
Abstract
It is generally accepted that all cyber attacks can not be prevented, and it is therefore necessary to have the ability to detect and respond to cyber attacks. Both connectionist and symbolic approaches are currently being employed for this purpose, but far less work has been done on the intersection of the two. This paper argues that the cyber security domain holds significant potential for applying neurosymbolic artificial intelligence (AI). We identify a set of challenges faced in cyber security today, and from this, we propose a set of neurosymbolic use cases that can help address the challenges. Feasibility is demonstrated through multiple experiments that apply neurosymbolic AI to cyber security. We find a significant overlap between the challenges in cyber security and the promises of neurosymbolic techniques, making it an interesting research direction for both the neurosymbolic AI and cyber security communities. This paper is an extended version of a paper published at the NeSy 2024 conference (Grov et al., 2024). The main additional contributions are further experimental evidence for our hypothesis that NeSy offers real benefits in this domain and a more in-depth treatment of knowledge graphs for cyber security.
Keywords
Introduction
Protecting assets in the cyber domain requires a combination of preventive measures, such as access control and firewalls, and the ability to defend against cyber operations when the preventive measures were not sufficient. 1
Our focus in this paper is on defending against offensive cyber operations, and before going into details, we put in place some concepts and terminology:
This is typically carried out in a Security Operations Centre (SOC), which consists of people, processes, and tools (Fysarakis et al., 2022). One of the objectives of a SOC is to detect and respond to threats and attacks, where security analysts play a crucial role. Knowledge of threats in the cyber domain is developed by conducting intrusion analysis and producing and consuming Cyber Threat Intelligence (CTI). Networks and systems to be protected are monitored, and events – for example, network traffic, file changes, or processes executing on a host – are forwarded and typically stored in a security information and event management (SIEM) system, where events can be investigated, correlated and enriched – and queried. We will use the term observations for such events resulting from monitoring. Suspicious activity that is observed may raise alerts, which may indicate an incident that has to be analysed and responded to in the SOC. Finally, Neurosymbolic artificial intelligence (AI) (Garcez & Lamb, 2023), which aims to combine connectionist and symbolic AI, will be abbreviated NeSy.
Why is a SOC relevant for NeSy? A SOC essentially conducts abductive reasoning by observing traces and identifying and analysing their cause in order to respond. This involves sifting through masses of events for suspicious behaviour, an area in which extensive research has been conducted for several decades using statistics and machine learning (ML). Identifying the cause of observed suspicious behaviour requires situational awareness, achieved by combining different types of evidence, applying reasoning, and deriving knowledge. There are various ways in which evidence and knowledge can be represented, such as structured events and alerts, unstructured reports, and semantic knowledge (Liu et al., 2022; Sikos, 2023).
In a SOC, the ability to learn models to detect suspicious activities and the ability to reason about identified activities to understand their cause and respond to them is thus required. These abilities are at the core of NeSy, and our hypothesis is as follows:
A SOC provides an ideal environment to study and apply NeSy with great potential for both scientific and financial impact.
Some early work has explored NeSy in the cyber security domain (Ding & Taylor, 2024; Himmelhuber et al., 2022; Jalaian & Bastian, 2023; Melacci et al., 2021; Onchis et al., 2022; Piplai et al., 2023) and our goal with this paper, which extends (Grov et al., 2024), is to showcase the possibilities and encourage the NeSy community to conduct research in the SOC field 2 with an emphasis on experiments.
Methodology. The identified SOC challenges are derived from a combination of existing published studies, the experience and expertise of the authors, and further discussions with SOC practitioners. The use cases result from reviewing NeSy literature in the context of the identified challenges, and the preliminary experiments conducted are based on a subset of the identified use cases.
Contributions. This paper is an extended version of Grov et al. (2024), published at the NeSy 2024 conference. We outline how AI is used today in a SOC and identify and structure a set of challenges faced by practitioners who use AI. We then create a set of promising use cases for applying NeSy in the context of a SOC, review current NeSy approaches in light of them, and demonstrate feasibility through proof-of-concept experiments. In this paper, we extend (Grov et al., 2024) with a more profound treatment of the use of knowledge graphs (KGs) when defending against cyber attacks, and crucially, we address the main limitation of Grov et al. (2024) – limited experimental evidence – with the following experiments: Our experiment with Logic Tensor Networks (LTNs) (Badreddine et al., 2022) in Grov et al. (2024) is remade with an LTN using the same structure as a published ML model for network intrusion detection (Rosay et al., 2020), and extended with further experiments addressing explainability aspects and prioritising crucial knowledge. A NeSy technique called Embed2Sym Aspis et al. (2022) is explored to analyse and contextualise alerts from intrusion detection systems. Building on Chetwyn et al. (2024a, 2024b), we explore the integration of large language models (LLMs) with a symbolic approach for threat hunting. We extend our previous work using data-driven enrichment of (symbolic) knowledge (Skjøtskift et al., 2025) with experiments using newly released data and explore the advantages NeSy provides for this challenge.
Paper Structure. In Section 2, we describe the typical use of AI in a SOC and the identified challenges. In Section 3, we make the case for NeSy and introduce the different NeSy techniques discussed in this paper. In Section 4, we outline the NeSy use cases and suggest NeSy techniques to address them. In Section 5, we describe the proof-of-concept experiments, before we conclude in Section 6.
Monitor-Analyse-Plan-Execute over shared Knowledge (MAPE-K) (Kephart & Chess, 2003) is a common reference model to structure the different phases when managing an incident. 3 For each phase of MAPE-K, we below discuss the use of AI, including underlying representations, and identify key challenges security practitioners face when using AI. 4
Monitor
In the monitor phase, systems and networks are monitored and telemetry is represented as sequences of events. An event could, for instance, be a network packet, a file update, a user that logs on to a service, or a process being executed. Events are typically structured as key-value pairs. In a large enterprise, tens of thousands of events may be generated per second. In this phase, a key objective is to detect suspicious behaviours from events and generate alerts, which are analysed and handled in the later phases of MAPE-K.
This is a topic where ML has been extensively studied by training ML models on the vast amount of captured event data (e.g., Ahmad et al., 2021). A challenge with such data is the lack of ground truth, in the sense that for the vast majority of events we do not know if they are benign or malicious. As most events will be benign (albeit we do not know which ones), one can exploit this assumption and use unsupervised methods to train anomaly detectors. This is a common approach. For at least research purposes, synthetic data sets from simulated attacks are also commonly used (Kilincer et al., 2021). However, synthetic data sets suffer from several issues (Apruzzese et al., 2023; Flood & Aspinall, 2024; Kenyon et al., 2020) and promising results in research papers using synthetic data often fail to be reproduced in real-world settings – whilst anomaly detectors often create a high number of false alerts 5 (Alahmadi & Axon, 2022; Sommer & Paxson, 2010). Our first challenge, which has also been identified by the European Union Agency for Cybersecurity (ENISA) (Pascu & Barros Lourenco, 2023), identifies this performance issue for ML models under real-world conditions:
Achieve optimal accuracy of ML models under real-world conditions.
As benign software and malware are continuously updated, the notion of concept drift is prevalent and ML models therefore must be re-trained regularly. There are some approaches that take such concept drift into account (Andresini et al., 2021; Olarra et al., 2025). In addition to the need for scalability, due to the large amount of data, real-world conditions introduce a significant level of noise (i.e. aleatoric uncertainty) in the data, which is not well reflected in synthetic data.
We know the ground truth of the associated alerts and events for previous incidents that have been handled. Compared to the set of all events, the alerts related to incidents make up only a tiny fraction. Typically, the majority of events will be benign, resulting in data sets that are heavily unbalanced. This imbalance is a challenge during both training and inference of ML models. Still, the previous incidents are vital as they are labelled and contain relevant data – either in terms of actual attacks experienced or false alerts that should be filtered out. One important challenge, also recognised by ENISA, is the ability to exploit such labelled ‘incident data sets’ and train ML models based on them:
Learning with small (labelled) data sets (from cyber incidents).
New knowledge about threats, attacks, malware, or vulnerability exploits is frequently published, often in the form of threat reports and advisories. The traditional, and still most common, method for threat detection is signature-based, where knowledge is encoded (often manually) as specific patterns (called signatures). Detection is achieved by matching events with these signatures and generating alerts. Although signature-based methods have their limitations, such knowledge could improve the performance of ML-based detection models, creating the need for the ability to extract relevant knowledge and include it in the ML models:
Extract knowledge (including about threats, malware, and vulnerabilities) and enrich ML-based detection models with it.
In recent years, some work has been done to encode cyber knowledge into AI systems to improve detection (Bizzarri et al., 2024; Himmelhuber et al., 2022). In addition to reports, dedicated knowledge bases, formal ontologies, and KGs can be used to enrich ML models with such knowledge. There are also attempts to extend the coverage domain for such ontologies, including the unified cyber ontology (Syed et al., 2016) and the SEPSES KG (Kiesling et al., 2019). To represent CTI, a commonly used schema is Structured Threat Information eXpression (STIX) (OASIS, 2025), with the associated threat actor context ontology (Mavroeidis et al., 2021). However, the maintenance of ontologies and KGs has its own challenges, as real-world domains are rarely static, meaning new concepts emerge, existing ones evolve, and old ones may become obsolete. In addition, domain-specific ontologies (tailored for specific use cases) often do not rely on a shared foundation, that is foundational ontologies. This causes duplicate efforts with incompatible structures (reinvention and misalignment of concepts) for common concepts, resulting in fragmented knowledge representation, which makes cross-domain data integration complex and error-prone. This might impact inferencing, ultimately leading to incomplete or incorrect results.
A widely used knowledge base for threat actors and attacks is MITRE ATT&CK (Mitre, 2025). ML, and in particular natural language processing (NLP), is being explored for extracting CTI into symbolic forms (e.g., STIX) (Marchiori et al., 2023) or to map it to MITRE ATT&CK (Li et al., 2022). LLMs are also explored for this topic (Haque et al., 2023; Liu & Zhan, 2023). Some limitations have been identified (Würsch et al., 2023), but this is an active area of development with improvements made all the time. We are unfamiliar with approaches that combine and integrate such knowledge with ML models for detection trained on events.
A different approach to identify malicious behaviour is cyber threat hunting. This is a hypothesis-driven approach in which hypotheses are formulated iteratively (typically using CTI) and validated using event logs, as well as other sources of information (Shu et al., 2018). Automating this process is our final challenge for the monitor phase: Automated generation of hypotheses from CTI and validation of hypotheses using observations for threat hunting.
The goal of the analyse phase is to understand the nature of the observed alerts, determine possible business impact, and create sufficient situational awareness to support the subsequent plan and execute phases.
Both malware and benign software continuously evolve. This makes it difficult to separate malicious from benign behaviour (Pascu & Barros Lourenco, 2023), even with continuous detection engineering efforts. For example, an update to benign software may cause a match with an existing malware signature and may also appear as an anomaly in the network traffic. As a result, most of the alerts would be either false or not sufficiently important for further investigation (Alahmadi & Axon, 2022), causing so-called alert fatigue among security analysts in a SOC. The analysis phase is, therefore, labour-intensive, where security analysts must plough through and analyse a large number of alerts – most of them false – to decide their nature and importance:
The volume of alerts leads to alert flooding and alert fatigue in SOCs.
Understanding the nature of alerts is essential, and studies have shown that a lack of understanding of the underlying scores or reasoning behind the alerts have led to misuse and mistrust of ML systems (Oesch et al., 2020). Studies (Alahmadi & Axon, 2022), along with guidance from ENISA (Pascu & Barros Lourenco, 2023), have highlighted the need for alerts to be reliable, explainable, and possible to analyse. The use of explainable AI to support this has shown some promise (Eriksson & Grov, 2022), and both KGs (Alahmadi & Axon, 2022) and LLMs 6 (Jüttner et al., 2024; Houssel et al., 2024; Khediri et al., 2024) have been identified as promising approaches.
An alert is often a single observation and needs to be placed into a larger context to determine an incident and provide the necessary situational awareness as a result of an analysis (Franke et al., 2022). Such contextualisation includes enriching alerts with relevant knowledge from previous incidents, common systems behaviour, infrastructure details, threats, assets, etc. The same attack – or the same phase of an attack – is likely to trigger many different alerts. Different ML techniques, particularly clustering, have been studied to fuse or aggregate related alerts (Kotenko et al., 2022; Syvertsen, 2023). In addition to understanding an incident and achieving situational awareness, contextualisation will also help a security analyst understand individual alerts. Similarly to challenge 3, contextualization of alerts will involve extracting a symbolic representation from a vast amount of available (and typically unstructured) information.
A cyber attack conducted by an advanced adversary will, in most cases, go through several phases to reach its objectives, creating a need to discover the relationships (between the alerts) across the different phases of an attack. A common reference model to relate such phases is the cyber kill chain, originally developed by Lockheed Martin and later refined into the unified cyber kill chain (Pols & van den Berg, 2017). Other formalisms that enable modelling different phases of attacks include MITRE Attack Flow (MITRE, 2025) and the meta attack language (Johnson et al., 2018). Different approaches have been studied to relate the different phases, including symbolic approaches (Ou et al., 2005), AI planning (Amos-Binks et al., 2017; Miller et al., 2018), KGs (Chetwyn et al., 2024b; Kurniawan et al., 2021), state machines (Wilkens et al., 2021), clustering (Haas & Fischer, 2018) and statistics (Haque et al., 2023). However, this research topic is considerably less mature compared with ML models for detection in the monitor phase. We summarise the challenges of combining, understanding and explaining observations in the following challenge: Combine observation with knowledge to analyse, develop, and communicate situational awareness.
When an incident is understood and sufficient situational awareness is achieved, a suitable amount of resources have to be allocated to handle the incident. There may be multiple incidents requiring some prioritisation between them. This involves understanding the risk and potential impact of the incident, including any mitigating actions that may be taken in subsequent MAPE-K phases:
Understanding the risk, impact, importance, and priority of incidents.
The last two phases of MAPE-K, plan and execute, focus on responding to detected incidents. This involves finding suitable responses in the plan phase and preparing and executing the response(s) in the execute phase. From an AI perspective, research in these phases is less mature than in the monitor and analyse phases. Therefore, we will only focus on the plan phase, which we consider to have more interesting AI-related challenges.
