
Abstract
Quality assessment (QA) plays a crucial role in translation and interpreting (T&I). The rapid digitalisation of communication and the growing demand for accessibility have expanded T&I services across multiple languages (multilingual), through various communication channels encompassing text, visuals, and audio (multimodal), and by different agents including humans, machines, and their hybrid forms (multiagent). This diversity in languages, modes, and agents, along with their combinations, significantly broadens the scope of QA. In this article, I first propose a unifying framework for conceptualising QA research. Then, I apply this framework to systematically analyse 306 research articles on QA, selected from 6,974 articles published in 22 representative sources between 2015 and 2024. The review reveals that: (a) most QA studies focus on language pairs involving English; (b) three assessment scenarios—machine evaluation of machine T&I, human evaluation of machine T&I, and human evaluation of human T&I—dominate, together accounting for 97.1% of all QA practices, and (c) the QA research primarily concerns such assessment facets as objects, agents, and instruments, while other facets remain under-explored. Based on these findings, I outline an agenda for advancing QA research to address overlooked facets and adapt to the evolving complexities of T&I practices.
1. Introduction
Quality assessment (QA) is a crucial process in various domains related to translation and interpreting (T&I), drawing significant attention from educators, industry professionals, policymakers, and researchers. In the educational context, QA serves both formative and summative functions in professional T&I training (Li, 2018; Setton & Dawrant, 2016). QA is also implemented in foreign language learning classrooms, where T&I functions as a pedagogical tool to enhance language proficiency (Giustini, 2020; Ramsden, 2021). In the language services industry, QA ensures that translations meet the required standards of accuracy, fluency, and terminological consistency, as evidenced by the implementation of national and regional quality standards for T&I services (Wright, 2019).
Furthermore, QA plays a critical role in the iterative development of machine translation (MT) systems, facilitating the detection of translation errors, benchmarking system performance, and optimising MT model training (Chatzikoumi, 2020; Rivera-Trigueros, 2022). In addition, QA is a key component of professional T&I certification testing, often instituted by governments to regulate access to the T&I job market (Salmi & Kivilehto, 2020; Turner et al., 2010; Zhao & Gu, 2016). Finally, QA is commonly employed in quantitatively oriented research as a method for providing measurements that inform the analysis of other research phenomena (Han, 2020, 2022a).
Currently, the QA landscape is undergoing significant changes, marked by three key trends. First, the rise of digitalisation and increased demand for accessibility has led to greater complexity in the source material to be translated. Today’s T&I services must address multilinguality, operating across various languages, and multimodality, involving text, visuals, and audio. Second, the advancement of MT and speech technologies has made automatic T&I possible, either augmenting or potentially replacing human translators and interpreters in certain contexts. This shift introduces the concept of multiagency, where T&I tasks can be performed by human translators, machines, or hybrid models (e.g., MT with human post-editing or computer-assisted human interpreting). This diversity in languages, modes, and agents, coupled with their intricate interactions (e.g., speech-to-text MT), significantly expands the scope and complexity of QA. Third, innovations in machine learning (ML), natural language processing (NLP), and large language models (LLMs) offer the potential to transform QA paradigms. The spectrum of QA now ranges from traditional manual assessment by humans to fully automated machine-based evaluation, with hybrid human–machine collaborations occupying the space in between.
The increasing complexities in QA practices have led to researchers from diverse fields investigating different aspects of QA. For instance, language teachers and testers have long been interested in exploring T&I as a means of assessing second/foreign language proficiency (Buck, 1992; Sun & Cheng, 2013; Tseng et al., 2018). They have also examined the psychometric properties of T&I assessments (Han, 2019; Stansfield & Hewitt, 2005). Meanwhile, T&I researchers focus on refining QA practices (Colina, 2008; Colman et al., 2023; Han & Xiao, 2021; Romero-Fresco & Pöchhacker, 2017; Yan & Luo, 2023) and exploring alternative methods (Eyckmans & Anckaert, 2017; Han, 2022b; Han & Shang, 2022; Kockaert & Segers, 2017). Similarly, MT and NLP researchers are developing sophisticated evaluation algorithms and metrics to make automatic assessments more accurate and efficient (Blain et al., 2023; Kocmi & Federmann, 2023).
Despite the efforts to advance QA in T&I, the research landscape seems to remain fragmented and lacks cohesion. This fragmentation is evident in three ways. First, QA research is conducted by scholars from different disciplines, often with little awareness of developments in other fields. Second, the research is grounded in diverse epistemological and methodological approaches, which can limit interdisciplinary collaboration, as researchers from differing traditions and paradigms may be less inclined to collaborate. 1 Third, the areas of focus for QA research often run in parallel, with little cross-fertilisation between them. For example, language testers often concentrate on the psychometrics of QA, while T&I researchers focus on procedural aspects of assessment, and MT researchers explore automatic evaluation through NLP techniques.
To advance the field of QA in T&I, a comprehensive research framework is needed—one that accommodates diverse QA practices, fosters interdisciplinary synergy, and informs future research. This article proposes such a unifying framework, grounded in the multilingual, multimodal, and multiagent nature of T&I practice and informed by a socio-cognitive/computational-psychometric model of performance assessment. The framework is built on two main pillars: (a) a QA matrix that crosses objects of assessment (various forms of T&I products) with assessment paradigms (human, machine, and hybrid assessments) and (b) a socio-cognitive/computational-psychometric model that integrates key facets of assessment and postulates potential interactions among them. This framework is designed to offer a systemic and structured overview of the QA research landscape, helping researchers from different fields understand the ecological niche their research occupies. In addition, it serves as a heuristic guide for planning and conducting QA research and enhances awareness of the complexities involved in QA, fostering interdisciplinary communication.
In the subsequent sections, I will first present a detailed description of the framework’s first pillar—a QA matrix that encapsulates QAM3 T&I—and discuss the significance of QA across different scenarios, highlighting how various QA scenarios are interconnected. In Section 3, I explain the socio-cognitive/computational-psychometric model of T&I assessment, which serves as the second pillar of the framework. In Section 4, I map existing QA research to the proposed framework, drawing on a systematic review of empirical studies published in high-quality outlets over the past decade (2015–2024). This mapping will reveal major patterns, trends, and gaps in the research. In Section 5, I propose a research agenda for QA based on the results of the mapping. Finally, in Section 6, I offer concluding remarks, re-affirming the importance of QA and advocating for more interdisciplinary research to advance the field.
2. Quality assessment in multilingual, multimodal, and multiagent translation and interpreting (QAM3 T&I)
Briefly, the QA matrix involves crossing objects of assessment with paradigms of assessment. In the following sections, I explain each of these two components before discussing the matrix in detail.
2.1 Objects of assessment
As discussed previously, the source materials to be translated or interpreted are first and foremost characterised by multilinguality and multimodality. The multilingual nature of the T&I practice refers to the growing demand to mediate between a diverse array of language pairs, with English being often used as a pivot language. Of particular interest for QA is mediation between syntactically asymmetric languages such as English and Chinese, where the asymmetries often involve word order, subject-verb-object placement, use of inflections, and the treatment of tense, mood, or aspect, as these issues pose substantial challenges for T&I (Ma et al., 2021; Setton, 1999). Another case of interest for QA relates to mediation between major languages and languages of lesser diffusion or between high- and low-resource languages, as the relatively limited experience and capacity for assessing minority languages can complicate the practice of QA (Goyal et al., 2022; Sindhujan et al., 2024).
The multimodal nature of T&I primarily refers to the transmission of source or target information through the visual versus auditory channel. Sign language interpreting, for instance, epitomises inter-modal language mediation, as interpreters work mainly between signed and spoken languages. Interlingual subtitling is another form of inter-modal mediation from speech to text. Audio description represents an additional form of inter-modal transmission of information, where key visual elements in a video or multimedia product are orally narrated and described. Finally, sight translation is inherently inter-modal, as it requires translation from text-based information to either spoken or signed languages.
On top of the two important dimensions above, technological advancements such as MT have added an extra layer of complexity and challenged the agency of human translators and interpreters, resulting in the multiagent nature of the T&I practice. While human translators still have an important role to play in many communicative contexts (e.g., legal, medical, and diplomatic settings), MT has demonstrated its capability in some use cases (Chung, 2023; Vieira et al., 2021; Way, 2013). Meanwhile, technology-augmented T&I is regarded as a viable and pragmatic approach, where humans team up with machines to increase productivity and efficiency. These human–machine collaborative cases include MT plus human post-editing (Jia et al., 2019; Yamada, 2019) and technology-assisted human interpreting (Chen & Kruger, 2023; Corpas Pastor & Defrancq, 2023).
As a result, the interactions among the three key dimensions of the T&I practice can lead to a diverse array of T&I products. This diversity presents challenges for downstream QA activities, as the object of assessment could take various forms such as live subtitles generated by MT from a major language to a minority language and AI-augmented simultaneous interpretation between syntactically asymmetric languages.
