
Abstract
Semantic word similarity is a quantitative method of determining how much two terms are contextually identical, which is a considerable challenge for computational linguistics. The research community has examined a range of approaches to address this issue. However, most of these approaches are for a comparatively limited set of languages, especially English. Research on semantic word similarity for South Asian languages, particularly Urdu, is immature. In recent years, transformer-based approaches have proved extremely successful for a range of language processing tasks. The primary aim of this study is to develop and compare a variety of transformer-based approaches to the cross-lingual English–Urdu semantic word similarity task. This study evaluated a publicly available benchmark USWS-19 corpus that comprises 518 word pairs. This study mainly explored four types of transformer-based approaches: (a) cross-lingual sentence transformer-based approaches using the original dataset, (b) cross-lingual sentence transformer-based approaches using the translated dataset (translation plus monolingual analysis [T+MA] approach), (c) the feature fusion approach (mixture of features), and large language models. In addition, this study also explores the word embedding-based approach using the translated dataset (T+MA approach). In total, this study developed 29 transformer-based models, with the highest results (Pearson correlation = 0.788) achieved using a feature fusion approach, that is, Best-Two-SBERT (where SBERT stands for sentence-bidirectional encoder representations from transformers; using T+MA) + BEST Baseline (with Bing translator) + Best cross-lingual SBERT. This approach improved by 7% over previously reported results on the same corpus.
Introduction
In the field of natural language processing (NLP), semantic word similarity (SWS) is a task that quantifies the relationship between pairs of words using a standard metric. Worth’s (2023) SWS is an important task as it has the potential to improve various research areas such as semantic web (Chahal & Singh, 2021), ontology generation (De Maio et al., 2009), word sense disambiguation (Karov & Edelman, 1998), semantic relatedness (Gabrilovich & Markovitch, 2007), information retrieval (Hliaoutakis et al., 2006), entity disambiguation (Zhu & Iglesias, 2018), spam filtering (Li & Huang, 2012), video retrieval (Aytar et al., 2008), and language translation (Duyck & Brysbaert, 2008; Tan et al., 2024).
The researcher explored two types of SWS (Camacho-Collados et al., 2017). These are: (a) monolingual SWS (ML-SWS) and (b) cross-lingual SWS (CL-SWS). ML-SWS deals with determining the semantic relatedness between two words that belong to the same language. In contrast, CL-SWS evaluates the degree of similarity between word pairs of two different languages. The focus of this research work is on CL-SWS for English–Urdu word pairs.
In recent years, significant studies have been conducted on CL-SWS for various language pairs, such as English–Persian (Jokar, 2024), English–Spanish (Tetzloff, 2024), English–Italian (Camacho-Collados et al., 2017), English–Romanian, Spanish–Romanian (Niewiarowski & Plichta, 2023), Spanish–Arabic (Ech-Charfi, 2023; Finkelstein et al., 2001), Chinese–English (Dai & Huang, 2011), and Tibetan–Chinese (Ma et al., 2020). Considering the CL-SWS task for the English–Urdu language pair, we found only one study conducted by Fatima et al. (2021a). In their study, they developed a benchmark corpus called the USWS-19 corpus for CL-SWS for the English–Urdu language pair and applied the translation plus monolingual analysis (T+MA) approach. The best results were obtained using the Bing translator approach with a Pearson correlation score of 0.716. As noted, there is still room for improvement in both results and approaches. To address this gap, the main aim of this study is to carry out a detailed and in-depth comparison of sentence transformer-based approaches with T+MA and without T+MA for CL-SWS for the English–Urdu language pair.
Urdu is the national language of Pakistan and is an important international language with more than 300 million speakers around the world (Ashraf & Khaleel, 2024; Daud et al., 2017). The vocabulary and grammar of Urdu are inherited from Persian, Arabic, and South Asian languages (Rahman, 2004). It is difficult to automatically process Urdu because it is a morphologically rich language. Some of its words may have up to 40 forms (Mehmood, 2021; Naseer & Hussain, 2009). In recent years, a lot of digital data has been generated for the Urdu language through social media websites, news articles, blogs, etc. Despite its wide usage, Urdu is still a poorly resourced language for NLP. Efforts are being made to create Urdu computational resources (Khattak et al., 2021).
