
Abstract
Time series tools are part and parcel of modern day research. Their usage in the biomedical field; specifically, in neuroscience, has not been previously quantified. A quantification of trends can tell about lacunae in the current uses and point towards future uses. We evaluated the principles and applications of few classical time series tools, such as Principal Component Analysis, Neural Networks, common Auto-regression Models, Markov Models, Hidden Markov Models, Fourier Analysis, Spectral Analysis, in addition to diverse work, generically lumped under time series category. We quantified the usage from two perspectives, one, information technology professionals’, other, researchers utilizing these tools for biomedical and neuroscience research. For understanding trends from the information technology perspective, we evaluated two of the largest open source question and answer databases of Stack Overflow and Cross Validated. We quantified the trends in their application in the biomedical domain, and specifically neuroscience, by searching literature and application usage on PubMed. While the use of all the time series tools continues to gain popularity in general biomedical and life science research, and also neuroscience, and so have been the total number of questions asked on Stack overflow and Cross Validated, the total views to questions on these are on a decrease in recent years, indicating well established texts, algorithms, and libraries, resulting in engineers not looking for what used to be common questions a few years back. The use of these tools in neuroscience clearly leaves room for improvement.
Keywords
Introduction
A time series comprises data recorded in a temporal manner. Generally, it is a succession recorded at uniformly distant positions. Time series forecasting is a technique to predict values based on historically recorded values. Conversely, time series analysis aims to obtain significant statistics from time series, which can be applied to real-world, continuous, or discrete numeric data. Time series can be used in any domain involving temporal measurements; thus, it finds application in a wide range of domains, such as statistics, weather forecasting, electroencephalography, electrocardiogram, etc. 1 In addition, time series data, which comprises numerical fields ordered chronologically, is always considered a whole instead of individual fields. Therefore, it requires specialized tools, known as time series tools, for the analysis.
In the last decade, the developments in Neuroscience involve a considerable increase in the size, dimensionality, and complexity of neural data.2,3 Much of these data are multi-dimensional, complex, and often cross multiple levels of organizations, such as neurons, circuits, systems, whole brain, etc.4,5 Deriving statistical inferences from these data heavily rely on the advances in time series tools. It is well established that no single tool can be chosen as the best for analysis in different situations.6-8 Hence, an evaluation of all major approaches is needed to determine the existing state-of-the-art in the area. Here, we quantify the usage of time series tools from engineering, biomedical, and neuroscience point of view, so that researchers can understand the trends and wisely use the right tool for their applications.
Time series tools can be categorized in varied ways. Some of the possible categorizations are time and frequency domain, univariate and multivariate, parametric and non-parametric. For the initial study, we have selected 7 classical tools and categorized them based on time and frequency domain. These tools are Principal Component Analysis (PCA), Neural Networks, ARMA-ARIMA (ie, Autoregressive moving average, Autoregressive integrated moving average) Models, Markov models, Fourier analysis, and Spectral analysis.
We undertake a twofold data-driven stance to quantify the state-of-the-art practices and trends related to the utilization of these tools. Firstly, to examine the recent developments from the perspective of IT-practitioners, programmers, and statisticians, we mine knowledge from community-driven popular Q&A websites: Stack Overflow and Cross Validated. The number of questions posted, number of accepted answers, views gathered, and content of the discussion were analyzed for twelve years. Subsequently, we emphasize the application of these tools in the biomedical sector, along with neuroscience, by quantifying the vast indexed database of PubMed. In addition, we conduct a rigorous literature survey for each tool to delineate their usage patterns among researchers.
Methods
Selection of time series tools and literature survey
We select 7 time series tools and split them into time and frequency domain. The tools, namely ARMA-ARIMA, Markov model, and Hidden Markov model, are time domain tools, whereas Fourier and Spectral Analysis are frequency domain. In addition, PCA and Neural Networks are categorized as general time series tools due to their usage in both the time and frequency domain (Supplemental Figure S1).
Stack overflow and cross validated analysis
Stack Overflow (SO), founded in 2008, is the largest community-driven question and answer (Q & A) website for IT practitioners, professionals, and enthusiast programmers. It features questions on a multitude of concepts in computer programming and information technology, ranging from software engineering, data science, machine learning to statistics. The link of stack overflow is https://stackoverflow.com/, and additional summary information is available on Wikipedia https://en.wikipedia.org/wiki/Stack_Overflow.
Cross Validated (CV) is a specially oriented website of Stack Exchange, https://stats.stackexchange.com/ network that features questions related to statistics, machine learning, data analysis, data mining, and data visualization. Summary of Stack Exchange can be found at https://en.wikipedia.org/wiki/Stack_Exchange. At the time, this analysis was conducted (3rd June 2019), the corpus consists of more than 42K time series tools related questions with approximately 1000 views per question (Supplemental Table S1).
To identify time series related questions, tags of each question posted at SO and CV were analyzed. IT-practitioners asking questions on these websites tend to provide a set of tags that accurately describes their question. These tags provide categorization to each question posted on these websites. Time series-related tags across each tool were manually selected and reported in Supplemental Table S2. The questions with at least 1 time series-related tag were selected for the analysis.
Each time series tool is analyzed based on the following parameters:
1) The number of questions posted from Jan 2008 to June 2019: this parameter provides us metric to understand the interest gathered around each time series tool among IT-practitioners and how this interest has evolved in the last 12 years.
2) The number of questions with an accepted answer: this parameter provides us the metric of satisfaction of users asking time series-related questions, as users asking a question can accept an answer that accurately and correctly answers users’ queries. Higher accepted answers corresponding to a time series tool indicate the satisfaction of the user.
3) Viewership: this parameter provides us the metric of visibility of time series tools. Higher the visibility of a time series tool, higher is the ease of availability of the necessary resources related to it, ranging from the methodology of usage to solutions of errors and bugs. Mean views have also been plotted corresponding to every year, providing an overall picture for the analysis. Sometimes, the mean views are observed to be higher than the maximum in the boxplot because the mean (or average) is susceptible to extreme values. On the contrary, the boxplots are created after the removal of outliers for visual aid.
4) Additionally, the content of questions related to each time series tool was studied to gain insights. A corpus of questions was created by aggregating the title and description of each question across various time series tools. All the embedded HTML code, along with special characters and stop words, were removed from the corpus. Word Clouds of discussion for each time series tool were created, where the size of a word represents its frequency.
PubMed analysis
PubMed is a search engine that indexes biomedical and life sciences research. Analysis of time series related research indexed in PubMed was used to study the use of time series tools in biomedical research and specifically neuroscience. The title, abstract, and text word of relevant PubMed articles were analyzed to determine the presence of several time series tools. Assessment of the evolution of these tools within Neuroscience domain is conducted by identifying time series related research on PubMed with keywords “Neuroscience,” “Mental Health,” “Brain,” “Mental Illness,” “Neurology,” “Psychology,” “Depression,” “Anxiety,” “Neurodegeneration,” “Mania,” “Schizophrenia,” “Delusion,” “Alcohol,” “Alcoholism,” “Addiction,” “Aggression,” “Violence,” “Neurophysiology,” and lumped the results together. This approach will approximate the results for the Neuroscience domain as the underlying limitation of this approach is that it would not be able to identify some small fraction of papers, which might not have any of these keywords in them and yet belong to neuroscience. The search commands used to explore the results are illustrated in Supplemental Table S3. The research papers indexed on PubMed are accounted on and before 5 October, 2019.
Throughout the analysis of Stack-overflow, Cross-validated, and PubMed, we observed a sudden fall in 2019. it is due to the fact that data were not available for the complete year.
General tools for time series analysis
Principal component analysis
PCA is a well-established linear dimensionality reduction approach that has been extensively used by the researchers. 9 It is used to convert potentially correlated variables to linearly uncorrelated principal components by the orthogonal transformation. In 1933, PCA was coined by an American statistician and an influential economist H. Hotelling, 7 who was inspired by the principal axis theorem, given by Karl Pearson. 6 Conventional statisticians used PCA as a dimensionality reduction tool; however, in recent developments, researchers have exploited latent properties of PCA to identify patterns within the data.
A considerable increase in time series data is observed across all domains, especially in business, medical, and scientific databases. 10 Analyzing a large multi-dimensional time series is a well-established limitation. Among others, these limitations have hindered the way for determining patterns associated with stocks, identifying aberrations in an online monitoring system, recognizing non-obvious relationships between 2 time series, and hypothesis testing among time series. 11 In the past, large multi-dimension time series have created challenges on multiple fronts, such as clustering, 12 classification,13,14 and mining of association rules. 15 Recently, such time series pose challenges to scalable computing, 16 data sharing, and reproducibility. 17 Several methods were developed to speed up the analysis of large time series; however, research shows that dimensionality reduction has emerged as the most prominent method. 10 Moreover, dimensionality reduction is crucial to the analysis of neural data, which are often large and multi-dimensional. 18 It includes data (1) with cross multiple organizational levels (eg, neurons, circuits, and brain) or (2) involving various biological domains (eg, anatomical and functional connectivity, genetic patterns and disease states, etc.). Therefore, dimensionality reduction plays a crucial role in time series analysis.
Applications
PCA is used in Bi-plot graphic display of matrices, which is often used to represent any matrix of rank two, comprising a vector for each cell of the matrix. Vector for an element is selected so that the inner product of vectors corresponding to its row and column yields the element. Notably, the rank corresponds to the maximum count of linearly independent columns in the vector space. Subsequent to PCA analysis, bi-plots depict interunit lengths and clustered units. In addition, they delineate variances, correlation and allows the visual appraisal of large data matrices structures. 19
PCA has also been used as a tool for estimation and analysis. For instance, it is used to estimate the origin of heavy metal pollution in sediments, which was conducted at Rybnik Reservoir, Southern Poland. 20 Moreover, PCA is utilized to analyze the timely variance of loading of trace components in bottom sediments. 20
PCA has medical applications as a method for the pattern analysis. 21 A knee osteoarthritis research was administered on fifty subjects, who suffered from end-stage knee osteoarthritis; in addition, it comprises an age representative control group of 63 subjects. Gait data is represented as temporal waveforms depicting joint measurements throughout the gait cycle. Feature space comprising temporal waveforms of n subjects on p variables were constructed. These features include knee alignment variables and bone geometry data. The analysis focused on 3 gait waveform measures: the knee flexion angle, flexion moment, and adduction moment. The aim was to determine the biomechanical features of these gait measures related to knee osteoarthritis. Hypothesis testing was done to identify group differences, and discriminant analysis to (1) quantify overall group difference, and (2) establish a hierarchy of discriminatory ability among the gait waveform features. The authors analyzed this feature space by using PCA analysis, not only as a data reduction tool but also as a method for further differential analysis.22,23 It was found that there exists a strong correlation between gait waveforms with respect to time. The study also proved that PCA can be used as a method of kinetic and kinematic analysis of gait waveforms.
Limitations
Underlying assumptions for the optimal working of PCA is that correlations in the data are linear. To address this limitation, Nonlinear Principal Component Analysis (NLPCA) was proposed that uses auto-associative neural networks. 24 It aims to create an identity map by learning a feedforward network such that input variables are recreated at the output layer. This neural net comprises lesser nodes as compared to the input or output layers; thus, it enables the production of a concise depiction of the variables.
Inferences from PubMed
PCA being a general purpose statistical technique, also has a style of reasoning. It is used as a ‘hypothesis generating’ tool, creating a statistical mechanics framework for biological systems modeling, without making any prior theoretical assumptions. For this very reason, it has been used in drug discovery and biomedical research. 25 For example, it was used as a truncation technique in the study of the classification of Mycobacteria using Raman spectra, 26 where the group compared classification accuracies after applying PCA and LDA (Linear discriminant analysis) with principal component selection methods across various centering and scaling options.
Multistage PCA (MSPCA) has been used for the study of abdominal electrocardiogram decomposition. 27 MSPCA aims to identify the variables that can be well estimated by a linear model. It involves 2 steps: top-down and down-top steps. The top-down step identifies an initial solution recursively, whereas the down-top step is introduced to penalize the maximum number of phases of the final solution. 28 To rephrase, dimensionality reduction is achieved by the eigenvectors with the most significant eigenvalues as a new orthonormal basis. 29 The electrical activity of the fetal heart has comparatively less energy; therefore, traditionally recommended component analysis fails to separate the 2 ECG signals: maternal and fetal ECGs. Thus, step-by-step extraction of abdominal ECG signal components, using multistage PCA is preferred. In addition, it has been used to create a simplistic aging equation that aims to predict the age by combining several biological factors of aging. 30 In one study, PCA revealed specific technical features that appeared to relate to skiers’ performance levels. 31 In a recent modification to PCA, poorly dimensioned data can also be processed, while maintaining the data clustering capacity. 32 Figure 1 looks at the trends of PCA use.