To plan a suitable response, three promising AI techniques are AI planning (e.g., Ghosh & Ghosh, 2012), reinforcement learning (RL – e.g., Hu et al., 2020; Nyberg et al., 2022) and recommender systems (e.g., Polatidis et al., 2020). Each of these techniques has pros and cons: AI planning requires considerable knowledge and formulation of the underlying environment, RL requires a considerable amount of interactions/simulations (often in the millions) and recommender systems typically require extensive knowledge of previous events. In certain cases, a quick response time is necessary, which means this level of interaction would be too time-consuming. When generating response actions, their risk and impact must be taken into account (including the risk and impact of not acting), which is an unsolved problem when using AI. Moreover, when proposing a response action, an AI-generated solution must be able to explain both what the response action will do and why it is suitable for the given problem: Generate and recommend suitable response actions in a timely manner that takes into account both risk and impact and are understandable for a security analyst.
The ‘K’ in MAPE-K stands for knowledge shared across the phases. We have, for instance, seen knowledge about threats and the infrastructure being protected used across different phases. Moreover, this knowledge takes different forms and representations (structured and unstructured) and is analysed using different techniques (symbolic and sub-symbolic). In addition to consuming knowledge, it is also important to share knowledge with key stakeholders, both technical and non-technical (Tsekmezoglou et al., 2023). This may be a report about an incident for internal use (e.g., to board members) or sharing threat information with a wider community, which lead us to our final challenge:
Generating suitable incident and CTI reports for the target audience.
We have shown the need to learn and reason across MAPE-K and that both symbolic and connectionist AI are being used across the phases. We have identified several challenges, which we in the following section will address from a NeSy perspective.
Neurosymbolic AI to Defend Against Cyber Attacks
Kahneman’s (Kahneman, 2011) distinction between (fast) instinctive and unconscious ‘system 1’ processes from (slow) more reasoned ‘system 2’ processes has often been used to illustrate the NeSy integration of neural networks (system 1) and logical reasoning (system 2). This interdisciplinary approach integrates neural networks adept at learning from vast amounts of unstructured data, with symbolic representations of knowledge and logical rules to enhance the interpretability and reasoning capabilities of AI systems. Building on the above analogy, system 1 can, in a SOC, be seen as the ML-based AI used to identify potentially malicious behaviour in the monitor phase. Here, a large amount of noise needs to be filtered out from the large amount of events (thus a need for speed and scalability). System 2 is the reasoning conducted in the analysis phase, where deeper insight is required, and the need for scalability is less significant. This dichotomy of requirements entails that neither end-to-end pure statistical nor pure logical approaches will be sufficient, and a NeSy combination seems ideal. Three commonly used reasons for pursuing NeSy are to design systems that are human auditable and augmentable, can learn with less and provide out-of-distribution generalisation (Gray, 2023). We have seen examples of each of these in the challenges described in Section 2: The use of knowledge to contextualise, analyse, and explain alerts; generate and explain response actions; learn from (relatively few) incidents; and handle concept drifts and noise in order to achieve high accuracy of ML models under real-world conditions.
There are multiple studies on the current trends in neurosymbolic AI (Besold et al., 2021; Garcez & Lamb, 2023; Sarker et al., 2022), which we will not repeat here. Instead, we will briefly describe the NeSY techniques we have found relevant for the use cases in Section 4, categorised according to the taxonomy first introduced by Henry Kautz during his AAAI Robert S. Engelmore memorial lecture (Kautz, 2022). This taxonomy was later revised at the 2024 Neurosymbolic AI summer school (Kautz, 2024). This revised Kautz taxonomy consists of the following eight categories:
Below we briefly describe the NeSy techniques used in Section 4 following this taxonomy. Note that (1) we only cover a subset of the categories and only discuss the ones to which a relevant NeSy technique belongs; (2) many techniques have aspects that mean they can fit into multiple categories. When this is the case, we have chosen the most relevant category.
Differentiable Probabilistic Answer Set Programming (dPASP) (Geh et al., 2023) is based on furnishing Answer Set Programming (ASP) (Brewka et al., 2011) with neural predicates as interface to both deep learning components and probabilistic features in order to afford differentiable neurosymbolic reasoning. dPASP is suitable for detecting under incomplete information, abductive reasoning, analysis of competing hypotheses (Heuer, 1999), and what-if reasoning.
PyReason (Aditya et al., 2023) is a python framework supporting both differentiable logics and temporal extensions. Additionally, it enables temporal reasoning over graphical structures with fully explainable traces of inference.
Neuro Symbolic Concept Learner (NS-CL) (Mao et al., 2019) builds models to learn visual perception, including semantic interpretation of the images without explicit supervision. It learns visual concepts, words, and semantic parsing jointly.
Neuro-Symbolic Inductive Learner (NSIL) (Cunnington et al., 2022) is an approach in which a neural network learns to extract latent concepts from raw data, while jointly learning a mapping of symbolic knowledge to latent concepts.
Differentiable Inductive Logic Programming (
DeepProbLog (Manhaeve et al., 2018) and DeepStochLog (Winters et al., 2022) incorporate reasoning, probability, and deep learning, by extending probabilistic logic programmes with neural predicates created from a neural classifier.
Neural Probabilistic Soft Logic (NeuPSL) (Pryor et al., 2023) is a neurosymbolic framework where the output from the trained neural networks is in (symbolic) Probabilistic Soft Logic (PSL) (Bach et al., 2017). This enables reasoning over low-level perceptions of deep neural networks.
NeurASP (Yang et al., 2023) is an extension of ASP that incorporates neural networks. This is achieved by treating the output from the neural classifier as a probability distribution over the atomic facts in the ASP. The ASP rules can also be used to improve the training of the neural networks.
Deep Symbolic Learning (DSL) (Daniele et al., 2023) is a neurosymbolic system that learns a set of perception functions, mapping images to symbols while also learning a symbolic function over the symbols in an end-to-end fashion.
STAR (Rajasekharan et al., 2023) combines LLMs with ASP. Knowledge is extracted to predicates using an LLM. ASP can then be employed to reason over the extracted knowledge.
Logic.py (Kesseli et al., 2025) is an approach to solving search-based problems with LLMs. The LLMs formalise a given problem in a domain-specific language Logic.py, which can be solved using a symbolic constraint solver.
Embed2Sym (Aspis et al., 2022) extracts latent concepts from a neural network architecture and assigns symbolic meanings to these concepts. This enables solving tasks involving both perception and reasoning.
Recurrent Reasoning Networks (RRNs) (Hohenecker & Lukasiewicz, 2020) is a neurosymbolic method for training a deep neural network to perform ontology reasoning. The RNN model is able to reason with an accuracy that is close to symbolic methods, while being more robust.
Logical Neural Networks (LNNs) (Riegel et al., 2020) are designed to simultaneously provide key properties of both neural nets (learning) and symbolic logic (knowledge and reasoning), enabling both logical inference and injecting desired knowledge into the neural architecture.
Logic Tensor Networks (Badreddine et al., 2022) is an approach where a membership function for concepts is learnt based on both labelled examples and abstract (logical) rules. LTN introduces a fully differentiable logical language, called real logic, where elements of first-order logic can be used to encode the underlying knowledge.
Modular Reasoning, Knowledge and Language (MRKL) (Karpas et al., 2022) systems present a neurosymbolic architecture to improve the utility of LLMs. The system consists of a set of expert modules and a router that routes incoming natural language to appropriate modules. The modules can be both neural (e.g. LLMs or vision modules) or symbolic (e.g. a calculator or an API call).
Phenomenal Yet Puzzling (Qiu et al., 2023) presents an approach for inductive reasoning with language models. Inductive reasoning is done through iterative hypothesis refinement, and consists of three steps: Proposing, selecting, and refining hypotheses. When coupled with a symbolic interpreter, accurate feedback can be given to refine the hypotheses.
LLMs Are Neurosymbolic Reasoners (Fang et al., 2024) investigates the application of LLMs as symbolic reasoners in text-based games. The LLM agents are given information about their role, observations, a set of valid actions arising from both the game environment, and a symbolic module. With this, agents can interact with the environment and solve text-based games involving symbolic tasks.
Symbolic Deep RL (SDRL) (Lyu et al., 2019) is a framework in which symbolic planning is introduced into deep RL. This enables both high-dimension sensor input and symbolic planning.
KG Enhanced Retrieval Augmented Generation (Kurniawan et al., 2024) deals with the limitations of LLMs – like hallucinations and difficulty with factual data – by integrating KGs for more reliable and contextually grounded outputs. This approach constructs a richer semantic context through ontology-based schemas and vector embeddings, enabling more effective retrieval and reasoning.
Neurosymbolic AI Use Cases to Improve Defending Against Cyber Attacks
From the challenges in Section 2, we here outline a set of NeSy use cases we believe are promising. For each use case, we identify suitable NeSy tools and techniques that show potential. We note that this work is incomplete and should be seen as a starting point (seeSection 6). Moreover, this section is speculative by nature, but we provide some evidence in terms of existing work and experiments conducted in Section 5 for selected use cases.
Monitor
The ability to integrate relevant knowledge into ML-based detection models (challenge 3) falls directly under the NeSy paradigm, and could both improve performance under real-world conditions (challenge 1) and help reduce the number of false alerts (challenge 5): Use (symbolic) knowledge of threats and assets to guide or constrain ML-based detection engines.
In challenge 2, we highlighted the need to learn from (relatively small) data sets, which is one of the key features of NeSy (Gray, 2023): Learn detection models from a limited number of (labelled) incidents.
Threat hunting involves generating suitable hypotheses, applying and validating them, then updating and iterating (challenge 4). Work has started investigating LLMs for this challenge (Perrina et al., 2023). It has been argued for symbolism in LLMs (Hammond & Leake, 2023), and based on that we define an LLM-based NeSy threat hunting use case: LLM-driven threat hunting using symbolic knowledge and reasoning capabilities.
Hypothesis generation is typically driven by CTI, which can be captured in a KG. The integration of LLMs and KGs is an active research field (Kurniawan et al., 2024; Pan et al., 2024). In addition, symbolic or computational methods could be used for other steps in the hunting process, including: Planning how to answer the hypothesis; reasoning about available data sources to execute this plan; ensuring correct translation to the required query language 7 to validate the hypothesis using the observations; and finally, reason about the results from the execution and provide input for any refinement of the hypothesis for a new hunting iteration. Additionally, ASP techniques, such as dPASP (Geh et al., 2023), can leverage existing LLM-ASP integrations to perform threat hunting, thus utilizing both knowledge and reasoning (Rajasekharan et al., 2023).
A prominent characteristic of NeSy is its ability to combine learning and reasoning. Such a combination is desirable in a SOC, and our next use case, which cuts across the monitor and analyse phases, addresses several of the challenges fromSection 2: Incorporate learning of detection models with the ability to reason about their outcomes to understand and explain their nature and impact.
Use case 4 is rather generic and can be broken down into several smaller sub-cases. The first such sub-case is the extraction of symbolic alerts, in order to support alert contextualisation, analysis, and explanation: Extracting alerts in a symbolic form.
A SOC typically receives a large volume of threat intelligence, which is too large to thoroughly analyse manually. Such intelligence is used to contextualise alerts, and it is thus desirable to enrich the SOCs knowledge bases with relevant intelligence reports: Use statistical AI to enrich or extract symbolic knowledge.
This ability to reason is crucial as the intelligence report may be incorrect or superseded for different reasons, including underlying (aleatoric) uncertainty, deterioration over time, or they may come from sources one does not fully trust. It may also simply not be relevant for our purposes, or more importantly, intelligence reports may conflict with our existing knowledge or our own observations. It is therefore desirable to have the ability to quantify and reason about knowledge, including the level of trust, from both our own observations and existing knowledge: Reason about and quantify knowledge.
As discussed in Section 2, a cyber attack conducted by an advanced adversary will consist of multiple phases. The ability to relate these phases is essential when developing cyber situational awareness (challenge 6): Relate the different phases of cyber incidents.
Neurosymbolic RL (NeuroRL) (Acharya et al., 2023) combines the respective advantages of RL and AI planning. NeuroRL can learn with fewer interactions compared to traditional RL by using inherent knowledge. This ability makes it more applicable than both RL and AI planning when (near) real-time response is required and a complete model of the environment is infeasible. Moreover, it has the promise of more explainable response actions, whilst a reasoning engine could, in principle, help to take into account both risk and impact
8
. Thus, this seems like a promising approach for challenge 8: Generating impact and risk-aware explainable response actions in a timely fashion using neurosymbolic RL.
A widely applied form of symbolic AI in the context of cyber security is in semantic ontologies. Ontologies provide a formal and structured way of representing knowledge that both humans and machines can interpret while accounting for interoperability across systems. Built upon symbolic AI principles, ontologies focus on knowledge representation, logic, and reasoning, using well-defined structured models of the world. They define concepts, their composition, and their relationships within a domain, and they provide a clear distinction between the data (and the information itself) and the underlying model that defines how that information is organised, represented, and processed. This paradigm enables model evolution without data disruption, a known limitation of traditional relational models and other data serialisation formats that inherently combine representations and data elements. This powerful paradigm allows for a more seamless integration of federated and siloed (in too many cases heterogeneous) data and can provide ensembles of contextual KGs in support of answering complex questions for decision-making. In addition, ontologies are the backbone of a knowledge base that can guide learning, ensure consistency, facilitate inference, and provide explainability, making neurosymbolic systems more capable of handling real-world, knowledge-intensive tasks. Our final use case directly addresses challenge 9. CTI is commonly shared in both structured and unstructured forms. LLMs are extensively studied for generating reports and this is also the case for cyber defence (Motlagh et al., 2024). It is important that the information generated is accurate, something (Kurniawan et al., 2024) can help with. The generation process is likely to use symbolism (e.g., KGs Pan et al., 2024). The reports need to be correct, which is an area in which symbolic AI can help (Hammond & Leake, 2023). We, therefore, rephrase challenge 9 as a NeSy use case: Generation of incident reports and CTI reports tailored for a given audience and/or formal requirements, using (symbolic) knowledge and LLMs.
We have outlined ten different uses of NeSy that can address the challenges outlined in Section 2, and identified promising NeSy techniques that can serve as a starting point. Table 1 summarises the relationship between these use cases and the underlying challenges fromSection 2. In addition, we indicate which use case and challenge each of the experiments in Section 5 addresses.
Relationship Between Challenges, use Cases and Conducted Experiment.

