
Abstract
Condorcet’s Jury Theorem states that the correct outcome is reached in direct majority voting systems with sufficiently large electorates as long as each voter’s independent probability of voting for that outcome is greater than 1/2. Previous research has found that switching to a hierarchical system always leads to an inferior result. Yet, in many situations direct voting is infeasible (e.g., due to high implementation or infrastructure costs), and hierarchical voting may provide a reasonable alternative. This paper examines differences in accuracy rates of hierarchical and direct voting systems for varying group sizes, abstention rates, and voter competences. We derive three main results. First, we prove that indirect two-tier systems differ most from their direct counterparts when group size and number are equal (i.e., when each equals
Introduction
Throughout the social, physical, and biological sciences, researchers are interested in better understanding collective decisions. Whether we are studying signal processing in the brain, artificial neural networks, animal communication, organizational design, or voting and elections, the structure of information transmission can help or hinder group performance. In this paper, we examine decision making with two outcomes using majority rule. Specifically, we extend a foundational theorem from social choice theory, the Condorcet Jury Theorem, to investigate how hierarchical majority elections shape collective accuracy. In hierarchical (or indirect) voting systems, preferences are first aggregated within subgroups and then aggregated across groups.
Condorcet’s Jury Theorem (de Condorcet, 2014) characterizes the probability that an electorate reaches a mutually beneficial outcome in a majority-rule election where voters are uncertain about which of two options leads to the best outcome. The theorem is a direct consequence of the weak law of large numbers (Kalai and Safra, 2006) and states that if each voter’s independent probability of supporting the best outcome is greater than 1/2 (that is, they are more likely to vote correctly than incorrectly), the group will increase its chance of arriving at the correct decision as more voters are added to the electorate. If each voter’s probability of voting correctly is less than 1/2, the likelihood of selecting the correct outcome decreases with more voters, and the probability of obtaining the correct outcome is maximized with a single decision maker. (When voters are equally likely to vote for the correct and incorrect outcome, the probability of a correct collective decision is 1/2 for any size electorate.)
Several remarks are in order to clarify the simplifying assumptions made by Condorcet. First, the theorem assumes a homogeneous pool of voters—both with respect to preferences and accuracy. Everyone votes for the correct outcome with equal probability. Second, it neglects social influence; voters are independent and cannot sway each other’s decisions (Böttcher et al., 2017). Third, in Condorcet’s setting, majority rule is applied to all decision makers simultaneously using direct elections. Fourth, the model assumes no abstention. Everyone votes with certainty. 1
The influence of certain aspects of heterogeneity, voter dependence, and hierarchical voting are discussed in Boland (1989). Heterogeneity in information can be captured by substituting the mean voter’s opinion for each individual’s probability of voting for the correct outcome. In addition, positive correlations among voters’ decisions have a negative impact on the effectiveness of direct majority voting systems, a finding confirmed more recently in Kaniovski and Zaigraev (2011). Previous work has shown that the probability of accepting the correct decision under Condorcet’s assumptions is larger in direct voting systems than in certain indirect systems (Boland, 1989; Boland et al., 1989). As discussed in Berg and Paroush (1998), indirect voting may outweigh direct systems when there is a tradeoff between effectiveness (or accuracy) and implementation costs, which may increase with both group number and size.
According to May’s theorem (May 1952), majority voting is the only voting rule that satisfies certain fairness properties. Alternative rules, such as unanimity voting, are often inferior to majority voting because they confer larger type I and type II errors (Feddersen and Pesendorfer, 1999). For example, Feddersent and Pesendorfer (1998) find that unanimity rule leads juries to be more likely to both convict an innocent person or acquit a guilty person. 2 For social choice problems with at least three voting alternatives, Arrow’s impossibility theorem (Arrow, 1950; Miller, 2019; Sen, 2020) states that there exists no social welfare function (or rank-order electoral system) that maps individual preferences to a societal preference order satisfying desired fairness conditions. As a further generalization of Condorcet’s direct binary choice voting scheme, majority runoff elections with three candidates and a continuous range of voter preferences are modeled in Bouton and Gratton (2015). In such multi-stage elections, the Condorcet winner (i.e., the candidate who wins a majority of head-to-head contests against any other candidate) may not even participate in the final runoff round (Bouton and Gratton, 2015).
In this paper, we examine differences in direct and indirect voting systems, focusing on variations in the size and number of groups, abstention rates, and voter competences. We start by introducing a simple model of hierarchical voting where preferences are first aggregated within subgroups and then aggregated across groups. We confirm that for any size electorate and number of groups, direct systems outperform indirect ones, so long as each voter’s probability of voting for the correct outcome, p, is greater than 1/2. Simply put, indirect voting introduces room for error. Although under certain conditions indirect systems approach the same outcome as in the direct voting model, adding layers of aggregation is always strictly dominated in expectation.
