
Abstract
It is commonly argued that a handful of technology firms own the infrastructure that underpins the proliferation of artificial neural networks. But little is known about how this concentration of computational resources manifests itself in new geographies of production. To address this disparity, this article introduces the theoretical framework of neural production networks: geographically dispersed but computationally enveloped production arrangements powered by artificial neural networks. The article substantiates this framework by probing the role of Amazon, Google and Microsoft as lead firms in neural production networks. By reconsidering three key categories of production network scholarship – value, embeddedness and power – in light of those lead firms, the article opens a space for economic–geographical research on artificial neural networks.
Keywords
Introduction: Artificial intelligence and technology giants
In 2015, AlphaGo, a computer programme developed by the London-based Google subsidiary DeepMind, became the first artificial intelligence (AI)-powered software to beat a professional human Go player, Fan Hui. Five months later, AlphaGo outcompeted Lee Sedol, a victory that attracted even more attention due to the fact that he was the world champion. In 2018, Lee retired from professional play, highlighting that ‘with the debut of AI in Go games, I’ve realized that I’m not at the top even if I become the number one [. . .] there is an entity that cannot be defeated’ (Vincent, 2019).
While AlphaGo is commonly regarded as a milestone in AI research, Broussard (2018: 36) recalls the fact that its programmers relied on 30 million human games to train AlphaGo’s artificial neural networks, ‘including data from the world’s best players who invisibly and over the course of years worked (without compensation) to create the training data’. AlphaGo’s creators extracted the collective work of thousands of players without their permission in order to develop a system that caused the world champion to retire. This story might be interpreted as a case study about a discursive spotlight on the model’s computational magic and an undervaluation of the accumulated human work without which it would not exist in the first place. But beyond such considerations of labour exploitation, the example of DeepMind’s Go-playing AI software points to the importance of another, largely unexplored, question associated with the proliferation of machine learning systems across society: How do technology giants act as lead firms within AI’s geographies of production?
Before providing a roadmap of how the article develops this answer, it is worth clarifying this research problem. A helpful starting point is that within contemporary public discourse and academic debates, the use of historical analogies is a common way to describe the dominance of technology firms and the cross-sectoral implications of AI. For example, as Plantin et al. (2018) write: Google, Facebook, and a handful of other corporate giants have learned to exploit the power of platforms [. . .] to gain footholds as the modern-day equivalents of the railroad, telephone, and electric utility monopolies of the late 19th and the 20th centuries. (pp. 306–307)
In other words, the highly concentrated ownership and control of quintessential resources that are in high demand is anything but a new phenomenon. While infrastructural monopolies are no unchartered territory, their current exponents differ from historical predecessors, so the argument goes.
Consequently, AI may become (or may already be) one of the frontiers in which a handful of technology companies ‘can align their crucial gatekeeping and monetizing functionalities across infrastructures and sectors’ (van Dijck, 2020: 2812). As ever more is speculated about AI’s long-term impacts – illustrated by marketing terms such as artificial general intelligence or superintelligence – there is a need to investigate AI’s actually existing infrastructural geographies. As one research group puts it, a focus on infrastructural geographies can foreground the ‘material and organizational structures of social life in diverse settings’ (Infrastructural Geographies 2022). Building on Edwards (2003), I thus understand infrastructure not as a ‘rigid background of overpowering technologies, but a constantly changing social response to problems of material production, communication, information, and control’ (p. 221). From ChatGPT and recommender systems to synthetic music, AI’s presence is ubiquitous, yet its underlying production geographies are difficult to pin down. New understandings of how lead firms such as Google enact AI’s infrastructural geographies are required.
The theoretical and empirical stakes of this task are significant. On a theoretical level, as Walker and Winders (2021) argue, insufficient ‘attention has been given to AI’s potentialities and ramifications in relation to place, space, and other foundational concepts in human geography’ (p. 165). Empirically, the economic–geographical evidence base of how networked production arrangements underpin real-world manifestations of AI remains scarce. This is a serious omission, as a conceptually informed understanding of how technology companies such as Google consolidate their power as lead firms is crucial for interrogating the impact of regulatory frameworks designed to curb their dominance. However, ‘AI’s complex geographies [. . .] may necessitate new theoretical frameworks, methodologies, and analytic approaches’ (Walker and Winders 2021: 164).
Precisely herein lies the contribution of this article. I introduce a new conceptual framework for empirically examining AI’s infrastructural geographies: the notion of neural production networks. I define neural production networks as geographically dispersed but computationally enveloped production arrangements powered by artificial neural networks. Because of the insinuation of AI into economic, political and cultural interactions, neural production networks already infiltrate the fabric of infrastructural life. Instead of engaging with long-termist fears about AI’s alleged existential risks to humanity in the future, I prefer to investigate AI’s geographies of production in the here and now. The article aims to show that neural production networks open up a fruitful space to examine artificial neural networks as economic–geographical objects of study.
It has become a cliché to say that AI is omnipresent. At times, the term appears as a promise. Occasionally, it is presented as a dystopian warning. Nonetheless, it often remains unclear how the term AI can be defined and how it relates to consumer-facing applications such as ChatGPT. To defy AI’s notorious definitional ambiguity, I suggest studying a methodologically observable and delineable set of empirical processes: the operations of Amazon, Google and Microsoft in enacting digital production arrangements powered by artificial neural networks – a longstanding computational paradigm that is inspired by simplified models of the brain’s neuronal connections (Wasserman, 1989). Today’s artificial neural networks typically deploy deep learning techniques: their layered structure of millions of individual neurons is not designed by human engineers, but is learnt from training datasets (LeCun et al., 2015). A spotlight on artificial neural networks as a discernible subset of AI offers an entry point to conceptualise some of the economic–geographical dynamics that structure AI’s power relations (Dyer-Witheford et al., 2019; Luitse and Denkena, 2021).
The article first juxtaposes neural production networks vis-a-vis global production networks. Second, it interrogates the operations of three lead firms in neural production networks: Amazon, Google and Microsoft. This discussion is structured based on three analytical categories that are commonly used in production network scholarship: value, embeddedness and power. Finally, the article concludes by sketching out the ramifications of neural production networks.
From global production networks to neural production networks?
On the most general level, a global production network can be conceptualised as ‘the nexus of interconnected functions and operations through which goods and services are produced, distributed, and consumed’ (Hess, 2018: 2). The concept has been frequently iterated by economic geographers (Coe and Yeung, 2019; Grabher and van Tuijl, 2020; McGrath, 2018; Werner, 2019). Scholars take inspiration from different disciplines and intellectual legacies, including economic sociology, international political economy and world-systems theory, and actor–network theory. As Werner (2019) puts it, global production network studies typically examine the ‘value, power and embeddedness of transactionally linked but geographically dispersed production arrangements’ (p. 948).