This study presents a range of 29 approaches for CL-SWS in the English–Urdu language pair. These approaches include T+MA with sentence transformer methods, cross-lingual sentence transformer-based methods, and five-word embedding-based methods. Each approach was applied with different combinations as feature fusion approaches. This was done to identify the best approach for CL-SWS. Our proposed feature fusion-based model outperformed the baseline and other methods. It achieved a Pearson correlation score of 0.788.
The rest of the paper is organized as follows: Section 2 presents the related work. Section 3 presents the approaches used for the English–Urdu SWS task. Section 4 presents the experimental setup. Section 5 shows the results and their analysis. Finally, Section 6 concludes the study.
Related Work
In the literature, various efforts have been made to develop novel approaches for the CL-SWS task. The following section details some prominent attempts for this task.
Brans and Bloem (2024) explored the CL-SWS task for the Dutch language. They used the SimLex-999 corpus dataset. Similarity judgments were collected from 235 native Dutch speakers. The study tested two transformer-based Dutch language models, Bertje and RobBERT. Bertje showed better alignment (0.42) with human judgments than RobBERT (0.24).
Researchers conducted a useful study on the Turkish–English CL-SWS task (Arslan et al., 2023). The study used three Google translated datasets: SemEval2017 (Camacho-Collados et al., 2017), MC-30 (Miller & Charles, 1991), and SimVerb-3500 (Gerz et al., 2016), to measure word similarity. Researchers utilized three word embedding models. The top scores were 0.62 for SemEval2017, 0.69 for MC-30, and 0.22 for SimVerb-3500, all obtained using a word embedding approach.
In a study by Hassan and Mihalcea (2009), the CL-SWS task was explored for four languages: English, Spanish, Arabic, and Romanian. The experiments used four corpora translated from two English corpora, MC-30 (Miller & Charles, 1991) and WordSim-353 (Finkelstein et al., 2001). Two approaches, Lesk and Cosine, were applied. The best results (in terms of Pearson correlation) achieved were: English–Spanish (0.43), English–Arabic (0.32), English–Romanian (0.50), Spanish–Arabic (0.20), Spanish–Romanian (0.38), and Arabic–Romanian (0.32).
The SemEval-2017 Task 2 (Camacho-Collados et al., 2017) organized an event on the CL-SWS task for four languages: English, Persian (Farsi), Spanish, and Italian. Twelve teams participated in the CL-SWS task (Camacho-Collados et al., 2017). The highest results were achieved by the Luminoso run2 team. 1 This team achieved the highest Pearson correlation values: 0.60 for English–Farsi, 0.77 for English–Italian, 0.62 for Spanish–Farsi, 0.74 for Spanish–Italian, and 0.60 for Italian–Farsi.
In another investigation (Vulic & Moens, 2013), the CL-SWS task is studied for four languages: English, Spanish, Dutch, and Italian. The experiments use three parallel language corpora: the IT-EN-W dataset, the Spanish–English (ES-EN-W) dataset, and the Dutch–English (NL-EN) dataset. The best results are attained by employing multilingual probabilistic topic models. The results are as follows: 0.89 for the IT-EN-W dataset, 0.63 for the ES-EN-W dataset, and 0.51 for the NL-EN dataset.
Researchers also conducted a useful study for the Chinese–English CL-SWS task (Xia et al., 2011). In this study, the experiments use HowNet 2 and a parallel corpus. The top correlation score of 0.80 is obtained using a corpus-based approach.
Similar to the previous one, another study on the Chinese–English CL-SWS task is Dai and Huang (2011). The experiments use attribute and relation-based measures. The best results are obtained using the corpus-based approach, with a top correlation score of 0.90.
In a study (Ma et al., 2020), Tibetan and Chinese CL-SWS are explored. The experiments use the Tibetan–Chinese Wikipedia corpus 3 for training and the MUSE library. 4 The best results are obtained using word embeddings, achieving a 0.67 Spearman’s correlation ratio.
Regarding Urdu, Fatima et al. (2021a) conducted a study on the English–Urdu SWS task. The experiments used the CLSW-19 corpus, which contains 518 word pairs. The best results were obtained using the path length measure, with a Pearson correlation of 0.71.