2.2 Paradigms of assessment
In tandem with the recent technological advances in ML, NLP, and LLMs, the QA paradigm is also witnessing transformative changes. Overall, manual assessment by humans remains popular in some scenarios, for instance, educational assessment of students’ T&I performance (Chen et al., 2022; Koby, 2015; Li, 2018), professional certification testing of T&I competence (International School of Linguistics, 2018; National Accreditation Authority for Translators and Interpreters [NAATI], 2024), quality assurance in the translation and localisation industry (Wright, 2019), and quantitatively oriented research (Han, 2022a). For human assessment, there are two prevalent evaluation methods: (a) error analysis, evidenced by the Multidimensional Quality Metrics framework (Lommel et al., 2013), the ATA Framework for Standardized Error Marking (Koby, 2015), and the Canadian Language Quality Measurement System (Sical) (Williams, 1989) and (b) rubric scoring, demonstrated by design, development and refinement of various rubrics for assessing T&I (Han, 2018; NAATI, 2024; Setton & Dawrant, 2016).
In parallel to human assessment, automatic assessment is commonplace in such scenarios as the development of MT systems. Various types of automated evaluation algorithms and metrics have been designed and deployed to assess the quality of MT, including n-gram-based metrics (e.g., BLEU, NIST, and METEOR), neural-based, reference-dependent metrics (e.g., BERTScore, BLEURT, and COMET), and quality estimation-based metrics (e.g., TransQuest and COMETKiwi) (Chatzikoumi, 2020; Han & Lu, 2025; Rivera-Trigueros, 2022). Recently, LLMs have also been leveraged as the foundation for quality estimation models (Kocmi & Federmann, 2023; Jiang et al., 2024).
Furthermore, there is significant potential for human–machine collaboration in assessing T&I quality (Han & Lu, 2021). In this hybrid approach to QA, each party can assume a greater, equal, or lesser role depending on the context and specific needs. Several configurations of human–machine teaming can be envisioned to leverage their respective strengths effectively. For instance, intelligent machines can augment humans in evaluative judgement, by automatically summarising and enumerating features or phenomena of translated or interpreted renditions without providing direct assessments. In addition, humans can choose to delegate part of evaluative judgement to intelligent machines, providing automatic assessment of formulaic structures and properties of languages like grammatical correctness and enabling humans to focus on more problematic and challenging aspects of evaluation. Moreover, intelligent machines such as LLMs can be instructed to provide direct assessments, using the same scoring method as humans do. Such assessments will subsequently be evaluated and cross-checked by humans regarding their validity.
2.3 The QA matrix
Based on the description of the objects and paradigms of assessment, this section explains the QA matrix. Notably, the matrix is formed by crossing the three agentic statuses of the T&I practice (i.e., human, machine, and human–machine hybrid) with the three assessment paradigms (i.e., human, machine, and human–machine teaming) (see Figure 1). The main reason for not crossing all three dimensions of T&I (i.e., multilinguality, multimodality, and multiagency) with the assessment paradigms is that such a fully crossed design will inevitably create a very complicated typology of scenarios, making it less useful and practical as part of the unified research framework. Nonetheless, multilinguality and multimodality will continue to play their role in the framework, as they will be operationalised as coding variables. In Section 4, I will demonstrate how the matrix can be utilised to analyse existing QA literature, while considering the multilingual and multimodal nature of T&I.
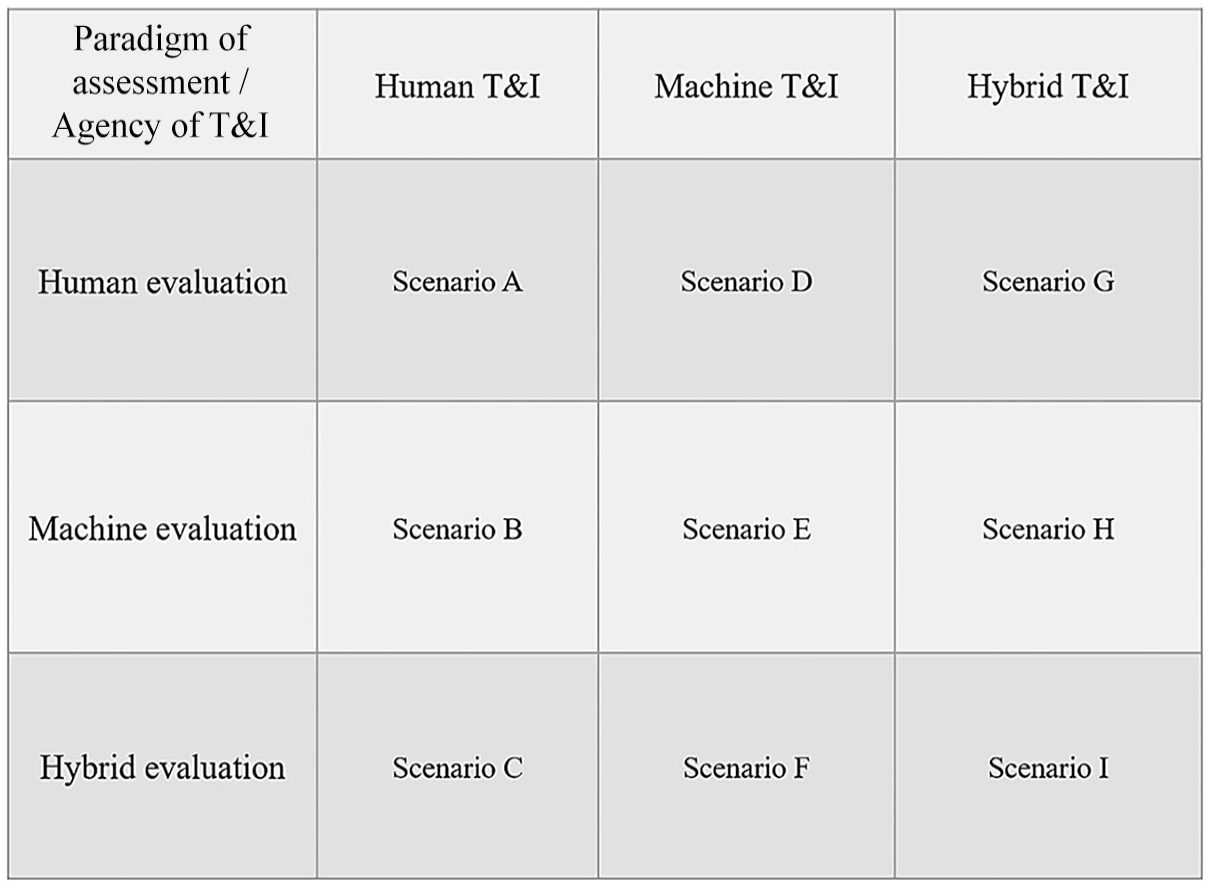
The Quality Assessment (QA) Matrix.
As can be seen in Figure 1, the crossing of the two dimensions creates a nine-rectangle or nine-square grid corresponding to nine assessment Scenarios A–I. Each scenario represents a unique case in which a specific assessment paradigm is used to assess T&I product generated by a human, non-human, or hybrid agent. Each of the scenarios potentially aligns with the real-life QA practice.
The first set of three scenarios (i.e., Scenarios A, D, and G) is related to human-based manual evaluation. In Scenario A, human evaluation of human T&I is essential for establishing and maintaining the highest professional standards in T&I, as expert evaluators can provide nuanced feedback on various quality aspects such as stylistic and cultural appropriateness of translated texts as well as prosodic and interactional features of interpreted renditions (see International School of Linguistics, 2018; NAATI, 2024). In Scenario D, human evaluation of machine T&I is vital for refining and training MT algorithms, especially in handling nuances, idioms, and cultural references, an area where machine T&I systems often fall short. In other words, human evaluation is regarded as the gold standard or the ground truth with which MT quality is compared (Läubli et al., 2020). In Scenario G, human evaluation of hybrid T&I is also valuable for two reasons: (a) on the one hand, human evaluation can provide a nuanced quality check to ensure the naturalness and readability as well as the cultural and contextual sensitivity of hybrid T&I products and (b) on the other hand, human evaluation can generate evidence of effectiveness of human–machine collaboration in the T&I practice (Daems & Macken, 2021; Jia et al., 2019).
In addition, the second set of three scenarios (i.e., Scenarios B, E, and H) is associated with machine-based automatic evaluation. In Scenario B, machine evaluation of human T&I is becoming increasingly important, especially when human T&I samples exist in large amounts (e.g., large-scale T&I testing) or are produced on a continuous basis for constant evaluation (e.g., formative assessment in language learning settings), and when qualified human evaluators are scarce or prohibitively expensive to recruit (Han & Lu, 2023; Lu & Han, 2023). In short, machine evaluation offers scalability and efficiency, requiring far fewer resources than human evaluation while handling great volumes of tasks. In Scenario E, machine evaluation of machine T&I via automated metrics such as COMET, TransQuest, BLEURT, and GEMBA allows for the continuous, inexpensive, and immediate evaluation of large quantities of machine T&I outputs, which is essential for the iterative process of MT system development (Rivera-Trigueros, 2022). It also has the potential to provide real-time QA in practical applications. In Scenario H, machine evaluation of hybrid T&I provides scalability, consistency, and efficiency in QA, while generating feedback to optimise the collaboration between humans and MT systems (Bentivogli et al., 2016).
