
Abstract
Collective decision-making constitutes a core function of social systems and is, therefore, a central tenet of collective intelligence research. From fish schools to human crowds, we start by interrogating ourselves about the very definition of collective decision-making and the scope of the scientific research that falls under it. We then summarize its history through the lenses of social choice theory and swarm intelligence and their accelerating collaboration over the past 20 or so years. Finally, we offer our perspective on the future of collective decision-making research in 3 mutually inclusive directions. We argue (1) that the possibility to collect data of a new nature, including fine-grain tracking information, virtual reality, and brain imaging inputs, will enable a direct link between plastic individual cognitive processes and the ontogeny of collective behaviors; (2) that current theoretical frameworks are not well suited to describe the long-term consequences of individual plasticity on collective decision-making processes and that, therefore, new formalisms are necessary; and finally (3) that applying the results of collective decision-making research to real-world situations will require the development of practical tools, the implementation of monitoring processes that respect civil liberties, and, possibly, government regulations of social interventions by public and private actors.
Collective decision-making: Definition and scope
Does a water molecule make a choice when the river reaches a fork? It, obviously, does not. But if all you can observe is the trajectory of that water molecule, how would you know? You could pick it up, drop it somewhere upstream, and observe its behavior again as it reaches the same fork. And repeat this a few dozen times at least. If the water molecule ends up on one side of the fork more often—statistically speaking—than on the other one, then maybe, after all, it has made a choice.
“Not so fast!”, an astute physics student interjects. “We have to account for asymmetries in the bed of the river and the size and relative orientation of the distributaries.” Very well then. You spend time and money equalizing the bed of the river and reshaping the fork so that it is perfectly symmetrical. And lo and behold, the water molecule does not anymore end up more often on one side of the fork than on the other. The water molecule does not make a choice.
“Not so fast!”, a cognitive scientist yells standing on the riverbank across from you, “By removing all asymmetries from the environment, you have also removed all sources of information available to the water molecule. Even if the water molecule could choose, it would not have any ground to do so.” And just like this, we are back at square one: how can one know if a water molecule can choose if all one can observe is its behavior?
This admittedly silly story is meant to illustrate that studying decision-making is no easy task. The process is often internal and, therefore, almost impossible to observe directly. It is also dependent on external inputs and, thus, cannot truly be studied in isolation. In that context, determining what constitutes a decision in a behavioral experiment is often arbitrary (Gigerenzer et al., 2000). It cannot be otherwise.
This issue is, of course, present as well in the study of collective decision-making: does the water stream as a whole make a decision at each embranchment of the river? If anything, it is made even worse by the fact that “collective” is another concept that can be difficult to pinpoint scientifically. In some cases, it is easy to delimit the group of individuals participating in a collective choice. This is, for instance, the case in democratic elections where the pools of eligible and participating voters are clearly defined, and the weight of each individual in the outcome is fixed and established.
However, in more “natural” collectives, establishing group membership and the weight of each individual in the outcome can be very difficult, even impossible. Indeed, except in very rare cases, a collective is rarely made of units that interact with all others at all times. Fish in a school, birds in a flock, or pedestrians in a crowd only interact with a few others at a given moment (e.g., their closest neighbors) and do not continuously do so (Camazine, 2001; Garnier et al., 2007; Moussaid et al., 2009; Sumpter, 2010). In many cases, they may not even interact directly with each other at all, such as when an individual is influenced by the stigmergic traces (Theraulaz and Bonabeau, 1999) others have left in the environment (e.g., an ant following a pheromone trail (Goss et al., 1990; Hölldobler and Wilson, 1990), or a pedestrian following in someone else’s footsteps in the snow (Helbing et al., 2001)). In these conditions, it can be particularly challenging to determine who belongs to a group, when they join or leave it, and what their impact on the collective outcome is. In behavioral experiments, group membership is often based on simple habitat sharing (e.g., all the fish in a tank) or on more sophisticated proxies for connectivity such as distances between individuals (Ballerini et al., 2008) or their presence in each other’s perceptual field (Gallup et al., 2012; Moussaïd et al., 2011; Rosenthal et al., 2015; Strandburg-Peshkin et al., 2013). But here again, arbitrary cutoffs must be set (e.g., maximum distance of perception) to construct a network of presumptive interactions between individuals.
In this context, how could one attempt to write a review on collective decision-making, given that neither the term “collective” nor “decision-making” can be unequivocally defined in the first place? We address this challenge by reducing the realm of possibilities, accepting that some important questions will be left out but hoping that what remains will be insightful enough. Choosing is eliminating, after all.
First, we choose to restrict the discussion on collective decision-making to the context of consensus-building amongst the members of a group (Conradt and Roper, 2005). Here, we define consensus-building as the process of selecting among multiple available options one by which all the members of a group will abide (the consensus), even if not all individuals are equally satisfied by the outcome. By doing so, we assume that a coherent collective response is more often than not beneficial to the members of the group. Therefore, we will not discuss much of the “whys” of collective decision-making, leaving the question of social evolution to others more qualified than us (Conradt and Roper, 2007; Conradt and Roper, 2009; Torney et al., 2015; Wenseleers et al., 2010). Rather, we will focus here more specifically on the “hows” and their consequences on group performance and group stability. In particular, we will concentrate our discussion on what Conradt and Roper called “shared consensus,” which is a consensus reached by a process involving all (or at least most) of the group members (Conradt and Roper, 2005).