To summarize, in the context of the English–Urdu CL-SWS task, only one contribution was found (Fatima et al., 2021b). This contribution used path length measures but ignored state-of-the-art approaches such as transformer-based methods. To address this gap, this study conducted a series of experiments using transformers and achieved state-of-the-art results. Sentence transformer-based approaches were not previously explored for CL-SWS for the English–Urdu language pair. We also propose feature fusion approaches with various combinations in this study. All these feature fusion approaches outperformed baseline results. Our proposed model improved the results by 7%. This combination has not been previously reported.
Approaches for CL-SWS
Cross-Lingual Sentence Transformer-Based Approaches
Several language representation models have been introduced in recent years. These include bidirectional encoder representations from transformers (BERT; Devlin et al., 2019; Peters et al., 2018), Universal Sentence Encoder (Cer et al., 2018), InferSent (Conneau et al., 2017), language-agnostic sentence representations (LASER; Feng et al., 2020), and RoBERTa (Liu et al., 2019). Recently, Reimers and Gurevych (2019) introduced the Sentence-BERT (SBERT) model. SBERT is a variant of the BERT neural network. It employs a triplet neural network and a Siamese neural network design to create semantically significant sentence embeddings. The effectiveness of SBERT models has been demonstrated in various NLP applications. These include mining bitext (Feng et al., 2020), paraphrase identification (Thakur et al., 2021; Fenogenova, 2021), document dating (Massidda, 2020), objective-based hierarchical clustering (Naumov et al., 2020; Darányi et al., 2023), text classification (Minaee et al., 2021), generating a missing part for story completion (Mori et al., 2020), identifying similar patent documents (Navrozidis & Jansson, 2020), semantic textual similarity (Guo et al., 2020), sentiment analysis (Ke et al., 2020), text ranking (Yates et al., 2021), question answering (He et al., 2020), and machine translation (Rei et al., 2020), among others.
For this study, we used a Python framework called Sentence Transformer. 5 This framework is based on the SBERT model (Reimers & Gurevych, 2019). The sentence transformer architecture can determine sentence embeddings for more than 100 languages. It also allows for independent training of sentence transformers for general and specific tasks. Pretrained general sentence transformers include BERT-base, BERT-large, BERT-base-Wikipedia-mean-token, RoBERTa-base, and RoBERTa-large. Special sentence transformers include paraphrase-distilroberta-base-v1 (for paraphrase detection), stsb-roberta-base-v2, stsb-distilroberta-base-v2 (for semantic textual similarity), quora-distilbert-base (for duplicate question detection), nq-distilbert-base-v1 (for information retrieval), and language-agnostic BERT sentence embedding (LaBSE; for bitext mining, Reimers & Gurevych, 2020).
The general sentence transformers are trained on a combination of the Stanford Natural Language Inference (SNLI) corpus 6 (Bowman et al., 2015) and the MultiGenre NLI (MultiNLI) corpus 7 (Williams et al., 2018). The specific sentence transformer for paraphrase detection is trained on 50 million English paraphrase pairs. The semantic textual similarity models are trained on SNLI + MultiNLI and fine-tuned on the semantic textual similarity benchmark dataset. 8 The duplicate questions detection model is fine-tuned on NLI+ semantic textual similarity benchmark dataset and then fine-tuned for quora duplicate questions. 9 The information retrieval model is trained on information retrieval from Google’s Natural Questions dataset 10 and a dataset with 100k real queries from Google search. It also uses translated pairs 11 (Feng et al., 2020) datasets.
For this study, we used four general sentence transformers: (a) bert-base-nli, (b) bert-large-nli, 12 (c) roberta-base-nli-mean-tokens, and (d) roberta-large-nli-mean-tokens. 13 These general sentence transformers were chosen because they have all been utilized and evaluated for SWS tasks in previous work using STS12-STS16, STSb, and SICK-R datasets (Reimers & Gurevych, 2019). The roberta-large-nli model has been proven to be the most successful for STS12, STS15, STS16, and on average across all datasets (Reimers & Gurevych, 2019). The performances of these datasets (Reimers & Gurevych, 2019) with Pearson were (74.53, 81.85, 76.82, and 76.68) on STS12, STS15, STS16, and on average, respectively. 14 There is only a minor difference between BERT and RoBERTa’s performance. Bert-large-nli has also shown the best performance for STS13, STS14, and STSb with Pearson scores of 78.46, 74.90, and 79.23, respectively. The performances of roberta-base-nli and bert-base-nli are slightly lower than roberta-large-nli and bert-large-nli. We evaluated the performance of all these models for CL-SWS similar to the STS task in Reimers and Gurevych (2019).
