
Abstract
Meta-analyses play an influential role in synthesizing the existing evidence on a particular topic. Consequently, it is especially important that meta-analyses are conducted and reported to the highest standards and that the risk of bias is minimized. Preregistration can help detect and reduce bias arising from opportunistic use of “researcher degrees of freedom.” However, little is known about the prevalence and practice of the preregistration of meta-analyses in psychology. In this study, we first measured the prevalence of preregistration in all psychology meta-analyses published in 2021. Next, for 100 randomly selected preregistered meta-analyses, we evaluated the preregistration’s coverage of key meta-analytic decisions and the extent to which published meta-analyses deviated from their preregistered protocols. Of all 1,403 eligible psychology meta-analyses published in 2021, 382 (27%) were preregistered. In our random sample, we found that key PRISMA-P decision items were often omitted from preregistered protocols—out of the 23 decision items that were examined, the median number of items covered was 13 (interquartile range [IQR] = 11–14). We also found that all 100 preregistered meta-analyses contained at least one deviation from the preregistered protocol (Mdn = 9, IQR = 6.75–11) and that most deviations were undisclosed (Mdn = 8, IQR = 6–11). These findings suggest that the infrequent use and poor implementation of preregistration in psychology meta-analyses undermines its potential to reduce bias and increase transparency.
Conducting a meta-analysis requires researchers to make multiple decisions, such as determining which studies to include, specifying the outcomes of interest, and selecting the statistical model (Johnson, 2021; Moreau & Gamble, 2022; Pigott & Polanin, 2020). Each decision may have several justifiable options (“researcher degrees of freedom”; Simmons et al., 2011; Wicherts et al., 2016), creating a multiplicity of possible outcomes. When researchers make decisions after seeing the data (data-dependent decisions), this may introduce bias, particularly when those decisions are influenced by whether the results align with the researchers’ preferred outcome (Hardwicke & Wagenmakers, 2023; Wicherts et al., 2016). Considering their influential role in synthesizing the existing evidence on a particular topic, it is especially important that meta-analyses are conducted and reported to the highest standards and that the risk of bias is minimized.
Preregistering a study protocol has been proposed as a tool for detecting and reducing data-dependent biases arising from researcher degrees of freedom (Munafò et al., 2017). The degree to which a preregistration minimizes the risk of bias depends on how clear and comprehensive that preregistration is, that is, how well the preregistration constrains data-dependent decision-making (Bakker et al., 2020; Hardwicke & Wagenmakers, 2023). In addition, deviations from preregistered decisions can increase the risk of bias (even if they may have other benefits, such as improving the validity of a poorly planned analysis) and should be explicitly disclosed and justified. It is therefore important to evaluate how often meta-analyses are being preregistered (i.e., assess their prevalence) and how effective those preregistrations may be at minimizing the risk of bias (i.e., assess their coverage of researcher degrees of freedom and the frequency and nature of any deviations).
Previous studies assessing preregistration prevalence have found that preregistration of empirical studies (including meta-analyses) is infrequent in psychology and the social sciences (e.g., Hardwicke et al., 2020, 2022), although increasing (Hardwicke et al., in press). Some recent studies have specifically examined the prevalence of preregistered protocols for systematic reviews and meta-analyses in subdomains of psychology. Polanin et al. (2020) found that 2% of 150 meta-analyses published in Psychological Bulletin from 1990 to 2017 were preregistered. López-Nicolás et al. (2022) found that 19% of a random sample of 100 meta-analyses on clinical-psychological interventions published between 2000 and 2023 were preregistered. Sandoval-Lentisco et al. (2024) found that 36% of 97 meta-analyses on cognitive training published between 1997 and 2023 (of which 40 were published from 2020) were preregistered. Currently, there is no available estimate for the prevalence of preregistered meta-analyses across the entire field of psychology.
