
Abstract
With the rapid development of information technology, today’s society has higher and higher requirements for the recommendation system, especially regarding recommendation accuracy. A significant feature of news recommendation is that it has high timeliness, and the popularity of a news article will decline exponentially in a week. The effectiveness of traditional recommendation methods in news recommendation could be more optimistic. In order to further improve the accuracy of news recommendations, a large number of knowledge graphs are applied to news recommendations, and the nodes and edges of the knowledge graph can better represent the relationship between entities in the article; compared with traditional recommendation methods, it can better solve the problems of data sparsity and cold start. This paper proposes a relational entity credibility discrimination model, eliminating the relational entities without credibility to improve news recommendations accuracy, the existence of some relational entities in the triad of the knowledge graph may distort the meaning of the article or have a near-zero impact on the article, which is considered untrustworthy for these two types of relational entities. Experimental results show the effectiveness and efficiency of the model.
Introduction
In this era of rapid development of the internet, the popularity of the internet is also increasing rapidly. Various media, such as Facebook, TikTok, and other enterprises, are also competing for the number of users. At this time, the requirements for the recommendation system also follow. How to accurately recommend users’ favorite items, articles, and other items to users has become a major means to attract new users and retain good users. An excellent recommendation system will create more value for an enterprise.
Generally speaking, news recommendation has higher requirements than a commodity, tourism, and other recommendations, mainly because the news has timeliness. The effect of news recommendation using the previous traditional recommendation methods is often not optimal. At this time, Wang et al. (2018) introduced the knowledge graph into news recommendation, such as a deep knowledge-aware network for news recommendation (DKN), which embeds the news title into the knowledge graph through knowledge graph embedding via dynamic mapping matrix (Trans-D; Ji et al., 2015) and extremely efficient hardware keypoint detection with a compact convolutional neural network (KCNN; Febbo et al., 2018), but the disadvantage is that if only the article title is embedded, it will inevitably encounter some situations with low consistency between the content and the title, which will greatly affect the recommendation results. Then, Liu et al. (2020) proposed knowledge-aware document representation for news recommendations (KRED), which embeds the whole article into the knowledge graph through knowledge graph attention network for recommendation (KGAT; Wang et al., 2019) model, a three-tier model is introduced to enhance the knowledge of article entities and then recommend them.
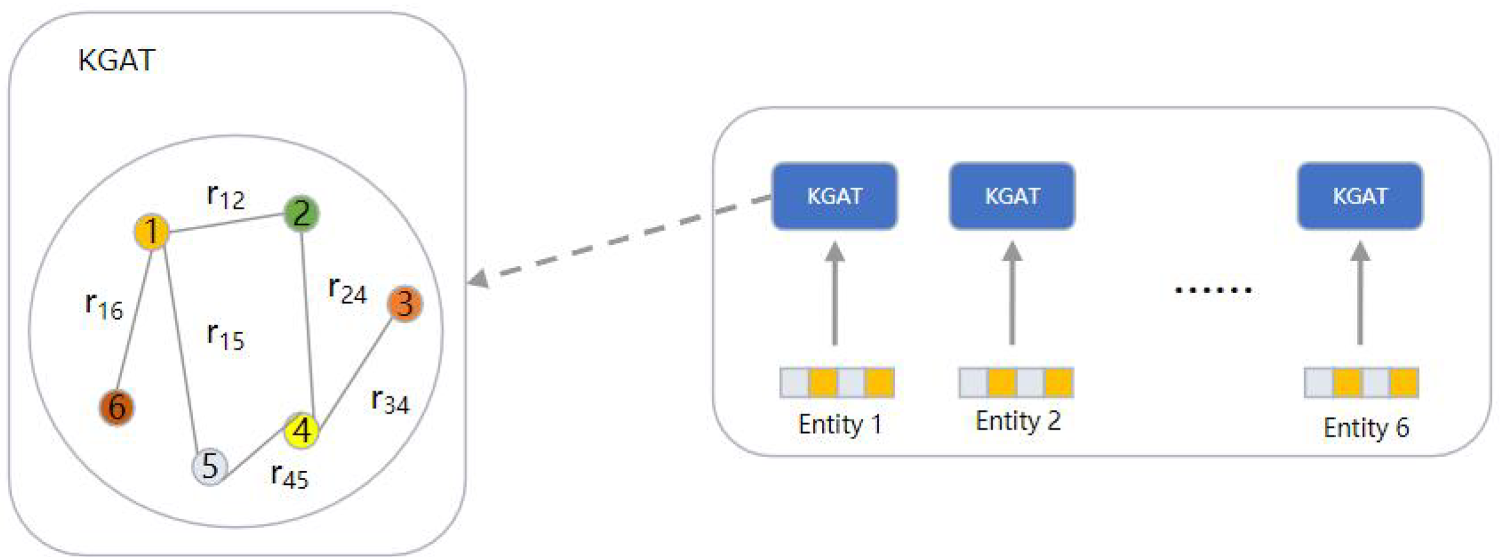
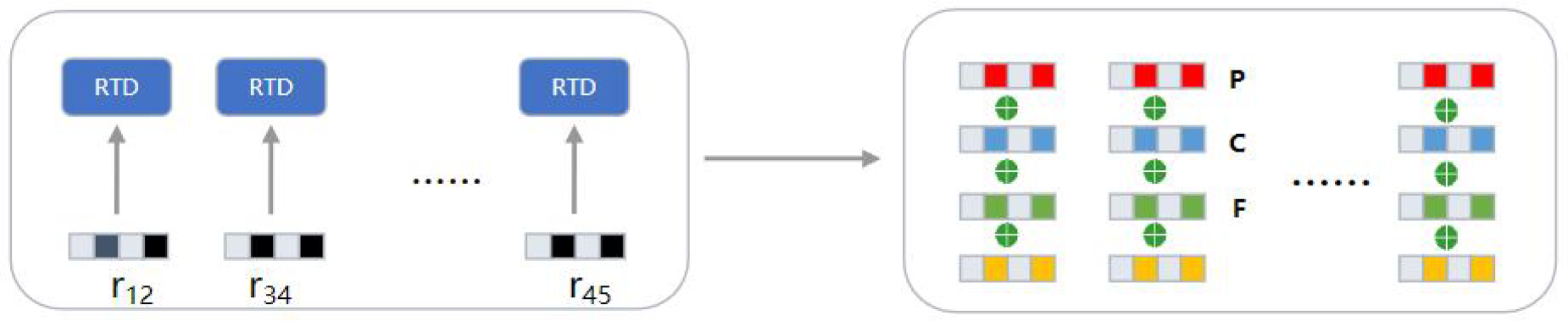
The previous news recommendation based on the knowledge graph mainly embeds the entities and relational entities in the news into the knowledge graph, but it is impossible to confirm whether the embedded relational entities will affect the results of the news recommendation. This paper proposes a relational entity credibility discrimination model. The model analyzes the credibility of the relational entities embedded in the knowledge graph and eliminates the relational entities whose credibility does not meet the standard, as shown in Figure 1. The main contributions of this paper are summarized as follows:
A relational entity credibility discrimination model is proposed to judge whether each relational entity in the knowledge graph has credibility. A two-layer confirmation model is designed to further improve the accuracy of the relationship entity credibility discrimination model. Experimental results on real datasets prove the efficiency and effectiveness of our model.

This is a real news about the US–Iraq war. After embedding it into the knowledge graph, we can see that there are various entities and relational entities in the knowledge graph, the red edge is the relationship entity to be deleted.
This section first introduces and defines commonly used concepts and notations.
Definitions
First, the minimum concept mentioned in the rest of this article is defined.
The
The
Next is the definition of some symbols (Table 1).
Commonly Used Notations.

Commonly Used Notations.
We divide the news recommendation method into two categories, namely, namely, news recommendation method based on nonneural network and news recommendation method based on neural network.
News Recommendation Method Based on Nonneural Network
