
Abstract
Association rule mining (ARM) is the task of discovering commonalities in data in the form of logical implications. ARM is used in the Internet of Things (IoT) for different tasks, including monitoring and decision-making. However, existing methods give limited consideration to IoT-specific requirements such as heterogeneity and volume. Furthermore, they do not utilize important static domain-specific description data about IoT systems, which is increasingly represented as knowledge graphs. In this paper, we propose a novel ARM pipeline for IoT data that utilizes both dynamic sensor data and static IoT system metadata. Furthermore, we propose an autoencoder-based neurosymbolic ARM method (Aerial) as part of the pipeline to address the high volume of IoT data and reduce the total number of rules that are resource-intensive to process. Aerial learns a neural representation of a given dataset and extracts association rules from this representation by exploiting the reconstruction (decoding) mechanism of an autoencoder. Extensive evaluations on three IoT datasets from two domains show that ARM on both static and dynamic IoT data results in more generically applicable rules while Aerial can learn a more concise set of high-quality association rules than the state-of-the-art, with full coverage over the datasets.
Keywords
Introduction
Association rule mining (ARM) is a common data mining task that aims to discover associations between features of a given dataset in the form of logical implications (Agrawal & Srikant, 1994). In Internet of Things (IoT) systems, ARM methods are utilized for various tasks, including monitoring, decision-making, and optimization, for example, of a system’s resources (Sunhare et al., 2022). Some IoT application domains in which ARM has been successfully utilized include agriculture (Fan et al., 2021), smart buildings (Degeler et al., 2014), and energy (Dolores et al., 2023). However, most applications of ARM in IoT give limited consideration to characteristics of IoT data, such as heterogeneity and volume (Ma et al., 2013), as they are mere adaptations of rule mining methods not specifically tailored to IoT requirements.
IoT systems can produce or use data from diverse sources, which can be categorized as static and dynamic. Static data refers to data that is not subject to frequent changes, such as system models, while dynamic data is subject to frequent changes, for instance, sensor data. The static part of IoT systems is increasingly represented as knowledge graphs (Karabulut et al., 2024; Rhayem et al., 2020), large databases of structured semantic information (Hogan et al., 2021). ARM algorithms are often run on the dynamic part of IoT data, not utilizing the valuable information in knowledge graphs. In addition, ARM algorithms can generate a high number of rules as the input dimension increases (Kaushik et al., 2023; Telikani et al., 2020), which is time-consuming to process and maintain. Generating a high number of rules can be the case for large-scale IoT environments, as each sensor is treated as a different data dimension.
To address these two issues, this paper presents two new contributions. The first contribution is a novel ARM pipeline for IoT data that combines knowledge graphs and sensor data to learn association rules with semantic properties, semantic association rules (Section 3), that represent IoT data as a whole (Section 4.1). We hypothesize that semantic association rules are more generically applicable than association rules based on sensor data only, requiring fewer rules to have full data coverage. We define generically applicable as having high support—the frequency with which a rule appears in the data—and high coverage—the proportion of the dataset to which the rule applies. As an example, an association rule based on sensor data only looks as follows: “if sensor1 measures a value in range R, then sensor2 must measure a value in range R2.” This rule can only be applied to sensor1 and sensor2 measurements. In contrast, semantic association rules are more contextual as seen in the following example in the water distribution network (WDN) domain: “if a water flow sensor wf1 placed in a pipe P1 with diameter
However, enriching sensor data with semantics from a knowledge graph increases input size and may result in a high number of rules. Hence, the second contribution of this paper is an autoencoder-based (Vincent et al., 2008) neurosymbolic ARM method (Aerial) as part of the proposed pipeline that can learn a concise set of high-quality rules with full data coverage (Section 4.1.3). Aerial learns a neural representation of a given input data and then extracts association rules from the neural representation. This approach can be supplemented by and is fully compatible with other ARM variations that aim to mine a smaller subset of high-quality rules, such as top-