Relationship Between Challenges, use Cases and Conducted Experiment.
‘✓’ indicates that a given challenge is addressed by the given use case, while ‘EN’ indicates that the challenge/use case is addressed by experiment N.
This section provides experimental evidence for our hypothesis that a SOC is an ideal environment for studying neurosymbolic approaches. The selection criteria we have used for the experiments is a combination of covering a broad set of challenges and use cases, as seen in Table 1, and that is sufficiently mature and feasible to conduct within our time frame. A consequence of the latter criteria is that the experiments only cover the monitor and analyse phases of MAPE-K, as we believe we find the most mature NeSy approaches there. We also note that our approaches should be seen as proof-of-concepts, and are far away from being in a state that can be used in a operational setting in a SOC. We have conducted the following five experiments:
In Experiment 1 (Section 5.1), we address use case 1 (using knowledge of threats and assets to guide ML-based detection engines.) This is shown by using LTNs Badreddine et al. (2022) to illustrate how cyber security knowledge in symbolic form can be used to improve an ML-based detection engine as well as improving explainability. In Experiment 2 (Section 5.2), we address use case 8 (relating different phases of cyber incidents). Here, LLMs and ASP are used to elicit and reason about adversary attack patterns and observed alerts for situational awareness. In Experiment 3 (Section 5.3), we address use case 4 (learning detection models with the ability to reason about their outcomes). This experiment also addresses elements from use case 5, use case 7 and use case 8. Here, a NeSy solution based on the Embed2Sym Aspis et al. (2022) approach is explored to contextualise alerts. That is, we use ASP and formalised domain knowledge to label clusters of embeddings according to what cyber kill chain phase they are likely to represent. In Experiment 4 (Section 5.4), we address use case 3 (LLM-driven threat hunting with symbolic knowledge and reasoning). Here, we build on Chetwyn et al. (2024a, 2024b) by exploring the integration of LLMs with a symbolic approach based on KGs for threat hunting. In Experiment 5 (Section 5.5), we address use case 6 (use statistical AI to enrich or extract symbolic knowledge). Additionally, some elements of use case 8 is addressed. Here, we extend our previous work using data-driven enrichment of (symbolic) knowledge (Skjøtskift et al., 2025) with experiments using newly released data and explore the advantages NeSy provides for this challenge.
ML-based intrusion detection systems need to learn how to correlate data and their classes 10 , capturing both simple and complex relationships. However, information that is not present or prevalent in the data might not be used, even if it is obvious to an analyst. For this reason, we use a LTN Badreddine et al. (2022) to learn from data while being guided by expressed knowledge. Most people intuitively know that a vulnerability in Microsoft Word is not a danger for machines without the software installed. Neural networks, on the other hand, need to learn this by seeing it repeatedly in training data. Common sense knowledge, such as this, can easily be expressed as logic statements, which are used to help guide the learning of the LTN model. In detection engineering, analysts often have information they use to support the detection process that is not expressed explicitly in the logs used by the detection engine. This information can come from the knowledge or experience of analysts or other sources of information, such as CTI reports.
This experiment addresses use case 1 and is placed in the monitor phase of MAPE-K. Here, the goal is to detect malicious traffic by training LTN-based classifiers to detect two types of malicious traffic: Brute force attacks and cross-site scripting (XSS) attacks. A brute force attack is a trial-and-error approach that, for instance, tries to guess the correct password, while XSS attacks essentially inject malicious code into webpages.
We train two LTN-based classifiers: one classifier that separates brute force attacks from benign traffic and one classifier that separates XSS attacks from benign traffic. 11 Both classifiers use aggregated traffic in the form of NetFlow entries (Claise, 2004). A NetFlow entry contains information about traffic between two distinct ports on distinct IP addresses for a given protocol within a given time frame (which may vary). It will typically contain information on the number of packets and the amount of data transferred, in addition to a wide range of other features. For our experiment, we used more than 80 different features extracted from the NetFlows.
The LTN-based intrusion detector will generate an alert if a NetFlow entry is classified as brute force or XSS. This alert will typically be manually inspected by a SOC analyst – or, as we will see in other experiments below – further enriched by for example other NeSy approaches.
Figure 1 shows an overview of the approach. As the learning is supervised, the model takes the ground truth label for each NetFlow entry as input in addition to the NetFlow entries themselves. The main difference from a standard fully connected neural network is that we encode and provide knowledge as real logic statements (Serafini & d’Avila Garcez, 2016). This could, for instance, be general knowledge, knowledge about the systems being protected, or CTI about the threat we are trying to detect. Real logic is a fully differentiable first-order fuzzy logical language, supporting connectives and quantifiers (Badreddine et al., 2022). This enables expressing knowledge that is hard or even impossible to express by purely adding extra information to the data points. 12 The statements are used in the classifier’s symbolic part, while the labels and NetFlows are used in its neural part.
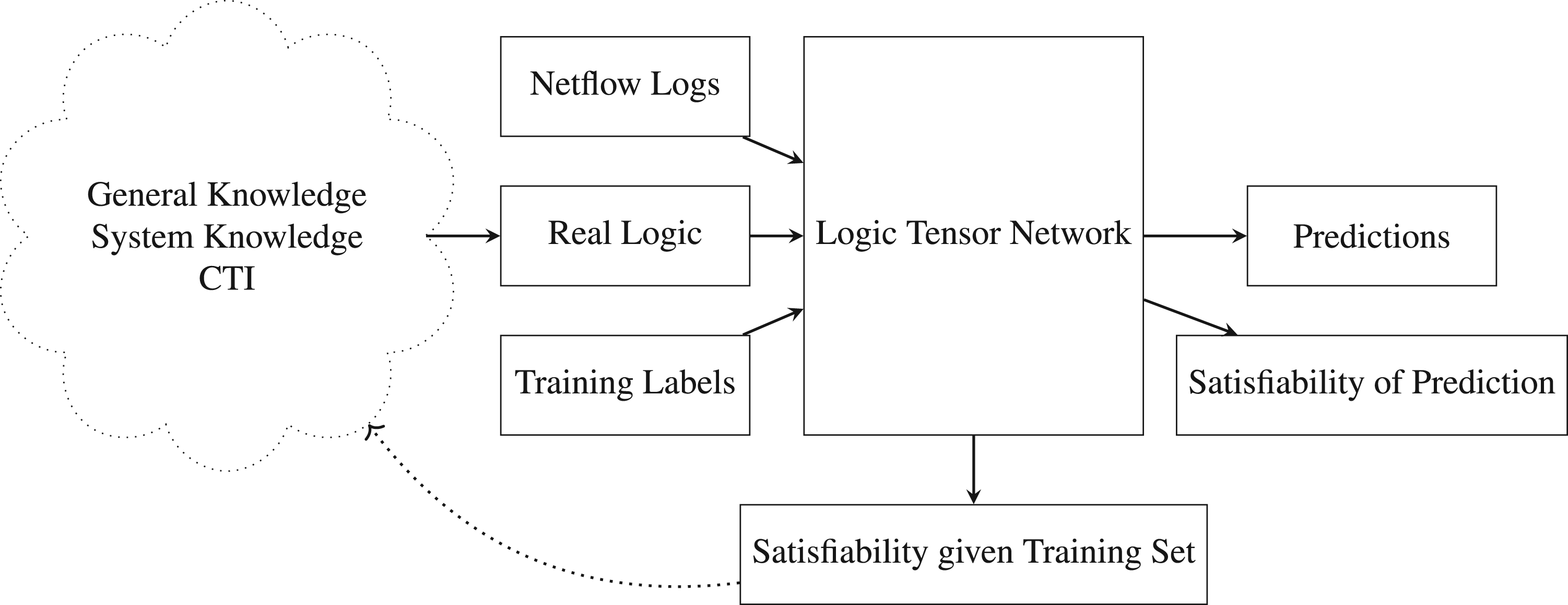
Overview of logic tensor network (LTN)-based approach.
The experiments seek to answer the following research question:
Will a classifier enriched with knowledge perform better and provide better insight into what has been learnt than a purely data-driven classifier?
The experiment consists of two parts: In the first part, a three-layered fully connected neural network is trained and used as a baseline. In the second part, a LTN with the same underlying neural network structure is enriched with additional knowledge (Badreddine et al., 2022). In both cases,
We use the CICIDS2017 data set (Sharafaldin et al., 2018) for our experiments. This data set simulates benign traffic and attacks over five days, varying the attacks performed each day. In our experiment, we use the subset called ‘Tuesday morning’. The labelled flows are categorized into three classes: ‘Benign’, ‘Web Attack – Brute Force’ and ‘Web Attack - XSS’. The classes are significantly imbalanced, with
The LTN consists of one predicate for class membership:
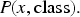
Real logic statements are used to shape the training of the neural network. The idea is that such statements should be created by a cyber security analyst and be based upon knowledge about the system, the current threat landscape, and any other relevant information the analyst has. Training consists of updating the neural network 

