
Abstract
This study is intended for researchers (and doctoral students) interested in learning more on the use of machine learning methods in non-investment crowdfunding (i.e., reward- and donation-based). In particular, the study illustrates the insights that machine learning methods could provide on non-investment crowdfunding, for example, through data and information visualization, the ranking of features importance, and prediction assessment metrics. Specifically, I use four machine learning methods (gradient boosted decision trees, random forests, shallow neural networks, and support vector machines). As the literature shows, machine learning methods outperform classical regression models when the underlying relations are nonlinear. As such, the study offers some insights on the nonlinear relationships that could exist between the explanatory variables and the likelihood of success for art projects (e.g., threshold and Goldilocks effects). The study also offers some guidance to art project creators.
1. Introduction
This study is intended for researchers and doctoral students interested in learning more on the use of machine learning methods in non-investment crowdfunding (i.e., reward- and donation-based). Crowdfunding has grown tremendously in the last decade as a source of alternative finance. For example, in 2020, $100.86 billion was raised worldwide in debt crowdfunding, US$8.4 B in non-investment crowdfunding, and US$4.41 B in equity crowdfunding (Statista, 2022). At the same time, academic research on crowdfunding has also grown (e.g., Deng et al., 2022; Kaartemo, 2017; Shneor and Vik, 2020; Shneor et al., 2020). The vast majority of studies on non-investment crowdfunding use parametric regression tools (e.g., Molick, 2014; Colombo et al., 2015; Butticè et al., 2017; Bi et al., 2017; Lin and Boh, 2021; Usman et al., 2020; Shneor et al., 2021; Li et al., 2022; Elitzur et al., 2023a) 1 . A number of studies use machine learning methods to study noninvestment crowdfunding (Duan et al., 2020, Peng et al., 2021; Elitzur & Solodoha, 2021; 2 Elitzur, Katz, et al., 2023; Oduro et al., 2022; Wang et al., 2021, 2022; Zhong et al., 2022)3, 4 . Woods et al. (2020) apply an interesting machine learning model to investigate the spatio-temporal dynamics of successful non-investment crowdfunding campaigns and demonstrate that geography matters, as well as the time of the location. Research shows that machine learning models outperform classical regression models when dealing with nonlinear relationships (Elitzur, Katz, et al., 2023; Liang et al., 2022; Rasekhschaffe and Jones, 2019). Such nonlinear relationships have been demonstrated in the context of non-investment crowdfunding (Elitzur et al., 2023a, 2023b) and, as such, machine learning methods should be better in analyzing them than classical regression models, commonly utilized in crowdfunding research. For example, Elitzur et al. (2023a) show overchoice effects with respect to the number of reward options. Overchoice refers to well documented phenomena where providing a consumer with choice increases participation up to a level where excessive choice occurs and adversely affects participation (Iyengar & Lepper, 2000; Gourville and Soman, 2005; Scheibehenne et al., 2010). As such, overchoice follows a nonlinear function. Elitzur et al. (2023) demonstrate threshold and Goldilocks effects in the context of crowdfunding. Threshold effects lead to changed behavior by backers once a certain threshold is reached (a “tipping point”). Goldilocks effects exist when campaign parameters need to be “just right” for backers to fund a project. Both threshold and Goldilocks effects lead to nonlinear relations between explanatory variables and the likelihood of crowdfunding success. As I demonstrate in this study, because of the nonlinearities in the relationships between explanatory variables and crowdfunding success, we should use machine learning in analyzing crowdfunding as opposed to the commonly used classical regression models.
This study contributes to the literature in four ways. First and foremost, it is provides a teaching tool on the application of machine learning methods in crowdfunding research. Second, the study provides some interesting insights on the nonlinear effects of variables on success for crowdfunding art campaigns (e.g., threshold and Goldilocks effects). Third, the study offers some insights on the effects of non-quantitative variables (specifically, text variables) on the likelihood of success of art projects. Fourth, the database that I created on arts crowdfunding projects, which contains detailed data on 14,612 Kickstarter projects that took place between March 2013 and May 2016, could be explored by researchers (whether using standard parametric regression methods or machine learning tools).
In addition, the study also offers some practical implications to project creators that can be used in the pre-campaign project design, or during the campaign itself, to optimize their likelihood of crowdfunding success.
2. Variables
2.1 General
List of Variables and their Definitions.
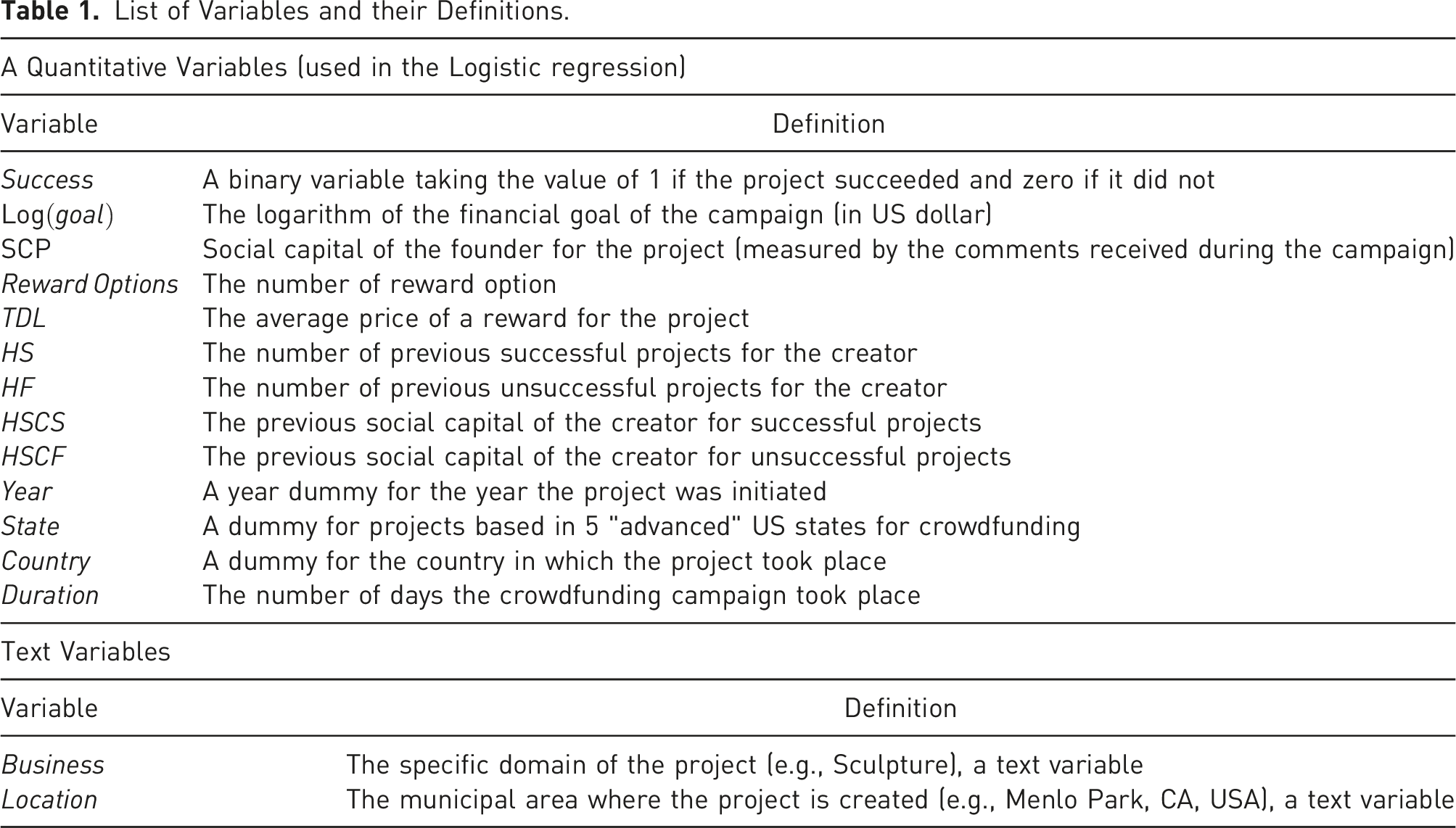
2.2 Dependent Variable
The dependent variable in our model, Success, is defined (and reported by Kickstarter) as achieving the stated funding goal. Success in Kickstarter is “an all or nothing” proposition (Mollick, 2014) and therefore it is a dichotomous variable, as commonly used in the literature (e.g., Colombo et al., 2015, Josephy et al., 2017; Butticè et al., 2017) 6 that takes the value of 1 when the campaign is successful and zero when it is not.
2.3 Numerical Independent Variables
Next, I will describe the independent numerical variables and their expected logistic regression coefficients, based on the literature. The effects are more complex for the machine learning methodology because of the embedded nonlinearities and, consequently, do not have necessarily a constant coefficient. Moreover, they can potentially have zero, negative, or positive effects on Success in different regions.
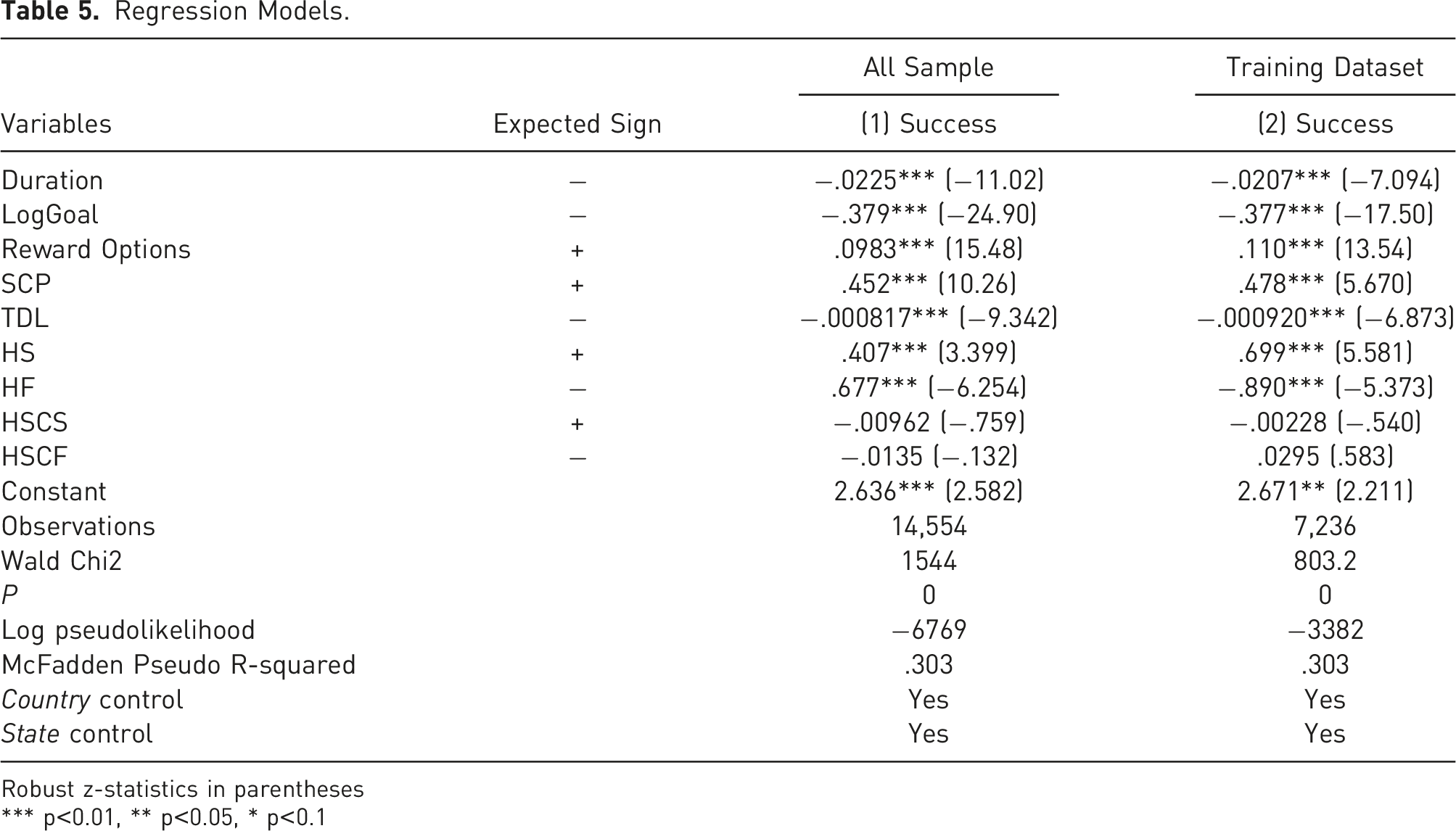
TDL (Threshold Donation Level) is the average price of a Rewards Options (defined below). This variable is expected to have a negative coefficient in a logistic regression model (Elitzur et al., 2023a; Shneor et al., 2021).