When empirical studies are preregistered, they often provide poor coverage of researcher degrees of freedom, such as when to stop data collection or how to define outliers (Bakker et al., 2020). In addition, deviations from preregistered protocols are frequent and seldom disclosed or discussed (Claesen et al., 2021; TARG Meta-Research Group & Collaborators, 2023; van den Akker et al., 2023). In the context of systematic reviews and meta-analyses, some studies have assessed protocol coverage, but these have mostly focused on the prespecification of outcomes of interest in medical trials. These studies found, for example, that 35% to 38.5% of assessed systematic reviews did not preregister any outcome measure (Parmelli et al., 2007; Tricco et al., 2016). Moreover, these and other studies suggest that deviations from preregistered protocols of systematic reviews and meta-analyses in medicine are common. Silagy et al. (2002) found that 43 out of 66 Cochrane reviews contained at least one major deviation from their preregistered protocol, including changes in the objectives, outcome measures, methods, and inclusion criteria. Studies have also found that 22% to 39% of systematic reviews and meta-analyses omitted or changed the outcomes of interest compared with what was stated in the registered protocol (Dwan et al., 2013; Kirkham et al., 2010; Page et al., 2014; Tricco et al., 2016). To our knowledge, no study has examined preregistered protocol coverage and deviations for meta-analyses published in psychology.
Aims of This Study
The present study had three aims. First, we measured the prevalence of preregistration in all meta-analyses published in psychology in 2021. Second, we assessed the coverage of preregistrations by examining the extent to which 100 randomly selected preregistered meta-analyses published in 2021 clearly prespecified key meta-analytic decisions that may incur a risk of bias. Finally, we assessed deviations from preregistrations by comparing the decisions reported in the final article with those specified in the preregistered protocol (for the same 100 randomly selected preregistered meta-analyses). When we identified deviations, we checked whether they were explicitly acknowledged and justified in the final article.
Disclosures
This study was preregistered on September 1, 2022 (https://osf.io/rnv5c). After starting data collection, we made minor amendments to the inclusion criteria on October 18, 2022, and again on February 20, 2023 (see the different versions of the protocol at https://osf.io/kf9dz). All deviations from the original protocol are disclosed and explained in https://osf.io/6kxgt. All materials, primary data, and analysis code are available at https://osf.io/ru5h4/. Below, we report how we determined our sample size, all data exclusions, all manipulations, and all measures in the study.
Method
Sampling Strategy
For our first research aim, measuring prevalence, the population we wished to generalize to was all meta-analyses published in psychology journals in 2021. To identify this population, we searched for meta-analyses published in journals included in the category of psychology in 2021 in the Web of Science Core Collection using the following search string in the Web of Science search platform accessed through the University of Murcia: ((TS = (meta-analy*)) AND WC = (Psychology)) AND PY = (2021).
For the second and third research aims, measuring coverage and deviations, we also wished to generalize to all preregistered meta-analyses published in psychology journals in 2021. Because the assessment process for the second and third research aims entailed considerable manual workload, we examined 100 randomly sampled preregistered meta-analyses rather than the entire population. This quantity was selected because it was within our resource constraints and yielded estimates with a margin of error that we believe to be reasonably accurate—a precision analysis indicated that the margin of error on a 95% confidence interval (CI) for a proportion of 0.5 was 0.098 (see Appendix A of the preregistered protocol, https://osf.io/rnv5c). We performed the random selection by generating a random number for each meta-analysis that was associated with a preregistration, sorting the meta-analyses by their assigned number, and choosing the first 100 eligible articles.
Inclusion Criteria
For articles to be included, we had to have full-text access, and they had to be in English language. For all research aims, articles were considered eligible if they conducted a meta-analysis synthesizing the evidence on any topic using any kind of meta-analytical methodology. We defined meta-analysis as “the statistical combination of results from two or more separate studies,” according to the Cochrane Handbook for Systematic Reviews of Interventions (Deeks et al., 2023, p. 243). Metaresearch or methodological articles related to the development of meta-analytic methods or evaluation of meta-analyses in practice were not included. Reanalyses of meta-analyses or internal meta-analyses were not included. Systematic reviews without a statistical synthesis of effect sizes were also not included. After conducting the search and checking the eligibility of each record, we also identified different types of studies that we did not consider before commencing the study (see deviation at https://osf.io/6kxgt).
For the second and third research aims, articles were not included in the random sample if we detected that the time between the registration date and the submission date was less than 1 month apart. When such articles were identified, they were excluded and replaced with the next one in the list.
