
Abstract
Experimental research on judicial decision-making is hampered by the difficulty of recruiting judges as experimental participants. Can students be used in judges’ stead? Unfortunately, no—at least if the objective is to study legal reasoning. We ran the same high-context 2 × 2 factorial experiment of judicial decision-making focused on legal reasoning with 31 U.S. federal judges and 91 elite U.S. law students. We obtained diametrically opposed results. Judges’ decisions were strongly associated with one factor (sympathy, i.e., bias) but not the other (law). For students, it was the other way around. Equality between the two groups is strongly rejected. Equality of document-view patterns—a proxy for thought processes—and written reasons is also strongly rejected.
Introduction
Experiments are the gold-standard of causal inference, and the causal determinants of judicial decisions are of obvious interest. Nevertheless, experiments with judges are rare. Judges are few and busy. The organizations that could mobilize them in greater number—courts, judges’ associations, and judicial agencies like the FJC—are wary of doing so. Some scholars have succeeded to recruit sufficient numbers of judges for vignette experiments over several rounds of judicial conferences or continuing legal education seminars. 1 Only two studies—one of which we replicate with students—have recruited judges for longer experiments mimicking features of real-world judicial decision-making. 2 In judges’ stead, many studies of legal reasoning and judicial decision-making employ (law) students. 3 If students were good proxies for judges, the rate of scientific discovery could be greatly enhanced. Are they?
Unfortunately, this paper’s answer is no—at least if the objective is to study legal reasoning. We conducted the same 2 × 2 factorial between-subject experiment with 31 U.S. federal judges and with 91 law students at three top-ranked U.S. law schools. Specifically, participants spend up to an hour deciding a fully briefed appeal in an international war crimes case. The experimental variations are (1) whether the precedent favors or disfavors the defendant and (2) whether the defendant is sympathetic or unsympathetic (in legally irrelevant ways). We separately reported the judge results in Spamann and Klöhn (2016): the 31 judges disproportionately ruled in favor of the more sympathetic defendant but were unmoved by precedent. As we report now, the 91 students did the opposite: their decisions did not differ between defendants but did differ strongly between precedents. In short, if one had run Spamann and Klöhn (2016) with students instead of judges, one would have found the opposite results. The probability of observing such differences by chance—if judge and student populations did not differ—is estimated to be only one in 500, i.e., the null hypothesis of equality of the two effects in the two populations is rejected at p < .002, notwithstanding the small sample size. Beyond their ultimate decisions, we also document that students significantly differ from judges in the reasons they write and in their reasoning process, to the extent we can observe it by tracking their use of legal documents in the experiment.
Our experiment gives students their best shot at mirroring judges’ behavior. Our experimental task, while relatively realistic, is one that students can easily comprehend. 4 We recruited our student participants at the very kind of schools—top-ranked U.S. law schools—that supply a large share of the U.S. federal judge population from which we draw our comparison sample (Iuliano & Stewart, 2016). 5 While our student and judge samples are not randomly drawn from their respective populations—participation is voluntary—we have no reason to suspect selection related to the results. 6 To be sure, it is theoretically possible that there is something idiosyncratic about our experimental task that divides judges and students in a way that most judicial tasks would not, but we would not know what that would be. We return to this question of external validity in greater depth in the discussion section.
The rest of this paper is structured as follows. Successive sections explain the experimental design; describe the sample; report the results; and discuss external validity, i.e., to what extent our results generalize to other uses of students in lieu of judges, also in light of related prior studies. A final section concludes. All data and code are available at doi.org/10.7910/DVN/3SRIDI, and all experimental materials are included as appendices here or in Spamann and Klöhn (2016).
Experimental Design
The main point of the present paper is, of course, to run the same experiment in two different samples that we describe in the subsequent section. The experiment itself is described in detail in Spamann and Klöhn (2016); here we only give a brief summary. All the study materials are provided in the online appendix of Spamann and Klöhn (2016), except the materials that differed for students: the recruitment ad reproduced in the next section, and the student informed consent form and exit questionnaires reproduced in this paper’s Appendix.
The experiment asks participants to imagine being a judge on the appeals chamber of the International Criminal Court for the Former Yugoslavia (ICTY) deciding a defendant’s appeal of his conviction for war crimes by the ICTY’s trial chamber. Participants have 50 min to decide. Participants receive a statement of agreed facts (written by us), briefs for the defendant and the prosecution (also written by us), the judgment below (taken from a real case, Prosecutor v. Perišić 7 , with only names and dates altered), a precedent (discussed below), and the ICTY statute. Besides their binary affirm/reverse decision, participants are asked to indicate brief reasons for their decision in a text box (on the same page), and to indicate an appropriate sentence on the next page. 8
Participants are randomly assigned one of two defendants and one of two precedents. 9 The randomization mechanism was designed to create 2 × 2 cells of equal sample size. In the judge sample, technical difficulties lead to slight group imbalance, as described in Spamann and Klöhn (2016).
Both defendants were fictitious military chiefs in Croatia and Serbia, respectively, responsible for organizing logistical support to their respective ethnic brethren in the Bosnian civil war. Besides the arguably different valence of “Croat” and “Serb” in U.S. perceptions of this war (NATO eventually bombed Serb positions, also again in Kosovo several years later), we interspersed several positive post-war facts, such as remorse, about the Croat and negative post-war facts about the Serb, such as spite for the ICTY, in the respective statement of facts, the trial judgment facts, and the briefs. We chose these attributes and their depiction to be clearly irrelevant from a strictly legal perspective, at least for the decision at hand (determination of guilt, not sentencing). We named the fictitious Croat and Serb defendants Horvat and Vuković, respectively, but for ease of reference this paper refers to them simply as “sympathetic” and “unsympathetic.” For a fuller description, see Spamann and Klöhn (2016) and the full experimental materials in its online appendix.