Cantador et al. (2008) believe that news content and user preference descriptions appear in domain ontology based on a set of concepts and develop a semantic context-aware recommendation model that personalizes the order in which news articles are displayed to users based on their long-term interest profile, as well as other models that reorder the list of news items taking into account the semantic context in which the user is currently interested, Jntema et al. (2010) focused on the benefits of using domain ontology rather than terminology-based methods to recommend news projects, so they proposed an ontology-based news model, Athena, which is an extension of the existing Hermes framework. Athena uses user profiles to store terms or concepts in news items that users browse. Based on this information, the framework uses traditional term frequency–inverse document frequency (TF–IDF)-based methods and several ontology-based methods to recommend new articles to users, Goossen et al. (2011) believe that most traditional algorithms are based on TF–IDF and term-based weighting methods, which are mainly used for information retrieval and text mining. Therefore, they proposed a personalized recommendation model based on semantic mining. The results show that using the semantics of domain ontology to adjust TF–IDF to produce conceptual frequency–inverse document frequency (CF–IDF) produces better results than using the original TF–IDF method. CF–IDF is built and tested in Athena, a recommended extension of the Hermes news personalization framework. Athena uses user profiles to store concepts or terms in news items that users browse. The framework uses traditional TF–IDF recommenders and CF–IDF recommenders to recommend new articles to users. Statistical evaluation of these two methods shows that using ontology can significantly improve the performance of traditional recommenders, and Capelle et al. (2012) believe that news recommendations typically use TF–IDF weighting techniques combined with cosine similarity measurements, but do not consider the actual meaning of words. Therefore, they proposed a semantic-based news recommendation model that utilizes five semantic similarity (SS) measures to calculate the similarity between news items in news recommendations, Capelle et al. (2013) also believe that traditional content-based news recommendation uses a word vector space model without considering the use of semantics. Therefore, they proposed a semantic news recommendation model that uses the similarity between text networks and Bing to extend the most advanced semantic dictionary-driven SS recommendation method by taking additional consideration of named entities. First, similar to SS, calculate the similarity between the WordNet synonym set in unread news items and the synonym set in read news items (stored in the user profile). Then, the number of pages of named entities retrieved from the Bing Web search engine is used to calculate named entity similarity between unread and read news items, Rao et al. (2013) focus on using background knowledge to obtain potential semantic relevance, thereby promoting personalized news recommendations. Therefore, they propose using personalized news recommendations obtained through web ontology to model articles and user configuration documents from larger real-world ontologies collected on the web, without requiring too much manual annotation, they further study the conceptual similarity and news user matching of this ontology by considering its naturally embedded ontology structure, and calculate news user similarity through the collaborative construction of the ontology structure. Kumar and Kulkarni (2013) have developed a new news personalization algorithm that uses the adaptive algorithm of the classic nearest neighbor algorithm and combines it with the knowledge graph they create. Using implicit user data, such as read and unread articles, their location and distance in the chart, the algorithm ranks new articles based on the user’s predicted interest in the content of the article. Joseph and Jiang (2019) believe that content-based news recommendation systems need to recommend news articles based on the topic and content of the article, rather than using user-specific information. Many news articles describe the occurrence and naming of specific events, including people, places, or objects. So they proposed a graph traversal algorithm and a new weighting scheme for content-based cold start news recommendations using these named entities. To create a higher degree of user-specific relevance, their algorithm calculates the shortest distance between named entities, across news articles, and on a large knowledge graph. However, the above methods have a low degree of personalization and are simple to innovate. They cannot use nonlinear activation functions to model nonlinearity in data, such as Softmax, ReLU, Sigmoid, and Tanh. Moreover, they can only use manual feature design, and their actual recommendation effect is not comparable to that of automatic feature identification recommendation models. Finally, in terms of flexibility, nonneural network news recommendation methods have low flexibility and have shortcomings in the use of many tools, such as TensorFlow, which cannot receive better tool support.
