
Abstract
Knowledge about causal effects is essential for building useful theories and designing effective interventions. The preferred design for learning about causal effects is randomized experiments (i.e., studies in which the researchers randomly assign units to treatment and control conditions). However, randomized experiments are often unethical or unfeasible. On the other hand, observational studies are usually feasible but lack the random assignment that renders randomized experiments causally informative. Natural experiments can sometimes offer unique opportunities for dealing with this dilemma, allowing causal inference on the basis of events that are not controlled by researchers but that nevertheless establish random or as-if random assignment to treatment and control conditions. Yet psychological researchers have rarely exploited natural experiments. To remedy this shortage, we describe three main types of studies exploiting natural experiments (standard natural experiments, instrumental-variable designs, and regression-discontinuity designs) and provide examples from psychology and economics to illustrate how natural experiments can be harnessed. Natural experiments are challenging to find, provide information about only specific causal effects, and involve assumptions that are difficult to validate empirically. Nevertheless, we argue that natural experiments provide valuable causal-inference opportunities that have not yet been sufficiently exploited by psychologists.
Keywords
Knowledge about causal effects is essential for building useful theories and designing effective interventions. One method for learning about causal effects is randomized experiments, that is, studies in which researchers randomly assign units (e.g., individuals, classrooms, hospitals) to treatment and control conditions. Randomized experiments are the preferred way of learning about causal effects because the random assignment eliminates many alternative explanations for an apparent treatment effect (e.g., Murnane & Willet, 2011; Pearl, 2009; Shadish et al., 2002).
In randomized laboratory experiments, researchers have a high level of control not only over the assignment of units but also over experimental conditions. This might enable researchers to demonstrate a causal effect even when there are hardly any opportunities to do so in the field. However, it is often unfeasible or unethical to create the conditions of interest in a randomized experiment. If it is feasible and ethical, the creation of the conditions by researchers may shape participants’ beliefs about researchers’ intentions or hypotheses or expectations more generally, which might alter participants’ behavior, a phenomenon called “demand effects” (e.g., Corneille & Lush, 2023). Finally, the effect sizes found in randomized experiments—particularly of those conducted in a laboratory setting—might not generalize to the populations, contexts, and conditions of interest because the samples, study conditions, and experimental manipulations are not representative of the populations of interest or of conditions, events, or interventions that occur in real life (e.g., Cesario, 2022; Diener et al., 2022; Galizzi & Navarro-Martinez, 2019; Shadish et al., 2002).
These issues tend to affect observational studies to a smaller extent. For example, data may be collected as part of large-scale survey studies without any immediately apparent study goal, thus avoiding certain types of demand effects. And because participants receive the “treatment” in real-life conditions, the generalizability to the context of interest is often higher than in laboratory experiments. However, all of these benefits come at a high price: Because of the lack of random assignment, it is often impossible to rule out that differences between the treated and untreated conditions are the result of confounding factors (e.g., Schafer & Kang, 2008).
Natural experiments offer unique opportunities to combine features of randomized experiments and observational studies. A natural experiment is a “naturally” occurring event or condition (i.e., an event or condition not created by researchers) that affects some but not all units of a population (e.g., Dunning, 2012; Sieweke & Santoni, 2020). What sets natural experiments apart from events and conditions that are studied in standard observational studies is that people are randomly or as-if randomly assigned to treatment and control conditions. This (as-if) random assignment also sets natural experiments apart from quasi-experiments, at least according to many common definitions of quasi-experiments. 1 Hence, in natural experiments, it can be assumed that there are no, or almost no, systematic differences between the treated and untreated individuals before the treatment. A classic example is the Vietnam lottery draft, in which a lottery determined which men were called to military service in the Vietnam War (e.g., Angrist, 1990). Natural experiments differ from (nonnatural) randomized experiments in that participants are not randomly assigned to the treatment and control groups by researchers, and researchers do not control the experimental manipulation and conditions. Hence, “natural experiments are not so much designed as discovered” (Dunning, 2012, p. 41).
The current work intends to promote natural experiments in the field of psychology, an area in which they have hardly been used so far, as we demonstrate in the following section. We also clarify the advantages of natural experiments, describe several types of natural experiments (for an overview, see Fig. 1), and provide inspiring examples that illustrate the potential of natural experiments in psychology. We want to familiarize readers with the general idea underlying these designs without too many technical details. We provide empirical examples with directed acyclic graphs 2 to illustrate some analysis options in Boxes 1 to 3. Excellent, more technical introductions to natural experiments, as well as discussions of their potential pitfalls, are available elsewhere and should be consulted when readers have decided to use natural experiments in their own work (for key references, see Boxes 1–3).

