
Abstract
In this tutorial, we suggest ways to improve current practices for measuring gender identity, sexual orientation, and demographics about relationships based on previous datasets and a newly collected survey of people’s behavior and perceptions of alternative-response formats. We apply lessons learned from racial identity/ethnicity to suggest broader principles of improving demographic measurement. We offer guides to meet the expectations of diverse stakeholders, including participants. The response options we recommend were curated to balance global identities and emerging trends to be applicable for online international research and in-person psychology research conducted primarily by U.S. institutions. We also offer practical suggestions for researchers to handle more complex data, including multiselect response options, which tend to be preferred by participants. Improved demographic data allow researchers to more fully capture multidimensional and complex social identities that are related to social inequities. In sum, the current tutorial is a guide to and discussion about challenges in collecting demographic data on social identities in which we use illustrative data to address important points related to measuring gender, sexuality, and relational demographics, specifically.
Keywords
Social identities, such as gender identity, sexual orientation, and racial identity/ethnicity, are related to people’s sense of self and how they move through the world. Social identities vary by region in how people are treated, such as racial identity, or what is legally allowed, such as expressions of sexual orientation and gender identity. Other works have robustly established the importance of social identities such as racial identity/ethnicity and gender (e.g., Barr et al., 2024; Boykin et al., 2010; Suyemoto et al., 2020). In the current tutorial, we provide practical recommendations for researchers collecting these social identities as demographic data, which are inextricably informed by institutions and history rather than fixed, inherent, unchanging properties that make group members who they are (Chao et al., 2013; Gelman, 2003; Ifekwunigwe, 2020), and the current tutorial provides new ways to measure what researchers want to know.
Although racial identity/ethnicity and gender may be the most commonly considered demographics in social-science research, other important demographics to understand lived experiences include but are not limited to country of residence, country of birth, heritage, language, skin color, body shape, education, (dis)ability, religion, socioeconomic status (SES), relationship status, relationship type, and more (Aggarwal et al., 2022; Hays, 2008; Hughes et al., 2016; Wadsworth et al., 2016). Social-identity labels are ultimately ambiguous and tied to cultural contexts. However, researchers are fundamentally interested in social identities because they are related to meaningful constructs, even across cultures (Boykin et al., 2010). Considering the culturally bound nature of social-identity labels, best practices are ever-changing, although social scientists tend to use consistent, prespecified labels. This becomes particularly evident when recruiting diverse samples, including using online methods which provide easier access than in-person methods to reach participants from around the world.
In the current article, we have multiple goals related to providing better (not best) practices for demographic collection of social identities related to gender, sexuality, and relational identities. Our recommendations are most appropriate for U.S. contexts using within-countries restrictions, in which approximately 6% of university students are international (Mowreader, 2025) and about 27% of the population is first- or second-generation immigrants (Taylor, 2013), or using unrestricted internet research. We use racial identity/ethnicity as a guiding model because some of the same issues exist across social-identity measurement. First, we address why new practices to measure the selected demographics are needed and what motivated us to share our experiences. Second, we use three illustrative data examples to highlight specific recommendations and broader principles for demographic collection. Third, new or overlooked demographic measures related to relationships, gender of relationship partners, and marginalization are proposed. Finally, we provide tips for managing more complex demographic data.
Why Are New Suggestions Needed?
Researchers must collect demographic data, whether for specific study purposes or to describe samples relative to other populations or representativeness. However, a persistent challenge with collecting demographics is the lack of consensus on how to handle the complexity of people’s identities. Thus, researchers often turn to authorities such as government bodies, for example, the U.S. Census Bureau (U.S. Census Bureau, 2021), or professional societies, for example, the American Psychological Association (American Psychological Association, 2023). These recommendations tend to be relatively static and are rarely updated to reflect shifting social and cultural norms around identity.
In contrast to the limited approaches typically taken to collect social-identity demographics in social-science research, the population in the United States and globally is becoming increasingly multicultural and multiracial, and the understanding of identity is diversifying (U.S. Census Bureau, 2021). The lack of racial diversity and geographic diversity in research participants has been widely noted by psychological scientists for more than a decade (e.g., Arnett, 2008; Henrich et al., 2010; Nielsen et al., 2017; Rad et al., 2018; Roberts, 2022). Likewise, there is a notable juxtaposition between increasing rates of sexual- and/or gender-minority (SGM) identification and the common use of demographic items about identity that are not inclusive in psychology (Magliozzi et al., 2016), medicine (Cahill & Makadon, 2014; Quinn et al., 2021), and national probability surveys (Federal Interagency Working Group, 2016a, 2016b; Patterson et al., 2017).
Much has previously been written about typical approaches to the collection of racial identity/ethnicity demographic data and the ways in which standard practice typically reflects U.S.- and White-centric perspectives (Ifekwunigwe, 2020). Commonly used response options reflect norms around how the United States has defined “race” (Lewis et al., 2023). Cross-nationally, different focuses are used in place of “race,” such as “ethnicity,” “indigenous identity,” or “migrant status” (Stillwell, 2022). The following are examples moving to decenter U.S.-centric perspectives. Because of globalization and immigration, “Black or African American,” used often in the United States, may not represent people from Africa’s racial identity/ethnicity with adequate precision (e.g., combining identities from across both African-majority and African-minority contexts). Internationally, the emphasis on ethnicity versus “race” is typically heightened (Boykin et al., 2010). To reflect this somewhat better, researchers have begun to break up large regions, such as “Asia,” into smaller regions that share more commonalities. Likewise, identities that may fall under labels such as “Native” or “Indigenous” come from all parts of the world. Although most people may not know all the Indigenous Peoples globally, one can use language to give options outside of people native to the Americas.