We also choose the consensus framework for practical reasons. Indeed, a consensus is a convenient benchmark for a researcher: it is either achieved or it is not, and one can easily measure by how much it was missed. As such, it is a natural performance target for comparing groups or decision mechanisms against each other. Consensus also allows for treating the group as a unit, making it possible to interpret experimental observations against the background of optimality and rationality theories. Optimality theory provides a well-established economic framework for linking decision mechanisms to their respective costs and benefits, allowing for the comparison of decision outcomes to their expected optimal value (Marshall et al., 2009). It allows for establishing global benchmarks or theoretical upper bounds to the performance of a system given the conditions it is placed in and independently from its internal mechanics. This is particularly useful, for instance, to understand whether the optimization of a system is restricted by the external conditions or by the composition of the system itself. Rationality theory, on the other hand, provides a convenient framework to reverse engineer the computations performed by the deciding system and to identify its (logical) limitations (Sasaki and Pratt, 2011, 2017). It focuses on determining the choices that maximize a system’s utility, given the information available to the system when making a decision. Any deviation from the utility maximization principle will indicate the existence of constraints during the decision-making process that can be used to infer the information processing pipeline of the system. In both cases (optimality and rationality theories), this opens up the possibility to draw up parallels between the processing capabilities of social systems and of, for instance, neuronal networks and computerized applications. Moreover, considering the group as a functional unit embedded in an environment allows for asking questions about the intricate relationship between individual and collective phenotypes, both in a proximate and an evolutionary context (Dalziel et al., 2021; Guttal and Couzin, 2010).
We will also restrict our discussion to situations in which the deciding collective system is presented with discrete options (Figure 1). The options may differ from each other on one or more variables, and members of the group may perceive and even interact with all the available options at once, but no individual member of the group should be able to benefit or suffer the consequences from more than one option at any given time. If that condition is not respected, then it is not possible anymore to unambiguously determine the quality of the consensus. This is not to say that this condition is always respected in natural situations—it is not, obviously—but it is desirable in experimental settings to disambiguate the interpretation of the results. Illustration of collective decision-making in various social systems. (a) A group of 5 golden shiners settled in one of the 6 possible arms of a radial arm maze. The colors represent the density of presence of the fish in all the parts of the maze (after Delcourt et al., 2018). (b) A crowd of 37 persons evacuating a building under emergency conditions. The density traces indicate a consensual decision toward one exit door (from Moussaïd et al., 2016). (c) Stacked images of an experiment showing the collective selection of the shorter path between a nest (left) and a food source (right) by a colony of ants. Darker portions of the maze are traveled more often by the ants (after Garnier et al., 2009).
Furthermore, if not respected, it can be difficult to distinguish between opinion averaging and collective decision-making. The latter implies the existence of a mechanism to break the symmetry between the available options, while the former simply calculates the central tendency of the group. When the available options are discretized, opinion averaging will result in the group sitting somewhere between them depending on the balance between the different opinions in the group; collective decision-making, on the other hand, will result in the group sitting at one of the options only or split between them if a consensus is not reached. If the options are not discretized, however, the outputs of opinion averaging and collective decision-making will resemble each other. Note that opinion averaging is often the first step of many collective decision-making processes, but it is then followed by a mechanism to break the symmetry. For instance, the ballot collection during a democratic election is a form of opinion averaging; the majority rule turns it into a consensus by selecting the winning option.
Finally, we will in this manuscript purposely conflate preferences and personal information into the word “opinion” (i.e., the expression of an individual’s choice). Preferences correspond to an individual’s ranking of the available options based on their relative utility. Personal information is the knowledge that has been integrated by an individual. Studies of human systems typically make a distinction between collective decision-making processes that aggregate personal information and those that aggregate preferences. In the first case, the options have similar relative utilities and the opinions are expressed based on the knowledge that each individual has about, for instance, the availability of the options in the environment or their ease of access. In the second case, the relative utilities of the options differ from one individual to another and the opinions reflect that conflict of preferences. In practice, however, individual opinions are rarely purely information- or preference-based. In fact, personal information and preferences are not independent of each other: personal information is interpreted through the prism of preferences (e.g., a piece of information may be disregarded because it conflicts with an individual’s preferences), whereas utility is a function of the information that the individual can collect and integrate (e.g., incomplete information about a product may reduce its perceived utility when compared to an identical product with more accessible information). Therefore, except for extremely controlled experimental conditions, it is difficult to separate practically the effect of personal information from that of preferences (especially in non-human systems), and we will, instead, refer to their combination as the individual’s opinion.
From Condorcet to swarm intelligence: A brief historical perspective
Even with all our self-imposed restrictions, the scientific study of collective decision-making has a long and rich history (Figure 2). The first studies, which may date back to the Middle Ages, were primarily interested in the statistical properties of various opinion pooling mechanisms and, in particular, their ability to lead to a fair and/or accurate choice (McLean, 1990). Some of the best examples of these early works are by Marie Jean Antoine Nicolas de Caritat, better known as Marquis of Condorcet. For instance, in his “Essay on the Application of Analysis to the Probability of Majority Decisions” (de Caritat (Marquis de Condorcet), 1785) published just a few years before the French Revolution, Condorcet showed that the probability of a majority decision to be correct increases with the group size, provided that the voters are individually more often right than wrong. This result—often referred to as Condorcet’s Jury Theorem—helped kickstart the field of Definitions of the main concepts discussed in the manuscript and how they link to one another.
Condorcet was also amongst the first to formally demonstrate that the implementation of a vote can have significant consequences on its final output. Most famously, the voting paradox that bears his name illustrates a situation where transitive preferences at the individual level can translate into non-transitive preferences at the population level, making it impossible to designate a winning option (de Caritat (Marquis de Condorcet), 1785). Down’s paradox of voting stated that, as the number of voters increases, the relative influence of each voter on the outcome decreases, possibly leading to a loss of interest in participating in the democratic process (Downs and Others, 1957). Later, Feddersen and Pesendorfer identified the “swing voter’s curse”—a situation in which indifferent or uninformed individuals are less likely to vote because of their higher likelihood of impacting the election by being the swing vote (Feddersen and Pesendorfer, 1996). Likewise, strategic voting—a vote that is made in response to the vote of others—can change the properties of judgment aggregation (T. Feddersen and Pesendorfer, 1999). In other words, voting is a free-rider problem.