Types of studies exploiting natural experiments. We distinguish between three types of studies exploiting natural experiments as implemented by Dunning (2012) and Sieweke and Santoni (2020).
Standard Natural Experiment

Note: For didactic reasons, Box 1 presents a slightly modified version of the design, notation, and analysis reported in Lindqvist et al. (2020). Red circles = outcome variable; blue circles = treatment variable.
Instrumental-Variable Estimation Using a Natural Experiment

Note: For didactic reasons, Box 2 presents a slightly modified version of the design, notation, and analysis reported in Green and Winik (2010). The data and R code for the analysis reported in Green and Winik can be found at https://isps.yale.edu/research/data/d028. Red circles = outcome variable; blue circles = treatment variable.
Regression-Discontinuity Design

Note: For didactic reasons, Box 3 presents a modified version of the design, notation, and analysis reported in Thistlethwaite and Campbell (1960). Red circles = outcome variable; blue circles = treatment variable.
How Frequently Are Natural Experiments Used in Psychological Research?
Psychological researchers rarely mention or make use of natural experiments. We conducted an electronic database search. It indicated that natural experiments were mentioned in 0.07% of all psychology abstracts that mention the word “study,” “studies,” “experiment,” or “data,” whereas natural experiments were mentioned in 1.50% of all business and economics abstracts that mention the word “study,” “studies,” “experiment,” or “data.” 3 We compared psychology to business and economics because economics is known for its focus on causal inference. Other related fields such as sociology or political science presumably fall somewhere in the middle ground between psychology and business and economics in terms of natural experiments. For example, natural experiments were mentioned in 0.32% of all sociology abstracts that mention the word “study,” “studies,” “experiment,” or “data.” Furthermore, we systematically reviewed and coded the research designs of 216 randomly sampled articles published in psychology and economics flagship journals in 2019. None of the 108 reviewed psychology articles used a natural experiment, whereas 36 of the 108 reviewed economics articles used a natural experiment (for details, see Table 1).
Review of a Random Sample of Economics and Psychology Articles

Note: We reviewed a random sample of 216 articles published in eight flagship journals from psychology and economics in the year 2019. We sampled articles from four empirical psychology journals that had a relatively high impact according to the 2021 SCImago Journal Rank (Journal of Applied Psychology, Journal of Personality and Social Psychology, Psychological Science, and Clinical Psychological Science) and the four of the top five economic journals (e.g., Heckman & Moktan, 2020) that publish largely empirical studies (American Economic Review, Journal of Political Economy, Quarterly Journal of Economics, and Review of Economic Studies). A student assistant coded basic information (e.g., authors, year, DOI, and whether the article contains an empirical study or not). The study designs of each article were independently coded by either two authors of the current work or by one of the authors and the student assistant (for coding manual, data, and interrater agreements, see Tables S1 to S3 on the OSF at https://osf.io/a5nxm). Disagreements and uncertainties were resolved by the first author. aOf the 36 natural experiments, 11 were borderline cases (for details, see Table S2). The total number of articles using natural experiments (36) is smaller than the sum of articles using specific types of natural experiments because some articles used more than one type.
Reasons for the more frequent use of natural experiments in economics than psychology might be that randomized experiments are hardly feasible in macroeconomics because researchers cannot experiment with countries’ economies, rendering natural experiments such as public policies an attractive alternative to randomized experiments. Moreover, economists often use administrative observational data to exploit a natural experiment (e.g., Angrist, 1990). Administrative data rarely include psychological measures that are needed to answer psychological research questions. Nevertheless, it would be possible to purposefully collect the required variables months or years after the natural experiment occurred (e.g., Ertola Navajas et al., 2022). A further reason for the lack of usage of and awareness about natural experiments in psychology might be a difference in research culture across fields. Whereas economists have embraced the challenge of estimating causal effects on the basis of observational data, psychologists have traditionally avoided making explicit inferences about causal effects in observational studies (e.g., Grosz et al., 2020). We think this avoidance of explicit causal inference in the absence of a randomized experiment has to some degree led researchers to neglect (the concept of) natural experiments. The resulting lack of studies exploiting natural experiments in the psychology literature has further exacerbated the problem because published work often inspires other researchers to use the same methodology for their own research questions—that is, to exploit the same or to discover a different natural experiment (Dunning, 2012).