SCP (Social Capital of the Project) is the social score of the founder, measured by the comments made on the campaign. We expect this variable to have a positive coefficient in a logistic regression model, i.e., it positively affects the probability of success (Butticè et al., 2017; Colombo et al., 2015; Elitzur et al., 2023a; Usman et al., 2020).
HS and HF are the previous successful campaigns of the creators and their unsuccessful ones, respectively. We expect these variables to have respectively positive and negative coefficients in the logistic regression (Butticè et al., 2017; Usman et al., 2020; Elitzur et al., 2023a).
HSCS and HSCF are the previous creators’ social score for successful campaigns and unsuccessful ones, respectively. We expect these variables to have respectively positive and negative coefficients in the logistic regression (Butticè et al., 2017; Usman et al., 2020; Elitzur et al., 2023a).
Goal is the monetary goal of the campaign. Consistent with the extant literature, we expect this variable to have a negative coefficient in logistic regression, i.e., it negatively affects the probability of success in a logistic regression model (Mollick, 2014; Colombo et al., 2015; Butticè et al., 2017; Bi et al., 2017; Usman et al., 2020; Lin and Boh, 2021; Li et al., 2022). For scaling purposes we will use the logarithm of the goal, Log (Goal).
Duration is the time period during which the campaign was active. Consistent with other studies in this area we expect this variable to have a negative coefficient in a logistic regression model, i.e., this variable negatively affects the probability of success (Mollick, 2014; Bi et al., 2017; Butticè et al., 2017; Colombo et al., 2015; Courtney et al., 2017; Li et al., 2022; Lin and Boh, 2021; Shneor et al., 2021; Skirnevskiy et al., 2017).
Rewards Options is the number of reward options. This variable is expected to have a positive coefficient as it provides more choices to backers. Consistent with the literature, we expect Rewards Options to have a positive coefficient in the logistic regression (Mollick, 2014; Courtney et al., 2017; Kuppuswamy & Bayus, 2017; Lin & Boh, 2021; Mollick, 2014; Shneor et al., 2021).
2.4 Numerical Control Variables
Year is the year of the project launch.
State is dummy variable for projects based in 5 “advanced” US states for crowdfunding (California, Florida, New York, Illinois and Massachusetts).
Country is a dummy variable for the country where the project is created.
2.5 Text Variables (used in the second stage of the machine learning analysis)
Business is the specific domain of the project (e.g., Sculpture).
Location is the municipal area where the project is created (e.g., Menlo Park, California, USA). As Woods et al. (2020) show the location is a major factor in the performance of the campaign.
3. Empirical Setting
3.1 Data Sources
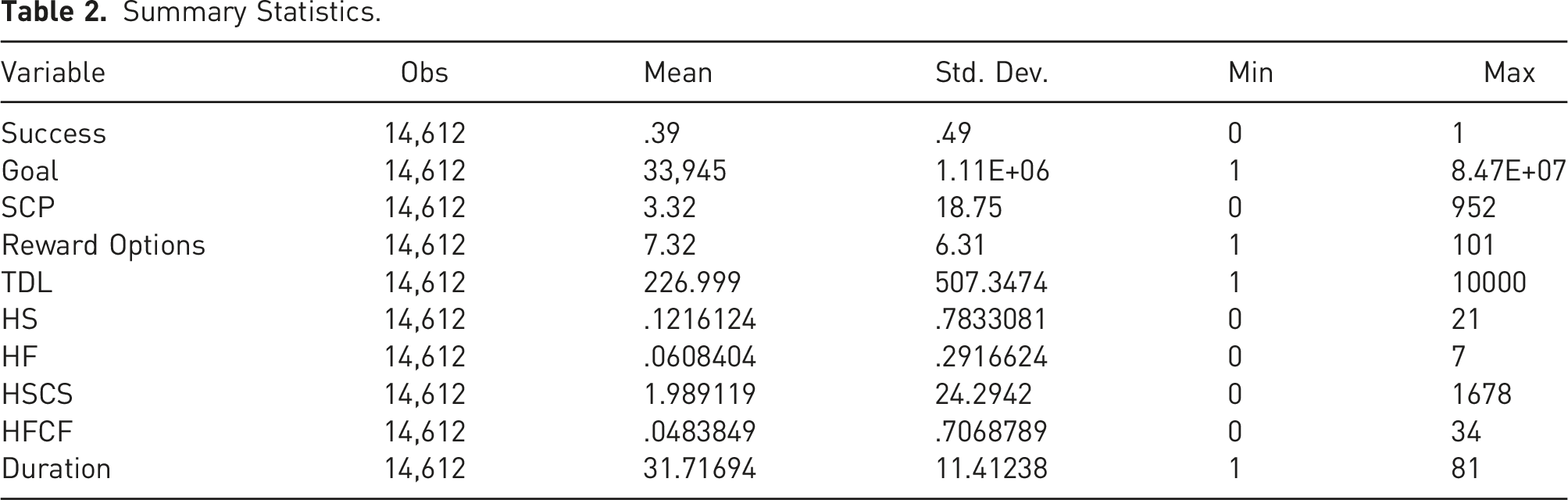
Summary Statistics.
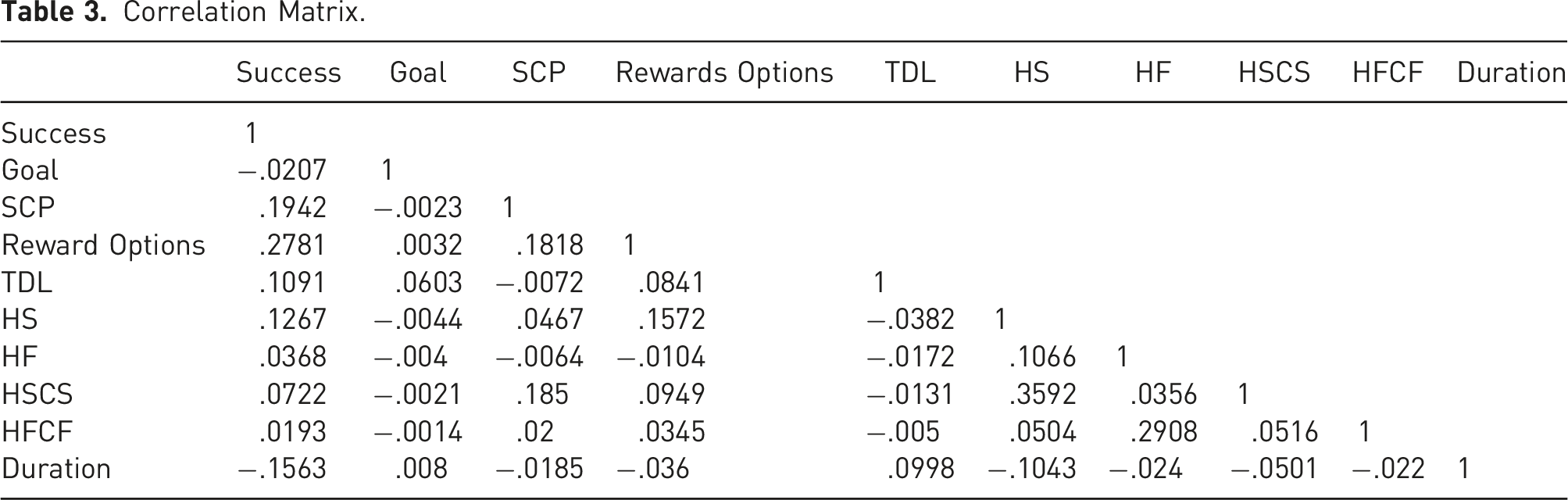
Correlation Matrix.
