
Abstract
In social learning models, truth-seeking agents learn both individually from direct evidence and socially by pooling beliefs with others. That learning can be undermined by two types of unreliable agents: zealots, who do not learn and promote the same fixed opinion and free riders, who lack access to evidence yet still influence others. In this paper, we explore how learning rules that incorporate memory can mitigate the effects of unreliable agents. To do so, we construct an agent-based model of social learning in which agents apply a probabilistic bounded confidence (BC) model that evaluates the similarity between themselves and others based on samples of recent beliefs rather than current beliefs only. When compared to a memoryless BC benchmark, BC with memory proves significantly less sensitive to the choice of similarity threshold governing agent interactions, to the extent that a fixed threshold is effective for avoiding all types of zealots. It is also less susceptible to high levels of distrust in evidence. The BC with memory model is then extended to social learning about multiple hypotheses, and we show that the robustness results generalise to the case in which beliefs are multi-dimensional probability distributions.
Introduction and background
Large interconnected populations can exploit social learning to share limited information, to compensate for noise, and to reach consensus about the state of the world (Heyes, 1994). For example, in certain species of social insects multiple signals from individuals are aggregated to inform collective decisions about potential nest sites or food sources (Galef and Laland, 2005; Leadbeater and Chittka, 2007). Social learning is also a fundamental part of all human societies and is a key driver of cultural evolution (Boyd et al., 2011). Furthermore, there is a growing interest in its application to the design of swarm robotics and multi-agent systems (Crosscombe et al., 2017; Valentini et al., 2017; Ndousse et al., 2021).
Social learning is often studied in terms of the interaction between two processes: individual learning in the form of updating from direct evidence and social interactions in which beliefs are fused or pooled. This dual process model has been investigated in a variety of different settings including economics (Jadbabaie et al., 2012), social epistemology (Douven and Kelp, 2011), and multi-agent AI systems (Crosscombe and Lawry, 2016; Lee et al., 2018). Ideally the complementarity of these two processes facilitates the collection and efficient propagation of information, driving population wide consensus, and which in turn can provide a mechanism for error correction in the presence of evidential noise. Here, we focus on a model in which agents’ beliefs are probability distributions and where both processes have natural probabilistic interpretations.
Social learning often leads to useful emergent population level effects such as consensus formation which can be exploited to provide solutions that are robust to environmental noise by harnessing multiple, locally efficient, computations and interactions. However, this can also make populations vulnerable to the presence of certain kinds of unreliable individuals since erroneous information can spread throughout the population resulting in convergence to false beliefs or fragmentation of the population into polarised groups (O’Connor and Weatherall, 2019). For example, recent work on opinion dynamics and swarm robotics has explored the effects of zealots on social learning populations (Karan et al., 2018; Mobilia, 2003). These are stubborn individuals who consistently promote a fixed biased opinion, neither learning from evidence or adapting to the beliefs of their peers. A number of ways have been investigated to mitigate the effects of such agents in collective systems. This includes constraining the structure of the underlying communication network between agents, introducing heterogeneity into the population, and cross-inhibiting highly conflicting opinions (Antonic et al., 2024; Njougouo et al., 2024; Reina et al., 2023). In this paper, we will focus on another well studied approach referred to as bounded confidence (BC), according to which individual agents judge the reliability of opinions expressed by others in the population based on how similar they are to their own.
The overarching research aim here is to identify local learning and updating rules that can facilitate effective social learning across a population of agents, where some individuals are unreliable. In a strong sense such rules are normative and the research has a range of engineering applications in the areas of multi-agent and multi-robot systems. In this context, social learning typically informs collective decision making, where artificial agents or robots explore an environment whilst receiving sensory data and also pooling information received when communicating with their peers. Based on these two sources of information, the aim of social learning is to enable an accurate consensus to emerge about the true state of the world. For example, best-of-n problems (Parker and Zhang, 2009; Valentini et al., 2017) are a widely studied form of collective decision making inspired by the foraging and nest site hunting behaviour of social insects (Franks et al., 2006). Specifically, in best-of-n there are n distinct options of varying but measurable quality. The social learning task is then for the population to reach consensus about which of these options has the highest quality. This challenge has also been extended to that of collectively ranking the n options by quality rather than just identifying the best (Crosscombe and Lawry, 2021; Lawry, 2024a). Other applications of social learning in robotics include anomaly detection (Madin et al., 2024) and collective mapping and classification tasks in which agents must classify different regions of the environment based on local sensing and pooled information (Shan and Mostaghim, 2024).
This normative perspective may also help to shed light on social learning as it occurs in biological systems and human societies. In particular, the advent of social media and the subsequent emergence of large and highly connected social networks has emphasised the problems of misinformation and polarisation in complex systems of this kind (Azzimonti and Fernandes, 2023; Denniss and Lindberg, 2025; Douven and Hegselmann, 2021; O’Connor and Weatherall, 2019). These problems have been widely studied in opinion dynamics where, for example, bounded confidence has been proposed as a driving mechanism that can result in the population converging to multiple different opinions (Bernardo et al., 2024). In light of this, one might ask why bounded confidence would ever arise as a collective behaviour in the first place. A possible reason is that restricting interactions to others with similar beliefs, can help an agent to avoid being misled by unreliable agents of various kinds (Douven and Hegselmann, 2021; Hegselmann and Krause, 2015; Karan et al., 2018; Lawry, 2024b; Mobilia, 2003). However, while bounded confidence can be an effective tool in this context its efficacy can be very sensitive to parameter choice when evaluating similarities (Douven and Hegselmann, 2021) and it can be adversely affected by other factors such as a high level of scepticism in evidence (Lawry, 2024). In this paper we will argue that many of these limitations can be avoided if similarity judgements incorporate memory. Indeed there are a number of studies that emphasise the role of memory when evaluating trustworthiness in human social interactions. For example, Chang et al. (2010) show that in iterated trust games people update their trust decisions based on past interactions with a partner. In addition, in Lee et al. (2016), studies show that adolescents use social information to keep track of others reliable or unreliable behaviour over repeated interactions, adjusting trust decisions accordingly.