One of the two precedents weakly favors the defendant’s position (obiter dictum), whereas the other weakly disfavors it (based on distinguishable facts). The briefs are adjusted accordingly. Specifically, the main question in Perišić—and the only question in our stripped-down case—was whether the defendant’s logistical support to the foreign group qualified as aiding and abetting under Article 7(1) of the ICTY statute even though it was not “specifically directed” at the war crimes (as opposed to the general war efforts). (There was no doubt that the defendant knew that the group committed war crimes.) The Trial Chamber in Perišić—and thus in our case—had answered in the affirmative. One of our two precedents supported this position: the ICTY Appeals Chamber’s Šainović opinion held “[t]hat ʻspecific directionʼ is not an element of aiding and abetting liability under customary international law” and affirmed the conviction of a defendant who did not “specifically direct” his aid at the crimes. 10 By contrast, our second precedent, the ICTY Appeals Chamber’s Vasiljević opinion, provides weak support for the contrary conclusion, defining aiding and abetting obiter dictum as “specifically directed to assist, encourage or lend moral support to the perpetration of a certain specific crime.” 11 For ease of reference and as a mnemonic for their holdings’ implications for our case, this paper refers to Vasiljević and Šainović as reverse and Affirm, respectively. Each participant receives a package with only one of reverse and Affirm, and with briefs discussing only that one precedent.
Participants perform the task on an iPad or computer as described in the next section. The machine records the paragraphs of the materials active on a participant’s screen in 10-s intervals, which we use to construct and compare “document view paths” as described in the results section.
Samples
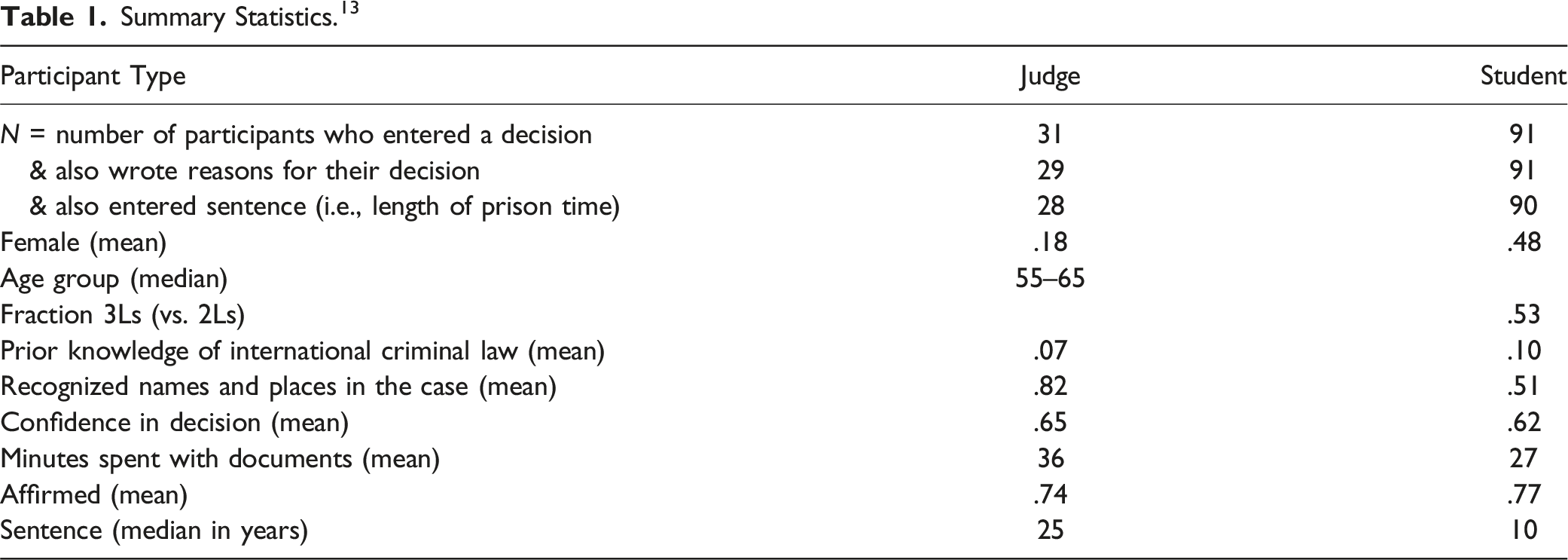
Summary Statistics. 13
We did not conduct dedicated comprehension checks. We did, however, ask two research assistants independently to read all judgment reasons and flag any that indicated a misunderstanding of the task. 14 The coding protocol is provided in Appendix A.4. Neither assistant found such a case.