The operations of lead firms are at the heart of the study of global production networks. As Coe and Yeung (2015) write, a lead firm is defined by its ‘capacity to coordinate and control directly its production network – be it in the role of a buyer, producer, coordinator, controller, or market-maker, or a composite of one or more of these roles’ (p. 39). Each lead firm constitutes its own production network, which makes it easier to identify similarities and differences between those networks. The advantage of centring the lead firm as an object of study is that this focus enables the identification of industry structures without having to map the entire industry. For instance, if the aim is to understand power asymmetries in global food chains, a spotlight on the operations of Nestlé helps to ensure methodological clarity and analytical precision.
In this context, scholars typically distinguish between networks that are buyer-driven and networks that are producer-driven. 1 While buyer-driven networks suggest that buyers, retailers or merchandisers are dominant in shaping economic outcomes, producer-driven networks indicate the dominance of producers and manufacturers. In both ideal types, lead firms in global production networks aim to gain control over other actors by exploiting territorial inequalities. In producer-driven networks, this occurs by ‘exerting control over ‘backward’ linkages to raw material and component suppliers, and ‘forward’ linkages with distributors and retailers’ (Coe, 2016: 333). In buyer-driven networks, this occurs by exerting control at the retail end (e.g. branding and design), while outsourcing actual production activities to other places.
If the territorial expansion of the space in which production takes place acts as the frame of reference, research questions may ask how lead firms exploit geographical inequalities to expand their market power. Take the case of outsourcing. As Peck (2017) writes, ‘while the outsourcing industry likes to convey the impression [. . .] that it has matured away from the cheap-labour model, the hard-to-escape reality is that cost suppression remains an existential condition’ (p. 16). Lead firms may achieve cost suppression by using labour pools in low-wage locations to produce goods and conduct services, such as data work for AI systems, at a cheaper cost. Uncovering those links between labour arbitrage and patterns of industry concentration remains highly relevant, particularly in an era of digital labour platforms as optimisers of cost suppression across territories (Howson et al., 2021).
However, for analysing AI’s infrastructural geographies, the applicability of this focus on territorial inequalities as the only analytical entry point requires critical scrutiny. By virtue of its name, the notion of global production networks foregrounds the territorial expansion of the space in which production takes place (i.e. its globe-spanning scale). By contrast, I propose an alternative point of reference: the computational envelopment of the space within which production takes place (i.e. its infrastructural reliance on computational processes). Lead firms in global production networks attempt to gain control over other actors by exploiting territorial inequalities. Conversely, lead firms in neural production networks attempt to gain control over other actors by enveloping the space of production activities. For example, whenever ChatGPT generates a text output, a computing process is triggered in a data centre operated by Microsoft, which signed an exclusive multi-year partnership with ChatGPT’s developer, OpenAI (Scott, 2020). This means that Microsoft not only underpinned the initial training of ChatGPT’s underlying large language model, but also provides the infrastructure for its day-to-day inference processes: the calculations necessary for generating text outputs. Although details about this form of computational envelopment remain sealed off by trade secrets, it is estimated that a simple ChatGPT conversation of 20–50 questions and answers consumes around 500 mL of clean freshwater to cool Microsoft’s data centres (Li et al., 2023).
Consequently, I argue that the computational space in which production powered by artificial neural networks takes place is enveloped by lead firms. In the context of video game interfaces, Ash (2015) defines envelopes as ‘localized foldings of space-time that work to shape human capacities to sense space and time for the explicit purpose of creating economic value’ (p. 3). My understanding is slightly different. I use the term envelopment to argue that, because they are computing systems, artificial neural networks – by definition – require computational processes. There cannot be neural production networks without computation. While global production networks can, in theory, exist without computational processes, neural production networks cannot. But neural production networks are neither free-floating arrangements in a computational vacuum, nor can they be understood as fixed infrastructures that are rooted in particular territories. Instead, they share with global production networks that they are ‘constituted through a variety of circuits and (non-linear) flows linking a variety of sites and spaces’ (Hudson, 2008: 422), mediating economic relations and interactions.
Therefore, I do not wish to imply that neural production networks replace global production networks, that the latter are no longer relevant or that some of them do not require computational processes. Neither do I suggest that those two types of production networks are mutually exclusive. Instead, a spotlight on computational envelopment accentuates the processual character of the space within which production arrangements powered by artificial neural networks take place. As Kitchin (2009) puts it, the key question triggered by this understanding of space is not ‘what space is’ but rather ‘what space becomes’ (p. 272). Consequently, the conundrum of this article is not what spaces of neural production are in any stable or static sense, but rather what they become as a result of the empirical operations of lead firms. How do spaces of neural production acquire their ‘form, function, and meaning through practice’ (Kitchin 2009: 272)?
In the next section, I argue that although value, embeddedness and power (Werner, 2019) remain crucial categories to answer this question systematically, their empirical manifestations in light of artificial neural networks necessitate critical thought. These categories matter in new ways. For elucidating those ways, the next section begins by justifying a focus on Amazon, Google and Microsoft.
Lead firms in neural production networks: Amazon, Google, Microsoft
Why is it useful to study Amazon, Google and Microsoft as lead firms? Within policy discourse and academic debates, several terms are used to refer to the world’s biggest platform-powered technology companies. Prominent terms are ‘Big Tech’ (Whittaker, 2021), ‘gatekeepers’ (European Commission, 2022), ‘Internet giants’ (Sandbu, 2018); ‘Big Four’ (Galloway, 2018) made up by ‘GAFA’ (i.e. Google, Amazon, Facebook, Apple), and ‘Big Five’ (van Dijck, 2020), which includes Microsoft. Although all those terms prioritise different aspects, such as the number of companies included or the fact that their success is related to the Internet or their role as gatekeepers, what unites them is an emphasis on the scale of specific technology firms.
