
Abstract
In this article, we provide a review of research-curation and knowledge-management efforts that may be leveraged to advance research and education in psychological science. After reviewing the approaches and content of other efforts, we focus on the metaBUS project’s platform, the most comprehensive effort to date. The metaBUS platform uses standards-based protocols in combination with human judgment to organize and make readily accessible a database of research findings, currently numbering more than 1 million. It allows users to conduct rudimentary, instant meta-analyses, and capacities for visualization and communication of meta-analytic findings have recently been added. We conclude by discussing challenges, opportunities, and recommendations for expanding the project beyond applied psychology.
Researchers across the sciences lament that research findings are effectively locked away in journal articles and relatively difficult to access for meta-analysis (e.g., Bosco, Steel, Oswald, Uggerslev, & Field, 2015; Jonnalagadda, Goyal, & Huffman, 2015). The millions of individual findings appearing in scientific journals have not been extracted, classified, and stored anywhere (i.e., curated) for ease of location and access. Rather, the corpora of many scientific domains are managed much as physical libraries were before the advent of the card catalogue. Given that scientific information is important for understanding the world, literature searches for meta-analyses should not take months to years to complete. Furthermore, the increasing scope of research summaries makes clear the need for advances in visualization and communication.
One contributor to inefficient access and communication is a nearly complete lack of knowledge management by scientists, and a lack of consensus-based protocols (e.g., ontologies) on which to rely (for an exception, see the Human Genome Project; Collins, Morgan, & Patrinos, 2003). In contrast, knowledge-management platforms used in Internet retail (e.g., amazon.com) offer flexibility to locate products using text-string search (e.g., “crock-pot”) or manual taxonomic classification (e.g., Home & Kitchen > Kitchen & Dining > Small Appliances > Slow Cookers). This approach yields a knowledge-management platform that is used easily by untrained individuals and provides results in mere milliseconds. Indeed, people do not very often lament about experiencing difficulty locating items on amazon.com.
One important barrier to the goal of a curated corpus of research findings is their extraction from primary sources. Recently, researchers have applied various approaches, ranging from manual coding to artificial intelligence, for extracting scientific information from documents. Although automated extraction is a science in its own right (Matsuo & Ishizuka, 2004) and many researchers and grant-funding agencies are enticed by the prospect of a “magic pill” automated solution for managing scientific knowledge, an automated solution coming close to the performance of manual coding has yet to be found (Jonnalagadda et al., 2015). That is, manual approaches, despite the relatively high effort levels required, remain superior to automated approaches in their net accuracy, especially for information needed for summarizing findings (i.e., meta-analysis). In short, although the prospect of a magic pill is alluring, we argue that some amount of elbow grease remains a necessary component of curating research findings. Indeed, the wide variety of reporting standards, the vocabulary problem (i.e., many terms refer to the same thing; Furnas, Landauer, Gomez, & Dumais, 1987), limitations to optical character recognition, and other issues at the present time preclude automated approaches from achieving the high level of precision needed for summaries of scientific research. Of course, this is not to say that a reliable, automated approach would not be desirable. It would. In fact, the Defense Advanced Research Projects Agency’s Automating Scientific Knowledge Extraction program (i.e., ASKE; Elliott, 2018) is one recent, important step toward this goal. However, our view is that such efforts can be buttressed by the products of relatively manual efforts that would likely yield high accuracy and high near-term return on investment.
Once an extraction approach is developed and a corpus of findings amassed, the potential uses and benefits will be many. Indeed, consider that much—perhaps most—of the time required to conduct a systematic review is spent filtering the candidate sources for relevance. In the typical case, meta-analysts submit search terms (e.g., variable or construct names) to Internet or library search engines (e.g., EBSCOhost, http://ebsco.com; Google Scholar, http://scholar.google.com) and then narrow the hundreds or thousands of search results to arrive at a set of dozens of relevant studies containing the needed information. What is worse, these efforts are typically noncumulative. That is, the effort spent to classify sources for a given meta-analysis is nontransferable to other meta-analyses, unless the meta-analyses happen to share topics and inclusion years. Furthermore, many of the identified sources (e.g., theoretical articles, commentaries, literature reviews) are deemed irrelevant because they discuss relevant topics but not relevant findings, and many are filtered out because they do not report studies of variables of interest but only mention those variables. Indeed, the word performance likely occurs in most articles published in Journal of Applied Psychology. Does this mean that most report effect sizes related to employee performance? Not necessarily. Thus, in many ways, a first step for ensuring advances and facilitating meta-analyses in the future is the development of a trustworthy, curated, easily searchable corpus of research findings (i.e., an index for a search engine).
Our purpose in this article is to introduce to the psychological community a knowledge-management platform from the field of management called metaBUS; its name is a portmanteau of meta-analysis and omnibus. Our goal is not to provide a wish list, a theory of knowledge management, or a description of an imagined future utopian state. Rather, we seek to demonstrate a currently available, accessible tool to enhance meta-analyses, a standards-based, tangible product that contains more than 1,000,000 findings and is, in fact, being used now to facilitate published meta-analyses in the area of management (for recent examples, see Chamberlin, Newton, & Lepine, 2017; Rudolph, Kooij, Rauvola, & Zacher, 2018; J. A. Schmidt & Pohler, 2018).
The remainder of this article is organized as follows. First, we provide a review of approaches for the extraction and curation of research findings. Next, we describe our tool, metaBUS, including its components and processes, as well as new use cases for this cloud-based platform that can enhance meta-analyses in psychology. Given that we have delineated use cases for the field of management in the past (Bosco, Uggerslev, & Steel, 2017), we focus on new developments in this platform (i.e., visualization and communication capabilities). In the Discussion section, we present challenges and recommendations for the expansion of the project to psychology more broadly and consider use cases, including educational use cases.
