
Abstract
Concerns about the veracity of psychological research have been growing. Many findings in psychological science are based on studies with insufficient statistical power and nonrepresentative samples, or may otherwise be limited to specific, ungeneralizable settings or populations. Crowdsourced research, a type of large-scale collaboration in which one or more research projects are conducted across multiple lab sites, offers a pragmatic solution to these and other current methodological challenges. The Psychological Science Accelerator (PSA) is a distributed network of laboratories designed to enable and support crowdsourced research projects. These projects can focus on novel research questions or replicate prior research in large, diverse samples. The PSA’s mission is to accelerate the accumulation of reliable and generalizable evidence in psychological science. Here, we describe the background, structure, principles, procedures, benefits, and challenges of the PSA. In contrast to other crowdsourced research networks, the PSA is ongoing (as opposed to time limited), efficient (in that structures and principles are reused for different projects), decentralized, diverse (in both subjects and researchers), and inclusive (of proposals, contributions, and other relevant input from anyone inside or outside the network). The PSA and other approaches to crowdsourced psychological science will advance understanding of mental processes and behaviors by enabling rigorous research and systematic examination of its generalizability.
Keywords
The Psychological Science Accelerator (PSA) is a distributed network of laboratories designed to enable and support crowdsourced research projects. The PSA’s mission is to accelerate the accumulation of reliable and generalizable evidence in psychological science. Following the example of the Many Labs initiatives (Ebersole et al., 2016; Klein et al., 2014; Klein et al., in press), Chartier (2017) called for psychological scientists to sign up to work together toward a more collaborative way of doing research. The initiative quickly grew into a network with more than 300 data-collection labs, an organized governance structure, and a set of policies for evaluating, preparing, and conducting studies and disseminating research products. Here, we introduce readers to the historical context from which the PSA emerged, the core principles of the PSA, the process by which we pursue our mission in line with these principles, and a short list of likely benefits and challenges of the PSA.
Background
Psychological science has a lofty goal—to describe, explain, and predict mental processes and behaviors. Currently, however, researchers’ ability to meet this goal is constrained by standard practices in conducting research and disseminating research products (Lykken, 1991; Nosek & Bar-Anan, 2012; Nosek, Spies, & Motyl, 2012; Simmons, Nelson, & Simonsohn, 2011). In particular, the composition and insufficient size of typical samples in psychological research introduce uncertainty about the veracity (S. F. Anderson & Maxwell, 2017; Cohen, 1992; Maxwell, 2004) and generalizability (Elwert & Winship, 2014; Henrich, Heine, & Norenzayan, 2010) of findings.
Concerns about the veracity and generalizability of published findings are not new or specific to psychology (Baker, 2016; Ioannidis, 2005), but, in recent years, psychological scientists have engaged in reflection and reform (Nelson, Simmons, & Simonsohn, 2018). As a result, standard methodological and dissemination practices in psychological science have evolved during the past decade. The field has begun to adopt long-recommended changes that can protect against common threats to statistical inference (Motyl et al., 2017), such as flexible data analysis (Simmons et al., 2011) and low statistical power (Button et al., 2013; Cohen, 1962). Psychologists have recognized the need for a greater focus on replication (i.e., conducting an experiment one or more additional times with new samples), using both a high degree of methodological similarity (also called direct or close replication; Brandt et al., 2014; Simons, 2014) and dissimilar methodologies (also called conceptual or distant replications; Crandall & Sherman, 2016). Increasingly, authors are encouraged to consider and explicitly indicate the populations and contexts to which they expect their findings to generalize (Kukull & Ganguli, 2012; Simons, Shoda, & Lindsay, 2017). Researchers are adopting more open scientific practices, such as sharing data, materials, and code to reproduce statistical analyses (Kidwell et al., 2016). These recent developments are moving the research community toward a more collaborative, reliable, and generalizable psychological science (Chartier et al., 2018).
During this period of reform, crowdsourced research projects in which multiple laboratories independently conduct the same study have become more prevalent. An early published example of this kind of crowdsourcing in psychological research, the Emerging Adulthood Measured at Multiple Institutions (EAMMI) project (Reifman & Grahe, 2016), was conducted in 2004. The EAMMI collaborators pooled data collected by undergraduate students in statistics and research-methods courses at 10 different institutions (see also The School Spirit Study Group, 2004). In more recent projects, such as the Many Labs project series (Ebersole et al., 2016; Klein et al., 2014), Many Babies (Frank et al., 2017), the Reproducibility Project: Psychology (Open Science Collaboration, 2015), the Pipeline Project (Schweinsberg et al., 2016), the Human Penguin Project (IJzerman et al., 2018), and Registered Replication Reports (Alogna et al., 2014; O’Donnell et al., 2018; Simons, Holcombe, & Spellman, 2014) research teams from many institutions have contributed to large-scale, geographically distributed data collection. These projects accomplish many of the methodological reforms mentioned earlier, either by design or as a by-product of large-scale collaboration. Indeed, crowdsourced research generally offers a pragmatic solution to four current methodological challenges.
First, crowdsourced research projects can achieve high statistical power by increasing sample size. A major limiting factor for individual researchers is the number of subjects available for a particular study, especially when the study requires in-person participation. Crowdsourced research mitigates this problem by aggregating data from many labs. Aggregation results in larger sample sizes and, as long as the features that might cause variations in effect sizes are well controlled, more precise effect-size estimates than any individual lab is likely to achieve independently. Thus, crowdsourced projects directly address concerns about statistical power within the published psychological literature (e.g., Fraley & Vazire, 2014) and are consistent with recent calls to emphasize meta-analytic thinking across multiple data sets (e.g., Cumming, 2014; LeBel, McCarthy, Earp, Elson, & Vanpaemel, 2018).