One way to operationalise the scale of technology firms is by considering their market capitalisation, which is determined by multiplying their current market price by the total number of outstanding common stock or ordinary shares. Using this metric to map platform companies with a market capitalisation above US$20 billion, Fernandez et al. (2020) lay bare the dominance of seven companies: Apple, Microsoft, Amazon, Alphabet (Google), Facebook, Tencent and Alibaba. According to the authors, it is paramount to distinguish those ‘seven companies – Big Tech’s ‘infrastructural core’ – from smaller platforms, which typically rely on their infrastructures’ (Fernandez et al. 2020: 8). Subsumed under the term ‘infrastructure-as-a-service’, the market research firm Gartner (2021) analysed the market shares of what it sees as ‘standardized, highly automated offerings in which computing resources owned by a service provider, complemented by storage and networking capabilities, are offered to customers’. In 2020, Amazon accounted for nearly half of the worldwide infrastructure-as-a-service market, followed by Microsoft (19.7%), Alibaba (9.5%) and Google (6.1%). As a basis to study AI’s infrastructural geographies, the defining feature of technology giants as lead firms is their dominance as providers of infrastructural services. 2
Against this backdrop, a constructive way to link this market power to the idea of neural production networks is to consider their computational envelopment not as a natural law, but as a result of economic–geographical processes enacted by lead firms. To reiterate, neural production networks inevitably remain enveloped by the necessity of computation. Consequently, those lead firms that control the computational resources that underpin and facilitate this envelopment are in a powerful position. Although this practice may require the exploitation of territorial inequalities (e.g. due to the strategic location of data centres), I argue that the envelopment of production activities requires a revision of the empirical focus and analytical categories of production network research. But instead of delegitimatising global production network scholarship, my rationale for coining a new term is to take seriously the analytical strengths of this strand of research while also accounting for AI’s infrastructural geographies.
In this context, it is pivotal to elaborate on what may be missing by taking a lead firm approach to this topic. Far from being self-sufficient, the lead firms included in this study are themselves dependent on a global ecosystem of contractors: chipmakers (e.g. AMD, Nvidia), semiconductor firms (e.g. TSMC, Qualcomm), server assemblers (e.g. Supermicro, Inventec) and data centre landlords (e.g. Equinix). Nvidia, for example, is estimated to control the lion’s share of the global market for graphics processors that can be used for machine learning, such as the firm’s A100 chips (The Economist, 2023). Amazon, Google and Microsoft are some of Nvidia’s biggest clients. When prioritising the operations of lead firms, their structural dependency on other firms should be taken into account. Production network scholarship often entails such trade-offs, as it requires making choices about what firms to focus on (Coe and Yeung, 2015).
Methodologically, the article is informed by a case study analysis that relies on document analysis. In production network scholarship, document analysis is a well-regarded methodological tool for understanding industry contexts that are difficult to access through fieldwork. When it comes to tracing the operations of lead firms across space and time, Goldstein and Newell (2020) distinguish between ‘ex situ’ and ‘in situ’ approaches. While ex situ approaches ‘construct linkages and identify hotspots’, in situ techniques ‘tend to focus on one or a few participants or study sites’ (p. 4). Given AI’s complexity, an ex situ approach is appropriate. I relied on a heterogeneous corpus of documentary sources, including technical articles and research articles, media articles, marketing materials and policy materials. By selecting document analysis as the data source, I posit that there is no lack of data on AI’s infrastructural geographies, but rather a lack of theoretical arguments to make sense of it.
Consequently, I situate my methodological approach as part of an interpretivist paradigm. Each of the documents fulfils a particular function for those who created it. For example, a marketing document serves to exaggerate the product or service that it promotes. A scientific article published by a lead firm is only publicly available because it has successfully passed multiple rounds of internal review, ensuring that it remains in line with official corporate policy. 3 The rationale is o to prevent journalists, competitors and regulators from inspecting their proprietary operations. As Hull (2012) puts it, we need to look at documents ‘rather than through them, is to treat them as mediators, things that “transform, translate, distort, and modify the meaning or the elements they are supposed to carry”’ (p. 253). My analysis is inspired by what Glaser and Strauss (2006) call the ‘constant comparative method’ (p. 106). When coding for a specific lead firm in a given category such as ‘proprietary hardware’, I compared that category with the other two lead firms included in the study. This iterative approach was useful to find intriguing structural similarities and differences.
The article uses selected excerpts from the analysis, rather than descriptively presenting all results. Although this empirical evidence substantiates the arguments of this article, its focus remains conceptual. As a signpost for the following empirically informed sections, Table 1 summarises the structural differences between neural production networks and global production networks. The next section begins with the category of value, before proceeding to embeddedness and power.
Analytical categories of global networks versus neural production networks.
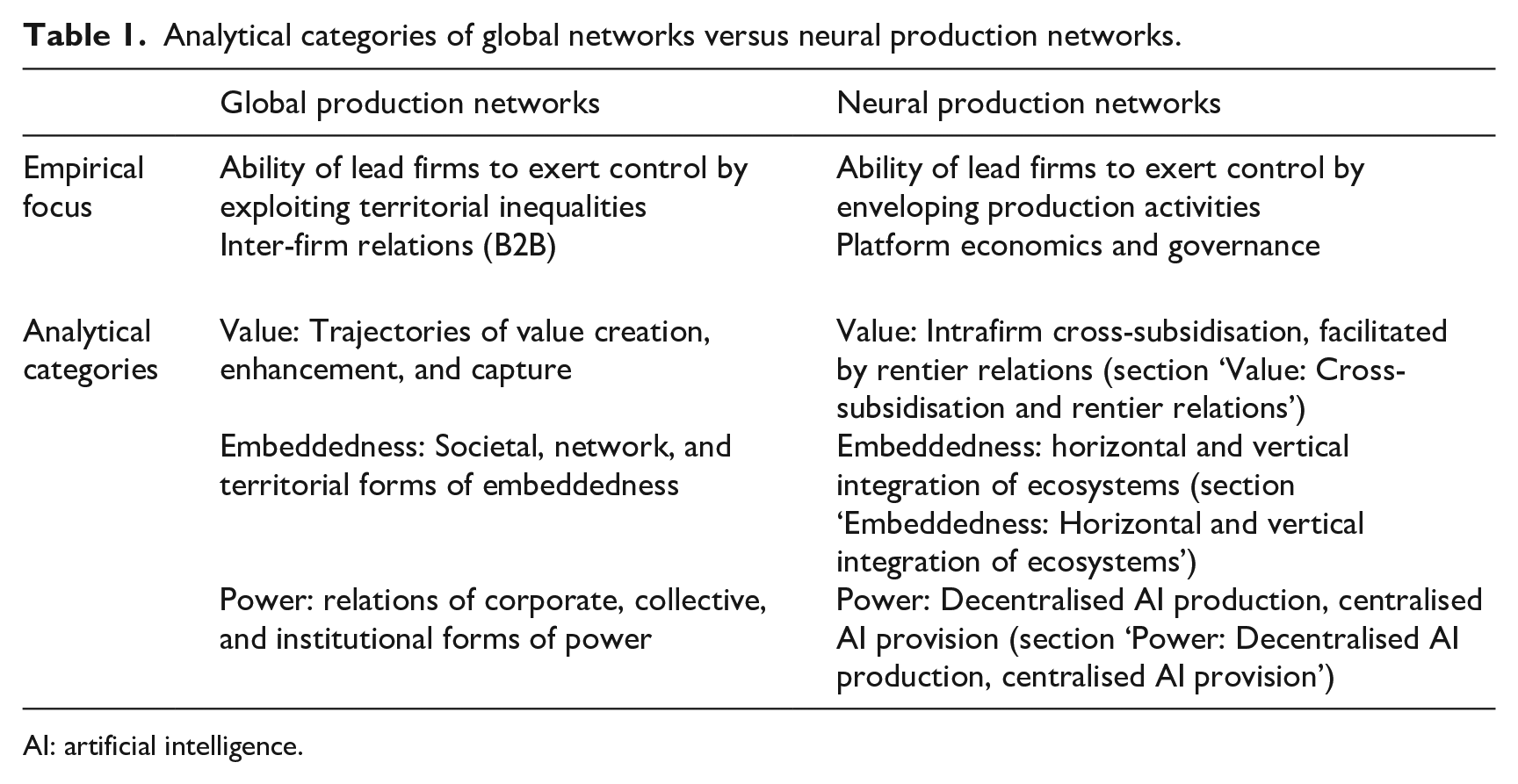
AI: artificial intelligence.