Research-Curation Methods
What is the ideal approach for extracting and classifying scientific information? What information should be extracted? How should the information be classified and organized? How should depth-breadth and speed-accuracy trade-offs be managed? These questions have been pondered widely—by research teams from a variety of scientific disciplines, computer scientists, businesses, and research funders. The scientific information targeted for extraction has included scales and items from questionnaires (Larsen & Bong, 2016, 2019); effect sizes, sample sizes, and intervention information used in meta-analyses (Bero & Rennie, 1995); effect sizes and methodological characteristics of primary studies for later meta-analysis (Bosco et al., 2017); hypothesis statements (Li & Larsen, 2011; Li, Larsen, & Abbasi, 2016); and many other kinds of information. Information-extraction methods vary from manual effort-driven methods (e.g., judgments of subject-matter experts, citizen-science approaches) to relatively automated ones (e.g., machine learning, artificial intelligence, natural-language processing). Each of the many extraction and curation approaches has its own benefits and drawbacks.
Although information-extraction approaches have been attempted in several domains, few of them have given rise to efficient knowledge management. The prevalence of citizen-science approaches, for example, has given rise to reviews of their methodological characteristics (e.g., Eitzel et al., 2017; Haklay, 2013). Some reviews use taxonomies to classify the approaches (e.g., Roy et al., 2012; Wiggins & Crowston, 2011), and, in fact, at least one review has integrated the taxonomies (Den Broeder, Devilee, Van Oers, Schuit, & Wagemakers, 2016). Den Broeder et al.’s (2016) integrated taxonomy classifies collaborative projects according to their aim (i.e., purpose: investigation, education, collective goods such as managing natural resources, or action), approach (i.e., crowdsourcing, distributed intelligence, participatory science, or extreme citizen science), and size (i.e., scope, distribution of citizens).
Inspired by Den Broeder et al.’s (2016) integrated taxonomy, we argue that methods for research curation may be classified according to their breadth (i.e., size of the scientific space covered: narrow vs. wide), depth (i.e., information complexity or inference level: shallow vs. deep), and automation (e.g., student coders vs. artificial intelligence, manual vs. automated). The UCSD map of science (Börner et al., 2012), which has curated articles’ co-citation information across the sciences, is an example of curation that is wide in breadth, shallow in depth, and high in automation. At the opposite end of the spectrum, Bergmann et al.’s (2018) curation of meta-analytic information on language acquisition is relatively narrow in breadth, extensive in depth, and low in reliance on automation for extraction. Do these distinctions matter? Which approach is best suited to building a knowledge-management platform for psychology?
One example of manual curation in psychology is the curatescience.org platform (LeBel, McCarthy, Earp, Elson, & Vanpaemel, 2018), a manual, crowdsourced effort to assess replication success by extracting information pertaining to studies’ methods and findings (also see the Archival Project; Arslan & Simon, 2016). Baldwin and Del Re (2016) developed an interactive repository of curated psychotherapy findings (also see Bergmann et al., 2018). The Cognitive Atlas project (Poldrack et al., 2011) offers a curated ontology of concepts (e.g., variables, constructs) studied in cognitive psychology. The Inter-Nomological Network (INN; Larsen & Bong, 2016, 2019), part of the Human Behavior Project, offers curated questionnaire information, including each scale’s original publication source (i.e., formatted reference) and the full text of questionnaire items, taken from more than 5,000 articles. These projects, along with most content analyses and meta-analyses in psychology, may be classified as manual curation efforts with low or moderate breadth (i.e., narrow topics), extensive depth (i.e., complex information), and low reliance on automation (i.e., manual classification).
Projects relying on automated extraction are also prevalent. The NeuroSynth project (Yarkoni, Poldrack, Nichols, Van Essen, & Wager, 2011) instantly meta-analyzes functional MRI images associated with topical tags (e.g., emotion). The University College London’s Human Behaviour-Change Project (Michie et al., 2017), so named because the initial ideas for the project came from the University of Colorado’s Human Behavior Project, aims to “develop and evaluate a ‘Knowledge System’ that automatically extracts, synthesises and interprets findings from [behavior-change intervention] evaluation reports to generate new insights about behaviour change and improve prediction of intervention effectiveness” (p. 1). However, most projects relying on automation operate at a somewhat shallower level. At the shallowest information level, algorithms designed to facilitate literature search during meta-analysis make very coarse classifications of articles (i.e., relevant or irrelevant for inclusion; Langlois, Nie, Thomas, Hong, & Pluye, 2018). Such algorithms for automated classification have shown promise for meta-analyses in the medical literature; semi-automating the search process in this literature can yield results roughly equivalent to those for manual classification, with time savings of roughly 60% (Chapman, Morgan, & Gartlehner, 2010). Looking at somewhat deeper information, Jonnalagadda et al. (2015) reviewed 26 published investigations of approaches to information extraction, mostly from the medical literature, targeting information such as sample characteristics (e.g., participants’ age and sex) and sample size. Although many investigations reported somewhat promising accuracy, Jonnalagadda et al. concluded that “most of the data elements that would need to be considered for systematic reviews have been insufficiently explored to date” (p. 14). Thus, although automated extraction approaches have begun to show promise, they have not yet provided high return on investment or a foundation needed for a trustworthy knowledge-management platform for meta-analysts.
Holding constant extraction and classification reliability, any increase in automation (i.e., effort reduction) would be highly desirable. However, reliability does not appear to be constant across approaches. Indeed, to our knowledge, at this time, no automated approach has achieved what most scientists would consider acceptable levels of accuracy for extracting or classifying even shallow information used as input to meta-analysis (Jonnalagadda et al., 2015). Indeed, if even effect sizes—the most fundamental information needed for the typical substantive meta-analysis (Aguinis, Dalton, Bosco, Pierce, & Dalton, 2011)—cannot yet be extracted reliably (T. Schmidt, 2017), then the overall efficacy of automated approaches for summarizing research findings is, at present, highly limited. Thus, we urge that consumers of science apply healthy skepticism by insisting on independent replication of the reliability of such approaches (e.g., by applying the algorithm to different samples).
