
Abstract
In recent years, the wide application of weakly supervised temporal action localization (WTAL) technology has accelerated the efficiency of video analysis. However, this domain continues to confront numerous challenges, especially due to the lack of precise temporal annotations. Consequently, this technique becomes highly susceptible to contextual background noise and overly reliant on prominent action segments, leading to less-than-ideal action localization. To alleviate this problem, we propose the contrastive learning-based action salience network (CLASNet), comprising two pivotal modules: feature contrast separation module (FCSM) and boundary refinement module (BRM). FCSM utilizes a contrastive learning approach to effectively separate action features from background features, thereby enhancing the discriminability of features. Concurrently, BRM introduces boundary refinement loss to rectify the temporal boundaries of actions, thereby further elevating the precision of temporal localization. The collaborative functioning of these two key modules effectively resolves the ambiguity issues in temporal action localization under weak supervision, markedly enhancing localization accuracy. Furthermore, CLASNet is versatile and can be integrated into different WTAL frameworks, achieving enhanced localization performance while preserving the original end-to-end training manner. Utilizing three large-scale benchmark action localization datasets, THUMOS14, ActivityNet v1.2, and ActivityNet v1.3, we embed CLASNet into various cutting-edge weakly supervised temporal action localization methods, such as CO2-Net, DELU, and ACRNet, for empirical substantiation. The experimental outcomes reveal that CLASNet significantly enhances the efficacy of these methods in action localization, offering novel perspectives for the advancement of temporal action localization technology.
Keywords
Introduction
With the continuous growth of online video creators and users, video content output has reached an unprecedented level, bringing video understanding to the forefront of computer vision research. However, the visibility and discriminability of actions in videos are influenced by their diverse characteristics, including type, duration, and frequency. Therefore, the task of temporal action localization is critical, which can accurately identify essential action information from complex videos, thereby enhancing the effectiveness and efficiency of video understanding. This task also has broad potential applications, which can bring convenience to various domains, including intelligent video analysis (Guo et al., 2021), surveillance (Vishwakarma and Agrawal, 2013), video summarization (Habib et al., 2021), video retrieval (Lin et al., 2022), and driving behavior detection (Gabeur et al., 2020).
Existing methods for temporal action localization can be classified into two categories based on the type of supervision: fully supervised temporal action localization and weakly supervised temporal action localization (WTAL). The majority of current research methods focus on the fully supervised setting, where precise frame-level annotations are available, enabling these methods to achieve high localization accuracy. However, video annotation is a time-consuming, laborious, and error-prone process, and the consistency and quality of the annotations are hard to guarantee. Consequently, the weakly supervised setting has recently garnered more attention from researchers. This task aims to recognize the categories of action instances (e.g., running, swimming, and high jump) in videos and precisely locate the temporal boundaries of each action, given only video-level labels without any additional information (Baraka and Mohd Noor, 2022).
Currently, researchers have conducted comprehensive investigations into the task of weakly supervised temporal action localization, proposing two categories of approaches: attention mechanism-based methods (Dou and Hu, 2023; He et al., 2022; Huang et al., 2022; Lee et al., 2022) and foreground–background modeling-based methods (Lee et al., 2021; Li et al., 2022; Moniruzzaman and Yin, 2023; Yang et al., 2021). The attention mechanism-based action localization method leverages the attention mechanism to identify the segments with a high probability of containing actions, thereby enabling the model to concentrate more effectively on the keyframes in the video and enhance the precision of action localization. However, this method is not without its limitations, as each video usually consists of multiple action segments, and with only video-level annotations, the model is prone to concentrate on the most distinctive action segments, or mistakenly attend to background segments. To deal with the complex background, researchers proposed foreground–background modeling-based action localization methods, which improve the robustness and accuracy of action localization by differentiating the action foreground from the irrelevant background in the video. However, this method is still plagued by underlocalization or overlocalization of ambiguous segments. There is an urgent need for more efficacious weakly supervised learning methods and models to enhance the discriminability of action features, the precision of action boundaries, and pave the way for broader applications.
To mitigate the aforementioned challenges, we propose the contrastive learning-based action salience network (CLASNet). Drawing inspiration from the successful deployment of contrast learning in weakly supervised semantic segmentation, we design a novel feature contrast separation module (FCSM). This module encompasses a time attention weight generation mechanism and a contrast separation mechanism. The former leverages temporal convolution network (TCN) to expand the receptive field of the model, enabling it to obtain the temporal information of the entire action instance and eliminate the temporal discontinuity caused by the short duration of the segments. It also captures the temporal dependencies among different segments within the receptive field. The latter utilizes the attention weights to separate the features and determine more reliable foreground regions. However, contrast learning may introduce noise separation of the features, which may degrade the localization performance of the model. Therefore, we introduce a boundary refinement module (BRM) to achieve more precise boundary localization. This module inputs the attention scores from the feature separation module and the temporal class activation sequence (TCAS) from the WTAL model. It employs a boundary refinement loss to enhance the alignment between the TCAS and the attention scores, which enables the correction of the temporal boundaries and the achievement of precise temporal localization. Through collaborative functioning, two modules effectively resolve the ambiguity issues in temporal action localization under weak supervision and enhance localization accuracy. Furthermore, the proposed CLASNet is a plug-and-play module that can be incorporated with any existing WTAL method, thereby boosting the action localization performance of the methods and achieving more accurate localization results.
The rest of the paper is organized as follows. Section 2 discusses related work about weakly supervised temporal action localization. Section 3 describes the proposed method in detail, including the conceptual framework for model construction, the basic modules, and the training strategies. Experimental results and discussions are presented in Section 4. Finally, we conclude the paper in Section 5.
Related Works
In recent years, weakly supervised temporal action localization tasks have gained increasing attention due to their advantages of low annotation cost, diverse action categories, and efficient localization. Researchers have actively explored various innovative methods to address the challenges in this domain. Some studies leverage convolutional neural network to extract video features and then utilize recurrent neural network to capture temporal features for action localization. However, these methods are limited in handling long-duration actions and consuming computational resources, thereby hindering the achievement of accurate action localization in videos. In contrast, humans can usually focus on the segments of interest when watching videos and thus capture action details more precisely. Inspired by this, researchers have incorporated attention mechanisms into weakly supervised temporal action localization. HAM-Net (Jalayer et al., 2022) employs a hybrid attention mechanism that captures the most discriminative frames by considering their relationships. CO2-Net (Hong et al., 2021) introduces a cross-modal consistency network that uses a cross-modal attention mechanism to readjust features by exploiting the global information of the primary modality and the cross-modal local information of the auxiliary modality to reduce the information redundancy irrelevant to the tasks. However, these methods often require additional regularization terms to ensure the distinctiveness or complementarity of scores across branches or attention mechanisms, making it challenging to determine an appropriate number of branches or attention for all action categories. To address this issue, researchers attempt to use intervideo information to guide attention allocation. ASM-Loc (He et al., 2022) uses intra- and intersegment attention to model action dynamics and capture temporal dependencies. RSPK (Huang et al., 2022) adopts a framework that effectively summarizes and propagates snippet-level knowledge across videos, which utilizes the expectation–maximization attention to process and capture the critical semantics of each video as representative segments. However, due to the complex background in the videos, the model tends to focus on the most distinctive action snippets or mistakenly focus on the background snippets.
