
Abstract
Paraphrasing involves rewording a text to maintain its meaning while using different language. In recent years, there has been growing interest among researchers in automatic paraphrase generation (APG). Previous studies have primarily focused on developing corpora and methods for APG tasks in English and other languages. However, there is a lack of comprehensive benchmark corpora and standardized methods specifically designed for APG in Urdu. To address this gap, this study introduces two extensive benchmark corpora: the Urdu Phrasal Paraphrase corpus (UPP-22 corpus) at the phrasal level and the Urdu Sentential Paraphrase corpus (USP-22 corpus) at the sentence level. The UPP-22 corpus contains 3,50,000 paraphrased pairs, while the USP-22 corpus consists of 11,000 paraphrased pairs, both specifically curated for the Urdu APG task. As a second major contribution, this research developed and applied various state-of-the-art deep learning models, including sequence-to-sequence models (using long short-term memory [LSTM], gated recurrent unit [GRU], bidirectional LSTM, and bidirectional GRU) and sequence-to-sequence models with attention mechanisms as baseline methods for the proposed Urdu Paraphrase corpora. Additionally, the study introduced a bidirectional and auto-regressive transformer-based model specifically tailored to these corpora as a third contribution. A fourth significant contribution was the development of a test corpus at the phrasal level, consisting of 10,000 instances, created through automatic translation, followed by manual inspection and correction, to evaluate the performance of APG tasks for the Urdu language. As a fifth major contribution, the study applied and fine-tuned a large language model (GPT-4-Mini) for APG in Urdu, resulting in significant performance improvements. The evaluation was carried out using the standard bilingual evaluation understudy (BLEU) metric. The best results were achieved with BLEU-1 = 75.89 for the UPP-22 corpus and BLEU-1 = 75.16 for the USP-22 corpus using the GPT-4-Mini model, representing a significant improvement over all other models including baseline. These corpora and methodologies will be made publicly available to encourage and promote further research in APG for under-resourced languages such as Urdu.
Introduction
Automatic paraphrase generation (APG) is a complex task in the field of natural language processing (NLP), aimed at creating sentences or phrases that convey the same meaning as the input text while maintaining semantic equivalence and grammatical accuracy. The significance of paraphrasing lies in its ability to enhance comprehension and improve communication in natural language understanding. However, manual paraphrase generation is an arduous and time-consuming task, particularly when dealing with large volumes of text. Consequently, automated paraphrase generation systems have gained increasing research attention in recent years.
For a wide range of NLP applications, such as machine translation (MT), question answering systems, text summarization, information retrieval, text reuse, and plagiarism detection (Vo et al., 2015), APG holds great potential. Additionally, it is a useful tool for producing training data for many NLP tasks, such as question-type categorization and paraphrase identification (Brad & Rebedea, 2017).
Paraphrase generation can be classified into two main types: local paraphrase generation, which involves paraphrasing specific words, phrases, sentences, or passages, and global paraphrase generation, which paraphrases the entire source document(s) to create a new document.
The APG task includes several subtasks, such as paraphrase identification, selection, and generation. These subtasks can be tackled using various techniques, including rule-based approaches, statistical machine learning, and neural-based models. Deep learning advancements, particularly sequence-to-sequence (Seq2Seq) models, have significantly advanced APG’s progress.
Despite these developments, APG faces several challenges. These include generating fluent, varied paraphrases, managing differences in vocabulary and sentence structure, and addressing the issue of semantic drift (Wu & Ma, 2017). Since language structure, semantics, and grammar are closely linked through co-reference connections, generating correct and automated paraphrases remains a difficult task.
The automated production of paraphrases has garnered significant attention from the academic community (Li et al., 2018), driven by the realization that fully automated paraphrase generation systems are faster and more cost-effective than human-based techniques.
According to (Rahman, 2004), Urdu, part of the Indo-Aryan language family, incorporates vocabulary and grammatical structures from various languages, such as Arabic, Persian, and South Asian languages. Its rich morphology poses challenges for automatic processing, as some words can take on over 40 forms (Naseer et al., 2009). With over 300 million speakers globally and approximately 151 million native speakers, Urdu is widely spoken, especially in Pakistan and among the South Asian diaspora (Daud et al., 2017; Hussain, 2008; Riaz, 2010). Despite its prominence, Urdu remains under-resourced in the NLP domain, and efforts to develop computational resources tailored to Urdu continue (Jawaid et al., 2014).
Generating grammatically correct, semantically equivalent, and contextually appropriate paraphrases is one of the primary challenges in APG. Researchers have proposed various solutions, including neural MT models with encoder–decoder architectures, attention mechanisms to highlight crucial input elements and pre-trained language models such as generative pre-trained transformer (GPT) and bidirectional encoder representations from transformers (BERT). While most APG systems have focused on English and a few other languages, APG research for the Urdu language, particularly with large-scale datasets and deep learning methods, remains underexplored.
To address this gap, this research aims to explore APG for the Urdu language. The study has three main goals: first, to generate two benchmark Urdu paraphrase corpora—the Urdu Phrasal Paraphrase corpus (UPP-22 corpus) and the USP-22 corpus); second, to develop and apply state-of-the-art deep learning methods for Urdu APG, including Seq2Seq models and attention-based models; and third, to apply and fine-tune a large language model (LLM: GPT-4-Mini) specifically for APG in Urdu, significantly improving performance. A transfer learning-based approach was proposed, developed, and evaluated on the new corpora. Additionally, a test corpus at the phrasal level, consisting of 10,000 instances, was developed using automatic translation, manual inspection, and correction to evaluate APG performance for Urdu.
This study’s primary contribution is the creation of two significant APG corpora for Urdu, containing 350,000 phrasal paraphrase pairs (UPP-22) and 11,000 sentential paraphrase pairs (USP-22), setting a gold standard for evaluation. Furthermore, the research applies and develops state-of-the-art deep learning methods for Urdu APG, including Seq2Seq models with attention and LLMs such as GPT-4-Mini, which significantly improved performance. To the best of our knowledge, this is the first study to document these corpora, methodologies, and the application of LLMs for the Urdu language.
The significance of this research is both theoretical and practical. The proposed corpora are expected to promote research in an under-resourced language, identify common paraphrasing techniques, and facilitate the development of Urdu-specific paraphrasing tools. The integration of LLMs, such as GPT-4-Mini, enables direct comparisons with existing APG methods and demonstrates the potential of advanced Artificial Intelligence techniques in enhancing paraphrase generation. This research provides a foundation for developing and testing new APG approaches for Urdu and other low-resource languages.
The subsequent sections of this paper are structured as follows: Section 2 examines the prevailing corpora and methodologies employed in paraphrase generation. Section 3 outlines the process of corpus generation employed to create the proposed corpora. Section 4 provides a comprehensive explanation of the novel methods proposed for APG. Section 5 details the experimental setup utilized in the study. Section 6 presents the results obtained and offers an in-depth analysis of the findings. Lastly, Section 7 concludes the paper by summarizing the key findings and suggesting potential directions for future research.
Related Work
In this section, we will present existing corpora and methods for the APG task.
