
Abstract
Review studies suggest that results that are statistically significant or consistent with hypotheses are preferred in the publication process and in reception. The mechanisms underlying this bias remain unclear, and prior research has focused on between-subjects rather than within-subjects designs. We conducted a within-subjects study, grounded in dual-process decision-making theories, to examine these dynamics. Across four online experiments, 303 clinical-psychology researchers evaluated 16 fictitious abstracts varying in statistical significance and hypothesis consistency. Participants provided fast, intuitive judgments about each abstract’s likelihood of being submitted, read, or cited, rated their feeling of rightness (FOR), and gave deliberated evaluations. We analyzed the data using multilevel and mediation models. Researchers rated statistically nonsignificant abstracts as less likely to be submitted, read, or cited compared with significant ones. No such bias was found for hypothesis-inconsistent results. Intuitive judgments were rarely revised, and FOR did not predict response changes. Overall, researchers favored statistically significant results, with deliberation and FOR playing minimal roles.
Keywords
Research practice in psychology is primarily empirical, often quantitative, and hypothesis-driven, involving the observation of multiple cases and the use of statistical significance to infer population characteristics from these observations: It is crucial for enabling a culture of cumulative science that results are published as fully as possible and are not withheld or discarded without being published (Scheel et al., 2021). Otherwise, biased findings, replication problems, and a waste of resources may result (Open Science Collaboration, 2015; Wieschowski et al., 2019). The nonpublication of study results because of characteristics other than study quality is referred to as “publication bias” (e.g., Dirnagl & Lauritzen, 2010; Lortie et al., 2007; Smulders, 2013).
More than 60 years ago, Sterling (1959) documented a publication bias of statistically significant findings in several psychological journals, including journals of clinical psychology. Greenwald (1975) documented the decision process leading to a publication bias and claimed that there are four choice points in the process when a bias could enter: “(a) the researcher’s formulation of a hypothesis, (b) his collection of data, (c) his evaluation of obtained results, and (d) an editor’s judgment of a manuscript reporting the research results” (p. 6).
Three more recent cohort studies also reported substantial rates of nonpublication. Fleming (2019) found that the results of 140 out of 450 clinical trials were not made available in a government registry. Likewise, of 1,509 clinical trials in Germany, 26% had not been published 6 years after completion (Wieschowski et al., 2019). Franco et al. (2014) found a strong negative association between null results and publication such that 64.6% of null results were not written up and only 20.8% were published; only 4.4% of statistically significant and hypothesis-consistent results were not written up, and 61.1% were published. Reasons given included the belief that null results would not be accepted for publication, lack of interest in nonsignificant results, or shifting focus to other projects.
Furthermore, regarding the acceptance of manuscripts for publication, little to no bias toward statistically significant results has been found on the part of editors in retrospective studies of real-life settings of manuscript-submission processes to journals (Lee et al., 2006; Okike et al., 2008; Olson et al., 2002; Timmer et al., 2002). Both Olson et al. (2002) and Lee et al. (2006) found that having statistically significant results did not improve the chance of a study being published after adjusting for other study characteristics. Okike et al. (2008) found that the only factor significantly associated with acceptance for publication was level of evidence. Timmer et al. (2002) found no statistically significant association between direction of study results and subsequent publication, although studies with nonsignificant findings were less likely to be published in high-impact journals.
Although “publication bias” refers to systematic suppression of results unrelated to study quality, we note that the mere nonpublication of null results is not necessarily evidence of bias. Reviewer decisions and researcher choices may also reflect valid concerns about study-design limitations or insufficient statistical power (Ioannidis, 2005; Smaldino & McElreath, 2016). Thus, detecting true bias requires demonstrating that publication decisions are influenced by outcome characteristics independent of quality or informativeness (Lee et al., 2006).
Experimental Studies on Publication Bias
Although many methodological and review studies have focused on identifying publication bias in published studies (Borenstein, 2019; Carter et al., 2019; Fanelli, 2011; Niemeyer et al., 2020; Scheel et al., 2021), experimental studies on publication decisions are crucial for determining the variables that affect the preference for positive results (Elson et al., 2020). However, only a few studies have experimentally investigated the influence of statistically nonsignificant and hypothesis-inconsistent results on the evaluations of researchers on the quality and publishability of studies (Atkinson et al., 1982; Augusteijn et al., 2023; Chopra et al., 2022; Elson et al., 2020; Epstein, 1990; Mahoney, 1977).
Although Mahoney (1977) and Atkinson et al. (1982) found significant preferences for positive compared with negative results in experimental manuscript studies, with reviewers and consulting editors more likely to recommend acceptance for positive results, other researchers found no statistically significant preference for positive results in relation to the rate of study acceptance (Epstein, 1990), the overall recommendation of a study in the review process (Elson et al., 2020), or several study-quality ratings (Augusteijn et al., 2023). However, all these between-subjects studies investigated the rating of only one experimentally varied stimulus (manuscript or abstract), which was pointed out as a clear limitation by Elson et al. (2020). The generalizability of the results to different stimuli may be constrained if only one experimentally varied stimulus is presented. The identified difference or absence of a difference between positive and negative results might result from an interaction between unique abstract characteristics and statistical significance or hypothesis consistency. Chopra et al.’s (2022) work stands out as an exception in this context because their study using a within-subjects design with researchers in the field of economics revealed a significant tendency to reject null results.
Nonreception
The publication of certain study results might also be considered unfavorable because researchers may expect negative consequences for subsequent citation and for their own reputation. This brings the relationship between publication bias, research quality, and the reception of published studies into focus. Results that are statistically significant or hypothesis consistent might serve a signaling function in the scientific system and generate attention such that the perception of results is tied to these characteristics. The nonpublication of null, inconclusive, or hypothesis-inconsistent results might therefore be attributable to both poorer chances of publication and lower expected reputational gains.
Questions of this kind regarding citations are discussed in metascience under the term “citation bias” (Jannot et al., 2013). Reviews in this area have yielded mixed findings. Although Callaham et al. (2002) found no effect of positive results on citation frequency, other studies have found higher citation rates for articles with statistically significant or hypothesis-consistent results (Duyx et al., 2017; Jannot et al., 2013).
To date, little attention has been paid to reception-related factors other than citations, such as reading decision, downloads, or altmetrics. 1 Tenopir and King (2002) found that electronic publishing and new search and communication tools have expanded scientists’ reading range across multiple journals. We assume that reception and/or citation bias occur in the context of a large supply of scientific literature, possibly because of time pressure and selective search strategies and reception decisions by researchers in the field. To the best of our knowledge, no experimental study has investigated the influence of statistical significance or hypothesis consistency to study citation and reading behavior in scientists.
Decision-Making Processes: Two-Response Paradigm
Experimental studies on publication bias have focused on assessing final quality judgments of manuscripts and abstracts (Atkinson et al., 1982; Augusteijn et al., 2023; Elson et al., 2020; Epstein, 1990; Mahoney, 1977), but the role of decision-making dynamics in judgments on submitting, citing, or reading an article has not been investigated by scholars in this field. Dual-process theories (DPTs) provide a theoretical framework to understand the relationship between fast, automatic judgment processes and more deliberate, analytic judgment processes (Evans, 2006; Evans & Frankish, 2009; Kahneman, 2003). To investigate when decision-making relies on fast and automatic (Type 1) or slow and deliberate (Type 2) processing, the interaction of these two processing systems has been investigated by two-response procedure experiments (Thompson et al., 2011; Thompson & Johnson, 2014). In two-response procedure experiments, participants are typically asked to provide three evaluations regarding a presented stimulus. They start with a quick and intuitive Stage 1 response that is assumed to indicate Type 1 processing (Evans, 1996; Thompson et al., 2011). This is followed by a question about the feeling of rightness (FOR) related to the Stage 1 response, which is defined as the “degree to which the first solution that comes to mind feels right” (Ackerman & Thompson, 2017, p. 608). 2 Finally, participants provide their Stage 2 response, during which they are allowed as much time as needed to reconsider their initial answer and provide a final answer, which is assumed to be indicative of Type 2 processing (Evans, 1996; Thompson & Johnson, 2014). Using this two-response paradigm, we propose to describe researchers’ decision-making concerning statistical significance and hypothesis consistency based on four assumptions.