In summary, the two contributions of this paper are: (1) a pipeline of operations to learn contextual semantic association rules from both static and dynamic IoT data as opposed to existing methods which consider sensor data only; and (2) an autoencoder-based ARM approach for learning a more concise set of high-quality semantic association rules than the state-of-the-art, with full data coverage. This approach is orthogonal and can be used with other ARM variations.
Related Work
This section introduces the related work and background concepts.
Association Rule Mining
ARM is the problem of learning commonalities in data in the form of logical implications, for example,
Recently, a few deep learning (DL)-based ARM algorithms have been proposed. Patel (2022) proposed to use autoencoders (Chen & Guo, 2023) to learn frequent patterns in a grocery dataset, however, no source code or pseudo-code was given. Berteloot et al. (2023) also utilized autoencoders (ARM-AE) to learn association rules directly from categorical tabular datasets. However, ARM-AE has fundamental issues while extracting association rules from an autoencoder, which we elaborate on in Section 5.2.2.
Numerical association rule mining (NARM) aims to identify intervals for numerical variables to generate high-quality association rules based on specific quality criteria. Following the recent systematic literature reviews (Kaushik et al., 2023; Telikani et al., 2020), the state-of-the-art in NARM is nature-inspired optimization-based algorithms which include evolutionary, differential evolution, swarm intelligence, and physics-based approaches. They employ heuristic search processes to find association rules that optimize one or more rule quality criteria and are used for both numerical and categorical datasets (Fister et al., 2018). However, optimization-based ARM methods too suffer from handling big high-dimensional data, together with other broader issues in NARM such as having a large number of rules, and explainability as also mentioned by Kaushik et al. and other works (Berteloot et al., 2023; Kishore et al., 2021; Telikani et al., 2020).
ARM in IoT
In IoT, both exhaustive ARM, such as Apriori and FP-Growth, and the optimization-based NARM methods are used for various tasks. Shang et al. (2021) utilized the Apriori algorithm for big data mining in IoT in the enterprise finance domain for financial risk detection. Sarker and Kayes (2020) utilized an exhaustive ARM approach with item constraints on phone usage data to learn user behaviors. Khedr et al. (2020) proposed a distributed exhaustive ARM approach that can run on a wireless sensor network. Fister Jr et al. (2023) proposed TS-NARM, an optimization-based NARM approach, and evaluated it on a smart agriculture use case with five optimization-based methods.
Sequential or temporal ARM is another ARM variant used in IoT (Wedashwara et al., 2019). The goal is to learn patterns between subsequent events, rather than events that happen in the same time frame, concurrent events. In this paper, we focus on mining association rules for concurrent events, rather than sequential events which is a different task.
Based on recent surveys (Karabulut et al., 2024; Listl et al., 2024), semantic web technologies such as ontologies (Gruber, 1993) and knowledge graphs (Hogan et al., 2021) have been used for knowledge representation in IoT, providing valuable knowledge related to IoT systems and its components. Naive SemRL (Karabulut et al., 2023) is the only ARM method that utilizes semantics when learning rules from pre-discretized sensor data. It is based on FP-Growth; however, the paper does not provide a complete evaluation. We adopt a similar semantic enrichment approach but develop a completely new DL-based pipeline, and provide an extensive evaluation.
Note that the term semantic association rules is also used when mining rules from knowledge graphs (Barati et al., 2017) only, which is a different task than rule learning from sensor data presented in this paper. To the best of our knowledge, there has been no fully DL-based ARM algorithm for learning association rules from concurrent events in IoT data.
Problem Definition
This research problem relates to learning association rules from sensor data in IoT systems with semantic properties from a knowledge graph describing the system and its components, properties, and the relations between them. We formulate the problems as follows:
Given a sensor dataset
Association rules are formal logical formulas in the form of implications, for example,
Note that the
Input
This section presents input notation. To help readers understand easier, Table 1 lists symbols used in the notation, high-level explanations, and examples from the WDN domain.
Input Notation, Explanations, and Examples from Water Networks Domain.

