
Abstract
Randomized experiments remain the “gold standard” for establishing causality, yet ethical and practical constraints in certain fields often require researchers to rely on observational data. Although psychologists recognize that correlation does not imply causality, the conventional cautionary statements regarding correlation typically found at the end of articles have not sufficiently advanced psychological science, particularly in subfields, such as developmental and personality psychology, that predominantly rely on observational data. Sensitivity analyses commonly used in biostatistics and epidemiology offer powerful tools to quantify the risk of unmeasured confounding in observational data analysis, essentially encouraging applied researchers to assess how strongly an unmeasured confounder must be associated with both the predictor and outcome to negate an observed predictor-outcome association (i.e., reduce the effect to null). In this tutorial, we explore the frequently overlooked but critical issue of unmeasured confounding in psychological research and introduce psychologists to the E-value, a novel and straightforward method for assessing the robustness of exposure-outcome associations to unmeasured confounding. We demonstrate the application of E-value using common psychological-research scenarios in R and discuss its strengths, limitations, and recommended best practices. Psychologists can more accurately assess and transparently report research findings, particularly in subfields relying primarily on observational data, by more explicitly considering unmeasured confounding and incorporating sensitivity-analysis techniques such as the E-value into their methodological tool kits.
Keywords
Randomized experiments remain the “gold standard” for establishing causality (Hariton & Locascio, 2018). However, circumstances sometimes render experiments unethical or unfeasible, leaving researchers to rely on observational data. Indeed, almost entire bodies of literature in psychology (e.g., parental warmth’s “effect” on youth adjustment) have long depended on nonexperimental data, (mis)guiding clinical practices even when evidence is weak and inconclusive because of lack of rigorous selection of confounders and considerations for the threat of (unmeasured) confounders (Davis et al., 2024).
Psychologists widely recognize that correlations identified in observational studies do not imply causality. This acknowledgment stems from the inherent susceptibility of observational studies to confounders—factors that, whether measured or unmeasured, causally influence both the treatment/exposure and the outcome, which can lead to spurious associations (Haneuse et al., 2019). Nevertheless, along with statistical-adjustment practices among applied researchers that are often deemed too flexible (Rohrer & Lucas, 2020; VanderWeele et al., 2020), the ubiquitous statement that “correlation does not infer causality” as a brief disclaimer in the limitations section of nonexperimental psychological studies has not effectively served the research community. This limitation impedes the advancement of cumulative psychological science, which ultimately relies on causal evidence (Brady et al., 2023; Grosz, 2023). In the causal-inference literature, the lack of randomization in observational studies often violates a central assumption termed the “exchangeability assumption” (i.e., no unmeasured confounding)—the idea that the treatment and control groups are comparable in all important ways except for the treatment/exposure (for brief explanations of key concepts in causal inference, see Table 1), making it challenging to establish valid counterfactual comparisons between treated and untreated groups. In the absence of random assignment, differences between these groups may be driven by confounding variables that influence both the exposure and the outcome rather than the exposure alone. Although methods that improve the plausibility of this assumption exist (e.g., regression control, propensity score matching [PSM]), the exchangeability assumption remains untestable. In practice, measuring and adjusting for all potential confounders is excruciatingly difficult—if not impossible. When observational data are used and rigorous statistical adjustments are made, it is advisable to conduct sensitivity analysis, such as the E-value technique, to quantify how much residual unmeasured confounding is needed to change the substantive conclusion of a given observational study’s finding (e.g., bringing the point estimate to null).
A Brief Primer of Key Concepts in the Causal-Inference Literature