To overcome the interference of complex backgrounds in videos, researchers have proposed foreground–background modeling-based methods. However, foreground–background separation is still extremely challenging due to the lack of video-level labels for background classes. Lee et al. (2021) apply uncertainty modeling to model background frames and separate action frames from them. BaS-Net (Kim and Cho, 2022) robustly separates the context (such as backgrounds with similar actions) by establishing a reliable background probability, which enables more accurate localization of action time intervals. Moreover, Chen et al. (2023) propose a cascade evidential learning framework at an evidence level, which combines multiscale temporal context and knowledge-guided prototype information to gradually collect cascaded and enhanced evidence for separating known actions, unknown actions, and backgrounds. However, these methods might neglect subactions with low identifiability or misclassify background segments resembling actions as actual actions, leading to underlocalization or overlocalization. Some researchers attempt to use contrastive learning to achieve foreground–background separation and enhance the discriminability of features. Tang et al. (2023) propose an overconfidence suppression strategy to mitigate the influence of overconfident pseudo-labels. Then, a simplified contrastive learning method be used to fine-tune the feature representation and increase the separation of foreground and background segments. Li et al. (2022) propose a novel de-noising cross-video contrastive algorithm, which aims to reduce the impact of segmentation errors on positive/negative sample pairs. Furthermore, CoLA (Zhang et al., 2021) exploits contrastive learning to perceive accurate temporal boundaries and avoid the interruption of time intervals, achieving classification and localization of ambiguous segments in videos. However, the absence of precise time-stamped labels might introduce noise from foreground and background segments. We propose the CLASNet. First, through the feature contrastive separation module, we utilize TCN (Bai et al., 2018) to capture the temporal information in the video, thereby guiding the multihead attention (MHA) to generate reliable attention weights. Then, we achieve the foreground–background separation by the contrastive loss, thus increasing the feature discriminability. Meanwhile, we introduce a BRM to solve the noise separation problem caused by contrastive learning, obtain fine-grained boundary information, and achieve accurate action localization. The BRM is a little similar to fine-grained temporal contrastive learning (Gao et al., 2022), which focuses on optimizing the distinction between actions and backgrounds through dynamic programming and contrastive learning, as well as extracting the longest common subsequence in videos. BRM focuses more on improving the precision of action boundaries rather than overall temporal contrastive learning. It should be emphasized that prior work designs fixed WTAL networks, that is, the overall framework process, which cannot be flexibly integrated as a plugin into other models. However, our CLASNet is a versatile module capable of improving various WTAL frameworks. Unlike existing studies focusing on enhancing localization performance based on preextracted segment-level features, this study emphasizes the general benefits derived from different WTAL frameworks through effective foreground–background separation.
Methodology
Structure Overview
The temporal localization of actions in unedited videos necessitates the application of the multiinstance paradigm (Maron and Lozano-Pérez, 1997). This paradigm views the entire video as a set of foreground action frames and background non-action frames, extracts the TCAS through the classifier, and optimizes it based on the provided video-level label to obtain accurate localization results. However, this process faces several challenges, which can be summarized in two aspects: (a) The attention mechanism-based action localization method tends to prioritize the most discriminative action segments or erroneously emphasize background segments. (b) While the foreground–background modeling-based action localization method enhances the robustness and accuracy of action localization, it encounters issues of underlocalization or overlocalization of ambiguous segments.
To tackle these challenges, we propose the CLASNet, comprising two modules: the FCSM and the BRM. Firstly, in the FCSM, we utilize the temporal attention weights generate mechanism and the contrast separation method. The former captures complete temporal information of action instances and produces reliable attention weights, while the latter enhances feature identifiability by effectively separating action features from background features. Secondly, the BRM expands the similarity between the TCAS output by the WTAL model and the attention score obtained by the feature separation module through a boundary refinement loss. This correction of temporal boundaries addresses issues caused by ambiguous model localization resulting from feature noise separation during contrast separation, ultimately achieving precise temporal localization.
By seamlessly integrating these two modules, we implement an end-to-end weakly supervised temporal action localization method that tackles ambiguity in weakly supervised environments. It achieves more precise localization performance by embedding different WTAL frameworks. Figure 1 illustrates the overall framework of the proposed CLASNet.
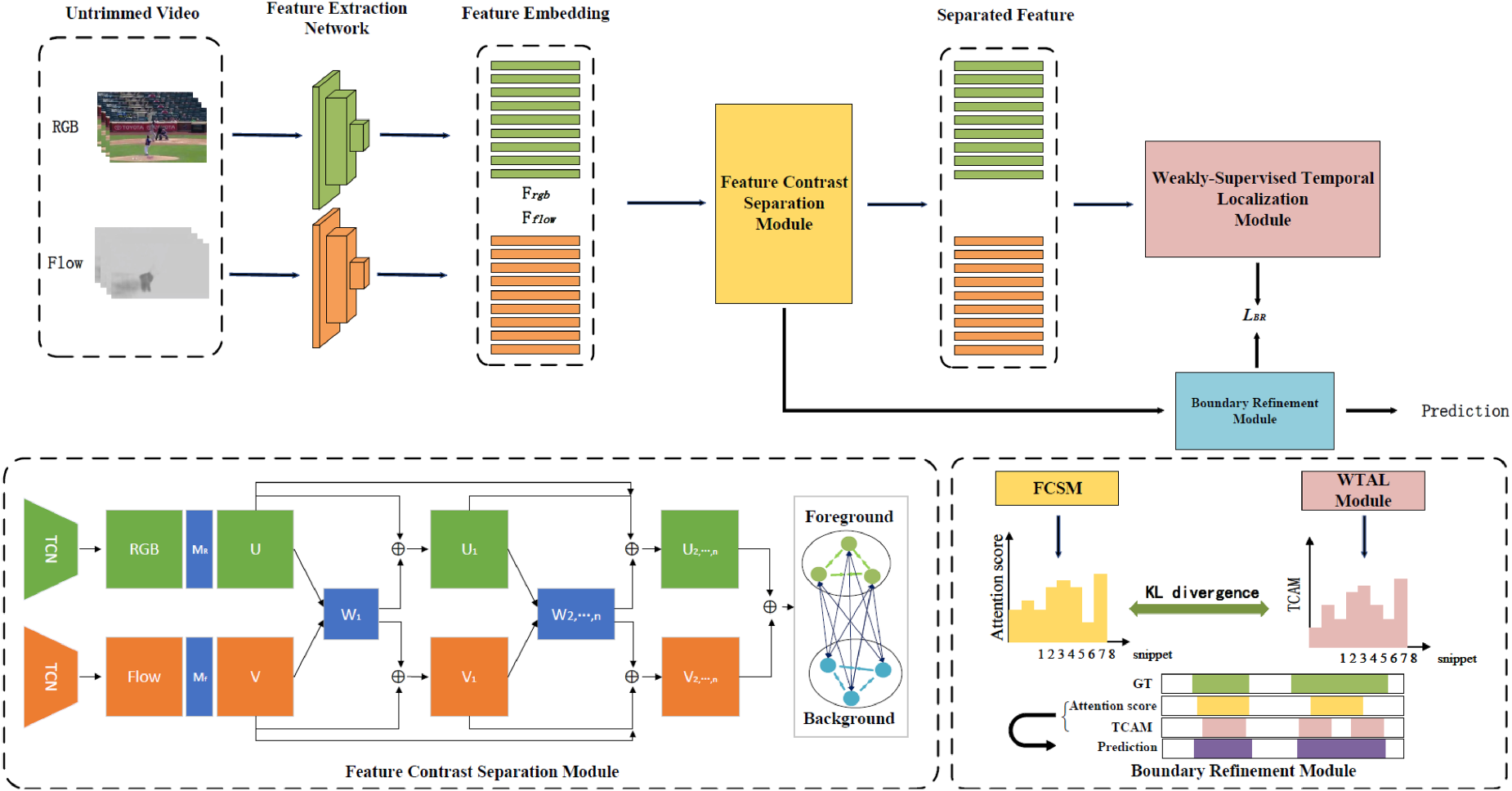
Overall framework of the proposed CLASNet. Note. CLASNet = contrastive learning-based action salience network.