In this paper, we extend the model proposed in Lawry (2024), so that agents base their confidence judgements on a sample of recent beliefs rather than just on the current beliefs of each agent with whom they are in contact. This limited exploitation of memory will be shown to greatly enhance the robustness of bounded confidence as a tool for social learning in the presence of unreliable agents. In particular, we will show that the memory-based BC model is much less sensitive to the value of the similarity threshold, and also much less influenced by the levels of evidential mistrust in the population, than memoryless BC. This can help to explain why bounded confidence might be adopted as a robust heuristic to mitigate the effect of unreliable agents in scenarios when individuals can to some extent track beliefs over time. As such it has potential applications in collective decision making where artificial agents are susceptible to malfunction or even malicious outside influence. Furthermore, perhaps emphasising that our reliability judgements about others should be well-informed and made over a period of time, rather than being snap judgements based on latest pronouncements, would go some way to reducing our vulnerability to fake news or to unreliable actors promoting a particular agenda.
As noted above, the original motivation for bounded confidence in opinion dynamics was as part of an explanatory model of how polarised opinions can naturally emerge in a population as individuals repeatedly aggregate their beliefs (Deffuant et al., 2000; Hegselmann and Krause, 2002). In these models, beliefs are represented by real numbers and aggregation is linear. In this setting, bounded confidence is implemented so that each agent evaluates the absolute difference between their belief and that of any one of their peers, judging them to be reliable if that difference value is less than a given fixed threshold. In the absence of any external evidence, and assuming random initial beliefs, then for particular threshold values, the population converges to a number of different belief values, that is, a form of polarisation. Furthermore, the incorporation of truth-seeking behaviours where agents also receive direct evidence about the state of the worlds captures a form of social learning (Hegselmann and Krause, 2006). In this case, for suitable threshold values, BC improves learning in the presence of zealots and also free riders, these being agents who while learning from others do not themselves receive evidence (Douven and Hegselmann, 2021). In contrast to these models where both aggregation and evidential updating are linear, Lawry (2024) introduces an explicitly probabilistic bounded confidence model in which evidential updating is Bayesian and probabilities are aggregated using a log-linear pooling operator. In this setting, bounded confidence can mitigate the effect of zealots, but its effectiveness is reduced in scenarios where agents are highly sceptical about the evidence they receive.
The majority of BC models are memoryless in the sense that confidence judgements are always made only on the basis of agents’ current beliefs. This means, however, that information about the way in which an agent’s beliefs have changed over time is ignored. Such information is nonetheless likely to be highly relevant when attempting to identify certain kinds of unreliable agents. For example, reliable learning agents should be regularly updating their beliefs as new evidence becomes available in contrast to stubborn zealots who will rarely if ever deviate from their established opinions. Existing studies have tended to focus on incorporating memory into BC models by making current judgements of trustworthiness to some extent contingent on similar past judgements (Mariano et al., 2020; Zhang et al., 2018). For example, Giola et al. (2020) propose an opinion dynamics model which takes into account the recent history of agreement or disagreement between individuals such that agents who have agreed in the past will be more likely to also agree also in the future. From a slightly different perspective, Jędrzejewski and Sznajd-Weron, 2018 model the effect of memory on the choice between conformity and independence in opinion formation. In particular, they consider an adaptation of the q-voter model in which conformists choose their opinion so as to conform with a set of q social neighbours if they are unanimous, while independent voters choose their opinion independently of others. The probability of an agent acting as a conformist then depends on the maximum utility they have received in the past while acting as a conformist relative to the maximum utility they have received while acting independently. Furthermore, in terms of performance, Becchetti et al. (2023) show that memoryless opinion dynamics have strict constraints on convergence times but then they present empirical results which suggest that even limited memory can significantly improve convergence time.
There are then also opinion dynamics models that implicitly assume a type of memory in their formulation. The voter model is a popular binary opinion model in which agents choose whether or not to switch between opinions based on the votes of their social network neighbours. A variant of the voting model requiring a simple form of memory has been proposed by Stark et al. (2008) in which the longer an agent has been in one belief state, the slower it is to transition to the other state. Somewhat counterintuitively, this gradual reduction in transition rates at the agent level can result in faster convergence at the population level. The Deffuant-Weisbuch (DW) model is another well studied model of opinion dynamics where beliefs are real numbers and aggregation is linear. In Lorenz and Urbig (2007), different communication strategies in the DW model are investigated. For example, a balancing strategy involves agents who have recently communicated with individuals with high belief values, actively seeking out individuals with low values. Alternatively, curious agents try to identify other individuals whose beliefs are changing in the same direction as their own. Both strategies involve an element of memory since agents must record trajectories of recent beliefs in order to implement them.
The research in this paper differs from that overviewed above in several clear respects. Primarily, while a variety of models of memory in opinion dynamics have been described, none of them are explicitly and directly linked to the similarity measurements underpinning BC. Here, we propose a model in which memory is inherent to such judgements, and this will turn out to fundamentally improve the robustness and hence applicability of BC. Furthermore, in most BC models, agents’ beliefs are either represented as binary states, for example, in the voting model, or as generic real numbers, for example, in the HK or DW models. Instead, here we frame social learning in terms of subjective probabilities applying, what are in this setting, established updating and pooling operations to provide a natural treatment of truth-seeking agents engaged in collective behaviour.
The overarching contribution of the paper is to demonstrate that incorporating memory into a bounded confidence model of social learning can significantly improve its effectiveness as a tool for avoiding unreliable agents of at least two different types. In particular, we introduce a probabilistic model of bounded confidence social learning in which agents evaluate their similarity to others based on samples of recent beliefs rather than just by measuring the similarity between current beliefs. We show that using memory in this way significantly increases the robustness of bounded confidence to the extent that a single value of the similarity threshold constraining agent interactions is effective for all types of zealots. It also makes social learning of this kind much less susceptible to high levels of population wide distrust in evidence than memoryless BC. These factors mean that integrating memory into BC increases its potential applicability in a variety of collective decision making scenarios.