News Recommendation Method Based On Neural Network
Wang et al. (2018) believe that the news language is highly condensed, full of knowledge entities and common sense, so they proposed a deep knowledge aware network news recommendation that combines knowledge graph entity embedding with neural networks and uses a convolutional neural network (KCNN) that combines knowledge to form a new embedding representation by merging the semantic representation of news and knowledge representation, then establish an attachment mechanism from the user’s news click history to candidate news, and select the news with higher scores to recommend to the user. Chu et al. (2019) believe that click sequences indicate the potential preferences of user Z from the interaction history and are used to predict their future preferences. Therefore, they propose a self-attention sequential knowledge awareness recommendation (Saskr) system composed of sequential awareness and knowledge awareness models. Use self-attention mechanisms to discover sequential patterns in sequential awareness models. Knowledge perception modeling uses knowledge graphs as side information to mine deep links between news, thereby improving the diversity and scalability of recommendations. Liu et al. (2020) feel that the key information carried by important entities helps to understand more direct content, so they propose a knowledge-enhanced news recommendation model that aggregates information from the neighborhood of the knowledge graph, thereby enriching the embeddedness of entities. Then, a context embedding layer is used to annotate the dynamic contexts of different entities, such as frequency, category, and location. Finally, the information rectification layer aggregates entities for embedding under the guidance of the original document representation and converts the document vector into a new document vector. It advocates optimizing the model under a multitasking framework to enable different news recommendation applications to unify and share useful information between different tasks, and Wang et al. (2020) in order to consider both knowledge and content factors, proposed a news recommendation method, known as knowledge and content aware news recommendation network (KCNR). KCNR represents users and news in the form of knowledge and content and then predicts the weight of user preferences on knowledge and content through a user preference prediction mechanism. In addition, based on the weight of user preferences on knowledge, it expands user preferences and entities in the knowledge graph (Raza and Ding, 2021). This paper proposes a deep neural network that jointly learns news and user representation in a unified framework. It learns the news representation (features) from the headlines, snippets (body), and taxonomy (category and subcategory) of news. The attention mechanism learns a reader’s long-term interests from the complete click history, short-term interests from recent clicks via long short-term memories, and diverse interests.
Although these models are effective, they have not considered whether the initial parameters have credibility. For example, whether the reference users or reference commodities of similarity measurement in the nonneural recommendation method need to be removed, whether the relationship entity vectors between entities in the neural recommendation method need to be removed, and whether the accuracy of recommendation will be improved after removal, and the above methods are different from nonneural recommendation methods. It has great innovation in the input of recommendation models, the embedding mode of knowledge graphs, and the aggregation mode of knowledge level components and text level components, with a high degree of personalization and innovation. And using neural network-based news recommendation has significant advantages in two aspects: first, neural network-based news recommendation can model users and items in a learning manner, can more accurately describe user interests and news article attributes, and has higher effectiveness in features that are difficult to capture by traditional methods, such as news article features, different types of news type features, improve the understanding of users and items in terms of depth and breadth, improve the interpretability of nonneural network news recommendation methods, and have strong fitting ability. Neural networks can accurately capture arbitrary relationships between users and news, such as nonlinear relationships, dynamic relationships, and space–time relationships, and can learn more accurate user news article interaction functions.