Quantification of trends related to PCA. (a) Although the beginning is marked by limited PCA related questions, they gather substantial views. This suggests that the developers and researchers were looking for a platform to discuss PCA, and SO & CV facilitated them; however, the quality of discussions seemed to discourage the users, which can be observed from a huge decline in the viewership in 2011. The number of questions depicts a linearly increasing trend that can be attributed to the use of PCA in several studies as a dimensionality reduction tool.9,33-35 One of the breakthroughs was the use of PCA in integrated dynamic analysis of the metro project. 36 The number of accepted answers resembles a bell-curve, that is, being constant in the period 2014-16, while following a slight decrease in 2018. (b) The boxplot shows that the mean number of views gained its highest value in 2010, that is, 35 000 views. Subsequently, a drastic fall is observed to approximately 5000 views in 2011, followed by a steady decrease. Moreover, 50% of the questions have less than 5000 views and the median value is close to quartile 1. (c) Among other generic PCA related terms, the discussion frequently mentions terms, such as data, variable, matrix, features, dimensions, and eigenvectors. Eigenvalues of the covariance represent the core of PCA. Eigenvectors help in determining the direction of the feature space, whereas the eigenvalues represent the magnitude. (d) We observe a gradual increase in the life sciences and biomedical related studies. Conversely, there are few studies on the intersection of neuroscience and PCA.
Neural network
The neural network is inspired by the nervous system.37,38 Its theoretical framework is formulated by McCulloch 39 and Pitts, 40 a neuroscientist and a logician. The authors derive motivation from the core idea of a neuron, that is, a cell living within a cell network. Each neuron acquires input and produces the output after computation.
The fundamental building blocks of these networks are neurons. 41 The neural network consists of interlinked neurons; each neuron comprises an activation function. 40 In a neural network, nodes represent neurons, whereas edges represent weighted neural interactions. Inputs are multiplied with the edge weight, then passed to the next layer as inputs. Generally, these networks comprise an input and output layer, along with some hidden layers.
Input to each node is calculated as follows,


where Wi are the weights associated with each arc, Xi is the values at each node, and b is the bias, which is added to each layer.
After each node has received input, the



