
Abstract
In this paper we investigate whether gender is associated with the content of judicial opinions in the U.S. courts of appeals. Using a topic model analysis, we find that gender is a significant predictor of the content of judicial opinions. Two causal pathways could explain this result: (1) men and women judges write differently about the same cases; (2) men and women judges write about different cases, either due to assignment or selection effects. To untangle these two pathways, we carry out three additional analyses. First, we examine whether the United States as a party is associated with judge gender. We next examine whether case codes are associated with judge gender. Finally, we examine the relationship between topic prevalence and gender, controlling for case codes. Our findings lend greater support to the second pathway than the first. This result raises the prospect that prior work on gender-based differences in judicial behavior may be confounded by assignment or selection effects. Our results also raise normative concerns about gender disparities in voice and influence in the U.S. courts.
Introduction
There is a considerable and longstanding empirical literature that examines judicial decision making on the U.S. courts of appeals (Cross, 2007; Epstein et al., 2013; Kaheny et al., 2008; Kastellec, 2013; Sunstein et al., 2006). There are contrasting accounts of the ways in which legal, psychological, ideological, institutional, and strategic factors affect how judges decide cases and shape the law (Epstein & Knight, 2013; Rachlinski & Wistrich, 2017). At the judge level, scholars have examined a range of characteristics, including party affiliation, prior work experience, and race (Rachlinski & Wistrich, 2017). Judge gender has been a particularly important area of study (Boyd et al., 2010).
There are several different methodological approaches that have been brought to bear in the judicial politics literature. An especially prevalent approach is based on observational data derived from the work of the courts themselves (Erikson, 2022). In the standard empirical setup, researchers take advantage of the apparent random assignment of cases to judicial panels to estimate differences in case outcomes that are associated with judicial characteristics. Random assignment has been thought to allow researchers to draw credible causal inferences based on correlations between outcomes and characteristics (Chilton & Levy, 2015). For example, if outcomes in criminal cases with Republican-majority panels are, statistically, more government friendly than those with Democratic-majority panels, the natural interpretation is that Republican judges tend to vote in a more government-friendly manner.
In these studies, information about case outcomes and other features are extracted from the content of judicial opinions, traditionally through the process of hand-coding (Hall & Wright, 2008). Advances in natural language processing and the digital availability of legal texts have also allowed researchers to use computational text analysis tools to extract useful information from legal opinions (Livermore & Rockmore, 2019). Computational tools allow researchers to increase the scope of their analyses beyond what would be feasible based on hand-coding, and to extract features that would be difficult for human readers to identify (Frankenreiter & Livermore, 2020).
In this paper, we analyze the text of over 300,000 opinions issued by the federal courts of appeals from 2001 through 2017 to estimate the relationship between the gender composition of panels and the content of opinions. For this analysis, we use a topic model, a tool that substantially reduces the dimensionality of a natural language text while preserving a considerable amount of semantic information. We find that there is a statistically significant and substantively meaningful relationship between the content of opinions (as captured by the topic model) and the gender of judges on the issuing panels.
There are two potential (and non-mutually exclusive) pathways that would explain the relationships that we identify through the topic model analysis. The first is that the gender composition of panels causes a change in opinion content. This would be the case if, in keeping with the standard assumptions in the literature, case characteristics are uncorrelated with judge gender. Stated counterfactually, the hypothesis is that if the same cases were assigned to panels with different gender makeups, the opinions would look different. Opinion content would be causally influenced by judge gender. We refer to this as the gender causation pathway.
A second pathway would be through case characteristics, which could occur if either: (1) cases are not randomly assigned to panels; or (2) there are gender-based selection effects in the pool of available decisions. Although it is common to assume random assignment, there is some evidence of at least a limited amount of non-randomness in how cases are assigned to panels (Chilton & Levy, 2015; Hall, 2010; Levy, 2017). Were judge attributes to affect case assignment, correlations between attributes and outcomes would not necessarily be due to differences in judicial behavior. Additionally, only some decisions are available for analysis, and judge characteristics may affect decisions concerning what opinions to make available. Our data includes both published and so-called “unpublished” opinions, but even this dataset does not include the dispositions of all cases (McAlister, 2021). 1 Because some cases are not reported, selection effects are a second mechanism through which case characteristics—and therefore the content of observable judicial opinions—could become associated with judge gender. We refer to these two possibilities together as the assignment/selection pathway.
We carry out three tests designed to distinguish between the gender causation pathway and the assignment/selection pathway. These tests involve identifying variables that are associated with case characteristics, but which are not under the control of judges. First, we examine the relationship between judge gender and case captions. Case captions are based on the names of the parties to litigation and have content not subject to judicial control. We target one particularly common party, the United States government. With random assignment and no selection effects, there should be no relationship between the gender composition of panels and whether the United States is a party to a case (once year and circuit are taken into account). We find, however, that there is a significant relationship between these variables.
Second, we construct and examine case codes, which are indicators of case subject matter based on information generated by attorneys and courts before cases are assigned to judge panels. 2 These codes should not be affected by the judges assigned to the case. Therefore, absent assignment or selection effects, case codes should not be related to judge gender. Again, however, we find that there are significant relationships between the gender composition of panels and case codes.
We then combine the two analyses to examine the relationship between topic prevalence and judge gender, controlling for case codes. We find that, for many topics, the relationship between topic prevalence and judge gender is substantially weakened when controlling for case codes.
The upshot of these analyses is that the association between the content of judicial opinions and the gender composition of panels is not entirely caused by judge gender. At least part of the relationship seems to result from differences in case characteristics that are correlated with gender. We discuss two implications of this finding.
First, systematic correlations between case characteristics and judge gender raise substantial questions concerning how to interpret prior work in judicial behavior. The assumptions that allowed credible inferences to be drawn between judge gender and case outcomes appear to be violated. As a consequence, it is unclear whether results that have been interpreted as causal are truly causal in nature. Instead, they may be a function of confounding assignment/selection effects. Research in judicial politics that does not account for the assignment/selection pathway [for example by using a comprehensive dataset, as was done in Hübert and Copus (2022)], should be understood and described as associational, rather than causal.
Second, our results indicate that male judges have a greater influence than female judges in some legal areas, and vice versa, and that judges engage in more specialization by subject matter than is generally supposed. These disparities may be a result of gender biases in case assignment or gender-based variations in the reporting of decisions. Either way, the topic disparities may be problematic, since they mean that the voice and influence of judges of certain demographic groups may be relatively attenuated in particular legal areas and amplified in others. Thus, our findings show how the numbers of judges from different demographic groups on courts (and thus, their proportional demographic representation) does not translate in a straightforward way to representation and voice—and potentially influence—across different areas of law.