A natural inquiry for hierarchical voting systems concerns how accuracy depends on both the number and size of groups. In accordance with Condorcet’s Jury Theorem, we show that the accuracy of a hierarchical voting system increases with the number of voters if both the number of layers and groups are kept constant. Previous research examining two-level hierarchical voting suggests that collective outcomes are greater for a large number of small groups than for a small number of large groups (Boland, 1989). A more recent study on binary decision making in animal groups provides numerical evidence that the difference between a two-tier indirect system (in our case, a voting system in which opinions are aggregated in two stages) and a direct system is greatest when the number of groups is similar to the number of members per group (Kao and Couzin, 2019). Using an asymptotic expansion of the derivative of the reliability function (or Banzhaf number [Berg, 1997]), we prove that the outcome for any indirect system with n tiers and Nd voters differs most from a direct voting system when group size and number equal
Finally, we examine how voter abstention impacts (and indeed changes) the superiority of direct versus indirect voting. To describe heterogeneous multitier voting systems analytically, we develop a corresponding generating function approach that does not rely on approximations to describe heterogeneity among voters. We find that when abstention and competency are independent, direct voting remains superior. However, when a person’s likelihood of turning out is correlated with their vote—as is likely the case in many electoral and managerial contexts—indirect voting may gain in its ability to represent the entire electorate. Indeed, in some cases, hierarchical voting dramatically outperforms direct voting. Another way to explain this finding is that when a voting system is meant to represent the preferences of eligible, rather than actual, voters, indirect elections provide a potential correction to direct voting.
Although the main focus of our work concerns elections, hierarchical systems of information aggregation play an important role in various other contexts. Majority rules and hierarchical decision making are relevant throughout studies of social choice (Brandt et al., 2016) and organizational design (Christensen et al., 2021; Christensen and Knudsen, 2010; Csaszar and Eggers, 2013; Gersbach et al., 2022; Sah and Stiglitz, 1984, 1988), but also appear in research about collective cognition in animal groups (Couzin, 2009). Previous studies have identified hierarchical or modular interaction structures in ant (Mersch et al., 2013; Pinter-Wollman et al., 2011) and honeybee (Naug, 2008) colonies, as well as with bird flocks (Nagy et al., 2010) and elephant herds (Wittemyer et al., 2005). At the individual level, information processing in the brain (Friston, 2008) is known to be affected by the hierarchical organization of cortical areas (Zeki and Shipp, 1988). Information aggregation that is based on majority voting is also relevant to describe synchronous interactions between grid cells in cellular automata (Gärtner and Zehmakan, 2017) and to perform renormalization operations in statistical mechanics (Böttcher and Herrmann, 2021). Artificial neural networks (Richards et al., 2006), and in particular ensemble machine learning, combine outcomes of individual classifiers using (weighted) majority voting to enhance model performance (Dietterich, 2000). In addition, von Neumann (1956) and Moore and Shannon (1956a, 1956b) examine how to optimize hierarchical computing circuits by combining unreliable electrical components. Thus, identifying factors that impact accuracy in hierarchical voting systems is crucial for our broad understanding of preference and information aggregation across fields.
A simple model of hierarchical voting
