
Abstract
Questionable research practices (QRPs) pose a significant threat to the quality of scientific research. However, historically, they remain ill-defined, and a comprehensive list of QRPs is lacking. In this article, we address this concern by defining, collecting, and categorizing QRPs using a community-consensus method. Collaborators of the study agreed on the following definition: QRPs are ways of producing, maintaining, sharing, analyzing, or interpreting data that are likely to produce misleading conclusions, typically in the interest of the researcher. QRPs are not normally considered to include research practices that are prohibited or proscribed in the researcher’s field (e.g., fraud, research misconduct). Neither do they include random researcher error (e.g., accidental data loss). Drawing from both iterative discussions and existing literature, we collected, defined, and categorized 40 QRPs for quantitative research. We also considered attributes such as potential harms, detectability, clues, and preventive measures for each QRP. The results suggest that QRPs are pervasive and versatile and have the potential to undermine all stages of the scientific enterprise. This work contributes to the maintenance of research integrity, transparency, and reliability by raising awareness for and improving the understanding of QRPs in quantitative psychological research.
Keywords
In recent decades, researchers have faced a reckoning with a crisis in replicability and credibility 1 of research, which has spurred efforts to improve psychological science (Eronen & Bringmann, 2021; Open Science Collaboration, 2015; Vazire, 2018; Yarkoni, 2020). Questionable research practices (QRPs) have been discussed as being one of the drivers of this credibility crisis. John et al. (2012) broadly defined QRPs as behaviors that “exploit . . . the gray area of acceptable [scientific] practice,” which “can spuriously increase the likelihood of finding evidence in support of a hypothesis” (p. 524). These QRPs might be a direct or indirect result of researchers having too much flexibility when it comes to analytic strategies (often referred to as “the garden of forking paths”; Gelman & Loken, n.d.) and using this flexibility to their advantage in an undisclosed manner (often referred to as having too many “researcher degrees of freedom”; Simmons et al., 2011). Some QRPs are well known, and their corresponding terms are widely used in the scientific community. For example, “HARKing” (Kerr, 1998) refers to the practice of hypothesizing after the results are known, and “p-hacking” refers to repeatedly testing closely related hypotheses until the desired effect is statistically confirmed and reporting only the analysis strategy that “worked” (Rosenthal, 1979). Apart from these, many more QRPs exist, eroding the scientific enterprise.
Exploring the landscape of QRPs reveals a patchwork of studies showing that these practices are ubiquitous. In the United States, John et al. (2012) uncovered a breadth of QRPs among researchers, illuminating how common these practices are in academic settings. In Europe, Fiedler and Schwarz (2016) documented similar concerns in German research institutions, echoing the widespread nature of QRPs. The situation is reflected among the next generation of researchers as well; Brachem et al. (2022) reported on the attitudes and engagement with QRPs among psychology students in Germany, Austria, and Switzerland. Likewise, Gopalakrishna et al. (2022) identified QRPs in the research community in the Netherlands, thus painting a picture of a practice that transcends cultural and academic boundaries.
Previous Attempts to Define QRPs
Despite the considerable attention given to QRPs in the last decade, researchers have yet to converge on a clear definition of the concept. To our knowledge, the first definition and discussion of QRPs appeared in a panel report on responsible science (National Academy of Sciences [US] et al., 1992). This joint venture of the U.S. National Academy of Sciences, the National Academy of Engineering, and the Institute of Medicine defined QRPs as actions that violate traditional values of the research enterprise and that may be detrimental to the research process. Questionable research practices do not directly damage the integrity of the research process and thus do not meet the panel’s criteria for inclusion in the definition of misconduct in science. (National Academy of Sciences [US] et al., 1992, pp. 5–6)
This definition did not include any reference to intentionality but clearly distinguished QRPs from research misconduct.
Years later, the widely influential article by Ioannidis (2005, “Why Most Published Research Findings Are False”) mentioned systemic biases in research that lead to misleading results. He defined these biases as “a combination of various design, data, analysis, and presentation factors that tend to produce research findings when they should not be produced” (Ioannidis, 2005, p. 697). Although he did not mention the term “QRP,” he clearly referred to a similar phenomenon. The field of biomedicine has also been tackling QRPs—usually referred to as “selective reporting”—since the early 2000s (e.g., Al-Marzouki et al., 2005, 2008). A definition of scientific misconduct, which we believe better aligns with our definition of QRPs, was suggested in 2005 as “behaviour by a researcher, whether intentional or not, that falls short of good ethical and scientific standards, and in particular can arise in the context of clinical trials” (Al-Marzouki et al., 2005, p. 332). According to Banks, O’Boyle et al. (2016), QRPs represent “design, analytic, or reporting practices that have been questioned because of the potential for the practice to be employed with the purpose of presenting biased evidence in favor of an assertion” (p. 7).
Lately, there have been more attempts to properly define QRPs. The Framework for Open and Reproducible Research Training (FORRT; Azevedo et al., 2019) defined QRPs very close to the first definition proposed by John et al. (2012) as “a range of activities that intentionally or unintentionally distort data in favor of a researcher’s own hypotheses — or omissions in reporting such practices — including; selective inclusion of data, hypothesizing after the results are known (HARKing), and p-hacking” (Elsherif et al., 2025, para. 1). In contrast, Lakens (2022) defined QRPs with reference to the Netherlands Code of Conduct for Research Integrity as all practices that directly violate its requirements, which state the following: “Make sure that the choice of research methods, data analysis, assessment of results and consideration of possible explanations is not determined by non-scientific or non-scholarly (e.g., commercial or political) interests, arguments or preferences” (KNAW et al., 2018, p. 17). Therefore, Lakens explicitly categorized QRPs as forms of research misconduct, a stance that aligns with the definition proposed by Al-Marzouki et al. (2005). However, although the definition by Al-Marzouki et al. would place QRPs under the broader umbrella of “scientific misconduct,” Lakens’s perspective frames them as specific violations of the Netherlands Code of Conduct for Research Integrity.
Some researchers have investigated questionable practices pertaining to specific parts of the research process or subdisciplines of the field. For example, Gerrits et al. (2019) used an expert-consensus approach to identify “questionable reporting practices” and arrived at the following definition: “to report, either intentionally or unintentionally, conclusions or messages that may lead to incorrect inferences and do not accurately reflect the objectives, the methodology or the results of the study.” Likewise, Wigboldus and Dotsch (2016) stated that “what makes certain research practices questionable or fraudulent are not the practices in themselves. It is the way they are reported (or not reported) that makes them questionable or fraudulent” (p. 30). They even argued that no data-analysis practices in and of themselves can be considered to be QRPs because QRPs are only about transparency—a conclusion we disagree with. Lack of transparency is often but not always the defining feature of QRPs. Moreover, Flake and Fried (2020) introduced the concept of “questionable measurement practices,” which they defined as “decisions researchers make that raise doubts about the validity of measure use in a study, and ultimately the study’s final conclusions” (p. 458). And even the field of metascience appears vulnerable to QRPs; “questionable metascience practices” have been defined as “a research practice, assumption, or perspective that several commentators have identified as potentially problematic for metascience and/or the science reform movement” (Rubin, 2023).
