
Abstract
Due to vast digital data collections and paraphrasing tools, researchers have shown growing interest in Cross-lingual Paraphrase Detection (CLPD). Open-access data and tools make paraphrasing easier and detection more challenging. Translation tools further exacerbate the issue by enabling effortless text translation across languages, leading to increased cross-lingual paraphrasing. Most existing CLPD studies focus on European languages, particularly English, while the English-Urdu language pair remains underexplored due to limited standard approaches and benchmark corpora.This study addresses this gap by developing the CLPD Corpus for English-Urdu (CLPD-EU), a gold-standard benchmark corpus at the sentence level. The corpus includes 5,801 sentence pairs, comprising 3,900 paraphrased and 1,901 non-paraphrased instances. Additionally, the study implements classical machine learning methods based on bilingual dictionaries, cross-lingual word embeddings, and transfer learning using sentence transformers.The research further incorporates state-of-the-art Large Language Models (LLMs) such as Mistral and LLaMA, significantly improving detection accuracy. Our proposed Feature Fusion Approach, ‘Comb-ST+BD,’ demonstrates strong performance with an F1 score of 0.739 for the CLPD task. The CLPD-EU corpus will be publicly available to encourage further research in CLPD, especially for under-resourced languages like Urdu.
Introduction
The term cross-lingual paraphrasing (CLP) refers to the process of paraphrasing text(s) in a source language (L1) to create new text(s) in a target language (L2) (Fernando & Stevenson, 2008). With the advent of various free-to-use and open-access digital repositories, such as Wikipedia, 1 and efficient machine translation methods, including Bing Translator 2 and Google Translator, 3 CLP has become a widely adopted norm for multilingual content generation. Cross-lingual paraphrase detection (CLPD) is the task of determining whether two texts—words, phrases, or sentences—are semantically equivalent while being expressed in different languages (Fernando & Stevenson, 2008). This is a core topic in natural language processing (NLP) with applications in information extraction (Shinyama & Sekine, 2003), CLPD, cross-lingual question answering, and cross-lingual information retrieval (Ferrero et al., 2017).
In our study, we further categorize the CLPD task into two main types: Cross-lingual local paraphrase detection (CL-LPD) and cross-lingual global paraphrase detection (CL-GPD) (Sameen et al., 2017). CL-LPD involves the generation of new text(s) in a target language (L2) from source text(s) in a language (L1), while CL-GPD refers to the creation of a new document(s) in language (L2) based on source document(s) in language (L1). A crucial distinction lies between cross-lingual paraphrasing and translation. While translation focuses on conveying the original meaning as closely as possible, often preserving the structure and wording, cross-lingual paraphrasing entails rephrasing the content for clarity, cultural relevance, or stylistic appropriateness in the target language. This process is particularly relevant in journalistic contexts, where information is frequently restructured to suit the preferences and sensibilities of diverse audiences.
Text can be paraphrased either manually or by automated techniques. This results in a further subdivision of the CLPD tasks as (1) artificial cases—where text rewriting tools and automatic translation tools are used to generate new text(s) in different languages, (2) simulated cases—where humans are involved in manually editing source text(s) to generate new text in a new language (L2), and (3) real cases—where journalists manually generate newspaper stories in a new language (L2) from the existing text(s) provided by any news agency in language (L1). This study is focused on developing and providing a benchmark CLPD corpus based on real cases of CLPD for the English-Urdu language pair.
In our research, we address the nuances of CLP by examining real cases where journalists manually generate newspaper stories in a new language (L2) based on existing text(s) from news agencies in a source language (L1). Here, we consider direct (human-made) translations as a form of cross-lingual paraphrase; however, we emphasize that the goal of CLP is to adapt and reformulate content rather than provide a verbatim translation. This adaptability involves taking into account cultural, contextual, and linguistic differences, allowing for a more engaging and relevant presentation of information in the target language.
To support our investigation into CLPD, we focus on developing a benchmark CLPD corpus based on real cases of CLPD for the English-Urdu language pair. This corpus serves as a valuable resource for training and evaluating models aimed at detecting paraphrasing across these two languages, particularly in the context of news reporting, where ethical considerations and the integrity of original content are paramount.
In previous studies, the investigation of CLPD has been accomplished for multiple language pairs, including English-Czech (Víta, 2020), English-German (Pataki, 2012; Yang et al., 2019), English-Spanish (Yang et al., 2019), English-Chinese (Yang et al., 2019), and English-Vietnamese (Nguyen & Dien, 2019). However, the problem of CLPD has not previously been investigated for the English-Urdu language pair, despite the fact that Urdu is an important language spoken widely. Ethnologue’s, 4 statistics show that Urdu is the 10th most extensively spoken and popular language worldwide. It is also Pakistan’s national language, with approximately 175 million speakers, which makes Urdu an important language to study. Another reason for its popularity is the availability of a large amount of Urdu text, books, articles, etc., in digital format through online digital repositories. Urdu is a morphologically rich language with an abundance of disambiguating words (Saeed et al., 2019). The complexity and challenges of the Urdu language have resulted in notably less work on the English-Urdu language pair in CLPD.
Importance of English-Urdu CLPD
CLPD plays a crucial role in addressing semantic similarity and “idea theft” across languages, particularly between English and Urdu. As globalization and digital content sharing become increasingly prevalent, the need for robust mechanisms to monitor and manage content reuse in multilingual contexts has never been more critical.
Ethical and Technical Challenges
Global Communication and Content Reuse: With the proliferation of online content and translation tools, the transfer of ideas across languages has accelerated, increasing the risk of content reuse without appropriate attribution. This raises ethical concerns about intellectual property rights, especially in cases of paraphrasing where direct plagiarism detection systems may fall short (Alzahrani et al., 2012; Potthast et al., 2010). Existing Gaps in Plagiarism Detection: Traditional plagiarism detection tools typically operate within monolingual contexts, making them ineffective for identifying cross-lingual similarities that involve paraphrasing. This limitation is particularly evident in academia, journalism, and digital media, where content is frequently adapted between languages (Franco-Salvador et al., 2016; Nawab et al., 2019). Underrepresented Language Pair: The English-Urdu language pair remains underrepresented in CLPD research despite Urdu being a primary language for millions in South Asia. The unique syntactic and morphological features of Urdu complicate direct translations, necessitating advanced techniques to ensure accurate semantic similarity (Barrón-Cedeño et al., 2013). Cultural Nuances: The complex nature of Urdu often results in words carrying multiple meanings or culturally specific connotations. This further emphasizes the need for sophisticated approaches that go beyond literal translations, enabling accurate paraphrase detection (Cer et al., 2018; Chitkara et al, 2018).