When guided by the causal-inference framework, researchers typically follow three key steps to approach causality. (a) Define the estimand: The first step is to define the causal quantity of interest, known as the “causal estimand.” This could be the average treatment effect (ATE) or the average treatment effect among the treated (ATT), depending on the study design and method used, which may estimate effects for different subpopulations. (b) Identify the causal estimand: Identifying the estimand refers to the process of determining whether the causal effect can be estimated from the data. This requires making assumptions such as exchangeability (i.e., treated and untreated groups are comparable after adjustment) and positivity (i.e., there is a positive probability of receiving each treatment level). (c) Estimate the effect: Once the causal estimand is identified, various methods can be used to estimate it (i.e., translating the causal estimand into a statistical estimand). In observational data, this often involves adjusting for confounders using methods such as regression, PSM, or instrumental variables (IVs; Rubin, 2005; for introductory texts for psychologists, see Grosz et al., 2024; Rohrer, 2018).
Recent methodological advancements in causal inference (Rubin, 2005; for introductory texts for psychologists, see Grosz et al., 2024; Rohrer, 2018) that are commonly applied in biostatistics and econometrics have provided researchers analyzing observational data with more effective tools to address the threat of confounders, 1 allowing them to better meet arguably the most crucial assumption—the exchangeability assumption—during the identification phase of causal inference so that the causal estimand of interest is identifiable (Angrist et al., 1996; Caliendo & Kopeinig, 2008; Emdin et al., 2017). For example, matching methods, such as PSM, that, unlike the traditional analysis, clearly separate the design and analysis phases and avoid obtaining an adjusted effect through extrapolation (Chan et al., 2022; Thoemmes & Ong, 2016) allow researchers to minimize the measured differences between a treatment group and a control group beyond the treatment itself. As a result, they enhance the validity of comparisons, ensuring they are more akin to comparing “apples with apples” (i.e., exchangeability) rather than “apples with oranges” (Caliendo & Kopeinig, 2008; Iacus et al., 2012). As another example, IV estimation 2 (Angrist et al., 1996; for an accessible introduction for psychologists, see Grosz et al., 2024) enables researchers to mitigate even unmeasured confounding, provided certain stringent assumptions are met (Lal et al., 2024). Even in the field of psychology, methodologists focusing on within-units analyses have started to explicitly situate these methods within the potential-outcome framework, a principled approach in the causal-inference literature (e.g., Usami, 2023; Usami et al., 2019). For example, models such as the random-intercept cross-lagged panel model (RI-CLPM), which account for stable time-insensitive trait variances (Hamaker et al., 2015), are increasingly used in psychology to control for unmeasured time-invariant confounders (e.g., Bi et al., 2024). Despite methodological advances both within and outside psychological science, psychologists, however, rarely explicitly discuss whether the causal-identification assumption of exchangeability is likely met when reporting their findings and the potential threats of unmeasured confounding (Grosz et al., 2020). Indeed, a notable gap exists in addressing confounding even in epidemiology, a field that traditionally emphasizes causal interpretations from observational data. For example, a recent study revealed that of 69 sampled articles in a prominent epidemiological journal, 75.4% (52/69) omitted comments on potential unmeasured confounding (Blum et al., 2020).
Sensitivity analysis, commonly applied in biostatistics and epidemiology, offers psychologists working with observational data a valuable tool to critically evaluate the potential threat of unmeasured confounding (i.e., violation of the exchangeability assumption). In essence, sensitivity analysis prompts the researcher to ask a fundamental but often overlooked question: How strongly would the unmeasured confounder(s) need to be associated with both the exposure variable (i.e., independent variable) and the outcome variable to reduce the observed exposure-outcome association to zero (e.g., an odds ratio [OR] of 1.00) or render it statistically nonsignificant? Although sensitivity analysis has a long history in the psychological literature and in medical and social sciences more broadly (Cornfield et al., 1959), with significant contributions by Paul Rosenbaum (Rosenbaum & Rubin, 1983; see also G. Hong, 2004), many of the existing approaches are criticized for relying on simplified but untestable assumptions about the unmeasured confounder(s) (Ding & VanderWeele, 2016). For example, common assumptions include that the unmeasured confounder is binary, that there are no interactions between the effects of exposure and the confounder on the outcome, or that only one unmeasured confounder exists (Rosenbaum & Rubin, 1983; Schlesselman, 1978).
VanderWeele and Ding (2017) proposed an intuitive and straightforward sensitivity analysis technique without these assumptions, termed the “E-value,” where “E” stands for evidence. The E-value represents the minimum strength of association an unmeasured confounder 3 would need to have with both the treatment and the outcome after accounting for measured confounders to fully explain the observed treatment-outcome relationship (for a conceptual model with more technical explanations, see Box 1). This metric is expressed on the risk-ratio (RR) scale 4 but can also be calculated from ORs, hazard ratios, and standardized mean differences (SMDs; Haneuse et al., 2019). For readers interested in the technical aspects of the E-value, we refer them to Ding and VanderWeele (2016) and VanderWeele et al. (2019). Compared with other sensitivity-analysis techniques, the E-value is more intuitive (i.e., the lowest possible E-value is an RR of 1.00), easier to implement, and less subjective and requires fewer assumptions (Ding & VanderWeele, 2016; Haneuse et al., 2019; Trinquart et al., 2019). Note also that the E-value does not tell one whether unmeasured confounding is actually present—it simply quantifies the strength of confounding needed to fully explain an observed association.
Technical Aspects of the E-Value

Let RRUD be the maximum risk ratio for the outcome when comparing any two categories of the unmeasured confounder (U) in either the exposed or unexposed group and let RREU be the maximum risk ratio for any specific level of the unmeasured confounder comparing individuals with and without treatment (i.e., the extent of confounder imbalance across treatment conditions). For example, RREU = 2.00 if the exposed group has a 40% prevalence of an unmeasured binary confounder and the unexposed group has a 20% prevalence (VanderWeele & Ding, 2017). To reduce RRED (the observed risk ratio for the exposure-outcome association) down to the null, RREU and RRUD must be at least as large as the E-value (i.e., the minimum required joint strength for both) when RREU equals RRUD. Ding and VanderWeele (2016) showed that adjusting RRED down to 1.00 (i.e., no effect) requires the magnitude of the confounder associations to produce confounding bias equal to RRED. That is, RRED divided by the bias factor must equal 1.00. This bias factor is determined by the equation RREU × RRUD / (RREU + RRUD – 1). Thus, the E-value formula provides the positive solution for the bias factor when RREU = RRUD. Note that because the maximum risk ratios were considered, the resultant E-value was considered a worst case scenario. This means that it is conservative, and any given unmeasured confounder(s) may or may not generate this amount of bias—for example, a confounder with low prevalence may not cause this amount of bias.
In other words, the E-value essentially represents the minimum association strength needed for both the exposure-confounder and confounder-outcome relationships to (potentially) adjust RRED down to null, conditional on measured confounders.
Although the E-value is increasingly used in epidemiology (Haneuse et al., 2019), it remains relatively unfamiliar to most psychologists. Therefore, in this tutorial, we introduce psychologists to the E-value, a novel sensitivity-analysis technique that can help assess the robustness of treatment-to-outcome associations against unmeasured confounding. Furthermore, our tutorial responds to recent calls from methodologists advocating for practices that strengthen causal inference in psychological science (e.g., Davis et al., 2024; Grosz et al., 2020; Hamaker et al., 2015; Rohrer, 2018; Rohrer & Murayama, 2023). We contend that psychologists, many of whom (at least sometimes) rely on observational data, can benefit from the appropriate and contextualized use of the E-value.
In this tutorial, we first demonstrate how to calculate E-values across various scenarios and parameter estimates, including RR, OR, SMDs, and linear-regression coefficient. Second, using the
Study Pipeline for Reporting E-Values of a Given Study
Specify the causal effect of interest (e.g., exposure on outcome), clearly identifying the estimand (e.g., average treatment effect) and key assumptions (e.g., exchangeability, consistency, positivity).
Adjust for measured confounders using appropriate statistical methods, such as regression, inverse probability weighting, or propensity score matching.
Calculate E-values using appropriate formulas to assess robustness to unmeasured confounding. This can be implemented using the EValue package in R. Report two E-values: (a) the E-value for the point estimate and (b) the E-value for the confidence interval.
Discuss if rigorous statistical control is achieved, report/tabulate the associations between the measured covariates and exposure/outcome, and interpret whether realistic magnitude of unmeasured confounding is possible to explain away and/or change the statistical significance of the observed exposure-outcome association and whether the E-value is small or large given the context.
Although the absence of evidence for causality is not the same as evidence of no causal effect, if E-values suggest vulnerability to unmeasured confounding, discuss how this affects the study’s conclusions and be transparent about how unmeasured confounding might have influenced the findings.
Definition and Implementation
As previously outlined, the E-value is calculated on the RR scale and measures the magnitude of association an unmeasured confounder would need to have with both the treatment and outcome to negate the observed treatment-outcome association in a nonexperimental study. In general, higher E-values indicate more robust treatment-outcome associations because unmeasured confounders would require correspondingly large RRs to negate the findings. In the sections that follow, we present the calculations of the E-value for four parameter estimates commonly of interest to psychologists, including RR, OR, SMD (Cohen’s d), and linear-regression coefficients. To facilitate understanding, we have provided numerical examples of how E-values can be calculated under different circumstances in Table 2.
Numerical E-Value Calculations Examples Under Different Scenarios