Corpora
Creating extensive and openly accessible resources for the study of APG is a challenging task. Nevertheless, in recent years, there have been multiple efforts to construct standardized corpora specifically for APG. It is important to note that most of these efforts have primarily focused on the English language.
Ganitkevitch et al. (2013) proposed the largest collection of the paraphrase database (PPDB) for over 20 languages, including English and Spanish. PPDB 1.0, released in 2013, consists of two main portions: English and Spanish. The English portion contains about 220 million paraphrase pairs, while the Spanish portion contains over 196 million paraphrase pairs. To assess the quality of the paraphrases, human annotators manually evaluated 1,900 randomly sampled predicate paraphrases on a scale of 1 to 5, with 5 being the best. The results showed a clear correlation between PPDB scores and human judgments.
The second version of the PPDB, PPDB 2.0 (Pavlick et al., 2015), was released in 2015. This version includes improved paraphrase rankings, with quality scores that correlate well with human judgment. PPDB 2.0 contains over 169 million paraphrases in English, and 26,000 paraphrases were manually rated by human judges to evaluate the quality of paraphrased pairs. PPDB has proven to be a valuable resource in various NLP applications, such as paraphrase detection (Kim et al., 2016; Sjöblom et al., 2018) and generation (Brad & Rebedea, 2017; Prakash et al., 2016).
In January 2017, Quora released a dataset to the public containing 404,351 question pairs, of which 150,000 were marked as duplicates and 255,000 as distinct (Imtiaz et al., 2020). These question pairs span various domains, including technology, philosophy, politics, entertainment, and culture. The dataset has been widely used in several studies for different purposes, such as identifying paraphrases (Alzubi et al., 2020; Chandra & Stefanus, 2020; Tomar et al., 2017), recognizing duplicate pairs (Abishek et al., 2019; Viswanathan et al., 2019), identifying duplicate question pairs (Godbole et al., 2018), measuring semantic textual similarity (Shajalal & Aono, 2020), developing dialog systems (Haponchyk et al., 2018), generating sentence embeddings (Reimers & Gurevych, 2019), conducting pointwise paraphrase appraisal (Chen et al., 2020), and generating paraphrases (Hegde & Patil, 2020; Kazemnejad et al., 2020; Qian et al., 2019). The corpus is available for research purposes. 1 This benchmark dataset has significantly boosted research in paraphrasing and has been used to develop models for both APG (Gupta et al., 2018; Li et al., 2018) and detection (Tomar et al., 2017).
The WikiAnswers dataset (Fader et al., 2013) is a large question paraphrase dataset containing approximately 18 million paraphrased question pairs. These paraphrases consist of different questions tagged as similar by users. To estimate the quality and accuracy of the paraphrase corpus, 100 pairs were randomly selected from the dataset and manually labeled as either “paraphrase” or “not paraphrase.” The results indicated that 55% of the selected pairs were valid paraphrases. This corpus is available for research purposes. 2
In a pioneering study conducted by Gudkov et al. (2020), a significant corpus named “ParaPhraser Plus” was developed and ranked for generating paraphrases in the Russian language. This corpus represents the first of its kind in Russian, comprising 7,227 sentence pairs. These pairs were carefully annotated and categorized into three groups: non-paraphrase (2,582 pairs), near-paraphrase (2,957 pairs), and precise-paraphrase (1,688 pairs). The creation of this corpus is instrumental in advancing tools and resources for the Russian language.
The Turkish Paraphrase Corpus, as described by Demir et al. (2012), consists of 1,270 paraphrased sentences. These sentences were collected from diverse sources, including 482 from novels, 108 from movie subtitles, 240 from news articles, and 440 from an English–Turkish parallel corpus. The annotation process involved two graduates manually annotating the sentences to ensure semantic equivalence. In cases of conflicting annotations, a third annotator resolved the discrepancies. Additionally, 14 native Turkish speakers provided word- and phrase-level annotations. This corpus was developed to encourage research on Turkish paraphrasing tasks, although it is not currently available for download.
The Microsoft Research Paraphrase Corpus (MRPC) (Dolan & Brockett, 2005) is a highly regarded and widely used corpus for sentence-level paraphrasing in English. It contains pairs of sentences extracted from online news articles. These pairs were initially selected automatically and then evaluated by two human judges, who rated them as either paraphrased or non-paraphrased. Any disagreements between the judges were resolved by a third judge. The final corpus contains 5,801 sentence pairs, with 67% marked as paraphrases and 33% as non-paraphrases. It is one of the earliest benchmark paraphrase corpora, available for free download. 3
Methods
Gupta et al. (2018) present a deep generative framework for the task of APG. The proposed framework combines the strengths of Seq2Seq models with LSTM (Sutskever et al., 2014) and deep generative models (variational autoencoder; Kingma & Welling, 2013) to develop a novel deep learning architecture for paraphrase generation. The framework was evaluated on two datasets: MSCOCO (Lin et al., 2014), which contains 120 K
In their work, Brad and Rebedea (2017) leveraged the neural MT method with transfer learning for neural paraphrase generation. The model was evaluated on three corpora: MRPC (Dolan & Brockett, 2005) (train: 3,854 instances; validation: 1,652 instances; test: 2,294 instances), PPDB
5
(train: 457,000 instances; validation: 114,888 instances), and SNLI
6
(train: 183,416 instances; validation: 3,329 instances; test: 3,368 instances). The highest score was BLEU = 15.76, achieved by the SNLI
Prakash et al. (2016) used a stacked residual LSTM network, with residual connections added between LSTM layers. The model was evaluated on PPDB 7 (training: 4,826,492 instances and testing: 20,000 instances), WikiAnswers 8 (training: 4,826,492 instances and testing: 20,000 instances), and the MSCOCO dataset (Lin et al., 2014) (training: 331,163 instances and testing: 20,000 instances). Performance was evaluated using BLEU, METEOR, TER, and emb greedy (word embeddings to compare the phrases) to quantitatively evaluate the model. For the PPDB corpus, the highest scores achieved with the residual LSTM model were BLEU = 20.3, METEOR = 23.1, TER = 77.1, and emb greedy = 34.77. For the WikiAnswers corpus, the best performance was BLEU = 37.0, METEOR = 32.1, TER = 27.0, and emb greedy = 75.13. For the MSCOCO corpus, the highest scores were BLEU = 36.7, METEOR = 27.3, TER = 52.3, and emb greedy = 69.69, achieved using the proposed residual LSTM model.
Li et al. (2018) explored deep reinforcement learning for paraphrase generation. They introduced a framework consisting of a generator and an evaluator, both trained from data. The generator is a Seq2Seq model with attention (Bahdanau et al., 2014; Luong et al., 2015), further enhanced by reinforcement learning, which generates multiple paraphrases of input sentences. These are then forwarded to the evaluator, a decomposable attention-based deep matching model (Parikh et al., 2016) improved by inverse reinforcement learning (Ng & Russell, 2000), to judge whether the sentences are paraphrases. The model was trained on the Quora dataset, 9 split into 100K training, 30K testing, and 3K validation sets. The best performance was achieved with a beam size of 10, resulting in BLEU = 42.49, METEOR = 31.87, ROUGE-1 = 63.81, and ROUGE-2 = 37.81, demonstrating that the proposed models outperform state-of-the-art methods in paraphrase generation.
