
Abstract
Analysis of variance (ANOVA) is widely used to assess the influence of one or more experimental (or quasi-experimental) manipulations on a continuous outcome. Traditionally, ANOVA is carried out in a frequentist manner using p values, but a Bayesian alternative has been proposed. Assuming that the proposed Bayesian ANOVA is closely modeled after its frequentist counterpart, one may be surprised to find that the two can yield very different conclusions when the design involves multiple repeated-measures factors. We illustrate such a discrepancy with a real data set from a two-factorial within-subject experiment. For this data set, the results of a frequentist and Bayesian ANOVA are in a disagreement about which main effect accounts for the variance in the data. The reason for this disagreement is that frequentist and the proposed Bayesian ANOVA use different model specifications. As currently implemented, the proposed Bayesian ANOVA assumes that there are no individual differences in the magnitude of effects. We suspect that this assumption is neither obvious to nor desired by most analysts because it is untenable in most applications. We argue here that the Bayesian ANOVA should be revised to allow for individual differences. As a default, we suggest the standard frequentist model specification but discuss a recently proposed alternative and provide guidance on how to choose the appropriate model specification. We end by discussing the implications of the revised model specification for previously published results of Bayesian ANOVAs.
Analysis of variance (ANOVA) is ubiquitous in experimental psychology, in which it is used to assess the influence of one or more experimental (or quasi-experimental) manipulations on a continuous outcome. For instance, in a Stroop task (Stroop, 1935) participants are asked to name the color of a printed word. It is typically found that participants respond faster when a word’s meaning and color are congruent (e.g., blue displayed in a blue font) and slower when these are incongruent (e.g., blue displayed in a red font). The relation between the congruency of the colored words and the response times of the participants can be analyzed with a (repeated-measures) ANOVA. Traditionally, ANOVAs are carried out in the frequentist paradigm, and p values are used to arrive at scientific conclusions. Rouder et al. (2012) proposed a general Bayesian modeling framework for linear models that they used to develop an influential Bayesian alternative approach to ANOVA (cited over 1,500 times; see also Rouder et al., 2017; van den Bergh et al., 2020). Assuming that this Bayesian ANOVA is closely modeled after its frequentist counterpart, one may be surprised to find that the two can yield very different conclusions when the design involves multiple repeated-measures factors. Using a real data set, we show that discrepancies between frequentist and the proposed Bayesian ANOVA reflect the fact that they use different model specifications. We believe that many analysts are unaware of this difference and, critically, that the model specification in the Bayesian ANOVA is usually inappropriate.
The frequentist and Bayesian approaches differ in how they model individual differences. The frequentist ANOVA allows for individual differences in treatment effects. The model specification includes separate error strata (i.e., Participant × Treatment interaction or random slopes) for all but the highest order repeated-measures interaction. The proposed Bayesian ANOVA does not. It includes random intercepts only (RIO)—we henceforth refer to this as the RIO-model specification. Although their modeling framework allows for random slopes, Rouder, Morey, and colleagues recommended to omit them (Rouder et al., 2012, 2017). This recommendation was based on two concerns: Random-slope terms greatly increase model complexity and complicate the interpretation of fixed effects—if a substantial portion of participants has a negative effect, does it make sense to interpret a positive fixed effect? These are important concerns, but we believe the omission of random slopes is inappropriate in most applications: The RIO-model specification implies the strong assumption of the complete absence of individual differences in the magnitude of the effects—a universal effect size for every subject. We are hard-pressed to think of any psychological effects for which this assumption seems plausible. We therefore recommend including random slopes in Bayesian ANOVA models.