Note: RR = risk ratio; OR = odds ratio; SMD = standardized mean difference.
RR
Because the E-value is on the RR scale, we first demonstrate how to compute the E-value from RRs. For any given parameter, it is recommended that researchers report two E-values: one for the point estimate and another for the limit of the 95% confidence interval (CI) that is closer to the null (i.e., the strength of unmeasured confounding needed to make the association statistically nonsignificant). The formula for 95% CI for RR is (eln(RR)–1.96×SE, eln(RR)+1.96×SE). The E-value for an observed outcome based on the RR is derived from the following equation 5 :
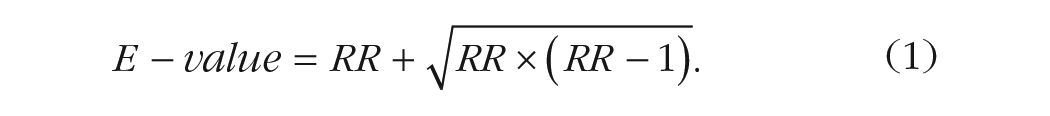
OR
To compute E-values from OR estimates, researchers must first assess the prevalence of the outcome at follow-up. Prevalence rates play a crucial role in how E-values are computed for ORs because the relationship between ORs and RRs changes depending on the prevalence of the outcome (VanderWeele, 2017). When the outcome is rare, the OR and RR are nearly equivalent, making it straightforward to use the OR in E-value calculations without adjustments. However, when the outcome is common, the OR tends to overestimate the RR, necessitating a transformation of the OR (e.g., a square root approximation; VanderWeele, 2017) to better approximate the RR before applying the E-value formula. If the prevalence of the outcome is relatively rare (< 15%),
6
Equation 1 can then be directly applied (Ding & VanderWeele, 2016). For outcomes that are common (> 15%), the E-value can be approximated by replacing the RR with the square root of the OR (i.e., RR ≈
Differences in continuous outcomes
Calculating the E-value from differences in continuous outcomes, such as SMDs, defined as the mean difference of the outcome divided by its pooled standard deviation (i.e., Cohen’s d), is slightly more complex. The RR can be approximated from Cohen’s d subject to distributional assumptions using Equation 2 (Chinn, 2000; Mathur et al., 2018): 7