Value: Cross-subsidisation and rentier relations
It is worth returning to the example mentioned at the beginning of this article: the Go-playing AI software that attracted significant media attention. When Lee Sedol – the defeated world champion – announced his retirement from professional play in 2018, AlphaGo had already been succeeded by a more potent version: AlphaGo Zero. As its developers at DeepMind emphasise in a Nature article, unlike its predecessor, this newer version ‘is based solely on reinforcement learning, without human data, guidance or domain knowledge beyond game rules’ (Silver et al., 2017: 354).
While the operations of technology giants are often seen as being black-boxed, especially with regard to their proprietary AI systems, AlphaGo Zero’s creators are rather transparent about the computational resources that were used to train the Go-playing models. To demonstrate the efficiency of their model, they note: ‘AlphaGo Zero used a single machine with 4 tensor processing units (TPUs), whereas AlphaGo was distributed over many machines and used 47 TPUs’ (Silver et al., 2017: 356). What may seem like a peripheral technical detail opens up the study of a bigger phenomenon – one that characterises a key pattern of how technology giants act as lead firms in neural production networks. Seen this way, AlphaGo is not a fairy tale of superhuman, alien-like intelligence powered by mathematical complexity. AlphaGo represents, rather unglamorously, an illuminating demonstration of intrafirm cross-subsidisation. Google does not act here as an infrastructure-as-a-service provider to other companies – the company subsidises a strategic node within its own production network: DeepMind’s resource-intensive research. How can this process be explained?
In 2016, Google announced that the company developed a proprietary hardware chip to accelerate the training of neural networks that had already been used in its data centres for over a year, tensor processing units (TPUs). As Outeiral (2020) explains, ‘unlike GPUs [i.e., graphics processing units, which are used to train artificial neural networks], TPUs have been designed from the ground up for deep learning, and they have been featured in most of DeepMind’s recent successes’. Crucially, DeepMind has been a loss-making business in recent years, with operating losses of £477 million in 2019. In the same year, Google waived the repayment of DeepMind’s intercompany loans and all accrued interest, which amounted to a total of £1.1 billion (Heller, 2020). Most of DeepMind’s revenues were generated by ‘applying deep reinforcement learning within Google to reduce power costs for cooling its servers’ (Heller, 2020).
The fact that Google financially backs its AI research lab is not an exceptional phenomenon. Extensive research on platform economics points to cross-subsidisation as a key feature (Fernandez et al., 2020; Klinge et al., 2022). That is, using profits in a sector that a platform dominates (e.g. advertising) to finance its entry and expansion into new sectors (e.g. health care). Beyond such flows of capital, the rarely discussed aspect that Google operates as an infrastructural provider of computational resources for its own subsidiary is more relevant for answering this article’s research question. This manifestation of cross-subsidisation goes beyond financial support – it occurs on an infrastructural level. And this level cannot be understood by exclusively considering financial statements or metrics. As Dickson (2020) writes: DeepMind’s ‘technical infrastructure’ runs mainly on Google’s huge cloud services and its special AI processors, the Tensor Processing Unit. DeepMind’s main area of research is deep reinforcement learning, which requires access to very expensive compute resources. [. . .] There are no public details to indicate how much Google charges DeepMind for access to its cloud AI services, but Google is most likely renting its TPUs at a discount. This means that without Google’s support and backing, the company’s expenses would have been much higher.
By operating as the infrastructural backbone for its London-based subsidiary, Google defies conventional articulations of value in production network scholarship in favour of a delayed realisation of gains through DeepMind’s scientific breakthroughs. Unlike a car manufacturer in a global production network, whose processes of value creation and capture occur consecutively (i.e. the firm must first create value before it can enhance and capture it), lead firms in neural production networks perform these three processes contemporaneously. Building on Sadowski (2019) and Birch and Cochrane (2022), I argue that lead firms are orchestrators of rentier relations ‘that bring users into the respective enclaves where they can be monetised’ (p. 6). Rentier relations can be defined as economic transactions ‘where rentiers capture revenue from providing access to digital assets’ (Bernevega and Gekker, 2022: 51). The notion of rentier relations captures that lead firms in neural production networks are proprietors of computational infrastructures without which other actors could not use AI.
Within policy discourse, a common example of rentier relations is the role of third-party sellers on Amazon Marketplace. On one hand, Amazon takes a specific commission for each transaction on its marketplace. Sellers can exploit the company’s network effects (i.e. accessing more clients) but have to pay a commission in exchange for gaining that advantage. On the other hand, Amazon can extract valuable data about those transactions for determining whether it makes sense to circumvent third-party sellers and directly sell particularly well-performing products (without having to share profits with intermediaries). This structural power asymmetry is so striking that it has been used as a fundamental piece of evidence to justify the necessity of new regulatory frameworks and instruments aimed at taming Amazon’s dual power as a market-maker and a retail behemoth. On a conceptual level, Birch and Cochrane (2022: 5) use the term ‘enclave rents’ to describe this duality, with lead firms ‘controlling an ecosystem of devices, apps, platforms, and other products’ and shaping and enforcing the rules for ‘users, developers, and others’ (see also van der Vlist & Helmond, 2021).
