
Abstract
When researchers model multilevel data, often a shared construct of interest is measured by individual-level observations, for example, students’ responses regarding how engaging their instructor’s teaching style is. In such cases, the construct of interest, “engaging teaching,” is shared at the cluster level across individuals, yet rarely are these shared constructs modeled as such. To address this gap, we discuss multilevel confirmatory factor analysis models that have been applied to item-level data obtained from multiple raters within given clusters, focusing particularly on measuring a characteristic at the cluster level. After discussing the parameters in each potential model, we make recommendations as to the appropriate modeling approach and the steps to be taken for model assessment given a set of data and hypothesized construct of interest. In particular, we encourage applied researchers not to use a model without constraints across the within-cluster level and the between-cluster level because such models assume that the average amount of the individual-level construct in a cluster does not differ across clusters. To illustrate this issue, we present simulation results and evaluate a series of models using empirical data from the Trends in International Mathematics and Science Study.
Researchers often write multiple items forming a scale to measure a construct of interest; such questionnaires are plentiful in psychology. The use of confirmatory factor analysis (CFA; Jöreskog, 1969) is a typical approach to evaluate and supply evidence of the underlying structure of a set of items. However, when data are nested—for example, when respondents are members of a group of interest—the measurement model can become more complex, especially if a cluster-level characteristic is the construct to be measured. Such measures are commonplace, and examples include ratings of instructors by multiple students, reports of workplace quality by employees, and ratings of neighborhood safety by citizens.
We believe that researchers should take a more thoughtful approach than is shown in most current applied studies, as the meaning of the construct at the individual level (Level 1) can be different from the meaning of the construct at the cluster level (Level 2), as acknowledged by Muthén (1994). In this article, we first briefly discuss the statistical models that support multilevel CFA and then address the models necessary to investigate shared constructs (e.g., constructs that are shared by all individuals within a given cluster; Stapleton, Yang, & Hancock, 2016). We present a best-practice modeling strategy based on a simulation conducted to demonstrate the results of applying these models to nested data. Finally, using item responses from an example data set (from the Trends in International Mathematics and Science Study, or TIMSS; Martin, Mullis, & Hooper, 2016), we illustrate our best-practice strategy and contrast the results obtained with different models.
Background
CFA is a typical approach to validating the structure of a measure. Suppose a six-item measure is purported to measure a single construct. The model in Figure 1 may be hypothesized to underlie the responses to these items; X1 to X6 represent manifest item responses from individuals, ξ1 represents the latent factor of interest, φ represents the variance of the latent factor, λ p represents the relation between the latent factor and the item response for item p, and ε p represents the item residual for item p (i.e., the part of the item response that is not a function of the latent factor). Not shown in the figure, but assumed, is that each item residual has a variance (θ p ) and that these item residuals do not covary (this assumption can be relaxed, however).
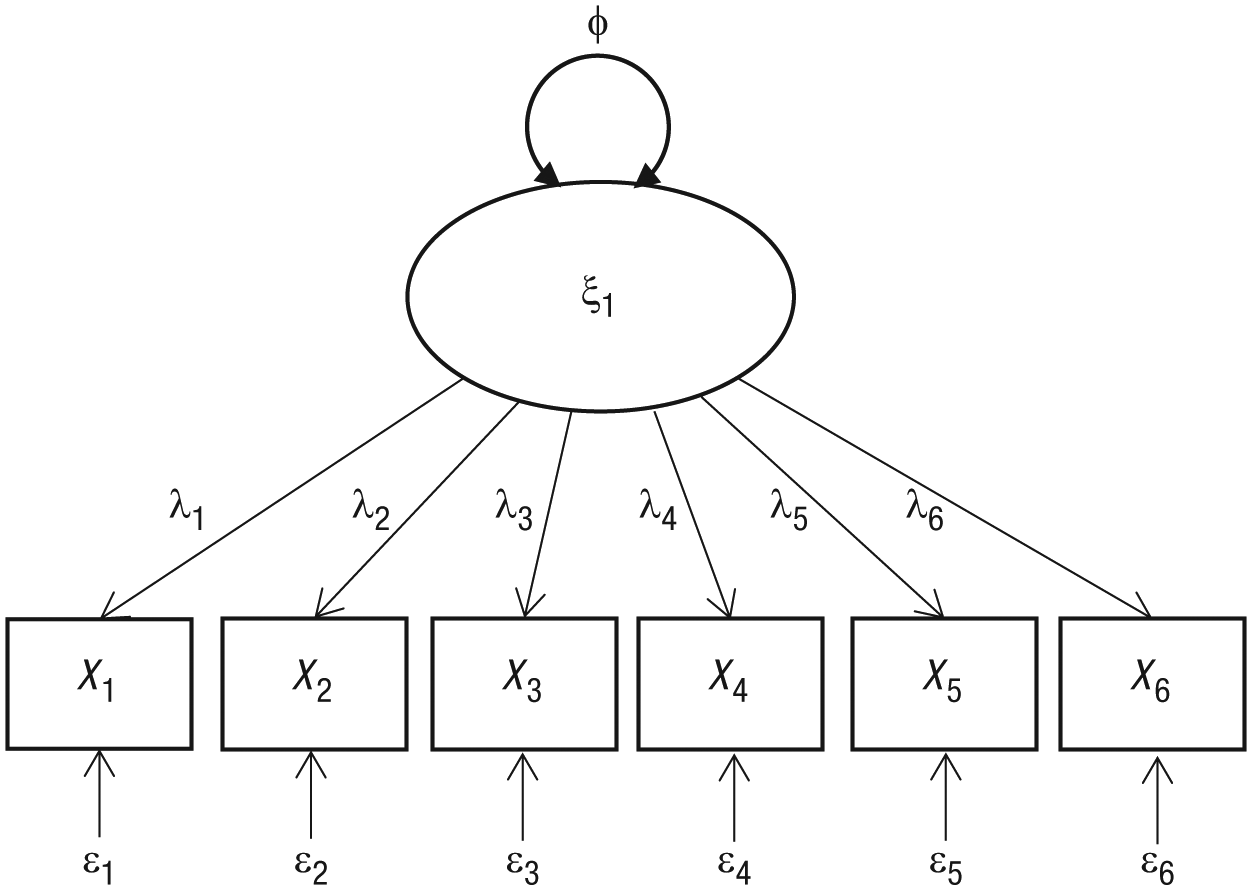
Hypothetical unidimensional factor structure for a six-item measure of a construct. X1 through X6 represent manifest item responses from individuals, ξ1 represents the latent factor of interest, φ represents the variance of the latent factor, λ p represents the relation between the latent factor and the item response for item p, and ε p represents the item residual for item p.
The plausibility of the hypothesized factor structure can be determined by comparing the model-implied covariance matrix given the model parameter set {θ},
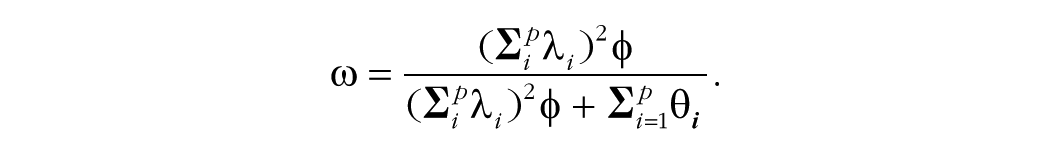
Measures of composite reliability reflect the ratio of a composite’s estimated true score variance to the total variance, and they are interpreted similarly to Cronbach’s alpha. However, ω is not dependent on alpha’s strict assumption related to loading equivalence (McDonald, 1970).
An important assumption underlying the estimation approaches typically used for CFA is that the observations that form the data set are independent. This assumption is common in many statistical applications and has implications for the estimation of sampling variances (or standard errors) and thus the χ2 test of model fit (Bollen, 1989; Stapleton, 2006). Many applications in the area of questionnaire development and validation, however, involve data collection within multiple existing clusters, for example, employees nested within organizations, participants nested within events, patients nested within clinics, individuals nested within churches, persons nested within neighborhoods, and students nested within classrooms and schools. Furthermore, many hypothesized constructs may not be defined at the individual level; although individuals may provide responses, the target of the questions may be the cluster. Examples of such constructs are quality of a program, supportiveness of an organization, and safety of a neighborhood. In fact, in a review of 72 multilevel CFA studies, Kim, Dedrick, Cao, and Ferron (2016) found that 58% were focused on evaluating constructs at the cluster level. Stapleton et al. (2016) referred to constructs that are characteristics of the cluster itself as shared constructs, a term introduced by Bliese (2000) in the organizational-psychology literature. Such constructs have also been labeled climate constructs (Marsh et al., 2012) and reflective constructs (Lüdtke, Marsh, Robitzsch, & Trautwein, 2011). Unfortunately, it appears that in many applied multilevel CFA studies, the shared cluster-level construct of interest has not been distinguished from the nuisance construct measured at the individual level and reflected at the cluster level; constructs have seemingly been conceptualized only via post hoc consideration of what was measured. In their review, Kim et al. found that “many studies did not provide extensive theoretical explanations of the meaning of their constructs within a multilevel framework” (p. 891). In this article, we demonstrate how a multilevel CFA model can be utilized to investigate the structure of a cluster-level shared characteristic measured by responses of individual raters.