Like the frequentist ANOVA, our recommended model specification contains the maximal set of random effects (MRE), which is why we henceforth refer to it as the MRE-model specification. Pivoting to the MRE-model specification is also consistent with recommendations within the broader framework of mixed models (Barr et al., 2013; Oberauer, 2022; van Doorn et al., 2023), of which repeated-measures ANOVA is a special case. For example, Oberauer (2022) showed in a simulation study on mixed models that, in the presence of random slopes, the use of RIO models can inflate Bayes factors and increases the risk of false-positive conclusions; we use a real data example to show that RIO models can similarly cause such questionable results in repeated-measures ANOVA. In addition to relaxing an untenable assumption, a universal effect size for every subject, the Bayesian MRE ANOVA resolves nontrivial differences in conclusions between the frequentist and Bayesian approach, such as the one we demonstrate below. The Bayesian MRE ANOVA relies on the modeling framework by Rouder et al. (2012) and may be thought of as a revision of the Bayesian RIO ANOVA as recommended in previous work (Rouder et al., 2012, 2017) and implemented in popular software, for example, the function
The outline of this article is as follows. First we introduce a real data set that we use to illustrate the divergence between the frequentist and Bayesian results using JASP (JASP Team, 2022). We then explain the different model specifications and demonstrate that the discrepancy is resolved with a Bayesian MRE ANOVA, which is implemented in JASP Version 0.16.3. Afterward we discuss the merits and demerits of both model specifications, as well as a third model specification that was recently proposed (Rouder et al., 2023). The article concludes with a discussion on how RIO ANOVA has affected published results of Bayesian ANOVAs.
Example Data: Stroop Effect
To illustrate how the model specification leads to discrepancies between frequentist and Bayesian ANOVA, we use an empirical data set kindly provided by Ronen Hershman and publicly available in the JASP Data Library (Hershman et al., 2022; Wagenmakers et al., 2020). The data were collected in an experiment on the Stroop effect (Stroop, 1935). Participants read color words (here blue, green, yellow, or red), which were presented in one of four font colors (blue, green, yellow, or red). The combination of color word and font color could be either congruent (e.g., blue displayed in a blue font) or incongruent (e.g., blue displayed in a red font). Participants were asked to ignore the meaning of the word and press one of four response buttons to indicate the font color. This paradigm is well known to produce the Stroop effect: Participants respond faster (and more accurately) to congruent than incongruent word-font color combinations; that is, participants appear to be unable to ignore the meaning of the words. In addition to congruent and incongruent combinations, the study at hand used neutral combinations of words and font color (e.g., the letters XXXX displayed in red font) to separately estimate the extent to which congruent combinations facilitate performance and incongruent combinations harm performance. The goal of the study was to investigate how the Stroop effect is affected by breaks from the task; consequently, the sequence of Stroop trials was interspersed with “break” trials (i.e., trials in which a black square, the rest stimulus, signaled that no response was required). This design makes it possible to compare performance on trials preceded by another Stroop trial with that on trials preceded by a break trial. Hence, the experiment used a 3 (Congruency: congruent vs. neutral vs. incongruent) × 2 (Preceding Trial, or PT: break vs. Stroop task) repeated-measures design. Each participant completed 144 congruent, neutral, and incongruent Stroop trials (totaling 432 trials) as well as 432 break trials in random order. Trials with incorrect or missing responses were excluded, and participants with less than 40 valid trials per condition were excluded from the analysis. 1 The raw data of all 19 participants are displayed in Figure 1. The top left of Figure 1 shows the average response times of the break and Stroop trials in each congruency condition, and the bottom left shows the associated within-subject differences; their average appears to be close to zero, suggesting that the nature of the PT has little systematic impact on Stroop performance. The top right of Figure 1 shows the average response times of congruent, neutral, and incongruent trials in each PT condition, and the bottom right shows the associated differences; it seems that, on average, congruent responses are faster than incongruent responses, congruent and neutral responses are approximately equally fast, and incongruent responses are slower than neutral responses.
