
Abstract
This Reflection Paper by the Special Interest Group on AI in Translation and Interpreting (hereafter T&I) of the European Language Council, comprising 25 scholars from 19 universities across 14 countries, calls for a more informed use of AI for T&I purposes. While acknowledging the potential of Generative AI and Large Language Models (LLMs), the authors point to several communicative, legal, and ethical concerns and risks and liabilities that occur when these concerns are not duly considered. The authors’ aim is to help policymakers and the wider public understand how LLMs ‘communicate’, what they are capable of, and where their limitations lie. They also seek to highlight communicative settings in which LLMs’ quality and reliability are insufficient, and in which the expertise of trained translators, interpreters, and T&I scholars is needed. A central claim is that LLMs offer powerful tools but not catch-all solutions. T&I are complex, human-centred communication activities that require much more than probabilistic prediction. In contexts where understanding, trustworthiness, and clarity are crucial, and especially where sensitive data and high-stakes settings are involved, professional expertise remains irreplaceable. Responsible AI use—anchored in human values, ethics, equity and the pursuit of quality in communication—is the only sustainable path forward.
Keywords
1. Introduction and rationale
Since the release of ChatGPT in November 2022, the popularity of generative artificial intelligence (hereafter GenAI) and its applications built on large language models (LLMs) has soared. Individuals, companies, and authorities have very rapidly adopted GenAI, using it for all kinds of tasks. These mainly involve either productivity increase and optimisation (e.g., of logistics, financial analysis, e-commerce, public security, spam filtering, medical diagnosis), or communication (e.g., writing emails or papers, correcting texts, searching for or through information, automating text summaries and information retrieval or simplification), including machine translation and interpreting. Today, literally thousands of tools are available, and even more are being developed by nearly 100,000 AI companies worldwide and counting, representing a 758-billion-dollar industry in 2025 (Naik, 2025), growing exponentially.
Tech companies have preached an AI revolution and have created an AI hype that presents AI, and in the foreseeable future, Artificial General Intelligence (AGI), 1 as a game-changing ‘general-purpose’ technology, expected to be ‘most productive when its ultimate range of results is neither foreseen nor controlled’ (Winner, 1978, p. 98, as cited in Eloundou et al., 2023). Tech companies maintain that AI, when developed without boundaries, will soon outperform humans in any activity involving information of any kind and that it is comparable in importance and potential for democratisation of knowledge to the invention of the printing press. 2 The neoliberal tech-optimism (Könings, 2022) and tech-solutionism eagerly spread by these companies are akin to the belief that technology is a synonym for progress, that AI can or will soon be able to do just about anything, and can, and therefore should, be used to improve just about anything. The persuasion is that innovation, acceleration, and unlimited investment in AI will make societies progress; 3 will make humans faster, better, stronger, and happier; and will solve even the most difficult issues of our time.
Aspirations are lofty, yet there are also strong concerns (Mikalef et al., 2022). Although AI-driven technologies have huge potential in a wide array of possible applications, AI will also have a wide-ranging impact on its users, the job market, the global economy, knowledge development and dissemination, democratic decision-making, human behaviour and well-being, as well as on the climate and the planet we inhabit. The technology’s disruptive effects on users and societies are surfacing already. It is increasingly clear that the conviction that technology is by definition an improvement is too coarse-grained as it fails to account for ecological footprint, legal and ethical issues, societal transformations, and anthropological and existential concerns. There is a growing unease regarding the negative and unintended consequences of the unbridled development and massive adoption of AI. Experts have started warning against the impact of AI on the worldwide economy and the overvaluation of AI shares 4 and predict that companies and investors will have to lower their expectations as to what AI can do and will be able to do in the near future (Challapally et al., 2025). Critical voices have emerged, denouncing the tech-optimist hype surrounding AI, advocating for realism instead of tech-solutionism, calling for a more prudent, responsible, and transparent development of AI, and promoting a time break in its uncontrolled expansion, pending proper risk assessment, and public policies. 5 Critics stress that AI is a tool, not a goal, and should be used accordingly, considering contexts and objectives, as well as what is desirable and what is not in terms of human well-being and unwanted side-effects.
With this Reflection Paper, the authors wish to add their voice to that critical choir, focusing in particular on the use and impact of LLMs in multi- and interlingual communication and mediation. Our aim, however, is not to defend anything or anyone, nor is it to advocate against the use of AI or to minimise the impact that it is bound to have, in T&I practices, professions, and education. Rather, it is to raise awareness with users, both laypersons and professionals, as well as policymakers, concerning:
how LLMs ‘communicate’, how this differs from human communication and what these differences imply when GenAI is used for T&I purposes (Section 1);
what impact AI is having and is likely to have in the future, in T&I professions, in terms of communication quality, workflows, job content, and job contentment (Section 2);
what uninvited ramifications should be considered and duly weighed against the possibilities offered by AI (Section 3);
and whether and how AI should be included in T&I education and training, that is, the formal education of future T&I professionals, as well as in-service training for current T&I professionals (Section 4).
2. GenAI and communication
2.1 How chatbots ‘communicate’
The way in which LLM-powered chatbots—such as ChatGPT (OpenAI), Gemini (Google), Copilot (Microsoft), Claude (Anthropic), or DeepSeek (owned by the Chinese hedge fund High-Flyer)—‘communicate’ simulates yet differs fundamentally from human communication. Users, unless they are data scientists or software developers, generally have no precise knowledge of how LLMs generate responses that look and feel like ‘natural’ language and reasoning, all the more so as the generated output appears on screen word for word.
Without going into too much technical detail, the best-known and most-used LLMs, OpenAI’s GPT series, are so-called ‘neural’ networks that have been pre-trained on massive datasets. Internet rumours estimate the dataset used for GPT-4 at approximately 1 petabyte of data, that is, 1 million gigabytes, or roughly 10 trillion words, from the internet and other sources. 6 The chatbot processes a prompt by running that input signal through a sequence of about 120 interconnected ‘layers’ that contain huge sets of parameters (an estimated 1.8 trillion in the case of GPT-4), also called ‘neurons’ by means of an anthropomorphism that underlines the tech companies’ ambitions of imitating, equalling, or even surpassing human intelligence. Each of those ‘layers’ processes the information in a prompt according to given parameters and then passes it on to the next layer containing another set of parameters (hence the notion of ‘deep learning’). As a result of that intricate process known as the ‘algorithm’, the chatbot ‘generates’ (hence ‘generative AI’) the most probable next word in a given sequence of words. 7 When the next word has been predicted, the sequence now extended with one word is fed back into the LLM to predict the following word in that sequence, and so on, thus generating an output answer. This is why LLMs need massive amounts of computing power. LLMs such as GPT-4o, Llama, or Claude, however, also must learn how to respond to questions or instructions provided in a prompt, rather than endlessly rambling. That alignment between prompt and generated output is key and is achieved by training the pre-trained LLM by so-called supervised instruction fine-tuning, that is, by high-quality instruction–response pairs, from which the model learns how to respond to instructions while retrieving the next probable words from the pre-training data. Finally, the way in which the model reacts is refined by reinforcement learning from human feedback. This very costly stage of development is needed to align AI with what tech companies consider to be human preferences and prevent what they consider to be harmful behaviour (such as illegal, aggressive, racist, sexual, or also ideologically undesirable content) (Christian, 2020).
The scale and complexity of the deep learning architectures used by LLM developers, like OpenAI, Microsoft, or Meta, are so enormous that it is impossible, even for the creators of these systems, to determine exactly how the algorithms make decisions when generating an answer, writing or translating a text, or performing a medical diagnosis. This tech puzzle reflects the ‘black box’ nature of LLMs (Adadi & Berrada, 2018) and comes with legal and ethical implications, all the more so due to the lack of transparency regarding training data or reinforcement criteria. We shall go into these implications in more detail in Section 3 of this article.
Algorithms follow a deterministic, mathematical logic, predicting the most likely next words, but are unable to select the most relevant or correct words. This deterministic prediction contrasts sharply with the impression of ‘understanding’ a prompt or ‘knowing’ the answer, created by the systems’ polished language, commonly referred to as ‘artificial eloquence’ (J. Bennett, 2024), and by the anthropomorphic terminology used by tech companies and taken over by the public, such as saying the tools ‘understand’, ‘know’, ‘communicate’, or ‘translate’, as if they were conscious beings endowed with intentionality, knowledge, and skills (Colombatto & Fleming, 2024). Although LLMs contain masses of information and perform processing tasks at a speed and scale unimaginable for humans—unlocking countless possibilities—the fact that LLMs predict the most likely next word in a sequence also comes with several challenges that users should be aware of:
First, in the media, much attention has been given, rightfully so, to the fact that the massive datasets compiled by large AI companies include copyright-protected materials, thus violating authors’ and creators’ rights, and indeed everyone’s rights as publicly available information is taken from internet fora and social media users without asking or paying for it, 8 and may include personal and sensitive information;
Second, another equally important issue that affects how LLMs ‘communicate’ has received much less attention: the datasets used for written or spoken language prediction are not curated and may include anything published by anyone, mainly in social media posts, blog posts, and other webpages, regardless of the quality and tone of the language used and irrespective of the veracity of the content. Moreover, the line between AI- and human-generated content is becoming increasingly obfuscated, and there are no established filters to warn about the presence of AI-generated content or spam. Therefore, what users receive is not just the most likely next word in a given context; it is the most likely next word in terms of word sequence frequencies across the entire pre-training dataset. In other words, LLMs produce not the most correct, relevant, original, or valuable piece of information, but (one of) the most frequent, thus most probable yet therefore also commonplace next word(s) (Chomsky et al., 2023). This is why AI-generated texts tend to feel somewhat ‘flat’ or ‘empty’, tedious, and monotonous;
Third, in addition to blogs and social media, LLMs’ training sets include historical data and data found in corpora of prose fiction and drama. This is another reason why LLMs are incapable of determining whether information is true or fictional, correct or distorted, objective or prejudiced, old or recent; they simply generate (one of) the most likely next word(s), which may bring them to ‘hallucinate’, making up information, or to spread misinformation and even disinformation 9 ;
Fourth, studies have found that training datasets contain stereotypes and human biases (racial stereotyping and bias, gender bias, class bias, discrimination of underrepresented minority groups and the LGBTQ community, systemic racism, traditional gendered workplace roles, and other preconceptions) (Gallegos et al., 2024). Such unwanted biases are perpetuated or even accentuated in AI-generated texts, as suggested by some. 10 In addition, Microsoft researchers have advised that GPT-4 may also exhibit cognitive biases such as confirmation bias, that is, the tendency to search for and favour information that supports one’s prior opinions, beliefs, and values (Bubeck et al., 2023). In combination with the tendency of social network algorithms to promote user engagement by prioritising content aligned with prior searches and interactions, confirmation bias is likely to amplify other forms of bias and further exacerbate socio-political polarisation;
Finally, the datasets used also perpetuate uneven power-relationships between languages and cultures, due to the overrepresentation of data in hegemonic languages and cultures (first and foremost English and Anglo-American culture, but also, albeit to a much lesser extent, Spanish, French, or Chinese). On the contrary, small or reputedly less (commercially) important languages and cultures with fewer resources (so-called ‘languages of lesser diffusion’) are underrepresented, if present at all. For these languages in particular, the demand for interlingual communication is especially high due to global migration and the linguistic diversity of migrant communities. However, the output quality of LLMs for languages of lesser diffusion remains problematic, as predictions are based on a considerably less reliable set of token sequences. From this point of view, LLMs pose a serious threat to the world’s linguistic, cultural, and ideological diversity. They reflect mainly Anglo-American—and in some cases, such as DeepSeek, Chinese—linguistic and cultural biases, along with the dominant ideologies expressed in those languages. This dominance risks silencing less-represented languages and perspectives, reinforcing global inequalities in communication and knowledge creation and dissemination.