Additional work is needed to further explore these implications. In particular, access to the PACER dataset, which contains all of the records of cases filed before the federal courts, could, in principle, allow researchers to eliminate at least the selection pathway. Analysis of either the entire PACER dataset, or a randomly selected portion thereof, could disentangle the causal mechanisms that lead to relationships between judge gender (and other judicial attributes) and the content of judicial decisions—including case outcomes. Unfortunately, the PACER dataset is currently behind a prohibitively expensive paywall that makes it functionally impossible to use for many research purposes (Clopton & Huq, 2024). Until the U.S. Courts decide to make the PACER dataset available to researchers, or Congress uses its power to make this resource available, questions concerning the causal role of judicial attributes in affecting judicial decisions may remain impossible to answer with confidence.
Prior Work
With the growing diversity of demographic representation on the federal courts in recent decades, the natural question arose of whether the increasing (if still insufficient) number of judges from traditionally underrepresented groups would affect legal outcomes. Harris and Sen (2019) summarize some of the theoretical reasons that judges’ race and gender might affect their decision-making. Gender and race may be associated with differences in perspective, differences in life experiences, and competing roles as substantive representatives of their respective groups. Observations in other domains of social and political life find ready correlations with race and gender: for example, gender is highly associated with liberal positions on public policy (Howell & Day, 2000).
The empirical literature on gender and judging in the U.S. courts is somewhat mixed but, on balance, supports the view that judge gender matters for legal outcomes, at least in certain contexts (Haire & Moyer, 2015). For example, in one well known study, Boyd et al. (2010) find that women and men judges vote differently in gender-related cases; they also identify panel effects, where the presence of a single woman judge on a panel influences the decisions of her male colleagues. These findings comport with results in several earlier studies (Songer et al., 1994; Farhang & Wawro, 2004; Peresie, 2005). Erikson (2022) reanalyzes the Boyd et al. (2010) results using different statistical techniques to arrive at similar results.
A smaller but growing body of work focuses on the potential effect of gender on other judicial decisions beyond voting Christensen & Szmer (2012) find a relationship between judge attributes and case disposition time. Moyer et al. (2021) find that opinions authored by female appellate court judges are, on average, two-thirds of a page longer than those authored by male judges. Hinkle (2021) examines the relationship between gender and publication decisions, finding that “gender diverse” panels—i.e., those that included at least one man and one woman—were less likely to publish their decisions than gender-homogenous panels. These findings, like those of gender effects on voting behavior, might be explained by the gender causation pathway, but alternatively they could be explained by non-random assignment or by selection effects.
Gender is correlated with other characteristics, such as party affiliation or prior work experience, that have also been found to influence judicial decision-making (Harris & Sen, 2019). Statistical controls for such correlations do not fully address the entangled relationship between gender and these other variables. For example, people’s experiences are affected by their gender, and those experiences may, in turn, affect their party affiliation. Gender may also influence how politicians in different parties view potential judicial nominees. Testing for gender effects across judges of the same party will mask these larger interactions between related judicial characteristics. It makes little sense, then, to ask how a judge would have voted had the judge been a man instead of a woman, because gender is a complex function of traits and experiences. As others have observed, “[t]he question of whether sex causes judges to behave differently is ill posed”—better to ask “whether male and female judges decide cases differently” (Boyd et al., 2010, p. 397). Because the literature nevertheless largely frames the inquiry in terms of causation, we refer to this as the gender “causation” pathway. An illuminating way of interpreting this pathway is not in terms of gender assigned to judges (counterfactually: the same judge, but with a different gender), but rather from the perspective of a litigant appraising the likelihood of victory. Under the gender causation pathway, litigants have good reason to update their estimates of their likelihood of success after the case has been assigned to a panel in light of the gender of the judges on the panel.
Overall, there are theoretical and empirical reasons to believe that judge gender affects judicial decision-making in the U.S. courts of appeals. The most robust empirical findings in the literature to date concern case outcomes in particular subsets of cases in which gender may be most salient. Female judges have been found to vote differently, and to influence their male peers to vote differently. These findings have been broadly influential in scholarly as well as non-expert understanding of the process of judicial decision-making and the politics of judicial appointments.
Previous studies have found some, although limited, evidence of non-random assignment at the federal courts of appeals (Chilton & Levy, 2015; Hall, 2010). Some studies of the relationship between judge gender and voting behavior acknowledge that random assignment cannot be assumed, and conduct tests meant to detect non-random assignment or perform matching exercises that compare cases with similar observable characteristics (e.g., Boyd et al., 2010). But these efforts do not deal with the problem of selection effects. Even if cases are perfectly matched within the observed pool, the cases tested may still be a non-representative subset of all cases. For example, female judges might be more inclined to refrain from reporting decisions in cases where they also tend to vote differently from their male peers. If that were the case, then a study, even one that used careful matching methods, might find no gender effects on voting behavior when such effects in fact do exist.
Approach
The approach in this paper is two-fold. First, we cast a broad net to find relationships between the gender composition of panels and the content of judicial opinions. 3 We analyze over 300,000 opinions, including both published (precedential) and unpublished (non-precedential) opinions. Unlike many studies of judicial decision-making, which rely on published opinions only, our dataset eliminates concerns that publication decisions are confounded with the variables under study (Carlson et al., 2020).
We use an unsupervised dimension-reduction tool for natural language texts to increase the potential semantic features of documents that we can subject to statistical analysis. Judicial opinions, like all texts, are extremely high-dimensional. Each word in a text is drawn from a vocabulary of tens of thousands, and those words each interact with each other. Accordingly, the space of one-hundred-word documents drawn from a ten-thousand-word vocabulary has a theoretical dimensionality of 10400—far too large to analyze. There are various dimensionality reduction tools that are available from the field of natural language processing (Frankenreiter & Livermore, 2020). We selected a topic model approach (cf., Blei, 2012) because it is unsupervised and is able to preserve considerable semantic information while still providing sufficiently coarse-grained representations of the text to allow statistical analysis and avoid overfitting. With the topic model representations in hand, we are able to estimate the relationship between judge characteristics and this high-level representation of the content of judicial opinions.
The second step in our analysis focuses on untangling the potential causal pathways that could explain associations between judge gender and opinion content. Many studies that identify correlations in data drawn from available opinions interpret those correlations as causal, running from judge characteristics to case outcomes. For example, the stated aim of Boyd et al. (2010, p. 393) is to “estimate the extent to which the presence of a female judge causes male judges to vote in a particular direction when they otherwise would not.” Similarly Erikson (2022, p. 426) aims to “understand[] the causal mechanisms underlying judges’ influence on each other.”