Kazemnejad et al. (2020) proposed the fine-grained sample-based editing transformer model within a retrieval-based framework for paraphrase generation. Experiments were conducted on the Quora Question Pairs dataset 10 and the Twitter URL paraphrasing corpus (Lan et al., 2017). For the Quora dataset, training (100K), testing (30K), and validation (3K) sets were used. For the Twitter URL paraphrasing corpus, 110K automatically labeled instances were selected for training, with two non-overlapping human-annotated subsets of 5K and 1K instances for testing and validation. The best scores on the Quora dataset were ROUGE-1 = 39.55, ROUGE-2 = 66.17, BLEU-4 = 33.46, BLEU-2 = 51.03, and METEOR = 38.57. For the Twitter URL paraphrasing corpus, the best scores were ROUGE-1 = 32.04, ROUGE-2 = 49.53, BLEU-4 = 34.62, BLEU-2 = 46.35, and METEOR = 31.67.
While previous studies have developed comprehensive corpora and methods for APG in languages such as English, Spanish, Russian, and Turkish, this study makes significant contributions to the under-resourced Urdu language. A key novelty of this research is the creation of two extensive benchmark corpora—the UPP-22 corpus and the USP-22 corpus—which set a new standard for evaluation in Urdu APG. A notable difference between these languages and Urdu lies in the rich morphology of Urdu, where words can take on over 40 different forms due to their derivational and inflectional complexities, as highlighted by Naseer et al. (2009). This presents a unique challenge in creating accurate paraphrase pairs compared to languages with less morphological variation. Furthermore, the scarcity of publicly available large-scale corpora for Urdu has historically complicated the development of high-performing models. By addressing these gaps, this study not only enhances the resources available for Urdu but also demonstrates the efficacy of state-of-the-art models, including the application of LLMs such as GPT-4-Mini, which significantly improve paraphrasing performance in Urdu.
To address the gap in resources, the primary objective of this study is to investigate APG for the Urdu language. The research has three main goals: first, the creation of two benchmark Urdu paraphrase corpora—the UPP-22 corpus and the USP-22 corpus; second, the development and application of cutting-edge deep learning techniques for the automatic generation of Urdu paraphrases, including the successful implementation of LLMs such as GPT-4-Mini; and third, the creation of a test corpus at the phrasal level, consisting of 10,000 instances, which includes automatic translation, manual inspection, and correction to evaluate APG performance in Urdu.
This study’s primary contributions are two extensive benchmarks, gold-standard APG corpora, each containing 350,000 pairs of paraphrases at the phrasal level and 11,000 pairs at the sentence level. Additionally, state-of-the-art deep learning techniques were developed and applied to the proposed Urdu Paraphrase Generation corpora for the APG task. Another significant contribution is the development of bidirectional and auto-regressive transformer (BART)-based methods for paraphrase generation at both phrasal and sentence levels for Urdu. Furthermore, the introduction of GPT-4-Mini represents a pioneering effort in applying LLMs for APG in Urdu. To the best of our knowledge, the corpora and techniques developed in this study are the first reported for the Urdu language, providing valuable resources to facilitate future research in this area.
Table 1 presents a comparative analysis of the newly created Urdu paraphrase datasets (UPP-22 and USP-22) against a selection of existing multilingual and monolingual paraphrase datasets. In this table, we detail key aspects such as the languages included, dataset sizes, types of paraphrases (phrasal or sentence-level), and notable features of each dataset. The UPP-22 dataset, containing 350,000 phrasal paraphrase instances, and the USP-22 dataset, comprising 11,000 sentence-level paraphrases, demonstrate a focused effort to provide high-quality, curated resources specifically for Urdu.
Comparison of Newly Created Urdu Paraphrase Datasets With Existing Multilingual and Monolingual Paraphrase Datasets.
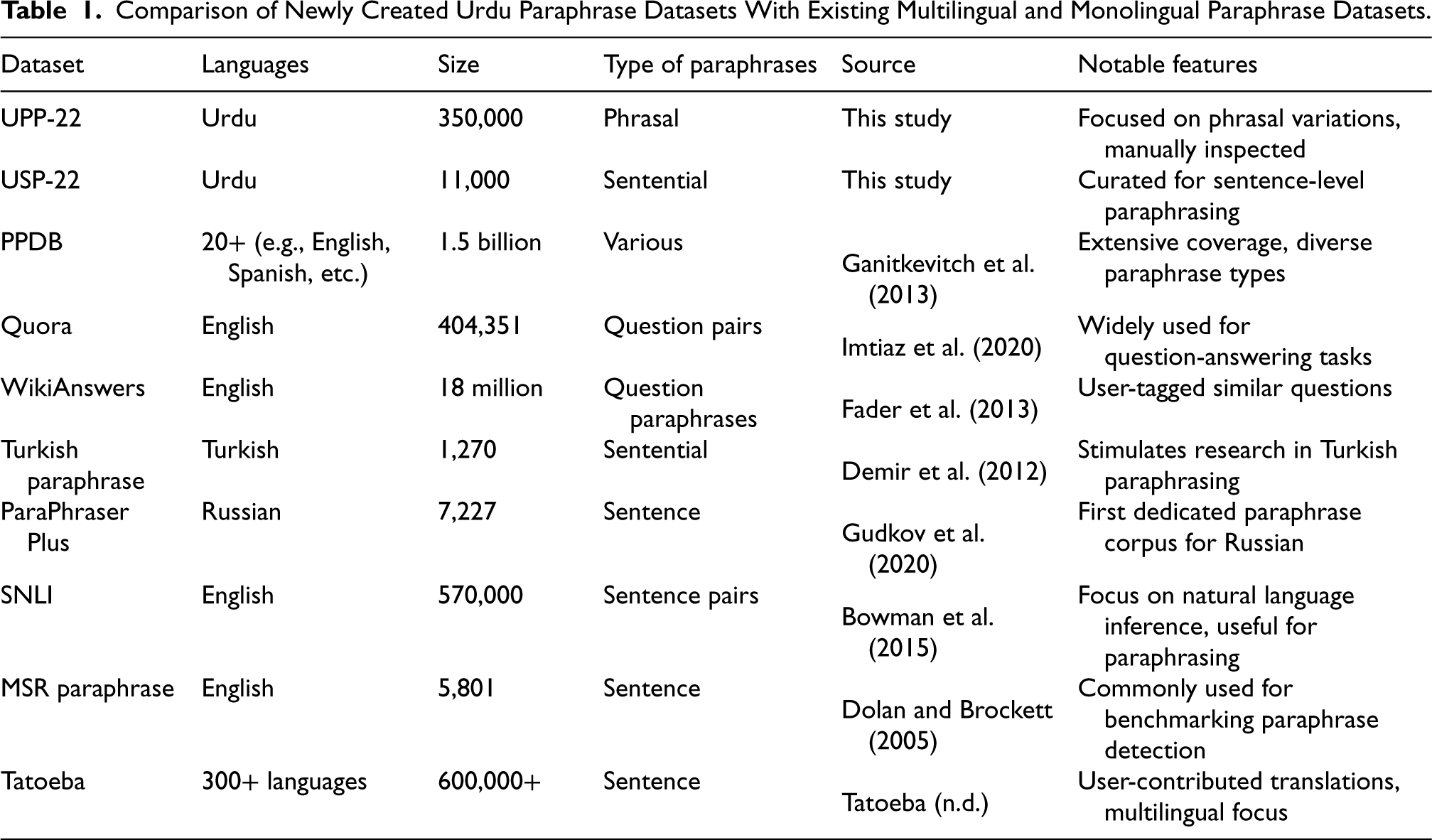
Comparison of Newly Created Urdu Paraphrase Datasets With Existing Multilingual and Monolingual Paraphrase Datasets.