Language around racial and ethnic identities is constantly in flux and varies substantially across world regions (Aspinall, 2007). Updating common data-collection practices, such as allowing participants to select multiple identities rather than limiting them to a single category and providing the option to write in identities when the appropriate category is not provided, gives participants flexibility, improves recruitment, and more accurately represents who researchers are recruiting (Call et al., 2023; Compton et al., 2010). Other approaches have tried to make dimensional or continuous measures of concepts underlying group identity (e.g., Galupo et al., 2014; Kinsey et al., 2003; Lambert & Penn, 2001) or related traits (e.g., Kachel et al., 2016; Pauletti et al., 2014) with some success. Yet social identities are still desirable to collect because group identification remains one of the most salient data-collection methods (Aspinall, 2007).
Compared with racial or ethnic identities, which are typically viewed as reflecting group-level interpersonal processes, collection of demographic-like social identities related to individual-level interpersonal processes, such as gender, sexual orientation, and romantic orientation, is comparatively less scrutinized in the social-science literature (cf. Pai et al., 2024; Pao et al., 2025). Advancements in gender assessment have recently proliferated with some common elements across different research groups (Beischel et al., 2023; Cameron & Stinson, 2019; Herman et al., 2024), but this is not yet the case for sexual orientation (cf. Galupo et al., 2017; van Anders, 2015).
Furthermore, few researchers consider romantic orientation as an identity to measure, even in the specific context of research on romantic relationships, despite its increasing use in queer communities and importance to people aligned with asexuality (Galupo et al., 2014). Expert discussions on sexuality and the co-occurring definitions and assumptions have identified related but distinct concepts to tap into nurturance or romantic attraction (Diamond, 2003; Galupo et al., 2017; van Anders, 2015). For example, Galupo et al. (2017) used matched continuous items to ask about sexual attraction versus romantic attraction to people of the same or different sexes. Our current goals are to guide researchers on how to include people’s identity labels that tap into gender, sex, sexual orientation, romantic orientation, number of partners, and other relationship characteristics.
Similar to racial and ethnic diversity, gender, sexual, and romantic diversity are currently substantially underrepresented in the psychological-science literature (Junkins, Dugan, et al., 2024; McGorray et al., 2023). Part of the problem is the common use of demographic measures that fail to allow people to reflect the relevant identities. In a past review, researchers found that almost 50% of U.S.-based relationship studies did not measure sexual orientation (Junkins, Dugan, et al., 2024). Previous and ongoing empirical research by these authors has sought to increase the representation of participants holding gender-, sexual-, and romantic-minority identities in psychological science. Recognizing that similar challenges apply to racial identity/ethnicity across cultural contexts, we sought to expand the development of principles previously applied to racial-identity/ethnicity demographic data to the collection of gender, sexual, and relational identities.
Motivation to Share Our Experiences
In 2019, our lab began undertaking research designed explicitly to increase the representation of SGM participants in psychological science. As part of this effort, we implemented novel methods of demographic collection, particularly with respect to SGM identities. First, we added romantic orientation alongside collection of sexual orientation. Romantic orientation describes a person’s romantic attraction to people of different genders (Asexuality, Attraction, and Romantic Orientation, 2021). Whereas sexual orientation concerns sexual attraction, the goal of romantic orientation is differentiating who someone may be likely to date, partner, or marry. Both are important elements that advance understanding of queer people, but romantic orientation was especially appealing because it shifts the focus to love/nurturance and not just sex (Diamond, 2003). Second, we allowed participants to “choose all that apply” when reporting their gender, sexual, and romantic identities, similar to the approach that is now commonly taken by researchers collecting racial-identity/ethnicity demographic information. In implementing this multiselect method, we received positive feedback and observed several outcomes in terms of the experience of research across several projects: a high rate of participation from members of traditionally underrepresented SGM identities, a high rate of positive feedback, a low rate of negative feedback, and a high frequency of participants making use of multiple checkboxes. Third, we included self-identified marginalization questions (e.g., “Do you identify as a sexual and/or gender minority?”), allowing our participants to self-categorize their marginalization status based on their experienced cultural context.
Based on these experiences, we developed an inclusive structure for demographic data collection of gender, sexual, and romantic identity. In the current article, we discuss challenges to measuring social identities, especially in U.S. contexts, and we provide concrete recommendations to measure gender identity, sexual orientation, romantic orientation, and other relational data researchers may want to know based on three data examples.
Examples in Three Surveys
We turn now to briefly describe the methods and results from three surveys implementing demographic-collection methods across a variety of data-collection efforts. For details of each study, see the Supplemental Material available online. Materials are shared on OSF: https://osf.io/np8ju/. For abbreviated demographics, see Table S4 in the Supplemental Material. Here, we briefly describe demographic characteristics in each study relevant to advancing understanding of participants’ behaviors and preferences when engaging with novel formats for the collection of gender-, sexual-, and romantic-identity data. Table 1 summarizes the three samples that we refer to throughout. First, missingness of multiselect gender, sexual orientation, and romantic orientation were between 0.17% and 1.35% across Sample 1 (queer oversample) and Sample 2 (nontargeted Prolific sample). In contrast, an open-text box for racial identity in Sample 1 had 4.73% missingness. Second, a large portion of respondents selected multiple gender-identity options (71.80% and 24.79%, respectively) in Sample 1 and Sample 2. Sexual orientation had fewer multiple selection in Sample 2 (3.68% and 3.68%, respectively) than Sample 1 (29.21% and 18.06%, respectively). Table 1 shows the proportions of respondents who identified as SGM based on one dichotomous question.
Brief Overview of the Three Samples

Note: SGM = sexual and/or gender minority.
In an initial sample as part of a larger survey of individual differences compared across diverse gender, sexual, and romantic identities (POWER study), we sought explicitly to oversample participants holding SGM identities. In this study, with an initial sample size of 1,777 recruited via social media, we implemented two novel strategies: (a) the multiselect box option for gender, sexual, and romantic identity, allowing participants to “select all that apply,” similar to modern methods of collecting racial identity/ethnicity, and (b) directly asking participants if they identified as SGM in their current context, a method that we had previously implemented (Junkins, Pantin, & Derringer, 2024) to overcome limitations of needing to infer minority status, which may differ based on cultural context and lived experience, from identity labels alone.
