
Abstract
Addressing core questions in diversity science requires quantifying causal effects (e.g., what drives social inequities and how to reduce them). Conventional approaches target the average causal effect (ACE), but ACE-based analyses suffer from limitations that undermine their relevance for diversity science. In this article, we introduce a novel alternative from the causal inference literature: the so-called incremental propensity score (IPS). First, we explain why the IPS is well suited for investigating core queries in diversity science. Unlike the ACE, the IPS does not demand conceptualizing unrealistic counterfactual scenarios in which everyone in the population is uniformly exposed versus unexposed to a causal factor. Instead, the IPS focuses on the effect of hypothetically shifting individuals’ chances of being exposed along a continuum. This allows seeing how the effect may be graded, offering a more realistic and policy-relevant quantification of the causal effect than a single ACE estimate. Moreover, the IPS does not require the positivity assumption, a necessary condition for estimating the ACE but which rarely holds in practice. Next, to broaden accessibility, we provide a step-by-step guide on estimating the IPS using R, a free and popular software. Finally, we illustrate the IPS using two real-world examples. The current article contributes to the methodological advancement in diversity science and offers researchers a more realistic, relevant, and meaningful approach.
Keywords
Social equity is a fundamental tenet of diversity science. Extensive research seeks to identify the causes of inequalities, evaluate their consequences, and develop strategies for transformation; see, for example, Devine and Ash (2022); Hebl et al. (2020); Juvonen et al. (2019); National Academies of Sciences, Engineering, and Medicine (2023); Paluck et al. (2021); and Valantine and Collins (2015). Example questions include: To what extent does racism drive racial disparities in life expectancies? What is the impact of social exclusion on mental health among the LGBTQ+ community? Do voters’ misperceptions of equality-enhancing policies spur their opposition to the policies? Does supervisor support have the potential to reduce gender disparities at work? Addressing these queries necessitates meaningful and realistic quantifications of causal effects.
When assessing the impact of a focal causal factor, researchers routinely estimate the so-called average causal effect (ACE). In this article, we explain why the ACE is inherently ill-suited for answering core causal queries in diversity science. We introduce an alternative causal quantity: the so-called incremental propensity score (IPS), a novel approach recently developed in the statistical literature (Kennedy, 2019; for recent applications in criminology and epidemiology, respectively, see Jacobs et al., 2023; Naimi, Rudolph, et al., 2021). In the following sections, we first explain what the IPS is and put forth that the IPS, although originally developed for quantifying the effects of interventions, can be applied broadly beyond intervention studies. In particular, we explain why the IPS is uniquely well suited for addressing important causal questions in diversity science. Next, we describe how to estimate the IPS. To increase the accessibility of the material for our target audience of social science and psychological researchers, we illustrate the procedure using the widely used and freely accessible statistical software R (R Core Team, 2023). Finally, we apply the IPS to two publicly available real-world data sets. All R scripts are available online at https://github.com/wwloh/ips-diversity.
Challenges of Using the ACE for Diversity Science
We first define and explain the ACE causal quantity routinely used in diversity science and social sciences broadly. We draw on concepts from the established potential outcomes framework, commonly called the Neyman-Rubin causal model (Rubin, 1990; Splawa-Neyman et al., 1990). Let