Real-world Applications and Examples
News Reporting: For instance, an English article about a political summit might be paraphrased by an Urdu outlet. The ability to detect such paraphrasing is essential to uphold journalistic integrity and protect original content from uncredited reuse. Implications for Journalism: Effective CLPD tools can assist journalists in monitoring their work across languages, thus preventing unauthorized content reuse and fostering ethical standards within the industry. For example, if an Urdu publication paraphrases key points from an English article, CLPD can identify this and ensure proper attribution. Impact on Academia: Researchers who publish findings in English and subsequently translate them into Urdu must safeguard their work from idea theft. CLPD systems can help academics track their research across languages, ensuring that proper credit is given to original contributions. Social Media and Content Sharing: With the rise of social media, users often share content across languages. CLPD can help recognize instances of paraphrasing on these platforms, promoting respect for intellectual property and encouraging ethical sharing practices. Legal and Ethical Considerations: As intellectual property laws evolve, CLPD can provide vital support in legal disputes involving content reuse across languages, establishing a case based on detected similarities and differences in phrasing.
Objectives and Goals of Developing an English-Urdu CLPD Corpus
Benchmark Dataset: The creation of an English-Urdu CLPD corpus provides a foundational dataset for training and testing CLPD models specific to this language pair, enhancing detection accuracy for similar content (Clough et al., 2002; Franco-Salvador et al., 2016). Improved Detection Techniques: Focusing on real-life news articles allows for the capture of authentic paraphrasing instances, enabling models to move beyond literal translations and account for context and nuance (Chitkara et al, 2018; Nawab et al., 2019). Unique Contribution of Using a News Corpus: News articles serve as a rich resource for studying CLPD due to their inherent nature of reporting similar events across languages. This context-driven approach improves the evaluation of CLPD techniques, making them applicable in real-world scenarios (Barrón-Cedeño et al., 2013). Practical Applications: The resulting CLPD models can be utilized in journalism, academia, and policy settings to monitor cross-lingual content usage, plagiarism, and idea misappropriation, ultimately protecting intellectual property across languages (Chitkara et al, 2018; Nawab et al., 2019).
In order to overcome this research gap, our research mainly focuses on constructing a large benchmark corpus, containing 5,801 (Paraphrasing = 3,900, and Non Paraphrasing = 1,901) CLP pairs. The second contribution is the development and application of bilingual dictionary-based approaches. The third contribution includes developing and applying cross-lingual word embedding-based approaches, state-of-the-art sentence transformers, and feature fusion approaches for CLPD at the sentence level for the English-Urdu language pair, with applications in cross-lingual plagiarism detection, cross-lingual information retrieval, etc. As a fourth and significant contribution, we incorporate advanced large language models (LLMs), Mistral and LLaMA.
We believe this research will be significant both theoretically and practically. The proposed corpus will have implications in (1) promoting the Urdu language (an under-resourced language) in current research, (2) building a strong foundation of knowledge regarding different human edit operations in cross-lingual paraphrasing, (3) directly comparing approaches for CLPD tasks from existing literature relevant to the English-Urdu language pair, and (4) developing, comparing, and evaluating new methodologies that focus on CLPD for the English-Urdu language pair.
Following is how the remaining sections of the paper are structured: Section 2 describes literature review, Section 3 depicts the complete process of corpus generation, Section 4 highlights the approaches for CLPD for English-Urdu Language pair, the experimental setup used in this study is represented in Section 5, Section 6 gives insights about detailed results and analysis, and at the end, the conclusion of the whole study is depicted in Section 7 beside some future directions that can be explored.
Literature Review
Some previously existing corpora and approaches related to CLPD are exhibited below in this section.
Recently, in a study, three large gold-standard cross-lingual text reuse detection (CLTRD) corpora have been developed for the task of CLTRD along with cross-lingual methods for the English-Urdu language pair by Muneer and Nawab (2022). The proposed cross-lingual corpora include CLEU-Lex, CLEU-Syn, and CLEU-Phr at the lexical, syntactical, and phrasal levels for the English-Urdu Language Pair.
The CLEU-Lex contains 66,485 pairs with the source text in English and reused text in Urdu based on simulated cases at the lexical level. The pairs were manually labeled into three classes (wholly derived—WD = 22,236, partially derived—PD = 20,315, non-derived—ND = 23,934) (Muneer & Nawab, 2022). Three different methods including baseline (Bi-lingual dictionary), and proposed (cross-lingual semantic tagger, CL-WE, and CL-ST). The best results were obtained with
The other proposed gold standard bench-mark ’CLEU-Syn’ corpus contains 60,267 pairs with the source text in English and reused text in Urdu based on simulated cases at the syntactical level. The pairs were manually labeled into three classes (WD = 20,007, PD = 16,979, ND = 23,281) (Muneer & Nawab, 2022). Three different methods including baseline (Bi-lingual dictionary), and proposed (Cross-lingual Semantic Tagger, CL-WE, and CL-ST). The best results were obtained with
The third gold standard bench-mark corpus named ‘CLEU-Phr’ contains 60,106 cross-lingual pairs with the source text in English and reused text in Urdu based on simulated cases at the phrasal level. The CLTR pairs were again manually labeled into three classes (WD = 23,862, PD = 15,878, ND = 20,366) (Muneer & Nawab, 2022). Three different methods including baseline (Bi-lingual dictionary), and proposed (Cross-lingual Semantic Tagger, CL-WE, and CL-ST). The best results were obtained with
Muneer and Nawab (2022) introduced a corpus for CLTRD, consisting of 21,669 simulated sentence pairs in English-Urdu. This corpus is annotated into three categories: WD with 7,655 pairs, PD with 6,461 pairs, and ND with 7,553 pairs. The approaches tested include Translation + Monolingual Analysis (T+MA) and Cross-Lingual Sentence Transformers, achieving an
The TREU corpus proposed by Sharjeel (2020) and Sharjeel et al. (2023) comprises real journalism examples with 2,257 document pairs, manually categorized into WD, PD, and ND, achieving the best
Muneer et al. (2019) provided a large corpus focused on English-Urdu, containing 3,235 pairs, achieving the highest
A study emphasizing Translation + Monolingual Analysis (T+ MA) approaches for the CLTRD problem was presented by Muneer and Nawab (2021). The reason behind their contribution was the lack of thorough and in-depth comparisons and explorations on CLTRD. The authors proposed various T+ MA approaches which were applied to a previously developed CLEU corpus. For CLTRD, the authors applied semantic similarity approaches, probabilistic approaches, monolingual word embedding approaches, monolingual sentence transformers approaches, and a combination of these approaches for both binary and ternary classification. The experiments claim that these proposed approaches outperform previously developed approaches for CLEU corpus which were
To sum up, there have been investigations and research done for CLPD and CLTRD for various language pairs having English it such as English-Hindi (Kothwal & Varma, 2013), English-Spanish (Li et al., 2018; Potthast et al., 2011), English-Russian (Bakhteev et al., 2019), English-Czech, (Ceska et al., 2008), English-German (Franco-Salvador et al., 2016) and English-Urdu (Muneer & Nawab, 2022; Muneer et al., 2019; Sharjeel, 2020). Currently available datasets include real, simulated, and artificial cases of CLTRD at sentence, passage, and document levels. From the literature analysis, it is clear that CLPD problem has been studied for different language pairs but it is yet to be investigated explicitly for English-Urdu Language pair. Undoubtedly, research has been done on English-Urdu pair in plagiarism detection and text reuse detection domains but not in the paraphrase detection domain. In the Cross-lingual plagiarism detection, CLUE (Hanif et al., 2015), CLPD-UE-19 (Haneef et al., 2019) are available. Alternatively, in the CLTRD domain, Cross-lingual text reuse corpus (Muneer & Nawab, 2022), CLEU (Muneer et al., 2019) and TREU (Sharjeel, 2020) are available. However, the literature shows that no adequate work is available for English-Urdu language pairs for CLPD task. Therefore, a dire need is to provide an efficient solution for English-Urdu Paraphrase Detection as well as to develop a benchmark corpus. To fulfill this research gap, our research focus is on CLPD for English-Urdu language pair.