A multilevel CFA requires parsing the item responses into two components: a within-cluster, or individual-level, component and a between-cluster, or cluster-level, component. The within-cluster component can be viewed as scores that have been centered at the mean of a given cluster, and the between-cluster component can be conceptually regarded as each cluster’s mean (Hox, Moerbeek, & van de Schoot, 2018). Readers familiar with multilevel modeling may notice that this parsing corresponds to a multivariate null model (an unconditional model for several outcome variables simultaneously; Hox et al., 2018). As shown in the following equation, each of the p observed variables is made up of a within-cluster residual (ηW) and a between-cluster random effect (ηB):
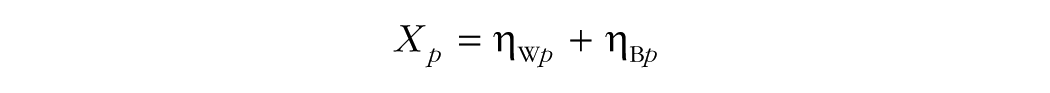
The within-cluster residuals may covary among the p variables at Level 1 (the individual level), and the between-cluster random effects may covary among the p variables at Level 2 (the cluster level).
The next step is to estimate two covariance matrices: The within-cluster matrix is based on the covariance among the ηWp values, and the between-cluster matrix is based on the covariance of the ηBp values across the clusters. Figure 2 shows the resulting measurement model for the hypothetical factor structure in Figure 1. Note that although the figure shows a single underlying factor at each level, we believe that this structure is not conceptually appropriate for measuring a shared construct, as we explain shortly.
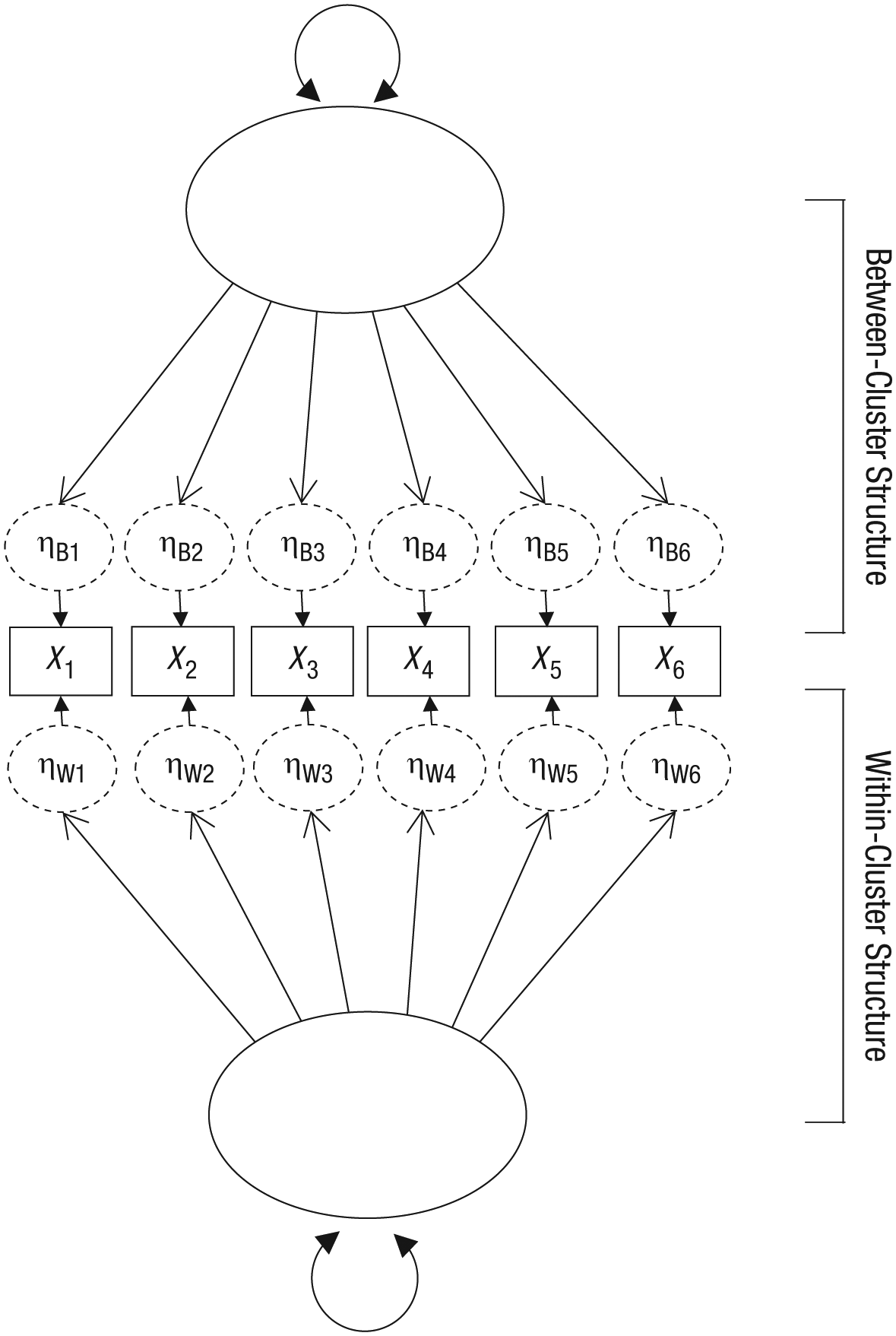
A standard path diagram representing the within- and between-cluster structure of the hypothetical structure in Figure 1. The dashed ovals represent the within-cluster and between-cluster components. The within-cluster and between-cluster latent constructs both have freely estimated disturbance terms, although they are not shown in the figure.
Having a defined covariance matrix at each level allows a researcher to posit a separate factor structure at each level, as desired. Assessing model fit in multilevel CFA contexts is a complex process, and Ryu and West (2009) described suggested approaches in detail. We do not address model-fit testing here, given page limitations, but instead focus on the conceptual meaning of the factor structure at the between-cluster level (Level 2).
Two types of constructs can exist at Level 2 (Stapleton et al., 2016): shared constructs and configural constructs. Briefly, a configural construct represents the average of the within-cluster construct as measured across individuals from the same cluster. For example, suppose that a questionnaire is intended to measure patients’ depressive symptomology and patients are clustered within therapists. At Level 2, a configural construct would be measured by the average level of depressive symptomology of a given therapist’s clients; that is, it would reflect the individual-level construct within the cluster overall. A shared construct, on the other hand, is a Level 2 construct that is assumed to be the same for all individuals in a given cluster (i.e., it is shared among the individuals in a cluster). Take, for another example, safety of a neighborhood. Each resident may be asked to rate the safety of the neighborhood, and each resident has been exposed to that same target or stimulus. In theory, a good measure of neighborhood safety would elicit the same response from all residents within the same neighborhood because they are serving as multiple raters of the same stimulus.
Unfortunately, as a result of many factors, researchers often do not have robust measures of Level 2 shared characteristics. Sometimes different raters base their ratings on different information (e.g., in this example, only some of the raters might have read a recent crime report or witnessed vandalism). Although variability in ratings of a shared construct may be considered measurement error, such variability may also reflect individual characteristics. For example, as people age, they may become less tolerant of being in areas that are not safe, and so their personal ratings of their neighborhood’s safety may be lower than those of younger people living in the same neighborhood. Such a differential would not be due to the neighborhood’s characteristic of safety, but rather would be due to individual differences. In other words, an individual’s responses to questionnaire items about neighborhood safety would reflect two things: actual, objective safety of the neighborhood (a shared cluster-level characteristic) and the individual’s tolerance for unsafe conditions. This multidimensionality of item responses presents a real problem in measuring a Level 2 shared construct; the analyst must peel away the individual-level construct from measurement of the shared construct.
Two factors typically are needed at Level 2 to validate the structure of a questionnaire measuring a cluster-level shared construct (Stapleton et al., 2016): the configural construct and the shared construct. Assuming that some sort of individual-level construct is present in the item responses, the researcher needs to model that construct at Level 1, as well as at Level 2, with factor loadings constrained to be equal across levels, to produce the Level 2 configural construct. Again, the latter construct can be seen as the average level of the individual-level construct in a given cluster (e.g., the average tolerance of residents for unsafe things in their neighborhood). Such a model may look like the one in Figure 3. Specifying the configural construct in this way allows the shared construct at Level 2 to be modeled with freely estimated factor loadings.