First, we assume that negative evaluations of abstracts because of statistically nonsignificant and hypothesis-inconsistent results (negative results) are prevalent in Stage 1 responses when fast and automatic Type 1 processing takes place because this type of processing relies on heuristics, mental shortcuts, and pattern recognition (Thompson et al., 2011; Thompson & Johnson, 2014). From our point of view, negative results can be viewed as salient patterns of research abstracts and articles that give researchers the impression of reduced publication and reception success.
Second, we assume that negative results are directly associated with more positive evaluations in Stage 2 compared with Stage 1. This results from more intensive and deliberate cognitive processing in Stage 2, which allows adjustment of initially biased decisions (Thompson et al., 2011; Thompson & Johnson, 2014). During deliberate thinking, researchers might be more aware of heuristics such as the negative-results bias in scientific decision-making and thus might reevaluate their initial negative responses.
Third, we propose that negative results are linked to lower FOR judgments after the intuitive processing. This assumption is derived from experimental observations: (a) FOR after Type 1 processing indicates the need for additional analysis (Type 2 processes; Thompson et al., 2011; Thompson & Johnson, 2014), and (b) lower FOR judgments are more likely to be triggered by conflict stimuli, which induce cognitive conflict in decision-making compared with nonconflict stimuli (Thompson & Johnson, 2014, p. 226). In our perspective, negative results can be regarded as conflict stimuli, potentially evoking conflicting cognitions in researchers. Two relevant conflicting cognitions for negative results might compete: an immediate, intuitive cognition (Type 1) that posits “it is challenging to publish null results” versus a more reflective, analytical cognition (Type 2) suggesting that based on ongoing discussions in the scientific community, “null results are equally worthy of publication.” We assume that this conflict is also relevant for reading and citing.
Fourth, we propose that lower FOR is associated with more positive evaluations in Stage 2 compared with Stage 1. This hypothesis is grounded in empirical observations in DPT experiments, that lower FOR is associated with higher response changes between Stage 1 and Stage 2 (Wang & Thompson, 2019, p. 37).
Furthermore, FOR and response changes might additionally be influenced by other factors, such as (a) the extent of knowledge about the detrimental consequences of publication bias for research quality, (b) the subjective pressure to publish, (c) or academic professional status. Researchers that are aware of the relevance of publication bias in their own research routine are expected to experience a lower FOR when rejecting nonsignificant results. Conversely, researchers who feel (more) pressured in the scientific systems to publish might avoid significant (and hypothesis-conforming) results to ensure that their results are published, resulting in higher FOR ratings and lower response changes. Furthermore, the general level of FOR and response changes might differ based on academic professional status.
Present Study
In the present study, we aimed to identify decision-making processes behind selective nonpublication and nonreception. Four online experiments were conducted in which fictitious abstracts were presented in a within-subjects design with statistical significance and hypothesis consistency as experimental treatment variables. Our nested within-subjects linear mixed-model design enabled us to isolate the effect of the treatment variables, statistical significance and hypothesis consistency, by estimating the between-abstracts heterogeneity. Furthermore, we investigated decision-making processes using the two-response procedure based on DPT (Kahneman, 2003; Thompson et al., 2011). Specifically, we examined intuitive (Type 1 processing) and considered evaluations (Type 2 processing) of research abstracts and the accompanying FOR of intuitive evaluations as functions of the experimental variation of statistical significance and hypothesis consistency. In summary, our study design addresses three gaps in the current literature: (a) experimental within-subjects design studies on publication bias in psychology, (b) experimental research on nonreception, and (c) role of decision-making processes in nonreception and nonpublication.
We assume that the decision-making processes that contribute to publication bias are likely relevant for all empirically oriented disciplines, but we focus on clinical psychology for two reasons: first, to have a rather homogeneous sample with respect to familiarity with the stimulus material (abstracts) and second, clinical psychology exerts a strong impact on the health-care system and society, including in terms of costs (Doran & Kinchin, 2017; Gabbard et al., 1997; Knapp & Wong, 2020; McDaid et al., 2019). Clinical decision-making and clinical practice should be evidence-based (Shapiro, 2002) and inform therapeutic work, and only efficacious treatments should be used and invested in (Niemeyer et al., 2012). For this purpose, it is also necessary to publish statistically nonsignificant findings and findings that do not confirm hypotheses. The replication crisis identified more than a decade ago has led to a high sensitivity to this issue in social and personality psychology, but further reform is necessary in the field of clinical psychology (Tackett et al., 2019).
Hypotheses
For each combination of the response—evaluations regarding (a) publishability, (b) citation, and (c) reading of research articles based on research abstracts—and the treatment variable, either (a) statistical significance or (b) hypothesis consistency, we tested the three hypotheses HX.1, HX.2.1, and HX.2.2, resulting in a total of 3 × 2 × 3 = 18 hypotheses. HX.1 was examined using a multilevel model (MLM) and investigated intuitive responses regarding the likelihood of submitting to publish, citing, or reading (LoSRC) an abstract. However, HX.2.1 and HX.2.2 were analyzed using a multilevel mediation model (MLMM) and examined changes in the likelihood of submitting to publish, citing, or reading (C-LoSRC) an abstract, which are defined as the difference between considered responses in Stage 2 and the intuitive responses in Stage 1. The hypothesized relationships between the variables are shown in Figure 1.

Hypothesized relationships between variables for (left) HX.1 and (right) HX.2. HX.1. Effect (β1) from treatment on intuitive responses. Researchers are more likely to give a negative evaluation of an abstract (report a lower LoSRC) if the abstract is statistically nonsignificant or inconsistent with the hypothesis (meaning the experimental treatment has the value 1). HX.2.1. Average direct effect (c’) from treatment on response change from Stage 1 to Stage 2. Researchers are more likely to give a more positive considered evaluation than the initial intuitive evaluation in submitting to publish, citing, or reading (report a higher C-LoSRC) if the abstract is statistically nonsignificant or inconsistent with the hypothesis (meaning the experimental treatment has the value 1). HX.2.2. Average causal mediation effect (a and b) from treatment on response change from Stage 1 to Stage 2 via FOR. Researchers are more likely to give a more positive considered evaluation than the initial intuitive evaluation in submitting to publish, citing, or reading (report a higher C-LoSRC) if the FOR of the initial evaluation was low, which itself will be more likely if the abstract is statistically nonsignificant or inconsistent with the hypothesis (meaning the experimental treatment has the value 1). LoSRC ij = intuitive response regarding the likelihood of submitting to publish, citing, or reading abstract i for individual j in Stage 1; C-LoSRC ij = response change regarding the likelihood of submitting to publish, citing, or reading abstract i for individual j between Stage 2 and Stage 1; FOR ij = feeling of rightness regarding individual j’s LoSRC response with respect to abstract i.