2.2 . . . and how human beings communicate
Human communication, however, does not work by predicting the most likely next word in a given sequence of words, as LLMs do. When human beings communicate, they consider communicative relevance and cooperation rather than statistical probability and are influenced by the linguistic and cultural contexts in which they communicate, the communicative intentionality and objectives they have, and the communication partner(s) they are communicating with (Adler et al., 2017; Sperber, 1995; Titsworth & Hosek, 2024). In addition, humans are receptive to the tone employed, continuously monitor their communication, evaluate its effectiveness, and adapt to what is needed for understanding to happen.
The cognitive, creative, and cultural processes involved in human communication are far more complex, nuanced, and especially context- and culture-sensitive than what probabilistic algorithms manage to simulate. Arguably, this is even more the case in communicative contexts that involve translation and interpreting. T&I contexts are characterised by communication breaches and potential misunderstandings and by cultural differences (Bassnett, 2007; Hale, 2013). These cannot be overcome unless duly trained professionals are called in. Contrary to a widespread belief that has also pervaded the approach to machine translation, translating or interpreting is not simply writing or saying ‘the same thing’ in another language. Languages do not have completely equivalent vocabularies, grammatical structures, or pragmatic ways of expressing attitudes and values such as politeness, agreement, trust, disbelief, and so on. In addition, languages inevitably come with cultures that may include other ways of expression, different habits and customs, may have a different legal system and terminology, may know other requirements for homologations and norms, or may perceive that ‘thing’ in different ways, with other connotations, or may not even know it altogether. Instead of saying ‘the same thing’ in another language, translators and interpreters reformulate, clarify, adapt, and adjust that ‘thing’ to their specific target audience. Translators and interpreters also guarantee terminological consistency (e.g., choosing the correct legal, medical, or technical terms) and content coherence throughout entire documents, or large portions of spoken language. On top of that, sensitive contexts such as legal and medical settings can be characterised by uneven power-relationships between communication partners (e.g., asylum seekers and authorities, suspects and policemen or judges, patients and health care providers), effectively turning translators and interpreters into mediators. Finally, unlike machines, T&I experts can deal with errors, terminology issues, ambivalences, or awkward phrasings in the source text or discourse they are translating or interpreting. Unlike algorithms used for machine translation and interpreting, where output quality heavily depends on the source text or discourse being of (near-)perfect quality, human translators and interpreters understand human communication, including its human imperfections. T&I professionals, unlike machines, were trained to understand what is meant despite grammatical errors, ill-chosen words, terminological inconsistencies, unintended ambiguities, accents, mispronunciations, redundancies, or slips of the tongue, and what is implied by facial expressions, by nuances, humour, irony, things left unsaid, undertones, innuendos, allusions, or connotations.
For all these reasons, although LLMs can be helpful when used appropriately (i.e., considering that they generate the most likely next words in a sequence, and when used as an aid rather than as a solution), and depending on communication needs (e.g., for conveying a simple message, in non-sensitive contexts), translation and interpreting should not be left entirely to algorithms that do not communicate but merely simulate communication. To rely completely on LLMs for inter- and multilingual communication is not only all too naïve and optimistic; in sensitive contexts (e.g., court hearings, police interrogations, asylum procedures, medical treatment or bad-news communication, etc.); their use can violate someone’s rights, lead to legal prejudice, and even be downright life-threatening. In business- and marketing-related contexts, relying on GenAI for communication, translation, and/or interpreting purposes can lead to serious security risks and legal and financial problems. 11 The fact that chatbots are easy to use, faster, and cheaper than a professional translator or interpreter should not blind users to quality problems and intercultural miscomprehensions, violations of rights, ethical issues, and potential financial, health, and security risks. Users should not be deceived by anthropomorphist marketing terminology that would have us believe that AI is like the human brain, or ‘thinks’, ‘knows’, and ‘communicates’ like humans do (Baria & Cross, 2021).
3. GenAI and professional T&I
3.1 Not the layperson’s doorway to multilingual communication
In the professional world of translation and interpreting, machines are not new. Computer-assisted translation (CAT) and computer-assisted interpreting (CAI) tools, that is, software applications to support the task of human translation or interpreting, have been around for many years and have certainly proven their usefulness in most T&I contexts and settings, in terms of productivity, terminological consistency, and overall product quality. Furthermore, machine translation and (since 2016) neural machine translation (NMT or AI-based machine translation) have long been integrated in CAT tools to create comprehensive translation environments conceived to support translators. Provided, that is, that they are used by duly trained inter- and multilingual communication professionals, capable of detecting content discrepancies and incoherences, non-idiomatic expressions, context-specific terminology problems, and intercultural issues. What is new, however, is the proliferation of the abovementioned tech-optimistic narrative, driven by the current AI hype, which has led many people—often unfamiliar with how LLMs actually work, the issues outlined above, and the key differences between GenAI and human communication (as discussed in Section 1)—to believe that machine translation is not just a tool, but the solution to multilingual communication. In this view, the rise of AI signals a future where translators and interpreters are no longer needed, as inter- and multilingual communication is increasingly seen as something that can be handled by algorithms. The impact of such naïve and tech-solutionist views of interlingual communication is already perceivable on the work floor, from on-site or remote interpreting in its various settings (conference, health care, court, etc.), to multilingual terminology and translation in its many fields (technical, tourist, legal, medical, audiovisual, even literary), as well as media accessibility. AI is indeed likely to redefine and revolutionise T&I workflows by its unpredictable and disruptive effects on processes, the profession, as well as on the quality of T&I products. For instance, translators are already receiving unrealistic demands from customers looking to cut costs rather than to ensure qualitative inter- and multilingual communication. Although machine learning has considerably improved the output of machine translation, that output is far from flawless. Translation and interpreting cannot be trustworthy or high-quality without duly trained professionals in the loop, much in the same way as medicine cannot be high-quality without duly trained medical staff, although symptoms and treatments can be found online, or good legal advice can only be given by trained and often specialised lawyers, although AI can help look through relevant legal documentation.
It is obvious that LLMs, when used properly, by professionals with specialised translation and/or interpreting training, offer a wealth of possibilities, especially in terms of productivity and cost efficiency. As for translation output quality, however, LLMs were conceived and developed as a general-purpose technology that generates text in response to a prompt. They lack specific translation training. Compared to NMT systems such as Google Translate, DeepL, or Microsoft Translator, LLMs do offer the advantage of allowing the user to adapt the translation to a specific target audience by means of prompting. Scientific studies, however, suggest that the translation output from current LLMs is still outperformed by domain-specific NMT systems. 12 Nevertheless, most companies specialising in CAT software have jumped on the AI bandwagon and have recently integrated GenAI into CAT systems, either as an assistant that provides help with using the tool itself, or as a translation aid that allows users to search, clarify, reformulate, or simplify given terms or text segments using LLMs, without leaving the CAT tool’s interface. Finally, a new feature is the integration of LLMs into CAT tools (e.g., memoQ AGT) to automatically adapt the style and terminology of the machine-generated output using resources such as translation memories and glossaries. Similarly, MT providers such as Google Translate and DeepL now offer LLM translations for certain language combinations (and, at the time of writing, only for paying customers). Finally, it is important to note that the issue of legal liability comes into play in any discussion of the use of LLMs or NMT in the publishing industry. As automatically generated content cannot be copyrighted and AI tools cannot be held liable in a legal context, an increased awareness of risks associated with the use of such tools is imminent.
3.2 T&I professionals’ reluctance to adopt GenAI
A close examination of translators’ comments on their use of GenAI on ProZ.com, an online community and workplace for language professionals, carried out in previous research (Rivas Ginel & Moorkens, 2024), as well as a survey we conducted from 20 March to 1 May 2024 (n = 600, from 55 countries) indicate that a high percentage of language professionals had not adopted GenAI at the time of this survey. The survey, consisting of 51 questions across four sections, gathered demographic data, examined the use of technologies in professional workflows, and explored the integration of AI tools. Importantly, it distinguished between neural machine translation (NMT) and GenAI (including LLMs), focusing on their practical applications, perceived impacts on the profession, and related ethical concerns. The large majority of the participants (translators, interpreters, and other language professionals, including research and teaching staff) report that they never use GenAI in their work (53%) or only very rarely use it (13.33%), while only 11.84% of the respondents use GenAI frequently or very frequently for their work (see Table 1). In terms of tasks, previous research reports that GenAI was used ‘as a source of inspiration (53%), for “summarising, drafting emails, looking up terms, looking up multiple term choices,” (45%) [. . .] rephrasing (41%), and understanding technical expressions (30%)’ (Rivas Ginel & Moorkens, 2024, pp. 268–269).
Adoption of GenAI Tools Among Language Professionals.