That general line of inquiries—looking into opinion pooling mechanisms better adapted to given decision-making scenarios—has had a very successful descent (see, e.g., Christian List’s theory of aggregating judgments (List, 2012)), with important repercussions in modern political sciences, obviously, but also more generally in the fields of decision science and computer science. Recent research has focused on elaborating new pooling mechanisms—beyond a crude majority—that could yield better collective decisions (Dietrich and List, 2007; Hastie and Kameda, 2005; Hertwig et al., 2019; Kerr and Tindale, 2004) or guarantee convergence to the truth in networks of influences (Degroot, 1974; Golub and Jackson, 2010). This, unsurprisingly, turned out to be a rich and complex challenge in which numerous factors played equally important roles: the statistical structure of the environment (Herzog et al., 2019), the group composition (Davis-Stober et al., 2015), the initial diversity of judgments (Ladha, 1992, 1995; Shi et al., 2019), the structure of the interaction network (Becker et al., 2017), or the degree of social influence within the group (Lorenz et al., 2011)—to name a few. Pooling mechanisms often involve weighing the judgments of the individuals before combining them using external cues such as the individuals’ confidence or their past performance. This resulted in real-world applications in a variety of domains, including medical diagnostics (Kämmer et al., 2017; Kurvers et al., 2016), and geopolitical and economic forecasts (Batchelor and Dua, 1995; Clemen, 1989; Hibon and Evgeniou, 2005).
Nearly 200 years after Marquis of Condorcet’s mysterious death in a revolutionary jail (Crépel, 2001), the then-nascent field of
The central paradigm of swarm intelligence is based on the theory of self-organization: consensus at the level of the group emerges from interactions between its members; interacting members locally align their opinions with each other, allowing for the progressive propagation of a consensus through the population; and when two or more opinions compete with each other in the population, the opinion with the fastest propagation properties (because of, for instance, a higher convincing rate or a larger initial share of supporters) is more likely to win (Camazine, 2001; Couzin, 2009; Couzin et al., 2005; Garnier et al., 2007). This general principle was identified in pretty much all animal societies, especially in situations where the cognitive abilities of individuals are overwhelmed by the sheer complexity of the information available to them. This is the case, for instance, in foraging ants that can collectively select the shortest path towards a food source out of many possible options, even though no individual ant ever compares them directly (Garnier et al., 2009; Goss et al., 1989; Reid et al., 2011). Likewise, a similar amplification effect also exists during the process of opinion formation in humans (Moussaïd, 2013).
Over the past 40 years or so, that swarm intelligence perspective has evolved to include more complex scenarios. Originally, it considered that all members of a group were identical or drawn from the same unimodal distribution. This helped simplify the models and their predictions and facilitated the study of the general principles underlying self-organized collective decision-making. Later research, however, showed that diversity in individual behaviors (Jolles et al., 2020) and sensitivity to social information (Sasaki et al., 2018) can have dramatic effects on the outcome of the collective process. For instance, individuals with higher physiological needs or with personal knowledge of the locations of resources will be more likely to initiate a collective decision, making them apparent—but de facto—leaders of the group (Conradt et al., 2009; Couzin et al., 2011; Couzin et al., 2005; Guttal and Couzin, 2011; Papageorgiou and Farine, 2020; Sueur, 2012).
This complexification is also illustrated by the increasing use of interaction networks to represent social connections (Croft et al., 2008; Farine and Whitehead, 2015; Proulx et al., 2005; Sosa et al., 2021). As a first simplification, early models often considered that individuals were influenced by their “neighbors” (e.g., the N closest individuals, or all those located within a certain interaction radius, see for instance Ballerini et al. (2008); Couzin et al. (2002)). Recent approaches, in contrast, highlight the existence of privileged social pathways through which information flows between individuals. These ties could be defined by visual perception capabilities (i.e., one interacts with those it can see), or by specific social relationships (friends, peers, family members) (Moussaïd et al., 2011; Rosenthal et al., 2015; Strandburg-Peshkin et al., 2013). Over time, new social ties often appear, and old ones die out, producing a complex and non-stationary network of interactions.
The two general lines of research—social choice theory and swarm intelligence—eventually met each other in the early 2000s to form a new research area that one—or maybe just we?—may call “swarm choice theory.” It was already apparent in Condorcet’s time that some of his original assumptions could not be realistically met. In particular, the assumption that agents form opinions independently of each other is virtually impossible to realize in a system that is, by nature, social. Moreover, the assumption that agents should not be—on average at least—biased toward unfavorable options is often difficult to meet when the information available to the agents is itself biased (for instance, by social or racial prejudice) or when the “better” option is a matter of taste and not of quantifiable outcomes (e.g., fashion choices, political views). In all these cases, Condorcet’s predictions fail more often than not, and new paradigms need to be invented to salvage the so-called “wisdom of the crowd” (Surowiecki, 2004).