Researchers have identified two routes through which confounding effects could bias causal estimates of judicial characteristics on case outcomes (and other decisions). The first is through non-random assignment of cases to panels. An assignment process in which some judges are more likely to be assigned certain types of cases could generate correlations between case features—which are likely to influence case outcomes—and judge characteristics. As discussed above, other researchers have found some, albeit fairly limited, evidence of non-random assignment.
In addition, the processes through which data becomes available to researchers can also introduce confounding effects. This is most obvious in the case of publication decisions, which have long been recognized as potentially biasing results (Atkins, 1992; Edwards & Livermore, 2009; Fischman, 2015; Keele et al., 2009; Ringquist & Emmert, 1999; Songer & Davis, 1990). As discussed above, Hinkle (2021) has found that judge gender is associated with publication decisions. Some researchers partially address this problem by using more comprehensive datasets that include unpublished opinions (e.g., Fischman, 2015; Peresie, 2005). But even this approach may be inadequate. Researchers have found that many cases decided by federal courts are not included in even the unpublished materials in commercial databases (Kagan et al., 2018; McAlister, 2021). Inasmuch as judge characteristics are associated with the availability of opinions in the relevant datasets, selection effects can confound results regarding the effect of gender on outcomes or other decision characteristics.
Together, assignment and selection can distort the available data in ways that could create the impression of causal effects where none exist. This constitutes the assignment/selection pathway described above.
To untangle the gender causation from the assignment/selection pathway, we identify metavariables associated with cases that are not influenced by judges themselves—these are case captions (i.e., the parties to a case) and case codes. The names of the parties are outside judges’ control, as are the case codes, which we generated from the Nature of Suit (NOS) and Appeal Type (APPTYPE) fields of the Federal Judicial Center’s Integrated Database (IDB). 4 Accordingly, any association between these variables and judge gender must be due to the assignment/selection pathway. 5 If we find correlations between the gender composition of panels and either case parties or case codes, we can conclude that assignment/selection has produced correlations between case characteristics and judge gender.
Additionally, we estimate the relationship between judge gender and opinion content while controlling for case codes. Controlling for case codes should not substantially reduce the net relationship between judge gender and opinion content if the gender difference in content is attributable to judge characteristics as opposed to case characteristics.
Data
Since 1976, every federal appellate court has adopted rules allowing for the designation of decisions as “not for publication.” These unpublished decisions are formally non-precedential, and they are not included in West’s Federal Reporter. In 2001, West also began producing the Federal Appendix as a supplement to its Reporter series. The Federal Appendix includes the opinions that are designated as not for publication. The Federal Appendix ran from September 2001 through 2021.
For our analysis, we are interested in both published and unpublished decisions. We access the version of the Federal Reporter and Federal Appendix that has been compiled in digital form by Harvard Law School’s Caselaw Access Project (CAP). 6 We collected data through 2017, which was the last year of CAP’s full coverage at the time we accessed the CAP data. Our data includes all opinions from 2001 through 2017 that are made available by CAP, except for the decisions of the Court of Appeals for the Federal Circuit. That court’s specialized subject-matter jurisdiction makes it a poor fit for automated content analysis (Carlson et al., 2020). We merge the textual data from CAP with judge-level demographic information collected by the Federal Judicial Center (FJC) using judge names, and to the FJC’s Integrated Database (for the purpose of collecting case codes) using court, docket number, and decision date.
Working with these criteria we ended up with 367, 943 raw observations in our data. We then dropped another 5,026 observations that we did not identify as decisions made by a three-judge panel. En banc panels and panels that had fewer than three judges make up a small part of the total data and pose difficulties for our statistical analyses. We also dropped cases that have fewer than nine-hundred characters so that there is sufficient textual information in each observation to allow for topic modelling. We run robustness tests for our non-text-based analyses using all cases with three-judge panels (i.e., ignoring the character cut-off); the cut-off makes no difference to the results. We arrive at a total number of 325,734 observations for our analysis. There are a total of 355 Court of Appeals judges in our data, 82 of whom are women. Because judges from other courts sometimes sit by designation, we also include data for 994 District Court judges, 238 of whom are women.
Our data collects reported decisions, both published and unpublished, but there is a larger universe of case dispositions. McAlister (2021) has established that a considerable number of case dispositions do not result in reported decisions. The decision whether to issue a reported decision could be affected by a range of factors, including case characteristics and judicial attributes. That only a subset of dispositions results in reported decisions creates the potential for the selection pathway discussed above.
Analysis
Topic Model
We begin by testing for relationships between the gender composition of panels and the content of the opinions they issue. Judicial opinions are rich sources of information concerning the cases before the federal courts, but they present a number of “big data” challenges associated with (mostly) unstructured textual corpora. The traditional procedure to convert the texts of judicial opinions into quantitative data for the purposes of statistical analysis relies on hand-coding, typically done by research assistants (Hall & Wright, 2008). These hand-coding exercises are valuable because they generate low-dimensional representations of legal opinions and they capitalize on the expert judgment of the coders, but a great deal of information is lost. Hand-coding is also expensive and infeasible for large data sets. Researchers now often use “text as data” tools in place of hand-coding to extract information from large collections of documents for the purposes of computational analysis (Grimmer & Stewart, 2013).
For this project, we analyze the texts of opinions using the technique of topic modeling (Blei et al., 2003; Blei & Lafferty, 2007). Topic models have become widespread among researchers within social sciences and humanities, and they have been used to study various kinds of documents, including legal ones (Quinn et al., 2010; Lauderdale & Clark, 2014; Law, 2016; Livermore et al., 2017; Macey & Mitts, 2014).
Like hand-coding, topic models generate low-dimensional representations of texts. This representation is realized as a distribution over “topics”, where topics are also distributions, but over the vocabulary in a corpus (Blei, 2012). Researchers understand the topic as effectively a triangulation of the meaning of those words with the highest weight in the distribution. These distributions are a coarse way to represent the content of texts. To begin, they are based on term frequencies, sometimes referred to as “bag-of-words models” that ignore word order. Documents are then represented over a relatively limited number of topics. Representing a document as a distribution over topics provides general information about the content of that document. For judicial opinions, a distribution over topics encodes information about the subject matter discussed—such as whether the case concerns contract interpretation or administrative law—but the specific legal consequence of the opinion is lost. That said, these topical representations are often useful, especially when there is a need to identify topics for a large number of documents (e.g., the hundreds of thousands of opinions that we analyze here).