In a second sample, we embedded our novel format of multiselect responses to gender-identity, sexuality, and relationship measures in a survey being collected by colleagues through the paid research platform Prolific (N = 2,606). The Prolific study had nonidentity-specific recruitment qualifications, which allows us to illustrate how these considerations appear in more general samples (Yoon, 2025). Despite the sample not being explicitly selected for diversity, participants in this sample made use of the opportunity to select multiple options for gender (24.79%), sexual orientation (3.68%), and romantic orientation (3.68%) with little missingness.
In a third sample, which we refer to as the “Preferences” survey, we asked participants to rate three response formats for social identities and provide general feedback on what they want researchers to know about each. In this survey (N = 461), participants recruited via social media responded to gender, sexual, and racial-identity/ethnicity questions in four formats (single choice, multiselect, single yes/no minority questions, and open text), allowing us to track differences in responses depending on the format of response offered.
We also asked participants to specifically rate their preferences among the alternative formats and asked about their impressions generally with the assessment of each demographic. As shown in Table S2 in the Supplemental Material, across gender, sexual-orientation, and racial-identity/ethnicity demographic questions, participants consistently rated the multiselect option, allowing them to “choose all that apply,” as being preferable compared with single-choice and open-text-field responses. The single yes/no minority questions were not provided to replace measures of identity, but we tracked performance across these formats to illustrate how response options may shape researchers’ perceptions and participants’ behavior. For the differences in responses across formats for sexual orientation, see Figure 1. The colored lines show how a respondent in the multiselect options responded in the single-choice format and the dichotomous SGM question; for example, some people who selected “queer” and “gay” in multiselect chose either “gay” or “queer” or “prefer add” in the single-choice option. Most of these respondents also said they were SGM.

The responses provided across three of the response formats for sexual orientation in the Preferences survey.
Recommendations for Collecting Diverse Gender, Sexual, and Romantic Identities
From the experiences described above, we recommend (a) specific formats of demographic data collection mirroring racial identity/ethnicity for gender identity, sexual orientation, romantic orientation, and other relational variables to collect and (b) a set of principles to guide researchers in adjusting these and assessing other social constructs as cultural context continues to shift. The goal of our recommendations is to allow for the complexity and multidimensionality of social identities to be visible in psychology not only in theory but also in practice.
For the specific categories we present as options in the standard multiselect (check all that apply) question about social identities, see Box A. From the recruitment examples described above, we found that across samples, more flexible response choices were commonly used by participants when given the option. When recruitment focused on other characteristics that are not directly related to particular social identities, the flexible choices did not create confusion or additional difficulty. Below, we address specific issues that apply to one or more of the social identities under consideration.
Better Questions and Answer Choices for Multiselect Identity Demographics

General principles of inclusive measurement learned from racial identity/ethnicity
“Other”
Othering forces someone to think about themselves as excluded from presumed “default” characteristics of privileged categories (Canales, 2000), such as by being reminded of the marginalization of an identity by selecting “other.” Although it seems small, the phenomenon of othering is overall well known, and participants readily identify the use of the term in response options. Use alternate language when someone needs additional or different terms. Try “prefer additional or alternate descriptors” or “prefer to self-describe.”
“Choose one” versus “select all”
Multiple-choice questions with only one selectable answer negate multicultural and multiracial identities or minimize them to “multiracial.” In reporting, researchers should allow people to select all that apply to them. For instance, people who describe themselves as three-quarters Black and one-quarter White might debate filling out only Black, African, or African American because it could be how they are perceived or for other reasons choose only one in this case. The decision to select either Black or multiracial is an identity conflict (Townsend et al., 2009). The United States, like other nations, is becoming more and more multiracial (Vespa et al., 2020). Improved measures may help to show just how multiracial people are and provide more information on how they describe their identities (Jones, 2021). Although the option to “select all” has become more commonplace for the collection of racial or ethnic demographic data, the same logic may apply to other social identities, that is, a single term may not adequately capture complex social experiences. The understanding of gender identity and sexual orientation is developing to encompass more complex identities that may not be described by a single term, and our experience has been that participants appreciate and make use of the flexible response options while not encountering additional difficulty responding.
Identity does not convey history
Where someone was born, what religion they grew up with, and the SES of their family may differ from their current place of residence, religion, and SES. Many researchers work with undergraduate students. Many major universities have large international populations, so their family situation and history may be quite diverse among people selecting the same identity. For example, in the Asian-identifying student population at a U.S. university, there may be some who lived or were raised in an Asian country, Europe, or Africa or were born and raised in the United States; choosing “Asian” on a demographic form does not convey specifics about a person’s individual history. Providing a range of response options with consistent levels of specificity across groups demonstrates to participants who is expected to engage with the research and provides valuable nuance in evaluation of sample characteristics.
Reduce the number of groups that must write in
There is usually one identity or select groups that are considered too hard to reach, so there will be very few people in that category. For example, many researchers obtain few responses from Indigenous Persons. However, it is important that researchers include the options of people who are commonly erased or undercounted. In part, doing so lessens the burden on these respondents. But respondents are also judging how researchers ask questions and what answers they provide to gauge the researchers’ values, knowledge, and goals. Omitting the few will not endear researchers to these groups or to individuals who are sensitive to survey design. For example, we believe it is important to include those identities for gender, sexuality, and romantic identity that indicate a reduced experience of that identity (i.e., agender, asexual, and aromatic identities). Although there may be comparatively few people who select these options or other minority identities, researchers should try to cover the range of experiences even if it is infeasible to include every variation (Call et al., 2023).