To calculate the similarity between cross-lingual sentence pairs, we need a multilingual sentence embedding model. For this study, we used the pretrained LaBSE. LaBSE extracts 768-dimensional averaged vectors for sentence data from both English and Urdu texts. The corpus includes 17 billion monolingual sentences and 6 billion bilingual translation pairs. We chose this model because it works well for translated pairs in several languages and supports 109 different languages (Feng et al., 2020).
For this experiment, we used the pretrained SBERT (distiluse-base-multilingual-cased-v2). This is a multilingual, distilled version of the Universal Sentence Encoder. Unlike the v1 model, which supports 15 languages, this version covers 50+ languages. It extracts 768-dimensional averaged vectors for both English and Urdu texts (Reimers & Gurevych, 2020). We chose this model because it performs well for information distillation across multiple languages and supports 50 different languages.
We also used another specific model for evaluation. The pretrained SBERT (quora-distilbert-multilingual) was selected. This model is a multilingual version of distilbert-base-nli-stsb-quora-ranking. It is fine-tuned with parallel data for 50+ languages and extracts 768-dimensional averaged vectors of sentences. We chose this model because it supports 50 languages and performs well for pair ranking in multiple languages (Reimers & Gurevych, 2020).
To test performance, we selected a different special model. For this experiment, we used the pretrained SBERT (quora-distilbert-multilingual). This model is a multilingual variant of quora-distilbert-base-multilingual, designed for English and Urdu texts. It was fine-tuned with parallel data for over 50 languages and extracts 768-dimensional averaged vectors of sentences. We chose this model because it effectively detects duplicate questions across multiple languages and supports 50 different languages (Reimers & Gurevych, 2020).
We selected additional special models developed for STS. We used the pretrained SBERT (stsb-xlm-r-multilingual). 15 This model was chosen because it supports 50 languages and works well for cross-lingual semantic textual similarity.
We also selected other models: bert-large-nli-stsb-mean-tokens, bert-base-nli-stsb-mean-tokens, xlm-r-100langs-bert-base-nli-mean-tokens, and xlm-r-100langs-bert-base-nli-stsb-mean-tokens. These models were selected to evaluate all models developed for cross-lingual semantic textual similarity that support multiple languages. Each model has different dimensions and is trained and fine-tuned on various datasets for STS tasks.
The process for determining the similarity between English–Urdu text pairs involves two steps. First, the English word was converted into a sentence embedding vector using an SBERT model. Second, the Urdu word was also transformed into a sentence embedding vector. In the second step, the cosine similarity metric was used to compare the embedding vectors of English–Urdu word pairs (see equation (1)). For scores between 0 and 4, the results were multiplied by 4.
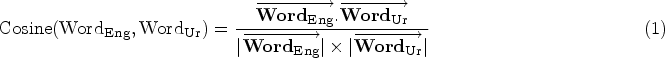
Large language models (LLMs) represent the current state-of-the-art in text generation as well as various downstream NLP tasks (Yadav et al., 2024). Through the application of prompt engineering techniques, LLMs can be optimized to yield improved outcomes, mitigating the necessity for costly fine-tuning processes (Sun et al., 2024). Although LLMs are predominantly designed for text generation, they have also been employed in tasks related to semantic similarity and paraphrasing.
Translation Plus Monolingual Analysis (T+MA)
Sentence Transformer Using T+MA-Based Approach
To carry out the detailed analysis, we used some monolingual and multilingual sentence transformers with a T+MA-based approach with Bing translator. For this study, we used some STS models and other special transformers.