More specifically, the paper makes the following technical contributions as follows: (1) we introduce a measure of similarity between sets of beliefs exploiting an established statistical test; (2) we present an agent-based model of probabilistic social learning in the presence of zealots incorporating memory and compare it to a memoryless benchmark; (3) we extend this binary model to multi-hypotheses by proposing a mapping from high-dimensional beliefs to real values and show that BC with memory continues to outperform the benchmark; (4) free rider agents are introduced into the population which further differentiates between the memory-based and memoryless approaches.
The next section introduces the core components of a probabilistic model of social learning based on the two processes of log-linear probability pooling and Bayesian evidential updating. We then investigate a binary (two hypotheses) agent-based model of BC with memory, exploring social learning performance and robustness with regard to the similarity threshold, agent connectivity, and varying levels of evidential distrust and noise, as compared to the memoryless benchmark described in Lawry (2024). Building on this model we generalise BC with memory to the multi-hypotheses case by introducing a mapping from the multi-dimensional probability simplex to the real numbers and then evaluating the similarity between these projected values. We then extend the BC with memory model in another direction so as to include free rider agents. Finally, we present some discussion and conclusions as well as identifying possible directions for future research.
Probabilistic social learning
In many BC models, agents’ beliefs are simply taken to be real numbers without any underlying interpretation being specified (Bernardo et al., 2024; Douven and Kelp, 2011; Hegselmann and Krause, 2002, 2006). Whilst having the advantage of generality this makes it difficult to motivate updating and pooling rules as lying within an established theory of reasoning for boundedly rational agents. Bayesian epistemology is a prominent framework capturing rational uncertain reasoning and subjective judgements where beliefs are represented as probabilities. The use of probability to quantify credence in this way also has an established operational justification in terms of betting behaviour (De Finetti, 1937; Ramsey, 1931), and there is a clear procedure for evidential updating based on Bayes theorem. Furthermore, there is a developed literature on probability pooling that can inform formalisations of social learning behaviour. From this perspective, we can gain insight from developing models of social learning and opinion dynamics within a probabilistic setting.
We consider a simple social learning problem, and apply a probabilistic approach along similar lines to that described in Lawry and Lee (2020) and Lee et al. (2018, 2021). More specifically, let H1, …, H
m
denote m mutually exclusive and exhaustive hypotheses, so that the belief of an agent A
i
can be characterised by a probability distribution in the form of a vector
The Log-Linear Pooling Operator
The pooled probability of H
j
for j = 1, …, m is given by:

The use of the log-linear operator for pooling can be justified in a number of different ways. For example, the supra-Bayesian interpretation imagines an oracle who updates their probability distribution over the hypotheses based only on the probability distributions of the agents in the pool (Genest and Zidek, 1986; Morris, 1974). If the oracle assumes independence between agents, that likelihoods take the form of Dirichlet distributions and that they have a uniform prior on hypotheses, then Bayesian updating results in a posterior distribution consistent with the log-linear operator (Lee et al., 2018). An alternative justification is in terms of information loss resulting from pooling. From this perspective it can be shown that the log-linear pooled distribution
The log-linear operator also has properties which impact on the way in which agents are able to dynamically learn from others so as to reach a consensus. Most notably it tends to amplify strongly held beliefs which are shared (Lee et al., 2018). More generally, the operator has the property that disagreement between agents increases uncertainty across the pool while agreement decreases it. While the first property is shared with linear pooling, the second its not. In particular, in contrast to linear pooling, log-linear pooling can result in a decrease in average entropy across the pool of agents, ensuring that under certain conditions social learning can lead to an increase in information.
In this model of social learning, agents also learn individually on the basis of evidence they receive directly and which reports one of the hypotheses as being true. On receiving such a piece of evidence E an agent updates their probability distribution according to Bayes theorem as follows (Lee et al., 2018):
Bayesian Evidential Updating
For E ∈ {H1, , …, H
m
} we have that:

In this case the likelihood P A (E|H j ) captures the agent A’s judgement about the reliability of the evidence E in the case that H j is the true hypothesis.
To implement Bayesian updating in this context each agent must quantify the reliability of the evidence received so as to evaluate P(E|H
j
). To make distinct judgements in each case would be challenging and hence we propose a simplified version of Definition 2 where the likelihood function has the following form:

Here, δ ∈ (0, 0.5] is a parameter quantifying the agent’s general level of distrust of evidence, taken in our model to be constant across all hypotheses and agents. In other words, all agents model the reliability of all evidence sources as follows: In the case that any given hypothesis H
j
is true then the probability that a source will accurately report this is 1 − δ, while there is probability δ that the source will erroneously report the wrong hypothesis divided uniformly between those H
i
where i ≠ j. For the two hypotheses case, Figure 1 illustrates the effect of evidential updating for different levels of distrust δ, by showing an agent’s posterior probability in H1 after updating for different prior probability values where the evidence supports H1, that is, E = H1. Notice that as δ → 0.5 then updating has a decreasing effect on the prior, that is, P
A
(H1|E) → P
A
(H1). In contrast, as δ → 0 then updating results in total certainty in the supported hypothesis, that is, if E = H1 then P
A
(H1|E) → 1, except in the case that P
A
(H1) = 0 when the updated probability is undefined in the limit. Updated probability of H1 given evidence E = H1 plotted against prior probability of H1 for different distrust values δ.
Bounded confidence with memory
Bounded confidence corresponds to the heuristic that an agent judges the reliability of its peers based on how similar their beliefs are to its own. In most BC models agents evaluate similarity at each time t by comparing their own current belief with the current beliefs of other agents to whom they are connected in their communication network. In probabilistic social learning we can formalise this idea by assuming that agents have a similarity measure
Statistical Distance
The statistical distance (sometimes called total variational distance) between two probability distributions

In this case, we take S(
Clearly basing similarity only on agents’ current belief values has significant limitations since during social learning such beliefs are inherently dynamic over time. An alternative would be for agents to record a sample of recent beliefs for both themselves and their communication network neighbours. Specifically, let
KS Test Statistic
Suppose


Now let D be a random variable corresponding to the KS test statistic on randomly sampled sets of values with the same number of elements as

This corresponds to the p-value of the two sample Kolmogorov-Smirnov significance test which can be determined numerically (Viehmann, 2021) or using limit distributions in the case of large samples (Feller, 1948).
