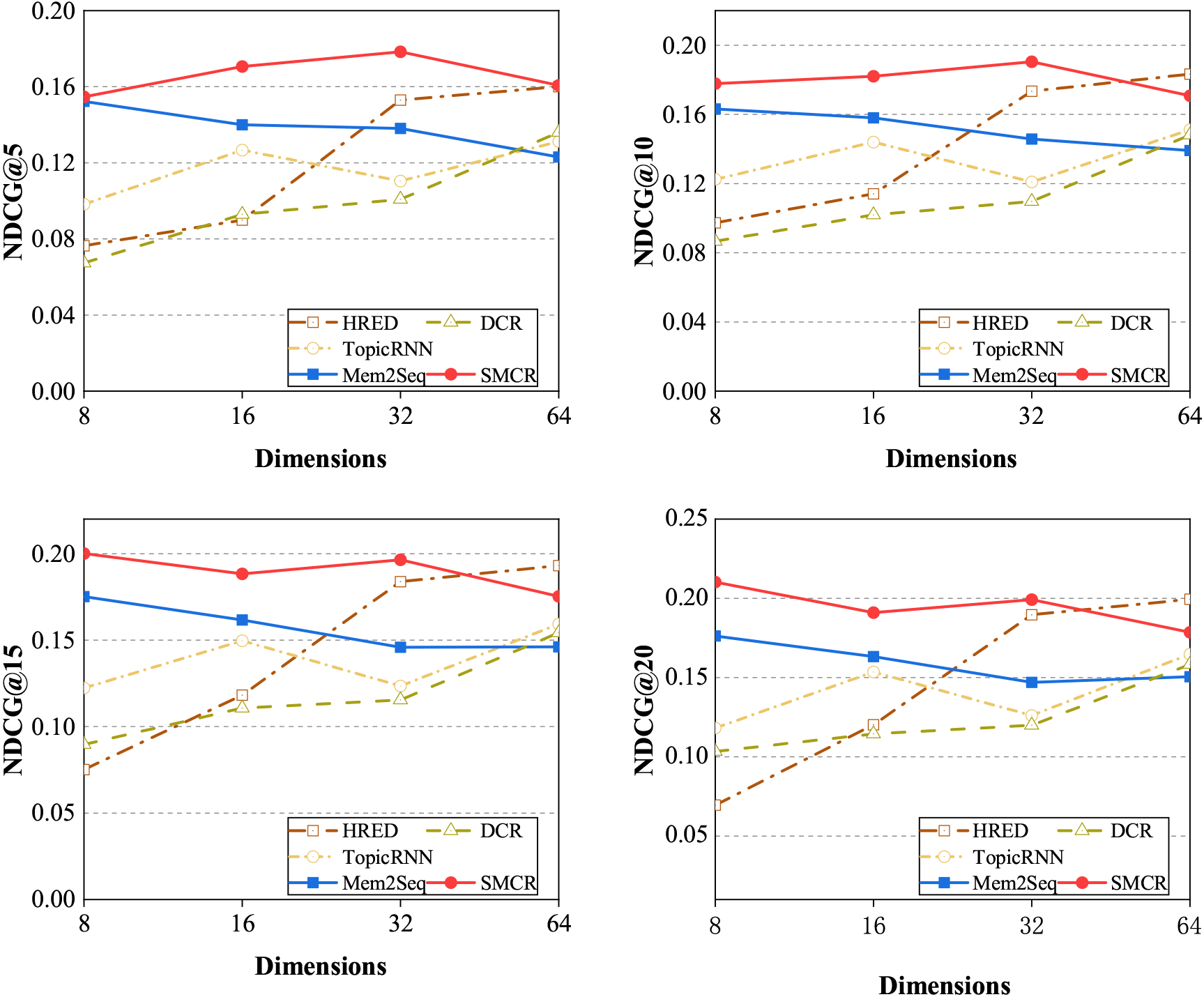
Performance (i.e., BLEU and Perplexity) of various conversational recommendation methods with respect to the different number of dimensions.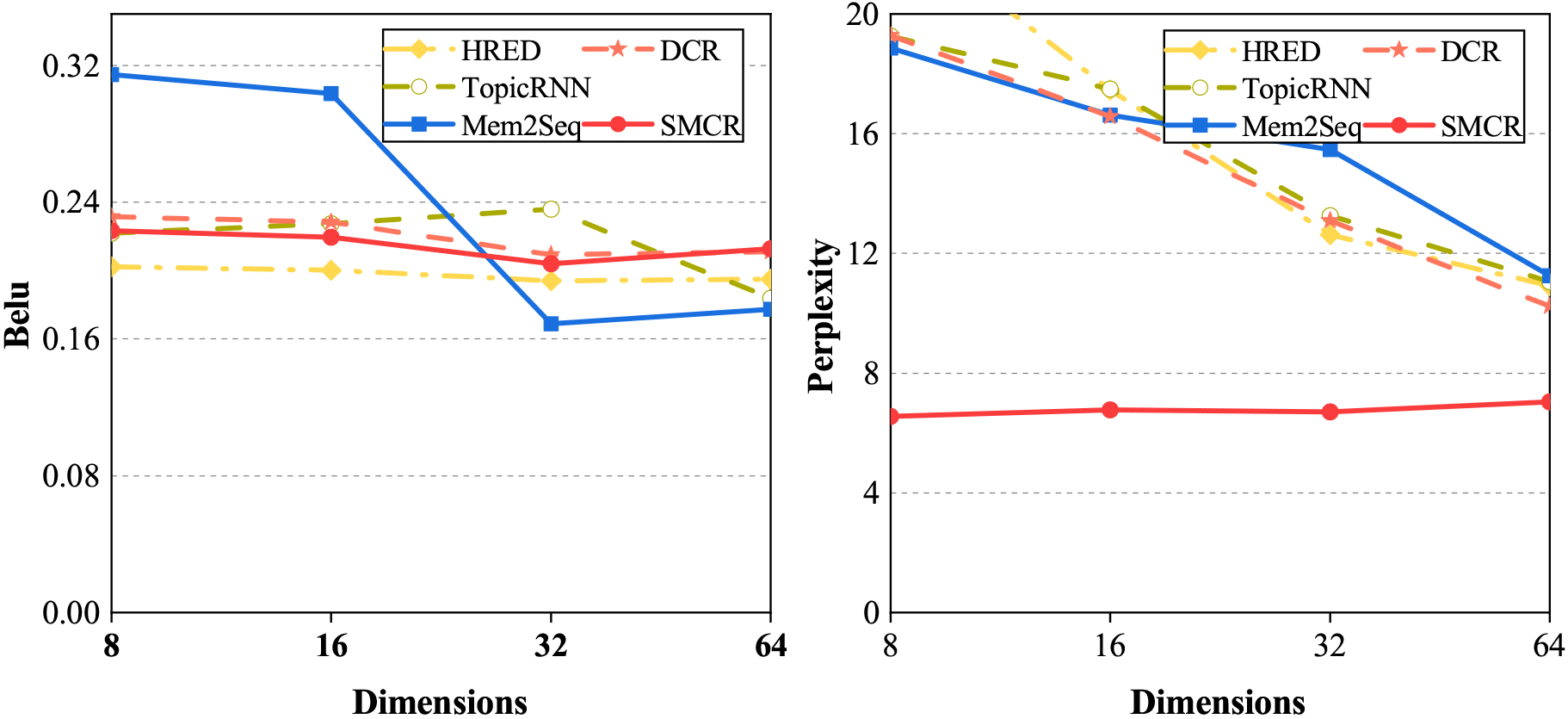
Performance(i.e., BLEU and Perplexity) of SMCR with respect to the different number of hops.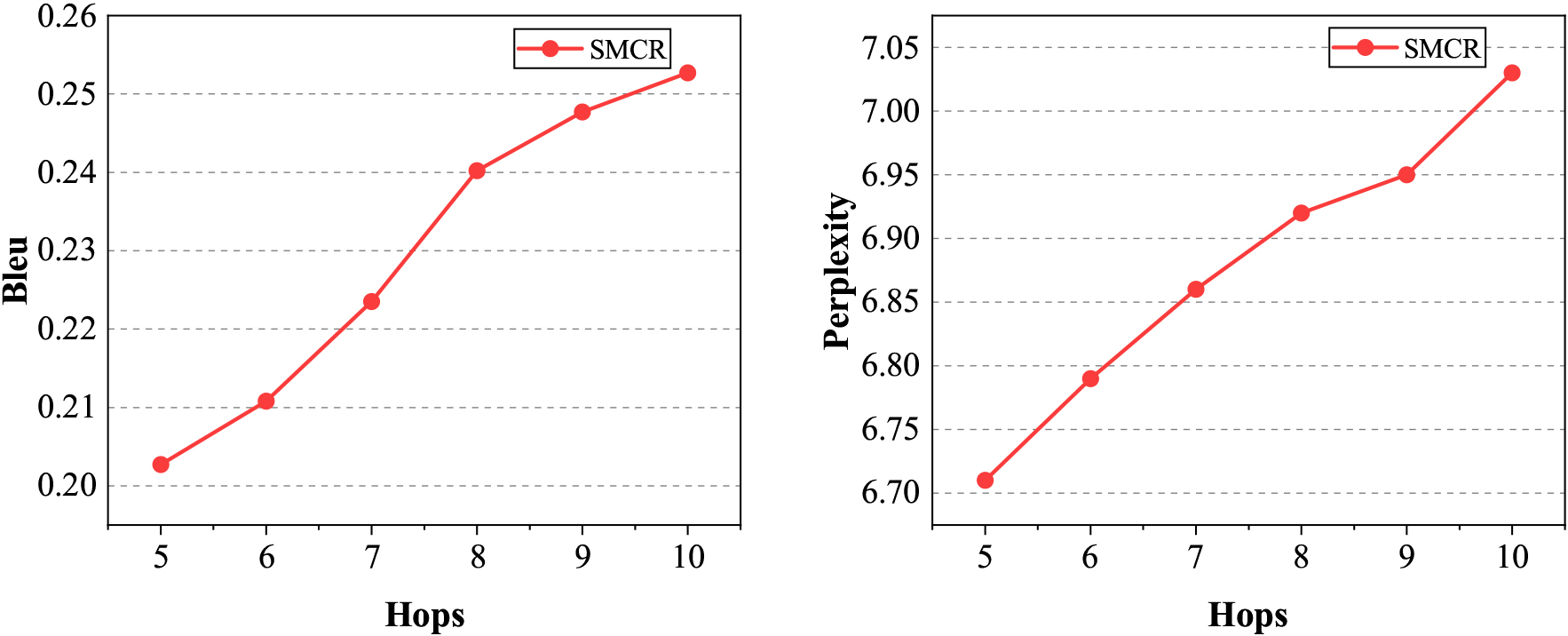
Figures 3–5 show the performance of our SMCR method and other baselines with the number of dimensions ranging from 8 to 64. We can observe that when the number of the dimensions is relatively small, our SMCR method achieves the best results in the most evaluation metrics, i.e., accuracy, recall, F1, NDCG@1, NDCG@5, BLEU, and Perplexity, and our method obtains the second-best result in the evaluation metrics of NDCG@10, NDCG@15, NDCG@20. Unfortunately, when the number of dimensions becomes larger, the