Why Psychologists Should Use Natural Experiments
We believe psychologists should use natural experiments more often than they currently do for several reasons. Because of the natural occurrence of the treatment in natural experiments, they can be an option when randomized experiments are unethical or unfeasible. For example, it is unethical and unfeasible to experimentally induce an earthquake to study its effects, but it is possible to study the effects of a naturally occurring earthquake: Oishi et al. (2018) studied the effects of a naturally occurring earthquake essentially by comparing people who completed an online survey just before versus after the Great East Japan Earthquake. Likewise, it would be unethical and unfeasible for researchers to randomly assign people to remain in school for an extra year or leave school a year early, but it is possible to study the effects of laws that increase the minimum school-leaving age: Davies et al. (2018) exploited the raising of the minimum school-leaving age in the United Kingdom in 1972 essentially by comparing people born immediately before September 1957 (i.e., not affected by the reform) with those born in or immediately after September 1957 (i.e., affected by the reform).
Furthermore, demand effects should, on average, affect natural experiments less than they affect randomized experiments. The main difference between a randomized and natural experiment is that the researcher induces the treatment in a randomized experiment but not in a natural experiment. Thus, the treatment can only induce any hypothesis-related expectations in a randomized experiment but not in a natural experiment. In addition, in randomized experiments, the outcome variable is typically assessed right after treatment administration because researchers are the ones applying the treatment. In natural experiments, researchers do not administer the treatment. Thus, the outcome variable is often measured months or years after the naturally occurring treatment has taken place. For example, cognitive abilities were measured decades after the minimum school-leaving age had been increased in the United Kingdom (Davies et al., 2018). Thus, the researchers’ hypotheses are usually less obvious and demand effects are usually less of an issue in natural experiments.
In addition, natural experiments overcome the dependence of randomized experiments on the willingness of the participants to be randomized: People do not have a choice about whether or not to be affected by a natural experiment that involves, for example, an earthquake or compulsory military service. They still need to agree to participate in a study investigating the effects of the natural experiment (unless administrative records are used). However, agreeing to participate may be a lower threshold in a natural than in a randomized experiment because the chances of receiving the desired or undesired treatment do not depend on study participation in a natural experiment.
Finally, natural experiments enable researchers to assess whether an effect that they found in a randomized experiment in the lab is detectable and of a relevant size in the populations, contexts, and conditions of interest. The samples from natural experiments tend to be more representative (e.g., systematic vs. convenience sampling), the treatments are real-world events (e.g., military service) rather than artificial manipulations (e.g., exposure to preselected violent stimuli), and the study conditions and contexts are ecologically exemplary. 4 Thus, natural experiments can be considered valuable complements to randomized experiments in triangulation efforts (i.e., the application of multiple approaches to causal inference in which each approach has different strengths, weaknesses, and sources and directions of bias; e.g., Hammerton & Munafò, 2021). For example, Cesario (2022) argued that traditional laboratory experiments in social psychology may not inform us about real-world group disparities. To address this issue, social psychologists could complement randomized experiments with studies exploiting natural experiments. For all these reasons, we consider natural experiments to be attractive complements to randomized experiments that might be particularly helpful in evaluating whether causal effects are of relevant size in the field.
Types of Studies Exploiting Natural Experiments
In line with Dunning (2012; see also Sieweke & Santoni, 2020), we distinguish between three types of studies exploiting natural experiments: standard natural experiments, instrumental-variable designs using a natural experiment, and regression-discontinuity designs (see Fig. 1). For the first two of these three types of studies, we distinguish between random assignment to treatment/instrument and as-if random assignment to treatment/instrument. Random assignment means that participants are assigned to the treatment/instrument through a randomization process with a known probability distribution. As-if random assignment means that participants are not assigned through an actual randomization process. However, because of the natural occurrence of the event/condition that constitutes the treatment/instrument, neither the experimenter nor the participant/unit have control over the treatment/instrument in a natural experiment with as-if randomization. For example, self-selection into treatment and control conditions is not possible. Nevertheless, units might be selected by someone/something (e.g., the government) into treatment and control conditions on the basis of factors that are related to the units (e.g., income, age). Thus, when using natural experiments with as-if randomization, it is particularly important to consider potential confounding factors because the absence of random assignment can lead to confounding bias in standard natural experiments and violations of assumptions in instrumental-variable designs using a natural experiment. For the third type of study that exploits natural experiments, regression-discontinuity designs, we distinguish between designs that are sharp and those that are fuzzy. The decision tree in Figure 2 illustrates how to determine whether an event or condition is a suitable natural experiment and which type of design can be used to exploit it.
