
Abstract
Psychological science is moving toward further specification of effect sizes when formulating hypotheses, performing power analyses, and considering the relevance of findings. This development has sparked an appreciation for the wider context in which such effect sizes are found because the importance assigned to specific sizes may vary from situation to situation. We add to this development a crucial but in psychology hitherto underappreciated contingency: There are mathematical limits to the magnitudes that population effect sizes can take within the common multivariate context in which psychology is situated, and these limits can be far more restrictive than typically assumed. The implication is that some hypothesized or preregistered effect sizes may be impossible. At the same time, these restrictions offer a way of statistically triangulating the plausible range of unknown effect sizes. We explain the reason for the existence of these limits, illustrate how to identify them, and offer recommendations and tools for improving hypothesized effect sizes by exploiting the broader multivariate context in which they occur.
Recent years have witnessed increased sophistication in the formulation and testing of hypotheses in psychology and its allied disciplines (Cumming, 2013). As part of improvements to research practices, psychologists pushed further the enrichment of hypotheses with approximate effect sizes. Doing so allows for a priori estimations of a required sample size (Cooper & Findley, 1982), helps to preemptively separate associations considered trivial in size from more substantial ones (Fritz et al., 2012), and in Bayesian analysis, helps to define one’s priors (Wagenmakers et al., 2018). Unsurprisingly, there is much debate about the question of what effect sizes are reasonable to expect. For example, it may be difficult to approximate an effect size associated with a novel hypothesis, and it may be challenging to state a priori whether the size of an effect in one context (e.g., in lab settings) will be the same elsewhere (e.g., in field settings; Giner-Sorolla et al., 2023; Greenwald et al., 2015). Simultaneously, methods of obtaining more accurate estimations of population-level effects, such as meta-analysis and meta-analytical structural equation modeling, have witnessed an increase in sophistication and popularity (Jak & Cheung, 2020; Johnson, 2021).
Much of the existing discussion about appropriateness of hypothesized effect sizes revolves around the theoretical basis for such claims or what empirical precedent exists. For example, a small effect size that affects humanity at large may be considered equally or more important than a large effect size that occurs among a specific subpopulation only. Furthermore, the typical magnitudes of effect sizes may vary across subdisciplines and paradigms, and size category labels may need to take such contingencies into account (Cohen, 1988; Funder & Ozer, 2019). We propose that there is another and more fundamental issue, underappreciated in quantitative psychology, that should be considered within this ongoing discourse: There are mathematical limits to the effect sizes that may exist in a population (and corresponding samples), and these may be surprisingly restrictive.
Understanding these limits helps appreciate the importance of considering the size of a hypothesized effect in light of what reality permits, which may require an appreciation of smaller effect sizes. Furthermore, these limits render some hypotheses entirely impossible. We demonstrate the mathematical basis for such limits, offer guidance for evaluating whether a hypothesis is impossible, and then illustrate how effect-size limits may be determined. Note that this article is written with the aim to be accessible to quantitative psychologists at large—inclusive of psychologists who possess but limited knowledge of statistics—and we accordingly forewarn the expert reader of our leisurely pace through the various arguments, equations, and examples. Practical recommendations and links to online tools are located in the latter half of this article.
Hypotheses as Statements About Correlation Matrices
A helpful way to think about hypotheses in quantitative psychology is to treat them as statements about presumed correlation matrices that describe a population in question. This is perhaps easiest to see for hypotheses that postulate simple associations between continuous variables, such as “Higher levels of social inclusion come with lower levels of anxiety,” for which one would accordingly expect a nonzero correlation—here a negative one in particular—between the two measured variables. A similar situation applies to hypotheses about group differences, such as “First-year students experience more anxiety than second-year students,” which essentially means that some level of covariance, and hence correlation, is expected to occur between anxiety and the dichotomous “student year” variable. Subsequent empirical studies, in turn, serve to test these predicted population-level correlations.
The above hypotheses are ordinal; that is to say, they postulate the sign of correlation but not its magnitude. There has been a disciplinary move away from such ordinal hypotheses toward more precise ones. For example, a researcher may hypothesize not merely that higher levels of social inclusion come with lower levels of anxiety but also that this association is “weak,” “moderate,” or “strong,” for example, corresponding to absolute correlations of around
To represent the above effect sizes into a correlation matrix, it is helpful to first define various concepts. For starters, the (population) “covariance” between Variables A and B is defined as

The covariance of a variable “with itself” (e.g., exchanging

A corresponding correlation—or normalized covariance—matrix M for two or more variables, labeled




Specifically, this correlation matrix M is square with k rows and k columns. The diagonal contains the correlations of a variable with itself, which equals 1; its off-diagonal entries contain real numbers that represent the strength and direction of correlation. The correlation matrix is diagonally symmetric because any covariance between
One of the benefits of using the correlation matrix is that the effect size can be directly incorporated in it. For example, Table 1 represents the hypothesis that level of social inclusion has a moderately strong negative association with level of anxiety (i.e.,
A Simple Hypothesis

