
Abstract
Despite widespread recognition of the need for general-purpose mechanisms in unified theories of cognition, accounts of human thinking often propose that performance is best explained by task- or problem-specific knowledge and heuristics, elements found even in theories proposing general-purpose mechanisms. Here, we argue that many of the effects explained by task- or problem-specific knowledge or heuristics can be better explained by two general mechanisms: maximisation of progress and learning from experience. In Experiment 1, performance on the Taxicab problem, variously described as requiring or not requiring insight, was unaffected by removal of content presumed to trigger a problem-specific heuristic. In Experiment 2, the order of move selection in the Hobbits and Orcs problem, usually described as a transformation problem that does not require insight to solve, was successfully modelled by a maximisation heuristic with conceptual encoding of intermediate states, irrespective of problem context. In Experiment 3, solution rates to the eight-coin puzzle, a problem generally accepted as requiring insight to solve, were increased by cueing moves. A parsimonious theory, based on progress maximisation plus conceptual learning during solution, appears sufficient to model performance across a wide range of problems.
Introduction
One of the key challenges in explaining how humans undertake intellectual activities such as problem-solving, imagination, insight and creativity is to understand how individuals can direct their attention across a potentially infinite space of possibilities to the areas most relevant to the task at hand. This challenge is characterised in artificial intelligence research as the frame problem (Dennett, 2006; Hayes, 1981), that is, how to determine from potentially infinite effects of information those that are relevant and irrelevant. In the case of creative thinking tasks, the frame problem concerns where, from within the infinite range of possibilities, an individual should seek to discover new ideas. In the case of creative problem-solving tasks, the question is more constrained; how does the individual seek and select information which is task-relevant and will successfully lead to a solution without first knowing the parameters of that solution (Ross & Vallée-Tourangeau, 2021)?
The generic solution to the frame problem adopted by researchers is to propose heuristics that focus or restrict the search for information to specific areas, ranges, or topics (or more psychologically: to percepts, memories, or inferences) that might yield useful ideas. Heuristics for thinking are commonly conceived of as being rules of thumb that, unlike trial and error, identify sets of information prior to evaluation being undertaken that are believed to have an increased probability of relevance when subsequently evaluated. In other words, they are short cuts that allow us to filter the field of infinite possibilities.
Statistical sampling heuristics
Some of the best-known heuristics are representativeness, availability, and anchoring with adjustment (Tversky & Kahneman, 1974). As an example of representativeness, consider the following puzzle: A father and son are in a car crash and are rushed to the hospital. The father dies. The boy is taken to the operating room and the surgeon says, ‘I can’t operate on this boy, because he is my son’. This puzzle arises if people fail to consider the feasibility of a female doctor, since historically the category ‘doctor’ has been characterised as a male employment domain (hopefully it is less of a puzzle in more enlightened days), These heuristics are generic (i.e., heuristics that can be applied to any task in any context) that harness the statistical properties of information (e.g. frequency, immediacy, prototypicality) to restrict the attention of individuals to information that has a greater probability of relevance or value. These heuristics form the initial ‘editing’ component of Kahneman and Tversky’s (1979) Prospect theory of judgement and decision-making. They operate to limit the range of possibilities that are considered (sometimes erroneously) to be most relevant to the task at hand. The erroneous nature of some heuristic selections is revealed in biases. A heuristic is a mechanism for creative thinking, and a bias is an effect that may arise from applying that mechanism. For example, the representativeness heuristic causes a bias in solving the puzzle above to consider one gender only. Biases impair many domains of thinking, such as the base rate fallacy in probability judgements (Bar-Hillel, 1980), confirmation bias in criminal investigations (e.g. Ask & Granhag, 2005) and belief bias in deductive reasoning (e.g. Markovits & Nantel, 1989).
Biases have also been shown to arise in creative problem-solving. For example, in a study of complex creative planning (to develop a secondary school leadership programme), Todd et al. (2019) found that individuals displaying a range of cognitive biases produced solutions that were judged as less creative by a panel of judges familiar with education and creativity literatures. As they note, ‘biases evident in active, conscious, analysis of complex, novel, ill-defined problems – biases such as illusory superiority, wishful thinking, use of irrelevant experiences, or justification of a limited number of methods for appraising a problem – all may act to lead people down the wrong road, resulting in the production of creative problem solutions of lower originality, quality, and elegance’ (p. 5).
Some theories of insight problem-solving also propose that biases limit the attempts sampled by solvers and explain the difficulty that problem-solvers have with these seemingly easy problems. 1 For example, the representational change theory (RCT) of Knoblich et al. (1999) proposes that prior knowledge triggered by perception and recalled from memory biases the moves that are sampled when solving insight puzzles. This bias leads to constraints being added to the problem that need to be relaxed to solve. They demonstrated these biases using matchstick algebra problems, where the task is to move a single matchstick to correct a mathematical sum made up of Roman numerals. For example, the sum l l = l l + l l can be solved by moving the vertical match of the plus sign to create an equals sign and thus create the solution l l = l l = l l. This problem is difficult, according to Knoblich et al., because everyday knowledge of mathematical functions restricts the matchstick moves a solver will consider to those that reflect the common fX = Y structure of mathematical equations and blocks consideration of the less common tautology required for solution. They describe this as ‘scope’, where the scope of the standard equation structure covers so much of mathematics knowledge that it biases solvers away from considering any other structure. Relaxing this constraint arises, according to Knoblich and colleagues, when solvers enter a state of impasse, that is, when all attempts made to solve under the current representation fail. Impasse has been shown to be a key determinant of problem-solving performance (Ross, 2023).
In the case of the tautologous solution to the matchstick algebra problem above, it seems straightforward to identify what bit of prior knowledge imposes constraints: it is the scope of equation knowledge that invokes the equivalent of a representativeness or availability heuristic (or possibly both). Yet, even with this example, the ‘scope’ of scope can be questioned. Ormerod and MacGregor (2020) found that the effects of equation knowledge scope could be removed by a simple manipulation of numerical values. As might be predicted by RCT, participants found problems presented as a tautology and requiring a standard equation solution (e.g. lV = l l = l l: solution is lV = l l + l l, 72% solved) easier than a standard l l = l l + l l problem (12% solved). However, insertion of high value cues into the standard problem (e.g. l l = L l – l l: solution is l l = l l + l l, 62% solved) increased solution rates markedly. Unless moves are sampled under a generic heuristic, then the results of Ormerod & MacGregor would suggest participants have to switch between different problem-specific heuristics, from sampling problem properties based on mathematical knowledge to sampling properties that maximise the value of moves.
Search heuristics
As well as sampling statistical properties of information available during creative thinking, heuristics have been proposed that limit the range of information an individual samples by imposing a directed search process. Perhaps the best known of these heuristics, means-ends analysis, uses processes of problem decomposition and operator sampling to select problem-solving attempts that reduce the difference(s) between the current state and the goal state of the thinker’s task. In other words, each move is assessed in the light of its progress from starting state to hypothesised goal state. In their seminal book ‘Human Problem-Solving’, Newell and Simon (1972) outline a theory and computational implementation of a General Problem Solver (GPS), intended to provide a unifying and predictive theory of how adult humans solve a wide range of problems. GPS is applied by the authors to a range of puzzles such as the Towers of Hanoi and the Hobbits and Orcs problems, 2 and to domains such as algebra problem-solving. GPS employs means-ends analysis as a generic heuristic to model human solutions (and failures) for each of these tasks.
The mechanism of means-ends analysis is to select operators (i.e., methods, techniques, move attempts, ideas, etc.) that appear make the most progress from the current state towards a goal state. If an operator cannot be applied immediately, a sub-goal is created to apply the operator and is added to a memory register of goals. The problem is successively decomposed into sub-goals until operators can be applied without further sub-goals.