Applications
The neural network has been extensively studied, which has led to its application in diversified fields, such as business applications, forecasting, classification, pattern recognition, and time series prediction. In addition, the neural network is being utilized on a day-to-day basis in real-world business applications, such as making stock market prediction, 41 which weighs many factors, for example, the rise and fall of stocks. The neural network can process the time series data, analyze its pattern, and predict stock prices. Apart from that, it is used for e-commerce fraud detection through credit cards,42,43 money laundering detection, and telecommunication fraud, 44 that is, a neuro-fuzzy model for predicting business bankruptcy.
Deep learning is referred to as combining several layers of the neural network to perform feature engineering, along with extracting latent features from the data. 45 The deep learning technique is highly advantageous, as it can process more complex information with high accuracy but requires a large dataset for training (or learning). For instance, Dialog-Tech facilitates a system for call attribution and conversion. 46 They use the neural network to classify inbound calls into predetermined categories or assign lead quality scores based on the call transcription and the marketing channel or keyword that drove the call. 47 This process required a considerable amount of historical data for training.
The neural network finds application in classification domain, such as Internet traffic classification, 48 using Bayesian neural networks without using the source or destination port information. It works by extracting the features from packet streams consisting of 1 or more packet headers pattern classification. 49 Image classification in medical imaging and signal processing is undergoing cutting-edge development. 50 It involves the detection and classification of tumors and X-rays, along with diagnostic systems for cancer and heart diseases. 51
Another application can be seen on LinkedIn that is a social networking site for professionals. 46 It uses the neural network along with text classifiers to (1) filter out the spam or abusive content from the user’s feed, (2) improve their recommendation system, and (3) search relevant products for members and customers. In addition to business forecasting, ANNs have been designed for forecasting tourism 52 in the Balearic Islands (Spain) and monthly energy 53 demand using the time series data for the last 6 years. Most artificial intelligence has neural networks at the heart of operations.
Inferences from PubMed
The neural network has been used to detect diabetic retinopathy 54 from a local diabetic retinal screening program. The study achieved sensitivity and specificity closer to 80% on the international and domestic databases (New Zealand). In addition, it has been used in colorization, that is, conversion of grayscale image to a colored one, which is supposed to be a challenging task since it requires labeling scribbles on the target images manually, or curation of a diverse set of colored reference images. 55 An electrocardiogram beat classification system was implemented by BIRCNN, that is, Bidirectional Recurrent Neural Network (BIRNN) combined with Convolutional Neural Network (CNN). The morphological features were drawn out using CNN, followed by considering them in the context using BIRNN. 56
In a study, a neural network was implemented with an auto organizing radial basis function to enhance accuracy and parsimony. The authors used an adaptive version of the swarm optimization algorithm, popularly known as Adaptive Particle Swarm Optimization (APSO). 57 Fine-tuning of weights and avoidance of local optimal is achieved by using non-linear regression. In addition, APSO is used to optimize the scale and parameters of the neural network with a radial basis function. Therefore, it efficiently produces a concise model that yields high accuracy. Producing accurate surgical simulations is essential in the medical domain. The neural network was used to generate a lifelike and stable simulation of soft tissue deformation in real-time. 58 (Figure 2).
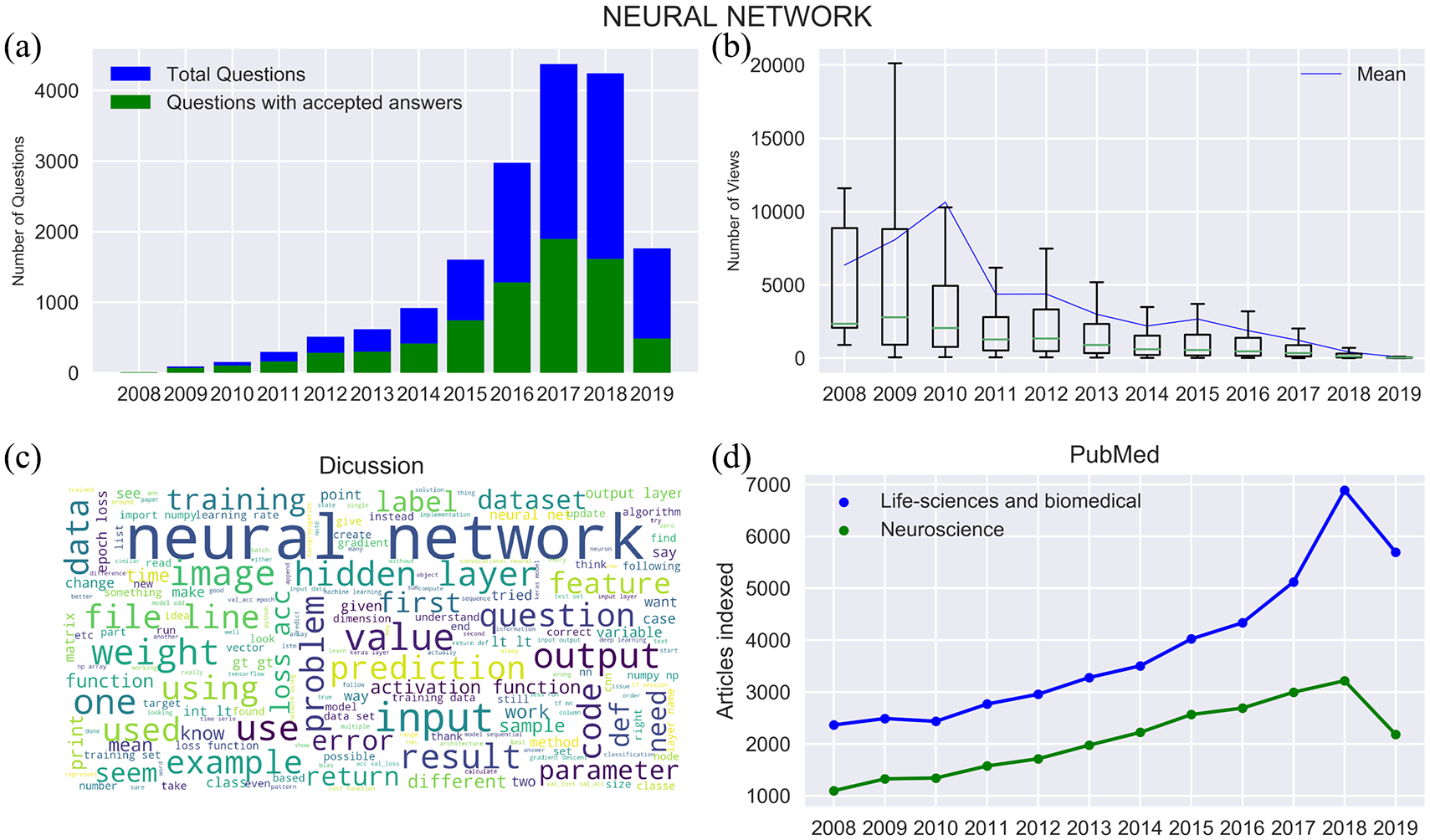
Quantification of trends related to neural networks. (a) The footprint of the neural network is visible from the beginning. The questions and accepted answers show an increasing trend. (b) A considerable amount of viewership is observed initially; however, approximately 50% of questions got less than 3K views throughout the time span. After 2009, there has been non-uniformity in the views gathered by questions as the mean views lie above the third quartile (mean value is susceptible to outliers). (c) The content of discussion frequently includes terms, such as the hidden layer, input, output, training, prediction, feature, activation function, and image. The mention of the term ‘image’ highlights the importance of CNN in the neural network domain. (d) The number of articles indexed in life sciences and biomedical resembles a polynomial growth. Approximately 7K life sciences related articles utilized the neural network in 2018, which was approximately 2200 articles in 2008. In neuroscience, the number of articles indexed has approximately increased from 1K to 3K between 2008 and 2018. The neural network is the most used time series tool in neuroscience research (also refer Figure 9).
Tools for time domain analysis
ARMA and ARIMA models
Two univariate models that represent stochastic dependence of time series data are ARMA and ARIMA models. Among others, they are useful in predictions of epidemiologic time series. They follow the “Box-Jenkins” approach. 59
ARMA model
Autoregressive (AR), when combined with the moving average (MA) model, forms the ARMA model. It was introduced by Peter Whittle in 1951
60
and has been widely used since 1970 after getting mentioned in the book by Box and Jenkins. Let us assume a continuous and equally spaced time series