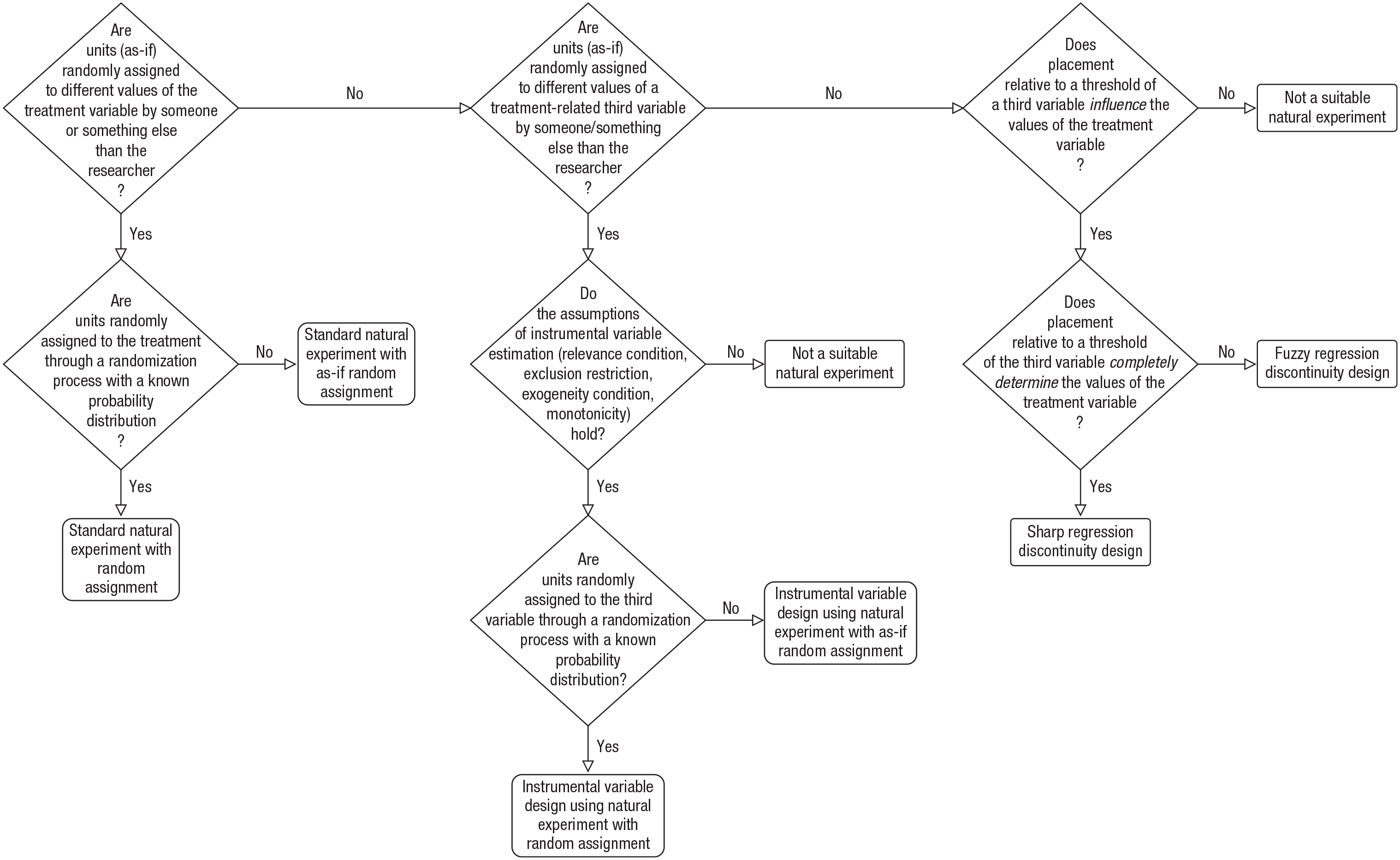
Decision tree for identifying (types of) natural experiments.