Take, as an example, the Hobbits and Orcs problem, whose solution is illustrated in Figure 1, a puzzle attributed to the scholar Alcuin (n.d.) (c. 735–804). The puzzle is as follows:
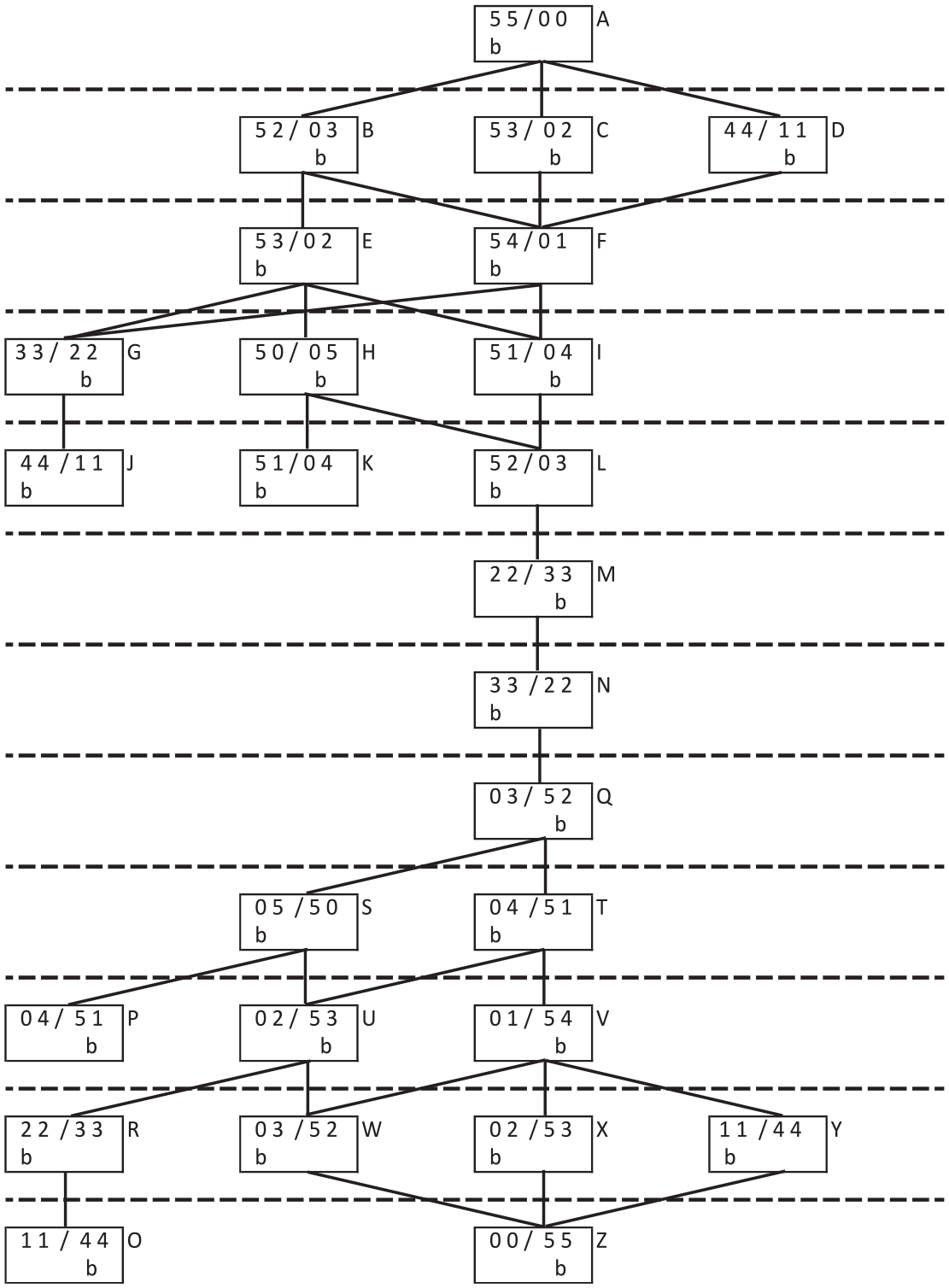
Legal Moves for the Hobbits and Orcs problem.
‘On one side of a river are five hobbits and five orcs. Orcs eat hobbits when they outnumber them. There is a boat that can carry three creatures at a time across the river (any hobbit or orc can pilot the boat). The goal is to transport all ten creatures to the other side of the river. At no point on either side of the river can orcs outnumber hobbits’.
Using means-ends analysis to solve, one would measure the difference between the current state (no hobbits and orcs on the desired side) and the goal state (all hobbits and orcs on the desired side) and set as a goal to transport as many hobbits from the wrong side to the right side as the boat could take. However, executing a move that took three creatures over immediately would violate the problem rules, leaving hobbits outnumbered by orcs on one side of the river. Thus, the solver sets a sub-goal to fill the boat with a subset of the passengers that will move them over without leaving hobbits outnumbered.
However, a rigorous application of means-ends analysis leads to predictions that are not supported empirically. Greeno (1974) points out that the heuristic constructs a goal stack (i.e. a list in memory of intermediate goals that must be achieved before the main goal can be reached). The goal stack cannot be executed until the very last sub-goal is identified, so the penultimate step in solving problems such as the Hobbits and Orcs problem ought to be the most difficult. Yet in practice, it is a simple step involving perceptual recognition of the desired end point. Perhaps as a consequence, Simon and his colleagues proposed problem-specific heuristics in addition to means-ends analysis. In the case of the Hobbits and Orcs problem, Simon and Reed (1976) proposed that solvers initially adopt problem-specific heuristics to select moves that balance the number of Hobbits and Orcs on each side of the river, and to avoid looping back to previous states. These balance and anti-looping heuristics pertain solely to the Hobbits and Orcs problem.
What is the smallest set of heuristics?
Heuristics for statistical sampling and search do different jobs, the former identifying properties of the space of possibilities, the latter directing a path through that space. It seems reasonable to speculate that both kinds are needed to model creative thought. Recently, Ormerod et al. (2024; see also Ormerod, 2023) proposed a computational model of insight problem-solving they call PRODIGI (PROgress and Discovery of Ideas in Generating Insights), which embodies this simple two-heuristic theory of creative thinking. The model operates through progress monitoring for selecting solution attempts that appear to make the most progress towards a hypothesised goal (search heuristics), and conceptual learning for discovering new types of solution attempt based on the properties that differentiate previous attempts (statistical sampling).
As an example of the application of PRODIGI, consider Maier’s (1930) nine-dot problem, shown in Figure 2, in which the task is to draw four straight lines to cancel each of nine dots arranged in a square grid without taking the pen off the page between lines. Solution rates are typically around 5% to 10%.
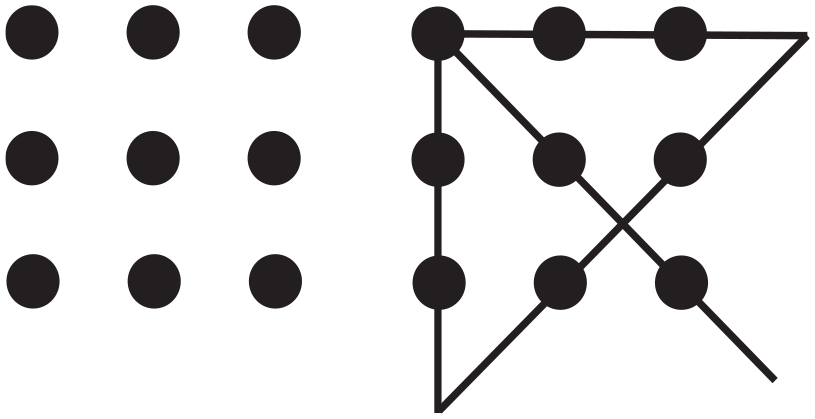
The nine-dot problem array (left) and its solution (right).