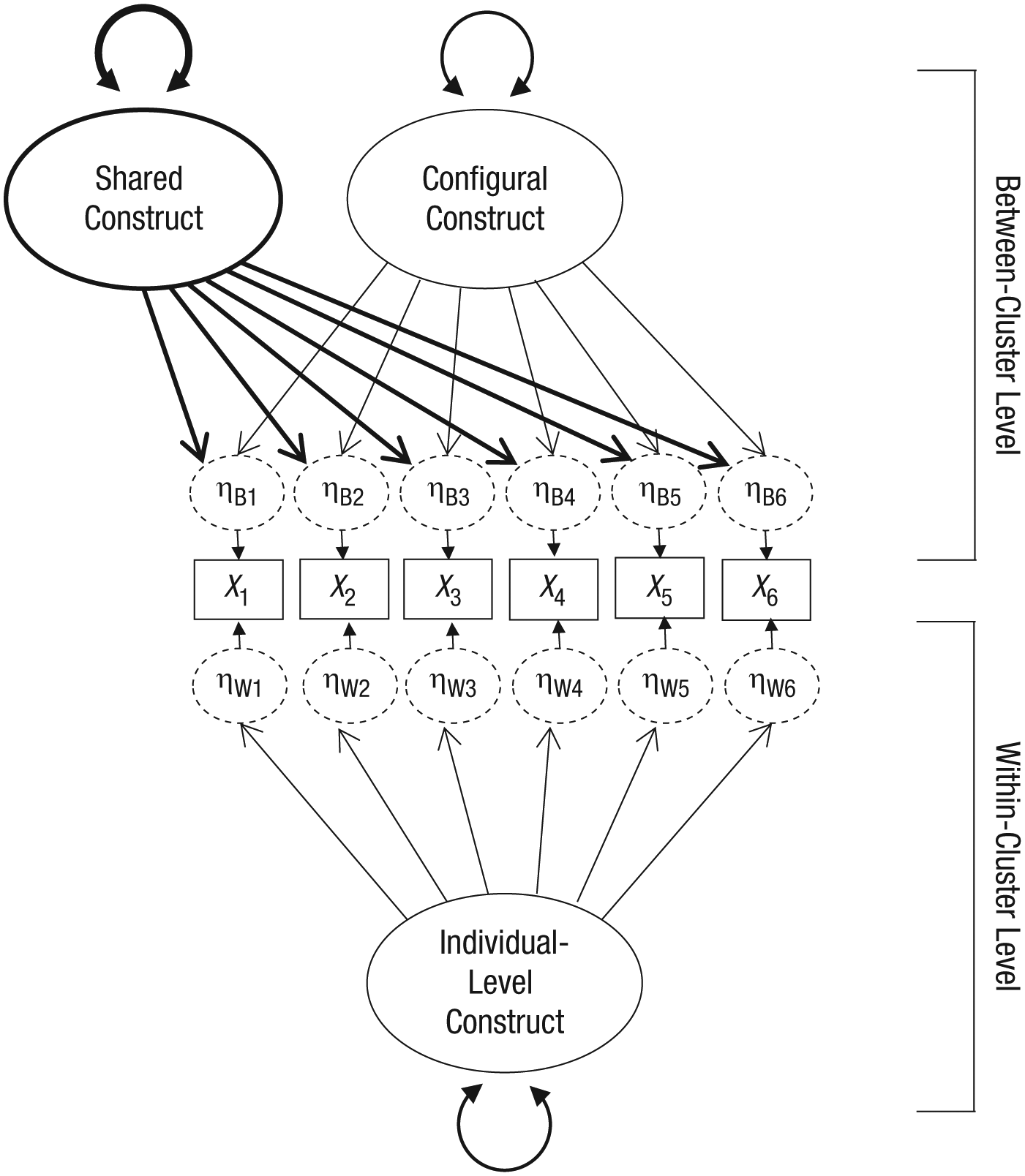
Multilevel model of the hypothetical unidimensional structure in Figure 1. The model includes an individual-level construct at the within-cluster level (Level 1) and simultaneous shared and configural constructs at the between-cluster level (Level 2). The latent constructs at the within-cluster and between-cluster levels both have freely estimated disturbance terms, although they are not shown in the figure. A given item’s factor loadings on the individual factor and the configural factor are constrained to be equal.
Unfortunately, this model is not straightforward to parameterize in current software and is not specified in detail in Stapleton et al. (2016). As just noted, a proper specification of this model must place constraints on a given item’s loadings on the individual factor measured at Level 1 and the configural factor measured at Level 2. Specifically, these loadings must be constrained to be equal, and even with these constraints, the model is locally underidentified: One cannot estimate the variances of the configural and shared factors at the between-cluster level using the same set of item responses. Identification in latent-variable models refers to whether there is sufficient information in the data (e.g., sample covariance matrix) to estimate the parameters in the model (Loehlin, 2003). A very simple example is the equation a + b = 5, which is referred to as underidentified because there is not enough information (the single value, 5) to inform the two parameters to be estimated. An infinite set of a and b values would satisfy the equation (e.g., –2 and 7, 4 and 1, 1.8 and 3.2). Alternately, if a second piece of information, such as a/b = 4, is added, the solution becomes identified, because only one set of values (4 and 1) satisfies the two equations. In the simultaneous shared-and-configural factor model we have just introduced, there is a local underidentification problem because for all of the equations for the implied between-cluster covariance matrix, the variances for both the configural and the shared factors are unknown elements, as detailed in Appendix A. Given any solution for the parameter set, a change in the estimated variance of the configural factor would simply result in a multiplicative shift in the parameter estimates related to the shared construct and an additive shift in the estimated residual variances. Therefore, there are nearly infinite possibilities for the set of parameter estimates. (A general discussion of this issue is provided in Hancock, Stapleton, & Arnold-Berkovits, 2009.) In order to identify the solution, two options are possible. One is to include additional Level 2 information in the model (e.g., crime rates of the neighborhood as an additional item loading on the shared factor at Level 2).
In the absence of additional available measures at Level 2, the model can instead be identified by fixing one of the parameters in the model. As a creative solution, we propose placing a constraint on one factor’s variance. Specifically, a researcher could assume a value of the intraclass correlation (ICC) of the individual-level construct, that is, the proportion of variance in that construct that is found at the cluster level. The ICC, also called ICC(1) by Shrout and Fleiss (1979), for an item response is calculated as follows:
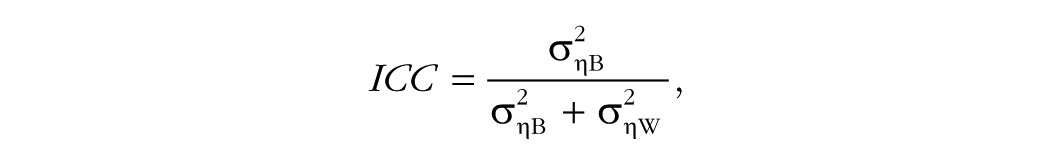
where
We demonstrate this process in our empirical example at the end of this article. Specifically, we demonstrate the modeling required to examine the structure of a hypothesized shared construct at the cluster level when one has item responses from individuals who are nested within clusters. In our example of sets of students rating multiple teachers for how engaging their teaching is, we expected the students to all be isomorphic raters of the unit of interest: the teacher. If there was any within-cluster item covariance, it would suggest that an individual-level construct other than engaging teaching was also being measured. Prior to walking through this empirical example, though, we demonstrate via simulation why the proposed model shown in Figure 3 (i.e., specifying both a shared and a configural construct at Level 2) is preferable to the approach shown in Figure 2 (i.e., specifying only a configural construct at Level 2).
Simulation Demonstration
To demonstrate the different results obtained from these two modeling approaches, we conducted a small simulation. Specifically, we tested the fit of an unconstrained model (Fig. 2) and a shared-and-configural model (Fig. 3) of item responses collected at the individual level. We generated data for five items within each cluster. The responses of individuals within a cluster were based on an individual characteristic (e.g., tolerance for unsafe things in a neighborhood). In addition, we made the average of this individual characteristic differ across clusters (e.g., respondents in some clusters tended to be more tolerant, on average, than respondents in other clusters). Under some conditions of the simulation, we also included a shared construct (e.g., neighborhood safety) that affected the responses of individuals within a cluster. The data-generation model was as shown in Figure 3, with the standardized loadings for the individual-level factor and the cluster-level configural factor equal to .7. When the shared factor was present, its standardized loadings were .4. The ICC of the individual-level latent variable was .5 (the variance of the configural factor was equal to the variance of the within-cluster factor). We generated item responses for 20 individuals in each cluster, and we generated data for 50, 100, 200, and 300 clusters in each condition.