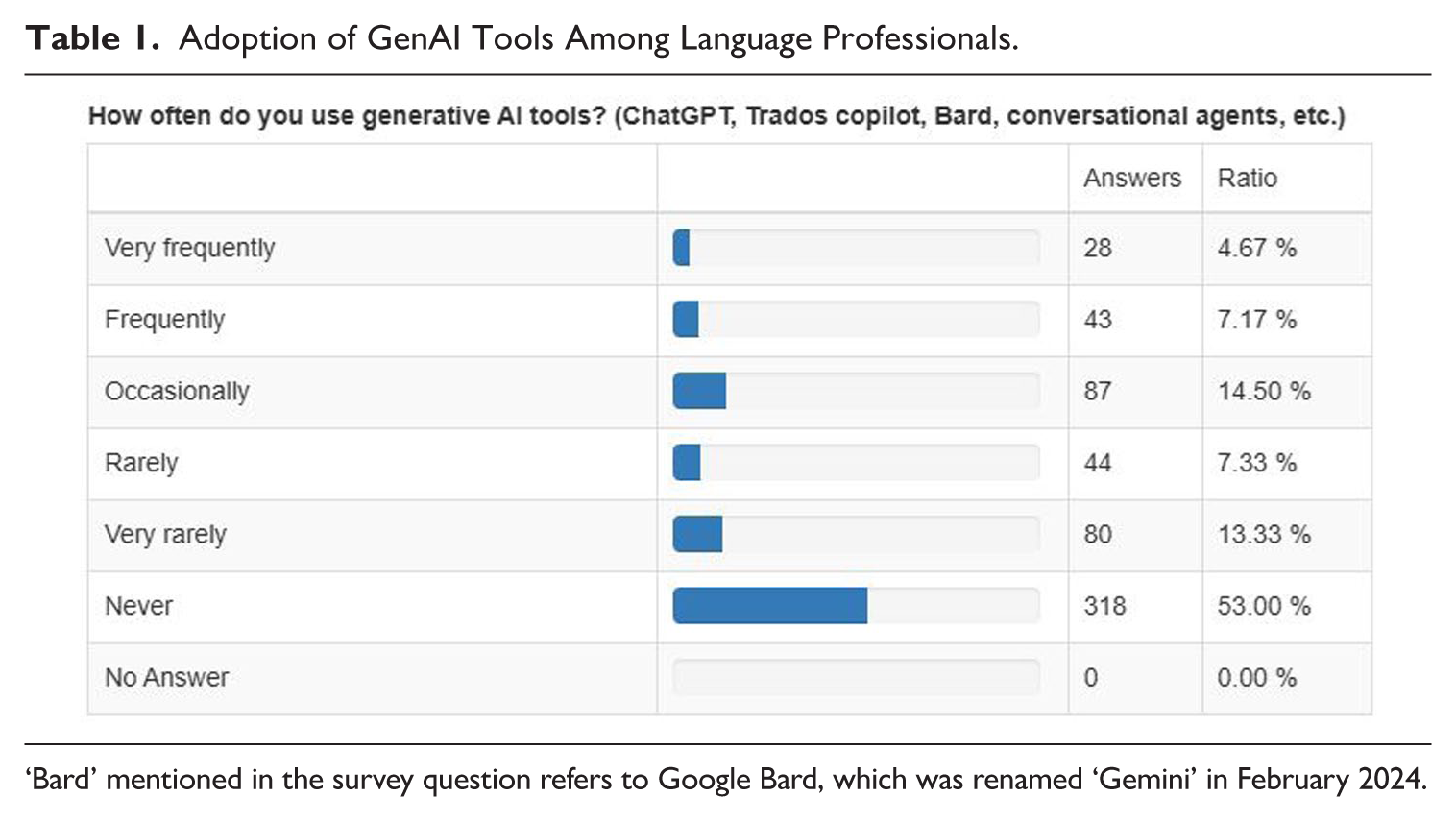
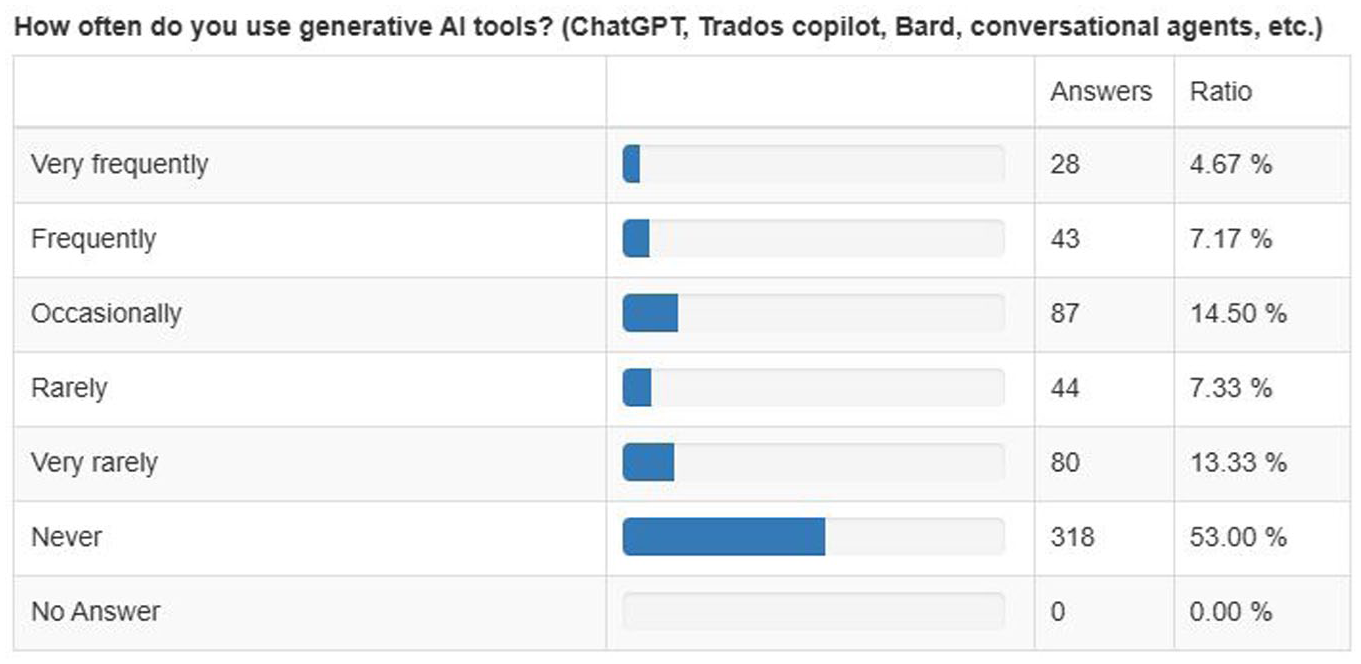
‘Bard’ mentioned in the survey question refers to Google Bard, which was renamed ‘Gemini’ in February 2024.
3.3 Reported benefits and drawbacks
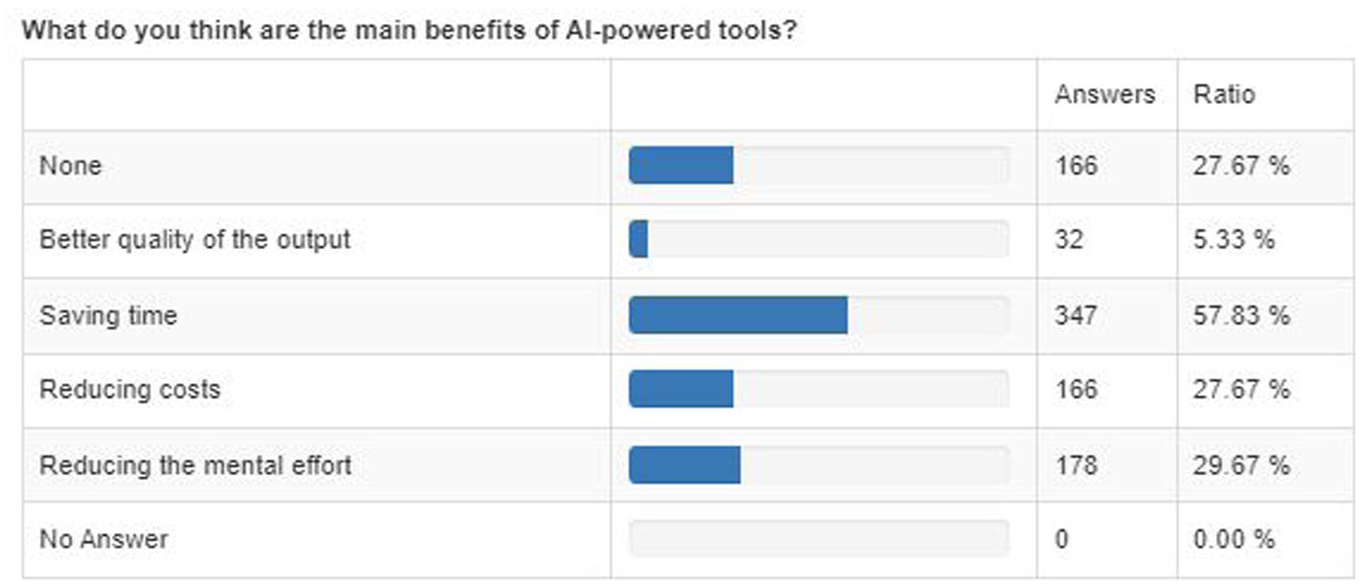
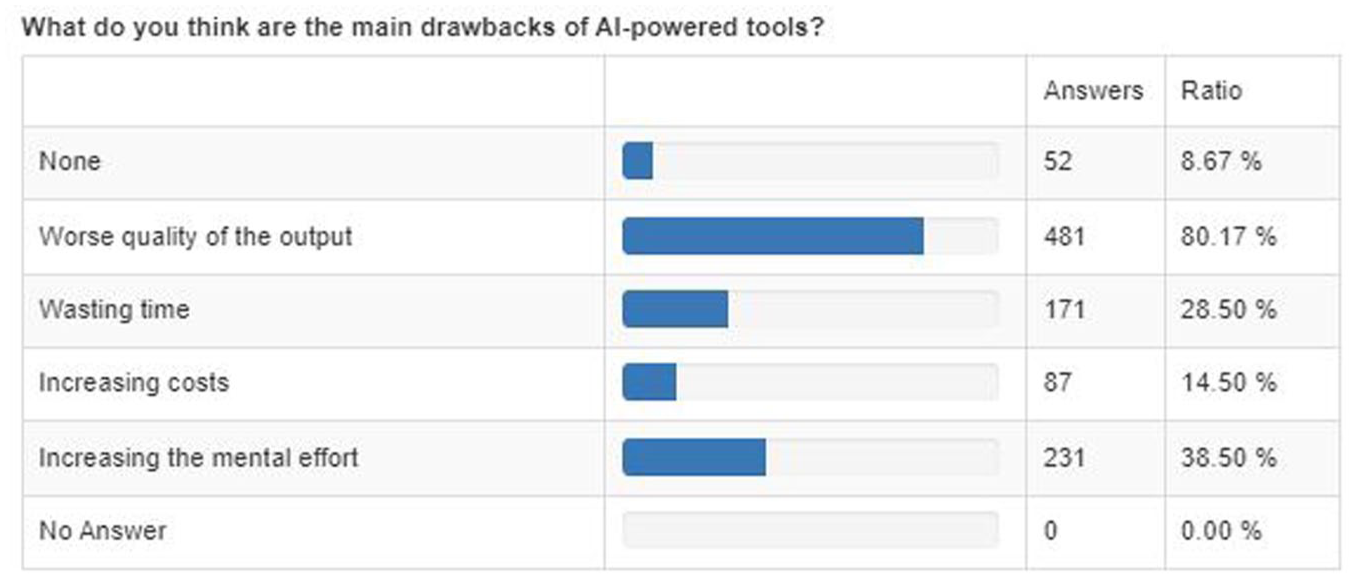
Among the reported benefits of using AI-powered tools for translation, the most frequently cited one, by 57.83% of the respondents, is the potential for timesaving (see Table 2). Besides the potential for increased productivity, another notable perceived benefit, reported by 29.67% of the respondents, is the potential for AI to reduce the mental effort required in translation and interpreting tasks. In fact, when asked directly about using AI tools when post-editing (i.e., revising and correcting machine-generated text to meet human standards) in comparison to translating from scratch, the results are consistent, as they indicate that 21.5% of respondents experience reduced mental effort. While this suggests that AI can potentially alleviate cognitive burdens, it is crucial to acknowledge that a much larger portion of respondents (48.8%) reported either increased or even greatly increased mental effort when using AI tools, which is closely related to the overall results of AI usage (see Table 3). These mixed responses highlight the varied experiences and subjective nature of perceived mental effort in relation to AI use, yet also reveal concerns about the cognitive demands of working with AI. Also worth noting is that a noticeable portion of the respondents (27.67%) do not see any benefit at all. Whereas very few consider the quality of the output as a benefit (only 5.33%), a very large proportion of respondents (80.17%) express concerns about the negative impact on output quality. This suggests that while concerns about quality are widespread, some professionals may be experiencing positive results depending on specific tools, language pairs, genres, and workflows. For a detailed overview regarding the main drivers of and barriers to the adoption of NMT tools and LLMs, please refer to Appendix 1.