Consider asking important related factors
In the Preferences survey, we collected open-ended responses asking for participants’ feedback on each demographic. The variety of suggestions for what to focus on with racial identity/ethnicity was vast. People wanted nationality to be considered more important than U.S. definitions of racial identity. People, especially non-U.S. people, called for less emphasis on words such as “White,” “Hispanic,” or “Native People” all in one option. One of the most common write-ins for these data and others we have collected is “Jewish” or “Ashkenazi Jewish.” Multiple people reported a need for researchers to include ethnoreligions or similar variations to get much more culturally informed groupings rather than the broad categories that the United States defines as race. Participants also called for a greater focus on socioeconomic class and education, which cannot in many contexts be disentangled from past harms and present inequalities across different racial groups (Boykin et al., 2010); each characteristic of interest should be assessed to understand the effects of social inequalities. In short, there was no single solution to account for different opinions on the social construction of racial identity, ethnicity, or other terms to get at background, ancestry, family history, and lived experience.
Be reflexive and willing to update understanding
We quickly learned some errors in language for the multiselect checkbox options of racial identity and ethnicity. “Southwest Asian and North African” (SWANA) is emerging as a common description from people who are of that identity rather than the Europe-centered term, “Middle Eastern and North African” (Maira & Shirazi, 2023). However, it is a newer effort of decolonization because a lot of U.S.-based people were accustomed to being considered Middle Eastern. Because we had “Southwest Asian” and “Middle Eastern and North African” as two options, we should have had “South Asian” and “Southwest Asian and North African/Middle Eastern.” Our own experience while trying to put together this tutorial highlighted how having a relatively homogeneous research team with less knowledge of different contexts is a hindrance; although our extended research team has included members holding SWANA identities (which is how we became aware of the issue), our relative inexperience led us to miss what was quickly identified as a typographical or logical error by our survey participants with relevant lived experience.
Better gender measurement
Complex, nonbinary gender identities are relevant to collection of demographic characteristics across psychological science. The way gender and sex assigned at birth are measured shows an emphasis on binary understandings of both sex and gender (e.g., Junkins, Dugan, et al., 2024). There are many great resources that explain the distinctions of sex and gender and why it is inappropriate to couch sex as being “biological sex” because it, too, involves social construction, complex realities, and very large within-groups variation and between-groups overlaps (Hyde et al., 2019). It is important to understand that how researchers ask about gender should reflect a shared understanding in science that neither gender nor sex is binary. “Cisgender” and “transgender” describe people’s experiences of gender broadly and are important if researchers want to understand differences in lived experience that may exist (e.g., transgender men and cisgender women may menstruate). Finally, “nonbinary” is not alone sufficient to encompass all people’s experiences with gender identity who do not align with man/woman binary distinctions (Richards et al., 2016). It is important to understand that variation in how people relate to masculine and feminine (or neither) is also not always exclusive to being nonbinary. A multidimensionality of gender identity is the number of people who will use both “man” or “woman” plus “nonbinary,” “genderqueer,” or “gender nonconforming” (see Figs. S2–S4 in the Supplemental Material). Overall, few people use “bigender,” “pangender,” or similar, but many do not experience themselves as singularly inside or outside the binary. Furthermore, agender people often do not feel an internal sense of gender, which is little researched and less understood, as evidenced by its lumping together with the broader nonbinary umbrella (Ferguson, 2022).
When transgender identity is relevant to sample description or survey goals, different approaches may be appropriate depending on context. One practice to address whether someone is transgender is to ask two separate questions (see Table S1 in the Supplemental Material), matching our single-choice option in the Preferences survey. Based on the responses to the separate transgender question in the single-choice set versus the inclusion of “transgender” and “cisgender” in the list for the multiselect option, there was not a single consensus for what was preferred. Many people wrote they appreciated being able to include or not include transgender in their identity (multiselect), whereas others do not see it as part of their current identity so preferred the separate question (single choice). For some people, there was a challenge with tense; even gender identity does not convey gender history. Should they report previous identities, their current identity, or both (similar for sexual orientation)? Question phrasing should help make this clear if needed. For alternative questions when it is critical to the research to know who holds a transgender or nonbinary identity, see the Supplemental Material. Challenges to separating out a question that asks people to identify as cisgender or transgender (e.g., Herman et al., 2024; Kidd et al., 2022) are that cisgender people often may not know that “cisgender” describes their identity and that not all nonbinary people reflect transgender as being applicable. By including them all in one question, people can include as many descriptors as needed without adding burden to either the majority, cisgender people, or the minority, transgender and nonbinary-aligned people.
In addition, some people reported disliking having sex assigned at birth asked at all. They did appreciate that the past tense was used for what was your sex assigned at birth and the inclusion of “intersex” as an option. If researchers ask sex assigned at birth in combination with current gender identity, they can check for discrepancy or consistency to assign transgender or cisgender status, but how intersex works in this framework and how not all nonbinary people use transgender in their self-description may affect the usefulness of sex assigned at birth. Note that none of the collected information implies any specific gender-affirming steps, either social or medical. In short, our multiselect choices worked quite well to expand the study of gender to include more experiences (Tate et al., 2014). For our recommended better practices, see Box A; for additional transgender-identification and nonbinary-identification questions when desired for study purposes, see the Supplemental Material.
Better sexual-orientation measurement
During each new data collection, we encountered new sexual-orientation labels, but we have come to a balance of an appropriate number of response options for the sampling strategies we use. We reflexively used write-in responses from our first data collection in 2021 to add “queer” in future surveys. Most of the sexual orientations have consistent meanings across English-speaking areas, but not all may have equivalent translations in other languages.