The same can be done for the example hypothesis that postulated between-groups differences in anxiety for first- and second-year students after transforming Cohen’s d to Pearson r (assuming equal group sizes, normality, and variance homogeneity; Cohen, 2013):

This can be extended to situations that involve more than two variables, such as in the two near-identical hypotheses, Hypotheses 1 and 2, in Table 2. For example, a researcher of nostalgia—a sentimental longing or wistful affection for the past (Sedikides et al., 2008) that is characterized by mixed or “bittersweet” feelings—may hypothesize that trait nostalgia (variable
Example Hypotheses 1 and 2

Note: PA = positive affect; NA = negative affect.
The only difference between the two versions of this hypothesis is that Hypothesis 1 proposes slightly larger correlations for nostalgia with positive and negative affect (
Why is Hypothesis 1 outright impossible? And why does Hypothesis 2 turn out to be impossible as soon as it is considered in a broader variable context? The correlations that nostalgia has are probably unrealistically strong. What determines such limits? And more generally, how might this temper the anticipation of effect sizes? We address these questions next.
Impossible Hypotheses
The issue regarding Hypothesis 1 can be formulated in a more general form: The presence of a correlation between two variables sets limits to how these variables might relate to another one. The explanation for this, and corresponding guidance on how to evaluate the impossibility or implausibility of hypotheses, requires a few steps. We start off by illustrating the issue for the case of the 3 × 3 correlation matrices mentioned above before moving to the general case for correlation matrices of any dimension.
Specific case: Our impossible hypothesis has an impossible geometry
An intuitively helpful feature of correlation coefficients is that one can think of them as representing the cosines of the angle between two variables’ axes (Gniazdowski, 2013). For example, two variables with a correlation of
Before we apply this reasoning to Hypotheses 1 and 2, first consider a case of three uncorrelated variables (i.e.,

Geometrical illustration of a positive correlation limit.
However, this is only half of the story. In addition to positive correlation limits, there are also limits to negative ones, which can be found by trying to rotate the

Geometrical illustration of a negative correlation limit and the case of Hypothesis 2.
We first apply the same reasoning to Hypothesis 2. The correlation between positive affect and negative affect
Specific case: Our impossible hypothesis violates limits to multiple correlation
Aside from interpreting correlations geometrically, readers with a psychology background are probably familiar with interpreting these correlations as the square roots of the proportion of variance that two variables have in common. Indeed, the limits of
Yet a closer inspection reveals that Hypothesis 1 does prove problematic in this regard. Although neither the correlation between
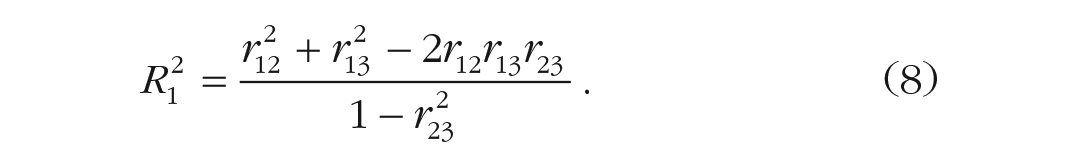
When we calculate the squared multiple correlation for each of the three variables in Hypothesis 1, we find that this value is 122% for nostalgia and 119% for both positive affect and negative affect. This is clearly impossible. For Hypothesis 2, on the other hand, we find values of 94%, 96%, and 96%, respectively—very high indeed but technically not impossible.
We can helpfully use Equation 8 to figure out what the minimum and maximum values are that a correlation coefficient can have by requiring



For example, assuming
One way to visualize the mathematical bounds dictated by Equation 8 is to realize that this equation defines the elliptical boundary of the pairs of

Ellipses that enclose allowed values of
General case: impossible hypotheses considering three or more variables
Examining whether hypotheses are impossible using squared multiple correlation may not have the intuitive appeal of the geometric interpretation explained earlier, but it has another desirable quality: It scales easily for any number of variables. In fact, Equation 8 that we used earlier to examine squared multiple correlations among three variables is a special case of (Neter et al., 1996)

In Equation 10,
The same can be done for correlation matrices with a larger number of variables. Consider the following example, loosely set to a social-identity context (Tajfel, 2010): A researcher studies social identification among English football fans with their various teams. Each participant will be asked to indicate their identification with three English teams: Manchester United, Liverpool, and Arsenal. The first two of these teams are allegedly fierce rivals, and one might accordingly expect a substantial negative correlation between identification with either team, say
Example Hypotheses 3 and 4