Table 1 summarizes some of the attempts that have been made to define QRPs. All of these definitions touch on the idea that QRPs involve actions or decisions in the research process that can lead to bias, misrepresentation, or distortion of research findings. However, only some acknowledge that engaging in QRPs can be unintentional (Gerrits et al., 2019; Elsherif et al., 2025). Lakens (2022) saw QRPs as actions that breach a code of conduct. From that perspective, behaviors such as research misconduct and fraud are also subsumed under the broader definition of QRPs. Finally, only one definition of QRPs explicitly excludes research misconduct (National Academy of Sciences [US] et al., 1992).
Previous Definitions of Questionable Research Practices

Note: We examined whether each definition a questionable research practice addresses researcher actions, discusses intentionality, considers the outcome of the action, and includes misconduct. The following research phases were considered: planning, data collection, data processing, data analysis, write-up, and publication.
Although this definition is about scientific misconduct, we see this to be a better fit for questionable research practices as they are regarded today.
Despite mentioning a “gray area,” they explicitly included data falsification as a questionable research practice.
We believe that several questions remain open that are not addressed by the reviewed definitions of QRPs. First, where do different QRPs stand on the continuum between unintentional (honest) research errors and intentional fraud or research misconduct? More specifically, can engaging in QRPs be unintentional, and should motivations therefore be excluded from a comprehensive QRP definition? Second, how wide or narrow should a definition of QRPs be? Should questionable measurement practices and other more specific practices be viewed as separate entities, or are they simply a subset of QRPs? Are different QRPs conceptually independent, or do QRPs constitute families of behaviors? Third, which stages of the research process are prone to QRPs?
Following previous definitions of QRPs, some researchers have examined their prevalence and attempted to quantify associated harms. In the next sections, we review the literature focused on the prevalence and negative impact of QRPs and then outline the aims of the current research.
Estimating the Prevalence of QRPs
Several studies in the field of psychology have endeavored to collect the most frequent QRPs. Many of these studies are based on the list of QRPs created by John et al. (2012), who reported self-admission rates between 1.7% and 66.5% for 10 different QRPs. The less severe and more justifiable a potential QRP was seen to be, the more often their sample of 2,155 American psychologists admitted having engaged in that practice at least once in their career.
Fiedler and Schwarz (2016) rephrased the 10 items John et al. (2012) used to make them less ambiguous, which resulted in considerably lower rates of self-admission among 1,138 German psychologists. In addition, the authors computed the estimated prevalence of QRPs by multiplying the proportion of yes responders with the average repetition percentage, which resulted in one-fifth of the prevalence estimate than what John et al. reported. Note that Fiedler and Schwarz did not deny the existence and problematic nature of QRPs; however, they did not share the pessimistic view that QRPs are the norm by which psychologists in academia conduct their research.
Recently, researchers have also examined the prevalence of QRPs in disciplines outside of psychology, including ecology and evolution (Fraser et al., 2018; Gould et al., 2023), linguistics (Coretta et al., 2023), health care (Artino et al., 2019), and communication science (B. N. Bakker et al., 2021), confirming prevalence estimates similar to those in psychology. Ravn and Sørensen (2021) found substantial variability in what is considered a QRP by researchers across disciplines. They conducted 22 focus-group interviews with researchers (N = 105) from the humanities, medical sciences, technical sciences, social sciences, and natural sciences, which yielded 40 QRPs. Only one of those QRPs repeatedly emerged across all five disciplines, and 19 of them came from only one of the disciplines.
A meta-analysis on the prevalence of research misconduct and QRPs in a wide array of research disciplines, such as medicine, biomedicine, economics, and psychology (k = 42), reported an estimate of 12.5% (95% confidence interval = [12.4%, 19.2%]) of researchers having engaged in one or more QRPs over the published research up to 2020 (Y. Xie et al., 2021), a number not as concerning as 66.5% but substantial nevertheless. Banks, O’Boyle et al. (2016) conducted a comprehensive narrative overview of evidence on engagement in QRPs from a multimethodological approach. The authors noted that only six studies out of 64 reported little to no evidence of engaging in QRPs, whereas 58 found overwhelming evidence that researchers engage in QRPs.
To summarize, studies collectively suggest that up to 50% of researchers across scientific disciplines may engage in QRPs to some extent (e.g., Brachem et al., 2022; Fiedler & Schwarz, 2016; Gopalakrishna et al., 2022; John et al., 2012; Y. Xie et al., 2021), highlighting the urgency for a concerted effort to globally address these practices (Lakens, 2022). Moreover, QRPs may be even more widespread in nonacademic research (Bespalov et al., 2018), for instance, advertising research (Bergkvist, 2020), market research, or public opinion polls.
The Negative Impact of QRPs
The first discussion of QRPs stated that “they can erode confidence in the integrity of the research process, violate traditions associated with science, affect scientific conclusions, waste time and resources, and weaken the education of new scientists” (National Academy of Sciences [US] et al., 1992, p. 6). Testing some of these potential harms is challenging, yet recent efforts have been made to assess the impact of QRPs on scientific conclusions, specifically, false-discovery rates and replication success.
More than a decade ago, Simmons et al. (2011) first demonstrated with simulated data how common QRPs—such as “optional stopping” and “selectively reporting conditions”—can dangerously inflate the likelihood of obtaining statistically significant results for effects that do not exist. Kravitz and Mitrof (2023) demonstrated the individual effect of three common QRPs (“mixing pilot- and main-study data,” optional stopping, “not publishing null findings”) and their combined effect on false-discovery rate. Although not publishing null findings led to the most serious inflation of false-discovery rate (up to .50), all three QRPs substantially inflated false-discovery rate.
Likewise, in a recent study, Stefan and Schönbrodt (2023) simulated the impact of 12 QRPs on false-discovery rate for four sample sizes (30, 50, 100, 300). The QRPs in question included optional stopping, “alternating between hypothesis tests” (parametric vs. nonparametric), “scale redefinition,” “outlier exclusion,” and “favorable imputation,” among others. The highest false-discovery rate varied between strategies from around 8% to 40%. Two trends emerged: The severity increased with increasing dissimilarity between tested data sets and an increasing number of tests conducted. Equally, one of the key findings of Banks, Rogelberg, et al. (2016) is that the extent to which engagement in QRPs is problematic likely varies by type and engagement frequency.
In another recent Monte Carlo simulation study focusing on effect-size estimates instead of false-discovery rate, Anderson and Liu (2023) demonstrated the effect of two “cherry-picking” strategies, one in which the outcomes pertained to the same construct and another in which they pertained to different constructs. They found that these QRPs are biasing the magnitude and increasing the heterogeneity of effect-size estimates, particularly when population effect sizes and the correlations of outcomes are small. Overall, existing evidence suggests that QRPs can have detrimental effects on scientific conclusions, especially on false-discovery rate and effect-size estimates.
QRPs may distort the original results and create unrealistic benchmarks for replication (Freuli et al., 2023). Practices such as cherry-picking outcomes or questionable interim analyses may inflate effect sizes and lower p values in the original study, setting a replication standard that is difficult to achieve under unbiased conditions. For instance, inflated original effect sizes lead to a phenomenon known as “shrinkage” in replication studies, in which the observed replication effect size is significantly smaller than the original. This discrepancy can cause the replication to fail the criterion of statistical significance even when the true effect exists (Freuli et al., 2023).
