
Abstract
Low-light image enhancement technique aims to improve the contrast and brightness of low-light images. Diffusion models, attributed to adeptness at capturing intricate details, have achieved good results in image enhancement, but there are problems such as inadequate estimation of noise characteristics and the emergence of color bias in the enhanced images. To address the aforementioned problems, this paper proposes a diffusion models-based method for low-light image enhancement, termed KANDiff. In the diffusion model architecture, this paper adds the nonlinear learnable activation function Kolmogorov–Arnold network to the noise estimation network U-Net to generate higher quality enhanced images. Additionally, KANDiff mitigates color bias in the enhanced images through a joint loss function and employs a patch-based image restoration strategy to significantly enhance the model generalization capability. The experimental results show that the KANDiff algorithm proposed in this paper can achieve high-quality image enhancement and achieve better enhancement effects compared to other algorithms.
Introduction
During image acquisition, images captured in low-light environments often exhibit various forms of degradation, including diminished contrast, reduced visibility, and heightened noise. These deficiencies can adversely impact subsequent visual tasks, such as target detection (Liang et al., 2021), image classification (Loh & Chan, 2019), and automated driving (Li et al., 2021), potentially compromising the efficacy of numerous computer vision systems. Consequently, the challenge of transforming low-light images into high-quality and well-exposed images has attracted the attention of researchers with substantial theoretical significance and practical applicability.
Traditional low-light enhancement methods primarily rely on the adjustment of contrast and brightness to enhance image visibility. In traditional methods, histogram equalization and Retinex theory are commonly used to enhance the low-light images. Histogram equalization-based methods (Ibrahim & Kong, 2007; Kim, 1997) improve image contrast by modifying the image histogram, and the methods based on Retinex theory (Land & McCann, 1971; Li et al., 2018) decompose the image into illumination and reflection components and achieve the enhancement of the dark light image by altering the dynamic range of the pixels in the illumination map and reducing the noise in the reflection map. Although traditional methods are characterized by simplicity in implementation and low computational cost, they may result in noise artifacts or color distortion, as they often fail to adequately account for the spatial information inherent in the image.
With the rapid advancement of deep learning, which has demonstrated significant advantages in processing complex scenes while preserving details and exhibiting adaptability, deep learning techniques have increasingly been adopted as a more comprehensive approach for low-light image enhancement. Methods for low-light image enhancement based on deep learning can be broadly categorized into learning-based approaches and generative model-based approaches. Learning-based low-light image enhancement methods typically employ structures such as convolutional neural networks (CNNs) to enhance low-light images by learning mapping relationships, with an emphasis on the direct enhancement of input images. Shen et al. (2017) conceptualized the traditional Retinex method as a feed-forward CNN utilizing varying Gaussian convolutional kernels, which facilitates end-to-end mapping from dark to bright images for enhancement purposes. Cai et al. (2018) implemented a two-stage CNN structure to solve the color bias problem associated with single-stage CNN architectures. Additionally, Hao et al. (2022) decoupled the enhancement model into two sequential stages to improve the network’s feature extraction capability, resulting in more natural and realistic enhanced images. Learning-based methods generally treat the enhancement task as a pixel-by-pixel mapping between low-light and normal-light images, employing pixel-by-pixel loss during the training process, and achieving acceptable enhancement results. However, these methods often encounter challenges in preserving visual fidelity, leading to suboptimal results.
Generative model-based methods for low-light image enhancement typically utilize generative models such as generative adversarial networks (GANs), diffusion models, and flow models, with a primary focus on generating realistic images rather than direct enhancement. Liu et al. (2021) employed the GANs in conjunction with a residual dense-patch encoder–decoder structure to effectively suppress noise while finely adjusting illumination, resulting in successful enhancement of low-light images even under extremely low illumination conditions. Wang et al. (2022) proposed an effective method for modeling the light distribution of an image using the normalizing flow technique, thereby achieving enhanced image quality through sophisticated image enhancement methods. Nevertheless, GAN-based methods and flow-based methods are often subject to unstable training and mode collapse, which may result in artifacts in the enhanced images.
In comparison to other generative models such as GANs and variational autoencoders, diffusion models (Ho et al., 2020) facilitate high-quality mapping from randomly sampled Gaussian noise to the target image or latent distribution by incorporating Gaussian noise into data samples and subsequently predicting the noise in a stepwise manner. Therefore, the diffusion model results in enhanced stability and robustness, and is less susceptible to problems such as mode collapse. Liu et al. (2024) decoupled the diffusion models into two distinct processes: residual diffusion and noise diffusion. This modification extended the traditional image restoration task into a unified and interpretable framework for image restoration. In Özdenizci and Legenstein (2023), images were decomposed into several patches, facilitating the recovery of images of varying sizes. The diffusion models are comprised of a forward diffusion process and an inverse diffusion process. In the forward diffusion process, Gaussian noise is added to the input data, which is ultimately transformed into an approximate pure Gaussian noise. In the inverse diffusion process, the original input data is recovered from its noisy state by iteratively predicting the noise to be removed at each denoising step through a noise estimation network, typically structured as the U-Net framework (Ronneberger et al., 2015). Existing studies have primarily focused on the application of pre-trained diffusion U-Nets to downstream tasks, while the internal characteristics of diffusion U-Nets have remained largely underexplored. Recently, Kolmogorov–Arnold network (KAN) (Liu et al., 2024) has garnered significant attention due to its outstanding performance. KAN introduces learnable activation functions on the network edges (i.e., weights) to enhance the flexibility and expressiveness of the model while preserving interpretability. Consequently, Li et al. (2024) integrated U-Net with KAN to yield a network characterized by strong interpretability, particularly in the context of medical image segmentation.
Diffusion model-based low-light image enhancement methods have made significant advancements in illuminance and detail restoration, but are still insufficient in noise estimation, which leads to problems such as image artifacts and inadequate color reproduction. To address the limitations of existing algorithms, this paper proposes a novel low-light image enhancement approach that utilizes a joint backbone network comprising U-Net and KAN as the noise estimation network, thereby enhancing the modeling capability of noise within the framework of diffusion models. Additionally, a patch-based strategy is employed to effectively enhance low-light images of varying sizes. The principal contributions of this paper are as follows:
This paper embedded KAN into U-Net network architecture and applied it as a noise predictor in a diffusion model for dark light image enhancement, and obtained the KANDiff algorithm. The KANDiff algorithm predicts noise more accurately and efficiently and improves the precision and accuracy of the generated images. In KANDiff, a patch-based image restoration structure is used to make the model applicable to images of varying sizes, which enhances the generalization ability of the model. The joint loss function is formulated to regulate the training process, aiding in error reduction, enhancing the fitting ability, bolstering model robustness, and minimizing the occurrence of the biased color phenomenon within model generation. The KANDiff method is assessed across a range of standard datasets, including synthetic pairwise datasets such as LOLv1 (Wei et al., 2018), VE-LOL (Liu et al., 2021), and LSRW (Hai et al., 2023), alongside real-world unpaired datasets such as DICM (Lee et al., 2013) and LIME (Guo et al., 2016), and tested on our own LIDS dataset. It is evidenced through the experiments that the KANDiff method proposed in this paper surpasses other existing low-light enhancement techniques in terms of its capacity for detail recovery.