Extraction and Coding of Information
For our first research aim, measuring prevalence, we manually inspected the title and abstract of all the articles identified by our search to see if they were eligible meta-analyses according to our inclusion criteria. If we had any doubts as to whether the article fulfilled our criteria, we inspected the full text. For eligible meta-analyses, we coded whether they reported having a preregistered protocol published in a journal or posted in any kind of repository/registry (e.g., PROSPERO, OSF, clinicaltrials.gov, or an institutional website) and whether it was accessible. For this inspection, we manually opened the document and performed a keyword search (ignoring case) with the words “registered,” “registration,” “protocol,” “PROSPERO,” “NCT,” and “OSF.” If searching for those keywords retrieved no results, we also manually inspected the abstract, author note, the start of the methods section, and any disclosure statements appearing after the discussion section. Two authors (A. Sandoval-Lentisco and M. Tortajada) independently coded all the articles. A third author (T. E. Hardwicke) helped to resolve coding differences. The interrater agreement of this process was high (96% agreement for assessing the eligibility; 98% agreement for assessing whether an article referred to a preregistration).
For the second and third research aims, assessing coverage and deviations, we extracted information about the research decisions that were reported in the preregistered protocols and their corresponding final articles using a structured coding form (see https://osf.io/tgh2p). For 62 articles, we found more than one protocol version available. In these cases, we based our assessment on the latest protocol version available before the data analysis, discarding those versions that were uploaded after the study was submitted to the journal or marked as completed.
We did not aim to cover all possible research decisions; given the diversity of meta-analytic methods, the number of possible decisions is likely to be enormous and difficult to specify. Instead, we decided to evaluate key decisions that are applicable to any meta-analysis as outlined in the Preferred Reporting Items for Systematic review and Meta-Analysis Protocols (PRISMA-P), an established reporting guideline based on an expert-consensus development process (Moher et al., 2015). 1 PRISMA-P includes a wide range of research decisions, such as the reporting of eligibility criteria, outcomes of interest, data synthesis, or methods to assess biases. 2
For most research decisions, we did not know the likelihood that a researcher would actually exploit that degree of freedom in practice (knowingly or unknowingly) or the potential impact on the results; we therefore included any decision noted in PRISMA-P that could potentially incur a risk of bias. 3 Specifically, we selected every item from PRISMA-P that refers to researcher decisions that can be adjusted after the results are known and can potentially change the results (see Supplemental Table 1 for the items that were included and any modifications from the original PRISMA-P checklist and Supplemental Table 2 for the original PRISMA-P items that were not included at https://osf.io/jq792). For cases in which single PRISMA-P items covered several research decisions, we divided these into individual items accordingly.
For each decision item, we recorded whether it was specified in the protocol, whether it was later mentioned in the final article, whether there was any deviation, and in case we found any deviation, whether the deviation was disclosed and explained. We considered that there was a deviation when the substantive information regarding a decision item differed between the protocol and the final article. We did not consider minor grammatical differences, such as inconsequential changes in wording, to be deviations. We distinguished three types of deviations: (a) decision item present in the protocol but not in the final article (an “omission”), (b) decision item in the final article but not specified in the protocol (an “addition”), and (c) decision item specified differently in the protocol and final article (a “modification”).
The assessment of coverage and deviations was performed in duplicate: A primary coder (A. Sandoval-Lentisco) coded all the articles, and two secondary coders (M. Tortajada and R. López-Nicolás) independently coded 72 and 28 articles each, respectively. The independent coding and resolution of coding differences was performed, periodically, in rounds of four to 10 articles. Information regarding protocol versions and time between protocol registration and manuscript submission was extracted by a sole author (A. Sandoval-Lentisco). For checking whether information was present in the protocol and final article and whether there was any deviation, the percentage agreement between raters ranged from 76% to 100% (for more details, see Supplemental Table 3 at https://osf.io/jq792).
Results
Below we report 95% CIs based on the Wilson score interval (Wilson, 1927) for binomial items and the Sison-Glaz method for multinomial items (Sison & Glaz, 1995). For information regarding the time between registration and publication, the number of protocol versions, and the research stages at which the studies were registered, see https://osf.io/2ab8n.