Increased false-discovery rate and biased effect-size estimates should result in reduced replicability; however, some researchers hold diverging, although less common, viewpoints. Ulrich and Miller (2020) argued that replicability might be low in research areas in which true effects are generally rare solely for statistical reasons and not just because certain QRPs run rampant. The study included a quantitative model of replication rate that took into account factors such as the level of significance, power, base rate of true effects, and influence of individual QRPs (i.e., “selective reporting” of significant studies, “failing to report all dependent measures,” “data peeking,” and selective outlier exclusion). This model allowed the estimation of the relative contribution of each of these factors to the replication rate. In line with other simulation studies (e.g., Witt, 2019), Ulrich and Miller showed that the modeled QRPs indeed inflated the false-discovery rate but also indicated that the relative contribution of QRPs may be small under certain circumstances. For example, when the base rates of true effects and true effect sizes are small, the net influence of QRPs on replicability seems to be small and can be compensated by increased statistical power. Unsurprisingly, the negative effect on replicability was more pronounced when QRPs were used more extensively.
To summarize, context and nuance are needed in the discussion of the potential negative effects of QRPs on individual empirical work and their threat to the overall quality of scientific outputs. In light of the work discussed here, we agree with the notion that QRPs pose a substantial threat to scientific conduct and quality. Although some studies have investigated important negative consequences of QRPs (e.g., inflated false-discovery rate, inflated effect size, and replication success), other harms (e.g., reduced confidence in science) might be more difficult to quantify. To be able to investigate the effects of QRPs, the field first needs a comprehensive list of QRPs and their associated negative effects.
Aims of This Study
In this study, we aimed to (a) reach a definition that focuses on researcher actions—rather than consequences—and distinguishes QRPs from similar but not identical concepts, research misconduct, and researcher errors and (b) list and categorize QRPs. This work provides a firm foundation for researchers to critically reflect and improve on their practice, for lecturers and students to teach and learn better practice, and for reviewers and editors to identify and assess the risk stemming from QRPs. This work can also provide a solid framework for future research investigating, for example, the prevalence of QRPs, the extent of associated harms, and the effectiveness of preventive measures.
Method
As a community of scientists, we used the expert-consensus procedure to allow for a collaborative effort in collecting and categorizing QRPs (referred to hereafter as “community consensus”). By bringing together individuals with diverse expertise, we aimed to create a comprehensive list of QRPs that could be used in future research. A hybrid hackathon and online group work provided opportunities for participants to collaborate regardless of location and time zone, creating a more inclusive and efficient data-collection and -analysis process.
Collaborators
At the onset, 37 collaborators from various branches of psychology joined the project in a hackathon event. The majority of initial participants hailed from the United States (n = 12), Canada (n = 6), Germany (n = 5), the United Kingdom (n = 5), and New Zealand (n = 2). In addition, one participant originated from Austria, Australia, Hungary, the Netherlands, North Macedonia, Poland, and Singapore. The collaborators represented a diverse range of academic positions, comprising one full professor, two associate professors, eight assistant professors, three research associates, nine postdoctoral fellows, 11 doctoral students and candidates, and three students (bachelor or master).
Nineteen collaborators continued to contribute off site and online until the manuscript’s completion. We collected a number of metrics indicating the expertise of the collaborators and demographic information indicating the diversity of the collaborators. Selected metrics are reported below; for a complete summary, see the online supplemental materials at https://osf.io/f7uqh/.
At the time of submission, the collaborators included one associate professor, six assistant professors, three research professionals, seven postdocs, and two PhD students. The majority (n = 18) of collaborators were trained in psychology; one was trained in special education. The collaborators have conducted research in the following fields: metascience (n = 10); social psychology (n = 9); cognitive psychology (n = 8); experimental psychology (n = 7); quantitative psychology (n = 6); personality psychology (n = 5); psychometrics (n = 4); education, health, industrial/organizational psychology, and neuropsychology (n = 3 each); clinical, cultural, developmental, environmental, and positive psychology (n = 2 each); and affective psychology, evolutionary psychology, forensic psychology, methods in psychology, and psychophysiology (n = 1 each). The collaborators have conducted research using the following methods: cross-sectional studies, experimental, and survey and questionnaire methods (n = 17 each); correlational studies (n = 16); meta-analysis (n = 12); longitudinal and qualitative methods (n = 10 each); observational methods (n = 9); randomized controlled trials (n = 8); quasi-experimental methods and simulation and computational models (n = 6 each); psychophysiological methods (n = 5); neuroimaging techniques (n = 3); archival research (n = 2); and case studies (n = 1).
The collaborators had between 2 and 16 years of experience conducting research (including PhD-related research; M = 8.8 years, SD = 4.0, Mdn = 9) and between 2 and 12 years of experience conducting metascientific research (e.g., involvement in Many Labs, Many Analysts, the Psychological Science Accelerator, the FORRT, the Collaborative Replication and Education Project; M = 5.2 years, SD = 2.8, Mdn = 4). The number of publications of peer-reviewed articles ranged between two and 137 across collaborators (M = 25.7, SD = 33.6, Mdn = 14), and their h-index ranged between 2 and 42 (M = 10.5, SD = 10.4, Mdn = 6.5).
Procedure
Overview of the process
We initiated the process of collecting QRPs in a hackathon 2 at the annual meeting of the Society for Improving Psychological Science (SIPS) in 2022 in Victoria, British Columbia, Canada. One of the lead authors (T. Nagy) organized the hackathon aiming to find a definition of QRPs, collect as many QRPs as possible, provide key characteristics and examples of each QRP, and ultimately, create a bestiary of QRPs. Participants of the hackathon collaborated both in person and online. In follow-up online sessions, participants engaged in reviewing relevant literature and merged and grouped the QRPs based on concept similarity. This process started at the conference and continued online (see Fig. 1). Note that the QRP definition was created during the SIPS 2022 conference and reflects the consensus reached by all initial collaborators. Subsequently, during the revision process, we decided to remove any notions of intentionality from the definition.

Flowchart of the community-consensus process. Rectangles = group activities of all collaborators; circles = small-group work; hexagons = lead authors’ work; dotted lines = asynchronous processes; solid lines = synchronous processes; circular arrows = iterative processes. The initial group at the hackathon was larger than the final number of collaborators. Asterisks indicate hybrid work, online and in person. The rest of the work took place exclusively online, both synchronously and asynchronously.
After the hackathon, we formed five online groups of three to five collaborators to further refine the list of QRPs. The lead authors (T. Nagy and J. Hergert) assigned each group seven to 10 QRPs, and the members worked individually and together to define the attributes of each QRP, including its name, aliases, research phase, potential harms, preventive measures, detectability, clues, examples, and references. Describing the QRPs was an iterative process: Each member provided suggestions, and all members could provide feedback and contribute to discussions. The result was moved to the next phase only when a group consensus was reached.
After reviewing and researching the assigned QRPs, the groups reconvened to pool their findings and reach a consensus on each QRP and its description. This was also an iterative process during which all members provided suggestions and feedback until a consensus was reached. T. Nagy and J. Hergert then reviewed the list, unified the language, and finalized the QRP attributes. Finally, all authors had the opportunity to suggest final changes to the QRP list.
