
Abstract
Peer review has become the gold standard in scientific publishing as a selection method and a refinement scheme for research reports. However, despite its pervasiveness and conferred importance, relatively little empirical research has been conducted to document its effectiveness. Further, there is evidence that factors other than a submission’s merits can substantially influence peer reviewers’ evaluations. We report the results of a metascientific field experiment on the effect of the originality of a study and the statistical significance of its primary outcome on reviewers’ evaluations. The general aim of this experiment, which was carried out in the peer-review process for a conference, was to demonstrate the feasibility and value of metascientific experiments on the peer-review process and thereby encourage research that will lead to understanding its mechanisms and determinants, effectively contextualizing it in psychological theories of various biases, and developing practical procedures to increase its utility.
Keywords
Recent work estimating the robustness of psychological research has given the research community pause for thought because a substantial proportion of published psychological investigations have not been successfully replicated (Camerer et al., 2018; Open Science Collaboration, 2015). How fundamental to this problem is the role of peer review? A population of reviewers who systematically value significant results more than nonsignificant results would incentivize researchers to use questionable research practices, such as p-hacking and cherry-picking (Simmons, Nelson, & Simonsohn, 2011), or may deter researchers from even trying to write up and publish nonsignificant results, and thus contribute to the file-drawer problem (Rosenthal, 1979). In a similar vein, reviewers influence whether replicating studies itself is valued, or whether emphasis is placed on originality. Despite the impactful role of peer review, little is known about its effectiveness and determinants (particularly in psychological science). In the study reported here, we aimed to contribute to closing this research gap by testing reviewers’ evaluations of significant versus nonsignificant results and original research versus replications in the peer-review process for a conference. Further, and more generally, we wanted to demonstrate the feasibility and value of metascientific field experiments on the peer-review process.
Peer Review: Objectives and Evidence
In writing about peer review, it has almost become a customary practice to adapt the famed statement by Winston Churchill on democracy as a form of government—to declare that peer review is the worst form of academic quality assessment, except for all the other forms that have been tried (see, e.g., Rennie, 2003a; Robin & Burke, 1987; Smith, 2006). Since the mid-20th century, peer review has been considered the gold standard of quality assurance in scientific publishing (Burnham, 1990; Spier, 2002). Through this process, peers influence which research is ever presented to the public and which remains in academics’ file drawers. Thus, depending on one’s perspective, peer reviewers can be considered the gatekeepers (Simmons et al., 2011), bottleneck (Pöschl, 2012), or hostage takers (Hammerschmidt, 1994) of scientific knowledge.
Jefferson, Wager, and Davidoff (2002) suggested that the two major functions of peer review are (a) selection and (b) refinement of scientific manuscripts. Although the empirical study of peer review, particularly through proper randomized control trials, has been very limited, there is some evidence documenting its underlying mechanisms. Descriptively, and probably unsurprisingly to any academic whose work has ever undergone academic peer review, there is often substantial disagreement among reviewers’ evaluations of a given manuscript (Bornmann, Mutz, & Daniel, 2010). This may be due to reviewers’ differences in competence, preferences and emphasis, or familiarity with relevant theory or methodology, but also may be due to reviewers’ idiosyncratic understanding of their role and the function of peer review itself (Bedeian, 2003). Overall convergence of evaluations would improve with a greater number of reviewers, but Forscher, Cox, Devine, and Brauer’s (2019) results suggest that achieving acceptable levels of reliability consistently (in grant reviews) would routinely require a double-digit number of reviewers, necessarily overburdening the pool of volunteers.
Perhaps more worryingly, the available evidence on the usefulness of peer review and the effectiveness of the entire process with regard to its two primary functions is somewhat mixed (Jefferson, Alderson, Wager, & Davidoff, 2002). Reassuringly, a range of studies suggest that research reports’ quality generally improves from their initially submitted versions to the published articles (Goodman, Berlin, Fletcher, & Fletcher, 1994), which indicates that manuscripts undergoing peer review do benefit from it. However, its utility as a selection method is challenged by surmounting evidence of bias against or in favor of manuscript and author characteristics not immediately relevant to the quality of the research.
Factors other than submissions’ merits can substantially influence peer reviewers’ evaluations of manuscripts and grant proposals. These factors include, but are not limited to, the conformity of study results to reviewers’ own predispositions (Ernst & Resch, 1994); the presence of formulas and equations even when they are meaningless (Eriksson, 2012); the statistical significance of reported results (Atkinson, Furlong, & Wampold, 1982; Emerson et al., 2010; Tsou, Schickore, & Sugimoto, 2014); the reviewers’ familiarity with the research program reported (Heesen & Romeijn, 2019); whether the research is a replication study (Tsou et al., 2014); reviewers’ resistance against innovations and unconventional theory, methods, and practice (Rennie, 2003b); characteristics, such as sex (Wood & Wessely, 2003) and prestige (Okike, Hug, Kocher, & Leopold, 2016), that are conveyed by unblinding authors’ names; and blinding of reviewers’ identities (Godlee, Gale, & Martyn, 1998). These biases, in turn, incentivize researchers to use some research practices that may be orthogonal or even detrimental to scientific ideals. They may also provide disincentives to beneficial behavior; for example, researchers may be disinclined to pursue publication of sound research if they believe that it is likely to be met with negative reviews (Cooper, DeNeve, & Charlton, 1997; Coursol & Wagner, 1986; Franco, Malhotra, & Simonovits, 2014). Given the available evidence, Heesen and Bright (2019) argued that abolishing prepublication peer review in its current form would have neutral or positive net value for the incentive structure in science and for individual researchers’ behavior.
Proposed solutions to ameliorate some systematic problems with peer review are aimed at increasing transparency of review processes (e.g., Wicherts, Kievit, Bakker, & Borsboom, 2012). Some of these measures have been employed by individual journals, such as F1000Research and Meta-Psychology, which publish the complete history of submitted manuscripts (including all versions and signed peer reviews) and encourage commenting on articles during and after publication. Other initiatives, such as JournalReviewer.org and SciRev.org, provide academics with a repository of authors’ experiences with review processes for the benefit of scholars considering submitting their work to journals.