Hypothesis 3 is impossible, and Hypothesis 4 appears to be possible. When we apply Equation 12 to these matrices, we find that the squared multiple correlations for Hypothesis 3 are impossibly large (
Impossible Hypotheses in Light of Their Multivariate Populations
As the above section progressed, we discussed hypotheses with increasingly more variables. Many hypotheses in psychology feature only two or three key variables. Does that mean that only two or three need to be considered when evaluating the impossibility of a hypothesis? Unfortunately not. Note that hypotheses are statements about the relationship between one or more variables in a population and that this population is likely to be characterized by many more variables than just the ones that feature in the hypothesis. Although researchers may collect a sample that features only the key variables from their hypothesis, the variables’ relationships in this sample will represent those in the (multivariate) population from which the sample is drawn (albeit imperfectly, e.g., because of measurement error). The notion that hypotheses, although tested with samples, refer to populations has an important implication: Whether a hypothesized effect size turns out to be impossible will depend on both how it is related to the other key hypothesis variable(s) and how these key variables relate to others in the same population.
Earlier, in passing, we mentioned that although Hypothesis 2 seemed possible, it most likely is not. Likewise, Hypothesis 4, although seemingly possible, can probably not describe a real situation. Why is that the case? As alluded to above, the issue for both Hypotheses 2 and 4 is that their viability hinges on the magnitude of correlations with other variables in the population—whether measured or not. With each of the hypothesis variables featuring substantial maximum squared multiple correlations, the existence of correlations with other variables in the same population could quickly reveal them as impossible.
To illustrate, reconsider Hypothesis 2. A closer look at the literature suggests that among other things, dispositional nostalgia tends to have a positive correlation with another form of affect: loneliness. Specifically, research suggests that people turn to nostalgic reverie to soothe psychological and physical discomfort (Van Tilburg et al., 2018; Wildschut & Sedikides, 2020; Zhou et al., 2012), and the correlation between nostalgia and loneliness has been estimated at
Extended Example Hypothesis 2*

Note: PA = positive affect; NA = negative affect.
Calculating the squared multiple correlations for our variables now reveals that they exceed their limits (
The same reasoning applies to Hypothesis 4. Again, the squared multiple correlations quickly exceed their limits if another population variable is added regardless of whether we plan to sample it. Consider, for example, what happens if we consider an additional local football team: Tottenham Hotspur, an alleged fierce rival of Arsenal. We might reasonably expect individuals socially identifying with Arsenal to identify less with Tottenham Hotspur, much in the same way as was the case for Manchester United and Liverpool (Table 5). This renders our adjusted Hypothesis 4* impossible as a result (
Extended Example Hypothesis 4*

Using the above squared multiple correlation method to detect impossible correlations expresses the issue of impossible hypotheses in terms of the familiar concept of explained variances. Alternatively, researchers may have encountered situations in which they found that a correlation matrix failed to be positive definite, that the matrix thus produced negative eigenvalues, that the determinant of a matrix proved zero or negative, or that the matrix was singular (Marcus & Minc, 1988). These are symptoms of the same underlying problem: The correlation matrix in question is impossible (Lorenzo-Seva & Ferrando, 2021).
Identifying Effect-Size Limits
The above sections reveal that the limits to effect sizes within a multivariate context may be more restrictive than typically assumed. Psychology examines extensively, perhaps even entirely, variables from multivariate populations. An obvious question following from the above sections is what effect sizes, then, are more reasonable to expect. Existing empirical work can then help in figuring out whether a specific proposed effect is realistic or not by piecing together a population correlation matrix that contains the variables of main interest alongside other ones. Specifically, as shown above, knowing how a focal pair of variables relates to other variables in the population, for example based on existing research, may help to then approximate the strength of association between this focal pair even if there is no prior evidence of the association between the focal pair of variables themselves yet. How can one use this prior information to identify possible limits to effect sizes?
Size limits for a single hypothesized effect
The simplest form of hypothesis formulation is probably when a single effect size is proposed. For example, a researcher may seek to hypothesize a specific correlation for the tentative association between nostalgia and positive affect. As we have shown above, one can use knowledge about the wider multivariate context to get a better idea of what effect size is possible. For example, our hypothetical researcher might be aware that nostalgia and loneliness may correlate at around
Estimating a Single Unknown Effect Size

Note: PA = positive affect; NA = negative affect.
Armed with knowledge about these other correlations, it is now possible for our researcher to narrow down the range in which the unknown effect size may fall. After all, its correlation value must not cause any of the squared multiple correlations to exceed 100%. Accordingly, we can solve Equation (10) for

Thus, if we can assume that the correlations obtained in prior studies give us an accurate impression of the population at large, then we know that the correlation between positive affect and nostalgia must lie between
Size limits for two hypothesized effects
It is far from uncommon for psychologists to formulate hypotheses about two associations rather just one. In our original nostalgia example, for instance, we predicted effect sizes for nostalgia’s association with both positive and negative affect. Can we estimate effect-size limits assuming that both are unknown? The answer is yes. Specifically, we need to solve