Description and classification of QRPs
For each QRP, we first formulated a descriptive name that would capture the actions and behaviors involved, collected alternative names, generated a definition, and provided examples. Next, to clarify that researchers may engage in different QRPs at different stages of the research process, we determined the research phase for each QRP: planning, data collection, data processing, data analysis, write-up, and publication. “Planning” encompassed all activities before data collection begins. “Data collection” referred to the period from the start to the end of obtaining data. “Data processing” involved operations on the data before hypothesis testing. “Data analysis” covered statistical modeling and inference, during which hypotheses and research questions are evaluated. The “write-up” phase included drafting the manuscript until submission, and “publication” encompassed all aspects of the publication process. The research stage thus provided one way of categorizing the QRPs.
Another categorization emerged during the iterative collection process because we recognized that some QRPs belong to the same family of research behaviors. We grouped these conceptually related QRPs under QRP umbrella terms.
Subsequently, we considered the consequences of each QRP in terms of potential harms to research outcomes or credibility. After describing harms, we collected possible preventive measures (methods and best practices) that researchers can take to avoid engaging in QRPs or indicate their lack of engagement with QRPs. Note that we focused on the researchers’ perspective rather than other stakeholders because considering preventive measures or remedies from the perspective of editors, publishers, reviewers, universities, and funding agencies would vary significantly. However, given that science constitutes a community of practice that has to be largely built on trust and researcher independence, we believe that researcher behaviors are an important starting point.
Finally, we assessed whether it is possible to detect the presence of each QRP. Assuming a scenario in which (a) an individual who possesses knowledge and skills of research methods and data analysis that are typically acquired in PhD programs (Ord et al., 2016) and (b) is somewhat knowledgeable of the research topic has read the publication, we classified detectability as either yes (detectable), no (not at all detectable), or maybe (detectable only with extra effort and/or extra material, e.g., preregistration or data). To complement detectability, we compiled clues that could indicate the presence of each QRP, noting that the mere presence of a single clue may not necessarily serve as evidence of a QRP but that the presence of multiple clues could justify further investigation. We additionally provided references to further resources that discuss each QRP.
Results
Data and code for reproducing the tables and summary statistics are available at https://osf.io/f7uqh/.
The definition of QRPs
We arrived at a definition that was accepted by all collaborators: Questionable research practices (QRPs) are ways of producing, maintaining, sharing, analyzing, or interpreting data that are likely to produce misleading conclusions, typically in the interest of the researcher. QRPs are not normally considered to include research practices that are prohibited or proscribed in the researcher’s field (e.g., fraud, research misconduct). Neither do they include random researcher error (e.g., data loss).
The definition provides a clear understanding of the types of research practices that are considered questionable and can lead to misleading conclusions. First, the definition specifies a wide variety of actions that may be associated with QRPs, such as research activities, including data collection and analysis, data presentation and interpretation, and data sharing. Second, the definition highlights the outcome of using QRPs because they are likely to produce misleading conclusions, which are typically in the interest of the researcher. We recognize that researchers often employ QRPs to support a hypothesis, but we also consider research in which QRPs are used to collect evidence for the absence of an effect. Third, the definition excludes fraud and random errors as QRPs. We considered fraud, for example, the fabrication of data, clearly unacceptable and therefore not questionable. We also acknowledge that errors may happen in the research process for many reasons (Kovacs et al., 2021).
While working on this manuscript, we had several discussions about the role of researchers’ intentions in QRPs. Our view is that QRPs lie on a continuum between (but not including) fraud and random error. QRPs may be strongly motivated or simply based on a lack of knowledge or social pressure, and it is important not to assume that all engagement in QRPs is intentional. Ultimately, we decided to stay clear of judgments of intentionality and instead focus on providing a detailed description of the behaviors and their attributes, indicators, and preventive measures.
List of QRPs
A total of 40 QRPs were collected; five QRPs pertained to the planning phase, four QRPs were dedicated to data collection, seven QRPs focused on data processing, five QRPs centered around data analysis, 14 QRPs involved the write-up process, and five QRPs concerned publication. Table 2 shows the identified QRPs by research phase, and Table 3 shows all QRPs and attributes.
List of Identified Questionable Research Practices by Research Phase

Questionable Research Practices and Their Attributes

Note: QRP = questionable research practice; CI = confidence interval; ANOVA = analysis of variance; APA = American Psychological Association; NA = not applicable; LMEMs = Linear Mixed-Effects Models.
QRP attributes
QRP umbrella terms
Certain QRPs have gained recognition as an extensive range of behaviors, including p-hacking and “citation engineering.” To enhance precision in delineating these practices, we aimed to disaggregate these overarching QRPs into more specific ones while retaining the commonly acknowledged terms. Consequently, we introduced the notion of QRP umbrella terms. These terms collect several QRPs that share common characteristics or features (see Table 4).
QRP Umbrella Terms
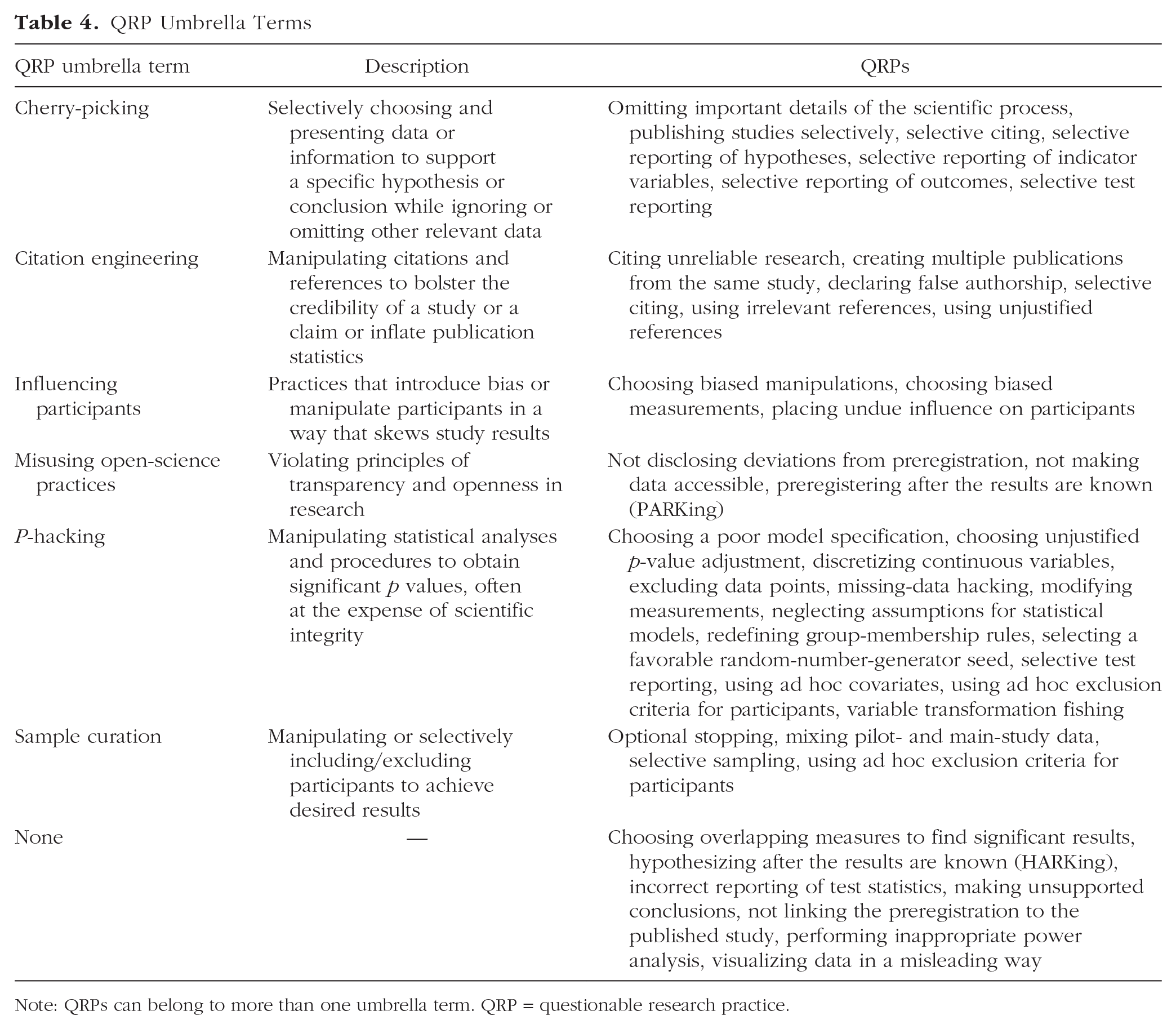
Note: QRPs can belong to more than one umbrella term. QRP = questionable research practice.