We consider two voting systems: one with indirect, or hierarchical, voting and another with direct voting. The hierarchical voting system we study is represented by a regular tree network G(n, k) with n layers. Each node (except leaf nodes which represent the “electorate”) has k child nodes, where k is an odd number. The total number of nodes in such an indirect majority voting model is Hierarchical and direct majority voting. (a) Example of a hierarchical voting system with four layers. Blue and red nodes are in states 0 and 1, respectively. (b) Proportion of correct voting outcomes in three direct voting systems (denoted by Pd(p) in the text) and three indirect voting systems (denoted by P
n
(p) in the text) as a function of the probability that an individual in the electorate votes for the correct outcome (denoted by p in the text). Different curves correspond to different numbers of layers n. In the shown examples, we set n = 3, 4, 5 and the number of voters in each majority voting group is k = 3. (c) Difference between Pd(p), the proportion of correct voting outcomes in direct voting systems, and P
n
(p) as a function of p. The number of voters in the direct voting system is Nd = k
n
. All parameters are as in (b). In the vicinity of the Condorcet threshold, p = 0.5, the slopes of the functions describing the voting outcome of direct majority voting are steeper than those observed in hierarchical voting systems with the same number of voters in the bottom layer, illustrating that direct majority systems lead to the correct outcome more often if p > 0.5.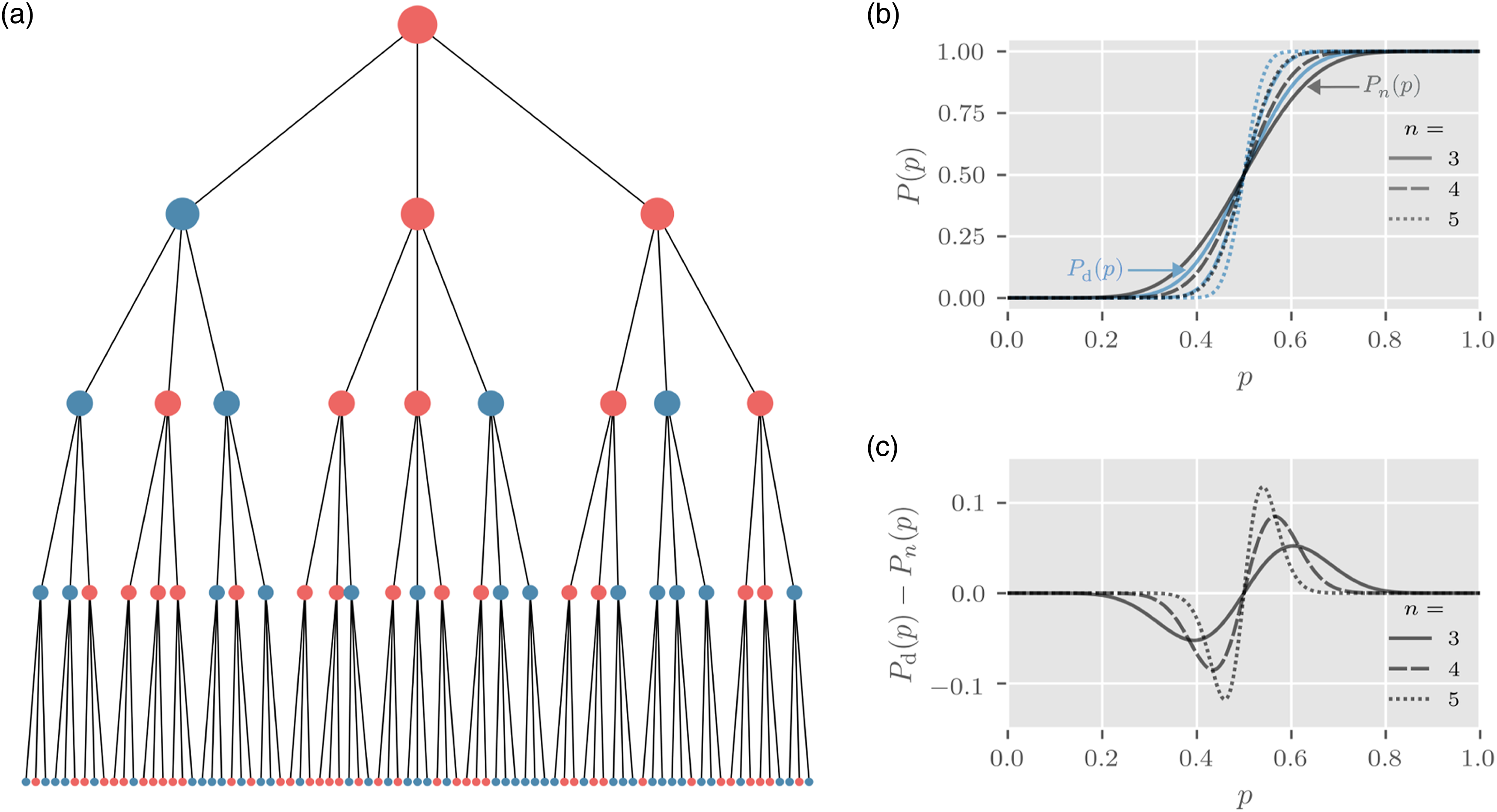
To characterize a hierarchical voting system mathematically, we denote by P
n
(p) and 1 − P
n
(p) the probabilities that the top node is in state 1 and 0, respectively. According to Condorcet’s theorem (de Condorcet, 2014), we have

For systems of finite size, the probability P
n
(p) does not jump from 0 to 1 at p = 0.5, but instead smoothly approaches 1 for large enough values of p Figure 1(b). The probability, P
n
(p), that the top node of such a finite system is in state 1 can be defined recursively in terms of the model parameters. Let X
i
be a binomial random variable representing the number of nodes in state 1 in stage i (1 ≤ i ≤ n). That is, X
i
∼ B(k, p
i
) where p
i
is the probability that a node in stage i is in state 1. For fixed values of k, n, and P0(p) = p, then, the recursion relation is given by

For a comparison with a direct voting system, we denote by P
d
(p) and 1 − P
d
(p) the corresponding probabilities of reaching a correct and incorrect voting outcome. Similar to equation (2), we define the reliability function of the direct voting system as

In the following theorem, we formalize and prove these observations for hierarchical majority voting systems with n > 1 layers.
Let P
d
(p) and P
n
(p) be the probabilities of reaching the correct voting outcome in direct and hierarchical majority voting systems with the same number of voters in the electorate who vote for the correct voting outcome with probability p. For a hierarchical voting system with at least n = 2 layers, it holds that (i) P
d
(p) = P
n
(p) for p ∈ {0, 0.5, 1}, (ii) P
d
(p) < P
n
(p) for p ∈ (0, 0.5), (iii) P
d
(p) > P
n
(p) for p ∈ (0.5, 1). (Points (i-iii) imply that the probability of accepting the correct voting outcome is larger in direct majority systems compared to hierarchical ones as long as p ∈ (0.5, 1).) The proof of Theorem 1 is in Appendix 1. For indirect voting systems with one layer, similar results are presented in Boland (1989) and Boland et al. (1989), where the authors consider an indirect voting system with n1 voter groups, each of size n2 (n1 and n2 being odd integers). Our proof applies to hierarchical voting systems with n layers, making it more general than the proof presented in Boland et al. (1989). Moreover, we also quantify the slope of the reliability functions P
d
(p) and P
n
(p) at p = 0.5. An overview of the main quantities and parameters used in our hierarchical voting model is provided in Table 1.