The final set of three scenarios (i.e., Scenarios C, F, and I) pertains to hybrid evaluation based on human–machine collaboration, corresponding to hybrid evaluation of human, machine, and hybrid T&I, respectively. This evaluation approach leverages the strengths of both humans and machines, offering relatively faster and more scalable evaluation solutions (via machine-generated, automated metrics) while also improving the accuracy and appropriateness of the translation of contextual, cultural, idiomatic, and stylistic nuances (via human judgement) (Han & Lu, 2021).
These assessment scenarios, while seemingly parallel, are interconnected. For example, insights from human evaluation can enhance assessment practices and contribute to developing psychometrically robust measures that can benchmark automated evaluation metrics. Exploration of various formats of hybrid evaluation can help identify the respective competitive edge of humans and machines as evaluators, helping improve human evaluation procedures and refine machine evaluation algorithms. Among these scenarios, human reception and evaluation of T&I outputs, regardless of their sources of agency, is fundamental to all evaluation exercises and T&I generation practices because in the human-dominated society, humans will and should be the end users and therefore the ultimate judges of T&I quality.
3. The socio-cognitive/computational-psychometric model of quality assessment
This section will first provide an overview of three models in the fields of language testing and educational assessment, each describing key facets and potential interactions in rater-mediated assessment, while highlighting their characteristics and limitations. It then builds on and extends the previous models to account for performance assessment from social, cognitive/computational, and psychometric perspectives, which will be used to analyse T&I assessment by different agents.
3.1 Previous models of rater-mediated assessment
One of the first models describing characteristics of rater-mediated, constructed-response assessment (e.g., writing or speaking assessment) is from McNamara (1996, pp. 120–121). McNamara’s model highlights two types of interaction between different assessment facets: (a) that between test candidates and test tasks to produce constructed responses (e.g., language performance samples) and (b) that between raters and rating scales to mediate the scoring of performances. This model also accentuates the important role of raters in constructed-response assessment, compared to traditional fixed-response assessment (e.g., multiple-choice tests). As a result, the model provides a conceptual framework for multi-faceted measurement and justifies Rasch analysis to model the functioning of each assessment facet and their potential interactions.
Another model targeting rater judgements in (writing) assessment is from Engelhard (2013, pp. 318–322) which is adapted from the lens model proposed by Brunswik (1952). The basic tenet of Engelhard’s model is that a latent variable (e.g., writing competence) can be made visible through a set of cues or intervening variables such as raters, assessment criteria, and rating scales. The key goal is to ensure a close correspondence between the latent variable and the observed ratings. However, the accuracy of the observed ratings, conceptualised under the principle of invariant measurement, may be affected by such factors as rater characteristics (e.g., rater’s schemata for processing information and reality). The model also views rater-mediated assessment as contextualised within specific assessment environments and systems or what Engelhard (2013) calls the “ecological context.”
An additional model is from Eckes (2015), who describes a conceptual-psychometric framework of rater-mediated assessment (pp. 48–54). The framework highlights two broad sets of facets in an assessment that constitute potential sources of variation in the ratings provided to examinees: (a) proximal facets that have an immediate impact on scores awarded to examinees, including test tasks, examinees, raters, assessment criteria, and rating scales and (b) distal facets that may exert additional and indirect influence on the ratings, including features of examinees (e.g., gender, ethnicity, and first language), features of raters (e.g., language and professional background), and (c) features of situations (e.g., physical environment and quality management policy). In addition, Eckes’s framework describes possible interactions between different assessment facets and their effects on the ratings, the dynamic of which is analysed by the psychometric model of many-facet Rasch measurement.
Taken together, these models have offered valuable insights into rater-mediated assessment. There are, however, several limitations. First, although the three models highlight the critical role of raters in evaluative judgement, none have explicitly underscored the cognitive mechanisms and processes underpinning raters’ decision-making (Bejar, 2012). This cognitive dimension is important, because raters’ internal processes in evaluative judgement are closely related to the validity of score-based interpretations (Messick, 1989; Weir, 2005). Second, these models largely focus on human raters as the agent of evaluation, neglecting intelligent machines that could also function as evaluators. Accordingly, computational mechanisms powering intelligent machines also need to be considered in parallel to raters’ cognitive processing (Bejar et al., 2016; Ferrara & Qunbar, 2022). Third, despite the fact that the authors of the three models have explicitly discussed psychometric properties of rater-generated scores, none have considered how these scores could be received by potential users and stakeholders (e.g., test organisers, test candidates, and the public at large), which largely pertains to the consequential validity aspect of score interpretation and use (Messick, 1989; Weir, 2005). Fourth, with the exception of Engelhard (2013), the other two models do not seem to explicitly consider social, cultural, and institutional contexts that may exert influence on various aspects of assessment such as the choice of criteria, selection and training of raters, and specific procedures involved in evaluation.
3.2 The socio-cognitive/computational-psychometric model
Based on the above review, this section aims to propose and describe a new model to account for the practice of QA in T&I. In general, the model consists of two layers: (a) a set of seven interconnected facets in QA and (b) important properties and characteristics relating to each facet. Notably, the model considers both humans and machines as the agent of evaluation, highlights the cognitive or computational basis of evaluation, emphasises the psychometric aspects of outcomes, addresses stakeholders’ reception, and recognises social, cultural, and institutional factors influencing QA practices. Because of these emphases and considerations, it is also referred to as a socio-cognitive/computational-psychometric model.
3.2.1 The first layer: main facets in QA
The first layer of the model highlights seven interconnected facets in QA (see Figure 2), including (a) Object of assessment (O), (b) Agency (A), (c) Instrumentation (I), (d) Process (P), (e) Product (P), (f) Reception (R), and (g) Context (C). Accordingly, it is also referred to as the O-AIPPR-C model. Notably, the proposed model, consisting of separate yet interrelated facets and phases, is primarily designed to conceptualise QA research. It is not intended to serve as a process model for describing or predicting real-world events or outcomes. Accordingly, the model is not designed to capture every detail of the QA practice but rather to represent the most critical components and phases of the assessment process. Focusing on these key facets enhances the model’s validity as a heuristic tool for conceptualisation and theoretical exploration.
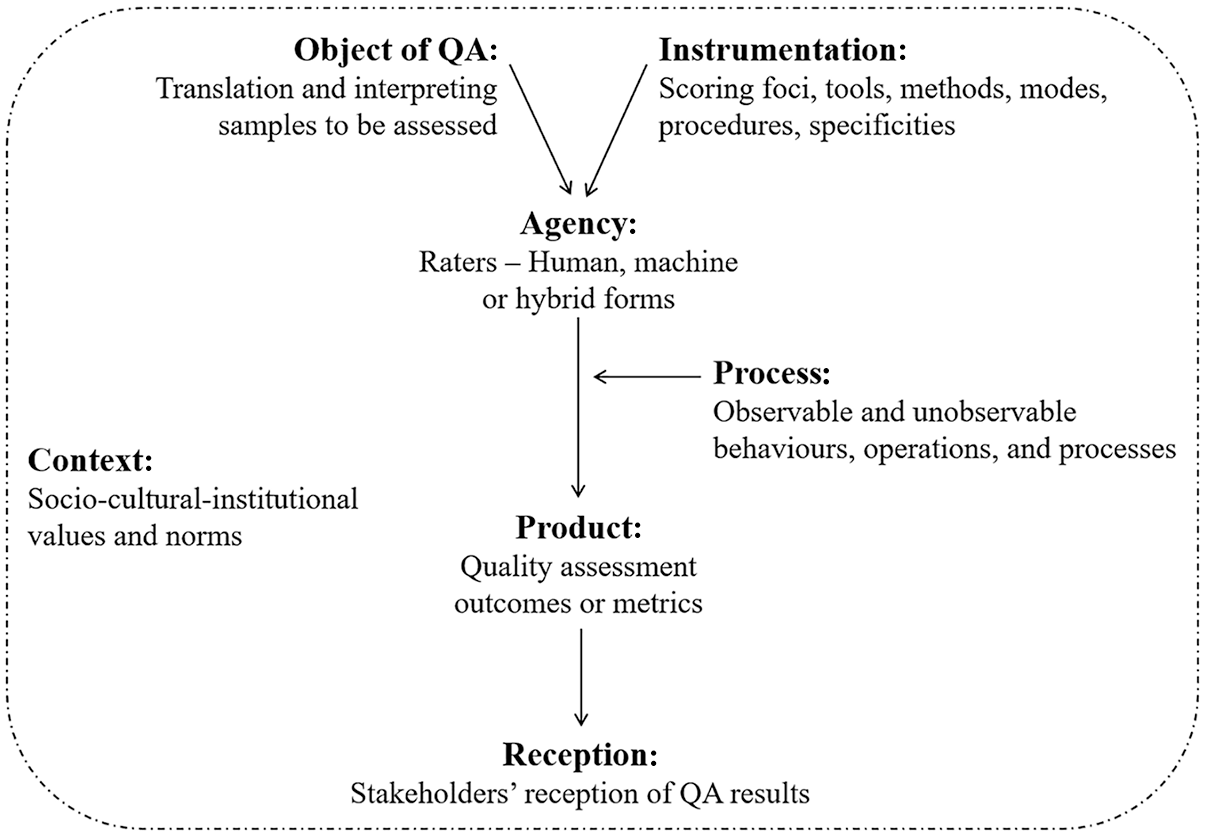
The Socio-Cognitive/Computational-Psychometric Model.
