
Abstract
Network psychometrics is a new direction in psychological research that conceptualizes psychological constructs as systems of interacting variables. In network analysis, variables are represented as nodes, and their interactions yield (partial) associations. Current estimation methods mostly use a frequentist approach, which does not allow for proper uncertainty quantification of the model and its parameters. Here, we outline a Bayesian approach to network analysis that offers three main benefits. In particular, applied researchers can use Bayesian methods to (1) determine structure uncertainty, (2) obtain evidence for edge inclusion and exclusion (i.e., distinguish conditional dependence or independence between variables), and (3) quantify parameter precision. In this article, we provide a conceptual introduction to Bayesian inference, describe how researchers can facilitate the three benefits for networks, and review the available R packages. In addition, we present two user-friendly software solutions: a new R package, easybgm, for fitting, extracting, and visualizing the Bayesian analysis of networks and a graphical user interface implementation in JASP. The methodology is illustrated with a worked-out example of a network of personality traits and mental health.
The multivariate analysis of psychological data using undirected graphical models or networks has gained increasing interest (Marsman & Rhemtulla, 2022; Robinaugh et al., 2020). Psychometric networks are weighted graphs that consist of nodes representing a measured quantity (e.g., symptoms of a disorder or educational scores) and edges representing the strength of the statistical association between nodes (Borsboom et al., 2021). With the increasing popularity of networks and their application to various research areas (e.g., Borsboom & Cramer, 2013; Dalege et al., 2018; Isvoranu et al., 2016; Petersen & Sporns, 2015), concerns grow about the stability of network models (Borsboom et al., 2017; Forbes et al., 2019, 2021; Fried et al., 2018; Jones et al., 2021). The possible lack of robustness of networks ranks among the field’s top priorities (Fried & Cramer, 2017; McNally, 2021): Researchers should be able to draw sound inferential conclusions on the basis of the networks they estimate. There are three potential statistical sources of network uncertainty that researchers are confronted with. First, how much more likely is one configuration of edges—a structure—compared with another configuration (i.e., structure uncertainty)? Second, how likely is a specific edge to be present or absent (i.e., edge-inclusion uncertainty)? Finally, how stable are the estimated parameters (i.e., parameter uncertainty)? Researchers need a way to quantify these uncertainties.
The commonly used frequentist approaches in network psychometrics cannot adequately quantify these three types of uncertainty. Although different frequentist procedures are used for selecting a single best network structure (e.g., minimizing the extended Bayesian information criterion, cross-validation, and iterative-model search; Epskamp, 2020; Epskamp et al., 2018; Haslbeck et al., 2019; Wysocki & Rhemtulla, 2021), none quantify the uncertainty that underlies this selection. Thus, researchers choose the optimal structure without considering the uncertainty underlying this structure, and thereby, they run the risk of drawing frail inferential conclusions (Hoeting et al., 1999). Furthermore, frequentist procedures cannot quantify the uncertainty in favor of edge exclusion. For instance, an edge could be absent because it has low precision, that is, the standard error of the estimate is very large and the true value of the parameter is very uncertain. The edge could also be absent because it is absent in the true model. Nonetheless, researchers interpret edges estimated to be absent as conditional independence or edge exclusion (e.g., Williams et al., 2021); this erroneous interpretation of accepting the null hypothesis is common to frequentist procedures (Greenland et al., 2016). Finally, frequentist approaches infer precision of network parameters through bootstrapping. However, the bootstrapped confidence interval is negatively affected by the least absolute shrinkage and selection operator (lasso) regularization underlying most methods and thereby does not allow for proper parameter-stability estimation (e.g., Bühlmann et al., 2014; Pötscher & Leeb, 2009).
Bayesian procedures offer a direct avenue to quantify the three types of uncertainty (Hoeting et al., 1999; Wagenmakers et al., 2018). They naturally quantify the uncertainty of possible network structures and corresponding parameters and leverage these uncertainty estimates to establish the statistical evidence for the inclusion and exclusion of individual edges (Marsman et al., 2022; Mohammadi & Wit, 2019; Rodriguez et al., 2020; Williams & Mulder, 2020a). Thus, the Bayesian inference addresses the outlined questions and allows for well-informed inferential conclusions.
In this article, we offer a conceptual introduction to the Bayesian analysis of psychometric networks. 1 In the first two sections, we explain the principles underlying Bayesian analyses and show how researchers can leverage Bayesian approaches to quantify a network’s uncertainty. Afterward, we review the existing software implementations in R allowing for Bayesian cross-sectional analysis of networks (R Core Team, 2020). In addition, we introduce two user-friendly software solutions: the R package easybgm for researchers with beginner/intermediate programming experience and an implementation in JASP, an open-source statistical software with a graphical user interface for researchers without programming experience (JASP Team, 2018; Ly et al., 2021; Marsman & Wagenmakers, 2017). Furthermore, we provide an example of a Bayesian analysis of networks assessing mental-health and personality variables. In the final section, we outline the unique challenges of the outlined Bayesian approach.
Bayesian Foundations
In this section, we offer a conceptual introduction to the Bayesian approach to network analysis.
2
The central aim of Bayesian inference is to use data to update knowledge about a construct. In network psychometrics, researchers wish to learn two things: the underlying network structure