The Need for Experimental Metascience in Peer Review
Although these measures may be helpful in increasing the transparency of academic publishing, systematic research is needed to substantiate peer review’s utility. Empirical evidence that would disentangle the mechanisms involved in editorial decision making is sparse, mostly because the process is so opaque that opportunities to study it from the outside are limited (Couzin-Frankel, 2013).
Considering its regulatory impact, making peer review a field of scientific study itself is inevitable, as the costs—financial, opportunity, and otherwise—of operating a dysfunctional quality-assurance system in scientific publishing are potentially enormous. A system that routinely selects bad science shifts competitive resources (funds, personnel, journal space, time, attention) toward degenerative research programs (Lakatos, 1969), allows false paradigms to persist (Akerlof & Michaillat, 2018), and causes other research lines that were not selected despite their value to remain unexplored, unfunded, and unpublished (Smaldino & McElreath, 2016).
However, as in other domains where effective fixes to a dysfunctional procedure need to be developed, a rigorous research program on the mechanisms of peer review cannot and should not be limited to observational and survey studies reifying pressing concerns: Experimental (field) research with carefully designed manipulations is necessary to identify and ideally isolate causes of human behavior and to implement interventions to modify these contingencies for the better. Although the number of studies testing interventions in peer review is slowly increasing (Malicˇki, von Elm, & Marušic, 2014), such studies are still rather underrepresented, and with few exceptions (e.g., Epstein, 1990; Mahoney, 1977), they are restricted to peer review in biomedicine. Certainly, although one may reasonably conclude that dysfunctional selection mechanisms could have much graver consequences in biomedical publishing than in other sciences, it is somewhat surprising to see peer review receiving relatively little attention by behavioral researchers given that this practice and the interactions of biases shaping it are ultimately psychological research objects (Mahoney, 1976).
The Present Study
We report results from a preregistered experimental study conducted in the regular peer-review process for a scientific conference on research in media psychology. This study was conducted to document the extent to which media psychologists show preferences for (a) original studies over direct replications and (b) statistically significant over statistically nonsignificant findings. Although our broad hypotheses concerned peer review in general, the hypotheses tested in our field study were specific to the conference context:
Compared with a conference submission reporting a replication study, original research has a higher chance of being accepted for presentation and will score higher on standardized reviewing criteria.
Compared with a conference submission reporting a statistically nonsignificant effect (p > .05), a submission reporting a statistically significant effect (p < .05) has a higher chance of being accepted for presentation and will score higher on standardized reviewing criteria.
Disclosures
Preregistration
The study’s rationale, hypotheses, stimulus materials, and measures were preregistered on the Open Science Framework (https://osf.io/t6hs9/). Regrettably, we did not preregister an analysis plan. We report all the analyses we conducted to test our hypotheses and welcome researchers to further explore the available data.
Data, materials, and online resources
All stimulus materials (https://osf.io/zxthq/); data (https://osf.io/zajx3/), including a codebook (https://osf.io/d5zj3/); and analysis scripts (https://osf.io/cfnvu/) underlying this report are available on the Open Science Framework. Note, however, that in order to protect the reviewers’ anonymity, the data set does not include their written comments about the submissions or information about their personal characteristics (see Additional Variables, later in the method section).
Reporting
We report how we determined our sample size, all data exclusions, all manipulations, and all measures in the study.
Ethical approval
This protocol was not approved by an institutional review board because, regrettably, such a committee did not exist at the first author’s institution at the time and obtaining ethical approval for social-science research, with few exceptions, is not required by law in Germany. We did, however, consult with an institutional review board that was not formally responsible.
Method
In a 2 × 2 between-subjects experiment, we manipulated the originality and statistical significance of the research reported in a fictitious abstract submitted to a small- to medium-sized conference and sent the abstract to voluntary reviewers. They evaluated it as part of the regular double-blind peer-review process and submitted a recommendation with a standardized reviewing form. The reviewers also evaluated regularly submitted abstracts that were, whenever possible, assigned to them on the basis of their expertise (although, depending on the volume of submissions, it is not unusual for reviewers to be assigned abstracts only tangentially relevant to their own research). The fabricated abstract was assigned to all reviewers regardless of their expertise.
Setting
This field experiment was conducted during the peer-review process of the ninth biennial international conference of the Media Psychology Division of the German Psychological Association (DGPs), held in September 2015 in Tübingen. DGPs is a nonprofit association with more than 4,000 members working in higher education, either in psychology or in a neighboring field. Its goal is to advance and expand scientific psychology. As an organization, it aims to represent psychology as a scientific discipline and promotes psychology’s role in policy making and the public sphere (Deutsche Gesellschaft für Psychologie, n.d.). The Media Psychology Division is an interdisciplinary section of DGPs dedicated to study human behavior, thought, and affect in the context of media use. At the time of the study, the second author was acting as the division’s chair, the third author as vice chair, and the first author as an early-career representative. All three authors were also the conference chairs. For the context of this study, it is relevant to note that the division (and its leadership at the time) can be characterized as rather progressive with regard to open-science ideals and practices. This is reflected, for example, in events at the conference, such as a keynote speech on open science given by Neuroskeptic (a pseudonymous science blogger) and a discussion panel on open science in media psychology, and in the promotion of transparent research practices by the division’s members (Elson & Przybylski, 2017; Krämer, 2015).
Stimulus materials
We designed a base study abstract that fit a media-psychology conference and was simple enough to allow nonspecialists to review it. The abstract was titled “Pictures of Misery: Effects of Facebook Use on Body Image,” and it described a simple laboratory experiment investigating how viewing other people’s Facebook pictures affects individuals’ body dissatisfaction. From the base version, we derived four variants for the experimental conditions: an original study with statistically significant findings, a replication study with statistically significant findings, an original study with statistically nonsignificant findings, and a replication study with statistically nonsignificant findings (see Table 1 for the text of two of these versions).
The Abstract Versions Used for the Original Study With Significant Results and the Replication Study With Nonsignificant Results

Note: Passages that differed between the two versions are indented and identified with labels in italic type. Readers may infer the text of the other two versions from what is shown here. All the versions are available at https://osf.io/zxthq/.