performance of the SMCR method decreases slightly. We infer that the possible reason is limited by the operating mechanism of the memory network, and current AI hardware accelerators cannot improve the memory network well. In particular, we also find an essential conclusion, that is, compared with other conversational recommendation methods, our SMCR method performance is very stable in the dimensions ranging from 8 to 64. Especially in the evaluation metrics of Perplexity, our method is far superior to other baseline algorithms. In addition, the external memory mechanism of the RNN-based model will not decay as the sequence length increases. The experiment result shows that we design a multi-hop attention network to encode dialogue context, which can quickly encode long dialogue sequences to capture long-term dependencies.
Figure 6 shows the Performance (i.e., BLEU and Perplexity) of our method SMCR with the number of hops ranging from 5 to 10. We can observe that as the number of hops increases, the BLEU score increases steadily. One of the possible explanations is that the memory vector in the multi-hop attention network seems to carry most of the semantic information of the sentence. Besides, the dot product of the query tensor and the memory vector models the interaction of different parts of the sentence. Unfortunately, there was a slight decrease in the perplexity score. We infer that a few stop words would not have been considered by us, and stop words will have a great impact on perplexity. But from semantic analysis, whether there are stop words does not fully represent the quality of sentence generation. In addition, meaningless information in sentences also affects perplexity.