3.2 Regression Equation
The equation for the logistic regression is as follows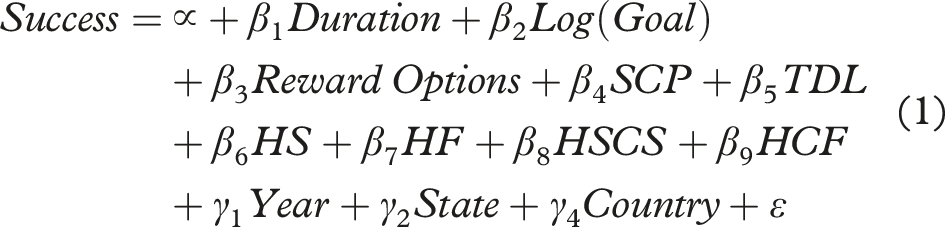
As discussed in the Variables section, consistent with literature, we expect to have negative coefficients for
3.3 Machine Learning Methods
As discussed the Variables section, I will first run the machine learning algorithms using only the same variables used in equation (1) to directly demonstrate the insights added from the nonlinear relations between the independent numerical variables and
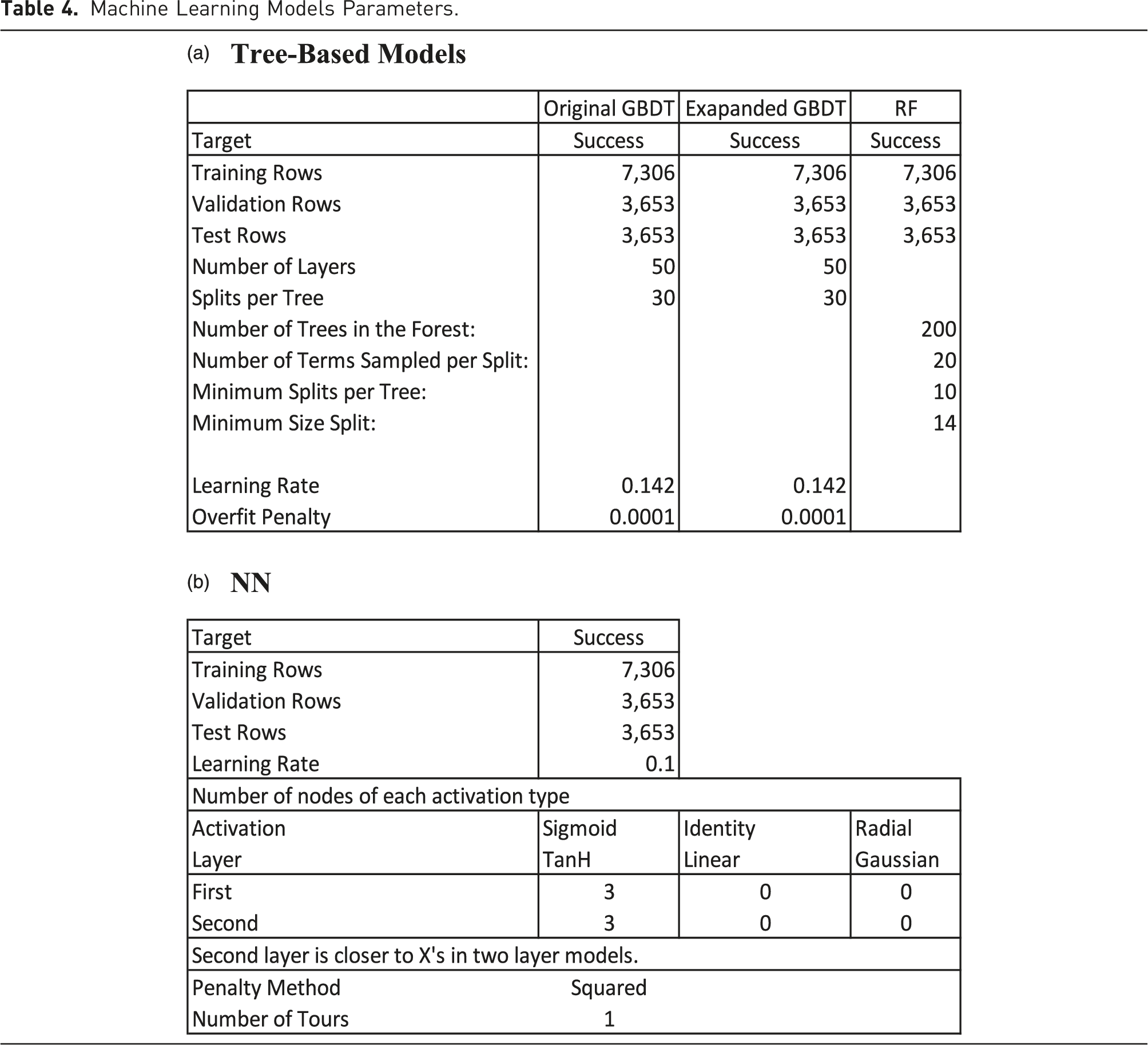
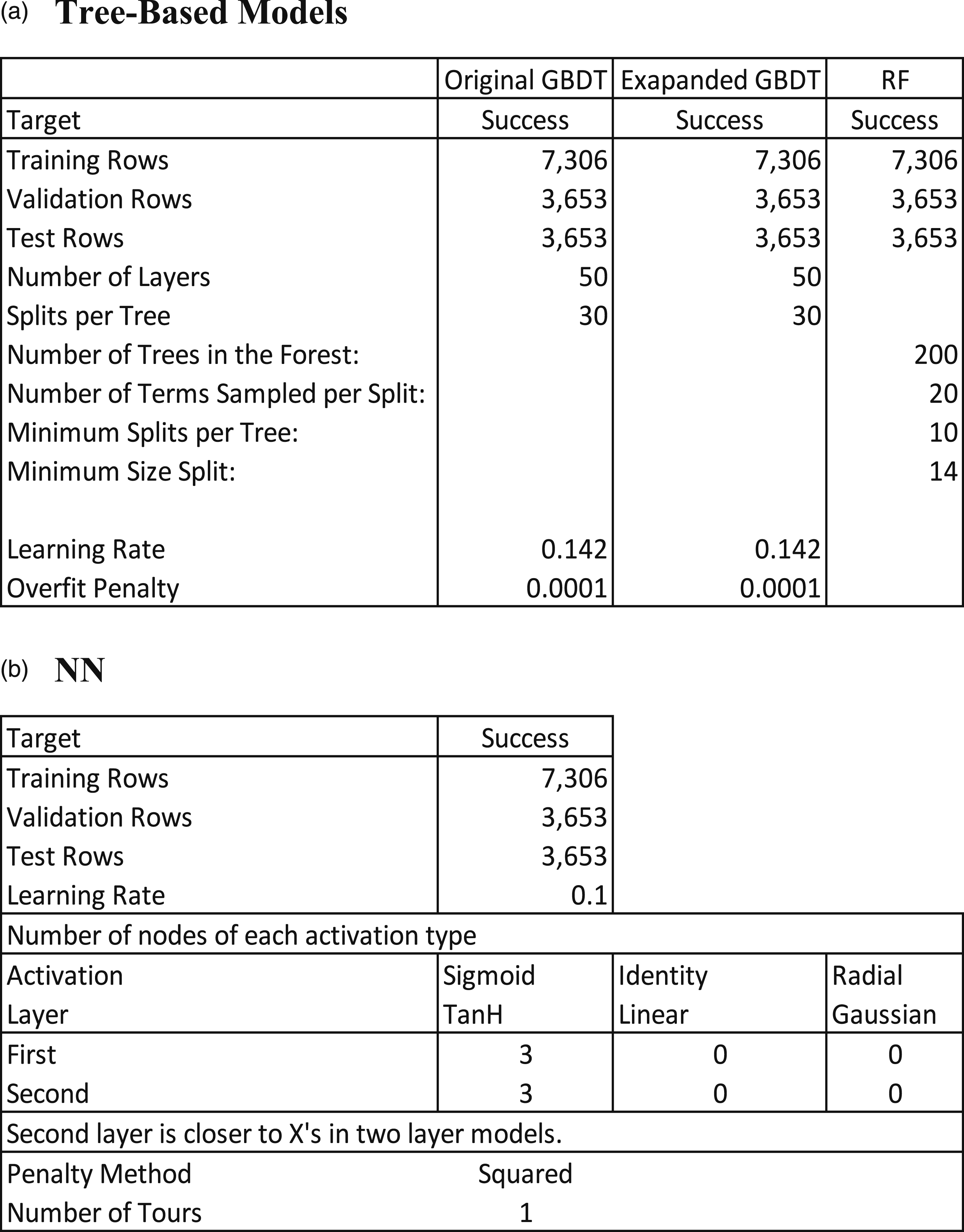
As discussed in Section 3.1 Data Sources, the sample is randomly partitioned into three datasets: training (7,306 observations, 50%), validation (3,653 observations, 25%), and test (3,653 observations, 25%). It is important to note that the test dataset (also known as holdout sample) contains observations that the system does not access when formulating the model and, as such, it is used to test the predictions of the model created first based on the training dataset and then finetuned based the validation dataset. The machine learning methods that I use include the following: (1) Gradient Boosted Decision Trees (GBDT) (2) Random Forests (RF) (3) Shallow Neural Networks (NN) (4) Support vector machines (SVM)
These methods, together with Deep Learning are the ones often used in predictive analytics (e.g., Chang et al., 2022; Ma et al., 2018; Zhong et al., 2022). These methods and the theory behind them are discussed at length in Elitzur e al. (2023b, 2023c). The goal of the system is to find the best predictor of success, often referred to as the best classifier, based on the independent variables (often referred to as features in machine learning). Elitzur et al. (2023b) show that Deep Convolutional Neural Networks CNN), a form of Deep Learning, did not provide better prediction than the above methods for their sample. The explanation that they provide is that tree-based machine learning algorithms are better when it comes to tabular data, while Deep Learning approaches perform better on computer vision and natural language processing tasks such as predicting taxi demand or cancer diagnosis (e.g., Liao et al., 2018; Litjens, 2016). The reason for this is that the application of Deep Learning requires a very large sample (millions of observations) to perform better than tree-based algorithms (Najafabadi et al., 2015). The data in Elitzur et al. (2023b) contains tabular data with only 108,223 observations, explaining why tree-based machine learning models performed better than the Deep Learning approach7, 8 . In this study I use tabular data with even a smaller sample than Elitzur et al. (2023b), 14,612 observations. As a result, I did not apply Deep CNN or other Deep Learning algorithms to this data.
Machine Learning Models Parameters.
4. Results
4.1 Regression Models
Regression Models.
Robust z-statistics in parentheses
*** p<0.01, ** p<0.05, * p<0.1
4.2 Machine Learning Models Results Compared with The Logistic Regression model
One of the commonly used metrics to assess predictive analytics is the Receiver Operating Characteristic (ROC) curve (e.g., Flach et al., 2011, Elitzur e al., 2023b, 2023c). The metric shows the tradeoff between sensitivity (known also as recall, or true positive rate, TPR) and specificity (false positive rate, FPR). The closer the ROC curve to the top-left corner the better is the prediction of the model.
A related metric is the area under the ROC curve (AUC), measuring the aggregated classification performance of both campaign successes and failures (Flach et al., 2011). The highest possible AUC with maximum prediction ability, is 100%.
One of the criteria to assess the quality of prediction is the stability of the ROC curve and the AUC under the three datasets.