Perceived Benefits of AI-Powered Tools for Translation and Interpreting.

Perceived Drawbacks of AI-Powered Tools for Translation and Interpreting.

When assessing the usefulness of AI tools in translation and interpreting, responses again reflected a wide spectrum of opinions. More than half of the respondents, 53.33%, deemed these tools moderately to extremely useful. Conversely, 29.17% found them to have limited utility. As for the degree of adoption of AI-assisted tools for interpreting, the lack of adoption is even higher. A substantial 76.17 % of the respondents who reported providing interpreting services selected ‘never’ and only 8.29% reported ‘frequent’ or ‘very frequent’ use. Likewise, the perceived usefulness of AI tools in interpreting was notably lower than in translation, with 25.39% of respondents choosing not to answer the question, and only 9.32% finding the tools ‘very useful’ or ‘extremely useful’. This disparity between translation and interpreting highlights distinct challenges and hesitations when it comes to embracing AI across different areas of the language industry.
3.4 A strong sense of professional and existential unease
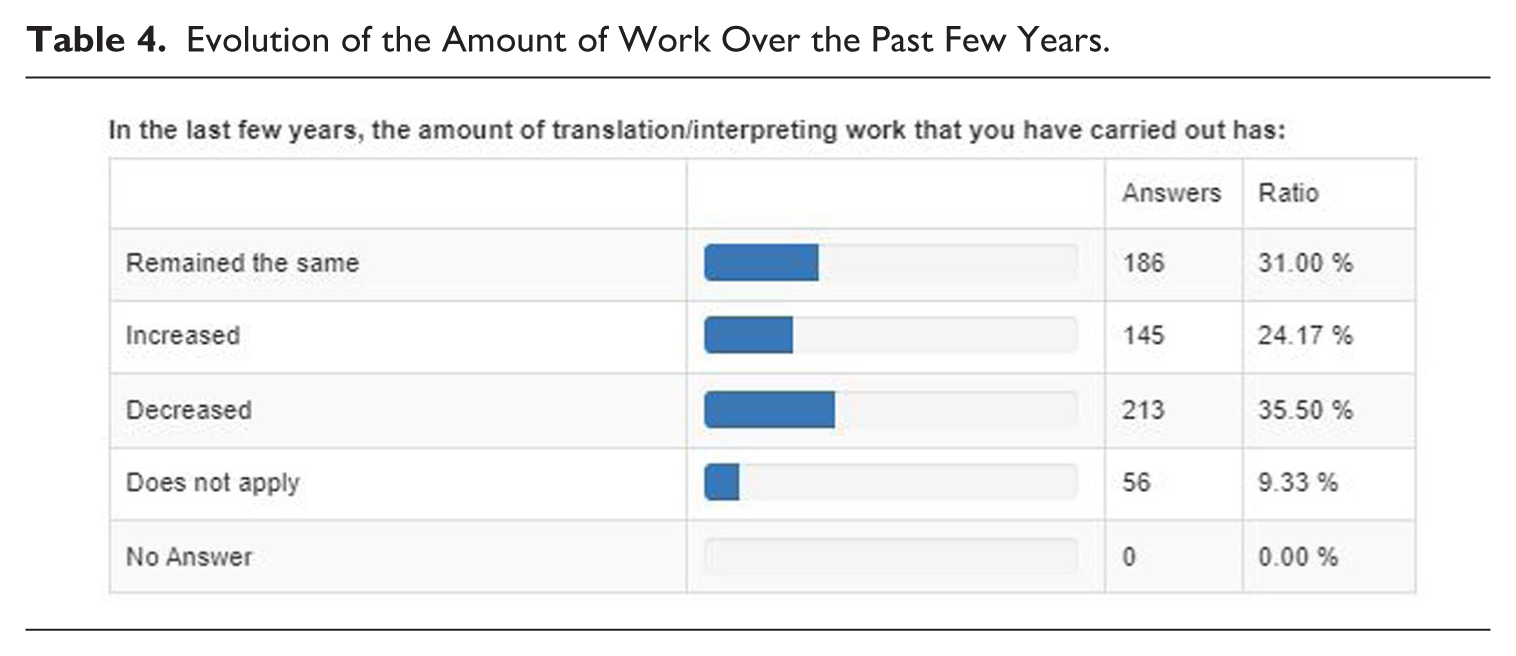
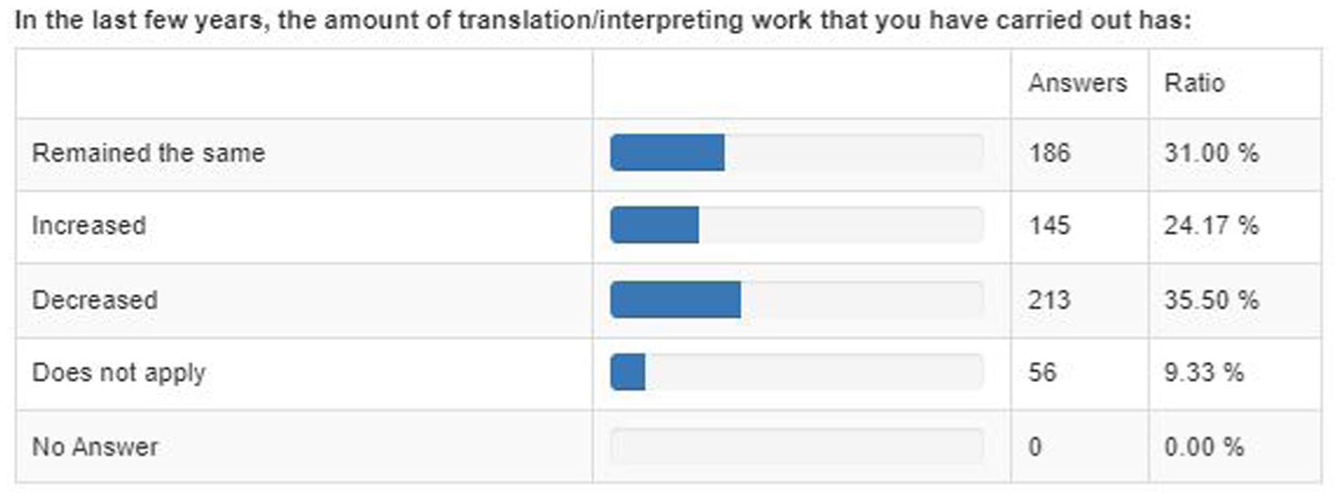
The uncritical, rushed, and large-scale adoption of AI-generated translations, in line with tech-optimist convictions and the widespread yet credulous belief that LLMs provide good translations for any and all purposes, is a cause for great concern to T&I professionals. 13 While they are no strangers to technological development, the speed at which GenAI seems to be entering the market is an important stress factor for many language professionals—but the same goes for many other professions, including authors, journalists, copywriters, graphic designers and fine arts professionals, songwriters and pop artists, data processors, customer service agents, software developers, financial and market analysts, . . . 14 To many T&I professionals, adopting GenAI and post-editing NMT in their workflows feels like opening the gate to a Trojan horse, or fouling their own nest given the pressure on rates that they already experience. The survey we conducted reveals a strong sense of unease regarding the future impact of GenAI on the profession and on T&I professionals’ livelihoods. Most respondents, 61.67%, believe that GenAI constitutes a threat to the financial viability of their profession. This sentiment seems to be further reinforced by the fact that 30.17% of respondents consider the future impact of AI-powered tools on job security to be ‘very high’, while 23.17% rate the expected impact as ‘high’. In 2024, at least 35.5% of our respondents report a decrease in the amount of work over the past few years (Table 4). 15 However, 31% report no change in this respect, and 24.17% even report an increase in the amount of work carried out.
Evolution of the Amount of Work Over the Past Few Years.