First, the term of Object refers to a diverse array of T&I samples that need to be assessed (see also Section 2.1). Second, Agency refers to the agentic status of assessors or evaluators—humans, machines, or hybrid forms (see also Section 2.2). Third, Instrumentation can be understood as scoring criteria, tools, methods, modes, procedures, and specificities (Han, 2022a) that are utilised or operationalised to assess T&I. Fourth, Process can be defined as internal and (un)observable processes concerning the evaluation agent that supports and underpins the assessment activities. For humans, such processes are associated with behavioural, cognitive, psychological, and affective characteristics, operations, and functioning. For machines, these processes can be broadly conceptualised as computational mechanisms and algorithmic procedures that transform T&I samples into target quality metrics. Fifth, Product simply means the outcome of assessment, which usually takes the form of quantitative measures (e.g., ranks, scores, ratings, grades). Sixth, Reception relates to perception, interpretation, and use of QA outcomes (i.e., Product) by different stakeholders. Finally, Context refers to the social, cultural, institutional settings where QA is situated.
As can be seen in Figure 2, the seven facets of QA are interconnected. In a broad sense, the socio-cultural-institutional values, beliefs, and regulations can influence how QA is practised and conducted. At the local level, either human or machine raters need to process T&I samples through a specific operationalisation of an instrument. As a result of these interactions, measurements are obtained and subsequently used by stakeholders of various types.
3.2.2 The second layer: key properties
Associated with each main facet of QA is a set of key properties that are of theoretical and practical value. These properties, characteristics or attributes can be viewed as important variables or factors relating to each facet of the QA practice. A change of these properties may produce a ripple effect on downstream activities or phases in QA.
Regarding the object of QA, T&I samples to be assessed can be characterised by multilinguality (i.e., language pairs and directionality), multimodality (i.e., intra- or inter-modality, spoken or signed language, visual or auditory channel, and simultaneous or consecutive mode), and multiagency (i.e., human, machine, or human–machine hybrid). They can also vary in terms of more fundamental properties such as lexical, syntactic, prosodic, stylistic, generic, and topical features. Such variation can influence the instrumentation of QA (e.g., focusing on word, sentence, or segment-level scoring) and (non-)human raters’ cognitive/computational processing of T&I.
As for agency, while human raters may vary in terms of educational and professional experience, language background, personality, cognitive style, as well as scoring and training experience, machine raters can be characterised by different foundational structures of scoring algorithms such as n-gram-based or character-based metrics (e.g., BLEU and chrF), edit distance-based metrics (e.g., TER and HTER), BERT-based metrics using sentence representation (e.g., BERTScore), COMET-based, pre-trained metrics using token or sentence embeddings (e.g., COMET-MULTI and COMET-QE), and LLM-based metrics like GEMBA (Kocmi & Federmann, 2023). These inherent properties of human or machine raters can affect how T&I samples are processed and evaluated.
With respect to instrumentation, for human raters, it may be characterised by different scoring dimensions (e.g., fidelity, fluency, grammaticality, or cultural appropriateness), tools (e.g., rating scale, checklist, or rubric), methods (e.g., error analysis, rubric scoring, or pairwise comparison), modes (e.g., traditional paper-and-pen vs digitalised scoring), procedures (e.g., analytic scoring vs holistic scoring and individual scoring vs group deliberation), and scoring specificities (e.g., use of exemplars/anchors as references, scoring at the sentence, segment, or text/document level, see Han, 2022a). In comparison, for machine raters, instrumentation could relate to deploying one or multiple references in QA, automatic scoring at the word, sentence, or segment level, or using different types of prompts in the case of LLM-based assessment.
The scoring process can be characterised by observable behaviours or actions taken by human raters while scoring, often captured using digital tools, including keystroking, mouse clicking, mouse movements, scrolling behaviour, touch gestures, window switching, digital annotation, and eye movements. It can also refer to unobservable processes such as comprehension, memorisation, allocation of attention, cognitive offloading, and decision-making that occur in the rater’s mind. One can imagine that changes or variations in T&I characteristics, rater background, and scoring operationalisation will affect how T&I samples are processed by humans. In parallel, the scoring process for statistically-based machine raters can be defined by their computational and algorithmic mechanisms, whereas such process is largely inexplainable for machine raters based on deep neural networks. Explainable AI may provide some insights into the inner working of neural-based e-raters.
The product of the QA is quantitative measures in the form of scores, ratings, ranks, or grades that are supposed to have encapsulated the substantive meaning of T&I quality accurately and reliably. 2 Thus, psychometric properties of these measures are of utmost importance, which can relate to statistical characteristics of measurements such as reliability, generalisability, and accuracy and to substantive meaning of measurements such as content, construct, and criterion validity. In addition, it can be argued that the psychometric properties of the QA product will be influenced by variations of characteristics in the preceding facets such as human raters’ language background and machine raters’ algorithmic structures.
The reception facet of QA can be characterised by attitudes (e.g., sense of trust), perceptions (e.g., perceived usefulness), interpretations, and uses of assessment outcomes by different types of stakeholders operating within a given context. One can posit that stakeholders’ reception of and reaction to QA outcomes could serve as feedback and feedforward to the QA practice.
The context in which QA is situated can be characterised by social values, cultural norms, and institutional policies that exert broad influences on how QA could be conducted. This means that QA does not operate in a vacuum, which is subject to influences by contextual forces and norms.
3.2.3 Highlights and implications of the proposed framework
Amalgamating the socio-cognitive/computational-psychometric model with each scenario of the QA matrix gives rise to the framework that has the potential to unify T&I and QA practices, respectively. Three core features of the unifying framework can be highlighted. First, conceptualising contemporary T&I practice around the three dimensions—multilinguality, multimodality, and multiagency—binds together a diverse array of loosely connected professional practices (e.g., from MT plus human post-editing to computer-assisted interpreting, and from human-based sign-to-voice interpreting to automatic audio description), therefore helping to develop a new perspective on the T&I practices. Second, describing the three paradigms of assessment, particularly highlighting the various possibilities of human–machine collaboration, helps to move beyond the binary dichotomy of human versus machine and highlight human–machine complementarity. Third, the socio-cognitive/computational-psychometric model captures and coalesces key players, parts, and phases in QA, consolidating the QA practice as an integral yet differentiated enterprise.
Because of these structures and attributes, the proposed framework has three important implications. From a theoretical point of view, the framework presents itself as a heuristic tool for fine-grained conceptual analysis of the diverse QA practices. From the practical perspective, the framework can be used to categorise and characterise existing research on QA. For example, Lee (2015) conducted an empirical study to develop an analytic scale for assessing Korean-to-English consecutive interpreting in the higher educational context in South Korea and examined the appropriateness of the analytic ratings in relation to an external criterion of holistic scores. Based on the proposed framework, Lee’s (2015) study can be categorised into Scenario A, focusing on the development of a scoring tool (i.e., Instrumentation) and the evaluation of its validity through psychometric analysis of analytic ratings (i.e., Product). The specific coding could be “analytic scale” for Instrumentation and “psychometrics: criterion validity” for Product. Furthermore, the proposed framework can serve as a roadmap for strategising and planning QA-related research. This kind of signposting is possible, when current research is systematically mapped onto the framework, revealing under-explored topics and domains as well as potential research niches and gaps worth further investigation.
4. Mapping of current research to the proposed framework
Sections 2 and 3 have provided detailed explanations of the framework and outlined its potential applications. In Section 4, I describe a systematic review performed to map existing QA research onto the proposed framework, with the aim to taking stock of and gaining insights into previous research efforts. Specifically, through the systematic review, I intend to answer the following three research questions (RQs):
RQ1: What types of T&I products have been most frequently assessed in research?
RQ2: Which scenario(s) from the QA matrix have been extensively examined?
RQ3: Which facets and inter-facet relationships described in the O-AIPPR-C model have been most frequently investigated?
4.1 Data sources
Considering the scope of the article, a targeted approach was adopted to identify relevant research on QA in T&I. Research articles were sourced from four key areas: (a) MT, (b) T&I studies, (c) language testing, and (d) educational assessment. The first two fields represent the primary sources for QA research, while the latter two serve as supplementary domains. In addition, while literature related to (a) is typically classified as MT literature, the literature pertaining to (b), (c), and (d) can be categorised as non-MT literature (i.e., MT vs non-MT literature).