Standard natural experiments
In an example for a standard natural experiment with random assignment, Lindqvist et al. (2020) compared Swedish lottery players who won a large sum of money with matched controls (i.e., lottery players who had the same sex, age, and number of lottery tickets but who did not win a large sum) to estimate the effect of wealth on well-being (Box 1). Other examples are public-policy interventions designed to be equitable by randomly allocating costs (e.g., Vietnam lottery draft) or benefits (e.g., Green Card Lottery), as well as randomized admission procedures (e.g., for medical school; Ketel et al., 2016). The standard natural experiment with random assignment is most similar to randomized experiments as routinely implemented by psychological researchers.
Examples of natural experiments with as-if randomization are naturally occurring events, such as famines or earthquakes (e.g., Belloc et al., 2016); policy interventions, such as the U.S. 1970 Clean Air Act amendments (Schwaba et al., 2021); alphabetical seating orders (e.g., Byrne, 1961); biological sex of a child or sibling (e.g., Dudek et al., 2022); or the randomization of offspring genotype during meiosis (i.e., offspring as-if randomly inherits one allele from each parent at every point in the genome; e.g., Madole & Harden, 2023). 5
As already alluded to above, in the case of as-if randomization, it is particularly important to check for potential confounding factors that might bias the effect estimation. Dudek et al. (2022) provided an example of how such checks might be performed. In their analysis of data from 85,887 people from 12 diverse samples covering nine countries, Dudek et al. aimed to estimate the causal effect of growing up with a next-younger sister rather than a next-younger brother on one’s personality. To be able to estimate this effect, Dudek et al. first needed to establish that the gender of the next younger sibling was as-if random. Although whether a younger sibling will be a male or female is essentially random at conception, sex differences in survival rates or sex-selective abortions could mean that the sex of the next younger sibling will not be completely random. To rule out such artifacts, Dudek et al. performed several balance checks to assess whether the two groups (people with a next younger sister vs. people with a next younger brother) were comparable before the birth of the next younger sibling. For example, they compared the two groups on a number of observable variables (e.g., number of older siblings) that were determined before the birth of the next younger sibling. If the gender of the next younger sibling was indeed random, there should be no systematic differences between the groups on such variables (including unobservable ones). Finally, they performed robustness checks by excluding data from three samples for which there were concerns about sex-selective abortion and other imbalances. Overall, they concluded that the sex of the next younger sibling was plausibly as-if random, and thus, they could use it to estimate the effect of the siblings’ sex on personality.
Instrumental-variable design using a natural experiment
A naturally randomized variable can serve not only as a treatment variable, as is the case in standard natural experiments, but also (alternatively) as an instrumental variable. An instrumental variable allows one to target variation in the treatment that is plausibly unconfounded. In that manner, an instrumental variable (Z) allows researchers to unbiasedly estimate the causal effect of some other treatment variable (X) on an outcome (Y), even if there is unobserved confounding between X and Y (U; see Fig. 3).

Directed acyclic graphs illustrating instrumental-variable estimation. The regression estimate
A classic example for an instrumental-variable approach was provided by Angrist (1990). He used draft eligibility determined by the Vietnam lottery draft (Z) as an instrument to estimate the causal effect of veteran status (X) on civilian earnings (Y). Such instrumental-variable estimation can work even when veteran status and civilian earnings are confounded by unobserved third variables, such as civilians’ earning potential (U)—men with few civilian job opportunities are more likely to enlist. Not only a naturally randomized variable (natural experiment) but also a variable randomized by a researcher (randomized experiment) can be used as an instrumental variable. However, the focus of the current article is exclusively on naturally randomized variables (natural experiments).
When does this approach work? Instrumental-variable estimation produces unbiased estimates of the effect of X on Y under several assumptions (e.g., Bollen, 2012; Lousdal, 2018; Wooldridge, 2010), among them the following three central ones 6 :
The three central assumptions might alternatively be met when Z does not have a direct causal effect on X but when X and Z share a common cause U * (for details, see Fig. S1 on the OSF at https://osf.io/a5nxm).
Only the relevance condition can be empirically tested. Natural experiments can help to meet the exchangeability condition because the random or as-if random assignment ensures that there are no (unobserved) common causes of Z and Y. For example, being eligible for the draft and civilian earnings should have no common causes because the birthdays that were drawn in the lottery were randomly determined (unless the lottery was rigged).