For this study, we use the structural topic model (STM) (Roberts et al., 2014), which has been validated in other contexts (Carlson et al., 2020). We set the number of topics at fifty (a standard prior), and in both models allow topic prevalence to vary by circuit and year. 7
After the topic model has generated its results, we engage in a subsequent analysis to estimate the relationship between topic prevalence and judge gender. For this analysis, we run a series of regressions (one for each topic) in which, for each regression, observations are opinions, the outcome is gender, the predictor variable is the prevalence for the topic under investigation, and controls are included for judge race and party as well as year, circuit, and circuit-year. 8
List of Topic Labels and Top Words for 50 Topic Model.
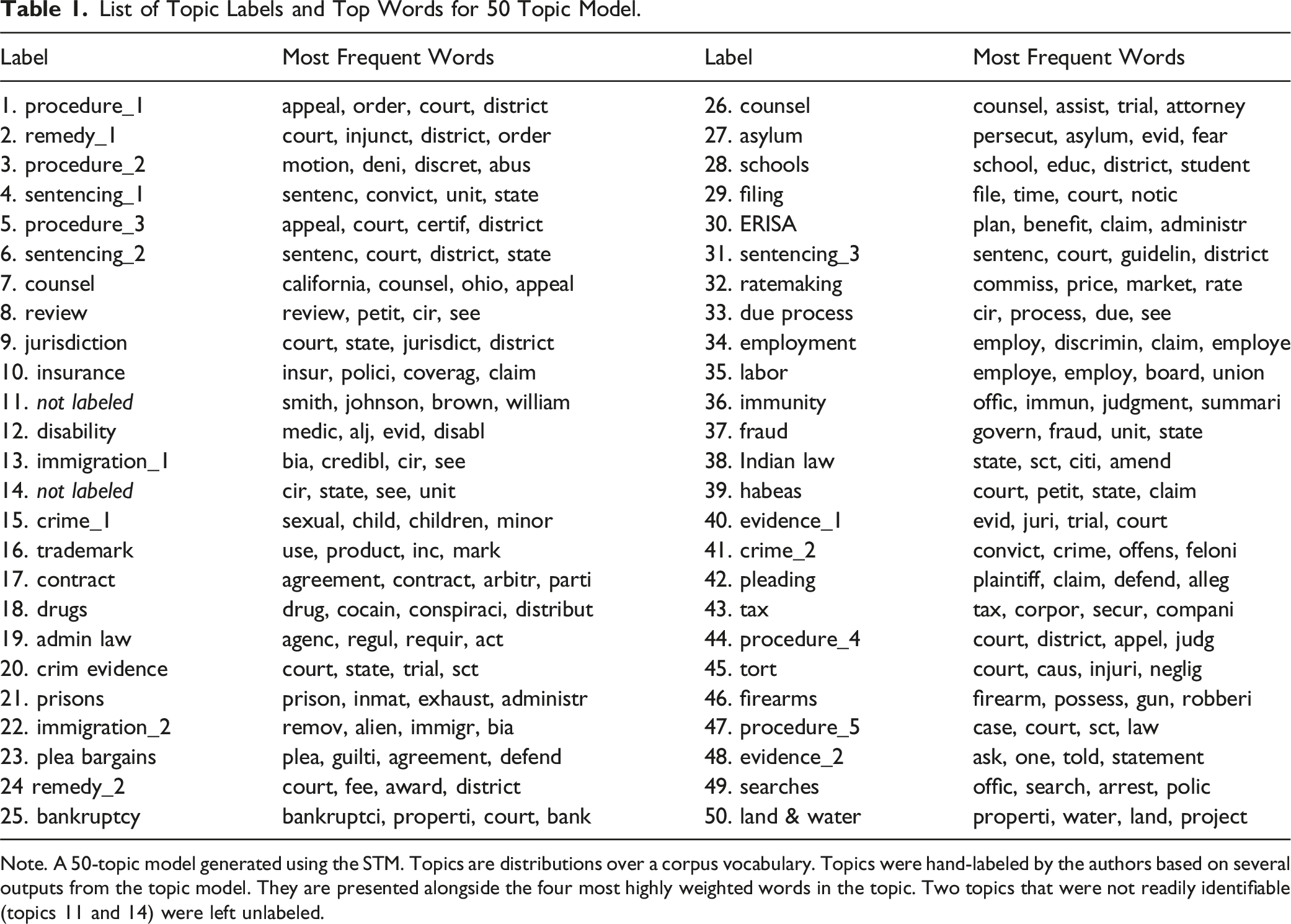
Note. A 50-topic model generated using the STM. Topics are distributions over a corpus vocabulary. Topics were hand-labeled by the authors based on several outputs from the topic model. They are presented alongside the four most highly weighted words in the topic. Two topics that were not readily identifiable (topics 11 and 14) were left unlabeled.
Topic Prevalence Predicts Panel Composition.
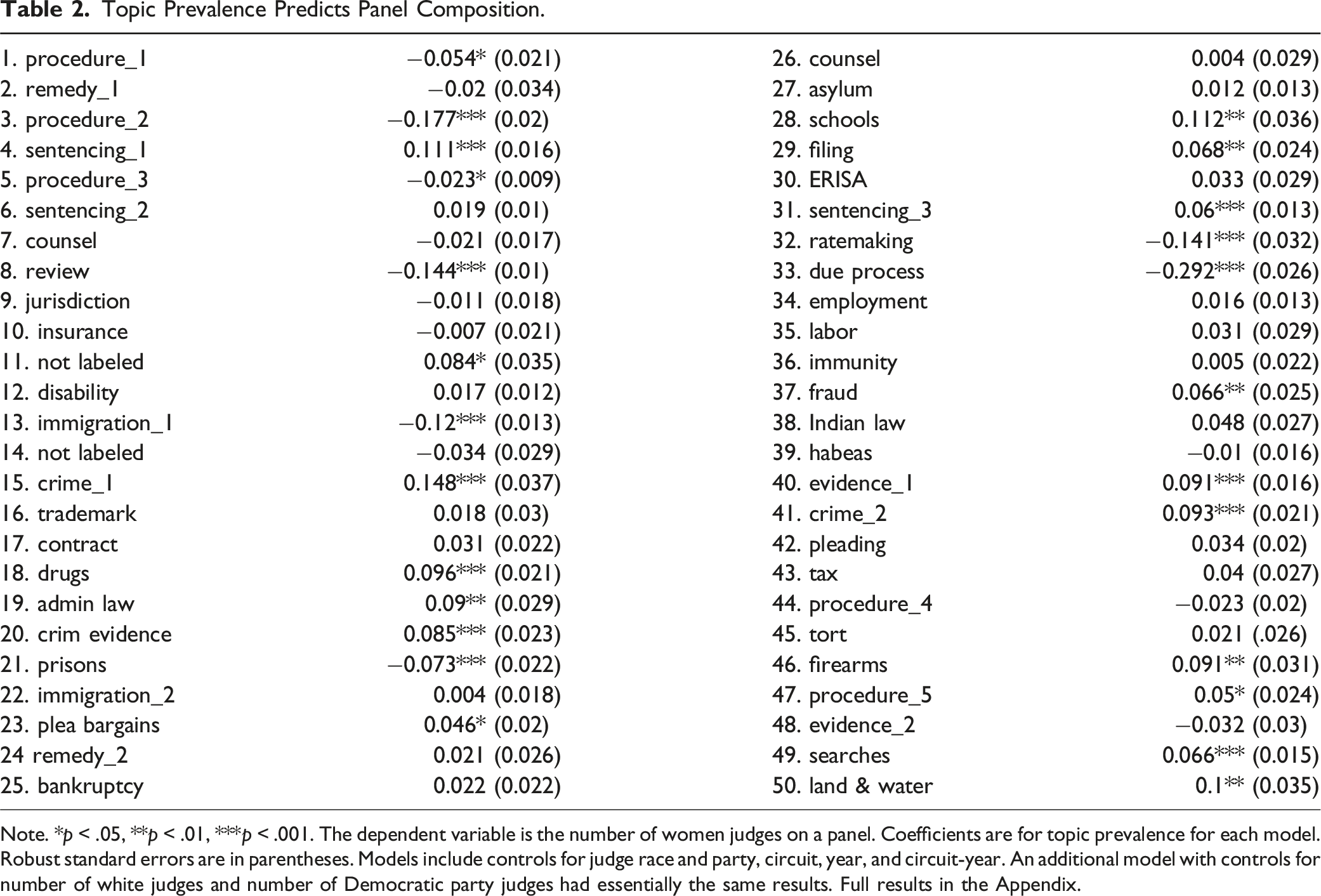
Note. *p < .05, **p < .01, ***p < .001. The dependent variable is the number of women judges on a panel. Coefficients are for topic prevalence for each model. Robust standard errors are in parentheses. Models include controls for judge race and party, circuit, year, and circuit-year. An additional model with controls for number of white judges and number of Democratic party judges had essentially the same results. Full results in the Appendix.
We find that for twenty-four topics, prevalence was a significant predictor at the p < .05 level, of which twenty were significant at the p < .01 level and fourteen at the p < .001 level. 9
Coefficients can be interpreted in terms of the effect on gender composition of an increase from zero to one in the value of θ for that topic, which is the maximum possible range. In reality, differences in topic proportions across documents are much smaller, and there is a substantial right skew, with a small number of very highly weighted documents and a larger number of documents with very low θ values. For example, for topic 3 (procedure_2) the mean value of θ is 0.03, the standard deviation is 0.06, and the maximum proportion for any document is 0.66. Accordingly, documents with the highest theta value for topic 3 would be predicted to have roughly 0.1 fewer woman judges on a panel than documents with the mean theta values.
The topic model finds meaningful associations between the content of opinions and the gender composition of authoring panels. Of course, there are many other variables in play, including the random creation of panels and the assignment of cases to panels. Predicting the gender composition of panels with variables for circuit-year only produces an R2 value of 0.0825, while introducing topic proportions to the model yields a negligible increase to 0.0846. Knowing the topic proportions in a document has relatively limited value in predicting the gender composition of the issuing panel, beyond a baseline inference based on year and circuit.