We trained one baseline model and one LTN model for each of the two attack classes. Both the baseline and LTN models use the same training and test sets, and have the same configuration of the underlying neural network. We trained both models over
Results From LTN Experiment.

LTN: logic tensor network; XSS: cross-site scripting.
The data set tries to reflect realistic data and is therefore highly unbalanced, with
The results show that both solutions have high recall when distinguishing benign traffic from attacks. The precision for both solutions is fairly low; however, this is to be expected as the data set is unbalanced. Most importantly, we can see that the precision of the LTN classifier is more than double that of the baseline classifier (
As a comparison, we look at two related works using purely neural techniques to create an NIDS on similar data sets. MLP4NIDS Rosay et al. (2020) uses a multi-layer perceptron (MLP) to create a multi-class classifier on the CIC-IDS-2017 data set. Kim et al. (2019) use a convolutional neural network as a multi-class classifier, testing it on the CSE-CIC-IDS 2018 data set. This paper only looks at a subset of CIC-IDS-2017 with only two attacks: XSS and brute force. Both works show good results overall. However, as both of them are trained on 16 attack types as opposed to two in the LTN classifier, we see that the result for classifying XSS and brute force attacks is comparable or worse in both cases. For MLP4NIDS, all XSS and brute force attacks are misclassified. In Kim et al., the F1 score for XSS is
Real logic statements in a LTN are an effective way of injecting knowledge into a neural classifier. They can also help in understanding and influencing the model’s training and focus. Next we explore different ways the explainability aspects of LTN can be used by a SOC analyst.
During training of the LTN, the goal is to maximize the aggregated truth of all the provided statements. This is done by deriving the loss of the model from the aggregated truth. Real logic is fuzzy logic, and we would not expect that all statements hold for all cases. After the training is completed, one can analyse how well the rules hold on all the provided training data to provide insights into how the model works. This can also be used as feedback to the analyst to help change or tweak the rules. In Figure 2(a), we plot the satisfiability of the five statements for the training set. Here, we can see that after training, rules four and five are generally satisfied. They are the rules that reduce false positives (false alerts) for the two attack classes. We can also see that the performance for the third rule, which classifies XSS, is significantly lower. This is in accordance with the results in Table 2.