where ϕ is called the auto-regression parameter, as
Consider a generalized AR model of order p:

MA model represents

where

Thus, by combining equations 6 and 7, we obtain

ARIMA model
Box and Jenkins
59
extended the early work of Yule and Wold61,62 to develop the ARIMA model to include the degree of integration to which the series has been differentiated to obtain a stationary series.
Suppose a non-stationary time series; however, the series of its first differentiation is stationary (see equation 9), where ∇ is an ordinary differentiating operator.

Consider a series that is differentiated d times to obtain stationary status; then, the model is called integrated ARIMA model of order p, d, q, or ARIMA.
Box-Jenkins approach
ARIMA models are realized using the Box-Jenkins approach. Box-Jenkins model includes identification, estimation, and diagnostic check.
Tools like autocorrelation, partial autocorrelation, and inverse autocorrelation are used for model identification. Autocorrelation function (ACF) characterize the dependence of a stationary series. ACF denotes the correlation between

ACF is approximated by empirical ACF (see equation 11),

where
Empirical ACF is the primary method for the determination of the ARIMA. ACF of
Model Estimation involves the estimation of model parameters (p, d, q). The tools involved in estimation are the Yule-Walker procedure, method of moments, and maximum likelihood. Out of which maximum likelihood estimation is widely used.
Empirical ACF involves checking the appropriateness of the model. When it fails to fit adequately, then the whole process of model identification is repeated, and an improved model is selected. Among the various models, a model having the fewest parameters and the least error is selected. Plots of residual can be used to diagnose the accuracy of the model.63,64
ARMA Model selection for small samples has been discussed in detail. 65 All models were approximated by conditional maximum likelihood. Stimulation is done to select the best criteria among AIC (Akaike information criterion), AICc (AIC with correction), HQ (Hannan-Quinn), and SIC (Schwarz information criterion). A hundred estimations were generated for the determination of the ARMA model. Out of 4 criteria, AICc frequently generated the optimal model; in twenty instances, it was typically better than the other criteria.
Linear limitation
ARIMA considers a linear form of the model as among the time series values, a linear correlation is assumed with nonlinear patterns. To address this limitation, the hybrid ARIMA model was combined with the neural network by G. Peter Zhang. The results indicate that the combined model enhances the forecasting accuracy effectively. 66
Hybrid ARIMA
A hybrid methodology, that is, the combination of ARIMA and neural network, was used to (1) utilize the distinct virtues of ARIMA models and neural network; and subsequently, (2) tackle a threefold problem in prediction. 66 The threefold problem as described by Zhang is as follows—firstly, when series is produced by linear or nonlinear process, which tool is more effective at sample forecasting owning to several variables like sampling variation, model selection, and structural changes; secondly, real-world data is often a combination of linear and nonlinear parameters; and thirdly, no single method is best in every situation. Perhaps in these situations, the ARIMA model does not consider nonlinear dependencies, whereas the neural network can efficiently model both linear and nonlinear dependencies.
To observe the desired results in Zhang’s Study, 66 all ARIMA models were implemented by SAS (Statistical Analysis System) /ETS (Error, Trend, Seasonal) system, whereas neural network models were implemented by the GRG2-based training system. GEG2 is a general-purpose nonlinear optimizer. One step or single day forecast is examined. In terms of mean squared error, the percentage enhancement of the proposed model against ARIMA and neural network were 16.13% and 9.89%, respectively. ARIMA and neural network were consistently outperformed by the hybrid model across multiple time durations; however, the enhancement of the hybrid model for longer durations was not impressive.
Transfer model functions
Transfer Model Functions was developed by Box & Jenkins 59 as an important way to analyze the relationship between 2 ARIMA series. Here, one series is “response” or “output” series and other series is called “input” or “explanatory” series. For example, input series as daily concentration of carbon dioxide in an area and output series as daily temperature recording of that area.
Inferences from PubMed
China, a country known for its quick adoption of data science and artificial intelligence, found the application of ARMA combined with generalized regression neural network (GRNN) to predict hepatitis cases in Heng county. 67 The combined model was trained on historical data of hepatitis cases from 2005 to 2012, along with individual models. The combined model was proved to be the best model and supported the potential decision for checking hepatitis infections. Seasonal ARIMA was used for the detection of the dengue hemorrhagic fever 68 without any constant and Tukey’s adjustments. In addition, China used these models to forecast the PM10, that is, an air pollutant, time series using wavelet analysis. 69 A study was conducted in South Iran for the prediction of the monthly trend of scorpion stings using a mixed seasonal ARMA model. Results confirmed the association between meteorological variables, such as temperature and humidity, and scorpion stings. 70 Neural networks, along with ARMA forecasting techniques, have been used to learn from a 5-year-old daily medical linear accelerator (Linac) quality assurance (QA) data 71 and is significant for continuous enhancement of the well-being of the patient. Another application is the dynamic forecasting of Zika virus outbreaks based on Google trends. 72 Sweden used the ARMA-ARIMA model to study the association between per capita alcohol consumption and alcohol-related harm using the data from 1987 to 2015, 73 which showed positive and significant association (Figure 3).

