
Abstract
Keywords
Introduction
The wisdom of the crowd idea is the claim that crowds can be smart even when their members are not (Becker et al., 2019). This broad idea has been made precise in two different ways: that the crowd’s aggregate opinion is better than that of its “average member” (see, e.g., Galton, 1907; many examples in Surowiecki, 2004; Davis-Stober et al., 2014), and that the aggregate opinion is better than that of even the crowd’s best (most expert or accurate) members (Hong and Page, 2004, 2025; Page, 2007; Prelec et al., 2017). While there is some evidence for both claims (see, e.g., the books by Surowiecki and Page), there is also evidence against the wisdom of the crowd idea generally (in that there is evidence even against the weaker, better-than-average reading). It has been found, for instance, that social influence can lead to herding and thus reduce collective accuracy (Lorenz et al., 2011; but cf. Navajas et al., 2018).
The mixed evidence has raised interest in the conditions under which crowds can be expected to be wise (e.g., the degree to which the opinions of members can be correlated or the presence of different kinds of bias; see Davis-Stober et al., 2014). Here, we are interested in a different question, having to do with the aggregation method that is used to extract wisdom from a crowd. Much research on crowd wisdom only considers the simple average (i.e., the arithmetic mean) as an aggregation method. In this paper, we go beyond that by considering a range of increasingly more sophisticated aggregation methods and testing them empirically, using a large dataset of probabilistic judgments from 376 participants on 1200 statements with known ground truth. Our results show that we can achieve different levels of crowd wisdom, some even yielding estimates that top those, not just of the “average,” but of the best participant.
In a preliminary stage, we conduct a baseline analysis by considering the simplest possible generalization of the standard approach to crowd wisdom, also looking at the geometric and harmonic mean. In the first real stage, we move to weighted averages, finding optimal weights for each participant. The main contributions of this paper are to be found in the second and third stages. In the second, we consider iterated averaging via a known model of opinion dynamics, specifically, the Hegselmann–Krause model (Hegselmann and Krause, 2002). And in the third stage, we go beyond predefined formulas and train two types of neural network to learn an optimal aggregation function directly from the data. We find that most methods do better than the average participant but that only the neural network aggregators outperform every individual participant.
We start by detailing the hierarchy of opinion aggregators we compare (Sect. 2), before presenting our empirical results (Sect. 3). As we will show, the method of aggregation is a decisive factor in determining the stage of wisdom a crowd can achieve. Finally, we discuss the broader implications of these findings, also pointing out some limitations of our work and mentioning some avenues for further research (Sect. 4).
Aggregators
“Wisdom of the crowd” is the heading for a broad thesis that is generally taken to apply to very different types of judgments. Classic examples include aggregate estimates of continuous quantities like the weight of an ox (Galton, 1907) or the height of the Eiffel tower (Navajas et al., 2018), but also aggregate categorical predictions—for instance, concerning which candidate will win an election—and rankings, such as ordering items by preference or quality (e.g., Landemore, 2012). Our data consist of probability judgments, and so we will be specifically interested in whether aggregating probability judgments—using various aggregation methods—yields “better than average” or even “better than best” probabilities. Naturally, this has consequences for which aggregators we consider; for instance, we do not consider voting rules, which operate on categorical judgments. Here are the aggregators to be considered in our study:
Simple averages
What is commonly referred to as “the average” is only one member of a family of means, sometimes called the f-means and defined as follows (Bullen, 2003, p. 266):

If we let f be any linear function (e.g., the identity function), this yields the arithmetic mean; if we let f be the logarithmic function, we obtain the geometric mean; and if we let f be the reciprocal function, we get the harmonic mean. These are arguably the best known means, and we consider them all. In addition, we consider the log-odds mean, which is the instance of the above schema with f the logit function (and so f−1 the logistic function), given that it has been advocated as the normative standard for probabilistic aggregation under the assumptions that individual judgments are conditionally independent and well-calibrated (see Genest and Zidek, 1986; Morris, 1983;).
Weighted averages
A still broader family of means are the weighted f-means, defined as

Dynamic aggregation
The Hegselmann–Krause model
Moving beyond static aggregation methods, we implement a modified version of the Hegselmann–Krause (HK) model of opinion dynamics (Hegselmann and Krause, 2002). Originally developed to study consensus formation and polarization in social networks, the HK model treats opinion aggregation as an iterative process in which agents update their opinions based on those of others that are “similar enough” to them (their “peers”).