Identification of Eligible Articles
Figure 1 summarizes the process of identifying eligible articles. Our search for meta-analyses published in psychology journals in 2021 identified 2,137 articles. Of these, 1,403 (66%) were considered eligible, 726 (34%) were considered not eligible, and we could not access the full text for eight (0.3%).
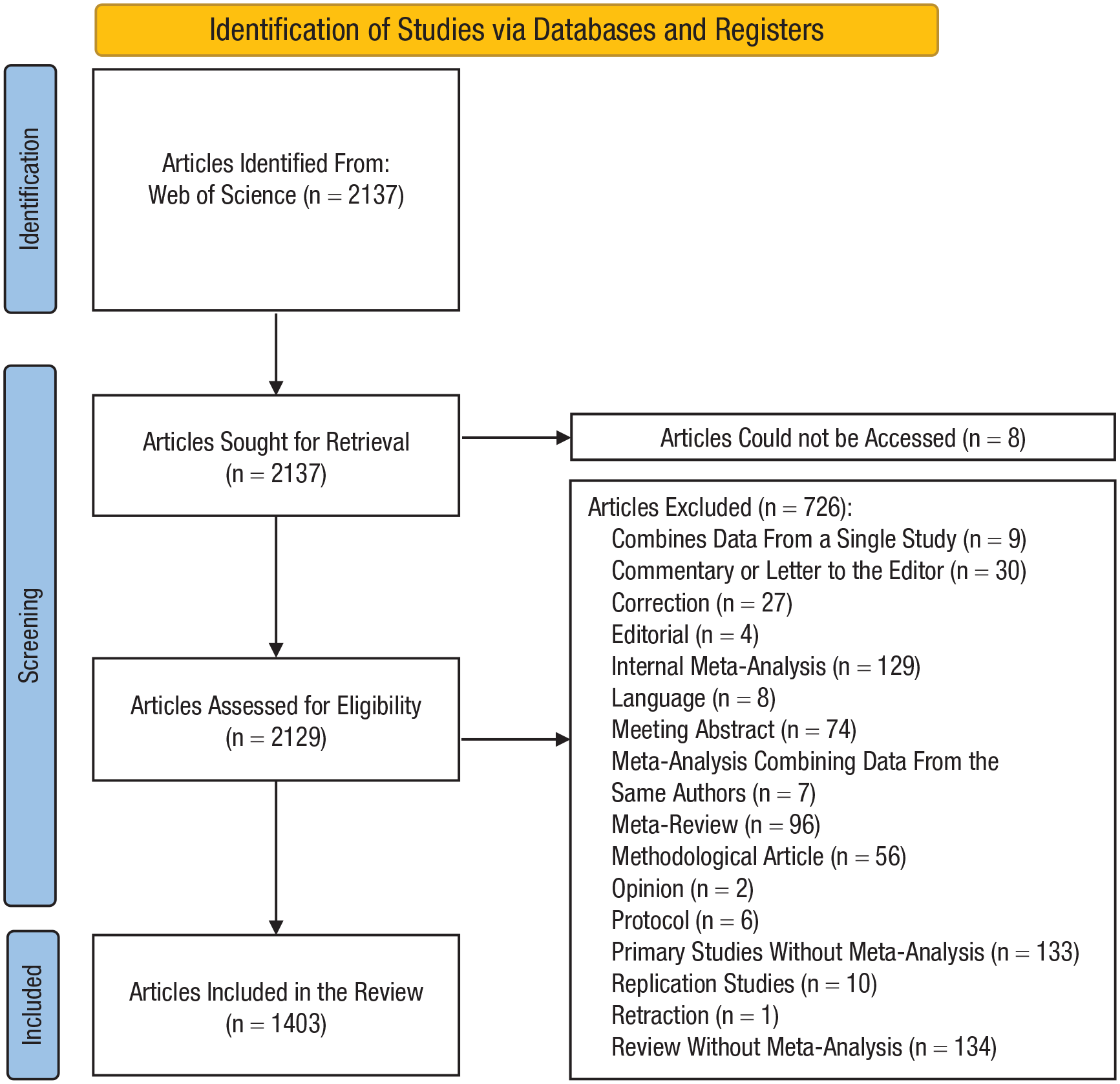
Preferred Reporting Items for Systematic review and Meta-Analysis 2020 flow diagram of the article selection process.