Figure 1 demonstrates the stability of the ROC curves and AUC’s under the three datasets, a criterion measuring the quality of prediction. For example, under all datasets the AUC is above 85% for all models. For example, if the AUC for GBDT, the best performing method in the test dataset (the most important one) it is 92.35% in the training set, 87.55% in the validation set and 88.72% in the test set. As expected, the AUC decreases for the test dataset relative to the training set as the predictions of the algorithms are tested on unseen data by them. It is also interesting to observe that the differences among all algorithms in the ROC curves are the largest in the training set (Figure 1(a)), get smaller in the validation dataset (Figure 1(b)) and are the smallest in the test dataset (Figure 1(c)). ROC and AUC comparisons. (a) Training dataset, (b) Validation dataset, (c) Validation dataset.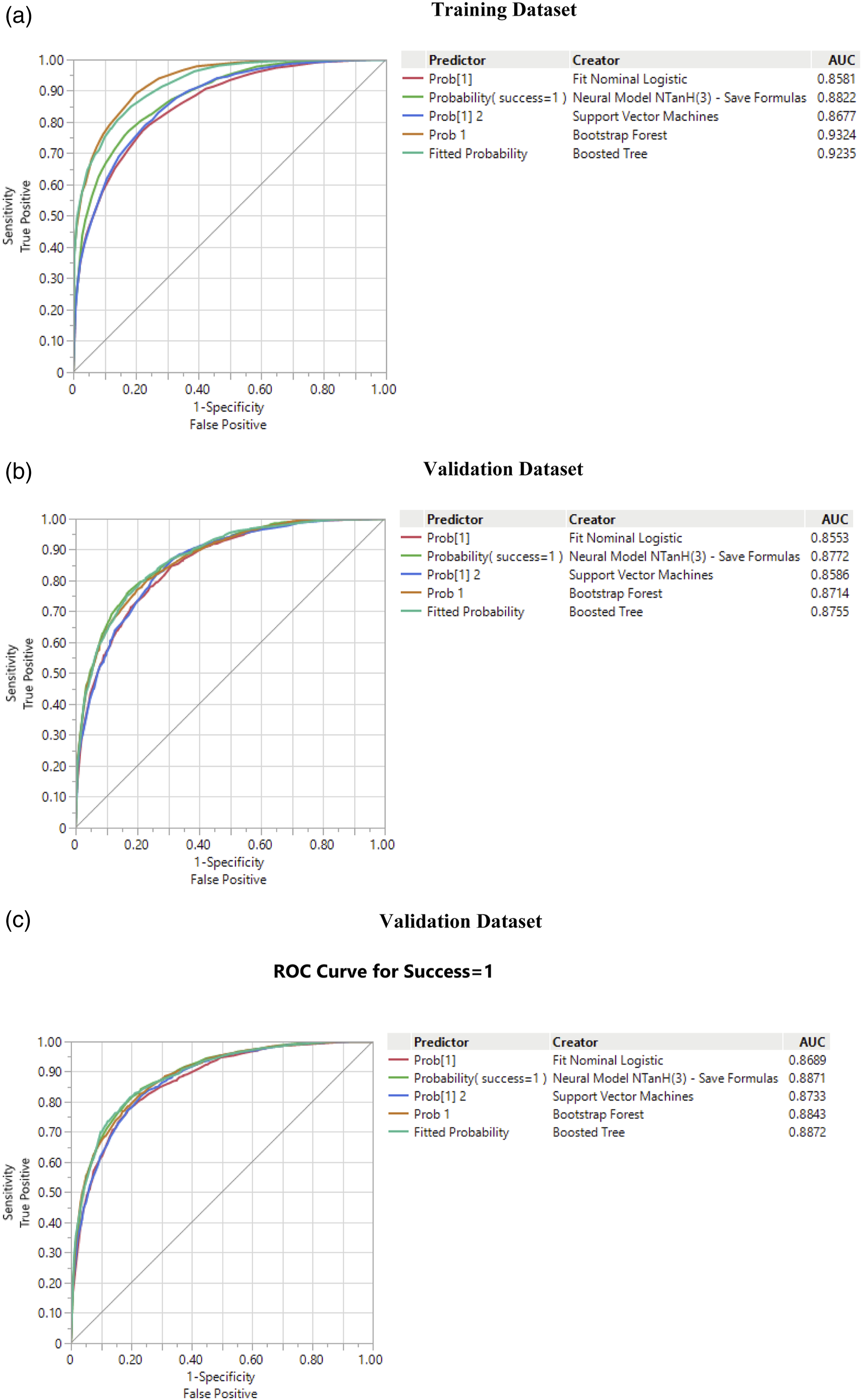
Figure 1(c) demonstrates that the best performing model is the boosted tree (GBDT), which is the closest to the upper left corner and has an AUC of about 88.72%. Next is the shallow neural network with an AUC of about 88.71, followed by Random Forest (RF) model, with an AUC of 88.43%, Support Vector Machines (SVM) with an AUC of 87.33% Last is the logistic regression model with an AUC of about 86.7%.
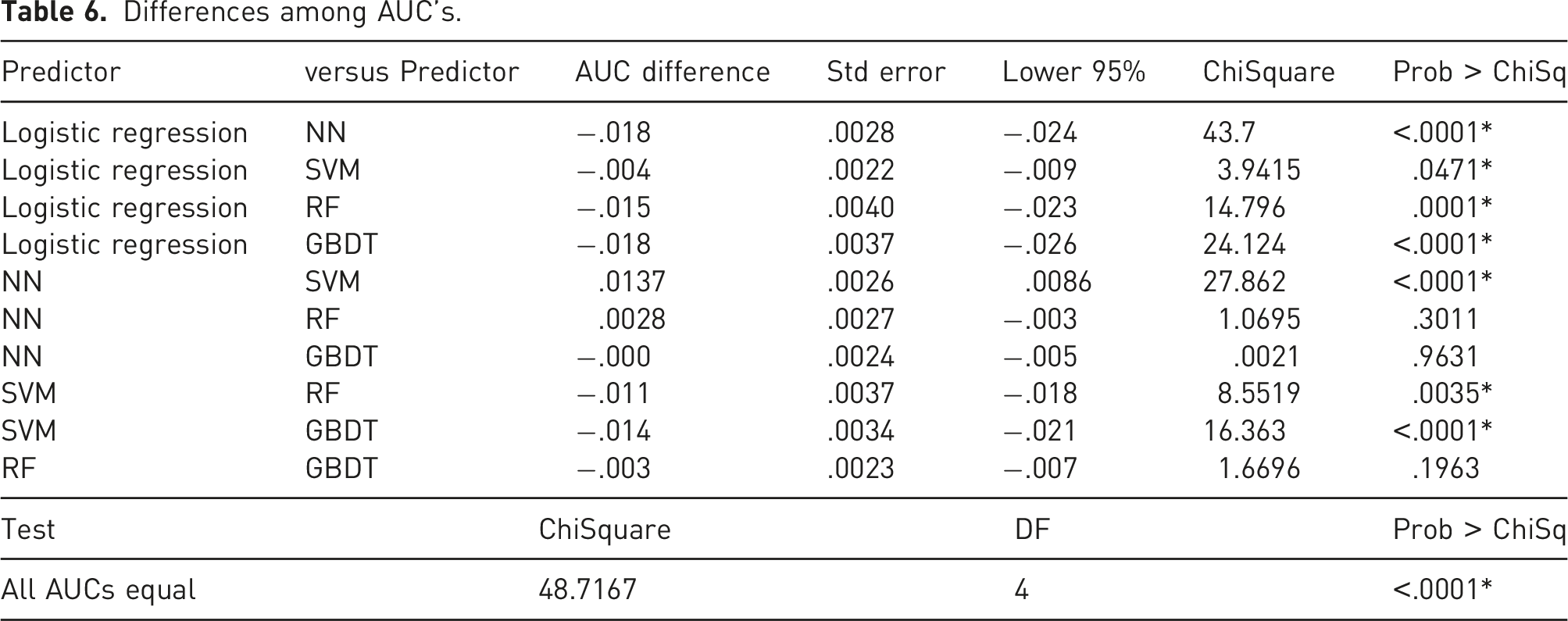
Differences among AUC’s.
Test Dataset Confusion Matrices.
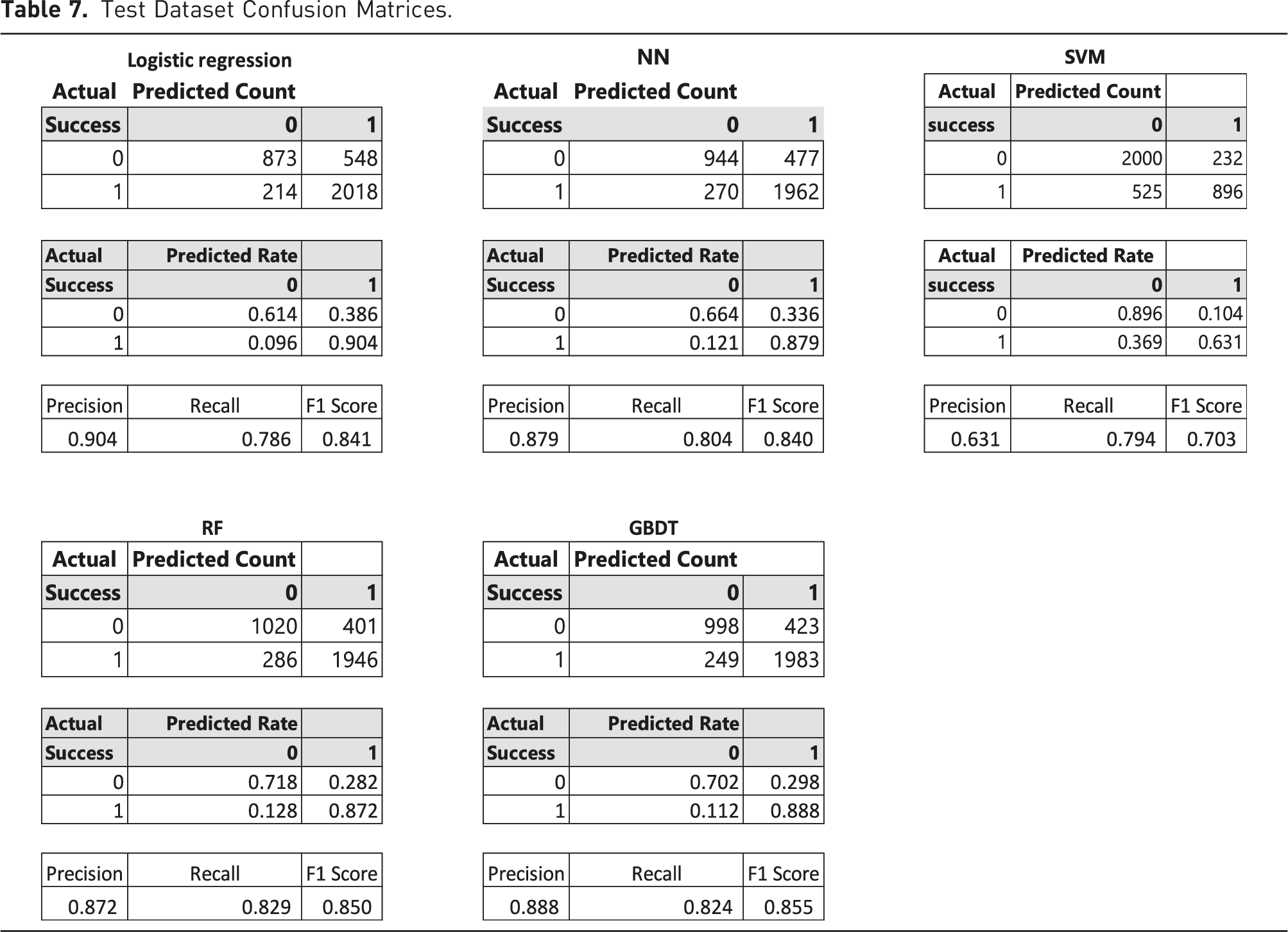
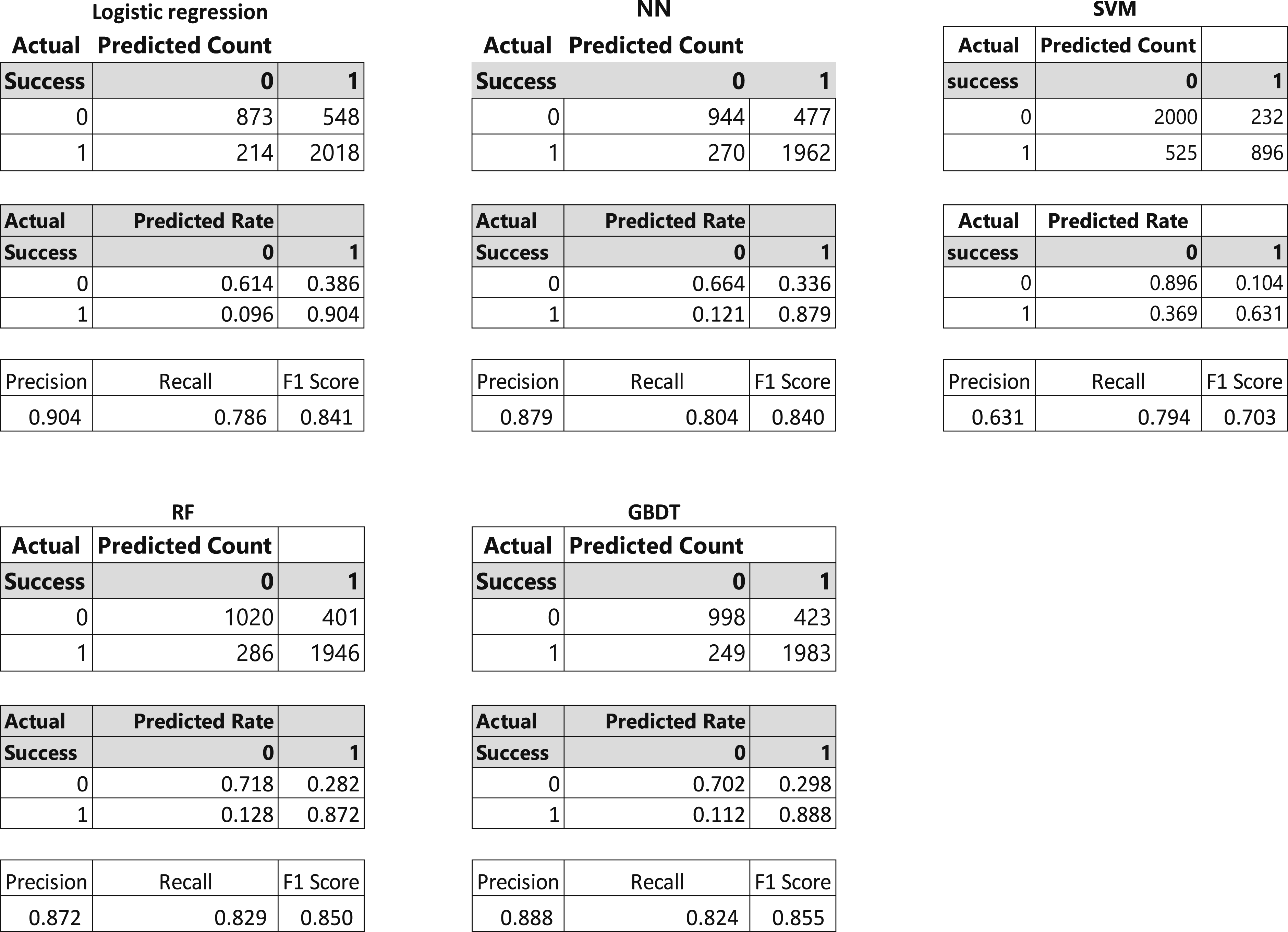