Model quantities and parameters. An overview of the main quantities and parameters used in the hierarchical voting model.

Optimal group size and number
In a hierarchical voting system, the probability of reaching the correct outcome depends not only on the number of layers but also on the voting group size and the number of groups. In a two-tier system (i.e., a voting system in which opinions are aggregated over n = 2 layers) with l groups and k voters per group (Figure 2), we have Effect of different group sizes on performance of two-tier voting systems. (a) A two-tier electoral system with l = 3 groups and k = 5 voters within each group. Arrows pointing upwards (red) and downwards (blue) represent individuals who vote for the correct and incorrect outcome, respectively. (b) For the same distribution of voter types in the electorate, the voting outcome is different than in (a) because of the different voting group structure. (c) The probability P2(p) of a correct outcome for different sized electorates, Nd = kl, and p = 0.5001 as a function of the number of groups l. For two of the selected electorate sizes, Nd = 1, 125 and 3, 375, the corresponding square roots are not integer values and approximately 34 and 58, respectively. Hence, the minimum of P2(p) is attained for group sizes lmin = 25 and 45 that are close but not equal to 


The probability P2(p) of reaching a correct voting outcome increases with the number of voters in the electorate Nd = kl for p > 0.5. If the number of voters Nd is constant, what is the most effective and least effective composition of voters per group k and numbers of groups l? Mathematically, for constant k, l, l > k, and p > 0.5, the probability P2(p) is maximized if one uses l groups with k members each (Berg, 1997). The opposite holds for l < k. Hence, the reliability function P2(p) is not symmetric in k, l. Earlier related observations (Boland, 1989) led to the conjecture that the collective performance of a group of independent voters is larger for a large number of small groups than for a small number of large groups. Indeed, next to direct voting, the most effective two-tier voting system is that with the smallest possible number of voters per group k since it resembles direct voting most closely. However, this observation does not imply that the least effective voting system is that with the maximum possible number of voters per group for constant Nd. Other work has suggested that the difference between indirect and direct voting models is greatest when group size and number are similar (Kao and Couzin, 2019). Kao and Couzin (2019) state that “the modular structure that leads to the lowest collective accuracy occurs very close to when there are
To examine this question, we use an asymptotic expansion of the derivative of the reliability function about one of its fixed points and formulate the following Square Theorem (Theorem 2), which shows that P n (p) is minimized when k = l.
For p ∈ (0.5, 1), the probability of reaching a correct voting outcome in a two-tier voting system is minimized asymptotically if the number of groups approaches the number of voters per group, that is, if In Appendix 2, we present a proof of the Square Theorem and provide numerical evidence that the above square root relation also holds for small electorates. According to the Square Theorem, when group size and number are equal, the indirect model deviates most from the direct model. Thus, for p > 0.5, arriving at the “correct” decision is least likely when k = l. However, when p < 0.5, an indirect model with k = l is most likely to produce the correct result.
3
We also prove in Appendix 2 that the Square Theorem can be extended to hierarchical voting systems with n layers and group sizes k(1), k(2), …, k(n). The accuracy of such a multitier voting system is minimized for Figure 2(c) shows the reliability function P2(p) for different numbers of voters in the electorate, Nd, as a function of group size l. In accordance with Condorcet’s Jury Theorem, we observe that the accuracy of a two-tier voting system increases with the number of voters Nd if the number of groups is kept constant. This finding also extends to hierarchical voting systems with more than two layers (see Appendix 1). We also observe in Figure 2(c) that the minimum of P2(p) is obtained for group sizes l that are close to The intuition behind the Square Theorem follows from the law of large numbers. First, in a direct voting system, as Nd increases, the share of voters needed to pass any particular outcome decreases. (For example, if there are 11 total voters, 6 (54.5%) are needed to vote for an outcome for it to pass. If there are 21 total voters, 11 (52.3%) are needed to pass an outcome.) Second, a direct system will always require more votes to win than an indirect system with the same number of voters. Consider an election where Nd = 81. In a direct system, at least 41 voters must support any given outcome for it to pass. However, in a two-tiered hierarchical system with 3 groups of 27 voters, the minimum number of voters is equal to 28 (14 in each of 2 groups). (The same minimum number of voters is obtained when there are 27 groups of 3 voters.) And even fewer voters (25) are needed if there are 9 voters in each of 9 groups (where exactly 5 voters favor a measure in each of 5 groups). As the minimum number of voters required to sway an outcome decreases, an indirect voting system deviates even more from a direct system. In fact, because the probability a correct outcome is achieved increases with the number of required votes to win an election, the fewest voters necessary to achieve any outcome in a two-tier hierarchical system always occurs when group size equals group number. We prove this, as well as the extension to an n-tier hierarchical system as stated in Theorem 3, in Appendix 3.