Based on the open-text responses in the Preferences survey, people felt using “straight” in addition to “heterosexual” was useful, especially for different age groups. Participants also sometimes expressed wanting “gay” and “lesbian” as separate options in the list, which we now include in our recommendations. It is still important that researchers do not assume gender by these labels. The inclusion of asexual identities in the list of prefilled options was extremely valued by people. The final common change was the addition of “heteroflexible.” It was a repeated label in the Preferences survey, we saw it written in during prior data collections, and it has been a topic of research (Carrillo & Hoffman, 2018). Other write-ins have been more common in our experience, but they did not make the list of additions we suggested (e.g., “polysexual,” “omnisexual,” “orchidsexual”). “Heteroflexible” implies some clinging to a more privileged identity to either not overstep into queer spaces and claim queer identities or the lack of normalization of identifying as something such as “bisexual,” for instance, and having a strong preference for one gender identity over others in relationship choices. Either way, few people used and suggested the term in the current data and past data that we have collected. More often, we expect people select “heterosexual” and a second term to describe how they are flexible in their sexuality in our multiselect options. Other write-ins that we saw in these data and previous datasets were “androsexual” and “gynosexual” because these terms match gender expression or physical characteristics of desired partners. “Prefer not to respond” was a common suggestion to include rather than assuming participants will skip a question they do not want to answer.
Overall, sexual orientation provides limited information beyond a general pattern of sexuality or self-labeling decisions. There is a lot of other information researchers may want to know that sexual orientation cannot provide. Therefore, our goal in the next section is to discuss what sexual orientation does not imply and what other information one might need to gather.
Asking the Right Questions
Lesson 1: measure romantic orientation to understand queer love
In earlier data collections, we experienced asexual and other respondents writing in romantic-orientation labels when we asked about sexual orientation. We took this feedback from respondents to include measures of romantic orientation moving forward. When studying sexual or romantic relationships, evaluations of sexual and romantic orientations are separable. For the relationship between responses of these identities for Sample 1, see Figure 2; for relationship in Sample 2, see Figure S5 in the Supplemental Material. Built into heteronormativity is also allonormativity and amatonormativity, the presumption that everyone strongly feels sexual and romantic attraction to other people, respectively, and that these orientations are equivalent (Komlenac & Hochleitner, 2023). Specific sexual orientations vary in their emphasis on sexual attraction (e.g., demisexual or asexual), and people also differ in the extent to which they prioritize sexual attraction in partner selection (e.g., Baumeister, 2000). A lot of research in psychology presumes that being allosexual and attracted to a different gender partner are the default. In short, sexual orientation and romantic orientation should both be used when either is of interest.
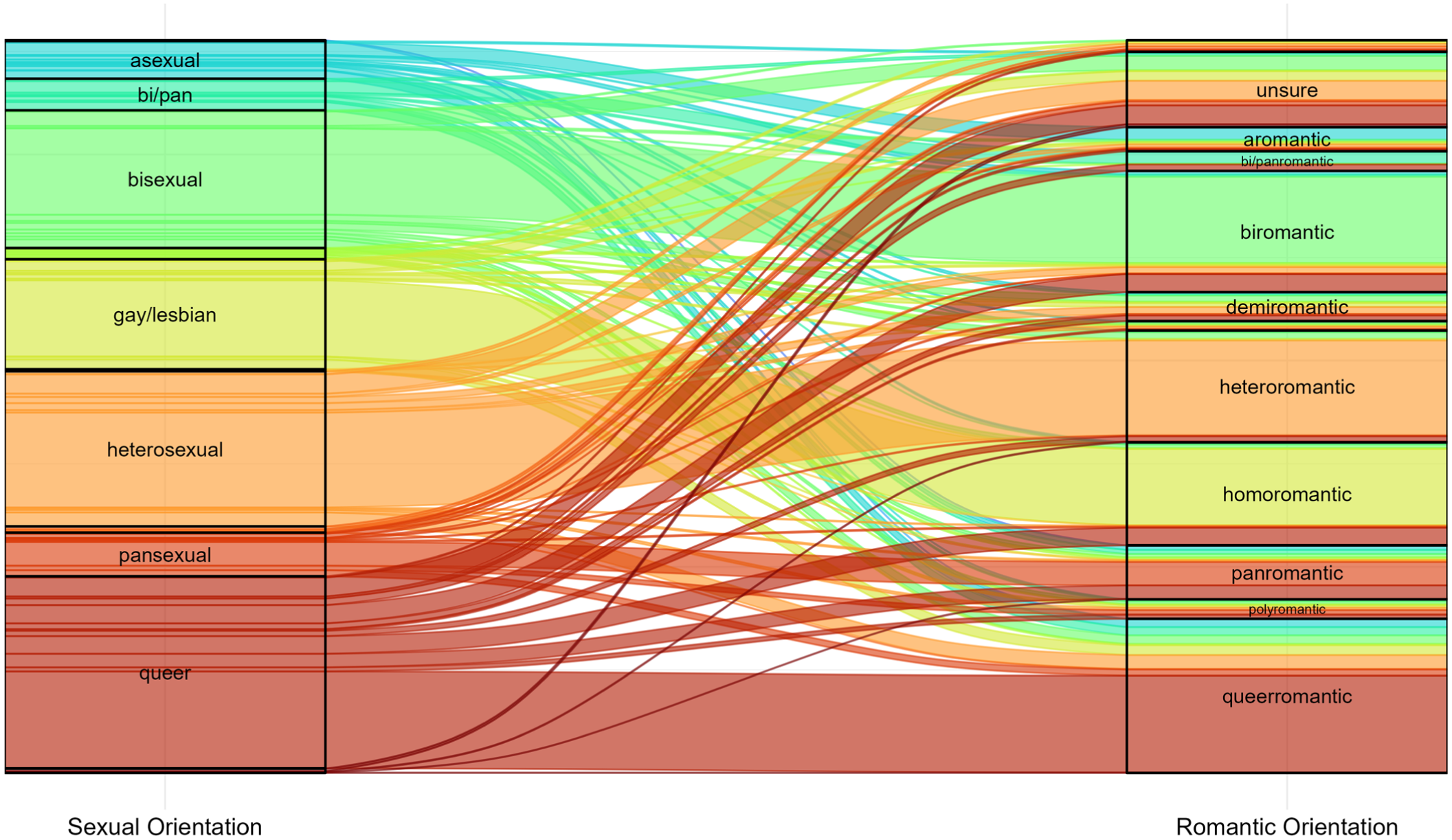
Flow of responses in Sample 1 from a cleaned version of sexual orientation and romantic orientation. “Queer” and “queerromantic” captured many of the responses with multiple orientations checked, especially when the definitions were distinct (e.g., heterosexual and asexual).