Average satisfiability on training set (after training). (a) Standard rules; (b) Standard rules + wrong rule.
When creating real logic statements, there is a risk of creating a statement that does not accurately reflect the data. This can be the result of errors made when defining rules or due to incorrect intuitions. For example, a rule asserting that only computers are targets of attacks does not accurately capture reality, as mobile phones are also targets. If a bad rule is introduced, we would expect that the LTN would have a hard time satisfying this rule at the same time as the other rules. We can therefore use the low satisfiability of a rule (after training) as an indication that there is a problem with the rule. The fact that the LTN was not able to find a way to make the rule true is an indication that it does not describe the data correctly. To demonstrate this, we conduct a small experiment where we introduce a new rule that is obviously not true stating that all traffic labelled as benign should be classified as brute force:

In addition to expressing rules, an analyst may be interested in expressing the relative importance of different rules. For example, a rule relating to a rare attack with limited consequences may be given a low priority. Conversely, a rule expressing something very prevalent and critical may be prioritised. To reflect this, we add weights to the rules to give a simple way of assigning the importance of a rule compared to the others, where a high weight results in the statement contributing more to the total aggregated truth.
To provide additional insights, the analyst can investigate the satisfiability of the different rules for a given NetFlow. For the majority of NetFlows, we expect all rules to hold, as this is what the LTN is optimising for. However, if some rules are not satisfied, we could pass the information on to an analyst to provide additional explanation and context for their analysis.
To summarise, this experiment illustrates the potential of using NeSy to embed additional knowledge into ML models to detect suspicious behaviour. We also see how LTNs can help analysts understand what the model learns and how it predicts. We have showcased that a neural classifier can be improved by adding knowledge in the form of real logic statements. When using the knowledge-enriched LTN, the number of false alerts was reduced without impacting recall. The LTN also provides multiple techniques to improve the model’s explainability. By examining the satisfiability of the statements after training, we can gain valuable insight into what the model has learnt or what it is not able to learn. With this information, we can change and improve the defined statements. The satisfiability can also be used to gain insight into the model’s predictions. This shows promise for using NeSy to enrich ML-based models with (symbolic) knowledge.
Experiment 1 provided an example of how alerts can be raised. In Section 2 we have also discussed the need for supporting alert analysis. In this experiment, we demonstrate such analysis by illustrating the use of NeSy to relate different phases of an attack (use case 8). Here, alerts sequenced by time are mapped to adversary attack patterns, gleaned from textual CTI reports into symbolic form using statistical methods (use case 6). The experiment is inspired by existing work such as: neurosymbolic plan recognition (Amado et al., 2023), attack plan recognition (Amos-Binks et al., 2017), and the use of LLMs to extract both linear temporal logic (LTL) (Fuggitti & Chakraborti, 2023) and CTI (in the form of MITRE ATT&CK tactics or techniques) 14 (Haque et al., 2023; Orbinato et al., 2022; You et al., 2022).
An LLM is first used to elicit formal representations of attack patterns described in CTI reports, affording us a rapid way to convert CTI to symbolic knowledge. Here, we use the
One prompt generated from NL2LTL, and the resulting conceptual adversary attack pattern, sequencing MITRE ATT&CK techniques is visualised in Figure 3.