The Table shows that while the logistic regression has the highest precision with respect to predicting success (90%) it also is the worst with the prediction of failure (61%). GBDT performs the best out of the machine learning methods with 89% precision in the prediction of success and 70% in the prediction of failure. Next is NN with 88% precision in the prediction of success and 66% in the prediction of failure, followed by RF with 87% precision in the prediction of success and 72% accuracy in the prediction of failure., and SVM with 63% precision in the prediction of success and 90% in the prediction of failure. The worst performing algorithm is NN with 88% precision in the prediction of success and 66% in the prediction of failure. In terms of recall (sensitivity or true positive rate), RF performs the best (82.9%), followed by GBDT (82.4%), NN (80.4%), SVM (79.4%), and Logistic Regression (78.6%). The F1 Score is an overall measure of prediction quality balancing precision and recall (calculated as
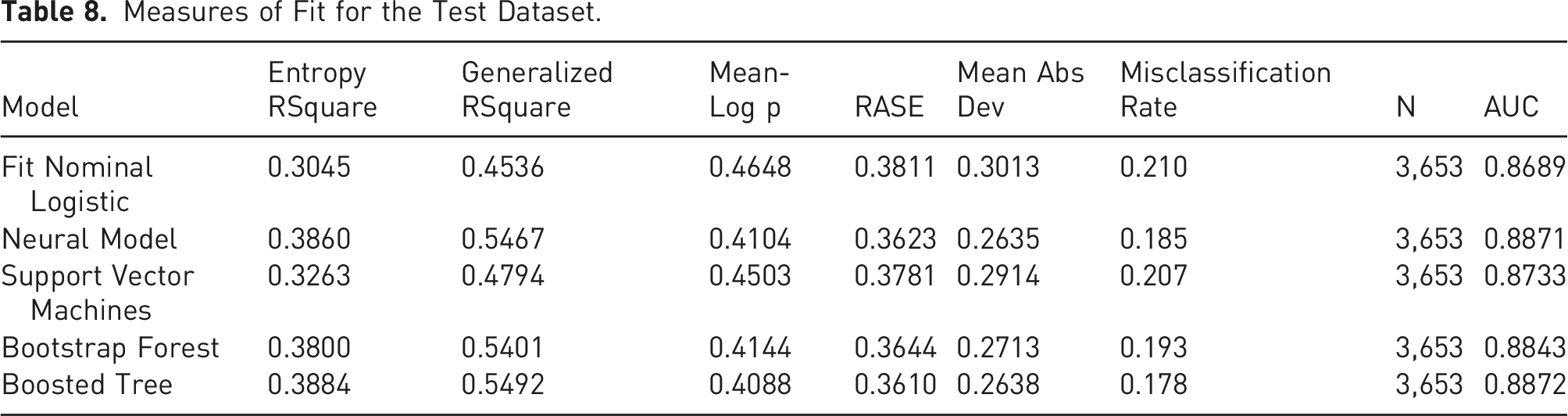
Measures of Fit for the Test Dataset.
4.3 Variable Importance
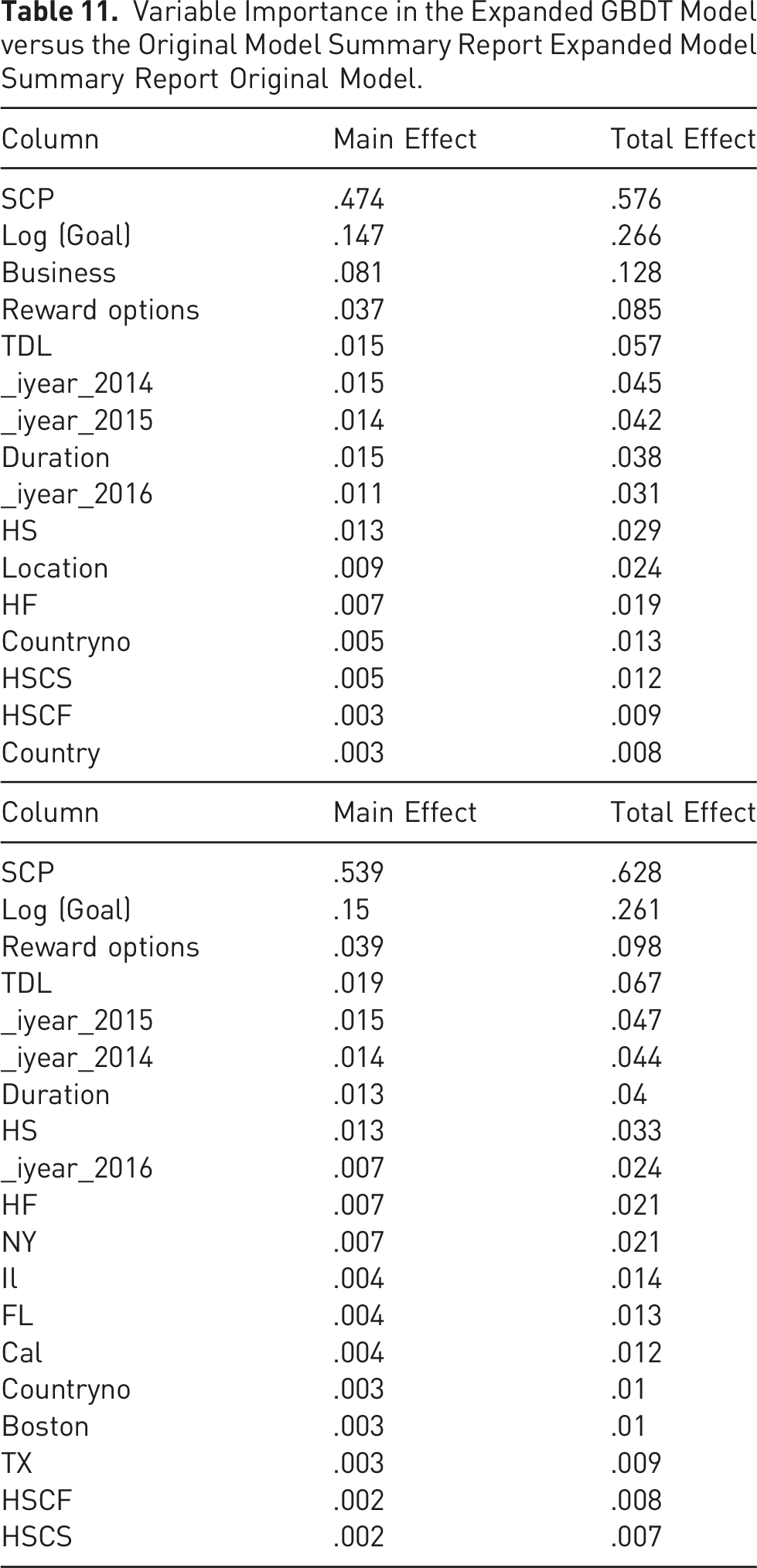
Machine learning provides insights on the effects on the outcome of each variable on its own (main effect) and in interaction with other variables (total effect). It is difficult to assess this effect in regression models as the variable effects relate not just to the size of their coefficients but also to the overall size of variables, as well as their interactions with other variables (which we do not know a priori). In contrast, machine learning models calculate the main and total effects of the variables and, moreover, automatically figure out interaction effects with other variables.