A surprising write-in occurred in Sample 2 that we had not previously experienced with romantic orientation. Many respondents (mostly heterosexual men) wrote in for romantic orientation that their attraction was limited to their wife or mentioned that they were married (Yoon, 2025). Yet they were able to choose “heterosexual/straight” for their sexual orientation. A brief definition of “romantic orientation” was provided, so despite not being familiar with the term, it was interesting to see this response pattern in multiple people (n = 8). Others in this sample wrote in variations of do not know (n = 68), attracted to women, interested only in women, straight, attracted to men, or that they were “normal” (n = 27). Respondents from Sample 2 were more confused by the question, and we perceived their annoyance at the question to be because they felt sexual attraction (sexual orientation) captured it all. The fact that society encourages people to label their sexuality but not think as critically about their love, nurturance, and emotional intimacy was apparent from some of these responses.
Lesson 2: measure minoritized lived experience
A single yes/no question of “Do you identify as a sexual and/or gender minority?” was introduced in some of our earliest data collections and showed that some people who would be classified by definition as SGM will not self-identify that way and vice versa 1 (see Fig. 1). The use of SGM as a framework for people who are gender minority or sexual minority versus people who are cisgender, “heterosexual” does not perfectly match with people’s perceptions. Although the National Institutes of Health uses such parsimony to define populations in need (Pérez-Stable, 2016), creating a monolith may limit the interpretation of heterogeneous groups that may exhibit different patterns of effects and may feel they experience discrimination differently or not at all. Likewise, we found that asking racial- and/or ethnic-minority status in one’s own culture or nation performed well (see Fig. S1 in the Supplemental Material). Although many nuances of participant identity are lost in this approach, directly asking participants if they consider themselves to be marginalized in their experienced cultural context potentially solves many coding ambiguities in the management of such complex social-identity data.
We introduced the simple yes/no items for racial/ethnic marginalized identities and SGM status to better categorize people for analysis when social experiences, such as discrimination, rather than specific identities are the level of analysis of interest. These dichotomous divisions allow for the understanding of broad, systems-level differences but overlook the specific experiences that people of different identities will have. However, if we already planned to lump participants based on their identity, we felt it was more important to consider how people identify themselves in their unique context (especially in psychology). For instance, even though we collected most of our data in the United States, some participants were from countries in Asia. Therefore, people identifying as East Asian are not in the minority in their current context, so we would be wrong to lump them with the racial-minority group. It is easy to assign people based on assumptions, but researchers cannot assume self-identification without asking. Given variation across regions, cultures, and nations on who is a minority and what their experience is, the single item may prove especially useful in situations in which one’s knowledge may be more limited. Herman et al. (2024) suggested an alternative option for gender identity with a similar goal of representing transgender and nonbinary experiences and allowing participants to choose how they would want to be categorized. Generally, we found the dichotomous questions were not well rated (see Table S2 in the Supplemental Material) to replace the more expansive options, but for the reasons we listed here, there is utility in using them in addition to the more expansive questions. In short, we provide these suggestions to ask about marginalization directly of respondents to understand their experience wherever they are geographically located.
Lesson 3: gender and sexuality are related but distinct
Although sexual orientation is often inferred from partner characteristics (e.g., same vs. different gender) and vice versa, this is not a reasonable assumption. The way that relationships are presumed to be heterosexual is heteronormativity, and it is also the way that scripts from man–woman dyads are assumed to be the standard that should similarly apply to all relationships (Hammack et al., 2019; Ogolsky, 2023). For example, when research on romantic relationships is limited to people in man-woman dyads, from study-sample descriptions, it is commonly unclear how often sexual orientation was presumed versus how often identity was measured for each person (Junkins, Dugan, et al., 2024). Someone who is heterosexual could easily be involved with someone who identifies otherwise. Study eligibility supposing that a man must be dating a woman to be eligible is not equivalent to “heterosexual relationships.” To further complicate matters, how people’s definitions of sexuality relate to gender or sex characteristics differs from person to person. “Hetero” means “mixed”; a mixed-gender relationship could include a nonbinary person and a man or a woman and a bigender person. Often, “queer” labels are more comfortable because stronger implications are inherent to using “heterosexual.” Most sexual orientations do not imply which gender someone is likely dating even when the respondent’s gender is known (e.g., bisexual, pansexual, demisexual, asexual). Because researchers cannot infer, we suggest measuring partner’s gender, gender-level description of the partnership, and partner orientations if this information is needed or would be otherwise presumed.
Lesson 4: monogamy should not be assumed
As a relationships researcher or a general researcher measuring relationship status, it is important to understand that no status precludes nonmonogamous relationships. We want to detour briefly to note that Sample 1 and Sample 2 both contained 314 and 108 people, respectively, who chose consensually nonmonogamous, polyamorous, or in open relationships, and 154 and 109, respectively, had two or more partners currently. Both samples also contained a large number of single people who reported never having had a relationship (ns = 52 and 151, respectively), despite average sample ages in the 20s and 40s, and being happy to remain single indefinitely (ns = 166 and 641, respectively). Relating to our repeated point, researchers can and should ask what they need to know.