The complexity of graph calculation (RQ3)
We further analyze the edges removed by SGAT. Figure 7 illustrates the effectiveness of the SGAT method in removing useless edges when modelling a knowledge graph on the MultiWOZ dataset. Due to the operation of the binary gate and the optimization of the
The number of edges in the knowledge graph changes with iteration.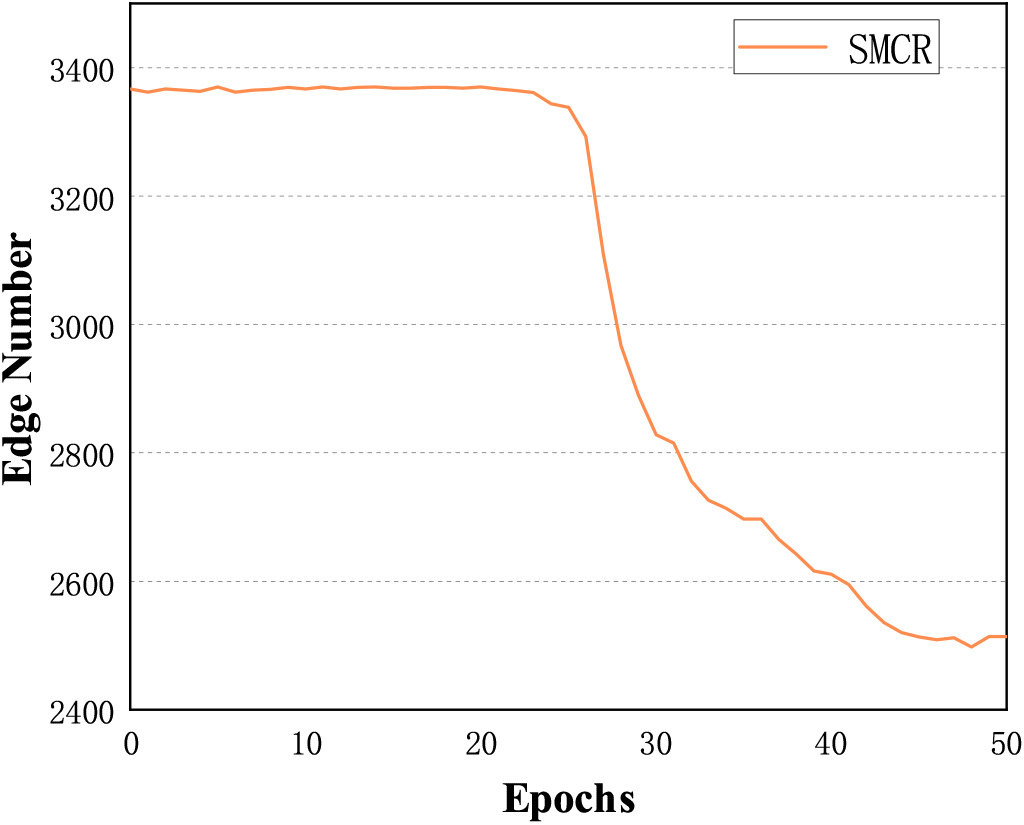
The evolution of the graph created by a synthetic dataset in 10 training epochs.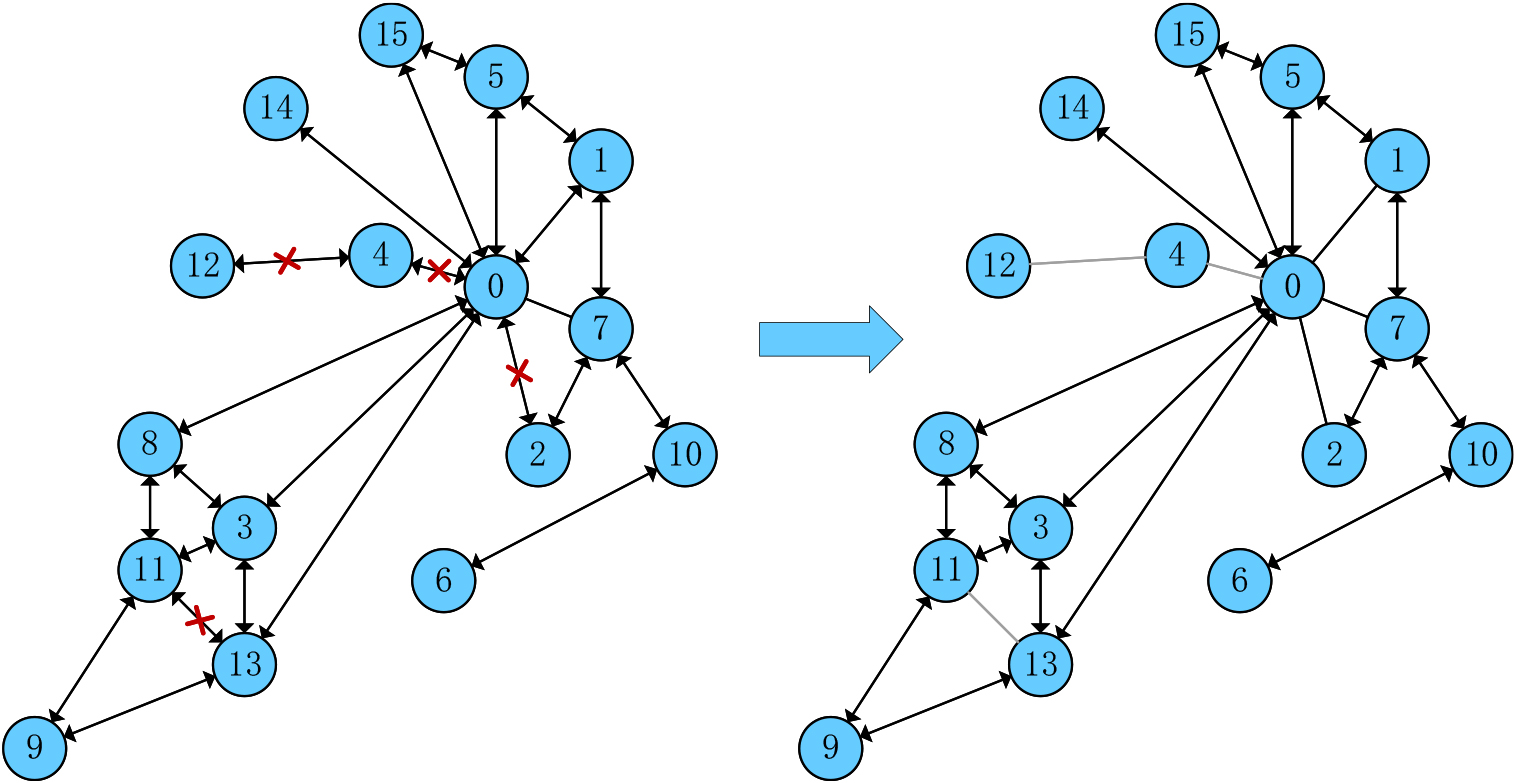
To illustrate how the sparse graph attention mechanism works, we construct a graph and randomly assign features and labels to nodes. Then we train a one-layer SGAT on the dataset to complete the node classification task. As shown in Fig. 8, we can find that most of the edges are retained; meanwhile, some useless edges are cut off. Furthermore, we make inferences about the reasons for the removal of edges. For example, the edge from node 13 to node 11 is removed. This is because the feature similarity between node 11 and node 8, node 3 and node 9 is higher, while node 13 is only connected to node 3 and node 9, so removing the edge connecting node 11 and node 13 will not affect node 11. The above experimental results also verify our scientific assumption. By developing a recommendation model based on sparse graph attention, we can accurately identify important edges by matching items with dialogue context, so as to reduce the complexity of graph computation and the interference of noisy nodes, but effectively improve the performance of the recommendation model.
In this work, we developed a conversational recommender system based on sparse graph attention and multi-hop attention. Our key argument is that conversational recommender based on the graph convolutional network has the same weights, and these weights are assigned to different neighbors in the same order neighborhood, resulting in a huge graph and a lot of noise, which may lead to overfitting of the model. Therefore, we design a recommendation model based