Input Notation, Explanations, and Examples from Water Networks Domain.
To express that
The output is a set of rules of the form described below.
Let 
Output Item Forms, Explanations, and Examples from the Water Network Domain (#: Equation 1, and the Symbols are Described in Table 1).

This section introduces our proposed ARM pipeline for IoT data and an autoencoder-based neurosymbolic ARM approach (Aerial) as part of the pipeline. The goal is to learn a concise set of high-quality semantic association rules from sensor data and knowledge graphs with full data coverage.
Pipeline
Figure 1 depicts the proposed ARM pipeline for IoT data, which consists of three main stages: (i) data preparation, (ii) training, and (iii) rule extraction.

Proposed ARM pipeline for IoT data to learn semantic association rules from sensor data and knowledge graphs. ARM: association rule mining; IoT: Internet of Things.
This stage of the pipeline pre-processes a given sensor dataset and a knowledge graph describing the IoT system and its components to form transactions, making the data ready for ARM. First, sensor data is aggregated into time frames (e.g., average measurements per minute for all sensors). Each row in the Sensor Data depiction in Figure 1 refers to a time frame that contains aggregated sensor measurements, representing the state of the IoT system within that time frame. Second, the numerical sensor measurements and the numerical properties in the knowledge graph are discretized (e.g., by applying equal-frequency discretization (Foorthuis, 2020)). This step is optional when using a numerical ARM method as part of the pipeline. Note that the method of sensor data aggregation and discretization is domain-dependent, and our approach is independent of the preferred aggregation and discretization method.
As the last step, binding
Example: To continue our WDN example, Figure 2 shows part of a WDN knowledge graph that we constructed for the LeakDB (Vrachimis & Kyriakou, 2018) dataset. The figure contains three pipe nodes in orange, three junction nodes in blue, four sensor nodes in beige, the properties of

Part of a WDN knowledge graph for LeakDB (Vrachimis & Kyriakou, 2018) using Neo4j (https://neo4j.com/). WDN: water distribution network.
This step of the pipeline vectorizes the semantically enriched transactions and trains an under-complete denoising autoencoder (Vincent et al., 2008) for ARM. Input transactions in standard ARM literature consist of binary attributes indicating the presence or absence of feature classes (Agrawal & Srikant, 1994; Kaushik et al., 2023). In line with the literature, we apply one-hot encoding to the semantically enriched transactions and obtain vectors of 0 and 1. The autoencoder is only aware of the binary vectors, and our rule extraction algorithm (Algorithm 1) keeps track of which feature value is fed into which neuron of the autoencoder. Let 
We employ an under-complete denoising autoencoder which creates a lower-dimensional representation of the noisy variant of its input (encoder) and then reconstructs the noise-free input from the dimensionally reduced version (decoder). In this way, the model learns a neural representation of the input data and becomes more robust to noise. After the one-hot encoding, a random noise
Our under-complete denoising autoencoder has three layers for encoding and decoding units. During training, 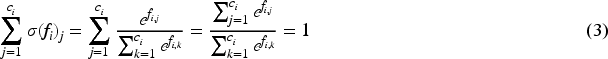
This leads to having one probability distribution per feature in the output layer. We will later exploit this to infer which class(es) of a feature are associated with other features’ class values. As the loss function, binary cross-entropy (BCE) loss is applied per feature, and the results are aggregated:

Example: Returning to our WDN example (Figure 2), consider the pressure sensor located at
Other parameters used in the training, such as the learning rate, are described in Section 5.1. Note that some parts of the architecture are kept flexible as they may vary depending on the downstream task to which the proposed approach is applied, such as the type of discretization and sensor data aggregation.
The last step of our pipeline is to extract association rules from a trained autoencoder using Algorithm 1. Aerial is a neurosymbolic approach to rule mining as it combines a neural network (an autoencoder) with an algorithm that can extract associations in the form of logical rules from a neural representation of input data created by training the autoencoder. Note that any other ARM algorithm can be used within the pipeline after the semantic enrichment step.
Intuition: Aerial exploits the reconstruction loss of a trained autoencoder to learn associations. If reconstruction for an input vector with marked features, test vector, is more successful than a similarity threshold, then we say that the marked features imply the successfully reconstructed features. Marking features is done by assigning 1 (100%) probability to a certain class value for a feature, 0 to the other classes for the same feature, and assigning equal probabilities to the rest of the features in an input vector. In the case of IoT data, the input test vector represents a partially defined environment via the marked features, and the autoencoder reconstructs the co-occurrences with the rest of the environment. Therefore, we hypothesize that the marked feature classes in the test vector represent the antecedents of a rule, while the reconstructed feature classes represent the consequent.
Example: Figure 3 depicts an example rule extraction process. Assume that there are only two features in the input vector with two and three possible class values, namely

Illustration of association rule extraction from a trained autoencoder with our Aerial approach.