Nevertheless, the differences detected here are meaningful, as they raise questions about the extent to which judges are randomly distributed across reported cases. Previous studies have mainly found and highlighted gender effects on voting behavior and case outcomes in issue areas with gender salient subject matter, such as sex discrimination (Erikson, 2022; Boyd et al., 2010; Peresie, 2005), whereas we find relationships between gender and subject matter across many topics bearing no apparent relationship to gender. 10 Our results do not necessarily conflict with prior findings that relationships between gender and outcome are limited to specific areas. Rather, our results show that a broader measure of opinion content can identify a more pervasive gender influence. This suggests that gender-based assignment or selection may be significantly skewing the total data available in reported decisions. Further, it suggests that male judges will have an outsized influence in certain areas of law, and female judges in others.
Second, notwithstanding the relatively high information density of topic representations of opinions—compared to binary voting data—topics are very coarse-grained representations of judicial opinions. They are based on term-frequency vectors, which are simplified representations of text that ignore word order. The topics themselves are highly aggregated, with variation along only fifty dimensions (in our model) used to account for the data. Such high-level representations of text suppress many differences that may nonetheless be important. A more sensitive language model might find even greater gender differences in the content of opinions.
We now turn to the causal mechanisms at play. Given the coarse-grained nature of topic representations of documents, it is natural to suspect that they correlate with case features. Judges are likely to vary stylistically in how they write opinions, and the substance of an opinion may also be affected by the authoring judge as well as the other judges on a panel. However, all judges are likely to draw from different (but internally consistent) vocabularies when discussing criminal law cases compared to family law cases. Since topic models pick up these differences across vocabularies, aggregated over many different judges, case characteristics rather than inter-judge differences are likely to drive, for the most part at least, the composition of topics. That we nonetheless find topic differences based on the gender composition of panels raises the possibility that judge gender is correlated with unobserved case characteristics. This prospect would cut against the standard causal interpretation of the correlations between case outcomes and judge attributes in the judicial politics literature. The following sections explore this possibility further.
US as a Party
Here we examine whether case parties are associated with judge demographics. 11 If cases are assigned randomly to panels and judge demographics are not associated with the likelihood that a case will be reported in our data, there is no reason to expect that the names of parties will be associated with judicial demographics, once year and circuit effects are taken into account.
Generally speaking, empirical studies of judicial decisions draw information about case characteristics from the content of judicial opinions. For the purposes of our study, this approach introduces a potential endogeneity issue, as judges are responsible for issuing opinions and therefore affect opinion content.
To avoid this problem, we conduct tests using only information that judges do not control. In this subsection, we focus on the names of the parties to litigation. This information is contained in case captions based on party names. For our analysis we construct a variable based on whether the United States was a party listed in the case caption. 12 Holding year and circuit constant, correlations between the identities of the parties and judicial demographics indicate biases in either case assignment or opinion reporting.