In summary, the neural network-based news recommendation method has several advantages:
Nonlinear transformation. Unlike other linear models, using neural networks can model nonlinearity in data using nonlinear activation functions, such as Softmax, ReLU, Sigmoid, and Tanh. This attribute makes it possible to capture complex user interaction patterns. The conventional method for sparse linear models such as FM is essentially linear models. Representation learning. Using neural networks can effectively learn potential explanatory factors and useful feature representations from model inputs. Generally, a large amount of descriptive information about news articles and users can be obtained in actual news recommendation applications. In this way, we can use this information to promote our understanding of news articles and users, thereby improving the accuracy of news recommendations. Therefore, representation learning in news recommendation models based on neural networks is a natural choice. Flexibility. Due to the high flexibility of neural network technology, especially with the emergence of many popular deep learning frameworks, such as Tensorflow, Keras, Caffe, MXnet, and DeepLearning4j. This also makes these tools available for news recommendation based on neural networks, and most of these tools are developed in a modular manner with active community and professional support. Good modularity makes news recommendation models based on neural networks have better tool support in the future. For example, it is easy to combine different neural structures to form a powerful hybrid model, or to replace one module with another. Therefore, we can easily build hybrid and composite recommendation models to capture different characteristics and factors simultaneously. Next, we introduce three key layers in RTD: the entity representation layer, the contextual embedding layer, and the information distillation layer, and the relational entity credibility discrimination model.
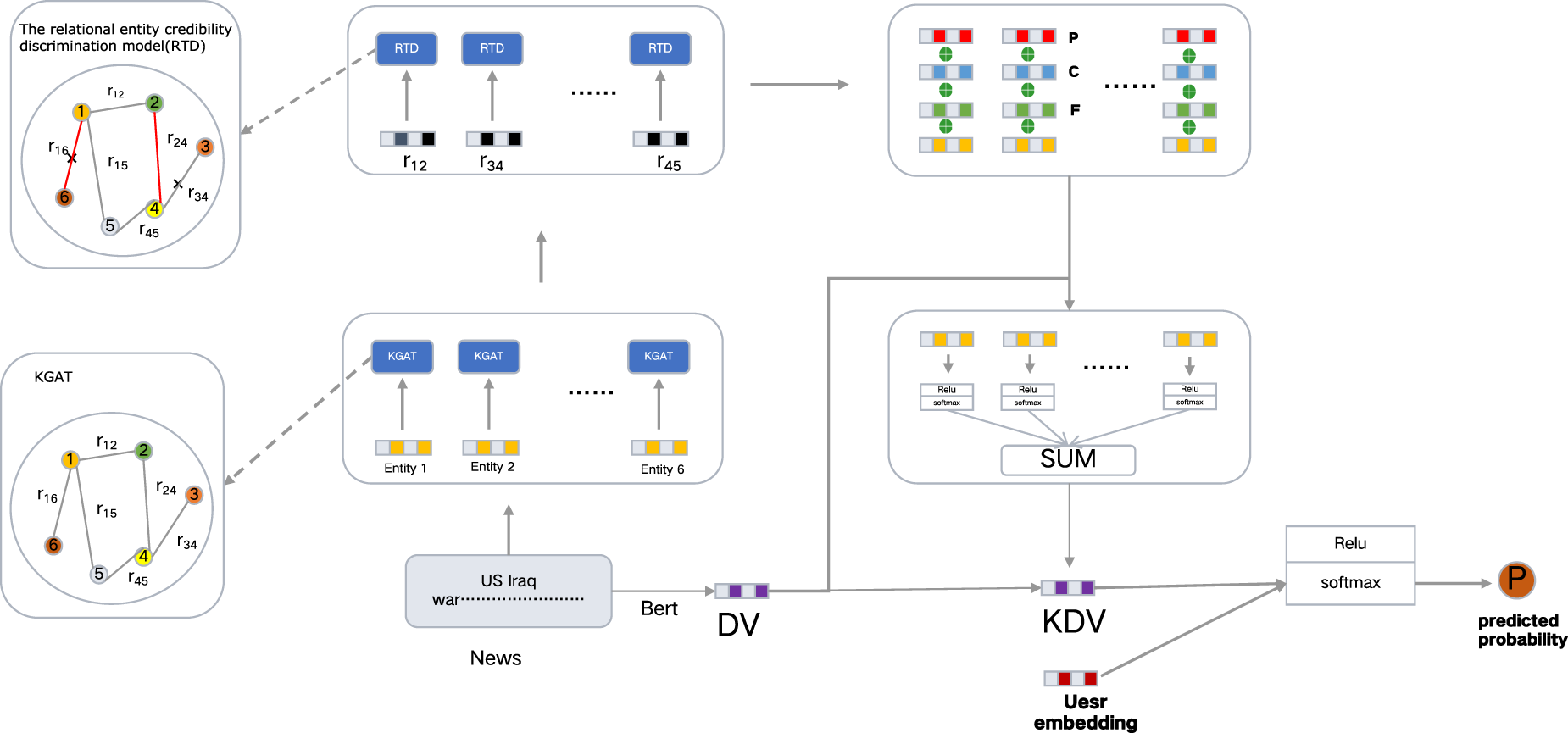
This is an overview of the model proposed in this paper,
We propose a recommendation model with knowledge enhancement and stability for news recommendations. As shown in Figure 2,
Construction of triplet of knowledge graph of news articles.