Second, to the extent that findings do vary across labs, crowdsourced research provides more information about the generalizability of the tested effects than most psychology research does. Conclusions from any individual instantiation of an effect (e.g., an effect demonstrated in a single study within a single sample at one point in time) are almost always overgeneralized (e.g., Greenwald, Pratkanis, Leippe, & Baumgardner, 1986). Any individual study occurs within an idiosyncratic, indefinite combination of contextual variables, most of which are irrelevant to current theory. Testing an effect across several levels and combinations of such contextual variables (which is a natural by-product of crowdsourcing) adds to knowledge of its generalizability. Further, crowdsourced data collection can allow for estimating effect heterogeneity across contexts and can facilitate the discovery of new psychological mechanisms through exploratory analyses.
Third, crowdsourced research fits naturally with—and benefits significantly from—open scientific practices, as demonstrated by several prominent crowdsourced projects (e.g., the Many Labs projects). Crowdsourced research requires providing many teams access to the experimental materials and procedures needed to complete the same study. This demands greater transparency and documentation of the research workflow. Data from these projects are frequently analyzed by teams at multiple institutions, which requires researchers to take much greater care to document and share data and analyses. Once materials and data are ready to share within a collaborating team, they are also ready to share with the broader community of fellow researchers and consumers of science. This open sharing allows for secondary publications based on insights gleaned from these data sets (e.g., Vadillo, Gold, & Osman, 2018; Van Bavel, Mende-Siedlecki, Brady, & Reinero, 2016).
Finally, crowdsourced research can promote inclusion and diversity within the research community, especially when the research takes place in a globally distributed network. Researchers who lack the resources to independently conduct a large project can contribute to high-quality, impactful research. Similarly, researchers and subjects from all over the world, including people from countries presently underrepresented in the scientific literature, can participate, bringing variation in language, culture, and traditions. In countries where most people do not have access to the Internet, studies administered online can produce inaccurate characterizations of the population (e.g., Batres & Perrett, 2014). For researchers who want to implement studies in countries with limited Internet access, crowdsourced collaborations offer a means of accessing more representative samples by enabling the implementation of in-person studies from a distance.
These inherent features of crowdsourced research can accelerate the accumulation of reliable and generalizable empirical evidence in psychology. However, there are many ways in which crowdsourced research can itself be accelerated, and additional benefits can emerge given the right organizational infrastructure and support. Crowdsourced research, as it has thus far been implemented, has a high barrier to entry because of the resources required to recruit and maintain large collaboration networks. As a result, most of the prominent crowdsourced projects in psychology have been created and led by a small subset of researchers who are connected to the requisite resources and professional networks. This has limited the impact of crowdsourced research to subdomains of psychology that reflect the idiosyncratic interests of the researchers leading these efforts.
Furthermore, even for the select groups of researchers who have managed these large-scale projects, recruitment of collaborators has been inefficient. Teams are formed ad hoc for each project, which requires a great deal of time and effort. Project leaders have often relied on crude methods, such as recruiting from the teams that contributed to their most recent crowdsourced project. This yields teams that are insular, rather than inclusive. Moreover, researchers who “skip” a project risk falling out of the recruitment network for subsequent projects, and thus reducing their opportunities for future involvement. For the reasons we have elaborated, and in order to make crowdsourced research more commonplace in psychology, to promote diversity in crowdsourcing, and to increase the efficiency of large-scale collaborations, we created the PSA.
Core Principles and Organizational Structure
The PSA is a standing, geographically distributed network of psychology laboratories willing to devote some of their research resources to large, multisite, collaborative studies, at their discretion. As described in detail later in this article, the PSA formalizes crowdsourced research by evaluating and selecting proposed projects, refining protocols, assigning them to participating labs, aiding in the ethics approval process, coordinating translation, and overseeing data collection and analysis. Projects supported by the PSA can focus on novel research questions or replicate prior research. Five core principles, which reflect the four Mertonian norms of science (universalism, communalism, disinterestedness, and skepticism; Merton, 1942/1973), guide the PSA, as follows:
The PSA endorses the principle of diversity and inclusion: We work toward diversity and inclusion in every aspect of the PSA’s functioning. Thus, we aim for cultural and geographic diversity among subjects and researchers involved in PSA-supported projects, as well as for a diversity of research topics.
The PSA endorses the principle of decentralized authority: PSA policies and procedures are set by committees in conjunction with the PSA community at large. Members collectively guide the direction of the PSA through the policies they vote for and the projects they support.
The PSA endorses the principle of transparency: The PSA mandates transparent practices in its own policies and procedures, as well as in the projects it supports. All PSA projects must be preregistered: When research is confirmatory, preregistration of hypotheses, methods, and analysis plans is required (e.g., Van ’t Veer & Giner-Sorolla, 2016), and when it is exploratory, an explicit statement must say so. In addition, open data, open code, open materials, and an open-access preprint report of the empirical results are required.
The PSA endorses the principle of rigor: The PSA currently enables, supports, and requires appropriately large samples (Cohen, 1992; Ioannidis, 2005); expert review of a project’s theoretical rationale (Cronbach & Meehl, 1955; LeBel, Berger, Campbell, & Loving, 2017); and vetting of methods by advisors with expertise in measurement and quantitative analysis.
The PSA endorses the principle of openness to criticism: The PSA integrates critical assessment of its policies and research products into its process, requiring extensive review of all projects and annually soliciting external feedback on the organization as a whole.