Adversary attack pattern.
Each ‘txxx’, where
The attack patterns in the programme are acquired by the elicitation step described above, and the sequences of observed alerts are assumed to come from a SIEM system. That is, the alerts produced are in a structured form amenable to be represented as Prolog/ASP terms. We assume that this conversion of alerts to symbolic form (use case 5) exists (see for example Himmelhuber et al., 2022). Furthermore, they are temporally ordered, inducing a sequence of alerts (where

Trace of alert observations.

Finally, we assume that all the alerts produced can be associated with ATT&CK techniques, which is the case for many signature-based alerts. Note, however, that it is a many-to-many relationship: An alert can be an indicator for several techniques, and a technique can have several alert indicators. This knowledge
15
can be represented in ASP with choice rules, as illustrated below:

The feasibility of using the outlined approach in practice on real data is a matter which requires further study. However, we note that the LTL-satisfiability problem is
Deciding which alerts are important and require attention, and understanding how they belong in the bigger picture, is essential in a SOC. However, this requires contextualising alerts with knowledge, such as about the systems and networks in which the alerts were raised, CTI, and background knowledge accumulated by analysts over time. This is illustrated in Figure 6, where the context allows an analyst to follow a continuous path through alerts and log events.
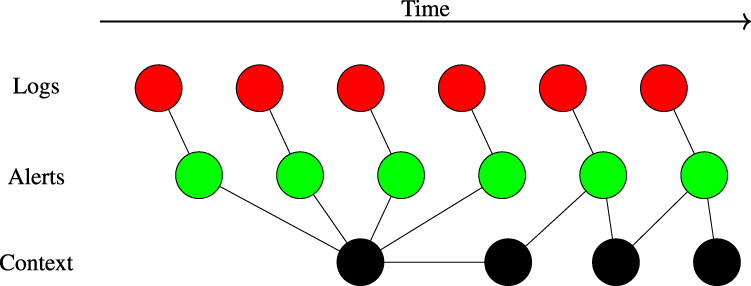
Illustration of how context contributes to creating a continuous path through logs and alerts.
In this experiment, we assume the existence of rule-based and anomaly-based alerts, which differ widely in contextual richness, and we aim to classify these alerts by the cyber kill chain step to which they are likely to belong. The experiment mainly addresses use case 4, but also includes aspects of use cases 5, 7 and 8.
Rule-based alerts are generally contextually richer than anomaly-based alerts; the former are mostly hand-crafted and contextualised with descriptive knowledge as to what type of suspicious behaviour it detects (e.g. which MITRE ATT&CK technique the alert indicates), while the latter are generally more primitive alerts that flag any abnormal attribute values (that deviate from normally seen values during training). Thus, these are less descriptive about what behaviour is detected. Hence, it is, for example, easier to associate cyber kill chain phases with rule-based alerts than with anomaly-based alerts. 16 On the downside, contrary to anomaly-based alerting, rule-based alerting is unable to detect novel and previously unseen suspicious behaviour. Both types of alerts are thus useful for detecting cyber attacks.
For this experiment
we wish to classify alerts according to cyber kill chain steps, yet we have alerts with a highly varying degree of contextual richness on which to do so.
The approach we explore in this experiment is that of using ASP and formalised domain knowledge to label clusters of alert embeddings according to what cyber kill chain phase they are likely to represent. Here, the embeddings are created using a neural component and then clustered into groups. The effect of this is that the clusters are likely to contain both descriptive and non-descriptive alerts. The task we formalise in ASP is essentially an optimisation problem, where we use weak constraints to promote cluster labelling. Specifically, we encode the following two label assignment preferences: The assigned cluster labels (i.e. the predicted cyber kill chain phase of the alerts in the cluster) should comply with (any) domain knowledge about the detection rules that were the origin of the alerts in the respective cluster. Example: The cluster that contains an alert generated by a rule that detects MITRE ATT&CK technique T1548 should ideally be labelled Privilege Escalation. When there are alerts in different clusters that share some context (e.g., same users, or overlapping source and destination addresses), then the cluster labels should be assigned in such a way that the temporal order of the alerts and the relative order of the cyber kill chain align. Example: Assume that
Turning to the technical details, we follow the approach presented in Aspis et al. (2022), referred to as Embed2Sym, where a neural perception and reasoning component is combined with a symbolic optimisation component to extract learnt latent concepts. The neural component is decomposed into two functions: A perception and a reasoning function. The latter function (reasoning) is designed to solve a downstream task, whereas the perception function creates vector embeddings of the input data. By solving the downstream task, the reasoning stage discovers structure in the data relevant to the domain. This is fed back to the perception function, influencing the vector embeddings. Finally, the embeddings are clustered, and symbolic optimisation using ASP is used to label the clusters according to the latent concepts.
This experiment is built upon logs and alerts from the data set described in Landauer et al. (2022) and Landauer et al. (2024). We are mainly interested in alerts, yet most of the contextual information remains in the log messages; hence we need the latter as well in order to adequately contextualise alerts. The logs and alerts are collected from a testbed emulating a small enterprise where a multi-step attack is being performed. The data also includes ground truth, making it possible to see exactly where in the logs and alerts the attack is captured, and also what hostile activity gave rise to each of these log lines and alerts.
We transform this data into graph form, projecting descriptive features that can be extracted from log messages onto the alerts they are associated with. We end up with alert graphs, that includes nodes representing other objects such as network resources, MITRE ATT&CK techniques, detection rules etc. These can be extracted from the log or alert information and can be used to link alerts through paths in the graph. The latent concepts of interest are the cyber kill chain stages. The cyber kill chain stages in the experiment are based upon the stages used in the attack described in Landauer et al. (2022): Reconnaissance Initial intrusion Obtain credentials Privilege escalation Lateral movement
Our instantiation of Embed2Sym is shown in Figure 7. The downstream task for the Embed2Sym reasoning function is in this case to classify alerts according to hostile activity, utilising the ground truth labelling in the data. This leads to a perception function whose output is an embedding function influenced by context learnt by the reasoning function.

Embed2Sym adapted to our experiment.
For the next step in the process, we consider the set of alerts that we wish to analyse. Using the embedding function, these alerts are transferred into the embedding space, where they are clustered. The intuition behind this step is that the downstream task of classifying the alerts according to the actual hostile activity should force the embeddings of alerts from the same stages of the attack closer together in the vector space.
The final step is to apply symbolic reasoning, utilising the alert graph and formalised domain knowledge, to label the clusters accordingly. The task is encoded as an ASP programme, shown in Figure 9, and the clustered alerts are represented as ASP facts, as shown in Figure 8.

Answer Set Programming (ASP) instance encoding.