1
In this case the null hypothesis is that the two samples are drawn from the same distribution and S (
Since the Kolmogorov-Smirnov test is only applicable to real-valued data, the above approach to bounded confidence cannot be applied directly in multi-hypotheses BC models where m > 2 since in such cases agents’ beliefs correspond to probability distribution in

In this paper we consider the case where g is the expected value of the hypotheses index i so that for probability distribution

In this case, g is a projection from elements of the probability simplex
Here, we investigate time-stepped agent-based simulation models of social learning in the presence of zealots. We assume there are two types of agent in the population: learning agents who learn individually from evidence, and socially by pooling with the beliefs of their neighbours in a communication network; zealots who do not learn but consistently transmit the same belief
All agents are part of a communication network in the form of a graph in which nodes are agents and an edge between two agents indicates that there is a direct channel of communication between them. For social learning, each learning agent keeps a record of its beliefs during a window of ω time steps so that at time step t this is given by Flow diagram showing the operations performed by a learning agent in one time step of the agent-based model.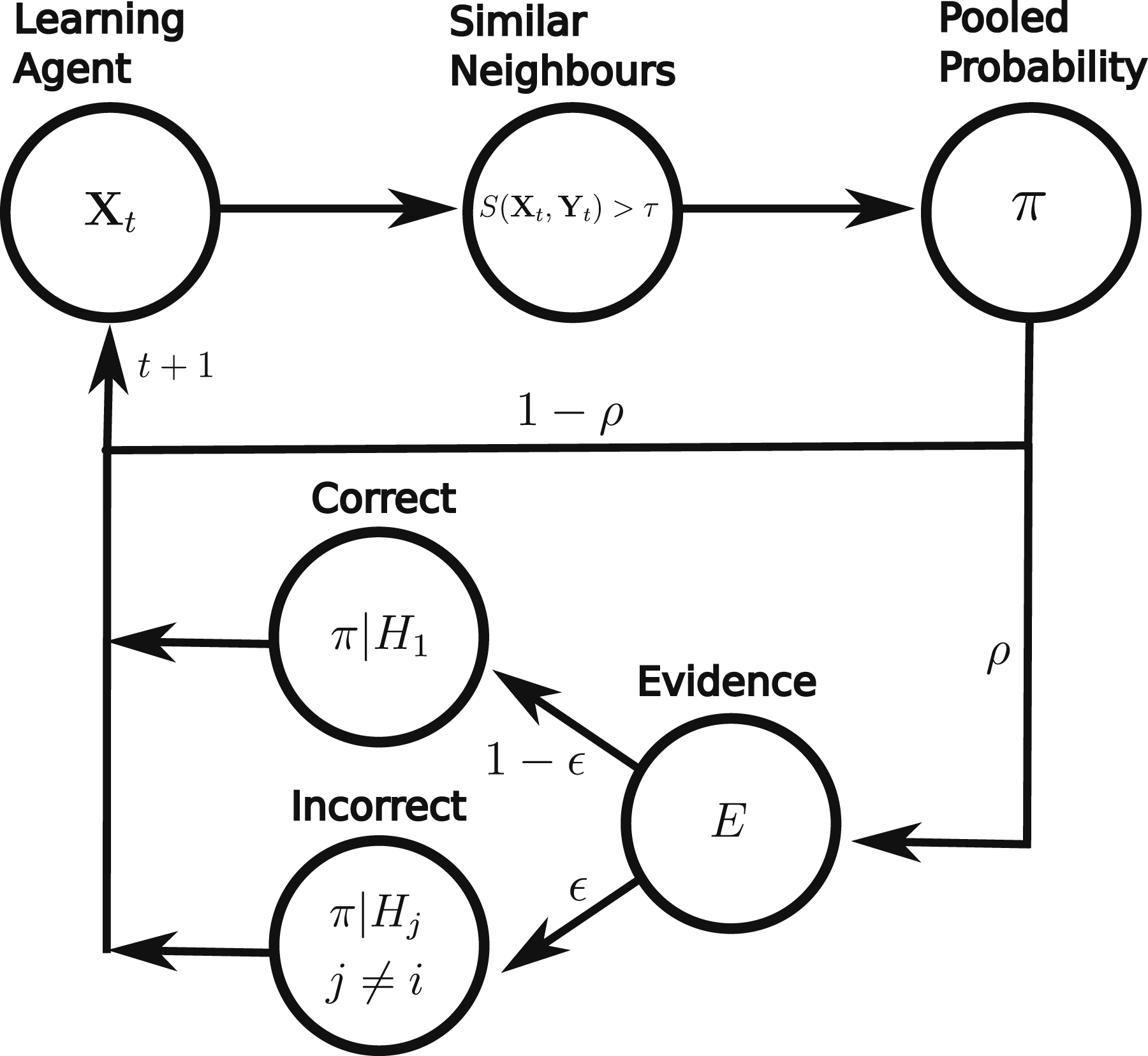
In this model it is assumed that communication network neighbours are able to transmit their full probability distributions over the m hypotheses during each time step. In the case of artificial agents this assumption is relatively unproblematic. For example, even for quite large values of m, sharing m − 1 dimensional vectors of real numbers should be easily within the memory and communication capabilities of most simple robots, although there are exceptions where operating conditions are particularly challenging, for example, under water robots. On the other hand, as a model of human behaviour it is clearly unrealistic in at least two respects. (1) Humans do not tend to communicate their beliefs in terms of real numbers, but rather use natural language. In this regard, all real-valued opinion dynamics models are unrealistic. (2) Humans do not tend to communicate the entirety of their beliefs across a whole set of hypotheses in one step, but instead only partially reveal their beliefs over time. Nonetheless, perhaps if viewed as a simplified model of collective learning our approach can still offer some insight into human behaviour. For instance, probability values could be viewed as being translations of natural language belief descriptions into a formal framework. In addition, a time step could be thought of as comprising multiple interactions during which an agent gradually reveals their full beliefs.