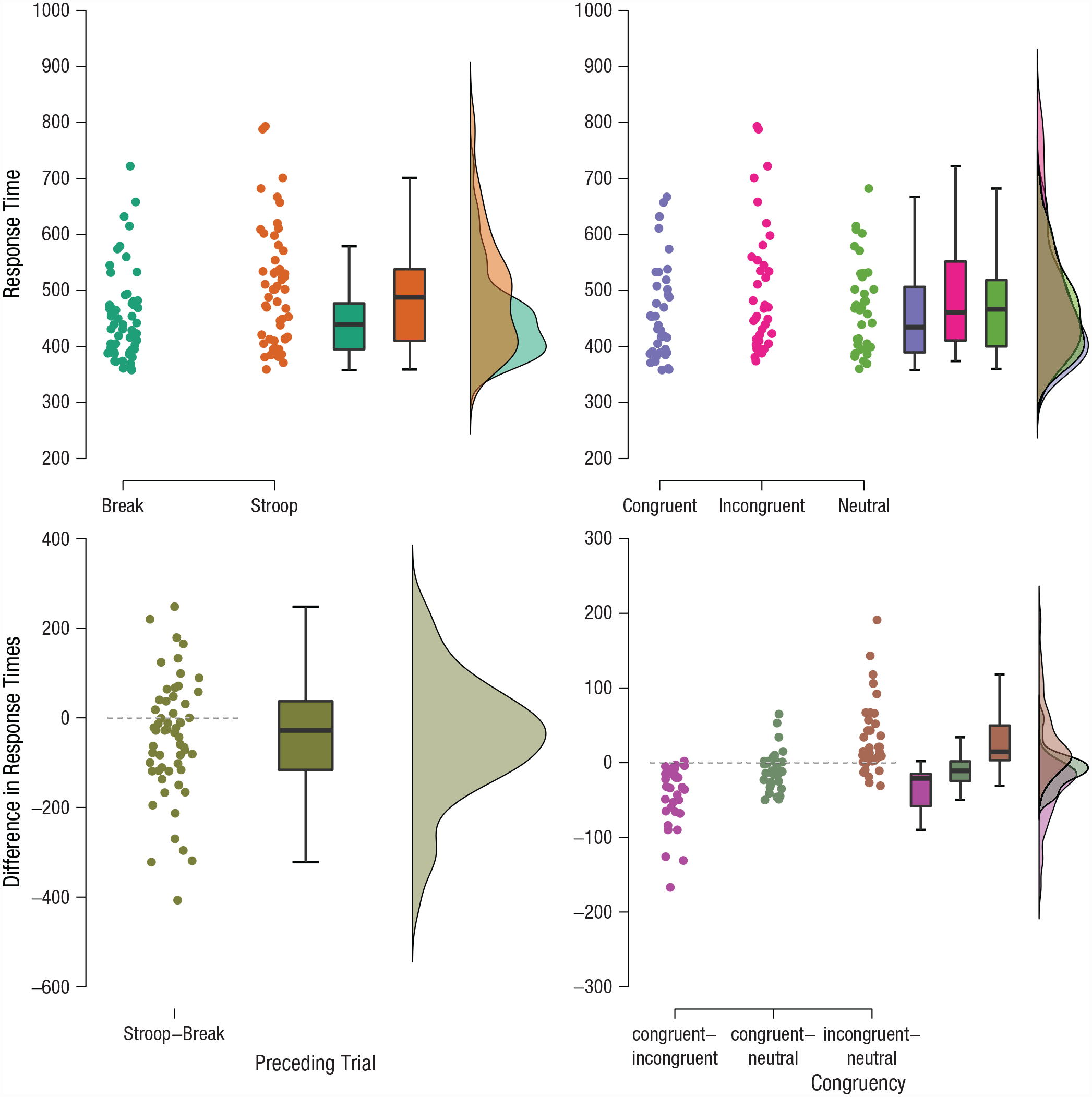
Raincloud plots of the raw data from the Hershman Stroop Study. The average response times (y-axis) are shown for the break and Stroop conditions (x-axis) in each congruency condition (top left). The average response times for the congruent, neutral, and incongruent conditions (x-axis) are shown for the preceding trial condition (top right). Pairwise differences in response time (y-axis) are shown between the break and Stroop conditions (bottom left). Pairwise differences in response time (y-axis) are shown for all pairs of the congruency factor (bottom right). Box plots and density estimates are shown on the right of each panel. See text for details.
Discrepancy between frequentist and Bayesian ANOVA
The frequentist repeated-measures ANOVA indicates that the main effect of PT and the interaction between PT and congruency are not significant,
In the Bayesian ANOVA, we use the Bayes factor to compare all models to the model that best predicts the data (in this case the model including only the PT effect). The results are shown in Table 1, which lists models according to their performance in decreasing order, with the best model in the first row and the worst model in the last row. The first column displays the predictors in the model. The second column and third column, P(M) and P(M|data), respectively, show the prior and posterior model probabilities. The fourth column,
Bayesian Comparisons of Models Including Random Intercepts but Not Random Slopes for Participants

Note: Model formulas omit random intercepts for participants (i.e., + participant), which are included in all models. P(M) and P(M|data) indicate prior and posterior model probabilities, respectively;
Most importantly, the worst performing model includes only congruency as a predictor—the only predictor associated with a significant p value. Note, however, that these Bayes factors are not directly analogous to any of the standard F-tests in the frequentist ANOVA. Rather than comparing each model to the best model of the set, frequentist F-tests reflect model comparisons designed to assess the unique variance associated with each factor. To contrast the frequentist and Bayesian results more directly, we first calculate Bayes factors that reflect the same model comparisons as the F-tests.