Similarly, we urge consumers to seek out information on limitations of existing technologies. For example Iliev, Dehghani, and Sagi (2015) cautioned readers about the limitations of automated approaches to natural-language processing, stating that human coders remain “the gold standard in the [natural-language processing] domain” and that “despite decades of research . . . by computer scientists, computational linguists, and cognitive psychologists, computers are still a long way away from matching human performance when it comes to identifying meaning” (p. 267).
In summary, unfortunately, manual approaches to information extraction are relatively time-consuming, and automated approaches are relatively unreliable. So, assuming that a massive, well-curated corpus of each field’s research findings would have high value—a reasonable assumption—how should such curation be conducted? We turn to this issue next by detailing the processes and components used by an already successful approach that combines semi-automated extraction and manual coding: the metaBUS project (Bosco et al., 2017).
The metaBUS Platform
The metaBUS project (http://metabus.org) began in the field of management and applied psychology, a subfield of psychology that, unlike much of experimental psychology, benefits from a highly standardized convention for reporting effect sizes: the correlation matrix. Indeed, the correlation matrix is a highly efficient mechanism for presenting many zero-order effects in a single table, and each correlation is typically suitable for use in meta-analysis regardless of its relevance to the article’s central research questions (Bosco, Aguinis, Singh, Field, & Pierce, 2015). Indeed, across the 10,000 articles contained in the metaBUS database (Version 2018.09.09), each article contains, on average, roughly 75 effects (i.e., zero-order correlations). Admittedly, the correlation-matrix format is not perfectly standardized (e.g., some matrices contain findings above and below the diagonal). However, metaBUS maintains a semi-automated, supervised matrix extraction protocol that trained coders apply with near-perfect accuracy, typically in 30 s or less per matrix.
Once a matrix is extracted, the manual classification process begins. Each variable in the matrix is classified according to a hierarchical taxonomy of nearly 5,000 variables and constructs studied in applied psychology (a screenshot displaying an abbreviated portion of the taxonomy is shown in Fig. 1). The metaBUS taxonomy is similar in function and design to the Medical Subject Headings (MeSH; Ebbert, Dupras, & Erwin, 2003), as it is a controlled vocabulary that exhibits a generic taxonomy structure wherein each node has a unique identifier. In metaBUS, major taxonomic branches include construct classes such as attitudes, behaviors, psychological traits, and the like. Because applied psychology is quite broad in scope, the taxonomy includes many constructs (and construct classes) from psychology proper (e.g., cognitive ability, psychological well-being, demographic variables). Taxonomic classification is an essential component of the platform, as it assists in circumventing the vocabulary problem and ultimately results in an ontology representing the field’s content. Each extracted variable is further manually coded for its reliability (i.e., the reported value of the reliability statistic and whether it is an alpha value), the response rate, the variable’s mean and standard deviation, the country of data collection, the participant type, the level of analysis, and other attributes. A detailed description of the extraction process and database schema is available elsewhere (Bosco et al., 2017).
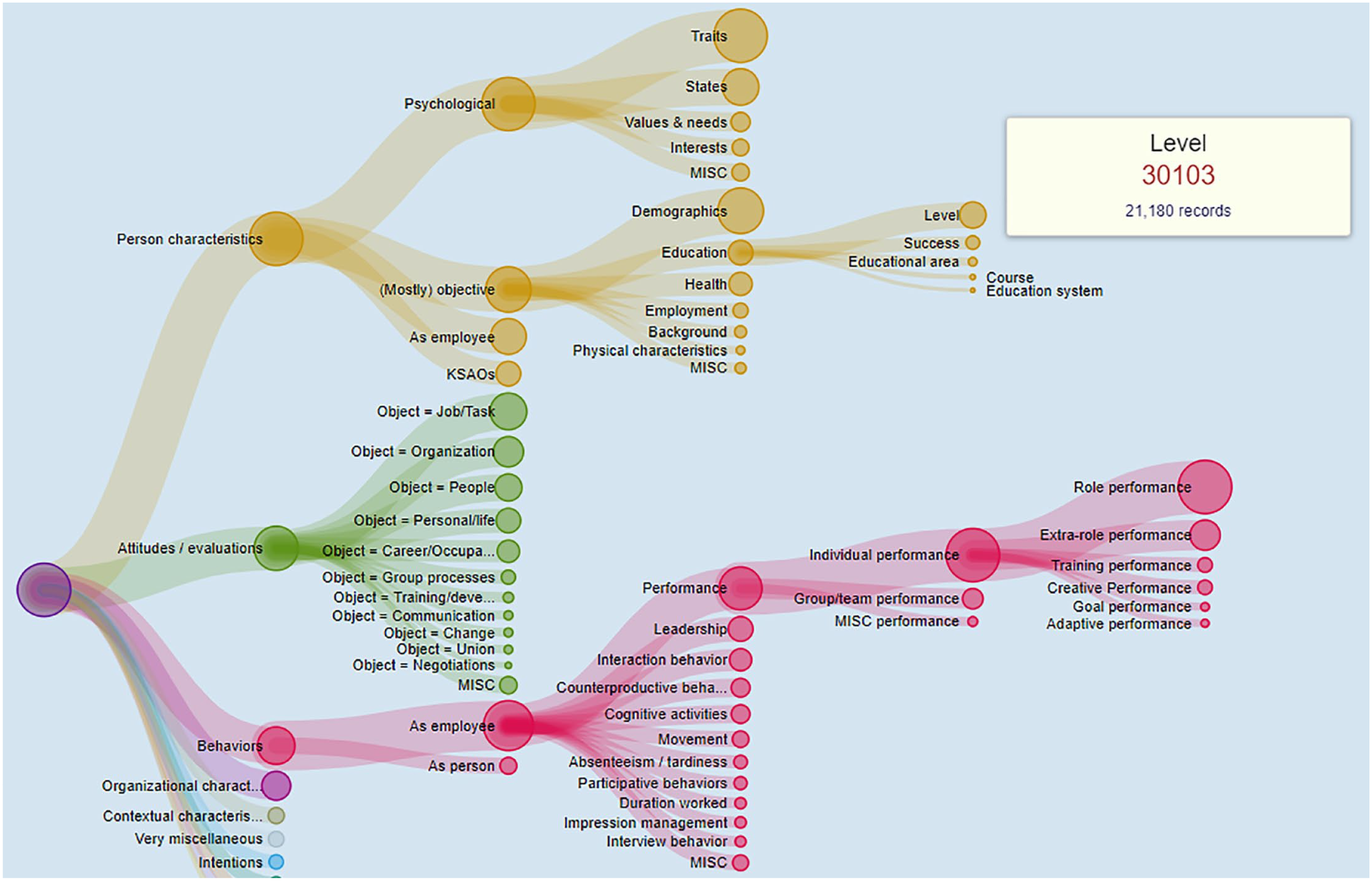
Screenshot of an abbreviated portion of the metaBUS taxonomy. The tooltip provides the unique identifier (30103) and the number of findings associated with education level (i.e., there are 21,180 effects involving education level).