Once we generated item responses, we imposed several models utilizing maximum likelihood estimation, as shown in the simple diagrams in Figure 4. Model 1, a configural model, hypothesized that there was no shared construct and that differences in responses at the cluster level were solely due to differences in the individuals that made up the different clusters. For a given item, the loading was constrained to be the same at the individual and cluster levels, and the item’s residual variance at the cluster level was constrained to 0. In this model, the variance of the factors at each level was freely estimated, and thus the ICC of the individual-level construct was estimated (indicated by an asterisk in the figure and later in Tables 1 and 2). In Model 2, an unconstrained model, the cluster-level construct was assumed to be different from the individual-level construct, and therefore no cross-level constraints were placed on the loadings. This model implicitly assumed an ICC of 0 for the individual-level construct. Models 3 through 6 were versions of a simultaneous shared-and-configural model, each with a different assumed ICC for the individual-level factor. The cluster-level variance of the configural factor was constrained to be a specific proportion of the individual-level factor variance, so as to result in the specific ICC values that are listed. The data-generation and model-analysis process was replicated 500 times. 1
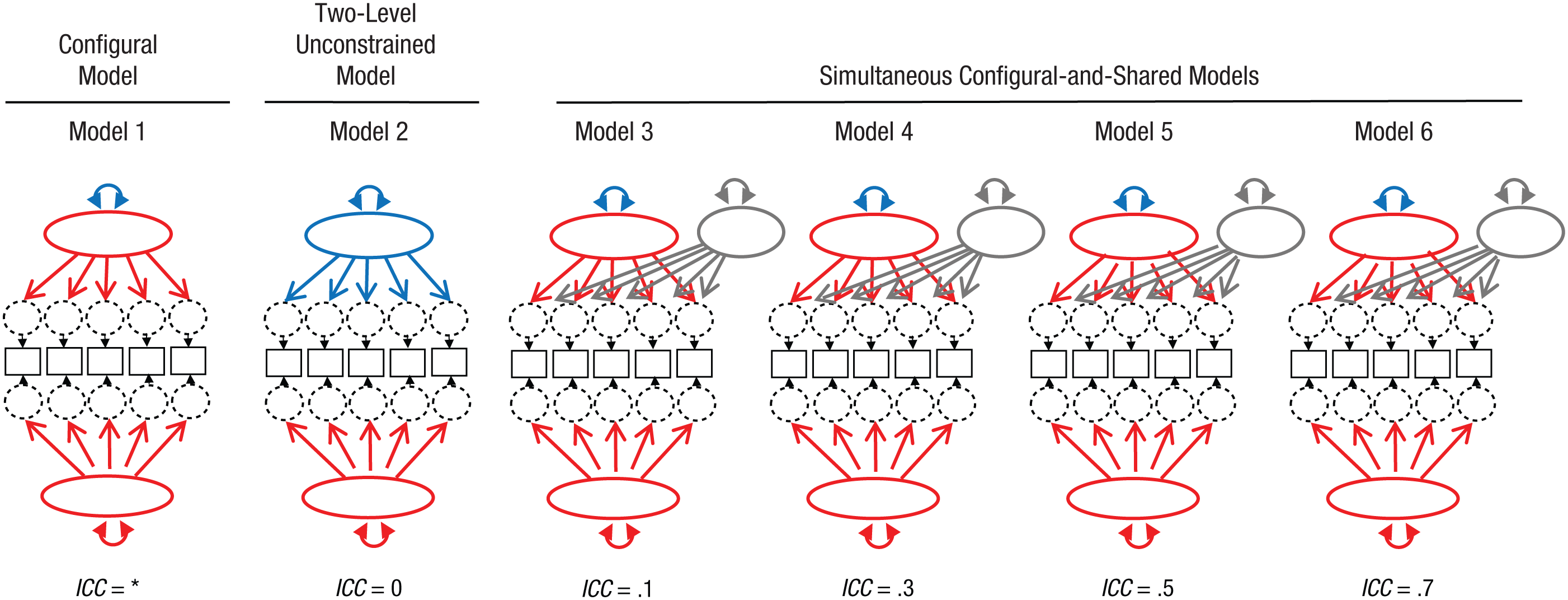
The models evaluated in the simulation demonstration. Corresponding paths shown in the same color were constrained to be equal. For example, in the configural model, all the arrows are red because the factor loadings of corresponding items were constrained to be equal. In the two-level unconstrained model, the arrows at the individual level are red and the arrows at the cluster level are blue because the factor loadings of corresponding items were unconstrained. The blue double-headed arrows represent cluster-level variance of the configural factor, which was freely estimated. (In the case of Model 2, unless the intraclass correlation coefficient is 0, the blue double-headed arrow represents the variance of a confound of the true configural and shared factors.) Gray arrows and ovals represent the shared factor.
Simulation Results: Model-Rejection Rates by Condition
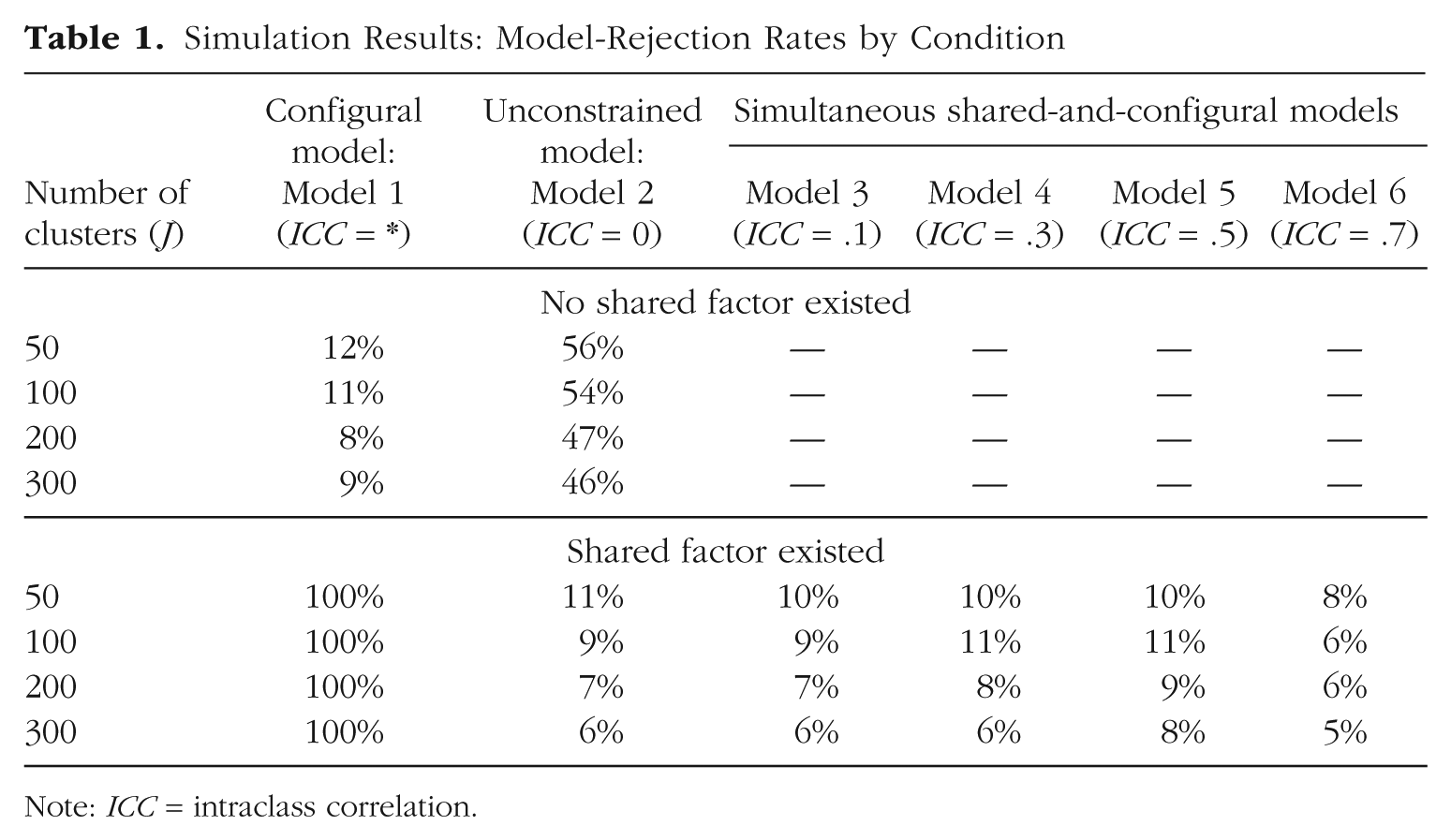
Note: ICC = intraclass correlation.
Simulation Results: Average Estimated Construct Reliability of the Cluster-Level Shared Factor When Items Measured a Shared Factor
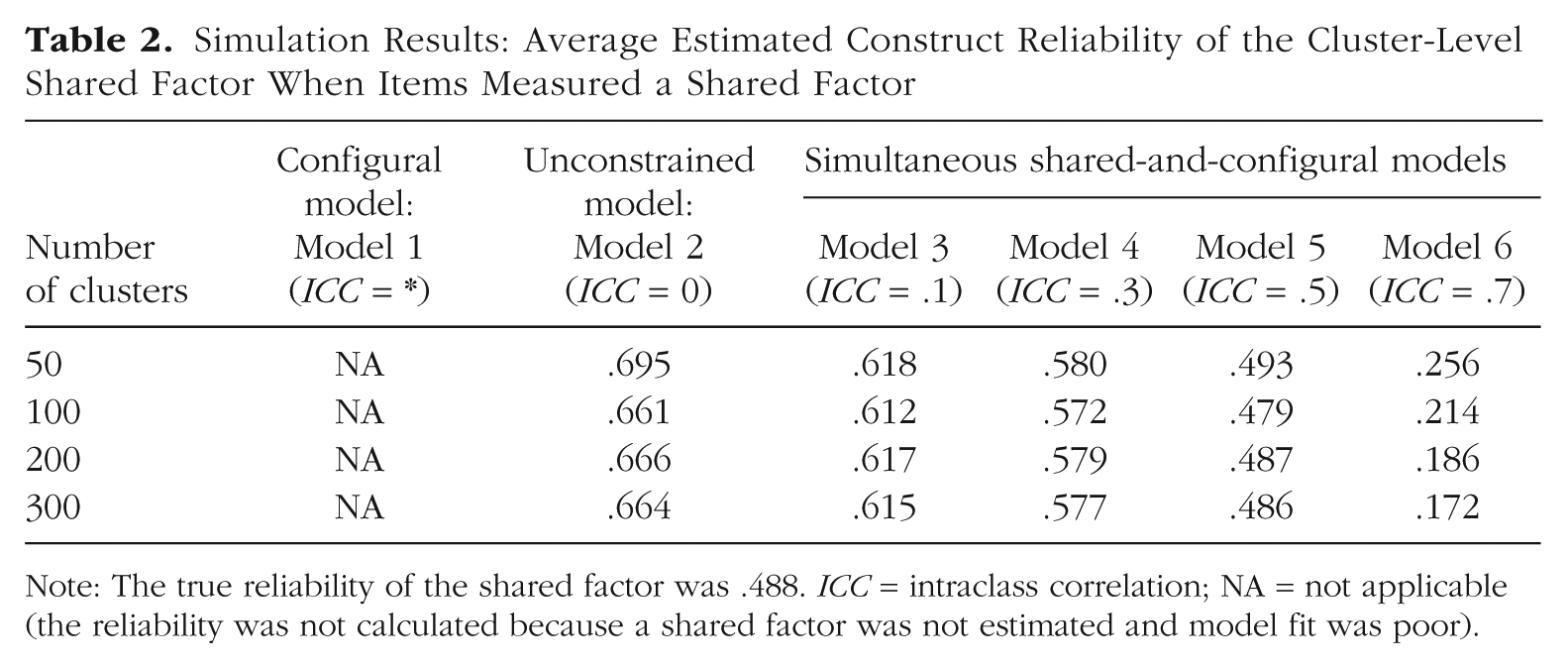
Note: The true reliability of the shared factor was .488. ICC = intraclass correlation; NA = not applicable (the reliability was not calculated because a shared factor was not estimated and model fit was poor).