The fewest voters necessary to sway an election occurs when Thus, the probability that a minority of voters sways the overall outcome toward the incorrect choice when p > 0.5, or the correct choice when p < 0.5, is maximized when the number of groups in each hierarchy equals
Influence of abstention
Thus far, we have assumed that all voters participate fully in the election. But in any system, people abstain from voting. In some cases, such as primary or midterm elections in the U.S., less than half of all eligible voters cast their ballot. More broadly, abstention-like behavior is also relevant to describe passive components in other information aggregation systems, such as non-functioning neurons in artificial neural networks (Douglas and Yu, 2018) and impaired prefrontal cortical areas in lesioned brains (Dehaene and Changeux, 1997). Studying the effect of abstention on hierarchical information processing is thus relevant in different scientific fields. In this section, we examine how abstention shapes the tradeoffs between direct and indirect voting.
To model abstention in a multi-stage voting system, let 
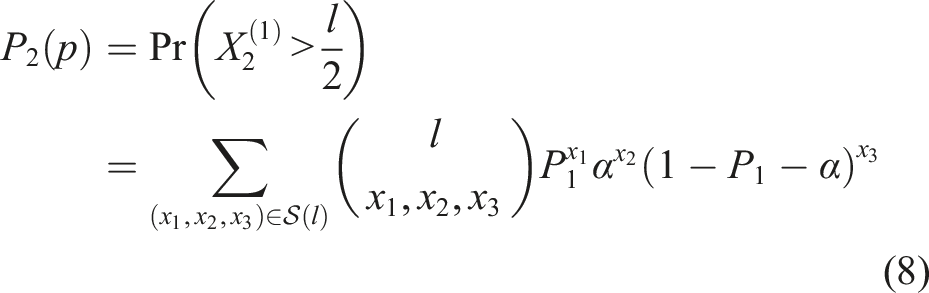
In the above description of (homogeneous) abstention, direct voting is still superior to indirect voting systems since α only reduces the domain of p from [0, 1] to [0, 1 − α] without altering other previous results.
In real-world scenarios, abstention is often correlated within voting groups. Residents of rural communities may have longer transportation times to reach their polling location, and thus vote at lower rates in the absence of mail-in ballots. Alternatively, voters may be discouraged from voting in urban areas when there are long lines to vote. Turnout is associated with political interest, information, and education (Sondheimer and Green, 2009), which are not homogeneously distributed across districts. People in economically disadvantaged districts may have fewer financial, temporal, and informational resources available that make voting accessible. Abstention is also related to an election’s competitiveness (Cancela and Geys, 2016; Simonovits, 2012) and the number of races on the ballot (Garmann, 2016; Kogan et al., 2018)—both of which can vary across districts. 4 Even random shocks—like a power outage, hail storm, or freeway accident—can cause geographical correlations in abstention. In a managerial setting, people in certain divisions of a firm may be less informed or interested in company decisions on which they have a vote. And, while all union members can participate and vote in labor decisions, full-time employees, as well as those receiving higher pay and requiring greater skill, are historically more likely to participate in union votes (Kolchin and Hyclak, 1984). Thus, for any number of reasons, it is important to examine cases where abstention is not homogeneously distributed across groups.
To model heterogeneous abstention and voter competences within districts, we incorporate the following modifications into our mathematical framework. We again consider a two-tier voting system and account for different abstention probabilities, α
j
∈ [0, 1] (1 ≤ j ≤ l), and voter competences, p
j
, in each of the l voting groups (or jurisdictions). The number of voters in group j that do not abstain is 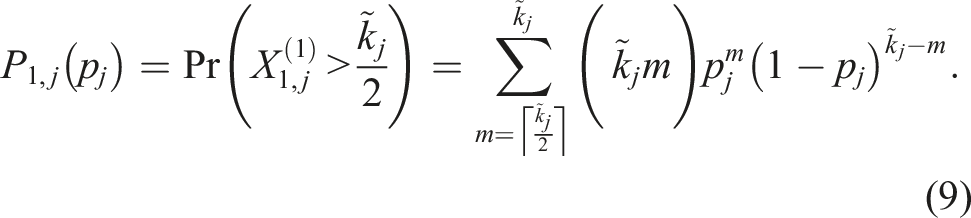
According to a theorem by Hoeffding (Boland, 1989; Hoeffding, 1956; Percus and Percus, 1985), the probability of a correct voting outcome after information aggregation across all voter groups satisfies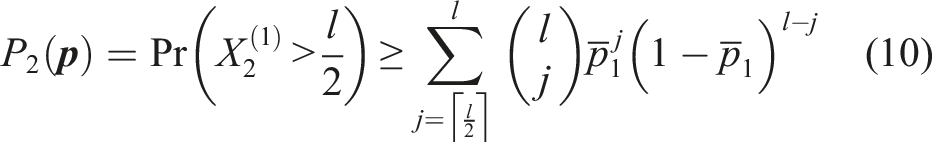
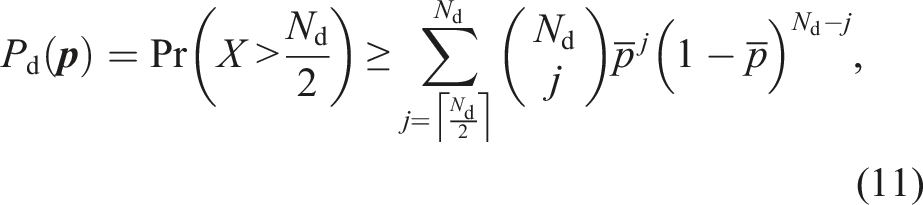
Previous work has relied on different bounds (Boland, 1989; Hoeffding, 1956; Hodges and Le Cam, 1960) to characterize heterogeneous systems. Instead of using Hoeffding bounds in equations (10) and (11), we derive a generating function in Appendix 4 to obtain an analytical expression for the reliability function of a two-tier voting system with abstention. To the best of our knowledge, this is the first paper to directly capture underlying heterogeneity in voting models without relying on further approximations. We find that the reliability function of a heterogeneous two-tier system is

Contrary to the differences between homogeneous and heterogeneous direct voting systems, as described by the Hoeffding bound (11), we find that hierarchical homogeneous systems outperform heterogeneous hierarchical systems. That is, when