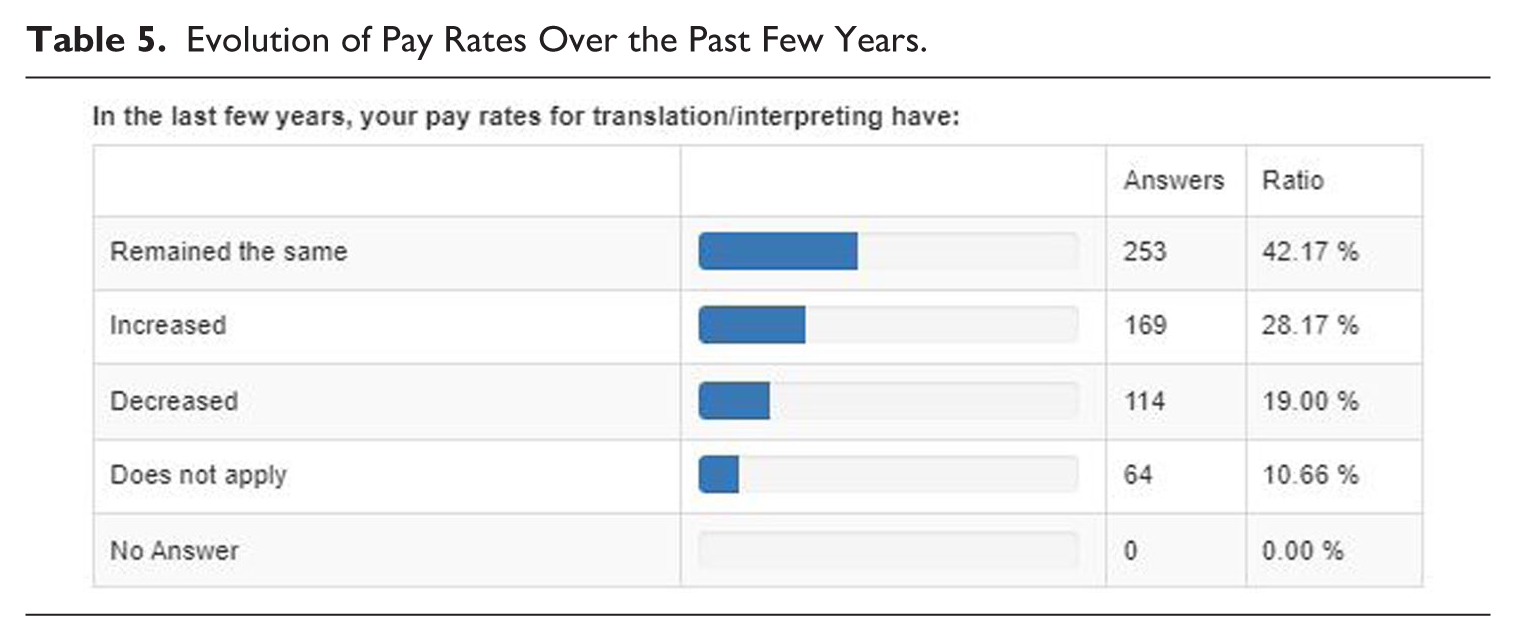
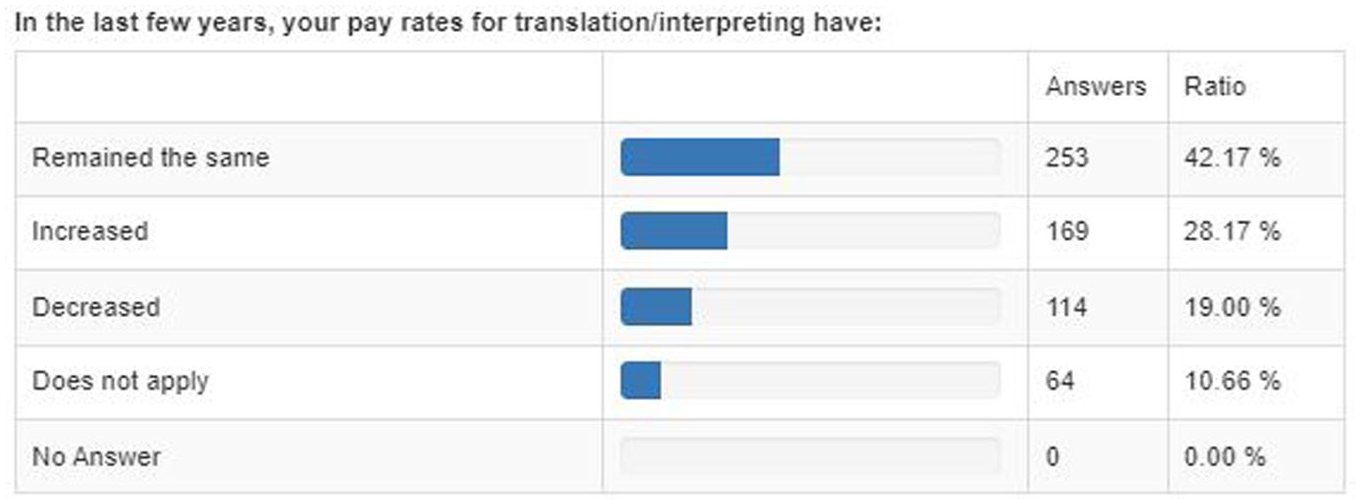
Regarding the pressure on translators’ and interpreters’ pay rates (Table 5), the responses show that 19% of the respondents declare that their pay rates have indeed decreased in the last few years, while a majority of 42.17% report no change and a considerable 28.17% state their pay rates have increased.
Evolution of Pay Rates Over the Past Few Years.
Overall, the concerns and unease expressed at the rapid and uncontrolled spread of GenAI are not limited to fears of job or income loss. For many language professionals, these worries also stem from seeing their work shift from a specialised, creative, and intellectually rewarding activity to one focused on correcting flawed machine output—often underpaid, repetitive, and demotivating. Beyond professional concerns, there is a deeper sense of declining human agency and a loss of control over communication quality, responsibility, and even over broader aspects of life.
3.5 Ethical and legal issues concerning AI and T&I
The survey also included questions about professionals’ concerns about ethical issues involved in using AI for their work (Table 6). The results show that the three main concerns are inaccuracy (80.67%), confidentiality (74.33%), and copyright issues (69.83%). In fifth position, we observe another concern linked to data and transparency, the potential result in legal implications (63,83%).
Language Professionals’ Ethical Concerns When Using AI.

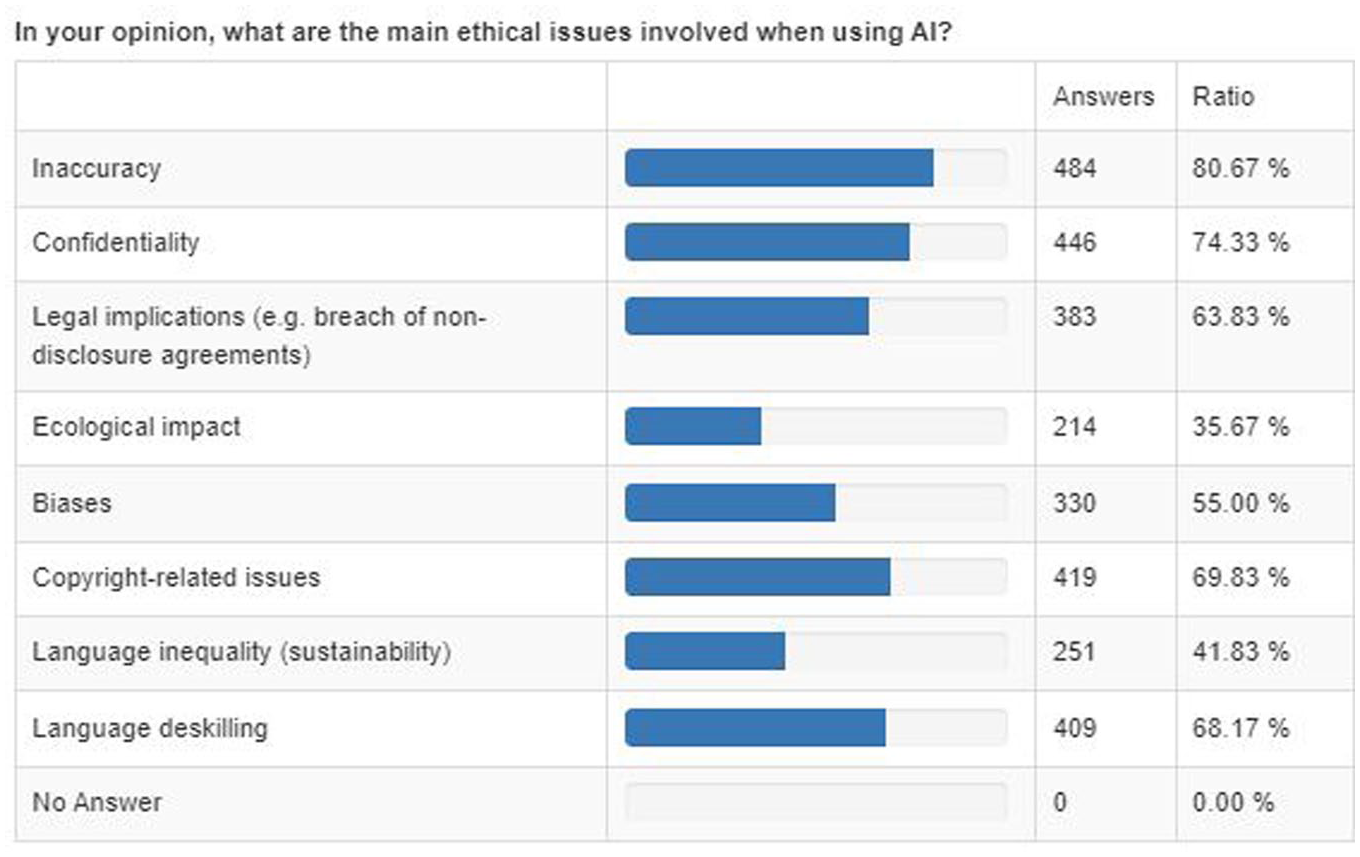
We shall go into these and other legal and ethical issues involved in more detail in Section 4.