Our main deliverable is a cloud-based platform that offers flexible querying of a database of more than 1 million findings extracted from 27 journals reporting applied-psychology findings from 1980 to 2018. (To our knowledge, metaBUS is the largest collection of research findings in the social sciences that does not rely on an automated extraction process.) Users can search with either exact letter strings or taxonomic classifiers—or a combination of the two. Furthermore, metaBUS offers two distinct report modes. The first, targeted search, requires users to specify a pair of search terms pertaining to a bivariate relation (e.g., conscientiousness–education level) and then returns all matching results and metadata. Following retrieval, the platform provides an on-the-fly meta-analysis of the records with which users may interact to refine the summary (e.g., filter by publication year, exclude individual entries). Figure 2 shows a partial screenshot of the instant meta-analysis of 122 findings returned for a search on the relation between conscientiousness and education level. (Details of the meta-analytic estimation procedure used by metaBUS are presented in Bosco et al., 2017.) A second, newly developed search mode, exploratory search, takes as input a single search term in the form of a taxonomic node and then conducts all possible meta-analyses with all other taxonomic nodes and produces an interactive plot of the meta-analytic relations. For example, a user may specify age (taxonomic identifier 20457) as the variable of interest and then peruse summaries of all possible meta-analytic relations involving age in the database. Currently, exploratory meta-analyses are not possible with text strings because of the massive number of possible combinations.
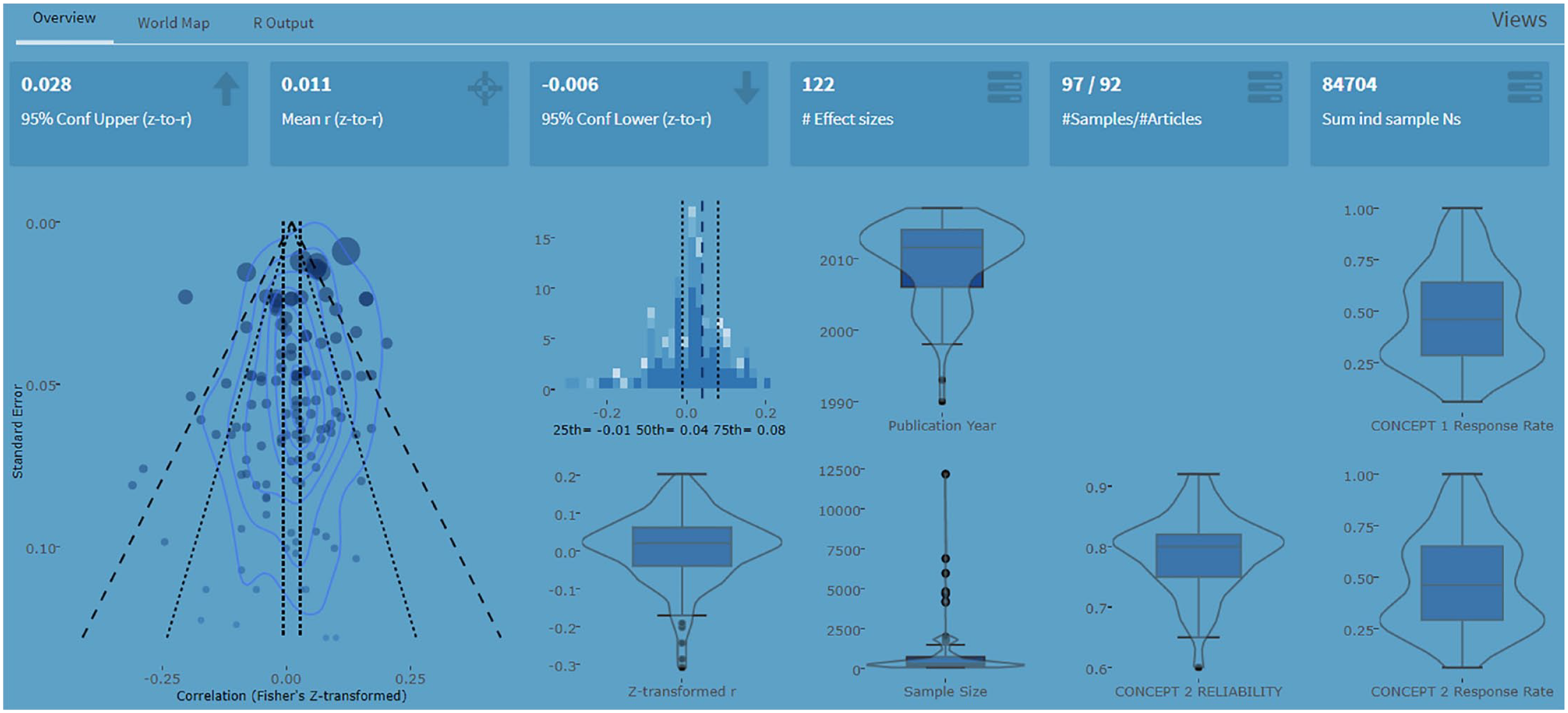
Partial screenshot of the metaBUS platform’s output for a mixed text-based and taxonomy-based query for the relation between conscientiousness and education level. The instant summary of 122 effects is shown. An interactive version of this output is available at https://shiny.metabus.org/q/e1753fe9-00db-4dc5-9dce-2b3e885dfa27/.