In this context, swarm intelligence provides tools and a theory to understand the dynamics of opinion emergence, spreading, and competition in networks of highly correlated individuals (O’Bryan et al., 2020). Therefore, it can help explain how information entering such networks can eventually bias an entire population (Lorenz et al., 2011; Moussaïd et al., 2015), or how the interaction dynamics within a population can lead to the emergence of more accurate decisions in some cases (Kao and Couzin, 2014; Mann, 2018; Marshall et al., 2019), but also of groupthink and opinion polarization in others (Hegselmann and Krause, 2002; Janis, 1982). Social choice theory then allows for evaluating the consequences of a crowd’s dynamics after a collective choice, by comparing its outcome to predictions from optimality and rationality theories. It also allows for determining which—if any—opinion pooling mechanism may help with correcting the negative consequences of crowd dynamics on the quality of the collective choice. For instance, common pooling mechanisms such as the majority or the confidence-weighted majority rules typically fail when most individuals are biased towards the wrong option (Hastie and Kameda, 2005). Nevertheless, these situations can be detected and dealt with by using, for instance, the “surprisingly popular” pooling rule (Prelec et al., 2017). This mechanism proposes that the option that is more popular than people predict is selected as the collective outcome (i.e., by asking group members what they think others will choose). Similarly, the “select-crowd strategy” proposes to average only the opinions of the individuals in a crowd who have previously demonstrated their judgment accuracy (Mannes et al., 2014), thereby combating the decrease in accuracy that large crowds can experience when making difficult decisions with largely inexperienced members (Galesic et al., 2016). In both cases, a bias in the statistical structure of the judgments can, therefore, be exploited to indicate the correct answer.
Future perspectives
The progressive merging of social choice theory with swarm intelligence has yielded a host of innovative ideas, as shown by a linear increase in the number of publications on the topic since the early 2000s (source: https://app.dimensions.ai/). But after 230 odd years of research, it is natural to wonder whether anything truly new remains to be discovered, or whether the field has reached maturity and is now focused on incrementally refining solidly established theories.
While the latter is certainly happening, we believe that much remains to be done in furthering our knowledge of collective decision-making, both in human and non-human social systems, both experimentally and theoretically. In fact, there are some good reasons to think that the study of collective decision-making is on its way to a (r)evolution on at least three fronts that we will discuss below: a methodological revolution that is in the making; a theoretical one that is going to be needed; and a societal one that is becoming pressing.
Methodological revolution
Since the early 2000s, the field of collective intelligence, in general, and the study of collective decision-making, in particular, have experienced sustained and steady growth. A significant contribution to this growth can be attributed to the development of observation technologies that can generate data on social systems in increasingly high quantity and quality (Dell et al., 2014; Kays et al., 2015; Lazer et al., 2009) (Figure 3). Methodological advances for the study of collective decision-making. (a) Progresses in video-tracking technologies have enabled the extraction of detailed behavioral information, such as fishes’ positions, body posture, and visual field in a school (from Walter and Couzin, 2021). (b) The miniaturization of onboard tracking technologies such as GPS chips, accelerometers, or audio recorders allows for the long-term tracking of the activities of animals in field conditions (Handcock et al., 2009; Markham and Altmann, 2008; O’Bryan et al., 2019), such as these GPS tracks of interacting male elephants (image courtesy of Maggie Wiśniewska and Gareth Russell). (c) Using multi-user virtual reality, groups of human participants can be simultaneously immersed in a shared virtual environment during behavioral experiments. In this example, the crowd has to choose a way out of a burning building—a design that would have not been possible in real-life (Moussaïd et al., 2016; Zhao et al., 2020). (d) Miniature brain imaging technologies, such as this portable two-photon microscopy headpiece (after Zong et al., 2021), allow for the live imaging of neuronal activities during social interactions, opening the door to connecting brain activity to individual social behaviors to collective output at the group level.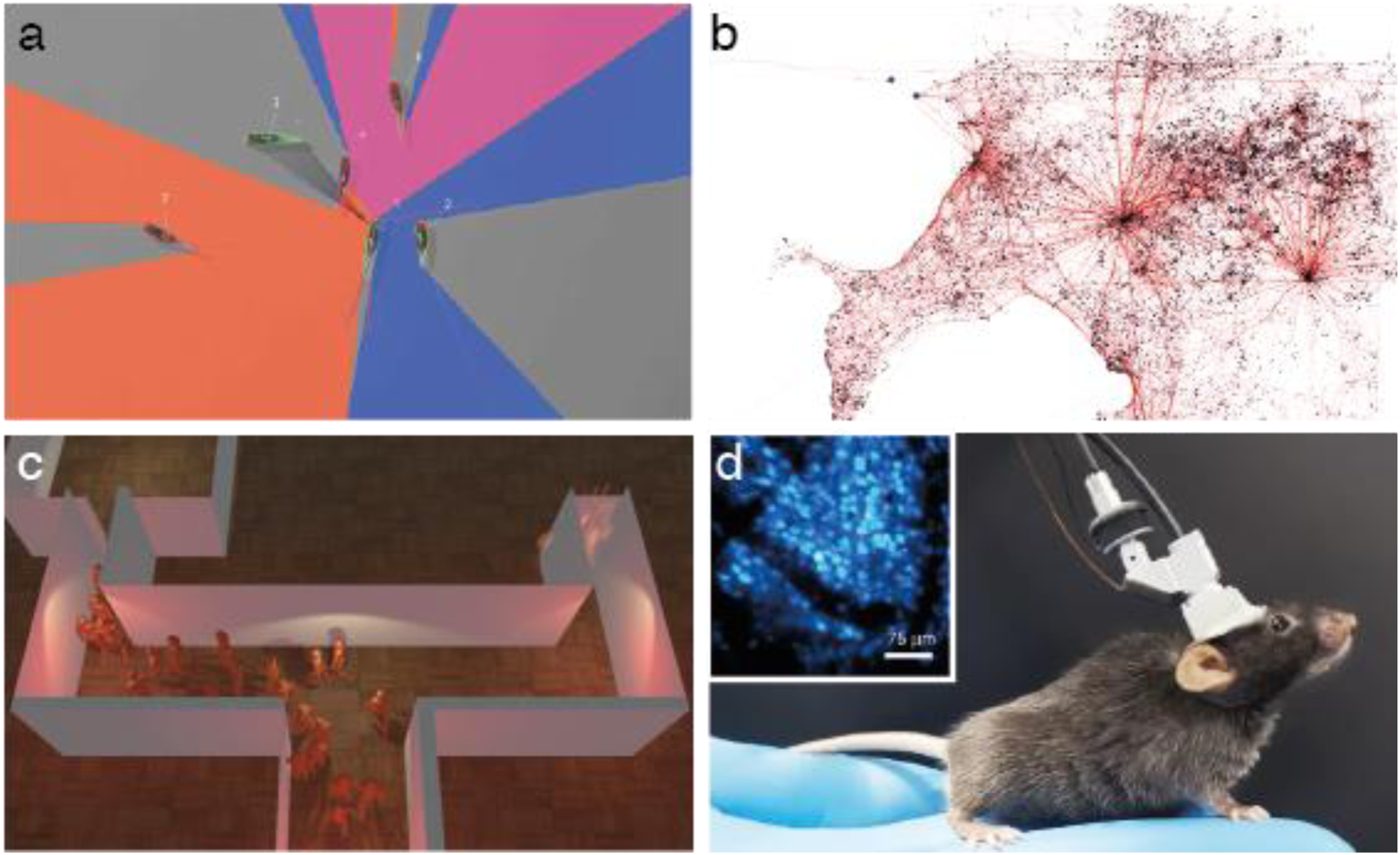
In laboratory and natural settings, video-tracking technologies allow for the automated quantification and classification of behaviors in a variety of animal models, including humans, with a level of precision never seen before (Ouyang and Wang, 2013; Pérez-Escudero et al., 2014; Shao et al., 2015; Walter and Couzin, 2021). Modern tracking technologies allow not only for measuring the position of individuals in a group but also fine-grained details such as the direction of their sight—thus informing us about how each agent perceives its local environment (Gallup et al., 2012).