TCAS or attention score inaccuracy in video action recognition primarily arises from the insufficient discriminability of segment-level features. To mitigate this issue, we propose a FCSM that captures the temporal information of the complete action instance within the video feature and generates reliable cross-modal attention weights through a mechanism for generating temporal attention weights and employing a contrast separation strategy. Subsequently, based on these attention weights, the video features are divided into action-related and non-action-related features. Contrastive learning is utilized to amplify their differences, thereby obtaining a more discriminative feature representation.
The existing approaches for video action recognition demonstrate insufficient utilization of temporal information, leading to limited localization performance. To address this issue, we propose the adoption of multilayer dilated convolution to expand the receptive field and capture long-range dependencies among segments within the field. This design enables the recognition model to comprehensively learn and exploit temporal features while leveraging segment information across the entire receptive field for enhanced discrimination of action instances. Specifically, we concatenate the red–green–blue (RGB) feature
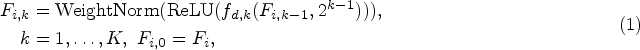
The receptive field size is expanded to

The utilization of multiple modalities facilitates the acquisition of a more comprehensive range of information compared to using a single modality. However, integrating different modalities may result in a reduction in specific intramodality details. To ensure reliable fusion and maximize cross-correlation between modality features, we utilize a cross-modal MHA mechanism inspired by previous studies (Ren et al., 2022) to generate attention weights. This mechanism not only enhances the representative capacity of the model but also captures a diverse array of features. Specifically, feature
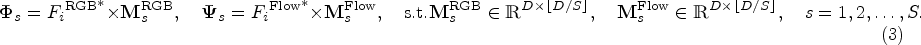
After obtaining the multihead input, we employ a learnable weight matrix

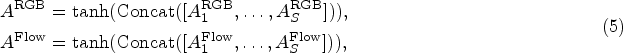
According to the obtained attention weights, we employ the pseudo-label generation method proposed in the literature (Ma et al., 2021) for selecting top-k segments that constitute the action segment set
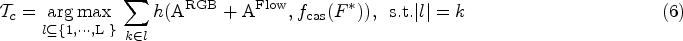

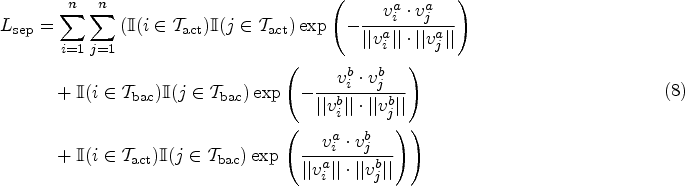
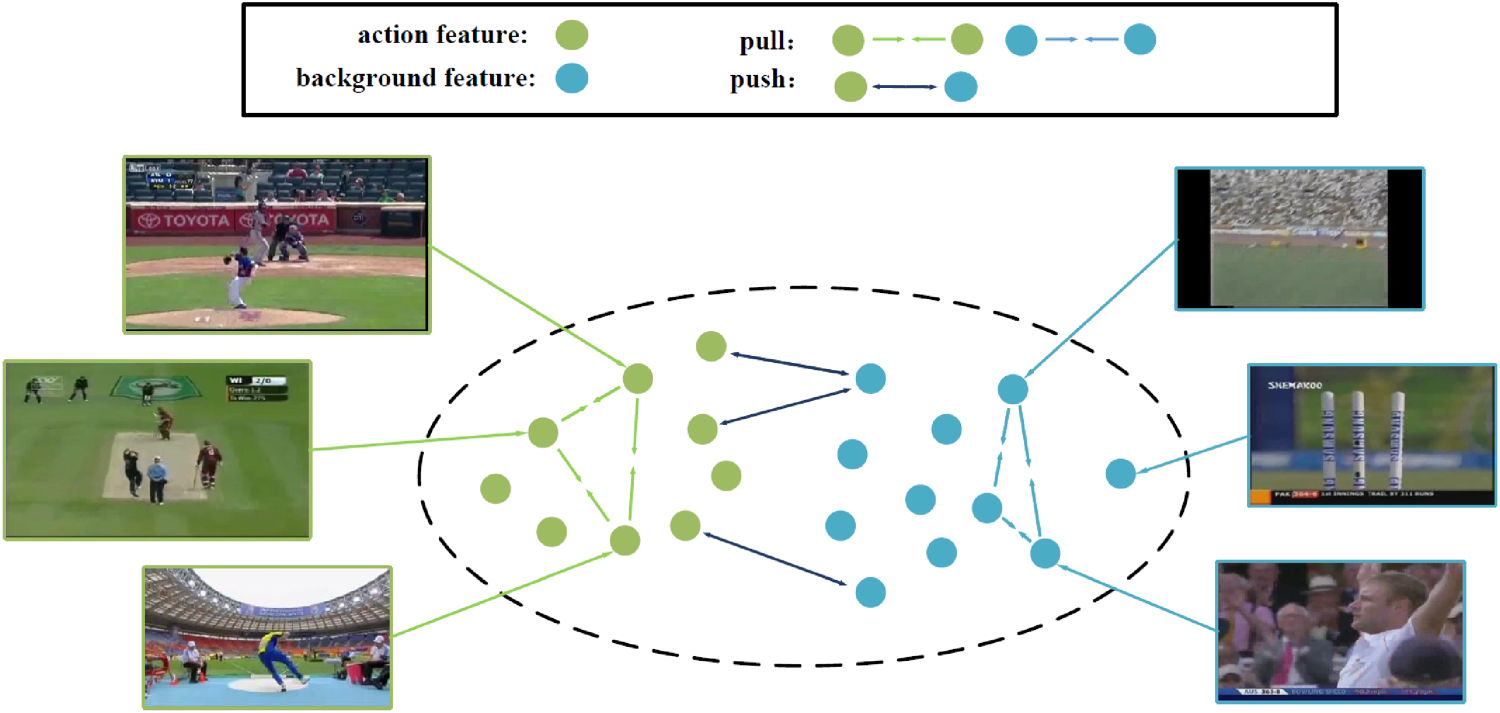
Visualization of the contrast separation.