Based on these five core principles, the PSA employs a broad committee structure to realize its mission (see the appendix for a list of the current committees). In keeping with the principle of decentralized authority, committees make all major PSA and project decisions on the basis of majority vote; the director oversees day-to-day operations and evaluates the functioning and policies of the PSA with respect to the core principles. This structure and the number and focus of committees were decided on by an interim leadership team appointed by the director early in the PSA’s formation. The committees navigate or oversee the necessary steps for completing crowdsourced research, such as selecting studies, making methodological revisions, ensuring that studies are conducted ethically, translating materials, managing and supporting labs as they implement protocols, analyzing and sharing data, writing and publishing manuscripts, and ensuring that people receive credit for their contributions. The operations of the PSA are transparent: Members of the PSA network—including participating data-collection labs, committee members, and any researcher who has opted to join the network—are able to observe and comment at each major decision point.
How the PSA Works
PSA projects undergo a specific step-by-step process, moving from submission and evaluation of a study proposal, through preparation for and implementation of data collection, to analysis and dissemination of research products. This process unfolds in four major phases (see Fig. 1).
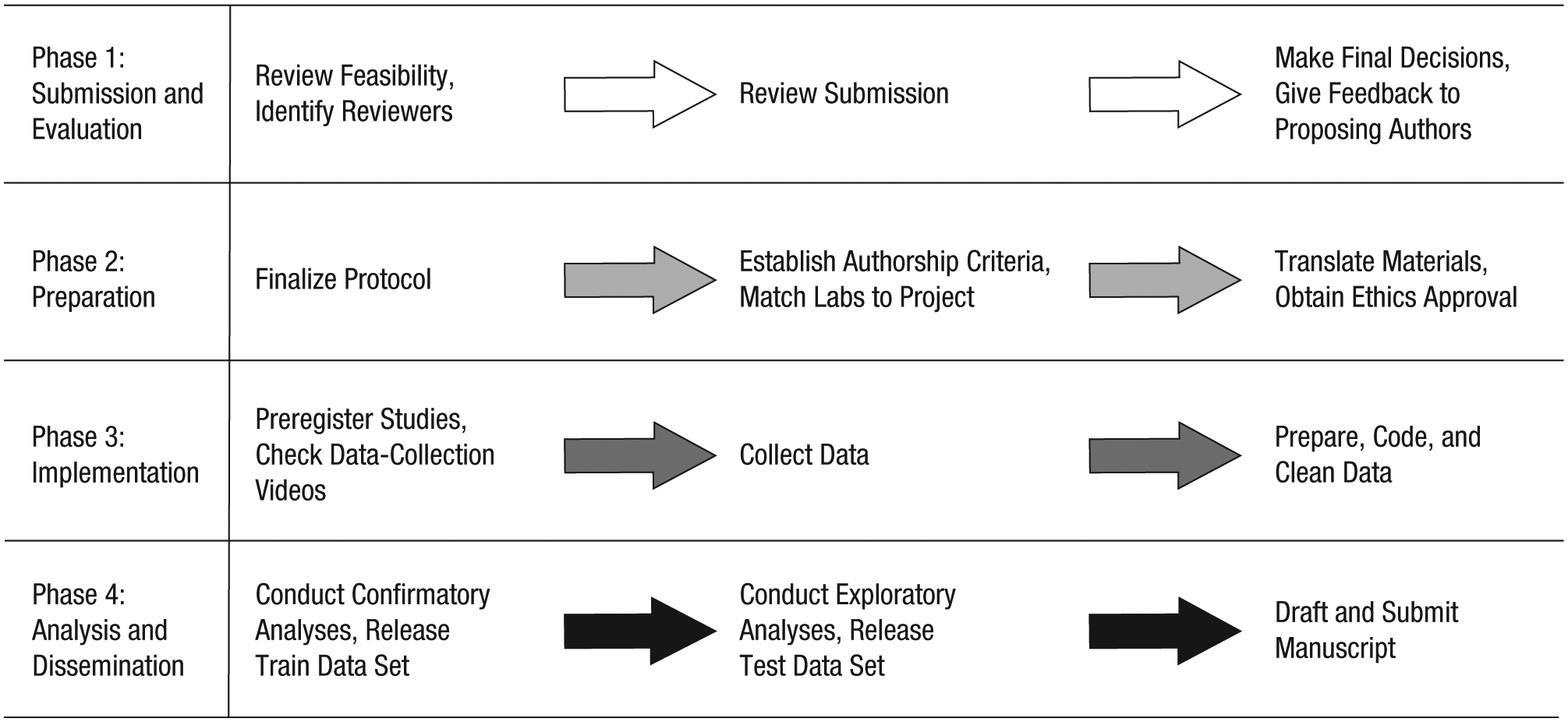
The four major phases of a Psychological Science Accelerator research project.
Phase 1: submission and evaluation
In response to an open call for submissions, proposing authors submit a description of the proposed study’s background, desired subject characteristics, materials, procedures, hypotheses, effect-size estimates, and data-analysis plan, including an analysis script and simulated data when possible. This proposal is much like a Stage 1 manuscript submitted under a Registered Reports model. Submissions are masked and evaluated according to a process overseen by the Study Selection Committee. Members of the network who have proposed a study or are close colleagues of proposing authors recuse themselves from participating in the evaluation not only of that particular proposal but also of all proposals submitted in response to the same call for studies.