Judges
We conducted the judge round of the experiment at an annual three-day workshop for U.S. federal judges organized jointly by Harvard Law School and the Federal Judicial Center in April 2015. All participants were U.S. federal judges including circuit judges, district judges, bankruptcy judges, and magistrates. 15 About 50 different judges attend each year, implying that a sizeable fraction of the approximately 1,800 federal Article III, bankruptcy, and magistrate judges must attend over time, such that selection into attendance cannot be too skewed. 16
The experiment was part of a session on “Behavioral Research on Judicial Decision-Making” in the middle of the second morning. Several weeks earlier, the judges had received an invitation to the experiment with all consent-relevant information (Spamann & Klöhn, 2016, online appendix A.1.1) and a reading “assignment”: Guthrie et al. (2007), which discusses biases in judicial fact-finding. The experiment was administered on iPads we provided to the judges. Participation was voluntary—informed consent was obtained on the first screen—but all the judges present in the room participated in the experiment. We lost some small number of participants due to technical problems with the iPads described in Spamann and Klöhn (2016). We ultimately have 31 judge participants. 17
Students
With permission of the respective deans, we recruited students at three top-ten U.S. law schools with the following ad sent through schools’ email lists and, in one case, Facebook groups used for announcing events and job opportunities: Title of ad: “Get paid to learn some international criminal law!” Text of ad: “If you are a 2L or 3L who has NOT taken either of international criminal law or international humanitarian law, you can participate in an online study conducted by [X]. You will spend an hour judging a fictitious but highly realistic and highly topical appeals case in that area. All the legal materials you need will be provided to you online. Upon completion of the task, you will receive an Amazon gift code for $20. You can access more information on the task here [link to the consent form at the online site of the experiment].”
In this quote, we have obscured the name, title, and affiliation of the faculty member X to avoid identification of the schools involved, as requested by their deans.
We insisted that student participants “NOT [have] taken either of international criminal law or international humanitarian law” to put them on equal footing with the judges, who generally do not have such cases on their docket and probably never took such class, certainly not recently. (As mentioned in the introduction, the fact that neither judges nor students are experts in the case’s subject matter is a feature, not a bug).
The ad and study ran first at school 1 in April 2015. We refer to this as student round 1, which recruited 21 participants. The ad ran again at schools 1 and 2 in late November 2015, at school 3 in early January 2016, and at schools 1 and 3 in early February 2016. We refer to this as student round 2, which recruited 70 participants (net of the three withdrawals mentioned below). The experiment site closed in mid-February 2016, long before Spamann and Klöhn (2016) was first publicly posted on SSRN.
In student round 2, our IRB requested changes to the informed consent form we had used in student round 1. These are marked in Appendix A.1. In student round 2, our IRB also required us to allow participants to withdraw their participation after completing the study and receiving the debriefing because our IRB then considered incomplete our pre-study description of our research goal as “to learn about the process of legal reasoning and the role of various legal materials therein.” Three students exercised this right.
As mentioned in the ad, we restricted participation to 2Ls and 3Ls at the respective schools. We could not directly enforce this, but it would have been pointless—or at least unpaid—for others to participate, and only three did. The consent form reproduced in Appendix A.1 informed participants that they would have to provide their official school email address to receive the Amazon voucher. All participants requested the voucher. One participant did not provide an official law school email, and two provided emails identifying them as LLM students. Neither of these three received the voucher. That said, we could not exclude these three participations because to protect anonymity of experimental responses, emails were collected in a separate file without a cross-walk to the experimental responses.
Differences Between Judge and Student Samples
There were only minor differences between the judge and student versions of the experiments. While any difference in setup might theoretically explain differences in results, we do not think this is plausible. If it were, then experimental research would be in even deeper trouble than student/judge differences: if the minor differences catalogued below impacted results enough to explain a non-negligeable part of our student-judge effect differences, no lab experiment could generate useful information about the real world. Note in this respect that the differences catalogued here are not differences in experimental treatment – within each subject group (judges or students), treatment and control group were completely statistically identical except for the explicit experimental variation. Thus, the differences cannot confound treatment results within groups. The only question is whether they vitiate comparison between groups. That is a question akin to ecological validity. Our argument is that if one thought the differences in administration here were large enough to explain such massive differences in results, then to be consistent, one should deny ecological validity of virtually any lab experiment, and vice versa.
The only difference in the administration of the experiment is that all judges did the study at the same time in the same seminar room on an iPad that we provided, whereas students did the study at their leisure in a location of their choosing on their preferred device. Recall that judges and students were also (inevitably) recruited differently, and only students were paid (note that, in the real world, judges are not paid by the case). The difference in recruitment includes, for example, that judges already sat through the first day of the workshop before participating, whereas students did not.
The main experimental materials—between the instructions and the exit questions—were identical for judges and students. 18 These main materials are reproduced in the online appendix of Spamann and Klöhn (2016). The instructions (Appendix A.2) were also identical for judges and students except for two logistical adjustments relating to online versus in-person administration of the study. The exit questionnaire for students (Appendix A.3) was adjusted to include more relevant questions (e.g., class year instead of whether they had previously worked as a prosecutor or public defender). The only documents that were more different for students and judges were the consent documents. When the students clicked on the link in the ad to participate in the study, they were first taken to the informed consent form reproduced in Appendix A.1. By contrast, the first screen on the judges’ iPads was a short reminder of a letter sent before the session. 19 Together, the judges’ letter and reminder contained the same information as that given to the students, albeit in abbreviated form.
As we emphasized in the introduction, we cannot determine why judges and students behave differently, in part because there are many plausible differences between the two populations that we do not observe. Here we comment only on the limited demographic information that we do have and show in Table 1. The differences between judges and students that stand out are that judges are obviously much older than most students, and that far fewer judges (.18) than students (.48) identified as female. Both were to be expected: in 2016, only 34% of U.S. federal judges identified as female, and in 2017, the median U.S. district judge was 61 years old. 20 In principle, these demographic differences could explain the differences in experimental behavior. We can rule this out empirically for gender since female and male students’ decisions are indistinguishable (unreported). For age, we have no way of investigating the confound empirically even in principle—almost all students are young—but for that very same reason the confound is not practically relevant: even if judges and students differ “merely” because of age, students cannot replace judges in experiments because students are too young. The same practical irrelevance holds for a potential experience confound, perhaps proxied here by the higher percentage of judges (82%) than students (51%) who recognized names and places in the case. Of final note, judges spent 4/3 as much time with the documents as students.