Various reasons have been proposed to account for the problem’s difficulty. Lung and Dominowski (1985) suggest prior experience with connect-the-dots drawings limits solvers to sampling attempts that start and end at dots. Kershaw and Ohlsson (2004) suggest solvers impose multiple constraints of prior knowledge, including that lines cannot be drawn outside the square, lines should turn in a place where there is a dot, and that moves involving diagonal lines are suppressed relative to horizontal and vertical lines. Ollinger et al. (2014) propose an RCT account of nine-dot problem solving that integrates these effects of prior knowledge. They borrow from the Gestalt account of problem difficulty (Scheerer, 1963), suggesting that the initial problem representation imposes a constraint that lines cannot cross a boundary implied by the perceptual representation of the dots. At impasse, this constraint is removed, and problem-specific heuristics such as one to seek non-dot turning points are applied to allow solution.
Ormerod et al. (2024) argue that people use generic rather than problem-specific heuristics in attempting the nine-dot problem. They select attempts that maximise the number of dots cancelled under a criterion of satisfactory progress, which generically is the ratio of the work that must be done to the resources available to complete the work. For the nine-dot problem, it is the number of dots remaining to be cancelled divided by the number of lines left. The reason for the problem’s difficulty is that there are many combinations of lines between dots that meet this criterion. Eventually, all criterion-satisfying moves are tried, and solvers enter a state impasse when no more can be found. At this point, the second heuristic, conceptual learning, kicks in. This heuristic samples the statistical properties of previous attempts that can be attended to perceptually and identifies dimensions on which attempts that made the most progress differ from each other. For the nine-dot problem, these dimensions include line length, angle, and trajectory. PRODIGI then varies these properties to find new moves that may eventually allow a solution to be found. In doing so, it reuses information implicitly held within records of previous failed attempts. We contend that two heuristics, one statistical, the other search-based, are sufficient to model problem solving, at least with knowledge-lean problems (i.e. problems that require no additional knowledge or skill to solve beyond the information given in the problem statement).
Experiment 1 – Testing a problem-specific heuristic account
The Representational Change Theory (RCT) of Knoblich and colleagues exemplifies how heuristics can be applied at a problem-specific level. Jones (2004) reports a study in which he used the Taxicab problem (illustrated in Figure 3) to test RCT. He suggests that the insight nature of the problem arises because participants impose a problem-specific constraint ‘that the taxi car cannot be moved before an exit pathway has been created. This self-imposed constraint may arise from people’s experiences in using taxis (in that they are always the passenger in such vehicles)’ (p. 1020).
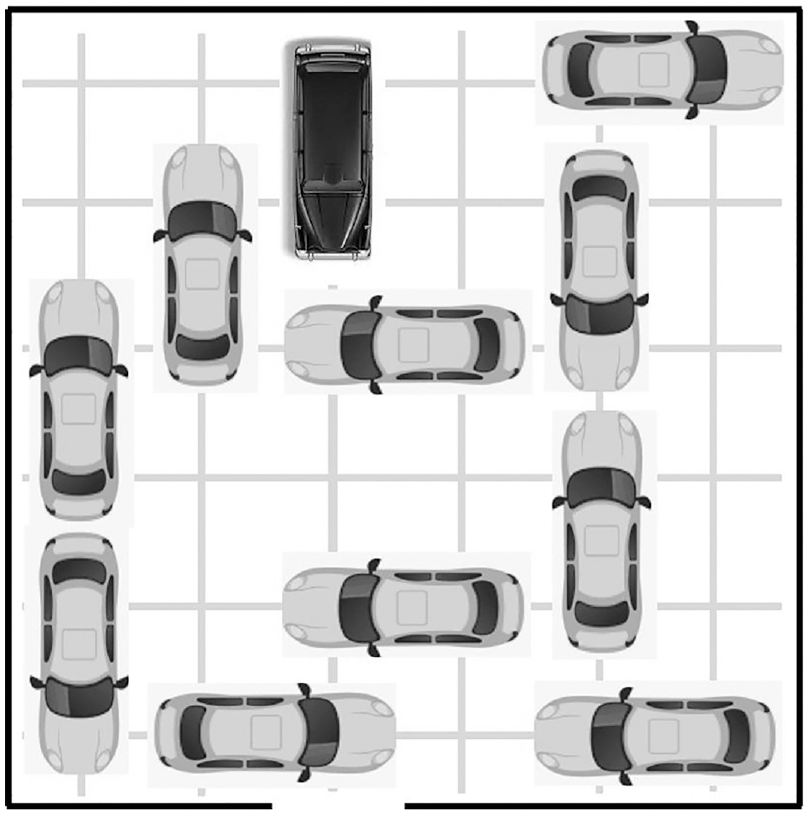
The Taxicab problem.
Jones’ study provided data that he suggested corroborates predictions derived from RCT. First, failures to solve did not include any attempts to move the taxi prior to the exit being clear of other cars, which is consistent with the operation of a constraint to move the taxi only once its exit is clear. Second, providing participants with easy practice problems that did not require planning moves ahead led to higher solution rates to the target problem than harder practice problems. Jones suggests the former were less likely to activate prior knowledge of the taxi constraint than the latter and thus serve to deactivate it. The suggestion seems to be that, if simple problems require little thought, then the content of those problems pertaining to taxis will receive less activation, and so the Taxi content of the target problem will have less activation when it is first viewed so the constraint will not be as strong.
Third, rotating the target problem through 90 degrees relative to the orientation of the practice problems led to more correct solutions, a result he interpreted as enabling restructuring of the problem representation. As Jones states: ‘In the rotated condition, the exit was rotated 90° so that it then appeared on the right-hand side of the car park. Insight was facilitated by encouraging participants to re-represent the problem because of a complete alteration of the problem scenario to what they had previously been exposed to. Neither of the manipulations sought to explicitly try to relax the taxi-move constraint; the manipulations merely sought to encourage its relaxation by altering other aspects of the representation of the insight problem’ (p. 1025).
Jones’ suggestion that prior knowledge of sitting in the back of taxis generates a constraint to avoid moving the taxi before the exit is clear seems somewhat tenuous. Our experience suggests quite the opposite: taxis will move into any space at the earliest opportunity, often causing traffic snarl-ups in the process. Leaving a taxi move till late in the problem-solving process would also be predicted by any planning-based theory of problem solving: to plan up to the required ‘taxi’ move would require a minimum lookahead of 10, beyond the cognitive capacity of most solvers. The search heuristic of progress maximisation generates precisely the same prediction: to maximise progress, solvers must move cars away from the exit path. The maximising moves prior to impasse do not involve movement of the taxi, so the taxi remains unmoved until late in the problem-solving process.
We question whether the effects of easy versus difficult practice problems, and of rotating the problem array, follow as seamlessly from RCT as Jones suggests. If the activation of prior knowledge inhibits moving the taxi before the exit is clear, it is not clear why solving practice problems of varying complexity would differentially activate this prior knowledge: surely it is either held or not held, and if held and there is a taxi present then it is activated. Moreover, rotating the problem array would not impact upon the problem representation in any way meaningful to finding a solution with respect to a relaxed constraint of prior knowledge.