Quantification of trends related to ARMA-ARIMA models. (a) ARMA-ARMA models were first observed during 2010-11; subsequently, a linear increment in questions and accepted answers were observed. During this time, these models were used in many projects,33,74 such as predicting tourism demand. 9 The Government of China found the application of the ARMA model to analyze the axial bolt force data of foundation pit in the China Zun Tower, and fit the specific change process of bolt axial of the anchor to predict the trend of change. 75 Several research studies can be found, includes testing the effectiveness of the ARMA model in stock prediction and software development. 76 (b) ARMA-ARIMA models garnered the highest mean views per question in 2011, which decreased exponentially. In addition, the IQR followed a decreasing trend. Notably, approximately 50% of questions have views less than 2.5K. ARMA-ARIMA models were extensively used in business for predicting a quantity and understanding its past trends, 77 for example, seasonal patterns in sales, 78 estimating the effect on the newly launched product, and stock prediction.79,80 (c) Some frequently used terms are time series, forecast, first order, parameter, parameter, and differential. All of them are related to the usage of ARMA-ARIMA models for forecasting. Generally, a non-stationary series can be transformed into a stationary using differentiation depending on the autocorrelation function for slow decay. 81 (d) Life sciences and biomedical followed an increasing trend in terms of articles indexed. However, ARMA-ARIMA has not been extensively used in Neuroscience, 20 articles were indexed in 2008 and 100 in 2018.
Markov model
Markov model assumes that the upcoming states are dependent merely on the present state and not on the historical states. Generally, the above assumption facilitates reasoning that could not have been possible otherwise. In the domains of predictive modeling and probabilistic forecasting, a given system must exhibit on the Markov property. In 1906, Markov came up with a study on Markov chain delineating that under specific conditions, average outcomes of these chains converge to a fixed vector of values; thus, validating a weak law of large numbers without the independence assumption. Mathematically, this is considered as a requirement for such laws to hold.
In addition, the segmental semi-markovian model has been helpful in the problem of automatically detecting specific patterns in time series data. It provides a systematic and coherent framework for leveraging both prior knowledge and training data. 82 The pattern of interest is modeled as a K-state segmental HMM, where each state is responsible for generating a component of overall shape using a shape-based regression function. Studies have been done on Plasma Etch process data, New York Stock Exchange data, etc. In all these cases algorithm was able to find patterns correctly.
Markov regression model
Regression analysis with the quasi-likelihood approach is done with time series data in. 83 “Observation-driven” models are a class of Markov models described in. 84 These models provide conditional mean and variances; in addition, the past is explicit functions of past outcomes. This class includes Markov chain and autoregressive models for continuous and categorical observation.
Inferences from PubMed
In Ontario, Canada, a study 85 used Markov modeling in assessing the monetary feasibility of a suicide prevention program. The study focused on variations in health and estimated the incremental expense per quality-adjusted life-year gained over fifty years for participants of a suicide-prevention program in comparison with no intervention. In England, a study used the Markov model coupled with decision trees to assess the monetary feasibility of ETB (P1 vital Oxford Emotional Test Battery) 86 monitoring over patients suffering from depression. Markov was also used to evaluate surgical treatment’s cost-effectiveness for the fix of anterior pelvic organ prolapse (POP) from the UK National Health Service. 87 Anterior compartment prolapse is the most common POP with a range of surgical treatment alternatives available. Markov model has been used as a decision model to evaluate disability worsening and progressive multifocal leukoencephalopathy (PML) risk in patients receiving natalizumab (NTZ), fingolimod (FGL), or glatiramer acetate (GA) over 30 years. 88 Markov models are widely used in the extraction of discrete brain states in many research work 89 (Figure 4).

Quantification of trends related to Markov models. (a) We observe the presence of Markov in terms of questions and accepted answers from 2008 onwards. There has been a uniform increase in questions every year with the exception to 2014. The trend of accepted answers shows many fluctuations between 2015 and 2018. (b) In the beginning, Markov garners several views, which suggests that enthusiasts were seeking a platform for discussion. Approximately 50% of questions, 2009 onwards, have less than 1K views; however, the mean views are quite high in the beginning due to outliers. There have been cutting-edge developments90,91 in the Markov model, especially in computational biology, including multiple sequence alignment, homology detection, protein sequences classification, and genomic annotation. 92 (c) Prominent words include probability, chain, amp, and state. Other terms of importance are transition matrix, function, model, and sequence. The transition matrix is a probability matrix depicting the transition probability from 1 state to another. (d) The number of articles indexed in biomedical and life sciences follows an increasing trend; however, non-uniform growth is observed until 2013. The neuroscience-related research indexed less than 250 papers in 2008 and reached 250 by the end of 2018.
Hidden Markov model
Hidden Markov model (HMM) is an advanced extension to the Markov model that assumes the system is a Markov process with unobserved (ie, hidden) states. The forward and backward transitions employed in HMM and calculations of marginal probabilities were introduced by Stratonovich in 1960; they were further expanded by Baum et al. 139 Their first applications involved speech recognition.
Applications
TMHMM, that is, transmembrane HMM, is a new membrane protein topology prediction method described and validated using HMM Model. 93 A detailed analysis of the prediction method shows that it correctly predicts 97% to 98% of the transmembrane helices.
A human action recognition model was made using HMM. It used a bottom-up method, that is, distinguished by its ability to learn and invariability of time. Experimental results for sequential images of sports scenes depict impressive recognition rates that can be further enhanced with an increase in persons used to produce the training dataset. 94 This indicates the possibility of implementing an action recognizer that is independent of the person.
In a study, HMMs are the building blocks for most modern automatic speech recognition systems for approximating the parameters of the HMM of speech recognition 95 . Parameter values are selected to maximize the mutual information between an acoustic observation sequence and its respective word sequence. 95 HMMs are used to comprehend speech patterns by comparing them with maximum likelihood estimation. Upon comparing the results of estimating parameters by maximizing the likelihood and that by maximizing mutual information, it was discovered that the training script had a significantly higher probability using maximum mutual information (10189 times higher), and it even had 18% fewer recognition errors.
Removing noise from the speech is very important as it interferes with the statistical characteristics and acoustic features of the speech during recognition. A technique of signal decomposing simultaneous process 96 utilizes the capability of HMMs to model signals with dynamic variations while accommodating simultaneous processes, which includes complex interfering signals, for example, speech.
Hierarchical HMM was developed as a recursive hierarchical generalization of hidden MARKOV models. 97 They are employed to detect various strokes that denote multiple characters in cursive handwriting.
Improvement
HMMs find usage in time series forecasting, with more advanced Bayesian inference methods, that is, Markov chain Monte Carlo (MCMC) sampling, these are proven to be favorable over finding a single maximum likelihood model in terms of accuracy and stability. 98
Inferences from PubMed
HMM has been used extensively in ecology and biology for understanding the hidden patterns in the environment, nature, and sequences. 99 Since its introduction in the 1960s, it has been used to identify patterns in multiple fields ranging from DNA to protein molecules, their structure and architecture that forms the basis of life to multicellular levels, such as movement analysis in humans. 100 research in Cambridge used HMMs 101 to develop a method for detecting physiological states associated with the outcome from time series physiologic measurements collected from patients admitted to Addenbrooke’s Hospital. In a study, HMMs have been used for estimating dynamic functional brain connectivity using sparse HMM, 102 and Gaussian graphical model. HMM was used in detecting topics from transcripts of patient-provider conversations. 103 This could improve patient satisfaction, cost-effectiveness, and care. Infinite HMMs can be used as a powerful tool to analyze single molecule sequential data without any prior setting of stat, which is required infinite HMMs. 104 In another study, it has been used as an application for the early prediction of a septic shock for Intensive Care Unit (ICU) patients, this approach (1) combines highly informative sequence patterns determined by several physiological features, and (2) identifies the interaction among patterns through coupled HMMs 105 (Figure 5).