Results
Experimental Treatment Effects
Fraction Affirmed.
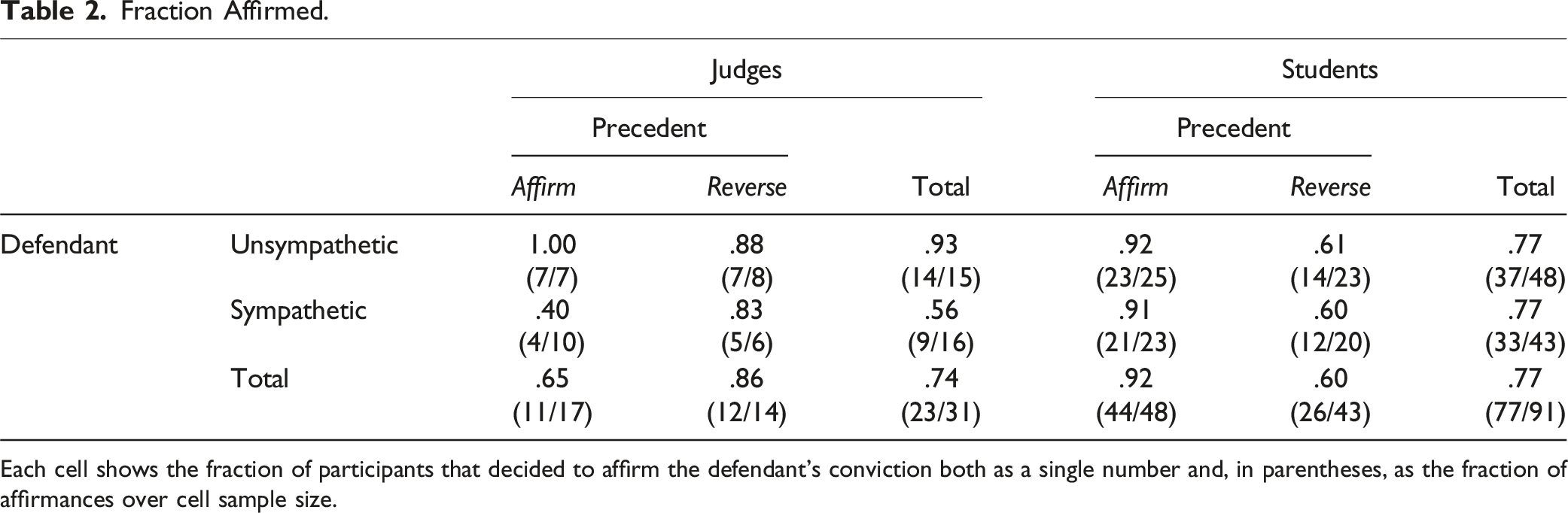
Each cell shows the fraction of participants that decided to affirm the defendant’s conviction both as a single number and, in parentheses, as the fraction of affirmances over cell sample size.
Focusing first on the left side of the table, and specifically on the bottom total row, it is readily apparent that the precedent made no difference for the judges. More judges affirmed the defendant’s conviction under reverse (86%) than under Affirm (65%) – the opposite of the expected precedent effect. By contrast, as predicted, far more judges affirmed the conviction of the unsympathetic defendant (93%) than of the sympathetic defendant (56%) (Boschloo 21 two-sided p = .024). These are the main results reported in Spamann and Klöhn (2016). 22
The results for students on the right side of the table are the inverse. Students affirmed the conviction of the sympathetic and unsympathetic defendants in identical proportions (77%). By contrast, many more students affirmed the conviction under the Affirm precedent (92%) than under reverse (60%) (Boschloo two-sided p = .0004).
Regressions.

95% confidence intervals in square brackets. The joint p-value for the interaction terms is from a Wald test (models 1 and 2) or score test (model 3).
All three models show the same basic pattern consistent with Table 2. The critical estimates are those of the interaction terms “student × reverse” and “student × unsympathetic” and their joint Wald or score test in the bottom row, which are highlighted by bold face. The interaction terms estimate the differences in precedent and defendant effect sizes, respectively, between judges and students. Relative to judges, students are estimated to move in the direction indicated by precedent 47 percentage points (model 1) or with almost 20:1 odds (models 2 and 3) more often than judges. Students are also estimated to be much less influenced by the defendant: the student interaction term estimate almost exactly offsets the baseline defendant estimate (which estimates the effect for judges). The 95% confidence intervals exclude equality with judge effects for precedent in all three models and for defendant in model 1. More to the point, the joint hypothesis that neither precedent nor sympathy effects differ between judges and students is soundly rejected in all three models at p ≤ .007, the best estimate probably being p = .002 from the exact model 3. In short, the estimated experimental effects for judges and students in our experiment do not merely happen to fall on different sides of significance thresholds but are substantively and statistically significantly different.