The FCSM proposed in Section 3.4 inevitably introduces some noise when selecting action-background segments, which may result in the noisy separation of features and consequently impact the action localization performance of the model. To address this issue, we present a BRM. It aims to achieve accurate action localization by performing more fine-grained optimization on the generated incomplete or overcomplete action segments using the attention scores





In order to obtain the optimal TCAS, CLASNet adopts a joint optimization method that utilizes four distinct loss functions to achieve more accurate classification and localization effects. These four loss functions are as follows: (a) Baseline model loss
In the action localization stage, CLASNet is utilized for joint optimization to obtain the optimal TCAS of the video, representing the probability distribution of each action class. However, due to the impracticality of directly utilizing this TCAS for action localization, a threshold is set to determine the specific action category within the video. The continuous sequence formed by all instances with a probability higher than this threshold is considered an actionable proposal. We use the outer–inter score method (Shou et al., 2018) on these proposals to assess their confidence scores. Additionally, attention weights are subjected to multiple thresholds to generate proposals at different scale levels. Finally, Soft-NMS (Bodla et al., 2017) is applied to eliminate overlapping action proposals and derive accurate final results for action localization.
Experiments
To validate the effectiveness and accuracy of CLASNet, we embed CLASNet into three various cutting-edge weakly supervised temporal action localization methods (CO2-Net, Hong et al., 2021; DELU, Chen et al., 2022; and ACRNet, Ren et al., 2023) and compare them with the current leading WTAL methods. The CLASNet undergoes extensive ablation experiments on various components to showcase the effectiveness of each module. By visually analyzing the localization results, it is demonstrated that the proposed model achieves precise localization of ambiguous segments.
Datasets and Implementation Details
To evaluate the performance improvement of CLASNet on temporal action localization compared with different methods, we conduct experiments on three datasets: THUMOS14 (Idrees, 2017), ActivityNet v1.2 (Heilbron et al., 2015), and ActivityNet v1.3. THUMOS14 dataset is a subset of UCF101 dataset, which consists of a validation set of 1,010 videos and a test set of 1,574 videos, covering 101 action categories, among which 20 categories have temporal annotations. This dataset is challenging because some videos contain multiple actions that are hard to distinguish. We adopted the same setting as the existing methods, using a validation set of 200 videos for model training and a test set of 213 videos for evaluation. ActivityNet v1.2 dataset contains 4,819 training videos, 2,383 validation videos, and 2,480 test videos, covering 100 action categories. ActivityNet v1.3 dataset is an extended version of ActivityNet v1.2, which contains 10,024 training videos, 4,926 validation videos, and 5,044 test videos, covering 200 action categories. Each video average contains 1.6 action instances. We implement the proposed CLASNet on PyTorch (Paszke et al, 2019), running on the Windows 10 operating system, with GeForce RTX 3060Ti GPU and Intel i7-11700K CPU. To ensure the fairness of comparison, we follow the previous methods (Chen et al., 2022; Hong et al., 2021; Ren et al., 2023). We use two-stream I3D (Kay, 2017) pretrained on the Kinetics-400 dataset (Carreira and Zisserman, 2018) to extract both the RGB and optical flow features. Video snippets are sampled every 16 frames and the feature dimension of each snippet is 1024. In the training process, for THUMOS14 dataset, we set the number of sampled segments to 800, the batch size to 32, and the hyperparameters
Evaluation Metrics
We adopt the standard evaluation method for temporal action localization, using the mean average precision (mAP) under different temporal intersection over union (t-IoU) thresholds to evaluate the WTAL performance on three benchmark datasets. The higher the mAP, the better the WTAL performance. For a fair comparison, we use the benchmark code provided by ActivityNet (Heilbron et al., 2015) to calculate the results. Specifically, the t-IoU thresholds for THUMOS14 are set to
Comparison With State-of-the-Art Methods
To verify the performance improvement of the proposed CLASNet on temporal action localization compared with different methods, we conduct comparative experiments on THUMOS14, ActivityNet v1.2, ActivityNet v1.3 datasets, and select the latest three models CO2-Net, DELU, and ACRNet as baselines for retraining. The experimental results are shown in Tables 1 to 3.
Performance Comparisons on THUMOS14 Testing Set.
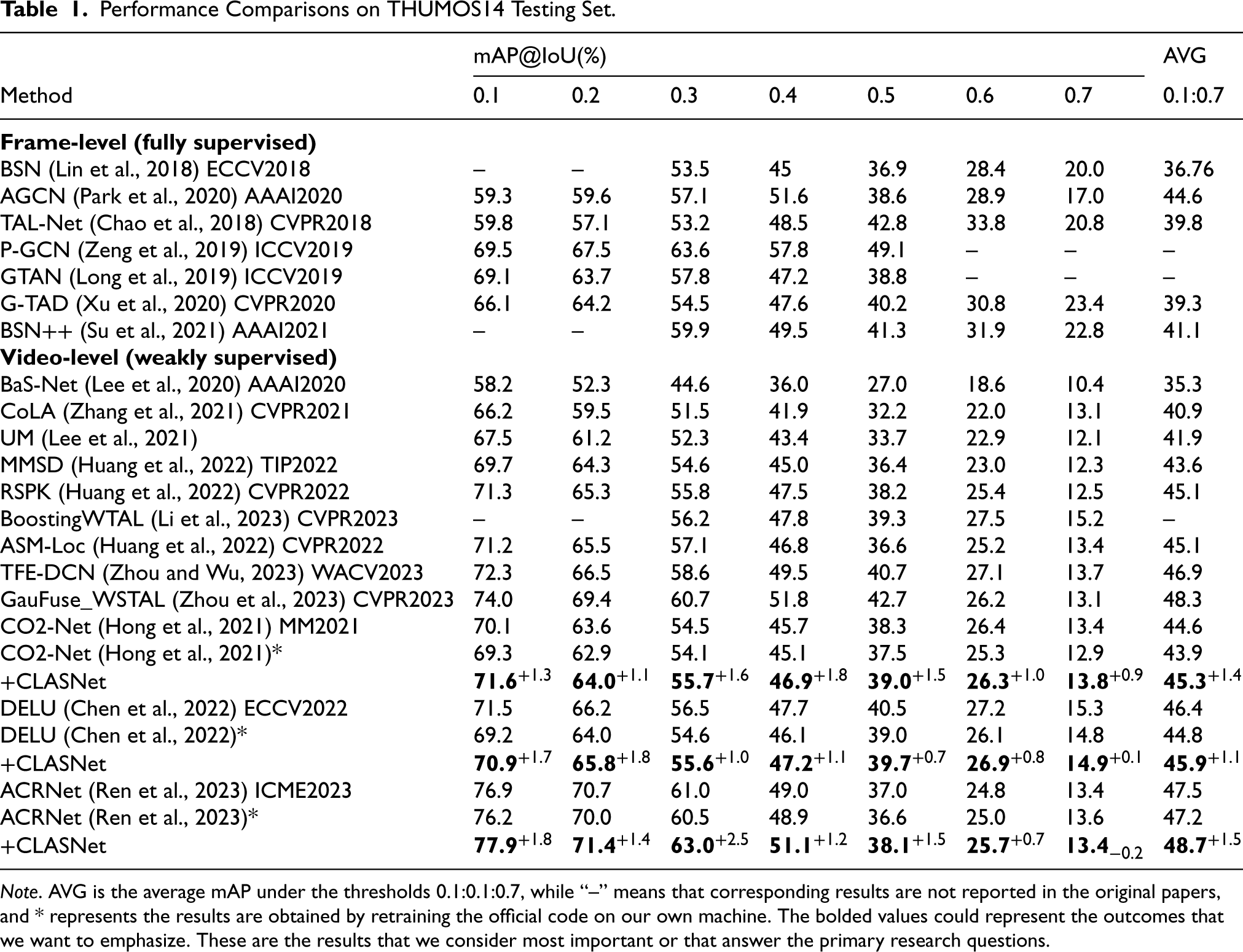
Performance Comparisons on THUMOS14 Testing Set.