The RR can then be used to calculate the E-value using Equation 1. For instance, with d = 0.32, the corresponding approximate risk ratio is 1.34, and the E-value is 2.01. An E-value of 2.01 suggests that the unmeasured confounder would need to be twice as prevalent among the exposed than among the unexposed (i.e., the exposure groups are highly imbalanced in the unmeasured confounder; VanderWeele & Ding, 2017) in addition to doubling the probability of being “high” versus “low” on the outcome following a hypothetical dichotomization of the continuous outcome conditional on covariates already adjusted for. Because effects of this magnitude (i.e., RRs ≥ 2 or 3) are relatively uncommon in medical and social sciences when the estimate is already conditional on important measured confounders, in many situations, an E-value of 2 would suggest relative robustness of findings, especially when the observed exposure-to-treatment effect is already conditional on a rigorous selection of measured known confounders (VanderWeele & Ding, 2017). To approximate the 95% CI for the corresponding RR, the standard error 8 of d is inserted into the following formula 9 : (exp{0.91 × d – 1.78 × SEd}, exp{0.91 × d + 1.78 × SEd}).
Linear-regression coefficient
Because linear-regression coefficients, both standardized and unstandardized, are among the most widely estimated parameters in psychological science, in this tutorial, we focus on detailing the calculation and interpretation of E-values derived from these coefficients.
In the context of a categorical exposure (e.g., no exposure vs. exposure, lowest quartile vs. highest quartile), linear-regression coefficients quantify the adjusted mean difference(s) between the reference group and comparison group(s), controlling for covariates. These coefficients represent the unique effects on the outcome above and beyond covariates. To convert a linear-regression coefficient into the SMD measure d, divide the coefficient by the residual standard error from the model, which reflects the variability in the outcome that is not explained by the exposure and covariates (Linden et al., 2020). Subsequently, the RR can be approximated from d using Equation 2 to compute the E-value using Equation 1.
When calculating the E-value for a continuous exposure, an additional parameter called “delta” is required. Delta defines a dichotomization of the exposure variable between a hypothetical group of participants with an exposure value equal to an arbitrary value c versus another hypothetical group with an exposure value equal to c + delta (Mathur et al., 2018). Delta, therefore, represents the contrast in the exposure variable, typically defined as a 1-unit change. For example, this could mean a 1-SD increase in the exposure variable. The process involves converting the linear-regression coefficient, which reflects the effect of the continuous exposure on the outcome, into an SMD (Cohen’s d). This conversion is achieved by dividing the regression coefficient by the residual standard error from the regression model. For example, if a 1-unit increase in the exposure results in a Cohen’s d of 0.32, the corresponding RR would be approximately 1.34. The E-value in this scenario would be calculated to be approximately 2.01. This implies that the unmeasured confounder would need to be twice as prevalent among the hypothetical exposed group (E = c + delta) than among the hypothetical unexposed group (E = c; i.e., the hypothetical exposure groups are highly imbalanced in the unmeasured confounder; VanderWeele & Ding, 2017) in addition to doubling the probability of being in the “high” versus “low” group on the dichotomized outcome variable to fully explain away the observed association conditional on covariates already adjusted for (Mathur et al., 2018). The use of delta allows the continuous exposure to be treated similarly to a binary exposure, making applying the E-value framework to continuous variables easier. In other words, delta essentially represents the hypothetical intervention “dosage” or the magnitude of the exposure change that researchers would consider clinically or theoretically meaningful had they had access to experimental data. Depending on the unit (e.g., a 1-point increase on a scale of 1 to 7 or a standardized 1-unit increase) and the chosen increment (1.0 unit or 2.0 units), the larger the difference of the increase (i.e., the larger the hypothetical dosage), the larger the resulting E-value will be. However, this comes with the caveat that two more extreme hypothetical exposure groups are likely more imbalanced on unmeasured confounders. This also implies that a larger E-value is needed for an indication of genuine robustness (VanderWeele et al., 2019). In general, we recommend a standardized 1-unit increase (i.e., delta = 1 with a standardized continuous exposure) as the unit of choice. Alternatively, one can categorize the continuous exposure into tertiles or quartiles and calculate the E-value by comparing the highest and lowest groups. This categorization approach is common in studies that calculated the E-value for continuous exposure (e.g., Chen et al., 2024; J. H. Hong et al., 2023; Kim et al., 2021, Kim, Wilkinson, Case, et al., 2024) because it allows the researchers to assess threshold effects and obtain more intuitive interpretations (Kim et al., 2021). In this case, one is essentially evaluating whether a hypothetical intervention that moves participants from, for example, the first tertile to the third tertile may have a potentially causal effect on an outcome of interest provided that the causal assumptions (e.g., exchangeability, positivity, and consistency) are met (Kim et al., 2021).
Transparency
The R script for the present tutorial is publicly available on OSF (https://osf.io/dbxm6/). The data set used is publicly available at https://www.icpsr.umich.edu/web/ICPSR/studies/21600.
Introducing the Data
In this tutorial, we use data from the public-use version of the National Longitudinal Study of Adolescent to Adult Health (Add Health; Harris et al., 2019), a population-based longitudinal cohort study of U.S. adolescents. It was approved by the Institutional Review Board of the University of North Carolina-Chapel Hill. For the purpose of our tutorial, we used data from Waves 1 (prebaseline, 1994–1995), 2 and 3 (baselines), and 4 and 5 (follow-ups) of the Add Health study. In the tutorial, we focus on three scenarios commonly encountered by psychologists: (a) regressing a binary rare outcome (occurrence of suicidal ideation) on a continuous exposure (depressive symptoms), (b) regressing a continuous outcome (poor self-rated health) on a continuous exposure (depressive symptoms), and (c) regressing a binary rare outcome (occurrence of binge drinking) on a binary exposure (recent volunteering). We note that the last scenario was a replication of Nakamura et al. (2024). Nakamura et al. recently used the Add Health study to understand the potentially causal effect of volunteering in young adulthood, a binary exposure assessed in Wave 3, on a range of subsequent health and psychosocial outcomes. They found that conditional on a rich set of covariates including both prebaseline outcome and retrospectively assessed volunteering during adolescence (a proxy for prebaseline exposure), the association between volunteering in young adulthood and reduced likelihood of binge drinking at Wave 5 (defined as at least one to two times a week of drinking four to five alcohols in a row [coded as 1] vs. fewer frequencies [coded as 0]) was at least moderately robust, with an E-value of 2.40. Here, we replicated this finding to demonstrate how to calculate the E-value for a binary exposure. All analyses control for several known confounders measured at prebaseline (Wave 1), including age, biological sex, family income, neighborhood satisfaction, and most importantly, prebaseline exposure and outcome, which are among the strongest confounders in many studies (VanderWeele et al., 2020). We chose to control for prebaseline confounders instead of baseline confounders to avoid overcontrolling in case the confounders we chose include potential mediators (Rohrer, 2018; VanderWeele et al., 2020), with the caveat that controlling for covariates in the prebaseline wave may not capture time-varying confounding that took place between the prebaseline wave and the baseline wave, 10 especially if the time interval is long (e.g., 10 years vs. 1 year; Pelham et al., 2021). Note that the statistical adjustment is simplified for demonstration purposes and that the adjustment is not comprehensive. Selecting appropriate confounders for a particular analysis requires strong domain knowledge and can benefit greatly from drawing directed acyclic graphs (DAGs)—a principled and systematic way to transparently and explicitly encode causal assumptions among variables through the use of visual graphs even if important variables (e.g., a confounder) are not measured (for an accessible introduction for psychologists, see Rohrer, 2018). For recommendations on what confounders to consider for longitudinal analysis in general, we refer readers to VanderWeele et al. (2020), Mathur and VanderWeele (2022), and Davis et al. (2024).
Analytic Plan
For Scenario 1, a multivariable logistic regression model was conducted via the
For Scenario 2, a multivariable linear-regression model was conducted via the lm() function and stored as an R object named
For Scenario 3, a multivariable logistic regression model was conducted via the
Computing an E-value From a Logistic-Regression Model for a Continuous Exposure
Because the logistic-regression model is stored in an object named