Considering the English-Urdu language pair, previous investigations have focused on CLTRD at the sentence, passage, and document levels. However, there has been no prior study supporting CLPD across different levels of rewrite using artificial, simulated, and real cases for the English-Urdu language pair on large benchmark datasets. This study aims to address these limitations by presenting a large sentential cross-lingual benchmark corpus for English-Urdu, comprising 5,801 sentence pairs with real cases of CLPD, including 3,900 paraphrased and 1,901 non-paraphrased pairs.
The secondary contribution is the development and application of bilingual dictionary-based approaches. As a third contribution, we developed and applied cross-lingual word embedding-based methods, advanced sentence transformer-based approaches, and feature fusion techniques for CLPD at the sentence level, with potential applications in cross-lingual information retrieval, cross-lingual plagiarism detection, and more. As a fourth contribution, we integrate advanced LLMs, specifically Mistral and LLaMA, to further elevate detection accuracy, demonstrating the effectiveness of these models in addressing the challenges of English-Urdu CLPD.
Table 1 provides a structured comparison of existing research on CLTRD and CLPD, focusing on corpus type, reuse type, obfuscation level, and applied methods. This format aids in identifying limitations across previous studies and situates our proposed work within these research gaps.
Summary of Literature Review with Limitations and Proposed Study.
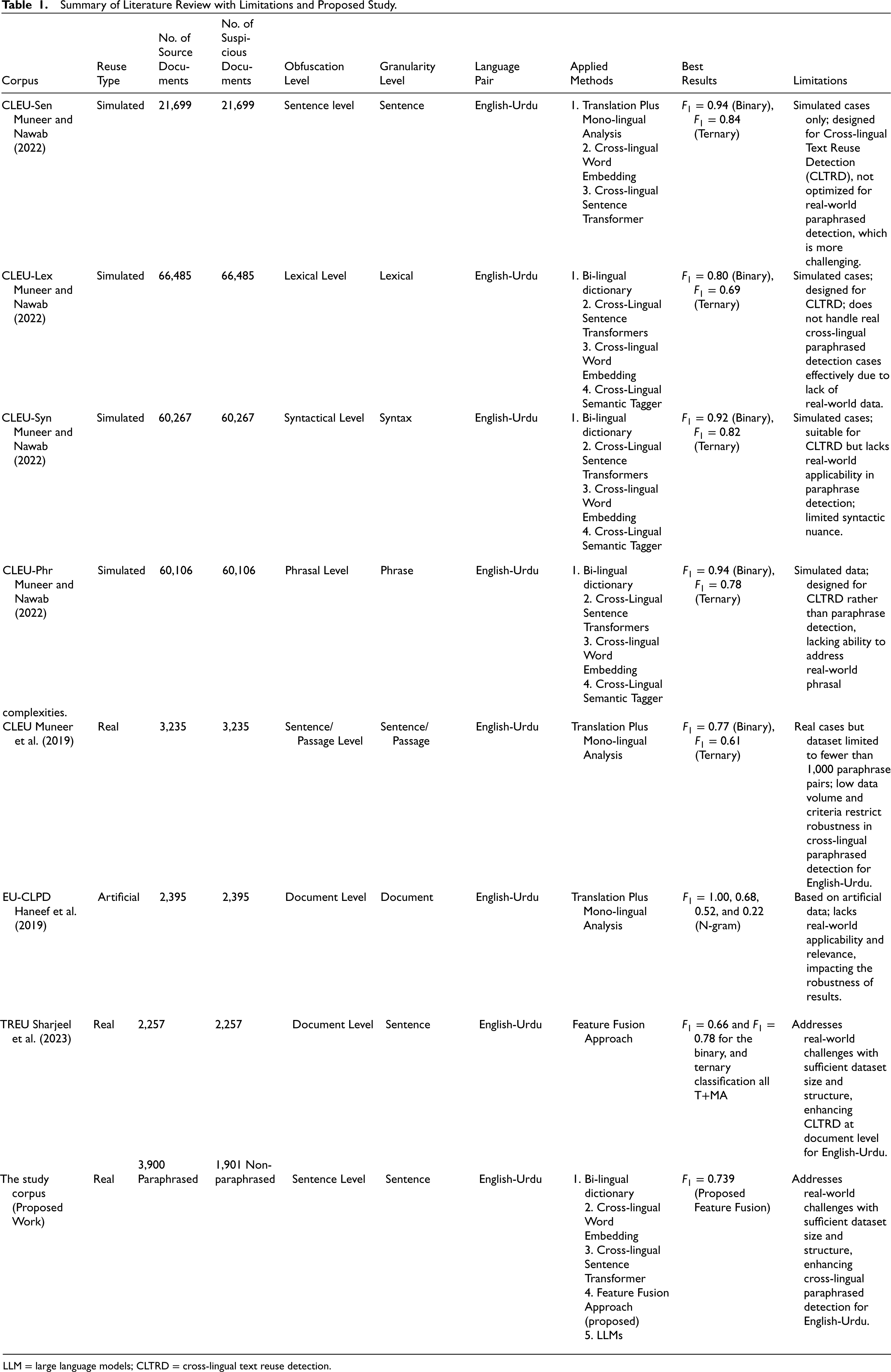
Summary of Literature Review with Limitations and Proposed Study.
LLM = large language models; CLTRD = cross-lingual text reuse detection.