With the United States as a Party variable in hand, we specify a linear regression with the number of women judges on a panel as the outcome variable, United States as a Party as the predictor of interest, and controls for circuit, year, and circuit-year. We find a significant positive correlation (p < .001) with a coefficient of 0.017. The implication is that shifting from a case without the United States as a party to one with the United States as a party increases by roughly 2% the predicted number of women judges on a panel. 13 For an intuitive sense of the magnitude of this coefficient, when the United States is a party, panels look as though there is about one additional female judge and one less male judge across the courts under study. 14
Average, corpus-wide relationships between judicial attributes and case characteristics that affect the pool of publicly available opinions may hide considerable variation at the year and circuit level. To address the issue of heterogeneity, first we test for effects on both sides of the distribution to examine whether judge attributes are under- and over-represented with respect to certain case types, depending on circuit and year. At the corpus level, such countervailing effects would weaken any overall average effects, but would nonetheless create local distortions. We find evidence of many circuit-years with both unexpectedly large and unexpectedly small numbers of decisions with all-male panels and the United States as a party (detailed results are reported in the Appendix). Second, we examine the relationship between judge gender (number of women on panel) and U.S. as a party over time, finding effects that run in opposite directions during different time periods, with effects rising in the early years in the study period and then falling off and turning negative, masking somewhat the size of these effects in the aggregate. 15
Case Codes
To construct our case codes, we relied on the Federal Judicial Center’s Integrated Database (IDB), which includes Nature of Suit (NOS) and Appeal Type (APPTYPE) fields, which are populated by attorneys and courts before cases are assigned to panels such that the judges on a panel should not have control over the values. When attorneys file complaints in the federal courts, they must include in their submissions a simple form that describes basic demographic information concerning the parties, along with an NOS (Nature of Suit) code. The NOS code is selected from a list of ninety codes corresponding to suit subject matter that are grouped into thirteen categories. Attorneys are instructed to select one, and only one, NOS code for the case. They are given some guidance to match their cases to appropriate NOS codes, although there are apparently no repercussions associated with selecting an inappropriate code.
NOS codes are used extensively in empirical scholarship of the federal courts, although they have met with some criticism (Boyd & Hoffman, 2017). Among the limitations of NOS codes, there is only one allowed per case, and litigation often involves a tangle of substantive and procedural issues that might not fit well within a single NOS category. Boyd and Hoffman have called for reforms to the system to improve the accuracy of NOS designations.
Such criticisms may have merit, but the inadequacies of the NOS codes are not relevant for our purposes. As with the names of parties to litigation, NOS codes will be correlated with case characteristics, and they are selected before cases are assigned to judges. Accordingly, there is no realistic causal pathway in which judge attributes could lead to a case having a different NOS code. 16 These data are therefore good candidates to explore the possible assignment/selection pathway as a mechanism that could link topic prevalence (presumably associated with case characteristics) and judge gender.
Following Hinkle (2021), in addition to the NOS codes we used APPTYPE values, which signify the type of appeal at the time of filing. Together, these two fields allow for the grouping of cases into seven intuitive categories: criminal, administrative, civil rights, civil (other), prisoner petitions, bankruptcy, and original jurisdiction. We put cases for which we were unable to identify a code into an additional category (“none”). 17 In parallel with the topic regressions above, we specified separate regressions for each of the case codes and used them, along with controls for circuit, year, and circuit-year, to predict the number of women judges on a panel.
We find significant effects for criminal cases, administrative cases, and original jurisdiction cases. For the significant case codes, the coefficients are small but meaningful, corresponding to 2%–4% effects on the predicted number of women on a panel. 18 This analysis provides further support for the assignment/selection pathway. After controlling for circuit and year, the gender composition of panels would not be associated with case codes unless there is a relationship either between gender and case assignment (the assignment branch of the assignment/selection pathway) or among gender, case characteristics, and whether cases are reported in our data (the selection branch of the assignment/selection pathway).
Controlling for Case Codes
Our final analysis combines case code and topic information into a single model. As before, we run a regression for each topic k to predict panel gender composition for a case j based on θ
kj
, plus a vector of controls for race, party, circuit, and year; but here we also include controls for the case codes (at the level of aggregation described above). If the coefficients on θ are lower in this regression, this is further evidence that relationships between case characteristics (as proxied by case codes) and gender drive some of the correlations between topic proportions and the gender composition of panels (Baron & Kenny, 1986). Conversely, if the coefficients on θ remain stable even after controlling for case characteristics, that would be indicate that judge gender (rather than case characteristics) predominantly influenced topic prevalence. Figure 1 shows the results of this analysis. Topics, Case Codes, and Gender. Note. Coefficients reported only for topics with p < .001 in either the original model or the model with case code controls (or both). Error bars are 95% confidence intervals of the original model. Diamonds are coefficients for model with case controls. Full results in the Appendix.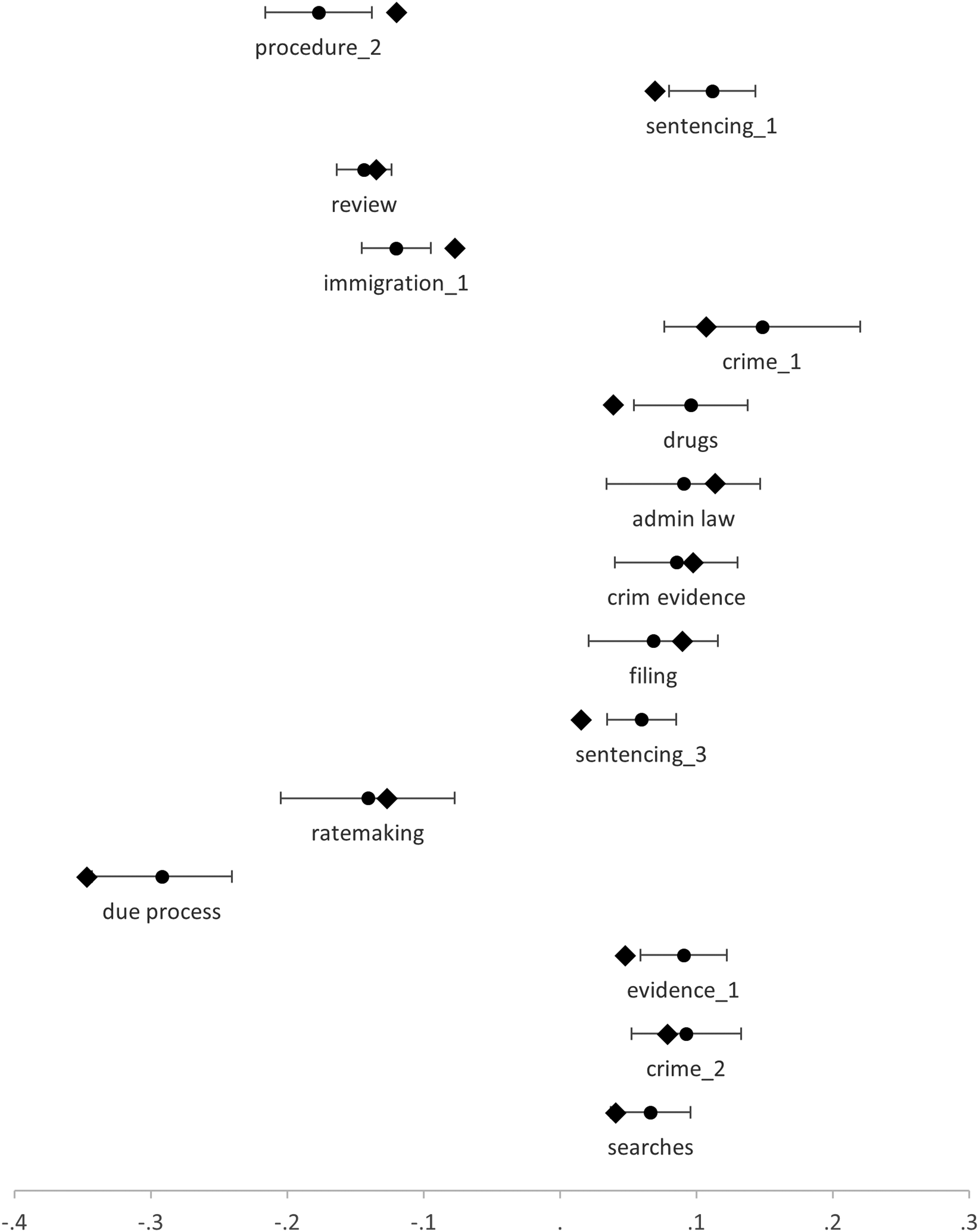
Focusing on the fifteen topics in Figure 1, coefficients in the With Case Controls model fall outside the 95% confidence interval of the Without Case Controls model in seven cases. Among those, the relationship is attenuated in six, and increases in one. The six topics in which the relationship is attenuated involve a mix of procedural (procedure_2, evidence_1), sentencing (sentencing_1, drugs, sentencing_3), and one of the immigration topics. There are also several topics for which there is very little difference between the With Case Controls and the Without Case Controls models.