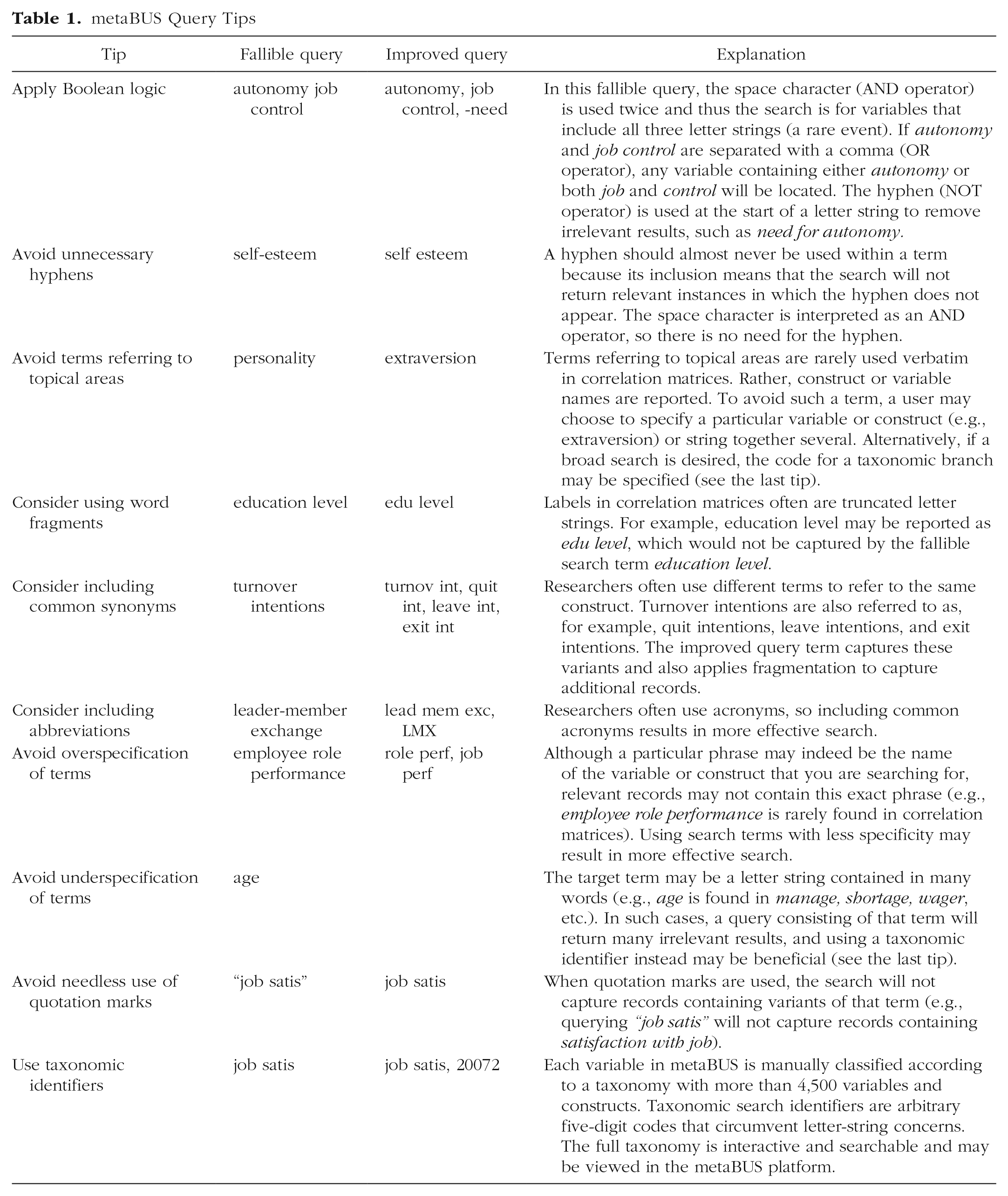
The search flexibility offered by metaBUS is advantageous, yet the various search specification options (e.g., text- vs. taxonomy-based search) mean that brief tutorials are needed to help researchers make effective use of the platform. For example, the two search-term types (i.e., text vs. taxonomy) serve to address shortcomings of each other, and, for some searches, text-based queries will be more suitable than taxonomy-based queries, and vice versa. As of March 2019, the platform (http://shiny.metaBUS.org) has logged more than 10,000 user queries. Queries are regularly reviewed by the metaBUS team, and over the years, we have witnessed query specifications that vary widely in effectiveness. Thus, in Table 1, we provide recommendations for running effective queries.
metaBUS Query Tips
Using metaBUS for Meta-Analyses in Psychology
As noted earlier, the potential uses for a large, well-curated corpus of research findings are many. Previously (Bosco et al., 2017), we described three use cases for metaBUS specifically, and we review those three use cases briefly here.
The first use case involves navigation of the metaBUS taxonomy to discover variants of a construct’s name. The taxonomy arranges related terms in hierarchical fashion, thus allowing meta-analysts familiar with a given variant (e.g., turnover intention) to locate this term within the taxonomy and then encounter sibling terms (e.g., quit intention, leave intention, exit intention). The second use case involves targeted queries for bivariate relations between two constructs (e.g., conscientiousness–education level). Such queries provide users with instant, rudimentary meta-analytic estimates that are highly useful for conducting power analyses and estimating Bayesian priors (Bosco, Aguinis, et al., 2015). Finally, metaBUS can be used as a simple search engine to locate findings overlooked during traditional meta-analytic literature search. In fact, we (Bosco et al., 2017) demonstrated this use case by locating findings that were overlooked in an existing meta-analysis. We expect that each of these existing capabilities of metaBUS may be used, in its current form, by meta-analysts pursuing a variety of correlational topics in personality or social psychology. We turn next to two additional use cases.