Open Practices
This study represents a Registered Report, and the predata-collection manuscript received in-principle acceptance at Advances in Methods and Practices in Psychological Science on September 21, 2023. The Registered Report Protocol was preregistered on OSF (https://osf.io/6tpm7). An anonymized data set, scripts, and materials have been made publicly available on OSF (https://osf.io/pzver/files/osfstorage). Changes to the preregistered analyses are described in the text. The scripts were prepared so that the data will be directly loaded from the OSF repository link (link: https://osf.io/pzver/files/osfstorage) without downloading the data manually to improve reproducibility. All main hypotheses are fully reproducible using the anonymized data set. However, the data underlying the exploratory analyses cannot be shared because of the inclusion of sensitive personal information (e.g., age, gender, country of affiliation).
Ethical Approval
The study protocol, materials, and methods were approved by the ethics committee of the Freie Universität Berlin.
Method
Procedure
The experiments were programmed in jsPsych (De Leeuw, 2015) and ran on the platform Pavlovia.org. The experimental procedure for all four experiments is depicted in Figure 2. During the experiments, the participants were initially given an introduction to read, which was already announced in the email invitation. In the introduction, they were told that we were interested in exploring how research abstracts are read and assessed in the context of routine procedures for literature review and preparing own publications in clinical-psychological research practice (see Appendix G in the Supplemental Material available online). Moreover, the researchers were told that we were interested in their spontaneous gut judgments and that it was therefore important to answer as quickly and honestly as possible.
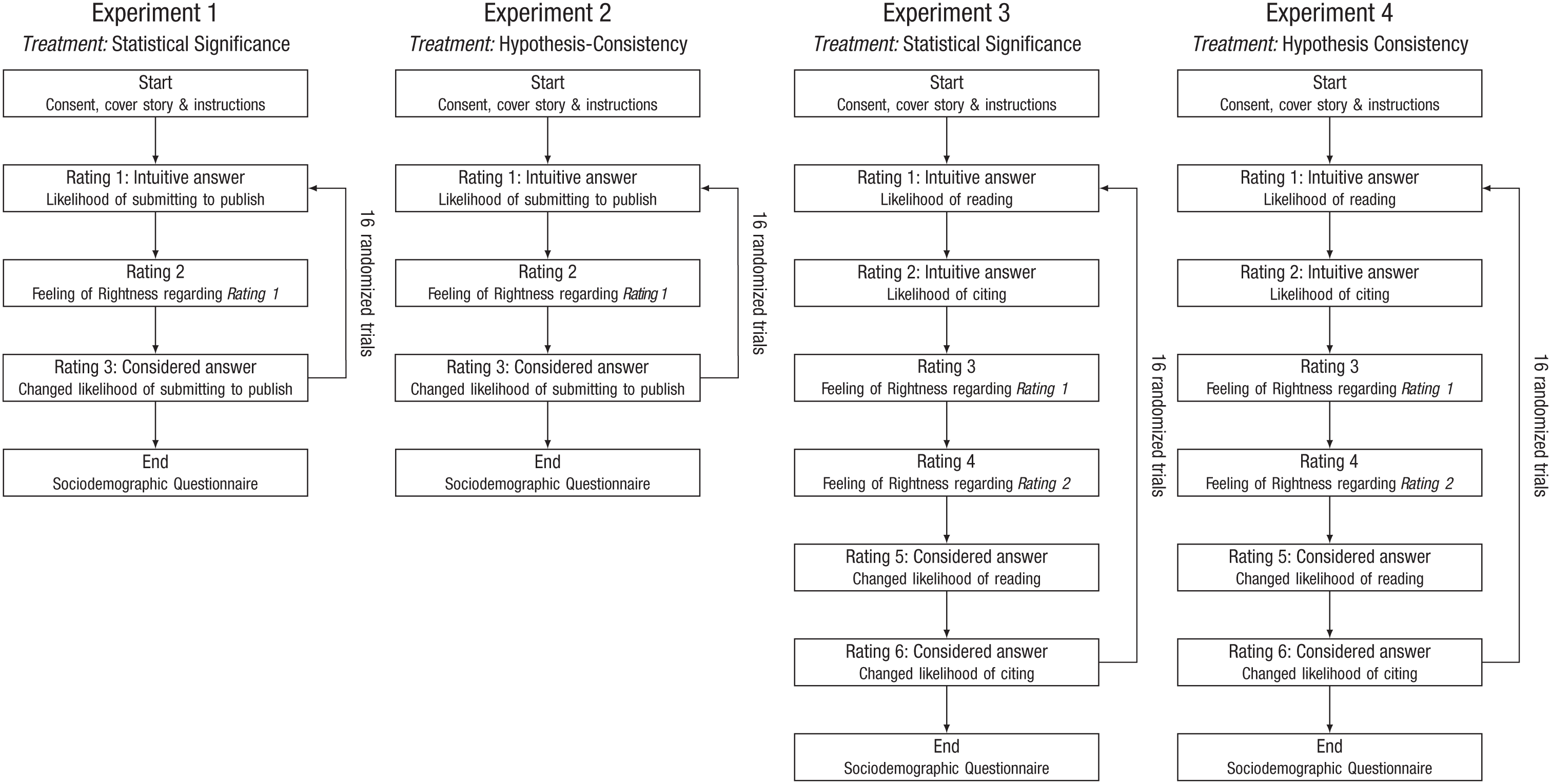
Experimental procedure.
The participants were then presented with the fictitious abstracts. Out of a total of 32 abstracts per experiment (16 pairs of abstracts), each participant was presented with 16 different abstracts, with only one example presented per pair. Within pairs, either only statistical significance (Experiments 1 and 3) or only hypothesis consistency (Experiments 2 and 4) was systematically varied. Otherwise, both abstracts in each pair were identical. The selection of abstracts to be presented was randomized and balanced. In Experiments 1 and 2, participants’ decisions in terms of publishability were assessed. Participants in Experiments 3 and 4 decided how likely it was that they would first, read and second, cite the entire article based on the respective abstracts.
We adapted the two-response procedure as follows. Participants were instructed to provide an initial, intuitive response to the problem. This first response was to be given quickly, intuitively, and with a minimum of thought. This was done to maximize the probability that participants provided the first answer that came to mind. This was followed by an assessment of FOR. In the second stage, the participants were allowed as much time as needed to reconsider their initial answer and provide a final answer. After rating 16 abstracts, they were asked to provide further sociodemographic and professional information. The reaction time in Stage 1 and the change in the decision in Stage 2 were recorded. Sensitivity analyses with respect to short reaction times in Stage 2 were conducted. The design of the four experiments was identical except for the instructions, stimulus material, and questions. Participation in the study took approximately 20 min per experiment. Participants were randomly invited to participate in only one experiment.
Sample-recruitment process
We conducted a power analysis (Westfall et al., 2014; for the code and details, see Appendix E in the Supplemental Material) with an expected effect size of d = 0.55 for the main question (Chopra et al., 2022) using a sample of 75 participants and 16 stimuli per experiment, resulting in an estimated power of .836. Online studies on publication bias with researchers have typically experienced very low response rates, ranging from 3.5% (Chopra et al., 2022) to 5.9% (Augusteijn et al., 2023). To address the challenge of low response rates, we employed a double-tracked sample-recruitment process.
First, we used a preexisting list of German clinical psychologists created for an ongoing metareview on publication bias. The foundation of this researcher list was a compilation of state university departments or laboratories (N = 91) focused on research in clinical psychology, psychotherapy, or related fields in Germany. Laboratories in hospitals were excluded from this list. The inclusion spanned from predoctoral levels to professors. We omitted universities in Berlin and Brandenburg from this approach because we had already invited researchers from these regions to participate in an additional ongoing interview study. We gathered email addresses and the size of the population pool from the respective department websites, which resulted in a total of 1,006 researchers in Germany.