Green and Winik (2010) applied instrumental-variable estimation to determine the effect of incarceration (X) on recidivism (Y; Box 2). They made use of the natural experiment that drug offenders were as-if randomly assigned to one of nine different judicial calendars (Z) in the U.S. District of Columbia Superior Court in 2002 and 2003. Because each calendar came with a different group of judges, and the judges varied in terms of how punitive/lenient they were, the sentences from the nine calendars varied in terms of prison and probation time, more so than one would expect by chance alone: The least punitive calendar incarcerated 23% of the offenders, and the average prison sentence was 5.1 months; the most punitive calendar incarcerated 65% of the offenders, and the average prison sentence was 11.9 months. Green and Winik used eight dummy variables that indicated which calendar the offender was assigned to (Z) as instruments for incarceration. This enabled them to estimate the impact of incarceration (X) on recidivism (Y), a crucial piece of information for legal proceedings in which psychologists often provide expert opinions on matters of imprisonment and release.
Regression-discontinuity design
The third type of study using a natural experiment is the regression-discontinuity design. In a regression-discontinuity design, a threshold of an assignment variable Z determines whether or not a unit receives treatment X (Fig. 4). The main identifying assumption in a regression-discontinuity design is that potential-outcome conditional-expectation functions are continuous at the discontinuity (i.e., at the threshold). In other words, the treatment variable changes discontinuously as a function of the assignment variable Z at the threshold, whereas the covariates (including unobserved confounders) change continuously or do not change at all as a function of the same assignment variables Z (i.e., the distributions of the covariates are a smooth function at the threshold; e.g., Hahn et al., 1999). In this case, causal identification is possible despite units not being (as-if) randomly assigned to the treatment variable X.
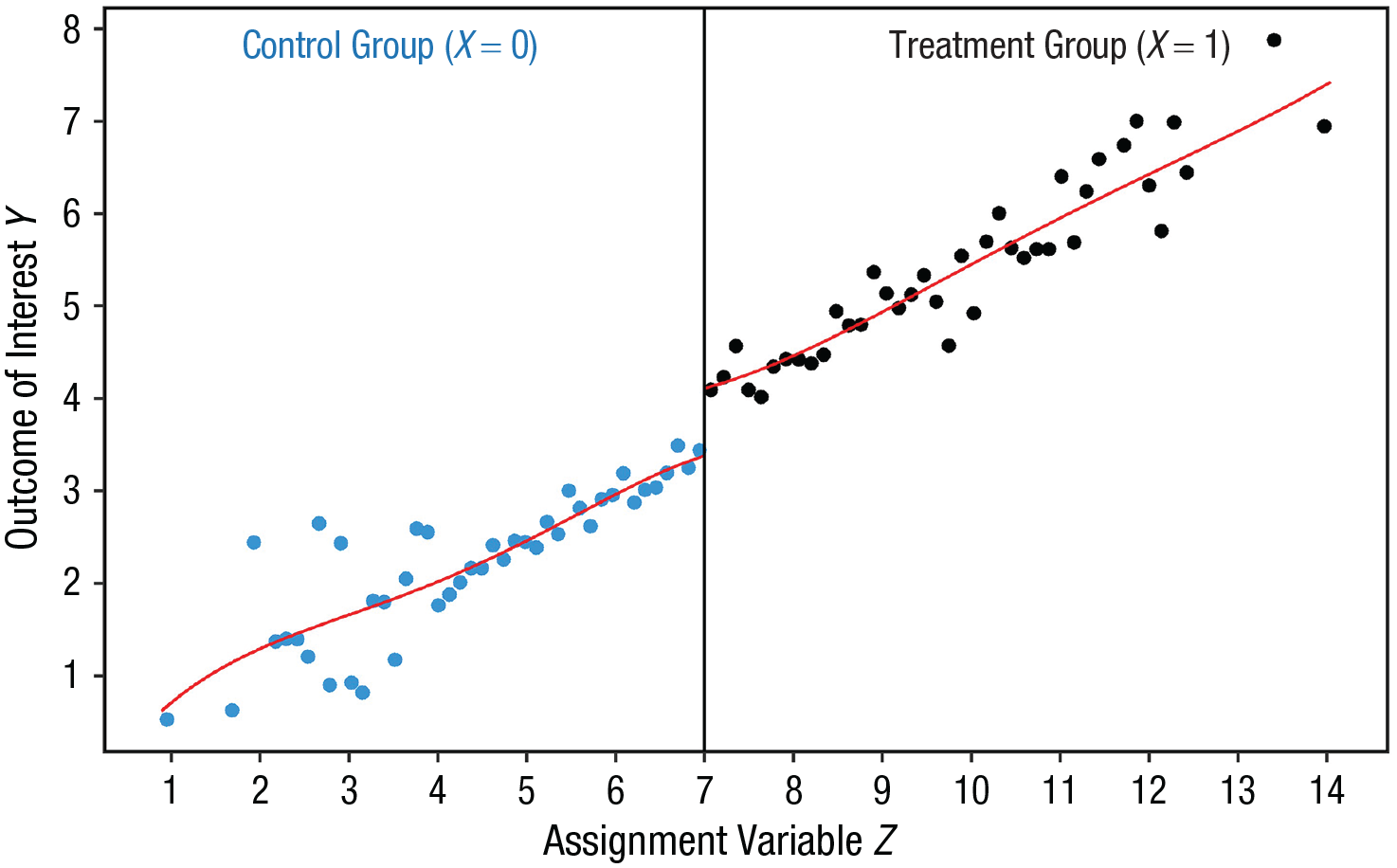
Illustration of a treatment effect in a regression-discontinuity design. We used the R package rdrobust (Version 2.1.0; Calonico et al., 2022) and ggplot2 (Version 3.3.6; Wickham, 2016) to plot simulated data illustrating a treatment effect on the outcome of interest. The vertical line indicates the threshold of the assignment variable (threshold value = 7). Units to the left of the vertical line (values < 7) did not receive the treatment; units to the right of the line (values > 7) received the treatment. We simulated data for 1,000 units. The graph displays the means of 100 bins, each containing 10 units. The R code for the simulation and plot can be found on the OSF at https://osf.io/a5nxm.