Yet another way to think about the difference between judges and students is to ask how likely one would draw a sample of 31 students from the student population that would give results as or more extreme than the actual sample of 31 judges. This approach quantifies the concern that we simply drew a highly unusual sample of judges. How unusual would the judge sample have to be if the populations of judges and students actually decided identically? We cannot answer this question precisely without access to the population of students, but we can approximate the answer with our sample of students. Specifically, we can estimate the student population affirmance probabilities for each treatment combination by the corresponding affirmance proportions in our student sample. Using these estimates, we derive the probability distribution of all possible contingency tables with 31 students distributed across the 2 × 2 treatment combinations like the judges in the actual judge sample. In other words, we analytically derive the full bootstrap distribution of a 31-student sub-sample. The probability of drawing a student (bootstrap) sample with an estimated effect in the same direction and a Fisher exact p-value as low as the judges’ is .1% for sympathy and .02% for precedent. In short, it would be extremely unlikely to draw a sample as seemingly unmoved by precedent but moved by defendant sympathies as our judge sample.
Process: Document View Paths
Given that judges and students differ strongly in their decisions, it stands to reason that they also differ in their reasoning process. That process is not observable as such, but we have access to a proxy: participants’ document view paths, as recorded by our system in 10-s increments as participants worked on the case. We introduced this method in Spamann et al. (2021) and refer to that paper and its supplementary materials for a more thorough discussion. While judges worked on iPads and students on their device of choice, both had roughly the same technological viewing experience: they had to use the same navigation tools, and the software prevented all from opening multiple tabs and skipping between windows while working on the case.
Figure 1 plots the view paths for judges on the left and students on the right. The horizontal axis is time, which is normalized by each participant’s total time, so that all paths are of the same length. Panel 1.a plots individual view paths for each participant, where participants are aligned on the vertical axis. Panel 1.b plots the state distribution, i.e., what proportion of participants of the respective group has a particular document open at a given time—here vertical height corresponds to that proportion. The “resolution” we show here is the document that participants were working on at any given moment. We recorded the paths at the paragraph level but have found this too detailed and heterogeneous to make sense of. Document view paths by participant type. By participant type, the graph shows (a) individual sequences (stacked vertically) and (b) the state distribution of documents live on participants’ screen from start to finish (horizontal axis).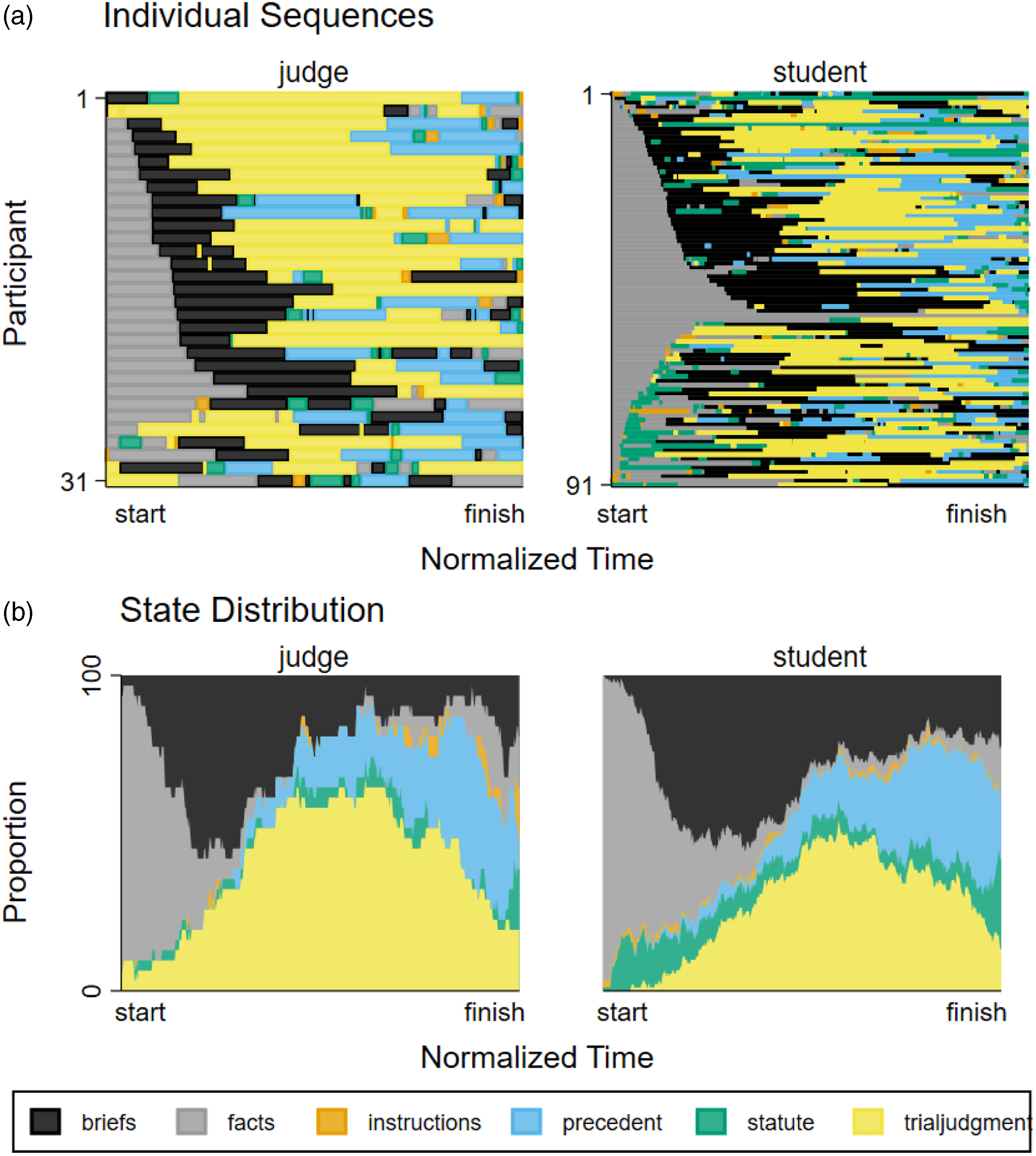
The document view paths give some indication that judges and students do not think alike. Panel 1.b makes it easy to see that judges tended to spend a larger proportion of their time with the trial judgment than students (40% vs. 27%), and that students consulted the statute much more frequently, especially early on. That said, the wide variety of different individual sequences shown in each group in panel 1.a suggests that individual differences dwarf differences between groups.