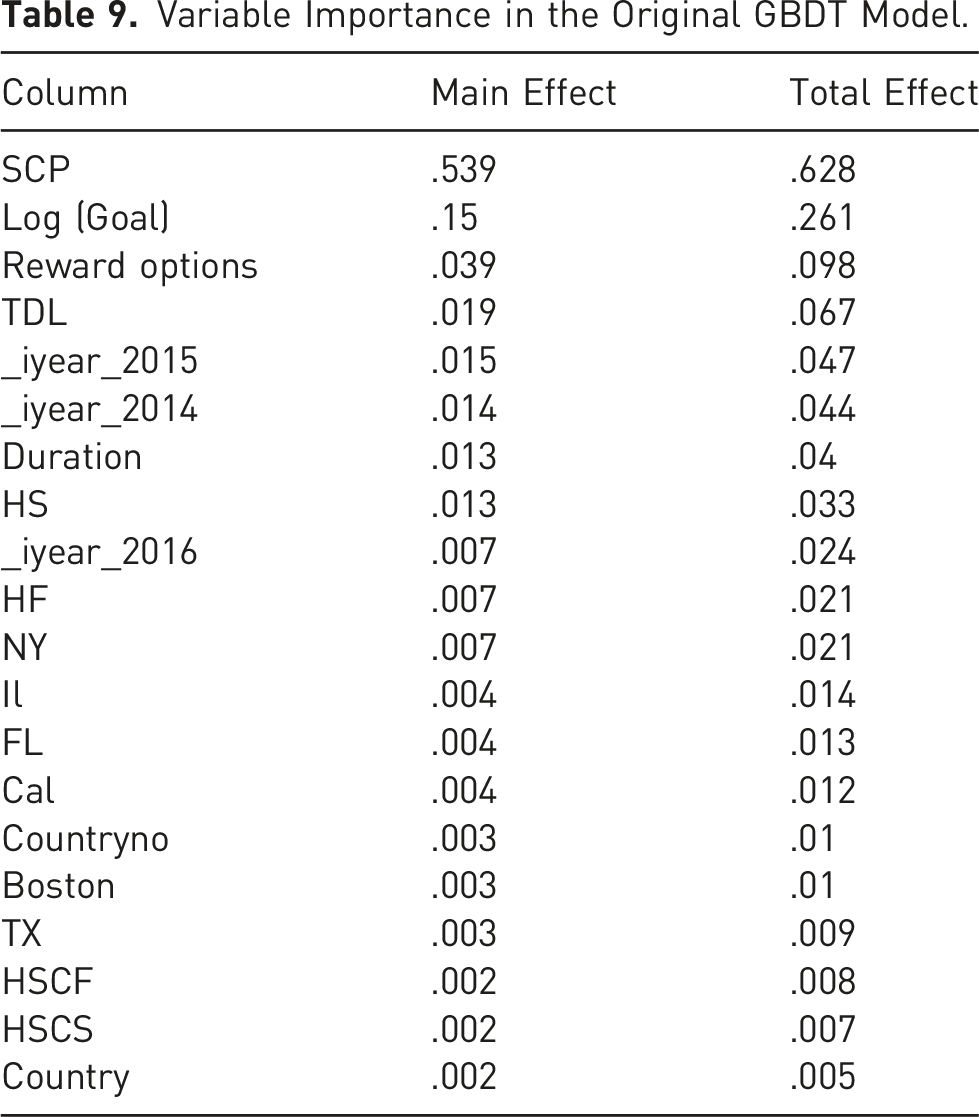
Variable Importance in the Original GBDT Model.
4.4 Visualization
As I previously discussed, machine learning algorithms are more effective than regression models in analyzing nonlinear relationships (e.g., Elitzur et al., 2023b). Consequently, visualization of the effects of the explanatory variables on the outcome could provide invaluable insights. For example, Elitzur et al. (2023b) demonstrate the presence of threshold and Goldilocks effects with respect to the full Kickstarter sample. Figures 2(a)-2(d) show the prediction profiler for the 4 most important variables when they are changed while the others are held constant. As such, the Figure depicts the effects of SCP, Log (Goal), Rewards Options and TDL on the likelihood of success for the best classifier, GBDT. The vertical axis is the probability of success, and the horizontal axis is the level of the explanatory variable plotted. Prediction profiler for the GBDT model. (a) SCP effects, (b) Log (Goal) effects, (c) Reward options effects, (d) TDL effects.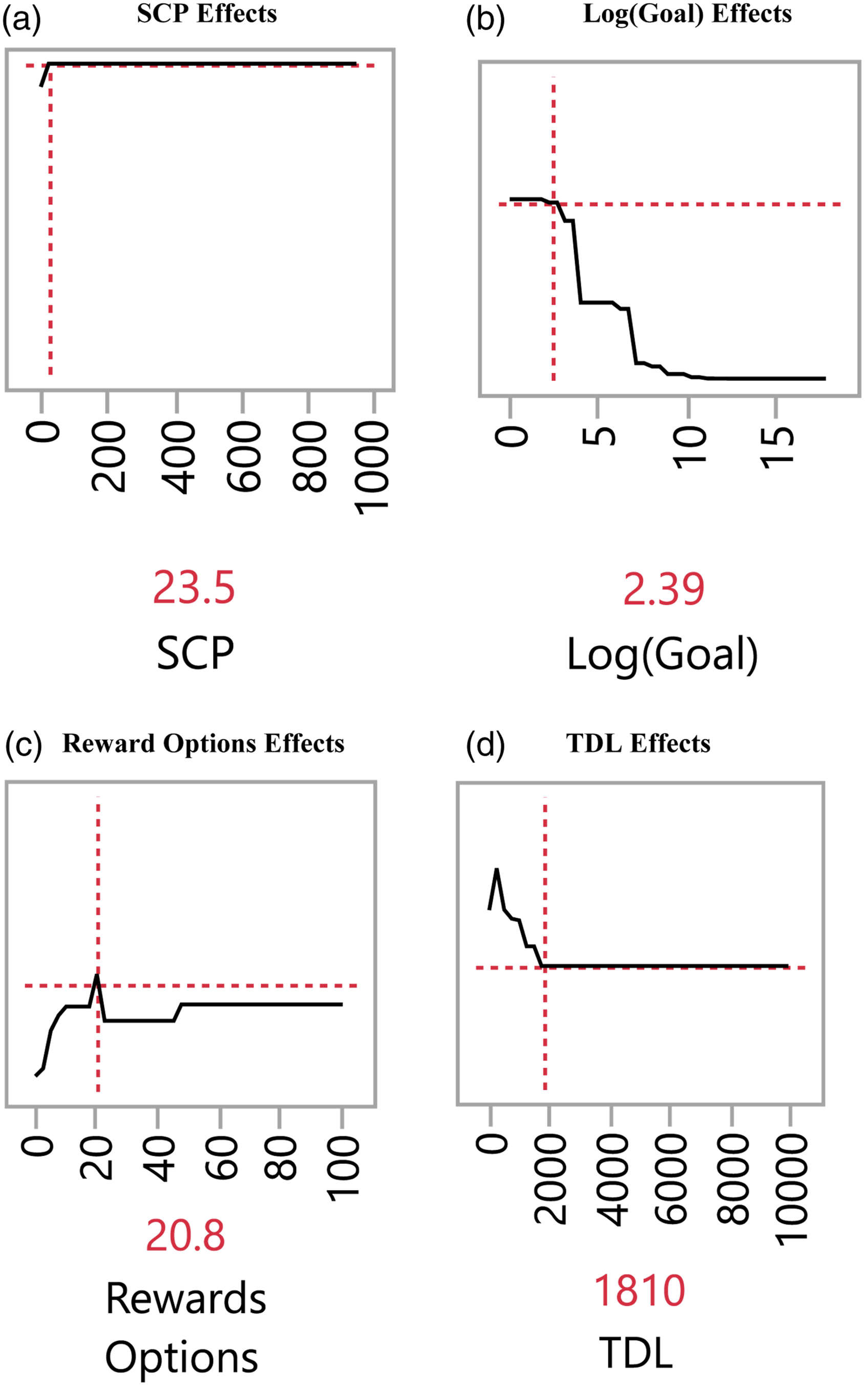
Figure 2(a) depicts the effects of SCP on the likelihood of success for art projects. It shows a threshold (tipping points) at SCP of 23.5. Note that the effects of SCP do not show a constant positive slope simplistic as the logistic regression and the literature predict (e.g., Butticè et al., 2017; Colombo et al., 2015; Usman et al., 2020).
Figure 2(b) demonstrates multiple threshold effects of the goal of the campaign (Log (Goal)) on the likelihood of success for art projects, taking a 3-step function shape. For example, the effect is flat until a threshold at Log (Goal) of 2.39 (translating to campaign goal of US$245.5). The effect then between Log (Goal) of 2.39 (US$245.5) and 3.36 (US$2,291) becomes moderately negative, followed by a negative effect with a steep slope, between Log (Goal) of 3.36 (US$2,291) and 4.53 (US$33,884), followed again by a flat region. This of course contradicts the logistic regression model’s, simplistic prediction of a constant negative positive slope. This also provides a refinement to the extant literature’s simplistic prediction of a constant negative positive slope (Mollick, 2014; Colombo et al., 2015; Butticè et al., 2017; Bi et al., 2017; Usman et al., 2020; Lin and Boh, 2021; Li et al., 2022), Figure 2(c) demonstrates the effect of the number of Reward Options on the likelihood of success for art projects. The Figure shows, consistent with Elitzur et al. (2023a), overchoice effects. Specifically, the likelihood of success increases up to a Goldilocks number of options, 21, beyond which the likelihood of success decreases. These nonlinear (threshold and Goldilocks effects) effects are in contrast with the simplistic predictions of a constant positive slope from the logistic regression, and the extant literature (Mollick, 2014; Courtney et al., 2017; Kuppuswamy & Bayus, 2017; Lin and Boh, 2021; Mollick, 2014; Shneor et al., 2021).
Figure 2(d) graphs the effects of TDL (the average price of a reward option). The Figure shows that up to a threshold TDL of US$270 the likelihood of success for an art campaign increases in TDL, then it declines up to a TDL of US$1,810 and then flattens out. The figure demonstrates a Goldilocks effect at 21, where the TDL is “just right”. These nonlinear (threshold and Goldilocks effects) effects are in contrast with the simplistic prediction of the logistic regression model (and the literature’s, e.g., Shneor et al., 2021) of a constant negative slope.
4.5 Decision Trees Graphs
In contrast with NN or Deep Learning where we cannot visualize prediction drivers, tree-based algorithms (GBDT and RF) can provide the decision trees leading to predictions. The ability to look at trees, branches, and leaves provides intuition on how the system structured trees and, moreover, provides a means to audit the models, and revise them if needed.