In the context of AI’s infrastructural geographies, the key implication of rentier relations is that artificial neural networks require computationally intensive training processes. The term ‘training’ refers to the iterative adjustment and fine-tuning of their layered architecture. The purpose of this training is to improve a model’s capacity to calculate accurate predictions. Computationally, the goal is to ‘efficiently and optimally set the weights and biases’ (Yui, 2019) of individual neurons, which are tied together by different layers within the neural network. This process is so resource-intensive that a key area of competition between lead firms revolves around who owns the most potent hardware to underpin this training. As an equivalent to Google’s TPUs, Amazon’s proprietary chips – AWS Inferentia – enhance services and products within Amazon’s production network, such as the voice assistant Alexa. Beyond this internal facilitation, Amazon also offers access to its chips to developers. Inferentia is designed to ‘make it easy for developers to integrate machine learning into their business applications’ (Amazon Web Services, 2022a). Herein lies the dual nature of value production in neural production networks: the capability of lead firms to distribute computational resources internally while simultaneously monetising them externally.
Using application programming interfaces (APIs) and software development kits (SDKs), all three lead firms provide gateways for users to build their own AI products and production pipelines on top of cloud-based infrastructure offerings. As Helmond (2015) explains, ‘the new architectural model of the platform explicitly opens up websites by enabling their programmability with a software interface’ (p. 1). The difference between APIs and SDKs is that the former is an interface for a service (e.g. uploading data to the cloud), whereas the latter is a more comprehensive set of tools and code fragments to build software (e.g. for creating a facial recognition system). APIs and SDKs represent bridges between lead firms in neural production networks and their clients. Staying with the conceptual metaphor of this article, these bridges are the technical underpinnings of computational envelopment. For instance, to facilitate the uptake of AWS Inferentia chips by users, Amazon offers a designated software development kit (SDK). Prices for those computational resources range from US$0.228/hour to US$4.721/hour, with discounts for multi-year ‘standard reserved instances’, while Amazon’s marketing pitch stresses reduced costs and increased data portability for developers.
Using the term computational envelopment is especially useful in this context as it enables a focus on both company-internal and company-external dimensions of AI’s infrastructural geographies. On one hand, technology giants can leverage their edge when it comes to computational resources and complex artificial neural networks to improve and optimise their own services (e.g. Amazon’s product recommendation algorithm or Google’s advertising systems). On the other hand, they can use those assets to enclave users by acting as ‘gatekeepers’ (European Commission, 2022), without whom it is not possible to build state-of-the-art neural networks in the first place. It is pivotal to consider lead firms in neural production networks not only as infrastructure providers for other actors but also as infrastructure providers for themselves. Beyond merely bringing together different user groups as a multi-sited market, Amazon, Google and Microsoft offer their proprietary AI services, which are typically more prominently advertised than third-party services.
In the following section, I build on those considerations around value to argue that the embeddedness of platform ecosystems is a second dimension to probe how technology giants act as lead firms within AI’s infrastructural geographies.
Embeddedness: Horizontal and vertical integration of ecosystems
Artificial neural networks are already omnipresent in social, economic and cultural life. They power Google’s search engine, Amazon’s product recommendation systems and Microsoft’s speech recognition algorithms. However, the expertise to develop artificial neural networks is not as distributed as their deployment. For lead firms, this concentration of computer science expertise and technological know-how goes hand in hand with two major competitive advantages. On one hand, they are able to attract new scientific staff not only by offering high salaries but also by offering them the opportunity to use superior computational resources. In recent years, there has been a ‘brain drain of researchers from academia to industry, particularly from elite institutions into technology companies such as Google, Microsoft and Facebook’ (Jurowetzki et al., 2021). On the other hand, they compound a ‘privatization of public knowledge’ (Ferrari et al., 2023) by providing AI-as-a-service offerings with the promise to democratise the uptake of artificial neural networks across society.
Amazon, Google and Microsoft provide a range of infrastructure offerings that gravitate around the notion of automated machine learning, abbreviated by AutoML. In the simplest terms, AutoML applies the foundational logic of machine learning (i.e. making predictions on the basis of pattern recognition) to the development of machine learning itself. Different training datasets and application domains require different computational models and algorithms, resulting in a myriad of potential artificial neural network architectures. How should the model’s parameters be fine-tuned? What is the most ideal mathematical weight for each individual neuron? In light of these challenges, AutoML aims to substitute laborious trial-and-error processes for building the most appropriate neural network architecture and creating well-performing AI models by automatically testing a multiplicity of potential training pipelines.
There is not only an abundance of particular algorithms to choose from when building a model, but these algorithms also have a long list of parameters ‘that need to be set “just right” if you want to squeeze every bit of extra accuracy’ (Das et al., 2019: 1). For example, Amazon’s solution to this problem, SageMaker Autopilot, ‘generate[s] a leaderboard of candidate models that the customer can choose from’. SageMaker Autopilot is one of the service features of the machine learning platform, SageMaker, which is a business segment of the cloud computing division, Amazon Web Services. But the crux is that Amazon’s AutoML service only integrates with other services from the same company when it comes to data storage and model deployment components of AI production processes. Understanding the implications of this embeddedness transcends territorial moments of grounding; it requires an expanded conceptualisation of embeddedness that includes platform ecosystems.
In this regard, it is helpful to build on platform studies scholarship that makes a distinction between the horizontal and vertical integration of these ecosystems. On a horizontal level, the embeddedness of Amazon’s AutoML as a part of the SageMaker platform serves to create a ‘lock-in to the platform’s conception of users, functionality, and design values’ (Plantin et al., 2018: 298). Such lock-in effects are key features of the ‘infrastructuralization of platforms’ (Plantin et al., 2018: 295) and therefore represent the strategic aims of Amazon, Google and Microsoft ‘to be the foundational infrastructure’ (Rahman and Thelen, 2019: 180) for AI. On a vertical level, AutoML services are parts of a lead firm’s arrangement of hardware configurations, compute power and data storage capacity, exemplifying what Plantin et al. (2018) call the ‘platformization of infrastructure’ (p. 295). In 2022, Amazon’s data centres were grouped into ‘84 Availability Zones within 26 geographic regions worldwide, with plans for 24 Availability Zones and 8 more AWS Regions in Australia, Canada, India, Israel, New Zealand, Spain, Switzerland and the United Arab Emirates (Amazon Web Services, 2022b).
Against that backdrop, Figure 1 visualises Amazon’s neural production network. As highlighted in the previous section, lead firms are able to cross-subsidise both their research and development efforts (e.g. Amazon Science) and their physical data centre infrastructure based on rentier relations. The fruits of R&D efforts feed into consumer-facing platforms (e.g. SageMaker), which allow users and developers to integrate their datasets and train their own models on top of Amazon’s hardware and software assets via APIs and SDKs. In addition, Figure 1 proposes a distinction between financial flows and data flows to add precision to the linkages within the neural production network. 4 To exclusively see Amazon’s neural production network as a horizontal web of AI services would neglect their territorial moments of grounding. To exclusively see Amazon’s neural production network as a vertical stack of hardware would neglect their software linkages. Instead, its horizontal and vertical embeddedness is inextricably intertwined.