Note that when no true shared construct existed and the between-cluster differences in item responses were solely due to individual differences of the people in the clusters, Model 1 was the correct model. In the case of the neighborhood-safety example, this situation might occur if all five items asked the individual about his or her level of tolerance for unsafe conditions but did not ask about conditions of the neighborhood specifically. In conditions with a true shared construct (e.g., if the items asked about the safety of the neighborhood itself and not just the individual’s tolerance), Model 1 was expected to have poor fit. Model 5 was the correct model in those cases, but given the equivalencies in the models, the data would not point to this; Models 2 through 6 were expected to fit approximately equally.
Table 1 shows the rates of model rejection, based on the χ2 test at α = .05. When the items did not measure a shared factor, none of the simultaneous shared-and-configural models (Models 3–6) converged, as was expected given that there was no between-cluster covariance to be modeled above that explained by the configural model. The unconstrained model (Model 2) was often rejected given that it was more complex than needed. Estimating five cluster-level residual variances and four cluster-level loadings used unnecessary degrees of freedom, and the χ2 test criterion was lowered so that small deviations in fit resulted in a significant departure from good fit. The configural model, Model 1, was expected to fit well (because it was the data-generation model in this case), and it did fit well in general, although it was rejected more often than it should have been given the nominal α level. As the number of clusters increased, the model-rejection rate grew more appropriate; this is typical of multilevel structural equation models with maximum likelihood estimation (Hox & Maas, 2001).
When the data generation included a shared factor having an effect on item responses, the configural model was rejected in 100% of the replications, as it should have been; this model hypothesized no additional influence on item responses outside of the individual characteristic. The model-rejection results indicated that Models 2 through 6 were equally plausible, on average, across the replications. There was nothing in the data that could distinguish the fit of these models. The researcher would be left to rely on theory regarding which one might be most plausible.
We also used the models’ parameter estimates to calculate the construct reliability of the shared factor. Suppose that a researcher were interested in evidence of the quality of his or her instrument as a measure of a cluster-level attribute (e.g., neighborhood safety). Construct reliability is one measure that could be used. Table 2 shows the construct reliability estimates for the simulation conditions in which a true shared construct existed and was measured by the items. Clearly, the reliabilities differed considerably depending on the assumed value of the ICC of the individual-level construct. In the unconstrained model assuming that the individual-level construct did not differ, on average, across clusters (ICC = 0), the construct reliability was fairly high (close to .7). However, this estimate was upwardly biased because it confounded the reliability of the configural factor with that of the shared factor (the true construct reliability based on the data-generation model was .488). Model 5, which correctly assumed an ICC of .5 for the individual-level factor, resulted in construct reliability estimates that hovered around truth. Unfortunately, however, a researcher will never know the true ICC of the individual-level factor. Running several plausible models, as we did in this simulation, can provide a range of possible reliability estimates.
We believe that this simulation demonstration provides clarity on the issues concerning how to select a multilevel CFA to validate questionnaire items that are intended to measure a cluster-level characteristic. On the basis of these findings, we propose a set of best-practice steps for this modeling process and provide a flowchart of these steps in Figure 5. The first step is to determine the type of construct that is hypothesized to underlie the item responses. Once that is determined, the set of models to run is defined.
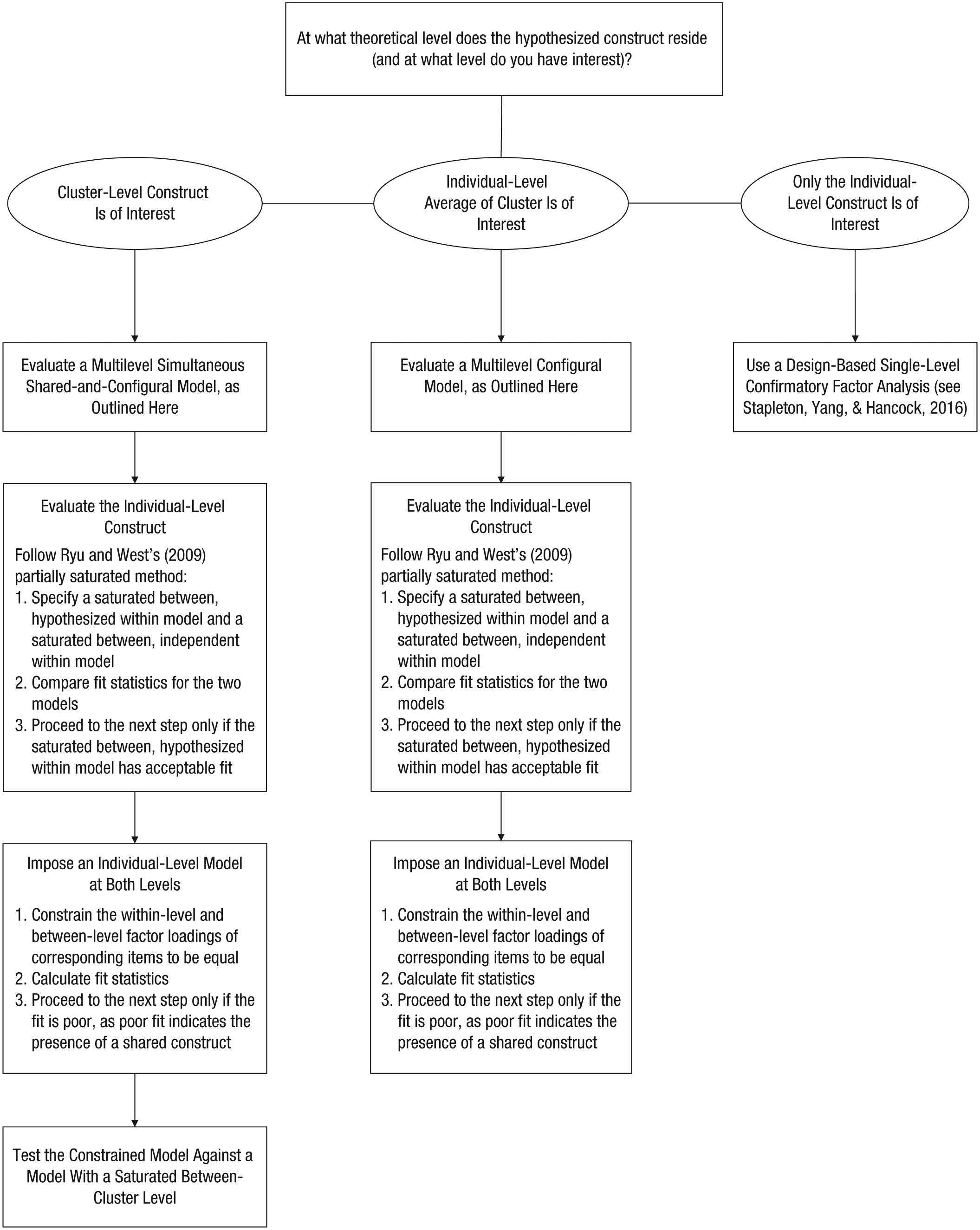
Flowchart of the proposed modeling approaches. The recommended steps depend on the type of construct that is of interest: a cluster-level construct (leftmost path), the individual-level average of a construct within clusters (middle path), or an individual-level construct (rightmost path). For a more complete discussion of specifying saturated models at the within-cluster and between-cluster levels, see Ryu and West (2009).
Illustrative Example
We now turn to demonstrating the process of conducting multilevel CFA when a cluster-level shared construct is of primary interest. We do so by applying the steps on the left side of the flowchart in Figure 5 to an empirical data set concerning evaluations of mathematics teachers. We present three analyses: a unidimensional multilevel CFA treating the cluster-level construct as simply a reflection of the individual-level construct (a configural construct), a model (often seen in the literature but one that we do not endorse) in which the parameters associated with the factor at Level 2 are freely estimated and not constrained to be related to the corresponding parameters at Level 1, and a multilevel CFA with two Level 2 factors partitioning the covariance at the between-cluster level into a configural construct and a shared construct. We demonstrate the implementation of model specification, comparison, and interpretation. Further, we explore factor reliabilities and the relation between factor scores and sum scores to highlight how a composite score (e.g., an average or summative score based on individual responses) within a cluster may not be the same as the shared-construct score, given that the composite score confounds the configural and shared constructs.
For this example, we used data from the TIMSS Advanced 2015 questionnaire administered to U.S. students (Martin, Mullis, Hooper, Yin, et al., 2016; Mullis, Martin, Foy, & Hooper, 2016). We selected six items to measure the cluster-level construct Engaging Teaching. The items, along with their codes, are provided in Table 3. Despite the fact that the questionnaire was administered according to a complex sampling design so as to provide nationally representative data from 12th-grade students who had ever enrolled in advanced math courses (LaRoche & Foy, 2016), we considered only classroom clustering in our analyses for simplicity. We return to the issue of modeling data obtained using complex sampling designs in the Discussion section. The original sample contained 2,954 respondents, 31 of whom failed to provide data on any of the six items. Thus, the final sample for our analyses consisted of 2,923 students. Models were estimated using a maximum likelihood estimator with robust standard errors, and full information maximum likelihood (FIML) was used to account for missing data (for more on methods for handling missing data, see Enders, 2010, 2013). 2 Item-level frequency distributions and item-level ICCs are presented in Table 4.