The ACE quantifies the average difference in potential outcomes for the entire study population. Continuing with our example, the ACE conceives the effect of social exclusion as the average difference between two extreme counterfactual scenarios: one in which all individuals are excluded and another in which all individuals are included.
Having defined the ACE causal quantity, we can now clarify two challenges of adopting the ACE for diversity science. First, the ACE may be uninterpretable. Although it is clear-cut to conceive competing counterfactual scenarios for a treatment whereby all individuals could be either exposed or unexposed in reality (e.g., a drug, the color of a visual stimulus, momentary sadness, spending time with a friend), this is rarely the case in diversity science. Causal factors of substantive interest in diversity science (e.g., the experiences of minoritized individuals, diversity-related attitudes and perceptions, and access to support or resources in times of need) are rarely experienced uniformly by all individuals in real-world settings. Instead, individuals’ conceivabilities of being exposed vary along a continuum—possibly as a function of different dimensions (e.g., intersecting social identities and socioeconomic status, among others; see e.g., Bhattacharyya & Berdahl, 2023; Hebl et al., 2020; Kurzban & Leary, 2001; Moss-Racusin, 2021). This renders contrasting two one-size-fits-all counterfactual scenarios (all individuals being exposed vs. unexposed) uninterpretable. This contrast undermines the ACE’s practical relevance for policy development: It is unrealistic for any intervention to result in either scenario.
Second, causal factors of interest in diversity science are often inextricably interrelated, such as unemployment and social exclusion (Boardman et al., 2022; Morrish & Medina-Lara, 2021), living conditions and access to health care (Caldwell et al., 2016; O’Shea et al., 2023), or minority status and diversity beliefs (Avery, 2011; Skinner-Dorkenoo et al., 2023). This can lead to violations of the so-called positivity assumption—a necessary condition when targeting the ACE. The positivity assumption (Petersen et al., 2012; Westreich & Cole, 2010) states that among individuals with the same values of the baseline or pretreatment covariates
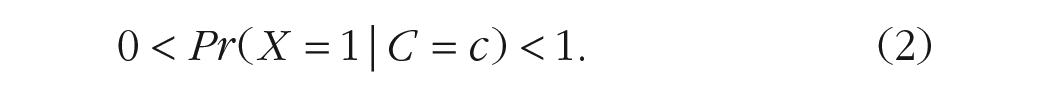
Note that the conditional probability of being exposed
Continuing our example, this assumption stipulates that there must be individuals who are exposed
In randomized experiments, positivity can be satisfied by design because researchers determine the chances of assignment (e.g.,
IPS as a Better-Suited Alternative to ACE for Assessing Causal Queries in Diversity Science
We now introduce a fresh approach for investigating the core causal questions in diversity science: the IPS (Kennedy, 2019). The IPS effectively addresses both challenges of the ACE, as we outlined in the previous section. First, the IPS quantifies an alternative causal estimand from shifting individuals’ chances for being exposed; hence, the IPS avoids the ACE-based comparison of extreme counterfactual scenarios for the entire population. Second, the IPS does not require the positivity assumption; hence, the IPS is robust to violations of the positivity assumption that would otherwise preclude ACE-based analyses. In the following sections, we explain what the IPS is and how to estimate its implied causal estimand.
The IPS aims to answer a straightforward question: “What would outcomes look like, on average, if the chances of exposure were changed by a given amount?” The IPS approach starts by envisaging a desired interventional probability of exposure to a causal factor
To focus ideas, consider an individual whose probability of being socially excluded is
Why Is the Incremental Propensity Score More Relevant Than the Average Causal Effect? A Hypothetical Example
Dr. A is interested in reducing the prevalence of depression among racial minorities. Social exclusion is an established risk factor for depression among this population. How should Dr. A quantify the causal effect of exclusion
Realistically, it is more meaningful to consider what would happen if individuals’ chances of being excluded could be reduced (instead of uniformly eliminated). This is precisely what the incremental propensity score (IPS) offers. Using the IPS, Dr. A can answer the causal question: What would depression, possibly contrary to fact, be on average if individuals’ propensity of being excluded were reduced by a given amount over the status quo? The IPS causal effect, therefore, represents the change in average depression among racial minorities that would be brought about if the propensity of being excluded were reduced (without necessarily being forced to zero). With this causal evidence in hand, researchers, practitioners, and policymakers can design and develop interventions toward a realistic goal—reducing the propensity of experiencing exclusion among racial minorities. Such interventions hold the promise of improving mental health outcomes in this population. (Note that the IPS is not intended to inform the specific designs of putative interventions; we return to this point in the Discussion section.)
We formally define an interventional probability distribution to answer this new causal query. Let

Solving for

We emphasize that π
The average potential outcome under a given IPS

where
The IPSCE can be interpreted as the average potential outcome when the given IPS
We emphasize that the IPS

The incremental propensity score
How to Estimate the IPSCE
In this section, we describe how to estimate the IPSCE
Step 1
Specify an outcome model that regresses

Then, for each individual, extract the predicted potential outcomes under both levels of
Step 2
Fit a propensity score model that regresses