3
The results are shown in Table 2 in the column
Comparison of ANOVA Results for the Hershman Stroop Study Across Different Analytic Approaches

Note: Column spanners indicate the random-effects structure assumed in the Bayesian ANOVA models; the maximal set of random effects is the new default in JASP. ANOVA = analysis of variance; PT = preceding trial;
Mauchly’s test of sphericity indicates that the assumption of sphericity is violated (p <. 05).
However, the Bayesian analysis is based on a comparison between two specific models. This approach ignores the possibility that both models may be outperformed by one or more of the other candidate models. The uncertainty about which models are the most appropriate can be taken into account by averaging across all models (Hinne et al., 2020; Hoeting et al., 1999). For example, to assess the support for the effect of PT, the performance of all models that include PT (i.e., PT, PT + congruency, and PT × Congruency) is contrasted to the performance of all models that exclude PT (i.e., congruency) and the null model. The resulting inclusion Bayes factor takes the entire model space into account. Applying the inclusion Bayes factor approach yields the results shown in the
In sum, regardless of the specific Bayes factor approach that is taken (i.e., comparing against the best model, contrasting two specific models, model averaging), the results indicate little evidence regarding the significant effect of congruency but strong evidence for the nonsignificant effect of PT. This conclusion, however, appears to contradict the data pattern in Figure 1 (bottom left), which suggests that there is no effect of PT.
Different model specifications
The notable discrepancies between the frequentist and Bayesian results outlined in the previous section are caused by a difference in the underlying model specification. The frequentist ANOVA uses the MRE-model specification, which specifies all estimable Participant × Treatment interactions (i.e., error strata) for repeated-measures variables (see Appendix of Barr et al., 2013). In mixed-model terms, these Participant × Treatment interactions amount to random slopes—they allow for individual differences in the effects of PTs and congruency. For our example, the full model including all factors is RT ~ 1 + congruency × PT + (1 + congruency + PT | participant). 4
In contrast, the Bayesian RIO ANOVA omits the Participant × Treatment interactions; only the participant main effect (i.e., the random intercept) is included. For our example, the full model including all factors is RT ~ 1 + congruency × PT + (1 | participant). This RIO-model specification implements the unreasonable assumption that there are no individual differences in the magnitude of the effects. Assuming interindividually constant main effects is unique to the current default Bayesian ANOVA and causes the divergence from the frequentist ANOVA. Moreover, this assumption is likely not obvious to most analysts and at odds with what they expect when conducting repeated-measures ANOVA.
RIO ANOVA is clearly misspecified for our example data: There is substantial variability in participants’ PT effects, as summarized in Table 3—the random-slope variance for PT even exceeds the random-intercept variance. When we repeat the Bayesian ANOVA with the standard model specification by including random slopes (Table 4), the conclusions change substantially: The model including only congruency is the best model, whereas the model including only PT is the worst model—a conclusion opposite to the one from our previous Bayesian RIO ANOVA. The results from simple model comparisons and model averaging are now both in agreement with the frequentist repeated-measures ANOVA. Table 2 summarizes the results for the frequentist ANOVA, the Bayesian RIO ANOVA without random slopes, and the Bayesian MRE ANOVA with random slopes.
Estimates of Participant Random-Effect Variances and Standard Deviations from a Maximal Hierarchical Linear Model for the Aggregated Data

Note: PT = preceding trial.