Prevalence
Of the 1,403 eligible articles, 1,008 (72%) did not report having a preregistered protocol. Thirteen (1%) reported that they were preregistered, but we could not verify this because eight did not provide a link or other identifier, four provided a link that did not lead to any preregistered information or files, and one was registered after the article was submitted to a journal. Ultimately, we identified 382 (27%) articles that were associated with a functional preregistration.
The majority of the 382 preregistered articles were registered in the PROSPERO registry (308 articles; 81%), followed by the OSF registry (62 articles; 16%), INPLASY registry (five articles; 1.3%), both OSF and PROSPERO registries (three articles; 0.8%), both the OSF registry and PsyArXiv (one article; 0.3%), the journal Systematic Reviews (one article; 0.3%), Research Registry (one article; 0.3%), and the IRCT registry (one article; 0.3%).
Coverage
Figure 2 shows the percentage of preregistered protocols that covered each PRISMA-P decision item. For a more detailed explanation of decision items, see Supplemental Table 1 at https://osf.io/jq792. In addition, supplemental figures (https://osf.io/683z7) provide a more detailed view of the coverage, deviations, and disclosure for each decision item using parallel-sets plots. Out of the 23 decisions items evaluated, preregistered protocols covered a median of 13 items (interquartile range [IQR] = 11–14). Information regarding the objectives (100%; 95% CI = [96%, 100%]), sources (100%; 95% CI = [96%, 00%]), eligibility criteria (99%; 95% CI = [95%, 100%]), and outcomes of interest (99%; 95% CI = [95%, 100%]) was present in almost every protocol. Likewise, risk of bias assessments (86%; 95% CI = [78%, 94%]), items to be extracted from primary studies (82%; 95% CI = [73%, 88%]), and additional analyses, such as moderator analyses or outlier analyses (80%; 95% CI = [71%, 87%]), were preregistered in most studies. Summary measures (72%; 95% CI = [63%, 80%]), screening process (70%; 95% CI = [60%, 78%]), searched dates (69%; 95% CI = [59%, 77%]), data-extraction process (65%; 95% CI = [55%, 73%]), and meta-analytic models (63%; 95% CI = [55%, 73%]) were also detailed in most studies. Information regarding dealing with missing data (51%; 95% CI = [41%, 61%]) and assessing heterogeneity (49%; 95% CI = [39%, 59%]) was present in about half of the protocols. Assessing publication bias (37%; 95% CI = [28%, 47%]), specific search strategies (37%; 95% CI = [28%, 47%]), and whether there was some kind of outcome prioritization (36%; 95% CI = [27%, 46%]) were not usually preregistered. Finally, methods for dealing with the possibility of multiple effect sizes from the same primary study (18%; 95% CI = [12%, 27%]), how a qualitative synthesis would be carried out if a quantitative analysis was not appropriate (13%; 95% CI = [27%, 46%]), the criteria for a primary study being included in a quantitative analysis (9%; 95% CI = [5%, 16%]), hypotheses (7%; 95% CI = [3%, 14%]), evaluating the strength of the evidence (6%; 95% CI = [3%, 12%]), and formula to compute effect sizes (4%; 95% CI = [2%, 10%]) were rarely preregistered.

Bar plot showing the percentage of preregistered meta-analysis protocols (N = 100) that covered each decision item. Confidence intervals are reported in the main text.