1
More specifically, the model considers a community V of agents whose opinions can all be represented by a real number in the unit interval. At each iteration, an agent updates its opinion by averaging those of its peers at the given iteration, where peerhood is formalized through the notion of a bounded confidence interval (BCI). An agent i’s BCI encompasses those agents whose opinions differ from i’s own opinion by no more than some value ϵ
i
∈ [0, 1], referred to as agent i’s confidence bound. Formally, at each iteration s, an agent i updates its opinion according to
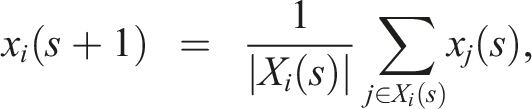
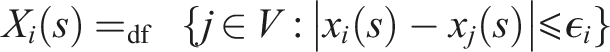
Note that in the standard HK model, every agent is always one of its own peers and also that, when updating, its opinion has exactly the same weight as those of its peers. As Fu et al. (2015) argue, that is not always realistic. In reality, we will often want to attach more weight to our own opinion, even if we also want to take into account those of others. They therefore propose a modification of the HK model in which each agent i is characterized by two parameters: α
i
∈ [0, 1] and ϵ
i
∈ [0, 1], where the former regulates the self-weight in opinion updating (i.e., how much weight the agent gives to its own opinion relative to the weight assigned to the average of its peers’ opinions) and the latter is again the threshold for peer selection based on opinion distance, although now the agent itself is excluded from counting as a peer. Their model then iteratively updates opinions according to

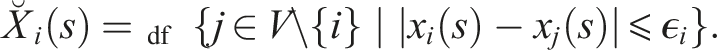
As presented here, both (HK) and (MHK) are one-dimensional models. However, opinions in the real world are rarely isolated. As a result, an individual’s belief state is best represented as a vector in a multi-dimensional opinion space. The Hegselmann–Krause framework was explicitly meant to be extensible to such multi-dimensional cases (Hegselmann and Krause, 2002), and various multi-dimensional extensions have been proposed and analyzed (Amblard and Deffuant, 2004; Chen et al., 2019; Deffuant et al., 2000; Douven and Hegselmann, 2022; Fortunato et al., 2005; Huet et al., 2008; Lorenz, 2007, 2008). These models generalize by replacing the one-dimensional opinion distance |x
i
− x
j
| with a multi-dimensional distance metric d (x
i
, x
j
) over the opinion vectors. We adopt this approach, applying it to the multi-dimensional generalization of (MHK). Specifically, we define the distance between two agents as the mean squared difference between their probability judgments across all 1200 claims:

This distance matrix, which reflects systematic patterns of agreement rather than claim-specific proximity, determines peerhood: agent j is a peer of agent i if and only if d ij ⩽ ϵ i . Importantly, we recompute this distance matrix at each iteration based on agents’ current (updated) probabilities, so that peer relationships can evolve as opinions converge.
Finally, while the first clause in Fu and colleagues’ model takes a weighted sum of the agent’s own opinion and the arithmetic mean of its peers’ opinions, one could use other means here. In our study, we consider again, next to the arithmetic mean, the geometric and harmonic means, 2 as well as the log-odds mean. For each of these four averaging variants, we optimize the 2N parameters (α i and ϵ i for each of N = 376 participants) on training data using multi-objective evolutionary optimization targeting both Brier score minimization and accuracy maximization (see below).
Neural network aggregators
Finally, we go beyond predefined aggregation formulas to allow machine learning models, specifically artificial neural networks, to learn optimal aggregation functions directly from the data. We implement two architectures: Multilayer perceptron (MLP): The MLP we will use consists of three fully connected layers with sizes 376 → 64 → 32 → 1, where 376 is the input dimension (corresponding to the number of participants), and the two hidden layers have 64 and 32 units, respectively. We use ReLU activation functions for the hidden layers and a sigmoid activation function for the output layer to ensure probability outputs. To avoid overfitting, we incorporate dropout regularization with a rate of 0.2 after each hidden layer. The network will be trained using the Adam optimizer with a learning rate of 0.001, minimizing binary cross-entropy loss over 25 epochs with a batch size of 16. Long short-term memory (LSTM) network: In our study, the recurrent architecture consists of two stacked LSTM layers with hidden sizes 32 and 16, respectively, taking as input sequences of vectors of dimension 376 (corresponding to the number of participants). The final LSTM layer is followed by a dense output layer with sigmoid activation. We will process each input through the network for 5 time steps, allowing the model to iteratively refine its predictions. This is meant to reflect somewhat the iterative updating that occurs in the MHK model. We use the RMSProp optimizer with default parameters, training for 25 epochs with the same batch size and loss function as the MLP.
