
Abstract
Knowing how to traverse complex unstructured environments is a difficult challenge, that humans achieve through logic, reasoning, and experience; yet some of the most beneficial use cases for autonomous systems require them to operate in complex environments without regular human intervention. Furthermore, for machines to support humans in such use cases, trust in decision making will be crucial, ensuring operators have confidence to deploy the capabilities. Despite its importance, enabling autonomous agents to navigate effectively and reliably in complex terrain remains an unsolved challenge. Advances in neurosymbolic artificial intelligence present an opportunity to enhance performance in complex, explainable, and uncertain decision making, such as autonomous traversability analysis. The challenge of complex environments is complicated by its non-deterministic nature; terrain will adapt and change through domains, and its properties can adapt rapidly based on external factors like weather or objects that are in proximity, which is true for one location on one day, will not persist. This article presents a new neurosymbolic model structure that was designed specifically for this task. It uses experience to build a world model, similar to that of a neural network, but with some key delineating features such as full explainability, through life adaptation or evolution, and zero-shot capability. This provides the reasoning backbone for an autonomous agent to determine the level of risk each object presents based on its context and therefore determine the best possible route.
Keywords
Introduction
Autonomous systems present an opportunity to transform the way humans complete some of the most dangerous, unpleasant, or persistent tasks, especially within domains such as Defence or Search and Rescue. These use cases present some of the greatest beneficiaries of autonomous systems, but have some of the most demanding requirements, most notably the ability to operate reliably in very complex terrain and dynamic domains, while maintaining a high degree of trust by their operators to complete their task at hand. Robustly operating in complex environments requires platforms to operate in both unstructured and uncertain terrain, where clear transition points between features may not exist, with high variation in slope, roughness and unpredictable terrain features like holes or depressions (Seraji & Howard, 2002; Silver et al., 2010; Siva et al., 2019). Furthermore, the characteristics of an object cannot be determined effectively without understanding the context in which it is found. Navigating requires inductive and deductive reasoning, an understanding of the environmental conditions, probabilistic judgement, and the ability to handle uncertainty. When considering autonomous agents, neither a symbolic nor a neural approach replicates them all sufficiently. Neural approaches generally fail to reason effectively and suffer from a lack of explainability but can be adaptive to out-of-distribution data, while symbolic approaches can reason but require a significant upfront knowledge base and cannot effectively generalize. Fundamentally, performing these activities within an autonomous platform is not a simple extrapolation of either approach. The traversal of complex environments remains an outstanding challenge in the field of autonomous systems (Fan et al., 2021; UK MOD, 2022).
Navigating complex terrain can be considered across a number of fields of research, such as perception, localization, cognition and motion control (Panigrahi & Bisoy, 2022). This article focuses on cognition and specifically on how to enable an agent to determine the traversability of a target object. When considering the prediction of traversability for a given object within complex environments, the continuous, layered structure of individual objects means that the assessment of an object in isolation is insufficient for making an accurate prediction. The images in Figure 1 show an example of two separate examples of the same trail object, both of which have separate performances, caused as a result of the adjacent objects. Furthermore, terrain characteristics are not consistent in all domains and environments; the performance of grass changes if it has rained in the last hour, and in winter, this may be the last day. As a result, such environmental information is the context and parameters of the overall prediction. Consideration must also be made to the rapid domain evolutions and inconsistencies required when operating within such an environment, meaning traversability predictions must have a broad generalization capacity, enabling routine handling of previously unseen situations.