Depicting forests for RF or all trees for GBDT is impractical. For example, As Table 4 shows, our GBDT model has 50 layers, with 30 splits each, which would make it impossible to look at all of them at once. Moreover, even showing a whole tree is impractical (due to 30 splits in each tree). We can however look at segments of the trees. As an example, Figure 3 shows a branch and leaves from layer 30 of the model. A branch and leaves from layer 30.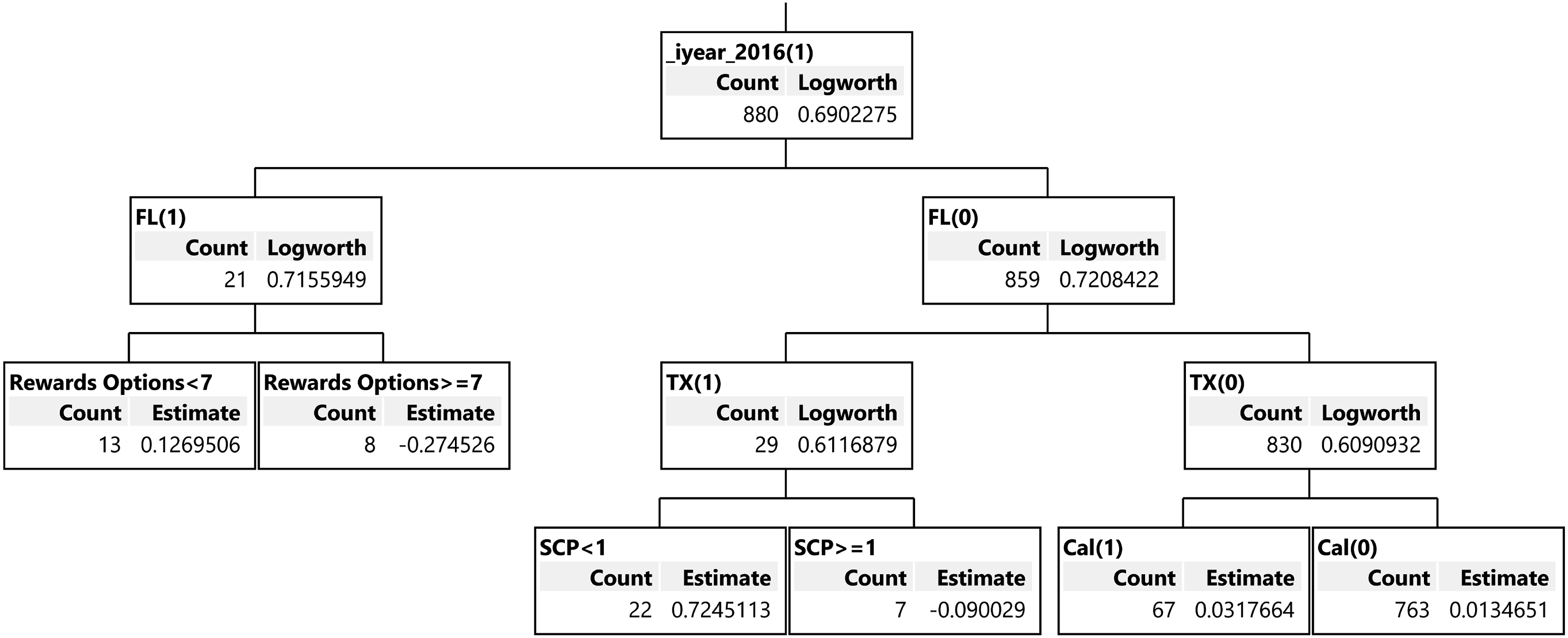
The top branch in Figure 3 shows projects from 2016 (denoted as _iyear_2016 (1)). On the second level it splits into those from Florida (left branch, denoted as FL (1)) and those outside of Florida (right branch, denoted as FL(O)). On the third level Florida projects, FL (1), are split into those with less than 7 rewards options (the leaf on the left, denoted as Rewards Options <7) and those with at least 7 reward options (the leaf on the right, denoted as Rewards Options >=7). Also, on the third level the non-Florida projects, FL (0),are split into those from outside of Texas (the leaf most to the right, denoted as TX (0)) and those from Texas (the next leaf on the left, Denoted as TX (1)). On the fourth level, the non-Texas projects, TX (0), are split into those outside of California (the leaf most to right, denoted as Cal(0)) and those from California (the next leaf to the left, denoted as Cal(1)). The Texas projects on the fourth level, TX (1), are split into projects without any SCP (the left leaf, denoted as SCP <1) and those with some SCP (the right leaf, denoted as SCP >=1).
4.6 Robustness Tests
The procedures that I used for machine learning models have some automatically built-in robustness tests. First, the random partitioning into the three sets where the system learns and finetunes itself (the training and validation datasets, respectively) and then evaluates the performance of its predictions on a dataset that the system did not previously access (the test dataset) is a robustness test to ascertain that the results are not spurious.
Second, running four alterative predictive analytics models and comparing them (logistic regression, GBDT, RF, SVM, and NN) offers another robustness test, ruling out that the results are not driven by some idiosyncratic methodological aspects of the model.
Third, I ran 5-Fold cross-validation as another means to validate the data. The advantage of K-Fold cross-validation analysis is it does not partition the data into three subsets but instead resamples the data, therefore in contrast with the training/validation/test dataset, it maintains the sample size (Shalev-Shwartz and Ben-David, 2014). The main disadvantage of K-Fold cross validation is its problem with external validity (MAQC Consortium, 2010; Rao & Fung, 2008; ) and, as such, it is used here as a robustness test rather than the main approach. The lack of external validity stems from the fact that K-Fold cross-validation is a resampling technique that uses different iterations on various parts of the data for training an algorithm and validating it. In contrast, our main approach uses a dataset, which was never seen by the algorithm, to maximize external validity 14 . Appendix A provides the output of the 5-Fold technique. Appendix A Panel A shows that the NN has the highest AUC (.8819). Appendix A Panel B shows that the AUC for the NN algorithm is significantly better than all other methods (at p < .01). This AUC however is worse than the under the three-set (.8872 for the GBDT and .8871 for NN). Moreover, Appendix A Panel D shows that the three-set validation method is better for all algorithms for precision, recall and the F-1score. As such, the three-set validation method (training/validation/test) provides better prediction ability than the 5-Fold validation method.
5. Expanding the Model to Include Text Variables
5.1 Text Variables Added
As discussed in the variable section the data contains two text variables that can add some insights and further prediction power: Business and Location. The analysis in this part uses GBDT, the best performing machine learning method, and assesses it with the metrics that were discussed in the Results section. As I show next, the expanded model (the one with the added text variables) significantly outperforms the original model in its predictions involving the test dataset.
5.2 ROC Curve Comparison
Figure 4 compares the ROC curves for the test dataset of the original model (in red) and the expanded model (the one with the added text variables) in blue. The Figure demonstrates that the expanded model clearly outperforms the original model, as the ROC curve for the expanded model is closer to the upper left corner than the original model. ROC comparison between GBDT models. (a) ROC curve, (b) AUC comparison.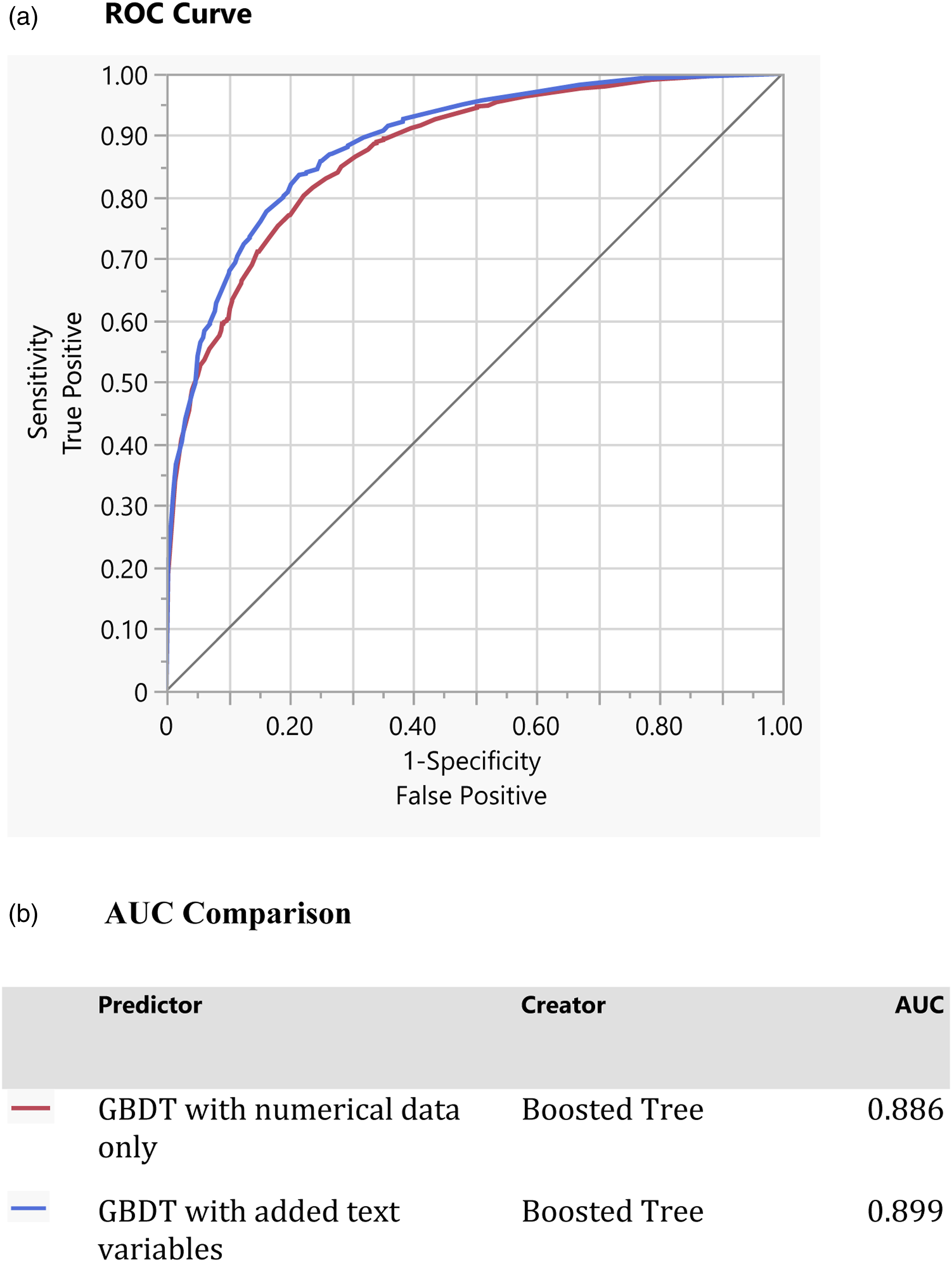
5.3 Performance Metrics Comparison
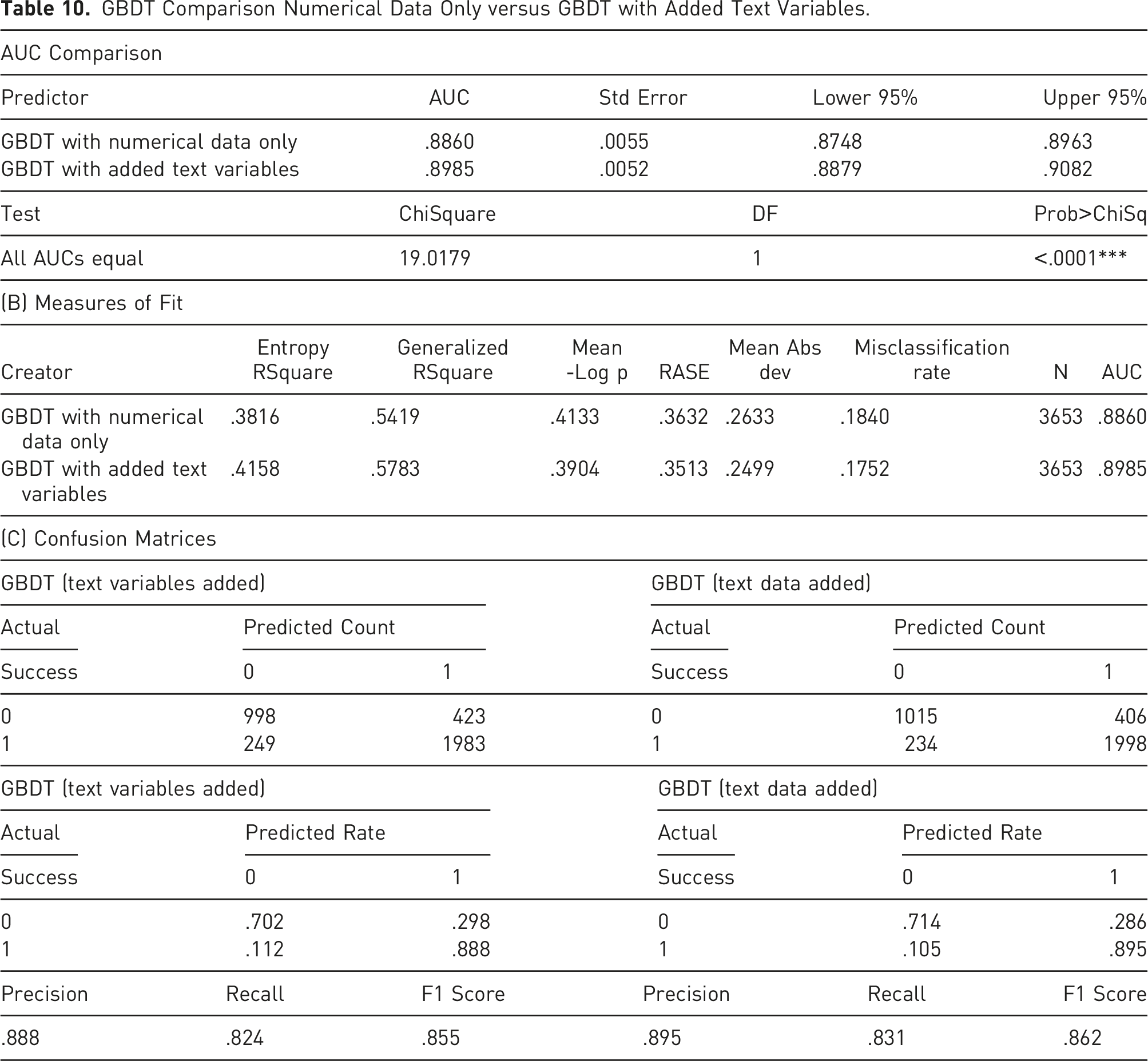
Table 9 Panel A compares the AUC of the original and expended GBDT models. It demonstrates the advantage of the expanded model by showing that the AUC for the expanded model (.899) is higher than the original model’s (.886). Table 9 Panel A shows that the difference between the two ROC curves is highly significant, having a Chi-Squared statistic of 19.02 with p < .0001.