Low-Light Image Enhancement
After decades of research, a variety of algorithms for low-light image enhancement have been proposed by researchers to improve image quality. Currently, low-light image enhancement methods are primarily categorized into two groups: traditional methods and deep learning-based methods. Traditional low-light image enhancement methods are primarily composed of histogram equalization-based and Retinex theory-based approaches. Histogram equalization is employed to uniformly adjust the dynamic range of the image, either in a linear or nonlinear manner, to enhance brightness. Dynamic histogram equalization, as proposed by Abdullah-Al-Wadud et al. (2007), realized image enhancement by partitioning the image histogram based on local minima and allocating specific grayscale ranges to each partition before equalizing them separately. Ooi and Isa (2010) improved image quality by segmenting the histogram into four sub-histograms and doing histogram equalization on each sub-histogram. These methods are simple and efficient, but they do not take into account the spatial information of the image, which may lead to artifacts resulting from over-enhancement or under-enhancement. Retinex theory (Land & McCann, 1971) simulates the human visual system by decomposing the image into illuminated and reflected components and optimizes the illuminated image to enhance both contrast and luminance. Fu et al. (2016) introduced a novel weighted variational model to provide a more robust prior representation in the regularization term, with the aim of preserving additional details in the estimated reflectance, yielding favorable outcomes in the enhancement of low-light images. Retinex-based methods are designed to address illumination issues, but they may fall short in mitigating color loss and could potentially induce further color distortion in the resultant image.
Deep learning-based methods have become the mainstream in image enhancement algorithms. In 2017, a stacked sparse denoising autoencoder was constructed by Lore et al. (2017), and it was introduced into a low-light image enhancement network, providing a reference example for the application of deep learning models to tasks such as low-light image enhancement. Wei et al. (2018) proposed a low-light enhancement method known as Retinex-net, which integrates Retinex theory with CNN. However, the modeling of the relationship between global long-range pixels within an image remains challenging, resulting in reconstructed images that exhibit substantial noise. To solve this problem, Jiang et al. (2021) and Guo et al. (2020) introduced effective unsupervised methods, Enlighten GAN and Zero-reference deep curve estimation (Zero-DCE), respectively, which enable the model to perform image enhancement without paired data. In 2022, Wang et al. (2022) introduced the LLFlow network, the LLFlow network effectively captures both local pixel dependencies and global image characteristics by modeling the pixel distribution of a normally exposed image, resulting in improved image enhancement quality. Despite the significant advancements made in low-light image enhancement by the aforementioned methods, problems still exist, such as pattern collapse and training instability plague GANs during training, while flow-based models may encounter challenges in modeling multi-peak distributions. In comparison to GAN-based and flow-based models, diffusion models are characterized by a more stable training process and a heightened capacity to recover the covered details by noise. In 2023, a wavelet-based conditional diffusion model was proposed by Jiang et al. (2023), which leveraged the generative capabilities of diffusion models to generate results with satisfactory perceptual fidelity. With the advantage of wavelet transform, the reasoning speed was accelerated significantly and the computing resources were reduced greatly without compromising information integrity. These operations led to the lightweight of the model, resulting in commendable enhancement outcomes. Additionally, Zhou et al. (2023) employed a novel pyramid diffusion technique, sampling technique, to incrementally increase the resolution in an inverse process, thus enhancing the performance and efficiency of the model.
Image Restoration Based on Diffusion Models
The improved denoising diffusion probabilistic model (DDPM) has achieved remarkable results in image generation, as a result, the diffusion models were introduced to the image restoration by researchers and demonstrated state-of-the-art (SOTA) performance across various low-level image restoration tasks. In the realm of image deblurring, an alternative framework for blind deblurring has been proposed by Whang et al. (2022), centered on conditional diffusion models. A stochastic sampler has been trained to enhance the output of a deterministic predictor, capable of generating a range of plausible reconstructions for a given input, leading to a notable enhancement in perceptual quality when compared to existing methods. Utilizing a noisy synthesis for training, guided by a domain-generalizable multiscale representation of the input image, the method proposed by Ren et al. (2022) has achieved superior performance relative to other methods. In the field of image super-resolution, SOTA levels have been attained across multiple datasets through the generation of images with augmented resolution employing a series of multiple diffusion models (Ho et al., 2022). In low-light enhancement, advances in image enhancement were made by Wang et al. (2023) through the proposition of a degradation-aware learning scheme for low-light image enhancement using diffusion models. This scheme adeptly integrates degradation and image priors into the diffusion process. Robust shadow removal was achieved by Guo et al. (2023) through the progressive refinement of degradation and generation of priors. Denoising diffusion restoration model (Kawar et al., 2022) utilized pre-trained diffusion models to address any linear inverse problem. In comparison to GAN-based models and normalized flow-based models, diffusion models exhibit superior performance in the domain of image restoration, capable of producing high-quality images in tasks such as super-resolution, image de-raining, and image dehazing (Özdenizci & Legenstein, 2023; Saharia et al., 2022).
In the realm of noise estimation networks, a new type of diffusion model, designated DiT, was proposed by Peebles and Xie (2023). The DiT model is based on the transformer architecture and utilizes the transformer in place of the U-Net, which serves as the backbone network for noise prediction within diffusion models, thereby demonstrating significant extensibility. Additionally, Si et al. (2024) proposed the Free-U network, which strategically realigns contributions derived from the U-Net jump connections and the backbone feature maps to leverage the strengths of both components of the U-Net architecture, resulting in a marked enhancement in the quality of image and video generation. However, the internal properties of diffusion U-Net remain only partially explored. In this paper, it is proposed that the combination of diffusion models with KAN may significantly enhance the quality of noise prediction and achieve more efficient and robust low-light image enhancement.
Kolmogorov–Arnold Network (KAN)
The theoretical foundation of the KAN is derived from the Kolmogorov–Arnold representation theorem (KART) (Kolmogorov, 1957), which was independently formulated by Andrei Kolmogorov and Vladimir Arnold in 1957. This theorem asserts that any multivariate continuous function
Recently, Liu et al. (2024) proposed a novel network architecture based on the Kolmogorov–Arnold theorem, termed the KAN. It is argued in the article that, within the finite superposition of unitary functions employed to represent multivariate functions, the unitary functions can be parameterized as B-spline functions. These B-spline functions are typically defined by a set of control points and a node vector, ensuring desirable smoothness properties. Furthermore, the original network architecture has been extended to accommodate arbitrary widths and depths, as opposed to the previous limitation of two depths and
Owing to its strong interpretability and expressive power, KAN has been successfully applied in various domains. For instance, Vaca-Rubio et al. (2024) employed the spline function as an activation function, which allows for adaptive adjustment of the activation pattern in accordance with the dynamic characteristics of time series data. This approach enables a more accurate capture of complex patterns and variations in time series, thereby demonstrating the unique advantages of KAN in enhancing the performance of prediction models through adaptive activation functions. Additionally, Bresson et al. (2024) applied KAN to graph learning tasks instead of the traditional multilayer perceptron (MLP) and demonstrated that KAN has significant advantages in graph regression tasks.