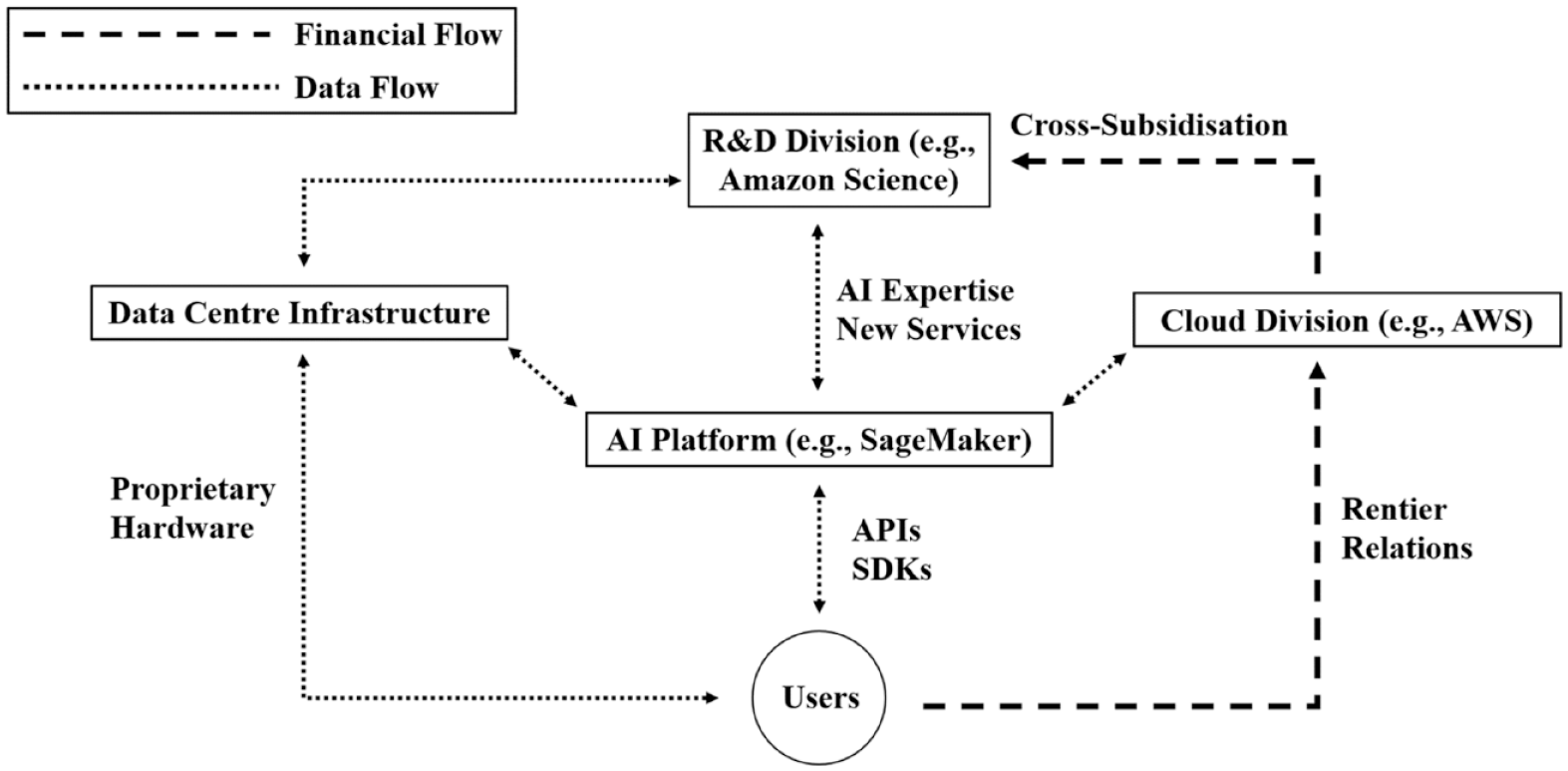
Simplified visualisation of Amazon’s neural production network.
For example, a marketing agency that aims to use AI-as-a-service offerings to analyse social media data could not combine AutoML tools from Amazon and cloud storage from Microsoft. The firm pays Amazon’s cloud division for using SageMaker, its AI platform (Figure 1). While all lead firms marketise their ambition to ‘democratise machine learning’ (Das et al., 2019: 1), their actually existing services are designed to create lock-in effects, whereby users are enveloped within their proprietary ecosystems. In overshadowing this process with emancipatory discourses of democratisation, lead firms not only obfuscate existing rentier relations but also attempt to foster their cross-sectoral expansion. This is how the abstraction of computational envelopment becomes a material reality – one that remains obfuscated by marketing rhetoric.
The discussion of AutoML offerings also raises questions about another form of embeddedness: the embeddedness of proprietary algorithms. In a comprehensive survey of AutoML offerings, He et al. (2021) explain that the challenge of Neural Architecture Search (NAS) is one of the most important research domains. The point of NAS is to search for a ‘robust and well-performing neural architecture by selecting and combining different basic operations from a predefined search space’ (He et al. 2021: 2). But while the deployment of techniques such as NAS is concealed by trade secrets, their existence complicates the study of how lead firms integrate their internal and external infrastructural services. In 2017, Google AI researchers developed reinforcement learning – the technique that later underpinned AlphaGo – for the challenge of NAS. A machine learning approach that was initially used to win against the world’s top Go player might have subsequently underpinned AI-as-a-service products for external clients. Given the complexity of such relations, opening up lead firms to regulatory scrutiny is a difficult task.
This section argued that lead firms in neural production networks do not fully ‘overcome the fetter of space’ (Dyer-Witheford et al., 2019: 52). Instead, they envelop the space of AI’s production activities. By applying proprietary computational techniques in cross-divisional ways, lead firms defy common theories of embeddedness in production geographies. In the following section, I contend that this capability raises sweeping power questions.
Power: Decentralised AI production, centralised AI provision
In terms of how lead firms consolidate their power in neural production networks, there is a tension between two seemingly opposed ends of a spectrum. On one hand, there is the emancipatory narrative of democratisation promoting AI’s benefits by virtue of widening access to hardware and software resources. For example, Google introduces its Google.ai platform by highlighting that ‘AI can meaningfully improve people’s lives and the biggest impact will come when everyone can access it’. On the other hand, lead firms boast about the powerful clients that use their paid AI-as-as-service offerings. Amazon Science (2020) promotes that ‘NASA is working with the Amazon Machine Learning Solutions Lab’. How can this contradiction be disentangled?