The evaluation process includes an initial feasibility check of the methods to gauge whether the PSA could run the proposed project given its currently available data-collection capacity, ethical concerns, and resource constraints; this feasibility check is decided by vote of the Study Selection Committee. Protocols that use, or could be adapted to use, open-source and easily transferable platforms are prioritized. Next, each protocol undergoes peer review by 10 individuals with appropriate expertise: 6 qualified PSA committee members who evaluate specific aspects of the proposal, 2 additional experts within the network, and 2 experts outside the network. These individuals submit brief reviews to the Study Selection Committee, and the director concurrently shares the submission with the full network to solicit feedback and assess network laboratories’ preliminary willingness to participate and ability to collect the data, should the study be selected. The Study Selection Committee votes on final selections on the basis of reviewers’ feedback and evaluations from the PSA network. Selected projects proceed to the next phase. Feedback from the review process is given to all proposing authors. Proposing authors whose projects are not selected may be encouraged to revise their protocols or use another network of team-based psychology researchers (e.g., StudySwap; McCarthy & Chartier, 2017), depending on the feedback received during the review process.
Phase 2: preparation
Next, the Methodology and Data Analysis Committee, whose members are selected on the basis of methodological and statistical expertise, evaluates and suggests revisions of the selected studies to help prepare the protocols for implementation. At least one committee member will work alongside a project’s proposing authors to provide sustained methodological support throughout the planning, implementation, and dissemination stages. The final protocols and analysis plans that emerge from this partnership are shared with the full network for a brief feedback period, after which the proposing authors make any necessary changes.
While the project’s methodology is evaluated and revised, drawing on general guidelines specified by the Authorship Criteria Committee, the proposing authors establish specific authorship criteria to share with all labs in the network who might collect data for the study. Next, the Logistics Committee identifies specific labs willing and able to run the specific protocols, bundling multiple short studies into single laboratory sessions to maximize data-collection efficiency when possible. The Logistics Committee then matches data-collection labs to projects. Not every network lab participates in data collection for every study or study bundle. Rather, the committee selects those willing and able labs that are best suited for a protocol given the sample size needed (derived from power analyses) and each lab’s capacity and technological resources (e.g., access to specific software), and with consideration of needs for geographic and other types of subject and lab diversity. Once data-collection labs have committed to collect data for a specific study, which includes agreeing to the authorship criteria and the proposed timeline for data collection, the Ethics Review Committee oversees the ethical-approval process, helping all the study sites secure this approval. Consideration is given to data sharing during this process. Data-collection labs revise templates of ethics materials as needed for their home institution and submit the revised documents to their local ethics-approval boards for review. Aided by the Translation and Cultural Diversity Committee, the labs translate the study materials as needed; translated materials are back-translated, and then the original translations are revised to rectify any discrepancies (Behling & Law, 2000; Brislin, 1970).
Phase 3: implementation
Implementation is the most time intensive and variable phase. It begins with preregistering the hypotheses and confirmatory or exploratory research questions, the data-collection protocol, and the analysis plan developed in Phase 2; instructional resources and support are provided to the proposing authors as needed by the Project Management Committee. Preregistration of analysis plans, methods, and hypotheses for confirmatory research is a minimum requirement of the PSA. The PSA encourages exploratory research and exploratory analyses, as long as these are transparently reported as such. Proposing authors are encouraged (but not required) to submit a Stage 1 Registered Report to a journal that accepts this format prior to data collection. They are also encouraged to write the analysis script and test it on simulated data when possible. Following preregistration, but prior to initiating data collection, the proposing authors establish and rehearse their data-collection procedures and record a demonstration video, when appropriate, with mock subjects. Each individual data-collection lab establishes its data-collection procedures, guided by the example video, and records a demonstration. In consultation with the proposing authors, the Project Management Committee evaluates these materials and makes decisions about procedural fidelity to ensure cross-site quality. If the committee finds differences across labs, the labs receive feedback and have a chance to respond. Once the Project Management Committee has given approval, the labs collect data.
Phase 4: analysis and dissemination
The proposing authors complete confirmatory data analyses, as described in their preregistration, and then draft the empirical report. They are encouraged to write the manuscript as a dynamic document, for example, using R Markdown. All contributing labs and other authors (e.g., the people involved in designing and implementing the project) are given the opportunity to provide feedback and approve the manuscript, with reasonable lead time prior to its submission for publication. Following the principle of transparency, the PSA prefers that project reports be published in open-access outlets or as open-access articles (i.e., that they are available via gold open access). At a minimum, green open access is required; that is, proposing authors must upload a preprint of their empirical report (i.e., the version of the report submitted for publication) on at least one stable, publicly accessible repository (e.g., PsyArXiv).
When the project is concluded, all materials, data, analytic code, and metadata are anonymized, posted in full, and made public, or made as publicly available as possible given ethical and legal constraints (Meyer, 2018). The Open Science Framework (OSF) is the repository chosen by default, but another independent repository (e.g., Databrary; Gilmore, Kennedy, & Adolph, 2018) may be selected on a case-by-case basis. The data are made available so that other researchers can conduct exploratory and planned secondary analyses. A PSA team is available to review the analysis code, data, and materials after the project is finished. Final responsibility for the project is shared by the PSA and proposing authors. Data releases are staged such that a “train” data set is publicly released quickly after data collection and preparation, and the remaining “test” data set is released several months later (e.g., as in Klein et al., in press). The exact timing of data release and the specific method of splitting the sample (e.g., the percentage of data held, whether and how the sampling procedure will account for clustering) are determined on a case-by-case basis to accommodate the unique goals and data structure of each project (M. L. Anderson & Magruder, 2017; Dwork et al., 2015; Fafchamps & Labonne, 2017). Plans for staged data release are described in a widely disseminated and early public announcement, which includes information about the exact timing. Any researcher can independently use additional cross-validation strategies to reduce the possibility that his or her inferences are based on overfitted models that leverage idiosyncratic features of a particular data set (see Yarkoni & Westfall, 2017). By staging data release, the PSA facilitates robust, transparent, and trustworthy exploratory analyses.