Method
Diffusion Models
DDPM (Ho et al., 2020) is characterized by a two-step process comprising a forward diffusion process and an inverse diffusion process. In the forward diffusion process, random noise is systematically added to the data, while in the inverse diffusion process, data samples are sampled from the noised data. The principles of the diffusion process are illustrated in Figure 1.
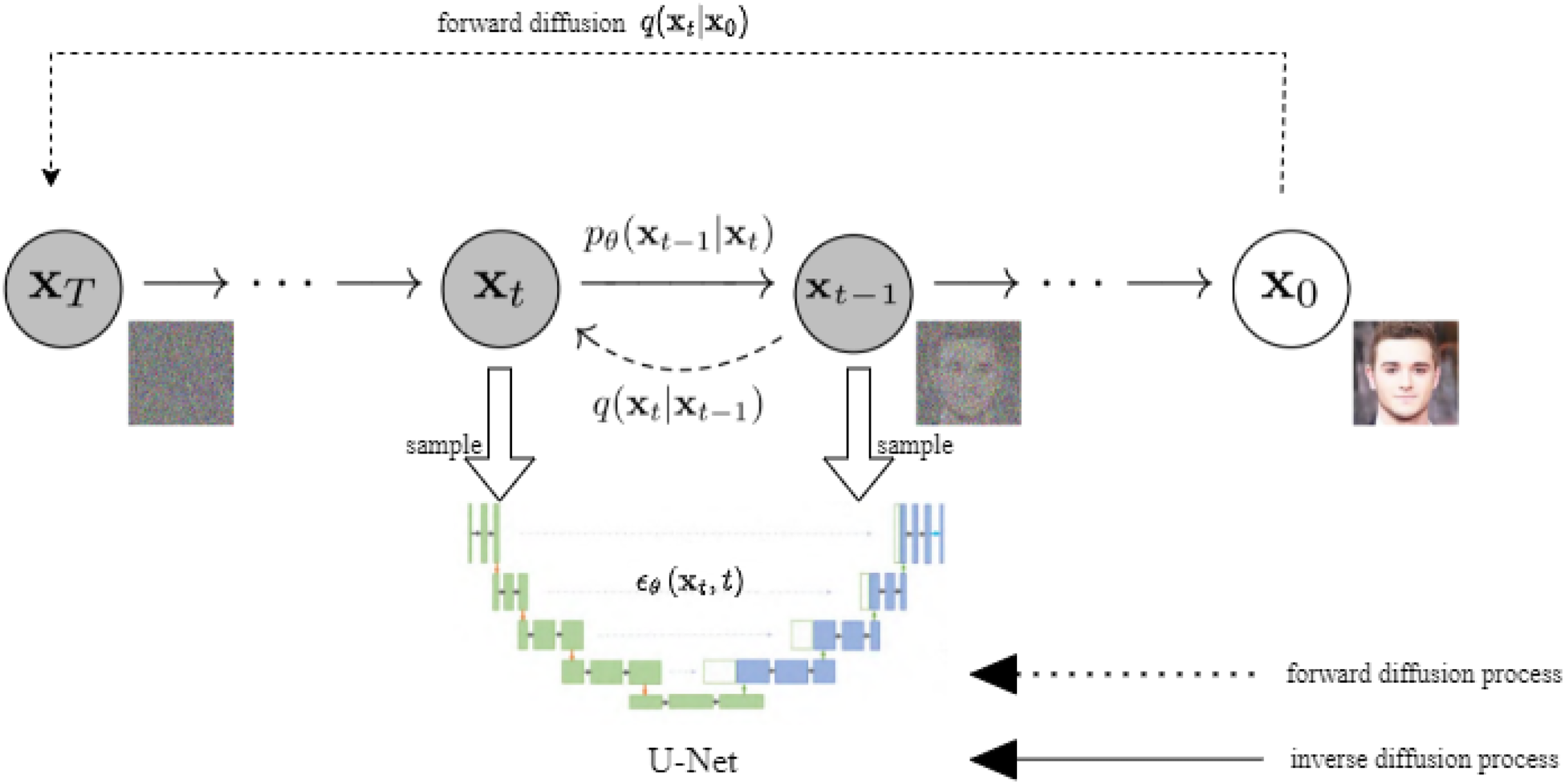
Diffusion models principle.
The DDPM defines a forward diffusion process
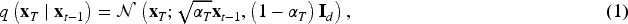
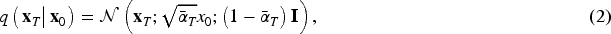
By combining equation (2) with the reparameterization technique, the relationship between

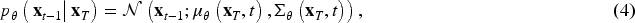
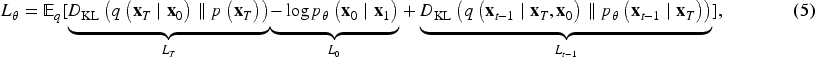
Since the term
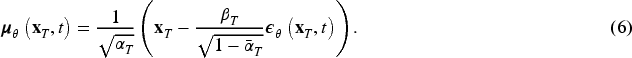
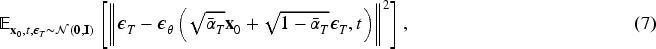
Although methods such as DDPM (Ho et al., 2020) and its improved variants are capable of generating realistic images, a notable gap remains between these approaches and mainstream methods based on GANs in terms of metrics such as Frechet inception distance. To address this issue, Ho and Salimans (2022) introduced classifier-free guidance, which enhances model constraints by incorporating category label information during the image generation process, thereby improving the quality of the generated images. The core idea is that, as illustrated in Figure 2, high fidelity to the data distribution is achieved for the sampled
Conditional diffusion models.
During training, we sample from paired data distributions (e.g., a normal-light image
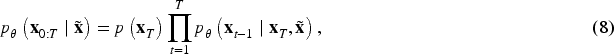
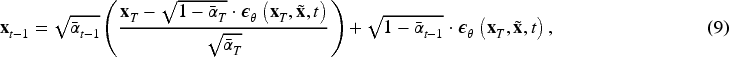
When designing low-light image enhancement models, most of the existing models assume that the size of the input image is fixed, but the actual image is often of varying sizes, which limits the practical application of the model. Recently, Whang et al. (2022) proposed an image deblurring algorithm based on diffusion models for images of unknown size. The core of the method lies in segmenting an image of arbitrary size into fixed-size blocks for deblurring operation, which ultimately eliminates the blurring in the image effectively. Although this design exhibits some advantages in processing input images of varying sizes, the implementation of this strategy relies on a fully convolutional network, which entails high computational demands, particularly during the testing phase. Moreover, to ensure efficient processing of the entire image, the model necessitates loading the complete image into memory, which can lead to a high memory expense in practice.