An example of two instances of trail objects with their surrounding context, resulting in separate risk assessments.
Vehicles will operate in close proximity to humans who, for both safety and functional reasons, need confidence in actions and to understand why a decision is to be made. As a result, operator trust must be considered within any agent cognition. This constraint makes any potential for context prediction within a conventional neural network-based solution (Gasparino et al., 2024; Jung et al., 2024; Vecchio et al., 2024; Visca et al., 2021) a barrier to practical deployment, as any decision justification would be concealed within the black-box nature of the model, inhibiting explainability. Conversely, explicit reasoning and logic are easier to interpret than neural architectures (von Eschenbach, 2021), as reasoning transcends the originator; it is communicable and can be understood externally (Mercier & Sperber, 2011). Through explicit reasoning, operators can interpret decisions and understand errors, making the prediction more deterministic and increasing trust (Ingram et al., 2021).
This concept paper builds on the concept of the World Model (LeCun, 2022), using neurosymbolic methods (Kautz, 2022) to develop a human-like approach to solving the challenge of autonomy in complex environments. It presents a model structure which enables an agent to make traversability predictions that account for an object’s context, learn dynamically with new experiences, and use causal relationships to generalize across evolving domains. This article outlines BeliefNet, a model designed to support explainable context-based prediction for complex environments.
BeliefNet uses a symbolically built neural architecture to form experience-based beliefs, overtime generating causal relationships between a target object, its context and traversability risk. The model is designed to train through life, learning with an agent’s experience, enabling adaptation to new environments. The model seeks to extrapolate causal relationships, enabling it to generalize effectively to different domains. It uses belief-based inference to form deterministic and explainable predictions, improving prediction accuracy, domain adaptation, and enhancing operator trust.
The contributions of this article are as follows: The proposal of BeliefNet, a Neuro[Symbolic] model structure for context-based traversability prediction for autonomous systems. A demonstration of the performance of BeliefNet in an adapted version of the Yamaha CMU (Wang, 2021) dataset, to increase the performance of agent cognition in complex environments. Comparison of context-based terrain traversability prediction and object-based prediction. A high-level traversability taxonomy for ground platforms based on risk and speed.
Traversability Assessment
The field of traversability has received significant attention in recent years, leading to the development of three primary approaches emerging to conduct traversability assessment: terrain mapping, terrain classification, and end-to-end solutions (Beycimen et al., 2023). Lidar analysis has been used extensively in traversability mapping approaches, both in direct obstacle avoidance (Larson & Trivedi, 2011; Su et al., 2021), or in more complex feature segmentation (Agha et al., 2021; Himmelsbach et al., 2010; Xie et al., 2023). While delivering promising results, such approaches are spatial in nature, potentially over simplifying the traversability calculus by ignoring the environmental and situational semantics. Furthermore, the active nature of Lidar presents challenges in use cases where light emissions have negative secondary effects.
Terrain classification presents a method to incorporate semantics. Advances in computer vision, with the introduction of models such as YOLO (Redmon & Farhadi, 2017) and approaches such as vision transformers (Dosovitskiy et al., 2020) and panoptic segmentation (Yang et al., 2022), have made this increasingly feasible, allowing real-time inference on edge-based devices. The use of computer vision enables terrains to be segmented into constituent objects, from which semantic labels and classes can be subsequently assigned. As the terrain classification of complex environments is non-trivial, resulting from the discontinuous nature of objects, feature overlap, and environmental conditions (Manduchi et al., 2005), this continues to be an area of active research (Agha et al., 2021; Castaño et al., 2017; Chavez-Garcia et al., 2018; Filitchkin & Byl, 2012; Fritz et al., 2023; Hodgdon et al., 2021; Siva et al., 2019; Valada et al., 2017). Vision and Lidar modalities have been combined to integrate visual semantics with the spatial representations of Lidar (Maturana et al., 2018).
Terrain classification is formed of two distinct components, first detecting and isolating a specific object within the scene, then assessing the traversability of the object. Although some, such as Agha et al. (2021) have integrated both components, most of the research focuses mainly on accurately determining the object, not assessing the traversability. One challenge in this approach is that it can neglect the need to consider the environment and context of a specific object, ignoring that some objects will directly impact the traversability of others. Without such context, it can be challenging to make an accurate and reasoned determination, which is exacerbated as the complexity of the environment increases.
End-to-end deep learning approaches have had success in classifying the traversability of an image (LeCun et al., 2005; Visca et al., 2021). Self-supervised approaches, in which a platform trains a model based on self-extracted features to predict the traversability of the terrain (Seo et al., 2023; Sevastopoulos et al., 2019), reduce the volume requirements for labeled data to some degree. Such approaches can be limited in generalization performance and crucially limit explainability due to the conventional neural architecture of end-to-end deep learning approaches. The use of image segmentation, coupled with self-supervised learning, presents a method to increase explainability, but the computational requirements are prohibitive and the explicit impact of object context is not explicit and unclear (Jung et al., 2024). Although research into traversability assessment for complex environments has been significant, it remains an open area of research and one in which significant advances are required to enable autonomous systems to complete the desired tasks.
Agent Cognition
Agent cognition within the field of robotics to model actions with high levels of uncertainty has had significant success using probabilistic methods. Markov logic networks (MLNs) in event modeling have been used successfully to classify events from images based on their context (Kardaş et al., 2013), but suffer in complex environments due to cross-domain adaptation, handling partial rule activation, and probabilistic complexity (Chen et al., 2024; Khot et al.). Markov decision processes (MDPs) have also been used in path planning and path trajectory, with partially observable MDPs (POMDPs) used to handle increasing levels of uncertainty and complex environments (Lauri et al., 2023). Belief states have been integrated into POMDP to extend planning horizons and mitigate the impact of partial observability (Gürtler & Kaminski, 2025; Kaelbling & Lozano-Pérez, 2013). Applications in robotics and autonomous systems focus primarily on action selection. In which state estimation is used to determine the best action to take across a given planning horizon, formulation of the reward for a given action (such as its predicted traversability value) is often adjacent to the model. Probabilistic programming using tools such as ProbLog has sought to overcome the complexity limitations faced by MDPs and MLNs, such as probability modeling and handling uncertainties in predictions (Nitti et al., 2015; Sztyler et al., 2018), but requires a firm logical foundation, which may not be easily available in complex environments.
The concept of a belief within Bayesian epistemology considers that beliefs are not consistent, and the degree to which a belief is believed is adapted to the available body of evidence (Lin, 2024). Pearl emphasizes the centrality of causality in beliefs, expanding beyond correlation (Pearl, 2009). Pearl introduces a three-layer model that supports causality in the concept of machine learning: association, intervention, and counterfactual; progression through these layers supports the classification of causal information and improves the degree of confidence in a given belief (Pearl, 2019). Graph structures have presented a method to effectively communicate causal relationships between entities, noting that such relationships are not hierarchical or linear (Lipsky & Greenland, 2022). The application of causality to machine learning has recently been identified as a method to significantly increase generalization and cross-task adaptation. It presents a complex challenge due to the nature of feature extraction from data. Scholkopf et al. presented a number of potential approaches, such as self-supervised learning and reinforcement learning. This research outlined the importance of observation and intervention in learning causal relationships (Schölkopf et al., 2021). The applications of causality have been applied to learn causal relationships and apply them within inference (Rakesh et al., 2018; Yang et al., 2021; Zhao & Liu, 2023). Causality within artificial intelligence (AI) presents significant promise, though limited within this challenge by the data volumes required by approaches such as autoencoders. The application of a priori knowledge to autoencoders has been applied by Komanduri et al. as a method of reducing upfront data requirements (Komanduri et al., 2022).
Advances in probabilistic modeling and decision making have had a significant impact on robotics, but the high levels of variability in object class, prediction confidence, object separation, and adaptive domains seen in complex environments make logical grounding and the application of finite rule sets insufficient to effectively model the complexity. The consideration of belief states and partial observability is very relevant to context-aware traversability. The state estimation is considered not as the state of the agent given an action, but estimation of the state of beliefs held about an object, it’s context, and the resulting traversability. The ability to make predictions with partially observed inputs and an incomplete understanding of object interactions, while being able to update understanding when new information is available, is very pertinent to complex environments and domain adaptation. The concepts of beliefs and causality are also of benefit to this problem set, supporting an agent to both learn from new experiences, and supporting generalization when facing uncertainty, both of which are common in complex environments.