Limitations in Existing Work: Previous datasets, such as CLEU-Lex, CLEU-Syn, and CLEU-Phr (Muneer & Nawab, 2022), are simulated and tailored for CLTRD, limiting their application to real-world CLPD, especially for challenging language pairs like English-Urdu. CLEU-Sen (Muneer & Nawab, 2022), while adaptable for paraphrase detection, is also based on simulated cases, lacking real-world complexity. CLEU (Muneer et al., 2019) remains the only real-case dataset but is limited by a small set of fewer than 1,000 sentence paraphrase pairs, insufficient for developing a comprehensive CLPD system. Additionally, its pair creation criteria do not align fully with CLPD needs, highlighting a significant gap in resources.
Proposed Study Contribution: The proposed study addresses these gaps by introducing a real-world dataset with 3,900 paraphrased and 1,901 non-paraphrased sentence pairs, providing a robust foundation for CLPD. Our feature fusion approach—integrating bilingual dictionary, cross-lingual word embedding, and cross-lingual sentence transformers—enables effective detection of nuanced cross-lingual paraphrasing across sentence structures. Additionally, we leverage state-of-the-art LLMs, Mistral and LLaMA. This combined approach (feature fusion) not only enhances robustness but also specifically addresses limitations in previous studies, positioning our work as a critical advancement for English-Urdu CLPD.
This table highlights the limitations in prior research while clearly delineating how the proposed study meets these needs, establishing a valuable and innovative resource in CLPD.
In this section, we discuss the corpus generation process which includes the data extraction, semi-automatic translation approach (automatic translation, and manual inspection and correction), corpus characteristics, and examples from the proposed CLPD-EU corpus. Below we describe the proposed corpus generation process in detail.
Data Extraction
To develop our proposed CLPD-EU, We selected Microsoft Research Paraphrase Corpus (MRPC) (Dolan & Brockett, 2005) as a base corpus. The reason behind the selection of MRPC is its popularity among researchers and the wide use of MRPC as a benchmark paraphrase corpus for the English language. In the literature, MRPC has been used as a base corpus in different research studies including (Dolan & Brockett, 2005; El Desouki et al., 2019; Lee & Cheah, 2016). MRPC is a widely used sentence-level paraphrase corpus that was harvested automatically from online news sources over a period of 2 years. It is a first of its kind benchmark paraphrase corpus published online with an option to download for free. 5 The main purpose of MRPC development was to provide a broad domain corpus of paraphrase pairs at the sentence level and encourage research in areas related to paraphrasing and sentential synonymy. It consists of 5,801 pairs based on real examples at the sentence level. There are 3,900 paraphrased and 1,901 non-paraphrased pairs in it. The corpus has two classes; 0 shows Non-paraphrased pairs and 1 shows Paraphrased pairs. We have extracted Sentence-1 from the MRPC to generate our CLPD corpus for the English-Urdu language pair (hereafter called CLPD-EU). 6
Semi-automatic Translation Approach
We have combined the strengths of automatic translation and manual translation called the “Semi-automatic Translation Approach” for CLPD-EU corpus generation.
Google Translate was chosen as the initial translation tool due to its accessibility and baseline effectiveness, which is particularly valuable for under-resourced languages like Urdu (Nguyen & Cherry, 2019; Zhang & Baldridge, 2020). Similar semi-automatic approaches, where machine translation is followed by human post-editing, have been effectively employed in various language studies to create accurate and high-quality corpora, especially for languages with limited NLP resources (Guzmán et al., 2019; Vázquez et al., 2019). This method combines automated translation with manual editing by a native Urdu speaker fluent in English, addressing limitations in machine-translated syntax, semantics, and context.
Studies on Spanish-English and Swahili-English have shown that using this combination approach allows for nuanced linguistic corrections, making the final dataset more reliable for research applications (Guzmán et al., 2019; Vázquez et al., 2019). In our study, a linguistically trained graduate student carefully reviewed and corrected each sentence in the translated text, which follows recommended practices in literature for balancing efficiency with translation quality (Koehn & Knowles, 2017; Toral & Way, 2018). This structured and human-guided correction process ensures that our English-Urdu corpus is of high quality and suitable for robust CLPD research.
Automatic Translation
Originally both sentences of the base corpus are in English. To convert the base corpus according to the targeted problem we converted sentence 02 into the Urdu language which ultimately created English-Urdu sentence pairs. For automatic translation of sentence 02, Google Translator 7 was used. 8 The reason for selecting Google Translator for automatic translation is, Google Translate is one of the most common and widely used tools for translation purposes (Haneef et al., 2019; Pataki, 2012). The results of translation from the English language to the Urdu language were best obtained, closer to human translation, and had comparatively fewer mistakes using Google Translate as compared to other translation tools. Figure 1 shows instances after the translation of sentence 02 from English to Urdu using Google Translate.