Note. AVG is the average mAP under the thresholds 0.1:0.1:0.7, while “–” means that corresponding results are not reported in the original papers, and * represents the results are obtained by retraining the official code on our own machine. The bolded values could represent the outcomes that we want to emphasize. These are the results that we consider most important or that answer the primary research questions.
Performance Comparisons on ActivityNet1.2 Validation Set.
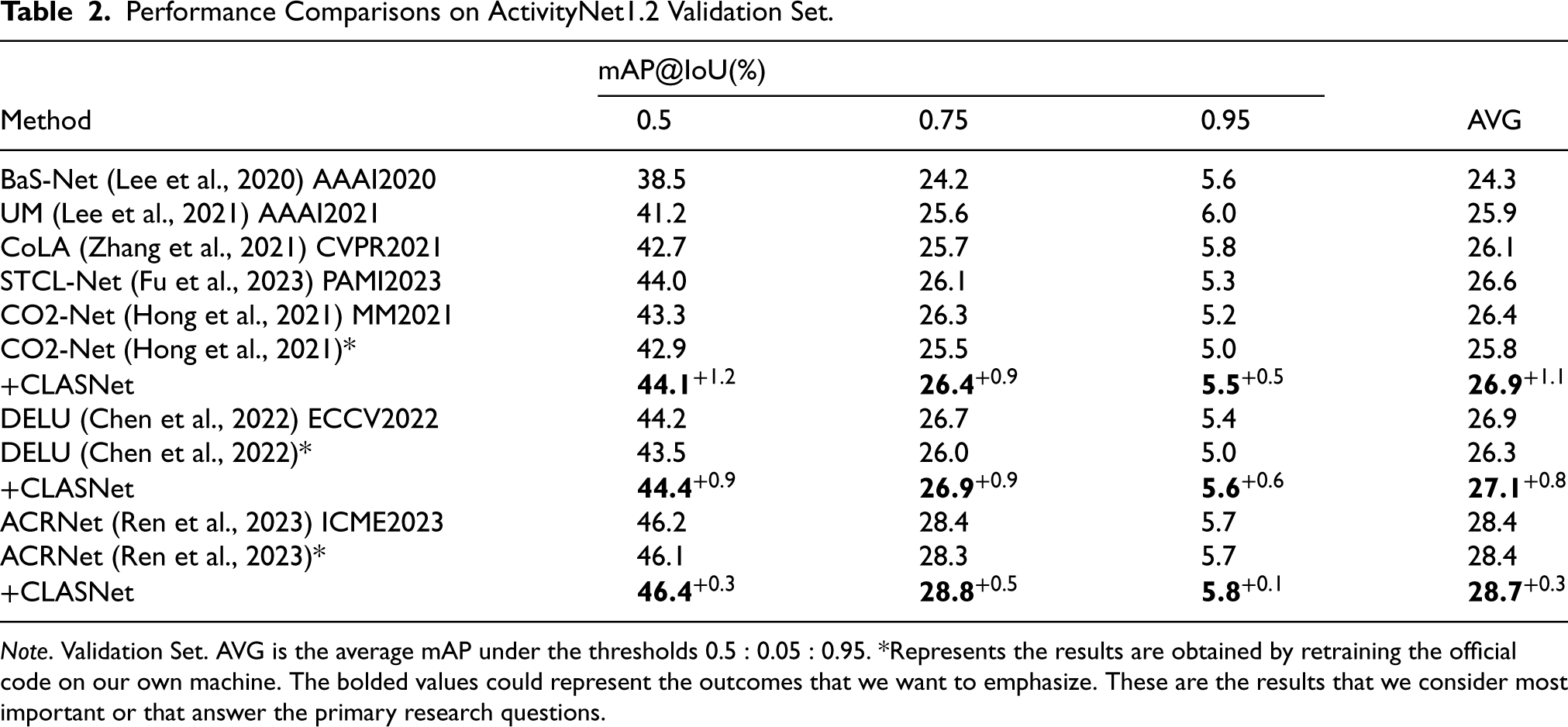
Note. Validation Set. AVG is the average mAP under the thresholds
Performance Comparisons on ActivityNet1.3 Validation Set.