Second, to obtain our targeted sample size, we extended our recruitment to include researchers beyond the initial countries. We had originally preregistered to obtain researcher contact information via PubMed from the United States, United Kingdom, Canada, Germany, Australia, and the Netherlands—countries assumed to contribute the most publications and citations in the field of psychology (Garcia Martinez et al., 2012; O’Gorman et al., 2012). However, focusing only on researchers from these countries did not yield the targeted recruitment goal of 300. Therefore, we expanded our recruitment strategy beyond the preregistered scope. This extension involved scraping additional researcher contact information from publicly available PubMed and Web of Science records, targeting a broader international pool of clinical-psychology researchers. For full details on the updated recruitment procedures, see Appendix H in the Supplemental Material. A similar mail-scraping approach using Web of Science was also recently used by another study on publication bias in psychology researchers (Augusteijn et al., 2023).
Between December 2023 and December 2024, we sent emails to all the gathered researchers from Approach 1 (n = 1,006), followed by emails to all researchers from Approach 2 (n = 32,918). After 2 to 4 weeks, we sent a reminder to the researchers to participate in our study. Overall, a total of 33,924 researchers were contacted. For 2,218 of them, we received a bounce notification indicating that the email could not be delivered, leaving us with 31,706 contacted researchers. Of these, 1,545 started the experiment (a response rate of 4.9%). However, 1,242 participants did not complete it. One likely reason for the high dropout rate is the comparatively high workload given that participants were asked to read and evaluate 16 abstracts—considerably more than in similar studies (Augusteijn et al., 2023; Chopra et al., 2022). Thus, data from 303 participants who completed the study were included in the analyses, resulting in a completion rate of 1.0%.
Pilot study
In a pilot phase, we tested whether the experiments ran smoothly and evaluated the perceived realism of the abstracts. For this purpose, from our own clinical-psychology department, we invited 10 participants for each experiment to take part in the pilot phase. Five subjects participated fully in Experiment 1, and two subjects participated in Experiments 2 through 4, respectively. Based on the results of the pilot study, 10 abstracts had to be changed slightly in wording (see below).
Inclusion
The participants for the main study were currently employed at a university in a department of clinical psychology or psychotherapy, or in a comparable research group (also possible: doctoral scholarship holders active in research). Because the abstracts were presented in English, participants had to be able to understand academic English and feel comfortable with reading English abstracts.
Exclusion
We ran a plausibility check of the response times of the participants and excluded all responses connected to initial abstract reading time below 2 s.
Reimbursement
Participants did not receive reimbursement for taking part in the study.
Debriefing
Information about the aim of the study was provided after the entire data collection was completed to prevent socially desirable responding.
Data security
All personal data are handled and stored in line with the requirements of the General Data Protection Regulation. The storage and backup of the research data was ensured during the project by the project leaders in cooperation with the responsible data-processing officer of the computer-media service of the university. For this purpose, the infrastructure of Freie Universität was used.
Materials
For each of the experiments, 16 case pairs of short abstracts were generated. Each pair consists of two abstracts that are identical with the exception of the statistical significance or hypothesis consistency of the results. The number of presented abstracts for the underlying counterbalanced design was determined using an a priori power analysis (Westfall et al., 2014). Stimuli were quasirandomly presented to the participants (eight statistically nonsignificant and eight statistically significant abstracts or eight hypothesis-consistent and eight hypothesis-inconsistent abstracts).
To generate the abstracts, we first developed a table to create abstract titles containing different relevant aspects of clinical-psychology research (population of interest, diagnosis, clinical intervention, intervention context or group comparison, outcome measure, mediating or moderating factors). This resulted in the creation of 60 fictitious research article titles (e.g., “Quality of Life Effects of Behavioral Activation in Teletherapy for Patients With Social Anxiety”) in a first step.
Next, with the help of wordblot.ai, an artificial-intelligence-powered writing assistant, we used the 32 titles to generate 32 prototypical abstracts, which we fundamentally adapted based on the criteria of realism, readability, and structure (background, method, results, conclusion). Subsequently, a native English speaker proofread the abstracts according to readability and English language. In our pilot study, we also asked colleagues to proofread and rate the abstracts according to realism (0% = very unrealistic, 100% = very realistic), resulting with a range of 10% to 99% and an average of 67.8%. With this in mind and on the basis of specific comments our colleagues made, we changed some wording in 10 abstracts.
In the background section of the abstracts, we used phrases such as “It was hypothesized”/“We hypothesized that” for Experiments 2 and 4 or phrases such as “We investigated whether” for Experiments 1 or 3. Although the method section remained the same for all variations, the results section differed for Experiments 2 and 4, with phrases such as “Our results confirm” or “Our hypotheses . . . could not be confirmed,” and for Experiments 1 or 3, with phrases such as “significantly predicted” or “did not significantly predict”/ “were non-significant.” Finally, the conclusion section was adjusted according to the results (e.g., “Our results might suggest that comparable to anxiety disorders, treatment success in OCD [obsessive compulsive disorder] might depend on an individual’s level of conscientiousness” or “Our results might suggest that there is no relevant relation between treatment success and an individual’s level of conscientiousness in patients with OCD”; see example in Appendix A in the Supplemental Material). To resemble real abstracts as closely as possible and to make it more difficult for participants to merely skim the abstracts, we did not include any subheadings for each section. The abstracts varying in statistical significance and the abstracts varying in hypothesis consistency have a mean length of 155.2 (SD = 29.4) words and 178.8 (SD = 26.6) words, respectively.
To ensure that participants would view the described studies as credible and adequately powered, we conducted an a priori power analysis for the sample sizes used in our vignette abstracts. This power analysis indicated that a sample size of 84 is sufficient to detect a medium-sized correlation (r = .30) with 80% power (α = .05). We used this as a minimum threshold and reported sample sizes in the abstracts ranging from 89 to 183. However, the majority of sample sizes reported in the 32 abstracts presented to participants were substantially larger than the minimum of N = 84 (M = 149.2, SD = 19.9). In the instructions, participants were explicitly told to assume that all studies had sufficient statistical power for the stated research question.
The stimulus set of 64 abstracts was published after completion of the study for future replication studies. The links to the stimuli are as follows: abstracts in which statistical significance was manipulated: https://osf.io/download/686fb93435565f99383eef68/; abstracts in which hypothesis consistency was manipulated: https://osf.io/download/686fb9353a2fb68174f6d6f0/. In Appendix A in the Supplemental Material, we provide tables for all abstracts including titles and sample sizes.
Measures
For each abstract, we measured the amount of time taken to read the abstract, the response time to generate the first response (answer fluency); the likelihood of submitting to publish/reading/citing (range = 0%–100%); the FOR rating (range = 1–7; “When I gave the answer, I felt . . .” very uncertain to very certain); the second, considered response regarding the likelihood of submitting to publish/reading/citing (range = 0%–100%); and the difference between the two likelihood responses (for experimental procedures, see Fig. 2). Response times for all experiments were converted to log10 before analysis (response times in the tables are reported in the original units). However, reaction time represents a control variable only for intuitive decision-making in our design.
After rating 16 abstracts, the participants provided information regarding their sociodemographic and professional characteristics. The questions included their age, their gender, the country to which their respective research organization is affiliated, their position at the research organization, their psychotherapeutic practice, their reviewer history (number of peer reviews), their authorship experience (number of articles as first and last author), their familiarity with open science and publication bias (each rated as 1 = not at all familiar, 5 = very familiar), how pressured they feel to publish their research (1 = not at all pressured, 5 = very pressured), their work in other areas of psychology (several options provided, e.g., social psychology, biological psychology), and the number of their own published articles that contained statistically nonsignificant results and hypothesis-inconsistent results. Finally, the researchers were presented with six items from the short forms of the Big Five Inventory–2 (BFI-2-S) Conscientiousness subscale (Soto & John, 2017).