We used all multilingual models with T+MA, which have been explored above on cross-lingual corpus including LaBSE (Feng et al., 2020), distiluse-base-multilingual-cased-v2 (Reimers & Gurevych, 2020), and especially developed for the STS task (stsb-bert-base, stsb-bert-large, stsb-roberta-base, stsb-distilroberta-base-v2, bert-large-nli-stsb-mean-tokens, and xlm-r-large-en-ko-nli-ststb). All these transformers are trained on STSb benchmark datasets and showed reasonable performance (Reimers & Gurevych, 2019). The selection of these models was made to evaluate all models created for both monolingual and multilingual semantic text similarity tasks. All of these models have distinct dimensions and were developed for STS tasks using various datasets.
We selected another special model to assess the performance. For this experiment, we used the pretrained SBERT (allenai-specter 16 ; Reimers & Gurevych, 2020 for English and translated-Urdu word text. The reason for selecting this model is that it works well for finding similar papers in a monolingual setting.
For all transformers, the following steps were used to determine the similarity between English–Urdu word pairings: The Urdu text was first translated into English using Bing translator. In the second step, English and translated-Urdu (in English) word pairs were converted to sentence embedding vectors using the SBERT model. The sentence embedding vectors of English and translated-Urdu word pairs were compared using the cosine similarity measure (see equation 2). For scores between 0 and 4, these results were multiplied by 4.
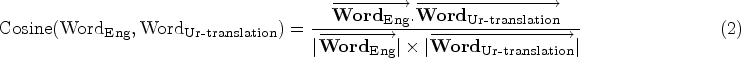
Word embedding approaches have been used in a range of applications including word sense disambiguation (Pelevina et al., 2016), short text similarity (Kenter & De Rijke, 2015), plagiarism detection (Ferrero et al., 2017; Khorsi et al., 2018), analyzing survey responses, and verbatim comments (Healy, 2019). For this study, we used the Google pretrained word embedding model (Ghannay et al., 2016). The word embedding approach was utilized to calculate the similarity between English and translated-Urdu word pairs.
The pretrained word embedding model was given English and translated-Urdu (in English) words in the first step. A pretrained Google word embedding model that was trained on a dataset of 100 billion words from Google News was used to identify 300 nearest neighbors for the English and translated-Urdu words. The following phase involved computing the degree of similarity between word embedding vectors from the English and translated-Urdu word pairs that had been reused using two different methods: (a) the sum of word embedding vectors approach and (b) the average of word embedding vectors approach.
The word embedding vectors of the English word were added together in the sum of the word embedding vectors approach to produce a single English word embedding vector. A single translated-Urdu word embedding vector was created by adding the vectors of translated-Urdu words. Following that, the similarity between the (summed) English and translated-Urdu word embedding vectors was calculated using the cosine similarity measure (2) and the Euclidean distance measure (3) (Vijaymeena & Kavitha, 2016), respectively.
The word embedding vectors of the English word were averaged to create a single English word embedding vector for the average word embedding vectors approach. To create a single translated-Urdu word embedding vector, the vectors of translated-Urdu were averaged. Following that, the similarity between the (averaged) English and translated-Urdu word embedding vectors was calculated using the cosine similarity measure (2) (Lahitani et al., 2016) and the Euclidean distance measure (3) (Vijaymeena & Kavitha, 2016), respectively.

To carry out the detailed analysis, we used different combinations to obtain good performance.
For feature fusion approach 1, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using Bing translator (Fatima et al., 2021b). We averaged both scores.
For feature fusion approach 2, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using Google translator (Fatima et al., 2021b). We averaged both scores.
For feature fusion approach 3, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using both Google translator and Bing translator (Fatima et al., 2021b). We averaged all scores.
For feature fusion approach 4, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using Bing translator (Fatima et al., 2021b). We also combined the best-performing two SBERT transformers using the T+MA approach (LaBSE and distiluse-base-multilingual-cased-v2) and averaged all scores.
For feature fusion approach 5, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using Google translator (Fatima et al., 2021b). We also combined the best-performing two SBERT transformers using the T+MA approach (LaBSE and distiluse-base-multilingual-cased-v2) and averaged all scores.
For feature fusion approach 6, we combined the best-performing crosslingual SBERT transformer (LaBSE) with the best baseline approach using both Bing and Google translators (Fatima et al., 2021b). We also combined the best-performing two SBERT transformers using the T+MA approach (LaBSE and distiluse-base-multilingual-cased-v2) and averaged all scores.