We selected these relatively simple architectures after preliminary experiments showed that larger networks did not provide additional benefit on this task, probably due to the limited training data (960 claims, being 80 % of the 1200 claims on which the dataset was based; see below). Both neural networks were implemented in Julia using the
Study
Materials and procedure
To test the various aggregation methods, we reanalyzed data from Stinson et al. (2025), which consist of probabilities assigned by 376 participants to 1200 general knowledge claims with known ground truth (e.g., “The first handheld calculator was built before 1975,” “Mexico was the main trading partner of the US in the 1990s”). The claims fall into six categories (history, geography, science, sports and leisure, social sciences and politics, arts and entertainment), with 200 claims per category, 100 of which are true and 100 false. Participants evaluated the claims in six online sessions, in each of which 200 unique claims were presented, in an order randomized per participant. Participants were not informed of the base rate. 3
As mentioned, that our data consist of probability judgments has consequences for which aggregation methods we can consider. At the same time, it has consequences for how to measure performance and thus how to determine whether one aggregator is better than another. For this purpose, we used two well-known criteria: (i) accuracy (or classification correctness), which is the proportion of binarized probabilities (true if
To ensure that our results are generalizable, we divided the 1200 claims into a training set (80 %) and a held-out test set (20 %). The final performance of all aggregators is reported on the test set.
For the models requiring optimization—the weighted averages and the MHK models—parameters were fit exclusively on the training set. To do this, we used a multi-objective evolutionary algorithm, specifically the Borg MOEA (Hadka and Reed, 2013). 4 In our case, the objectives for the algorithm to simultaneously optimize were minimizing the aggregate Brier score and maximizing the aggregate classification accuracy. The algorithm evolves a population of “candidate solutions” (i.e., vectors of parameters) over many generations to discover a set of non-dominated, or Pareto-optimal, solutions. However, it turned out that our objectives were sufficiently aligned that optimization consistently converged to a single Pareto-optimal solution rather than a frontier of trade-offs. 5
To assess the stability and uncertainty of our models’ performance, we employed validation procedures appropriate to each model’s structure and computational cost. For the simple and weighted averaging methods, as well as the MHK models, we conducted a bootstrap analysis by repeatedly resampling the 376 participants with replacement from the test set (N = 1, 000 resamples for simple/weighted averages; N = 500 for the MHK models) and recalculating the performance metrics. For the neural network models, we assessed stability by training each architecture 100 times from different random initializations and we report the mean and standard deviation of the performance on the test set. This mixed-method approach to validation provides robust uncertainty estimates while remaining computationally feasible, given that a full bootstrap re-optimization was, at least for the more complex models, computationally much too costly. 6
For the optimization of the parameters of the MHK model, we simulated the model for 100 iterations within each call of the objective function. As can be seen in the Supplemental Materials, analysis of the full opinion dynamics over 250 iterations revealed that both the Brier score and accuracy of the aggregate opinion largely converge within the first 100 iterations. Extending the simulation during the optimization phase would have substantially increased the computation time with little expected improvement in the quality of the discovered parameters. In the bootstrap procedure for this model, we chose the same number of iterations.
Results
The performance of all 11 aggregation procedures on the held-out test data is summarized in Figure 1. The results reveal a clear trend: as the sophistication of the aggregation method increases, collective performance, measured by both mean Brier score (lower is better) and classification accuracy (higher is better), improves. Mean Brier score (left panel, lower is better) and mean classification accuracy (right panel, higher is better) for 11 aggregation methods on the held-out test set. Methods are grouped by type: simple unweighted averages (blue), optimized weighted averages (orange), MHK dynamic models (green), and neural networks (pink). Error bars represent 95 % confidence intervals from bootstrap analysis (for the first three groups) or ±1 standard deviation from 100 independent training runs (for the neural networks). Horizontal lines indicate the performance of the average individual participant (dashed) and the best individual participant (dotted) in the test set (where the best individual was different for the two criteria). The results show a clear trend of improving performance with increasing aggregator sophistication, culminating in the neural networks, which are the only methods to do better than the best individual on both criteria.