Note that the reference mentioned in all four versions was also fabricated (no detailed information other than the alleged authors’ names and the publication year was provided, which made it hard for reviewers to verify that it does not actually exist). The formatting requirements of the conference limited the abstract’s length to 300 words. The review process was double-blind.
Dependent variables
The dependent variables relevant to our preregistered hypotheses were five evaluation criteria, overall recommendation, and a total score. Additionally, the conference’s submission system allowed reviewers to recommend accepting a submission as a poster instead of the presentation type preferred by the author (a talk in the case of the fabricated abstract) and encouraged reviewers to provide written comments. Neither poster recommendations nor written comments were part of our preregistered study plan, and they are not discussed further in this article.
Evaluation
On a scale from 0 to 10, in 2-point steps (0, 2, 4, 6, 8, 10), each abstract was evaluated on the following five criteria: significance to media psychology, quality of the writing, sophistication of the theory and conceptualization, appropriateness of the methods and research design, and quality of the presentation and discussion of results.
Recommendation
Additionally, reviewers were asked to provide an overall recommendation on a scale from 0, definitely reject, to 10, definitely accept.
Total score
For each review, a total score was computed from the evaluation ratings (each worth 10%) and the recommendation rating (worth 50%). In the case of regularly submitted abstracts, the mean of total scores across the assigned reviewers ultimately determined acceptance to the conference.
Additional variables
The reviewers were asked to indicate their own familiarity with each assigned abstract’s topic (on a scale from 0 to 10, in 2-point steps). Further, three potentially relevant, publicly available personal characteristics of all the reviewers were collected from their university websites: gender, academic rank (doctoral candidate, postdoc, junior or assistant professor, associate or full professor), and academic age (years since approval of the doctoral dissertation).
Sample
We used the Media Psychology Division’s member list and department websites of division members to identify 197 German researchers working in the field of media psychology and invited these researchers to participate in the conference’s review process via e-mail (see https://osf.io/jv5ac/). Further, after the conference’s submission deadline (March 1, 2015), researchers who had submitted an abstract and were not among the initial 197 were also invited to serve as a reviewer.
For ethical reasons, the invitation emphasized that the division would be working on evaluating and improving its own peer-review process and that, for this reason, reviewers’ workload would be higher than usual (no further details on the nature of the evaluation were provided). Thus, researchers volunteering as reviewers were made aware that they had also opted in to participate in the evaluation. In total, 142 experts agreed to participate in the review process. Reviewers were assigned no more than four submissions to review; one of these was the manipulated abstract. Of the 142 reviewers, 7 were excluded a priori from participation in the experiment because they were either aware of our plans for the study or involved in designing the study. Seven additional reviewers, all from the same department, noticed the manipulation during a meeting in which senior researchers provided early-career researchers with guidance regarding their peer-review assignments for the conference. 1 In addition, 1 reviewer did not submit an assessment. Thus, the final sample consisted of 127 reviewers. Of these, 45.7% were women, 26.7% were doctoral candidates, 35.4% were postdocs, 3.9% were junior or assistant professors, and 33.9% were associate or full professors. The self-reported familiarity with the topic of the fictitious abstract was normally distributed, with a moderate mean slightly above the scale’s midpoint (M = 6.35, SD = 1.95, Mdn = 6, range = 2–10).
As we were also the organizing committee of the conference, one further ethical concern was that we would be able to inspect each individual reviewer’s recommendations, including the one that constituted data for this study. To ensure that our professional relationships with the reviewers would not be affected, we arranged for a hypothesis-blind research assistant to export and subsequently delete the reviews of the fictitious abstract from the conference’s submission system. After collecting the personal data on the reviewers from their university websites the assistant purged the names of the reviewers from the exported file before finally handing over the fully anonymized data to us.
Reviewers were debriefed at the conference and through a written report about the results of the study that was disseminated after the conference.
Statistical power and sensitivity
Note that no a priori power analysis was conducted because we knew that the pool of potential reviewers was rather limited and continued data collection would not be possible given the planning and scheduling of the conference. Further, the researchers we invited might be relatively close to a total population sample of German media psychologists. Our preregistered plan stated that if the final sample of eligible reviewers was less than 120 (before data collection), we would discard the originality manipulation and run the study as a 2 × 1 between-subjects experiment.
The final sample of 127 reviewers provided 80% power to detect bivariate correlations greater than .245 2 (90% power for r > .282, and 95% power for r > .312 ). The study had 80% power to detect main effects (standardized mean differences) with a d value greater than 0.503 (90% power for d > 0.582 and 95% power for d > 0.647).
Results
The descriptive statistics for each variable in each condition are reported in Table 2. Figure 1 displays the relative response frequencies for each evaluation criterion and the overall recommendation in each condition. The distribution of the total score in each condition is displayed in Figure 2. Zero-order correlations are reported in Table 3.