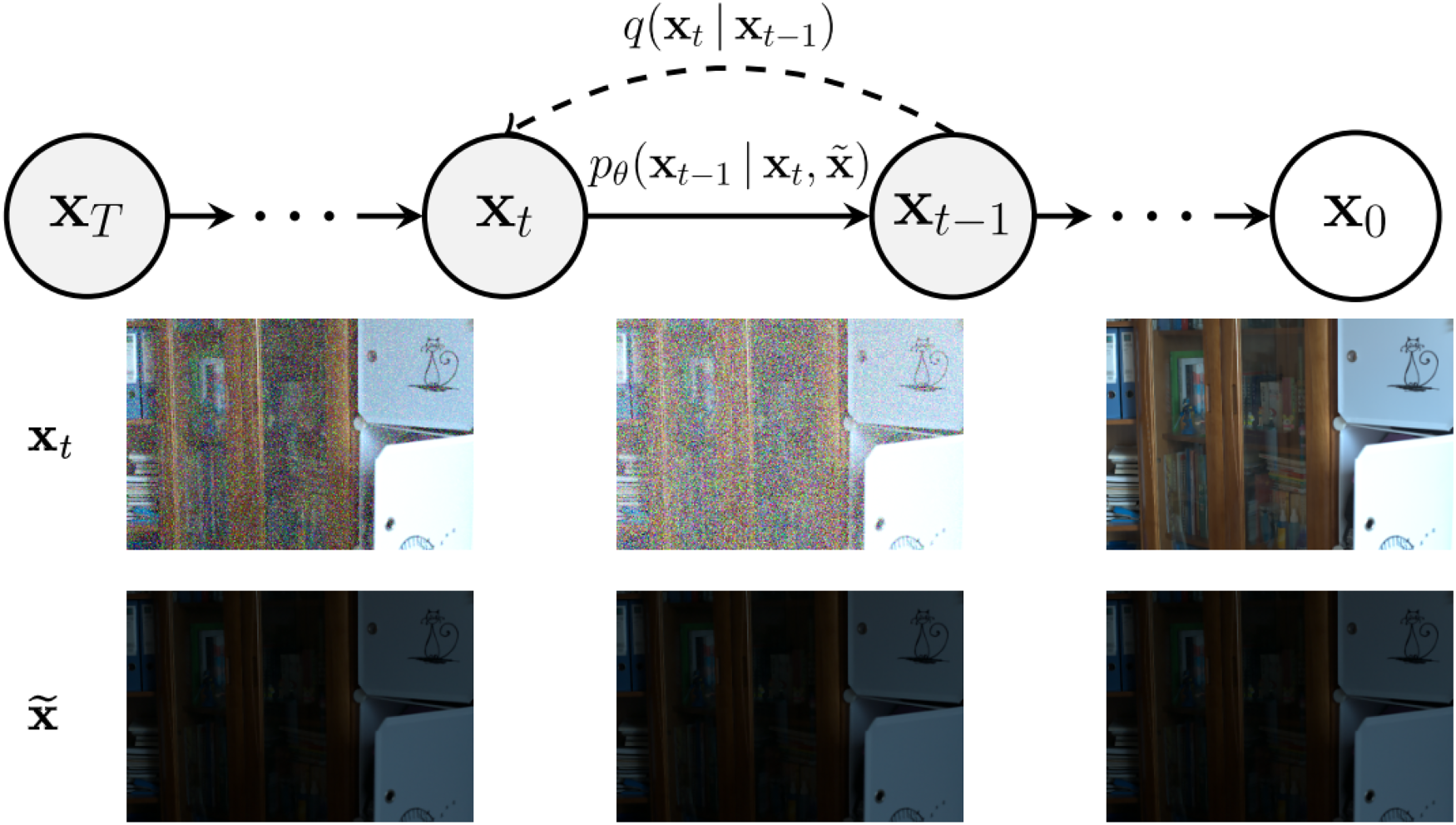
Drawing on the core idea of the algorithm, the patch-based method is proposed (Özdenizci & Legenstein, 2023). The general idea of the method is to divide the input image into sample blocks of the same size (also known as patches), use the diffusion model to perform local operations on each patch, and finally merge the results to obtain the global image, the split operation is shown in Figure 3. However, since the recovery of each patch is performed independently, artifacts may arise during the merging process. To mitigate this issue, the model is designed to reduce the appearance of artifacts by guiding the backsampling process, thereby achieving smoother transitions between neighboring patches. An image of arbitrary size is defined as
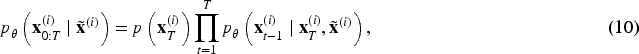
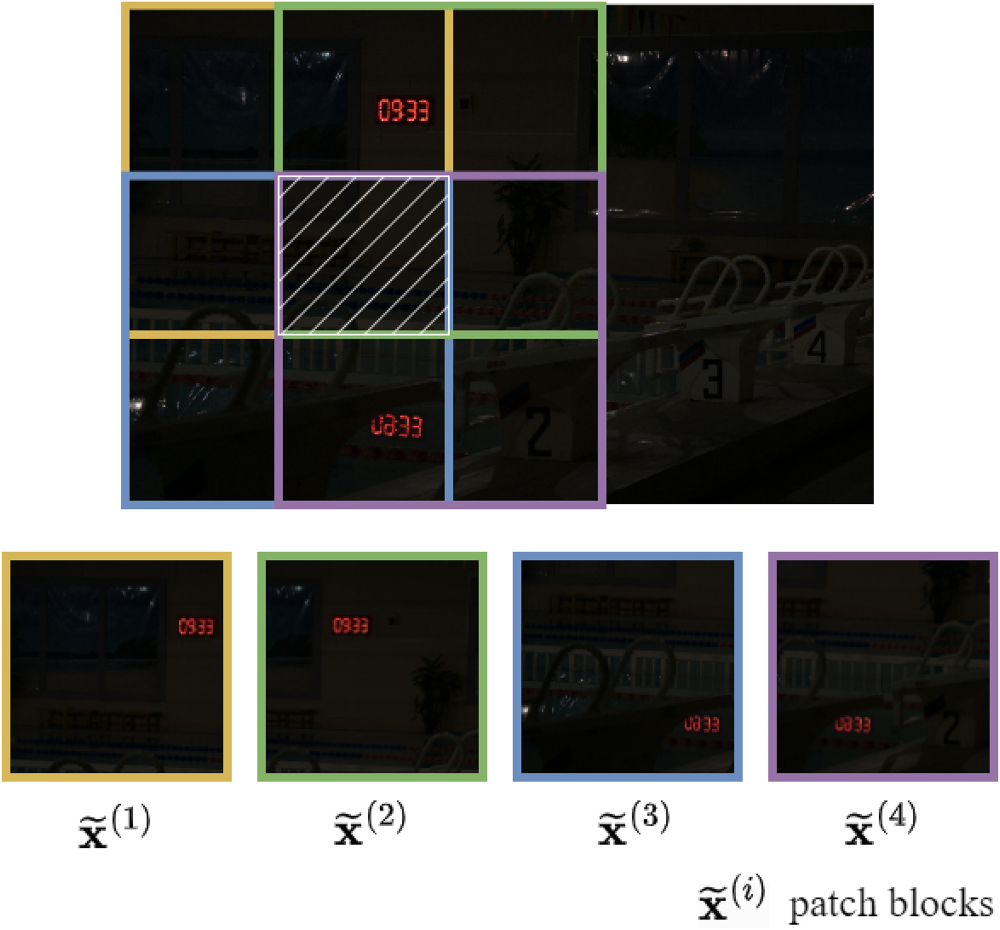
Illustration of overlapping patch operation. The image shows a simplified schematic of this operation, where the colored blocks are the different patch blocks and the white grid lines are the parts where the four patch blocks overlap, and we will sample the pixels in the region to update them based on the average estimated noise of the four patch blocks at each denoising time step
By minimizing the loss function, the network can narrow the distance between the output image and the standard image to achieve the purpose of low-light enhancement. Different loss functions have different feature extraction capabilities; in order to get a higher-quality output image, a joint loss function is used in this paper. Considering the structural information and contextual information between images, in addition to the loss function

Images captured in low-light environments frequently exhibit structural distortion. The structural similarity index (SSIM), a widely recognized metric for assessing the similarity between two images, is commonly employed to evaluate the degree of similarity before and after distortion, as well as to determine the fidelity of images generated by models. Therefore, in this paper, the SSIM metric is utilized to formulate a structural loss function aimed at minimizing the disparity between the generated image and the reference image. The equation for this metric is presented as follows, equations (12) and (13):
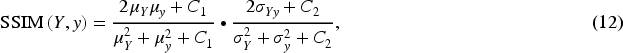