As a benchmark we will use the memoryless BC model described in Lawry (2024) in which an agent, at time t, judges the reliability of its social network neighbours based on the similarity of their current beliefs
Binary bounded confidence
Summary table of parameters in agent-based simulation experiments.

Successful social learning in this model will result in the average probability allocated to the true hypothesis across agents, approaching a value close to 1 over time. For reasonable levels of noise, this will also occur in the case of individual learning where agents only learn directly from evidence, since over time the evidential signal will, on average, reinforce belief in the true hypothesis. Hence, an important potential benefit of social learning in this context is to increase the rate of learning so that agents converge on a high probability for the true hypothesis more quickly. In other words, if social learning, as specified by a certain set of parameters, does not converge more quickly than individual learning for the same evidential noise levels, then arguably there is no benefit from social learning in that case. As we will see the presence of certain types of zealots can sometimes remove the utility of social learning in this sense. Therefore, as a performance metric we will primarily adopt convergence time here defined to be the shortest time at which the average probability of the true hypothesis H1 across non-zealot agents has exceeded 0.95 for 100 consecutive time steps, that is, this is the number of time steps required for the average probability of the true hypothesis to be consistently within 0.05 of 1. The number of time steps is capped at 500, this being the value returned if the convergence criterion is not met. Results are averaged over 50 independent experimental runs fixed at the relevant parameter settings and error bars show 90% percentiles across the runs. The only exceptions are heat maps where the results are averaged over 10 runs. The communication network is randomly generated for each run of the simulation as a Watts-Strogatz (small-world) graph. This form of random graph has been proposed as a possible model of certain kinds of human social networks (Newman et al., 2002) as well as of communication constrained interactions between individual robots in multi-robot systems or swarms (Crosscombe and Lawry, 2022). A Watts-Strogatz graph is defined by two parameters; the number of neighbours of each agent (node) and a (typically small) reconnecting probability of rewiring an existing edge from a neighbour to a different agent.
We now present a series of simulation experiments to investigate the following research questions: (1) Is memory-based BC less sensitive to the choice of similarity threshold than the memoryless benchmark for different types of zealot? The relevant model parameters to be investigated are τ and z. (2) Is memory-based BC less affected by high levels of doubt in evidence compared to the memoryless benchmark? For this question the relevant model parameter is δ. (3) Is memory-based BC able to cope with high levels of evidential noise? Here, the relevant model parameter to investigate is ϵ. (4) Is memory-based BC effective if agents are only able to keep track of a small number of neighbours? For this question the relevant model parameter is the number of Watt-Strogatz neighbours.
Initially, we investigate the robustness of both the memory-based and the memoryless model to the choice of the similarity threshold τ. As discussed in Lawry (2024), the memoryless bounded confidence model is sensitive to the choice of τ, and of particular concern is that the effective mitigation of different types of zealots requires different τ values. For example, Figure 3(c) shows average convergence time for memoryless BC plotted against τ for three types of zealots: zealots promoting the false hypothesis with z = 0.1 (black line); zealots promoting uncertainty with z = 0.5 (red line); zealots promoting the true hypothesis with z = 0.9 (blue line). Notice that while convergence time is minimised with τ ≈ 0.7 in the z = 0.1 and z = 0.5 cases, convergence time is optimal for z = 0.9 when τ = 1. Indeed for this latter case τ = 1 is the only threshold value for which the convergence requirement is met and corresponds to evidence only individual learning where agents consistently forgo the option of learning from their peers. The sensitivity of the memoryless model to τ means that it cannot achieve good performance with a fixed threshold value for a variety of zealot types. This is illustrated in Figure 4(a) where the blue line shows average convergence time for the memoryless model plotted against z when τ = 0.7 (as is optimal for z = 0.1). Although performance is good for z between 0.1 and 0.5, convergence times increase significantly for z > 0.5 and for high values the convergence threshold is not met. One might not intuitively expect that the presence of zealots promoting the true hypothesis to some degree could be so disruptive to the memoryless approach. Some additional insight can be gained from Figures 5(a) and (b) showing trajectories of the probability of the true hypothesis for individual agents against time for z = 0.6 and z = 0.9, respectively. Even though both types of zealots to some degree promote the true hypothesis, it is nonetheless clear from the trajectories that by constantly promoting the same opinion in the memoryless model they disrupt consensus formation amongst learning agents around a strong belief in H1. Social learning performance for varying similarity thresholds τ: z = 0.1 (black line), z = 0.5 (red line), and z = 0.9 (blue line). Social learning convergence time plotted against varying parameters modelling types of zealots, evidential distrust, social network connectivity, and evidential noise. Black lines are for BC incorporating memory with τ = 0.01, blue lines are for memoryless BC with τ = 0.7 and green lines are for individual learning only. (a) Convergence time versus zealots, (b) convergence time versus distrust, (c) convergence time versus neighbours, and (d) convergence time versus noise. Probability of the true hypothesis plotted against time for populations with zealots (red lines) z = 0.6 and z = 0.9. Figures 5(a) and (b) are for the memoryless benchmark, while Figures 5(c) and (d) show equivalent results for BC incorporating memory. (a) Memoryless bounded confidence with z = 0.6, (b) memoryless bounded confidence with z = 0.9, (c) bounded confidence with memory and z = 0.6, and (d) bounded confidence with memory and z = 0.9.