Pre-stage: Simple averages
We first established a baseline using simple, unweighted f-means (blue bars in Figure 1). In this category, the geometric mean (GM) emerged as the winner, achieving a mean Brier score of 0.143 (95 % CI [0.139, 0.148]) and an accuracy of 0.829 (95 % CI [0.806, 0.853]). The other three means performed significantly worse, on both criteria (as confirmed by a series of t-tests, with all ps < .0001 and all associated effect sizes, measured via Cohen’s d, being large). While the log-odds mean is often considered a normative benchmark (Morris, 1983), that it does not come out on top here simply suggests that the model’s core assumption—that individual judgments are well-calibrated and conditionally independent—are violated in our data set, which is a common issue with real-world human data (Genest and Zidek, 1986). Nevertheless, the arithmetic, geometric, and log-odds means all support the “better-than-average” claim of crowd wisdom, as their performance exceeded that of the average individual participant (dashed line). However, none of these simple aggregators approached the performance of the crowd’s best individual member (dotted line). 7
Stage I: Weighted averages
In the first stage of sophistication, we used the Borg MOEA evolutionary algorithm described above to find an optimal set of weights for each participant, moving from equal to differential weighting (orange bars). An optimization procedure was run for each of the arithmetic, geometric, harmonic, and log-odds means. The optimally weighted geometric (wGM) and log-odds (wLog) means were ex-aequo winners, the former doing significantly better than the latter with respect to accuracy (0.841, with 95 % CI [0.818, 0.865], vs 0.8, with 95 % CI [0.774, 0.829]; t < .0001, d = 5.35), while for the other criterion it was the other way around (0.14, with 95 % CI [0.131, 0.146] vs 0.141, with 95 % CI [0.136, 0.147]; t < .0001, d = 0.83). Both weighted means achieved a significantly better mean Brier score than the simple geometric mean, as confirmed by two t-tests (p < .0001 for both, with Cohen’s d equal to 1.75 for wGM and equal to 2.31 for wLog), and the weighted geometric mean (but not wLog) also achieved a significantly higher accuracy than the simple geometric mean (t < .0001, d = 0.59). The other two optimally weighted averages did significantly worse than the weighted geometric and log-odds means but significantly better than their unweighted counterparts. Overall, the results confirm that even a simple form of data-driven optimization—learning to give more influence to some participants—can extract additional wisdom from the crowd. 8 Interestingly, correlations between, on the one hand, optimal weights for any of the means and, on the other, either participants’ accuracy or their average Brier score was invariably low, with all |r| < .32.
Stage II: Dynamic aggregation
In the second stage, we moved from static aggregation to a dynamic, iterative process modeled on social learning, using the modified Hegselmann–Krause (MHK) model introduced earlier (green bars). As mentioned, we used the Borg MOEA algorithm to find optimal α and ϵ values for the participants, running a separate optimization procedure for each of the means of interest.
The shift to iterative averaging produced a significant leap in performance. The MHK model that used the log-odds mean to average peer opinions (HK-Log) achieved the lowest Brier score in this group at 0.119 (95 % CI [0.0912, 0.151]), an improvement that was statistically significant compared to the (on this criterion) best weighted average model wLog (p < .0001, d = 2.74). On the other hand, the MHK model using the geometric mean did best on the other criterion, achieving an accuracy of 0.872 (95 % CI [0.841, 0.899]), which was a significant improvement over the (on this criterion) best weighted average model wGM (p < .0001, d = 3.1). These results indicate that modeling a structured social interaction, where agents update their beliefs based on a network of trusted peers, is a more powerful mechanism for aggregation than static weighting alone. The underlying opinion dynamics of this process is illustrated in the Supplemental Materials.
Similar to the correlation analysis in the first stage, we checked whether there was a relation between the optimal α and ϵ parameters for the given means and the participants’ accuracies and average Brier scores running a linear regression with either α parameters or ϵ parameters as dependent variable, and with accuracies and average Brier scores as predictors, also including ϵ parameters (when α parameters were the dependent variable) or α parameters (when ϵ parameters were the dependent variable) as covariate. In none of these regressions did any of the predictors turn out to be significant.
It is further noteworthy that the optimized MHK parameters revealed substantial heterogeneity across participants. The Supplemental Materials contains plots of the various distributions, showing that both α and ϵ parameters span nearly the full [0, 1] range for all pooling variants, with no strong clustering patterns. This indicates that some participants optimally retain high self-weight while others defer substantially to peers, and that some benefit from broad confidence bounds (interacting with diverse others) while others perform best with selective peer groups.