The Charbonnier loss is similar to the L1 loss, but it has a smoothing, data stabilization feature that exhibits the behavior of the L2 loss at smaller errors, while maintaining similar linear properties to the L1 loss at larger errors. The smoothing property helps to mitigate the gradient vanishing problem and makes the optimization process more stable. The problem of gradient instability at small errors is avoided by adding a small constant

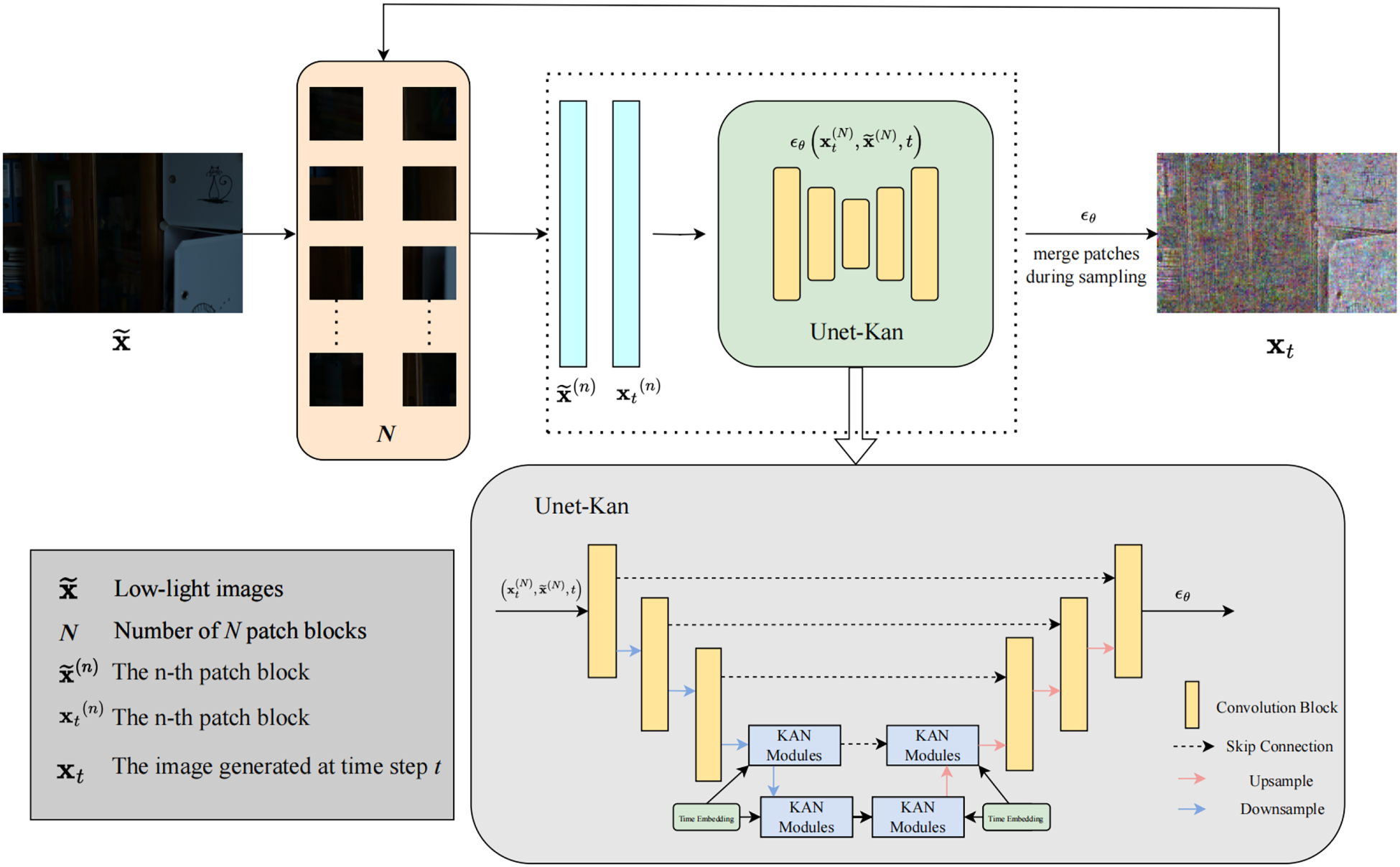
In this paper, KANDiff, a dark light image enhancement method, is proposed by combining the patch-based network structure with the diffusion model and utilizing KAN to enhance the noise estimation ability of the diffusion model. The model network structure is shown in Figure 4. The overall structure adheres to the framework of forward noise addition and reverse denoising characteristic of diffusion models. The model employs a patch-based image recovery strategy, where the image is divided into
Overall network framework diagram.
In comparison to the noise estimation networks utilized in conventional diffusion models, excessive convolution operations can result in the loss of high-frequency detail information. Consequently, the skip connection is implemented to ensure that the extracted features encapsulate richer semantic information. Additionally, since traditional noise estimation networks do not adequately meet the demands for image restoration in predicting noise, KAN has been integrated into the noise estimation network to enhance its generative capacity. This integration aims to improve the network’s accuracy in estimating noise, thereby enabling the high-quality enhancement of low-light images.
In the backward denoising process of the diffusion models, the noise estimation network estimates the noise while denoising the image to complete the image recovery. The image quality depends on the estimation accuracy of the noise estimation network, and since KAN has a stronger noise estimation ability, this paper combines it with U-Net to obtain Unet-Kan, which realizes more accurate noise estimation and thus improves the quality of the recovered image. Firstly, the image is down-sampled to obtain different levels of image features; then the time embedding is added in the intermediate layer to perform the feature extraction through the KAN module, and finally, the up-sampling is used to obtain high-quality and accurate noise prediction results. The structure of the KAN module is shown in Figure 5.