“P-hacking” was the most common QRP umbrella term, consisting of 13 QRPs, referring to manipulating statistical analyses and procedures to obtain significant p values at the expense of scientific integrity. We categorized seven QRPs into the “cherry-picking” umbrella term, meaning to selectively choose and present data or information to support a specific hypothesis or conclusion while ignoring or omitting other relevant data. Six QRPs were categorized under “citation engineering,” involving the manipulation of citations and references to bolster the credibility of a study or a claim or to inflate publication statistics. Four QRPs were classified as “sample curation,” which refers to manipulating or selectively including/excluding participants to achieve desired results. Three QRPs were classified as “influencing participants,” including practices that introduce bias or manipulate participants in a way that skews study results. In addition, there were three QRPs classified as “misusing open-science practices,” containing practices that violate principles of transparency and openness in research. Seven QRPs did not belong to any specific umbrella term.
Potential harms
Although all QRPs result in misleading conclusions by definition, some QRPs lead to more specific forms of harm. Likewise, it is worth considering that QRPs may have direct and indirect harms. For example, reduced replicability can be a direct harm, whereas the loss of resources (e.g., time, money) because of attempting to replicate an unreliable study would be an indirect harm. In this study, we focused on specific and direct harms (see Table 5).
Potential Harms Associated With Each QRP

Note: Biased effect-size estimate: Several QRPs can inflate or deflate observed effect sizes, leading to over- or underestimation of the true effect size. Biased statistical error rate: QRPs can directly or indirectly influence the probability of Type I (false positive) or Type II (false negative) errors, distorting statistical inference and leading to incorrect conclusions about the presence or absence of effects. Inflated credibility: QRPs can cause an impression that the study is more robust or reliable than it is in reality. Compromised generalizability: QRPs can lead to claiming representativeness in which representativeness is limited, undermining the external validity of the research and the broader applicability of the findings. Reduced replicability: QRPs can decrease the likelihood that independent researchers achieve similar results when repeating a study with new data even if the methodology is identical. Reduced reproducibility: QRPs can impair the ability to recreate the analytical process using the original data set, which makes it difficult to verify the results of the original study. Other harms include those that appeared fewer than three times (see text). For three QRPs (making unsupported conclusions, visualizing data in a misleading way, and not linking the preregistration to the study), no unique harms beyond the generic harm of misleading readers or distorting the interpretation of research findings were identified, although they fully meet our criteria for classification as QRPs. QRP = questionable research practice.
A range of negative consequences can affect the transparency, efficiency, and credibility of scientific research. Among the most prevalent potential harms, we identified “biased statistical error rates” (i.e., inflated or deflated Type I or Type II error) in 27 cases (see Table 5). This means that several QRPs may result in false-positive or false-negative conclusions. Twenty-three QRPs were associated with reduced replicability. Reduced replicability undermines the reliability and trustworthiness of research outcomes. In addition, 21 QRPs can cause “biased (i.e., inflated or deflated) effect-size estimates,” and 13 QRPs were identified to “reduce reproducibility” of the research, which prevents other researchers from verifying findings. Twelve QRPs may directly “inflate credibility” by overstating the quality of key aspects of the scientific process. Such overstatements may affect how particular claims, referenced studies, and scholarly publications are perceived. Note that inflated credibility can be considered an indirect harm as well (e.g., as a consequence of biased statistical error rates that increase confidence in the results). “Compromised generalizability” was identified as a potential harm for 10 QRPs, referring to the tendency for these practices to artificially bolster the perceived applicability of research findings beyond their appropriate scope or context.
Several harms were associated with fewer QRPs but still warrant attention (referred to as “specific harms” in Table 5). These included “reduced validity of the measure,” “inflated or deflated reliability of the measure,” “publication bias,” “restricted potential for secondary data analysis,” and “lack of deserved credit for contributing authors.”
As can be assumed from Table 5, certain harms are interconnected, with one potentially leading to or exacerbating another, and others arise from distinct, unrelated factors. For example, biased statistical error rates can undermine replicability, but reduced replicability may also result from separate issues, such as the “using biased measurement tools” or the “failure to disclose deviations from preregistered protocols.” These latter practices can independently and directly affect the ability to replicate findings.
Preventive measures
We also collected preventive measures that may help to avoid engaging in specific QRPs and provide guidance to enhance research integrity. Although several preventive measures are rather unique to specific QRPs, common properties can be identified. Thus, we grouped the preventive measures into eight broader categories (see Table 6).