Bayesian Comparisons of Models Including Random Intercepts and Random Slopes for Participants
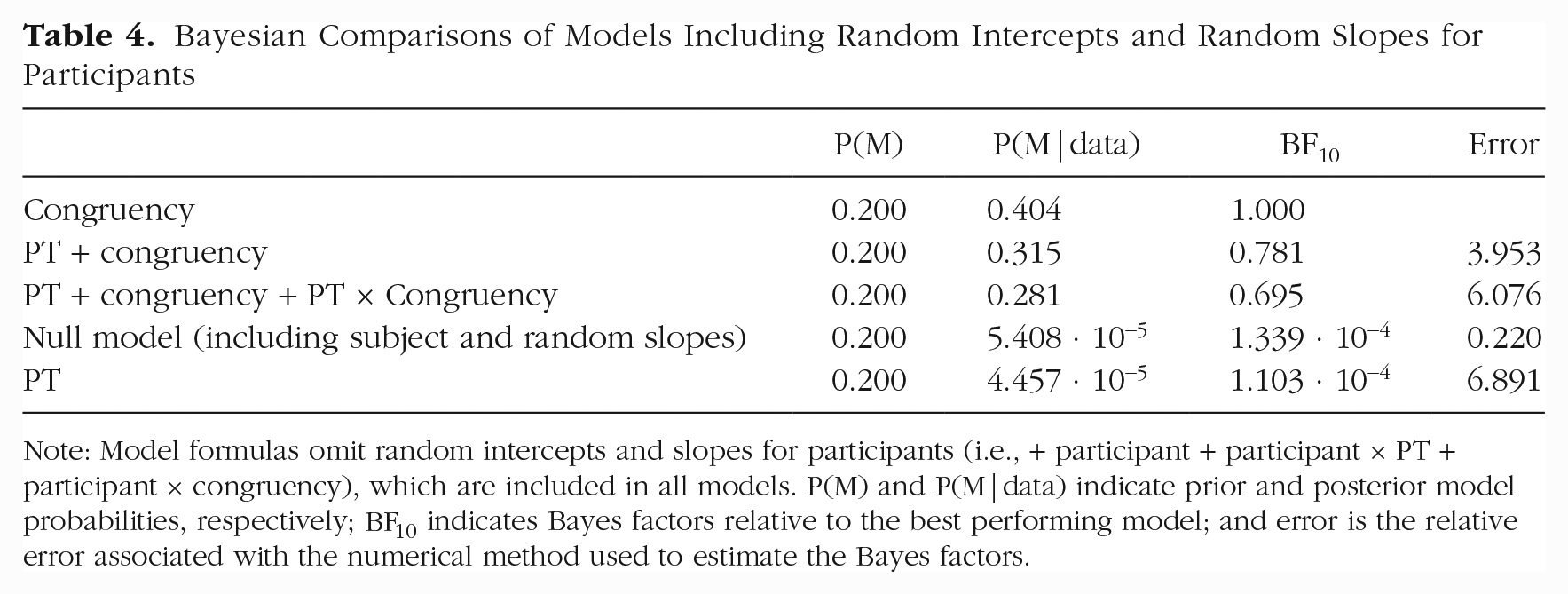
Note: Model formulas omit random intercepts and slopes for participants (i.e., + participant + participant × PT + participant × congruency), which are included in all models. P(M) and P(M|data) indicate prior and posterior model probabilities, respectively;
A third model specification that sits between RIO and MRE ANOVA was recently proposed (Rouder et al., 2023). Whereas RIO ANOVA always omits random slopes, MRE ANOVA never omits them—even if the corresponding fixed effect is removed from the model. For example, the model that includes a main effect of PT but not congruency is RT ~ 1 + PT + (1 + congruency + PT | participant). Rouder et al. (2023) argued that this implies the unreasonable assumption that, when an effect is absent, the population is split between individuals with positive and individuals with negative effects, which cancel out to a null effect overall. Instead, Rouder et al. (2023) proposed omitting random slopes whenever the corresponding fixed effect is omitted. So the model that includes a main effect of PT, but not congruency, would be RT ~ 1 + PT + (1 + PT | participant).
As in MRE ANOVA, this model specification assumes that if an effect is present, there are individual differences in the magnitude of this effect. Conversely, if an effect is absent, it is absent in every individual—as in RIO ANOVA. Because this model specification always simultaneously introduces fixed and random effects, we refer to it as SFR ANOVA. In JASP this model specification can be used by enforcing the principle of marginality for random slopes.
The results of the SFR ANOVA for the Stroop example are shown in Table 2 (rightmost columns). Unsurprisingly, the results of the SFR ANOVA differ from the other two model specifications. The SFR ANOVA indicates that there is substantial evidence to include both PT and congruency. It is likely that the SFR ANOVA favors including PT because there is substantial random-slope variance (see Table 3) and not because there is a substantial fixed effect. The performance of the individual models under the SFR ANOVA are shown in Table C1.