For heterogeneous abstention and homogeneous voter competences (i.e., p j = p), direct voting systems are still preferable over indirect ones. However, if abstention rates are associated with greater within-group voter accuracy, hierarchical voting can outweigh the potential underrepresentation of voter groups with high abstention rates in direct voting systems. Thus, indirect voting can provide an opportunity not only for more efficient preference aggregation, but also for greater representation. All else equal, this would suggest that countries with significant geographic correlation between vote choice and abstention should achieve greater representation with large legislatures.
Figure 3(a) shows an example of a two-tier voting system in which heterogeneous abstention and voter competences impact the final voting outcome. There are l = 3 voter groups with k1 = k2 = 3 (α1 = α2 = 0.4) and k3 = 5 (α3 = 0), and the voter-group competences are p1 = p2 = p and p3 = 1 − p, respectively. Figure 3(b) shows the corresponding direct voting system. For p ≥ 0.5, hierarchical voting is associated with a larger probability of a correct voting outcome [Figure 3(c)]. For p ≈ 0.5, the Hoeffding bounds [dashed lines in Figure 3(c)] provide good characterizations of P2( Heterogeneous abstention in indirect and direct voting systems. (a) An indirect voting system with l = 3 voter groups and voter-group competences p1 = p2 = p and p3 = 1 − p. The number of voters per group are 
Discussion and conclusion
Most democracies use some form of indirect voting, be it through representative democracy (e.g., members of parliament selecting a Prime Minister) or an electoral college (e.g., the U.S. presidential race). In the U.S. electoral college, whichever candidate wins a plurality of a state’s votes receives all of that state’s electoral college votes. (The exception is in Maine and Nebraska, where electoral votes can be split across candidates.) As a result, the electoral college winner may not win the popular vote—a result that has occurred in five presidential elections, including George W. Bush’s (2000) Donald Trump’s (2016) wins. Had the U.S. tallied votes using a direct election instead, Al Gore and Hillary Clinton would have won in each respective election. Of course, if the U.S. switched to a popular vote to select the president, voting turnout would likely change as well. Candidates would spend less time than they currently do on populous battleground states, such as Florida, Ohio, and Pennsylvania, and more time mobilizing votes in large safe states that candidates currently all but ignore (except to fundraise), such as such as California or Texas. Electoral colleges are rarely used outside of the U.S. to select the head of government, though many countries have experimented with electoral colleges over time. For example, Charles de Gaulle was chosen under an electoral college in the first election of the Fifth Republic. After that, the country moved to a direct election for president. Indirect systems are frequently employed when selecting leaders within parties, so as to set aside a share of votes going to members of parliament, rank and file party members, and unions, for example.
In this paper, we have investigated differences in accuracy between hierarchical voting systems and their direct counterparts for varying voter competences, group sizes, and abstention rates. In our analysis of two-tier voting systems, we build on previous work (Boland, 1989; Kao and Couzin, 2019) and prove that the lowest collective accuracy is reached if the number of voters per group is equal to the number of groups. Moreover, we generalize this finding to multitier hierarchical voting systems, proving that collective accuracy is minimized asymptotically when group sizes equal
For homogeneous competences and abstention rates across voter groups, direct voting always outperforms hierarchical voting. For heterogeneous voter competences and abstention rates, we develop a generating function approach to analytically describe voting systems without relying on approximations used in earlier studies (Boland et al., 1989; Hoeffding, 1956; Hodges and Le Cam, 1960). We provide an example illustrating how indirect voting systems can correct for the underrepresentation of voters in groups or jurisdictions with high abstention rates. It is worth noting that most governments allocate seats in proportion to population, rather than turnout, for precisely these reasons. If abstention is correlated with accuracy or preferences, indirect systems can level the playing field by ensuring that districts with lower turnout are equally represented. Moreover, these methods may prove useful for research on hierarchical systems in areas outside politics—especially where information processing units fail or become inactive, such as for artificial neural networks with idle activation functions (Douglas and Yu, 2018) or lesioned brains (Dehaene and Changeux, 1997).