Algorithm: The rule extraction algorithm is given in Algorithm 1. The parameters are the set of input vectors (X), a trained autoencoder (AE), a similarity threshold (
Two different experimental settings are used to evaluate the two main contributions of this paper.
First, to evaluate the impact of utilizing semantics in rule mining from IoT data (our proposed pipeline), we designed the Experimental Setting 1 where we run multiple ARM methods (including ours) with and without semantics. And we compare the results before and after adding semantics based on various rule quality criteria and execution times. Second, in Experimental Setting 2, we evaluate our proposed neurosymbolic ARM method Aerial across eight baselines of different types, including exhaustive, optimization-based, and DL-based ARM algorithms. We made our best effort to compare different types of approaches fairly, based on the number of rules, rule quality, and execution time. Furthermore, we investigated the impact of the similarity threshold hyperparameter of Aerial in a separate experiment (Experiment 3).
This section first describes common elements across both settings such as datasets, and then describes setting-specific points including baselines. Additional experiments that are not directly relevant to the two settings are given in Appendix A2.
Setup
This section describes the common elements for both of the evaluation settings.
Overall Comparison of Evaluated ARM Approaches.

Overall Comparison of Evaluated ARM Approaches.
ARM: association rule mining; DL: deep learning.
This section describes the two core experimental settings together with baselines in each setting. Refer to Table 3 for baseline methods described in the settings.
Setting 1: Semantics Versus Without Semantics
To show that semantics can enable learning more generically applicable rules with higher support and data coverage, two different ARM algorithms, our Aerial approach and a popular exhaustive method FP-Growth (Han et al., 2000), are run with and without semantically enriched sensor data. Two algorithms are used to show that including semantics is beneficial regardless of the ARM method applied. The results are compared based on the number of rules, average rule support, confidence and coverage, and execution time. FP-Growth is implemented using MLxtend (Raschka, 2018). This experimental setting does not aim to evaluate the capability of each ARM algorithm to learn high-quality rules, but only focuses on the impact of utilizing semantics. The prior is performed as part of the second experimental setting.
Setting 2: Aerial Versus State-of-the-art
The goal is to evaluate the proposed Aerial method for IoT data, and the experiments are run on sensor data with semantics. The only existing semantic ARM approach, Naive SemRL (Karabulut et al., 2023), is chosen as a baseline and executed with the exhaustive FP-Growth (as in the original paper) and HMine algorithms. In addition, the optimization-based NARM method TS-NARM (Fister Jr et al., 2023) with standard confidence metric as optimization goal is run with five algorithms (as in the original paper): differential evolution (Storn & Price, 1997), particle swarm optimization (Kennedy & Eberhart, 1995), genetic algorithm (Goldberg, 1989), jDE (Brest et al., 2006), and LSHADE (Viktorin et al., 2016)). TS-NARM is implemented using NiaPy (Vrbanˇiˇ et al., 2018) and NiaARM (Stupan & Fister, 2022), and FP-Growth and HMine are implemented using MLxtend (Raschka, 2018). All rule quality criteria described earlier are used in the comparison.
ARM-AE (Berteloot et al., 2023), another autoencoder-based ARM method, uses an autoencoder with equal-sized layers (no dimensionality reduction), does not distinguish between features (e.g., by applying softmax per feature as in our approach), and assumes that input to the trained autoencoder represents a consequent while the output represents an antecedent. We argue that this assumption does not hold, and the evaluation of ARM-AE resulted in exceptionally low rule quality both in their paper (33% confidence on the Nursery dataset and 50% confidence on the chess dataset) and also based on our results. Therefore, we opted not to include it in the core Evaluation section. Refer to Experiment 6 in the Appendix for the evaluation of ARM-AE.
Challenges in Comparison
The distinct nature of different types of algorithms makes comparability a challenge. The exhaustive algorithms can find all rules with a given support and confidence threshold. The execution time of the five optimization-based approaches (TS-NARM) is directly controlled by the pre-set maximum evaluation parameter. And running them longer leads to better results up to a certain point (Section 5.3.2). The quality of the rules learned by the DL-based ARM approaches depends on the given similarity threshold parameter (or likeness for ARM-AE). Given these differences, we made our best effort to compare algorithms fairly and showed the trade-offs under different conditions. Table 4 lists the parameters of each algorithm for both of the settings, unless otherwise specified. For TS-NARM, the population size is set to 200 which represents an initial set of solutions, and the maximum evaluation is set to 50,000 which represents the number of fitness function evaluations before convergence. The parameters of the five optimization-based methods, population size, and maximum evaluation count are the same as in the original paper. The antecedent length of both exhaustive and DL-based ARM methods is set to two for fairness unless otherwise specified. The minimum support threshold of the exhaustive methods is set to half of the average support of the rules learned by our Aerial method so that both approaches will result in a similar average support value for fairness.
Aerial, Baselines, and Their Parameters.