We use the construction idea of KRED and use the technology of Trans-E (Bordes et al., 2013) to embed the entities and related entities in the text into the knowledge graph, where the triple 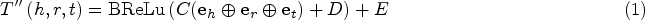
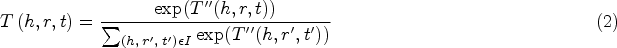
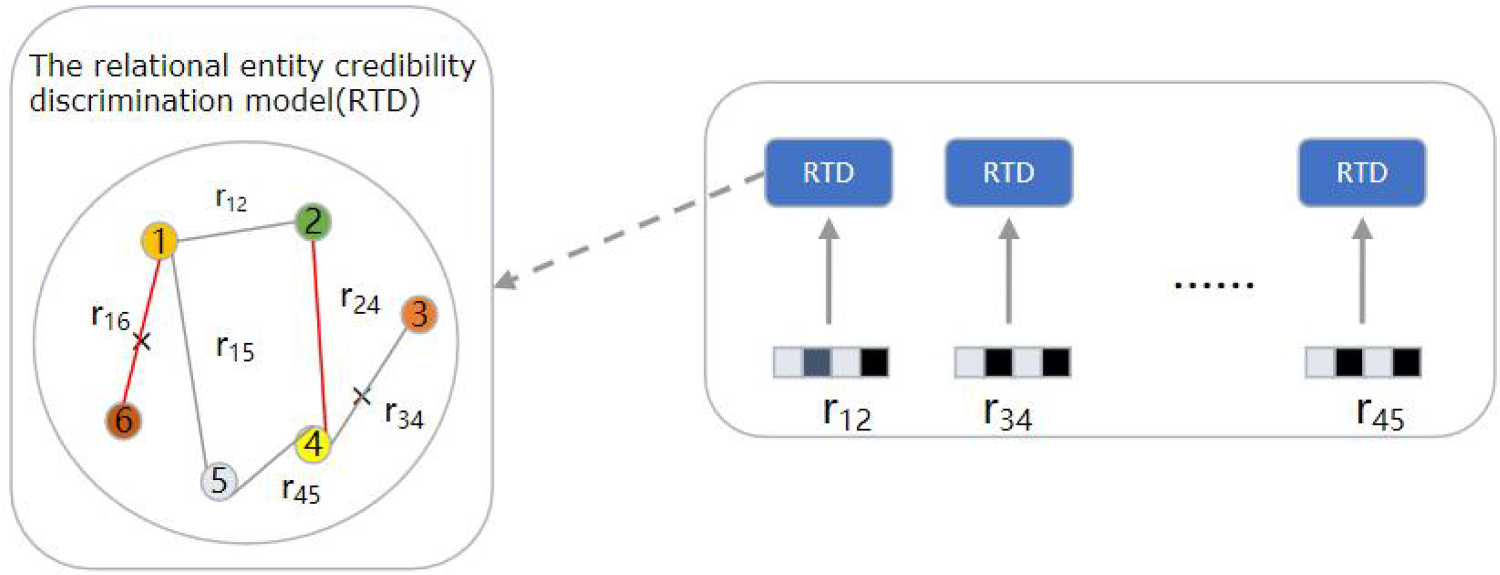
Construction of Relationship Entity Credibility Identification Model (RTD).
Where 
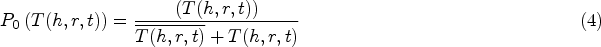
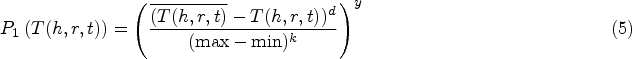

Through the above-mentioned two-layer evaluation standard model, we mark the
Using the idea of KGAT to generate an entity vector of triples, its representation is as follows (Liu et al., 2020):
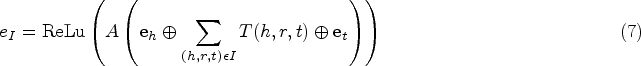
The weights of different entities in news articles should introduce other relevant factors, such as the location information and frequency of occurrence of an entity, 
Embedding other entity information in context embedding layer.
The key entities to be expressed in each article are different. In order to further enhance the purpose of the article vector, we take the original text vector as input and perform knowledge enhancement through this layer model (Figure 6). The representation is as follows (Liu et al., 2020):
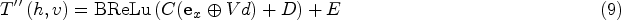


Information distillation layer knowledge enhancement process.
The construction method of 


Dataset and Settings
We use Microsoft News 3’s real-world dataset and knowledge graph. A set of news was collected from January 15, 2019 to January 28, 2019. For personalized recommendation tasks, the first week is used for training and validation sets, and the next week is used for test sets. To establish a user profile, collect logs for another two weeks before training, and aggregate each user’s behavior for user modeling. Filter out users who clicked on fewer than five articles during profile creation. After filtering, there are 665,034 users, 24,542 news articles, and 1,590,092 interactions in the instance set. The average number of words in a document is 701. 1
Algorithm and Parameter Settings
In models with machine learning or deep learning, parameter settings are particularly important because in different experimental environments and datasets, it may be necessary to set parameters to achieve the highest accuracy of the model. In this study, we specifically introduce the setting of four parameters: learning rate and regularization coefficient

Evaluation Indicators
AUC is the area under the curve. When comparing different classification models, you can draw the receiver operating characteristic curve of each model and compare the AUC as an indicator of the advantages and disadvantages of the model.