A network structure that consists of nodes and undirected, unweighted edges (left). All possible structures for a network with three nodes (right).
To start the Bayesian learning process, prior beliefs about the network must be specified. Beliefs are formulated through probability distributions that describe what types of networks are expected. For network psychometrics, researchers need to specify prior distributions about the network’s structure

Specifically, prior beliefs about the structure and about the parameters are updated using a predictive updating factor, which evaluates how well the prior structures and the prior parameters have predicted the observed data. Structures and parameter values that predicted the observed data well increase in plausibility, whereas those with poor predictions suffer a decline (Wagenmakers et al., 2016). The Bayesian updating cycle is completed by using the posterior distribution as a prior distribution in future analyses.
This framework also allows one to use the data to test hypotheses about networks. For example, one may compare the predictive performance of two competing structures, say Structure 1 (

The Bayes factor is a continuous measure of support. A Bayes factor
Facilitating Bayesian Analysis for Uncertainty Quantification in Networks
As outlined in the introduction, there are three types of uncertainties that researchers should acknowledge when analyzing networks: (1) structure uncertainty, (2) evidence for edge inclusion and exclusion, and (3) parameter precision. Below, we explain how Bayesian methods can quantify these uncertainties.
Goal 1: quantify structure uncertainty
Many network structures are possible (e.g., Fig. 1), and researchers must be able to assess the relative plausibility of the structures to report their network results with confidence. In the Bayesian approach to network analysis, a posterior structure probability expresses how likely a particular structure is given the data and can be used to compare the plausibility of different structures (see the Bayes factor in Equation 1). To obtain this posterior probability, a prior distribution on the structures must first be specified. 5 There are several ways to do this (e.g., Consonni et al., 2018).
In the simplest version, researchers specify only the prior probability of including edges (Mohammadi & Wit, 2019), which can fall between 0 and 1. More densely connected structures can be expected if higher edge-inclusion probabilities are specified and vice versa. Uniform or hierarchical priors on the structures could also be stipulated (Marsman et al., 2022). The uniform prior assumes that all
The prior probability of the structure is updated with the data to form the posterior probability. Computing this posterior probability analytically is challenging. Therefore, most Bayesian approaches use simulation-based techniques that update the structure in each iteration, including or excluding edges from the current structure to form a new structure. The proportion of times a particular structure is visited in the simulation is an unbiased estimate of the posterior structure probability (George & McCulloch, 1993). Equipped with the posterior structure probability, researchers can assess the uncertainty of the underlying structure and the network complexity. If the sampler visit many different structures, researchers must be careful because this indicates that there is uncertainty about the underlying structure.