The aim of Experiment 1 was to provide a critical test of whether the problem-specific heuristics as proposed by Jones or the generic heuristics of PRODIGI best explain performance with the Taxicab problem. We conducted a replication of Jones’s experiment with an appropriately powered sample (n = 32 per condition) 3 and extended it with additional conditions to manipulate the Taxi context. In we added target problem conditions in which we replaced the Taxis content of the target problem with abstract content concerning movement of coloured blocks. We also added conditions replacing Taxi content in the harder practice problems used by Jones with coloured block content. If problem-specific heuristics impact upon performance, then removing the Taxi content from the target problem should facilitate release of the target. Conversely, removing Taxi content from the practice problems should remove inhibitory effects of harder practice problems found by Jones.
We chose not to repeat the ‘rotated’ condition used by Jones because it does not provide a discriminatory test. While 12 of his participants solved the rotated target problem compared with 7 with the non-rotated target, solvers of the rotated target took nearly twice as long as with the non-rotated target (mean = 95.8 s vs. 53.4 s) and made more moves (means = 32.6 vs. 23.0). Thus, any advantage in solution rates for the rotated target can be accounted for by a much more extensive search of the problem space, which would be needed if the ‘practice’ that participants received prior to the target problem was made irrelevant (and possibly misleading) by rotating the problem array.
Method
Participants
A sample size of 192 was calculated for the study design using G* Power 3 (Faul et al., 2007) with a medium effect size of 0.25 and power of 0.8. Eighty male and 112 female undergraduate students from Lancaster University (Mage = 22.4 years, SD = 6.2 years) were paid £3 each to participate and were assigned to one of four conditions (n = 32 per condition).
Materials
The target task was presented as a physical model, which adopted the same layout for the target problem used by Jones in his digital version of the problem. The task is illustrated in Figure 3 and was constructed with tiles that could be slid either horizontally or vertically within a wooden box arranged as a 6 × 6 grid. Movement was constrained by tongues in the tiles that could only move along grooves in the box. Practice problems were made up similarly. They comprised the four harder practice problems used by Jones, each requiring approximately six moves, with one tile only blocking the exit, and the target tile not needing to be moved until the final move. The problem instructions were adapted from Jones to read as follows (alternative wordings for each condition shown in square brackets):
‘You are going to be shown a [car park/square grid] which has [cars parked/tiles arranged] in it. Your task is to get the [black taxicab/black tile piece] out of the [car park/ square grid] so that it can [go out and pick up a customer/be removed from the puzzle]. All [cars/tiles] can be moved forward or backward only’.
Design
A 2 × 3 between-subjects design was used, with three factors: Practice (taxi content vs. colour content vs. no practice) and Target (taxi vs. colour content). The dependent variables were number of correct solutions, solution times, and number of moves made.
Procedure
Participants were assigned initially to either Taxi, Colour or No practice problem conditions, and then to either Taxi or Colour target problem conditions, giving six separate groups. They were read the problem instructions and then were given a maximum of 1 min to attempt each practice problem (except for the no-practice group) and a maximum of 10 min to attempt the target problem. The moves made by participants were video recorded and transcribed. Solution times were recorded by stopwatch to the nearest second.
Results and discussion
Table 1 shows the mean number of correct solutions, mean solution times, and mean number of moves to target problems in each condition. Despite some differences between Jones’ (2004) experiment and the current experiment, notably the use of computer-generated problem displays in the former and the use of physical displays in the latter, performance across studies was similar: In the ‘standard’ condition of Jones’s experiment (equivalent to the Taxi practice + Taxi Target condition here), the mean solution time was 53.4 s and the mean number of moves was 22.0.
Solution rates, times and number of moves for each condition in Experiment 1.
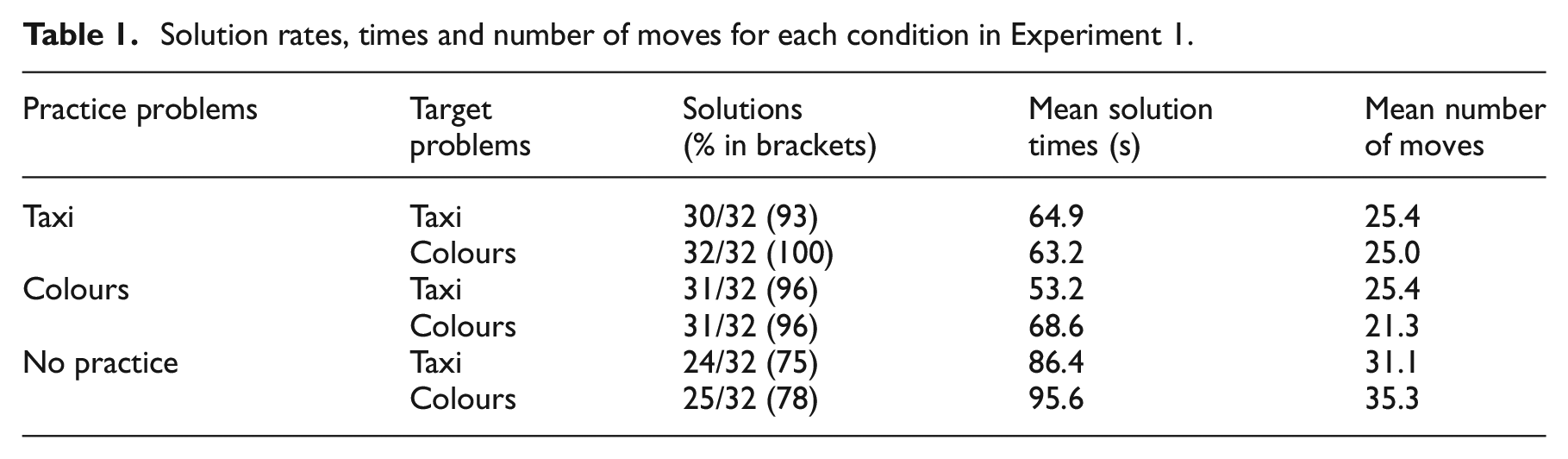
A logistic regression conducted on the solution rate data using Practice (taxicab vs. colour vs. no practice), Target (taxicab vs. colour) and the interaction between these factors as predictors yielded a significant model, χ2(3, N = 192) = 21.29, p < .001, with Practice (Wald = 15.10, p < .001) the only significant predictor in the model.
Analysis of variance conducted on the solution times (solvers only) yielded a significant effect of Practice, F(2, 165) = 9.89, p < .001, partial η2 = .107. A post-hoc Sheffe’s test showed the no-practice conditions produced significantly slower solutions than the other conditions, all ps < .01. The effects of Target, F(1, 165) = 2.02, p = .158, and the interaction between Practice and Target, F(2, 165) = 0.92, p = .399, were not significant. Similarly, analysis of variance conducted on the number of moves (solvers only) yielded a significant effect of Practice, F(2, 165) = 7.96, p < .001, partial η2 = .088. A post-hoc Sheffe’s test shows the no-practice conditions produced significantly more moves than the other conditions, all ps < .05. The effects of Target, F(1, 165) = .03, p = .870, and the interaction between Practice and Target, F(2, 165) = 1.69, p < .118, were not significant.
In this experiment, we manipulated the presence of thematic content pertaining to Taxis, replacing it in some conditions with abstract coloured block content. As predicted, removing the Taxi content made no difference to solution rates or times. This finding accords with PRODIGI, where the thematic content of the task plays no role in solution attempts but goes against the RCT prediction that prior knowledge of taxicab behaviour imposes a constraint on the moves sampled. Similarly, removal of the Taxi content from the harder practice problems did not lead to more solutions to the target problem. This result undermines the explanation of practice problem effects offered by Jones: without Taxi content, the harder problems could not amplify the activation of the prior knowledge constraint, yet the same performance in target problem conditions was found irrespective of the practice problem content. The results suggest that the imposition of a constraint of prior knowledge of taxi drivers’ behaviour is not the source of difficulty in this problem. In an ideal world, we would have also manipulated the thematic content of easy practice problems, by adding Taxi content to them. However, we felt that the intellectual gain of recruiting 64 more participants to test this minor hypothesis was limited.