Neurosymbolic AI
Neurosymbolic AI is a promising area of research in machine decision making, explainability, and reasoning (Bhuyan et al., 2024). This area of research presents architectures to integrate the reasoning performance of symbolic reasoning and the learning power of sub-symbolic, connectionist or neural network-based approaches (Kautz, 2022), based on the system-1/system-2 approach defined by Kahneman (2011). The field is still growing and there remains diversity in approaches, but all have in common the structure of perception, integrated with existing knowledge (Sheth et al., 2023), and their explainability and reasoning performance make them particularly beneficial in use cases with high levels of human–machine interaction (Barnes & Hutson, 2024). Within the broader field of autonomous system navigation, neurosymbolic architectures have been used to integrate physics rules into a neural network to determine the vehicle dynamics required to traverse a given path (Zhao et al., 2024). Neurosymbolic architectures are commonly represented by six core approaches (DeLong et al., 2025; Kautz, 2022), two of particular relevance to this article are defined as NEURO;SYMBOLIC and NEURO[SYMBOLIC] (Kokel, 2020).
NEURO;SYMBOLIC represents a system in which a symbolic and neural systems work in concert with each other, communicating and passing information between them, to achieve a common objective (Kautz, 2022). Examples of this are knowledge graph integration with neural networks (DeLong et al., 2025) that allow a neural network to query, input to, and validate symbolic knowledge graphs. NSNnet, which passes between neural and symbolic modules in an attempt to solve hand-written Sudoku challenges, presents a unique perspective that maps both input and output to a non-symbolic output, with a central symbolic reasoning engine (Agarwal et al., 2021). Both examples are dependent on a core level of symbolic reasoning. The neuro-symbolic concept learner (NCSL) is designed to unify text and visual concepts through the learning of image and question-answer pairs (Mao et al., 2019). This model presents an interesting advance as it enables symbolic concepts to be learned, without implicit knowledge being defined upfront.
In contrast, the NEURO[SYMBOLIC] system is one in which a neural network learns to reason about relationships between neural entities (Kautz, 2022; Lamb et al., 2020), in effect forming a neural network of symbolic entities. This is perhaps the most complex and least mature area of research within the field. Logic tensor networks (LTNs) and logic neural networks (LNNs), which form networks from symbolic relationships and enable weighted training of the relationships using back-propagation based on a set of first-order logic statements (Badreddine et al., 2022; Riegel et al., 2020). The pLogicNet model mostly precedes the core definitions of neurosymbolic AI and represents a method similar to LTNs based on the application of MLNs (Qu & Tang, 2019). The LTN and pLogicNet are designed to improve, validate, or deconflict a set of a priori logical statements. The challenge with these approaches when applied to an agent-based approach is that they require upfront knowledge that may not be practical to achieve. Models such as the neuro symbolic reinforcement learner, INSIGHT, by Luo et al. use a neural network to learn symbolic policies that support the agent in its decision-making, enabling reasoning to be learned from the environment (Luo et al., 2024).
Neurosymbolic systems have shown significant promise in vision and multimodal tasks, such as visual question answering and scene graph generation (Bauer et al., 2025; Junaid Khan et al., 2025; Li et al., 2024). Despite success in these areas, multimodal neurosymbolic systems remain challenged in ensuring consistency between modalities as the deployment domain evolves (Lu et al., 2024). From an autonomous system perspective, this might have the most impact at the point that multiple sensors are combined into a single collaborative neurosymbolic architecture, such as the camera and Lidar, as shown previously, a common approach. Although this remains an open challenge, it could limit the breadth of neurosymbolic architecture application in autonomous vehicles.
The current state of neurosymbolic AI presents significant advances in both reasoning and explainability, the NEURO[SYMBOLIC] concept of a single neural network which encapsulates symbolic reasoning presents an opportunity to represent an agent’s world model. As with probabilistic approaches, current methods often rely on a set of a priori logic statements, leading to similar constraints on domain adaptation. As a result, BeliefNet has taken the concept of a symbolic network trained using sub-symbolic approaches, but in a manner that reflects the domain learning capabilities of models such as INSIGHT or the NSCL in which beliefs can be inferred from training. In the generation of beliefs, in opposition to rules, BeliefNet provides the ability to learn continuously from an agent’s experience, avoiding the constraint of domain-specific logic that fails to support out-of-distribution inference.
Approach
Overview
BeliefNet is a graph-based directed network in which nodes represent symbolic information, and unlike a neural network, the edges are not fully connected, but instead form relationships based on observation and counterfactual evidence. The network nodes and edges then act as neurons and connections in a neural network supporting weight optimization. This structure enables the model to make traversability adaptations with very small amounts of data when compared with a conventional neural network, while retaining absolute explainability in the model’s deduction. The relationship between a given set of input predicates and output results represents a belief within the model. Beliefs are something the system has some degree of confidence in being true (Newman, 2023), based on its own experiences. Conceptually, human beliefs continually evolve and adapt to our experiences and our current domain, and we learn through life. When we face something unknown, we find the set of closest beliefs, use them to make a prediction, then create a new belief that captures the separation between the prediction and the truth, often captured within the concept of predictive coding (Millidge et al., 2023). It is this function that the BeliefNet model looks to model; conventional neural networks struggle with this approach requiring full validation after each evolution. In contrast, the graph structure of BeliefNet makes domain adaptation and counterfactual generation a deterministic function of the model throughout its use.
The BeliefNet model is designed to operate post perception, so it can be agnostic to the object classification model, or even the modality. It is also capable of integrating new predicates into the model, which means new classes can be added to a perception model, and these will be incorporated into BeliefNet as they are experienced. The model is built logically before training, in which connections between objects, their context, or existing relationships (in the case of counterfactuals) are generated dynamically. After which, a forward pass through the model is made, followed by optimization and back-propagation using a conventional loss function. This can be achieved using a conventional upfront training set and continued further as the agent experiences its environment, providing an intervention mechanism overtime generating causal beliefs. Combined with the symbolism retained within each node, the structure provides the ability to activate only relevant sections of the model during inference, aiding explainability and providing reasoning in unknown situations. This approach acts as a zero-shot domain adaptation model, without the need for the high data volumes conventionally required through existing zero-shot approaches.
The model is designed for human interaction. The symbolic nature of the nodes and deliberate relationships means that any prediction can be traced through the model directly and that contributing nodes can be clearly identified. This enables operators to interact with the agent’s cognition in novel methods, which are likely to significantly enhance trust. Operators can clearly determine why a decision was made, and can actively correct the result and use this to directly train the model. Furthermore, if they hold logic that had not yet been experienced by the model, this can be integrated as testimonial knowledge, within the network directly. As a result, BeliefNet presents an approach capable of context-based traversability prediction and the ability to generate trust between the agent and the operator.
High Level Structure
The model is formed of a number of components, some of which are adaptations of existing deep-learning approaches and some which are specific to BeliefNet. At a high level, the model should be considered as post-processing of a perception model, it initializes by taking the perception output and transforming this into a graph structure, known as an instance graph. The instance graph is generated as the output of a semantic segmentation model, such as YOLO (Jocher, 2020). The predictions are further enhanced through a depth perception model (Bhat et al., 2023), estimated three-dimensional (3D) separation between objects, and augmented with environmental tags that represent the weather, light, and domain. The instance graph is a dense symbolic representation of a given image. During training the instance graphs are converted to a series of context graphs, representing a target object and the surrounding objects, distances, and environmental tags for a given object for which a prediction is made. Context graphs are passed to the building algorithm, which is a custom training method designed to extract causal relationships between objects, context, and a traversability value. This will occur even during inference, enabling new relationships to be formed as they are identified. This forms the basis of the network; each node has an activation function, bias parameter, and each edge has a connection weight. To make a prediction, the predicates within the context graph are activated and propagated through relationships in the graph, generating values at the output nodes. When training or when provided with feedback, the optimization step occurs, which uses conventional back-propagation, such as the Adam algorithm (Kingma & Ba, 2015) to adapt the weights in a supervised manner. It is the combination of the logical build process before the back-propagation which provides the reasoning capacity and explainability of the structure. The architecture in Figure 2 visually shows how these components fit together within the model.