Quantification of trends related to Hidden Markov models. (a) Although the questions are below 10 during 2008-10, they garnered the highest mean views. Subsequently, we witnessed an increment in questions; however, it was accompanied by a decline in the mean views. HMMs can be used in varied fields to recover or predict sequential data based on past activities, for example, speech recognition, part-of-speech tagging, cryptanalysis, and handwriting recognition. 106 We observed an increase in the accepted answers in 2012 and 2017, which can be attributed to the research works in varied fields, such as the clustering of multivariate time-series, 107 adverse drug reaction, 108 and emotion detection from textual data. 109 (b) Views have descended similar to the other time series tools. The IQR shows that 50% of the questions have shown less than 1K views. Although whiskers depict that approximately 25% of questions have gained approximately 5K views, IQR decreases. (c) The frequently used words are state, hidden, sequence algorithms, and observation. Concepts of HMM are similar to the Markov model, except that states are observed directly in the Markov model, whereas states are hidden in the HMM. (d) The PubMed graph shows much fluctuation for the articles indexed in life sciences and biomedical. In contrast, for neuroscience, the articles indexed follows a gradually increasing trend.
Tools for frequency domain analysis
Fourier analysis
Fourier analysis aims to represent a general function as an approximated sum of more straightforward trigonometric functions. There exist at least 2 perspectives on the application of Fourier techniques. First, perceiving Fourier analysis merely as a transformation of the data to new representation, for example, from the time to frequency domain. Second, interpreting data in terms of a model with the distinction of the deterministic and nondeterministic models.
Development of Fourier analysis commenced in 1754 when Alexis Clairaut used a variant of Discrete Fourier Transform (DFT) to compute an orbit. His work was merely a cosine-only series. In 1759, Joseph L Lagrange developed a sine only series for computing the coefficients of a trigonometric series for a vibrating string. Lagrange used a complex Fourier decomposition to study the solution of cubic roots which was marked as early development of Fourier. 110 Further, in 1805, Gauss developed cosine and sine DFT while calculating trigonometric interpolation of asteroid orbits.
The deterministic and nondeterministic models behave differently under Fourier analysis. A deterministic model assumes that no randomness is involved in the development of future states and assumes predictability connected with the deterministic character of classical and non-quantum physical processes, for example, a nova or supernova light curve. Within deterministic models, periodic and non-periodic also behave differently under a Fourier analysis, so it is required to distinguish between the two. Integral of Fourier transform exists only if the function
Nondeterministic models are unpredictable and have random noise, for example, radioactive decay. Definite predictions cannot be made about a non-deterministic variation
An approach to apply Fourier transactions is described in. 111 Inequalities are the most important tools in Fourier analysis. W.H. Young extended the Parseval theorem for Fourier transform and convolution and observed that inequality for the Fourier transform could be obtained from a convolution inequality. 112 sform on Periodic, Stochastic, and a combination of periodic, non-periodic, and stochastic functions. Short-time Fourier transform is the output of an arbitrary bank of filters, for simplicity identical, symmetric, band-pass filters are uniformly spaced in frequency.
Fourier synthesis
The process of decomposing a function into frequency components is called Fourier analysis, while the operation of rebuilding the function from these components is known as Fourier synthesis. There are majorly 2 methods for Fourier synthesis: Filter-Bank Summation (FBS) and Overlap add (OLA) methods. The advantages, disadvantages, and applications of these methods are discussed in detail by Jont and Lawrence. 113
Limitations
Practical datasets need not be uniformly spaced. Data spacing has a limiting effect on the accuracy of Fourier analysis. Deeming 111 has designed an analysis algorithm that does not depend upon data spacing and works, with both unequally and equally sized data. A systematic method was developed by Ablowitz et al., 114 which facilitates the identification of specific evolution class equations. It can be regarded as extended Fourier for nonlinear processes.
Inferences from PubMed
Fourier-transform infrared spectroscopy (FTIR) is a method extensively employed115-117 in biomedical, life sciences, and neuroscience. It aims to derive an infrared spectrum of absorption or emission of a solid, liquid, and gas. An FTIR spectrometer concurrently gathers high-spectral-resolution data across a wide spectral range. This depicts a major advantage over a dispersive spectrometer, which computes intensity over a narrow range of wavelengths. Fast Fourier transform has been used in the analysis of EEG (Electroencephalography) signals during mouth breathing. 118 Fourier had its applications in wave-front reconstruction, which effectively decreased the processing time for large telescopes with large degrees of freedom. 119 Fourier has been used in understanding the complexities of modern optics and has been widely applied in optical information processing, imaging, holography, etc. In 1 study, FTIR was used to validate that patients who exercise regularly tend to have better proteostasis, living, along with inflammatory, oxidative stress, and vasoactive biomarkers in adults with hypertension. 120 In a different study, Fourier was used in the clock genes disruption of ICU patients. 121 Often the environment of ICU and nonphotic synchronizers disrupt the cardiac rhythms of patients, which raises a question of whether critically patients have desynchronization at the molecular level after 1 week of stay in the ICU (Figure 6).