To evaluate the differences between judges’ and students’ document paths rigorously taking into account the ordering of document views, we employ the method of Spamann et al. (2021). The basic idea is to check if the paths within each group (judges or students, as the case may be) are more similar to each other than to paths in the other group. We measure pairwise similarity by the Levenshtein edit distance between two paths, discretized to 500 time periods. 23 Following Studer et al. (2011), we then compare the pseudo-R 2 of the actual groups to randomly labelled groups of equal size. 24 In 100,000 random labellings, we only once observed a pseudo-R 2 as high as that of the actual groups, i.e., we reject equality of judges’ and students’ distributions of document view paths at p = 10−5.
Given the novelty of the method, it is difficult to gauge substantive as opposed to statistical significance. On the one hand, the pseudo-R 2 is only .016, consistent with the visual impression that individual differences dwarf group differences. Specifically, a pseudo-R 2 of .016 means, roughly, that the distance between the two groups is only 1.6% of the average distance between individual participants. On the other hand, this pseudo-R 2 is almost twice as high as that between common and civil law jurisdictions and almost two fifths of that between individual countries considered in Spamann et al. (2021). When we nearest-neighbor-match students to judges based on the Levenshtein distance of their document view paths, students no longer differ from judges with respect to defendant effects but still differ strongly by precedent effect. This hints that the differences in sequences are meaningful, but the small effective sample of only 24 students (one student could be the closest neighbor to multiple judges) does not allow strong inferences.
Written Reasons
Finally, we have written reasons from all participants except two judges. Caution is required in comparing them because judges had to write with pen and paper or on the iPad’s touchscreen keyboard, whereas students could type on whatever device they chose to use, presumably a personal computer with a physical keyboard. It is thus not surprising that the average student wrote considerably more words (162) than the average judge (100).
Two research assistants independently coded the arguments in participants’ judgment reasons using the coding protocol in Appendix A.4. The protocol asked for binary answers to the questions “did the participant mention” (1) “precedent, even without the name of the precedent;” (2) “the statute”; (3) “policy Prevalence of reasons by type. Means and 95% bootstrap confidence intervals of mentions of specified reasons by individual participants. In the upper panel, the mean is taken over indicators whether an individual participant mentioned the feature in the reasons. In the lower panel, the type mean is divided by the average number of words in reasons by that type.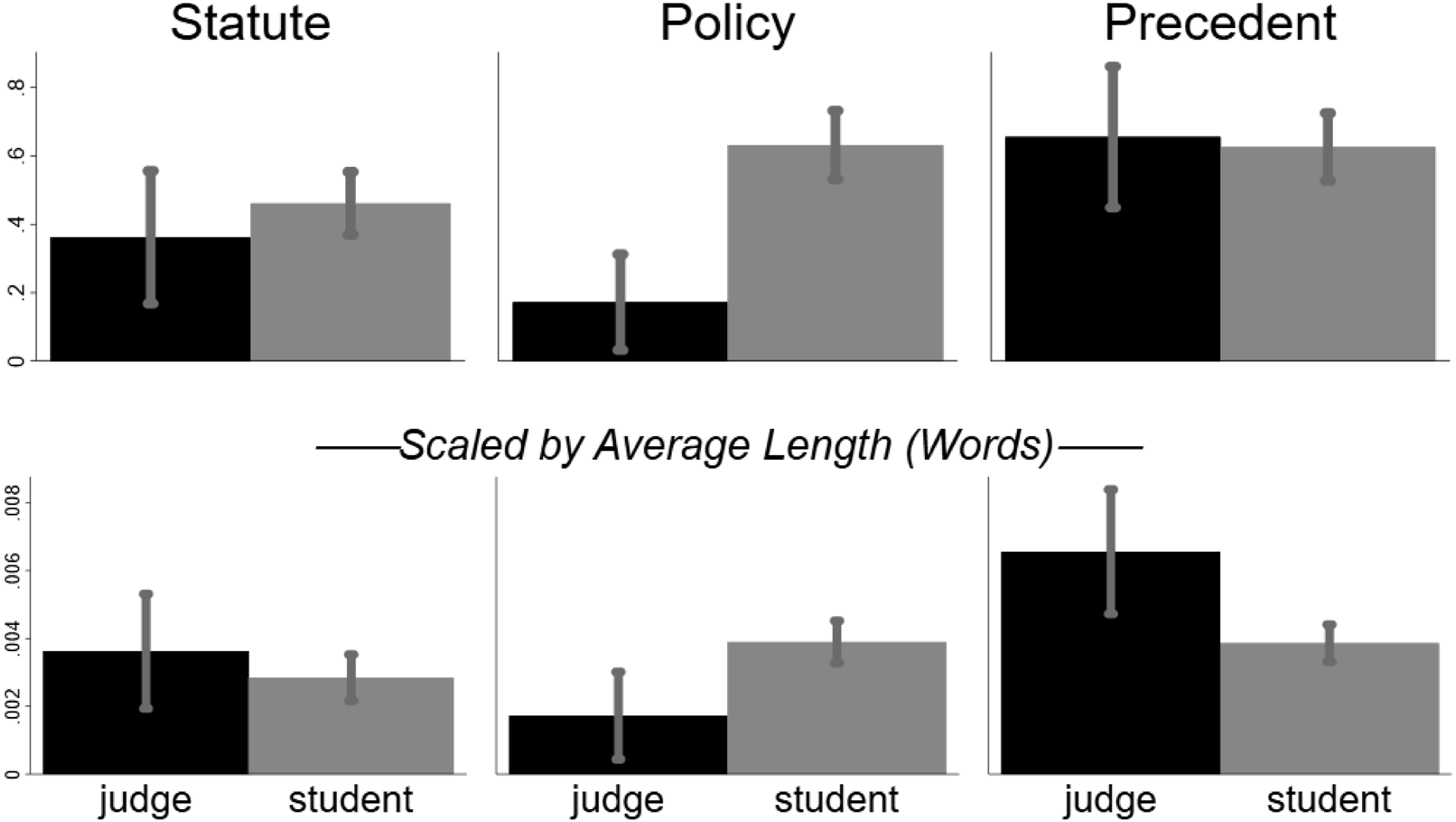
Figure 2 shows the prevalence of the three arguments by participant type (judge or student) with 95% bootstrap confidence intervals. The top panel shows the raw prevalence, i.e., the proportion of the respective participant type that used the argument. As mentioned, judges on average wrote shorter reasons and hence might have had less opportunity to mention some argument. To address this, the bottom panel divides the prevalence by the average number of words written by that participant type.
A multivariate test strongly rejects equality of the joint distribution of the three arguments between judges and students (MANOVA using Pillai’s trace, p ≤ 10−4 regardless of scaling). The primary driver is mentions of policy, which were considerably more frequent by students than judges (63% vs. 17%, Fisher exact p < .001), a difference that remains substantively and statistically significant even after scaling. By contrast, students and judges barely differed in referring to the statute, scaled or not. For precedent, there is no difference in unscaled prevalence (about 63% of each type mentioned it), and judges even have a higher scaled prevalence (t = 2.83, p = .008). This is ironic because only the students’ decisions differed by precedent.