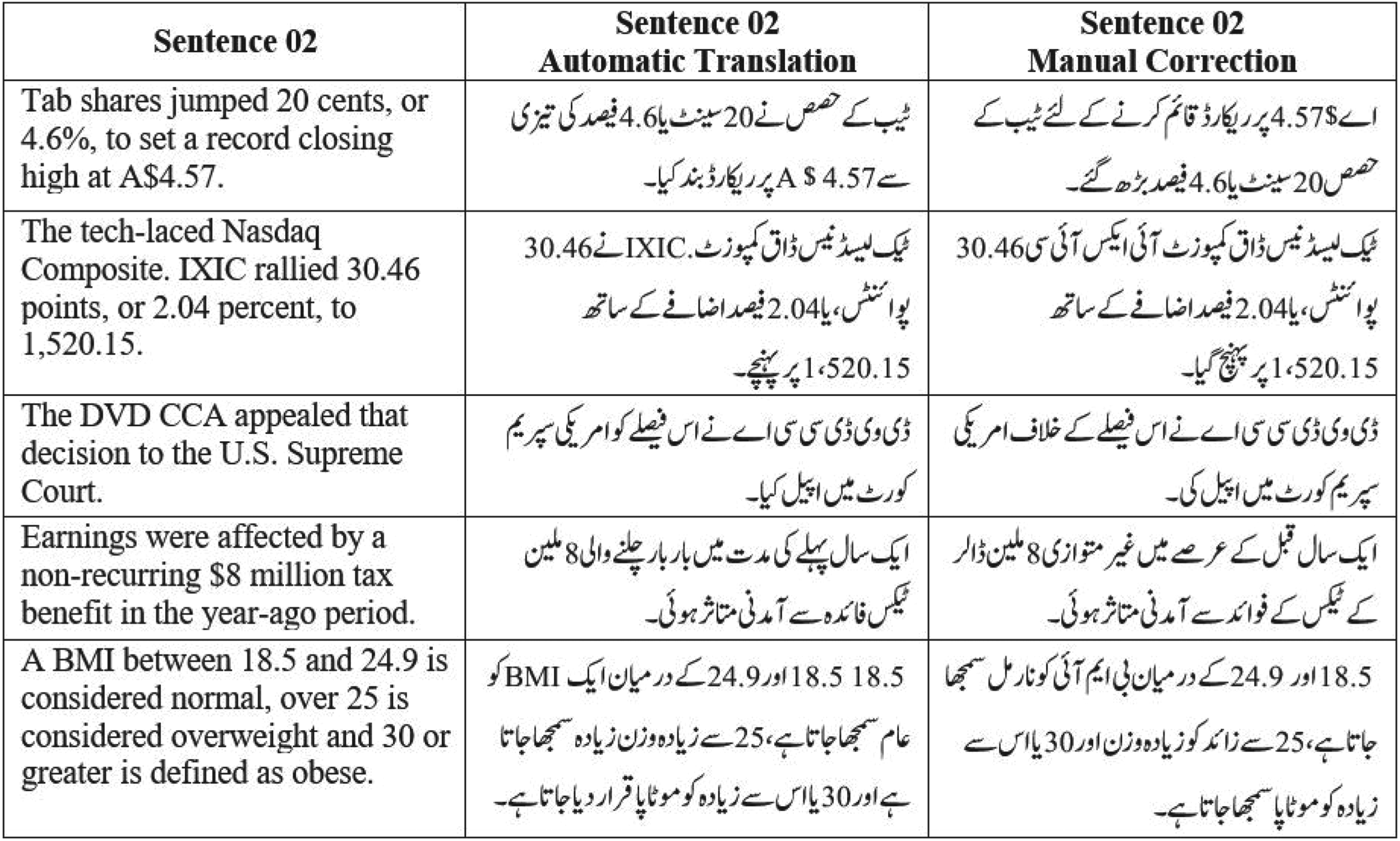
Manual inspection and correction.
The automatically translated text can contain errors, mistakes and noisy texts such as some English words (which are not translated), wrong translation of text into Urdu, wrong context, and useless characters etc. To improve the quality of the corpus, after automatic translation, the translation (Urdu) of the proposed corpus was manually inspected and corrected by a linguistic expert. All the translations were manually inspected by a graduate-level research student who is a native Urdu speaker having good command and expertise in the English language as well. After this manual inspection, the errors/mistakes found in the Urdu translation were corrected manually by the same student to develop the CLPD-EU corpus. 9 This whole process improved the translation and also ensured the quality of the corpus. Developing a benchmark corpora quality is an important factor as the approaches developed and results obtained are highly dependent on the excellence of the corpus. Figure 1 shows the instances with manual correction of sentence 02 translation.
Corpus Standardization
Our proposed corpus CLPD-EU is standardized in CSV file format. The CLPD-EU contains 5,801 sentence pairs for the English-Urdu language pair. The CLPD-EU contains in total 114,740 English and 261,924 Urdu tokens. This shows that the length of Urdu text is larger than English text. More detailed statistics can be found in Table 2. The corpus will be publicly accessible to download for research purposes under a Creative Commons CC-BY-NC-SA license. 10 This proposed corpus can be accessed from the available link for the reviewers 11
Corpus Statistics.

Corpus Statistics.
The examples of paraphrased and non-paraphrased sentence pairs from CLPD-EU are given: Figure 2 shows an example of Paraphrased Sentence Pair and Figure 3 shows an example of Non-Paraphrased Sentence Pair 12

Paraphrased sentence pair example.

Non-paraphrased sentence pair example.
In this section, we have explained our proposed approaches in detail which are applied to our proposed CLPD-EU corpus. To demonstrate how CLPD-EU corpus is utilized for the development of the comparison, analysis, and evaluation of Cross-lingual Paraphrased Detection systems for the English-Urdu language pair, we have applied various approaches including (1) bilingual dictionary based approaches (baseline) (2) Cross-lingual Word Embedding Based Approaches (proposed), (3) Sentence Transformers Based Approaches (proposed), and (4) feature fusion approaches (proposed). We made a detailed comparison between baseline and proposed approaches. According to the information that we have these approaches have not been used earlier for Paraphrase Detection for English-Urdu language pair focusing on real cases. In the following section, we will explain these approaches thoroughly.
Baseline Approaches
Bilingual Dictionary Based Approaches
In a previous study, a bilingual dictionary was used for translating different search queries across languages for cross-language information retrieval (CLIR) (Grefenstette, 1998). The motivation behind using a bilingual dictionary is to translate texts across two languages easily in order to under the texts or language. It is advantageous for the development of cross-lingual translation systems. In addition, there are numerous functional applications of a bilingual dictionary in NLP such as CLPD, cross-lingual semantic text similarity, cross-lingual machine translation, CLTRD, cross-lingual duplicate content detection and cross-lingual questioning answering. To acquire quick and suitable translations, a bilingual dictionary can be very worthwhile.
Considering CLPD, the derived text’s terms as well as phrases can be easily translated back to the source texts for better mapping across languages. In these conditions, it can be helpful for context analysis as well to check whether the translation and terms are contextually the same or not (Daille & Morin, 2008).
We have used a bilingual dictionary presented by Muneer (2016) for our experiment related to bilingual dictionary approach. The dictionary is structured to have English translations of each Urdu term available in it. Taking into consideration sentence 01, and 02 from the proposed CLPD-EU corpus, the following steps were involved in our baseline bilingual dictionary approach. (1) Sentence 01 and sentence 02 both were tokenized. (2) Using a bilingual dictionary, each word in sentence 02 (Urdu) was translated to English in such a way that tokens of both sentences got translated into English. (3) Similarity between sentence 01 and sentence 02 was calculated with two different similarity coefficients: Overlap similarity coefficient 13 (Equation (1)), and Jaccard similarity coefficient (Equation (2)).
We selected the bilingual dictionary-based approach as our baseline for several reasons:
Benchmarking: It serves as a fundamental benchmark for cross-lingual tasks, facilitating comparisons with more advanced methods (Reimers & Gurevych, 2019). Effectiveness for Under-Resourced Languages: This approach is particularly beneficial for languages like Urdu, where resources are limited, as it effectively utilizes available lexical alignments (Nguyen & Cherry, 2019). Inapplicability of Other Methods: Other cross-lingual approaches, such as cross-lingual character n-grams and explicit semantic similarity, are not applicable to Urdu due to language-specific challenges (Zhang & Baldridge, 2020). Historical Use: Previous studies have successfully employed bilingual dictionary methods as benchmarks, validating their relevance (Toral & Way, 2018).