Goal 2: obtain evidence for edge inclusion or exclusion
A central goal of network analysis is to determine conditional (in)dependence, that is, the presence or absence of particular edges (Borsboom et al., 2021; Ryan et al., 2022). Although frequentist inference allows one to classify edge presence, it entails no information about edge absence. An estimated edge can be absent because either the edge weight has low precision/large standard errors (i.e., absence of evidence) or because it genuinely does not exist (i.e., evidence of absence; Keysers et al., 2020). Bayesians distinguish between absence of evidence and evidence of absence using the Bayes factor (or the posterior odds) in Equation 1. One can use the Bayes factor to compare how much more likely the data are under a structure in which the edge is present against a structure in which it is absent. This practice has been adopted to network models in which one compares the full model with all edges present against the full model with the focal edge removed (Williams & Mulder, 2020a). For example, one could compare Structures 1 and 2 in Figure 1 to obtain an evidence estimate for the edge A–B; this comparison assumes that all other edges are absent. Note, however, that one could have also compared Structures 7 and 8 and assumed all other edges are present. However, this comparison might yield a different evidence assessment because it is conditioned on a different set of edges. To obtain a single assessment of the posterior evidence for edge inclusion or exclusion, one may consider all possible structures simultaneously. This procedure is known as “Bayesian model averaging” (BMA; Hinne et al., 2020; Hoeting et al., 1999). Through BMA, one can obtain the prior and posterior odds of edge inclusion and exclusion and thereby obtain a Bayes factor for edge inclusion and exclusion:

This inclusion Bayes factor is an aggregate of the previously described structure uncertainty. For networks, an edge-evidence plot illustrates the evidence for inclusion and exclusion for each edge (Huth et al., 2021), also illustrated in Figure 4a and 4b. In the network, edges are colored according to their inclusion Bayes factor: Red edges indicate evidence of absence, gray edges indicate the absence of evidence, and blue edges indicate evidence of presence. Equipped with the edge-evidence plot, researchers are able to decide which statistical relations are worth basing inferential conclusions on (i.e., red and blue edges) and which absent edges actually indicate conditional independence between variables (i.e., red edges). Gray edges indicate inconclusive evidence, and inferential conclusions should be avoided.

Goal 3: determine parameter precision
Assessing the uncertainty of association parameters between variables of a network is another crucial component of network analysis. In the Bayesian context, the posterior distribution of the parameters captures their stability. It expresses knowledge about the parameter after seeing the data. To obtain the posterior density, one must first stipulate a prior distribution on the parameters

Illustration of the continuous spike-and-slab prior. Bayesian updating under the spike prior: the prior heavily shrinks the parameter estimate toward zero. Bayesian updating under the slab prior: the weakly informative prior hardly affects the posterior distribution.
One can summarize the posterior parameter distribution in several ways. Credible intervals are suitable measures for parameter uncertainty: Wide intervals indicate high uncertainty, and narrow intervals indicate reduced uncertainty. We propose to use the 95% highest posterior density interval because it is the shortest interval that captures 95% of the posterior distribution.

Software Implementations in R
In this section, we review available R (R Core Team, 2020) packages for the Bayesian analysis of networks and introduce a new user-friendly package, easybgm. The existing R packages allow estimating the most popular types of cross-sectional networks—that is, the Gaussian graphical model (GGM), Ising model, ordinal Markov random fields, and mixed-graphical model. First, we introduce the three major existing packages (i.e., BDgraph, BGGM, and bgms) below. Their performances are compared in the appendix. Second, we introduce the new package easybgm, which is a wrapper around the existing packages. Table 1 provides an overview of the functionalities of the packages. An annotated analysis script with example code for each package is available on OSF. 7
Overview of Software Packages for Cross-Sectional Bayesian Analysis of Networks