Choosing an appropriate model specification
Which of these three model specifications is most appropriate? 5 It depends. The choice should ideally be guided by substantive considerations. First, analysts should ask whether it is plausible that there are no individual differences if an effect is present. Whenever this strong assumption is met, the inferences from RIO ANOVA are valid and efficient; however, when this assumption is violated, as in the Stroop example, inferences may be severely biased. We are hard-pressed to think of any psychological effects that afford the use of RIO ANOVA. We recommend practitioners who nevertheless wish to use the RIO ANOVA to safeguard themselves against model misspecification by inspecting the random slopes with a mixed-effects model. MRE and SFR ANOVA both assume the presence of individual differences for nonnull effects, which makes them more robust and more widely applicable than RIO ANOVA.
Next, analysts should ask whether it is plausible to assume that there are individual differences around null effects. If this is the case, the common MRE ANOVA is appropriate; if not, SFR ANOVA is appropriate. Because the SFR ANOVA always simultaneously introduces fixed and random effects, it purposefully confounds evidence in favor or against a nonzero average population effect and individual differences around this effect. The result is a model comparison that examines “whether at least one individual shows an effect” (van Doorn et al., 2022, p. 8). For example, in the study of extrasensory perception (Bem, 2011), SFR ANOVA is the natural choice. The model comparison is well tailored to the research question: Identifying even a single individual who feels the future would be sensational. Moreover, when studying whether people can foresee which randomly selected stimulus is about to be presented, it is highly implausible that a null effect would emerge because some participants can feel the future and reliably perform above chance, whereas others also feel the future and somehow reliably perform below chance. Generally speaking, the SFR-model specification seems appropriate when researchers are interested in any effects at the level of the individual (e.g., general principles of cognition). But researchers interested in individual-level effects would be well advised to consider forgoing ANOVA altogether and use a mixed-effects model to analyze the unaggregated data instead.
The MRE ANOVA always includes all random effects and constructs model comparisons that target only fixed effects. These model comparisons examine whether there is an effect on average, assuming that individuals differ in any case. Thus, MRE ANOVA is appropriate when researchers are interested in population averages (e.g., public policy). Inference is less likely to be driven by outlying individuals with atypically strong effects (van Doorn et al., 2022, p. 9). But this robustness comes at a cost: As cautioned by Rouder et al. (2012), the added random effects substantially increase the flexibility of MRE ANOVA null models. As a result MRE ANOVA can be less sensitive than SFR ANOVA when there are large individual differences (Rouder et al., 2023, pp. 9–10).
To sum up, RIO ANOVA makes the strong assumption of the complete absence of individual differences. We believe that in most psychological applications this assumption is untenable and requires a strong justification. The recently proposed SFR ANOVA is a principled and powerful approach that is particularly appropriate when individual differences are of interest. As such, it seems unlikely that evidence for an effect from SFR ANOVA is the end result and likely calls for more targeted follow-up analyses. MRE ANOVA is most appropriate when the population average is of primary interest, and it is more robust to outlying individuals. We also refer interested readers to a recent special issue on Bayes factors for linear mixed-effect models that further discusses the choice between SFR- and MRE-model specifications (Rouder et al., 2023; Singmann et al., 2023; van Doorn et al., 2021, 2022, 2023).
JASP users can choose between all three model specifications. As discussed above, we believe that RIO ANOVA is inappropriate for most applications and, therefore, it is no longer the default option. 6 SFR ANOVA has only recently been proposed to address individual differences; it is the subject of controversial debate (see Oberauer, 2022; van Doorn et al., 2023) and new to most analysts, and appropriate follow-up analyses are not readily available. 7 For these reasons, the Bayesian repeated-measures ANOVA in JASP now by default uses the MRE-model specification. We believe the MRE-model specification is most consistent with analysts’ expectations—it resolves nontrivial discrepancies with results from frequentist ANOVA. In addition, this change is in line with recommendations from recent work on mixed models (e.g., Oberauer, 2022; van Doorn et al., 2023; Veríssimo, 2023). The new version of JASP introduces additional changes designed to increase the flexibility of Bayesian ANOVA. These changes are unrelated to the discrepancy and model-specification issues discussed above, which is why we have relegated them to Appendix B.