Building on the combined insights of the previous two sections, I argue that lead firms consolidate their power by decentralising the production of AI and centralising the provision of AI. Proving the relationship between decentralisation and centralisation is of great relevance for disentangling the double discourse of technology giants as lavish enablers of user empowerment and providers for powerful organisations such as NASA. To develop this argument, it is worth considering the strategic motives of lead firms to make certain infrastructure offerings freely accessible to users.
In February 2017, Google released a freely accessible version of its TensorFlow framework, which used to be a proprietary software package. TensorFlow contains a wide range of components and modules, from packages for simplifying the creation of artificial neural networks to integrating these models into Google’s cloud computing infrastructure. TensorFlow acts as a field of action for producing AI systems, enabling and constraining the agency of developers when using it to build their own models. While my focus is not on TensorFlow’s technical details, it is worth stressing Google’s rationale for making the software freely accessible in the first place. The relevant literature on this topic suggests two main explanations for Google’s strategy. Dyer-Witheford et al. (2019) contend that open-source frameworks such as TensorFlow actually ‘act as ‘on-ramps’ to the proprietorial infrastructures of large AI companies’, luring in potential clients for the generation of rentier relations (p. 55). Srnicek (2020) adds a slightly different aspect, by arguing that free software such as TensorFlow is useful for lead firms insofar as it helps to ‘build up a community of developers trained in a company’s workflow and tools’. Both claims deserve attention.
To start with the first explanation, at the heart of this mode of reasoning is the problem of interoperability. This term can be defined as the ability of computer systems or software to exchange and make use of information. As a result of this, lead firms have an economic interest in consolidating their power by preventing users to switch between providers. Despite its open-source nature and the discursive portrayal through Google as a harbinger of access to AI for everyone, TensorFlow remains embedded in Google’s proprietary ecosystem. For example, TensorFlow allows its users to train their models on TPUs, with Google prominently advertising the computational benefits of making use of this paid service. Seen this way, tracing the link between open-source tools and neural production networks offers a glimpse behind the shiny façade of democratisation imaginaries in order to consider them as integral features of the consolidation of power. Nevertheless, this power is not hegemonic or all-encompassing, given that users have made use of TensorFlow’s affordances in ways not intended by Google’s designers. A prominent example to underpin this argument is FakeApp, a user-generated software ‘that uses Google’s TensorFlow machine learning to morph faces in videos’ (Robertson, 2018). In 2018, the software generated significant media attention it was used to face-swap celebrity faces onto porn performers’ bodies as featured in videos that were circulated on Reddit. While much scholarship mushroomed around deep fakes, TensorFlow’s role as the foundational infrastructure often remains a footnote. As such, what do the efforts of lead firms to foster the widespread adoption of AI imply for how power operates in neural production networks?
To answer this question, the second explanation as to why lead firms offer free AI software – the aim of building a community of developers – provides useful hints. By circulating their open-source AI tools as widely as possible, lead firms put themselves in a position in which they can influence economic, social, cultural and educational outcomes in ways that go beyond the provision of a service in exchange for money. As Gershgorn (2018) explains, there are recursive forces at play as well, given that ‘people outside the company find and fix [TensorFlow’s] bugs, and students are being taught on the software in undergrad and PhD programs, creating a funnel for new talent that already know the company’s internal tools’. This manifestation of power destabilises a quintessential assumption of global production network scholarship: the idea that lead firms bring a clearly definable economic output into being – irrespective of whether that is a natural resource or a physical commodity.
On the contrary, it is notoriously difficult to delineate the market in which those lead firms actually operate. This analytical vagueness enables Amazon, Google and Microsoft to downplay their power when they need to. For example, when asked about Amazon’s dominance as a provider of cloud computing, the company’s UK director of public policy declared during a House of Lords session on Internet regulation that ‘there is such enormous competition and speed, and there is a difference between dominance and prevalence’ (Donnelly, 2019). This anecdote typifies Srnicek’s (2020) argument that ‘the inability to theoretically pin down a relevant market has led these companies to routinely argue that they in fact occupy only a small portion of the market’ (p. 87). As a result of such discursive manoeuvres, it is not straightforward for regulators to find effective ways to push back against the market power of a handful of lead firms.
In neural production networks, this discursive downplaying of power is further complicated by open-source tools such as TensorFlow. When Google’s involvement in Project Maven made headline news, a company spokesperson quickly emphasised that ‘this specific project is a pilot with the Department of Defence, to provide open source TensorFlow APIs that can assist in object recognition on unclassified data’ (Conger, 2018). The spokesperson made it sound as if there was no economic incentive for Google to engage in the project, given TensorFlow’s open-sourced nature. However, as leaked emails by company executives indicate, ‘Google’s business development arm expected the military drone artificial intelligence revenue to ramp up from an initial $15 million to an eventual $250 million per year’ (Fang, 2018) – an opportunity that Amazon and Microsoft were also keen to secure. After protests by Google employees had forced the company to cancel the contract, Microsoft released a public statement stressing its support of the Pentagon – and ended up winning a US$10 billion cloud computing contract in 2019, outcompeting Amazon. Nine months after Amazon’s UK public policy director downplayed the firms’ dominance, an Amazon US spokesperson said: ‘We’re surprised about this conclusion [i.e., Microsoft winning the contract]. Amazon Web Services is the clear leader in cloud computing, and an assessment purely on the comparative offerings clearly led to a different conclusion’ (Simonite, 2019, my emphasis). This case unveils two insights. First, the operations of lead firms in neural production networks as AI-as-a-service providers are directly linked to their dominance as cloud computing providers. Second, the ways in which lead firms articulate their own power are entirely dependent on whether it is beneficial to tactically downplay it or not.
Consequently, their double discourse as providers of open-source software and infrastructural backbones of potent clients appears in a new light. When signalling their infrastructural role, lead firms have a strategic interest in putting a discursive emphasis on decentralised production of AI, while downplaying the provision of AI. Instead of marking two opposed ends of a spectrum, there is a recursive relationship between those practices. For example, without receiving valuable bug fixes from thousands of users due to TensorFlow’s open-source nature, Google might not have been in a position to improve its software. Representing an example of platform-based network effects, if more clients make use of lead firms’ paid services, more profit can be used to cross-subsidise their unpaid AI-as-a-service offerings: a virtuous circle.
Conclusion: The ramifications of neural production networks
Companies such as Alphabet, with a market cap in the neighbourhood of three quarters of a trillion dollars, have claimed to be neutral arbiters and spaces of informational exchange. No one really believes that anymore, but we lack language to grasp the way these platforms collapse profit and the social, culture and capital.