Model architecture, the high level architecture of the model is based on the structure of a neural network, but with adaptations to enable the symbolism to be retained throughout training and inference.
Context Graph
The context graph represents a target object for which a prediction is to be made, the relevant object, and environmental tags detected in proximity to the target object (the context) and how they each relate in proximity and position. It is the context graph which acts in effect as the input data to the core belief-net model. Within a given instance, there may be multiple objects about which a traversability assessment may want to be made. For each of these, a context graph (
Each edge

By way of an example, consider a target object





BeliefNet is fundamentally a supervised model, relying on labeled samples from which to learn. Context graphs are labeled with a traversability index value. Such a value could be infinitely complex and very specific to an individual agent’s performance characteristics. To increase generalized performance, a level of abstraction was selected which outlined the behavioral impact, rather than physical or mechanical. The developed traversability index categorizes expected speed (relative to an agent’s default) and the level of caution the agent will require in their traversability. The traversability risk analysis framework proposed by Fan et al. (2021), in which multiple metrics such as risk of collision, slippage, and contact loss are combined into a single risk measure, serves as the basis for a unitary caution value. Although traversability risk can be a regression problem (Inotsume & Kubota, 2022), discrete values are required for classification. Through the abstraction of metrics into behavioral categories, 11 distinct values were defined enabling relative traversability across platforms to be compared. These values are shown in the diagram in Figure 3.
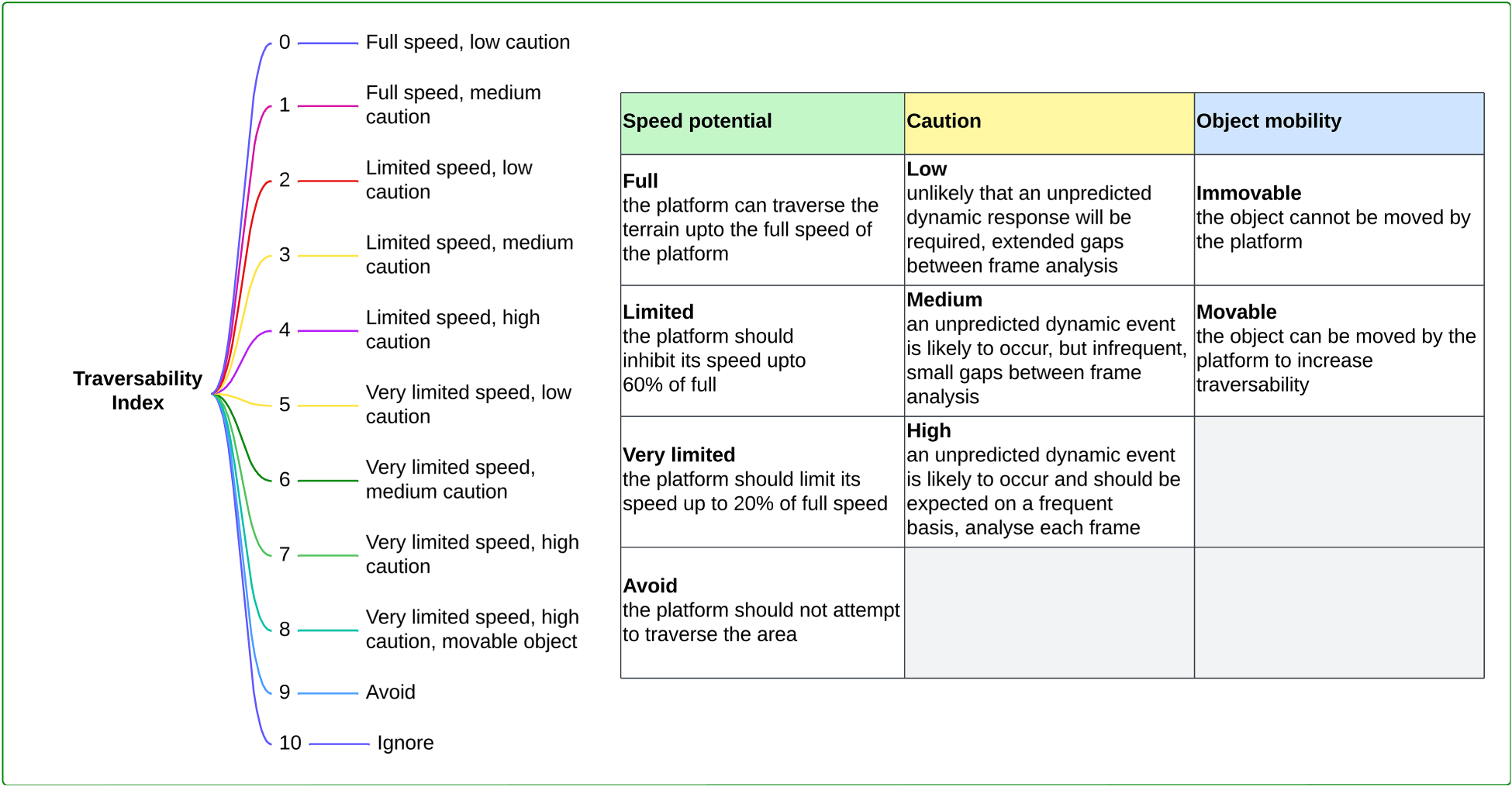
Traversability index, there are 11 discrete traversability components, which increase in complexity as defined by the variables in the right hand table. These are categories that dictate the relative speed, level of caution the platform requires and the mobility of an object. In this context, caution can be represented as the frequency of cognitive analysis, low caution objects can hold a greater frame separation between detailed processing, than high caution in which every frame may be analyzed. They are assessed based on the individual perception of a single platform, therefore these cam be considered relative to the performance characteristics of an specific platform.
Labels are assigned to a context graph in two ways, depending on the phase of training. Firstly, human labeling enables a foundational training set to be developed, in which the target objects are assigned a relevant label based upon their context. This is used for initial supervised learning, where a large dataset is of value. Secondly, the agent can self-label the target objects based upon direct traversability experience. BeliefNet provides a prediction of the behavior expected when traversing a given object. Once traversed, using methods such as those outlined by Zhao et al. (2024), the separation from expected behavior is used to generate appropriate labels for the context graph of objects. This method provides the data structures to support through-life learning of the model and the domain adaptation.
BeliefNet Nodes
BeliefNet is fundamentally based on a graphical structure of nodes and edges. As with a conventional neuron (Popescu et al., 2009), each node