Aggregated Preventive Measures Associated With Each QRP
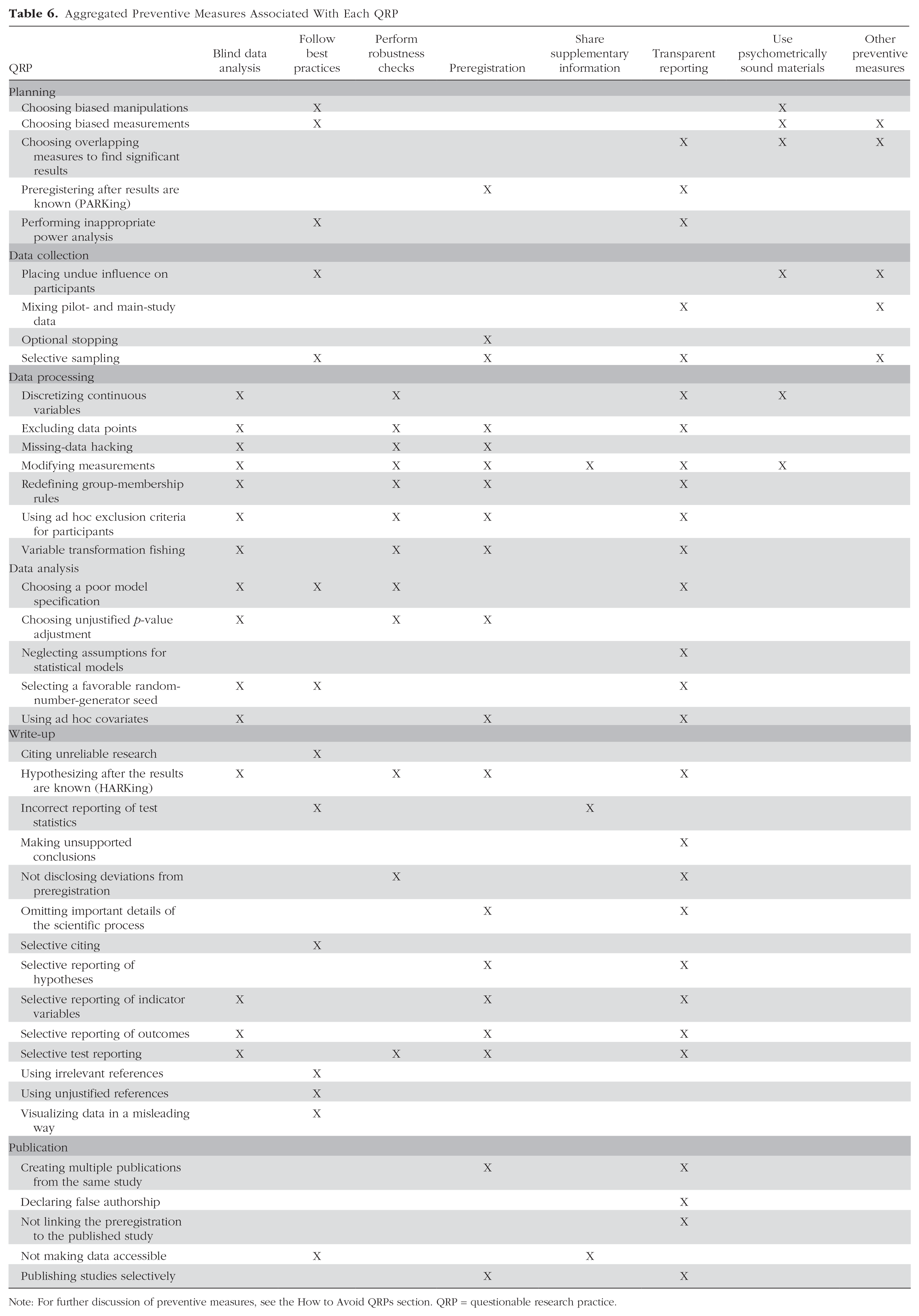
Note: For further discussion of preventive measures, see the How to Avoid QRPs section. QRP = questionable research practice.
The most common category of preventive measures was transparent reporting, in 27 instances, underscoring its importance in ensuring research findings are communicated accurately and comprehensively. Preregistration emerged as a recommended practice in 19 cases, and blind data analysis was advocated in 15 instances. Following best practices was mentioned in 14 instances, emphasizing the value of adhering to established guidelines and standards to promote research integrity. Performing robustness checks, including sensitivity analysis, specification-curve analysis, and assumption checks, was suggested as a preventive measure in 12 cases. The use of psychometrically sound materials was recommended as a preventive measure in six instances, highlighting the importance of employing reliable and valid measures and stimuli. Sharing supplementary information was advocated as a preventive measure in three instances.
Other, more specific preventive measures were identified in five instances, indicating the presence of additional strategies tailored to addressing particular QRPs not covered by the aforementioned categories. Because these other remedies are typically specific to only one or two QRPs, we do not elaborate on them here. Instead, we direct interested readers to Table 3, which provides a comprehensive listing of each preventive measure.
Detectability and clues
As Table 7 shows, out of the total number of QRPs, we categorized 18 as detectable by readers possessing sufficient knowledge of the field if relying solely on the information presented in the publication. Conversely, three QRPs were deemed undetectable (“placing undue influence on participants,” “publishing studies selectively,” “declaring false authorship”). As for the remaining 19 QRPs, their detection is contingent on the availability of supplementary information, such as open data, preregistration records, or other relevant resources. We found that the clues used to identify a QRP exhibit a high degree of idiosyncrasy. In other words, the majority of clues are unique to each specific QRP and do not apply universally across different QRPs. We identified 97 separate clues, and only a few were associated with multiple QRPs. Note that observing any of the clues that we collected for each QRP does not automatically imply a questionable practice. Some well-justified actions in scientific practice might appear similar to QRPs only upon initial observation (Sacco et al., 2019).
Detectability of QRPs

Note: QRP = questionable research practice.
Discussion
In this study, we aimed to define, collect, and categorize QRPs in quantitative psychological research. We used community consensus to develop a definition and a list of 40 QRPs and their aliases, examples, detectability, clues, associated harms, and preventive measures. We also implemented a higher-order categorization—QRP umbrella terms—to group conceptually related QRPs and specified the phase in the research process during which researchers may engage in QRPs. Our definition distinguishes QRPs from research misconduct and random error, and the QRPs bestiary specifies the actions that may produce misleading conclusions. The outcomes of QRPs are often in the interest of the researcher, but we leave discussions of intentionality aside. We hope that this bestiary will provide a useful resource for researchers and educators in and possibly beyond psychology.
Most of the previous studies investigating QRPs did not provide a definition and presented examples instead. There are two notable exceptions: a definition by Elsherif et al. (2025) and one by Gerrits et al. (2019), although the definition by Elsherif et al. considered only actions that distort data, and the definition by Gerrits et al. focused on reporting. We consider QRPs from a broader perspective (similar to the definition proposed by Banks, O’Boyle, et al., 2016), also referring to the collection and interpretation of data and the overall presentation of the research. Unlike the definitions by Lakens (2022) and Al-Marzouki et al. (2005), we explicitly distinguish research misconduct and fraud from QRPs, which legitimizes using the term “questionable” in the first place. Misconduct and fraud by definition can never be questionable and should therefore be viewed and treated differently from QRPs. In our view, questionable measurement practices, as suggested by Flake and Fried (2020), are a subset of QRPs that specifically deal with QRPs related to the measurement of constructs.
We identified 40 QRPs corresponding to six research phases from research planning to publication. Prior studies that listed QRPs did not collect them systematically and, rather, used those found in published articles, originating from the first study by John et al. (2012). Lakens (2022) collected 15 studies attempting to estimate the prevalence of QRPs and found a union of 12 items. This difference in number indicates that a substantial portion of the QRPs we described were previously unlisted even though they are generally recognized as QRPs (e.g., “grooming participants,” “visualizing data in a misleading way,” “citing unreliable research”). Note that we decided to drop “falsifying data,” a practice listed by John et al. as a QRP, because we believe it is research misconduct and therefore outside our definition of QRPs.
While trying to define widely used terms such as “p-hacking” and “cherry-picking,” we realized that they actually cover several otherwise distinguishable QRPs. By breaking up these and other broad terms into smaller units, we were able to clarify definitions, harms, and preventive measures more precisely. Concurrently, we introduced the concept of QRP umbrella terms to keep these existing labels without compromising the distinctiveness of individual QRPs. Keeping these widely used terms as broader categories emphasizes that it is important to be specific about the actual QRP implied when using an umbrella term, such as “p-hacking,” in the future.