Descriptive Statistics
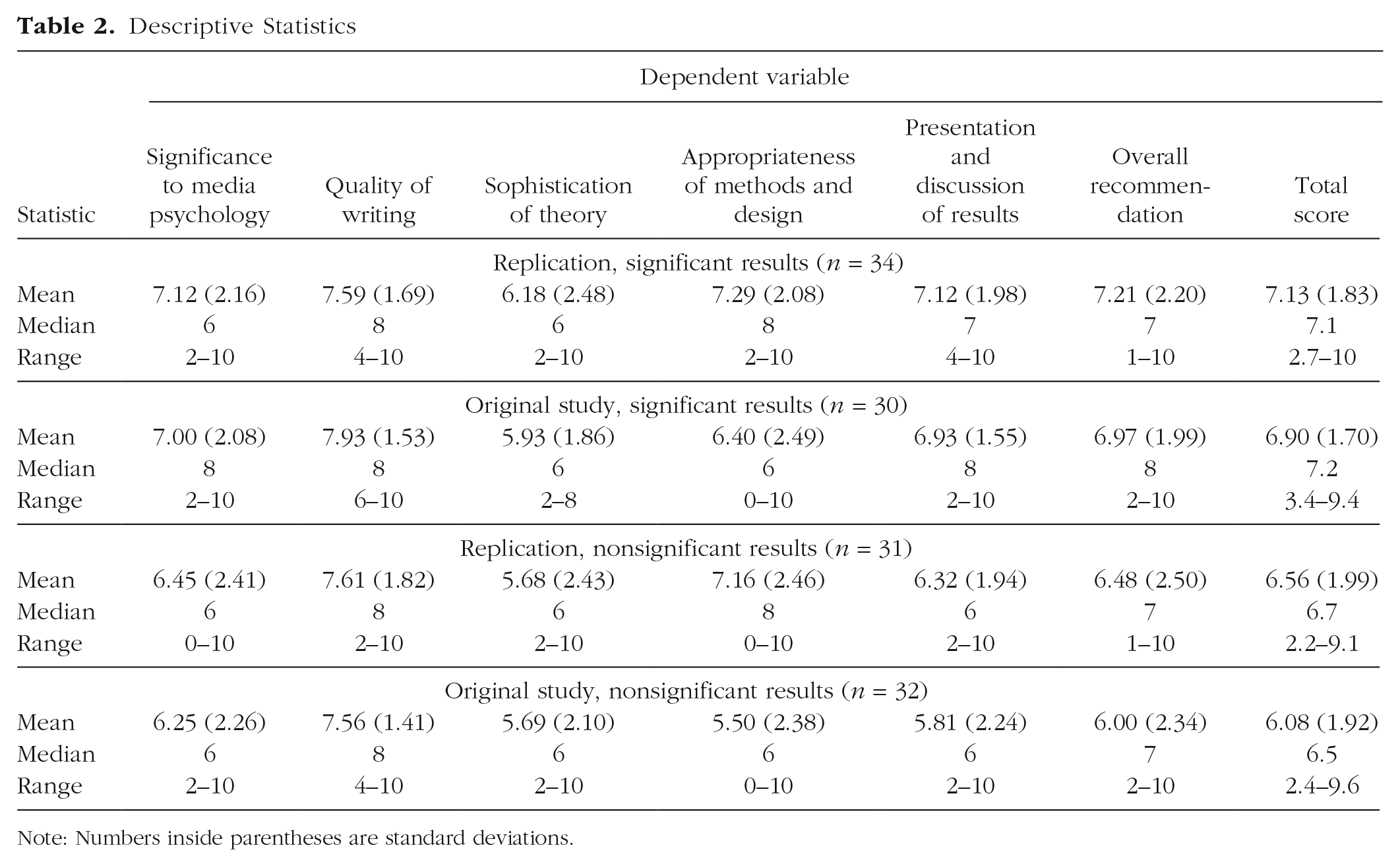
Note: Numbers inside parentheses are standard deviations.
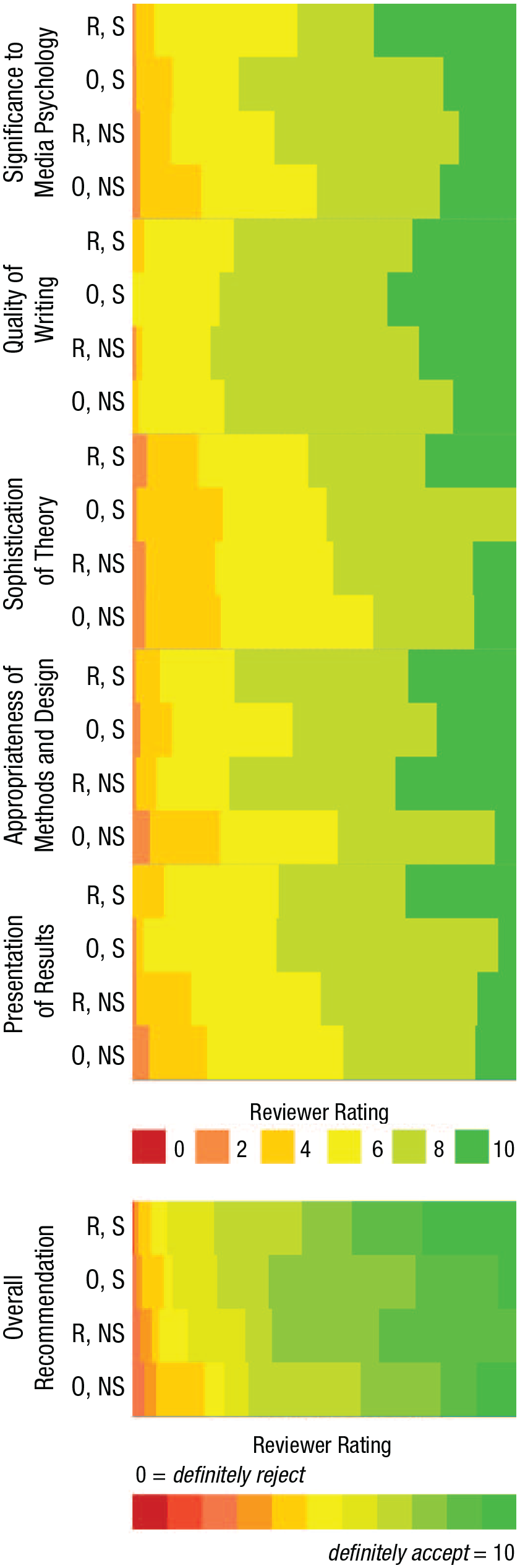
Relative response frequencies for each dependent variable by condition. The condition names have been abbreviated as follows: R, S = replication, significant results; O, S = original study, significant results; R, NS = replication, nonsignificant results; O, NS = original study, nonsignificant results.