Experimental Setup
This section presents the experimental setup, including the corpus, applied approaches used to measure cross in the English–Urdu language pair, and evaluation measures.
Corpus
This study used the USWS-19 corpus constructed by Fatima et al. (2021a) to evaluate the proposed approaches. The corpus contains 518 word pairs. The corpus is created for the crosslingual English–Urdu SWS task. To construct the USWS-19 corpus, source data was obtained from the SemEval-500 corpus. 17 Two popular translators (Google and Bing) were used to translate the English word pairs of the source corpus (SemEval-500 corpus) into Urdu word pairs (USWS-19 corpus).
Following the standard practice of research, each word pair was annotated by 12 native Urdu speakers on a scale of 0–4. A score of 0 represents dissimilar and 4 represents very similar. The annotators’ qualifications varied from graduate students to doctorate professors. Furthermore, the corpus contains 676 nouns, 11 verbs, 35 adjectives, one adverb, 185 multiword expressions, and 128 named entities. The corpus is freely and publicly available for research purposes under the Creative Commons License. 18
Approaches
A range of transformer-based approaches was applied to the corpus. Table 1 shows all approaches that were applied to the CL-SWS corpus. Figure 1 shows the proposed model on which we obtained the highest results. This is the feature fusion approach. The proposed model is based on the combination of different features coming from different approaches. It can be noted from the figure (Figure 1) that to achieve the top results, the model combined the features from five types of approaches. These approaches include (a) cross-lingual LaBSE transformer, (b) LaBSE transformer with T+MA, (c) best baseline approach with Bing translation, (d) Universal Sentence Encoder transformer with T+MA, and (e) LLMs).
Applied Approaches.

Applied Approaches.
Note. SBERT = sentence-bidirectional encoder representations from transformers; T+MA = translation plus monolingual analysis.
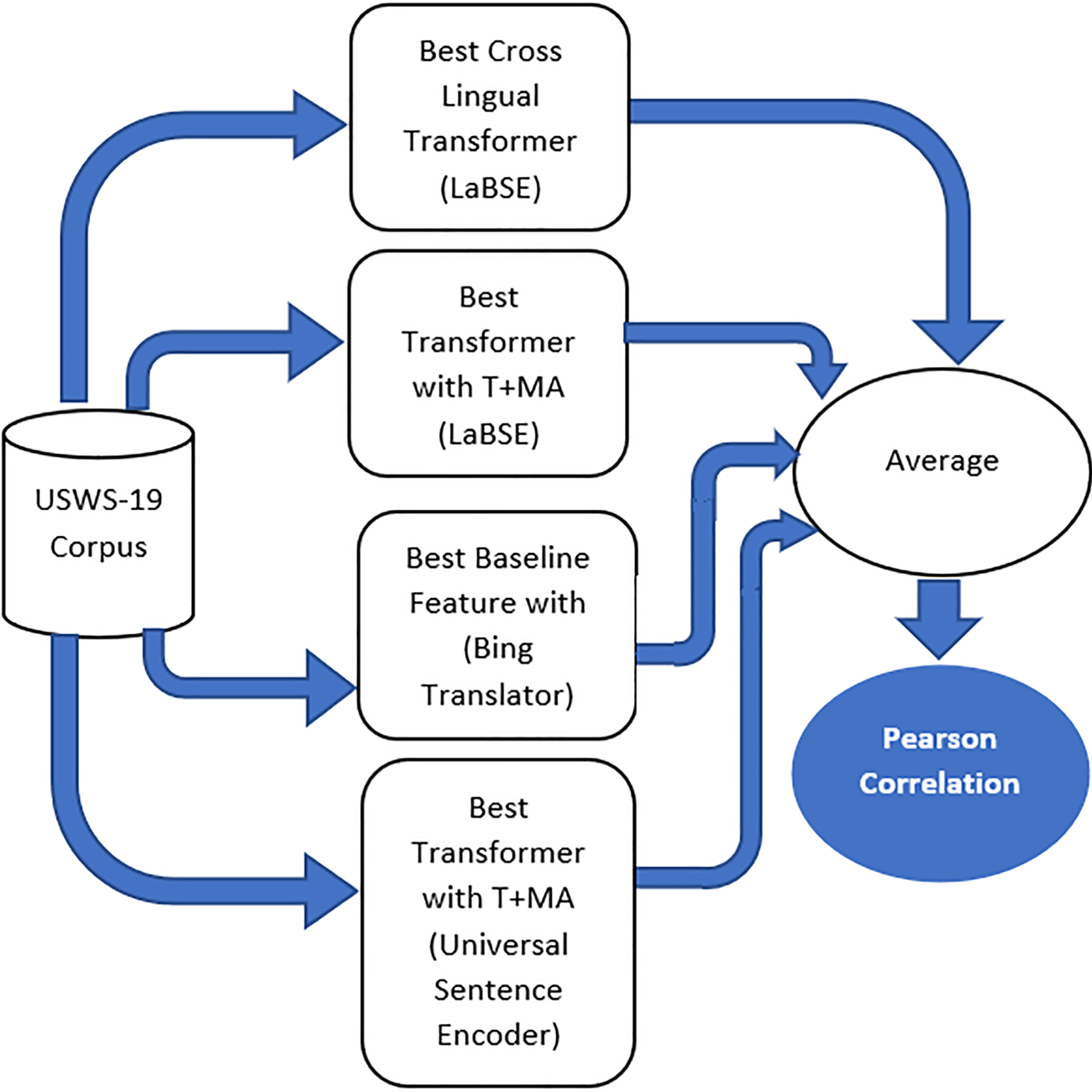
Proposed model.
The evaluation of proposed approaches was carried out using Pearson correlation (Camacho-Collados et al., 2017). The formula to compute Pearson correlation is given in equation (4).

Table 2 shows Pearson scores obtained on the USWS-19 corpus using various transformer-based approaches for CL-SWS for the English–Urdu pair. In this table, the first two rows represent the baseline results achieved using two translators, that is, Google and Bing (Fatima et al., 2021a). The results show that Bing translator exhibits more promising results.
Comparison of Proposed Results With Baseline Results.

Comparison of Proposed Results With Baseline Results.
Note. SBERT = sentence-bidirectional encoder representations from transformers; T+MA = translation plus monolingual analysis.