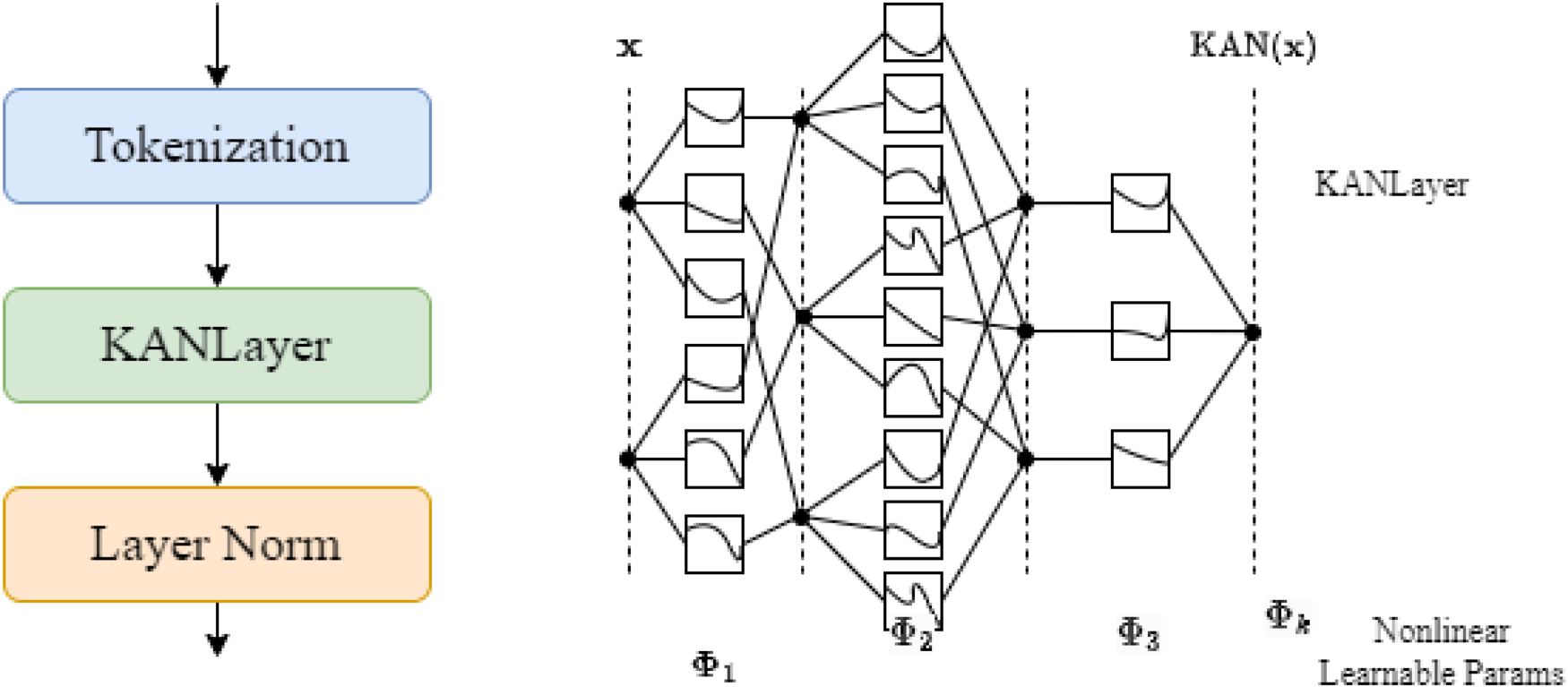
Internal structure of Kolmogorov–Arnold network (KAN) module.
When the feature map

When tokenization is completed, the desired tokens are obtained and passed to the KAN layer, which is similar in principle to the MLP and consists of multiple layers of nested activation functions, each with fixed input and output dimensions, allowing for more efficient and interpretable feature extraction. A
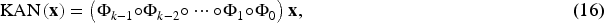
The results of KAN computation from the
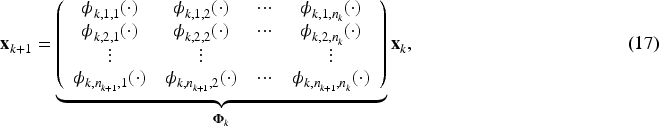
After each KAN layer, the application layer normalizes and passes the output features to the next block, for example, the output of the

In addition, the noise prediction network Unet-Kan whose purpose is to predict the noise

Experimental Setup and Datasets
The KANDiff model is trained to utilize the PyTorch framework on an NVIDIA Tesla T4 GPU. The initial learning rate for network training is uniformly set to
The model is trained on LOLv1 (Wei et al., 2018) dataset, which has a total of 500 image pairs, of which 485 pairs are allocated for training and 15 pairs for validation. Furthermore, the performance of the KANDiff is evaluated on two synthetics pairwise datasets: VE-LOL (Liu et al., 2021) and LSRW (Hai et al., 2023). The VE-LOL dataset consists of 500 image pairs designated for training and 100 pairs for validation, whereas the LSRW dataset includes 5,650 image pairs sourced from diverse scenes, with 5,600 pairs randomly selected for training and the remaining 50 pairs reserved for validation. In this paper, we also test the generalization ability of the proposed method to unknown scenes on two commonly used real-world unpaired datasets DICM (Lee et al., 2013) and LIME (Guo et al., 2016). Moreover, this paper proposes a low-light dataset LIDS with 16 low-light images of different sizes.
Evaluation Indicators
To objectively assess the performance of the model, this paper employs the peak signal-to-noise ratio (PSNR) and SSIM as the primary evaluation metrics for paired datasets. For unpaired datasets, natural image quality evaluation (NIQE) serves as the main evaluation criterion.
PSNR is a widely used metric to quantify the quality of an image or video, typically comparing the quality of a compressed image with its original counterpart. Higher PSNR values generally indicate superior image quality.
SSIM is a metric designed to evaluate the perceptual similarity between two images. Unlike PSNR, SSIM incorporates factors such as luminance, contrast, and structural information, providing a metric that aligns more closely with human visual perception. The SSIM value ranges from 0 to 1, with higher values indicating greater similarity between the two images.
NIQE is a widely adopted metric for assessing the quality of an image in the absence of a reference image. Lower NIQE values signify higher image quality, as the image exhibits characteristics more closely resembling those of natural images.
Ablation Experiments
To evaluate the effectiveness of KANDiff, we conducted two ablation experiments; ablation experiment 1 used the original U-Net for model training; ablation experiment 2 used a patch size of

Comparison of the effect of this paper’s method with ablation experiments.