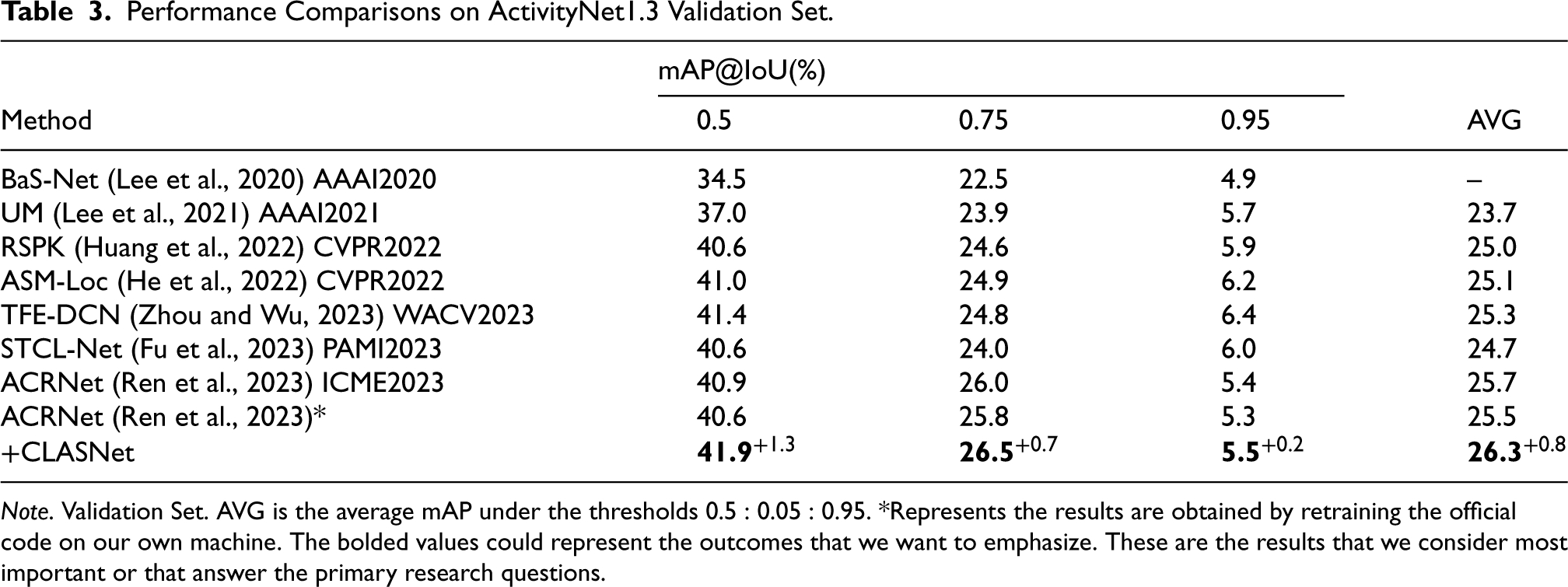
Note. Validation Set. AVG is the average mAP under the thresholds
The experimental results on the THUMOS14 dataset (shown in Table 1) demonstrate a significant enhancement in the performance of the three localization networks under various IoU thresholds with the introduction of CLASNet. Notably, when the IoU threshold is set at 0.5, CO2-Net, DELU, and ACRNet achieve absolute improvements of 1.6%, 1.0%, and 2.5% on mAP, respectively. This enhancement can primarily be attributed to the ability of CLASNet to capture comprehensive temporal information of action instances through dilated convolution, generate reliable attention weights, enhance identifiability of action features through contrast separation, and ultimately achieve precise action localization via boundary refinement techniques. It is worth mentioning that there is no significant improvement observed in the DELU due to its enhanced identifiability of segment features through background modeling. However, incorporating our proposed BRM into DELU architecture enables it to capture more detailed boundary information, improving localization accuracy. The obtained results validate the efficacy of leveraging action-background separation in a weakly supervised setting, leading to significant enhancements in the localization performance of WTAL that are comparable to those achieved by certain fully supervised approaches.
The experimental results on ActivityNet v1.2 and v1.3 datasets (shown in Tables 2 and 3, respectively) are similar to the observations on THUMOS14. The CLASNet enhances the existing WTAL frameworks under all IoU thresholds, especially the improvement on CO2-Net, which is remarkable. For example, on the ActivityNet v1.2 dataset, when the IoU threshold is 0.5, CO2-Net, DELU, and ACRNet improve the mAP by 1.2%, 0.9%, and 0.3%, respectively. On the ActivityNet v1.3 dataset, ACRNet improves the mAP by 1.3%. This result mainly benefits from CLASNet improving the discriminability of action features by contrastive separation, effectively overcoming the ambiguity problem of action segments under weakly supervised information, and achieving precise action localization.
To evaluate the improvement effect of CLASNet on the baseline models more comprehensively, we perform a visual analysis of the experimental results (shown in Figure 3). As depicted in Figure 3, CLASNet demonstrates performance enhancements across various models and datasets. Especially on the THUMOS14 dataset, the localization performance improvement exceeded that of the ActivityNet v1.2 dataset, which may be due to the longer video length, more diverse and less distinguishable video categories in the ActivityNet v1.2 dataset, resulting in a relatively small improvement in localization performance on this dataset. However, the experimental results show that CLASNet effectively improved the action localization effect by embedding it into different WTAL methods and achieving more accurate localization performance, further proving the superiority of the proposed network.
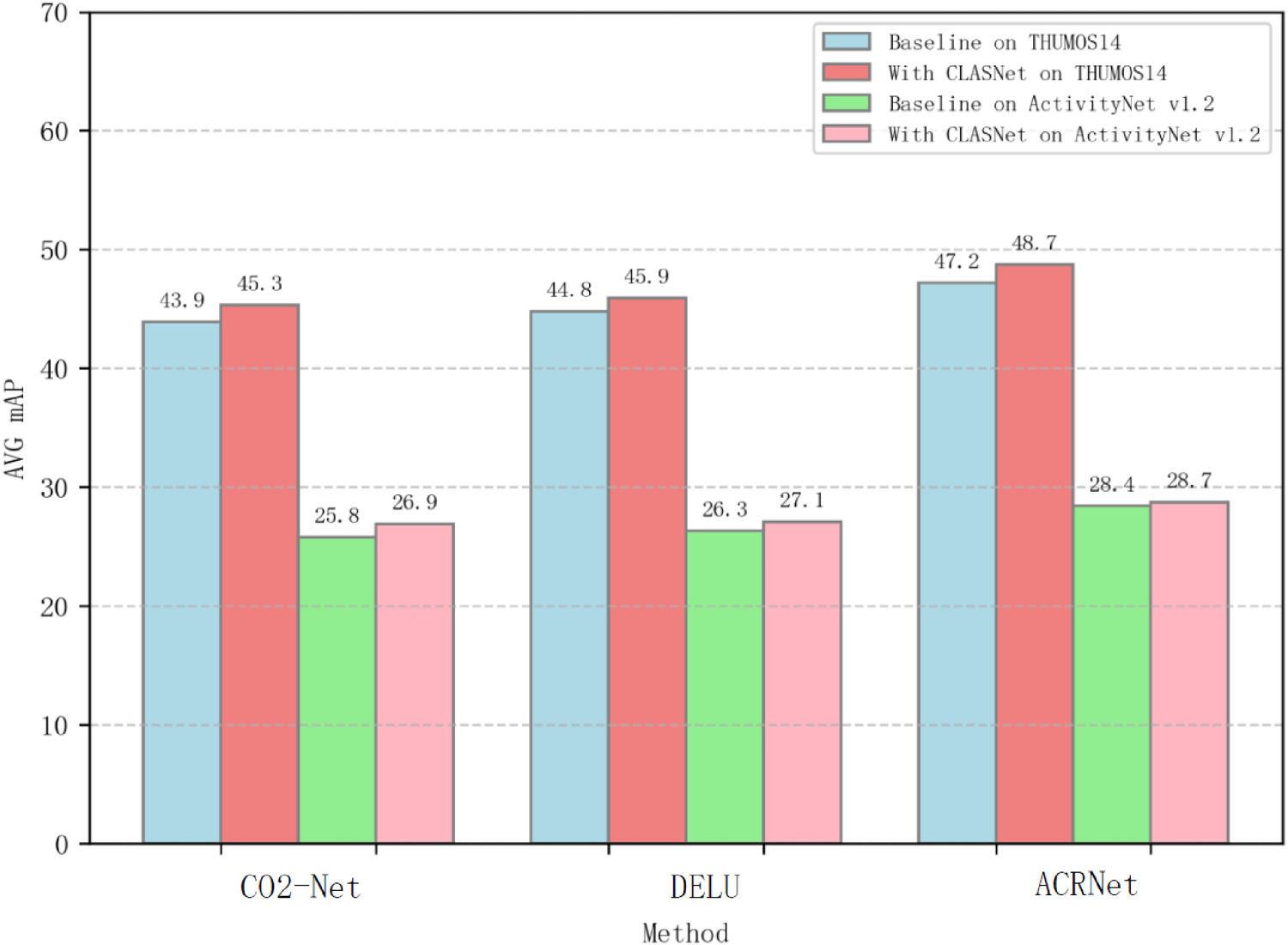
Performance comparison of different models under different datasets.