The R package BDgraph (Mohammadi & Wit, 2019) offers tools for the Bayesian analysis of networks for (a mix of) continuous, ordinal, and binary variables. The package consists of several simulation-based procedures for exploring the structure space, which is implemented in C++ with parallel computing capabilities. BDgraph can estimate GGMs to analyze continuous data (Mohammadi et al., 2023; Mohammadi & Wit, 2015), and Gaussian copula graphical models (GCGMs) to analyze (a mix of) ordinal, binary, and continuous data (Mohammadi et al., 2017; Vinciotti et al., 2022). The package also allows the estimation of a discrete-graphical model (DGM) for ordinal and binary data using a marginal pseudolikelihood approach (Dobra & Mohammadi, 2018). Users can provide either the raw data or the covariance matrix (for GGM and GCGM) and choose between three distinct sampling algorithms; the reversible-jump Markov chain Monte Carlo (MCMC), continuous-time birth–death MCMC, or hill-climbing algorithm. The specification of priors depends on the type of model to be estimated. For the GGM and the GCGM, users can specify the edge-inclusion probability (i.e., g.prior), the initial configuration of edge inclusion (i.e., g.start), and the degrees of freedom for the prior on the precision estimate (i.e., df.prior), which is a G-Wishart distribution. The higher the degrees of freedom is, the more informative the prior is. Alternatively, users can make use of a regularization prior through the closely related package ssgraph (Mohammadi, 2019). The package implements a continuous spike-and-slab prior distribution for the precision matrix. For a DGM, BDgraph stipulates a Dirichlet distribution on the prior precision matrix for which users can specify an alpha hyperparameter. The package output consists of the model-averaged precision estimates (i.e., can be transformed into partial interactions), the posterior-inclusion probability, and the visited structures. It does not allow for missing data handling.
The R package BGGM offers tools for estimating and testing graphical models (Williams & Mulder, 2020b). The BGGM package can estimate a GGM to analyze continuous data and a GCGM to analyze (a mix of) binary, ordinal, and continuous data. 8 Users can specify the prior standard deviation (i.e., prior_sd) of the matrix-F distribution, a scale mixture of Wishart distributions, stipulated on the precision matrix. The package output consists of the posterior mode of the model parameters and the posterior edge-inclusion probabilities. Unlike BDgraph, BGGM does not explore the structure space and thus cannot provide model-averaged estimates. However, contrary to the other packages, BGGM can handle missing data by imputing missing values (Buuren & Groothuis-Oudshoorn, 2011) and provides a wide variety of other features, such as one-sided edge testing (i.e., testing for a positive interaction) and estimating and testing subgroup differences.
Marsman and Haslbeck (2023) recently developed the bgms package that focuses on the Bayesian analysis of binary and ordinal Markov random field models. The package uses Bayesian variable-selection methods to model the underlying network structure. The methods are organized around two general approaches for Bayesian variable selection: (a) expectation-maximization (EM) variable selection (Ročková & George, 2014) and (b) Gibbs variable selection (George & McCulloch, 1993). The EM variable selection function bgm.em uses the continuous spike-and-slab prior specification of Marsman et al. (2022) stipulated on the pairwise interactions and generalizes it to Markov random field models for (mixed) binary and ordinal variables. The Gibbs variable selection function bgm, on the other hand, uses a discrete spike-and-slab prior distribution for the pairwise interactions, which can set the interactions to exact zeroes. To account for the discontinuity at zero, the Metropolis approach of Gottardo and Raftery (2008) is embedded in a Gibbs sampler. Currently, the slab distribution is either a unit-information type prior (for details, see Marsman and Haslbeck, 2023) or a Cauchy distribution with a scale that can be set by the user. A Beta-prime distribution is used for the exponentiated category parameters, and a uniform prior is used for the edge-indicator variables (i.e., the prior probability that an edge is included is
The reviewed R packages are powerful tools for a Bayesian analysis of networks. However, they can be difficult to use for researchers with limited programming experience. Therefore, we introduce a new R package, easybgm, that provides a user-friendly and intuitive set of functions for estimating all types of models and visualizing their results. Our package builds functions around the introduced R packages (i.e., BDgraph, bgms, and BGGM) and a large set of functions to help visualize the results. To initiate estimation, researchers specify the data set and the data type (i.e., continuous, mixed, ordinal, or binary). Based on the data-type specification, easybgm estimates the network using the appropriate R package (i.e., BDgraph for continuous and mixed data and bgms for ordinal and binary data). Users can deviate from the default package choice by specifying their preferred R package. Based on the different estimates, easybgm outputs the results, including the parameter estimates, the posterior-inclusion probability, the inclusion Bayes factor, and optionally the posterior samples of the parameters and strength centrality samples. In addition, easybgm comes with an extensive set of visualization functions, such as the plots shown in the example of this article. In particular, users can obtain a network plot showing the parameter estimates, an edge-evidence plot showing the inclusion Bayes factor, and various plots to assess the structure uncertainty.
Example: Mental Health and Personality
In this section, we illustrate the Bayesian benefits through a concrete example. In particular, we explore whether and to what extent common personality traits are associated with mental-health concerns. We use an open data set on the Depression, Anxiety, and Stress scales (DASS) from the openpsychometric website, administered between 2017 and 2019. For this tutorial, we used a random subset of 2,000 out of 39,775 participants. We include 13 nodes in the network, representing scores of the three mental-health subscales (i.e., depression, anxiety, and stress) and 10 personality traits. We encourage readers to download the openly available data set “Answers to the Depression Anxiety Stress Scales” at https://openpsychometrics.org/_rawdata/ and explore the cross-sectional Bayesian analysis of networks with the annotated scripts.
9
Following previous research, we specified a uniform prior on the network structure (i.e., prior edge-inclusion probability of 0.5) and a
Structure uncertainty
There are