We also identified six potential harms (e.g., biased statistical error rates, reduced replicability, inflated credibility) associated with several different QRPs and many more that were specific to individual QRPs. Determining harms may help to clarify why QRPs pose a threat to scientific integrity. However, as Stefan and Schönbrodt (2023) pointed out in their simulation study, QRPs vary in the extent to which they can bias the interpretation of results, such as inflating statistical error rates. Although the methodology of our study is adequate to identify the potential harms, it is up to future studies to empirically test and quantify the extent of associated harms.
Our findings indicate that several QRPs may be detectable based on the original publication- and domain-specific knowledge. Other QRPs might be detected if supplementary materials, such as preregistration, open data, analysis code, and so on, are provided. We collected several clues that can indicate—but not unequivocally prove—if a study’s authors potentially engaged in a specific QRP. This list of clues can be used to improve the peer-review process either by providing a checklist for human reviewers or by providing prompts to artificial-intelligence systems for automatic risk assessment.
How to avoid QRPs
In addition to cataloging QRPs and their attributes, we also assembled a list of preventive measures that may help researchers to prevent engaging in QRPs. In this section, we explore a few general strategies that have emerged as promising approaches to thwart QRPs.
One of the fundamental ways to avoid QRPs is by embracing best practices and using comprehensive checklists. Researchers should adopt rigorous and transparent methodologies, adhering to established guidelines and protocols specific to their field (Appelbaum et al., 2018). By following standardized procedures and employing systematic checklists, researchers can ensure that critical steps are not omitted, minimizing the potential for QRPs to influence their findings (e.g., see checklist provided by Aczel et al., 2020).
Preregistration has gained significant attention as a powerful tool in reducing QRPs (Nosek et al., 2018). By publicly registering their research plans, including hypotheses, methodologies, and analysis strategies, before data collection, researchers establish a predetermined framework that guards against selective reporting, data manipulation, and HARKing. Preregistration enhances transparency, encourages hypothesis-driven research, and helps to demarcate confirmatory from exploratory analyses, thereby mitigating the impact of QRPs on study outcomes (Sarafoglou et al., 2022; van den Akker, Bakker, et al., 2024; van den Akker, van Assen, et al., 2024). Although preregistration does not eliminate QRPs, as demonstrated by van den Akker, Bakker, et al. (2024), it is an important preventive tool.
Extending preregistration, registered reports offer additional safeguards for maintaining high research quality. This approach divides the scientific process into two distinct stages: a peer-reviewed planning phase and an execution stage (Chambers et al., 2015; Chambers & Tzavella, 2022). This separation ensures that the research design is rigorously assessed before data collection begins. By doing so, registered reports enhance the credibility of subsequent findings and contribute to overall research robustness and transparency. This methodology helps to identify potential biases and methodological issues early on, leading to more reliable knowledge generation. Our bestiary might help researchers identify QRPs during the preregistration before engaging in them.
Blind data analysis is another emerging trend that can help prevent several QRPs (MacCoun & Perlmutter, 2015). In blind analysis, researchers carry out data processing and analysis without access to the labels of conditions (or key outcomes). These labels are added to the data set only once the exact data-analysis strategy and code are finalized. By eliminating awareness of conditions and correlations with the main outcomes in the first stage, researchers prevent conscious or subconscious manipulation of the analytical process to yield desired results. This approach can safeguard against QRPs, such as p-hacking, cherry-picking results, or adjusting methodologies to fit preconceived notions, and help to adhere to the preregistered analysis (Dutilh et al., 2021; Sarafoglou et al., 2023).
Robust statistical methods and error checking play a vital role in combating QRPs. Researchers should employ rigorous statistical techniques, such as appropriate power analysis, multiple comparison corrections, and effect-size estimation, to ensure that their findings are statistically sound. In addition, implementing thorough error-checking procedures, such as data and result validation, helps to identify and rectify potential errors or anomalies that could be indicative of QRPs, for example, impossible values in summary statistics or when test statistics do not match p values (Brown & Heathers, 2017; Nuijten, 2022; Nuijten et al., 2016).
Replication can be another way to counteract and limit the harms of QRPs. By demonstrating consistent results across multiple replications, researchers enhance the reliability and generalizability of their findings. Replications can be done using a separate data collection or using an unobserved subset of the data as a test set (i.e., holdout data set) to verify the results (Weston et al., 2019; Yarkoni & Westfall, 2017).
Sensitivity analysis involves systematically varying key parameters and assumptions in a study to assess the robustness of the findings. This process helps researchers understand the potential impact of different choices on their results, thereby enhancing transparency and reducing the likelihood of QRPs. Specification-curve analysis (also called “multiverse analysis”; see Steegen et al., 2016), a more recent development, takes sensitivity analysis a step further by exploring a wide range of modeling specifications to create a comprehensive view of how different analytical choices influence outcomes (Simonsohn et al., 2020). This approach aids in uncovering the potential effects of undisclosed decisions that might have otherwise remained hidden, reducing the temptation for researchers to employ QRPs that lead to positive results.
Collaborative validation, such as adversarial collaborations (Rakow, 2022), multianalyst approaches (Aczel et al., 2021; Silberzahn & Uhlmann, 2015; Wagenmakers et al., 2022), and red teaming (Lakens, 2020), provides an innovative, although resource-intensive, approach to identifying and addressing potential QRPs. In this collaborative setup, multiple independent analysts with diverse perspectives and expertise critically evaluate and replicate each other’s work. By subjecting research to rigorous scrutiny and incorporating dissenting viewpoints, collaborative validation fosters intellectual honesty and exposes potential QRPs, resulting in more reliable and robust scientific conclusions (Aczel et al., 2021).
Finally, fostering open-science practices contributes significantly to the mitigation of QRPs. Researchers should actively embrace the principles of openness by sharing their data, research materials, and code with the scientific community. By making these resources openly accessible, other researchers can verify and replicate the findings, increasing transparency and accountability. Although the open sharing of supplementary information and data is listed as a preventive measure against QRPs only sparingly, its real value lies in facilitating the detection of questionable practices. Practices such as “born open data,” in which data sets are automatically archived at the time of creation, represent an even more transparent approach (Kekecs et al., 2023; Rouder, 2016).
Although our list of preventive measures offers valuable strategies to prevent QRPs, this compilation may not be exhaustive. QRPs can manifest in diverse ways across research contexts, and addressing them requires ongoing vigilance and adaptability. Nonetheless, the provided preventive measures serve as a starting point to promote transparency, rigor, and the cultivation of trustworthy scientific outcomes. These preventive measures and safeguards provide a foundation for increasing the reliability and reproducibility of scientific findings, ultimately advancing the pursuit of knowledge and benefiting society as a whole. The first step to any prevention of QRPs is increasing awareness and ability to recognize potential QRPs, for which this bestiary provides a helpful starting point.
Concepts similar to QRPs
In other areas of research, scholars have sought to define and catalog threats to scientific integrity independently from QRPs. Wicherts et al. (2016) provided a wide definition for researcher degrees of freedom that was accompanied by a list of 34 items. Researcher degrees of freedom are choice points in which researchers make decisions about how to proceed in the scientific process. Although some of these choices can be justified, others may be questionable. For instance, the researcher degrees of freedom of “measuring a dependent variable in several alternative ways” becomes a QRP only if not all outcomes are reported (“selective reporting of outcomes” in our bestiary), potentially leading to false conclusions.