There are three types of nodes within the model, which are loosely equivalent to a single neuron within a neural network: an input node

The belief nodes can have relationships with other belief nodes, indicating counterfactual or divergent beliefs. Overtime, this component enables complex reasoning and causal relationships to emerge. If a third predicate

The output nodes represent a specific output categorization. Output nodes are combined into layers, in which each node represents a traversability index value, and a the layer is indexed to the object being classified. This provides the model with the ability to classify multiple different objects with the same model backbone. As they are a multiclass classification output, each output layer is combined with a Softmax function (Bridle, 1989). It is important to note that the Softmax only applies to the specific prediction object output layer, not all outputs. This approach also sets the foundation for cross-task generalization, in which separate layers can exist for multiple tasks. Currently, it uses for object traversability risk layers; however, this could be more granular, with layers for variables like speed, roughness, and traction, each using the common model backbone.
The model

It is important to node that
By way of an example, suppose that the input layer is a set of three atomic predicates:


Then edges are defined between the nodes (details explained in the model build section).

Model Build Process
The model is designed to be persistent and adaptive throughout the lifecycle of an autonomous agent, meaning that it can be trained from no beliefs or use new instances, gained through experience, to update existing beliefs; both use the same build methodology. Conventionally, neural networks have an initialized architecture that remains constant throughout the life cycle of the model, enabling the use of matrix multiplication. However, this inhibits adaptability and explainability. As a result, BeliefNet integrates a build phase prior to weight optimization, in which relationships between predicates, beliefs, and outputs are dynamically formed, based upon presence within a supplied context graph. This occurs in the presentation of each context graph, which means that bulk training or experiential interventions retain the same capability.
The build process uses individual context graphs or instances

However, in the event that a partial belief node already existed, it would create a edges with the existing partial node, such that:


The model build can be augmented with a priori knowledge during the build phase, where testimonial knowledge can be represented in effect in first-order logic. Relationships between specific predicates can be unified as knowledge with a direct relationship to the output node. This alone would not be sufficient to capture knowledge; therefore, knowledge nodes are initiated with high default parameter values for the weights and biases, often 1, this value has obvious impact on the model, so the value must be tested based on the domain. These parameters can be included or excluded from the optimizer, meaning they can be fixed or adapt with back-propagation. This represents the fact that knowledge could be permanently infallible, which is useful for human defined ‘‘red lines,” or could be feasibly disproved by future evidence. Both are viable options within the model. This feature enables the model to draw on some of the benefits of tools such as the LTN (Badreddine et al., 2022), which reasons over a corpus of provided knowledge, while allowing the system to add or adapt this knowledge based on induction. Unlike comparative models, this is optional and not a pre-requisite, the model can be very performant without the addition of knowledge.

The concept of relevant beliefs is also a separation from conventional ML, which has been seen in neurosymbolic AI through the freezing of specific input nodes and network dissection (Mileo, 2024). The input layer is considered to be all atomic beliefs (those of the lowest fidelity) from a given context graph; only the atomic beliefs represented in the graph are activated; this is propagated through the network. Conventionally, layers in a model are defined by depth; however, as each union of predicates adds additional information to a belief, this is referred to as the fidelity of a belief. Activated atomic beliefs are combined recursively to activate or partially activate higher-fidelity beliefs. Any node that has been activated or partially activated can be considered a relevant belief. In the output layer, all relevant beliefs are passed to the activation function (Figure 4).


An example of the dynamic activation based on relevant beliefs, and how this propagates through the model.
Once the model is built, the model weights are then optimized using conventional back-propagation techniques. Relevant beliefs are activated by passing a scaled distance value, represented within the context graph, where
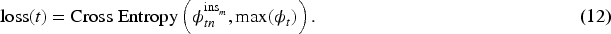
The generation of an output also has some key separations from a conventional neural network. As mentioned above, no matrix multiplication is conducted as part of the inference process. Although this could have a performance impact, this is offset by the overall sparsity of the model; for a given inference, there may only be a small proportion of the overall model activated at any time. However, the output nodes still need to draw on the precursor nodes to formulate an output. This is done through recursive activation of nodes, in which each node calls back through the network, extracting the output of the relevant beliefs


A key feature of the model structure is the inherent traceability through the model to determine the factors that have led to a given prediction. This can be advantageous in highly regulated domains or environments where human–machine collaboration may be high. The traceability is a direct by-product of avoiding fully connected layers, meaning that an individual belief or input node can be simply and deterministically assessed for its contribution to a given output. The model nodes retain their previous outputs in state, meaning a critical path to prediction can be traced from each output node to the input node by recursively presenting the highest