In addition, we applied Cross-Lingual Word Embedding, as utilized in prior English-Urdu studies, to enhance our approach (Haneef et al., 2019). This baseline enables us to effectively demonstrate the benefits of our novel feature fusion techniques.
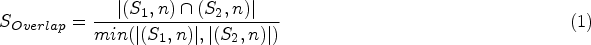

Cross-lingual Word Embedding Based Approaches
A feature extraction approach used to generate feature vectors that are truly the representation of a particular word in numerical form is typically known as Word embedding. The major strengths of this approach lie in providing dense vectors, capturing semantic and syntactic similarity, capturing relation with other words, and expressing distinct aspects of a word. Word embedding is applied in countless tasks of NLP including plagiarism detection (Ferrero et al., 2017; Khorsi et al., 2018), short text similarity (Kenter & De Rijke, 2015), recommendation service (Ozsoy, 2016), word sense disambiguation (Pelevina et al., 2017) and analyzing survey responses and verbatim comments (Akella et al., 2017).
In this approach, two different models were used (1) Google pre-trained word embedding model 14 (Ghannay et al., 2016) for source sentence 01 in English and (2) a pre-trained Urdu word embedding model 15 (Kanwal et al., 2019) for Urdu sentence 02 has been used.
To implement the Cross-lingual Word Embedding approach, the following steps were undertaken. The initial step involved tokenizing both sentences (sentence 01 and sentence 02). The subsequent step involved extracting embedding vectors for each sentence. For sentence 01, we utilized the pre-trained Google Word2Vec model (Ghannay et al., 2016), which generates word vectors with a dimensionality of 300. Specifically, we retrieved the 300 nearest neighbors for each word in sentence 01 to enhance the lexicon before averaging the embeddings. Similarly, for sentence 02, we employed a pre-trained Urdu word embedding model (Kanwal et al., 2019), which also extracted 300 nearest neighbors for each word, facilitating the enrichment of the lexicon prior to embedding aggregation. In the third and last step, the generated word embedding vectors of both sentences were used for similarity computation between sentence 01 and sentence 02 using two methods: (1) Sum of the word embedding vectors method and (2) average of the word embedding vectors method.
Sum of the word embedding vectors was applied to obtain a single source word embedding vector achieved by adding all word embedding vectors of the source words. Likewise, a single derived word embedding vector was obtained by adding all the derived words. Hereafter, we calculated the similarity between the (added) source and derived word embedding vectors with two measures which are Cosine similarity measure (Equation (3)) and the Euclidean distance measure (Equation (4)).
The subsequent method (average of the word embedding vectors) was aimed to obtain a single word embedding vector for sentence 01 and sentence 02 by using average function. By taking average of all word embedding vectors present in sentence 01, a single averaged embedding vector was generated for sentence 01. Similarly, a single averaged embedding vector was generated for sentence 02 by averaging all word embedding vectors present in sentence 02. Eventually, the similarity scores were calculated between the averaged word embedding vectors for both sentences with two measures which are Cosine similarity measure (Equation (3)) (Lahitani et al., 2016) and Euclidean distance measure (Equation (4)) (Vijaymeena & Kavitha, 2016).

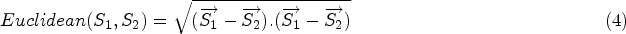
Another prime contribution of this study is the development of sentence transformers-based approaches. We have proposed, developed and applied Sentence Transformers Based Approaches on our proposed CLPD-EU corpus because the approaches based on contextual representations are fairly efficient for many tasks in NLP (Li et al., 2020).
The success of the transformer models has resulted in the development of various pre-trained language representation models. These include Language-Agnostic SEntence Representations (LASER) (Feng et al., 2020), InferSent (Conneau et al., 2017), Universal Sentence Encoder (Cer et al., 2018), BERT (Devlin et al., 2019; Peters et al., 2018), and Roberta (Liu et al., 2019). Recently, another language representation model named Sentence-BERT (SBERT) is introduced by Reimers and Gurevych (2019). SBERT was developed as a variation of the BERT neural network (Devlin et al., 2019). SBERT uses the architecture of siamese neural network and triplet neural networks for generating sentence embeddings that are semantically meaningful. It has been demonstrated to be viable for a variety of problems in NLP domain including paraphrase identification (Fenogenova, 2021; Thakur et al., 2021), semantic textual similarity (Guo et al., 2020), text classification (Minaee et al., 2021), bitext mining (Feng et al., 2020), hierarchical clustering (Naumov et al., 2020), story completion by missing part generation (Mori et al., 2020), Document dating (Massidda, 2020), similar documents identification (Navrozidis & Jansson, 2020), sentimental analysis (Ke et al., 2020), text ranking (Yates et al., 2021), question answering (He et al., 2020), and machine translation (Rei et al., 2020) etc.
In this study we have applied Sentence BERT (SBERT) 16 (Reimers & Gurevych, 2019), which are primarily based on Transformer. The pre-trained Sentence Transformer models have the ability to generate meaningful sentence embedding vectors for more than 100 languages. Furthermore, sentence transformers can be separately trained for different general and specific problems. A few general purpose pre-trained sentence transformers are Bert-large, Roberta-large, Bert-base, Roberta-base, Bert-base-wekipedia-mean-token etc. The general purpose sentence transformers are pre-trained using a combination of two corpora including the Stanford Natural Language Inference (SNLI) corpus 17 (Bowman et al., 2015), and the MultiGenre NLI (MultiNLI) Corpus 18 (Williams et al., 2018). Likewise, a few special purpose pre-trained sentence transformers are paraphrase-distilroberta-base-v1 (for paraphrase detection), stsb-distilroberta-base-v2, stsb-roberta-base-v2 (for semantic textual similarity), nq-distilbert-base-v1 (for information retrieval), quora-distilbert-base (for duplicate questions detection) and LaBSE (for bitext mining) (Reimers & Gurevych, 2020). The special purpose paraphrase detection sentence transformer is pre-trained using 50 Million English paraphrase pairs 19 (Reimers & Gurevych, 2020). The sentence transformers for semantic textual similarity tasks are pre-trained on SNLI+MultiNLI datasets, and semantic textual similarity dataset 20 was used for its fine-tuning. The duplicate questions detection sentence transformer is fined tuned using NLI + semantic textual similarity dataset, and then fine-tune for quora duplicate questions. 21 The information retrieval sentence transformer is pre-trained using information retrieval Google’s Natural questions dataset, 22 a dataset with 100k real queries from Google search, and translated pairs 23 (Feng et al., 2020) datasets, respectively.