Then, for each individual, obtain the fitted value of
Step 3
For a given value of
“data,” the observed data set;
“mu.hat,” the predicted outcomes from Step 1;
“pi.hat,” the predicted (organic) propensity score from Step 2;
“delta.fixed,” the given value of
“treat.name,” the variable name for
“outcome.name,” the variable name for
Continuing our example, the R code for estimating the IPSCE for

Step 4
Repeat Step 3 for a user-selected sequence of values of
Illustrations of IPS Using Real-World Data
In this section, we used two publicly available real-world data sets to illustrate the IPS.
Misperception of equality-enhancing policy hinders equality
Why do people oppose equality-enhancing policies? Brown et al. (2022) proposed misperceptions of equality-enhancing policies as a potential explanation. To examine the effect of misperceptions on policy opposition, the authors used a sample of White and Asian registered voters in the November 2020 California general election. Participants completed surveys regarding California Proposition 16 (which proposed removing the ban on affirmative action in public employment and public university admissions decisions) at Time 1 (between October 12 and 19, 2020) and Time 2 (between October 27 and November, 2 2020). Further details on the study are provided in Brown et al. 6
For the sole purpose of illustration, we analyzed whether misperceiving Proposition 16 as harmful (i.e., harms advantaged in-group resource access) at Time 1
To simplify the illustration, we assumed that the following self-reported and demographic variables sufficed for no unmeasured confounding to hold: age, gender, race, explicit prejudice, social dominance orientation, system-justifying beliefs, zero-sum beliefs, and overall political orientation. We considered the 645 participants with complete data recorded on these variables used for the analysis.
As we explained in the previous sections, the ACE demands conjuring up extreme, unrealistic scenarios in which everyone uniformly believes that the policy is harmful versus not harmful. Instead, the IPSCE allows us to answer a more meaningful causal question: What is the effect of hypothetically reducing people’s chances of adopting this misperception?
Another motivation for using the IPSCE is when positivity is violated. One way to check for this empirically is by plotting the predicted (organic) propensity scores for each group

Estimates of the organic propensity score for each treatment group in the equality-enhancing policy example.
For illustration, we postulated a set of values for

Estimates of the incremental propensity score causal estimand (IPSCE) in the equality-enhancing policy example. Each circle corresponded to an IPSCE estimate, and each vertical line corresponded to the 95% confidence interval (CI) for a given value of
We now interpret the results. As expected, the estimate equaled 0 (the sample mean after mean-centering the outcomes) when
Impact of supervisor support among women and men in the workplace
Does supervisor support represent a protective factor for workers’ well-being? How does the effect differ between women and men? We used a data set collected by McIlroy et al. (2021) to explore these questions. McIlroy et al. conducted an online survey to evaluate the effect of supervisor support on employees’ well-being (along with other performance and relational outcomes). A sample of workers in the UK recalled whether they received support from their supervisor after requesting it in the past month. Participants then answered questions about their attitudes, feelings, and behaviors following the situation they described. For the sole purpose of illustration, we assessed whether the absence of supervisor support affected workers’ well-being. 7
Supervisor support

Estimates of the incremental propensity score causal estimand (IPSCE) in the supervisor support example. Each circle corresponded to an IPSCE estimate, and each vertical line corresponded to the 95% confidence interval (CI) for a given value of
Next, we investigated gender differences. We first plotted the organic propensity scores for each gender subgroup 8 in Figure 5. We can see that women workers were less likely to receive supervisor support even after conditioning on the other covariates. We then estimated the conditional IPSCE for each gender subgroup (men or women). Details on calculating these estimators are provided in Appendix C.

Estimates of the organic propensity score for each gender in the supervisor-support example.
The resulting estimates and 95% CIs were then plotted against the values in Δ, as shown in Figure 6. As the plot showed, women had lower average well-being than men, as indicated by the lower outcomes for women given each posited value of