The models graph explanation function showing the top 5 critical path contributors to the overall output, this is visualized graphically. Contributions are calculated recursively, with each layer showing the contribution to the subsequent node.
To test the BeliefNet approach, we applied the model to a traversability scenario in which it was presented with a pre-segmented and labeled image, and sought to correctly classify the traversability of specific objects within the image. Within this scenario, we sought to test three factors: Terrain classification comparison: How does BeliefNet compare to a static value approach, a graph neural network approach, and a random forest classifier? Data size comparison: How does BeliefNet compare to a graph neural network and random forests as the size of the training data increases? Activation function comparison: How does the model adapt with different combinations of activation functions across the model layers?
A comparative test to an end-to-end model was not conducted, due to a reliance upon both Lidar and imagery for most approaches, and the comparison of a segmented classification and pixel/voxel classification is not a simple translation.
The experimentation dataset is made up of a layered ontology used to label the Yamaha CMU data set (Wang, 2021) to better reflect the complexity of the environment. This enables object class, environmental meta-data, and class properties to be analyzed by BeliefNet. The ontology is hierarchical, with classes, subclasses, and types, increasing the overall class numbers from 11 to 72. Enabling fidelity such as
Methodology
The test was targeted at generated responses for the “grass,” “hardcore,” “soil,” “sand,” and “paved” ontology objects, which are the primary traversable objects. Multiple instances existed per training image, meaning that in total there were c.350 training samples. This is a small amount for a traditional complex network, but represents a reasonable amount of varied terrain data that an autonomous system could realistically gather about a given domain. It enables us to test the ability of the model to adapt to smaller perturbations in the domain and data. The test set was extracted as 20% of the overall training set. At all points in the test, this was used to ensure comparability. The random samples were then taken from the training set in increasing increments from 25 samples to the entire data set, and the models for each set were trained. Each model was then tested against the test set and the accuracy was judged on the correct categorization of the risk value against the human adjusted value. This was repeated 15 times and averaged for each model, with a new random test set identified for each iteration. The data holds large variability; due to its size, randomly selecting test data through multiple iterations ensures a broad set of complex challenges, especially zero-shot prediction, are represented in the test.
The comparison models selected were a random forest and a graph neural network (GraphSAGE) (Hamilton et al., 2017) combined with an XGBoost (Chen & Guestrin, 2016) classification head. The methodology for selecting these models was that they separately present a neural and a symbolic approach fit the problem, and in initial testing against a broad set of models demonstrated the most potential for extracting sufficient information from a context-based data structure, when compared to models such as a linear neural network or XGBoost alone. A key contributor to this was the volume of data the experiment was constrained to; this was a conscious choice to ensure any outcomes represented how the model could feasibly be used on a platform. Existing end-to-end approaches favor a continuous traversability classification, rather than discrete, making direct comparison not feasible. The input to BeliefNet is segmented objects from a detection model; for a conventional terrain classification model using state-of-the-art segmentation capabilities such as YOLO architectures (Jocher, 2020) or vision transformers, this object would be allocated a direct traversability value; this is, directly equivalent to the baseline traversability value. As a result, the baseline comparison value represents the performance of such approaches.
Metrics
As the overall classification metrics in this case are risk-based and incremental, performance can also be assessed by assessing the distance in separation between the predicted and actual values. A model that gets its predictions closer to the actual classification performs better than a model that is further away. To capture this, we will look at both an absolute classification and a fuzzy accuracy, which assesses the score as
Variables
The baseline accuracy is using the default values for an object based on its ontological class and value, compared with the human-edited values; this would be heavily skewed by sampling, so a consistent baseline from the full dataset was taken as 23% absolute accuracy and 43% with fuzzy accuracy.
In addition to the baseline values, we tested three additional approaches: BeliefNet model as described in this article. A random forest classifier (Breiman, 2001), which was chosen to as a comparator due to its reasoning capacity with small datasets, and its ability to explain its results, making it the most similar in output to BeliefNet A graph neural network, GraphSAGE which uses an LSTM-based architecture (Hawthorne, 2021) to learn and generate context graph embedding and then passes the embedding to an XGBoost algorithm, acting as a classification head, to conduct supervised classification (Chen & Guestrin, 2016).
When BeliefNet was trained to predict the outputs of the traversable object classes in the ontology (grass, hardcore, soil, sand, complex, and rock), using the full dataset it achieved 47% absolute and 81% fuzzy accuracy; this did not include a priori knowledge. When scaled with the dataset, this is, performed as shown in Figure 7. This test was repeated with only grass objects, as these present the highest proportion of the dataset and are terrain characteristics with the highest variation in the traversability index within the class; the results of which are shown in Figure 8. The average results for each model are shown in Table 1. The comparison between baseline and BeliefNet against multiple prediction objects can be seen in Figure 6, noting that the number of samples is not consistent between object types, which is related to the increased variance in some objects over others; for example, the low grass distribution is significantly lower than tall grass. In the more challenging object, tall grass, due to the higher variation, BeliefNet outperformed the baseline in both absolute and fuzzy accuracy.
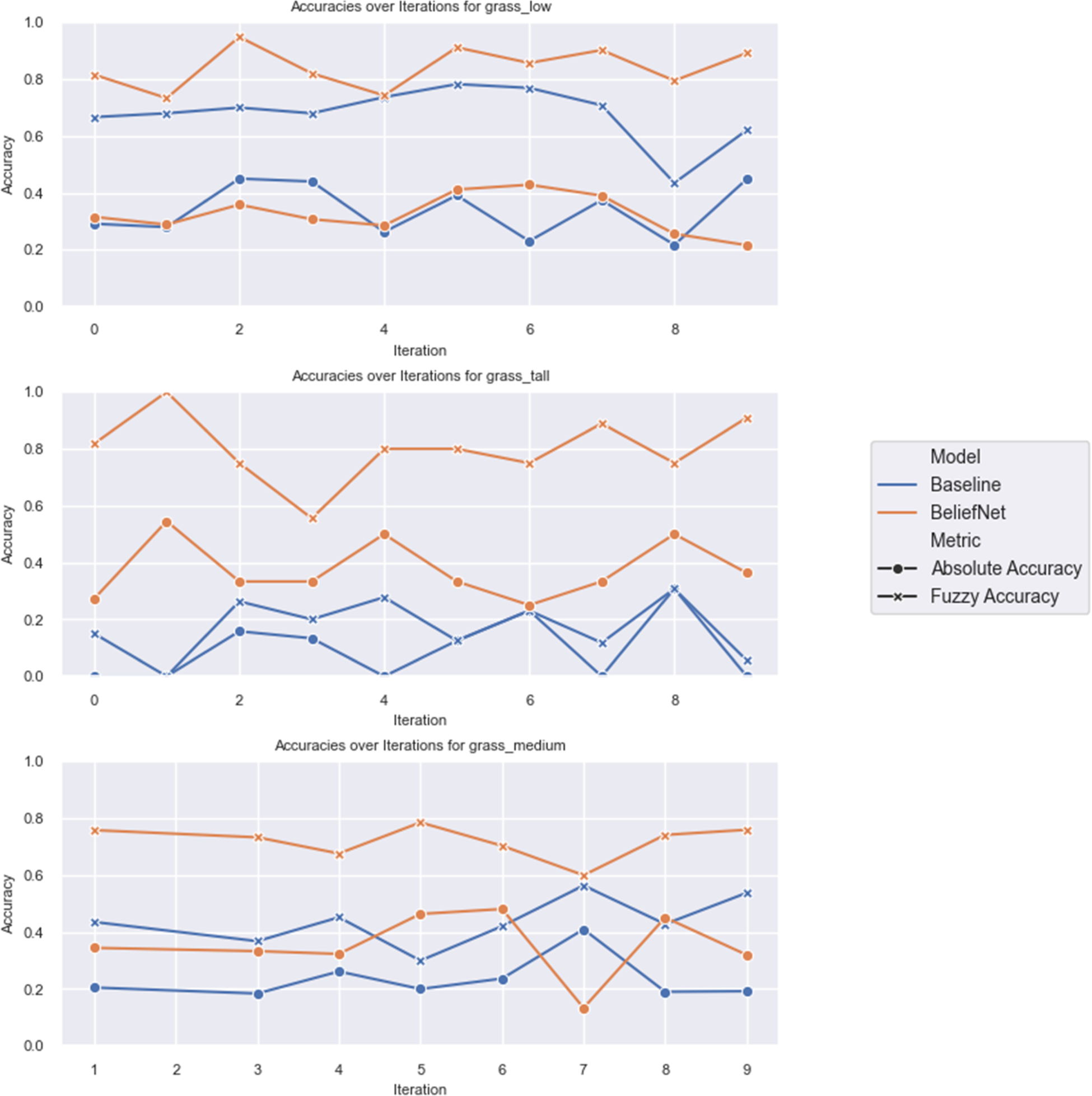
Experiment comparison of BeliefNet and the baseline absolute and fuzzy accuracy for individual grass prediction objects, the variance in prediction value increases in objects left to right.