In addition, the miniaturization of remote sensing technologies (e.g., onboard GPS and accelerometers) allows for tracking the position, activities, and even communications between social animals in the wild using custom-made and commercially available tracking collars (Strandburg-Peshkin et al., 2017), and between humans using, for instance, connected apps installed on participants’ cell phones (Blanke et al., 2014; Wirz et al., 2013). This, in turn, facilitates the extractions of empirical interaction networks, revealing how information circulates among group members (Farine and Whitehead, 2015), and how interactions of different natures contribute to producing collective decisions (Finn et al., 2019). Besides, the development of language processing and opinion mining technologies allows us to understand precisely the nature of the information that circulates between humans (e.g. on social media platforms) and to measure how the level of agreement increases or decreases over time (Serrano-Guerrero et al., 2021).
In the laboratory, virtual reality is increasingly used to create tailored immersive environments for human (Moussaïd et al., 2018) and non-human (Ioannou et al., 2012; Stowers et al., 2017) experiments. Recent developments of this technology have enabled multiple participants to join a shared virtual environment in which they can move and interact in real-time (Moussaïd et al., 2016; Wu et al., 2021; Zhao et al., 2020). The level of control offered by this evolution is unprecedented, enabling, for instance, the experimenter to change the environment dynamically or create artificial social signals using virtual agents.
Moreover, online sharing technologies have permitted the creation of platforms for running experiments involving very large numbers of participants, sometimes distributed all over the globe (Mason and Suri, 2010). Online controlled experiments involving up to a hundred interacting participants have already been conducted in the field of social psychology and network science (Judd et al., 2010; Mao et al., 2016; Mason and Watts, 2012), and the scale of these experiments is continuously pushed up, with social network corporations routinely performing A-B testing with thousands of their users at once, albeit not necessarily for a scientific purpose (Kramer et al., 2014).
Finally, and in parallel, the field of cognitive neurosciences has experienced a similar—maybe even greater—technological jump. Recent advances in brain imaging (e.g., multiphoton microscopy) make it possible to observe brain activity in live laboratory models such as mice (Zong et al., 2021) or zebrafish (Dreosti et al., 2015; Tunbak et al., 2020), for instance. Combined with the presentation of dynamical social stimuli in virtual reality environments (Larsch and Baier, 2018) and the precise tracking of behavioral responses (Romero-Ferrero et al., 2019; Walter and Couzin, 2021), these imaging methods allow for establishing causal relationships between social information, patterns of brain activity, and motor outputs.
Inevitably, the methods described above will soon allow for relating the processing of social information in the brain to both its individual and collective behavioral outcomes. In particular, this methodological “revolution” can facilitate the study of the role of individual behavioral plasticity in the ontogenesis of collective actions and decision-making. Indeed, the behavior of living organisms is not static over time; it is transformed by its history. For instance, mechanisms for learning and memory present in even the simplest of organisms allow them to adjust their behavior in response to past experiences (Dussutour, 2021; Perry et al., 2017/8). Likewise, models of opinion competition produce different collective dynamics depending on the nature of the social contagion at play. In the case of a “simple contagion,” the adoption occurs through pairwise interactions and a single exposure is sufficient for an individual to adopt a new opinion. In contrast, with “complex contagion,” exposure to multiple sources is required for the contagion to occur (Centola and Macy, 2007; Guilbeault et al., 2018). While simple and complex contagion mechanisms may coexist in a given population (Min and San Miguel, 2018; Weng et al., 2013), empirical pieces of evidence suggest that numerous social phenomena are better described by complex rather than simple contagion (Hodas and Lerman, 2014; Mønsted et al., 2017; Moussaïd et al., 2017). Although learning and memory are not necessary ingredients to describe complex contagion (e.g., when multiple expositions happen simultaneously), some models of complex contagion suggest that individuals memorize and integrate the past stimuli they were exposed to in order to determine their next “state” (Dodds and Watts, 2005, 2004). Therefore, understanding how the social history of an individual affects its response to future interactions is a critical element to take into account (Lemanski et al., 2021; Moussaïd et al., 2017). The aforementioned advances in behavioral tracking, virtual reality, and brain imaging will make this possible in the coming years. This will not only allow to fine-tune existing models but also yield a paradigm shift in current modeling approaches—moving the field past the “individual-as-particle” formalism to “process-based” approaches. This upcoming theoretical advance is discussed in the next section.