Implementation period
The study was conducted in the second half of 2023. Data collection began in December 2023 and was completed in January 2024. Data analysis was conducted in January 2024.
Statistical analysis
HX.1 hypotheses are investigated using MLMs, and HX.2.1 and HX.2.2 hypotheses are examined using MLMMs. In all models, positive results, statistically significant or hypothesis-consistent results, are coded as 0 (control), and negative results, statistically nonsignificant or hypothesis-inconsistent results, are coded as 1 (treatment).
HX.1: MLMs
In our MLMs, we assumed that data points are nested within both participants and abstracts. We therefore proposed that the reported likelihood of submitting to publish (LoS), reading (LoR), or citing (LoC) an abstract is influenced by both participant and abstract characteristics. However, the experimental data structure is not perfectly hierarchical because in each experiment, we presented the same 16 abstracts to the participants with the exception of the manipulation of statistical significance or hypothesis consistency in the results and discussion sections of the abstracts. Thus, we obtained a cross-classified data structure with a counterbalanced design, which can be adequately modeled with cross-classified multilevel modeling (Hox, 2002). To explore the association between statistical significance and LoS (H1.1), LoR (H3A.1), and LoC (H3B.1) and the association between hypothesis consistency and LoS (H2.1), LoR (H4A.1), and LoC (H4B.1), we specified the following X.1 general model using the lme4 (Bates et al., 2014) and lmerTest (Kuznetsova et al., 2017) packages for linear mixed models with restricted maximum likelihood estimation: LoSRC ~ treatment + (treatment|participant ) + (1|abstract).
Our models conceptually subdivide the variation of LoSRC of participant j reading abstract i into random and fixed effects. The term “(treatment | participant)” indicates (a) a random slope for participants on the treatment variable and (b) a random intercept on the participant level, and (c) the term “(1 | abstract)” represents a random intercept on the abstract level. The term “treatment” captures the fixed regression effect for the manipulation of statistical significance or hypothesis consistency.
HX.2.1 and HX.2.2: MLMMs
For our MLMMs, we dropped the random intercept for abstracts because causal multilevel mediation using the mediation package (Tingley et al., 2014) is supported for only two levels and cross-classified approaches are technically processed as three-level frameworks. Thus, we supposed that the changes in LoS (C-Los) from Stage 1 to Stage 2 (C-LoS = LoSt1 – LoSt0), the changes in the LoR (C-LoR) from Stage 1 to Stage 2 (C-LoR = LoRt1 – LoRt0), and the changes in LoC (C-LoC) from Stage 1 to Stage 2 (C-LoC = LoRt1 – LoRt0) are influenced (a) directly by the treatment as suggested by HX.2.1 and (b) indirectly by the treatment via FOR as suggested by HX.2.2. In addition, we assume that (c) the intercept of C-LoSRC differs between participants and (d) that the effects proposed in (a) and (b) above differ between subjects in the form of random slopes. Specifically, we explore the association between statistical significance and C-LoS (H1.2), C-LoR (H3A.2), and C-LoC (H3B.2) and the association between hypothesis consistency and LoS (H2.2), C-LoR (H4A.2), and C-LoC (H4B.2). We specify the following X.2 basic models for all MLMMs: path_a = FOR ~ treatment + (treatment | subject) path_b_c = C-LoSRC ~ FOR + treatment + (treatment | subject) mediate(path_a, path_b_c, treat = “treatment,” mediator = “FOR”).
The mediation package reports estimated 95% confidence intervals and p values for essential mediation indices: average causal mediation effect, average direct effect, total effect, and proportion mediated.
Further model specifications
The α level was set at .05. Normality of residuals as a function of model and level and homogeneity of variance in all models was examined for all MLMs (Finch et al., 2019). Standardized beta coefficients were used as effect-size measures for regression coefficients (Lorah, 2018) and interpreted as small (β ≤ 0.3), medium (0.3 ≤ β ≤ 0.5), and large (β ≤ 0.5). Because MLMs and MLMMs sometimes result in uninterpretable results because of lack of model convergence (Demian, 2019), we first dropped random slopes on the subject level, and if models still failed to converge, we decided to report a 2 × 16 repeated-measures analysis of variance for MLM or a mediation model without level specification for MLMMs. For the R Code, assumption testing, and the further model results, see Appendices B through D in the Supplemental Material.
Exploratory analyses
We tested the influence of six categories of variables in exploratory analyses and applied Bonferroni corrections to all linear mixed models to control for the increased risk of Type I errors because of multiple comparisons. For an overview of all exploratory analyses, see Table 1.
Overview on Exploratory Analyses

Note: MLM = multilevel model; MLMM = multilevel mediation model; GM = grand mean centering; NC = no centering.
First, we examined the influence of familiarity with publication bias on LoSRC, FOR, and C-LoSRC. Therefore, we included responses on an item on familiarity (familiarity_PB) with publication bias as a quasimetric additive and interaction term (familiarity_PB × treatment) with treatment into the MLM and MLMM.
Second, we analyzed the influence of pressure to publish on LoSRC, FOR, and C-LoSRC. In addition, the pressure to publish variable (pub_pressure) was introduced as a quasimetric additive and interaction term with treatment (pub_pressure × treatment) to the MLM and MLMM.
Third, we investigated the influence of professional-status group on LoSRC in the MLM. We separated the categorical variable professional-status group (levels: predoctoral level, postdoctoral level, professor level) into two dichotomous predictors: postdoc and professor. Hence, predoctoral level served as the reference category. We included additive terms for both status-group predictors and the treatment into the MLM and MLMM.
Fourth, we investigated for both the MLM and MLMM whether fatigue influences the decisions of researchers because both motivation and concentration are likely to vary between the beginning, the middle, and the end of evaluating 16 research abstracts. Therefore, we incorporated a position variable (numeric; value range = 1–16; indexes when which abstract was presented) as an additive term into the MLM and MLMM.
Fifth, we investigated whether the researcher’s tendency to rate an abstract again after giving a first response is driven by conscientiousness rather than the treatment or FOR. Individuals scoring high on conscientiousness might exhibit a heightened likelihood of altering their initial responses. This propensity could potentially arise from conscientious individuals’ inclination to feel a stronger sense of obligation in modifying their responses when prompted by instructions to reconsider the problem and provide a secondary response. Therefore, we introduced the BFI-2-S Conscientiousness subscale as a covariate (conscientiousness) to the MLMM.
Sixth, we analyzed differences between researchers from different countries. We introduced additive regression terms for researchers from the Netherlands (ned), United Kingdom (uk), Canada (can), United States (us), Australia (aus), and other countries (other) into the MLM and MLMM. Researchers from Germany represent the reference category. Controlling for country had not only the intention to control for national differences but also the intention to take potential confounders of the two different recruitment processes into account.
Incorporating these exploratory analyses into the models resulted in the following lme4 and mediation specifications:
Models X.1.C: exploratory specification for Stage 1 MLMs: LoSRC ~ treatment × familiarity_PB + treatment × pub_pressure + postdoc + professor + trial_position + nd + uk + us + can + aus + other + (treatment | subject) + (1 |abstract)
Models X.2.C: exploratory specification for Stage 2 MLMMs : path_a = FOR ~ treatment × familiarity_PB + treatment × pub_pressure + (treatment | subject) path_b_c = CLoSRC ~ treatment × familiarity_PB + treatment × pub_pressure + FOR + conscientiousness + trial_position + postdoc + professor + nd + uk + us + can + aus + other + (treatment | subject) mediate(path_a, path_b_c, treat = “treatment,” mediator = “FOR”).