We see a number of directions for future research. First, it would be interesting to investigate a dual outcome model in which voters receive utility from both the overall and local outcome (that is, the within-group winner). Such a model could be used in both the standard Condorcet framework where there exists one “correct” outcome, or it could include an extension to allow for heterogeneous preferences over two competing outcomes. Second, future research may allow individuals to base their decision on multiple cues (perhaps from different sources) about the accuracy of each outcome, rather than a single signal (Kao and Couzin, 2014). Third, individuals (and animals) do not act independently; rather, they exchange information with diverse actors in forming group decisions (Adler and Gordon, 1992; Kao and Couzin, 2019). Thus, future research may investigate different effects of homophily (i.e., the tendency of individuals to form groups with similar individuals) on the tradeoffs between hierarchical and direct voting (Kossinets and Watts, 2009; Massen and Koski, 2014). Last, it would be fruitful to test the empirical implications of our work by examining multi-candidate elections (Boehmer and Schaar, 2022), electoral volatility, the quality of representation, and voter satisfaction as a function of different indirect electoral designs.
Footnotes
Acknowledgements
The authors thank Wendelin Werner for his lecture on “Randomness and Stability” at GYSS 2020 that inspired parts of this work. The authors also thank Malte Henkel, PJ Lamberson, Josh LeClair, and two anonymous reviewers for valuable comments, as well as Xiaofeng Lin for research assistance. We are especially grateful to Scott E. Page, who suggested that the Square Theorem may apply beyond two layers.
Declaration of conflicting interests
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
LB acknowledges financial support from the SNF (P2EZP2_191888).
Notes
Direct versus hierarchical voting systems
To formulate our proof of Theorem 1, let k = 2k′ + 1 and
Point (i) of Theorem 1 (Pd(p) = P
n
(p) for p ∈ {0, 0.5, 1}) can be readily obtained from the definitions of Pd(p) and Pi+1(p). • For p = 0, we find Pd(p) = P
n
(p) = 0 (note that • For p = 0.5, we obtain P1(p) = (1–0.5)
k′
0.5
k′
+14
k′
= 0.5 and thus P
i
(p) = 0.5 for all i ∈ {1, …, n}. Similarly, we find Pd(p) = 0.5 for p = 0.5 and conclude that Pd(p) = P
n
(p) = 0.5 for p = 0.5. • For p = 1, the last term in the sums (14) and (15) dominates; i.e., Pd(p) = P
n
(p) = 1. Alternatively, we can use the identity
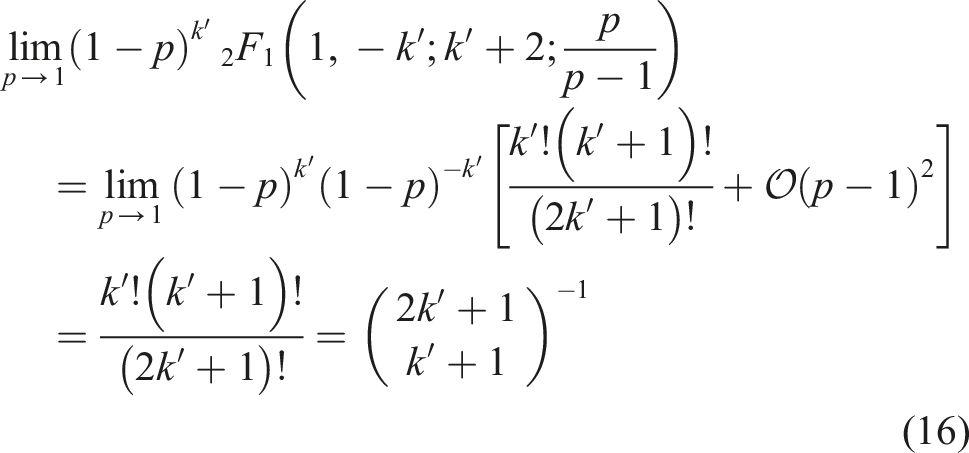
A graphical interpretation of Pi+1(p) = Pi(p) for p ∈ {0, 0.5, 1} is that 0, 0.5, and 1 are fixed points of the iteration Pi+1(P) = g(Pi(p)) [black disks in Figure 4(a)].