Stage III: Neural network aggregators
In the final stage, we abandoned predefined formulas entirely and trained two neural network architectures to learn an optimal aggregation function directly from the data (pink bars). This approach yielded by far the best performance. The multilayer perceptron (MLP) and the long short-term memory (LSTM) network achieved nearly identical results. The MLP reached a mean Brier score of 0.068 (±0.008) and a mean accuracy of 0.913 (±0.011), while the LSTM network reached a mean Brier score of 0.076 (±0.018) and a mean accuracy of 0.906 (±0.021). On both criteria, the MLP scored significantly better (both ps < .005), but the effect size was small in both cases (both ds < 0.46). However, both network architectures significantly improved, given either of our criteria, over the most accurate MHK model HK-GM (both ps < .0001, d = 2.23 for the MLP, d = 1.58 for the LSTM network) as well as over HK-Log, which is the MHK model with the lowest Brier scores (both ps < .0001, d = 3.95 for the MLP, d = 3.51 for the LSTM network).
It is important to note that the neural network approach is the only one that decisively surpasses the performance of the crowd member with best Brier score and the crowd member with best accuracy, showing that a non-linear aggregator (and perhaps only such aggregators) can reach the “better-than-best” level of crowd wisdom. The similar performance of the two distinct architectures also suggests that this finding is robust and not an artifact of a specific model choice. 9
Discussion
Our study systematically investigated how collective performance depends on the choice of aggregation method. The results present a clear picture: the wisdom that can be extracted from a crowd is not a fixed quantity, but is contingent on the sophistication of the aggregator. Moving from simple averages to optimized weights, then to dynamic social models, and finally to learned functions, we observed a statistically significant improvement in performance at each stage (Figure 1).
The most significant finding is the performance of the neural network aggregators, which provides strong empirical support for the “better-than-best” conception of crowd wisdom (Hong and Page, 2004; Page, 2007). While simpler methods confirmed that crowds can outperform their average member, only a non-linear aggregator was able to synthesize the judgments of 376 individuals into a final prediction that was superior to that of the single best crowd member. This suggests that in settings like ours, where the available inputs are limited to forecasters’ raw probability judgments, the highest levels of collective intelligence may be achievable most readily when (and perhaps even only when) we go beyond predefined formulas and allow an aggregation mechanism to learn complex, non-obvious patterns of reliability and interaction directly from the data. The robustness of this finding, demonstrated by the nearly identical performance of two different neural architectures, further strengthens this conclusion.
The same finding also establishes a conceptual and empirical bridge between the study of collective intelligence in social science and the principles of ensemble learning in machine learning. 10 In that area, it has long been known that combining multiple, diverse models often yields a better performance than any individual model on its own (Breiman, 1996; see also Huang et al., 2024; Schoenegger et al., 2024). Our results show that this principle also holds when the “individual models” are human agents and we conceptualize a crowd as a “human ensemble.” Such ensembles, we saw, can achieve remarkable predictive power if we let the right kind of aggregator learn to optimally combine the judgments of their members.
It is important to acknowledge the limitations of our study, the most notable one being due to the computational cost of our more advanced models. Our validation approach—using population bootstraps for simpler models and multi-seed runs for the neural networks—was a pragmatic response to the fact that a full bootstrap re-optimization would have kept our computer busy for weeks (or would have required spending a small fortune on Amazon’s AWS). While our validation approach provides reliable uncertainty estimates for each model class, allowing for principled statistical comparisons between successive stages, we admit that a full bootstrap re-optimization would be required to validate the stability of the entire parameter-finding pipeline itself. This must be left for future work, hopefully to be carried out with access to greater computational resources.
Moreover, our findings are based on a single, albeit large, dataset of probabilistic judgments where the primary goal was to maximize predictive performance as measured by accuracy and Brier score. We have shown that under these conditions, a learned, non-linear aggregator can decisively outperform all other methods. But what the best aggregation strategy is may be context-dependent, varying with the nature of the task, the structure of the crowd, or the specific goals of the aggregation (e.g., Shinitzky et al., 2025). Future work could compare the aggregators considered in this paper on other datasets, and could also consider their use for other purposes (e.g., if the ultimate goal is to reach optimal group decisions).