Theoretical revolution
New empirical insights always call for a subsequent change of the theoretical framework that explains them. In fact, the “individual-as-particle” formalism that has been dominant in human and non-human studies since the 1990s is already evolving. That framework reduces individual behaviors to so-called “social forces” modulated solely by point-to-point relationships between individuals (Castellano et al., 2009; Helbing and Molnar, 1995). While very fecund and useful in its own right—physics-inspired models have boosted research and inspired numerous real-world applications—this approach masks important theoretical questions about the nature of social information that circulates between evolving cognitive agents and not between immutable physical objects.
Since the 2010s, ideas and concepts from cognitive science have become more popular for describing the collective dynamics of a social system: outcome models describing an agent’s behavior using attractive and repulsive forces have been gradually challenged by process models describing the underlying cognitive process that gives rise to the behavior (Moussaïd and Nelson, 2014). Whereas the former are excellent at reproducing observations under specific conditions, the latter aim at capturing the intrinsic cognitive mechanisms operating at the level of the individual. Cognitive heuristics, for instance—simple rules of thumb that operate fast and based on limited information and reduced cognitive capabilities—can capture the process by which individuals make decisions in a large group (Gigerenzer et al., 2000; Hertwig et al., 1999; Moussaïd et al., 2011; Seitz et al., 2016).
More importantly, process models are convenient tools to include individual behavioral plasticity in our descriptions of collective decision-making mechanisms. In particular, they can help us understand how the outcome of a collective action, which results from the aggregation of individual behaviors, may in turn affect the future behavior of the individuals (Biro et al., 2016). Indeed, in numerous situations, individuals can have access directly or indirectly to information about the quality of their collective decision—a fact that is often ignored in other existing theoretical frameworks (Kao et al., 2014). For instance, the perceived performance of elected officials at the end of their mandate can often—but not always—predict their likelihood of reelection, indicating that individual voters integrate the consequences of their previous collective choice into their next individual decision, at least partially (Asunka, 2016; Horkin et al., 2014). Similarly in ants, a mismatch between the strength of social advertising for a given food source and its quality as experienced by a given ant worker can push that individual to lower or even abandon its foraging effort (Czaczkes et al., 2013; Oberhauser and Czaczkes, 2018; Wenig et al., 2021). These examples support the notion that individuals in a group are not oblivious to the consequences of their collective decisions, even when they cannot assess them in their globality. Yet, the “individual-as-particle” formalism often assumes that they are and, in most models of collective decision-making (and collective behavior more generally), the behavior of the individual agents is unchanged by the outcome of the collective process.
This assumption is, of course, perfectly reasonable when studying one-off collective choices. However, it does not hold anymore when studying social systems undergoing repeated consensus-making processes where the individuals can adjust their behavioral rules in response to the outcome of a collective choice. This question has been, so far, mostly investigated in an evolutionary context, considering the fitness consequences of collective decisions on the evolution of individual behaviors (Boyd and Richerson, 1988; Guttal and Couzin, 2011; Herbert-Read et al., 2019; Mesoudi and Thornton, 2018).
However, this applies as well to much shorter timescales, in particular when the members of the group can perceive and learn from the consequences of their collective actions (Berdahl et al., 2018). This is a corollary of our previous point on the importance of taking individual cognitive processes into account in the study of collective decision-making. Most vertebrate groups, for example, are small enough (typically no more than a few hundred individuals (Reiczigel et al., 2008)) and their members have, generally speaking, high-enough cognitive abilities to appreciate the consequences of their collective actions and learn from them. In such situations, the locality assumption (i.e., the idea that individuals “do not know” about the global state of the group) is broken and the collective outcome can feedback directly onto the individual level from one decision cycle to the next. This is not saying that the individuals have full knowledge of everything that is happening within their group (this would be preposterous), but that they can perceive proxies of the collective outcome (e.g., success in finding resources), establish a link with their own actions preceding that outcome, and, therefore, adjust their future behavior accordingly. In experiments with humans, for instance, it has been shown that social interactions among individuals are constantly modulated by the quality of the group’s past decisions (Almaatouq et al., 2020; Moussaïd et al., 2017; Wolf et al., 2013): people adapt the weight they give to their neighbors’ opinion, break ties with those who were wrong, and create links with those who provided good information. Even the rules they use to integrate social information may vary depending on the group’s previous decisions.
All of the mathematical tools that are commonly used in the field to formalize theories on social systems (ODEs, PDEs, ABMs, etc.) assume that these systems follow a form of “classical” emergence in which there is a causal, unidirectional relationship between the behavior of the parts at one level of observation and the behavior of the whole at the level above (Camazine, 2001; Garnier et al., 2007; Sumpter, 2010). However, there is currently no mathematical formalism in the field that allows for the lower behavioral rules and their parameters to evolve in response to the behavior of the collective. In the case where the timescales of the different levels are vastly different (e.g. when considering the evolution of social systems), it may be enough to solve the equations for a given generation with a given rule set, derive the collective consequences from them, and use that as the starting point for solving the equations for the next generation with an adjusted rule set, and simply ignore the introduced discontinuities (Winklmayr et al., 2020).
However, when the timescales are closer together and the collective consequences may more quickly feedback onto the lower-level behavioral rules, that approach will not work anymore because the collective level may not reach a stationary state before it already starts modifying the individual level rules from which it is also emerging. This frequent feedback of the collective outcome on the behavior of the individuals calls for the development of new modular theoretical frameworks in which local and global information could be included simultaneously in determining individual behaviors, depending on the cognitive resources and information available to the individuals.