For example, Thistlethwaite and Campbell (1960) investigated the effect of public recognition (X) on subsequent academic achievement (Y) by comparing students who received certificates of merit with similar students who did not (Box 3). Students received a certificate of merit if their test score on the Scholarship Qualifying Test (Z) was at least equal to the qualifying score in the student’s state. Students whose scores equaled the qualifying score were classified by Thistlethwaite and Campbell in Interval 11, and those whose scores were 1 unit lower than the qualifying score were classified in Interval 10. The assumption of continuous confounder distribution was plausible only for students near the qualifying score in the student’s state. For example, students in Interval 11 were probably very similar in their pretreatment characteristics to students in Interval 10, even more so if the exam did not have perfect reliability and thus introduced some random variability into the exam scores. Therefore, when comparing students in Intervals 10 to students in Interval 11, any confounding influences are arguably negligible, and marked differences between these groups in the outcome variable (i.e., subsequent academic achievement) could actually be attributed to the treatment (i.e., recognition via certificate of merit).
The assumption of continuity of the confounder distribution is plausible only if units (e.g., students) in a close neighborhood around the threshold have no direct control over the assignment variable. That is, students just below the threshold cannot manipulate their test scores in such a way that they still obtain the certificate of merit. This assumption cannot be tested directly; violations could be suggested by a lack of balance on covariates and a bunching of units on one side of the threshold of the assignment variable (e.g., Cattaneo et al., 2020; McCrary, 2008; Thoemmes et al., 2017).
Typical thresholds in a regression-discontinuity design are population- and size-based thresholds, such as class size in school and number of employees (e.g., antidiscrimination law that applies only to firms with at least 15 employees; Hahn et al., 1999). Other thresholds are time-based thresholds (e.g., if the time at which a survey was completed was before vs. after an earthquake; Oishi et al., 2018), age or birth date (e.g., school-entry age cutoffs; Ritchie & Tucker-Drob, 2018), eligibility criteria (e.g., college admission cutoff scores on high school exit exams; Dasgupta et al., 2022), and indices (i.e., a composite score that combines information from several variables; Dunning, 2012).
The kind of regression-discontinuity design that we have portrayed so far is sometimes called a sharp regression-discontinuity design because the placement relative to the threshold completely determines whether the treatment is received. In a fuzzy regression-discontinuity design, the placement relative to the threshold influences the receipt of the treatment but does not determine it completely. In such cases, to estimate the causal effect, the assignment variable is used as an instrumental variable, and the assumptions of instrumental-variable estimation need to hold (see above).