The posterior probabilities of different network structures and their complexity. The left plot indicates the posterior probabilities of the visited structures, sorted from the most to the least probable. Each dot represents one structure. The gray dashed line denotes the prior probability for each structure. The right plot indicates the posterior probability for different structure complexities, where complexity comprises the network density. The gray xs denote the prior probability for each structure complexity.
Edge evidence
We illustrate the evidence for inclusion and exclusion for each edge with the networks in Figures 4a and 4b. The edge-evidence plot aids researchers in deciding which edges provide robust inferential conclusions: Red edges indicate evidence for edge absence, gray edges indicate the absence of evidence, and blue edges indicate evidence for edge presence. Figure 4a shows edges with an inclusion Bayes factor larger than 1, deemed included. Nodes mostly link within the respective clusters: The three mental-health measures are all connected, and most personality traits are conditionally dependent. Several links connect mental-health measures and personality factors. In addition, there are many edges that are included in the network but for which we do not have sufficient evidence for the inclusion (i.e., gray edges), especially for the edges linking to extraverted and disorganized. Figure 4b shows edges with an inclusion Bayes factor lower than 1 deemed excluded. Anxiety is conditionally independent of several personality items, and open is conditionally independent from mental-health and personality factors. Furthermore, several edges are deemed excluded, but there is not sufficient evidence to conclude edge