Results
Descriptive statistics
We invited 33,924 participants to the study. In Pavlovia, only data of fully completed responses were saved as data sets. We preregistered collecting data from 75 participants per experiment. However, because of the timing of participant enrollment on Pavlovia, more participants completed the study before we were able to close it. As a result, the final sample sizes were n = 76 in Experiment 1, n = 77 in Experiment 2, and n = 75 in Experiments 3 and 4 each. We included all participants who completed the study. However, this oversampling might result in slightly larger sample sizes for Experiments 1 and 2. Therefore, we report model sensitivity analyses for the oversampling in Appendix I in the Supplemental Material.
Across all experiments, 176 (58%) participants identified as female, 122 (40%) identified as male, and 5 (2%) identified as diverse. Eight (3%) were ages between 18 and 25, 110 (36%) were ages between 26 and 35, 101 (33%) were ages between 36 and 45, 48 (16%) were ages between 46 and 55, and 36 (12%) were over 55. Eighty-two (27%) were on the predoctoral level, 89 (29%) were on the postdoctoral level, and 132 (44%) were professors. Most researchers came from Europe (n = 171, 56.4%), followed by North America (n = 68, 22.4%), Asia (n = 31, 10.2%), Oceania (n = 17, 5.6%), Africa (n = 8, 2.6%), and South and Central America (n = 7, 2.3%). The 15 most frequently represented countries were the United States (n = 54, 17.8%), Germany (n = 50, 16.5%), the Netherlands (n = 20, 6.6%), the United Kingdom (n = 19, 6.3%), Spain (n = 16, 5.3%), Australia (n = 16, 5.3%), Canada (n = 14, 4.6%), Italy (n = 10, 3.3%), China (n = 9, 3.0%), India (n = 8, 2.6%), Norway (n = 8, 2.6%), Switzerland (n = 7, 2.3%), Japan (n = 6, 2%), France (n = 5, 1.7%), and Turkey (n = 5, 1.7%). All other countries were mentioned fewer than five times.
Results for Stage 1
Across all abstracts, the mean LoS was 52.60% (SD = 26.03%, range = 0%–100%), the mean LoR was 49.46% (SD = 26.59%, range = 0%–100%), and the mean LoC was 40.40% (SD = 27.36%, range = 0%–100%). Table 2 shows the LoSRC separately for significant and nonsignificant and hypothesis-consistent and -nonconsistent results.
Descriptive Statistics for the Likelihood of Submitting for Publication, Reading, and Citing Significant and Nonsignificant and Hypothesis-Consistent and -Nonconsistent Results

The results for the Stage 1 MLMs are presented in Table 3. For further results for Stage 1 MLMs, see Appendix D in the Supplemental Material. Graphical examination of residual plots (Appendix C in the Supplemental Material) revealed that the assumption of normality of residuals for the random-slope models is met for all models.
Model Parameters for All Stage 1 Main Models

Note: Sig. = statistical significance; HC = hypothesis consistency; none = random slope dropped because of singularity; Est. = Estimate.
p ≤ .001.
Statistical significance had a consistent but small effect on participants’ evaluations. In Experiment 1, abstracts with nonsignificant results were rated as less publishable (LoS), with a significant negative effect (b = −6.49, p < .001; β = −0.12). Likewise, in Experiment 3, nonsignificant results reduced LoR (b = −7.14, p < .001; β = −0.13) and LoC (b = −6.32, p < .001; β = −0.12) the abstracts.
In contrast, hypothesis consistency showed no significant effects across experiments. It did not predict perceived publishability in Experiment 2 (b = −1.21, p = .303; β = −0.02), nor did it influence reading (Experiment 4A: b = −1.29, p = .281; β = −0.03) or citation likelihood (Experiment 4B: b = −1.44, p = .222; β = −0.03).
Results for Stage 2 and FOR
The mean response changes were −0.76 (SD = 10.95, range = −80 to 100) for LoS, −0.30 (SD = 8.94, range = −58 to 89) for LoR, and −0.43 (SD = 8.91, range = −70 to 71) for LoC. Mean FOR judgments for initial LoS were 5.08 (SD = 1.17, range = 1–7 ), mean FOR judgments for LoR were 5.31 (SD = 1.09, range = 1–7), and mean FOR judgments for LoC were 5.11 (SD = 1.22, range = 1–7).
The results for the Stage 2 MLMs are presented in Table 4. In Experiment 1, the effect of statistical significance on C-LoS was significantly mediated by FOR despite a nonsignificant direct effect (direct path: b = 0.02, p = .784; mediated path: b = −0.16, p = .006). As expected, nonsignificant abstracts lowered FOR (b = −0.16, p = .006), but unexpectedly, higher FOR predicted increased C-LoS (b = 1.03, p < .001). However, across all other models, no other significant mediation effects emerged (mediated paths: Model 2.2: b = 0.03, p = .470; Model 3A.2: b = 0.01, p = .684; Model 3B.2: b = 0.00, p = .844; Model 4A.2: b = 0.02, p = .468; Model 4B.2: b = −0.02, p = .590).
Model Parameters for All Response-Change Random-Slope Models

Note: ACME = average causal mediation effect; N-Sig. = statistically nonsignificant abstract; FOR = feeling of rightness; RC = response change; ADE = average direct effect; H-Inc. = hypothesis-inconsistent abstract; CI = confidence interval.
p ≤ 0.05. **p ≤ 0.01. ***p ≤ .001.
In Experiment 2, hypothesis inconsistency was significantly associated with FOR (b = −0.11, p = .027) but not C-LoS (direct path: b = −0.39, p = .494; mediated path: b = 0.03, p = .470; FOR → C-LoS: b = −0.22, p = .473). For reception-related outcomes (reading and citation likelihood), neither statistical significance (Experiments 3A and 3B) nor hypothesis consistency (Experiments 4A and 4B) showed meaningful mediation effects. One exception was a direct effect of hypothesis inconsistency on changes in reading ratings (C-LoR) in Experiment 4A (b = 1.44, p = .008), although this was not mediated by FOR (b = 0.01, p = .468). All other direct and mediated paths were nonsignificant (all ps > .05).
Exploratory analyses
In our exploratory analyses (summarized in Table 1), we investigated the influence of six variable categories on LoSRC, FOR, and C-LoSRC. Consistent with our main models for Stage 1, we found significant effects for statistical significance in the exploratory Stage 1 models for Experiment 1 (b = −6.69, p = .005), Experiment 3A (b = −7.13, p < .001), and Experiment 3B (b = −6.32, p < .001), even after correcting for multiple comparisons using the Bonferroni method. In contrast, hypothesis consistency showed nonsignificant effects in the Bonferroni-corrected exploratory models for Experiment 2 (b = −1.12, p = 1.00), Experiment 4A (b = −1.14, p = 1.00), and Experiment 4B (b = −1.23, p = 1.00). In line with our main models for Stage 2, we found a significant mediated effect of statistical significance on decision changes via FOR in Experiment 1 (b = −0.17, p = .006) and a significant direct path from hypothesis consistency to decision changes in Experiment 4A (b = 1.51, p = .004); all other mediation effects were nonsignificant. Even after including several covariates, the overall pattern of treatment effects remained constant across all Stage 1 models and Stage 2 models.