BC incorporating memory tends to be much less sensitive to the choice of value for τ as illustrated in Figures 3(a) and (b) showing convergence time plotted against τ. Figure 3(a) shows the results for τ values ranging between 0 and 1 where the two extreme cases correspond, respectively, to no constraints on social learning and individual learning only. Values of τ between 0 and 1 then result in better performance than these two limiting cases, but with a gradual decline in performance for increasing τ > 0. Indeed very low values of τ appear to be optimal as shown in Figure 3(b) which plots convergence times for τ between 0.01 and 0.1 in steps of 0.01. Furthermore, notice that in contrast to memoryless model shown in Figure 3(c), in Figures 3(a) and (b), the plots are almost identical for the three zealot types z = 0.1, z = 0.5, and z = 0.9. This is important since it raises the possibility of agents adopting a single fixed similarity threshold allowing for good performance across a range of scenarios. For example, in Figure 4(a), the black line shows the convergence time for the memory-based model for varying z with τ = 0.01, indicating consistently good performance across zealot types. Consequently, for the remainder of the paper we fix τ = 0.01 for bounded confidence with memory in all subsequent experiments and make no attempt to adapt the similarity threshold in order to optimise performance in specific learning scenarios. In contrast, in light of the sensitivity of the memoryless model to τ, and in order for it to provide a suitable benchmark, we attempt to select a threshold value providing close to optimal performance in different experimental scenarios.
Figure 4 illustrates the sensitivity of both BC with memory and the memoryless benchmark to a number of model parameters. For the latter ,we have used the similarity threshold τ = 0.7 which is optimal for mitigating the effect of zealots that strongly promote the false hypothesis as discussed above and shown in Figure 3(c).
High levels of distrust in evidence can often occur across a population during collective learning and decision making. Agents may be aware that certain evidence is unreliable, for example due to noise resulting from inaccurate measurements from imprecise or even malfunctioning sensors. For example, the robots used in swarms tend to be relatively low cost with limited low resolution sensors. Furthermore, in applications such as search and rescue these robots may be required to operate under difficult conditions, for example, in poor weather or in smoke filled buildings (Kegeleirs and Birattari, 2025). These factors mean that the accuracy of sensor data is often inherently uncertain. In addition, belief perseverance is a common psychological phenomenon according to which individuals are reluctant to update ingrained beliefs in the face of evidence that may contradict them (Guenther and Alicke, 2008). In our probabilistic model, evidential distrust is quantified by the parameter δ, corresponding to an agent’s belief that evidence will erroneously support the false hypothesis. If δ is high, that is, close to 0.5, then the evidential signal driving agents to update their beliefs towards having higher probability in the true hypothesis is much reduced (see Figure 1). This can make it harder for agents to detect zealots since, in some circumstances, a zealot’s trajectory of unchanging beliefs could resemble their own. Results presented in Lawry (2024) suggest that the effectiveness of memoryless BC is significantly reduced as learning agents’ level of distrust in evidence increases. This is also shown here in Figure 4(b) which plots convergence time against δ. For δ > 0.15 the convergence time for memoryless BC (blue line) exceeds that for individual learning only (green line) in the presence of zealots with z = 0.1. In other words, since in such cases, belief pooling in the presence of zealots results in a slower convergence time than achieved with individual learning from direct evidence only, there is no benefit from social learning. On the other hand, while the convergence time for BC with memory (black line) also increases with the level of distrust, it is nonetheless always less than that for individual learning. Consequently, even for high levels of distrust resulting a weak evidential signal, as shown in Figure 1, BC with memory is still able to mitigate the presence of zealots, albeit requiring a longer learning time in which to do so, as the doubt level increases.
Another potentially important factor in social learning is agent connectivity as captured in our model by the number of neighbours specified for the Watts-Strogatz graph. Figure 4(c) shows convergence times for Watts-Strogatz graphs with a fixed rewiring probability of 0.1 but varying numbers of neighbours. Note that for both BC with and without memory, increasing connectivity reduces convergence time in the presence of zealots with z = 0.1 . BC with memory is slightly slower for low levels of connectivity, but the two models are broadly comparable as the number of neighbours increases. Unless otherwise stated we will assume a relatively low connectivity level as represented by 10 neighbours in the Watts-Strogatz model. This result is also important for practical applications of memory-based BC on social networks. More specifically, the proposed use of memory to evaluate similarity between agents requires that each agent keeps track of its network neighbours, recording their beliefs over a period of time. Even if that period is relatively short such data collection has an inevitable cost. For example, in physical environments where agents move across a spatial region, an agent must track the position of its peers, linking, as it does so, different agents in different locations to fixed identities, as positions change dynamically. Alternatively, online agents must track their network neighbours across different platforms, matching online identities to particular individuals. Hence, in practice agents may need to limit the number of individuals that they track, and consequently if a version of memory-based BC is to be applied in practice then we need to ensure its effectiveness on communication networks with limited connectivity as represented by agents having relatively few neighbours. Figure 4(c) provides some evidence that this is indeed the case.
In almost all social learning contexts, there is an element of unreliability associated with evidence obtained from the environment. For instance, sensors tend to have limited resolution and may be imperfectly calibrated, difficult environmental conditions can make accurate measurement impossible, and environmental complexity can mean that only a small proportion of features can be captured. Here, we consider the effect of evidential noise as modelled by the parameter ϵ, corresponding to the probability that evidence received asserts the false hypothesis. Figure 4(d) shows convergence time plotted against ϵ in the presence of zealots with z = 0.1. For all values of ϵ between 0 and 0.45 both BC models converge to a high average belief in the true hypothesis faster than individual learning with the same level of evidential noise (green line) in the presence of zealots with z = 0.1, meaning that the benefits of social learning are preserved even if noise is very high. However, for very high levels of noise where ϵ ≥ 0.4, BC with memory (black line) is significantly slower to converge than memoryless BC (blue line).
In this section, we have compared BC models with and without memory for probabilistic social learning with two hypotheses where beliefs can be represented by single probability values. For learning problems of this kind results suggest that BC with memory is more robust at mitigating the presence of zealots in the population than the memoryless benchmark. In particular, BC with memory is much less sensitive to the choice of similarity threshold τ, and furthermore the same value of τ = 0.01 is effective for all zealot types with z between 0.1 and 0.9. This is important for the efficacy of the approach since, unlike memoryless BC, no prior information is required concerning the type of zealots present in the population. Furthermore, BC with memory is significantly more robust to high levels of evidential distrust than memoryless BC. Indeed even for relatively low levels of distrust, for example, δ ≈ 0.15, the memoryless model is slower to converge than individual learning, while for δ ≥ 0.2 the convergence requirement is not met within the allocated 500 time steps. However, there are some circumstances in which BC with memory, although mitigating the effect of zealots, is significantly slower to converge than the memoryless benchmark with optimal τ. This includes scenarios in where there is very high noise or very low connectivity. In the next section, we now investigate the effectiveness of BC with memory for multiple hypotheses where m > 2.