on sparse graph attention to match items with dialogue context, reducing the complexity of graph computing and the interference of noisy nodes.In addition, the conversation recommendation model has a long-term dependency problem when generating conversation topics. Because the model cannot accurately capture the dependency between words, which will affect the overall structure of sentences but is very important to ensure smooth communication between users and agents. To address this point, we design a multi-hop focus network that can quickly encode long conversation sequences to capture long-term dependencies, and learn topic information through a variable automatic encoder optimized by KL cost annealing. We conducted empirical studies to validate the effectiveness of our SMCR methods. Experiment results show that our SMCR method outperforms other state-of-the-art methods in both the evaluations of recommendation and dialogue generation. While our algorithm has demonstrated promising results, it is important to acknowledge its limitations. The algorithm may have high computational complexity, especially when dealing with large-scale datasets or complex problem domains. This can potentially limit its scalability and efficiency in real-world applications. The algorithm may lack interpretability, meaning it may be challenging to understand and interpret the underlying reasoning or decision-making process.
In future, we will continue our work in two directions. First, we will explore the masked language model to further boost the performance of response generation. Second, we will try to perceive the spatial characteristics of the knowledge graph to enhance the recommendation performance.
Footnotes
Acknowledgments
The work is supported bythe Science and Technology Research Program of Chongqing Municipal Education Commission (No. KJZD-K202101105, KJQN202001136), Humanities and Social Sciences Research Program of Chongqing Municipal Education Commission (No. 22SKGH302), the National Natural Science Foundation of China (No. 61702063).