Specifically, I examined a representative collection of 20 Scopus-indexed, peer-reviewed journals and proceedings from two prominent MT conferences (the Workshop on Machine Translation [WMT] and the European Association for Machine Translation [EAMT] conference) published over the past decade (2015–2024). 3 The 20 journals were categorised into four groups aligned with the topical areas mentioned above:
Machine translation: including Machine Translation (now part of Language Resources and Evaluation);
T&I studies: comprising Across Languages and Cultures, Babel, Interpreting, Journal of Specialised Translation, Linguistica Antverpiensia New Series—Themes in Translation Studies, Perspectives, Target, Interpreter and Translator Trainer, The Translator, Translation and Interpreting Studies, and Translation Studies;
Language testing: including Language Testing, Language Assessment Quarterly, Language Testing in Asia, and Studies in Language Assessment;
Educational assessment: including Assessment and Evaluation in Higher Education, Assessment in Education: Principles, Policy & Practice, and Studies in Educational Evaluation.
4.2 Screening and selection process
To screen and select studies, I led a team of five coders, including myself. The four other coders, all postgraduate-level researchers in T&I with ongoing PhD studies in QA in T&I, were well-versed in QA literature and had prior experience with systematic reviews and coding processes.
The coders independently reviewed research articles from the selected journals and conference proceedings, focusing on materials published between 2015 and 2024. Non-research pieces (e.g., book reviews, editorials, and commentaries) were excluded, resulting in a total number of 6,974 research articles. Each coder then analysed titles, abstracts, and keywords based on two eligibility criteria: (a) journal articles or conference papers must focus on QA in T&I or include QA as a main component 4 and (b) studies must present empirical research analysing quantitative data. Theoretical or conceptual discussions of QA and systematic reviews of QA practices were therefore excluded.
This initial screening yielded 342 articles, all of which underwent a detailed review of their full texts. I acted as an auditor, double-checking the selected items and further excluding 36 illegible articles. Importantly, research involving QA as a dependent variable to examine its relationship with other variables was included only if the study contained a dedicated discussion of QA in sections like the literature review or methodology. However, studies that treated QA solely as a data-generation tool with minimal description were excluded.
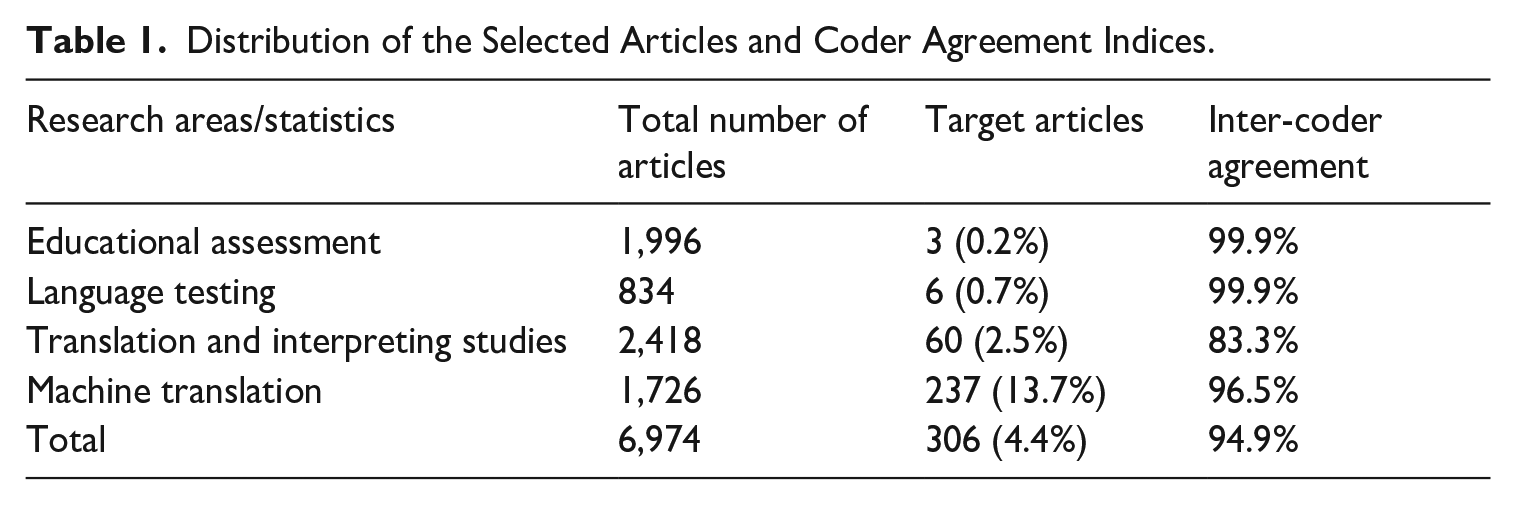
Ultimately, 306 articles were included in the corpus for further coding. Inter-coder agreement, measured using the per cent agreement index, was high (approximately 95%). Table 1 summarises the distribution of articles across the four research areas and the inter-coder agreement indices.
Distribution of the Selected Articles and Coder Agreement Indices.
4.3 Coding
The shortlisted studies were examined and coded based on the framework outlined in Sections 2 and 3 (see Appendix 1 for the coding scheme). I served as the primary coder. Initially, I used the QA matrix from the framework to categorise each study into one of the nine scenarios depicted in Figure 1. Characteristics related to multilinguality were also coded, including (a) language pairs and (b) T&I directionality. Multimodal features were also analysed, focusing on whether mediation was (a) intra- or inter-modal, (b) based on spoken or signed languages, (c) through visual or auditory channels, (d) using simultaneous or consecutive modes, and (e) in specific forms, such as MT, spoken-language interpreting, subtitling, or respeaking.
In the second stage, I applied the socio-cognitive/computational-psychometric model to code and characterise key variables and factors investigated in the studies. For example, a study might examine how human translation and hybrid translation (e.g., MT plus post-editing or MTPE) affect human rater scoring processes and quality measures. Here, two types of translated texts (human vs MTPE) are treated as independent variables, while scoring processes and assessment results are operationalised as dependent variables. In other words, this study examines how characteristics of scoring process and outcomes vary as a function of the assessment object. To label this study, directional relationships can be signified with an arrow (→), for example, “Object → Process” or “Object → Product,” while non-directional relationships are denoted with a plus sign (+), e.g., “Process + Product.” Taken together, the study can be coded as “Object → Process + Product” (i.e., research design notation), which effectively indicates the three variables or facets under investigation, while revealing connections between these facets.
To ensure reliability, 50 randomly selected studies (approximately 18% of the corpus) were re-examined and re-coded by the author after a 2-week interval, following the same procedure. Intra-coder agreement across 32 coding items was high, averaging 96.3%, demonstrating strong coding consistency. However, one item (i.e., Research design notation) exhibited low intra-coder agreement (56.0%). Consequently, this item was re-examined and re-coded for the remaining 256 studies. Detailed intra-coder agreement for each coding item is provided in Appendix 1.
4.4 Data analysis
As the systematic mapping aimed to describe the current state and research patterns in QA, I employed descriptive statistics (e.g., frequency counts and percentages) to summarise the frequency and distribution of codes across characteristics/properties, scenarios, and assessment facets. In addition, network graphs were generated using ggraph (Pedersen, 2024) in the R environment to visualise the frequencies of assessment facets and relationships between different facets explored in previous research. In these network graphs, each node represents one of the seven facets in the O-AIPPR-C model, with large node size indicating higher frequencies of that facet being examined in the research corpus. Directional edges connect nodes to represent the relationships between facets.
For example, in a study labelled “Object → Product,” the two assessment facets—“Object” and “Product”—are depicted as nodes, while a directional edge illustrates the relationship from “Object” to “Product.” The frequency of such edges reflects how often particular inter-facet relationships have been investigated. A greater number of directional edges from one facet to another indicates a stronger research focus on that relationship. These analyses were designed to address the three RQs described above.