We can then plot the resultant inequality with two unknowns for ease of interpretation. Figure 4 displays the corresponding ellipse that encloses the possible values that these two correlations may take. This figure reveals that there exists a trade-off between the effect sizes one may hypothesize for
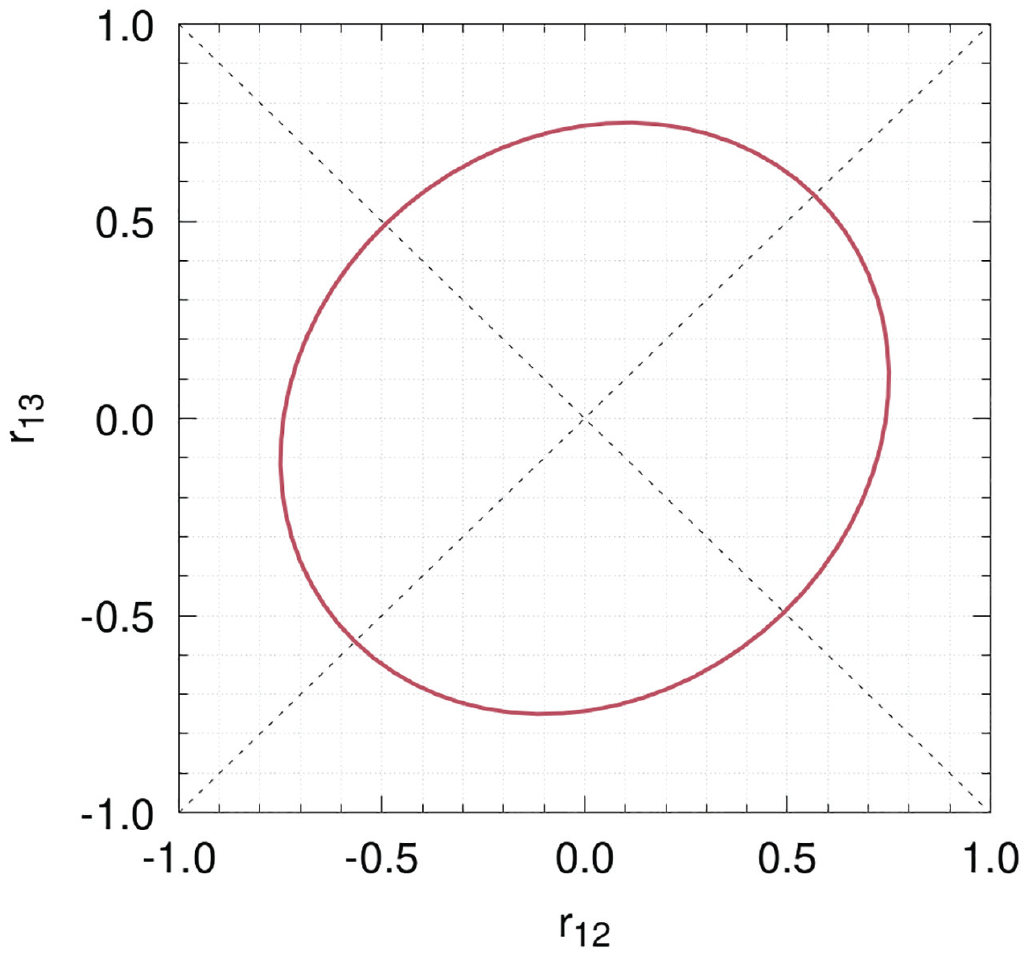
Ellipse that encloses possible values for
Of course, a similar approach can be adopted for cases in which three or more effect sizes need to be hypothesized. The downside is that clear visual guides such as Figure 4 are impossible to produce with a number of unknown variables greater than three.
Size limits for hypothesized group differences
The previous sections covered the existence of impossible hypotheses in the form of correlation matrices. These sections showed that effect-size limits may often be more restrictive than the typically assumed limits of
Consider, for example, a study in which a psychologist wishes to test if a gratitude intervention can help reduce state boredom. As part of this intervention, people list, on a daily basis, things they are grateful about for a period of several days (Emmonse & Mccullough, 2003; Sztachańska et al., 2019). This intervention is then compared against a condition in which participants listed memorable events instead. What is the possible range that the effect size can take? Published work on the impact of a gratitude intervention on boredom is absent at the time of this writing. However, both these variables have been independently examined in context of self-reported gratitude and well-being. Specifically, a meta-analysis showed that such gratitude interventions increase self-reported gratitude with a size of
After transforming the Cohen’s d values into correlation coefficients following Equation 7, we can complete most of the correlation matrix that approximates the effect sizes among the (e.g., dummy-coded) gratitude intervention, state boredom, self-reported gratitude, and well-being (Table 7).
Estimating a Single Unknown Effect Size for a Group Comparison
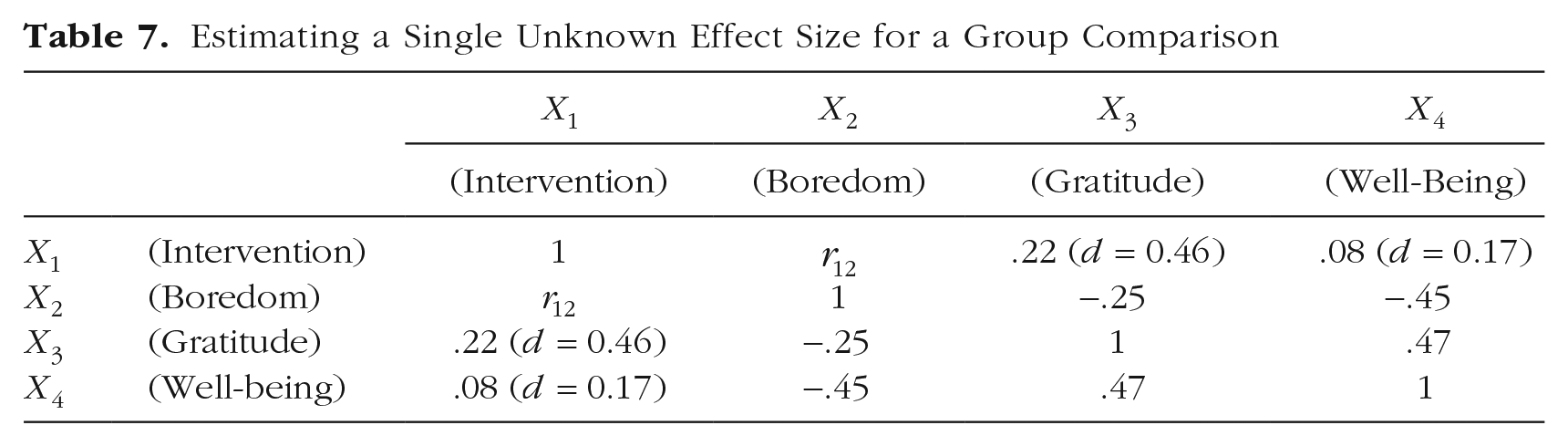
We can now use Equation 10 to compute the limits of
Practical Recommendations and Online Tools