Codes and Text for the Items Used in the Empirical Example (From Martin, Mullis, Hooper, Yin, et al., 2016)
Response Distributions and Intraclass Correlations (ICCs) for the Items Used in the Empirical Example
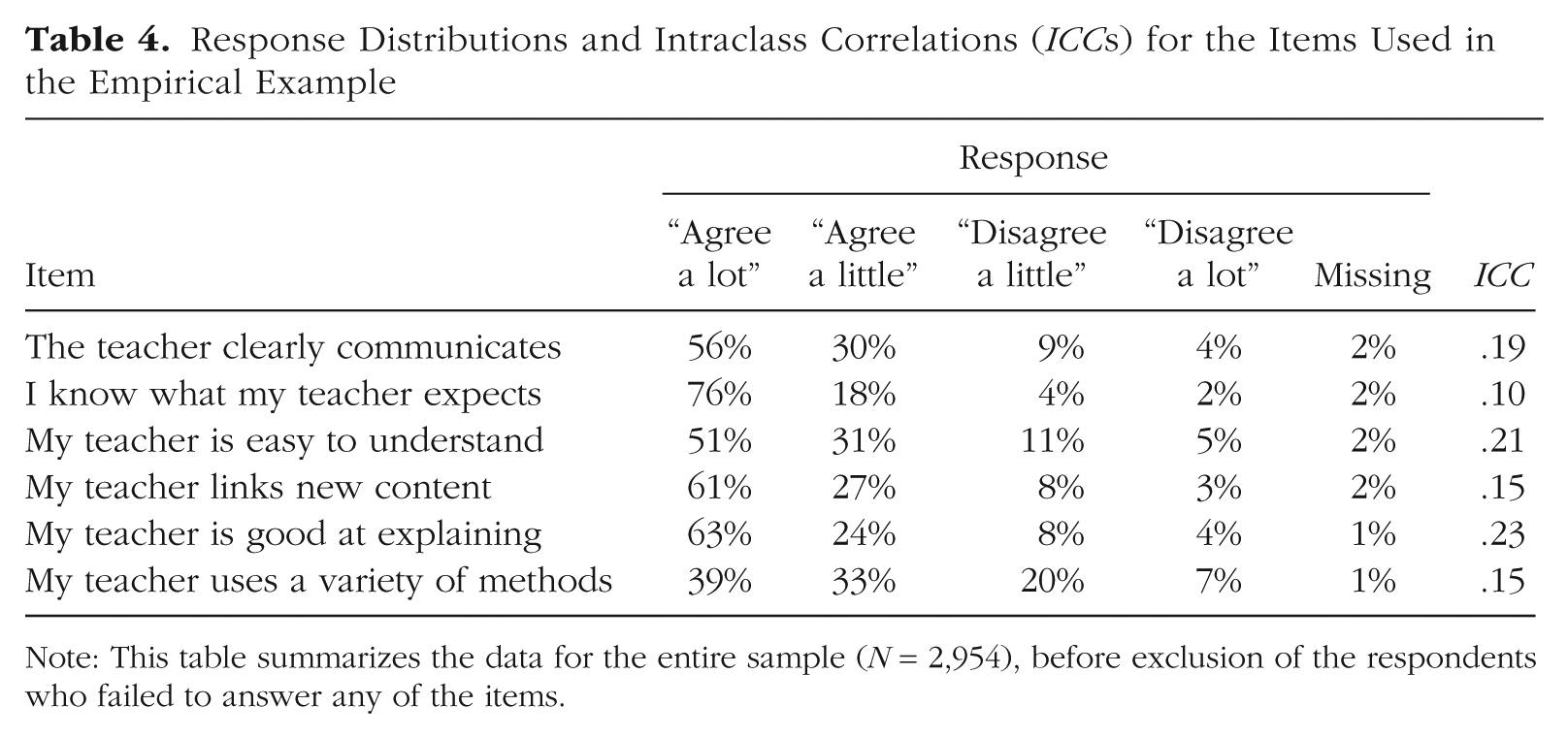
Note: This table summarizes the data for the entire sample (N = 2,954), before exclusion of the respondents who failed to answer any of the items.
Prior to beginning any analyses, we had to consider what the constructs at each level might represent. For example, at Level 1, why would item responses be expected to differ among individuals within a cluster? Given that each student in a cluster was exposed to the same stimulus (i.e., the same instructor), within-cluster variability of the responses did not reflect varying characteristics of the instructor; rather, within-cluster variability reflected attributes of the raters. Perhaps some students exhibited more acquiescence bias, or “yea saying,” than others (Krosnick, 1991). Thus, we needed to define this hypothesized within-cluster construct, Acquiescence. Note that individual-level constructs may represent a range of possible nuisance characteristics or conditions, and we merely posited students’ Acquiescence as one possible construct. At the cluster level, we of course hypothesized the existence of an instructor characteristic, Engaging Teaching, that might differ across clusters. We interpreted the Level 2 configural construct of Acquiescence as representing possible between-classroom differences in students’ average level of acquiescence.
In the first analysis, we treated the cluster-level construct as simply a reflection of the individual-level construct. In this configural model (see Model 1 in Fig. 4; note that we connect this discussion with the models depicted in Fig. 4, although some of the specific values are not the same), we hypothesized that Level 1 Acquiescence differed across students within a classroom and that the cluster average of Acquiescence was measured at Level 2. We constrained the factor loadings at the between-cluster level to be equal to the factor loadings at the within-cluster level, and residual variances at the between-cluster level were constrained to be 0. 3 In our second analysis, we used an unconstrained model (see Model 2 in Fig. 4), which allowed both the factor loadings and the residual variances at the between-cluster level to be freely estimated. We considered this model to likely be incorrect because it confounded the reflective configural construct with any true shared construct at Level 2; however, we include this model in our discussion here because it is commonly used in practice and we want to highlight the assumption made when running it. Specifically, this model assumes that the ICC for the Level 1 construct, Acquiescence in this example, is 0; all clusters have the same value for average Acquiescence. The final models that we estimated were shared-and-configural models (see Fig. 3 and Models 3–6 in Fig. 4), wherein we modeled two constructs at Level 2: the average of the Level 1 construct (configural) and the Level 2 characteristic (shared). In this context, we were estimating the tendency to acquiesce among individuals at the within-cluster level (and the average of that tendency at Level 2), as well as the instructor characteristic of Engaging Teaching.
Model-fit statistics for all the models are provided in Table 5. As presented in the flowchart (Fig. 5), we started by assessing the fit of the individual-level construct, utilizing the comparative fit index (CFI) and the root mean square error of approximation (RMSEA) from the partially saturated model (Ryu & West, 2009). This assessment involved specifying the model with a saturated cluster-level structure and imposing the hypothesized construct at the individual level (note that the null model used in the CFI calculation was specified with a saturated cluster-level structure and an independence structure at the individual level). The fit of the partially saturated model was satisfactory (CFI = 0.99, RMSEA = 0.05), according to popular conventions (see Hu & Bentler, 1999). This result indicated that the hypothesized individual-level construct was adequately specified.
Results for the Empirical Example: Model Fit for the Engaging Teaching Construct (n = 2,923)
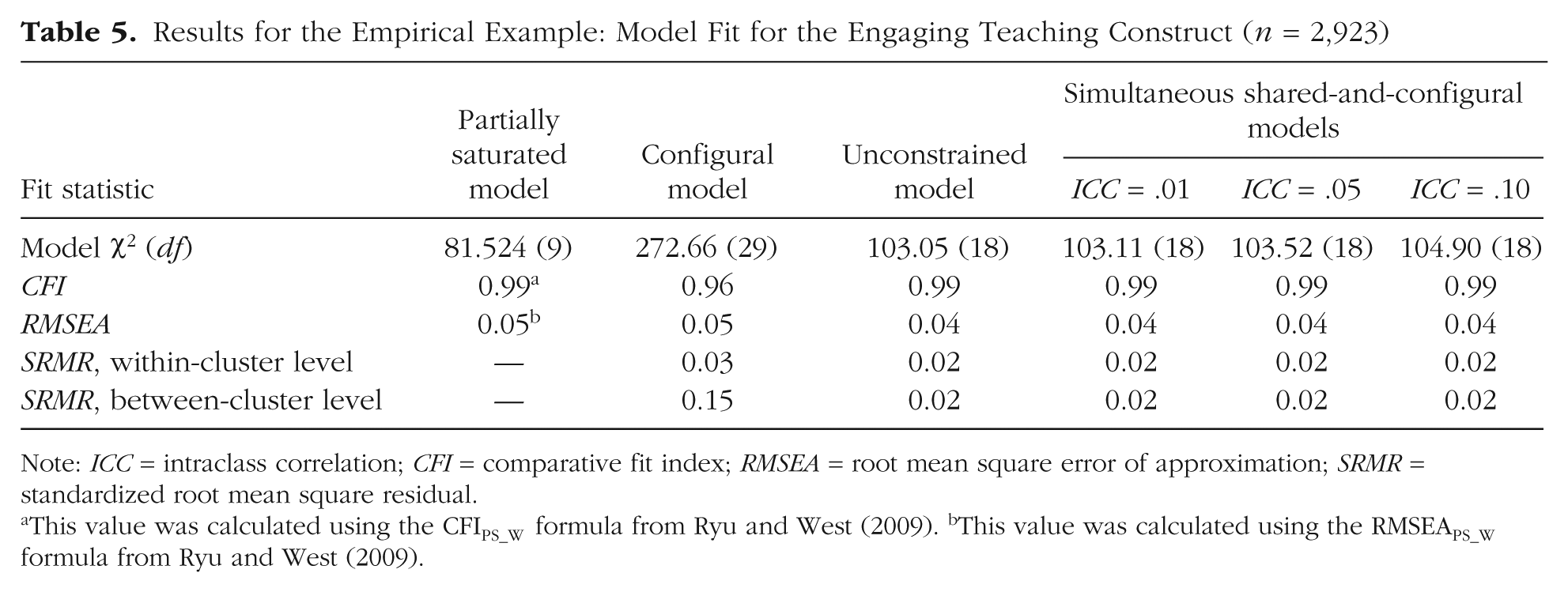
Note: ICC = intraclass correlation; CFI = comparative fit index; RMSEA = root mean square error of approximation; SRMR = standardized root mean square residual.