Societal revolution
In human systems, the way information flows between individuals and the subsequent nature of their collective decisions are increasingly shaped by modern communication technologies (Bakshy et al., 2012). In the digital age, information does not only circulate among neighbors but literally across the entire planet—at almost the speed of light. Social dynamics that used to be restricted to geographically distinct areas—a town, a village, and a public place—are now globalized, with consequences that can be difficult to predict and, in the worst cases, to mitigate.
For instance, human-made online recommendation systems tend to expose people to a biased sample of others who often share the same opinion as them—giving users an artificial feeling of being in a majority (Flaxman et al., 2016). As a consequence, information tends to loop endlessly inside closed opinion bubbles, undergoing gradual distortion to make it support the opinion of those exposed to it (Moussaïd, 2013; Moussaïd et al., 2015). In their most extreme cases, these social echo chambers can lead to the complete isolation of online communities from each other—even though some of them may be neighbors in real life—and to their disconnection from fact-based reality and traditional sources of information (e.g., traditional news media, governmental agencies). In this context, the perception that these communities have of reality becomes incompatible with that of the rest of the population, and, without a common information ground, a peaceful consensus—that is a consensus that does not require repressive enforcement to be maintained—is not possible anymore, an observation that the recent global pandemic has made evident to many (Milosh et al., 2020; Rekker, 2021).
This form of community isolation, based on the social reinforcement of shared beliefs, is not specific to modern communication technologies (Boxell et al., 2017). It has probably appeared as soon as human groups have become large enough to allow for competing opinions to each reach a critical mass of followers. However, modern communication technologies have enabled this phenomenon at the scale of entire countries (Tokita et al., 2021). Indeed, recent studies of the political discourse and opinions in several democratic countries have shown a significant shift towards polarized political alternatives that appear increasingly incompatible with each other in their presentation (Böttcher and Gersbach, 2020; Conover et al., 2011). This phenomenon can be attributed, at least partly, to the dynamics of information exchange on social media that favors a simplification of the political discourse to the point of Manicheism and that enables a herd-like mentality across groups of millions of people at once. Pushed to the extreme, it is easy to understand how that trend may lead to dramatic consensus-breaking in what used to be considered unshakable democracies just a few years ago.
The solution to that problem, we believe, cannot come from traditional social choice theory alone. Indeed, the core of the issue—distributed social influence at a global scale—is fundamentally separate from the centralized tools traditionally used to make consensus (e.g., voting). Yet, the two types of processes are unavoidably linked since the deciding body (e.g., the voters) is necessarily part of the globally connected population and, hence, subject to its spontaneous polarizing tendencies. Consequently, the key to maintaining healthy democracies and to managing them in times of crisis will be understanding how large-scale social influence interacts with the processes of consensus decision-making. This is a task that the new area of swarm choice theory that we have introduced earlier has started working on in recent years, fueled by the technological and theoretical progress we have described in the previous sections (Bak-Coleman et al., 2021). The lessons learned so far suggest to us three challenges for the reformation of modern democracies into robust consensus-making systems: (1) the design of efficient and respectful social interventions; (2) the creation of global regulations to create financially sustainable yet societally beneficial social platforms; and (3) the implementation of longitudinal systems to monitor the long-term effects of (1) and (2) on our societal well-being.
Social interventions
For about 30 years now, research on collective behaviors, political science, psychology, and economics have proposed approaches to empower people’s opinions and, ultimately collective decisions (Lorenz-Spreen et al., 2020). Amongst the earliest examples, nudges are slight modifications of our online, physical, and/or social environment designed to guide people’s decisions in a particular direction (Thaler and Sunstein, 2008). They can be used, for instance, to target the spread of misinformation on social media—and thus the accuracy of people’s collective decisions when it comes to voting for a policy or choosing a president. Indeed, recent research has shown that people tend to share wrong information simply because they did not pay enough attention to the news accuracy (Pennycook et al., 2021). Thus, a simple intervention asking the user to rate the accuracy of a piece of news before sharing it reduces considerably the likelihood that the individual will subsequently press the “share” button for a wrong piece of information (Pennycook and Rand, 2021). This, at the same time, preserves the person’s freedom of choice.
Nevertheless, nudges are often blamed for being paternalistic and for raising ethical issues (who decides, in the first place, what “the correct option” is?) (Barton and Grüne-Yanoff, 2015). Another form of policy intervention is the boost (Hertwig and Grüne-Yanoff, 2017). Boosts aim at fostering people’s competence in a relevant domain without explicitly steering their decision towards a particular option. Whereas nudges often consider people as “somewhat mindless, passive decision makers” (Thaler and Sunstein, 2008), boosts rather see them as competent decision-makers whose skills can be improved. For instance, a short message teaching people the manipulation techniques commonly used to spread most false information can considerably reduce the impact of climate change misinformation (Cook et al., 2017). Similar approaches have shown promising results for boosting people’s ability to detect COVID-19 false information (Van der Linden et al., 2020) or micro-targeted advertising (Lorenz-Spreen et al., 2021). Likewise, boosts can be used to help people understand how opinion bubbles function or give them keys to grasp statistical health information (Lorenz-Spreen et al., 2020, 2021). This ability, in turn, could empower their judgments in situations of group decision-making.
Finally, research using both theoretical and real-life social networks clearly showed that the structure of the network itself as well as the algorithm responsible for selecting the information displayed to the users have an important role in the progressive isolation of communities online (Bakshy et al., 2015; Epstein and Robertson, 2015; Lazer, 2015), although individuals themselves also tend to deliberately limit their exposure to ideologically adverse content (Bakshy et al., 2015). Recent results suggest that diversifying the sources of information users are exposed to rather than tailoring them to their preferences may help combat community isolation and the formation of opinion bubbles (Tabrizi and Shakery, 2019).