Aerial, Baselines, and Their Parameters.
Optimization refers to TS-NARM and Exhaustive to Naive SemRL. See Experiment 6 in the Appendix for the evaluation of ARM-AE (R: rules learned by Aerial).
DE: differential evolution; GA: genetic algorithm; PSO: particle swarm optimization; DL: deep learning; NARM: numerical association rule mining.
This section presents the experimental results for both settings.
Setting 1: Semantics Versus Without Semantics
Comparison of ARM on Sensor Data with Semantics (w-s, Our Pipeline) and Without (wo-s), Showing a Significant Increase in Support and Rule Coverage (cov.) with Semantics.

Comparison of ARM on Sensor Data with Semantics (w-s, Our Pipeline) and Without (wo-s), Showing a Significant Increase in Support and Rule Coverage (cov.) with Semantics.
The results indicate that association rules learned from sensor data and semantics are more generically applicable than rules learned from sensor data only, as the support and rule coverage values are significantly higher. Furthermore, this experiment is repeated with varying numbers of sensors, and the results (Experiment 4 in the Appendix) show that a higher number of sensors results in more generically applicable rules. The comparison of rule count and confidence for different approaches will be investigated in Experimental Setting 2.
Figure 4 shows the effect of including semantics on the execution time of FP-Growth and Aerial (training + rule extraction time). The increase in the execution time of FP-Growth is 3–12 times, while it is 2–3 times in Aerial and is more stable. However, since the semantic association rules have higher support and data coverage, a smaller number of them can have full data coverage (which is the case for Aerial and will be investigated in Experimental Setting 2). Therefore, we argue that the increment in the execution time is acceptable. Note that despite FP-Growth running faster with the parameters given in Table 4, it is strictly dependent on the preset minimum support threshold value, and it runs slower for lower thresholds. This is investigated in Experiment 2.1.

Effect of using semantics (indicated as w-s for semantics, and wo-s for without semantics) on execution time.
Association Rule Examples with Semantics (Top) and Without Semantics (Bottom) Learned from the LeakDB Dataset.

The exhaustive methods’ execution time and number of rules they mine are strictly dependent on the preset minimum support threshold and the number of antecedents. Figure 5 shows how the number of rules and execution time change based on antecedents (for 1, 2, 3, and 4 antecedents) and minimum support thresholds (for 0.05, 0.1, 0.2, and 0.3). The results show that the execution time increases as the support threshold decreases and the number of rules increases above 10 million for LeakDB, while it reaches 1–2 million for LBNL and L-Town datasets, which are highly costly to post-process. Similarly, as the number of antecedents increases, the number of rules reaches the levels of millions, while the execution time reaches minutes. The execution did not terminate for the LeakDB dataset when using four antecedents after 30 min.