Experiment comparison of BeliefNet and a random forest, with a scaled dataset comparing classification of objects “grass,” “sand,” “hardcore,” “complex,” and “soil” risk classifications.

Experiment comparison of BeliefNet and a random forest, with a scaled dataset comparing classification of grass objects
The Summary Results Using a Full Dataset Over 15 Iterations With Random Test Sets for Each of the Test Models.

The graph embedding model failed to learn effective patterns within the data; this is, likely due to the additional abstraction generated by the embeddings and the small amount of data for a given prediction, preventing the model from being able to generalize effectively. This resulted in the model returning the same value for instances of a given terrain and not identifying any factors that would shift the risk. Even after training using the full dataset, the model returned an absolute score of 33% and a fuzzy score of 52%. The GraphSAGE model is the comparator to a conventional neural network; the inability to converge on a solution demonstrates the importance of a neurosymbolic approach in a complex reasoning task.
The random forest was more successful and was able to make comparable predictions in both actual and fuzzy accuracy, with the full training data achieving 79% fuzzy accuracy, compared to 81% for BeliefNet, as shown in Figure 8. Furthermore, random forests present two additional downsides compared to the BeliefNet model.
The nature of random forests means that it is challenging for them to form predictions across multiple classifications and classification objects. As a result, each classification object, such as grass_low, required its own model. While this is a standard practice, it comes with a number of drawbacks; firstly, it prevents generalized concepts from being formed across multiple terrain types, in effect reducing the training data available to each model, and this will impact domain adaptation. Secondly, in practice, there will be an i/o cost to loading new models, which could be a bottleneck in situations with more than one traversable object. Given the volume of assessments required in a continuous terrain classification, this will have a significant cost. Some instances in the dataset had five target objects, meaning five separate models would need to be loaded for one image. In contrast, BeliefNet is capable of having multiple output layers simultaneously for a single model backbone. This means that the model is able to draw generalized concepts rather than terrain-specific ones, which provides significant advantages when the domain ontology adapts. This can be seen in the data; a random forest was trained for each object, meaning that throughout the training it has always seen a representation of the object previously, whereas it is possible that BeliefNet makes classifications with no prior knowledge of an object. In all evaluation runs, BeliefNet would make a prediction on at least one class that was not in its training distribution. This represents a trade-off between accuracy and generalization and is demonstrated clearly by the separation between absolute accuracy in all prediction objects. Although this is a separation of 3%, it is likely that this is the benefit of having a specific model for each class. While this is beneficial, this is outweighed significantly by the model being able to make predictions on unseen data classes, as the BeliefNet demonstrates.
An additional advantage of BeliefNet over a random forest is related to the fixed inputs required for a random forest. The input data for the model are a fixed shape array with each item in the array reflecting a possible context object and the distance from that object. This has two drawbacks; firstly, in an ontology such as the one used in this model, with more than 70 objects, this results in a very sparse set of input data, which can lead to overfitting (Zhang & Lu, 2022) and may be a contributor to the flat learning profile. Secondly, the fixed nature means that the model cannot adapt to new objects identified within the domain. If a new object was identified, based on a new or adapted sensor classifier, the model would require retraining. In contrast, BeliefNet has a dynamic input length requiring only the predicates that are sensed to be passed, and it is designed to be extensible, and when a new predicate is identified, this can be directly integrated into the model. In this case, weights are initialized with a default value, but can then be fine-tuned, but in a manner which constrains the adaptation only to the relevant predicates, as only they are activated. This prevents having an adverse impact on existing and unrelated concepts. This flexibility and adaptive structure is core to BeliefNet’s domain generalization and establishes it as a through-life model, which grows with the agent’s understanding of the world.
To validate the performance characteristics of the model, we tested the grass sample set using a number of activation functions; in doing so, we were able to see how the model adapts over different combinations. Activation functions were assigned to the input layer and belief nodes separately, noting that they each had separate behaviors. Several functions were used: Leaky-rectified linear unit. Linear activation, in effect the identity of the input. Hard-sigmoid. Learnable rectified linear unit (ReLU), which was generated with a learnable scalar parameter
The experiment sought to identify any key variations in the results from the separate activation functions. Each combination was repeated 15 times and the mean results are shown in Figure 9, using a consistent learning rate of 0.001 and over 15 epochs of learning. The model performed consistently across the models. The best performing combinations were those that involved a linear function at the input layer. As the input is a function of distance, this suggests that the model benefits from retaining the symbolic information. The learnable activation functions performed well, but did not significantly outperform, suggesting that there are sufficient model parameters without the requirement to augment (Table 2).