Deviations
We found that every meta-analysis contained at least one deviation from the preregistered protocol, and there was a median of nine deviations (IQR = 6.75–11) per meta-analysis (see histogram in Supplemental Figure 1 at https://osf.io/4wqzv). Figure 3 shows the percentage of deviations for each decision item and the type of deviation. As noted above, supplemental figures (https://osf.io/683z7) provide a more detailed view of the coverage, deviations, and disclosure for each decision item using parallel-sets plots. The highest rates of deviations were found regarding decisions items such as additional analyses (87%; 95% CI = [79%, 92%]), publication bias (66%; 95% CI = [56%, 74%]), items to be extracted from primary studies (60%; 95% CI = [50%, 69%]), assessment of heterogeneity (59%; 95% CI = [49%, 68%]), summary measures (58%; 95% CI = [48%, 67%]), search strategies (57%; 95% CI = [47%, 66%]), sources to retrieve the primary studies (56%; 95% CI = [46%, 65%]), and eligibility criteria (53%; 95% CI = [43%, 62%]).

Bar plot showing the percentage of meta-analyses (N = 100) containing deviations for each decision item and the deviation type (modification, omission, addition). Confidence intervals are reported in the main text.
In the case of additional analyses, eligibility criteria, sources, information to be extracted, and summary measures, these deviations were mainly because information was present in both protocol and final article but with modifications—that is, decision items were specified differently in the protocol and the final article (for an example of each type of deviation, see Table 1). Deviations regarding the assessment of publication bias, heterogeneity, and search strategies were mainly due to information being present in the final article but not specified in advance in the protocol, that is, additions (see Table 1).
Examples From Our Sample for the Different Types of Protocol Deviations (Modification, Omission, and Addition)

Note: BMI = body mass index; AN = Anorexia Nervosa.
We also found frequent deviations for decision items related to dealing with multiple data from the same primary study (49%; 95% CI = [39%, 59%]), statistical model (48%; 95% CI = [38%, 58%]), screening process (44%; 95% CI = [35%, 54%]), data-extraction process (42%; 95% CI = [33%, 52%]), outcomes of interest (34%; 95% CI = [25%, 44%]), dates that would be searched (32%; 95% CI = [24%, 42%]), assessment of the risk of bias (32%; 95% CI = [24%, 42%]), dealing with missing data (31%; 95% CI = [23%, 41%]), and objectives (29%; 95% CI = [21%, 39%]).
In the case of the statistical model, screening, data extraction, dates, and missing data, these deviations were mainly because information regarding these decision items was not present in the protocol but was later specified in the final article (additions). In turn, deviations regarding multiplicity of data, outcomes, and objectives were almost always in the form of modifications.
Finally, we also found deviations in the prioritization of outcomes (17%; 95% CI = [11%, 26%]), hypotheses (12%; 95% CI = [7%, 20%]), criteria for the studies to be included in the quantitative analysis (12%; 95% CI = [7%, 20%]), assessment of the strength of the evidence (10%; 95% CI = [6%, 17%]), and formulas to compute the effect sizes (8%; 95% CI = [4%, 15%]); description of the qualitative synthesis in a case study was not included in the quantitative synthesis (5%; 95% CI = [2%, 11%]).
In the case of the prioritization of outcomes, the deviations were mainly due to omissions because some kind of prioritization was specified in the protocol, but this was not mentioned in the final article (see Table 1). For the hypotheses, criteria for quantitative analysis, assessment of the strength of the evidence, formulas, and description of a qualitative synthesis, deviations were mostly due to additions because protocols did not specify any information about these decision items but final articles did.
For most decision items, deviations were rarely disclosed. Every meta-analysis contained at least one undisclosed deviation, with a median of eight undisclosed deviations (IQR = 6–11) per meta-analysis (see histogram in Supplemental Figure 2 at https://osf.io/4wqzv). Figure 4 shows the percentage of deviations that were disclosed for each decision item. The deviations that were disclosed most frequently were those regarding the eligibility criteria (26%; 95% CI = [16%, 40%]), hypotheses (25%; 95% CI = [9%, 53%]), additional analyses (24%; 95% CI = [16%, 34%]), outcomes of interest (18%;95% CI = [8%, 36%]), and objectives (17%; 95% CI = [8%, 35%]). When deviations in objectives and hypotheses were disclosed, authors always provided an explanation. However, when deviations in eligibility criteria, outcomes, or additional analyses were disclosed, authors sometimes disclosed only some but not all the deviations and/or did not always provide an explanation.