We found significant effects across practice problems in solution times and number of moves. Mean solution times decreased from 14.9 s for problem 1 to 8.2 s for problem 4, F(3, 336) = 82.1, p < .001, partial η2 = .402. Mean number of moves decreased from 13.1 for problem 1 to 7.8 for problem 4, F(3, 336) = 105.2, p < .001, partial η2 = .463. The interactions between Target and Practice content were not significant for either measure (both Fs < 0.62, both ps > .600), suggesting that any decreases in solution time or number of moves across practice problems were not a function of the Taxi content.
Jones did not report differences across practice problems: here, we show that participants are improving with practice, and we contend that this practice is likely to have impacted on their target problem performance. In Jones’ rotated target condition, the knowledge acquired in practice would be irrelevant or misleading, and the difference in target problem performance he found after easy versus harder practice problems is explained by the greater opportunity to acquire knowledge from the harder practice problems. We dispute the claim of Jones that his experiments successfully discriminated between RCT and a precursor to PRODIGI, Criterion of Satisfactory Progress theory (CSP –MacGregor et al., 2001). We therefore contend that the two heuristics at the heart of PRODIGI are a better explanation of the data.
Experiment 2 – General heuristics for transformation problems
As noted above, Simon and Reed (1976) suggest that people solve problems such as the Hobbits and Orcs problem using the generic search heuristic means-ends analysis aided by two problem-specific heuristics: balance and anti-looping. A related model developed by Jeffries et al. (1977) also proposes that balance and means-ends analysis heuristics operate in parallel during solution attempts to this problem, complemented by a ‘choose a move that leads to a new state’ heuristic. In contrast, PRODIGI holds that only maximisation and conceptual discovery heuristics are used. In Experiment 2, we compared the effectiveness in explaining move selections of a problem-specific balance heuristic (to ensure the numbers of Hobbits and Orcs were the same on each of the sides of the river) and a maximisation heuristic (to select moves that make the most progress towards the goal by taking as many creatures across to the right bank and moving as few back to the left bank as possible).
The state space of the Hobbits and Orcs problem has no instances where a move that loops back to a previous state would have a maximising value. Thus, PRODIGI dispenses with an anti-looping heuristic: Looping moves are ignored because higher value moves are available. Consequently, there are no predicted differences across the accounts between using or not using an anti-looping heuristic.
In proposing problem-specific heuristics for the Hobbits and Orcs problem, Simon and Reed compared the frequency of move choices, finding across an analysis of their previous data plus that of Jeffries et al. that participants made more balanced than maximising moves overall. However, the data presented by Simon and Reed cannot discriminate between problem-specific and generic accounts because they give only relative frequencies of each move type (balanced vs. maximising) during solution. Move frequencies are affected by the problem’s state space. For example, the only moves available at states M and N (see Figure 2) are balance moves.
In fact, the data presented by Simon & Reed (their Table 2, which reports the frequencies of moves made by participants between any two of the states shown in Figure 2) are not as clear-cut as they suggest. There are few places where participants face a choice between a maximising or a balancing move. On their first move, participants have four choices, one of which is maximising (A to B), and one balancing (A to D). Here, participants are equally likely to select either move in their data (mean = 0.5), which favours neither balancing or maximisation. On the second move, if participants started with move A to B, then they can select either a maximising move (B to E: mean = 0.7) or a non-maximising unbalanced move (B to F: mean = 0.1), so participants are mostly selecting maximising moves. If they have selected BE for their second move, then they can select either a balanced move (E to G: mean = 0.5), a maximising move (E to H: mean = 0.2) or an unbalanced non-maximising alternative (E to I: mean = 0.7), which favours neither balancing or maximisation. On their fourth move (assuming linear progress without backtracking) if they had previously chosen FG, the only move available t them is a balancing move (G to J: mean = 0.8), hence the high selection rate.
Move selections in the Hobbits and Orcs problem of Experiment 2.
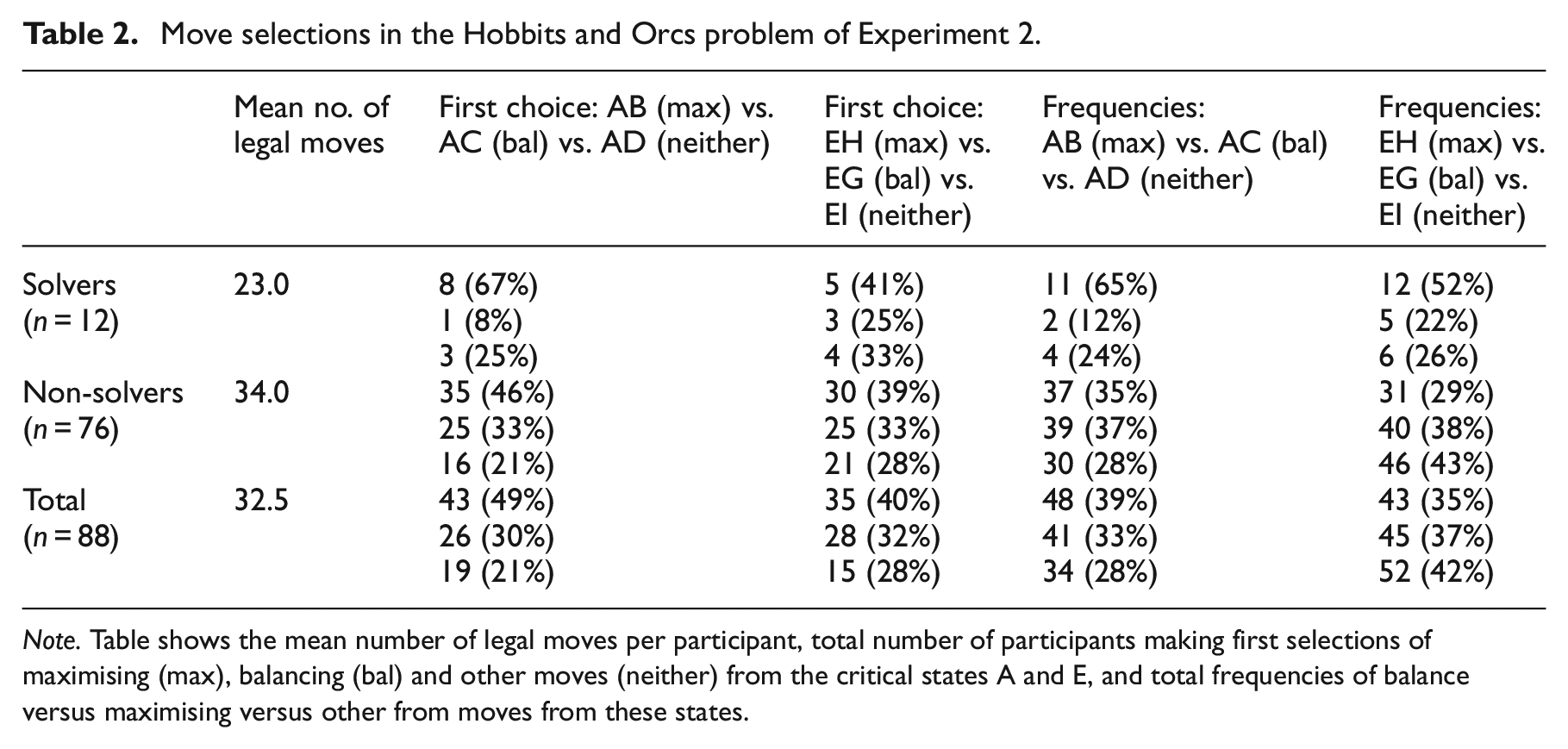
Note. Table shows the mean number of legal moves per participant, total number of participants making first selections of maximising (max), balancing (bal) and other moves (neither) from the critical states A and E, and total frequencies of balance versus maximising versus other from moves from these states.