Discussion—External Validity
We believe the judge-student differences in our experiment undermine the use of students in lieu of judges in any experiment involving legal reasoning. That is, we believe our experiment has external validity for other possible experiments of legal reasoning. Ours is a form of “meta-external validity”: to the extent our experiment has external validity for other experiments, those other experiments, if conducted with students, do not have external validity for another population, namely judges.
There are many a priori reasons not to believe that students have external validity for judges. Judges and students differ from each other on just about any dimension besides being a human adult with a high level of education including legal training. At a minimum, they differ in age, life experience, legal experience, and judging experience. The latter two differences will, by logical necessity, always be present, no matter how clever the experimental design, and they may be important: one may well approach a particular legal question differently depending on whether one has already lived through the experience of, e.g., personally sending convicted criminals to prison. Additionally, there is likely to be strong selection into the judiciary on dimensions such as ability, diligence, public service orientation, importance of status, socio-demographics, etc. Any of these differences could well generate differences in experimental behavior.
To bridge this a priori gap, legal reasoning would need to be universal, a hypothesis that is rejected by our data. Specifically, to extrapolate from students to judges, one would need to hypothesize that they reason legally alike either because all humans do or, more likely, all legally trained people do. One version of such hypothesis is the classical legal model of judicial behavior and legal reasoning: lawyers in general and judges in particular just follow the law, i.e., the law itself is outcome-determinative. One could enlarge the classical model to allow for the influence of principles outside the formal legal materials (à la Dworkin). One might even adopt a broader realist theory that judges will mold the law to fit some desired outcome derived from other grounds. And one could allow for noise. But the hypothesis would need to be that the noise, desired outcomes, or principles, as the case may be, are the same for judges and students. This hypothesis runs counter to a large jurisprudential literature stressing that judges are special (e.g., Kahan et al., 2016; Llewellyn, 1940; Schauer, 2010; Spamann & Klöhn, 2016). That literature does not argue that judges are necessarily more legalistic: judges might be better at manipulating legal materials to get to their desired result (Kennedy, 1998). 25 Our judge results point in this latter direction; in any event, our contrary results with students empirically reject the universality hypothesis.
There is nothing special about our experiment that would make a divergence of judges and students more likely than in other experiments—at least nothing of a sort that could not also be said about most other experiments. That is, while it is theoretically conceivable that judges and students might diverge in ours but not most other experiments, there is no obvious theory why that would be so. To be sure, our experiment involved an armed confrontation—the Bosnian civil war—that the judges lived through while most students did not, and one of several elements of one of our two manipulations—the valence of Croat versus Serb in the defendant manipulation—may thus not have resonated with students. But this difference in experience does not affect our other manipulation and tests, where we also find differences between judges and students. In any event, differences in experience would almost always be present. Judges have sentenced defendants, while students have not. Judges probably have been paying a mortgage or other major contract, while students have not. Judges are parents, grandparents, and perhaps divorced, while students are not. And so on.