In contrast, widely recognized datasets such as the PPDB and the Quora Question Pairs dataset offer extensive multilingual coverage and have been extensively utilized in various NLP tasks. Notably, PPDB includes over 1.5 billion paraphrase pairs across more than 20 languages, showcasing its breadth compared to our datasets. The table also highlights the unique challenges faced in the Urdu language, such as its rich morphology and the complexities involved in creating reliable paraphrases. By comparing the performance and characteristics of our datasets with those of existing resources, we aim to establish the relevance and contribution of our work to the broader field of paraphrase generation.
In this section, we will discuss the corpus generation process which includes data collection, data translation, data manual inspection, data manual correction, and corpus characteristics. Below we describe the proposed corpus generation process in detail.
USP-22 Corpus Generation Process
Data Collection and Translation
To create our proposed USP-22 corpus, we used a subset of data from the Quora corpus 11 (Chen et al., 2018). In previous studies, this corpus has been used for various tasks including widely used for the task of APG (Hegde & Patil, 2020; Kazemnejad et al., 2020; Qian et al., 2019), paraphrase identification (Alzubi et al., 2020; Chandra & Stefanus, 2020; Tomar et al., 2017), duplicate pairs recognition (Abishek et al., 2019; Viswanathan et al., 2019), duplicate question pairs identification (Godbole et al., 2018), semantic textual similarity (Shajalal & Aono, 2020) dialog systems (Haponchyk et al., 2018), sentence embedding (Reimers & Gurevych, 2019), and pointwise paraphrase appraisal (Chen et al., 2020). Quora question pair dataset contains 4+ million sentence pairs from which approximately 155K sentences are tagged as duplicates. We separated a total of 1,55,000 question pairs that were marked as duplicates.
For the development of the USP-22 corpus, we first extracted 12,000 sentences from the Quora corpus. The subset
12
of text pairs extracted from the Quora Question Pairs corpus is in the English language, that is, monolingual. To generate the Urdu paraphrase parallel corpus, we used Google translate API
13
to generate English
Data Manual Inspection
After the automatic translation of the Quora question pair dataset, a manual inspection was conducted by a linguistic expert proficient in both English and Urdu to evaluate the translation quality. Detailed translation rating guidelines were developed for this task. Subsequently, a sample of 200 paraphrase pairs 14 was extracted from the dataset, and two native Urdu speakers, who are experts in paraphrasing, were assigned to review the quality of the translations and provide ratings for each sentence according to the established guidelines. The results of the manual inspection are presented in Table 2.
Manual Inspection Results for Translated Quora Question Pair Dataset.

Manual Inspection Results for Translated Quora Question Pair Dataset.
After measuring the accuracy of the translated corpus from manual inspection, we found out that the translation quality of the Quora question pair dataset was unacceptable mainly because of the increasing sentence length. So, the human annotators took a sample of 11,800 translated sentence pairs, manually rated each sentence, and corrected some minor errors in translation manually to improve the translation quality. After this time-taking process, we were able to extract 11,000 correctly translated sentential Urdu paraphrase pairs for our model training and testing.
Corpus Characteristics
The proposed USP-22 corpus contains a total of 11,000 manually rated sentence paraphrase pairs. Table 4 shows detailed statistics of the proposed corpus. The proposed USP-22 contains in total of 7,035 Urdu tokens. More detailed statistics can be found in Table 4. The corpus is standardized in comma-separated values (CSV) format and will be publicly accessible to download for research purposes under a Creative Commons CC-BY-NC-SA license. 15 This corpus can be accessed from the available link for the reviewers. 16 Examples 3 and 4 illustrate the Urdu paraphrased pairs presented in Table 3.
Examples From Corpus.

Examples From Corpus.
Urdu Sentential Paraphrase Corpus Characteristics.

Data Collection and Translation
To create our proposed UPP-22 corpus at the phrasal level, we have used a subset of data from the PPDB 2.0 corpus 17 (Pavlick et al., 2015). These corpora contain approximately 169 million phrasal (multiword to single/multiword), syntactic (paraphrase rules containing non-terminal symbols), and lexical (single word to single word) paraphrase pairs. Previous research has utilized these datasets for diverse purposes, such as automatic detection and generation of paraphrases (Ganitkevitch et al., 2013), sentential paraphrasing by treating it as black-box MT (Napoles et al., 2016), simplifying PPDBs (Pavlick et al., 2015), and developing models for compositional paraphrasing (Wieting et al., 2015).
The PPDB 2.0 provides different types of datasets in different sizes for the phrasal paraphrase dataset, we used the small size dataset which contains 10 million phrasal pairs. The “s” size contains only the highest-scoring pairs, for the highest precision. PPDB-2.0-s-Phrasal contains 1,04,112 phrasal paraphrase pairs. We have extracted a subset of 4 million phrasal pairs from the PPDB-2.0-s-Phrasal corpus.
18
These pairs were automatically translated into the Urdu language. To generate the Urdu paraphrase parallel corpus, we used Google translate API
19
to generate English
Corpus Characteristics
The proposed UPP-22 corpus contains a total of 3,50,000 paraphrase pairs at the phrasal level. Table 5 shows detailed statistics of the proposed corpus. Table 4 contains more detailed statistics regarding the corpus, which is available in standardized CSV format and can be downloaded for research purposes. The corpus is publicly accessible under a Creative Commons CC-BY-NC-SA license. 20 Reviewers can access the corpus using the provided link. 21 Examples 1 and 2 illustrate the Urdu paraphrased pairs presented in Table 3.
Urdu Phrasal Paraphrase Corpus Characteristics.

Urdu Phrasal Paraphrase Corpus Characteristics.
Predictions From Corpora.

To illustrate how the newly suggested corpora can be utilized to create APG systems for Urdu, we implemented two techniques: Seq2Seq with LSTM, GRU, bidirectional long short-term memory (Bi-LSTM), and bidirectional GRU (Bi-GRU), and Seq2Seq with an extra attention layer, which was introduced in Bahdanau et al. (2014). To the best of our knowledge, these techniques have not been used before for APG in Urdu. We will now elaborate on these methods.
Sequence to Sequence (Seq2Seq)
Seq2Seq modeling, a neural network architecture, is applied in various NLP tasks, including MT (Tiwari et al., 2020), text summarization (Cohan & Goharian, 2021), and dialog generation (Yin et al., 2021). This model processes input sequences of varying lengths and generates output sequences of variable lengths.
In NLP, Seq2Seq modeling is commonly used for tasks such as MT (Tiwari et al., 2020), text summarization (Cohan & Goharian, 2021), and conversation creation (Yin et al., 2021). This neural network architecture is designed to handle input sequences of varying lengths and produce corresponding output sequences of variable lengths.