Comparison of Our Method Between the Methods in This Paper and Ablation Experiments on LOLv1, VE-LOL and LSRW Datasets. Ablation Experiment 1 Used the Original U-Net for Model Training, Ablation Experiment 2 Used a Patch Size of
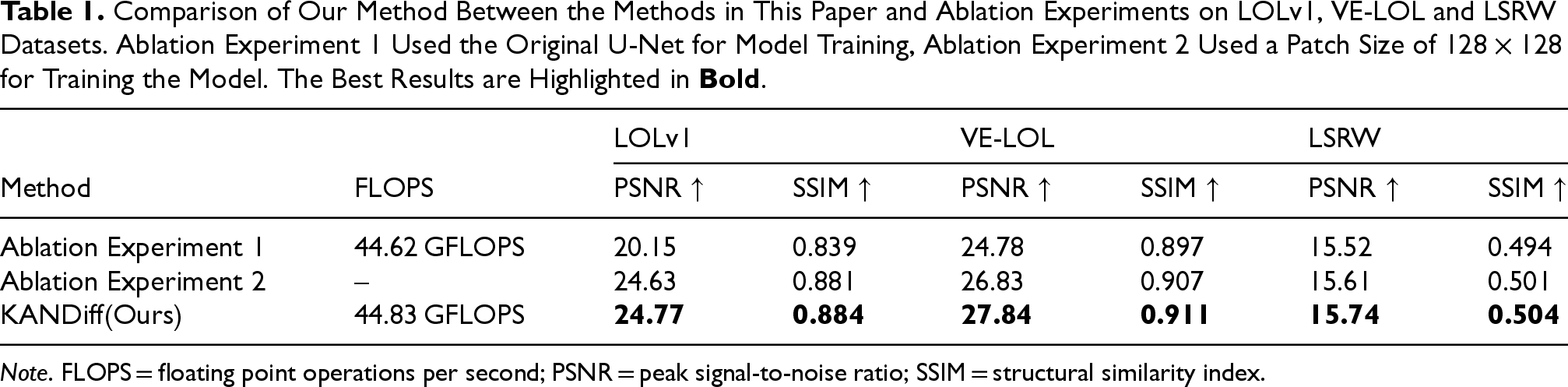
Note. FLOPS = floating point operations per second; PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
The KANDiff proposed in this paper is compared with RetinexNet (Wei et al., 2018), Zero-DCE (Guo et al., 2020), EnlightenGAN (Jiang et al., 2021), Restormer (Zamir et al., 2022), UHD-LL (Li et al., 2023), LLFlow (Wang et al., 2022), and LLFormer (Wang et al., 2023) across the LOLv1, VE-LOL, and LSRW datasets. Two evaluation metrics, PSNR and SSIM, are employed for performance assessment. The results, presented in Table 2, indicate that the proposed method achieves the highest performance in both PSNR and SSIM on the VE-LOL dataset. On the LOLv1 and LSRW datasets, the KANDiff outperforms the other methods in terms of SSIM, and the difference in PSNR between KANDiff and the best-performing method is only 0.988 and 1.56. In summary, on LOL, VE-LOL, and LSRW datasets, the algorithm in this paper combines the advantages of the diffusion model and KAN and achieves the best image enhancement effect, which can prove the effectiveness of the proposed method in this paper.
Comparison of our Method With Mainstream Low-Light Enhancement Methods on LOLv1, VE-LOL, and LSRW Datasets. The Best Results are Highlighted in Bold .
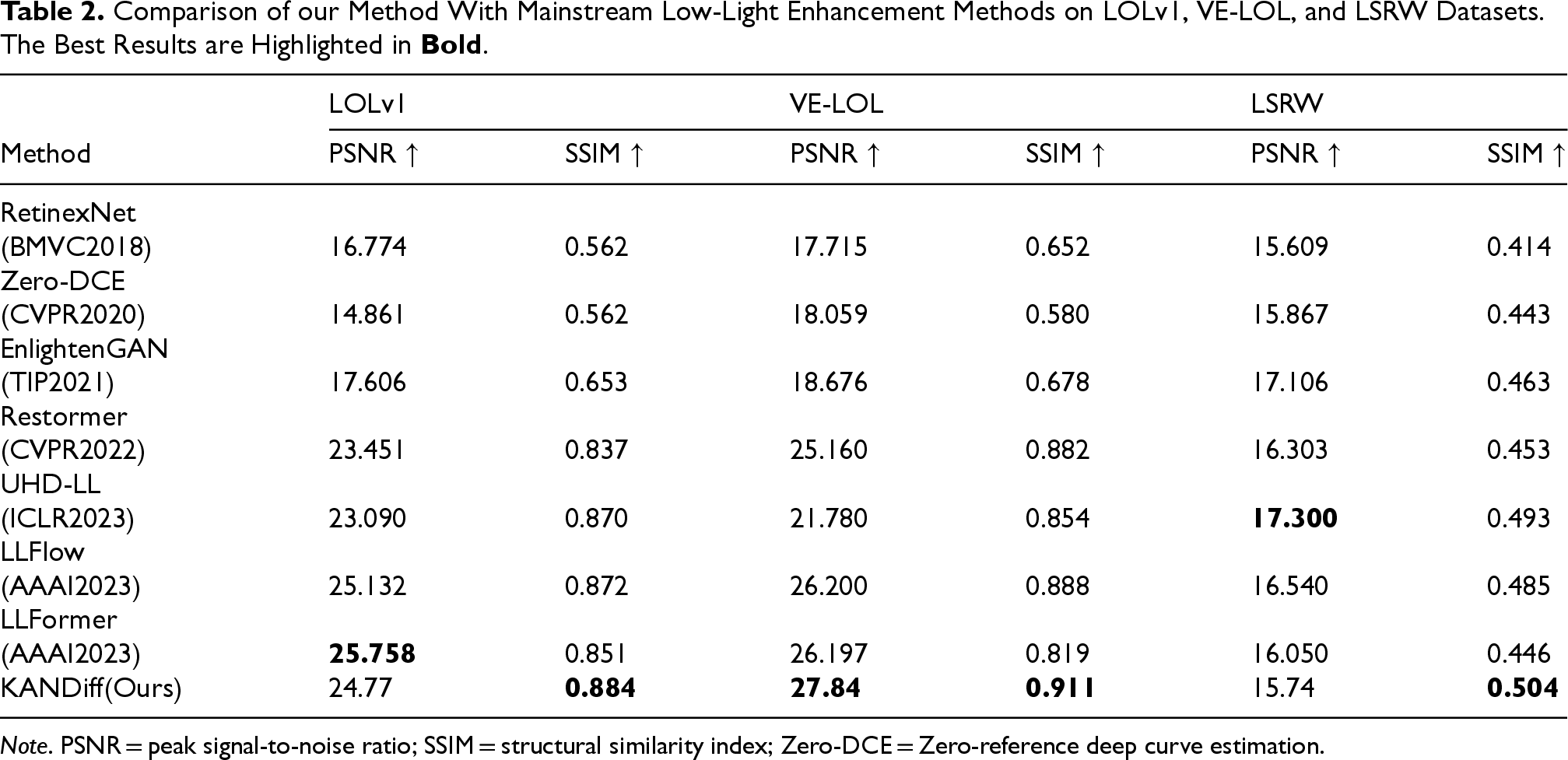
Comparison of our Method With Mainstream Low-Light Enhancement Methods on LOLv1, VE-LOL, and LSRW Datasets. The Best Results are Highlighted in
Note. PSNR = peak signal-to-noise ratio; SSIM = structural similarity index; Zero-DCE = Zero-reference deep curve estimation.
In order to better illustrate the low-light enhancement ability of the images generated by the model in this paper, the image visualization of two datasets, LOLv1 and VE-LOL, are selected and compared with the images generated by other algorithms, and as shown in Figures 7 and 8, the KANDiff effectively enhances the image contrast and recovers the details of the image in the low-light environment.