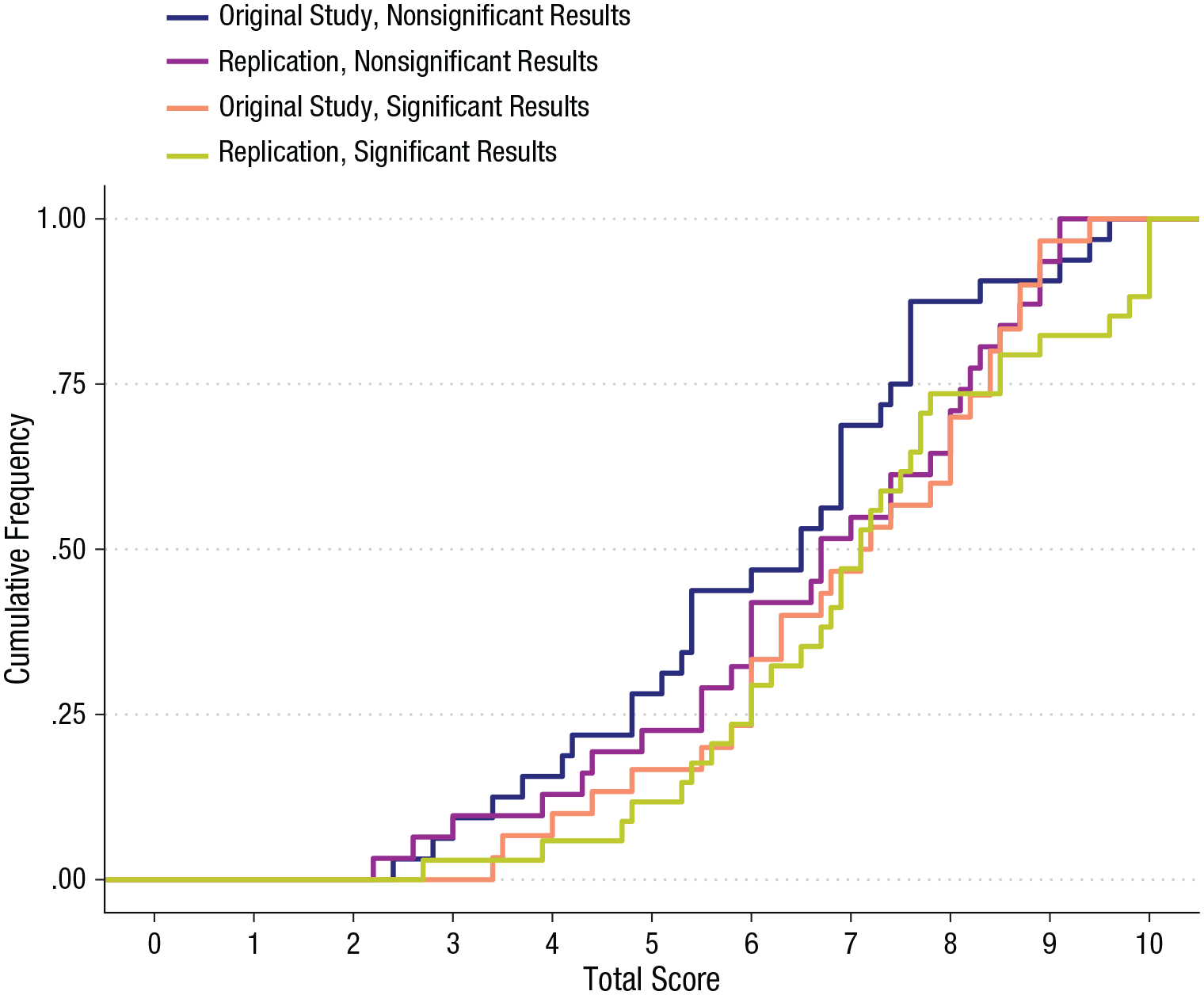
Empirical cumulative distribution of the total score in each condition.
Zero-Order Correlations
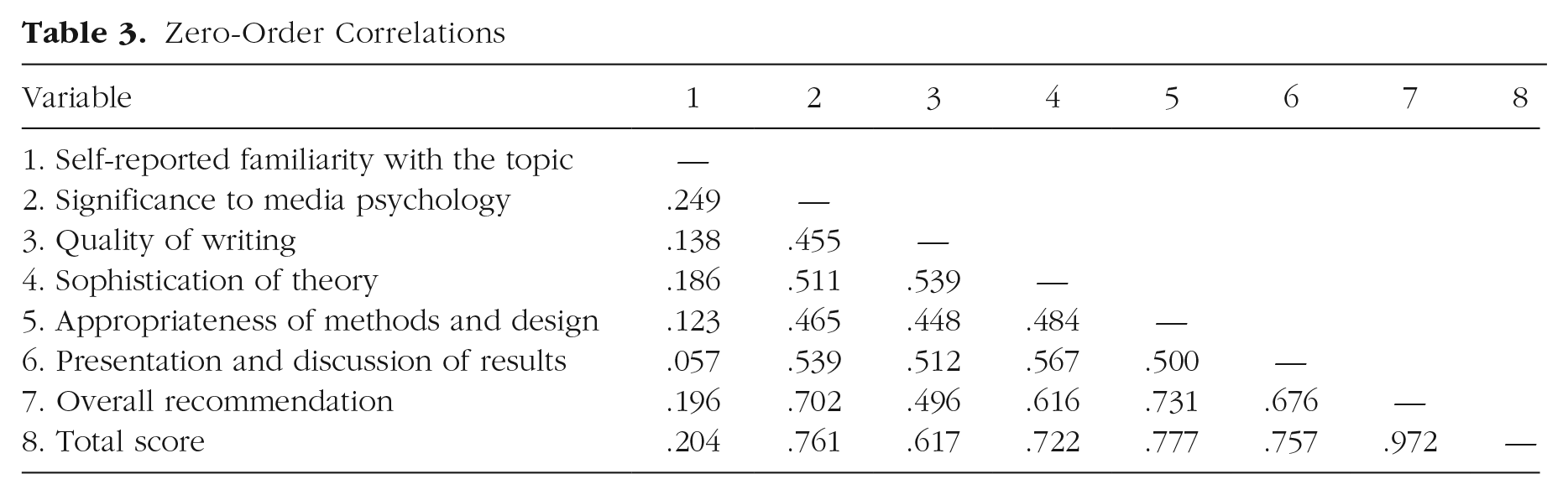
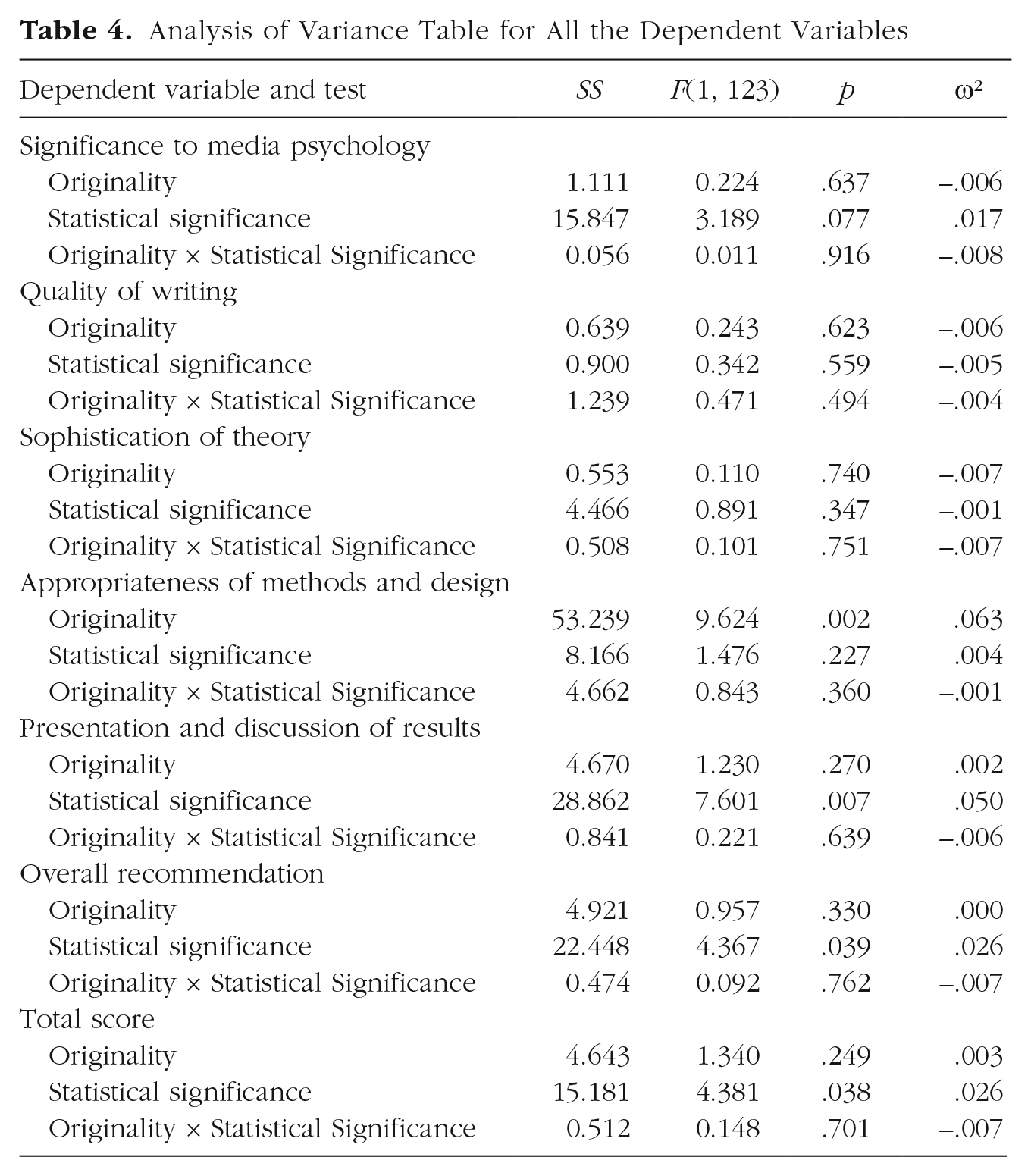
Overall, the evaluations and recommendations showed relatively small differences between conditions. Compared with reviewers in the nonsignificant-results conditions, those in the significant-results conditions evaluated the study’s significance to media psychology (ω² = .017) and the quality of the presentation and discussion of results (ω² = .050) slightly more positively and gave slightly more favorable recommendations for acceptance (ω² = .026). As a result, total scores were higher in the significant-results conditions than in the nonsignificant-results conditions (ω² = .026). The originality of the study affected only the ratings of the appropriateness of the methods and research design: Replication studies were rated higher than original studies (ω² = .063). There were no appreciable interaction effects. All significance tests are reported in detail in Table 4. Given the number of tests, there was an inflated probability of false positives for a default criterion of Cronbach’s α = .05. Therefore, for all main effects, we conducted two-tailed equivalence tests with lower and upper bounds of Cohen’s d = −0.50 and +0.50 (which corresponded to our sensitivity analysis at 80% power) and α = .05 (see Table 5). These tests underscore that, because of our sample size, the precision of effect-size estimates was rather low.