If they had chosen E to H, then they could choose a maximising move (H to K: mean = 0.2) or an unbalanced non-maximising alternative (H to L: mean = 0.3). At first sight, this looks problematic for maximisation. However, one issue that Simon and Reed ignore, somewhat surprisingly given that means-ends analysis is a heuristic that enables solvers to plan, is the issue of ‘lookahead’, that is, the steps they plan before executing a move. Planning before action is a vital part of thinking about possibilities (Baumeister, 2023). MacGregor et al. (2001) have shown that participants solving these kinds of problems tend to operate at either one-, two-, or three-lookahead. MacGregor et al. estimated that roughly a third of solver are operating at each of the lookahead levels at any one time. Under a maximisation heuristic, the move after E to H would require sending back two items whereas it would be only one if E to I were selected. Thus, if participants select move with either two- or three-lookahead, they will choose E to I as ultimately delivering the most progress towards the goal.
Whichever way one interprets the data of Simon and Reed, it does not appear to offer a straightforward and objective comparison between the problem-specific heuristic of balancing and the generic heuristic of maximisation. To provide a discriminating test, in Experiment 2, we examined the order in which moves were sampled as well as their overall frequency. Problem-specific heuristic accounts would predict that balance moves will be selected
Method
Participants
Thirty male and 58 female first-year undergraduate students from Lancaster University (Mage = 19.1 years, SD = 3.1 years) participated voluntarily as part of a laboratory class on Cognitive Psychology.
Materials
Participants were presented with a river crossing drawn on paper, a shallow tray (to simulate a boat) and five black and five white 1.5 cm discs to represent Hobbits and Orcs, respectively.
Procedure
The experiment was conducted during a series of laboratory classes on Human Problem Solving conducted by the author. Students worked in pairs, choosing to take part either as a participant attempting to solve or as an experimenter who recorded the moves made and checked them for validity. Participants were given the following instructions:
‘In front of you is a task known as the Hobbits and Orcs problem. Three Hobbits and three Orcs arrive at a riverbank, and they all wish to cross onto the other side. There is a boat, but it can only hold two creatures at one time (any of the creatures can pilot the boat). Whenever there are more Orcs than Hobbits on one side of the river, the Orcs will attack the Hobbits and eat them up. Consequently, you should never leave more Orcs than Hobbits on any riverbank. How should the problem be solved? Place the disks (Black = Hobbits, White = Orcs) into the boat and move them across the river shown on the paper to signal each move you make’.
Participants were given 5 min to attempt a solution, and their attempts were videorecorded. If a participant made an illegal move, the experimenter pointed this out to the participant and to reset the move.
Results and discussion
We collected and examined only 5 min of participants’ solution attempts, since pilot research showed that almost all the relevant choice points (moving from states A and E) fell within this time. The video recordings were coded to reveal solutions, the frequency with participants chose balancing or maximising moves at A and E, both as a first choice (i.e. the first time they found themselves choosing from that state) and overall (i.e. including subsequent choices once they had started again or backtracked to that state).
Of the 88 participants, 12 solved the problem within 5 min. Table 2 summarises the move selection data. Overall, the pattern predicted by a balance strategy does not emerge. Of the 88 participants, for their first move choice (from state A, the start), 49% chose the maximising move compared with 30% for the balanced move and 21% for the remaining alternative, χ2 (2, 88) = 15.58, p < .001. For the first move away from state E, 40% chose the maximising move compared with 32% for the balanced move and 28% for the remaining alternative, χ2 (2, 88) = 11.25, p = .036. Thus, it appears that participants prioritise maximising moves over others.
Looking at the total frequencies of each selected move, for moves from state A, 39% were maximising, 33% were balanced and 28% were the other alternative, χ2 (2, 115) = 4.48, p = .107. For moves from state E, 29% were maximising, 38% were balanced and 43% were the other alternative, χ2 (2, 117) = 5.25, p = .072. A relative reduction in maximising moves in overall frequencies is to be expected: once a move has been sampled it is less likely to be revisited. Continuing search will lead to other states being explored, and so one would expect relative move frequencies for the three alternative move choices to head towards equality (i.e. each of three move choices being sampled approximately a third of the time), which approximates to the pattern of selections shown in Table 2.
Although the number of solvers in our sample was small, some patterns are evident. Solvers made fewer moves overall (presumably a result of completing the problem within the 5-min time limit) and were proportionally more likely to select a maximising move first (particularly from state A) and to revisit maximising choices more often (particularly with state E). It suggests that early maximisation may be beneficial for solvers compared with other heuristics.
Experiment 3 – General heuristics for insight problems
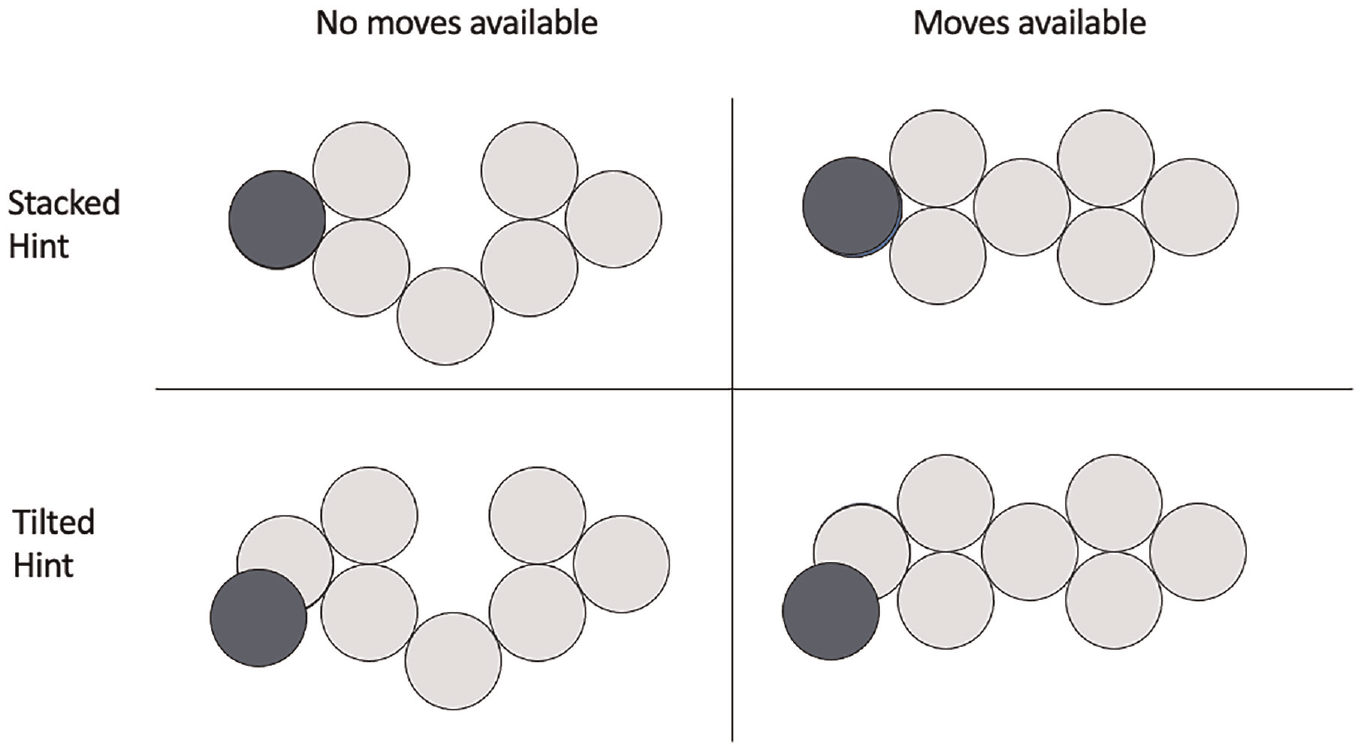
In Experiment 3, we tested our two-generic heuristics account of problem-solving using variants of the eight-coin problem, in which the task is to re-arrange coins such that each coin touches exactly three others. The solution to this problem (shown in Figure 3) is to stack two of the coins on top of others, indicating an ‘insight’ to switch from moving coins on a two-dimensional plane to moving them in three dimensions. The experiment discriminates between theories that propose problem-specific heuristics for this problem (Öllinger et al., 2013) and the PRODIGI account that proposes the application of the same statistical and search heuristics that are used to attempt any knowledge-lean problem.