Reporting Complex, Messy Data
We next discuss how to handle multiselect and open-text responses because these are more complex data than the single-choice options traditionally provide. Because we are pushing for more complex data collection, we want to lessen the burden of handling this information. We provide the survey data we collected and scripts on OSF (https://osf.io/np8ju/) to show an example of cleaning this type of data. We also provided a base template of demographics to collect with REDCap and Qualtrics surveys. As we have shown, people very commonly select more than one option when given the opportunity, so cleaning may often include a categorization step. The first thing to do is categorize the responses in the “prefer to add additional” write-in. Then, combine all multiselect options and the categorized or raw “prefer to add” column. From here, review and categorize the responses based on study purposes with the goal of making multifaceted identities visible.
For instance, “multiracial” may often be reported as one category of racial identity, but this provides no information on who makes up this group (Ifekwunigwe, 2020). Alternatively, researchers may report each option as a separate percentage that together sum to more than 100%, so again, one cannot parse the multiracial portion of the sample. We suggest three potential ways to report multiracial or multidimensional identities. First, create a table of each single identity, as most articles do. Then, explain only the multiracial identities in the text. The table will sum to more than 100%, but the text will clarify how to make it equal to 100%. Second, include in parentheses following each monoracial identity some of the multiracial overlaps, for example, In the current study, 50% of the sample identified as White, European (3% also identified as African, African American, or Black, and 4% also identified as Southwest Asian); 12% identified as African, African American, or Black; 8% identified as Asian; 15% identified as Hispanic or Latin American; and 6% identified as American Indian, Alaska Native, or Indigenous Persons (2% also identified as Hispanic).
Third and last, we offer a parsimonious option for when word counts restrict how willing researchers are to go in-depth on sample descriptives. We suggest doing the normal monoracial reporting and then providing a breakdown of the multiracial participants and additional details in the supplement, for example, In the current study, 50% of the sample identified as White, European; 12% identified as African, African American, or Black; 8% identified as Asian; 15% identified as Hispanic or Latin American; 6% identified as American Indian, Alaska Native, or Indigenous Persons; and 9% identified as multiracial, selecting more than one choice (see supplement).
We recommend using one of the first two options and resorting to the third option only when needed.
For gender, one option is to start with a small number of broad categories, such as men, women, and nonbinary, that are then further described. For example, describe the sample as men (% transgender, % cisgender), women (% transgender, % cisgender), and nonbinary (% transgender, % femme/women, % masc/men, % genderfluid). Many nonbinary people relate their identity in relation to society’s labels, man or woman, so it can be useful to still reflect this in reporting. If transgender status or minority-gender experience is specifically of interest, then a different categorization may be necessary. Always use study purpose to help guide reporting, but unless minority-gender experience is key, it is better practice to include transgender people with their respective gender identities. Transgender is not by definition a gender-identity category distinct from men, women, or nonbinary; being transgender is a description of experience and only one part of gender identity that not all people prefer to include in their self-description.
For reporting sexual and romantic orientation, we suggest following similar guides as racial identity/ethnicity to capture participants who identify with multiple categories. Alternatively, report the most populous categories in the text and include the rest in the supplement, as many currently do. We suggest researchers avoid recoding identities regarding perceived experience or marginalized status, such as heterosexual and nonheterosexual or heterosexual and sexual minority, unless these categorizations are provided by the participants themselves.
Strategies to categorize open-text responses
The cleaning of the open-text-response option for single-choice and multiselect options and a purely open-text response is quite similar. We start by organizing open text alphabetically for ease of categorizing common write-ins, such as “white,” across any misspellings. We categorize responses using a system that can be developed from reading responses or from study purposes. Depending on the research context, we may seek to closely match categories to U.S. racial categories for consistency and then include further ethnicity categories for when people give highly specific national, religious, or tribal information or other information that does not fit into the U.S. definition of race. When participants write in their country of origin or ancestry (e.g., “Scottish”), we sometimes categorize based on cardinal direction and continent, a slightly more detailed version of our multiselect options (e.g., West Europe). Many identities entered require a quick search to check our understanding, which is to be expected (e.g., Where is Anguilla?). Once the entries have been alphabetized, the majority can be easily categorized based on one word that many entered (e.g., “woman” or “female”). A smaller proportion will require a decision to be made on how to categorize them (e.g., Is “Belgian Chinese” referring to multicultural family or nationality and ethnicity, and which is which?). How researchers categorize will depend on the study purpose and how they view racial identity and ethnicity and their own positionality but avoid using problematic or othering language.
Although there will always be some respondents who will opt to write in a more in-depth explanation of their identities, researchers should bear in mind that fully open text boxes for demographics were not rated highly by participants. Many wrote in to say that open text was more difficult for them, and missing data was more frequent overall. Respondents often intuit the response they think is appropriate from the list of responses given. As a brief example, if only “nonbinary” or “woman” were allowed single-choice responses, few people who identify with both will write in to specify their labels. Instead, they will pick the one “most” fitting or that they feel comfortable disclosing in that situation. How to handle open-ended demographics and what can be learned from it is an ongoing conversation (Pao et al., 2025).
Reflexivity and Broader Principles
Social identities, especially gender identity and sexual orientation, are not fixed, static demographics; they are fluid and change across the life span (Diamond & Butterworth, 2008). The use of terms may also change within and between societies across time (Hammack et al., 2022; Jones, 2024). Demographic shifts, such as the direction of immigration and increasing multiculturalism, are leading to more multiethnic and mixed cultural backgrounds (U.S. Census Bureau, 2021). Researchers should remain reflexive with respect to all social identities when planning and reporting their study demographics. If researchers take up more expansive demographic descriptions of samples, the possibilities for future meta-analyses are much more interesting. Many of these lessons we discussed can apply to other key demographics, but as researchers of SGM relationships, these were the features of standard demographics that we found most notably absent from discussion of participant diversity. In the current tutorial, we attempt to update demographics-collection practices for gender, sexuality, and relational identities by providing useful suggestions for participant classification and evidence of preferred methods from respondents’ own points of view.