Analysis of Variance Table for All the Dependent Variables
Summary of the Equivalence Tests for All Main Effects on the Dependent Variables
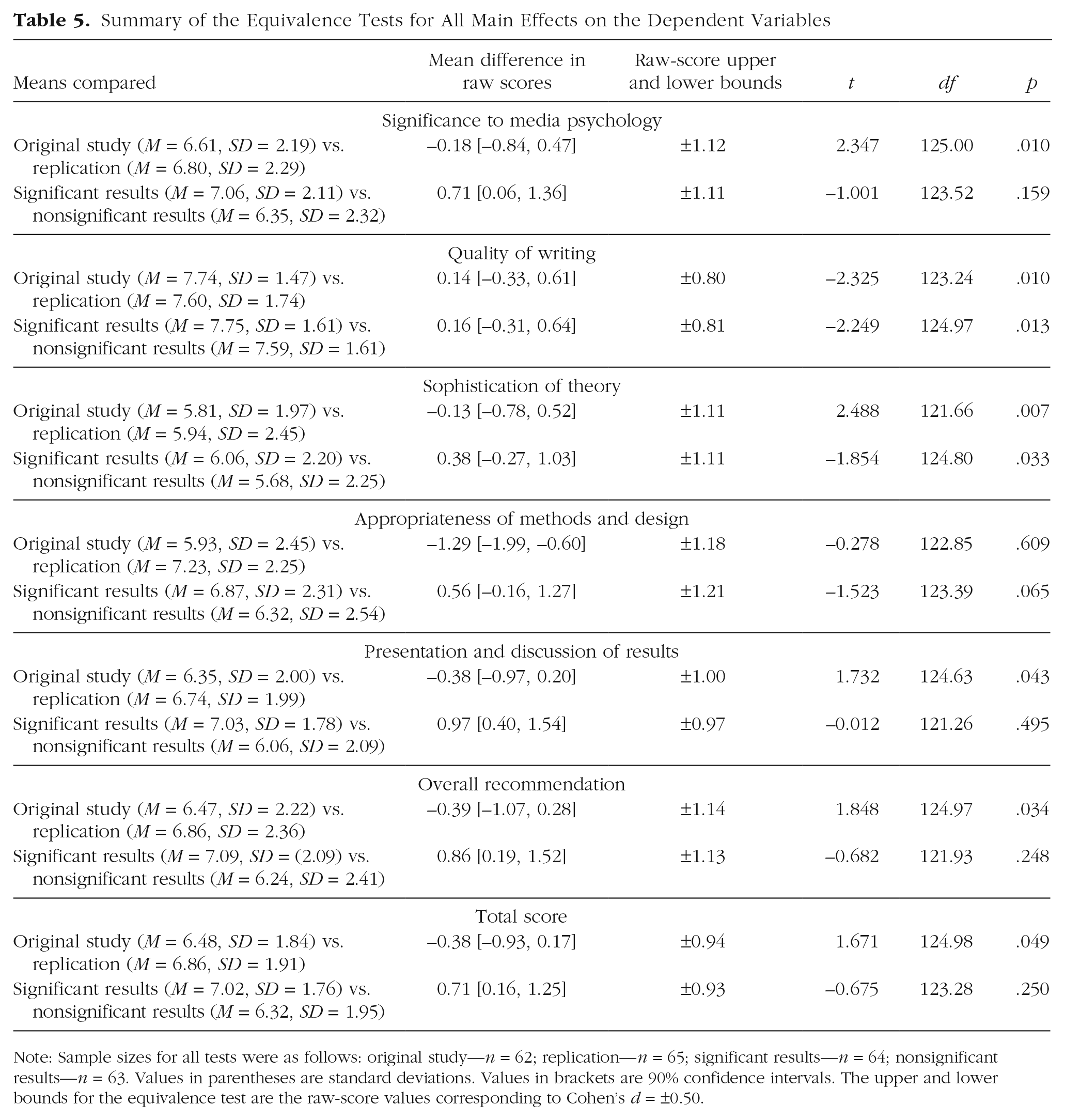
Note: Sample sizes for all tests were as follows: original study—n = 62; replication—n = 65; significant results—n = 64; nonsignificant results—n = 63. Values in parentheses are standard deviations. Values in brackets are 90% confidence intervals. The upper and lower bounds for the equivalence test are the raw-score values corresponding to Cohen’s d = ±0.50.
Discussion
This study had two purposes: The first was to investigate if two characteristics of a research report, its originality and the statistical significance of its main effect, affect peer review. The second, and more important, purpose of this study was to demonstrate the value, necessity, and feasibility of metascientific field experiments on the peer-review process.
We observed some evidence for a small bias in favor of significant results. At least for this particular conference, though, it is unlikely that the effect was large enough to notably affect acceptance rates. We did not observe an aversion to replication studies documented elsewhere (Zwaan, Etz, Lucas, & Donnellan, 2018), which could be a tangible result of the continued debate regarding (media) psychology’s robustness and the value of replications that had started a few years before this experiment was conceived. One practical outcome with regard to the Media Psychology Division is that submissions to the 11th conference (held in 2019) were no longer allowed to include study results.
Lessons and limitations
There are contextual and design constraints on the generalizability of our observations. We used only (four slight variations of) one abstract with one specific research question. A fictitious abstract from another research domain, or even a different abstract of the same quality in the same domain, might have received different evaluations. Ideally, we would have used multiple abstract sets as a within-subjects factor to allow controlling for person (i.e., reviewer) characteristics (e.g., general strictness), and we would have treated the variation in abstracts as a random factor to determine between-abstract heterogeneity (to have a stronger basis for generalizing to other possible abstracts).
Each version of the abstract was shorter than 300 words, and therefore the information available to thoroughly evaluate these submissions on each criterion was limited. For instance, the entire statistical summary of the empirical evidence was reduced to an F value, degrees of freedom, and a corresponding p value (which is not uncommon for a conference abstract). The abstract reported no further tests of evidentiary value (e.g., equivalence tests or Bayesian analyses); no supporting information, such as an effect-size estimate, standard error, or confidence interval; and no descriptive statistics (means, standard deviations)—all of which are typically considered when interpreting data and evaluating a full-length study report. The absence of a statistical description of the underlying data certainly made it difficult for reviewers to properly assess the outcome of the study, and this ambiguity was likely greater for the statistically nonsignificant results than for the significant results (which means the information carried was asymmetrical across conditions). This may have affected the reviewers’ evaluation scores, in particular with regard to the quality of presentation and discussion of results.
The sample was rather small for a 2 × 2 between-subjects design, allowing us to reliably detect only main effects that were at least half a standard deviation in magnitude. Certainly, there could have been effects our study was simply not equipped to detect, particularly given the low reliability of peer-review instruments (Bornmann et al., 2010). Conversely, the low precision of the effect-size estimates limits the confidence that can be placed in both our findings of modest effects and our findings of negligible effects: Without taking any other design limitations or contextually introduced biases into account, the modest effects we observed could in fact be null, or in some cases could even be effects in the opposite direction, whereas the seemingly negligible effects could actually be substantial. However, as mentioned earlier, the full population of German-speaking media psychologists was probably exhausted to a large degree by the recruiting process. The necessary conclusion for future field experiments in relatively small research areas is that one should plan clean, parsimonious designs that rigorously test simple, incremental hypotheses.