4. Ethical and legal issues
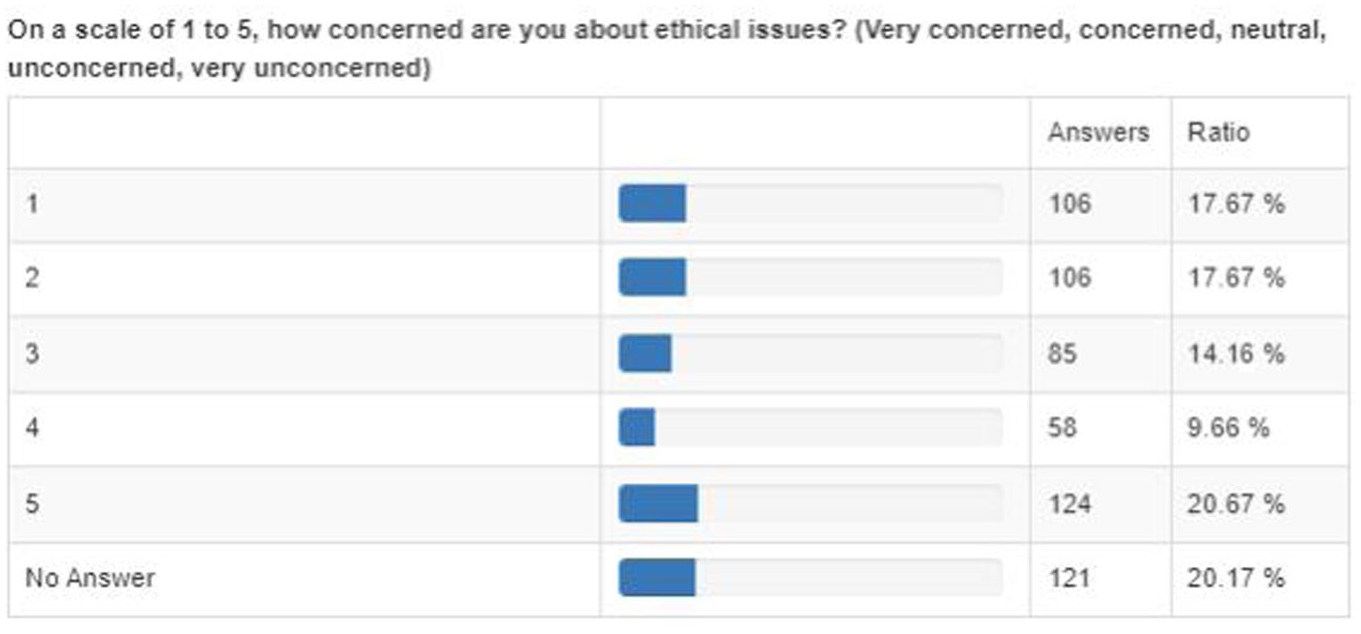
The current, unbridled development of AI does indeed come with a number of ethical and legal issues, both general and specific to T&I, when general-purpose GenAI is used for translation, interpreting, and inter- or intralingual mediation tasks. 16 It is somewhat surprising to notice in the European Language Council (ELC) survey results—despite translators’ and interpreters’ reluctance to implement AI in their workflows and the concerns and unease they express—that respondents provided mixed answers to the question of how concerned they are about ethics. As shown in Table 7, 35.34% of the respondents are either very concerned or concerned about ethical issues, while 14.17% provide a neutral response and 30.34% declare they are unconcerned or very unconcerned, while 20.17% did not provide an answer. The latter might be related to the fact that 62.83% of the respondents do not integrate AI in their workflow and therefore may not have felt concerned by this question—although the reluctance to integrate AI in their work may in itself be the result of ethical objections. However, these numbers may also reflect the general public’s relative unawareness of important ethical questions related not to using GenAI specifically for translation and interpreting purposes, but to GenAI in all types of uses and applications.
Degree of Language Professionals’ Concern With Ethical Issues.

The ethical issues mentioned in the survey (see Table 6) are relevant to all agents involved in AI, from those who build the systems to those who use them. Duly addressing those ethical questions, for which we provide more substantial argumentation below, implies the involvement of scholars from the fields of linguistics, communication, translation and interpreting, sociology, anthropology, ethics, and human rights, working together with AI companies in a cooperative ecosystem that allows for the development of a more ethical, fair, and trustworthy AI (Şahin & Gürses, 2023).
4.1 Climate and environmental impact
GenAI and LLMs require massive amounts of computing power and data storing and processing facilities. Tech companies, therefore, rely on over 10,000 data centres worldwide and are constructing more at a rapid and ever-increasing pace. These data centres have a huge ecological footprint due to the enormous amounts of energy they need—a search using ChatGPT allegedly consumes 10 times the energy of a conventional search with Google. The International Energy Agency (IEA) estimated the amount of electricity used by data centres worldwide at 460 terawatt-hours (TWh) in 2022, which is roughly 1% to 1.5% of the global electricity demand, and that was before the major AI boom that has taken place since. According to the IEA, data centres’ total electricity consumption is expected to rise exponentially and reach over 1.000 TWh by 2026, that is, more than the entire African continent and about 40% of the projected electricity consumption in the entire European Union. 17 A second factor that affects AI’s impact on global ecology is the amount of freshwater used to cool servers. Data centres’ projected water usage is estimated at 6.6 billion cubic metres by 2027 (Pengfei et al., 2023), which brings it to a level of water usage comparable to a small-sized European country such as Denmark. Data centres are also responsible for huge amounts of emissions. To give but one example: Google’s emissions of greenhouse gases increased by nearly 50% between 2019 and 2023 due to the exploding demand for AI, despite its self-declared ambition of achieving zero emissions by 2030. 18 Morgan Stanley estimated that data centre emissions globally will accumulate 2.5 billion tonnes of CO2 by 2030, 19 while The Guardian has pointed to the so-called Big Five’s (i.e., Alphabet, Amazon, Apple, Google, and Microsoft’s) creative accounting with renewable energy certificates, artificially deflating their location-based and in-house emissions with credits for renewable energy that does not need to be consumed by the certificate’s owner. In fact, The Guardian claims data centre emissions of CO2 are up to six or seven times more than what the big tech companies report, and at the level of the 33rd highest-emitting country, despite carbon neutrality claims of all five big tech companies. 20 Besides energy and freshwater consumption and emissions of CO2 and greenhouse gases, server infrastructures associated with AI require rare earth minerals such as lithium, gallium, or germanium, often extracted through polluting open-pit mining, and also produce substantial amounts of electronic waste. These infrastructures are expected to produce up to 5 million tonnes of e-waste containing toxic materials by 2030, according to a study recently published in Nature Computational Sciences (Wang et al., 2024).
4.2 Copyright, data protection, and legal accountability
As previously mentioned, AI companies pillage any and all information, including copyrighted information—which is their most valuable asset—for training purposes, without permission or payment, which is an important ethical as well as legal concern, that led to lawsuits such as the New York Times versus OpenAI. Given the ‘black box’ nature of the deep learning architectures used in LLMs, data traceability is not possible. As a result, users are blind about the nature and characteristics of the data used to generate output (even if GenAI now progresses towards so-called XAI, that is, explainable AI which aims at improving the transparency of algorithms). This leads to uncertainties regarding the question of who owns the copyright to AI-generated content, including written or spoken foreign language output, especially when based on copyrighted sources, even unintentionally. Legally speaking, AI is in a grey zone and many things, including legal property and accountability of AI developers, vendors, and users (including their employers when AI is used at work), are currently unclear.
Another issue is data protection, including the so-called data-deletion conundrum: while users in Europe have the legal right, since the GDPR and Data Protection Act, to have their personal data protected, to modify their personal data, or to ask that it be removed from AI training materials and models, it is nearly impossible to do so without resetting the model, thus forfeiting the extensive sums of money put into the training of LLMs. Client confidentiality is an issue that T&I professionals are very concerned about (see Table 6). Especially in sensitive settings, T&I may indeed involve confidential or personal information that needs to be protected, in health care or legal and police contexts, but also for commercial reasons, copyright-related reasons akin to technical development and patents of invention, for instance, or because documents contain GDPR-protected data such as names or trade secrets that are not meant for external communication. Using online AI-powered translation tools such as Google Translate, or free versions of ChatGPT or DeepL, may in addition involve risks in relation to data storage, as well as usage (Bowker, 2020). Providers of free online AI translation tools may store such sensitive data, and they may reuse it for the purpose of training their AI models. Given the lack of transparency regarding how precisely AI models are trained, translators and interpreters working with sensitive data find it hard to trust that their translations will not be used for training purposes, even when companies commit themselves to not tap into user data for training purposes (generally in paid versions of their AI tools). In sensitive corporate, legal, or medical settings, language professionals who provide translation and interpreting services are bound by client confidentiality or even non-disclosure agreements. If the data entered in the system were to be stored or reused by tech companies, that would constitute a breach of confidentiality and could potentially have legal implications. Currently, the legal responsibility and accountability of all agents involved in AI-generated translation and interpreting (AI developers, T&I professionals, and their clients) are unclear.
4.3 Inaccuracy
Potential legal implications can also stem from issues related to output quality, which typically go unnoticed when users are not proficient in both languages involved. Inaccuracies can result in legal and economic consequences for both clients and translators, in addition to reputational loss and the subsequent loss of income. Clients and all participants in the translation process need to be aware of the limitations of AI-generated translations. Uncritical reliance on such outputs can lead to serious legal and ethical consequences, particularly in sensitive areas like immigration or asylum, where AI may inaccurately assess language ability or relationships. Even with professional post-editing, errors can slip through, raising difficult questions about responsibility. Furthermore, the lack of transparency in how AI systems operate makes it hard for professionals to assess the basis of automated decisions, such as translation quality. Users and clients should also understand that AI translation tools, being data-driven, do not perform equally well across all languages or language pairs. Concerns around translation quality, as well as ethical and legal risks, should take precedence over unrealistic ambitions to cut costs under the assumption that they can be quickly or easily ‘checked’. Poor translations can be far more expensive for companies and public bodies than high-quality translations provided by a professional. 21
Professionals’ concerns about accuracy problems in AI-generated translation output (see Table 6) can also be related to the so-called ‘deceptive fluency’ (Way, 2020) of AI-generated content, including translations—they read smoothly but can contain serious content errors or hallucinations, especially when translating from English into low-resource languages (Guerreiro et al., 2023). These inaccuracies are hard to detect, particularly for non-professional users unfamiliar with either the source or target language, yet they can have serious legal, medical, or financial consequences. The risk increases when both source and target languages are low-resource (Gehman et al., 2020; Guerreiro et al., 2023). As automatic translations become embedded in platforms like browsers and social media, users may not even realise that they are reading machine-generated content. Without a proper understanding of how these systems work or of the languages and cultures involved, translation quality declines, with potentially harmful outcomes.