Answer Set Programming (ASP) programme encoding the problem.
Starting with the encoding of the instance data, lines 1–3 of Figure 8 encode that an alert belongs to a cluster, that it happened at a certain unix epoch time, and the alerted event occurred on a specific host, respectively. Line 5 encodes that the alert was generated by a rule that detects instances of MITRE ATT&CK tactic T1000, while lines 6–8 encode the IP-address that initiated the event that led to the alert, the username associated with the event, and the username that originally initiated the event (e.g., a
Proceeding to the encoding of the task itself (Figure 9), the first part establishes some basic cyber kill chain and TTP domain knowledge. That is, lines 2–4 define the cyber kill chain phases, and their relative ordering in the chain, while lines 6–10 map MITRE ATT&CK techniques to the cyber kill chain phases used in our experiment.
The next part introduces rules pertaining to the order and shared features of alerted events. The rule in line 13 captures the temporal order of alerted events, while lines 13-28 capture shared features between alerts, such as sharing users, source and destination addresses, etc.
The following part, shown in lines 31–34, deals with defining what constitutes labels and clusters, while lines 37–38 are responsible for allocating labels. That is, the choice rule in line 37 ensures that each cluster is assigned a label, and line 38 ensures that each cluster is only assigned a single label. Line 39 is a convenience rule that in practice classifies an alert based on the assigned label of the cluster it belongs to. Finally, lines 43–50 capture the two weak constraints that encode the optimisation tasks described in the beginning of this section.
For the experimental run itself, we clustered 1900 alerts from the data set into six clusters (number of cyber kill chain steps plus one ‘benign’). Of these 1900 alerts, 290 had information that associated them with MITRE ATT&CK tactics. For convenience, we identified the clusters with meaningful names in order to make validation easier (e.g. cluster2 was named ‘webshell’). We then ran the ASP encoding of the task and instance data through the

Although this experiment was limited to detecting one specific instantiation of a cyber kill chain within a generated but realistic data set, we believe that the results indicate that the approach is feasible for classifying alerts according to cyber kill chain steps even when contextual information regarding the alerts varies widely. We note, however, that deciding if a model is stable and optimal for a disjunctive ASP programme with optimisation statements is
The previous experiments have focused on intrusion detection and subsequent analysis of the raised alerts. This experiment focuses on a different approach to discovering malicious behaviour called threat hunting (see challenge 4). The experiment addresses use case 3 and explores the efficacy of leveraging LLMs to develop a taxonomy of behavioural indicators for the (symbolic) indicators of behaviour (IOB) approach to threat hunting (Chetwyn et al., 2024a, 2024b). This symbolic threat hunting approach utilises an ontology and semantic reasoning to infer a set of contextualised adversarial behaviours across a series of logged security event data. Whilst this IOB-concept has previously been demonstrated (Chetwyn et al., 2024a, 2024b), it lacks a taxonomy of behaviours and reusable IOB identifiers. Since the IOB knowledge base is an emerging concept, it requires continuous additions to its knowledge base to increase maturity. We explore the efficacies of LLMs to aid in the semi-automated development of the IOB taxonomy and knowledge base.
NLP techniques have been utilised for extracting Indicators of Compromise (IOCs) from CTI Reports (Long et al., 2019) and, more recently, extended to the utilisation of LLMs for extracting IOCs from CTI reports (Tseng et al., 2024). Here, we explore the implementation of LLMs for developing an IOB taxonomy. The utilisation of LLMs for generating detection logic from a conceptualised task has been demonstrated in industry (Shiebler, 2024). Motivated by this work, we explore the automated development of semantic rule-based reasoning into our taxonomy in this experiment.
Threat hunting involves the generation of suitable hypotheses, followed by applying and then validating the hypotheses (see challenge 4). This experiment uses a scenario-driven approach to IOB development, where the scenario is a hypothesis describing what an adversary, tool or general user is trying to achieve. For a given scenario, the LLM is tasked with generating a set of low-level behavioural indicators that analyse syntax, commands and other properties at a low-level of details and reason over these indicators to infer a higher level of abstraction.
A simple example of such a scenario is
To semi-automate this scenario-driven approach to developing an IOB taxonomy, we require an LLM that can: Contextualise elements of the cyber security domain. Contextualise how adversaries behave. Generate behavioural scenarios and transform these scenarios into a chain of events. Contextualise how tools, systems or programmes operate in a given scenario. Generate a set of reusable IOB identifiers. Relate low-level security events together to form a higher level of abstraction and context. Transform an IOB scenario into a symbolic representation. Transform the detection logic for low-level events into semantic web rules language (SWRL)
18
. Be both granular and descriptive to provide context commonly missing from MITRE ATT&CK technique procedures (Chetwyn et al., 2024b).
These requirements are a mix of concepts and subject areas, where tailored LLMs may struggle to fulfil some requirements and excel in others. As a result of this, we primarily focus on general-purpose LLMs rather than purpose-built LLMs. We compare the following models for their ability to semi-automate the development of an IOB taxonomy:The first three models are general purpose, while the last model is purpose-built for the cyber security domain. Various GPT-models have been used in the cyber security domain for a variety of purposes (Motlagh et al., 2024), including payload generation for offensive security tasks, leveraging knowledge from the MITRE ATT&CK framework and detection engineering. Llama has been available for research (Meta, 2024), and SecurityLLM is based on Llama with the intent to provide cyber security guidance (Zysec, 2024), including threat hunting, cyber kill chains and MITRE ATT&CK. Both Llama 3.2-3b and SecurityLLM were used offline for this experiment.
The scale of symbolic security event data makes it inefficient to process line-by-line via an LLM, due to context size and memory limits. To illustrate, the symbolic event data file generated from a single node in an emulated attack scenario used for our experiment contains
LLMs perform more accurately when prompts utilise chain-of-thought prompting (Wei et al., 2024) and least-to-most prompting (Zhou et al., 2022), which we combine in a hybrid approach. Chain-of-thought prompting is used to create a set of behaviours, an abstract definition, a summary, detection logic and the semantics are different concepts. Least-to-most prompting is used to create sub-tasks for the model to maintain accuracy and reduce the risk of LLM hallucination. Each sub-task has an updated prompt instruction set. Each model is tested without a system prompt. The GPT-models are non-configurable, hosted by the OpenAI, and operated in the web browser. Therefore, no configurations are available to share. Llama and SecurityLLM are open and their configurations are included during assessment.
Each model has two tasks: Create the IOB scenario. Create the symbolic representation.
The prompt task specification, seen in Figure 11, is developed based on the requirements for symbolic threat hunting, as elucidated in the requirements of an LLM for symbolic threat hunting. Each task specification defines the constraints and explicit requirements when processing the prompt. Prompts (A) and (B) are examples of how the scope of the task is defined for creating an IOB scenario and a generalised taxonomy of IOBs. Prompts (A) and (B) develop a holistic set of interconnected threat actor behaviours forming a scenario.

Prompts used for NeSy-driven threat hunting.
Prompts (C) and (D) demonstrate the task specification for transforming IOBs into a set of user defined reasoning rules. These user-defined reasoning rules utilise the SWRL for more nuanced symbolic reasoning. Overall, prompts (A)–(D) demonstrate the generation of symbolic representation aspects of this experiment.
An output of prompt task specifications (A) and (B) is found in Figure 12. Note that each IOB has a Behaviour ID. This Behaviour ID is a uniform resource identifier, used to uniquely identify each IOB in the ontology. The prefix is a naming convention to ascertain which level an IOB is. L is for Low. M is for Medium and H is for High. More information on these levels can be found in Chetwyn et al. (2024b) and Chetwyn et al. (2024a).

An example scenario generated by GPT-4 Omni for generating an IOB taxonomy. This scenario is transformed into an OWL ontology and processed by a reasoning engine. The behaviours IDs are a URI and identifying property used in the ontology. SWRL reasoning logic is generated from the list of commands. IOB: indicators of behaviour; SWRL: semantic web rules language.
GPT4-Omni was the best-performing model. Without a system prompt, it produced various IOB scenarios and transformed these into a taxonomy. Like most of the models, it arbitrarily chose an IOB ID rather than generating the same each time when a system prompt was not provided. The model worked best with a system prompt, producing consistent IOB scenarios that can be concatenated into a behavioural taxonomy. An example scenario output by GPT4-Omni can be seen in Figure 12.
The scenario in Figure 12 creates the top-level behaviour H01 (‘Data Exfiltration via Command Prompt’) and generates a set of associated behaviours for this scenario. This is the optimal output expected from the LLM. Unlike Llama, this model was capable of producing an SWRL rule-set based on the possible command examples present in the IOB scenario. However, without the contextualised prompt instructions, it would create its own taxonomy. Instead of using SWRLs built-in regular expressions
21
to trigger within the ‘

Example class hierarchy of indicators of behaviour (IOB) behaviours for the CommandPromptBehaviour class. Each indent is a subclass. This class hierarchy was generated by GPT-4 Omni.
The same limitations found in GPT4-Omni were also present in GPT3.5, and there was little variance between the findings for these two models. Llama 3.2-3b primarily used its default configuration. 23 When including a system prompt, Llama was able to perform the IOB scenario generation task and develop a general taxonomy of behaviours. However, the model is prone to inconsistencies with its output. Without a system prompt, the model arbitrarily chooses its IOB identifier, making repeatable scenarios challenging without human input. The model had challenges when generating SWRL, generating nonsensical URIs to domain concepts that didn’t exist. Similarly, inventing its own schema and annotation property. An example SWRL rule had to be provided in its task description to ensure the model consistently produced SWRL rules in the correct syntax. Without this in-context learning the model was prone to hallucinations. Once this context was provided the model consistently output SWRL rules for any detection logic generated in the taxonomy task. An example output can be found in Figure 14, where events that match the conditions are classified as the relevant IOB class.