4.5 Results of the systematic mapping
4.5.1 RQ1: properties of T&I products
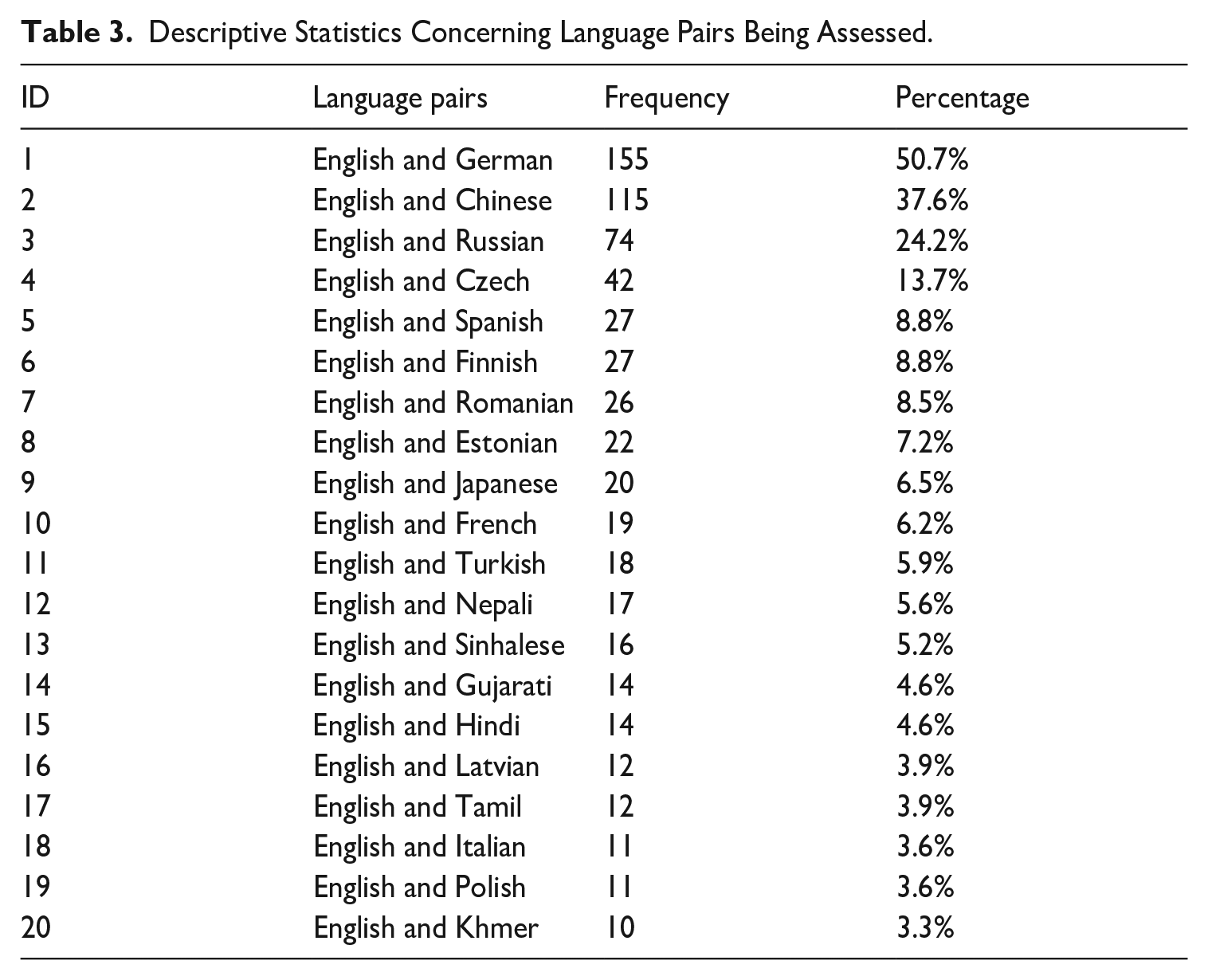
Table 2 presents the statistical results for key properties of T&I products assessed in the 306 research publications analysed. In terms of multilinguality, the analysis identified 99 language pairs examined in previous research, with 84 pairs (84.8%) involving English and another language, underscoring the central role of English in T&I-mediated communication. Table 3 further highlights the 20 most frequently assessed language pairs, each studied at least ten times. The most commonly examined language pair is English-German (n = 155), accounting for approximately half of all publications, followed by English-Chinese (n = 115, 37.6%) and English-Russian (n = 74, 24.2%). While high-resource languages dominate the dataset, low-resource languages, such as English-Nepali, English-Sinhalese, and English-Gujarati, also appear, indicating growing attention to less-studied language combinations.
Descriptive Statistics Concerning Properties of the T&I Products Assessed.

Note. T&I = translation and interpreting; CI: confidence interval; SI: simultaneous interpreting.
The simultaneous mode refers to any type of translation and interpreting practice conducted in real time, including simultaneous spoken-language interpreting, simultaneous signed language interpreting, respeaking, and live subtitling. bIn six studies, both human-created and machine-generated translations were examined, resulting in a total frequency of 312 across the three categories.
Descriptive Statistics Concerning Language Pairs Being Assessed.
Regarding directionality, about 40% of the studies focused on T&I into non-English languages (n = 128, 41.8%), while an equal proportion addressed T&I into both English and non-English languages (n = 128, 41.8%). Comparatively fewer studies focused solely on T&I into English (n = 38, 12.4%).
As regards multimodality, nearly all studies analysed (n = 297, 97.1%) assessed intra-modal T&I, where input and output modalities matched (e.g., text-to-text or verbal-to-verbal). Similarly, most research (n = 303, 99.0%) focused on spoken language, with only three studies examining signed language. In addition, as shown in Table 2, the majority of assessed T&I products were visually based (e.g., translated texts, n = 264, 86.3%), while auditory products (e.g., recorded interpretations) accounted for about 12% (n = 38). Within the auditory category, consecutive and simultaneous modes of T&I were represented in nearly equal proportions, comprising 6–8% of the total research. Regarding the specific forms of T&I, MT dominated the dataset (n = 240, 78.4%), appearing in 78.4% of publications (n = 240). Other forms included consecutive interpreting (n = 23, 7.5%), written or typed translation (n = 18, 5.9%), and simultaneous interpreting (n = 10, 3.3%). Rarely studied forms, such as subtitling, respeaking, and post-editing, accounted for about 1% of the publications, respectively.
Concerning multiagency, about 80% of the studies (n = 242) assessed machine-generated T&I products, followed by human-created products (n = 64, 20.9%) and those produced through human–machine collaboration (n = 6, 2.0%).
4.5.2 RQ2: the QA matrix
Table 4 provides a statistical summary of the nine assessment scenarios outlined in the QA matrix, with results further categorised into MT and non-MT literature. The MT literature includes studies published in Machine Translation as well as proceedings form the WMT and EAMT conferences. The non-MT literature encompasses research from three areas: (a) T&I studies, (b) language testing, and (c) educational assessment.
Descriptive Statistics Concerning Different Assessment Scenarios.
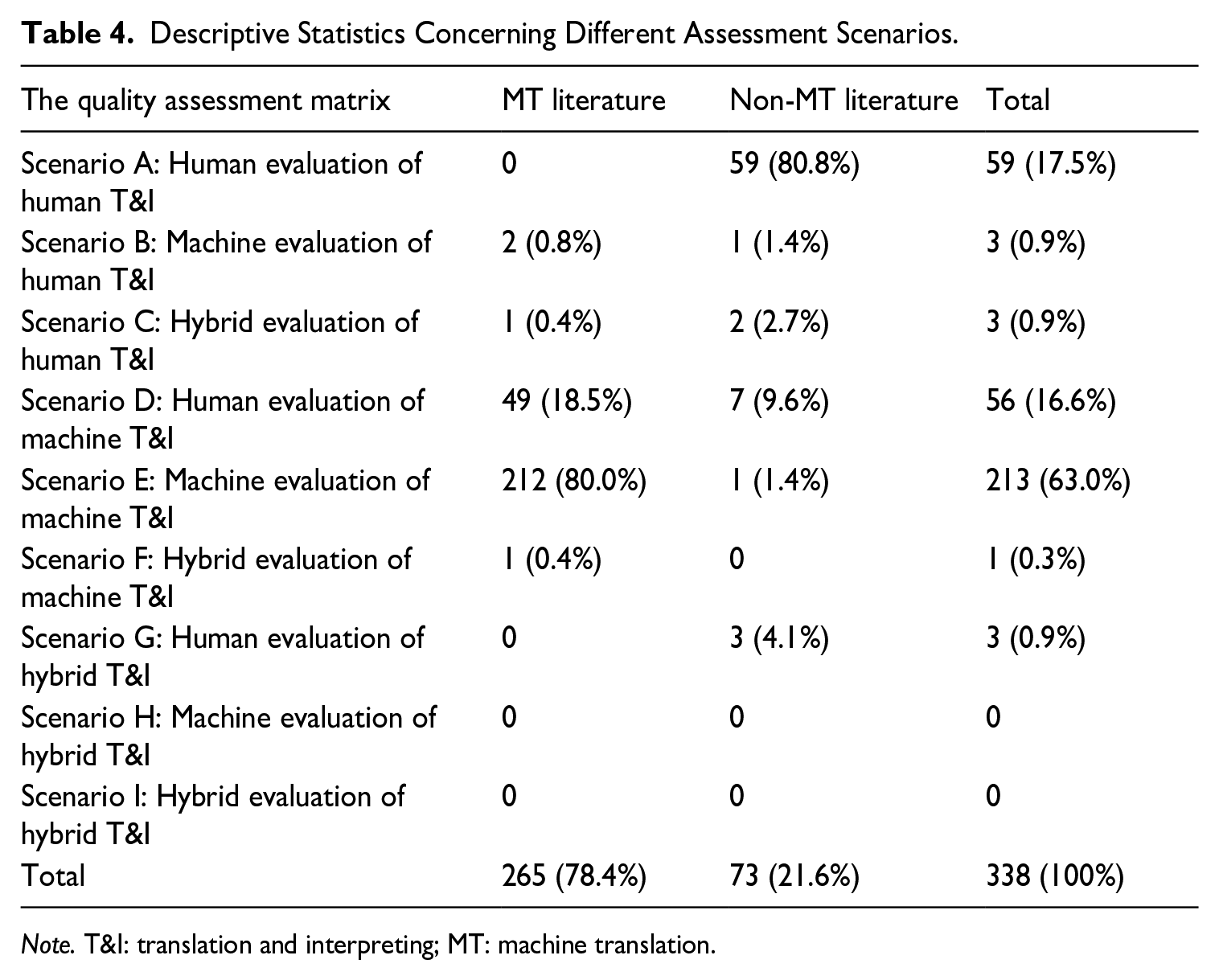
Note. T&I: translation and interpreting; MT: machine translation.