Quantification of trends related to Fourier analysis. (a) Fourier analysis related discussion started in 2011; subsequently, it acquired an average of 9 to 10 questions per year and approximately 25 accepted answers throughout the timespan with vast fluctuations. (b) Similar to the questions and accepted answers, the mean views resembles a zig-zag pattern till 2015, the fluctuations are between 1K and 1.7K views. In the end, the trend is decreasing, like other tools. The mean views across questions have been uniform throughout, and mean value lies between the IQR. (c) Word cloud depicts the significance of terms, such as signal, frequency, distribution, phase, amplitude, period, and FFT (Fast Fourier Transform). Notably, an emphasis on signal processing is observed. (d) Although questions on SO and CV are low, a multitude of articles indexed is on the PUBMED. In 2008, approximately 4K life-sciences and biomedical research utilized Fourier analysis; in addition, 7K articles were observed in 2018. The graph follows an increasing trend. For neuroscience, the data delineated 500 research articles in 2008 and 1000 in 2018.
Singular spectrum analysis
Singular Spectrum Analysis (SSA) is a nonparametric spectral estimation method. The idea of SSA was planted during the conceptualization of the spectral decomposition of the covariance operator of random processes by Karhunen and Loève in the 1940s. SSA and multichannel SSA (M-SSA) were introduced by Broomhead and King19,140 and, later by Fraedrich 132 in context to nonlinear dynamics. Further, around the 1990s, the analogies were drawn by Ghil and Vautard24,141,142 between the trajectory matrix of Broomhead–King, and Karhunen–Loeve decomposition, that lead to the formulation of SSA.
Applications
SSA is used in the evaluation of the Paleoclimatic time series. 141 Authors needed a tool to analyze short and noisy records; after analyzing the available tools, they came up with SSA. SSA provided qualitative and quantitative information about the deterministic and stochastic parts of system characteristics observed in a time series, even if it is short and noisy. As described by, 141 the other important features of SSA are: (1) it yields estimates of the statistical dimension, (2) explains main physical phenomena represented by the data, and (3) clarifies noise characteristics of the data. All of these features are exploited in the study of 4 paleoclimatic records.
Another significant study is utilizing SSA deals with the smoothing of raw kinematic signals. 143 With several examples, the study shows that SSA outperforms conventional digital filtering methods. Systematic errors were introduced as noise while recording displacement signals for the biochemical analysis. This noise gets amplified by the differentiation of displacement signals to obtain velocity and acceleration, which is undesirable. To escape this deformity, it is mandatory to smoothen these signals before differentiating them to avoid the introduction of noise.
The observed time series was decomposed by means of SSA into several additive series, such that each series represents a part of modulated signal or random noise.
Oropeza and Sacchi came up with Multichannel singular spectrum analysis (MSSA), which is used for concurrent seismic denoising and reconstruction of the data. 144 They used the concepts of MSSA, which required organizing spatial data at a given temporal frequency into a block Hankel matrix. Ideally, the Hankel matrix is of rank k, where k is the number of plane waves in the window of analysis. Additive noise and missing data increase the rank of the block Hankel matrix. Therefore, the rank reduction method is used as a means of noise attenuation and recovering missing traces. They presented an iterative algorithm similar to seismic data reconstruction with the method of projection onto convex sets.
Additionally, they proposed the idea of using randomized singular value decomposition to accelerate the rank reduction stage of the algorithm. They applied the MSSA reconstruction algorithm on synthetic examples to test the capabilities of this technique on 2 different samples: noise-free data and noisy data. The results showed very low reconstruction errors in both cases, which is an optimal resolution. They also examined a field dataset containing a 2D pre-stack volume that depended upon common midpoints and offsets to find the missing offsets, and simultaneously increase the signal-to-noise ratio of the seismic volume.
The study involving the application of SSA on economic data details 2 approaches for forecasting a noisy time series. 145 First, disregard the noise and proceed with forecasting, and second, filter the noise time series for the reduction of noise, and then proceed with forecasting. The latter has proven to be more effective.
Single-Valued Decomposition-based methods have been very successful at reducing the noise in deterministic time series. According to the research, economic and financial time series can be regarded as linearly deterministic, which implies that they can undergo modeling and forecasting. In some cases, financial time series was found to be non-linear, which means having a model that can handle both linear and non-linear time series is required. SSA satisfies all the aforementioned constraints. Therefore, SSA is a nonparametric tool that incorporates the features of conventional time series analysis, multivariate statistics, multivariate geometry, dynamical systems, and signal processing.
Inferences from PubMed
Spectral analysis was used in quantitative temporal analysis of hypoxic regions in human glioblastoma, one of the most common types of primary brain tumors. 122 The authors identify the hypoxic regions of the brain affected by glioblastoma, followed by determining an optimal time for the scan. Spectral analysis has been used to monitor the brain to forecast migraine incidences. 123 Although migraine attacks are unpredictable, there exist neurophysiological variations in the brain approximately 24 to 48 hours prior to the migraine incidence, which can be recorded through EEG. This could help in facilitating essential pre-symptom forecasts and early intervention. In one of the studies, spectral analysis has been used to detect the generalized tonic-clonic seizures (GTCS) in daily life, using the ACM wrist band. 124 It could be helpful in providing early alerts to caregivers to prevent risks associated with GTCS. In Oman, spectral analysis was used as a non-invasive tool to distinguish the preeclamptic pregnant group from the normal. 125 The concept behind the study was that spectral analysis of the heart rate variability depicts a power reduction of the high-frequency component in preeclamptic subjects compared with the normal pregnancy. Raman Hyperspectroscopy and ANNs were used in the diagnosis of Alzheimer’s disease based on the analysis of saliva. 126 The techniques were applied to the spectral dataset to build a diagnostic algorithm (Figure 7).

Quantification of trends related to Spectral analysis. (a) The presence of spectral analysis was first marked in 2009. It is observed to follows an incremental trend from 2011 onwards. Subsequently, we observe irregular fluctuations in questions between 2015 and 2018. A similar trend is observed for the questions with accepted answers. (b) From 2010 to 2012, we observed the highest mean views approximately equal to 4K for each year. Afterward, we observe that mean views have decreased substantially in the last few years. (c) Some significant terms are clustering, spectral density, frequency, FFT, spectrum, PSD (Power Spectral Density), and MATLAB. MATLAB is used by scientists and programmers for numerical computation. (d) The number of articles indexed in life sciences and biomedical had started from 2800 in 2008. It has been increasing, reaching 3700 in 2015; however, the graph of neuroscience is nearly constant at approximately 500 articles per year.
Time series analysis
Some studies in the life sciences and biomedical domain focus on the analysis of non-stationary time series for biological rhythms. 127 These studies propose methods to study characteristics of time series, such as methods to prove and determine, if time series comprises a rhythm. In addition, other applications are regenerating time series from ordinal works, 128 and RNA sequence data of Escherichia coli represents a time series, the authors present Elucidation of its sequential transcriptional activity. 129 Decoding brain patterns from reactions when subjected to neuroimaging data, for example, MEG and EEG, address research concerns related to cognition. 130 Brain decoding methods are suitable for the analysis of the fMRI data. Recently, these methods have been applied to understand unexplained observations in cognitive neuroscience. 130 In this study, 131 the BOLD (blood-oxygen-level-dependent) time series was decomposed by the wavelet transformation, followed by computing the wavelet entropy. The wavelet entropy was compared with Shannon and spectral entropy by developing a model time series comprising several harmonics and non-stationary components (Figures 8 and 9).