Example output of SWRL rule generation based on IOB scenario – Generated by Llama 3.2. SWRL: semantic web rules language; IOB: indicators of behaviour.
SecurityLLM primarily used its default configuration 24 , and performed the worst in this experiment. System prompts were not possible, which limited the ability to narrow the scope for the experiment. The model is capable of providing abstract definitions for IOB concepts and the process of developing a taxonomy of behaviours, but not any of the other tasks, regardless of how prompts and tasks were tweaked.
To summarize, except SecurityLLM, all models fulfiled all the requirements for developing an IOB taxonomy, but there were difficulties in handling symbolic aspects for all cases. Without prompt instructions defining the context and the ontology schema, each model would create its own taxonomy with variance between each of them. This variance makes it difficult to integrate when the concepts, rules and relationships vary each time. Once this context, constraints and rules were established, each model (except SecurityLLM) were capable of transforming the taxonomy into an OWL2 schema. The GPT-models were capable of creating SWRL rules without an example rule provided, whereas Llama had difficulties in understanding this context and tried to form its own ontology for rules.
This experiment bridges the gap between the lack of an IOB taxonomy (Chetwyn et al., 2024a, 2024b) and the symbolic approach to threat hunting, thus demonstrating the value of NeSy. The symbolic approach to threat hunting has previously shown that reasoning engines can infer complex adversarial behaviours (Chetwyn et al., 2024a, 2024b), but rely on user-defined rule-based reasoning. We have shown that LLM-models can aid in the semi-automation of IOB development and automating the transformation of IOB scenarios into symbolic representations amendable for such reasoning.
We have previously Skjøtskift et al. (2025) applied data-driven enrichment of symbolic knowledge to help incident responders answer the questions: ‘What did most likely happen prior to this observation?’ ‘What are the adversary’s most likely next steps given this observation?’ A comparison of TIE and the tools presented in Skjøtskift et al. (2025) New experiments using the TIE data set, including a discussion of the new results and conclusions A new analysis of the TIE data set and the the data set used in Skjøtskift et al. (2025)
One of the major issues we faced in this research was the lack of sufficient data on computer security incidents. MITRE Engenuity recently published the tool Technique Inference Engine (TIE)
25
, which uses a recommender model to infer a list of related techniques given a list of observed techniques. The data set used to train the TIE model is available on Github
26
, and covers more than
The available data for our method and TIE is a set of known incidents. Each incident contains an unordered set of MITRE ATT&CK techniques and sub-techniques. TIE uses this data to train a recommender model, which, when given a set of observed techniques as input, will output a set of techniques that most likely were used in the same incident. This gives incident responders guidance on what they should investigate, that is, which techniques to look for. It does not cover the temporal aspect, that is what happened just before and after a specific observation of a technique. TIE’s approach does not include symbolic knowledge – it is purely data-driven. To answer our two questions above, that is the most likely prior and next steps with the available data sets, a NeSy approach is needed.
Our first step is the symbolic part, that is, to formally model our knowledge of techniques. Every technique requires a set of abilities to be executed. Furthermore, every technique provides a set of abilities when executed. We developed a vocabulary of these abilities and mapped them to all the techniques and sub-techniques in ATT&CK. We then developed a tool
27
, which when given a set of techniques and the mapped abilities as input, would output a set of stages with the techniques that are possible to execute at each stage. The stages represent a temporal ordering of the technique: A technique in stage
Our second step was to apply the symbolic model to add temporal information to the data set. For each incident in the data set, we record each instance of an ability being provided by one technique in that incident to another technique that requires that ability in the same incident. We transform the data set to a set of abilities, where each ability contains a set of techniques and a count of how many times we have observed each technique provide that ability to another technique in the same incident. Figure 15 shows an example of the technique counts for the ability ‘

The number of times that techniques have provided the ability

Box plot with whisker boundary 1.5 interquartile range, showing the original data set to the left and the Technique Inference Engine (TIE) data set to the right. The data used to create the box plot is the highest Markov chain transition probability for each ability. The outliers close to
Finally, we implemented a tool
28
that uses the technique counts from the previous step to determine the transition probabilities of a Markov chain, as explained in Skjøtskift et al. (2025). We then used Markov chain Monte Carlo simulations to determine the most likely technique prior to the observed technique. Our conclusions in Skjøtskift et al. (2025) were that this approach is able to determine the prior technique with high probability, but if we try to determine a long attack chain, for example from observed exfiltration all the way back to initial access, then the most likely attack chain still has a very low probability. The example given for Exfiltration over C2 Channel (T1041) had a probability
After running the same experiments on the TIE data set, our results are similar. In one of the examples from Skjøtskift et al. (2025), we see a clear improvement in the probability when we try to predict the prior technique: the most probable attack chain for the technique User Execution (T1204) had the probability
To illustrate the difference between the data sets, we extracted the maximum Markov chain transition probability for each of the abilities in the transformed data set and created a box plot, shown in Figure 16. The plot shows that the TIE data set has a lower median than the original data set, which means that in general a long attack chain generated from the TIE data set will have a lower probability than one created from the original data set (used in Skjøtskift et al., 2025).
Our conclusions from Skjøtskift et al. (2025) are unchanged after testing our tools on the TIE data set: we are able to answer the questions in the introduction. However, our remarks that the low probability of long attack chains due to a lack of training data are not valid. Attackers are different and they use a varied set of techniques. Furthermore, new techniques are added to ATT&CK with each new revision. Based on the new experiments with the large TIE data set, we conclude that our approach is unlikely to give useful results for very long attack chains, and that our tools should rather be used iteratively during incident response: predict the most likely prior step, investigate, and then repeat the process once the prior attack step is confirmed.
Our main goal with this paper has been to showcase and demonstrate through experiments the possibilities for NeSy in cyber security, focussing on problems within SOCs. We hope this will help stimulate a concerted effort in studying NeSy in this domain. The use of NeSy for defending against cyber attacks is in its infancy, with some work having appeared over the last few years, including using NeSy for detection (Bizzarri et al., 2024; Onchis et al., 2022), generating symbolic alerts (Himmelhuber et al., 2022) and extracting semantic knowledge from reports (Marchiori et al., 2023). In addition, there exists work using NeSy in the cyber security domain that falls out of the scope of our paper, such as Melacci et al. (2021), where the focus is on adversarial attacks.
We have demonstrated that a considerable amount of symbolic and statistics-based AI is studied in SOC settings, and using it in real-world settings presents several challenges. We believe NeSy can address many of these challenges. Others have made some of the same points (Jalaian & Bastian, 2023; Piplai et al., 2023), but not to the extent as we do here.
We have contributed by defining a set of NeSy use cases to address identified challenges, and mapping promising NeSy approaches to the use cases that serve as a starting point for further research. Several of the approaches have been demonstrated in our experiments, which are the main new contributions of this paper compared with Grov et al. (2024). An overview of the challenges, use cases, and experiments in this paper is presented in Table 3. This work is just a start, and we both hope and expect that many new use cases and promising NeSy approaches that we have not covered here will appear in the not-too-distant future.
Overview of Use Cases With Related Challenges and Experiments.

MAPE- K: monitor-analyse-plan-execute over shared knowledge; ML: machine learning; LLM: large language model; CTI: Cyber Threat Intelligence; AI: artificial intelligence.
A challenge with AI in the cyber security domain is available data sets. Due to issues such as privacy, confidentiality, and lack of ground truth, researchers tend to use synthetic data, which have their limitations (Apruzzese et al., 2023; Kenyon et al., 2020). Furthermore, such data sets tend to focus only on detection (monitor phase), containing only events, and lack the additional (symbolic) knowledge, which is important in SOCs and for our use cases. An important first step will be to develop synthetic data sets that contain both events for detection and necessary knowledge in order to address the use cases. This can either be achieved by extending existing ‘detection data sets (Kilincer et al., 2021) with the necessary knowledge or by developing new ‘NeSy data sets’ from scratch.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers for the constructive feedback, which has helped improve the paper’s quality.
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work was partially funded by the European Union as part of the European Defence Fund (EDF) project AInception (GA No. 101103385). Views and opinions expressed are, however, those of the authors only and do not necessarily reflect those of the European Union (EU). The EU cannot be held responsible for them.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.