As shown in Table 4, the three most extensively researched assessment scenarios are: (a) Scenario E: machine evaluation of machine T&I (n = 213, 63.0%), (b) Scenario A: human evaluation of human T&I (n = 59, 17.5%), and (c) Scenario D: human evaluation of machine T&I (n = 56, 16.6%). In contrast, other scenarios remain unexplored. This is notable given the potential of machine-based assessment to streamline the evaluation of human T&I, particularly in large-scale testing contexts, and the promising role of human–machine collaboration in enhancing scoring validity, reliability, and practicality.
Further analysis by research type reveals distinct trends: the MT literature predominantly focuses on machine evaluation of machine T&I (n = 212, 80.0%), while the non-MT literature centres on human evaluation of human T&I (n = 59, 80.8%). This distribution reflects the divergent research priorities and the parallel nature of these research streams. Interestingly, human evaluation of machine T&I (n = 49, 14.5%) represents a significant proportion of the MT literature, highlighting the importance of human evaluation as a benchmarking standard for machine-based assessments.
4.5.3 RQ3: assessment facets and inter-facet relationships
Table 5 summarises the statistical results regarding inter-facet relationships examined in previous research. Overall, 17 types of research investigate different assessment facets and their potential relationships. The top 5 examined inter-facet relationships are: (a) “Object + Agency → Product” (n = 97, 31.7%), (b) “Object + Agency + Instrumentation → Product” (n = 75, 24.5%), (c) “Object → Product” (n = 46, 15.0%), (d) “Instrumentation → Product” (n = 26, 8.5%), and (e) “Object + Instrumentation → Product” (n = 26, 8.5%). These findings indicate that previous research primarily focuses on understanding how characteristics of assessment object (e.g., language pairs and directionalities), assessment agency (e.g., automated evaluation metrics and different types of human raters), and instrumentation (e.g., scoring granularity and scoring methods) influence the assessment product and its properties.
Descriptive Statistics Concerning Inter-Facet Relationships Examined in the Research.

Further analysis by research type reveals distinct trends. The MT literature mainly explores two types of inter-facet relationship: (a) “Object + Agency → Product” (n = 96, 40.5%) and (b) “Object + Agency + Instrumentation → Product” (n = 66, 27.8%). In contrast, the non-MT literature focuses more on the following three types of inter-facet relationship: (a) “Instrumentation → Product” (n = 16, 23.3%), “Object → Product” (n = 15, 21.7%), and “Object + Instrumentation → Product” (n = 16, 23.2%). While both research streams share an interest in examining how the assessment object impacts outcomes (as reflected in the frequent presence of “Object” and “Product” in their designs), their emphasis differs. The MT research often compares the effects of different automated evaluation algorithms (i.e., agency of assessment), whereas the non-MT literature seems to prioritise the instrumentation of scoring practices, such as the impact of scoring methods on assessment outcomes. In addition, the non-MT literature includes studies addressing the process of assessment and the reception of assessment outcomes, topics that are largely absent from the MT literature. This distinction highlights the broader scope of non-MT research in exploring under-examined facets of QA.
The network graphs provide a visual presentation of the most frequently investigated assessment facets and inter-facet relationships in previous research (see Figure 3(a)–(c)). As shown in Figure 3(a), the analysis of the 306 publications reveals a primary focus on four assessment facets: Object, Agency, Instrumentation, and Product, with a particular emphasis on exploring how Object, Agency, or Instrumentation influences assessment outcomes (Product). Figure 3(b) highlights that the MT literature primarily examines the facets of Object, Agency, and Instrumentation, along with their respective impacts on assessment outcomes. Figure 3(c) illustrates that the non-MT literature focuses more on Object and Instrumentation, and their effects on assessment outcomes.
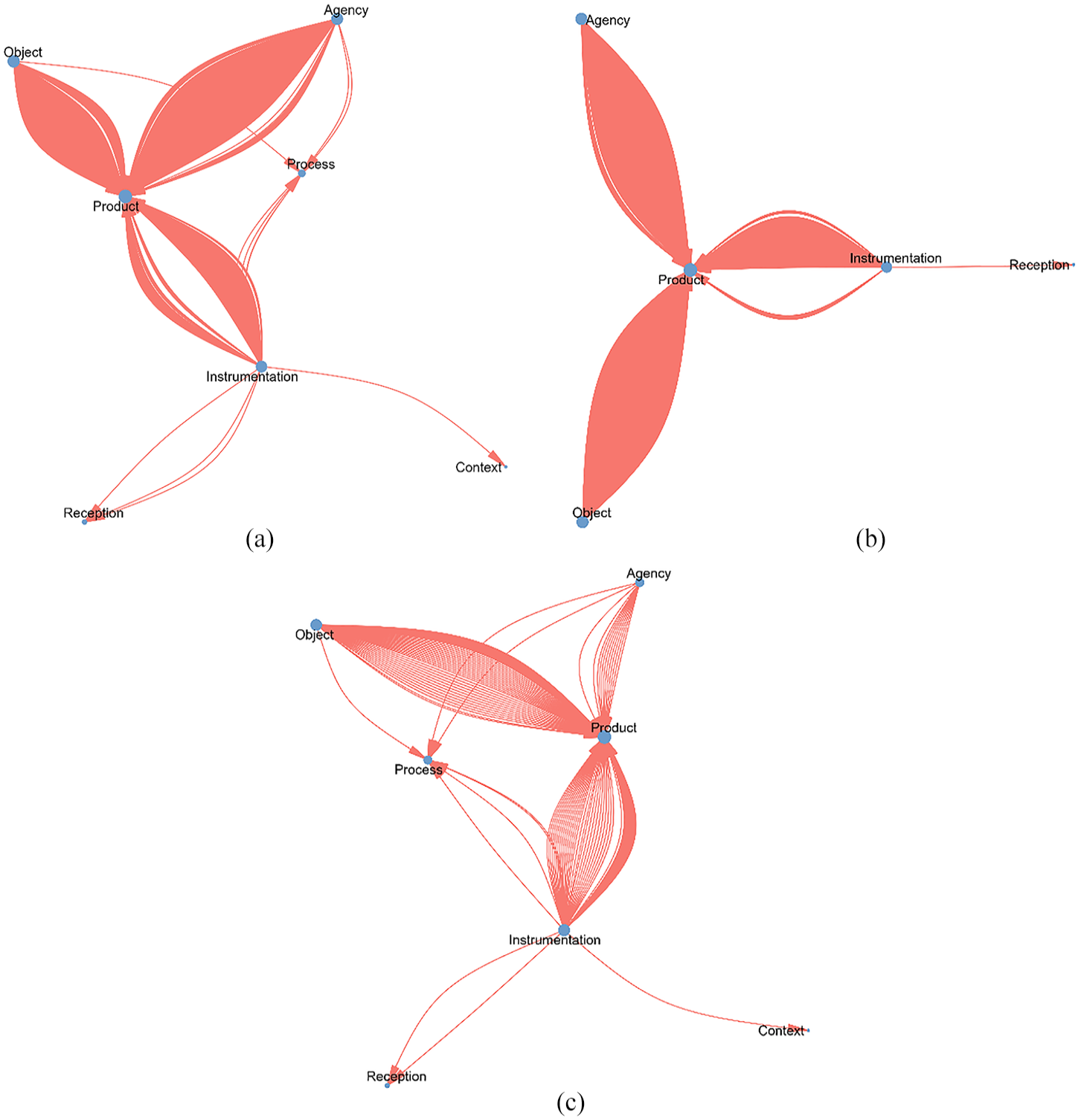
(a) The Network Graph (all research publications). (b) The Network Graph (MT). (c) The Network Graph (non-MT).
Taken together, these findings suggest significant gaps in the existing literature. Little attention has been paid to understanding what characterises the scoring process (Process), how assessment outcomes are received by stakeholders (Reception), and how Context influences other facets, particularly the scoring process and reception. Addressing these overlooked areas could provide a more comprehensive understanding of QA practices in T&I.
5. A research agenda
Our initial screening of 6,974 publications reveals a notable disparity in research focus on QA. While approximately 14% of the MT literature addresses QA, significantly less attention—about 1% of the literature in T&I studies and language testing—has been dedicated to this area. Based on the systematic analysis, several research gaps have emerged as promising avenues for further exploration.
Regarding multilinguality, the analysis highlights that although QA research has assessed T&I quality for 99 language pairs, the majority (n = 84) involve English and another language. Only 15 studies have focused on translation or interpreting between two non-English languages, underscoring the need for more sustained attention to non-English language pairs. In addition, among the English-centric pairs, low-resource languages (e.g., Zulu, Thai, Uzbek, and Swahili) are under-represented. Future research should expand QA to cover T&I between English and low-resource languages (Han, 2022a).