A recent preprint introduced Seaboat (https://www.seaboat.io/), a consensus-based tool that evaluates the most common threats to the validity of empirical research (Schiavone et al., 2023). Seaboat was designed to help reviewers evaluate the quality of quantitative empirical research and make the peer-review process more systematic. It focuses on four types of validities and 32 potential threats to these. The list consists of five threats to construct validity (e.g., insufficient information about operationalization), eight threats to internal validity (e.g., order effects in within-persons designs not ruled out), six threats to external validity (e.g., overgeneralizations), and 13 threats to statistical-conclusion validity (e.g., data exclusion not justified). As shown in the examples, threats to validity and QRPs overlap considerably, but these constructs are not identical. QRPs are actions, whereas threats to validity represent attributes of the article and/or the research. However, some of these threats can be a result of QRPs that have been part of the research process, whereas others (e.g., the neglect of order effects) are arguably more likely to stem from insufficient statistical rigor and may not introduce systematic bias.
The Catalog of Bias is an ongoing collaboration of health researchers to compile an up-to-date and exhaustive list of biases “which may distort the design, execution, analysis, and interpretation of research” (Sackett, 1979, p. 51). The catalog not only collects biases but also provides definitions and potential impacts on empirical research. As a result, Sackett (1979) listed 35 biases regarding sampling and measurement in clinical trials and 56 biases that may potentially affect case-control and cohort studies. Throughout the years, the list has changed, and currently, the catalog consists of 65 biases (https://catalogofbias.org/). Examples include “selection bias,” “allocation bias,” and “detection bias.” We consider such biases as harmful research outcomes, whereas QRPs are all specific actions.
Furthermore, FORRT (Parsons et al., 2022) introduced another compilation of QRPs accompanied by definitions. Their methodology involves presenting a QRP alongside a definition from a specific published finding, leaving ambiguity in the selection process when multiple interpretations exist. In contrast, we have created a systematic list based on community consensus, providing a more objective perspective. Our bestiary can be used as a peer-reviewed compendium of QRPs and their respective definitions, clues, harms, and preventive measures.
Strengths, limitations, and future directions
We chose to use the community-consensus method to identify as many QRPs as possible without the constraints of relying only on existing lists of QRPs that usually focused on QRPs that were creating false-positive findings. This allowed us to acknowledge that in some fields, QRPs may be used to produce false null findings. For example, researchers may want to downplay the side effects of an intervention or want to maintain the status quo to keep getting funding. Our approach considered this possibility for each QRP. In addition, we aimed to provide evidence for the listed research practices as being questionable; therefore, we collected references for each. This approach enriched the community consensus with additional support from the existing literature.
Despite concerns about the reliability of community consensus (or expert consensus) as a form of evidence (see Minas & Jorm, 2010), we chose this method specifically because we believed it might be better suited for finding lesser known QRPs, particularly when including collaborators who are more interested in research methodology. Moreover, in this instance, finding a QRP that is seldom used may cause less harm than not finding an important QRP. Therefore, we prioritized comprehensiveness even if it meant including rare QRPs. In fact, some practices that were previously not recognized as QRPs (e.g., “selecting a favorable random-number-generator seed” or “visualizing data in a misleading way”) have references that mention them, proving that other researchers have encountered these.
Our particular approach to community consensus may also raise concerns about bias or representativeness because of its deviation from more established protocols, such as the Delphi method (Dalkey & Helmer, 1963). Unlike the Delphi method, we did not adhere to certain key aspects of expert selection and anonymity in our process. Note that these deviations could potentially affect the validity of our findings. However, our study did incorporate several essential elements commonly associated with consensus-building methods. First, we held the initial hackathon at a conference that focused on metascience and methodological advancement in psychological science, attracting a diverse group of 37 highly engaged experts, and 19 collaborators remained after the hackathon. Multiple rounds of feedback allowed collaborators to iteratively refine the contributions to the bestiary. Although our approach might differ from the strict procedures of the Delphi method, the inclusion of these fundamental elements allowed us to engage collaborators in a constructive dialogue. This dialogue facilitated the exchange of perspectives and ideas, ultimately contributing to a more informed decision-making process. In response to a reviewer’s suggestion, we also conducted a thorough review of published literature specifically addressing QRPs and their broader categories (Banks, O’Boyle, et al., 2016; Banks, Rogelberg, et al., 2016; Ravn & Sørensen, 2021; Suter, 2020; Y. Xie et al., 2021). This review allowed us to cross-reference our list of QRPs and identify any practices that we might have inadvertently omitted. We did not identify any further QRPs that would fit our definition.
Although our list is probably the most comprehensive list of QRPs to date, it is likely incomplete. As Stefan and Schönbrodt (2023) already noted, compiling a truly exhaustive list of QRPs seems like an impossible endeavor, especially because many highly specialized fields of research—both within and outside of psychological science—have very specific ways of designing studies and collecting, processing, and analyzing data. However, we hope that our list contains most of the QRPs used in psychology and the social sciences in general. Moreover, we see our work as more than just a list of QRPs because it also represents a systematic approach to QRPs (e.g., describing actions and behaviors related to specific QRPs, providing a definition, identifying the research phase and associated harms and remedies). This systematic approach is likely more enduring than the items on the list.
Note that our bestiary was developed exclusively for quantitative research methods, although some of the QRPs (e.g., placing undue influence on participants or QRPs associated with the write-up phase) might be relevant for qualitative research as well. We believe that our work might inform similar endeavors aimed at improving research practices in the qualitative-research community.
The aim of this work was to create an extended list of QRPs in terms of specific behaviors that may result in specific harms. Because we are providing a new list of QRPs, their prevalence and the impact of associated harms are largely unknown and require further research to quantify. In addition, even for the more prominent QRPs, only a few potential harms have been investigated (effects on statistical error rate, estimated effect size, and replicability), and other harms are more difficult to quantify (e.g., effect on credibility and reproducibility). With this work, we hope to spark future research interest aimed at estimating the prevalence of engagement in QRPs, the effectiveness of preventive measures, and the severity of QRP-associated harms.
Conclusion
Our goal with this bestiary is to help researchers avoid QRPs, thus ultimately raising the standard of psychological research. This community-consensus study showed that a proper definition of QRPs is essential and achievable, as is their collection and categorization. Among the 40 QRPs identified in our study, many were previously unrecognized. Moreover, we found that some formerly known QRPs (e.g., p-hacking) actually comprised several well-distinguishable QRPs—we named these “QRP umbrella terms.” We concluded that most QRPs can be detected, especially when journals and institutions embrace open-science practices, such as data sharing and preregistration. Moreover, specific harms were identified for each QRP along with preventive measures that can help to avoid or mitigate the detrimental effects of QRPs on the integrity and validity of research findings. Finally, this work can be used for further research on QRPs, (self-)education, and peer review.
Footnotes
Transparency
Action Editor: Katie Corker
Editor: David A. Sbarra
Author Contributions
T. Nagy and J. Hergert are shared first authors.