Benefits and Challenges
Our proposal to supplement the typical individual-lab approach with a crowdsourced approach to psychological science might seem utopian. However, teams of psychologists have already succeeded in completing large-scale projects (Ebersole et al., 2016; Grahe et al., 2017; IJzerman et al., 2018; Klein et al., 2014; Leighton, Legate, LePine, Anderson, & Grahe, 2018; Open Science Collaboration, 2015; Reifman & Grahe, 2016; Schweinsberg et al., 2016), thereby demonstrating that crowdsourced research is indeed both practical and generative. Accordingly, since its inception approximately 10 months prior to this writing, the PSA community has steadily grown to include 346 labs, and we have approved three projects that are in various phases of the process described in the previous section. We are cultivating and working to maintain required expertise to capitalize on the benefits and overcome the challenges of our standing-network approach to crowdsourcing research.
Benefits
Although the PSA leverages the same strengths available to other crowdsourced research, its unique features afford additional strengths. First, the PSA reaps benefits above and beyond the resource-sharing benefits of typical crowdsourced research because its standing nature reduces the costs and inefficiency of recruiting new research teams for every project. This lowers the barrier for entry to crowdsourced research and allows more crowdsourced projects to take place.
Second, the size, diversity, and standing nature of the PSA network enables researchers to discover meaningful variation in phenomena that is undetectable in typical samples collected at a single location (e.g., Corker, Donnellan, Kim, Schwartz, & Zamboanga, 2017; Hartshorne & Germine, 2015; Murre, Janssen, Rouw, & Meeter, 2013; Rentfrow, Gosling, & Potter, 2008) or in other typical forms of crowdsourced research. Unlike studies based on meta-analysis and other retrospective methods of synthesizing existing primary research, PSA-supported projects can intentionally introduce and explicitly model methodological and contextual variation (e.g., in time, location, language, and culture). In addition, anyone can use PSA-generated data to make such discoveries on an exploratory or confirmatory basis.
Third, by adopting transparent science practices, including preregistration, open data, open code, and open materials, the PSA maximizes the informational value of its research products (Munafò et al., 2017; Nosek & Bar-Anan, 2012). This results in a large increase in the chances that psychologists can develop formal theories. As a side benefit, the adoption of transparent practices improves the trustworthiness of the products of the PSA and psychological science more broadly (Vazire, 2017). Moreover, because lack of education and information about transparent science practices often impedes their use, the PSA could increase adoption of transparent practices by exposing hundreds of participating researchers to them. Furthermore, by creating a crowdsourcing research community that values open science, we provide a vehicle whereby adherence to recommended scientific practices is increased and perpetuated (see Banks, Rogelberg, Woznyj, Landis, & Rupp, 2016).
Fourth, because of its democratic and distributed research process, the PSA is unlikely to produce research that reflects the errors or biases of an individual. No one person has complete control over how the research questions are selected, the materials are prepared, the protocol and analysis plans are developed, the methods are implemented, the effects are tested, or the findings are reported. For each of these tasks, committees populated with content and methodological experts work with proposing authors to identify methods and practices that lead to high levels of scientific rigor. Furthermore, the PSA’s process facilitates detection and correction of errors. The number of people involved at each stage, the oversight provided by expert committees, and the PSA’s commitment to transparency (e.g., of data, materials, and workflow; Nosek et al., 2012) all increase the likelihood of detecting errors. Driven by our goal to maximize diversity and inclusion of both subjects and scientists, decisions reflect input from varied perspectives. Altogether, the PSA depends on distributed expertise, a model likely to reduce many common mistakes that researchers make during the course of independent projects.
Fifth, the PSA provides an ideal context in which to train early-career psychological scientists, and in which psychological scientists at all career stages can learn about new methodological practices and paradigms. With more than 300 laboratories in our network, the PSA serves as a natural training ground. Early-career researchers contribute to PSA projects by serving on committees, running subjects, and otherwise supporting high-quality projects that have benefited from the expertise of a broad range of scientific constituencies and that reflect the core principles discussed earlier. The PSA demonstrates these core principles and practices to a large number of scientists, including trainees.
Sixth, the PSA provides tools to foster research collaborations in addition to the projects ultimately selected for PSA implementation. For example, anyone within or outside the standing network of labs can use our interactive and searchable map (psysciacc.org/map) to potentially locate collaborators for very specific research questions by geographic region. Because all labs in the network are, in principle, open to multisite collaborations, invitations to collaborate may be more likely to be accepted by labs within the network than by those outside it.
Finally, the PSA provides a unique opportunity for methodological advancement. As a routine part of their work, the methodology and translation committees proactively consider analytic challenges and opportunities presented by crowdsourced research (e.g., assessing cross-site measurement invariance, accounting for heterogeneity across populations, using simulations to assess power). In doing so, the PSA can help researchers identify and question critical assumptions that pertain to measurement reliability and analysis generally and with respect to cross-cultural, large-scale collaborations. As a result, the PSA enables methodological insights and research to the benefit of the PSA and the broader scientific community.
Challenges
The PSA also faces a number of logistic challenges arising from the same features that give the PSA its utility: namely, its decentralized approach, in which all researchers in the network can voice their perspectives, and in which decision making, responsibility, and credit are distributed among a large number of diverse labs. By anticipating specific challenges and enlisting the help of people who have navigated other crowdsourced projects, however, the PSA is well positioned to meet the logistic demands inherent to its functioning.
First, the ability to pool resources from many institutions is a strength of the PSA, but one that comes with a great deal of responsibility. For each of its projects, the PSA draws on resources that could have been spent investigating other ideas. Our study-selection process is meant to mitigate the risks of wasting valuable research resources and appropriately calibrate investment of resources to the potential of research questions. We work to avoid the imperfect calibration of opportunity costs by requiring proposing authors to justify their projects’ required resources, a priori, to the PSA committees and the broader community.