Exhaustive methods have higher execution times (dotted lines) and produce a larger number of rules (bars) as the number of antecedents (top chart, conf=0.8, sup=0.1) increases or minimum support threshold (bottom chart, antecedents=3) decrease.
Execution time, number of rules, as well as the quality of the rules mined by the optimization-based methods (TS-NARM) strictly depend on the number of evaluations. Table 7 shows the effect of the maximum evaluations parameter on the execution time, number of rules, and confidence of the rules for the LeakDB dataset (the results are consistent across datasets, see Experiment 5 in the Appendix). The results show that longer executions lead to a higher number of rules with higher confidence for all five algorithms. The maximum evaluation is chosen as 50,000 for the rule quality experiment (Experiment 2.2) as this is also the case in the original paper.
TS-NARM Needs Long Evaluations for Good Performance (LeakDB).
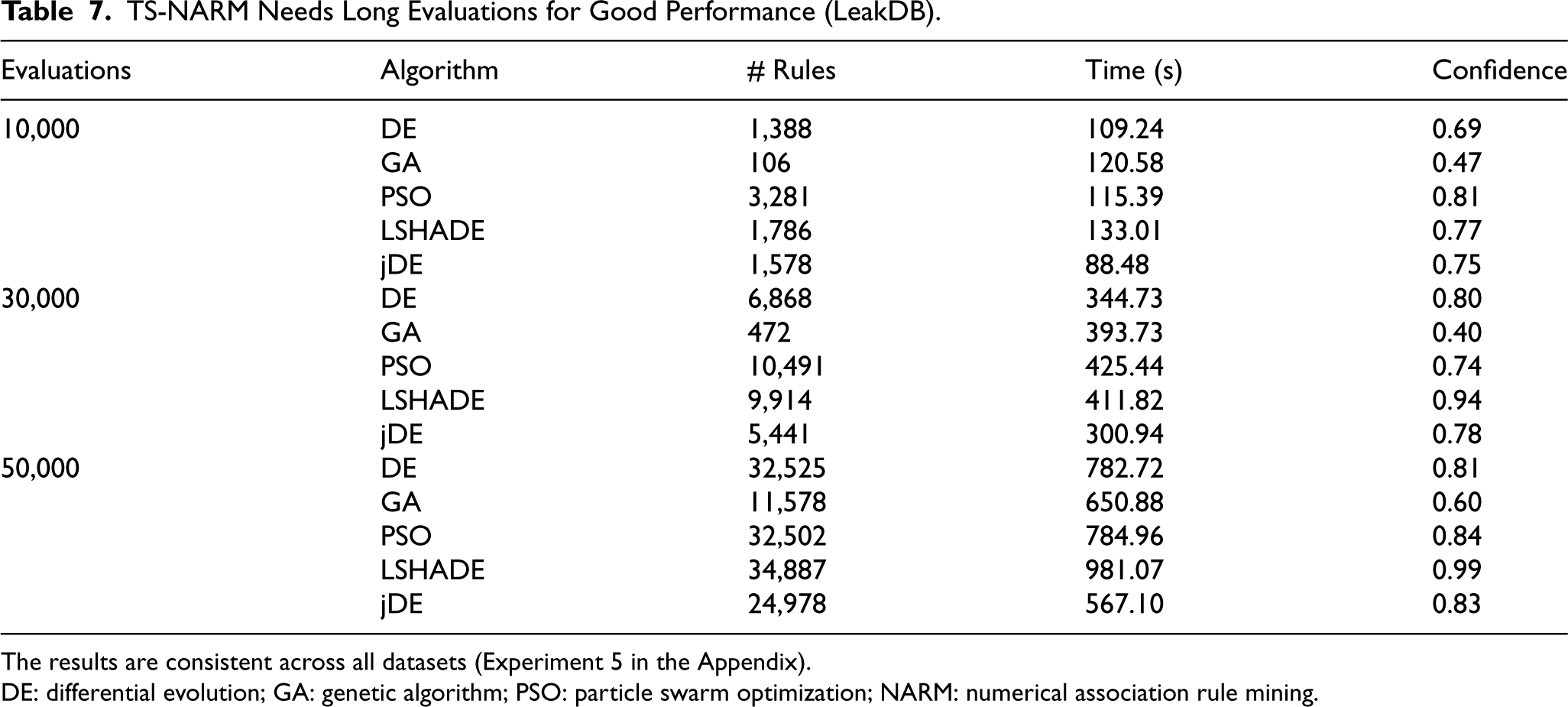
The results are consistent across all datasets (Experiment 5 in the Appendix).
DE: differential evolution; GA: genetic algorithm; PSO: particle swarm optimization; NARM: numerical association rule mining.
Lastly, the rule extraction time of the proposed Aerial approach is affected by the number of antecedent parameters, as it increases the number of test vectors used in the algorithm. Figure 6 shows the effect of increasing the number of antecedents on the number of rules and execution time. The number of learned rules is 10–100 times lower than the exhaustive methods. Exhaustive methods run slower on datasets with low support rules, LeakDB (see Tables 5 and 8), while running faster on datasets with high support rules, L-Town and LBNL. Both Aerial and exhaustive methods run faster than the optimization-based methods for at least a low-to-medium-size antecedent (1–4).