The Seq2Seq model architecture typically consists of an encoder and a decoder, both of which are based on recurrent neural networks (RNNs). The encoder processes the input sequence and generates a context vector, a fixed-length vector containing relevant information from the input sequence. The decoder then uses this context vector to produce the output sequence, token by token.
The encoder RNN processes each input token sequentially, generating a series of hidden states. The last hidden state, which encodes information about the input sequence, serves as the context vector. This context vector is used as the initial hidden state of the decoder RNN, which generates the output sequence token by token. At each time step, the decoder selects a token from the probability distribution over the output vocabulary generated by the model.
During training, the model is optimized to minimize the difference between the expected output sequence and the predicted output sequence. This is typically achieved using the cross-entropy loss function. During inference, the decoder generates the output sequence using a beam search algorithm, which selects the most probable output sequence given the input. The goal is to improve the model’s performance in generating accurate and coherent output sequences.
In this work, we define paraphrase generation as a Seq2Seq learning problem. The goal is to learn a model
The training process is as follows:
The training involved the use of four models, each comprising two layers that acted as the encoder and decoder. The models used were LSTM, GRU, Bi-LSTM, and Bi-GRU. A Keras embedding layer was used in the encoder model to generate a 256-dimensional context vector. During training on the UPP-22 corpus, the Adam optimizer was employed with two hidden layers, a batch size of 64, 1,024 units, and a maximum sequence length of 20. The trained model was validated on a subset containing 20% of the training samples. Similarly, training on the USP-22 corpus used the Adam optimizer with a batch size of 64, 1,024 units, and a maximum sequence length of 20 over five epochs.
Seq2Seq With Attention
The Seq2Seq model is an enhanced version that addresses certain limitations of its original design. In the basic Seq2Seq architecture, the input sequence is encoded into a fixed-length vector and then decoded into an output sequence. However, this fixed-length encoding may not effectively capture all essential information from the input sequence, especially for longer sequences (Cho et al., 2014).
To address this issue, attention mechanisms have been introduced, allowing the decoder to selectively focus on different parts of the input sequence during each decoding step. Instead of encoding the entire input sequence into a single fixed-length vector, the attention mechanism generates a series of context vectors for each time step. These context vectors are derived from a weighted sum of the encoder’s hidden states, with the weights determined by a learned attention function that depends on the decoder’s hidden state at each step (Bahdanau et al., 2014). The encoder thus maps the input sentence into a sequence of annotations, where each annotation contains information about the input sequence, with a particular focus on the surrounding words. A context vector is then produced by computing the weighted sum of these annotations.
In the decoding process, attention mechanisms generate a sequence of context vectors, as opposed to using a single fixed-length vector for the entire input sequence. The weights for each context vector are determined by the learned attention function, based on the decoder’s current hidden state. These context vectors are computed from the weighted sum of the encoder’s hidden states (Bahdanau et al., 2014). In this method, the encoder associates the input sentence with a sequence of annotations, each capturing relevant information about the input, particularly the surrounding context of the annotated word. A context vector is calculated by aggregating these annotations using a weighted sum.
The weighted sum of these annotations forms an alignment model. The probability associated with each weight in the alignment model is passed to the decoder, determining the significance of each annotation and guiding the next state. This process establishes the attention mechanism in the decoder, which assesses how well the inputs around position
This attention mechanism allows the model to selectively focus on different parts of the input sequence at various stages during decoding, based on the context and the output generated so far. Consequently, the model performs better on tasks like text summarization and MT, as the attention mechanism enables more effective extraction of relevant information from the input sequence.
The training process used four models with two layers of LSTM, GRU, Bi-LSTM, and Bi-GRU serving as the encoder and decoder. An additional attention layer was included, enabling the system to automatically identify the parts of the source sentence that are most relevant for predicting each target word. During inference, the trained model automatically generated paraphrases of the given sentences, which were then used for evaluation.
Bidirectional and Auto-Regressive Transformer (BART)
Facebook Artificial Intelligence Research has developed a pre-trained language model called BART (Lewis et al., 2020). BART follows a conventional Seq2Seq/MT architecture, comprising an auto-regressive decoder similar to GPT and an auto-directional encoder similar to BERT. The pre-training of BART involves two steps: (1) introducing random noise to the text using a random function, and (2) training the model to reconstruct the original text.
BART, a flexible language model, can be adapted for diverse NLP tasks, including text generation (He, 2021), summarization (Chen & Song, 2021; Yadav et al., 2023), pseudocode generation from source code (Alokla et al., 2022), and language translation (Liu et al., 2020). A notable characteristic of BART is its capability to undergo training in both auto-regressive and denoising auto-encoder modes, enabling it to capture the interdependencies between word sequences in both forward and backward directions.
Several studies have shown that BART-based models can achieve state-of-the-art results on paraphrase generation tasks (Li et al., 2022), outperforming previous methods. BART’s ability to capture both local and global dependencies in natural language, combined with its bidirectional encoder and auto-regressive decoder, makes it well-suited for paraphrase generation tasks.
In order to leverage BART for paraphrase generation, various implementation strategies have been suggested. One prevalent method involves fine-tuning the pre-trained BART model on an extensive collection of sentence pairs, wherein each pair consists of a source sentence and its corresponding paraphrased version. During the fine-tuning process, the parameters of the BART model are updated using a supervised learning approach, wherein the model is trained to accurately predict the paraphrase given the source sentence. In our study, we employed this approach by fine-tuning the pre-trained BART model on our proposed corpora for APG.
The process of fine-tuning the model works as follows:
In the first step, data was preprocessed by tokenizing the sentences and encoding them into numerical vectors using a “facebook/bart-large”
22
tokenizer. In the second step, we fine-tuned the pre-trained BART model to generate paraphrases of the input sentence by minimizing a loss function that measures the similarity between the generated paraphrase and the ground truth paraphrase. The fine-tuning process was conducted using a supervised learning approach with hyper-parameter tuning, including a learning rate of
LLM Approach
LLMs are current state-of-the-art for text generation and many other downstream NLP tasks (Yadav et al., 2024). Simple prompt engineering can enable the LLMs to produce better results, without the need for expensive finetuning (Sun et al., 2024). While LLMs are primarily aimed at text generation tasks, they have been utilized for semantic similarity tasks and also paraphrasing tasks. GPT-4-Mini offers a promising avenue for experimentation in APG, particularly for the Urdu language. Its architecture allows for the generation of high-quality paraphrases by leveraging its extensive training on diverse text data, which includes various languages and dialects (Brown et al., 2020; Zhang et al., 2021). Researchers can utilize GPT-4-Mini to explore various aspects of APG, including the generation of phrasal and sentential paraphrases, while also fine-tuning the model by adjusting prompts and exploring different configurations, researchers can assess the model’s effectiveness in producing contextually relevant and semantically accurate paraphrases (Liu et al., 2021). Furthermore, the model’s ability to handle complex morphological variations in Urdu makes it an ideal candidate for addressing the unique challenges associated with paraphrase generation in this under-resourced language, thereby enhancing the quality and availability of Urdu paraphrasing tools (Naseer et al., 2009).