Then, we convert the coefficient (the log OR) to OR by exponentiating it via the

Then, we need to install and load the
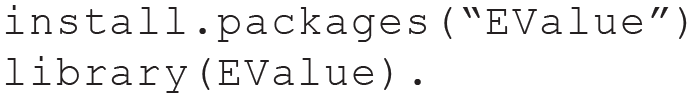
Finally, we insert the resulting OR (

Then, we inspect and interpret the results by running the following code:

The E-value for our logistic-regression model with depressive symptoms at baseline predicting suicidal ideation at follow-up conditional on a relatively robust set of confounders was 1.81, indicating that an unmeasured confounder’s association with both the exposure and outcome would need to have an RR of at least 1.81 to fully negate the observed association between depressive symptoms and suicidal ideation. To render the observed association statistically nonsignificant and shift the 95% CI to include the null, an E-value of 1.37 is needed. If the unmeasured confounder has a weaker association with either the treatment (depressive symptoms) or the outcome (suicidal ideation) than the E-value suggests (i.e., less than an RR of 1.81), this would necessitate a stronger association with the other variable to fully explain away the observed effect. For example, if the confounder has an association equivalent to an RR of 1.50 with depressive symptoms, it would need a stronger association with suicidal ideation—greater than an RR of 1.81—to negate the exposure-outcome association. Conversely, if the unmeasured confounder has an association stronger than an RR of 1.81 with one variable, the required association with the other variable to negate the exposure-outcome association will be weaker than an RR of 1.81. To gain a better understanding of how the unmeasured confounder’s impact depends jointly on the strengths of its associations with both the exposure and outcome, one can plot a bias plot using the

Bias plot for empirical Example 1. RREU and RRUD represent the maximum magnitude of association that the unmeasured confounding has with the exposure/predictor and the outcome, respectively (for technical details, see Box 1). The equation in the plot is used to calculate the bias factor. By setting RREU = RRUD, solving RREU × RRUD / (RREU + RRUD – 1) = 1.25, where 1.25 is the exposure-outcome risk-ratio association conditional on the measured confounder, gives us the E-value for this particular observed exposure-outcome association, which is 1.81 (the positive solution). This plot illustrates how the unmeasured confounder’s impact depends jointly on the strengths of its associations with both the exposure and outcome. It shows that when the strength of one association (e.g., RREU) is larger than the E-value of 1.81, the strength of RRUD needed to negate the observed exposure-outcome association will be lower than 1.81.
Computing an E-value From a Linear-Regression Model for a Continuous Exposure
The linear-regression model is stored in an object labeled

Then, we can calculate the residual standard deviation of the outcome (a more conservative calculation of the outcome’s standard deviation is to calculate it via
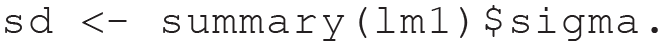
Then, we can insert the
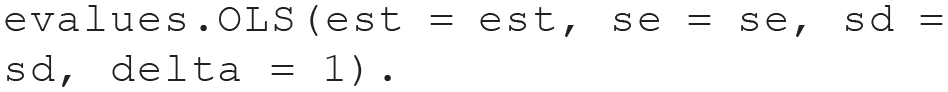
Then, we inspect and interpret the results by running the following code:

In our linear-regression model analyzing the effect of depressive symptoms at baseline on poor self-rated health at follow-up, conditional on measured confounders, the E-value was 1.37. This indicates that for unmeasured confounding to fully explain away the observed association, it needs to have an association equivalent to an RR of 1.37 with both the exposure and the outcome above and beyond the confounders already adjusted for, but weaker confounding could not. In addition, to render the observed association’s 95% CI to include zero (i.e., rendering the observed association statistically nonsignificant), an E-value of 1.24 is needed, but weaker confounding could not. These values suggest that the observed association between depressive symptoms and subsequent self-rated health could, at most, be viewed as only somewhat robust to unmeasured confounding. However, this relatively small E-value should be viewed in light of the fact that depressive symptoms and self-rated health at prebaseline and other measured confounders were statistically controlled for. It should be noted that a smaller E-value can only suggest the evidence of causality for a given association is relatively weak—that is, the absence of evidence for causality is not the same as evidence of no causal effect (VanderWeele & Ding, 2017).
Computing an E-Value From a Logistic-Regression Model for a Binary Exposure
The logistic-regression model with a binary exposure is stored in an object labeled

Then, we convert the coefficient (the log OR) to OR by exponentiating it via the

Finally, we insert the resulting OR (

Then, we inspect and interpret the results by running the following code:

In our logistic-regression model with a binary exposure, the effect of recent volunteering at baseline on binge drinking at follow-up, conditional on measured confounders, was marginally significant (OR = 0.76, p = .082). Had we passed the conventional significance test and obtained a p < .05, we would have proceeded and obtained an E-value of 1.96. An E-value of this magnitude would suggest that for an unmeasured confounder to fully explain away the observed association, it would need to have an association equivalent to an RR of 1.96 with both the exposure and outcome above and beyond the confounders already adjusted for, but weaker confounding could not. Because the effect’s 95% CI includes null, the E-value for the 95% confidence limit would be 1.00. The calculated E-value for our analytic sample was 1.96, lower than the E-value of 2.40 that Nakamura et al. (2024) reported. The discrepancy in magnitude and significance testing can arise from (a) different analytic approaches and data preprocessing decisions (e.g., they may have used Poisson regression with a “log” link to directly estimate the RR), (b) our use of listwise deletion, and (c) our use of the public-use version of the Add Health data set, which has a smaller sample size than the sample size of Nakamura et al. Furthermore, given the binary nature of both exposure and outcome,
15
we showcased how to tabulate associations between covariates and exposure/outcome in Table 3. Regarding covariate-outcome associations, the E-value (1.96) in this analysis is larger than all covariates’ effects on the outcome except the effects of biological sex (RR = 2.57). Regarding covariate-exposure associations, the E-value (1.96) is larger than all exposure-confounder associations except for the associations between exposure and the prior exposure value (RR = 2.66) and the association between exposure and the prior outcome value (RR = 2.34). These comparisons helped contextualize the E-value’s strengths. The E-value suggests that an unmeasured confounder is associated with both the outcome and exposure with a strength similar to biological sex’s association with the outcome (the association between exposure and biological sex has an RR of 1.12); conditional measured confounders including but not limited to both prior exposure and outcome would negate the observed association, implying moderate robustness of the study finding. Furthermore, because the exposure of this example is binary (0 = no volunteering vs. 1 = volunteering), a scenario in which researchers may naturally be inclined to use matching/weighting methods to arrive at the statistical estimand because these methods clearly separate the design phase from the inference phase (Chan et al., 2022), we also describe how E-values can be calculated from an analysis based on PSM, which generally targets ATT, and inverse probability of treatment weighting (IPTW), which generally targets the ATE. For PSM, we estimated the probability of each participant getting into treatment (volunteering = 1), or the so-called propensity score, using logistic regression by regressing the treatment on all measured confounders, assuming conditional exchangeability. We then applied nearest neighbor matching with a caliper of 0.09 (higher and thus less stringent calipers such as 0.20 and 0.10 led to unacceptable imbalances in some confounders) via the
Associations Between Measured Covariates and Exposure/Outcome in Empirical Example 3