After applying Bonferroni correction for multiple testing, no additional exploratory variables (e.g., familiarity with publication bias, pressure to publish, professional status, conscientiousness, stimulus position, or country) showed consistent or significant effects across experiments in either Stage 1 or Stage 2 models (for details, see Appendix D in the Supplemental Material).
Sensitivity analyses
Sensitivity Analyses 1
Because we slightly oversampled Experiment 1 (n = 76) and Experiment 2 (n = 77), we reanalyzed all model results for these experiments using only the first 75 participants, in line with our original target sample (for details, see Appendix I in the Supplemental Material). The pattern of results was consistent with the main analyses. The key findings regarding the effect of statistical significance remained robust in both the direct and mediation models, and effects were in the same direction. Effects of hypothesis consistency remained nonsignificant, mirroring the original findings.
Sensitivity Analyses 2
Because our preregistered recruitment procedure did not result in sufficient sample sizes and we made changes to our recruitment strategy to reach the preregistered sample sizes, we report sensitivity analyses representing our preregistered approach of including only researchers who report being from Australia, Canada, Germany, Netherlands, the United Kingdom, and the United States (for details, see Appendix J in the Supplemental Material). Overall, the pattern of results was consistent with the main analyses. The core findings for statistical significance remained robust across outcomes, and effects stayed significant and in the same direction. Effects of hypothesis consistency were mostly nonsignificant in both the main and sensitivity samples, and mediation models largely replicated the original patterns, with only minor deviations.
Discussion
The results of the present study shed light on the decision-making processes that contribute to selective nonpublication and nonreception. By fitting several within-subjects models with significance and hypothesis consistency as experimental treatment variables, we were able to isolate the effects of these factors using a nested linear mixed-model approach. Our study also used a two-response decision-making procedure based on DPT to investigate the role of fast, automatic responses in Stage 1 versus analytical decision-making processes in Stage 2 and the relevance of FOR within a mediation framework.
Stage 1
Publishability
Previous reviews and meta-analyses have illustrated that significant findings and hypothesis-consistent studies are more likely to be submitted for publication than nonsignificant findings (Fanelli, 2011; Scheel et al., 2021), but evidence from experimental studies on publication bias is mixed (Atkinson et al., 1982; Augusteijn et al., 2023; Elson et al., 2020; Epstein, 1990; Mahoney, 1977). However, only a few studies have experimentally investigated the influence of nonsignificant and hypothesis-inconsistent results on the evaluations of researchers on the quality and publishability of studies (Atkinson et al., 1982; Augusteijn et al., 2023; Elson et al., 2020; Epstein, 1990; Mahoney, 1977). Because studies in this field have exclusively deployed between-subjects findings, this mixed finding might result from the influence of single abstract characteristics presented in these studies.
Hypothesis 1.1
First, we investigated whether the intuitive, fast choice for publication depended on statistical significance (Hypothesis 1.1). As predicted, statistically nonsignificant findings were less likely chosen to be submitted for publication than significant findings.
Hypothesis 2.1
Second, we investigated the same for hypothesis consistency (Hypothesis 2.1). Inconsistently with our initial hypothesis, hypothesis-inconsistent findings were not less likely chosen to be submitted for publication than hypothesis-consistent findings.
Reception and citation
Results regarding citation bias have been mixed, and other reception-related factors, such as reading decision, have not yet been investigated. Although Callaham et al. (2002) found no bias in citation frequency, other studies found higher citation rates for articles with significant or hypothesis-consistent results (Duyx et al. 2017; Jannot et al. 2013). However, no experimental study has investigated reception or citation of nonsignificant or hypothesis-inconsistent findings.
Thus, we investigated whether immediate preferences for reading and citing also depend on significance or hypothesis consistency (Hypotheses 3A.1–Hypotheses 4B.1).
Hypothesis 3A.1
In line with our hypothesis, statistically nonsignificant findings were less likely chosen to be read than significant findings.
Hypothesis 3B.1
As predicted, statistically nonsignificant findings were less likely chosen to be cited than significant findings.
Hypothesis 4A.1
Contrary to our hypothesis, our results indicate that there is no effect of hypothesis consistency in the decision of a researcher to read an article.
Hypothesis 4B.1
Inconsistent with our initial hypotheses, our results indicate that there is no effect of hypothesis consistency in the decision of a researcher to cite an article.
Stage 2 and FOR
Studies on publication bias have not investigated the dynamics in decision-making process related to submitting, citing, or reading an article. By applying an MLMM in our experimental design, we aimed to explore the relationship between fast, automatic judgment processes and more deliberate, analytic judgment processes and FOR judgments as suggested by DPT.
Overall, we found little evidence that deliberation systematically altered the initial reliance on statistical significance or hypothesis consistency. The majority of the models showed no clear pattern of response changes associated with the experimental manipulations. However, two exceptions emerged. First, researchers were more likely to reconsider and positively revise their reading decisions when faced with hypothesis-inconsistent abstracts. Second, the influence of statistical significance on submission decisions was mediated by researchers’ FOR judgments—nonsignificant results led to lower FOR ratings, which, in turn, prompted participants to revise their initial submission decisions and rate their considered submission decisions more negatively. This finding contrasts with our hypothesis that low FOR judgments would result in more positive reconsidered submission decisions.
Exploratory analyses
The exploratory analyses sought to identify possible confounding factors influencing the relationship between intuitive responses (LoSRC), subsequent changes in researchers’ responses (C-LoSRC), and FOR. In total, despite considering several covariates and correcting for multiple comparison using the Bonferroni method, the overall pattern of treatment effects remained consistent across all Stage 1 and Stage 2 models. Although a few covariates showed isolated significant effects based on uncorrected p values in individual models, none demonstrated consistent influence after correction. However, given the relatively high conditional R2 values (ranging between .39 and .50 for the main models) and especially large subject-level random-intercept variances, it is likely that other unmeasured subject-level factors—such as individual attitudes, disciplinary norms, or prior experiences—may have systematically influenced participants’ abstract ratings but were not captured by the covariates included in the models.
Conclusion of experiments
Taken together, our data suggest that in controlled clinical-psychology vignette experiments, statistically nonsignificant but not hypothesis-inconsistent results are significantly less likely to be chosen for submission to publication in intuitive responses. Furthermore, the experiments showed that in line with the results regarding publication decisions, statistically nonsignificant but not hypothesis-inconsistent results are significantly more likely to be rejected in intuitive responses on reading the full article and in intuitive responses on citing the article. Although our findings provide evidence of a statistically significant influence of result significance on researchers’ decisions, it is important to emphasize that the observed effect sizes were small, with fixed effects accounting for 1% to 2% of variance in most main models. Consequently, these small effect sizes might reflect the inherently multifactorial nature of publication and reception decisions, in which numerous considerations—including methodological rigor, theoretical relevance, and novelty—combine to shape outcomes.
However, drawing on a two-response paradigm, we were able to show that considered positive responses indicative of deliberate and analytic Type 2 processing regarding decisions to submit to publish and cite are not significantly more likely for statistically nonsignificant and hypothesis-inconsistent abstracts, with one minor exception related to reading decisions. We also found no evidence that response changes are significantly mediated by FOR judgments, with an exception related to submission decisions. Additional factors, such as researchers’ professional status and the order of abstracts presented, appear to consistently shape initial evaluations but do not systematically influence later, more deliberate stages of decision-making.