Execution time and the number of rules learned by Aerial depend on the number of antecedents.
Rule Qualities of All Algorithms Across All Datasets (Exhaustive Refers to FP-Growth and HMine Algorithms).

DE: differential evolution; GA: genetic algorithm; PSO: particle swarm optimization.
The goal of this experiment is to assess the quality of rules found by Aerial and baselines, highlighting the trade-offs between algorithms. How to read the results? The evaluation results are shown in Table 8, and the highest scores are intentionally not emphasized as ideal rule quality values can vary by task. As an example, high-support rules can be good at discovering trends in the data, while low-support rules may be better at detecting anomalies. The focus is on understanding each algorithm’s strengths under diverse conditions; therefore, results should be interpreted together.
Aerial was able to find a concise set of rules that have full data coverage with 90%+ confidence, the highest association strength (Zhang’s metric) in the LeakDB and L-Town datasets, and the second highest in the LBNL dataset. The FP-Growth and HMine algorithms yield the same results as they are Exhaustive. They have full data coverage, resulted in a high number of rules except for the LBNL dataset, and had very low association strength on L-Town and LBNL. The optimization-based methods had low confidence except for the LSHADE, which had a high confidence score on all datasets, the highest association strength among other optimization-based methods, and the highest in LBNL among all algorithms.
These results show that Aerial was able to find prominent patterns in the datasets that have high association strength and achieved full data coverage with a concise number of rules in comparison to state-of-the-art, which was the initially stated goal. In addition, Experiment 3 shows that higher similarity thresholds in Aerial lead to even higher-quality association rules.
The similarity threshold parameter of our Aerial method affects the quality of the rules learned. This experiment investigates the effect of the similarity threshold parameter of Aerial on all three datasets.
Table 9 presents the results for all three datasets. We observe that as the similarity threshold increases, the number of learned rules decreases, while the average support, confidence, and association strength (Zhang’s metric) increase, with the exception when the similarity threshold is 0.9. In that case, we observe a decrease in the association strength except in the LeakDB dataset. We argue that this is due to both the relatively low number of rules (6 and 116) learned in comparison to a relatively higher number of rules in LeakDB (412), and LeakDB being a low-support dataset (see Table 5), meaning that the average rule support for association rules in the LeakDB dataset is significantly lower than the other two datasets.