Second, because the PSA is international, it faces theoretical and methodological challenges related to both literal linguistic translations of stimuli and instructions and more general translational issues related to cultural differences. There are a host of assumptions to consider when designing studies to suit culturally diverse samples and when interpreting the final results. We are proactive in addressing these challenges, as members of our Translation and Cultural Diversity Committee and Methodology and Data Analysis Committee have experience with managing these difficulties. However, unforeseen challenges with managing such broad collaborations will still occur. Of course, the PSA was designed for these challenges and is committed to resolving them. We encourage studies that leverage the expertise of our diverse network.
Third, many of the PSA’s unique benefits arise from its diverse and inclusive nature; a major challenge facing the PSA is to achieve diversity and inclusion with our member labs and subject population. As shown in Figure 2, we have recruited large numbers of labs in North America and Europe but far fewer labs in Africa, South America, and Asia. In addition to geographic and cultural diversity, a diverse range of topic expertise is represented in the network and on each committee, in ways that we believe facilitates diversity in the topics that the PSA studies. Maintaining and broadening diversity in expertise and geographic location requires concerted outreach, and entails identifying and eliminating the barriers that have resulted in underrepresentation of labs from some regions, countries, and types of institutions.
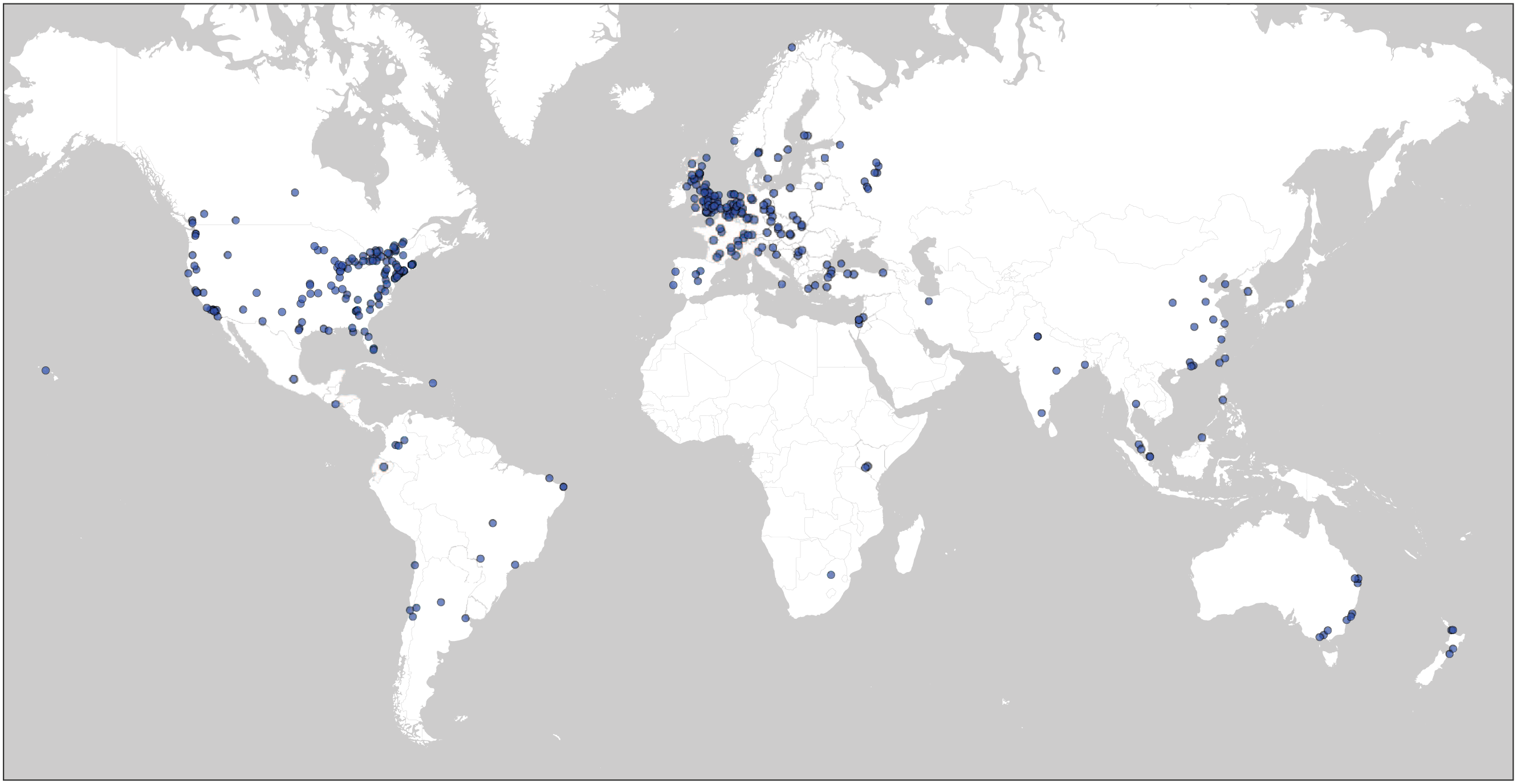
The global network of the Psychological Science Accelerator as of July 2018. At that time, the network consisted of 346 laboratories at 305 institutions in 53 countries.
Fourth, the PSA faces the challenge of protecting the rights of subjects and their data. The Ethics Review Committee oversees the protection of human subjects at every site for every project. Different countries and institutions have different guidelines and requirements for research on human subjects. The PSA is committed to ensuring compliance with ethical principles and guidelines at each collection site, which requires attention and effort from all participating researchers.