A multi-hypotheses model
Here, we extend the BC to model with memory to scenarios in which there are multiple competing hypotheses by mapping any given probability distribution on hypotheses
Using this approach and the agent-based simulation model shown in Figure 2 we initially consider the case where m = 3 as this still allows for relatively straightforward visualisation of results. Figure 6(a) shows a ternary heat map of convergence times of BC with memory for a population with 20% zealots promoting varying probability distributions Social learning performance in the case of multiple hypotheses for different types of zealots. Figures 6(a) and (b) are ternary heat maps of convergence time for zealots promoting probability distributions across Convergence time against τ for the three and five hypotheses cases in the presence of zealots strongly promoting H2. For three hypotheses (black line) 

To further investigate the scalability of BC with memory, we now consider the case where there are m = 5 hypotheses. For this ,we consider zealots promoting probability distributions lying on two lines in Convergence time where there are five hypotheses for varying zealot probability distributions of two types. The left hand side of Figure 8 shows convergence times in the presence of zealots promoting H2 to different degrees, while the right hand side is where zealots are promoting H1 to different degrees. For multi-hypotheses social learning we have adopted a memory window length of 20 time steps, that is, ω = 20; BC with memory (black line), memoryless benchmark with τ = 0.6 (blue line).


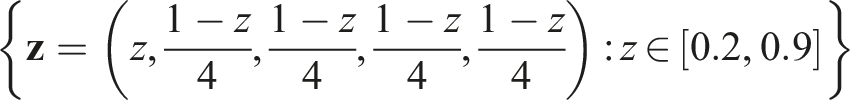
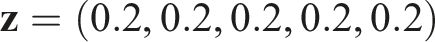


In summary, the proposed model of BC with memory generalises well to social learning with multiple hypotheses, showing robust performance in the presence of most types of zealots. In contrast, memoryless BC, when optimised to mitigate zealots strongly promoting a false hypothesis, is then susceptible to disruption from zealots who are either stubbornly uncertain or promote the true hypothesis to some limited extent. Indeed for large numbers of hypotheses memoryless BC is now slower to converge than BC with memory even for zealots promoting a false hypothesis to a weaker extent (see Figure 8). In the next section we introduce one additional type of agent that while able to socially learn from its peers has no direct access to evidence.
Agents without access to evidence
It is often the case in social learning that only a minority of agents have any direct access to evidence. Unlike zealots such agents are willing and able to learn from their neighbours, some of whom may have access to evidence, and they can therefore potentially learn the true hypothesis. However, they are likely to be more susceptible than learning agents to the influence of zealots and to emerging erroneous beliefs in general. In this section, we will investigate social learning by populations consisting of three types of agents, the first two of which have already been the focus of previous sections; zealots who constantly promote the same belief, learning agents who learning socially but who also have access to evidence and hence learn individually based on evidence they receive; and free riders who learn socially from their neighbours but do not receive evidence. Populations consisting of these three agent types were studied for the HK bounded confidence model in Douven and Hegselmann (2022) with results suggesting that for a suitable choice of learning parameters social learning can be effective provided the proportion of free riders in the population is not too high relative to the proportion of zealots, but is significantly impeded if both proportions are too high. The HK model is memoryless and in this section we will consider the performance of BC with memory for these kinds of mixed populations. Specifically, we extend the agent-based model defined above to include free riders where the operations performed by such an agent in a time step are as shown by the flow diagram in Figure 9, and then investigate social learning performance in the binary hypotheses cases for varying proportions of agent types. Flow diagram showing the operations performed by a free rider agent in one time step of the agent-based model.
Figure 10(a) is a ternary heat map for BC with memory showing the average probability of the true hypothesis at convergence across non-zealots, that is, learning agents and free riders, for varying proportions of the three agents, and where zealots promote z = 0.1. BC with memory converges (Figure 10(a)) to a high average probability in the true hypothesis across non-zealots for a broad range of population types with varying proportions of the three types of agents. This includes where there is a relatively low proportion of learning agents compared to zealots and free riders. In contrast, for memoryless BC (Figure 10(b)) performance in the presence of zealots is degraded if there is also a significant proportion of free riders in the population. For these benchmark results the similarity threshold was set to τ = 0.8 on the basis of simulation experiments shown in Figure 11. This shows average probability of H1 across non-zealots for three different populations, all with 20% zealots with z = 0.1, but with varying proportions of free riders and learning agents. Threshold value τ = 0.8 gives optimal or close to optimal performance in all three cases. Comparison of BC incorporating memory with the memoryless benchmark for different mixtures of three agent types; zealots (z = 0.1), free riders and learning agents. Figures 10(a) and (b) are ternary heat maps showing average probability of the true hypothesis across non-zealots at convergence for varying proportions of the three types. (a) BC with memory and mixtures of agents; τ = 0.01, (b) Memoryless BC and mixtures of agents; τ = 0.8. Memoryless BC and mixtures of agents: Average probability of the true hypothesis across non-zealots plotted against τ for three different mixtures of agent types; 20% zealots (z = 0.1), 70% free riders, 10% learning agents (black line); 20% zealots (z = 0.1), 40% free rider, 40% learning agents (red line); 20% zealots (z = 0.1), 10% free riders, 70% learning agents (blue line).