For experiments of this study, we have used ten different sentence transformers for feature extraction which are listed below: LaBSE, paraphrase-mpnet-base-v2, paraphrase-multilingual-mpnet-base-v2, distiluse-base-multilingual-cased-v2, paraphrase-multilingual-MiniLM-L12-v2, all-mpnet-base-v2, all-MiniLM-L6-v2, xlm-r-distilroberta-base-paraphrase-v1, xlm-r-100langs-bert-base-nli-stsb-mean-tokens, xlm-r-100langs-bert-base-nli-mean-tokens
The mentioned Sentence Transformers were preferred because of their more reasonable performance as compared to the other transformers on paraphrase detection (Reimers & Gurevych, 2020) and semantic textual similarity (Muneer & Nawab, 2021; Reimers & Gurevych, 2019, 2020) tasks.
In the first step, both sentence 01 and sentence 02 were passed to Sentence Transformer models and to generate sentence embedding vectors. In the second step, we calculated the similarity between the sentence embedding vectors of sentence 01 and sentence 02 texts with cosine similarity measure (Equation (3)).
Feature Fusion Approaches
We have also developed and applied feature fusion approaches on our proposed CLPD-EU corpus for exploring and analyzing the combined result of the mentioned approaches as well as to know the best performing combination of approaches for CLPD. Feature fusion approaches include different combinations such as:
For feature fusion approach one: We have proposed Comb-ST+BD Feature fusion approach for CLPD task, and evaluated it on proposed corpus. We have combined features from 10 Sentence Transformer based Approaches and 2 bilingual dictionary based approaches (12 features in total). For feature fusion approach two: We have proposed Comb-WE+BD Feature fusion approach for CLPD task, and evaluated it on proposed corpus. We have combined 2 features from bilingual dictionary based approaches and 4 cross-lingual word embedding based approaches (6 features in total). For feature fusion approach three, we have proposed Comb-WE+ST Feature fusion approach for CLPD task, and evaluated it on proposed corpus. We have combined 10 features from Sentence Transformers Based approaches and 4 features from cross-lingual word embedding based approaches (14 features in total). For feature fusion approach four, we have proposed Comb-All feature fusion approach for the task of English-Urdu paraphrase detection and evaluated it on proposed CLPD-EU corpus. We have combined all features including combined features from 2 bilingual dictionary based approaches, 4 word embedding based approaches, and 10 sentence transformers based approaches (16 features in total).
LLMs represent the current state-of-the-art in text generation and a wide array of downstream NLP tasks (Yadav et al., 2024). Through simple prompt engineering, LLMs can deliver enhanced performance without the need for resource-intensive fine-tuning (Sun et al., 2024). Although primarily developed for text generation, LLMs have also been effectively utilized for tasks involving semantic similarity and paraphrasing.
For our experiments, we employed the pre-trained Llama-3 model (Dubey et al., 2024), available in two configurations: (1) An 18B parameter version and (2) a 70B parameter version, both provided as pre-trained and instruction-tuned models. Llama-3 operates using an auto-regressive approach based on an optimized transformer architecture. We utilized the quantized 4-bit version of Llama-3 (8B parameters) due to GPU constraints, leveraging the Unsloth AI and Google Colab platforms . 24 For embedding generation, we used a straightforward prompt, “Generate the embeddings of the text input,” to obtain embeddings for Text 01 and Text 02. These embeddings were then employed to calculate the similarity scores between sentence pairs. Notably, we did not apply additional prompt engineering to maintain consistency with the similarity-based approach and k-fold cross-validation employed across all experiments.
Experimental Setup
Corpus
The proposed CLPD-EU corpus is used for performing all the experiments. It contains 5,801 sentence pairs having 3,900 paraphrased and 1,901 non-paraphrased sentence pairs. Sentence 01 is in English language whereas sentence 02 is in Urdu language. Each sentence contains a label either 0 or 1 depicting non-paraphrased and paraphrased sentence pairs respectively.
Approaches
For the task of CLPD, we developed and evaluated several approaches. Our baseline approach employs bilingual dictionary-based techniques, against which we compare three additional methodologies: Cross-lingual word embedding-based approaches, sentence transformer-based approaches, and feature fusion approaches.
The methodologies applied to the proposed CLPD-EU corpus for CLPD are summarized in Table 3. Initially, the bilingual dictionary-based approach was used as a baseline. We then implemented and compared cross-lingual word embedding, sentence transformer, and feature fusion approaches to assess performance.
Approaches Used for CLPD-EU Corpus.
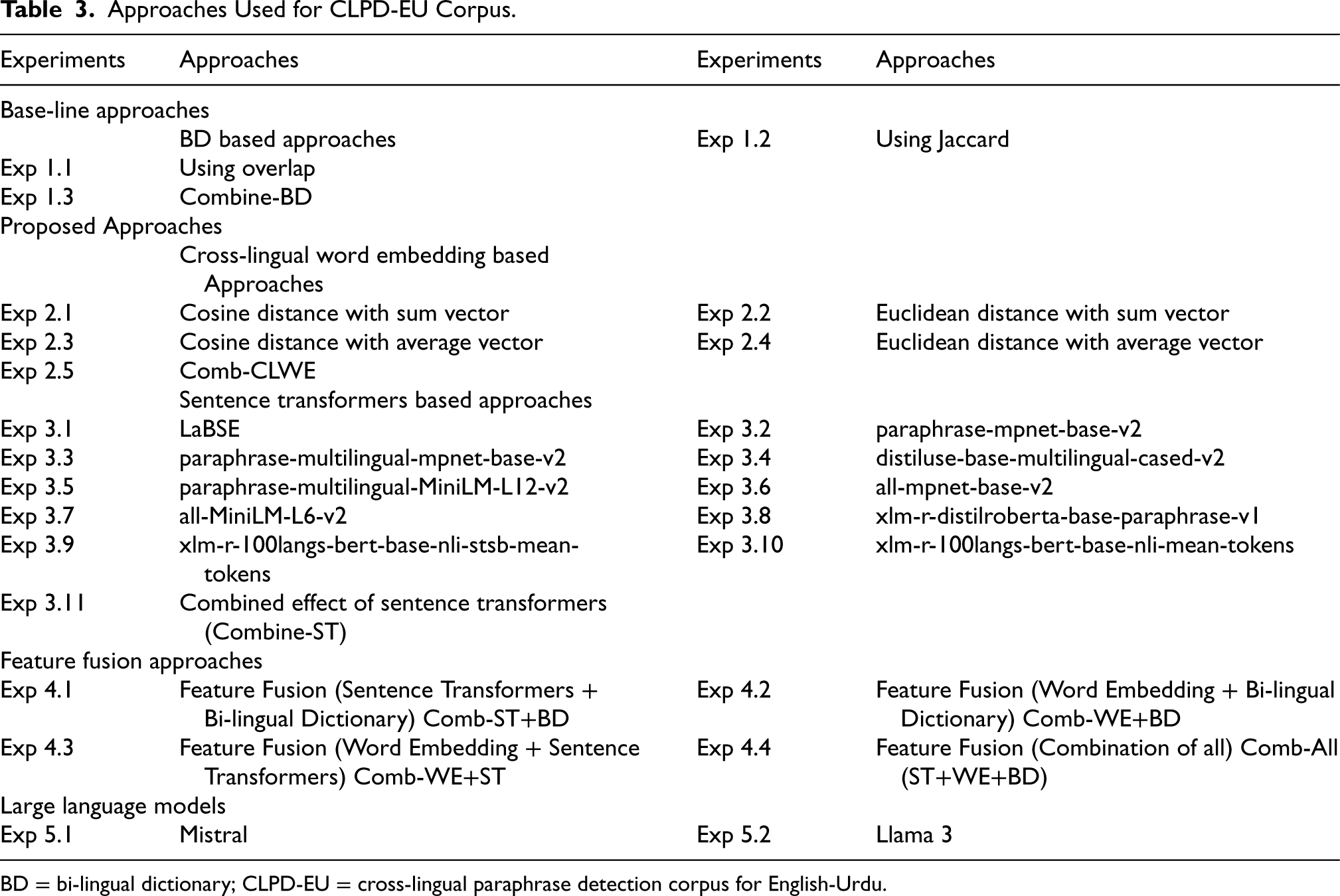
Approaches Used for CLPD-EU Corpus.