Of course, all three model specifications are also available in the R package BayesFactor. The RIO ANOVA is conveniently available through the function
A practical consequence of using the MRE- and SFR-model specifications is that the added random slopes greatly increase the number of parameters and make the models more challenging to fit. This leads not only to longer computation times but also more variation in the Bayes factors (Pfister, 2021). If the computation time becomes infeasible, we recommend to first explore the model space using a Laplace approximation. Once the most relevant subset of models has been determined, these models should be fit using the default method. To mitigate the increased variability in the results we recommend increasing the number of samples if the error percentage for any of the Bayes factors exceeds 20% (van Doorn et al., 2021).
Deciding on one of the discussed model specifications commits to a set of assumptions about the random-effects structure of repeated-measures ANOVA. Instead, we could also model average over the complete model space. Specifically, we could consider a model space in which each random slope can be present or absent rather than assuming their presence a priori. In this model-averaging approach the data would decide whether each random slope matters or not. We opted against the model-averaging approach for three reasons. First, if random slopes matter, then models without random slopes have a negligible posterior probability. For example, in the Stroop data the best performing model without random slopes had a posterior probability of the order
Concluding Comments
We illustrated a dramatic discrepancy in conclusions between the standard frequentist and previously recommended Bayesian repeated-measures ANOVA. This discrepancy is caused by a a difference in model specifications: The Bayesian ANOVA omits random slopes for repeated-measures factors, which are included in the frequentist ANOVA. As we have argued, the implied assumption of an absence of individual differences is likely not obvious to most analysts and inappropriate for most applications. When the model specification with random slopes, which allows for individual differences, is used for the Bayesian ANOVA its results agree with those from the frequentist ANOVA.
The degree to which the previously recommended RIO-model specification of the Bayesian repeated-measures ANOVA in BayesFactor (with the function
Footnotes
Appendix A
Within-Participant Effects With Sphericity Corrections

| Cases | Sphericity Correction | Sum of Squares | df | Mean square | F | p |
|---|---|---|---|---|---|---|
| PT | — | 57,532.64 | 1.00 | 57,532.64 | 2.24 | .152 |
| Residuals | — | 461,800.53 | 18.00 | 25,655.59 | ||
| Congruency | — | 33,727.79 | 2.00 | 16,863.89 | 22.16 | < .001 |
| Greenhouse-Geisser | 33,727.79 | 1.51 | 22,314.52 | 22.16 | < .001 | |
| Huynh-Feldt | 33,727.79 | 1.62 | 20,814.49 | 22.16 | < .001 | |
| Residuals | — | 27,398.21 | 36.00 | 761.06 | ||
| Greenhouse-Geisser | 27,398.21 | 27.21 | 1,007.05 | |||
| Huynh-Feldt | 27,398.21 | 29.17 | 939.35 | |||
| PT × Congruency | — | 3,124.49 | 2.00 | 1,562.25 | 2.29 | .115 |
| Greenhouse-Geisser | 3,124.49 | 1.33 | 2,345.32 | 2.29 | .137 | |
| Huynh-Feldt | 3,124.49 | 1.39 | 2,233.94 | 2.29 | .134 | |
| Residuals | — | 24,488.84 | 36.00 | 680.25 | ||
| Greenhouse-Geisser | 24,488.84 | 23.98 | 1,021.22 | |||
| Huynh-Feldt | 24,488.842 | 25.18 | 972.72 |
Note: Identical to Table 2 but includes sphericity corrections; the general results remain unchanged. PT = preceding trial. Table from JASP.
Appendix B
Appendix C
Bayesian Comparisons of Models While Introducing Fixed and Random Effects Simultaneously

| Model | P(M) | P(M|data) | BF10 | Error |
|---|---|---|---|---|
| PT + congruency | 0.200 | 0.615 | 1.000 | |
| PT + congruency + PT × Congruency | 0.200 | 0.385 | 0.627 | 3.893 |
| PT | 0.200 | 2.235 · 10−5 | 3.636 · 10−5 | 9.973 |
| Null model (including subject and random slopes) | 0.200 | 1.637 · 10−26 | 2.663 · 10−26 | 1.903 |
| Congruency | 0.200 | 7.185 · 10−30 | 1.169 · 10−29 | 1.906 |
Note: Model formulas simultaneously introduce fixed effects and random slopes (i.e., PT + PT × Participant). P(M) and P(M|data) indicate prior and posterior model probabilities, respectively;
Acknowledgements
We thank Ronen Hershman for providing the illustrative data example.
Transparency
Action Editor: Yasemin Kisbu-Sakarya
Editor: David A. Sbarra
Author Contribution(s)