Bar plot showing the percentage of deviations for each decision item that were fully disclosed and explained, fully disclosed without any explanation, only partially disclosed but with explanation, partially disclosed without any explanation, and not disclosed (n indicates the number of deviations in each item). Confidence intervals are reported in the main text.
The rest of the decision-item deviations were all disclosed less than 10% of the time, and in some cases, the manuscript did not address all the deviations that we encountered or provide a justification for those deviations. Deviations regarding search strategies, screening, prioritization of outcomes, criteria for a quantitative synthesis, formulas to compute effect sizes, description of a qualitative synthesis, and assessment of the strength of the evidence were not discussed in any article.
Discussion
In this study, we assessed the preregistration of meta-analyses in psychology. Of 1,403 eligible meta-analyses published in psychology in 2021, 382 (27%) were preregistered. This implies that the remaining 77% were exposed to a risk of bias from data-dependent decision-making. In a random sample of 100 preregistered meta-analyses, we found that key PRISMA-P decision items were often omitted from preregistered protocols—the median number of items covered was 13 (IQR = 11–14). We also found that all 100 assessed meta-analyses contained at least one deviation from the preregistered protocol (Mdn = 9; IQR = 6.75–11). This implies that even preregistered meta-analyses incur a risk of bias from data-dependent decision-making because they do not preregister key research decisions or indicate when they deviate from the preregistered plan. Concerningly, most deviations were undisclosed (Mdn = 8; IQR = 6–11), which could potentially mislead readers and undermine their ability to calibrate their confidence in the reported results.
To our knowledge, these findings provide the first field-wide examination of the prevalence and practice of preregistration in psychology meta-analyses. Other studies have provided a range of estimates (2%–36%) for the prevalence of meta-analysis preregistration in various subfields of psychology (López-Nicolás et al., 2022; Polanin et al., 2020; Sandoval-Lentisco et al., 2024). Direct comparison is difficult because of differences in timeframe; however, considering these studies and our results, there is some evidence of a positive trend in meta-analysis preregistration. 4 Comparing the prevalence measure in the current study (27%) to a recent field-wide estimate (7%) for the prevalence of preregistration in empirical psychology (Hardwicke et al., in press) suggests that preregistration is more common for meta-analyses relative to empirical studies in general in psychology. This may be due to the influence of reporting guidelines such as PRISMA and organizations such as Cochrane (both of which recommend that meta-analyses be preregistered) in the community of psychologists who conduct meta-analyses and the existence of a dedicated platform (PROSPERO) specifically focused on preregistrations of systematic reviews and meta-analyses (PROPSPERO was the most popular registry among the preregistered meta-analyses we identified in this study).
Our findings of poor coverage of key research decisions in preregistered meta-analysis protocols and high frequency of undisclosed deviations align with other metaresearch studies examining preregistration of primary studies (Bakker et al., 2020; Claesen et al., 2021; TARG Meta-Research Group & Collaborators, 2023; van den Akker et al., 2023) and systematic reviews in medicine (Kirkham et al., 2010; Page et al., 2014; Siebert et al., 2023; Tricco et al., 2016). Taken together, these findings imply serious shortfalls in the implementation of preregistration that compromise its ability to minimize risk of bias and transparently communicate such risk to readers. Nonetheless, at the same time, these studies also illustrate the usefulness of preregistration as a tool that facilitates identification of risk of bias.
Considering the results shown here, we have some recommendations for researchers conducting meta-analyses in psychology. First, we encourage authors to be more specific and exhaustive in their protocols and pay special attention to decision items that we found to be frequently omitted from preregistered protocols (e.g., how to assess the presence of publication bias, deal with the multiplicity of effect sizes, assess the heterogeneity, and specify the meta-analysis model that will be assumed). To ensure the coverage of important decisions in preregistered protocols, authors can use tools such as PRISMA-P (Moher et al., 2015), which provides a checklist of the key decision items to be included in most meta-analyses. However, it is important to acknowledge that neither PRISMA-P nor PROSPERO provides complete coverage of all meta-analytic decisions, and therefore, authors need to specify more information than what these tools require by default. For better planning of the analyses, it has been suggested that authors simulate data to better understand the decisions to be made (Gambarota & Altoè, 2024; Nosek et al., 2019). Nonetheless, we acknowledge that specifying all meta-analytic decisions in advance can be difficult because many decisions depend on the characteristics of the data at hand (e.g., the choice of the meta-analysis model may depend on whether there are statistically dependent effect sizes). In this regard, handbooks (e.g., Cooper et al., 2019; Higgins et al., 2023) and guidelines (e.g., Carter et al., 2019; López-López et al., 2018; Nakagawa et al., 2022) may help to create prespecified decision rules for different scenarios that may occur.