The multimodality analysis indicates a significant under-representation of inter-modal translational practices (e.g., sign-to-voice interpreting) and auditory-mediated communication (e.g., spoken-language interpreting), compared to written/typed translation and MT. Research should explore under-examined modalities, including sign language interpreting, audio description, subtitling, respeaking, and dubbing (Fryer, 2019; Han & Xiao, 2021; Pedersen, 2017; Romero-Fresco & Pöchhacker, 2017; Yan & Luo, 2023) and compare them with intra-lingual modalities, thus broadening the scope of research on multimodal T&I-mediated communication and its implications.
With regard to multiagency, the majority of studies (n = 242, 79.1%) have focused on machine-generated T&I, leaving human T&I assessment relatively under-explored. This gap is especially pronounced in educational contexts where T&I is used as a pedagogical tool. In addition, hybrid T&I, such as machine translation with post-editing (MTPE) and AI-assisted interpreting, warrants closer investigation as these collaborative approaches increasingly dominate T&I production.
Analysis of the QA matrix reveals six under-examined scenarios: machine and hybrid evaluation of human T&I (Scenarios A and B), hybrid evaluation of machine T&I (Scenario F), and human, machine, and hybrid evaluation of hybrid T&I (Scenarios G, H, and I). Despite their practical relevance, these scenarios have received little attention. Notably, hybrid evaluation—human–machine collaboration in QA—is under-explored (Han & Lu, 2021). Similarly, machine-based automatic evaluation of human and hybrid T&I remains limited. Recent advances in LLMs as evaluators show promise, with studies demonstrating their remarkable ability to assess both human and machine-generated T&I (Jiang et al., 2024; Kocmi & Federmann, 2023). Future research should investigate how LLMs can enhance assessment validity and efficiency, particularly in human-centred approaches.
Analysis of the previous literature based on the O-AIPPR-C model shows that three assessment facets—Process, Reception, and Context—and their inter-facet relationships remain severely under-explored. These facets merit attention for several reasons: (a) regarding the fact of Process, understanding the internal mechanisms of human and machine assessment enhances the substantive meaning and validity of assessment outcomes (Messick, 1989; Weir, 2005), (b) regarding the facet of Reception, investigating how stakeholders perceive, interpret, and use assessment results is crucial to the assessment enterprise (Messick, 1989), and (c) for the facet of Context, contextual factors such as social values, cultural norms, and institutional policies can influence assessment practices (Wolfe, 2005). Therefore, future research should focus on demystifying the black-box nature of scoring processes in both human and machine assessment, uncovering the scoring process of human judgement (Guzmán et al., 2015; Han et al., 2024),) and improving the interpretability of machine scoring algorithms (Leiter et al., 2024; Perrella et al., 2024). Future research should also aim at exploring stakeholders’ reception, interpretation, and use of assessment outcomes in applied settings and examining the contextual factors shaping QA practices.
To advance research in the above areas, there is an urgent need for robust research infrastructure, particularly benchmark databases for QA in T&I. Such databases should include various text genres and types translated or interpreted into different languages and rigorously assessed by trained human raters to provide the ground truth. These benchmarks could be used to train new raters, validate automated evaluation metrics, and develop human–machine collaborative assessment methods. While WMT annually releases datasets for MT evaluation, similar resources for evaluation of human or hybrid T&I are scarce, therefore highlighting the need for future efforts in this direction. A recent example of such a database is the Interpreting Quality Evaluation Corpus, in which a total of 1600-plus English-Chinese interpretations for 35 tasks are assessed by human raters (see Han & Lu, 2025).
6. Concluding remarks
In this article, I have argued for the need to advance QA in multilingual, multimodal, and multiagent T&I and proposed a unifying framework for conceptualising and analysing research on QA. The framework consists of two key components: (a) a QA matrix, which integrates three agentic statuses (i.e., human, machine, and human–machine hybrid) with three assessment paradigms (i.e., human, machine, and human–machine collaborative assessment), and (b) a socio-cognitive/computational-psychometric model or the O-AIPPR-C model comprising seven interrelated facets: Object, Agency, Instrumentation, Process, Product, Reception, and Context.
Using this framework, I systematically analysed 306 studies on QA, sourced from 6,974 research articles published between 2015 and 2024 in 20 representative journals and two major MT conference proceedings. This analysis yielded the three main findings: (a) the object of assessment primarily involved language pairs featuring English and another language, often in the context of MT, (b) three assessment scenarios—machine evaluation of machine T&I, human evaluation of machine T&I, and human evaluation of human T&I—accounted for 97.1% of all QA practices, and (c) four facets in the O-AIPPR-C model—Object, Agency, Instrumentation, and Product—and their inter-relationships have been the primary focus of previous research. Despite these prominent patterns, the analysis identified several promising areas for future research, including machine and hybrid evaluation of non-English language pairs, inter-modal T&I practices (such as sign language interpreting, subtitling, and audio description), and human–machine jointly created T&I. Future research could also focus on Process, Reception, and Context in QA.
While offering useful insights, the study has three limitations: (a) limited scope of literature sources (i.e., restricted to a specific set of journals and conferences), (b) timeframe constraints (from 2015 to 2024), and (c) broad-stroke analysis which focused on overarching characteristics of QA research rather than fine-grained details. Future research should expand the range of publication venues and extend the timeframe of analysis to enhance generalisability. Moreover, more granular analyses are needed. For example, the facet of Instrumentation could be examined in terms of specific evaluation methods (e.g., error analysis, scoring rubrics, pairwise comparisons, and rankings), different levels of scoring granularity (e.g., word, sentence, segment, or text), and reliance on reference translations. Such nuanced investigations would provide deeper insights into QA practices and their implications.
Given the centrality of QA in the T&I practice across all modalities and agentic configurations, this article calls for more substantive and interdisciplinary research into diverse aspects of QA. Special attention should be directed towards under-explored topics and inter-facet relationships identified in this study. Advancing QA research in these directions has the potential to contribute to more robust, reliable, and equitable assessment practices in the evolving landscape of T&I.
Footnotes
Appendix
The Coding Scheme and Inter-coder Agreement Indices for Each Coding Item.

| Coding items | Publication ID #1 (Sample coding) | Intra-coder agreement |
|---|---|---|
|
|
2015 A linguistically motivated taxonomy for machine translation error analysis | n/a |
|
|
Object + Agency + Instrumentation → Product | 56.0% |
|
|
n/a | n/a |
| 1.1 Language pairs (open coding) | English and Portuguese | 88.0% |
| 1.2 Directionality (open coding) | English into Portuguese | 88.0% |
|
|
n/a | n/a |
| 2.1 Intra versus inter-modal | Intra-modal | 100% |
| 2.2 Spoken versus signed | Spoken | 100% |
| 2.3 Visual or auditory channel | Visual | 100% |
| 2.4 Simultaneous versus consecutive | n/a | 100% |
| 2.5 Specific form (open coding) | Machine translation | 100% |
| n/a | n/a | |
| 3.1 Human T&I | 0 | 94.0% |
| 3.2 Machine T&I | 1 | 100% |
| 3.3 Hybrid T&I | 0 | 100% |
| n/a | n/a | |
| 4.1 Human assessment | 1 | 100% |
| 4.2 Machine assessment | 1 | 100% |
| 4.3 Hybrid assessment | 0 | 100% |
| n/a | n/a | |
| 5.1 Scenario A: Human evaluation of human T&I | 0 | 98.0% |
| 5.2 Scenario B: Machine evaluation of human T&I | 0 | 100% |
| 5.3 Scenario C: Hybrid evaluation of human T&I | 0 | 100% |
| 5.4 Scenario D: Human evaluation of machine T&I | 1 | 100% |
| 5.5 Scenario E: Machine evaluation of machine T&I | 1 | 98.0% |
| 5.6 Scenario F: Hybrid evaluation of machine T&I | 0 | 100% |
| 5.7 Scenario G: Human evaluation of hybrid T&I | 0 | 100% |
| 5.8 Scenario H: Machine evaluation of hybrid T&I | 0 | 100% |
| 5.9 Scenario I: Hybrid evaluation of hybrid T&I | 0 | 100% |
| 1 [(a) different MT systems and (b) different domains of source texts] | 82.0% | |
| n/a | n/a | |
| 7.1 Human raters | 0 | 94.0% |
| 7.2 Machine raters | 1 [two metrics: BLEU and METEOR] | 94.0% |
| 7.3 Human–machine (hybrid) collaboration | 0 | 100.0% |
| 1 [error taxonomy and ranking] | 88.0% | |
| 0 | 100.0% | |
| 1 [inter-annotation agreement and error frequency] | 100.0% | |
| 0 | 100.0% | |
| 0 | 100.0% |
Notes: T&I = translation and interpreting; The inter-coder agreement indices were calculated based on the double-coding of 50 randomly selected articles by the author. [Details: ?] means that specific information concerning characteristics of a given facet needs to be provided.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Start-up Grant from the National University of Singapore (A-0009869-00-00).