Aerial Learns a more Concise Set of Higher-Quality Rules as the Similarity Threshold (sim.) Increases.
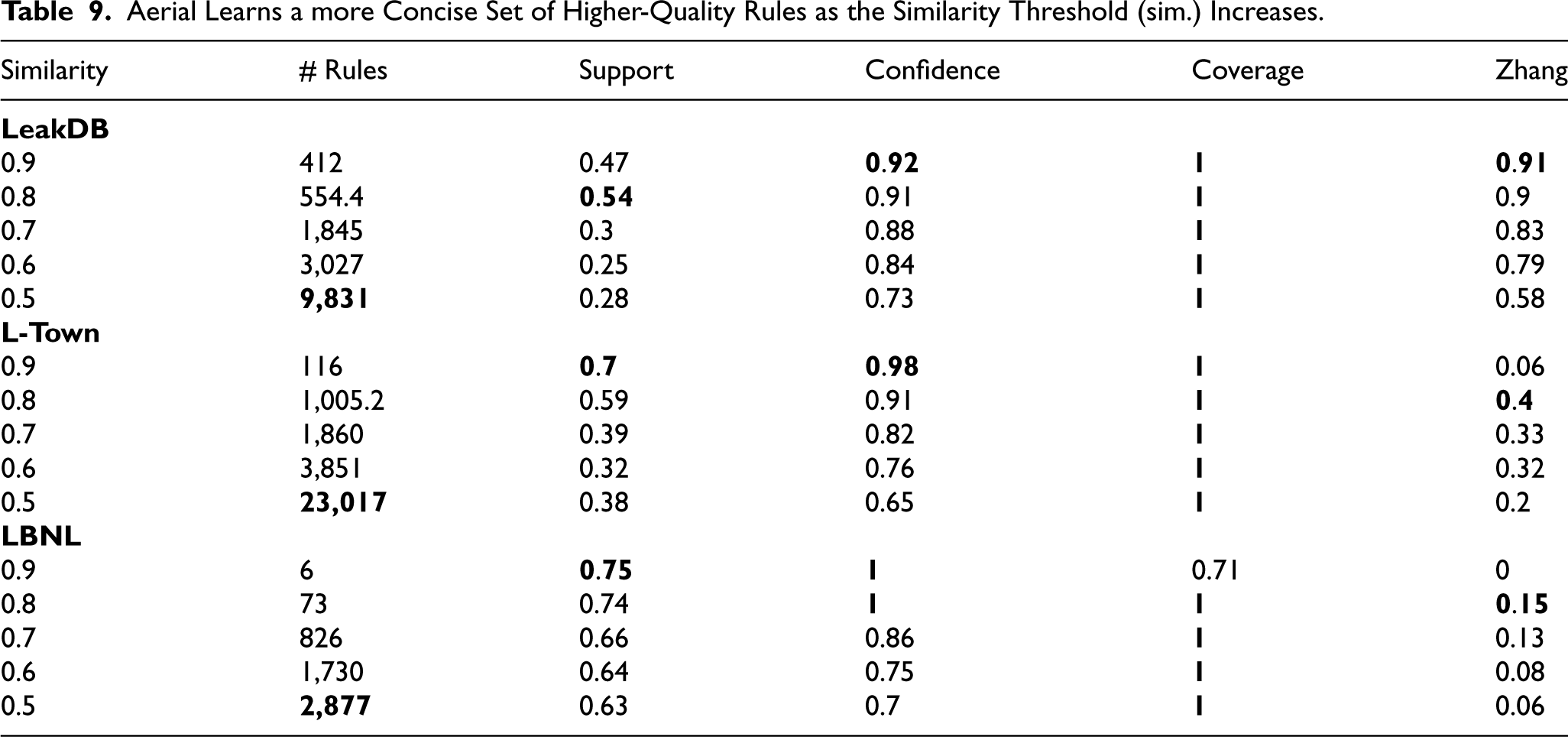
These results imply that increasing the similarity threshold results in more prominent rules but fewer in number, acting similarly to the minimum confidence threshold of the exhaustive algorithms.
This section discusses and summarizes the experimental findings.
Conclusion and Future Work
This paper introduced two contributions: (i) a novel ARM pipeline for IoT systems and (ii) a neurosymbolic ARM method (Aerial). In contrast to the state-of-the-art, our pipeline utilizes both dynamic sensor data and static knowledge graphs that describe the metadata of IoT systems. Aerial creates a neural representation of the given input data using an autoencoder and then extracts association rules from the neural representation. The experiments showed that the proposed pipeline can learn rules with up to 2–3 times higher support and coverage, which are therefore more generically applicable than ARM on sensor data only. Moreover, the experiments further demonstrated that Aerial can learn a more concise set of high-quality association rules than the state-of-the-art, with full data coverage. Aerial is also compatible with existing work on addressing the high number of rule problems in the ARM literature.
In future work, we first plan to investigate other neural network architectures for their capabilities of learning associations and develop new methods to extract rules from neural representations created using various architectures. This includes experimenting with other autoencoder architectures, for example, an over-complete autoencoder, as well as graph neural networks that can better capture the semantic relation in an IoT knowledge graph, leading to better semantic enrichment. Second, we plan to investigate the impact of semantic modeling in knowledge graphs on the rules learned, and measure the capability of our approach to capture the semantics of the underlying ontology, such as the symmetry or the transitivity of the relations. Third, we plan to investigate better semantic enrichment methods, potentially incorporating graph neural networks to utilize their strength in capturing graph structures. Finally, we plan to apply our methods to downstream tasks such as leakage detection in water networks or fault diagnosis in energy systems.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has received support from The Dutch Research Council (NWO), in the scope of the Digital Twin for Evolutionary Changes in water networks (DiTEC) project, file number 19454.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.