Even if the preregistered protocol has been carefully specified, deviating from the plan may be necessary to maintain the validity of the analyses (Nosek et al., 2019). When deviations occur, authors should clearly disclose them and provide a justification to help readers, reviewers, and editors understand why such decisions were made and the extent to which they incur a risk of bias. Some journals require preregistration deviations to be prominently disclosed and seek dedicated peer review of preregistrations (Hardwicke & Vazire, 2024; TARG Meta-Research Group & Collaborators, 2022). Authors might also consider using deviation-disclosure tables to clearly communicate deviations and their implications to readers (Moreau & Gamble, 2022; Willroth & Atherton, 2024). The Registered Report format might improve deviation disclosures (Claesen et al., 2021; Serghiou et al., 2023) given their emphasis on compliance with the Stage 1 (preregistered) protocol (Chambers & Tzavella, 2022; Hardwicke & Ioannidis, 2018). Because protocols are peer reviewed, Registered Reports may also improve protocol coverage and quality, potentially resulting in fewer deviations. Finally, multiverse analyses (Steegen et al., 2016; Voracek et al., 2019) may increase transparency and reduce the risk of data-dependent decisions in meta-analyses. In this approach, instead of selecting only one analytical pathway, researchers perform many combinations of theoretically reasonable analysis specifications.
Limitations and Future Directions
An important limitation of our study is that we did not evaluate the impact of the decision-item coverage and deviations that we found. Although the decision items we evaluated theoretically incur a risk of bias, it is possible that in practice, they did not have a substantial impact on the results or conclusions of the meta-analyses. Future studies could evaluate whether these discrepancies could lead to substantial changes in the results by conducting different analyses with the different specifications reported in the protocols and the final articles.
Another limitation is that 62 articles had more than one protocol version available. In 35 of these cases, the protocols were updated after the study was completed or submitted to the journal. In such cases, we inspected only the protocol versions that were registered before completing or submitting the study. Twenty-seven articles had several protocol versions before the study was completed. For these articles, we selected the latest version available before the data analysis began. We decided to do this because it is possible that after commencing the study, researchers thought that a certain decision should be done differently before that decision was actually implemented. Nonetheless, it is also possible that authors updated their protocols after decisions were implemented, changing already completed aspects to match what they finally did. If this happened, we could have missed some deviations. In this sense, our criterion can be considered conservative. Despite this, the large number of deviations found makes it unlikely that authors were frequently adjusting their protocols retrospectively to hide these deviations.
Finally, the interrater agreement regarding some decision items, such as the deviations for the objectives or the eligibility criteria, was only moderate. This result highlights that evaluating whether a deviation occurred can be challenging in some cases.
Conclusions
Preregistration can be a useful way to minimize researcher biases and increase transparency, but its effectiveness relies on protocols covering key research decisions and protocol deviations being disclosed. We found that most meta-analyses published in psychology in 2021 were not preregistered, implying they are at risk of bias from data-dependent decision-making. When meta-analyses were preregistered, their protocols often provided poor coverage of key research decisions, and researchers frequently deviated from them, often without disclosing that a deviation had occurred. Thus, even preregistered meta-analyses often incurred a risk of bias. In sum, although preregistration is useful to detect risk of bias, its infrequent use and poor implementation in psychology meta-analyses undermine its potential to reduce bias and increase transparency.
Footnotes
Acknowledgements
We thank Robert Thibault for providing valuable feedback at an early stage of the study.
Transparency
Action Editor: Pamela-Davis Kean
Editor: David A. Sbarra
Author Contributions