BD = bi-lingual dictionary; CLPD-EU = cross-lingual paraphrase detection corpus for English-Urdu.
In addition to these, we introduced experiments with two state-of-the-art LLMs, LLaMA-3 and Mistral. These models were evaluated for embedding generation to calculate sentence similarity scores, thereby extending the diversity and robustness of our approach. Each experiment is labeled with a unique identifier in Table 3 for clarity and reference.
We used 3 evaluation measures: Precision (Equation 5), Recall (Equation 6), and
The proportion of correctly positive predicted cases is generally termed as Precision (P):



The CLPD problem for the English-Urdu language pair was tackled as a supervised text classification task. The binary classification strived to distinguish CLPD at two levels: (1) Paraphrased and (2) Non-Paraphrased.
We used ten different machine learning which includes Gradient Boosting Classifier (GBC), k-NN, Decision Tree (DT), Ada Boost (AB), Support Vector Machine (SVM), Multi-Layer Perception (MLP), Logistic Regression (LG), Random Forest (RF), Gaussian Naive Bayes (GNB), and Bernoulli Naive Bayes (BNB). 25 Furthermore, 10-fold cross-validation was used for better performance analysis of machine learning algorithms. The input that we provided to the machine learning algorithms was obtained from various approaches (Section 4.2) of similarity/distance scores calculation.
We have reported Macro-averaged
Results and Analysis
Table 4 summarizes the best results obtained from various approaches applied to the CLPD task 26 are shown. Given the dataset’s majority baseline of approximately 67%, we focus our analysis on models and approaches that exceed this threshold, as results below this baseline indicate limited predictive utility for the task.
Summarized Results.

Summarized Results.
Feature Fusion Approaches: The Comb-ST+BD approach achieved the highest performance, with an
The integration of these feature types allows the model to leverage both surface-level similarities (through dictionary-based mappings) and deeper context-based similarities (via transformer embeddings). This combination effectively captures subtle variations in paraphrasing and translation, which single-feature approaches often miss, making it especially useful for English-Urdu paraphrase detection, where linguistic and cultural nuances are prominent.
The Comb-All (ST+WE+BD) fusion approach also performed strongly with an
Sentence Transformer-Based Approaches: Among sentence transformer approaches, the Comb-All-ST achieved an
Low Performance of Cross-Lingual Word Embedding Approaches: Results from cross-lingual word embedding approaches, such as Comb-WE, were below the 67% baseline (e.g.,
Low Performance of LLMs: The performance of LLMs, specifically LLaMA and Mistral, fell below the baseline in certain experiments (e.g.,
Summary Approaches exceeding the baseline, including Comb-ST+BD, Comb-All, and transformer models like xlm-r-100langs-bert-base, underscore the importance of feature fusion and advanced multilingual embedding in CLPD. The superior performance of approaches like Comb-ST+BD and Comb-All reflects the effectiveness of integrating complementary features to capture both lexical and contextual similarities.
This study aims at providing corpus and approaches for CLPD for English-Urdu language pair. Urdu is an extensively spoken language worldwide but the work done for the Urdu language in CLPD is notably less. In literature, authors have proposed their studies on the Urdu language in Cross-lingual plagiarism detection and text reuse domains but the literature shows no adequate work on CLPD specifically for English-Urdu language pair. To get over this research gap, we have developed a large benchmark corpus containing 5,801 sentence pairs with 3,900 paraphrased and 1,901 non-paraphrased pairs. We have proposed, developed, applied, and evaluated different approaches including bilingual dictionary based approaches (baseline approach), cross-lingual word embedding based approaches, sentence transformers based approaches, and feature fusion approaches. We have also compared the results from the baseline and our proposed approaches. The results obtained show that Comb-ST+BD achieved the best results for CLPD task as compared to individual bilingual dictionary based approaches, cross-lingual word embedding based approaches, and sentence transformers based approaches.
Considering future research, we plan to explore the proposed approaches for other languages at document level for CLPD task. Moreover, proposed approaches can be further improved with state-of-the-art transfer learning and deep learning approaches to build higher quality and latest paraphrase detection systems. We can also explore custom-trained models for the CLPD task for English-Urdu language pair.
Footnotes
Acknowledgments
Rao Muhammad Adeel Nawab is an Assistant Professor in the Department of Computer Science and IT at COMSATS University Islamabad, Lahore Campus, Punjab, Pakistan. His research interests focus on machine learning and NLP, with a particular emphasis on text processing. Iqra Muneer serves as an Assistant Professor at the University of Engineering and Technology, Lahore (Narowal Campus), Punjab, Pakistan. Her research expertise spans data mining, data modeling, NLP, and machine learning. Adnan Ashraf Saeed is an Assistant Professor in the Department of Computer Science and IT at COMSATS University Islamabad, Lahore Campus, Pakistan. His research interests include NLP and machine learning. Nida Waheed is a research scholar who completed her Master of Science in Computer Science (MSCS) from the Department of Computer Science and IT at COMSATS University Islamabad, Lahore Campus.
Author Contribution
Conceptualization: Muhammad Adeel Nawab Methodology: Iqra Muneer Resources: Nida Waheed Writing—original draft preparation: Iqra Muneer Writing—review and editing: Adnan Asraf Visualization: Iqra Muneer, Adnan Ashraf Supervision: Rao Muhammad Adeel Nawab.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.