Our article adds a tool to researchers’ statistical arsenal with two procedures. The first is a way to to tell researchers whether a hypothesis is possible on the basis of the squared multiple correlations of the included population variables. The second serves as advisory tool that tells researchers the range in which an effect size can be expected to fall after specifying an incomplete hypothesis—a population correlation matrix with at least one unknown. Both uses operate through Equation 10; Equation 8 serves the specific case of three variables. An interactive and easy-to-use web application featuring these tools is available at https://wapvantilburg.shinyapps.io/Hypothesis_Evaluation_Tool/. 1 There are various scenarios in which our evaluative and advisory procedures may aid researchers, discussed below. Note that we also highlight more specific extensions of our work in the Supplemental Material, including the link between the current work and “Voodoo” correlations (Fiedler, 2011; Vul et al., 2009), conventions on effect-size labels and categories, and experimental-design applications.
Use 1: testing whether a fully formed hypothesis is possible
The first use of our tool is a rather obvious one: Before finalizing power analysis, preregistering a study, and then conducting it, we recommend that researchers test whether their hypothesis is in fact possible. Doing so can prevent conducting a study that, from its onset, will inevitably cause the hypothesis to be empirically unsupported when it is statistically impossible. The abovementioned web application allows researchers to do this, as does Equation 10.
Use 2: examining how close hypothesized effect sizes are to their limits
This scenario may apply in at least two cases. First, researchers who have discovered that their hypothesis proved impossible may wish to scrutinize the specified correlations further. Any of the correlations specified in a hypothesis might in principle cause it to be impossible. Nonetheless, it may be helpful to see just by how much individual correlations require adjustment for the hypothesis to become possible. To examine this, a researcher could estimate ranges for each of the correlations in turn, each time treating it as unknown while retaining the others as originally specified. Doing so results in a matrix of possible correlation ranges against which the original correlations can then be compared. As an example, we performed this procedure on the impossible Hypothesis 1, which gave the ranges in Table 8.
Effect-Size Ranges for Hypotheses 1