Figure 12 shows trajectories of average probability of the true hypothesis against time for the three types of agents in a population in which there are 40% learning agents, 40% free riders, and 20% zealots. Average probabilities are shown in black for learning agents, blue for free riders, and red for zealots. Figures 12(a)–(c) show the trajectories for memoryless BC for zealots with z = 0.1, z = 0.5, and z = 0.9, respectively. Notice that for all three types of zealots, a significant proportion of free riders do not learn effectively. Some free riders converge to very low probability values in H1, and this happens even in the case in which the zealots to an extent promote H1. In these latter cases, this may result from free riders being misled by learning agents who have received erroneous evidence. Furthermore, some free riders converge on an intermediate probability value expressing ongoing uncertainty resulting from the direct and indirect influence of zealots. For BC with memory, as shown in Figures 12(d)–(f), the vast majority of free riders converge to a high probability in the true belief in the presence of all three types of zealots. A relatively small number of free riders still do not learn effectively, but these converge to a range of different and widely distributed probability values. Probability of the true hypothesis plotted against time for populations with 20% zealots (red lines), 40% freeloaders (blue lines), and 40% learning agents (black line), and where the zealots promote z = 0.1, z = 0.5, and z = 0.9. Figures 12(a)–(c) show results for memoryless bounded confidence, while Figures 12(d)–(f) show results for bounded confidence incorporating memory. (a) Memoryless BC with z = 0.1, (b) Memoryless BC with z = 0.5, (c) Memoryless BC with z = 0.9, (d) BC with memory with z = 0.1, (e) BC with memory with z = 0.5, and (f) BC with memory with z = 0.9.
Conclusions and future work
We have proposed a probabilistic model of social learning that incorporates bounded confidence with memory. This uses the Kolmogorov-Smirnov test to measure the similarity between sets of probability values, and hence allows for the application of bounded confidence to trajectories of recent probability values over a time window rather than just current values. Agent-based simulation experiments suggest that BC with memory is less sensitive to the choice of similarity threshold than the memoryless probabilistic benchmark model. Furthermore, learning performance is much less susceptible to high levels of distrust in evidence across agents. These results then generalise from the two to the multi-hypotheses case in which case bounded confidence is evaluated based on sets of real values in the form projections of multi-dimensional probability distributions. Finally, we have shown that incorporating memory into bounded confidence allows for effective social learning in a broad range of mixed populations comprising of free riders agents as well as zealots and learning agents.
The power of social learning comes from its capacity to exploit emergent effects driven by the two local processes of evidential updating and opinion pooling to reach a population level consensus about the true state of the world. However, this can also make it vulnerable to the influence of unreliable agents, since these same underlying mechanisms can also facilitate the spread of false beliefs. Bounded confidence provides a potential heuristic strategy that agents can deploy to avoid unreliable individuals during learning. The intuition behind BC in this setting is that as an honest truth-seeking agent your belief will evolve in a particular way over time, and the beliefs of other reliable agents will follow a similar trajectory. This contrasts with unreliable, or at least less reliable agents, whose beliefs will tend to change in a different way, if at all. However, if the comparison between agents’ is based only on current beliefs then relevant information is lost about the evolution of opinions. This can result in the effectiveness of BC as a detection tool being highly contingent on choosing the right similarity threshold, and where this value is dependent on the type of unreliable agents present in the population. This significantly reduces the applicability of BC since prior knowledge about agent types is rarely available in practice. The experiments in this paper show that incorporating memory into BC by making similarity judgements based on samples of recent beliefs, greatly increases its robustness by making it much less sensitive to the choice of parameter values, and hence reducing the need for prior knowledge about the makeup of the agent population. This opens up the possibility for collective decision making applications in multi-agent and multi-robot systems where there is an inherent vulnerability to malfunctioning or malicious interventions causing cascading failures. It also serves to emphasise the importance of basing reliability assessments on a sufficient amount of information gathered over repeated interactions, and this may serve to guide us as we navigate social media and other online platforms.
The agent-based models investigated in this paper have a number of limitations which point to possible directions for future research. For example, modelling zealots as stubborn individuals who constantly signal the same probability value or distribution is simplistic. At any time such agents are likely to be much more reactive to the current spread of opinions across individuals with whom they are in communication, so as to best influence the emerging consensus and whilst also avoiding being classified as unreliable. This can perhaps be formulated as a multi-objective optimisation problem for zealots to choose to transmit a trajectory of distributions which are sufficiently close to those of its neighbours to avoid exclusion, but where the inclusion of its stated distributions in pooling will tend, over time, to draw those neighbours closer to its target opinion. As well as more sophisticated models of unreliable agents it would be interesting to increase the heterogeneity of the agent population. For instance, we might model learning agents who obtain evidence at varying rates, of varying reliability and with different levels of distrust.
The current model includes only a simple static model of agent communications in the form of a randomly generated small-world network. Of course, communications could be structured differently and it would be interesting to consider other types of graph, some of which could be more extreme than others. Furthermore, in practice communication between agents may change dynamically, for examples as agents move around a physical environment and therefore drop in and out of communication range with their peers. In this context it may be useful to study multi-agent models which a dynamic physical element in which agents change their relative positions over time. Such models may also incorporate communication errors or noise of different types.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially funded by the INFORMED-AI project EP/Y028732/1.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Statement of significance
Social learning allows individuals to collectively learn from each other as well as from direct evidence. This has many advantages including by enabling agents to compare beliefs so as to correct errors and misconceptions, and by providing an efficient mechanism to disseminate knowledge across a population. However, these strengths can also make social learning vulnerable to the presence of unreliable agents who may distort opinions resulting in the spread of false information. There is a simple local heuristic called bounded confidence that can help filter out unreliable opinions, and which requires that agents only pay attention to opinions that are sufficiently similar to their own. The effectiveness of this rule as a filtering mechanism is known to be very sensitive to exactly how agents determine sufficient similarity. This paper introduces a model of social learning with bounded confidence, but with the additional feature that similarity judgements involve an element of memory and are made based on trajectories of recent opinions as they have evolved over time, rather than just based on current opinions. Within this model it is shown that incorporating memory into bounded confidence makes it much more robust and less sensitive to the choice of the filtering threshold. This research has the potential to help improve the design of multi-agent and multi-robot systems when performing collective decision making tasks by providing an effective local norm for reliability detection. It can also help us to understand the role that bounded confidence could play in human collective behaviour.