Panel B in Table 9 demonstrates that the expanded model outperforms the original model in any measure of fit for the test dataset. It has a higher Entropy R2 (41.6% vs. 38.2%), a higher Generalized R2 (58% vs. 54%), a lower Mean-Log p (.39 vs. .41), a lower RASE (.35 vs. .36), a lower Mean Abs Dev (.25 vs. .26), a lower misclassification rate (17.5% vs. 18.4%), and as previously pointed out a significantly higher AUC (.899 vs. .866).
Panel C in Table 9 shows the confusion matrix for the test dataset. It demonstrates that the expanded model is more precise in both predicting success (.895 vs. .888) and failure (.714 vs. .702). Moreover, the expanded model outperforms the original model in precision (.895 vs. .888), recall (.831 vs. .824), and F1 Score (.862 vs. .855).
5.4 Importance of Variables Comparison
GBDT Comparison Numerical Data Only versus GBDT with Added Text Variables.
5.5 Visualization of the Added Text Variables
Figure 5 shows the Prediction Profiler for Business.
15
Figure 5(a) shows that the highest likelihood of success occurs when the stated business is nonspecific (art). Figures 5(b) and 5(c) show, respectively, that the two domains with the next highest likelihood of success are Installation and Performance Art. Figure 5(d) demonstrates that do-it-yourself (DIY) projects have the lowest likelihood of success. In summary, the Figure shows that beyond the project category, which has been shown to be important in the literature (e.g., Mollick, 2014; Buttice` et al., 2017; Colombo et al., 2015) the domain of the project could profoundly affect the likelihood of success. Prediction profiler for business in the expanded GBDT Model. (a) Generic description, (b) Installation, (c) Perf. Arts FIGURE 5D - DIY.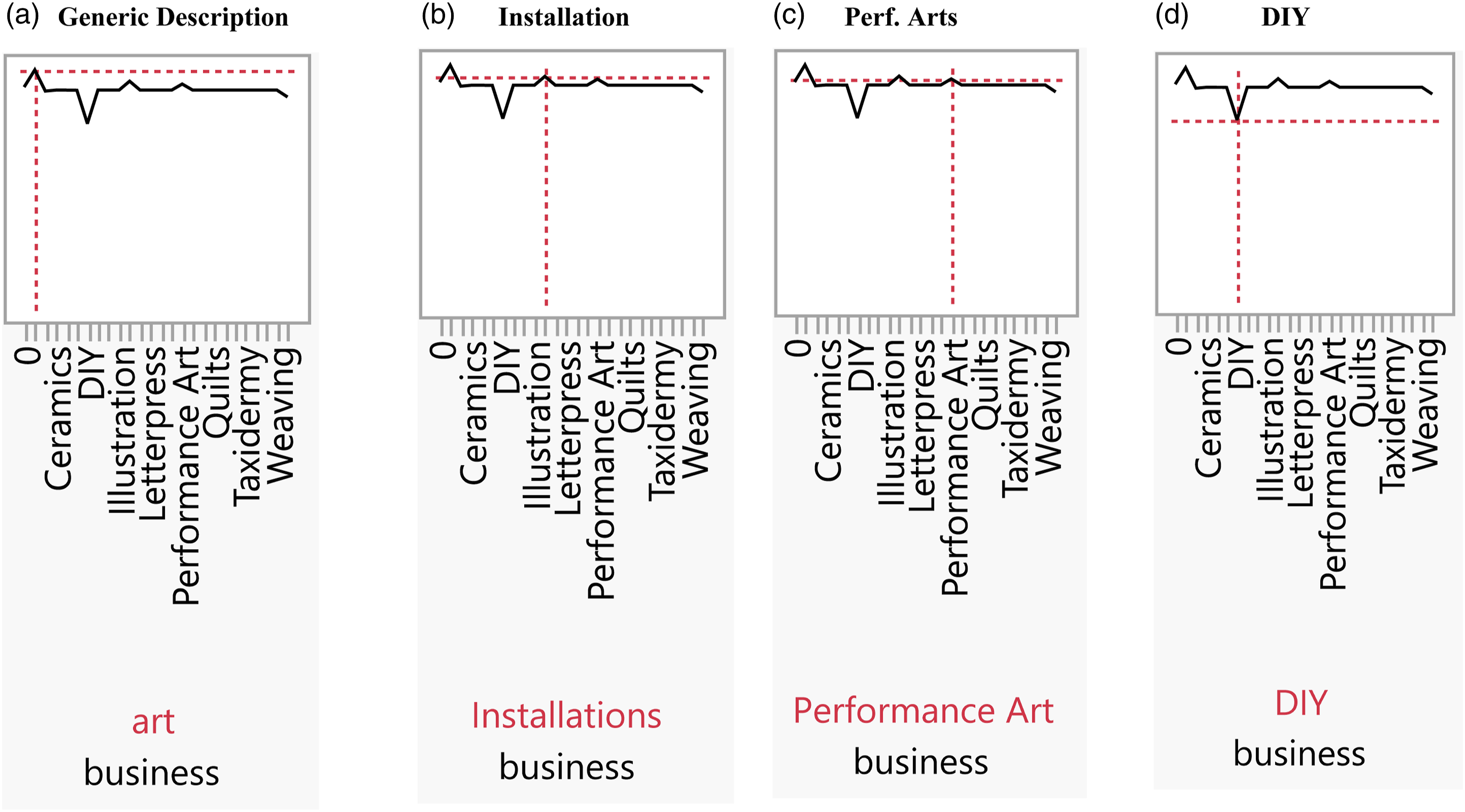
6. Discussion
6.1 Contribution to the Academic Literature
Variable Importance in the Expanded GBDT Model versus the Original Model Summary Report Expanded Model Summary Report Original Model.
Second, the study provides some interesting insights on the nonlinear relationships between the explanatory variables and the likelihood of success for art projects. For example, the output shows the existence of threshold and Goldilocks effects, which contradicts the constant positive or negative coefficients that the literature predicts with respect to the explanatory and control variables (e.g., Butticè et al., 2017; Colombo et al., 2015; Courtney et al., 2017; Li et al., 2022; Lin & Boh, 2021; Mollick, 2014; Shneor et al., 2021; Skirnevskiy et al., 2017; Usman et al., 2020).
Third, the model imparts some insights on the effects of non-quantitative variables (text variables in this study) on the likelihood of success.
Fourth, the database used in this study will be made available to researchers and could be utilized by them to conduct research.
6.2 Practical Implication
In addition to its contribution to academic literature, this study provides some practical implications to creators of art projects. They could choose, for example, not to label the specific project domain and just use a generic “art” label, maximizing the likelihood of success, as shown in section 5.
In addition, creators of arts projects should carefully choose the optimal goal of the campaign, the number of reward options, the duration of the campaign, and the average price of reward options (TDL). In making their decisions art projects creators need to consider the fact that their decisions today also affect their future campaigns and therefore should look at this as a multiperiod game rather than a one-period one.
One of the results of this study is that creators must tap into their entire social capital striving to maximize the number of the campaign.
Last, in their decisions creators of art projects must consider the nonlinear effects of their choice on the likelihood of success (in particular, threshold and Goldilocks effects).
6.3 Limitations
This is an exploratory and pedagogical study and like all studies it suffers from some inherent limitations, some of which can be addressed in an extension to this study.
One limitation is the size of the sample. While the number of observations is large and enables robust logistic regression and tree-based machine learning modeling, it cannot be used for Deep Learning. This is a limitation that unfortunately cannot be addressed because Deep Learning models require millions of observations, a sample size that is impossible to achieve for any single platform even if we include all projects in that platform.
A second limitation, which can be addressed in an extension to this study, is that the entire sample is from one platform, Kickstarter. Kickstarter is a major non-investment platform and has been used in a myriad of studies. Nevertheless, having data from only one platform, important as it is, could potentially lead to self-selection bias due to the idiosyncrasies of the specific platform. The robustness tests that in this study potentially minimize this possibility but a better way to address this problem would be an extension to this study using data from other non-investment platforms.
A third limitation is the fact that the data relates to the period from 2013 to 2016 and, as such, things could have changed since then. Given the fact that the study is meant as a teaching tool and the data is used only to illustrate the analysis, this concern is not major. Nevertheless, this concern should be addressed in a future study.
7. Conclusion
This study aims to enhance the knowledge of crowdfunding researchers and doctoral students on the use of machine learning models. First, it provides a structured guide on the use of machine learning methods that are available for crowdfunding research and related best practices. The study also could help academics better understand what types of insights can be obtained from machine learning methods. For example, through data and information visualization. Another contribution of the study is the insights it provides on the effects of text variables on the likelihood of art projects’ success. The study also provides some interesting insights on the nonlinear relationships between the explanatory variables and the likelihood of success for art projects (e.g., threshold and Goldilocks effects).
The study also offers some practical implications to art project creators. For example, creators of arts projects could use the guidance from this study on their description of the art domain of the project, the targeted amount of the campaign, the number of reward options offered to backers, the average price of reward options, the optimal duration of the project, and how to mobilize their social capital before and during the campaign. In doing so creators need to be cognizant of the nonlinear effects of their choices on the likelihood of success, as well as the fact that their choices today affect not just current campaigns but future ones as well.
Supplemental Material
Supplemental Material for Machine Learning and Non-Investment Crowdfunding Research: A Tutorial
Supplemental Material for Machine Learning and Non-Investment Crowdfunding Research: A Primer by Ramy Elitzur in Journal of Alternative Finance
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.