These results highlight two possibilities. First, they provide further support for the assignment/selection pathway as a mechanism for the relationship between the content of opinions and the gender composition of panels reported in Table 2 above. Case codes themselves are highly unlikely to cause differences in how judges write about cases, but they are likely to be correlated with case characteristics that will be a major factor in determining the content of opinions. More likely, case characteristics are associated with judge attributes (through assignment or selection), and those case characteristics that are associated with case codes are part of the causal pathway through which content becomes associated with the gender composition of panels.
But the foregoing analysis also illustrates that the gender causation and assignment/selection pathways can work in opposite directions. It may be, for example, that gender panel composition affects both the content of opinions (holding case characteristics constant) and the likelihood that cases will be reported (holding content constant). These effects could run in countervailing directions—for example if gender is substantively associated with defendant-friendly content (holding case characteristics constant) but negatively associated with the types of case that give rise to defendant-friendly content. Together, these effects would work in opposite directions in the data, making them difficult to detect.
In any event, the two pathways appear to be highly entangled, with case characteristics and judge gender interacting in complex ways to produce publicly available judicial opinions.
Discussion
Data Bias and the Empirical Study of Judicial Decisionmaking
The prior analyses established that there is a relationship between opinion content and the gender composition of judicial panels and investigated alternative mechanisms that could lead to these results. Under the standard interpretation adopted in the judicial politics literature, correlations between features of judicial opinions (such as case outcome) and judicial attributes (such as gender or party affiliation) are interpretated to imply that judicial attributes play a causal role: i.e., that Democratic and Republican judges, or women and men judges, faced with similar cases, make different decisions. An alternative possibility, less explored in the literature but with some support, considers the possibility that case characteristics (and therefore potentially outcome) become associated with judicial attributes via some other mechanism, such as case assignment, or decisions about what cases to publish or report.
Broadly speaking, we find substantial support for an assignment/selection pathway through which opinion content—as summarized by a topic model—and the gender composition of panels become associated with each other. This finding is consistent with the coarse-graining achieved through the topic model, which represents opinion content in a low-dimensional space that is likely to track case characteristics.
Although our findings support the assignment/selection pathway, we cannot exclude the possibility of a gender causation pathway as well. The two are not mutually exclusive. Indeed, in the analysis reported in Figure 1, controlling for case code increased the relationship between topic proportions and judge gender for some topics, which suggests that gender and not case characteristics could be responsible for some of the differences in opinion content. Nor can we exclude the possibility that the assignment/selection pathway is primarily operative at the corpus level, but that substantial gender effects on decision characteristics may be hidden away within substantive, temporal, or spatial corners of our data. The results in Boyd et al. (2010) are consistent with that possibility.
This uncertainty over causal pathways applies to most (if not all) prior work on the gender effects of judging. Studies that find relationships between judge gender and case outcome have not adequately separated out effects due to the assignment/selection pathway from effects due to the gender causation pathway. While some studies do attend to the possibility of non-random assignment, they do not adequately address the possibility of selection as a separate confounding factor. Our results indicate that the assignment/selection pathway is at work at least some of the time in generating relationships between opinion content and judge gender. Additional work is needed to understand how widespread this effect may be, and how it should alter interpretation of statistical analyses of judicial opinions.
It bears noting that, even if relationships between case outcome and judge gender are due to the assignment/selection pathway, that does not mean that they are not important. As noted in Hinkle (2021), publication decisions are important because they bear on broader policy influence. If judge gender, race, party, or some other factor affects decisions regarding whether to publish, or report at all, that could have important consequences for the shape of the law.
But effects due to the assignment/selection pathway are quite different, from a normative perspective, from effects due to the gender causation pathway. The first goes to policy influence, the second goes to the fundamental fairness of the judicial process. If case outcomes are partly determined by the random assignment of judges to cases, that raises legitimate fairness and rule of law concerns. At the same time, judicial discretion will inevitably lead to inter-judge variation in outcomes—either due to disagreement, error, or both (Fischman, 2014). Understanding that variation and the causal factors associated with outcomes is a core concern of empirical legal studies. Separating out effects due to assignment/selection from those due to genuine disagreement between judges concerning case outcomes should be a serious research priority for the field.
Unfortunately, existing data and practices of the federal courts pose a major barrier to addressing that pressing research question. All existing publicly available datasets of outcomes in the federal courts are generated through non-random processes that create the possibility of selection effects. For this reason, analyses cannot separate out inter-judge disagreement (or assignment effects) from these selection effects. The most promising avenue to pull apart these effects would be through comprehensive data, which is in fact collected by the federal courts and exists in digital format in the court’s Public Access to Court Electronics Records (PACER) system.