The model was utilized for Urdu paraphrase generation through a prompt-based method, without the need for fine-tuning. In this approach, carefully crafted prompts were designed to guide the model in generating paraphrased sentences. These prompts provided contextual cues and specific instructions to encourage the model to produce variations of sentences that maintain the same meaning. The training and testing data were organized into separate files, ensuring a clear distinction between the two datasets. After generating paraphrases using the prompts, the model’s performance was evaluated using the BLEU score. This metric provided a quantitative assessment of the quality of the generated paraphrases by comparing them to reference sentences. By leveraging the model’s pre-trained knowledge and employing this systematic approach, relevant and contextually appropriate paraphrases were produced while effectively evaluating their performance.
Experimental Setup
This section describes the corpora, evaluation methodology, and evaluation measures used for the APG experiments applied to paraphrased corpora.
Corpus
The Urdu sentential paraphrase (USP-22) corpus contains a total of 11,000 paraphrase sentences from which we selected 10,000 and 1,000 sentence pairs as training and test sets, respectively. The test set from the corpus can be accessed from the available link for the reviewers. 23
UPP-22 Test Corpus
For APG at the phrasal level, we have developed the test data which is manually inspected and corrected, unlike the training dataset at the phrasal level. The UPP-22 corpus contains 350,000 instances that are infeasible to be investigated manually. To achieve better quality on test data, we have separately developed a test dataset.
The steps to create test data are as follows.
We have extracted a subset of 10,000 phrasal pairs from the PPDB-2.0-s-Phrasal corpus.
24
We translated the PPDB phrasal paraphrase data to the Urdu language using Google translate API to generate English After translation, we performed a manual inspection to examine the translation quality for the Urdu phrasal paraphrase dataset. For this task, we took a sample of 200 paraphrase pairs
25
from Urdu phrasal paraphrase dataset. Two native Urdu speakers and paraphrase experts were assigned to check the translation quality and rate each sentence by following the translation rating guidelines. The results of the manual inspection are shown in Table 7. After measuring the accuracy of the translated corpus from manual inspection, we found out that the translation quality for the PPDB phrasal dataset was quite satisfactory. So, from a phrasal dataset, we automatically translated 10K paraphrase pairs, and human annotators manually inspected each paraphrase pair and manually correct the translation mistakes to increase the accuracy. The corpus is standardized in CSV format and will be publicly accessible to download for research purposes under a Creative Commons CC-BY-NC-SA license.
26
This corpus can be accessed from the available link for the reviewers.
27
Manual Inspection Results for Translated PPDB Phrasal Dataset.

We have concentrated on applying two types of techniques to our proposed corpus: (1) Seq2Seq and (2) Seq2Seq with attention. Table 8 shows all applied methods on both corpora, first, four experiments were performed using Seq2Seq, and, for the other four experiments, Seq2Seq with attention was used.
Applied Methods.

Applied Methods.
Notes. LSTM=long short-term memory; GRU=gated recurrent unit; Bi-LSTM=bidirectional LSTM: Bi-GRU=bidirectional GRU; LSTM-atten=LSTM with attention; GRU-atten=GRU with attention; Bi-LSTM-atten=Bi-LSTM with attention; Bi-GRU-atten=Bi-GRU with attention; BART = bidirectional and auto-regressive transformer.
BLEU is a widely accepted metric for paraphrase generation, consistent with common practices in the existing literature, thereby facilitating straightforward comparisons with similar studies (Asghari & Ghanbari, 2015; Papineni et al., 2002; Ramesh & Kumari, 2021; Zhang et al., 2021). BLEU uses a modified form of precision to compare a candidate sequence against multiple reference sequence(s). BLEU-N measures unigram, bigram, trigram, and higher-order n-gram overlap.
Evaluation Methodology
In this study, we address the challenges associated with text generation by focusing on the problem of APG. One of the primary obstacles to effective paraphrase production is the selection and specification of appropriate evaluation metrics. These metrics must accurately assess the semantic similarity between generated paraphrases and their corresponding source sentences. We employed the widely recognized BLEU metric (Asghari & Ghanbari, 2015) as the primary evaluation criterion for our paraphrase generation models. This metric, originally developed for MT, has been adapted for APG tasks due to its robust performance in measuring n-gram overlap. Previous studies have demonstrated that metrics such as BLEU can effectively evaluate paraphrase recognition systems (Madnani et al., 2012) and correlate well with human judgments regarding the quality of generated paraphrases (Li et al., 2018). By utilizing BLEU and extending our evaluation to include additional metrics such as ROUGE and METEOR, we aim to provide a comprehensive analysis of our models’ performance, particularly with the newly developed corpora for Urdu.
Results and Analysis
Tables 9 and 10 summarize the BLEU scores achieved by various models for the UPP-22 and USP-22 corpora, respectively. For both corpora, the GPT-4-Mini model demonstrated a significant improvement, outperforming previous models with a BLEU-1 score of 75.89 for the UPP-22 corpus and 75.16 for the USP-22 corpus. These results represent a substantial increase from the best-performing baseline models, which achieved a BLEU-1 score of 31.11 (BART) for UPP-22 and 42.25 (Bi-LSTM with Attention) for USP-22.
Results on UPP-22 Corpus.
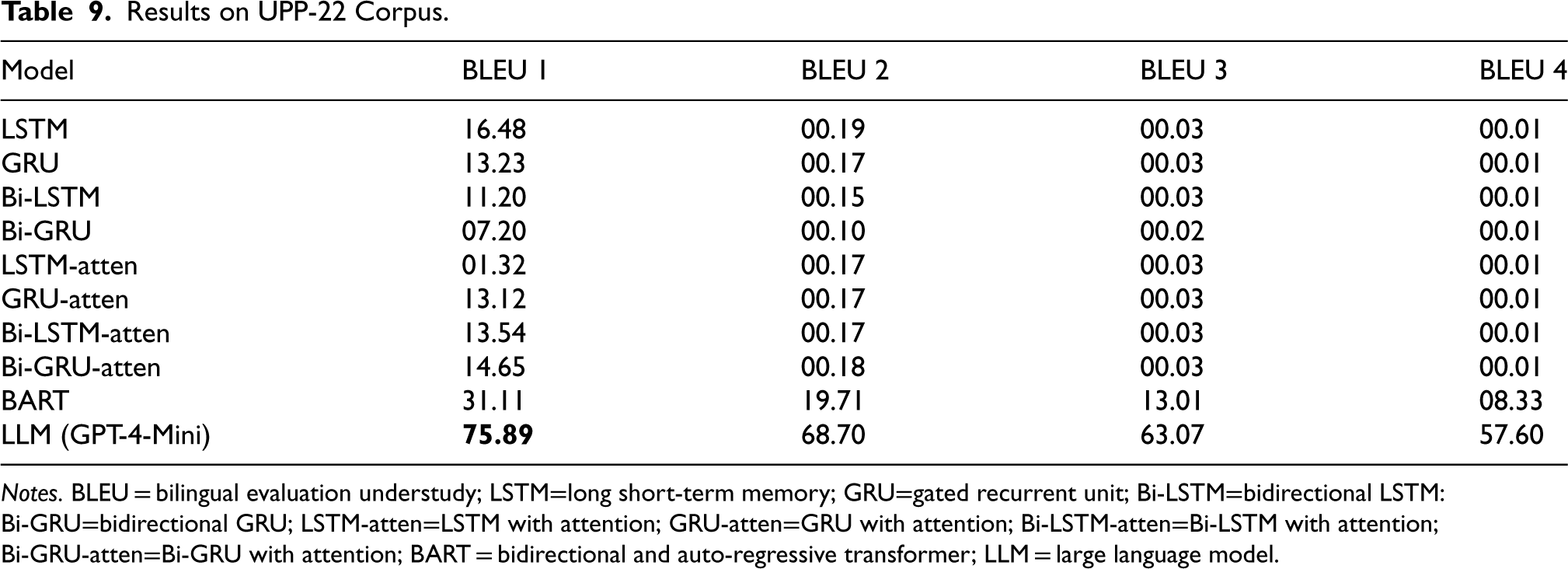
Results on UPP-22 Corpus.