Öllinger, Jones, Faber & Knoblich conducted an experiment to test Representational Change Theory (RCT –Knoblich et al., 1999; Ohlsson, 2011). The experiment was a partial replication of studies reported by Ormerod et al. (2002), who explored performance on the eight-coin puzzle illustrated in Figure 4. The problem elicits characteristic phenomena of insight: it is easy to state but hard to solve, solvers enter a state of impasse during solution attempts, and solution is typically greeted by an ‘aha’ experience.
The eight-coin problem.
To test the maximisation heuristic, Ormerod et al. manipulated the availability of moves in the two-dimensional array that appear to make progress towards the solution (i.e. moves in which the position of a coin currently touching an incorrect number of coins is changed such that it touches the correct number). In their first experiment, move availability affected solution rates, but only after the provision of two verbal hints, first that the solution requires the use of two separate groups of coins, and second that the solution requires the use of three dimensions. In their second experiment, participants made more effective use of a cue to three dimensions given in the initial problem array, comprising a coin stacked vertically upon another coin, when they attempted no-move-available problems. Solvers, they argued attempt to maximise perceived progress (moving a coin from a position where it does not touch three others to a position where it does). Only when all attempts to maximise progress fail in the current representation does the solver make use of additional information such as solution hints.
The rationale behind Öllinger et al.’s (2013) study was to manipulate two problem-specific factors predicted by RCT to be necessary for solution. The first was chunk decomposition, in which conceptually meaningful chunks are decomposed into smaller units, allowing the discovery of new move attempts. Chunk decomposition was operationalised in their study as the degree of tightness of coins in the array, measured as the total number of contacts between coins. The second factor was constraint relaxation, that is, the removal of a constraint of inappropriate prior knowledge that coins must be moved in two dimensions blocks consideration of correct move attempts. Constraint relaxation was operationalised as the provision of solution hints, specifically the visual hint of a stacked coin introduced by Ormerod et al.
Öllinger et al. compared performance across eight problem variants. They found that solution rates for problems where the initial problem array is decomposed into smaller units (i.e. separate groups of coins) were higher than those for problems presented as a single cluster. The highest solution rates were found for problems that presented a visual cue to a 3D solution in the form of a coin positioned offset on another (i.e. tilted off the edge of a coin). Öllinger et al. interpreted these results as providing strong support for RCT and as falsifying evidence for CSP.
There are two key differences between Öllinger et al.’s study and that reported by Ormerod et al. First, the manipulation that presents problems in separate groups fundamentally changes the problem space in terms of the numbers of unique moves that might be discoverable. These problems do more than test tightness of chunk: they present a partial solution by arranging coins into separate groups. As Ormerod et al. found, most participants needed a hint to use two groups for them to solve.
Second, Ormerod et al. provided a stacked coin that fitted flush over another coin. Öllinger et al. provide a hint of a coin offset (tilting) over another coin. In doing so, they inadvertently provided a cue to the starting move in addition to a hint to work in three dimensions. It is immediately obvious, from inspecting the problem array, that a tilted coin must be moved since it clearly does not touch three others. It is less obvious with a stacked coin fitted flush to another: it is surrounded by three other coins even if it does not quite touch all of them. Consistent with this interpretation, the percentage of participants using the hint coin in a first move in Öllinger et al.’s study was between 29% and 60%, depending on the variant used. In contrast, only 8% of participants in Ormerod et al.’s study (Experiment 2) used the hint coin in their first move.
Experiment 3 was conducted to test systematically the effects of the different hints used in the studies by Ormerod et al. and by Öllinger et al., and to examine whether the hint effectiveness would be differentially affected by move availability in the initial array.
Method
Participants
A sample size of 128 was calculated for the study design using G* Power 3 (Faul et al., 2007) with a medium effect size of 0.25 and power of 0.8 s.
Fifty-eight male and 70 female undergraduate students from Surrey University (Mage age = 23.5 years, SD = 7.2 years) were paid £5 each to participate and were assigned to one of four conditions (n = 32 per condition).
Materials
Puzzles were constructed from eight hexagonal metal tokens, with a length of side of 15 mm and a thickness of 3 mm. Hexagonal tokens were used because they made it easier for participants to evaluate the number of mutual contacts. The arrangements given to participants are illustrated in Figure 3.
Design
The experiment had two between-subjects factors: Hint and Moves. Participants were assigned to one of two groups, solving with either a stacked coin hint or a tilted coin hint, and within these to either move-available or no-move conditions. Dependent variables were solution rates, solution times and first move selections.
Procedure
Participants were randomly assigned to one of four experimental conditions and tested individually. They were instructed to rearrange the coins displayed in front of them, moving two coins only, so that all eight coins were touching exactly three others. If after moving two coins, participants had not solved the problem, the coins were returned to their original positions and another attempt was made. Participants were given 6 min to work on the problem and were allowed to make as many solution attempts as they wished. Participants’ attempts were scored as successful or unsuccessful. First moves were also recorded.
Results and discussion
Table 3 shows the mean number of correct solutions and mean number of first moves involving the ‘hint’ coin in each condition. A logistic regression conducted on the solution rate data using Hint (stacked vs. offset), Moves (available vs. none) and the interaction between these factors as predictors yielded a significant model, χ2(3, N = 128) = 23.13, p < .001, with Hint (Wald = 15.10, p < .001), and the interaction between Hint and Moves (Wald = 6.75, p = .009) significant predictors in the model. The effect of Moves (Wald = 0.001, p = .977) was not significant. These results show that the type of hint is a key determinant of whether participants solve or not. The offset hint (a tilted coin) appears to facilitate participants’ discovery of the solution considerably more than a stacked coin hint, even though both convey the same ‘insight’ to use coin moves in three dimensions. The significant interaction indicates that both the cueing of a first move by the offset hint and early criterion failure (where no moves are available to make progress in two dimensions) are necessary to maximise solution performance.
Solutions and first move choices (n = 32) in Experiment 3.