absence (i.e., gray edges). Separating the evidence of absence (i.e., red edges) and absence of evidence (i.e., gray edges) is a unique benefit of the Bayesian approach and thus allows one to obtain evidence for conditional independence. In contrast, the frequentist approach would only be able to deem edges included, not whether there is evidence of edge absence.
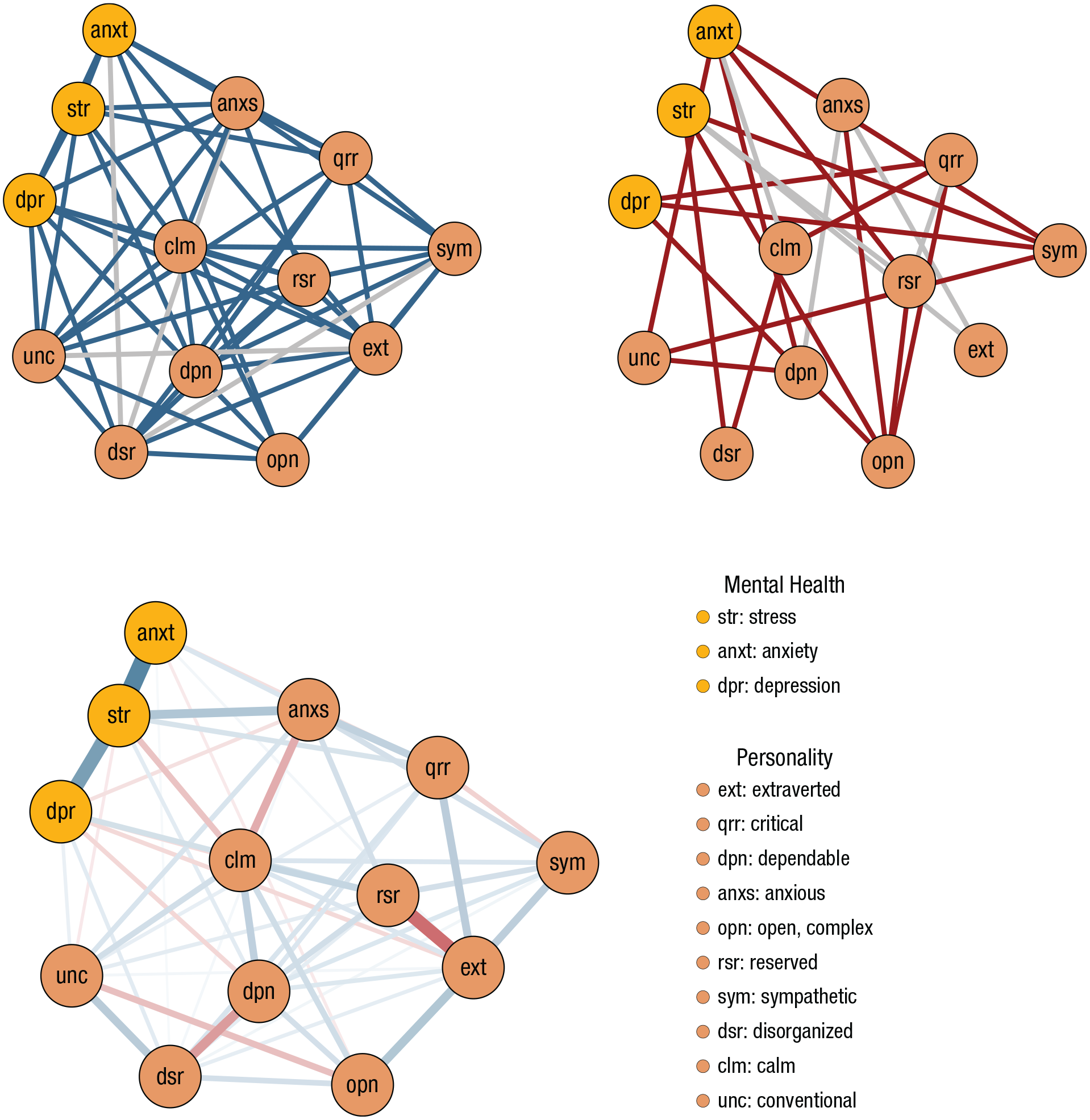
Networks showing the edge-evidence plots (top row) and the respective strength and nature of associations (bottom row). (a) Edge-evidence plot showing present edges (i.e., BF10 > 1), where blue edges represent evidence for inclusion (BF10 > 10) and gray edges absence of evidence (1 < BF10 < 10). (b) Edge-evidence plot depicting absent edges (i.e., BF10 < 1); evidence for exclusion is shown as red (BF10 < 0.1), and inconclusive evidence is shown as gray (0.1 < BF10 < 1). (c) The parameter-estimate plot shows all edges with an inclusion Bayes factor larger than 1. Edge thickness and saturation represent the strength of the association; the thicker the edge, the stronger the association. Red edges indicate negative relations, and blue edges indicate positive associations.
Parameter estimation and precision
In Figure 4c, we show the parameter-estimate plot of included edges, thus, edges with an inclusion Bayes factor of at least 1 (i.e., commonly called “median probability model”). Researchers could also choose other cutoffs of parameters to be shown (e.g., edges with strong evidence for inclusion;
As an illustration, Figure 5 shows the posterior distribution of two parameters of the network model obtained through BMA. Figure 5a shows a near-symmetrical distribution of an edge parameter in which most posterior mass lies between