For example, Kuehnle and Oberfichtner (2020) used a fuzzy regression-discontinuity design to estimate the effects of universal childcare (X) on children’s cognitive skills and personality traits (Y). They capitalized on the fact that the time at which a child was enrolled in childcare in West Germany was influenced by the calendar year in which the child turned 3. Many children born toward the end of a year start receiving childcare in the summer before their third birthday; by contrast, many children born at the beginning of the subsequent calendar year start receiving childcare in the summer after their third birthday. Thus, the average age at which children began receiving childcare jumped discontinuously by 5 months between the birth months December and January in the data analyzed by importantly, the December/January threshold did not affect the time at which the children began formal schooling, and the children on the two sides of the threshold did not differ in relevant observable characteristics, such as the mother’s native language or education. Because the probability of starting childcare earlier did not switch from 0 to 1 between December and January, their approach was a fuzzy rather than a sharp regression-discontinuity design. Kuehnle and Oberfichtner used a dummy as an instrumental variable predicting the age at which children began childcare to indicate whether a child was born before or after the December/January threshold (Z). They used this instrumental variable to estimate the causal effect of starting universal childcare 4 months earlier, around age 3, on the responses to standardized cognitive tests, Big Five personality questionnaires, and other measures at age 15.
As another example, Gauriot and Page (2019) used a fuzzy regression-discontinuity design to estimate the momentum effect, that is, the effect of the success of sports behavior (X) on subsequent sports performance (Y). They exploited the fact that the probability of whether a player will win a point in tennis varies discontinuously as a function of the location of the ball on the court. The player loses a point if the ball hit by the player lands just outside the court lines. Conversely, the play continues if the ball lands just inside the court lines, giving the player a chance to win the point. Gauriot and Page extracted a very small share of points for which the ball bounced within a few centimeters of the court lines from a large data set on precise ball location during tennis matches between professional tennis players. Because the location of the ball does not completely determine whether a player will win or lose a point—the play continues if the ball lands inside—their design was a fuzzy rather than a sharp regression-discontinuity design. Gauriot and Page predicted winning a point (X) by a dummy instrumental variable indicating whether the ball landed inside or outside the court lines (Z). They used this instrumental variable to estimate the causal effect of winning or losing a point on the player’s subsequent performance.
The Challenges of Using Natural Experiments
Despite their advantages, natural experiments are not a panacea. Like many other causal-inference methods, natural experiments rely on assumptions that are often challenging or impossible to validate empirically. Identifying and analyzing natural experiments often requires profound knowledge and an understanding of subjects that fall outside of many psychologists’ core areas of expertise. For example, it might be necessary to know the level of compliance with a policy reform and how it was implemented to evaluate whether the reform can serve as a suitable natural experiment that meets the required assumptions (e.g., Lillebø et al., in press). Likewise, it might be necessary to have a deep understanding of biology and genetics (e.g., issues such as pleiotropy and assortative mating) to evaluate whether and how the random allocation of genetic variants from parents to their children can be used as natural experiments to estimate causal effects (e.g., Madole & Harden, 2023; Sanderson et al., 2022).
Another notable challenge is finding a suitable natural experiment for a particular study. Even if a relevant natural experiment can be found, it might not precisely constitute the treatment of interest or it might only allow researchers to identify a particular causal effect. For example, in Dudek et al. (2022), the effect of the sex of the next younger sibling was identified but not the effect of the sex of the next older sibling or of any other sibling. Out of substantive considerations, all of these effects would be relevant to provide a full picture of how siblings shape personality. Thus, focusing exclusively on natural experiments would narrow down the causal effects that could be studied by psychologists.
Nonetheless, we believe that natural experiments offer attractive opportunities for estimating causal effects, especially when randomized experiments are unethical, unfeasible, or generalize poorly to the populations, contexts, and conditions of interest. Thus, we hope that the current work and the examples highlighted herein will inspire readers to be on the lookout for suitable applications in their own work, thus leading to the wider use of natural experiments in psychology and, ultimately, a broader toolbox for causal inference in our field.
Footnotes
Acknowledgements
We thank Jane Zagorski for language editing, Felix Thoemmes for stimulating discussions and suggestions, and Jan Lorenz Westermann for help with the literature review (searching for and coding studies, preparing the R code, etc.). S. Bücker is now at the School of Psychology and Psychotherapy, Witten/Herdecke University, and A. Zapko-Willmes is now at the Department of Psychology, University of Siegen.
Transparency
Action Editor: David A. Sbarra
Editor: David A. Sbarra
Author Contributions