NDCG can be decomposed into four components, which are normalization (N), discounted (D) subtraction, cumulative (C) accumulation, and gain (G). The four components are represented as NDCG by the following equation. where
The
Benchmark Model Comparison and Experiments
FM (Rendle, 2010) is a matrix decomposition-based recommendation method that captures the interaction characteristics between users and items. Compared with the model in this paper, FM focuses on linear interactions, while the model in this paper uses the knowledge graph structure and information about entities and relationships to capture more complex relationships. DKN (Wang et al., 2018) is a recommendation model that combines knowledge graphs with convolutional neural networks. It uses the entity and relationship information in the knowledge graph to enhance article representation. Compared with the model in this paper, DKN focuses on the entity information of the knowledge graph, but does not explicitly consider the paths between entities. NAML (Wu et al., 2019) uses multiview learning and attention mechanisms to extract multiple features of news content. Compared with the model in this paper, NAML focuses on extracting features from articles, while the model in this paper uses entity and relationship information from the knowledge graph to construct recommendations. STCKA (Chen et al., 2019) uses stacked co-attentive mechanisms to capture interaction features between users and items and uses knowledge graphs to provide additional contextual information. In contrast to the model in this paper, STCKA focuses on the entity information of the knowledge graph, but does not explicitly consider the paths between entities. ERNIE (Zhang et al., 2019) is a pretraining-based language model that uses knowledge graphs to enhance text representation. Compared with the model in this paper, ERNIE focuses on the improvement of text representation, while the model in this paper combines entity and relationship information from the knowledge graph to construct recommendations. KRED (Liu et al., 2020) combining knowledge graph and user behavior data to improve recommendation accuracy and diversity. Compared with the model in this paper, it does not consider whether there are cases where relational entities can misinterpret the general meaning of the article and cases where they have no influence on the article, and it is not comprehensive in terms of details.
The relational entity credibility recognition model (RTD) proposed in this paper outperforms other models in terms of recommendation effectiveness through news data within a week after removing untrusted relational entities considered by the model, demonstrating the effectiveness of the model in terms of news timeliness and the feasibility of the model. These news recommendation models are comparable to the model in this paper in that they both try to use knowledge graphs or other external information to improve the accuracy and relevance of recommendations. However, they differ in their implementations and concerns, making it meaningful to compare their performance and features for research.
Deleting Any Criteria Will Degrade Performance.

Deleting Any Criteria Will Degrade Performance.
Next, we will explore whether the experimental results will be affected after deleting one of the two judgment conditions
When we delete one of the two judgment conditions in the relational entity credibility identification model, we can see that when the judgment condition
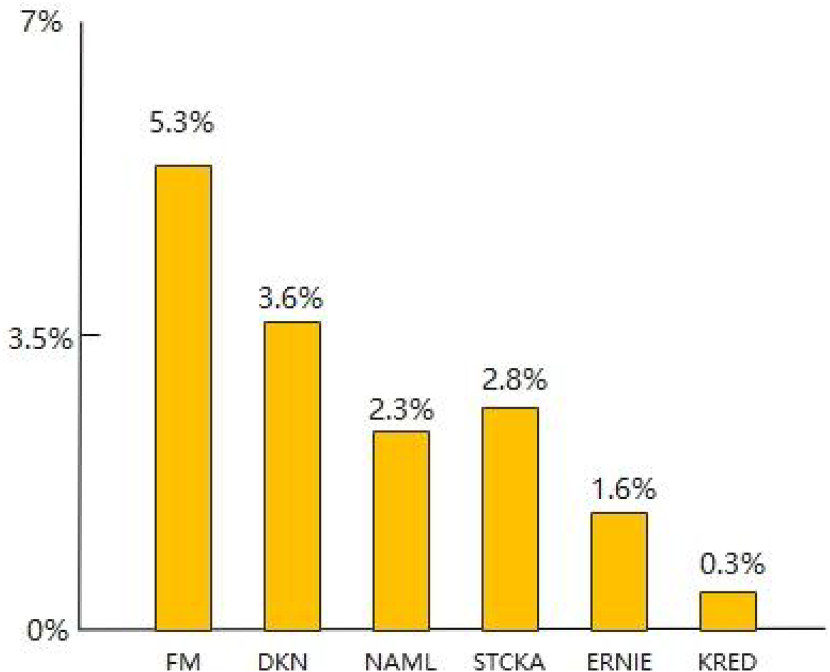
Improvement rate of RTD in AUC index compared with other benchmark models. Note. AUC = area under the curve.