4.4 Perpetuation and even reinforcement of human biases
As mentioned before, the training data and algorithms behind the scenes of LLMs and GenAI come with uninvited biases, such as racial stereotyping, gender bias, or discrimination against underrepresented minority groups. These stem mainly from historical data and internet fora and are thus baked into the systems, uncurated. As a result, GenAI output, although it is seemingly objective, may influence decision-making in ways that can reinforce existing preconceptions, disparities, and discriminations. One example is a recruitment tool developed by Amazon that favoured male applicants because it had been trained with resumes coming mainly from men. 22 Another example is racial bias in the US health care system: when US hospitals used AI to predict which patients would need extra medical care, the system heavily favoured White over Black patients, because the variable of patients’ health care cost history in the algorithm proved to be correlated to race (Obermayer et al., 2019). 23 In addition, biases may also come from a lack of representative data, for example, images and text descriptions of female engineers, men taking care of children or preparing a meal in the kitchen, or surgeons who are not elderly White men. While bias mitigation strategies exist, these do not capture all forms and sources of bias (Nemani et al., 2024) and often lead to overcorrections, such as suddenly making all doctors female (Spillner, 2024). Research has also suggested that automated evaluation of AI-generated translations using machine metrics raises ethical concerns as it is found to not always correlate with translation evaluations made by humans (Moorkens, 2022). Finally, it is not clear on the basis of which criteria the reinforcement training of the algorithm has taken place (e.g., how was ‘good’ and ‘bad’ defined in the model, and who took that decision?). At this stage, exclusion bias may occur. As a result, AI seems to be flawed with racial, gender, and minorities stereotyping and discrimination and may even produce these at a more general and larger scale than humans do, with potentially greater negative effects (Hacker et al., 2025). These could be amplified due to the previously mentioned confirmation bias, that is, the tendency to favour information that is in line with previously retrieved information or information that supports one’s prior opinions and values.
4.5 Linguistic and cultural inequality and epistemicide
As explained above, LLMs contain much more data for certain large and hegemonic languages, thus duplicating the unequal competition between languages that characterise the global language system (De Swaan, 2001). English being the hypercentral, hegemonic language of international business and tech development, as well as the language of the Big Five and the largest language by far on the internet, (American) English is also the hypercentral language of AI. French, Spanish, Chinese, Arabic, Japanese, Russian, German, Portuguese, and Malaysian follow at a respectable distance. Together with English (which has approximately 400 million native speakers and a good 1 billion non-native speakers), these 10 languages represent over 80% of the entire content of the internet, 24 as well as the large majority of existing parallel corpora, yet only about half of the world’s population. For other, so-called low-resource languages or languages of lesser diffusion, research has shown that LLMs perform (much) worse, although these include large languages such as Hindi (about 600 million speakers), Bengali (about 275 million), Urdu (230 million), Marathi (near 100 million), Tamil (85 million), Swahili (around 80 million), or Farsi (78 million). But poor quality is not the only problem. AI’s tendency to favour hegemonic languages—American English in particular—over commercially less interesting languages has been related to what was coined by K. Bennett (2013) and Bowker (2020), among others, as ‘cultural epistemicide’. This notion refers to the fact that LLM output in languages other than English can be negatively impacted because, in addition to poor quality, it is also heavily influenced by linguistic structures and cultural habits typical of English. Due to this phenomenon, LLMs have been characterised as ‘multilingual but monocultural’ (Walker Rettberg, 2022) in the sense that they produce output in various languages while, however, reproducing cultural patterns from the dominant (mainly American) English language. Finally, of the more or less 7000 languages in the world (about half of which are known to be written), many especially indigenous and minority languages are not supported by Unicode, the ‘world’ standard for digital text and emoticons at the basis of the internet and used by all existing browsers, search engines, and AI algorithms. 25 The digital divide between social groups, but also between central languages, languages with Latin-based and non-Latin-based scripts, Unicode- and non-Unicode-supported scripts, is rapidly turning into an even greater divide between AI-powered and non-AI-powered languages and cultures. Unless the development of AI becomes more equitable, its rapid deployment may lead to a considerable loss of linguistic and cultural ecodiversity, as well as social and cultural diversity (Atari et al., 2023; Boelaert et al., 2024).
4.6 Human well-being
This is probably the most important ethical concern that should be duly addressed. It is also the most wide-ranging, as well as the one most difficult to grasp. The rapid and overwhelming spread of AI in technologically advanced societies has brought with it significant concern, psychological stress, and existential anxiety. Added to this are the difficult working conditions and mental health challenges faced by annotators, moderators, and fact-checkers—especially in low-wage countries—who label data for LLMs and remove harmful content from social media and the internet. According to the IMF, almost 40% of global employment is exposed to AI; in advanced economies, that impact is expected to attain about 60% of all jobs, including high-skilled jobs (Cazzagina et al., 2024). AI is likely to change people’s lives in general, which may lead to feelings of loss of control over one’s own decisions. AI-related societal problems have already arisen, such as chatbots spreading disinformation, deepfakes and deep nudes, unauthorised uses and plagiarism of texts, images, artwork, and voices, users becoming emotionally dependent on chatbots 26 or even infatuated with them, or developing an AI addiction, all of which can cause mental health distress. Another source of great concern is the especially unclear disruptive effects of near-permanent exposure to AI-generated social media content and technology in general on children and youngsters’ well-being and their cognitive, linguistic, cultural, and social skills. A still further important open question is related to how AI will influence the ways in which humans think, process, and produce knowledge, perceive reality and each other, differentiate fact from fiction, decide what is real and what is artificial, and view what is creative or original and what is not. In brief, AI may influence the ways in which humans know, interact, and communicate. In this respect, a key problem is the fact that the massive amounts of AI-generated content that are flooding the internet and social media—Amazon estimates the amount of AI-generated content on the internet at over 50%—are now fed back into the systems, which are now being trained with their own output. As a result, AI systems are no longer duplicating human language, but cloning themselves, with so-called ‘synthetic’ data flawed with linguistic errors and biases. How this ‘Ouroboros effect’ (Moorkens, 2023) 27 will affect knowledge creation and dissemination in the future is an issue of great concern, especially with regard to the question of who will generate new knowledge when knowledge workers increasingly rely on AI systems that produce more and more synthetic data, thereby increasingly becoming a closed system of repeated probabilities. Finally, the development of AI comes with enormous power, now in the hands of very few, non-elected, and extremely rich and influential individuals. How this economic and increasingly political power position in the hands of very few relates to processes of democratic decision-making, social equity, and the protection and promotion of human rights and the rights of minorities, is unclear, but recent geopolitical conflicts and elections across the Western world have illustrated how AI can be used to spread disinformation, to sabotage democratic decision-making processes, or to boost warfare. The existential key questions remain unanswered: How do we ensure that the development of AI does not tarnish fundamental human rights and freedoms and values? How precisely will AI affect our lives? Who will decide how it will affect our lives? What should be, and should not be, developed? Who will make that decision? Will AI make our lives better, our societies more equitable? Will it help preserve the planet? What will happen if the power with which it comes falls into the wrong hands? Or is it already in the wrong hands? Has big tech created a marvel, or a monster, and if so, who can control that monster?
4.7 Language deskilling
All of this is a cause for much concern. In addition, language professionals are very concerned about the language deskilling they feel is likely to occur (see Table 6) when people believe that language learning is no longer needed, because the machines can communicate effectively in any language (quod non). The risk of deskilling is a more general issue, which is related to humans’ tendency to count on machines to solve their problems. Users, especially younger generations, tend to develop diminished attention spans, to use their brains less (Kosmyna et al., 2025), 28 and to grow lazy and leave their decision-making to technology, thereby becoming increasingly dominated by it (Mahalakshmi, 2021; Sutton et al., 2018). Deskilling relates to the question of why we should learn something—especially more difficult and demanding skills—when machines can (often, supposedly) do it for us. One of those demanding skills is language, particularly reading and processing larger portions of text and learning a foreign language, culture, and, even more so, learning how to translate and interpret between languages and cultures. Communication is a complex human activity; the potential of AI to support meaningful human-AI collaboration is in dire need of much more analysis; it is central to the role of AI in education and training.
5. AI in T&I education and training
5.1 Disruptive effects
Due to the rapid progression of AI, the professional realities of T&I have been significantly transformed and will not remain as they were. AI-assisted or AI-generated translations and automated interpreting services have been claimed to yield important advantages, notably in terms of accessibility to multilingual communication—especially in situations where there are no professional translators or interpreters at hand, or where it would be impossible to call in professional services. However, these situations often involve languages of lesser diffusion for which AI quality is typically poor. Other perceived advantages include cost-effectiveness (i.e., not counting environmental and human costs) and convenience. Nonetheless, the ease-of-use and deceptive fluency of AI-generated texts have massively disruptive effects in educational contexts. Universities and other educational institutions worldwide are confronted with the impact of deskilling and students producing and handing in AI-corrected or even AI-generated texts in their first (native) and second (foreign) languages. In addition, academic staff struggle to keep up with the latest developments, so there is a dire need to train the trainers. Both students’ use of AI and staff’s unfamiliarity with AI have put massive pressure on how educational institutions conceive learning, knowledge, and plagiarism, causing them to struggle with, or against, some students’ reluctance to learn complex skills that they increasingly leave to the algorithms.
In society at large, the convenience of relying on AI-generated translation and interpreting has led to tech-solutionist uses of GenAI, including in situations in which T&I professionals could well be called in, yet are not, generally for reasons of cutting what is naively perceived as a now unnecessary cost. Relying on automatically produced T&I output in line with tech-optimism has a detrimental impact on communication quality and comes with several concerns and risks, discussed above. One of those risks is closely related to T&I education and training, namely the risk of neglecting, deskilling, and decentring human communicative competences such as high-level idiomatic proficiency, cultural and intercultural competence, terminological accuracy, and critical thinking, which are all germane to the professional profile of translators and interpreters. In the language industry, the profession of ‘translator’ and ‘interpreter’ is under pressure of being replaced by labels such as ‘linguist’, ‘localisation specialist’, ‘language quality specialist’, or even ‘language engineer’ (Briva-Iglesias & O’Brien, 2022). Such labels are not innocent as they have an effect on how students consider themselves, which could further undermine their subjectification process (Şahin & Oral, 2021), at the risk of turning them into ‘echoborgs’ (Mossop, 2021), that is, persons whose words and actions are determined by AI, thus becoming themselves ‘stochastic parrots’ mimicking the speech patterns of AI (Bender et al., 2021). Therefore, AI in education and training should be presented as a tool that can be useful for numerous applications, including foreign language learning and translation training, yet on the condition that the human being remains central in the T&I loop and in control of quality and communication. T&I students as well as professionals are in dire need of training. In this endeavour, it is crucial to train the trainers as well, not only in integrating AI effectively into their teaching, but also in duly considering the side-effects and ethical and legal issues discussed above.