The highest performance was achieved in Experiment 3.4, yielding a Pearson correlation of 0.788. This experiment employed the “Best-Two-SBERT (using T+MA) + BEST Baseline (with Bing translator) + Best Cross-lingual SBERT” methodology. These results surpass the previously reported state-of-the-art baseline on this corpus, which had a Pearson correlation of 0.71. This significant improvement demonstrates that our proposed approach outperforms the current state-of-the-art, making it more effective for CL-SWS tasks involving the English–Urdu language pair on this corpus. The findings suggest that this combination is particularly advantageous for detecting CL-SWS in the English–Urdu language pair.
Among the cross-lingual sentence transformer-based approaches, the best performance was achieved in Experiment 1.2, which utilized the “LaBSE” transformer approach, resulting in a Pearson correlation of 0.736. This outcome surpasses the baseline results. The superior performance of the LaBSE model can be attributed to its support for 109 languages, enabling it to effectively handle translated pairs across multiple languages. Consequently, it extracts high-quality feature vectors for cross-lingual pairs. These findings suggest that this approach is more effective for detecting CL-SWS compared to individual SBERT models and baseline methods.
In word embedding-based approaches, the highest performance was achieved in Experiment 4.5, which utilized the “Average-of-all-WE features” method, yielding a Pearson correlation of 0.452. However, this result is significantly lower than the baseline performance. The suboptimal outcome is attributed to the extraction of low-quality feature vectors for cross-lingual word pairs from the USWS-19 corpus, which hinders effectiveness in cross-lingual semantic similarity tasks. These findings indicate that word embedding-based methods are less effective for detecting CL-SWS compared to other approaches.
XLM-RoBERTa and Llama exhibit lower performance in SWS tasks compared to SBERT transformers and T+MA approaches due to their general-purpose design and training. XLM-RoBERTa, while broad in multilingual coverage, is not specifically fine-tuned for semantic similarity, which limits its ability to capture nuanced relationships. In contrast, SBERT transformers are explicitly optimized for generating high-quality embeddings for semantic similarity, and T+MA methods leverage precise translation and monolingual embeddings for enhanced semantic matching. Similarly, Llama, optimized for text generation, does not align with the specific requirements of semantic similarity tasks. Its embeddings are less effective for this purpose compared to those produced by models that are fine-tuned or adapted specifically for similarity detection.