Comparison of images generated by this paper’s method with other methods in the LOLv1 dataset with normal light and low light images.

Comparison of images generated by this paper’s method with other methods in the VE-LOL dataset with normal light and low light images.
For evaluating the performance of the model on dark–light images of unknown sizes, this paper proposes an unpaired dark–light image dataset containing images of different sizes, named LIDS. In the experiments on the LIDS dataset, the method proposed in this paper effectively enhances the contrast of the image and significantly recovers the dark details. By comparing the results of the experiments (shown in Figure 9), it can be clearly observed that the method in this paper maintains high image quality when dealing with low-light images of different sizes. This indicates that the method proposed in this paper has a relatively strong generalization ability to adapt to various unknown sizes of low-light images, thus demonstrating good results and potential in practical applications.

Comparison of the images generated by this paper’s method in the LIDS dataset with low-light images.
To further verify the generalization ability of this paper’s algorithm, experiments are conducted on the unpaired datasets LIME and DICM, and systematic comparisons are made with the current mainstream low-light enhancement approaches Zero-DCE and Restormer. The comparison results are shown in Figure 10. In the DICM dataset, the image enhanced by KANDiff effectively enhances the brightness of the indoor low-light region, while preserving the image details well in the enhancement process. This result shows the effectiveness and applicability of the proposed method in low-light conditions. On the LIME dataset, the images enhanced by both Zero-DCE and Restormer methods showed different degrees of color bias, which affected the overall quality of the images. In contrast, the proposed KANDiff successfully recovers the details of the image, no color bias occurs during the enhancement process, and the overall visual effect is superior.

Comparison of the effectiveness of this paper’s method with other methods on LIME and DICM datasets.
In addition, the evaluation metric NIQE for unpaired datasets is introduced in this paper to quantify the performance of different methods in image enhancement. The data analysis in Table 3 shows that the NIQE values of the proposed KANDiff are both the lowest, 4.171 and 3.898, respectively, indicating the superiority of the proposed methods in image quality assessment. The experimental results show that the method in this paper exhibits good generalization ability on a wide range of datasets and has higher reliability.
Comparison of NIQE Values on the Unpaired Datasets LIME and DICM. Lower NIQE Values Represent Higher Image Quality. The Best Results are Highlighted in

Note. NIQE = natural image quality evaluation; Zero-DCE = Zero-reference deep curve estimation.
While the proposed method has demonstrated SOTA performance in low-light image enhancement, we further explore its potential for cross-domain adaptation. Underwater image enhancement presents unique challenges due to wavelength-dependent light attenuation and scattering effects caused by suspended particles, which manifest as color casts and low contrast. Addressing these issues holds critical implications for marine exploration and ecological monitoring, driving continuous interdisciplinary innovations in computational imaging and underwater robotics, with significant scientific research value and real-world application urgency.
We extended the approach presented in this paper to the field of underwater image enhancement and conducted training and testing on the UIEB dataset. As shown in Table 4, the proposed method outperforms the methods of Water-net (Li et al., 2019) and PUGAN (Cong et al., 2023) in terms of both PSNR and SSIM, achieving the best results. Furthermore, the visual results of the proposed method are illustrated in Figure 11.

The method proposed in this article generates images on the UIEB dataset.
Comparison Between Our Method and Mainstream Underwater Image Enhancement Methods on the UIEB Dataset. The Best Results are Highlighted in
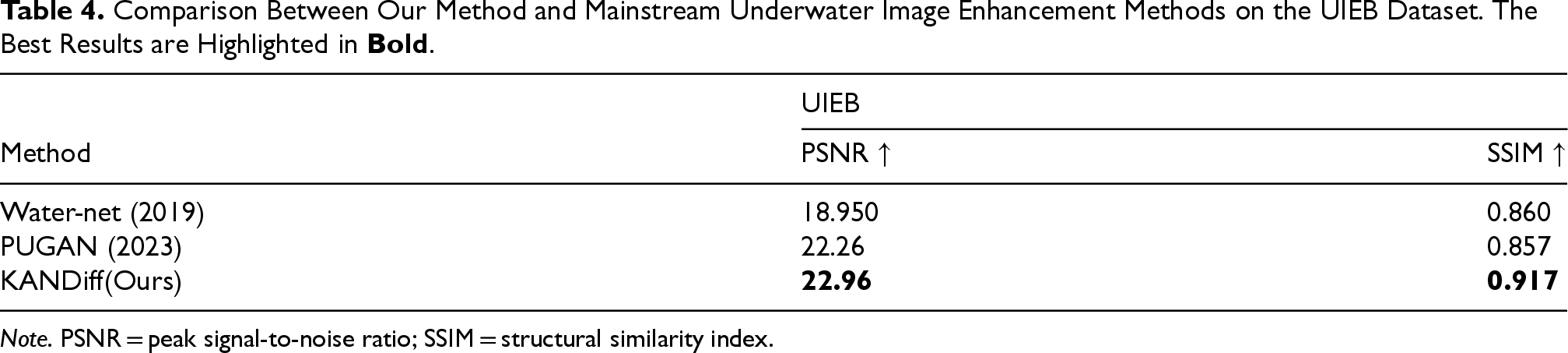
Note. PSNR = peak signal-to-noise ratio; SSIM = structural similarity index.
In this paper, a diffusion models-based low-light image enhancement network, named KANDiff, is proposed. The network significantly improves the accuracy of the model in the noise estimation process by combining KAN with the noise estimation network, which in turn achieves an efficient inverse diffusion process to achieve high-quality image enhancement. In addition, KANDiff adopts a patch-based image restoration strategy that enables it to handle images of unknown size, further enhancing the generalization ability of the model, and introducing a hybrid loss function that effectively suppresses the production of bias color phenomenon.
The proposed method is systematically evaluated on several popular low-light image datasets. The experimental results show that the KANDiff in this paper exhibits significant enhancement in several objective metrics (e.g., PSNR and SSIM) compared to other existing algorithms, and reaches the optimal level in most cases. In addition, experimental validation on underwater image enhancement scenarios has demonstrated KANDiff’s robustness and adaptability across diverse environments. The subjective evaluation results also show that KANDiff exhibits good enhancement performance on real-world unpaired datasets, and the analysis of NIQE metrics further demonstrates that the enhanced images are able to contain more detailed information and are more in line with the standards of human visual perception. The research results in this paper provide an important theoretical foundation and practical guidance for the development of image enhancement techniques in a low-light environment.
While KANDiff exhibits impressive performance in the domain of low-light image enhancement, several promising avenues for further research remain. First, the computational efficiency of diffusion models continues to pose a significant challenge. Future studies could investigate the application of knowledge distillation techniques or the development of lightweight variants of KANDiff, aimed at facilitating real-time processing on resource-constrained devices. Additionally, expanding the current framework to accommodate dynamic video sequences, as opposed to static images, would greatly enhance its potential applications in fields such as surveillance and mobile photography.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project has received funding from The National Natural Science Foundation of China (Grant Nos. 62001272 and 62472264) and Shandong Provincial Natural Science Foundation, China (Grant No. ZR2023MF015).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.