Exploring and visualizing meta-analytic results
In several areas of psychology, the number of meta-analytic estimates, crossed with moderator levels, often yields results tables that span many pages and may not present a clear, digestible picture of the results. Just as visualizations are useful for big-data studies (Tay et al., 2017), innovative visualizations can benefit meta-analyses. Our approach, which we label exploratory meta-analytic visualization (EMV), may be applied at the meta-analytic effect-size level to provide a picture of all of a given construct’s bivariate relations. The user specifies an anchor search term (e.g., job satisfaction) and then may view and interact with tens or hundreds of meta-analytic plots, each showing a relation between job satisfaction and something else.
Any taxonomic node—at any level of the hierarchy—may be submitted to an EMV. For example, a user may conduct a very broad exploratory meta-analysis by designating all attitudes (taxonomic code 20115) as the anchor. Figure 3 provides an EMV for a narrower meta-analysis of job satisfaction (taxonomic code 20072). In this example, each of the 77 nodes (excluding the largest one, representing the search term) depicts a distinct meta-analytic relationship with job satisfaction. The user may specify the minimum number of effects to be summarized per node, which in this case was 300. The size of each node represents the number of effects (i.e., frequency of study), and the degree of shading represents the meta-analyzed mean effect estimate. For example, the tooltip in Figure 3 shows that 753 effects in 335 articles reporting on 389 samples yielded a correlation of .53 between job satisfaction and turnover intentions. Compared with the other meta-analytic summary estimates in the EMV, this is a relatively strong effect. The EMV depicts overall weak relations between job satisfaction and person characteristics and behaviors, yet relatively strong relations between job satisfaction and other attitudes. It is worth noting that this plot took only seconds to generate and summarizes and visualizes tens of thousands of findings.
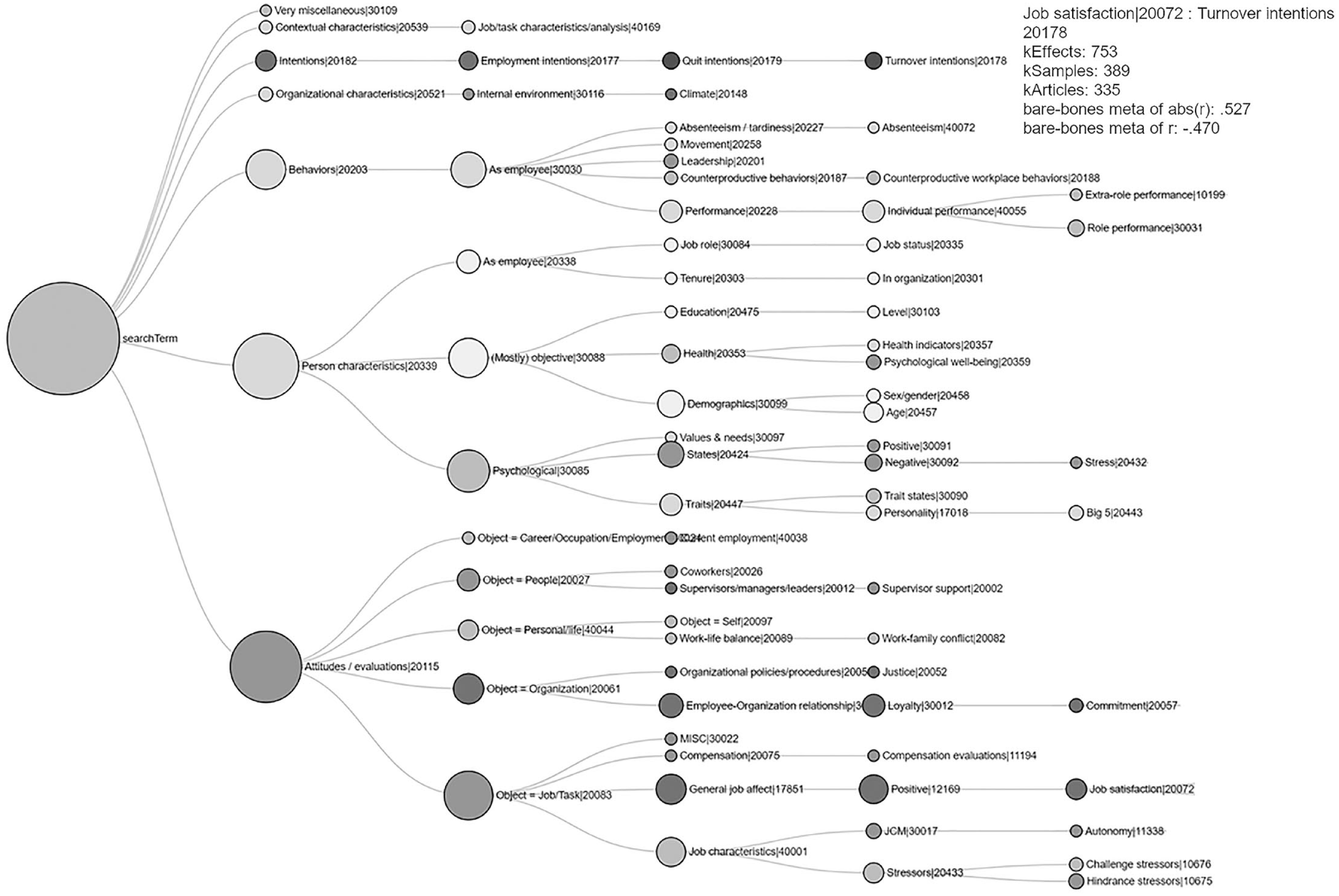
Exploratory meta-analytic visualization for the search term job satisfaction (taxonomic code = 20072). In this example, only nodes with at least 300 effects are shown, and effect summaries take as input the absolute values of correlations. Each node represents a meta-analytic relation between job satisfaction and the node’s label. The size of each node indicates the frequency of study, and the degree of shading indicates the meta-analyzed mean effect-size estimate. The sample tooltip provides additional detail for 1 of the 77 relations (i.e., job satisfaction–turnover intentions).