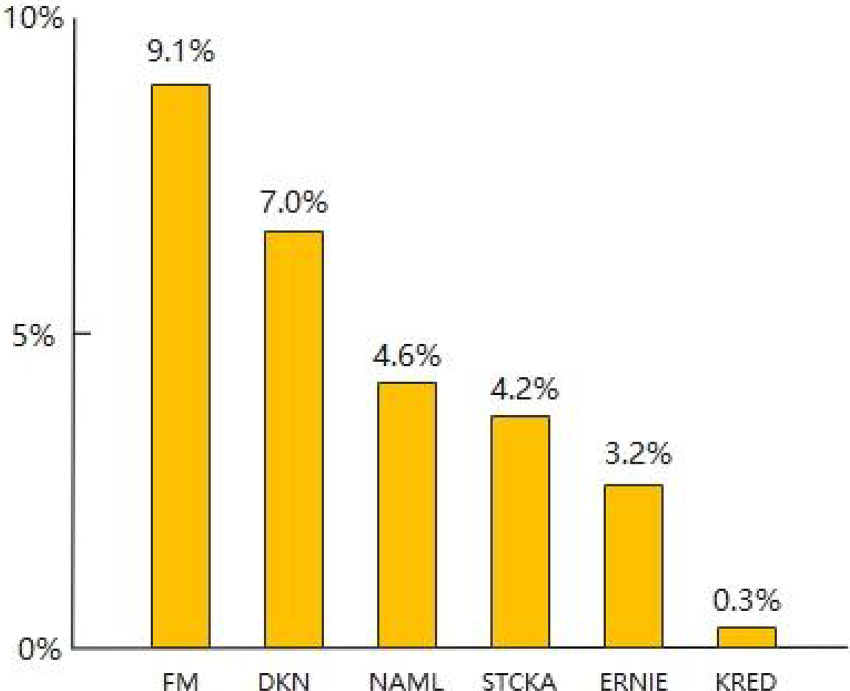
Improvement rate of RTD in NDCG@10 index compared with other benchmark models.
It can be seen from Figures 7 and 8 that the proposed RTD model has the most improvement compared to the benchmark model FM in terms of AUC and NDCG, mainly because FM models differ from other deep learning models in that they use manual identification features as input, and in practical work, it is considered that the operability of identification features is not as good as the automatic identification features of deep learning. The second is the DKN model. Although DKN, STCKA, and ERNIE are three different types of knowledge-aware document understanding models, DKN only outputs the title of the article. When the title of the article does not match the content of the article, its recommendation system will be reduced (Figure 9).
By comparing and analyzing the results of experiments conducted on datasets between the proposed model RTD and other benchmark models, it can be concluded that RTD has higher performance than the other six classic benchmark models, and has a higher improvement compared to FM and DKN. The main reason is that the information used by FM is not comprehensive enough. DKN uses KG, but only outputs the headlines of news, and the content of news is not fully utilized. The model RTD in this article uses the idea of KRED to fully utilize the content of the entire news text, thereby improving the comprehensiveness of the information used in the model. Compared with NAML, RTD adheres to the idea of KRED and judges the frequency, category, and location of other entities in news text, which makes it more advantageous in processing entity details in news text. STCKA, ERNIE, and KRED do not consider the credibility of entities. During training, all entity information of news text is calculated, and the purpose of news article vectors is not strong. As shown in Tables 2 to 4, there are two judgment conditions
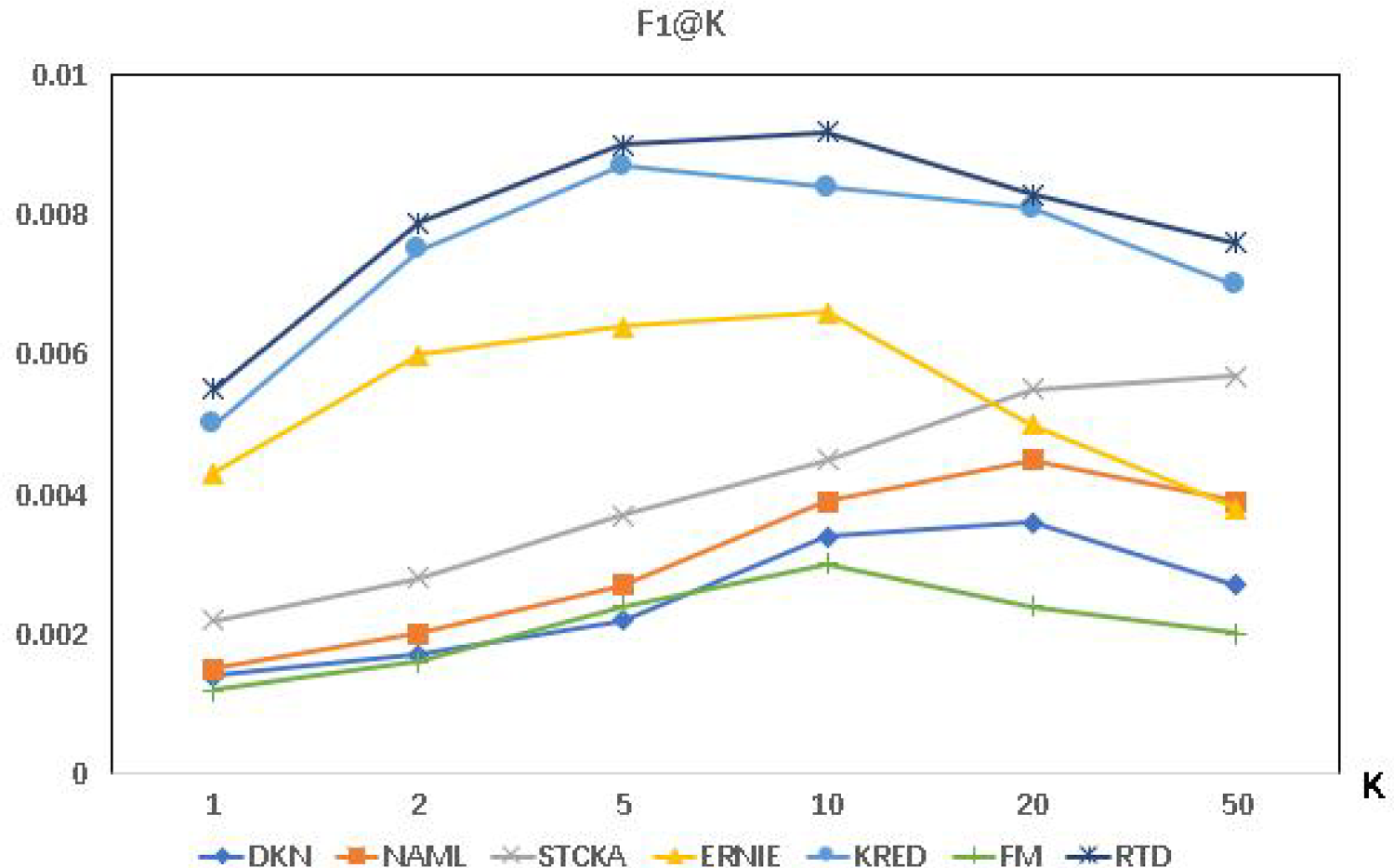
F1@K in top-K recommendation for MicrosoftNews3.