Writing in the Los Angeles Review of Books, Weatherby (2018) contends that there is a need for new conceptual vocabulary to account for the role of platforms as paradigm-shifting forms of industrial organisation. I respond to this call for theory building by elucidating a distinct manifestation of platformised industrial organisation: the rise of neural production networks. But beyond their manifestations studied in this article, expounding a new understanding of those distinctly neural spaces of production also motivates a plethora of opportunities for future research. Much more is there to investigate if we take seriously the argument of this article that established ways to imagine border-crossing economic networks need to be reworked to account for the discontinuities of a world mediated by artificial neural networks. The ubiquity of artificial neural networks in facilitating the development of new products and markets for AI-driven applications (e.g. ChatGPT or Stable Diffusion) is not a hypothetical future scenario, but a realistic assessment of the here and now.
Those products and markets will continue to depend on computational resources, with rising demands for processing power. In future years, computational envelopment will take different forms and shapes, and it is important to consider those processes as what they are: ways to solidify economic dominance. Analytically speaking, the most important task for future research is to maintain an ‘awareness of essential things [that] so quickly fades into “beaten paths of impercipience”’ (Peters, 2015: 31). By leveraging their proprietary computational resources both as a gateway to underpin company-internal research and a gatekeeping tool to create user lock-ins, lead firms consolidate their power in ways that go beyond what can be captured with quantitative metrics such as market shares or financial statements. A more comprehensive analysis of lead firms is required – one that transcends the dimension of platform economics.
The infrastructural dominance of lead firms in neural production networks raises sweeping questions about their cultural ramifications. If it is not primarily the relative or distance between territorial sites of production and sites of consumption that constitutes the cultural impacts of AI’s production geographies, what else does? How can artificial neural networks be seen as geographical objects of study without fetishising them as deterministic drivers of cultural change? As Castree (2001) notes, in their efforts to rejuvenate the Marxian critique of commodity fetishism, scholars followed an ‘urge to ground commodities in a specific site and a particular constituency: namely, the site of production and the constituency of spatially dispersed labour’ (p. 1520). However, a problem with this tendency is that ‘the trope of ‘unveiling’ not only underplays the positivities of consumption but – as Jean Baudrillard showed – also fails to take seriously the semiology of commodity surfaces’ (Castree, 2001: 1520). A narrow perspective on the territorial journeys of commodities risks legitimising the objects of its critique. Along similar lines, a narrow focus on the computational journeys of artificial neural networks risks legitimising the objects of its critique. Artificial neural networks do not only shape cultural practices – they are also shaped by cultural practices (Ferrari and McKelvey, 2022). They should not be seen as inevitable computational forces with intrinsic values, but as modifiable governance objects that are embedded in particular empirical industry contexts.
In recent years, a range of scholars has argued that we witness a dissolution of the commodity form in certain industries – a development that coincides with changing cultural practices. Bernevega and Gekker (2022) argue that modern video games, such as the highly successful free-to-play online game Fortnite, are ‘neither produced nor monetized as a commodity’ (p. 53). Instead, game studios aim to extract value from micro-transactions, whereby players buy virtual assets to equip their avatars with fancy clothes or eccentric hairstyles. These virtual assets are computationally reproducible and thus extremely profitable sources of revenue for game producers. This argument, however, is by no means restricted to games. As Sadowski (2019) states, ‘the surge of companies that describe themselves as ‘Uber-for-X’ or ‘X-as-a-service’ – whether start-ups in search of funding or incumbents looking to rebrand – are creating rentier relations by another name’ (p. 6). This interplay between economic interactions and cultural practices inspired the idea of neural production networks.
A shift in focus from territorial expansion to computational envelopment is also reasonable when it comes to questions of regulation. This crucial area points to the relationship between conceptual abstraction on the one hand and regulatory intervention on the other hand. Far from being restricted to scholarly debates, ideas emanating from economic geography had direct impacts on regulatory frameworks around the world. For example, the idea of ‘global value chains’ fed into numerous corporate disclosure and due diligence laws on the social and environmental impacts of economic production (Salminen and Rajavuori, 2019). Importantly, such laws apply to lead firms even if their actual production activity takes place outside a specific jurisdiction that enforces such regulations. Theorising that there are global value chains has been a prerequisite not only for researching their problematic outcomes but also for appraising the efficacy of regulatory proposals, which aim to mitigate those outcomes. Abstraction is thus a means of regulating AI’s infrastructural geographies, making them ‘available for manipulation and management’ (McCormack, 2012: 722).
Along similar lines, theorising that there are neural production networks will be a prerequisite not only for studying how lead firms consolidate their dominance but also for appraising the efficacy of regulatory frameworks, which aim to curb this dominance. This task goes beyond emphasising the mismatch between the national or regional scale of some regulatory frameworks and the border-crossing scale of production activities, which complicates the implementation of effective regulatory regimes across the globe (Salminen and Rajavuori, 2019). Beyond such considerations of scalar mismatches, the notion of neural production networks also affords the possibility to theorise the complex positioning of states as co-creators of AI’s infrastructural geographies. For example, with the Artificial Intelligence Act, the Digital Markets Act, and the Digital Services Act, the European Union (EU) establishes itself as a key geopolitical actor in the field of digital policy. But such regulatory frameworks have not yet been systematically contrasted with empirical findings on how technology giants act as lead firms in neural production networks – although production network scholarship provides useful anchor points to conceptualise different state roles (Horner, 2017).
Neural production networks are already diffusing into all manners of seemingly disconnected directions. As they come to infiltrate ever-more economic, political and cultural spheres, locating them in time and space will be challenging. They will shape things and processes that we can neither anticipate nor envision. But just because their diffusion is unpredictable, this does not mean that it cannot be theorised. Tracing their movement requires new understandings of production geographies.
Footnotes
Acknowledgements
An early version of this article has been presented at the 2020 conference of the American Association of Geographers in a session on ‘What to Do with Artificial Intelligence? Methods, Epistemology and Emerging Technologies’. Many thanks to Jamie Winders and Margath Walker for organising the session and to Ryan Burns for helpful feedback. The article also benefitted from constructive feedback by Mark Graham, Derek McCormack, Jonathan Gray, Jean-Christophe Plantin, the editors of EPF and the two anonymous reviewers.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the Economic and Social Research Council (ESRC) under Grant ES/P000649/1, Studentship No. 2094254, as part of the Grand Union Doctoral Training Partnership (DTP) and the University of Oxford (Scatcherd European Scholarship). Financial support also came from Dutch Research Council (NWO) as part of the Spinoza Prize awarded in 2021 to José van Dijck (Utrecht University).