Also, while our findings connect with a substantial literature on expert forecast aggregation in decision analysis, this literature has produced numerous sophisticated methods, including contribution-based weighting that estimates forecasters’ marginal contributions to accuracy (Budescu and Chen, 2015), IRT-based models that jointly estimate item difficulty and forecaster ability (Bo et al., 2017), and regularized approaches to learning forecaster-specific parameters (Satopää, 2022). Our study is not intended as an exhaustive benchmark of all available aggregation methods. Rather, our goal was twofold: first, to introduce a new application of bounded-confidence opinion dynamics to probability aggregation, showing that the Hegselmann–Krause model—originally developed to model social influence—can serve as an effective aggregation mechanism; and second, to show that neural networks can substantially outperform both classical aggregation methods and our HK-based approach. Nevertheless, a systematic comparison across the full range of proposed aggregators (and then ideally, as just mentioned, also using multiple datasets) would be a fruitful project.
As a further avenue for future research, we mention that prediction markets offer a unique opportunity for real-world validation of our aggregation methods. Suppose that we still had access to the participants in the study reported in Stinson et al. (2025). Then we could try to recruit them again, now for forecasting tasks, and aggregate their predicted probabilities using our trained neural networks. In a next step, these aggregated forecasts could be tested against market prices on platforms such as Polymarket (https://polymarket.com/) or Metaculus (https://www.metaculus.com/). If trades based on these aggregated predictions were consistently or mostly profitable, that would be strong evidence that sophisticated aggregation can uncover information that even efficient markets miss. 11
Our approach of improving collective performance by using increasingly more sophisticated aggregators is to be distinguished from, yet complementary to, another tested strategy for improving collective performance, viz., improving the quality of judgments through structured social interaction. For instance, Navajas et al. (2018) showed that allowing small subgroups to deliberate and form a consensus before averaging these consensus estimates also produces an aggregate that is superior to the traditional wisdom of large crowds. Note that their “procedural” solution improves the inputs to aggregation, while our “algorithmic” solution improves the aggregation function itself. An interesting avenue for future research would be to combine these approaches: first, to use deliberation to generate higher-quality initial judgments and then apply a learned aggregator, such as a neural network, to optimally combine those refined judgments.
In summary, our findings argue for a shift in perspective. Rather than asking whether crowds are wise, or under what conditions they are wise, we asked how their wisdom can be unlocked. Our results suggest that the limits of collective intelligence often lie not in the crowd itself but in the tools we use to listen to it. At least as far as our data go, we can conclude that, by recruiting more sophisticated aggregation methods, it is possible to progress through distinct stages of crowd wisdom, ultimately achieving a collective intelligence that goes beyond the abilities of any individual member.
Supplemental material
Suppplemental Material - Three and a half stages of crowd wisdom
Suppplemental Material for Three and a half stages of crowd wisdom by Igor Douven, Nikolaus Kriegeskorte, Patrick Stinson in Collective Intelligence
Footnotes
Acknowledgments
We are indebted to Christopher von Bülow and two anonymous referees for valuable comments on previous versions.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Significance statement
When groups of people make predictions—about election outcomes, economic trends, or scientific questions—their combined judgment is often surprisingly accurate, a phenomenon known as the “wisdom of the crowd.” But how should we combine individual opinions into a collective prediction? Most research simply averages them. We show that this choice matters enormously. Using a dataset of 376 individuals’ probability judgments on 1200 factual claims, we compared aggregation methods of increasing sophistication: simple averages, optimized weighted averages, a dynamic model of social learning, and neural networks. Performance improved at every step. Simple averages outperformed the typical individual but fell short of the crowd’s best member. Optimized weights and a dynamic model based on bounded-confidence opinion dynamics—where individuals iteratively update their beliefs by attending to like-minded peers—pushed performance further. Neural networks, which learn an aggregation function directly from data, surpassed even the single best individual in the crowd, achieving a level of collective accuracy that no predefined formula could match. These findings reframe crowd wisdom not as a fixed property of a group but as something that can be unlocked to different degrees depending on the aggregation method employed. For basic science, this establishes a conceptual bridge between collective intelligence research and ensemble learning in machine learning, showing that human crowds function as “human ensembles” whose potential is constrained by how we listen to them.
Supplemental material
Supplemental material for this article is available online.
Supplementary Materials, containing the Julia code (Bezanson et al., 2017) used for the simulations and analyses we report, can be downloaded from this repository: ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.