To verify the effectiveness of each component, we choose ACRNet[26] as the baseline and conduct a series of ablation studies. ACRNet performs the best among the three baseline models due to its flexibility and effectiveness. Following the methods of previous works (He et al., 2022; Ren et al., 2022; Tang et al., 2023), all ablation experiments are conducted on the THUMOS14 test set. The ablation study results of the CLASNet loss function (shown in Table 4) aimed to explore the contribution of each component to the final loss function. In the experiment, it was not changed since it is the objective function of the baseline model. The specific experimental settings included: (A) baseline model; (B) sparsifying the attention weights based on the baseline model; (C) adding only the feature contrastive separation module to the baseline model; (D) adding only the BRM to the baseline model; (E) adding the feature contrastive separation module based on (B); (F) adding the BRM based on (B); (G) adding the BRM based on (C); and (H) sparsifying the attention weights based on (G).
Ablation of Different Components of the Final Loss Function on the THUMOS14 Test Set.

Ablation of Different Components of the Final Loss Function on the THUMOS14 Test Set.
Note. AVG = average.
By comparing (A) with (B), (C) with (E), and (G) with (H), it is observed that sparsifying the attention score can lead to a slight improvement in mAP. This could be attributed to eliminating non-critical attention through sparsification, thereby marginally enhancing model performance. Adding only the FCSM results in an increased mAP of 59.0%, indicating its effectiveness in segregating action features from background features using contrastive learning methodology, thereby improving feature identifiability and positively impacting performance. Similarly, incorporating only the BRM increases mAP to 58.9%, suggesting its positive effect on performance by expanding the similarity between TCAS and attention score, thus correcting temporal boundaries. Combining the FCSM and BRM further improves mAP to 60.1%, highlighting significant enhancement in action localization accuracy achieved by effectively integrating these two modules. The CLASNet comprising all integrated modules within (H) achieves optimal performance, underscoring their collective contribution toward achieving more comprehensive action localization results.
Furthermore, we validate the effectiveness of the components in the FCSM. The module encompasses two parts: an attention weight generation mechanism and a contrast separation part. Multilayer dilated convolution and MHA are essential for generating attention weights. Firstly, we enlarge the receptive field using multilayer dilated convolution, which captures the temporal dependency among segments. Then, MHA models the intermodality relationships for generating attention weights. However, an excessive number of receptive fields may capture irrelevant segments, while increasing the number of attention heads can reduce the feature dimension of each attention head and impact its representation ability. We conduct ablation studies by varying the numbers of dilated convolution layers
We compare the performance under different settings of
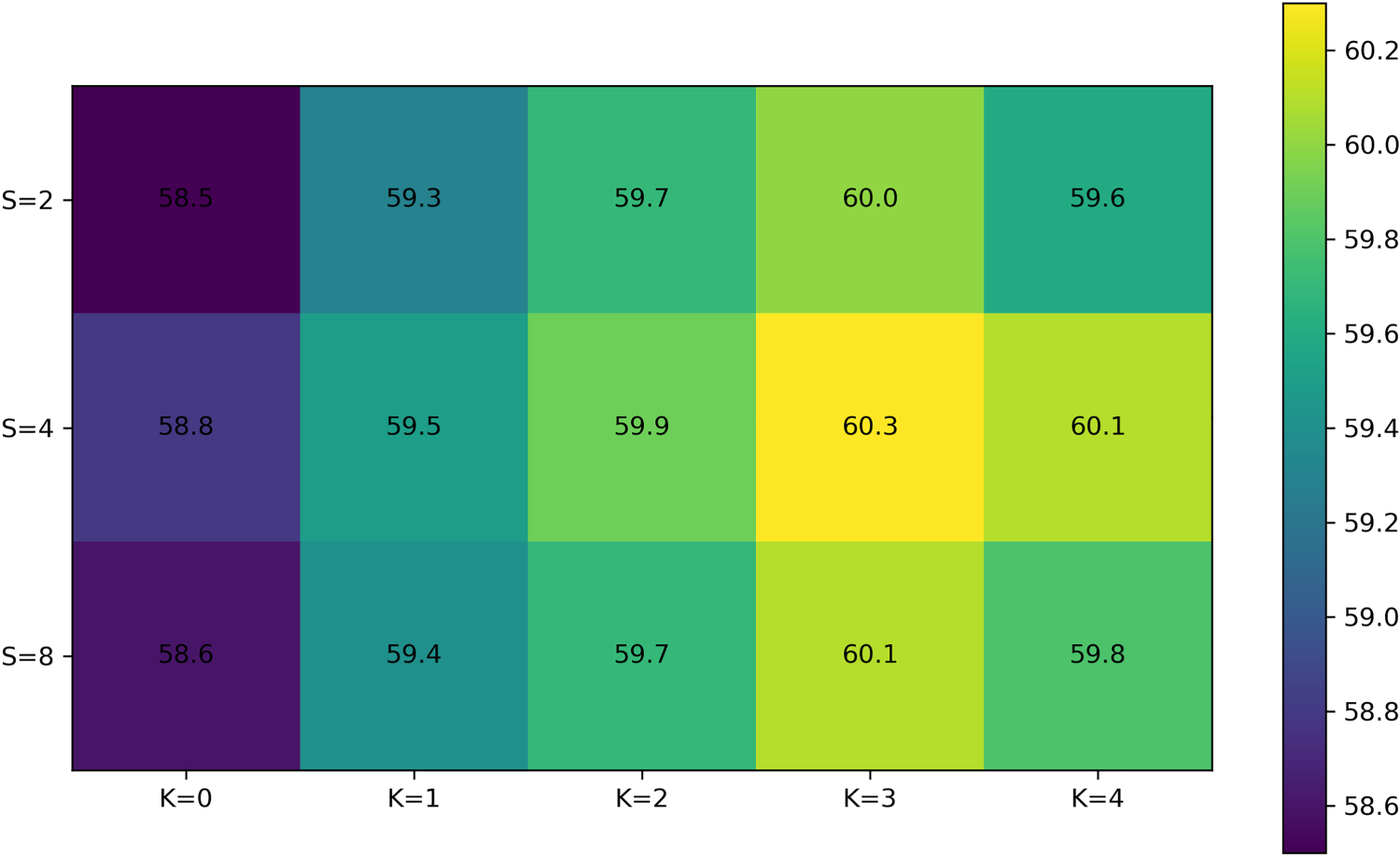
Experimental results of different expansion convolution layers
It is worth mentioning that after embedding CLASNet into ACRNet, the parameters increased from 22.33 million to 33.24 million. In addition, we counted the number of parameters and floating-point operations for the other two baseline models CO2-Net and DELU (shown in Table 5). Although this increased the complexity of the model, the increase in complexity is acceptable considering the flexibility and significant performance improvement of CLASNet.