Note: PA = positive affect; NA = negative affect.
With this information at hand and, of course, mindful of existing theory and prior findings, the researcher can then set out to develop a more realistic hypothesis.
Alternatively, cautious researchers may want to check how close the correlations of a hypothesis are to their range limits even if the hypothesis itself is technically possible. After all, given that there may well be (unknown) other variables in the population that might further limit ranges of effect sizes, it is probably safer to avoid close proximity to those limits. (Although whether an effect size is judged too close to its limit will remain up to the researcher.) The same procedure can be used as highlighted above, where individual correlation limits are calculated and then compared with those featuring in the hypothesis. Our web application returns these individual correlation ranges simultaneously with the overall evaluation of whether the hypothesis is possible.
Use 3: obtaining guidance on the possible range of an effect size
There are likely many situations in which it is difficult to form an expectation of what size an effect may take—for example, because of a lack of prior literature or when prior findings employed very different populations or methods. By estimating the possible range of such an unknown effect size, the researcher will gain a better understanding of where approximately this effect must lie. Although the obtained range will not give a conclusive indication of what effect size should be hypothesized, it may nonetheless help steer a researcher away from unrealistic sizes and toward more reasonable ones instead.
Use 4: guidance on effect sizes for power analysis
An a priori power analysis estimates the sample size required to detect a “minimum meaningful effect size” (MMES) after specifying required statistical power, Type I error rate, and statistical test features. Although determining what value this MMES should have will of course depend on the research context (Giner-Sorolla et al., 2023; Greenwald et al., 2015), it may prove helpful to make this decision while keeping in mind the possible range that the hypothesized effect size can take (e.g., using our web application).
Calculating the possible range of the hypothesized effect will result in one of two outcomes. First, this range may exclude zero (e.g.,
Some researchers use a sensitivity power analysis instead. This type of power analysis estimates the effect size that a study can detect after specifying required statistical power, Type I error rate, and sample size. For cases in which sensitivity analysis is performed, we recommend comparing the sensitivity power analysis estimate with the possible range of the hypothesized effect. If the sensitivity analysis returns a value of greater magnitude than that of the range’s largest limit, then the study will not be sensitive enough to detect the actual effects.
Causes of impossible hypotheses and inaccurate population estimates
There are a number of reasons why a hypothesis, characterized as a predicted population correlation matrix, may prove impossible. Perhaps the most obvious reason is that a researcher may assign a size to an unknown effect based on typical size categories (e.g., postulating a “large” correlation between positive affect and nostalgia in Table 6, equivalent to
Another reason for having an impossible hypothesis can be linear dependency or very high correlations between variables (Lorenzo-Seva & Ferrando, 2021), in which some included variables are essentially redundant with one another. This may occur, for example, when one includes a separate dummy for each level of a categorical variable or when both a composite variable and its components are included (e.g., total score and its subscores). Although not necessarily causing hypotheses to be impossible, the presence of latent variables with which multiple variables in the hypothesis correlate can cause those variables in the hypothesis to be very highly correlated.
In addition to the above, there are several reasons why an effect size obtained on the basis of prior literature may be inaccurate. Recall that a key assumption is that one can rely on the known relationships among population variables to spot impossible hypotheses and to identify limits to effect sizes. Estimating effects that exist in the population is itself a challenging endeavor. Whether a particular study or sample offers an accurate estimate for one’s population depends on issues such as population representativeness, methodological and measurement characteristics, and sample size. Accordingly, if one were to derive correlations for a hypothesis from prior studies, then it is important to be aware of the various sources of inaccuracy that may be present in these estimates. For starters, there will be inaccuracy in the empirical data themselves because they provide only an approximation of the population effect. Issues such as poor reliability and validity, large standard errors, and small sample sizes can each undermine the accuracy of the