Our goal in developing this novel approach for visualizing meta-analytic findings was to allow scientists to rapidly scan large landscapes of research findings. To our knowledge, no knowledge-management platform anywhere in the social sciences is capable of summarizing research findings with such flexibility, speed, and accuracy. Indeed, it should be possible, with enough information, to create a map of an entire field that would allow researchers to investigate patterns among research findings to support inductive research efforts (cf. Woo, O’Boyle, & Spector, 2017). Additionally, although Figure 3 plots a one-to-many relationship (i.e., the relation between job satisfaction and other constructs), one could envision an alternative visualization, such as an arc diagram that takes as input a series of construct pairs and depicts the frequency of study and effect size for each pair by varying the arcs’ width and shading, respectively.
Communicating meta-analytic results
Proponents of the open-science movement have urged researchers to make available the host of materials and data needed to replicate research findings (Munafò et al., 2017). To our knowledge, few options exist for hosting, sharing, and interacting with meta-analytic inputs, but the concept of the living or dynamic meta-analysis (e.g., Bergmann et al., 2018), wherein users may add findings to a cloud-based database, is especially promising. The metaBUS platform allows researchers to run bivariate queries, customize and filter the results, and then share the results publicly. For example, we have made available the results of a first-pass meta-analysis on the relation between conscientiousness and education level (https://shiny.metabus.org/q/e1753fe9-00db-4dc5-9dce-2b3e885dfa27). In this example, 122 effect sizes from 92 articles reveal a mean r of .01 (95% confidence interval = [–.01, .03]). Furthermore, one may interact with the posted results by toggling to include and exclude samples so as to assess the robustness of the summary estimates.
We envision such functionality to be highly useful during the manuscript review process (e.g., to alert authors about previous findings relevant to their manuscript), for collaboration among members of research teams, and for educational purposes.
Discussion
The metaBUS platform was developed for management and applied psychology, a field in which native meta-analytic summary estimates are correlation coefficients in 90% of cases (Aguinis et al., 2011). Thus, a curation effort focusing on correlation matrices was an ideal starting point for the project. In addition, because the typical correlation matrix contains zero-order effects, each correlation is a viable candidate for inclusion in later meta-analysis. However, in other areas of psychology (e.g., experimental psychology), higher-order effect-size indices (e.g., partial eta squared) are more prevalent, and statistical tests of null hypotheses may less frequently be tests of zero-order effects. Although meta-analyses of higher-order effects are possible, the specific combinations of conditions that gave rise to those effects are unlikely to occur with high prevalence across samples. How, then, would it be possible to expand the metaBUS project across psychology?
Expanding metaBUS throughout psychology
Expansion of metaBUS to other areas of psychology following a correlational tradition—in contrast to an experimental tradition—would require coordinated efforts, but existing metaBUS components could be adapted with relative ease. For example, the taxonomy would need to be expanded to capture variables and constructs in other content areas. To this end, expansion teams may wish to automate the extraction of verbatim variable names found in matrices and then work to reach consensus on how to arrange these terms in the taxonomy. In addition, database fields (i.e., codes) may require revision or supplementation to address major topics of interest in added content areas. For example, educational or personality psychologists may wish to add database fields to capture demographic information for all samples. Regardless of the area of expansion, human coders will need to be recruited, trained, and motivated; metaBUS used a piece-rate compensation model (i.e., roughly $1 per variable manually coded), with supervisor-conducted error checks. Although the promise of crowdsourcing is alluring, we note that existing crowdsourced efforts have yielded relatively little growth.
The challenges go beyond the challenges for curating correlational research findings because research in experimental psychology involves diverse types of effect sizes. Indeed, experimental manipulations may be made within or between participants and may have any number of levels; in addition, sample size may vary across groups, and manipulation magnitudes are not necessarily equal across studies. (Nuijten, Hartgerink, van Assen, Epskamp, & Wicherts’s, 2016, approach for automated extraction of statistical information is a valuable starting point for extracting the variety of effects.) Furthermore, some reported variables (e.g., self-esteem) may have been measured in some studies but manipulated in others, and thus may require additional methodological metadata in the form of database fields or finer taxonomic branches. Ultimately, we expect that the curation of experimental research, compared with correlational research, will require a substantially greater investment of resources and greater training and, unfortunately, will have lower potential for speedy progress.
Recommendations for reporting
As suggestions for all researchers (meta-analysts or otherwise), we offer the following reporting recommendations to facilitate future curation efforts, whether they rely on manual coding or automation. Given that future curation efforts will likely rely heavily on tables of results, the comprehensiveness and disambiguation of information presented in tables is essential. We offer three main recommendations, based on difficulties we have experienced during extraction of information. First, choose variable names carefully (i.e., use frequently used terminology), and should abbreviations be required, explain them explicitly in table notes. For example, in the metaBUS database, there are many instances of matrices containing the term turnover, but closer inspection of these articles’ Method sections reveals that the authors mean turnover intentions. These are very different constructs. Second, for each variable, include the exact sample size. Many correlation matrices extracted by metaBUS contain table notes indicating only that sample size varied (e.g., “n ranged from 100 to 150 because of missing data”). Failing to report exact sample sizes prevents future estimation of statistics such as the exact p value. Finally, although this is not typical practice in some areas of psychology, consider reporting correlation matrices of all variables whenever possible (e.g., consider reporting bivariate contrasts).
The future might bring about reporting standards that are far more advantageous than those currently in place. For example, should it become convention to post all raw data through services such as the Open Science Framework, bridges could be built to extract a multitude of effect sizes from such sources. Additionally, at the time of publication, authors could code journal articles using identifiers from controlled vocabularies (i.e., variable taxonomies). Of course, these bridges will not be built overnight. However, our suggestions are intended to provide the greatest return for curation in the short term.