Posterior distribution of two network parameters. Densities show the model-averaged estimate of both parameters. The left plot shows an estimate of an included edge and the right plot of an edge without enough evidence to conclude on inclusion or exclusion: (a) included edge, (b) inconclusive edge.
Advanced benefits
On the basis of the three Bayesian benefits, researchers can facilitate other benefits for their analysis, for example, obtaining credible intervals around centrality estimates. Researchers often use centrality measures to obtain aggregated information for each node, for example, the connectedness quantified in the strength centrality. Credible intervals for strength centrality can be obtained by calculating the centrality measure for each sample of the posterior parameter distribution. Strength-centrality estimates and highest density intervals (HDIs) are shown in Figure 6. The higher the centrality is, the more strongly connected the node is; error bars represent the 95% HDI. Stress is the most central node; the least central nodes were conventional and sympathetic. The HDIs of all variables are narrow, and thus, we can be relatively confident about the strength-centrality estimates.

Strength centrality. The yellow dots and lines represent the mental-health variables, and the orange dots and lines are the personality items.
JASP Implementation
BDgraph’s functionality (Mohammadi & Wit, 2019) was recently implemented in JASP (JASP Team, 2018), allowing researchers without programming experience to estimate networks in a Bayesian framework. 10 In this section, we walk the reader through performing a Bayesian analysis of networks in JASP using the previous example. Readers can find the associated annotated JASP script on OSF. 11 We refer readers new to JASP to its tutorial (Wagenmakers et al., 2018). Figure 7 provides a screenshot of the Bayesian network module.

Screenshot of the Bayesian network implementation of BDgraph in JASP. The left panel shows the analysis input options, and the right panel shows the associated output.
Input
To initiate the estimation, researchers specify the variables to include in the network, after which they specify the estimation method; implemented are “ggm” (i.e., Gaussian graphical model for continuous data) or “gcgm” (i.e., Gaussian copula graphical model, for a mix of binary, ordinal, count and continuous data). Subsequently, JASP will output the number of present edges in the estimated network. Note that “gcgm” is computationally intensive and might take substantial time to show output.
Output
Users have several options to gain insight into the underlying network and its three uncertainties. First, to quantify the structure uncertainty, users can find the “Posterior Structure Probability” and the “Posterior Complexity Plot” options in the “Network structure selection” tab. Second, users can assess the support for individual edges via a table and a plot. By default, the table contains the posterior-inclusion probabilities for each edge in the network. With one click, the user can opt to show Bayes factors instead: for inclusion (i.e.,
Advanced specifications
Centrality measures
In the “Graphical options” tab, users can choose which measures the centrality plot should display. By default, it shows the most common centrality measures: strength, betweenness, closeness, and expected influence. The Bayesian network module provides posterior means and the option for 95% HDIs for the centrality measures.
Sampling options
BDgraph works with MCMC sampling. Users can specify the number of iterations for the MCMC-sampling procedure. Estimates become more precise if more iterations are used, but the wait is longer. By default, JASP runs the sampler for
Prior
The user can specify prior beliefs about the network’s structure
Challenges and Outlook
Notwithstanding the benefits outlined above, the Bayesian approach comes with challenges of its own. First, Bayesian versions of some network-analysis tools are unavailable or concealed for a general audience because of advanced statistical writing. Therefore, Bayesian enthusiasts might fall back to frequentist alternatives. However, recent years have seen an insurgence of Bayesian tools for network analysis. For example, Bayesian tools for testing network differences in subgroups were formulated in the R package BGGM (Williams et al., 2020; Williams & Mulder, 2020b), and credible intervals for centrality estimates became available (Huth et al., 2021; Jongerling et al., 2023; Williams & Mulder, 2020a). Furthermore, through the outlined R package easybgm and the JASP implementation, researchers can analyze their data with limited or no prior programming experience.
Second, the Bayesian estimation of networks is computationally intensive, especially with the structure-selection step being cumbersome. The model space of
Finally, the specification of appropriate prior distributions is not straightforward, yet their choice can influence the results. This concern holds for all Bayesian applications and is discussed in other work (see e.g., Wagenmakers et al., 2018). Robustness checks of priors are a tool to address this issue because they allow one to determine that conclusions do not rely solely on a particular prior specification. At the same time, informed priors could advance statistical inference by implementing prior knowledge or theory in the inferential cycle. This could be particularly promising in idiographic-network modeling (Burger et al., 2022) because such models are difficult to fully recover with the available data (Mansueto et al., 2022).
Concluding Comments
In this article, we provided a conceptual introduction to Bayesian analysis for psychometric, cross-sectional networks and demonstrated its application in assessing the interrelations of personality traits with mental health in a tutorial. The Bayesian approach provides the applied researcher with a tool for sound inferential conclusions, particularly through quantifying structure uncertainty, determining evidence for edge inclusion and exclusion, and quantifying parameter precision. With its conceptual introduction, newly developed R package easybgm, and user-friendly JASP implementation, we hope this work will enable a broader audience to make use of the Bayesian benefits to network psychometrics.
Footnotes
Appendix
Acknowledgements
Transparency
Action Editor: Rogier Kievit
Editor: David A. Sbarra
Author Contribution(s)