Estimates of the incremental propensity score causal estimand (IPSCE) for each gender subgroup in the supervisor support example. Each circle corresponded to an IPSCE estimate, and each vertical line corresponded to the 95% confidence interval (CI) for a given value of
Discussion
In this article, we introduced the IPS as a novel approach to answer core causal questions in diversity science. A central strength of the IPS for diversity science is that it offers a more realistic and policy-relevant quantification of the causal effect than a single ACE. Using the IPS, researchers can readily investigate a wide range of causal questions in diversity science, such as quantifying the impact of adverse exposures that are often experienced by minority groups (e.g., racism, sexism, bullying, microaggression, harassment, dehumanization), examining the effects of diversity-related perceptions or misperceptions, understanding what hinders the public’s support for equality-enhancing policies, and identifying possible exposures (e.g., access to supervisor support among women employees) that hold the promise of reducing inequalities, among others. Note that these exposures or factors are all conceptually manipulable causes. The effects of nonmanipulable causes, such as gender and race, are pertinent and essential for diversity science. For example, what is the gender difference in income? How does a person’s race affect the person’s chances of accessing health care? These are important research questions in diversity science but require different conceptual (see e.g., VanderWeele & Hernán, 2012) and methodological (see e.g., Loh & Ren, 2023b) considerations beyond the context of this article.
The IPS is not intended to inform the specific designs of putative interventions or programs. 9 Continuing our example of gender disparities at work, various strategies may increase women’s chances of receiving supervisor support. For example, organizations may consider offering training sessions for managers on best supporting women employees, creating tools and resources for women to be heard and their needs addressed, and formalizing mentoring programs in which women may seek advice and support. However, the design of such interventions or programs, such as the content of the materials or length of the sessions, is outside of what IPS offers. Researchers should rely on their domain expertise and subject-matter knowledge in interpreting and gauging the feasibility of putative interventions for changing the (organic) propensity score.
Although the focus of this article is on the IPS, there are three general issues that are not unique to the IPS but require careful attention by researchers when seeking to draw causal conclusions. First, as with all causal inferences of nonrandomized treatments, the assumption of no unmeasured confounding (formally stated as Equation C1 in Appendix C) is a prerequisite for the IPSCE to be consistently estimated. This assumption cannot be verified empirically alone—it must be grounded in and rationalized using theoretical knowledge and subject-matter expertise (Hernán & Robins, 2020; Steiner et al., 2010; VanderWeele, 2019). We reiterate two suggestions from the literature. Researchers should strive to record and adjust for all predictors of the outcomes of interest (VanderWeele, 2019). Adjusting for covariates that are strongly associated with the outcome can improve the finite sample precision of the estimators even if they are unhelpful for confounding when weakly (or un)associated with the treatment (Brookhart et al., 2006; Loh & Ren, 2023a). In contrast, covariates that are associated solely with the treatment—and not with the outcome—are redundant for confounding, yet adjusting for them results in inefficient estimators that are prone to finite-sample bias simply because of sampling variability (Brookhart et al., 2006; Kelcey, 2011).
Second, we assumed that all covariates in
Finally, model misspecification may arise when modeling the propensity score or outcome. In the current presentation, we used parametric regression models, an approach familiar to psychologists and consistent with prevalent practices in the field. However, these models may have been incorrectly specified, which can induce biases (Naimi, Mishler, & Kennedy, 2021). To avoid the risks of such biases when modeling the propensity score or outcome, researchers may consider using (supervised) machine or statistical learning prediction algorithms, such as generalized additive models (Hastie et al., 2009), least absolute shrinkage and selection operator (LASSO; Tibshirani, 2011), or tree-based algorithms (e.g., random forests; Breiman, 2001), among others. Such flexible, nonparametric machine learning–based estimators of the IPS causal effects are readily implemented using the ipsi function in the excellent R package npcausal (Kennedy, 2021). We refer interested readers to Kennedy (2019) for the underlying statistical theory that ensures unbiased estimation and valid CIs while using such flexible methods.
Conclusion
In conclusion, IPS is an appealing alternative to the ACE for addressing core causal questions in diversity science. The IPS accounts for nonuniform exposures to causal factors, enabling more realistic and policy-relevant interpretations. Moreover, the IPS is robust to the stringent positivity assumption—necessary for estimating the ACE—that is likely to be violated in this context. We hope this nontechnical introduction to the IPS empowers researchers to engage in more meaningful assessments and methodical investigations of the core causal questions in diversity science.
Footnotes
Appendix A
Appendix B
Appendix C
Acknowledgements
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contributions
Both authors contributed equally to this article and share joint first authorship but they are listed alphabetically by last name.