The Media Psychology Division’s conference is certainly less competitive than larger conferences or other publication venues. Accordingly, the regularly submitted abstracts had a rather generous mean total score of 7.2 (on a scale from 0 to 10). Thus, it is unclear to what extent the findings can be generalized to peer-review processes in which the reviewers are more critical of the work they are assigned. In those publication venues, reviewers are usually selected on the basis of their expertise, whereas in our study, the fictitious abstract was assigned to any volunteer. Although self-reported expertise was only weakly correlated with any dependent variable in our study, it could be an important factor to consider when studying biases against nonsignificant findings, particularly in failed replications (see, e.g., Ernst & Resch, 1994).
Almost all the previous empirical research we have discussed in this article was conducted on peer review of journal submissions (and in some cases, grant applications), and therefore we only cautiously integrate our own observations with the literature. Certainly, differences between disciplines and subdisciplines regarding the perceived value of publishing in journals versus books versus proceedings affect the immediate relevance of this field experiment.
Finally, it is also conceivable that the conference’s theme, the reputation of the division’s leadership as open-science advocates, or awareness of other metascientific research in which we were involved affected the reviewers’ responses to direct replications (which had been rarely presented at previous instances of this conference).
A blueprint for metascientific field experiments on peer review
As regards the second purpose of this study, we note that there are, of course, practical and ethical challenges to this type of research that need careful consideration. Experiments on peer review face the same ethical challenges as does any field study in which subjects are not provided complete information about the research design or even may be deceived. Studies guiding evidence-based practice by rigorously comparing several policies (e.g., different instructions to reviewers, different levels of blinding) in an A/B design may face strong objections by the community (i.e., the subject pool), even when the untested implementation of either A or B would be unobjectionable (Meyer et al., 2019). Objections to experimentation (principled or not) naturally depend on the design, but we argue not only that experimental research on peer review can be conducted ethically, but also that there is an ethical obligation to conduct such research considering the costs of maintaining an unchecked quality-assurance procedure (Meyer, 2015). Simply put, the alternatives to evidence-based peer-review procedures—including the status quo, with its documented failures (Jefferson, Alderson, et al., 2002)—have not been subjected to systematic testing.
Given the nature of conferences, and their deadlines for submissions, reviews, and eventually presentations, our study had particular constraints that would be less relevant in a field setting where continuous data collection is possible (e.g., journal review). Although reviewers may not be told a priori to which condition specifically they were assigned, or what exactly is part of the study (which may be more obvious in typical laboratory experiments), psychologists studying peer review can design their research in a way that allows potential reviewers to make an informed choice about their participation. We propose a model in which a pool of reviewers (e.g. everyone registered with a journal’s submission system) is informed that some experimental studies will be conducted within a specified time frame in the future. This initial information sheet could outline the types of study designs planned or characteristics that might be experimentally manipulated (and refer to the resulting additional workload beyond that required by conventional review, if any), without specifying which of these will be realized. Reviewers may then pick and choose how much time they would be willing to commit to this research, and which of the potential manipulations they do or do not consent to. For example, some reviewers may be unconcerned about reviewing real manuscripts under procedural manipulations (such as omitting Results sections from manuscripts), but less inclined to review entirely fictitious manuscripts that serve no purpose other than the research itself. Both opt-in (van Rooyen, Godlee, Evans, Smith, & Black, 1998) and opt-out (Okike et al., 2016) procedures seem practically feasible and ethically unproblematic.
Naturally, when metascientists use real manuscripts as stimulus materials to investigate peer review, another challenge is to prevent the experimental manipulations from inducing systematic or selective disadvantages for authors. For example, it is conceivable that some design decisions would affect the strictness of reviews (e.g., by guiding the attention of reviewers to certain manuscript characteristics or prompting them to submit more critical remarks) but not the quality of the selection process or the refinement of submissions. Depending on the magnitude and risk of the manipulation, it may be necessary to use conventional or accepted review procedures to guide editorial decision making and to use the experimental reviews exclusively for research purposes. This approach may also reduce the community’s objections to the experimental study of peer review (Meyer et al., 2019). Metascientists may even find some benefit in this approach, as the status quo reviews could be used as natural control-group data (possibly even without obtaining consent).
Conclusions
We hope that this study encourages psychologists, as individuals and on institutional levels (associations, journals, conferences), to conduct experimental research on peer review, and that the preregistered field experiment we have reported may serve as a blueprint of the type of research we argue is necessary to cumulatively build a rigorous knowledge base on the peer-review process. We believe it prudent to eventually develop and implement evidence-based interventions that address documented shortcomings in academic publishing. We also believe that an improved understanding of peer review will increase the sustainability of the quality-management system in its entirety and reduce strain on the army of volunteer reviewers, as the current pronounced randomness of the process provides an incentive to ignore comments (even when they are valuable) and resubmit manuscripts elsewhere unchanged.
Going back to Churchill, we note that peer review cannot be described, with sufficient certainty, as the worst form of academic quality assessment except for all other forms, because very little is known about its performance in general, and because it is not particularly clear how well peer review fares against other forms of academic quality assessment, simply because not many have been tried in a systematic way. Experimental field research on peer review is necessary to understand its mechanisms, effectively contextualize it in psychological theories of various biases, and develop practical procedures to increase its utility. If peer review is maintained as the primary mechanism of arbitration in the competitive selection of research reports and funding, then the scientific community needs to make sure it is not arbitrary.
Supplemental Material
Elson_Rev_Open_Practices_Disclosure – Supplemental material for Metascience on Peer Review: Testing the Effects of a Study’s Originality and Statistical Significance in a Field Experiment
Supplemental material, Elson_Rev_Open_Practices_Disclosure for Metascience on Peer Review: Testing the Effects of a Study’s Originality and Statistical Significance in a Field Experiment by Malte Elson, Markus Huff and Sonja Utz in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We sincerely thank Johannes Breuer and James Ivory for their help in designing the stimulus materials. We further thank Sebastian Strauß for his assistance with the data preparation.
Transparency
Action Editor: Simine Vazire
Editor: Daniel J. Simons
Author Contributions
M. Elson, M. Huff, and S. Utz jointly generated the idea for the study. M. Elson designed the study and collected the data. M. Elson wrote the analysis code and analyzed the data. M. Elson wrote the first draft of the manuscript, and all three authors critically edited it. All the authors approved the final submitted version of the manuscript.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.