This value was calculated using the CFIPS_W formula from Ryu and West (2009). bThis value was calculated using the RMSEAPS_W formula from Ryu and West (2009).
Next, we imposed the configural factor structure at the cluster level. The configural model yielded acceptable fit according to the RMSEA (RMSEA = 0.05) and the standardized root mean square residual at the within-cluster level (SRMR = 0.03); however, the fit at the between-cluster level was quite poor (SRMR = 0.15). This model assumed that the items’ cluster-level averages covaried only because of differences in the average level of the Level 1 construct—clearly a problematic assumption given that the target of the items was a Level 2 construct. In other words, our theory indicates that the covariance among items at Level 2 should be explained by both a shared teaching factor and a configural factor representing aggregated individual differences because the teaching factor was measured at the individual level. The poor fit of this model is a good sign that the items measured an additional construct at the cluster level.
When researchers find that the fit of this constrained, configural, model is poor, they often turn to releasing the loading constraints and freeing the estimation of the residual error variance at the cluster level. To be clear, this practice rests on the implicit assumption that the ICC of the Level 1 factor (Acquiescence, in this case) is 0. This unconstrained model provided an improvement in the fit at the between-cluster level (SRMR = 0.02) and was statistically significantly better in overall model fit (Δ in scaled χ2 = 204.69, df = 11). Considering the improvement in fit at the between-cluster level, a researcher might be tempted to select the unconstrained model as the final model; however, as discussed previously, we consider this model to be potentially inappropriate because it possibly confounds the average of the individual-level construct and a true cluster-level shared characteristic. To consider the Level 2 factor as representing Engaging Teaching, this model assumes that the average level of Acquiescence is equivalent across all classrooms. However, given that acquiescence has been found to differ by gender in adolescents (Hamilton, 1968; Watkins & Cheung, 1995), it is likely that classrooms with proportionately more girls may have had higher levels of average Acquiescence.
Next, as a type of sensitivity test, we fit a series of two-factor, shared-and-configural models with the individual-level factor ICCs fixed at a range of reasonable values. (Note that the unconstrained model can be seen as a shared-and-configural model in which the ICC of the configural construct, Acquiescence, is fixed to 0.) In the shared-and-configural models, the factor loadings for the configural construct at the between-cluster level were fixed to be equal to the loadings at the within-cluster level (as shown in Fig. 3), and the loadings for the shared construct at the between-cluster level and the item residual variances at the between-cluster level were freely estimated. One way to identify a shared-and-configural model is to specify the ICC of the individual-level factor, that is, to not estimate the variance of the configural construct at the between-cluster level and instead to constrain that value to a fixed proportion of the variance of the individual-level factor at the within-cluster level. Here, we discuss models with three different assumed ICC values for the individual-level construct: .01, .05, and .10 (code for a two-factor, shared-and-configural model with the ICC fixed to .05 is given in Appendix B). Models with ICC values of .15 and higher were not supported by the data because they produced convergence problems in estimation; therefore, we do not provide results for these models.
As shown in Table 5, the shared-and-configural models were equivalent or nearly equivalent to one another and to the unconstrained model. Thus, model-fit statistics did not provide a rationale for selecting one model over another (MacCallum, Wegener, Uchino, & Fabrigar, 1993). Once we determined that the shared-and-configural models yielded adequate fit (e.g., RMSEA = 0.04, SRMR = 0.02), we proceeded to evaluate their substantive interpretation, reliability, and parameter estimates. Though we deem the unconstrained model to be an incorrect model specification, because we believe it does not accurately represent the theorized presence of a true shared construct of Engaging Teaching at the between-cluster level, we include this model in our discussion in order to provide a comparison to the appropriate shared-and-configural models.
In Table 6, the standardized loadings (standardized within level) and the composite reliability for the cluster-level constructs are presented for the shared-and-configural and unconstrained models. In the unconstrained model, which assumed no cluster-level differences in the construct of Acquiescence, the standardized loadings were extremely high, save for the item that queried students about the instructor’s use of a variety of teaching methods. In the shared-and-configural models, the composite reliability of the shared factor decreased with higher values of the fixed ICC, and the highest composite reliability, associated with the model with ICC equal to .01, was just slightly higher than that of the unconstrained model, which assumed an ICC of 0 (ω = 0.976). This effect occurred because the variance was partitioned away from the hypothesized shared construct and toward the reflective construct as the value of the ICC increased. Note also that the magnitude of the standardized loadings for the shared factor of the shared-and-configural models decreased rather substantially with increasing value of the ICC (e.g., the loading for the item asking about the instructor’s clarity decreased from .972 to .809 as the ICC increased from .01 to .10). The composite reliability at the cluster level remained quite high for the shared construct because of near-zero cluster-level residual variances (see Geldhof, Preacher, & Zyphur, 2014). As more variance was attributed to the configural factor, its standardized loadings increased along with its composite reliability.
Results for the Empirical Example: Standardized Loadings and Reliabilities of the Constructs at the Between-Cluster Level in the Unconstrained Model and the Simultaneous Shared-and-Configural Models (n = 2,923)
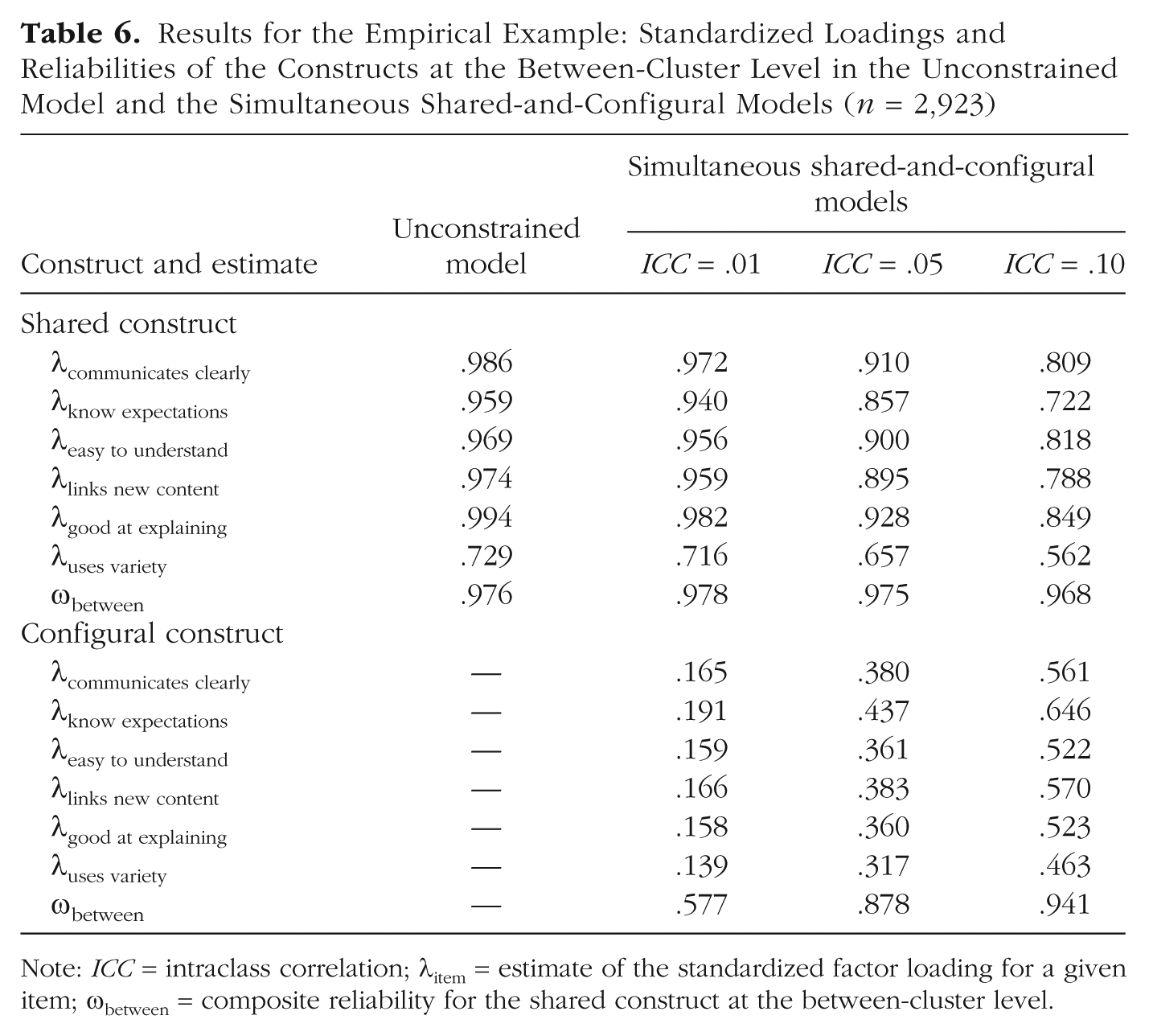
Note: ICC = intraclass correlation; λitem = estimate of the standardized factor loading for a given item; ωbetween = composite reliability for the shared construct at the between-cluster level.