Notes. BLEU = bilingual evaluation understudy; LSTM=long short-term memory; GRU=gated recurrent unit; Bi-LSTM=bidirectional LSTM: Bi-GRU=bidirectional GRU; LSTM-atten=LSTM with attention; GRU-atten=GRU with attention; Bi-LSTM-atten=Bi-LSTM with attention; Bi-GRU-atten=Bi-GRU with attention; BART = bidirectional and auto-regressive transformer; LLM = large language model.
Results on USP-22 Corpus.
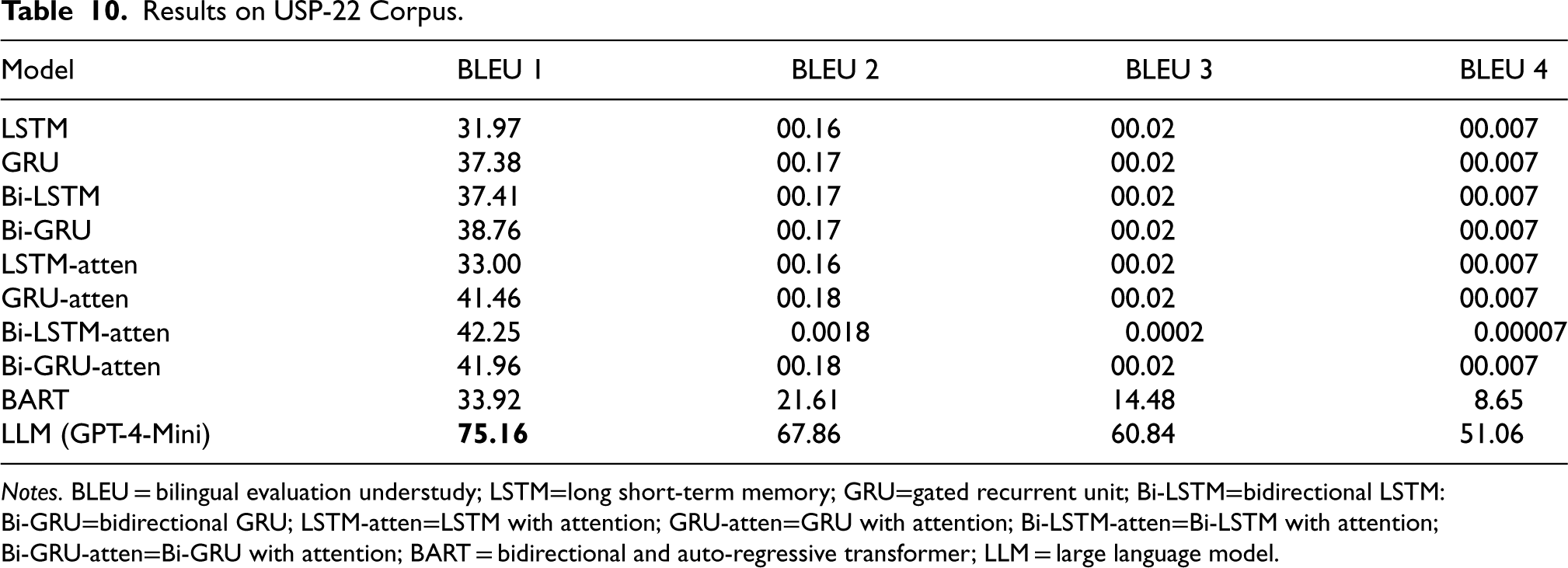
Notes. BLEU = bilingual evaluation understudy; LSTM=long short-term memory; GRU=gated recurrent unit; Bi-LSTM=bidirectional LSTM: Bi-GRU=bidirectional GRU; LSTM-atten=LSTM with attention; GRU-atten=GRU with attention; Bi-LSTM-atten=Bi-LSTM with attention; Bi-GRU-atten=Bi-GRU with attention; BART = bidirectional and auto-regressive transformer; LLM = large language model.
The GPT-4-Mini model’s improvement can be attributed to its enhanced ability to capture nuanced linguistic patterns and generate more accurate paraphrases. Unlike traditional Seq2Seq models or models using attention mechanisms, GPT-4-Mini benefits from its larger training data and more advanced architecture, allowing it to better understand contextual dependencies, particularly in a morphologically rich language such as Urdu.
This improvement highlights the potential of LLMs such as GPT-4-Mini in low-resource language tasks, such as Urdu paraphrase generation. The increased BLEU scores across multiple n-gram levels (BLEU-1 to BLEU-4) further underscore the model’s capability to generate fluent, semantically accurate paraphrases that closely align with the reference outputs.
In conclusion, GPT-4-Mini significantly boosts performance over baseline methods, achieving BLEU-1 scores of over 75 on both corpora. This sets a new standard for APG in Urdu, particularly at the phrasal and sentential levels.
The BART model demonstrates the most favorable performance after GPT-4-mini (LLM) for the UPP-22 corpus due to several factors. Firstly, BART is a sizable pre-trained model that benefits from an extensive amount of training data. Its access to a larger and more diverse collection of phrasal paraphrase examples contributes to its superior performance in handling phrasal data. Secondly, transformers, including BART, exhibit strong modeling abilities in capturing contextual information and long-range dependencies within text. Since phrasal paraphrases often involve understanding the relationships between words or phrases within a smaller unit of text, Transformers excel in modeling these dependencies. Compared to recurrent models such as LSTM, Bi-LSTM, GRU, and Bi-GRU, Transformers such as BART are more effective at capturing subtle linguistic variations. Thirdly, BART derives advantages from its pre-training on extensive corpora, which exposes it to a wide array of linguistic patterns and semantic representations. This pre-training enables BART to acquire rich contextual embeddings that can be fine-tuned for downstream tasks such as APG. The transfer learning capability of BART contributes to its exceptional performance when compared to LSTM, Bi-LSTM, GRU, and Bi-GRU models. These recurrent models often require more intensive task-specific training and may struggle to capture nuanced paraphrasing patterns.