Scientific implications
Our findings speak to a narrow but informative slice of the broader publication process: the rapid, abstract-level evaluations that researchers make when first encountering study results. In that constrained context, we observed a consistent devaluation of statistically nonsignificant findings, suggesting one early cognitive pathway through which publication bias could emerge. Our design does not capture later, higher-stakes stages of the research-to-publication pipeline—such as manuscript preparation, editorial triage, or full peer review—and therefore cannot quantify the overall prevalence or magnitude of publication bias in psychology. Our primary aim in this study was to identify the causal impact of two well-theorized decision cues—statistical significance and hypothesis consistency—on researchers’ immediate evaluations. Achieving that aim required a design that (a) held all other information constant, (b) ensured every participant saw every treatment level, and (c) permitted precise estimation of within-persons effects.
Although our nested within-subjects design allows precise estimation of preference effects, it cannot substitute for field studies with real-world incentives. Our results highlight the role of heuristic cognitive mechanisms in abstract-level evaluations that future research—ideally, using field experiments with actual manuscripts and real publication incentives—can target. In short, our study highlights potential points at which bias may arise, but how strongly these patterns translate into real-world publication outcomes remains unclear and should be examined using designs that more closely mirror actual scholarly workflows.
Limitations
Replicating the classic evidence of publication bias—first noted by Sterling (1959)—in a controlled experiment let us examine how strongly preferences for statistically significant and hypothesis-consistent results shape researchers’ evaluations of abstracts with respect to publication, citation, and reception. Although the study achieves that aim, it is not without weaknesses. In the sections that follow, we detail those limitations.
First, only about 1% of the 33,924 researchers we contacted completed the experiment. This low uptake means our participant pool was self-selected—likely skewed toward individuals who (a) have the time and motivation to complete a metascience survey and (b) may already be more sensitized to issues of publication bias than the broader population of clinical-psychology researchers. Consequently, the magnitude (and perhaps even the direction) of the effects we observed could differ for the larger community of scholars who evaluate manuscripts under heavier workloads, stronger career incentives, or lower methodological awareness. Any generalization beyond this self-selected group therefore requires caution and, ideally, replication in settings in which participation is obligatory (e.g., journal peer review or editorial decision-making).
Second, we deviated from our preregistered recruitment strategy because of initially insufficient response rates. Restricting our recruitment to six countries (Australia, Canada, Germany, the Netherlands, the United Kingdom, and the United States) did not yield the planned number of participants. To reach the preregistered sample size of 75 participants per experiment, we included researchers from additional countries using a web-scraping approach via PubMed and Web of Science. Although this strategy allowed us to meet our sample-size goals, it introduced variability beyond what was initially specified in the preregistration. Sensitivity analyses suggest that this deviation did not affect the results.
Third, in real-world research practice, studies may yield null results not only because of the absence of true effects but also because of insufficient statistical power; such studies are understandably less likely to be published because of legitimate concerns about evidentiary strength or interpretability (Ioannidis, 2005). Therefore, our findings should not be interpreted as suggesting that nonpublication of all null results is inherently problematic. Future research could build on our design by explicitly manipulating cues about statistical power or sample size to further explore how these factors interact with publication and reception decisions.
Fourth, although presenting abstracts may be a suitable format for decisions on reception (reading/citing), it is questionable in terms of making decisions about one’s own publications because researchers usually have much more information at hand when deciding whether to submit their own research for publication (Augusteijn et al., 2023). Reading and citing an abstract also depends on contextual factors and researchers’ own research interests, which will likely influence the reception of the abstracts of this study.
Fifth, we investigated the effect of only statistical significance and hypothesis consistency. However, recent experimental studies on publication bias also investigated the effects for sample size and statistical reporting error (Augusteijn et al., 2023) and originality (Elson et al., 2020) and its interaction with statistical significance. Unfortunately, because of power restrictions, we were not able to include further experimental treatment variables into our design.
Sixth, our abstracts were designed in a textbook fashion. In general, hypotheses are often not in the abstract of a publication, possibly indicating hypothesis after results are known or approaches that are not preregistered. For the present study, it was necessary for abstracts to be more simplified because sometimes several results—some significant, some nonsignificant—are presented in abstracts.
Seventh, p values and statistical significance are often challenged in methodological discussions in psychology; instead, effect sizes, confidence intervals, or Bayesian statistics are possible alternatives for reporting results. Furthermore, clinical relevance is not directly reflected by statistical outcomes (Cuijpers et al., 2014), so biases and effects of clinical studies might be less clear than in other fields (e.g., in psychophysics with well-powered studies of multiple trials and well-defined outcome criteria). Hence, it is important to use experimental settings to clarify decision-making in clinical research.
Eighth, the presence of social desirability in response patterns could compromise the study’s validity. Future research should add a social-desirability questionnaire or qualitative questions on how decisions were made when evaluating abstracts.
Future research
Moving forward, the central challenge is to close the gap between tightly controlled vignette studies such as ours—whose key advantage is the precise isolation of causal decision cues—and the complex, incentive-laden contexts in which real publication and reception decisions unfold. These limitations point to concrete directions for the next wave of work. Unfortunately, nearly all experiments that have ventured into higher-ecological-validity territory are now more than 35 years old: Mahoney’s (1977) classic manuscript-review study, Atkinson et al.’s (1982) journal-reviewer experiment, and Epstein’s (1990) audit of real editorial decisions. A notable contemporary exception is Elson et al.’s (2020) field experiment, which embedded manipulations into a live conference peer-review system, but its focus on a single meeting and decision stage leaves many contexts unexplored.
Abstract-level judgments offer a useful first glimpse, but reviewers in practice weigh many additional cues: sample size, analytic transparency, adherence to reporting standards, open data, theoretical novelty, and so on. Future studies should therefore randomize statistical-significance statements in otherwise identical full articles.
Beyond significance and hypothesis consistency, other attributes may trigger selective (non)publication: such as perceived originality (Elson et al., 2020), “hot” topics (Bittermann & Fischer, 2018), or sample size (Augusteijn et al., 2023). Multifactorial field experiments could orthogonally vary significance, originality, “trendiness,” and sample-size statements to examine how these cues interact under real incentives.
By migrating from vignette studies to real-stake field experiments, future work can chart not only that bias emerges along the research sequence but also how large it is at every step, revealing the overall distortion accumulated in the published record.
Supplemental Material
sj-docx-1-amp-10.1177_25152459251372134 – Supplemental material for Publication Bias in Academic Decision-Making in Clinical Psychology
Supplemental material, sj-docx-1-amp-10.1177_25152459251372134 for Publication Bias in Academic Decision-Making in Clinical Psychology by Louis Schiekiera, Kristina Eichel, Felicitas Heßelmann, Jacqueline Sachse, Sophie P. Müller and Helen Niemeyer in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
Thanks to the Berlin University Alliance for funding this project (for a description of the overall project, see ![]() ) and to the Open Access funds of Freie Universität Berlin for funding the publication. Thanks to the Clinical-Psychological Interventions team at Freie Universität Berlin for participating in our pilot study and giving helpful feedback along the way. Thanks for the feedback from the students of the summer semester 2022 in “Good Science, Bad Science.” Thanks to Olmo van den Akker for providing helpful comments. Thank you to all of the participants of the study. Thanks as well to Manuel Heinrich for important suggestions concerning the statistical modeling.
) and to the Open Access funds of Freie Universität Berlin for funding the publication. Thanks to the Clinical-Psychological Interventions team at Freie Universität Berlin for participating in our pilot study and giving helpful feedback along the way. Thanks for the feedback from the students of the summer semester 2022 in “Good Science, Bad Science.” Thanks to Olmo van den Akker for providing helpful comments. Thank you to all of the participants of the study. Thanks as well to Manuel Heinrich for important suggestions concerning the statistical modeling.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.