The Number of Parameters and Floating-Point Operations for the Baseline Models.
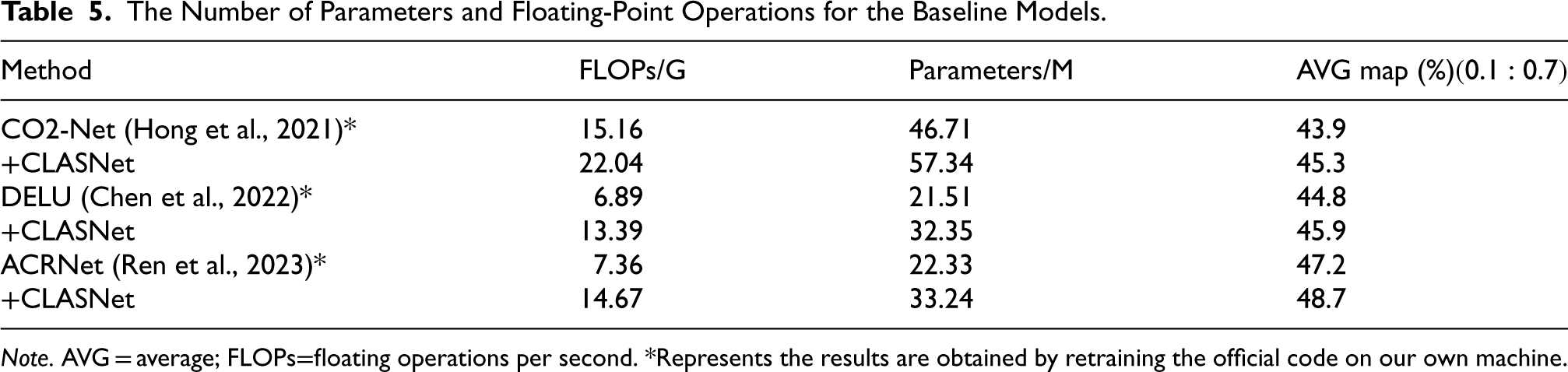
Note. AVG = average; FLOPs=floating operations per second. *Represents the results are obtained by retraining the official code on our own machine.
To visually demonstrate the efficacy of CLASNet in enhancing action localization, we present a comprehensive qualitative visual analysis of the detected action segments using Figure 5. Figure 5 showcases video clips along with baseline ground truth (GT) actions, CAS, and localization results produced by the baseline model ACRNet (Baseline), as well as CAS and localization results obtained from CLASNet+ACRNet (ours). Among these representations, GT, ACRnet (Baseline), and CLASnet+ACRnet (ours) are depicted in blue, brown, and purple, respectively. Additionally, specific intricate cases undetected by ACRnet but successfully located by our proposed model are highlighted within a red box.
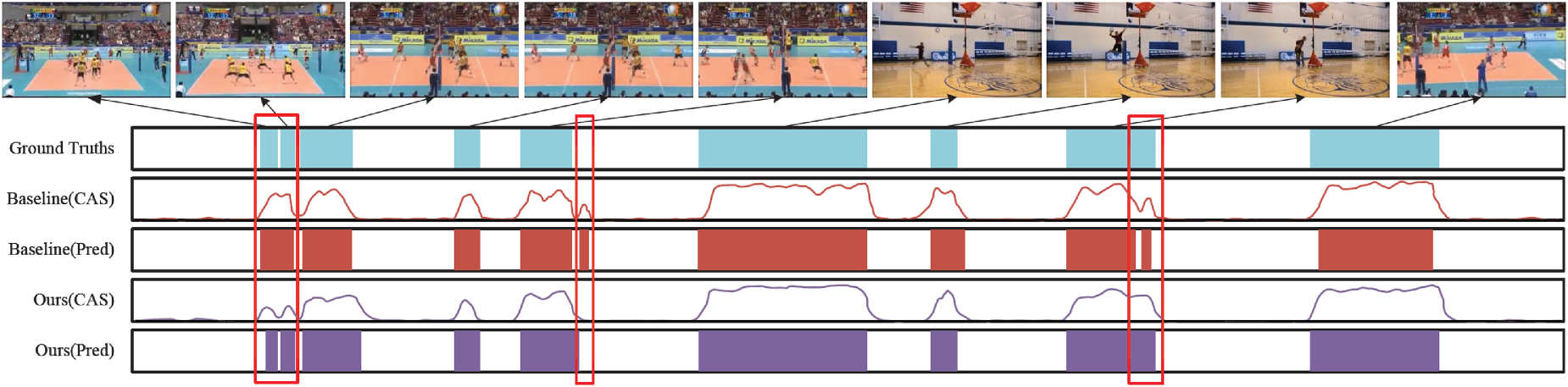
Qualitative visualization of a video example on the THUMOS14 dataset.
Through comparative visual analysis, it becomes evident that our proposed model demonstrates a remarkable improvement in localizing ambiguous segments. Initially, ACRNet misidentified three regions, marked by red boxes, but with the aid of CLASNet, these were accurately corrected. For instance, the correct segment within the first box should include two teams sequentially participating in a volleyball game. However, ACRNet erroneously treats these two segments as one continuous action. By leveraging CLASNet introduced in this study, these two segments are correctly identified and distinguished. In the region marked by the second red box, ACRNet incorrectly identifies a segment devoid of action as containing an action, due to complex background interference. Conversely, CLASNet achieves identical accuracy of the GT prediction. Regarding the third area demarcated by the red box, ACRNet erroneously partitions a continuous hitting volleyball action into two segments, leading to inaccurate truncation. However, despite intricate background interference, CLASNet successfully identifies this constant action. Furthermore, based on all localization results obtained thus far, it is clear that our proposed model can precisely locate easily recognizable segments and accurately discern ambiguous ones. This indicates the effective segregation of action features from non-action features and refinement of localization boundaries, leading to improved performance in action localization tasks. The model has improved both classification accuracy and localization precision.
The weakly supervised temporal action localization technique, which relies solely on video-level annotations, thereby holds significant scientific significance and practical value in enhancing the efficiency and precision of video analysis. We propose the CLASNet to enhance the localization problem of ambiguous segments. By effectively distinguishing features through contrastive separation, thereby improving localization accuracy. Firstly, CLASNet resolves the interference issue of non-action features on localization by employing a feature comparison separation module, effectively distinguishing action features from non-action ones. Secondly, it addresses the noise problem in contrast separation and enhances contrast accuracy by capturing precise boundary fine-grained information through a BRM. The extensive experiments conducted on the THUMOS14 and ActivityNet datasets show that CLASNet outperforms both baseline methods and state-of-the-art approaches in weakly supervised temporal action localization tasks. This plug-and-play module is applicable to WTAL tasks and shows promise for broader domains, including fully supervised temporal action localization and action recognition.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their helpful comments and suggestions.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.