Quantification of trends related to time series. (a) We observe a steady increment in questions from 2009 to 2018, whereas the increment in accepted answers becomes stagnant in 2016-2017, they subsequently became constant. This shows an increment in their usage in the past decade. This may be attributed to the emerging data science as a promising field, which considers time series an integral part of prediction and forecasting. (b) The time series tag gains the highest mean views per question in 2010, along with that the IQR is approximately 4K. Subsequently, we observe a decrement in the number of views; however, it has bagged the highest number of accepted answers in 2018. (c) The frequently used words are data, value, model, variable, data frame, function, result, nan, period, mean, and forecast. All of these words are related to either time series modeling or forecasting. Notably, nan represents the missing data in the time series. (d) For life sciences and biomedical, we observe an increasing graph from 4.5K in 2008 to 8.5K in 2018, approximately, whereas for neuroscience, it increases from 0.2K to 1.8K, approximately.
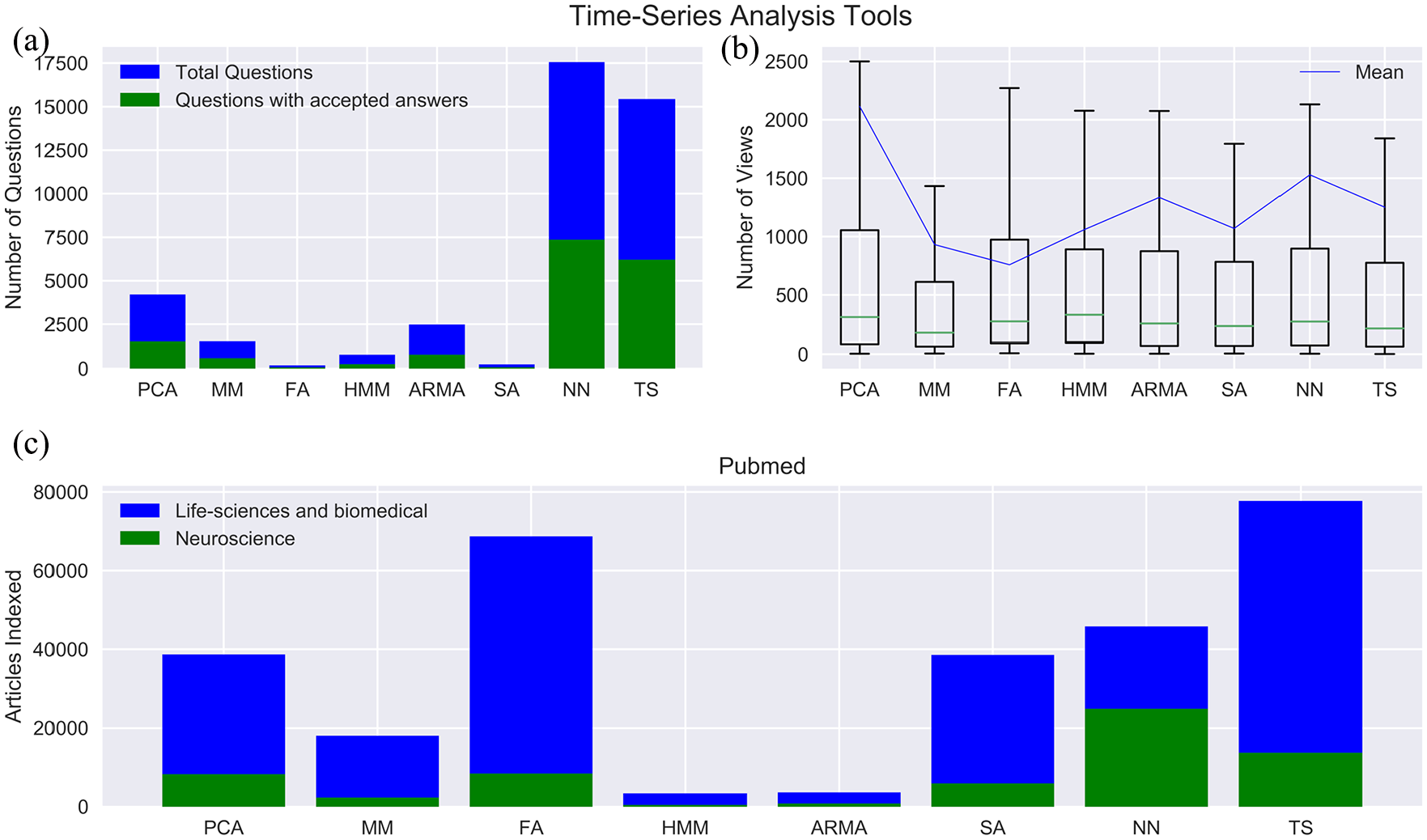
Comparison among time series tools. (a) In terms of questions asked and accepted answers, the neural network has recorded the most units, followed by PCA, ARMA-ARIMA, Markov models, HMM, Spectral, and Fourier analyses. Markov model, HMM, Spectral analysis, and Fourier series have applications in the frequency domain; thus, they exhibit significant but limited presence. Contrary to other tools, the neural network and PCA find application in different types of data and problem statements, ranging from classification to dimensionality reduction. However, an exception to this is ARMA-ARIMA models, which specifically deals with time series analysis and modeling. This may be a consequence of their straightforward concept and the vast amount of research available. Notably, almost all the tools have 40% accepted answers compared to the number of questions asked. (b) PCA has the highest number of views, followed by ARMA-ARIMA and neural networks, which has almost equal mean views; however, Fourier has the least mean views. In every time series tool, we observe that 50% of the questions have less than 300 views. The easy access to the internet and social connectivity has led to ample resources related to these topics, providing users with several alternatives. Among others, this could be the reason for a decline in mean viewership per question. (c) To our surprise, Fourier is the most used time series tool in biomedical and life science research, followed by PCA, Markov model, Neural network, and ARMA-ARIMA. Conversely, the neural network is the most used time series tool in neuroscience research, followed by PCA, Fourier, Spectral, Markov, and HMM.
Discussion
We have discussed seven classical time series tools in this work. Our focus has been the applications of these tools in biomedical, life sciences, and neuroscience. Due to the advent of internet technology and its explosive boom out in the last 2 decades, the exploitation of these tools increased globally. People all over the world, especially from China, Japan, USA, Canada, and some European countries have been early adopters of this technology. Our study quantified the use and evolution of these tools from several perspectives by analyzing the databases of SO, CV, and PubMed. It also sums up varied utilization all over the world, sharing ideas and giving a better idea of future scope.
Conversely, Fourier transformation shows no trend and exhibits high fluctuations in the number of questions asked and accepted answers. Neural Network is the only time series tool that shows a polynomial growth in terms of questions asked and accepted answers. The neural network has always been a hot topic for research, and its application in various fields garnered questions over a range of 1K to 4K. Recent advancements in neural networks include a combination of CNN (Convolution Neural Network), RNN (Recurrent Neural Network) with artificial intelligence. This makes the neural network the most popular time series tool in SO and CV. The range of questions asked and accepted answers have been maximum for neural network followed by PCA and ARMA-ARIMA. In contrast, tools, such as Spectral, Markov, and HMM, gather 0 to 50 questions (Figures 5-7).
Most of these tools were used in combination with some other tools, not as an individual tool, especially Neural Networks and PCA, as they find application in both time and frequency domains.
Our analysis shows that a continuous rise in usage is not accompanied by a similar rise in questions with the accepted answer. Trends in the application of these tools from the biomedical and neuroscience perspective would introduce respective researchers to the current usage patterns of these resources. We hope this analysis would be useful for a wide range of professionals, ranging from IT-practitioners to Neuroscientists, in facilitating them with the right choice of tools. Also, it will guide to fill lacunae.
Supplemental Material
sj-docx-1-exn-10.1177_2633105520963045 – Supplemental material for Utilization of Time Series Tools in Life-sciences and Neuroscience
Supplemental material, sj-docx-1-exn-10.1177_2633105520963045 for Utilization of Time Series Tools in Life-sciences and Neuroscience by Harshit Gujral, Ajay Kumar Kushwaha and Sukant Khurana in Neuroscience Insights
Footnotes
Acknowledgements
Authors acknowledge sincere efforts of Akshat Garg (Jaypee Institute of Information Technology, Sector 128) for his help in the curation of this research.
Funding:
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Contributions
HG and AKK conducted the study and wrote the paper. HG scraped the data and created the visualizations. SK edited the paper. All three authors designed the study.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.