5.2 Human agency, AI literacy, and communicative skills
The formal education of pre-service translators and interpreters should emphasise human agency in students’ learning process and in the professional practices and workflows of (future) language professionals. However, it is imperative that pre-service as well as in-service T&I professionals develop their AI literacy, that is, the necessary awareness, knowledge, and critical understanding of how NMT and GenAI systems work, of their opportunities and drawbacks (Tully et al., 2025), as well as the necessary skills, attitudes, and values associated with a critical, ethical, and responsible integration of AI in human-centred T&I learning, training, and workflows, where and when useful. Among other things, this implies the following:
Due attention to the affordances and negative consequences of using NMT and LLMs for T&I purposes. This includes improving pre- and in-service translators’ and interpreters’ NMT- and AI-literacy and related knowledge, understanding, and skills, such as understanding how GenAI systems and LLMs work, prompt engineering, and post-editing NMT and GenAI output, considering potential issues, such as adequacy, hallucinations and perturbations, deceptive fluency, cognitive and other unwanted biases, terminological inconsistency, and linguistic and cultural epistemicide. In this respect, the specific set of skills needed for post-editing GenAI-generated translations (using, e.g., ChatGPT, Gemini, Copilot, or the less well-known Llama, Falcon, Cohere, Claude, or Notion AI) may not be the same as what is needed for post-editing NMT output (e.g., Google Translate, Deepl, Bing, Systran, Amazon Translate, or Modern MT). As GenAI and NMT outputs are both heavily influenced by the quality of the source text, pre-processing and pre-editing source materials should receive due attention. In addition, GenAI output seems more liable to show hallucinations, deceptive fluency, and stylistic flatness and is known to be heavily influenced by the quality of prompts and prompt reiteration strategies used (i.e., the process of systematically refining and adjusting the prompts given to a GenAI tool to improve the relevance of the generated output; Gehman et al., 2020) and the domain-specificity of prompts (Peng et al., 2023). Finally, the successful use of GenAI in T&I also depends on what it is used for, in what contexts and settings, and at what stage or stages in the translation and interpreting process (i.e., when pre-processing source text materials, when formulating prompts, and when doing post-editing and revision). Students, as well as in-service translators and interpreters, urgently require training on how to use AI responsibly, where and when relevant, and how to evaluate its impact and ethical and legal downsides. While the latest European Language Industry Survey (ELIS 2025) results show that universities have started implementing AI in their translation education programmes, indicating that this is a major challenge they face, 29 the ELC survey offers valuable insights into translators’ and interpreters’ AI-skill level. A large majority of respondents (62.83%) report that they do not integrate AI into their workflow. Furthermore, 54.66% rated their skill level with regard to integrating AI-powered tools into their work as moderate, while only 5% reported their AI-skill as being outstanding. This is a worrying result, which reflects a general trend of moderate confidence in handling AI technologies, with only a small fraction of T&I professionals feeling particularly adept;
Training regarding data protection, data use, and confidentiality is key, as well as training concerning the ethical and legal implications of using GenAI for T&I purposes, especially where sensitive data and sensitive contexts and settings are involved. In particular, students should be made aware that data used for training AI and the output produced by GenAI are not necessarily objective;
Training should also be provided on how to communicate with clients, potential clients, and the general public regarding the use of GenAI and NMT in translation and interpreting, concerning how LLMs work, how they can or should be integrated into professional, human-centred inter- and multilingual communication, as well as about potential ethical and financial risks, matters of data protection, legal accountability, and ethics of communication;
The education of future language professionals should not only include training on how to implement AI in the learning process and future professional workflow in a critical, ethical, and responsible way. It should also reinforce students’ human agency and subjectification, with a clear focus on effective communication, high-level language proficiency and idiomaticity in their native and foreign languages, and due knowledge and understanding of the cultures and intercultural differences involved. The ability to detect deceptive fluency, biased information, incoherences, and terminological and intercultural issues in AI-generated output will only become more important and depend on future language professionals’ linguistic, cultural, and intercultural proficiency. Finally, the education of future language professionals should reflect the increased importance of the so-called ‘soft’ skills, such as empathy, creativity, critical reading, and most importantly critical thinking, that cannot be simulated by an algorithm yet are instrumental to the ethical and responsible use of AI, where and when it constitutes an added value.
6. Concluding remarks
Despite the undeniable potential of AI, including for instance for language learning, much remains uncertain. What we do know is that AI is likely to have a considerable and possibly disruptive impact on the world economy, on educational systems, on professions and individuals, as well as on human communication itself. The aim of the present article, in which we focused on multilingual communication and mediation, is not, however, to deny or disregard these tools’ potential or to advise against them. Rather, it is to warn against overly naive tech-solutionism and the resulting inconsiderate and unsuspecting use of AI for T&I, not as a tool but as a ready-made, fast and cheap, purported solution. AI as a tool well-used can be part of the solution, but it also is a deceptively easy recipe for multilingual communication problems, when these are approached independent of the context and purpose of communication, the communication partners involved, and the needs of both users and their target audiences: clients, patients, customers, citizens, asylum seekers, who have the right to clear, correct, relevant, and trustworthy communication. With this article, we have sought to raise awareness of a number of issues that often go unnoticed when lay users resort to LLMs to solve their multilingual communication problems without seeking help from a well-trained professional translator or interpreter. The potential unwanted ramifications are manifold and may lead to serious financial and legal consequences and even health prejudice, especially in sensitive corporate, policing, legal, or medical contexts. Besides the more general ethical and legal considerations such as copyright, legal accountability and confidentiality, ecological impact, and disruptive effects on democratic participation and human well-being, we call upon users and policymakers to duly consider the communicative shortcomings related to the very architecture of GenAI tools and LLMs, even more germane to their use for translation or interpreting.
6.1 Communicative shortcomings of LLMs include
the systems’ artificial eloquence, that merely mimics human communication and heavily relies on the language quality of the input (source text in language A and prompt);
their deceptive fluency, which obscures inaccuracies in translated content (target output in language B) that typically go unnoticed as lay users are generally not proficient in both languages involved, yet may severely hinder communication;
their deterministic and probabilistic prediction of next words in the output generated, regardless of veracity and objectivity, and of context, unless duly included in the prompt;
their tendency to reproduce and even reinforce cultural preconceptions, biases, stereotypes, and discriminations; and
their disruptive effect on the global language system, increasing the divide between the supercentral language and culture of big tech, and low-resource languages (languages of lesser diffusion), resulting not only in poorer T&I quality (in terms of content, as well as so-called ‘translationese’) for and especially between those languages, but also in cultural epistemicide and a general impoverishment of the world’s linguistic and cultural ecosystem, reinforcing global inequalities in economic development and knowledge creation and dissemination.
6.2 For all these reasons, we call upon
general users (individuals, companies, care providers, authorities) to duly consider, when using GenAI for translation and interpreting purposes, in addition to the ethical issues related to the use of AI:
the context and purpose of communication, and how much quality is needed in this respect;
how LLMs ‘communicate’, what LLMs can and cannot do as compared to professional translators and interpreters;
what languages are involved and how this may affect the quality of AI-generated translation and interpreting;
which rights, risks, and liabilities should be considered, especially in sensitive contexts;
what professional help by a trained and experienced translator or interpreter may bring to the table in terms of multilingual communication quality, trustworthiness, reliability, and accountability, at a fair rate.
European and national policymakers and funding organisations to include policy measures and substantial funding possibilities, to
allow for the development of a more ethical, fair, and trustworthy cooperative ecosystem for AI, by including scholars in the social sciences and humanities (linguists, communication specialists, T&I scholars, sociologists, anthropologists, ethicists, human rights specialists) in all funding programmes related to AI;
develop policies and research-based training programmes that duly consider ethical and legal issues, as well as the communicative side-effects of using LLMs for T&I purposes;
take measures that enhance communication professionals’ as well as the general public’s AI literacy;
subsidise the development of pre-service and in-service training programmes for students and professionals of T&I, including programmes to train the trainers, as well as public information campaigns for laypeople;
duly invest in the reinforcement of human agency alongside the technical development of AI systems and tools.
GenAI and its application in the form of LLMs offer powerful tools but not catch-all solutions. Translation and interpreting are complex, human-centred communication activities that require much more than probabilistic prediction. In contexts where understanding, trustworthiness, and clarity are crucial, and especially where sensitive data are involved, professional expertise remains irreplaceable and should be pursued and duly rewarded at fair rates. Responsible AI use—anchored in human values, ethics, equity, and the pursuit of quality of communication—is the only sustainable path forward.
Footnotes
Appendix
Authors’ note
This Reflection Paper is based on a large-scale survey on AI in translation and interpreting, by the Special Interest Group (SIG) on AI in Translation and Interpreting of the ELC. In addition to the authors, the collaborators are: Claudia Angelelli (Heriot-Watt University), Francesca Accogli (University of Trieste), Martina Bajčić (University of Rijeka), Fidel Çakmak (Alanya Alaaddin Keykubat University), Esther de Boe (University of Antwerp), Pascale Elbaz (ISIT Paris), Anne-Catherine Gieshoff (ZHAW—Zurich University of Applied Sciences), Sabri Gürses (Üsküdar University), Janiça Hackenbuchner (University of Ghent), Monja Jannet (Dublin City University), Ralph Krüger (University of Cologne), Ekaterina Lapshinova-Koltunski (University of Hildesheim), Renáta Panocová (University of Košice), María Luisa Romana García (Comillas University Madrid), Lina Sader Feghali (Saint Joseph University Beirut), Carmen Valero Garcés (University of Alcalá), Maurizio Viezzi (University of Trieste), and Binhua Wang (University of Leeds).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethics approval statement
This article does not contain any studies with human or animal participants.
Notes
Biographies
![]() ) platform to raise awareness about gender bias in MT and collect instances of gender bias. Since 2023, they have been a member of the organising committee of GITT, the international workshop on Gender-Inclusive Translation Technologies. In addition to their academic work, they teach courses on translation technology, machine translation post-editing, technical writing, and ethics for human-centred AI.
) platform to raise awareness about gender bias in MT and collect instances of gender bias. Since 2023, they have been a member of the organising committee of GITT, the international workshop on Gender-Inclusive Translation Technologies. In addition to their academic work, they teach courses on translation technology, machine translation post-editing, technical writing, and ethics for human-centred AI.
![]() ). Her research interests include the use of translation technology in the language industry, the applications of artificial intelligence for accessibility, and the role of translation and technology in disaster and crisis settings.
). Her research interests include the use of translation technology in the language industry, the applications of artificial intelligence for accessibility, and the role of translation and technology in disaster and crisis settings.