Comparison Results With Other Baseline Methods.
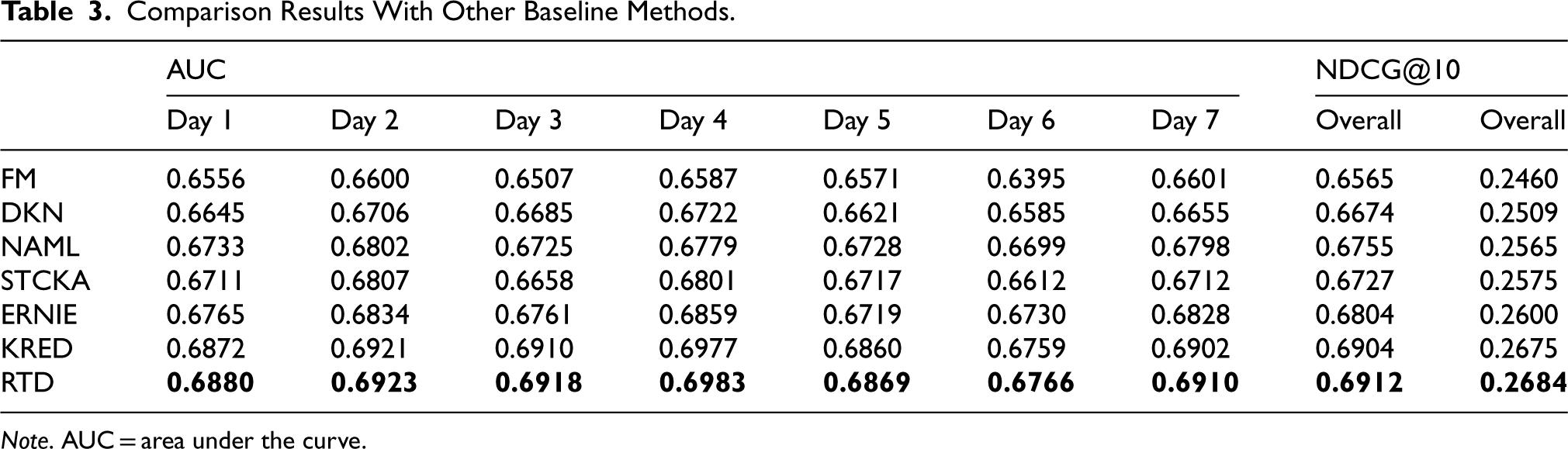
Note. AUC = area under the curve.
Deleting Any Criteria Will Degrade Performance.

Note. AUC = area under the curve.
We provide a case study on how to approximate the weight of relational entities in the article. As shown in Figure 1, the core view expressed in the article is that it is wrong for the United States to launch the war in Iraq, but because of the statements made by militants many times in the article, “the war in Iraq is correct,” it is likely to lead to the excessive weight of statements that are correct in the war in Iraq during the training process. Thus, the general meaning of the article is misinterpreted. To solve the above problems, we may consider extracting the statements with excessive weight and comparing them with other articles in the same event to see whether the weight of the statements is similar to that of the relevant statements in other articles. If not, reduce the weight of this statement in the article.
Conlusions
We propose a stability model to evaluate the credibility of each entity and its relational entities. The concept of credibility: that is, the impact on the semantics of the article is almost zero, or the entity vector and its relational entities that may distort the general meaning of the article in the semantics of the news article are eliminated. It puts forward a two-layer confirmation model. That is, a double evaluation standard is added to the credibility. Each entity and its related entities must meet two conditions at the same time to be judged not to be eligible. Our research is mainly applied to news recommendations. A large number of experiments show that our model is superior to other baseline models. In the future, we will further study the problems raised in the case of the above research.
Footnotes
Funding
This work was supported by Xihua University Science and Technology Innovation Competition Project for Postgraduate Students(Grant No:YK20240148).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.