Fifth, because the PSA relies on the resources held by participating labs, as is the case with other forms of research and collaboration, the PSA is limited in the studies that it can conduct without external funding. Some types of studies are more difficult for us to support than others (e.g., studies involving small-group interactions or behavioral observation, protocols that require the use of specialized materials or supplies). Currently, the studies we select are limited to those that do not require expensive or uncommon equipment and are otherwise easy to implement across a wide variety of laboratories. As a result, deserving research questions may not be selected by the PSA for feasibility reasons. We actively seek funding to support the organization and expand the range of feasible studies. For now, researchers can apply for and use grant funding to support project implementation via the PSA. There are currently a handful of labs in the network with specialized resources (e.g., functional MRI), and we hope that the network will eventually grow enough to support projects that require such specialized resources (e.g., developmental research that requires eye tracking and research assistants trained to work with young children). Further, we are in the process of forming a new funding committee devoted solely to the pursuit of financial support for the PSA and its member labs.
A final set of challenges for the PSA arises from the inherently collaborative nature of the research that it is intended to support. Coordinating decision making among hundreds of people is difficult. The PSA’s policies and committee structure were designed to facilitate effective communication and efficient decision making, but these systems are subject to revision and adaptation as needed. For example, decision deadlines are established publicly, and can sometimes be extended on request. Moreover, the network’s size is a great advantage because if people, labs, or other individual components of the network are unable to meet commitments or deadlines, the network can proceed either without these contributions or with substituted contributions from others in the network. Another challenge that arises from the collaborative nature of the PSA’s products is awarding credit to the many people involved. Contributions to PSA-affiliated projects are clearly and transparently reported using the CRediT taxonomy (Brand, Allen, Altman, Hlava, & Scott, 2015). Authorship on empirical reports resulting from a PSA project is granted according to predetermined standards established by the proposing authors of the project and differs from project to project. Finally, the collaborative and decentralized structure of the PSA increases the risk that responsibility for discrete research tasks such as error checking becomes too diffuse for any one person to take action. Our committee structure was designed in part to address this concern: Committees comprising small groups of people take responsibility for executing specific tasks, such as translation. These committees implement quality-control procedures, such as back-translation, to increase the probability that when errors occur, they are caught and corrected. Diffusion of responsibility is an ongoing concern that we will continue to monitor and address as our network expands and changes.
In sum, the PSA faces a number of challenges. We believe these are more than offset by its potential benefits. We take a proactive and innovative approach to facing these and any other challenges we encounter by addressing them explicitly through collaboratively developed and transparent policies. By establishing flexible systems to manage the inherent challenges of large-scale, crowdsourced research, the PSA is able to offer unprecedented support for psychological scientists who would like to conduct rigorous research on a global scale.
Conclusion
In a brief period of time, the PSA has assembled a diverse network of globally distributed researchers and subject samples. We have also assembled a team with wide-ranging design and analysis expertise and considerable experience in coordinating multisite collaborations. As a result, the PSA provides the infrastructure needed to accelerate rigorous psychological science. The full value of this initiative will not be known for years or perhaps decades. Individually manageable investments of time, energy, and resources, if distributed across an adequately large collaboration of labs, have the potential to yield important, lasting contributions to the understanding of psychology.
Success in this endeavor is far from certain. However, striving toward collaborative, multilab, and culturally diverse research initiatives like the PSA can allow the field not only to advance understanding of specific phenomena and potentially resolve past disputes in the empirical literature, but also advance methodology and psychological theorizing. We thus call on all researchers with an interest in psychological science, regardless of their discipline or subarea, their geographic location, the extent of their resources, and their career stage, to join us and transform the PSA into a powerful tool for gathering reliable and generalizable evidence about human behavior and mental processes. If you are interested in joining the project, or getting regular updates about our work, please complete our brief Sign-up Form (https://psysciacc.org/get-involved/). Please join us; you are welcome in this collective endeavor.
Footnotes
Appendix
Organizational Structure of the Psychological Science Accelerator (PSA)

| Role and description | Current occupant or occupants |
|---|---|
| Director: The director oversees all operations of the PSA, appoints members of committees, and ensures that the PSA’s activities are directly aligned with its mission and core principles. | Christopher R. Chartier (Ashland University) |
| Leadership Team: This group oversees the development of PSA committees and policy documents. It will soon establish procedures for electing its own members as well as the members of all other PSA committees. | Sau-Chin Chen (Tzu-Chi University), Lisa M. DeBruine (University of Glasgow), Charles R. Ebersole (University of Virginia), Hans IJzerman (Université Grenoble Alpes), Steve M. J. Janssen (University of Nottingham Malaysia Campus), Melissa Kline (Massachusetts Institute of Technology), Darko Loncˇarić (University of Rijeka), Heather L. Urry (Tufts University) |
| Study Selection Committee: This committee reviews study submissions and selects which proposals will be pursued by the PSA. | Jan Antfolk (Åbo Akademi University), Melissa Kline (Massachusetts Institute of Technology), Randy J. McCarthy (Northern Illinois University), Kathleen Schmidt (Southern Illinois University, Carbondale), Miroslav Sirota (University of Essex) |