Global regulations
While these results show promising avenues for promoting access to more reliable social information, social interventions are often incompatible with the economic models underlying most social networks. These companies rely on capturing the users’ attention for generating ad-based revenue and are often met with opposition from parts of their user base when taking action against the spread of false information on their networks (Otala et al., 2021; Newell et al., 2016). Solving this conundrum is undoubtedly a priority for promoting good collective decisions. Government-imposed regulations may ultimately be required to drive that change of economic model, for instance, by restricting the use of personal data for targeted advertising, as was done by the European General Data Protection Regulation (Hoofnagle et al., 2019) that came into effect in 2018.
However, a somewhat softer political approach may also be contemplated here. Important theoretical results generated in recent years have shown that the incentive structure in social systems (that is, how individuals are rewarded for making accurate predictions about the best of multiple options) can have dramatic consequences on the accuracy of their collective decisions (Bazazi et al., 2019; Lichtendahl et al., 2013; Pfeifer, 2016). For instance, so-called “market rewards” split the incentive equally amongst the individuals who made a correct prediction (Hong et al., 2012), while “minority rewards” only pay individuals who made a correct prediction if they represent less than one half of the population (Mann and Helbing, 2017). Mathematical analysis shows that the former incentive structure—which resembles that of actual prediction and financial markets—results in individuals paying attention to only a few informational factors (herding effect) and ignoring less popular attributes that may, in aggregate, lead to more accurate collective predictions (Hong et al., 2012; Mann and Helbing, 2017). The latter incentive structure, however, encourages individuals to include a more diverse set of factors in their predictions (they are only rewarded if they are correct while the majority is not), leading to near-optimal collective predictions (Mann and Helbing, 2017; Page, 2008). While theoretical, such results should inspire governments and other institutions to implement post-voting incentives that reward citizens and employees who were found later to have been right against the majority. This will, of course, come with some practical challenges (for instance, how long after the vote should the correctness of the collective decision be evaluated to maintain the attractiveness of the incentive? How should the questions be phrased to include an explicit measurable outcome?) and will not apply to situations where ground truth is not attainable (for instance, to moral and ethical questions). However, we think it is reasonable to imagine that such incentives could be implemented in organizations with clear quantifiable objectives (e.g., commercial businesses) and even in countries where local- and/or state-level decisions are regularly made by referendum (as in Switzerland and Taiwan, for instance).
Longitudinal monitoring
Human societies are complex systems. As such, they can display extreme inertia that makes them robust to perturbations but also highly non-linear dynamics that can be triggered by seemingly minute changes in operating conditions or behavioral rules (Ball, 2004; Castellano et al., 2009). Both properties are obvious challenges to implementing distributed social interventions and global regulations as those we described above. Social inertia may simply prevent any external action from being effective at all while non-linear dynamics may, on the contrary, amplify its effect to undesirable levels. In that context, how can practitioners (e.g., policymakers, social media companies) be reasonably confident that a given intervention or regulation will have an effect at all and, if it has, that it will be the desired one?
Given the harmful potential of social interventions and regulations, we suggest here that their design and rollout should follow an open and cautious procedure that resembles that accompanying the development and commercialization of medications (Lipsky and Sharp, 2001). Ideally, this procedure would start with extensive testing of the proposed changes with mathematical models and computer simulations to identify the range of effective parameters and potential non-linear catastrophic effects associated with them. It would then be followed by experimental testing using animal models—when available and relevant to the specific problem—and “clinical” testing with larger and larger groups of informed volunteers. Finally, long-term longitudinal monitoring would take place after a social intervention or regulation has been implemented to measure its effectiveness and detect negative outcomes that were not caught during the pre-implementation testing phase. This could follow a model similar to that of the postmarketing longitudinal monitoring of medical drugs, with reporting mechanisms that protect the privacy and individual freedom of citizens (Meyboom, 1997; Woodcock et al., 2011).
Ultimately, mechanisms for standardizing the testing steps, reporting the results, approving the implementation, and monitoring the outcomes will have to be created to move the field out of the confines of academia and into real-world applications. Of course, we are not assuming that this will be an easy feat to achieve. Important social, cultural, economical, and political constraints will need to be considered, but our suggestion should be seen primarily as a general framework for thinking about how collective decision-making research could shape smarter societies in a globalized world.
Conclusion
Nearly 250 years after Marquis de Condorcet’s insights about majority decisions, research on collective decision-making remains, more than ever, alive, needed, and relevant. Even more than that: we believe that it has reached a critical point that will lead to future major discoveries and a prominent role in society. Initially restricted to human societies, the science of how to make good collective decisions together has since merged with the field of swarm intelligence, resulting in a growing wave of exciting findings since the early 2000s. Two decades later, the discipline is opening up at least three major fronts that we expect will largely determine its future. From a methodological point of view, new technologies such as behavioral tracking, virtual reality, and brain imaging have already started providing us with an unprecedented amount of data, at a precision level that has never been reached in the past. In parallel, this empirical material of a new nature seems to accelerate a theoretical transition whereby existing physics-inspired outcome models are being challenged by cognitive, process models. Additional cognitive capabilities, such as learning from others, from the past, and from the group are increasingly considered when elaborating decision models. Finally, the growing maturity of the field is also accompanying a societal transition. Better understanding the mechanisms of social influence, the social pathways through which information flows, and the pros and cons of different opinion pooling rules are essential tools to act judiciously in the decision environment. These ongoing and upcoming research directions, if appropriately applied to societal issues, promise to enhance our ability to decide together and more generally, will further push forward the field of collective intelligence.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: S.G. was supported by DARPA Young Faculty Award #D19AP00046, SNF Scientific Exchanges grant #IZSEZ0_200785, and NSF IIS grant #1955210.