Note: Continuous variables were dichotomized with a median split. We recoded volunteering (a protective factor) so that nonvolunteering now equals 1 (i.e., a higher risk “exposure” for an undesirable outcome). Likewise, protective confounders (with an OR/RR < 1.00) were reverse-scored. The OR estimates for the confounder-outcome associations were obtained from separate bivariate logistic regressions used to estimate each individual (binary) confounder’s effect on the outcome; given the rare prevalence of the outcome (binge drinking), RR is approximately equivalent to OR when predicting outcome. The RR association between exposure and each (binary) confounder is obtained by calculating the prevalence of each (binary) confounder and comparing the exposure group with the nonexposure group. For each binary confounder, a score of 1 (vs. 0) corresponds to the level that increases the risk for the outcome of binge drinking, which is the default following the reverse-scoring procedure mentioned earlier. The exposure-covariate association’s direction (RR
EU
; see Box 1) is in relation to the covariate’s effect on the outcome (RR
UD
) and thus may be lower than 1.00. Using the bias-factor formula provided in Box 1, we can calculate, for example, a hypothetical unmeasured confounder with the exact same associations (both in magnitude and direction) as (dichotomized) age’s associations with exposure and outcome that would produce minimum bias (i.e., (1.22 × 0.92) / (1.22 + 0.92 – 1) = 0.98). For a hypothetical unmeasured confounder that has the exact same strength and direction as age’s effect on the outcome to exert bias greater than 1.00 (i.e., to adjust down the observed exposure-outcome effect), its imbalance (age = 1) across exposure levels needs to be in the opposite direction as the age variable in relation to the exposure (i.e., the prevalence of age level = 1 is greater among the exposed group than among the unexposed group). If a hypothetical unmeasured binary confounder has the same magnitude of effect on the outcome as the age variable but with its coding reversed, its association with the exposure must be assessed in relation to the level (the current score of 1) that is associated with higher risks for the outcome (i.e.,
Discussion
In this tutorial, we address a notable gap in nonexperimental psychological research: the lack of discussion surrounding unmeasured confounding. We introduce psychologists to the E-value, a sensitivity-analysis technique that offers an accessible means to enhance observational studies focused on causal inquiries, whether implicitly or explicitly (VanderWeele & Ding, 2017). We illustrate how to compute E-values using the
The importance of contextualizing E-values and best practices
As highlighted by VanderWeele and Ding (2017), the interpretation of E-values does not follow strict cutoffs that classify them into small, medium, and large ranges. This underscores the importance of contextualizing E-values within the specific parameters of each study. For example, an E-value even as high as 5 may not be meaningful if existing known risk factors demonstrate RRs of 6 or 7, in which case, the observed association is still considered susceptible to unmeasured confounding. Conversely, a smaller E-value (e.g., 1.5) may indicate robust association if the known risk factors have lower RRs (e.g., 1.3; Chung & Chung, 2023). Moreover, to provide richer information in a given context, researchers are recommended to report two E-values for each potentially causal association—that is, both the E-value that negates the observed association and the E-value that makes an association statistically nonsignificant (VanderWeele & Mathur, 2020). Furthermore, the E-value cannot replace rigorous and thoughtful statistical adjustments, such as matching methods and regression analysis, because its sole purpose is to assess the plausibility of the exchangeability assumption. Studies that rigorously identify, measure, and control for known confounding before computing E-values to contextualize their findings will demonstrate (much) greater robustness (Chung & Chung, 2023). For example, studies that adjust for prebaseline exposure and outcome reduce the risk of reverse causality and likely report an E-value that is smaller than a similar study that does not adjust for prior measurements of the exposure and outcome, two of the strongest confounders influencing both the exposure and subsequent outcome (VanderWeele et al., 2020). As a result, researchers should always conduct a thorough literature review and explicitly state all known confounders of the exposure-outcome relationship under study, even those not measured in their research (VanderWeele & Mathur, 2020), in which case, the lack of control over known unmeasured confounding may bias the results and warrants thoughtful discussion (e.g., on whether the magnitude of association is known in the literature, how it compares with the E-value, and/or acknowledging its omission as a limitation). When important known and measured confounders, such as prior measurements of the exposure and outcome, are not controlled for, the E-value can be artificially inflated because the observed association may partly reflect the effects of these uncontrolled confounders rather than a true causal effect. In this case, the E-value suggests that a stronger unmeasured confounder would be needed to explain away the association, but this may be misleading because the effect is already confounded by factors that should have been accounted for. Conversely, when these known confounders are properly controlled for, the observed association becomes more accurate, and the E-value reflects the “true” robustness of the association to unmeasured confounding. This often results in a smaller but more realistic E-value that provides a more accurate assessment of how vulnerable the observed association is to potential unmeasured confounders.
Given the aforementioned considerations, we believe that the E-values are particularly promising (a) in longitudinal studies that control for both prior assessments of exposure and outcome (and ideally along with a rich set of measured confounders 16 ; i.e., as in VanderWeele’s outcome-wide framework) and (b) in studies that use a rigorous selection of potential confounders using DAGs to block the majority of the noncausal paths (i.e., in the causal-graph framework). The latter criterion also implies that the E-value is most informative when only one unmeasured known confounder is present and all other known confounders are adequately controlled. In cases in which multiple known distinct confounders are unmeasured, the data may not be sufficient to answer the research questions effectively in the first place. Meanwhile, to gauge whether an E-value is small or large (i.e., the robustness of findings), researchers are recommended to report and comment on the magnitude of associations between each measured confounder (inverted for protective factors and median dichotomized for continuous confounders) and the exposure/outcome because as they are compared with the E-value (VanderWeele & Mathur, 2020; for an example, see the comment section of Table 4 focusing on Kaster et al. 2022). Although it is unlikely for the E-value to be larger than the association between the prior outcome values and the outcome and the association between the prior exposure values and the exposure, if the E-value is larger than every other strong known confounder statistically controlled for, the researcher may be more confident that the observed association is indeed causal. In other words, the E-value facilitates a more meaningful discussion, on the end of both the authors and the reviewers, on causal thinking by encouraging researchers to consider the strength of unmeasured confounding relative to known measured confounders. From an author’s perspective, when a reviewer raises issues with the use of observational data to infer causality because of the lack of measurement of a known key confounder, the authors can present a more meaningful discussion by employing sensitivity analyses, such as the E-value, by comparing the effects of that unmeasured but known confounder on the exposure and outcome—as reported and approximated in the literature—with the E-value. When a reviewer expresses concerns about the threat of unknown confounding, the authors can then provide context regarding the robustness of the observed exposure-outcome association (i.e., the E-value) by reporting and comparing the measured confounders’ effects with the reported E-value, assuming that the analysis is based on a rigorous selection of covariates. For example, if a strong known confounder shows a larger association with the exposure or outcome than the E-value, the exposure-outcome association may be seen as less robust and may necessitate more thoughtful discussions in the limitations section because an unmeasured confounder of similar magnitude could negate the observed association. Conversely, when the E-value exceeds the effects of a strongly measured confounder on the exposure and outcome, a stronger case for causality can be made. To further illustrate how E-values can be appropriately applied, we listed and commented on several recent articles—most focused on psychological constructs—that we believe have made good use of the E-value technique in Table 4. From a reviewer’s perspective, a deeper consideration of unmeasured confounding allows a critical evaluation of the quality of measured confounders in a longitudinal study. When the quality of measured confounders is deemed insufficient, a reviewer may require the authors to (a) apply more rigorous statistical control over the exposure-outcome association to evaluate whether the new results are consistent with the primary findings and (b) conduct sensitivity analyses, such as the E-value, to assess how sensitive the exposure-outcome association is to unmeasured confounding.
Recent Exemplary Articles With Application of the E-Value