To prove points (ii-iii), we will use that Pd(p) and P
n
(p) are monotonically increasing with p and convex for p ∈ (0, 0.5) (Boland, 1989). For Pd(p) this follows directly from the definition (14) and for P
n
(p) this follows from the way it is constructed via an iteration from P0(p) as we illustrate in Figure 4(a). Everything that is left to show is that the derivative Fixed-point iteration and hierarchical voting. (a) The probability P
n
(p) of reaching the correct voting outcome in a hierarchical voting system as a function of p, the probability that voters in the electorate vote for the correct outcome. One can obtain Pn+1(p) from P
n
(p) via an iteration (black arrows) from n = 1 → n + 1 = 2. Black disks indicate fixed points of the iteration. (b) The slope of P
n
(p) (black disks) and Pd(p) (blue triangles) at p = 0.5. For n ≥ 2, 
For P0(p) = g(p), we find
The derivative of P
n
(p) is
Using g(p = 0.5) = 0.5 yields
Note that ∂
p
Pd(p = 0.5) = ∂
p
P
n
(p = 0.5) for n = 1 and arbitrary k. According to equation (20),
Group size associated with lowest performance
Number of groups with the lowest performance as a function of the electorate size. Black dots were obtained by numerically determining the minimum of the product (24). Note that equation (24) admits real-valued solutions of lmin. The solid black line describes the number of groups with the lowest performance according to 
We aim at determining the values of k (number of voters per group), l (number of groups) that are associated with the lowest collective accuracy in a two-hierarchy system [i.e., with the smallest value of P2(p; k) for p > 0.5 in equation (5)]. As in Appendix 1, we use k′ = (k − 1)/2 and l′ = (l − 1)/2. Note that l′ is a function of k′ for fixed N = kl.
To determine the values of k′ and l′, and hence of k and l, that are associated with the smallest values of P2(p; k) for p > 0.5, we study the slope of P2(p; l′) as a function of l′ in the vicinity of p = 0.5. Since the considered reliability functions are concave increasing in the interval [1/2, 1] (Boland, 1989; Berg, 1997), it is sufficient to evaluate P2(p; l′) for a fixed value of p and varying l′. An expansion of P2(p; l′) about (p, l′) = (0.5 + Δp, l′) with Δp > 0 yields
The derivative ∂
p
P2 (or Banzhaf number [Berg, 1997]) is
As a side note, observe that it is symmetric in (k, l) = (k, Nd/k). This symmetry in (k, l) is a consequence of the fixed-point behavior of P2 at p = 0.5 [black disks in Figure 4(a)].
For evaluating ∂
p
P2, we use equation (18), which we rewrite to obtain
Invoking Stirling’s approximation in the limit of large k′, we approximate the ratio of the Gamma functions in equation (23) according to
To derive the corresponding asymptotic relation for the hypergeometric function
We thus find
For large k and l, we set k′ ∼ k/2, l′ ∼ Nd/(2k) and obtain
The minimum of equation (28) is attained for
We thus conclude that the minimum of the first derivative of P2(p; l) in the vicinity of p = 0.5 is attained asymptotically for
We derived equation (29) using different asymptotic relations which are valid for large k′ and l′. Based on numerical calculations, we observe that the minimum of the product (24) follows the same square root law for small values of k′ and l′ (Figure 5).
The above proof can be extended to general hierarchical systems with groups of sizes k(1), k(2), …, k(n) in layers 1, 2, …, n, respectively. The total number of voters in the electorate is Nd = k(1)k(2)⋯k(n). In accordance with equations (24) and (27), observe that the derivative of the reliability function P
n
(p) of a hierarchical voting system with n layers factorizes at the fixed point p = 0.5 and is given by
The solution of the above set of equations is
The fewest voters needed to sway an outcome occurs at N d
In a two-tier hierarchical system, the lowest number of voters needed to support a winning measure is equal to
Taking the derivative of equation (33) with respect to k gives
Setting this to zero and solving for k reveals that
This number is positive for
More generally, in an n level hierarchy with k(i) groups (voters) at each level i = 1, …, n, where k(i) is odd for all i, the fewest voters needed to support a winning measure can be found by searching for the minimum of
For each i ∈ {1, …, n − 1} the partial derivative of this quantity with respect to k(i) is
The unique positive solution to
Since these are both positive, the Hessian is positive definite, so
Generating function approach
Let X
i
be a Bernoulli random variable for which Pr(X
i
= 1) = p
i
and Pr(X
i
= 0) = q
i
= 1 − p
i
. In what follows, we assume that p
i
≠ 1. To derive the probability mass function of the number of positive outcomes
we start from the generating function (Percus and Percus, 1985)
The probability that Σ
n
is equal to s ≤ n is
To calculate the sth elementary symmetric polynomial, we utilize the recursion relation (“Newton’s identities”) (Mead, 1992)
To apply equation (39) to the voting system with abstention and heterogeneous opinions (see main text), positive outcomes (X
i
= 1) have to be in the majority. For n = 2n′ + 1, positive outcomes are in the majority if Σ
n
≥ n′ + 1. The corresponding probability is
As an example, we consider the case with n = 3 independent Bernoulli random variables. Positive outcomes are in the majority if Σ3 ≥ 2. Using the elementary symmetric polynomials for n = 3 and s = 2, 3 (Table 2), the probability of Σ3 ≥ 2 is