The suggestions for gender identity and sexual orientation may function quite similarly internationally; however, language and translation may require a multistep process to find appropriate comparable terms for some identities. The suggestions provided can be continually improved by reflexive practices acknowledging one’s area and one’s study populations (Call et al., 2023). Our response options for racial identity/ethnicity were based on challenges we saw with U.S.-based practices and may not be appropriate in other contexts (Aggarwal et al., 2022). In many ways, the United States is an outlier, yet U.S.-centric norms pervade academic journals, societies, and guides (Altman & Cohen, 2021; IJzerman et al., 2021). We provide recommendations for better (not best) demographic measurement that can be implemented readily in human research and cleaned using the steps provided.
Deserving of a mention as well is that in every data collection we have engaged in, some participants deny the premise of gender identity, sexuality, and racial identity. It is important as researchers that we bear in mind that this perspective exists, but the resulting action is not to ignore social identities; there are real inequalities that affect people globally based on these constructed characteristics (Cech & Rothwell, 2020; Grant et al., 2011; Roberts & Rizzo, 2021). Some participants will always be dissatisfied, but the questions remain: Who are researchers serving? What are researchers trying to accomplish? And what is researchers’ scientific understanding of social identities and the effects of discrimination or inequality? These questions should guide how researchers attend to the various participant attitudes and experiences.
Although the recommendations we presented were illustrated using three data examples, our experience with online data collection spans years of research experience and many conversations with academics and nonacademics about identity and survey design. In our data collection, we tried to minimize bots and fraudulent behavior; however, we cannot fully discount that some fraud was likely. Public survey links, paid incentive, malicious intent, careless responding (Stosic et al., 2024), and duplicate survey takers are all forms of fraud (Johnson et al., 2024), which can be minimized before and after data collection but cannot be fully eliminated. We used CAPTCHA, zero or minimal incentives, attention checks, time to respond, and open-ended text to minimize fraud. Attention checks (Silber et al., 2022), social desirability, and inconsistent responding (Teitcher et al., 2015) may fail because of inattention or misunderstanding, whereas fraudsters may not be honest when posed with inconsistent, lie-detecting, or social-desirability questions and may pass speeding or attention checks (Asare-Marfo et al., 2020). From multiple data-collection efforts, including both datasets discussed here, checks of criterion, convergent, and discriminant validity have suggested that the data collected online with minimal or no incentives show data-quality metrics comparable with other common data-collection methods in the social sciences (Junkins et al., 2025; Junkins, Pantin, & Derringer, 2024). In sum, the validity of our findings assumes some level of faithfulness and a smaller portion of carelessness.
We provide additional materials on OSF to cover a range of demographic identities outside the scope of the current article and to provide a downloadable template for use with Qualtrics or REDCap software. As we stated earlier, SES, social class, education, age, disability, religion, language, profession (Aggarwal et al., 2022), multiracial perception (Ifekwunigwe, 2020), neighborhood, and ethnicity centrality (Wadsworth et al., 2016; Williams, 2020) are important social identities. In the current tutorial, we focused on existing and new demographics related to gender, sexuality, and relational identities that need to be rethought or added to better account for people’s lived experience.
Conclusion
It is imperative that researchers consider the global context in which respondents exist. As a whole, psychology underrepresents sexual- and gender-diverse people’s experiences (Junkins, Dugan, et al., 2024; McGorray et al., 2023; Rosendale et al., 2021; Tseng et al., 2021) and racially diverse and/or non-U.S. people (Buchanan et al., 2021; Henrich et al., 2010; Roberts et al., 2020). International research on racial identity/ethnicity is challenging because of terminology and how racial identity/ethnicity is defined across different contexts, whereas SGM identities are often overlooked altogether. By excluding certain groups from demographic measures, researchers do not fully address representativeness and implicitly present minority experiences as not being part and parcel of the subject (e.g., transgender experiences within gender; Tate et al., 2014). We applied lessons learned from racial identity/ethnicity to develop broader principles to improve demographic data collection for gender, sexuality, and relational identities.
It is always important to consider the research, the goals, and who may be sampled before employing demographic measures and balance that with legal concerns and demands from funders. In short, in the current research, we address better (not best) practices at this time for measuring social identities related to gender, sexuality, and relational identities; we aimed to strike a balance between how major institutions have been doing the work for decades and improving both participant experience and data validity. Researchers can reduce biases by collecting and reporting demographics in a way that allows for the complex, multifaceted, and diverse nature of social identities to be apparent. In sum, the current tutorial is a guide and discussion about some of the issues we see in current practices and suggestions for better practices to meet the demands of today.
Supplemental Material
sj-docx-1-amp-10.1177_25152459251391186 – Supplemental material for Gather Demographic Data About Gender, Sexuality, and Relational Identities: Asking the Right Questions
Supplemental material, sj-docx-1-amp-10.1177_25152459251391186 for Gather Demographic Data About Gender, Sexuality, and Relational Identities: Asking the Right Questions by Eleanor J. Junkins and Jaime Derringer in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We thank Hee Jun Yoon and Brent Roberts for implementing our demographic suggestions and sharing the results with us. We also thank friends and colleagues who gave feedback on a draft or shared with us their perspectives on social identities. We also want to acknowledge the positionality of the authors. E. J. Junkins discloses that they are White, born and raised in the United States, from a middle-class background, and both parents were college graduates. They are not religious. They identify as a genderqueer woman who is queer and uses mixed pronouns (she/they). E. J. Junkins is currently a postdoctoral researcher. J. Derringer is a White-presenting, straight, cisgender woman who is Jewish by paternal ancestry and maternal conversion, uses mixed pronouns (she/they), and identifies additionally as autigender. She was born and raised in an upper-class U.S. household with two parents holding advanced degrees and is a tenured professor.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.