| Ethics Review Committee: This committee reviews all study submissions, identifies possible ethical challenges, and assists participating labs in getting ethics approval from their institutions. | Cody Christopherson (Southern Oregon University), Michael C. Mensink (University of Wisconsin–Stout), Erica D. Musser (Florida International University), Kim Peters (University of Queensland), Gerit Pfuhl (UiT The Arctic University of Norway) |
| Logistics Committee: This committee manages the final matching of selected projects and contributing labs. | Susann Fiedler (Max Planck Institute for Research on Collective Goods), Jill Jacobson (Queen’s University at Kingston), Benedict Jones (University of Glasgow) |
| Community Building and Network Expansion Committee: This committee works to improve the reach of and access to the PSA, both internally and externally. Activities include recruiting labs and posting on social media. | Jack D. Arnal (McDaniel College), Nicholas A. Coles (University of Tennessee), Crystal N. Steltenpohl (University of Southern Indiana), Anna Szabelska (Queen’s University Belfast), Evie Vergauwe (University of Geneva) |
| Methodology and Data Analysis Committee: This committee provides guidance to team leaders regarding the feasibility of design, power to detect effects, sample size, etc. It is also involved in meeting the novel methodological challenges and taking advantage of the novel opportunities of the PSA. | Balazs Aczel (ELTE Eötvös Loránd University), Burak Aydin (RTE University), Jessica Kay Flake (McGill University), Patrick S. Forscher (University of Arkansas), Nicholas W. Fox (Rutgers University), S. Mason Garrison (Vanderbilt University), Kai T. Horstmann (Humboldt-Universität zu Berlin), Peder M. Isager (Eindhoven University of Technology), Zoltan Kekecs (Lund University), Hause Lin (University of Toronto), Anna Szabelska (Queen’s University Belfast) |
| Authorship Criteria Committee: This committee assists proposing authors in determining authorship requirements. | Denis Cousineau (University of Ottawa), Steve M. J. Janssen (University of Nottingham Malaysia Campus), William Jiménez-Leal (Universidad de los Andes) |
| Project Management Committee: This committee provides guidance to team leaders regarding the management of projects. | Charles R. Ebersole (University of Virginia), Jon E. Grahe (Pacific Lutheran University), Hannah Moshontz (Duke University), John Protzko (University of California, Santa Barbara) |
| Translation and Cultural Diversity Committee: This committee advises project leaders and committees with regard to standards and best practices for translations, as well as possible challenges in cross-cultural research. It also proposes actions to support cultural diversification of research and participation of otherwise underrepresented cultures and ethnic groups. | Sau-Chin Chen (Tzu-Chi University), Diego A. Forero (Universidad Antonio Nariño), Chuan-Peng Hu (Johannes Gutenberg University Medical Center), Hans IJzerman (Université Grenoble Alpes), Darko Loncˇarić (University of Rijeka), Oscar Oviedo-Trespalacios (Queensland University of Technology), Asil Ali Özdoğru (Üsküdar University), Miguel A. Silan (University of the Philippines Diliman), Stefan Stieger (Karl Landsteiner University of Health Sciences), Janis H. Zickfeld (University of Oslo) |
| Publication and Dissemination Committee: This committee oversees the publication and dissemination of PSA-supported research products. | Chris Chambers (Registered Reports, Cardiff University), Melissa Kline (Preprints, Massachusetts Institute of Technology), Etienne LeBel (Curate Science), David Mellor (Preregistration and open access, Center for Open Science) |
Acknowledgements
We thank Chris Chambers, Chuan-Peng Hu, Cody Christopherson, Darko Loncˇarić, David Mellor, Denis Cousineau, Etienne LeBel, Jill Jacobson, Kim Peters, and William Jiménez-Leal for their commitment to the Psychological Science Accelerator through their service as members of our organizational committees.
Action Editor
Daniel J. Simons served as action editor for this article.
Author Contributions
Authors are listed in tiers according to their contributions. Within tiers, authors are listed in alphabetical order. H. Moshontz and C. R. Chartier oversaw the preparation of the original draft of the manuscript and its subsequent review and editing. Authors in the first tier (H. Moshontz through H. L. Urry) were central to drafting, reviewing, and editing the manuscript. Authors in the second tier (P. S. Forscher through E. D. Musser) contributed substantially to drafting, reviewing, and editing the manuscript. Authors in the third tier (J. Antfolk through J. Protzko) contributed to specific sections of the original draft of the manuscript and provided reviewing and editing. Authors in the fourth tier (B. Aczel through J. H. Zickfeld) contributed to reviewing and editing the manuscript. Authors in the fifth tier (J. D. Arnal through M. A. Silan) contributed to conceptualization of the project by drafting policy and procedural documents upon which the manuscript is built, and also helped review and edit the manuscript. G. Pfuhl created Figure 1, and J. Olsen created ![]() . C. R. Chartier initiated the project and oversees all activities of the Psychological Science Accelerator.
. C. R. Chartier initiated the project and oversees all activities of the Psychological Science Accelerator.
ORCID iDs
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Funding
H. IJzerman’s research is partly supported by the French National Research Agency in the framework of the “Investissements d’avenir” program (ANR-15-IDEX-02). E. D. Musser’s work is supported in part by the U.S. National Institute of Mental Health (Grant R03MH110812-02). S. Fiedler’s work is supported in part by the Gielen-Leyendecker Foundation. D. A. Forero is supported by research grants from Colciencias and Vicerrectoría de Ciencia, Tecnología e Innovación. This material is based on work that has been supported by the National Science Foundation Graduate Research Fellowship awarded to N. A. Coles and by a National Science Foundation grant (DGE-1445197) to S. M. Garrison. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. T. Gill’s work is partially supported by the Canada Research Chairs Program (Social Sciences and Humanities Research Council of Canada). M. A. Vadillo’s work is supported by Comunidad de Madrid (Programa de Atracción de Talento Investigador, Grant 2016-T1/SOC-1395). E. Vergauwe’s work is supported in part by the Swiss National Science Foundation (Grant PZ00P1_154911). L. M. DeBruine’s work is partially supported by the European Research Council (Grant 647910, KINSHIP). A. M. Fernandez’s work is partially supported by Fondecyt (Grant 1181114). P. M. Isager’s work is partially supported by the Netherlands Organisation for Scientific Research (VIDI Grant 452-17-013).