In concluding our assessment of the shared-and-configural models, we note that we cannot state which of them is the “best” model because that depends on the unknown ICC of the individual-level construct. In general, we recommend reporting results for the range of plausible models, and we hope we have demonstrated that imposing ICC constraints will have corresponding implications for the reliability of measurement of the shared construct. From this demonstration, we hope that it is apparent that the unconstrained and the shared-and-configural models are indistinguishable in terms of fit. Theoretically, however, they differ greatly in that the latter models do not make the assumption that the individual construct has an ICC of 0 across the clusters. Relaxing this assumption allows for more appropriate evaluation of the validity of the cluster-level shared construct.
Finally, we compared the factor scores generated by our shared-and-configural models. Given that a common practice is to use the item sum scores as a proxy for a cluster’s latent variable (e.g., to use the average summed instructor ratings within a cluster to represent a characteristic of the instructor’s instructional skill), we compared item sum scores and factor scores for the shared Engaging Teaching factor. We calculated sum scores without weighting, imputing missing data for respondents with at least one item response using the normal-model approach without rounding (Wu, Jia, & Enders, 2015). Factor scores for the factor at the between-cluster level were calculated using the regression method (missing data were treated using FIML; for more information on construction of factor scores and their use, see McDonald & Burr, 1967, and Skrondal & Laake, 2001). Scatterplots of the scores obtained using the two methods are presented in Figure 6.
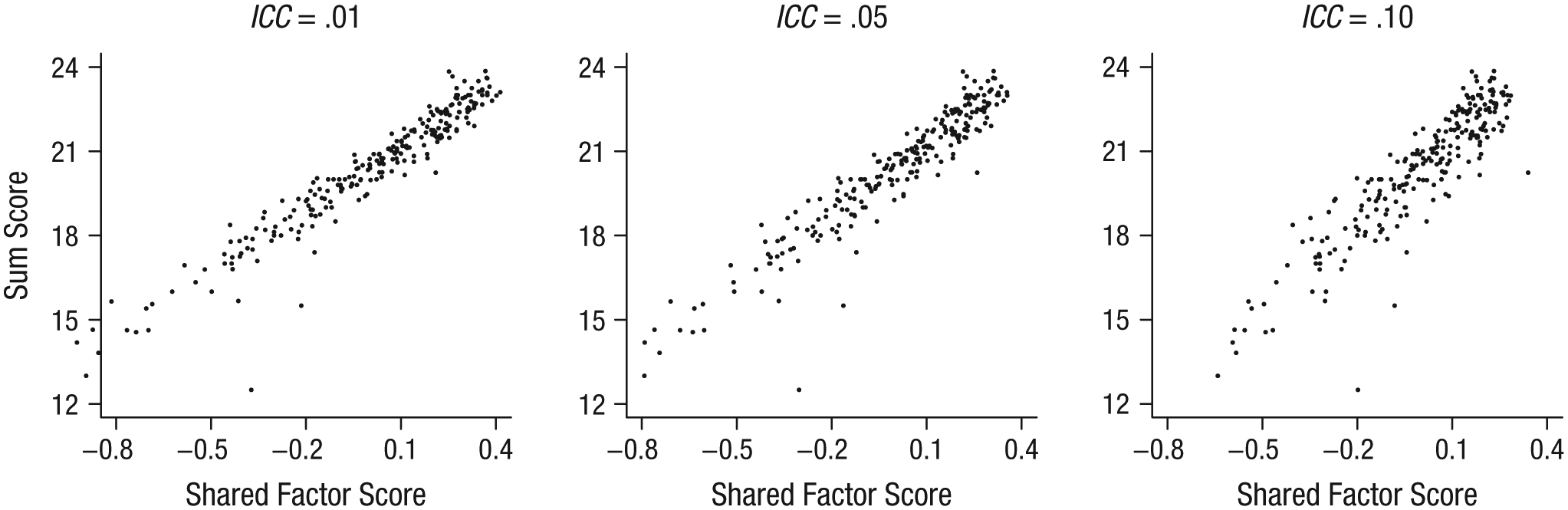
Scatterplots showing the relation between sum scores for engaging teaching and the factor score for the Engaging Teaching shared construct obtained from the shared-and-configural models with different values for the intraclass correlation (ICC) of the individual construct.
The correlation between the sum scores and the shared-factor scores obtained from the parameter estimates ranged from .96 for the assumed ICC of .01 to .91 for the assumed ICC of .10. As the ICC of the individual-level construct increases, the correlation between the sum score and the Level 2 shared-construct score is expected to weaken, given that the sum score contains a confounder: the cluster-level differences on the individual-level factor. In contexts where multiple, fallible raters are used to measure a cluster characteristic and an individual-level response mechanism that may differ across clusters is expected to be operating, sum scores should be used with caution.
Discussion
We hope that we have alerted readers to the need for more careful thought regarding model specification when cluster-level measures are validated. Specifically, the assumptions made in multilevel CFA, as typically specified, must be recognized. We have argued that these assumptions are not appropriate if a shared construct is being measured and have proposed the use of a shared-and-configural model in such cases. That the ICC of the individual-level construct must be fixed to arbitrary values is a limitation of the model that we have advocated. However, given that a range of values can be easily specified, we encourage researchers to report models with a range of assumed ICCs, thus providing plausible lower and upper bounds at the between-cluster level for the standardized loadings on the shared factor and the composite reliability of the shared factor. As we found in our empirical example, the data themselves may suggest upper limits on the possible ICC. In addition, for modeling data with variables related to education, resources such as the Online Intraclass Correlation Database (http://stateva.ci.northwestern.edu/) can be used to determine possible values of ICCs based on a range of achievement measures and grade levels. A possible alternative approach not evaluated in this article is to use additional items, measured at the cluster level and not at the individual level, to identify a model instead of imposing restrictions on the parameter estimates. Such an approach requires thoughtful a priori data collection.
Future research is needed on methods to estimate shared-and-configural models in the presence of data complexities such as missingness, partial nesting, multiple membership, and complex sampling structures. As mentioned earlier, we simplified the analysis in our empirical example by assuming that observations were obtained via a simple random sample of classrooms and a simple random sample of students within selected classrooms, and that nonresponse could be ignored. More typical in national data collection is sampling disproportionately within strata and in multiple stages. Currently, the most flexible latent-variable software to handle these designs for multilevel CFA, incorporating stratification and weighting, are Mplus (see Asparouhov & Muthén, 2006) and Stata (see Rabe-Hesketh & Skrondal, 2006). Examples of multilevel analyses using five frequently used national data sets, and incorporating sampling design elements not discussed here, are available in Stapleton and Kang (2018).
Even given these limitations in our presentation of modeling alternatives, we believe that this work has important implications for validation of cluster-level measurements. Without recognition of the model assumptions that result in a confounding of Level 1 and Level 2 constructs, the work in developing measures for cluster-level characteristics cannot advance.
Footnotes
Appendix A: Population-Level Explanation of Local Underidentification
To better understand the issue of local underidentification, consider a situation in which four items are being used to measure two constructs of interest, as shown in Figure A1. For simplicity, we present this at a single level, but it is representative of the model being imposed on the between-cluster covariance matrix. In this model, there are 14 parameters of interest: eight factor loadings (λ11–λ42), two factor variances (φ11 and φ22), and four residual variances (θ11–θ44). Using path tracing (Loehlin, 2003) for this model, we can enumerate the expected values of the implied covariance matrix as follows:
Given that the configural factor will have its loadings constrained to the values identified for the individual-level factor, we can treat its item loadings as fixed. Additionally, one loading will need to be fixed for scaling purposes for the shared factor (λ12 was chosen for this purpose). These simplifications lead to the following implied covariances, with nine parameters to estimate:
With 10 pieces of information in the sample covariance matrix and only nine parameters to estimate, the situation appears to be overidentified, and it should be possible to find a single best set of parameter estimates. However, note that the variance for the configural factor, φ11, and the variance for the shared factor, φ22, appear in every decomposition. A multiplicative shift in the φ11 estimate would result in a complementary (inverse) multiplicative shift in the φ22 estimate and the estimates of items’ loadings on the second factor. The estimates of residual variances would shift to accommodate any difference in the implied and sample variances. Therefore, the set of possible solutions is nearly infinite (however, negative variance estimates are not possible in most software programs). This identification problem (the global model appears to be overidentified but a part of the model is nonestimable) is referred to as local underidentification.
Appendix B: Sample Mplus Code for the Empirical Example
This appendix presents the Mplus code (Version 8.1; Muthén & Muthén, 2017) for the shared-and-configural model with an intraclass correlation of .05.
Action Editor
Jennifer L. Tackett served as action editor for this article.
Author Contributions
L. M. Stapleton conducted the simulation study; wrote the introduction, the section on the simulation, and the concluding discussion; and coordinated the integration of the manuscript. T. L. Johnson conducted the empirical analyses, wrote the section on the empirical example, and edited the manuscript.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Open Practices
Open Data: no
Open Materials: no
Preregistration: not applicable