Within the T+MA-based approaches using sentence transformers, LaBSE demonstrated strong performance with translated data, achieving a Pearson correlation of 0.721. This performance surpasses that of other transformers, including monolingual models specifically designed for English. While these results are marginally better than the baseline, they remain slightly lower than the best-performing crosslingual sentence transformer-based approach.
In the feature fusion approaches, all combinations outperformed the baseline results:
“Experiment 3.1” combined the best-performing cross-lingual sentence transformer with the baseline feature using Bing translator, resulting in a Pearson correlation of 0.770. This is higher than both the baseline and individual transformer results but lower than the best-performing results. This indicates that this feature fusion approach is effective for CL-SWS detection. “Experiment 3.2” replaced Bing translator with Google translator in the same fusion approach, yielding a Pearson correlation of 0.761. Although this still outperforms the baseline and individual transformers, it falls short of the best results. The performance decline may be due to the lower translation quality of Google translator. “Experiment 3.3” added Google translator to the best-performing cross-lingual sentence transformer and Bing translator combination, but the Pearson correlation remained at 0.761. This suggests that adding Google translator did not enhance performance, indicating that this combination is less effective for CL-SWS detection. “Experiment 3.5” combined the best cross-lingual sentence transformer, Google translator, and the two best-performing T+MA-based sentence transformer features, achieving a Pearson correlation of 0.770. While this surpasses the baseline and individual approaches, it is still lower than the best results. The slightly lower performance compared to Experiment 3.4 may be due to using Google translator instead of Bing translator, highlighting the impact of translation quality. However, incorporating the two top T+MA-based features was beneficial. “Experiment 3.6” combined the best cross-lingual sentence transformer, both Bing and Google translators, and the two best T+MA-based features, achieving a Pearson correlation of 0.777. Although this result exceeds the baseline and other fusion approaches, it remains slightly below the best performance. This combination demonstrates that feature fusion approaches can effectively enhance CL-SWS detection.
The selection of sentence transformer-based approaches is motivated by their promising performance in related tasks, such as text reuse detection (akin to CL-SWS; Muneer & Nawab, 2021, 2022; Muneer et al., 2023) and paraphrase detection (Reimers & Gurevych, 2019, 2020). Top-performing models such as LaBSE and the Universal Sentence Transformer (distiluse-base-multilingual-cased-v2) have demonstrated their capability to generate high-quality feature vectors for crosslingual pairs. To optimize performance, we averaged the outputs of these top-performing transformers with the best baseline feature (using Bing translator), which has proven effective in enhancing results.
To conclude, the main findings obtained after our extensive experimentation are as follows: First, the best performance is shown by the combination of two best-performing transformers with T+MA. It is also shown by one best-performing cross-lingual sentence transformer and the best baseline feature (using Bing translator). Second, this shows that different SBERT frameworks affect the performance of CL-SWS. Third, the LaBSE framework extracts more qualitative feature vectors for CL-SWS for the English–Urdu language pair. Fourth, the low performance of the T+MA-based transformer compared to the crosslingual sentence transformer-based approach shows that the translation quality is still low.
This paper presents a range of transformer-based approaches for CL-SWS for the English–Urdu language pair. This study reports a comparison of transformer-based approaches and feature fusion approaches to CL-SWS for the English–Urdu word pairs. For the SWS task, the USWS-19 corpus was used. Results demonstrate that our proposed model based on feature fusion approaches outperforms previously reported approaches. In the future, we plan to explore word embeddings. We also plan to explore knowledge graphs and stacked auto-encoder approaches for the CL-SWS task to further improve the results.
Footnotes
Author Contributions
Rao Muhammad Adeel Nawab contributed to Conceptualization. Methodology: Iqra Muneer contributed to the methodology. Iqra Muneer contributed to writing—original draft preparation. Ali Saeed contributed to writing—review and editing. Iqra Muneer and Ali Saeed contributed to the visualization. Rao Muhammad Adeel Nawab contributed to supervision.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.