The “Bi-LSTM-atten” model demonstrates the second highest performance performance for USP-22 in the context of APG. Several reasons contribute to its superior performance to other deep learning models: Firstly, Bi-LSTM networks excel at capturing contextual information from both preceding and succeeding states of words within a sequence. This bidirectional nature enables a comprehensive understanding of word meanings within their sentence contexts, which is crucial for generating accurate paraphrases. Secondly, the model employs an attention mechanism that selectively focuses on different segments of the input sequence during the encoding phase. By assigning varying weights to specific parts of the sentence, it highlights important words and phrases essential for generating precise paraphrases. This attention mechanism empowers the Bi-LSTM model to effectively attend to relevant information, resulting in improved performance. Thirdly, APG tasks often involve capturing dependencies between words that are distantly located within a sentence. The recurrent nature of Bi-LSTMs enables them to capture these long-range dependencies more effectively than other models. Through the retention of information from earlier sentence components and its propagation through time via an internal memory cell, the model attains a better understanding of complex sentence structures. Lastly, the performance of deep learning models heavily relies on the quality and availability of training data. In the case of the Bi-LSTM model with attention, it has benefited from training on a large and diverse dataset specifically curated for the APG task, such as USP-22. This dataset underwent meticulous manual inspection and correction, ensuring high-quality data. Consequently, the model has developed a robust comprehension of underlying paraphrase patterns and variations, leading to its enhanced performance.
A detailed comparison of BLEU scores and model performance across languages highlights the variations in the difficulty of APG tasks. Table 11 presents a comparison of BLEU-1 scores achieved in different languages, including Urdu (using the proposed UPP-22 and USP-22 corpora) and previously reported results on corpora in English, Spanish, Russian, and Turkish. This comparison illustrates the unique challenges of working with a morphologically rich and low-resource language such as Urdu.
Comparative BLEU-1 Scores Across Languages for APG Tasks.
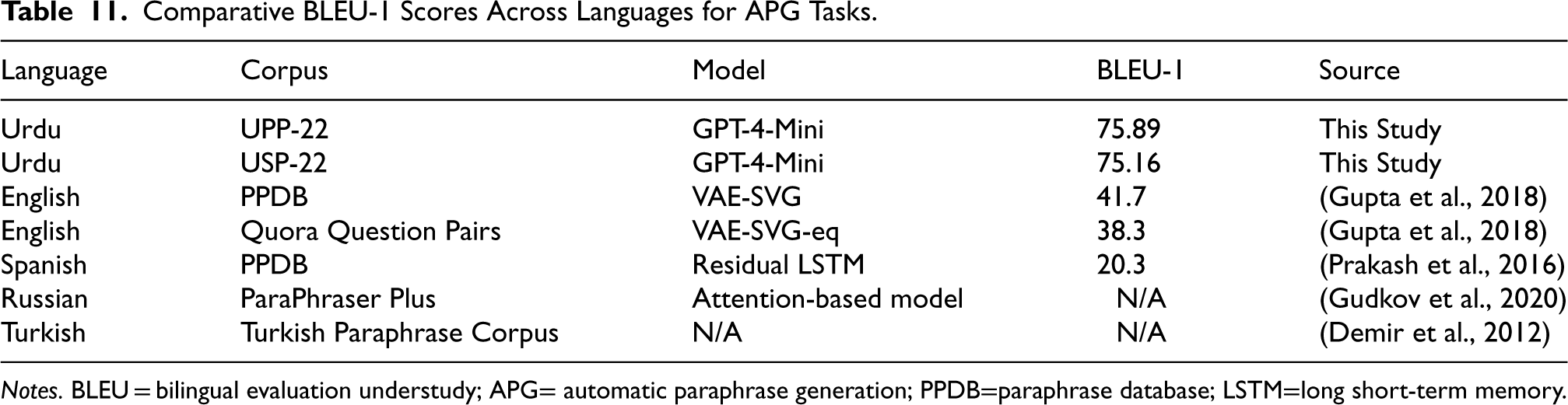
Notes. BLEU = bilingual evaluation understudy; APG= automatic paraphrase generation; PPDB=paraphrase database; LSTM=long short-term memory.
Despite the morphological complexity of Urdu and the historical challenges posed by limited high-quality training data, GPT-4-Mini’s substantial performance improvements demonstrate the potential of advanced LLMs to overcome these barriers. This contrasts with models trained on more resource-rich languages, such as English (e.g., VAE-SVG), where the gap in performance is now bridged or even exceeded by the introduction of LLMs.
In comparison, languages such as Spanish and Turkish, which have relatively less complex morphology but richer computational resources, still exhibit lower BLEU scores, further emphasizing the unique challenges posed by Urdu. However, GPT-4-Mini’s success suggests that, with the right models, even under-resourced languages can achieve comparable or superior performance to resource-rich languages, provided sufficient computational power and fine-tuning are applied.
In conclusion, our extensive experimentation led to several key findings. Firstly, a notable performance difference was observed between UPP-22 and USP-22, with the introduction of GPT-4-Mini resulting in substantial improvements across both corpora. The superior performance of GPT-4-Mini highlights the transformative impact of LLMs in handling complex linguistic patterns, especially in low-resource languages such as Urdu. Secondly, among all the models tested, GPT-4-Mini significantly outperformed the best model, Bi-LSTM with attention from baseline approaches, for USP-22, achieving a BLEU-1 score of 75.16. Thirdly, GPT-4-Mini also surpassed the BART model on UPP-22, setting a new BLEU-1 score of 75.89. Lastly, the Seq2Seq models with attention, while still outperforming traditional Seq2Seq models, were ultimately outclassed by GPT-4-Mini across both datasets, underscoring the superior ability of LLMs to capture both local and global dependencies in paraphrase generation tasks for the Urdu language.
This research paper introduces two extensive corpora for APG in the Urdu language, consisting of 350,000 phrasal-level pairs and 11,000 sentence-level pairs. These corpora serve as valuable resources for the development, evaluation, and comparison of automatic paraphrase-generation methods specifically designed for Urdu. A test corpus with 10,000 instances was created to evaluate the performance of APG tasks in Urdu, incorporating automatic translation, manual inspection, and correction. Notably, the implementation of the GPT-4-Mini model resulted in substantial improvements, achieving BLEU-1 scores of 75.89 for the UPP-22 corpus and 75.16 for the USP-22 corpus, demonstrating its effectiveness in the Urdu paraphrasing task. Moving forward, the researchers plan to explore APG at the lexical and syntactical levels and investigate the application of transfer learning methods using the proposed corpora for performance comparison at different levels. We will continue to analyze the performance of GPT-4-Mini to further understand its capabilities and refine its application in APG. Additionally, we aim to incorporate data augmentation techniques to enhance model robustness. Furthermore, we recognize the importance of conducting a comparative analysis of APG tasks in other languages to contextualize the challenges and progress in Urdu APG relative to other languages.
Footnotes
Author Note
Ahmad Mahmood Instituto Politécnico Nacional, Mexico City, Mexico.
Author Contributions
Rao Muhammad Adeel Nawab contributed to conceptualization. Zara Khan and Ahmad Mehmood contributed to the methodology. Iqra Muneer contributed to writing—original draft preparation. Adnan Asraf contributed to writing—review and editing. Iqra Muneer contributed to visualization. Rao Muhammad Adeel Nawab contributed to supervision.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.