Of the three prior experimental studies of legal reasoning comparing students and judges, two also find judge-student differences, thus confirming that the problem is not with our experiment but with the use of students instead of judges. No other experiment of legal reasoning employs our degree of realism, which may be required for ecological validity, i.e., for experimental results to generalize to judges’ behavior in the real world (Holste & Spamann, forthcoming). 26 There are, however, three vignette studies of legal reasoning with judges and students. Redding and Reppucci (1999) and Kahan et al. (2016) both test whether experimental subjects opportunistically inflect their legal views to favor ideologically desired outcomes. While neither formally tests the difference between student and judge inflections, both find such inflection only in students. The only experimental legal reasoning study that does not find differences between judges and students is Chen and Li (2018), which also bleeds more strongly into the application of law to facts—as opposed to pure questions of legal interpretation—than our study. 27 Many but not all studies of fact-finding also find differences between judges and students. By contrast, judges and students unsurprisingly perform similarly on tasks that are not specific to judging. Holste & Spamann (forthcoming) provide a recent thorough review.
It is not good enough for student experiments’ external validity if students decide like judges in some experiments; thus, we do not need to show that they decide differently in all. If students decide differently in the only experiment directly on point (ours) and a few related ones (those reviewed in the last paragraph), then there is no basis to generalize from students to judges in the next experiment. Imagine students decided like judges in half of all experiments and the opposite way in the rest, but we do not know which experiment belongs to which group (more on that in the next paragraph). Then we would learn nothing about judges from experiments with students (assuming we are testing directional effects). If we dial up the proportion of experiments in which students decide like judges and soften what happens in the others (e.g., random rather than opposite results), student experiments become more informative, but it is a long way before one can comfortably assume that the students mimic the judges.
There might well be particular types of legal reasoning experiments where students decide like judges, but currently we have no way of identifying them. Even in our experiment, students resembled judges on some dimensions, such as their virtually identical overall affirmance rates (.77 vs. .74)—albeit not in the treatment effects, which is ultimately what matters in experiments. Obviously, students and judges are likely to behave similarly in experiments testing general human behavior, but our concern is with experiments of legal reasoning. A necessary condition would be to understand why judges decide legal questions differently in our and related studies. This condition is not sufficient because it may not offer practically implementable fixes: for example, if the explanations is experience on the bench, then nothing done with students will resemble what would happen with judges. In any event, we currently do not understand why judges and students are different. Our results are consistent with many explanations, reaching from simple demographics to expertise. Our data are of no help: they contain only the most rudimentary demographic information, and our sample is too small to disentangle multiple variables.
We do not argue that students cannot have any role in the study of judicial decision-making. For example, Gilbert (2011) uses students’ survey answers as a legal baseline against which to compare real-world judicial decisions, on the theory that students’ interpretation and application of text without knowledge of the stakes approximates “the law.” In Gilbert (2011), students do not stand in for judges, which is what we argue students cannot do.
Conclusion
The behavior of law students and federal judges differs significantly in our study of legal reasoning, both statistically and substantively. Observationally, we find major differences in document view paths and written reasons. More to the point, we obtain diametrically opposed experimental treatment effects in the two groups: judges’ decisions differ by the bias treatment factor but not the precedent treatment factor, while students’ decisions exhibit the opposite pattern. Like any experimental finding, ours could be due to chance, but we estimate the likelihood of that to be one in 500 or less. The upshot is unfortunate for the experimental study of judicial decision-making: law students, who are easy to recruit, cannot stand in as experimental subjects for judges, who are very difficult to recruit.
This finding leads to at least two related research question, one substantive and one methodological. The substantive question is when and how law students morph into judges in the course of their career, and/or what distinguishes the law students that ultimately become judges. That students matched on document sequence judge more similarly but still differently from judges might suggest that both selection and maturation are involved but this is at best a hint, among other things due to the small effective sample size for this exercise. 28 The methodological question is whether other actors in the legal system, particularly practicing attorneys and arbitrators, behave like judges in experiments (as in Kahan et al., 2016), such that they could stand in for them (arbitrators being, however, similarly hard to recruit). It is also possible, albeit unlikely, that the federal judges in our experiment differ from state judges, or at least certain kinds of state judges (e.g., elected judges). These remain fascinating questions for future study – but they themselves will need to surmount the difficulty of recruiting judges.
Supplemental Material
Supplemental Material - Can Law Students Replace Judges in Experiments of Judicial Decision-Making?
Supplemental Material for Can Law Students Replace Judges in Experiments of Judicial Decision-Making? by Holger Spamann and Lars Klöhn in Journal of Law and Empirical Analysis
Footnotes
Acknowledgements
We thank Ludwig-Maximilians-Universität for financial support; Roland Ramthun of Docustorm for programming the experimental interface; Julian Franke, JohneHenre Rzodkiewicz, and Oliver Schön for research assistance; Alex Whiting for suggesting the aiding and abetting controversy; Nancy Gertner, John Manning, Denise Neary, and the FJC for arranging the session at which the judge experiment was conducted; the three law school deans for permission to advertise to their students; and above all the judges and students for their participation. For very helpful comments, we thank seminar participants at Berkeley, Harvard, UT Austin, UVA, the Conference on Empirical Legal Studies 2022 (especially our commentator Greg Mitchell), the Experimental Methods in Legal Scholarship Conference 2022 (especially our commentator Alex Morell), the Michigan-USC-Virginia Virtual Law and Economics Series, Michael Gilbert, the editor Christoph Engel, and three anonymous referees.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical Statement
Data Availability Statement
All data and code are available at doi.org/10.7910/DVN/3SRIDI with the exception of raw U.S. judge demographics, which pursuant to IRB conditions can only be obtained from Spamann upon signing a confidentiality agreement. All experimental materials are included as appendices to this paper or Spamann & Klöhn (2016).
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.