produced effects. Further inaccuracy may stem from methodological differences between studies. The “inaccuracy” in such cases need not be due to empirical imperfections but can stem from incorrectly assuming equivalence in effect sizes across methods. For example, the effect size observed for a dependent variable will likely be greater in a study that used a heavy-handed experimental induction compared with one that featured a subtle one. Another potential source of impossible hypotheses present in the literature is questionable research practices or possibly even misconduct, leading effect sizes to become “too good to be true” (Francis & Thunell, 2022). Although questionable research practices or misconduct may produce impossible effect sizes, the occurrence of an impossible effect size does not need to indicate that questionable research practices or misconduct occurred—there are several reasons, as reviewed here, that can lead an effect size in the literature to be impossible. In addition, it is also possible that effect sizes differ between populations, and assuming an effect size found in a study on one population may prove inaccurate for another. To illustrate, consider the following two imaginary population-level correlations for nostalgia, each coming from a different population (e.g., different cultures, different [non]clinical groups) in Table 9. Each correlation matrix is itself possible. Yet if researchers were to form their own hypothesis using the correlations between positive affect and negative affect from Population 2 and the remaining correlations from Population 1, then the resultant correlation matrix (i.e., Hypothesis 1) is an inaccurate description of either one and in this case, even impossible. 2
Correlations in Different Populations
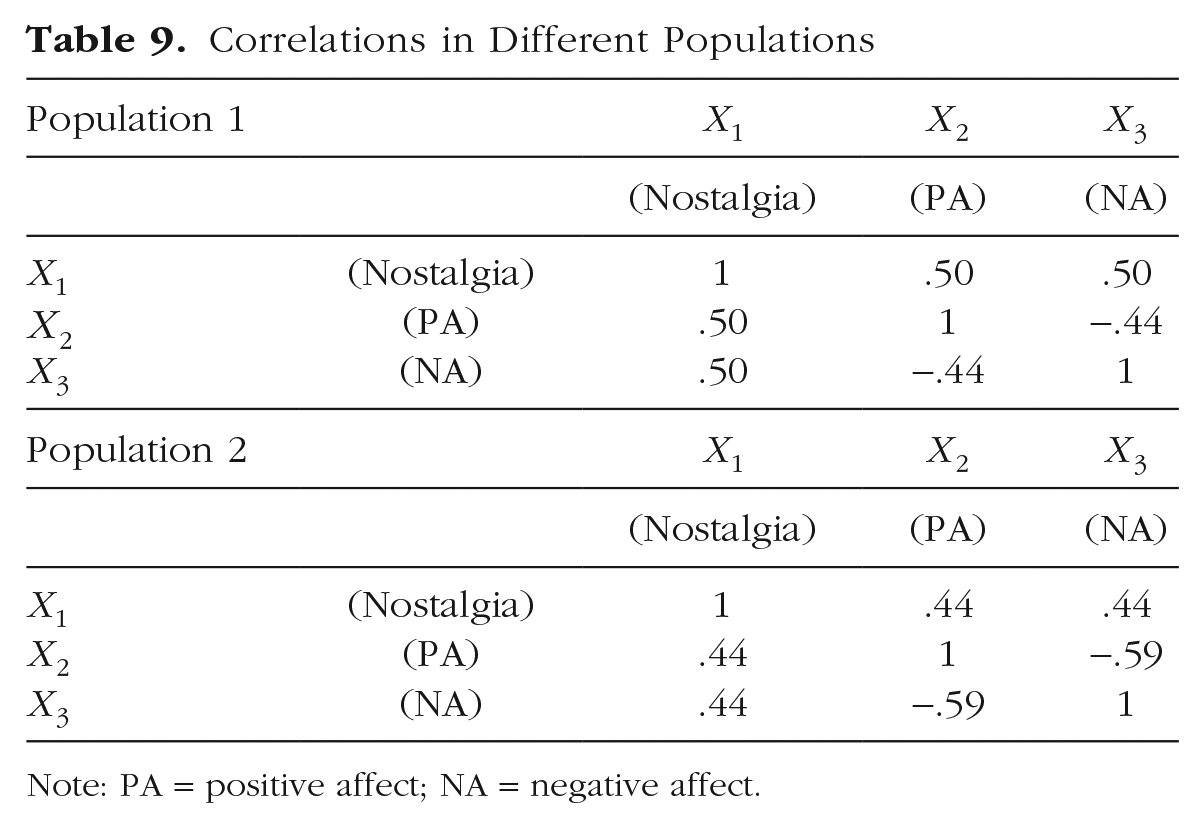
Note: PA = positive affect; NA = negative affect.
Obtaining good population estimates
Identifying accurate estimates of population-level correlations is, as evident from the above, a challenging endeavor. What are promising ways to do so? One potential source of effect sizes to be included in a proposed population correlation matrix is a meta-analysis. This analysis considers multiple studies simultaneously when estimating the size of an effect, which ought to improve the accuracy of the corresponding estimate. For example, the effect size assigned earlier to the impact of the gratitude intervention on well-being
Although “regular” meta-analyses can be a more accurate source of population effect-size estimations than single-study results, another promising and ambitious source of population effect-size estimates is meta-analytic structural equation modeling (MASEM; Becker, 1992, 1995; Cheung, 2013), which is an extension of multivariate meta-analysis (Becker, 2000). MAESM differs from regular meta-analysis in its capacity to perform meta-analyses on entire correlation matrices. Note that the individual studies that contribute to MASEM do not have to feature all variables in the correlation matrix in question but may contribute a part (Bergh et al., 2016). This is particularly useful for application in the detection of impossible hypotheses or effect-size limits for newly researched effects because studies that comprise the full set of relevant variables are unlikely to exist. In addition, MASEM allows researchers to include more specific relations between variables, such as mediation. The recent development of one-stage MASEM furthermore supports estimations of and corrections for heterogeneity across studies and allows the inclusion of categorical and continuous moderators to account for this (Jak & Cheung, 2020). To make this promising method more accessible for researchers, Jak et al. (2021) and Cheung (2015) developed practical guidance, an interactive web application, and a dedicated R package.
Note, however, that even meta-analyses are subject to sources of inaccuracy. Issues such as heterogeneity across studies, questionable research practices, publication bias, and selective reporting can all bias meta-analytic results (Ioannidis, 2008; Ones et al., 2017). In the attempt to gauge the accuracy of effect sizes obtained through meta-analysis in particular, researchers may turn to tools such as sensitivity analysis, the p-curve and p-uniform methods (Carter et al., 2019), and correcting for range restrictions in the data (Hunter et al., 2006). In a sensitivity analysis, the meta-analytic effect is compared across study subgroups (e.g., based on methodological differences or sample differences; Impellizzeri & Bizzini, 2012), and this can expose heterogeneity in study estimates. The p-curve and p-uniform methods can help find publication bias and, in the latter case, provide a bias-corrected effect-size estimate (Simonsohn et al., 2014; Van Aert et al., 2016). Range restrictions, in which variance is underestimated because of, for example, censored observations (Ree et al., 1994), can be remedied using procedures developed by Hunter et al. (2006) and validated by Le and Schmidt (2006).