Application potential
If the barriers to curating psychology as a whole are overcome, we have hope that expansion of metaBUS—or projects like it—can be leveraged for many purposes. For scientists, the platform is effective for locating research findings to conduct first-pass, rudimentary meta-analyses when existing meta-analyses are not yet available. If a systematic review is already underway, metaBUS may be used to locate findings that were overlooked during a traditional literature search (Bosco et al., 2017). In addition, metaBUS may be used to conduct metascientific (i.e., science-of-science) research, such as research identifying erroneous findings, research on temporal trends in methodological attributes (e.g., sample size), and inductive research. During the manuscript review process, metaBUS may be useful to assess the thoroughness or accuracy of past summaries of findings.
We expect knowledge-management platforms like metaBUS to be highly effective for educational purposes as well (Bennett, Bosco, & Field, 2018). As a thought experiment, consider for a moment a field of research with which psychological scientists are typically not intimately familiar: sociology. Although they may be aware of some key researchers’ names or foundational principles from an introductory course in college, most psychological scientists do not know the variety of things sociologists study. If a taxonomy of variables and constructs like that used in metaBUS were available for sociology, gaining a rapid and at least rudimentary familiarity with the variety of topics in the field would be massively facilitated. The same point applies to the various subfields of psychology; for example, experimental psychologists may be interested to peruse Figure 1, which clearly shows (through node size) that the behaviors most studied by applied psychologists are (in order of frequency) employee performance, leadership, interaction behavior, and counterproductive behavior.
Furthermore, by employing advanced visualization techniques, one could rapidly gain an understanding of the relative frequency of topics and, with a sufficiently large corpus, the magnitude of their observed effect sizes. Indeed, the metaBUS taxonomy arranges virtually all variables and constructs studied within a given scientific domain. Thus, students conducting literature searches may benefit from locating related terms and understanding one possible classification scheme for topics studied. Of course, students and other users may benefit from consulting metaBUS to locate relevant findings while writing manuscripts. Finally, curated research may facilitate communication between scientists and practitioners (Bosco, Aguinis, et al., 2015), policymakers, or the general public.
Lessons learned and suggestions for expansion efforts
The metaBUS project began in 2011, under a different name, when the first author began developing the semi-automated extraction protocol, manual coding protocol, and construct taxonomy. Although the space available here precludes a detailed project history, we offer the following suggestions for expansion teams. Many are based on mistakes we made along the way.
Resist the temptation to rely on a fully unattended (i.e., automated) approach. Although we admire attempts to develop automated approaches for extracting research information, and we look forward to their eventual development, we find it somewhat ironic that funds allocated to developing such technologies have likely already surpassed the funds needed to hire trained coders to complete the same task on the existing backlog with higher reliability. Furthermore, an existing, trustworthy corpus of curated findings can facilitate the development of automated approaches. Indeed, the manually coded information would serve as an ideal “answer key” to judge the accuracy of automated approaches. Furthermore, the manually coded information would provide return on investment along the way.
At first, rely on paid data collection using trained coders and supervisory error checking, double-coding, or both. Although we admire crowdsourced efforts, such efforts in psychology have thus far been unable to attract the low-cost or free labor required to create a massive corpus of findings. Furthermore, curating evidence in psychology requires high-level inferences. In contrast, many successful crowdsourced efforts across the sciences have relied on low-level inferences and, consequently, minimal training requirements. There is no shortage of well-trained psychology students interested in employment and experience during the summer months, which, for this reason, are by far our most productive data-collection months.
Develop standards- and consensus-based taxonomies. Although we developed a taxonomy of the constructs in our scientific space, we did not rely on a quantitative consensus-based approach. Rather, we applied a relatively informal approach relying on discussions among subject-matter experts (see Bosco, Aguinis, et al., 2015, for details). Card sorting or similar approaches that rely on inspection of similarity matrices may give rise to higher levels of community acceptance than do approaches relying on relatively informal discussions by and judgments of subject-matter experts. Furthermore, consider a generic taxonomy structure (cf. National Information Standards Organization, 2005) relying on is a statements that are not guided by theory. For example, Cascio and Aguinis’s (2008) taxonomy for classifying article topics placed personality assessment beneath the node for predictors of performance (Cascio & Aguinis, 2008), but personality assessments are used for a host of other purposes. A generic taxonomy requires that is a links are always true.
Build software platforms in a language currently used by members of the field. Over the years of the metaBUS project, we developed four separate cloud-based software platforms. In two of these cases, the platforms were developed by professional software engineers working outside of academia. Currently, academics in psychology are most familiar with two languages (i.e., R, Python); their popularity is likely attributable to the availability of add-on packages for advanced statistical analyses. However, many developers outside of academia are either not familiar with these languages or prefer others. Academic teams who develop platforms like ours in languages other than those with which the academic community is familiar may experience dependence on a particular software team to update and modify the code. Our current platform is built entirely in the R language, and our interface relies on R shiny (Chang, Cheng, Allaire, Xie, & McPherson, 2019), so we can leverage community knowledge to expand the platform’s features (i.e., volunteers in the community may write script to enhance the platform).
Conclusion
With a database of more than 1 million findings, metaBUS, a standards-based platform for curating applied-psychology research, is, to our knowledge, the platform that maintains the largest collection of manually curated research in the social sciences. We expect the platform to facilitate future meta-analyses and the curation of psychological research more broadly, especially for areas in which correlation matrices are frequently reported. We are hopeful that expansion of metaBUS to experimental research will be possible but expect that additional effort will be required. We hope that, in the spirit of open science, research teams will choose to leverage our existing efforts and build upon them.
Footnotes
Transparency
Action Editor: Frederick L. Oswald
Editor: Daniel J. Simons
Author Contributions
F. A. Bosco generated the idea for the article. F. A. Bosco wrote the first draft of the manuscript, with the assistance of K. R. Larsen, J. G. Field, Y. Chang, and K. L. Uggerslev. All the authors critically edited the manuscript and approved the final submitted version.