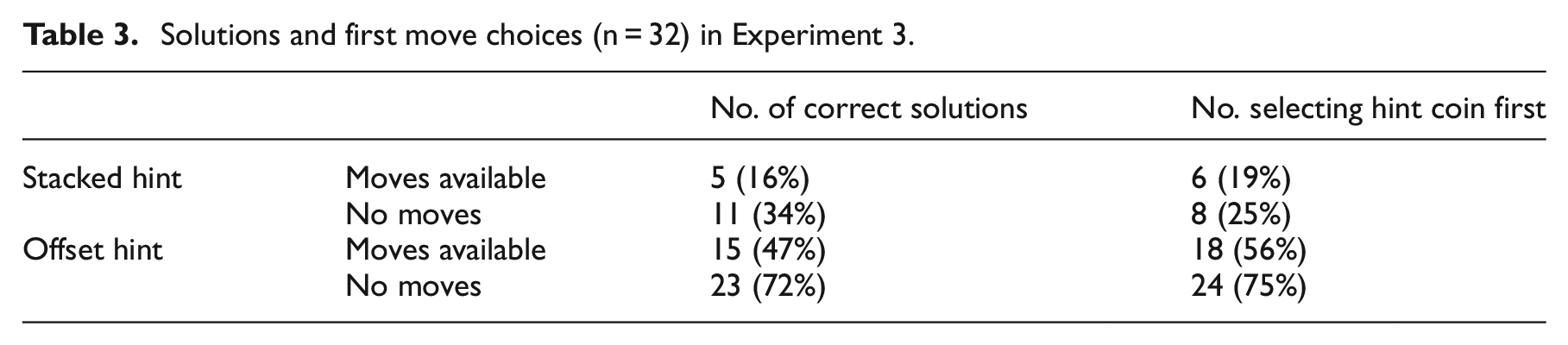
A logistic regression on the first move data using Hint (stacked vs. offset), Moves (available vs. none) and the interaction between these factors as predictors yielded a significant model, χ2(3, N = 128) = 28.72, p < .001, with Hint (Wald = 23.03, p < .001), a significant predictor in the model. The effects of Moves (Wald = 0.346, p = .556) and the interaction between Hint and Moves (Wald = 2.22, p = .136) were not significant. These results provide strong evidence that the offset hint is providing a strong cue to participants as to which coin to move first.
In the analysis offered by Öllinger et al., they claim their results provide strong evidence for RCT, and that their results conflict with CSP. Experiment 3 calls this claim into question. Providing a hint to use three dimensions in the form of an offset rather than a flush stacked coin does not ‘overcome the self-imposed constraints that prevent a problem solver from finding the correct solution’ (Öllinger et al., 2013, p. 931). Instead, it cues participants to a correct first move, thereby radically reducing the search space.
Interestingly, the analysis offered by Öllinger et al. of the most frequent destinations of first moved coins shows a strong tendency for participants to try to fill the gap between chunks in the initial array of multi-chunk problems, where the most common move was to place a coin in a position that linked the separate clusters. This tendency provides evidence that the ‘loose’ chunks of a split coin array are not creating some conceptual change in participants’ understanding of the problem relative to the ‘tight’ chunk of a single group array. If it were so, why would participants immediately try to reverse this conceptual insight by filling the gap between coins? This phenomenon is, however, entirely consistent with a search for novel moves. In three out of four of Öllinger et al.’s problem variants, the most frequent first move attempt not only closed the gap but also increased the number of touching coins, in line with predictions of CSP.
General discussion
In three experiments, we tested whether a simple theory of problem-solving that uses two generic heuristics can predict performance across a range of knowledge-lean problems, some believed to require insight to solve, others solvable without insight. In Experiment 1, the removal of thematic content believed to trigger a problem-specific heuristic based on prior knowledge that biases the moves sampled by participants was shown to have no effect on performance. Instead, in all conditions, performance was consistent with the application of a generic heuristic of progress maximisation. In Experiment 2, performance on a non-insight transformation problem was shown to be explained better by progress maximisation than by a problem-specific heuristic. In Experiment 3, the effect of hints to an insight solution was shown to be influenced by reduction in the search space and by the availability of moves in the initial representation that appear to make progress but that do not lie on the solution path.
In each of the experiments, the possibility that performance is determined by problem-specific heuristics triggered by prior knowledge was shown to be incorrect. In the experiments reported here, the key to explaining and predicting performance is progress maximisation. In the PRODIGI model, this heuristic is modelled as hill-climbing, in which the first implementable move that maximises progress is selected. Hill climbing is a weaker heuristic than means-ends analysis because it does not create sub-goals to implement moves; it simply does what it can do immediately. Despite its simplicity, we contend that it provides a parsimonious explanation for much of human problem-solving, at least with knowledge-lean problems.
What of the second heuristic of conceptual learning? It may appear that, since our experiments indicate that problem-specific heuristics cannot easily explain performance on a range of problems, and since problem-specific heuristics are likely derived from statistical sampling in the same way that generic heuristics like representativeness and availability work, we can dispense with the latter. However, while the operation of this heuristic has not been tested directly in the experiments reported here against a problem-specific alternative, its influence can be seen in the results of each experiment.
In Experiment 1, participants improved performance over a set of practice Taxicab problems, irrespective of whether these involved Taxi content. We suggest that this improvement represents conceptual learning that was applied to solving the target problem. In the absence of this practice, participant solution rates were lower, solution times were longer, and participants required more moves to solve. The practice problems enabled the acquisition of move sequences that participants could call on in devising solutions to the target problem. In Experiment 2, changes in the proportions of each choice made at the critical states A and E suggest that participants were learning to explore new paths. In Experiment 3, conceptual learning may explain why many participants who did not immediately capitalise upon the hint information given by the stacked and offset coins did appear to do so eventually. We did not run a no-control condition in this study but comparing performance against no-hint controls in the experiments of Ormerod et al. (2002), both types of hints appear to have been facilitatory. However, the interaction between Hint and Moves suggests that it was only after participants had experienced a failure to find progress maximising moves that they capitalised upon the knowledge inherent in the hint. This result illustrates how the search (progress monitoring) and statistical (concept learning) heuristics are symbiotic, working in parallel to manage and harvest the problem space. This symbiosis captures what can be described as a Cardamom moment in problem-solving, when the efforts of search and statistical learning combine to yield a conceptual breakthrough.
Arguably, the conceptual learning mechanism within PRODOGI may be implemented as representativeness, availability, and anchoring heuristics. Alternatively, representativeness, availability, and anchoring may be by-products of conceptual learning. This chicken-and-egg dilemma is probably not solvable, and nor need it be: Both approaches use the statistical properties of problem information (notably differences between previous and new states) to guide (or limit) the moves sampled by problem-solvers.
Our proposal, which is implemented in the PRODIGI computational model of problem-solving (Ormerod et al., 2024), is that solvers tackle problems using just two heuristics, one for search, the other for conceptual learning. For knowledge-lean problems, the source of conceptual learning is in the properties of previous attempts. Thus, our solution to the frame problem noted earlier is that new ideas come from exploring the statistical properties of things that have already been tried. A concern with problem-specific heuristics is that there appears to be no principled way of determining a priori which features of the problem display or prior knowledge will inform the selection of a relevant heuristic. With conceptual learning, there is no such dilemma: the relevance of exploring the properties of previous attempts is signalled by the act of generating and remembering them. In this way, the search and discovery heuristics described here offer a principled way of generating possibilities that are relevant to the task in hand. We suggest that any theory of possibility generation must, from the outset, specify how the frame problem is tackled, otherwise the theory cannot ultimately be implemented or tested. If anything is possible, then nothing is.
To what extent do the heuristics of PRODIGI offer a more general theory of creative thinking? The tasks explored here all have solutions that can be objectively determined as correct, and consequently they are not original, in the sense that they are pre-specified. However, they are original to the individual solver, inasmuch as they require discovery of solution ideas that were previously unknown by that individual. As such, the creative practice exemplified by these puzzles is an example of the ‘mini-C’ form of creative thinking espoused by Beghetto & Kaufman, 2007), which they describe as ‘the creative processes involved in the construction of personal knowledge and understanding’ (p. 73). It remains to be seen whether complex creative activities such as artistic composition and design can be captured in any meaningful way by such simple heuristics, but our contention is that, before devising complex theories to unpick complex domains, we should first apply the most simple, parsimonious theory and see what remains to be accounted for.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.