Experiment comparison of BeliefNet using separate activation functions (input and belief node) when classifying the grass objects (
The comparison of varying activation functions across the accuracy metrics.
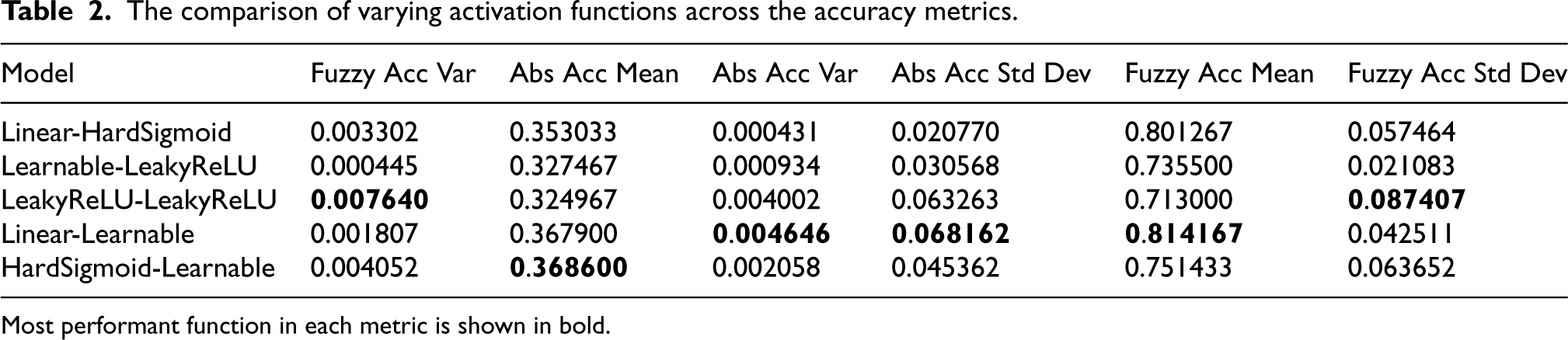
Most performant function in each metric is shown in bold.
BeliefNet presents an opportunity to provide a unified reasoning engine to support terrain traversal, in a manner which enables an agent to make an informed decision about risk and traversability. It is inherently extensible, meaning that it can use what it has learnt within one domain, and adapt this to unknown environments, and its inherent explainability means that operators can interpret, understand and impact decision making. This approach significantly increases performance when compared with the static value approach, and enhances the flexibility and explainability when compared to an end-to-end model. This article demonstrated the application of the BeliefNet model within an autonomous agent traversability reasoning task; however, this model structure has the potential to be applied more widely across similar tasks with high complexity and underlying logic, which may not be immediately accessible. This could be particularly relevant to domains with high-assurance or regulatory requirements, which traditionally AI struggles to meet.
Deployment Considerations
When the deployment of BeliefNet to an autonomous system is considered, there are a number of topics worthy of discussion. A key challenge of capability deployment to an autonomous system is that power and space are finite and broadly shared, and there are competing priorities. As a result, the computational overhead of any single system must be considered in the context of the system as a whole. As a component of the navigational system, BeliefNet will be expected to have comparable performance to a perception system likely running at >10 fps. Although explicit benchmarking of speed performance was out of scope for this research, the removal of matrix multiplication could have a negative impact on inference speed as the model scales. This was not seen within this experimentation, but could be mitigated by the set-based nature of nodes within the model, meaning that model size will grow logarithmically with experience. This could also be further enhanced through the addition of more complex conjunctives, such as NOT and OR, which could aggregate beliefs more succinctly.
When considering how BeliefNet fits within a deployed platform, it is valuable to consider the full information processing pipeline. This research explored the cognition element alone, but has dependencies on both the perception module and low-level control of the platform. BeliefNet does not require fixing to any given perception model, or require retraining if the perception model is. However, there is a critical dependency between the two models; for BeliefNet to make accurate context-based predictions, it depends on accurate classifications of objects within the scene. Classification errors could have a potentially greater impact on cognition output. While vision was the focus of this research, BeliefNet was intended to work with any classification modality. Platform low-level control both depends on and provides to BeliefNet. It relies on abstracted traversability values to predict the platform kinematics required to effectively traverse an object of a given value. Furthermore, once traversing an object, the performance of the platform, versus expected, provides a valuable feedback mechanism that can be used directly to inform optimization.
Further Work
This research outlines the potential for BeliefNet in the domain of complex environment traversability, but there are opportunities for further development, which could enhance its applicability. Firstly, extending the solution further to include the connection of a single, or multimodality sensor module would be the next step towards platform integration. This would also provide an opportunity for Lidar/vision combinations to test the capability of BeliefNet to collaborate across modalities. Secondly, considering the platform conversion of exteroceptive and interoceptive sensing outputs into a traversability assessment, thus creating a full learning loop for the agent, this could be another application of BeliefNet. Another area to be considered is experimentation with the learning rate for manual learning/human intervention such that learning is effective, without adversely skewing model outputs. Finally, this research into the model’s performance was completed against a single objective function; expanding the research to support multi-objective optimization would enable additional agency in more complex situations. For example, the ability for BeliefNet to support the risk/time trade-off when assessing tactical route planning.
Conclusion
In this article, we have defined the challenge of traversability assessment for autonomous systems when operating in complex environments, demonstrated the importance of context within predictions, and detailed BeliefNet as a novel neurosymbolic model capable of generating context-based predictions for traversability. BeliefNet is capable of learning through life from the experience of an autonomous agent, providing a method to enhance domain adaptation, and uses causal beliefs to support predictions in unknown situations. By retaining a symbolic structure within the network, it remains explainable and provides operators with the ability to interact with model training directly, enhancing trust. BeliefNet presents an advance towards enabling autonomous system deployment and performance in complex, demanding environments.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.