Fortunately, current recommendations for meta-analysis in psychology tend to feature recommendations for the inclusion of such bias-detection measures (e.g., Carter et al., 2019; Johnson, 2021), making it easier for researchers to evaluate their accuracy. Nevertheless, when population estimates, derived from meta-analysis or otherwise, are rather uncertain, one may treat corresponding effect-size limits more as rough guide rather than an exact estimation.
Caveats
Psychological hypotheses are increasingly enriched with specific effect sizes. We called for and demonstrated above the importance of considering mathematical limits to effect sizes and whether their corresponding hypotheses might prove impossible. Within the predominantly multivariate populations that psychology considers, the maximum and minimum sizes that effects can take may be more restrictive then researchers might assume. This notion adds further nuance to the existing debate about what effect sizes are reasonable to expect. It aids researchers in interpreting measured effect sizes and enables them to predict limits on the possible correlations within populations. We wish to preempt a number of tentative misunderstandings about the work presented above, listed below.
First, it is important to underscore that the effect-size limits as computed in the current article refer to populations and not merely to specific samples. One of the implications of this is that whether or not a particular variable is part of one’s empirical sample is irrelevant to the limits of the size that an effect may take; what matters is if this variable features in the population. Thus, even if studies deal with a small number of focal variables, one may consider other variables in the population in estimating realistic effect sizes.
Second, our treatise of hypotheses and effect sizes has been applied only to cases of linear models with multivariate normal distributions. We suspect that the vast majority of psychological models are indeed linear and assume multivariate normality. However, our findings may not generalize readily to nonlinear models or variables that feature different distributions. Future work may look into these other settings.
A third word of caution is warranted about the role of null correlations. It may seem intuitively appealing to assume that a correlation between two variables of
Fourth, we emphasize that our approach deals with whether or not hypotheses, in the form of correlation matrices, are possible and within what range an effect can be expected to fall. Our approach does not tell the researcher whether a hypothesis or effect-size range is also theoretically or practically important. The theoretical or practical importance of effect sizes is something that will depend, instead, on context (Busseri, 2018; Fritz et al., 2012; Giner-Sorolla et al., 2023).
Conclusion
It has become increasingly common in psychological science to accompany hypotheses with statements about the size that an effect may take, explicitly in the hypotheses themselves or in associated power analyses. Estimating such effect sizes a priori can be a challenge because they may vary across contexts, methodologies, and populations. Different from much recent work on this topic, we examined how one can be more accurate in hypothesizing effect sizes based on their statistical qualities. Effect sizes that pertain to variables within multivariate populations—as is common in psychology—may require a more restrictive size range than often assumed. Accordingly, it is important to consider the wider multivariate population context in which a hypothesis is made. By examining how other variables in the population (likely) relate to those that feature in the hypothesis, one can narrow down the limits between which the hypothesized effect may fall. This statistical triangulation process even works, and is perhaps particularly useful, if prior evidence for a hypothesised effect size is lacking—a typical scenario for novel hypotheses. Accordingly, estimating limits to effect sizes in the context of the broader multivariate population may help to prevent proposing impossible hypotheses and can give researchers a better idea of the size range in which their effects will reside.
Supplemental Material
sj-pdf-1-amp-10.1177_25152459231197605 – Supplemental material for Impossible Hypotheses and Effect-Size Limits
Supplemental material, sj-pdf-1-amp-10.1177_25152459231197605 for Impossible Hypotheses and Effect-Size Limits by Wijnand A. P. van Tilburg and Lennert J. A. van Tilburg in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We thank Paul H. P. Hanel, Reinhard Pekrun, and Nikhila Mahadevan for their helpful feedback on a draft of this article. For the purpose of Open Access, the authors have applied a CC BY public copyright license to any Author Accepted Manuscript (AAM) version arising from this submission. All authors consented to the submission of this manuscript.
Transparency
Action Editor: Jessica Kay Flake
Editor: David A. Sbarra
Author Contribution(s)
Correction (December 2023):
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.