PACER is something of a misnomer, in that “public access” is quite limited due to an expensive paywall. Individuals are granted a small number of annual requests per year, but after that limit is reached, a fee per-page is levied for access. Inasmuch as such costs are part of the normal cost of business for attorneys seeking court records in individual cases, they are not necessarily troubling. But from a research perspective, the costs are prohibitive. An ideal study would involve comprehensive data, but the costs of acquiring even a sufficiently large random sample of cases would be prohibitive for most researchers (Clopton & Huq, 2024).
Unfortunately, the courts have not proven amenable to granting access to PACER data for research purposes. 19 Although there may be legitimate privacy issues at stake, court records are already available (for a cost), as are both published and unpublished opinions. Furthermore, programs across government exist to allow researchers access to even highly sensitive data. There is no reason, in principle, why whatever obstacles to granting research access to PACER data cannot be overcome.
Until comprehensive data becomes available, researchers will likely be stymied in their attempts to separate out the causal mechanisms that affect the work of the U.S. judiciary. For the time being, the best that can be done is to interpret results cautiously, being clear that multiple possible pathways may be responsible for them.
Disproportionate Voice and Representation
Our findings using each of the three measures of case subject matter—topic prevalence from topic models, US as a party to the case, and case topics generated from IDB codes—indicate that the number of women on a panel is associated with case subject matter. The number of women on a panel is positively associated with some topics (e.g., criminal law) and negatively associated with others (e.g., administrative law and original jurisdiction). This raises normative questions about judicial administration. Even if these disparities are a result of selection effects and not case assignment, they are noteworthy because judicial decisions in unreported cases have much less legal and policy influence than decisions in reported cases. Our results suggest that men exercise outsized influence in particular legal areas and women exercise outsized influence in others, and that federal judges may engage in some subject matter specialization that runs along the lines of gender.
The rules of random assignment are meant to ensure that judges receive roughly equal mixes of cases, according to issue area as well as importance, and that work is equitably distributed across judges (Krotoszynski, 2014; Samaha, 2009). It is a long-standing norm in the federal appellate courts that judges do not specialize in terms of subject matter; some circuits even have internal rules prohibiting such specialization (Baker, 1994; Cheng, 2008). 20 Neutral selection of judges is meant to help “preserve judicial integrity,” ensuring that a judge is not disproportionately likely or unlikely to hear a case just because of the kinds of issues involved and judges across the spectrum of views and experiences have equal chances of being assigned to a given case (Brown & Lee, 2000). Some judges have suggested that a system of generalist judges protects against routinization, where judges continually adjudicate the same kind of disputes in “assembly line” style (Arnold, 1999, p. 669, Wood, 1997, p. 1756). Random case assignment might also support “feelings of equal status” and fulfill judicial preferences “for a diverse docket” (Samaha, 2009, pp. 48, 72). Further, some scholars have suggested that specialization can bias case outcomes because judges with certain backgrounds might gravitate toward particular areas of law and those backgrounds might mean that they are more likely to take a pro-defendant or pro-plaintiff view (Howard, 1981, pp. 247, 260). Scholars thus describe “random panel assignments” as a “structural impediment to specialization” (Cheng, 2008, p. 527).
But our results indicate that random assignment rules and procedures are not actually standing in the way of at least some detectable specialization. Even if random assignment is working to ensure that judges are adjudicating equal distributions of cases across subject matter, if some judges are more likely than others to report decisions in certain issue areas, then some judges will have disproportionate voice and influence in particular areas of law, since reported decisions have much greater influence on law and policy than unreported ones. Further, our analyses indicate that the current rules may not be working to equitably distribute labor across judges regardless of gender, since some legal areas may be more important or complex than others.
Our results show that the numbers of judges from different groups on courts does not translate in a straightforward way to representation within specific areas of law. Gender-based topic disparities may be problematic from a judicial administration standpoint because they indicate that the voice and influence of judges of certain demographic groups are relatively attenuated in some legal areas and amplified in others.
Conclusion
In this paper, we consider whether gender is associated with the content of judicial opinions in the US courts of appeals. We address this descriptive question by applying the structural topic model to the corpus of published and unpublished appellate court decisions that have been made available by the Harvard Law School Caselaw Access Project. We find that, indeed, the gender composition of panels is associated with the prevalence of many topics in opinions. This is true controlling for year and circuit, and remains the case when controls are added for judge race and party affiliation. We explore two potential causal mechanisms. One is the gender causation pathway, which is the causal model that is assumed in much of the work in judicial behavior. Under this mechanism, judges see similar cases, regardless of gender, and they decide and write about them differently. The second mechanism that we explore is the assignment/selection pathway in which case characteristics become associated with judge gender either through the panel creation process, or due to selection in the cases that lead to reported opinions (published and unpublished). We carry out several analyses to untangle these two possibilities and find considerable support for the assignment/selection pathway. Our findings have significant normative implications for the judicial process and legal system more broadly. Our results also have broad importance for the field of empirical legal studies and should help to inform future studies of judicial decision-making as well as the interpretation of previous ones.
Normatively, our results indicate that the voice and influence of judges of certain demographic groups are relatively attenuated in particular legal areas and amplified in others, due to processes of case assignment or reporting. Additional investigation of these processes, and potential reforms to increase transparency, may be warranted. With respect to empirical legal studies, our results indicate that the findings of prior research linking judicial attributes to case outcomes may be confounded by the assignment/selection pathway. Although correlations between case outcomes and judicial attributes in reported cases are quite robust, the causal interpretation of those associations—and their normative implications—depend entirely on how they come about.
Supplemental Material
Supplemental Material - Gendered Judicial Opinions
Supplemental Material for Gendered Judicial Opinions by Michael A. Livermore, Keith Carlson, Daniel N. Rockmore, and Nina Varsava in Journal of Law and Empirical Analysis
Footnotes
Author’s Note
For helpful comments, we are grateful to two anonymous reviewers, Christina Boyd, Christopher Drahozal, Sean Farhang, Peter Grajzl, William Hubbard, Christine Jolls, Jason Rantanen, and Miriam Seifter, as well as participants of the 2022 Conference on Empirical Legal Studies, the 2022 American Law and Economics Association Annual Meeting, the 2022 Midwest Law and Economics Association Annual Meeting, an Online Workshop on the Computational Analysis of Law in 2022, and of workshops at NYU School of Law and the Wisconsin Law School. We thank Saloni Bhogale and Leigha Hildur Vilen for excellent research assistance.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by the Office of the Vice Chancellor for Research and Graduate Education at the University of Wisconsin-Madison with funding from the Wisconsin Alumni Research Foundation.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.