Applicability of the E-value in more complicated scenarios
Although the E-value has shown to be useful in longitudinal analyses in which a single exposure predicts a future outcome, its applicability in more complex modeling frameworks requires careful consideration. To date, E-values have primarily been applied in three contexts: (a) longitudinal regression that measures a single exposure (e.g., Kim, Wilkinson, Case, et al., 2024); (b) weighting-based methods, which create pseudopopulations to address both general and/or time-varying confounders (e.g., Zhong et al., 2018); and (c) matching-based methods, which minimize differences in measured confounders between the exposed group and nonexposed group (e.g., Fisher et al., 2018). Moreover, the E-value can also be applied in mediation models—when rigorous control of confounders is done for all important paths (i.e., exposure-outcome association, exposure-mediator association, and mediator-outcome association) and fits naturally under a causal-mediation framework (for an accessible application of E-value in this context for psychologists, see Li et al., 2023). The E-value can theoretically be used in the context of the cross-lagged panel model (CLPM). However, this approach is not emphasized here because of critiques of CLPM’s large set of parametric assumptions (Mulder, Luijken, et al., 2024) and more importantly, its confluence of within- and between-units variances (i.e., convergence; Hamaker et al., 2015). In addition, in CLPMs, when only prior outcomes are controlled, assumptions of exchangeability may likely be violated because of residual confounding, which can “inflate” the E-value artificially. This issue is especially common in CLPM-based psychological studies in which comprehensive confounder control is infrequent, highlighting the need for caution in using the E-value in complex modeling scenarios in which residual confounding and assumption violations may affect interpretability. Furthermore, as we note in our Limitations section, to the best of our knowledge, the E-value has seldom been applied in models that use only within-units variations over time, such as multilevel modeling of intensive longitudinal data, fixed-effects models, and RI-CLPMs. In such cases, interpreting E-values is challenging, especially when few (benchmark) important time-varying confounders are incorporated to help contextualize the E-value, as is commonly done in psychological studies testing within-units associations. Although within-persons analysis is robust to unmeasured time-invariant confounders, which by definition cannot cause/confound within-persons variations, it is still susceptible to unmeasured time-varying confounding (Usami et al., 2019). The common practice of omitting time-varying confounders in within-units analysis, such as RI-CLPM, among applied psychologists may preclude meaningful interpretations of sensitivity analysis such as the E-value in this context. Because of these observations, we believe that the E-value may be of limited value to within-units methods, especially as they are currently being applied in psychological research. Finally, a key issue across interdependent models—such as path models, CLPM, and RI-CLPM—is that one misspecified path could have implications for the rest of the model. When working with large multivariate models that require calculating several E-values, the challenge lies in interpreting them collectively, but it is important to consider all key paths together to assess the overall robustness of the model.
Limitations of E-value
Although the E-value technique provides useful insights, it is crucial to acknowledge its limitations. First, although E-values are a valuable tool for assessing the robustness of an observed association to unmeasured confounding, they do not address other important issues in causal inference. These include but are not limited to measurement error, sample-selection bias, treatment-effect heterogeneity, and bias introduced by third variables that do not necessarily cause both the treatment and outcome (i.e., collider bias; Elwert & Winship, 2014; Matthay & Glymour, 2020). It is important for researchers to consider these additional sources of bias when interpreting causal estimates. Second, E-values do not address common questionable practices in psychological science, such as p-hacking and selective statistical control (Friese & Frankenbach, 2020; VanderWeele & Ding, 2017). When selective statistical control is apparent (e.g., not adjusting for known confounders, including prebaseline exposure and outcome), the reporting of the E-value can give a false sense of confidence in results (Blum et al., 2020). Third, the primary purpose of E-values is to determine whether an observed effect could be completely confounded to the point of negating the association. However, the goal of research often extends beyond simply establishing whether an effect is significant; researchers also seek to accurately estimate the magnitude of the causal effect. In this regard, E-values offer limited utility because they do not directly contribute to estimating the size of the causal effect but rather assess the robustness of the association to potential unmeasured confounding. Consequently, although E-values are valuable for sensitivity analysis, other methods are needed to estimate causal effects accurately. Fourth, when the outcome is continuous, the E-value is less elegant, and additional assumptions are invoked (Ding & VanderWeele, 2016). When converting Cohen’s d to OR, the distributions of the continuous outcome in both groups are assumed to follow a logistic (approximately normal) distribution with equal variances (Anzures-Cabrera et al., 2011; Borenstein et al., 2009). The OR may be upwardly or downwardly biased depending on the specifics of the distributions, including assumptions about logistic distribution and equal variances and the nature of the control- and treatment-group risks. When these assumptions are unmet, the direction and magnitude of the bias will vary, leading to potential overestimation or underestimation of the true OR (for a comprehensive simulation, see Anzures-Cabrera et al., 2011). Furthermore, many other sensitivity-analysis approaches exist for estimating how strong the associations of unmeasured confounders would need to be to neutralize an observed effect, and the E-value represents only one of several recent perspectives (e.g., Cinelli & Hazlett, 2019) assessing the impact of unmeasured confounders. For example, the robustness value proposed by Cinelli and Hazlett (2019) is conceptually similar to E-values (for an accessible tutorial on the robustness value and related metrics in R and Stata, see Cinelli et al., 2020). The E-value is an approximation for effect measures other than RRs, whereas if linear regression is used to estimate an effect, the robustness value is exact. Although the robustness value expresses the confounding’s association with the treatment and outcome in terms of the percentage of variance explained (partial R2), the E-value represents these associations using RRs. In the case of a linear-regression model with a continuous outcome, we recommend that researchers become familiar with both sensitivity analyses and conduct both of them. In the case of binary outcomes, we recommend researchers conduct E-value as the go-to sensitivity analysis. In other words, the choice among the wide array of sensitivity-analysis techniques depends on the specific research context (e.g., when plausible assumptions regarding the prevalence of the unmeasured confounder can be made; Haneuse et al., 2019). Finally, for demonstration purposes, we controlled for only a limited set of sociodemographic covariates in addition to the prior outcome and the prior exposure and did not control for a wider range of covariates like most of the exemplary articles we highlighted in Table 2 that reported the E-value. For empirical observational studies conducted in the real world to be methodologically rigorous, the researcher should (a) control for most known confounders and (b) report and tabulate the associations between every confounder controlled for and the exposure/outcome as they are compared with the E-value.
Conclusion
We anticipate that this tutorial will assist psychologists in acknowledging the importance of explicitly evaluating the potential threat posed by unmeasured confounding. We believe that incorporating the reporting of E-values or metrics from other related sensitivity-analysis techniques in psychological research can contribute to this endeavor and move cumulative psychological science forward as the field moves toward greater emphasis on causal interpretations of findings (Brady et al., 2023; Davis et al., 2024; Grosz, 2023).
Footnotes
Acknowledgements
We thank Michael P. Grosz and the other anonymous reviewer for their constructive and insightful feedback.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions