
Abstract
Data generated by high-throughput screening (HTS) technologies are prone to spatial bias. Traditionally, bias correction methods used in HTS assume either a simple additive or, more recently, a simple multiplicative spatial bias model. These models do not, however, always provide an accurate correction of measurements in wells located at the intersection of rows and columns affected by spatial bias. The measurements in these wells depend on the nature of interaction between the involved biases. Here, we propose two novel additive and two novel multiplicative spatial bias models accounting for different types of bias interactions. We describe a statistical procedure that allows for detecting and removing different types of additive and multiplicative spatial biases from multiwell plates. We show how this procedure can be applied by analyzing data generated by the four HTS technologies (homogeneous, microorganism, cell-based, and gene expression HTS), the three high-content screening (HCS) technologies (area, intensity, and cell-count HCS), and the only small-molecule microarray technology available in the ChemBank small-molecule screening database. The proposed methods are included in the AssayCorrector program, implemented in R, and available on CRAN.
Keywords
Introduction
The amount of data generated by high-throughput screening (HTS) technologies that can be used to identify active compounds, such as small molecules, small interfering RNAs (siRNAs), or gene expression profiles, has exploded in recent years.1,2 This breakthrough has been triggered by a significant drop in the cost of screening technologies. Data generated by HTS technologies are, however, often subject to different types of spatial bias, which negatively influence the outcomes of HTS campaigns.3,4 Spatial bias is usually caused by environmental (e.g., irregular changes in the temperature, incubation time, lighting, and air flow) or technical (e.g., pipette and reader effects) factors.5–7 Plate-specific spatial bias (i.e., plate-specific systematic error) is evident as an under- or overestimation of measurements in certain rows and columns of a given plate. Often, spatial bias affects the edges of a given plate, causing the so-called edge effect. The intersection of rows and columns affected by spatial biases can be of particular interest because the resulting activity measurements depend on the interaction between these biases.
Plate-specific spatial bias in HTS has been traditionally assumed to fit the following additive model 8 (Equation 1):
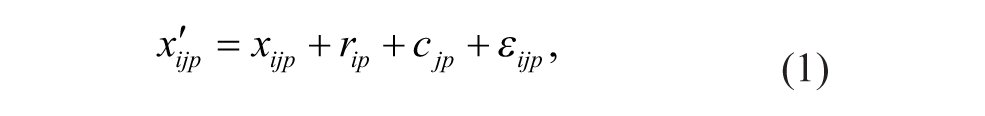
where
Recent studies have suggested that plate-specific spatial bias can also be of the multiplicative kind 9 (Equation 2):
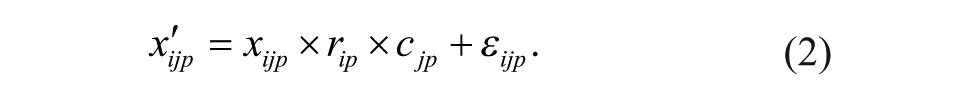
Correction methods based on different statistical procedures have been developed to remove systematic error using either the classical additive or classical multiplicative spatial bias models. For instance, the additive bias model was used in the following bias correction techniques: B-score, 10 R-score, 11 additive partial mean polish (aPMP), 12 and SPAWN. 13 The diffusion model 3 and the multiplicative PMP (mPMP) method 9 are among a few multiplicative bias models. The issue of correcting measurements located at the intersection of biased rows and columns has not, however, been addressed so far.
In this article, we introduce two additive and two multiplicative bias models, proposing different treatments of measurements located at the intersections of biased rows and columns, and a new statistical procedure, based on the use of the Anderson–Darling (AD) 14 or Cramer–von Mises (CVM) 15 goodness-of-fit tests, which allows one to select the most appropriate spatial bias model for a given plate. This procedure includes modeling bias effects by using traditional additive and multiplicative bias equations (Equations 1–2) as well as the arithmetic and geometric means to describe possible interactions between row and column spatial biases. The Mann–Whitney U test is used in our procedure to identify rows and columns of a given plate that are affected by spatial bias. A new variant of the PMP algorithm9,12 will be used to remove systematic error from biased plate measurements. The discussed statistical procedure will be applied to analyze experimental data generated by high-throughput (HTS), high-content (HCS), and small-molecule microarray (SMM) screening technologies, publicly available at ChemBank. 16
Methods
In this section, we present the statistical methods we propose to carry out to detect and remove additive and multiplicative spatial biases from multiwell plates used in screening technologies. Spatial bias present in rows and columns of a given plate is first detected using the nonparametric Mann–Whitney U test. Then, the most appropriate additive or multiplicative bias model will be determined, and the corresponding bias removal algorithm will be carried out. Six spatial bias models will be described here, including four new models. The CVM and AD tests will be used to assess the goodness-of-fit between raw and corrected screening measurements.
Spatial Bias Detection in Multiwell Plates
The nonparametric Mann–Whitney U test was applied to identify rows and columns of a given plate that are affected by spatial bias. In contrast to the t-test, which was used for example in Dragiev et al., 12 the Mann–Whitney U test makes no assumptions about the underlying distribution (e.g., normality), is at least 86.4% asymptotically as efficient as the t-test, 17 and is robust to outlying observations.
Our spatial bias detection algorithm proceeds by assessing the difference in the compound activity values between a given row or column (Sample 1) and the rest of the plate’s measurements (Sample 2). Once all rows and columns have been assessed in turn, the row or column with the smallest statistically significant p-value is added to the set of biased locations (i.e., rows and columns). The process continues either until convergence (i.e., until no more significant p-values are found) or until a fixed proportion of rows and columns containing spatial bias has been found.
Correction of Plate-Specific Bias
Plate-specific biases affecting rows and columns of a given plate p with m rows and n columns can fit either the additive (Models 1–3, below) or multiplicative (Models 4–6, below) bias model, which can be described by the following equations (with 1 ≤ i ≤ m and 1 ≤ j ≤ n).
Model 1: Additive Model
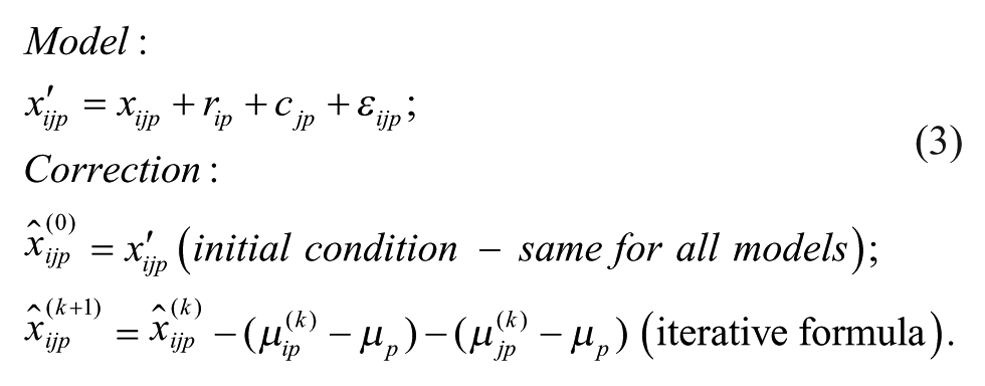
Model 2: Additive Model with Arithmetic Mean at the Intersection

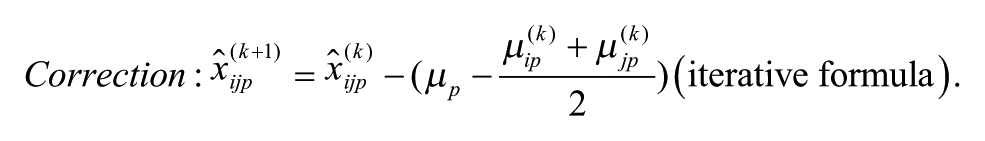
Model 3: Additive Model with Multiplicative Interaction of Biases at the Intersection
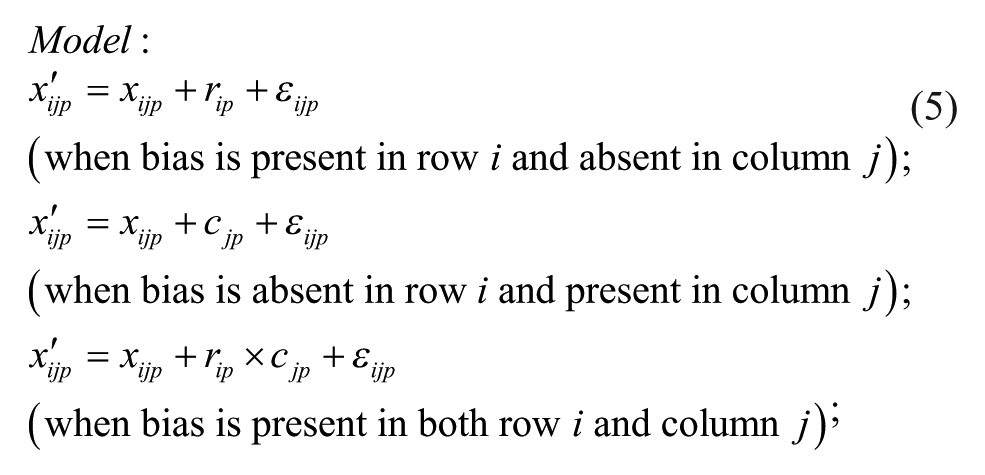
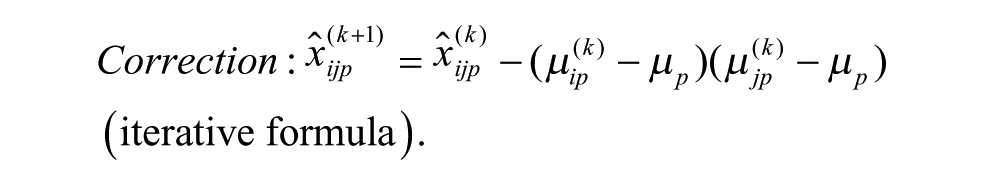
Model 4: Multiplicative Model
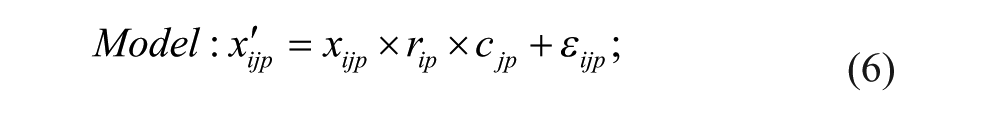
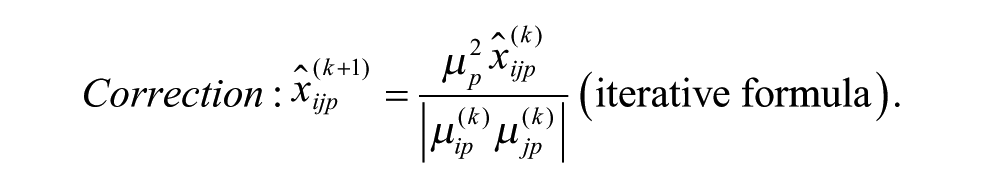
Model 5: Multiplicative Model with Arithmetic Mean at the Intersection
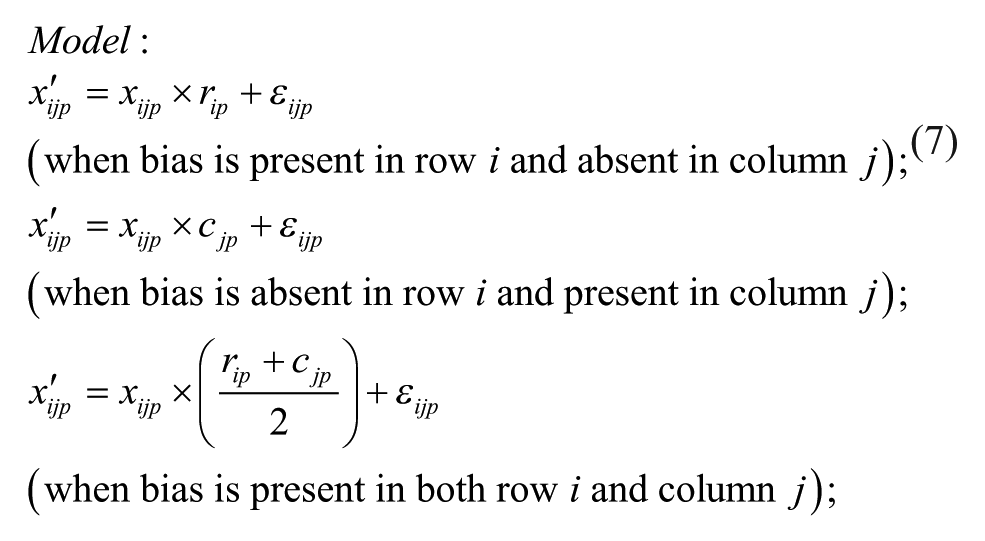
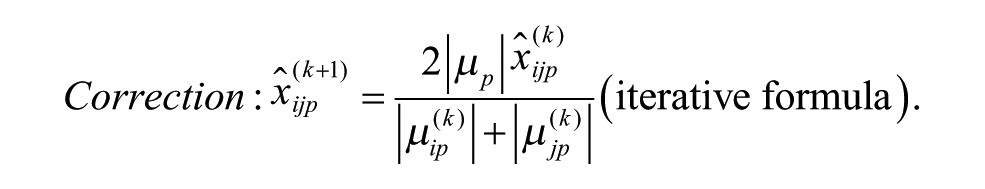
Model 6: Multiplicative Model with Geometric Mean at the Intersection
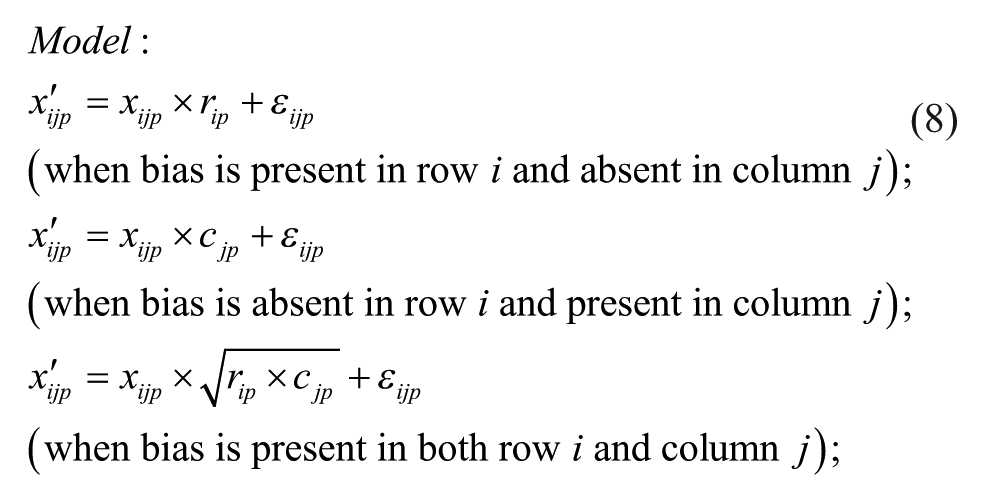
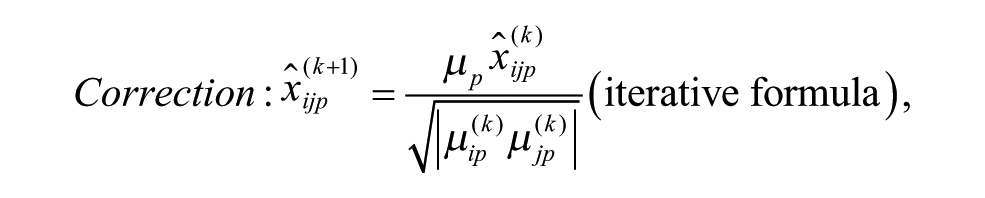
where
Model 1 is the traditional additive model, which is assumed in many bias correction methods.10,12,13 Model 2 is an additive model that assumes that the row and column biases at the intersections are combined through their arithmetic mean. Model 3 is an additive model that assumes that the row and column biases at the intersections interact in a multiplicative fashion. Model 4 is a recently introduced basic multiplicative bias model. Model 5 is a multiplicative model that assumes that the intersection effects of row and column biases are combined through their arithmetic mean. Model 6 is a multiplicative model that assumes that the row and column biases at the intersection are combined through their geometric mean. Models 2 and 3 can be viewed as extensions of the additive PMP model (Model 1), whereas Models 5 and 6 can be viewed as extensions of the multiplicative PMP model (Model 4). PMP algorithms9,12 are variations of Tukey’s median polish, 18 which iteratively removes spatial bias from the rows and columns affected.
Model Selection for Removing Plate-Specific Spatial Bias
In this section, we present a data-processing protocol that can be used to identify the most appropriate spatial bias model for a given plate. If the presence of spatial bias in a given plate has been detected using the Mann–Whitney U test, then we first partition all wells of the plate into (1) wells with no bias detected and (2) wells located in biased rows and columns. Control wells should be excluded from all computations. Wells affected by spatial bias can then be corrected using the six iterative methods (Models 1–6) discussed above. Our procedure generates seven sets of data: a set of unbiased wells, and six sets of biased wells corrected by each of the six methods. The AD or CVM test can then be used on the set of unbiased wells and on each of the six corrected sets of wells to assess goodness-of-fit of the corrections performed. The resulting p-values can then be used to determine the most appropriate bias model (among Models 1–6) for the data at hand. In this work, the significance level α was set to 0.01 for all three statistical tests being performed (the Mann–Whitney U test, AD test, and CVM test). Both the AD and CVM tests can be used in the algorithm below, but the AD test is preferred due to its higher power. 21
Our algorithm proceeds as follows:
i. Perform the Mann–Whitney U test on each individual plate of the assay (i.e., plate-wise correction) to identify biased rows and columns.
For each plate containing biased rows and/or columns, perform:
ii. Apply each of the six additive and multiplicative PMP algorithms corresponding to Models 1–6, as discussed in this section (see the related iterative formulas 3 to 8).
iii. Apply the AD or CVM two-sample test on the corrected plates after the application of the six versions of the PMP algorithm. Compute the corresponding p-values (three additive and three multiplicative).
iv. If all additive and multiplicative p-values are higher than the selected significance level α, the bias model for this plate is the model with the highest p-value (low confidence).
v. If all additive p-values are lower than the selected significance level α, and all multiplicative p-values are higher than a, the bias model for this plate is multiplicative (high confidence).
vi. If all multiplicative p-values are lower than the selected significance level α, and all additive p-values are higher than α, the bias model for this plate is additive (high confidence).
vii. If none of the conditions specified in Steps iv to vi apply, then the bias model is undefined.
viii. If the bias model has been identified (i.e., it is not undefined), then correct the plate measurements using the corresponding bias correction procedure.
Traditional and Modified Partial Mean Polish Algorithms
In this section, we present the details of the aPMP and mPMP algorithms corresponding to Models 1 to 6, discussed above. The main advantage of these algorithms compared to the popular B-score method of Brideau et al. 10 is that they do not reduce the original measurements to residuals and do not modify the unbiased measurements.
Our generalized PMP algorithm proceeds as follows:
Let
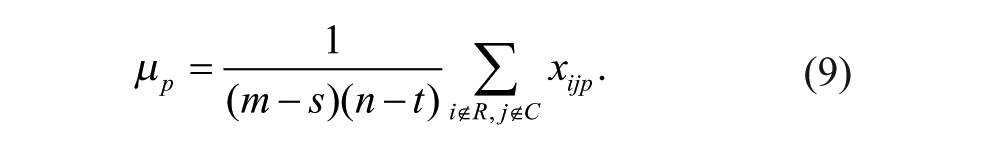
For each biased row i : 1 ≤ i ≤ sn, calculate the mean value,
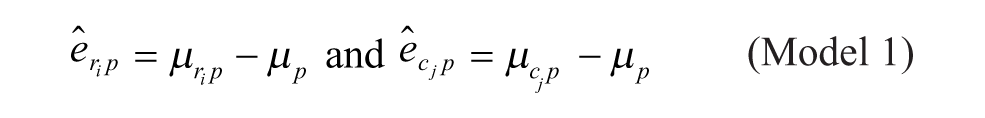
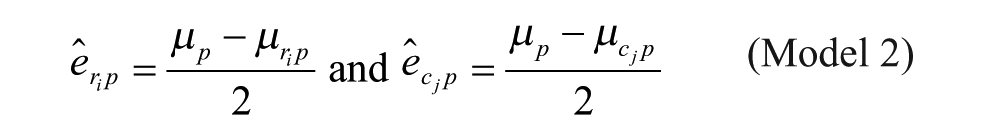
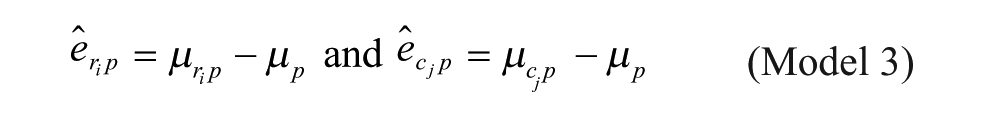
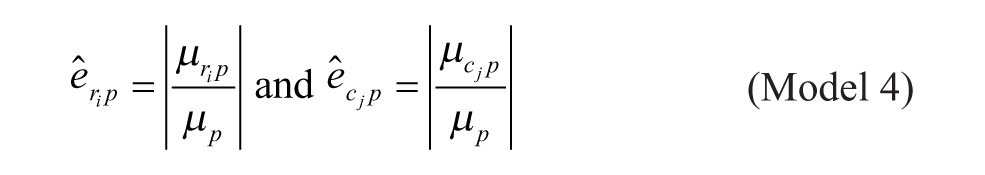
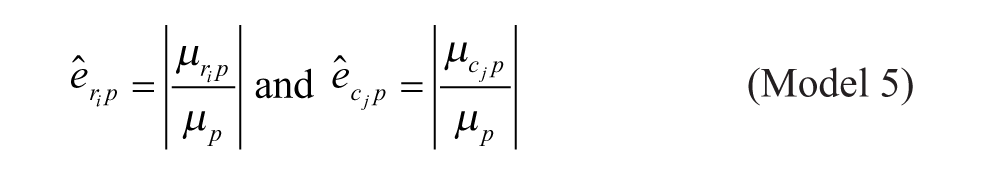
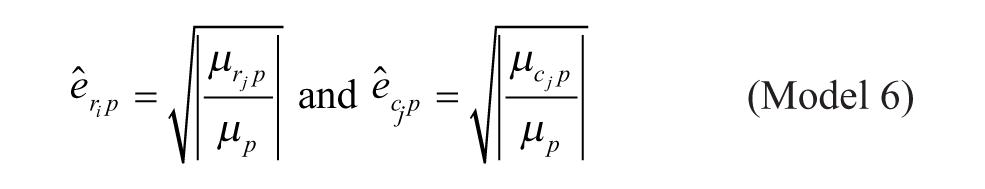
For all rows and columns affected by spatial bias, iteratively adjust their measurements using the error estimates determined in Step 2. In other words, for all
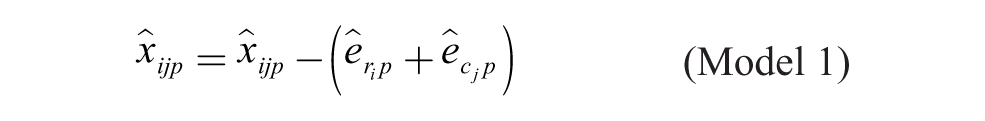
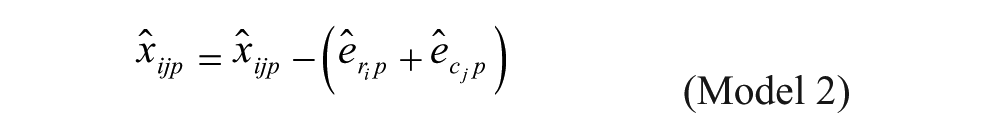




If
where ε is a small, fixed, positive threshold.
Choice of Statistical Test to Determine the Bias Model
Two statistical tests, used in Step iii of the above-presented bias correction protocol, were examined to assess the goodness-of-fit between raw and corrected measurements: the CVM and AD tests. The AD test is based on a quadratic empirical distribution function (EDF) statistic. Importantly, the AD test has been shown to be the most powerful among the EDF tests. 19 The CVM test is a special case of AD that puts less weight on the tails of the distribution. It has been shown that the power of the AD test is higher than that of the Kolmogorov–Smirnov, 20 probability-plot, L moments, and chi-square (χ2) tests. 21 Moreover, the AD test is generally more powerful than the CVM test. 22 These conclusions mirror those formulated by Stephens. 23
Simulations
We conducted a simulation study to estimate the efficiency of our new additive and multiplicative bias models (Models 1–6, above) and the corresponding versions of the PMP algorithm (see Fig. 1 ). We generated synthetic HTS data with known hits and plate-specific spatial biases to compare the performances of our new algorithm to those of the no-correction and B-score 10 methods. It is worth noting that B-score remains the most popular bias correction method used in HTS. In our simulation study, we followed the data generation procedure initially described by Dragiev et al. 12 Precisely, we generated synthetic HTS data for 100 assays, each consisting of 100 plates of size (16×24), which is the most popular plate format in ChemBank, 16 for every combination of parameters reported below. The values of nonhit compound measurements followed the standard normal distribution. Hit values were generated using the normal distribution with the following parameters: ~N(µ – 6SD, SD), where µ and SD were the mean and standard deviation of nonhit compounds, set to 0 and 1, respectively. Hit positions within plates were selected using rejection sampling with the following hit percentages: 0.5%, 1%, 2%, 3%, 4%, and 5%. Spatial bias was then added to selected rows and columns of the generated HTS plates using bias Models 1 to 6. In our simulations, at most 8 rows and 12 columns of each plate could be affected by bias. For every plate, the number of biased rows was sampled from a ~Geometric(p = 0.622) distribution, and the number of biased columns was sampled from a ~Geometric(p = 0.430) distribution. These parameters were estimated from experimental screening data consisting of 2441 non-empty plates of the 175 ChemBank assays considered in our work (see Suppl. Table 1 ). The maximum likelihood approach was applied to the distribution of the numbers of biased rows and columns in these assays (see Fig. 2 ) to get these parameters. The Mann–Whitney U test was used to detect the presence of spatial bias in the experimental ChemBank data.
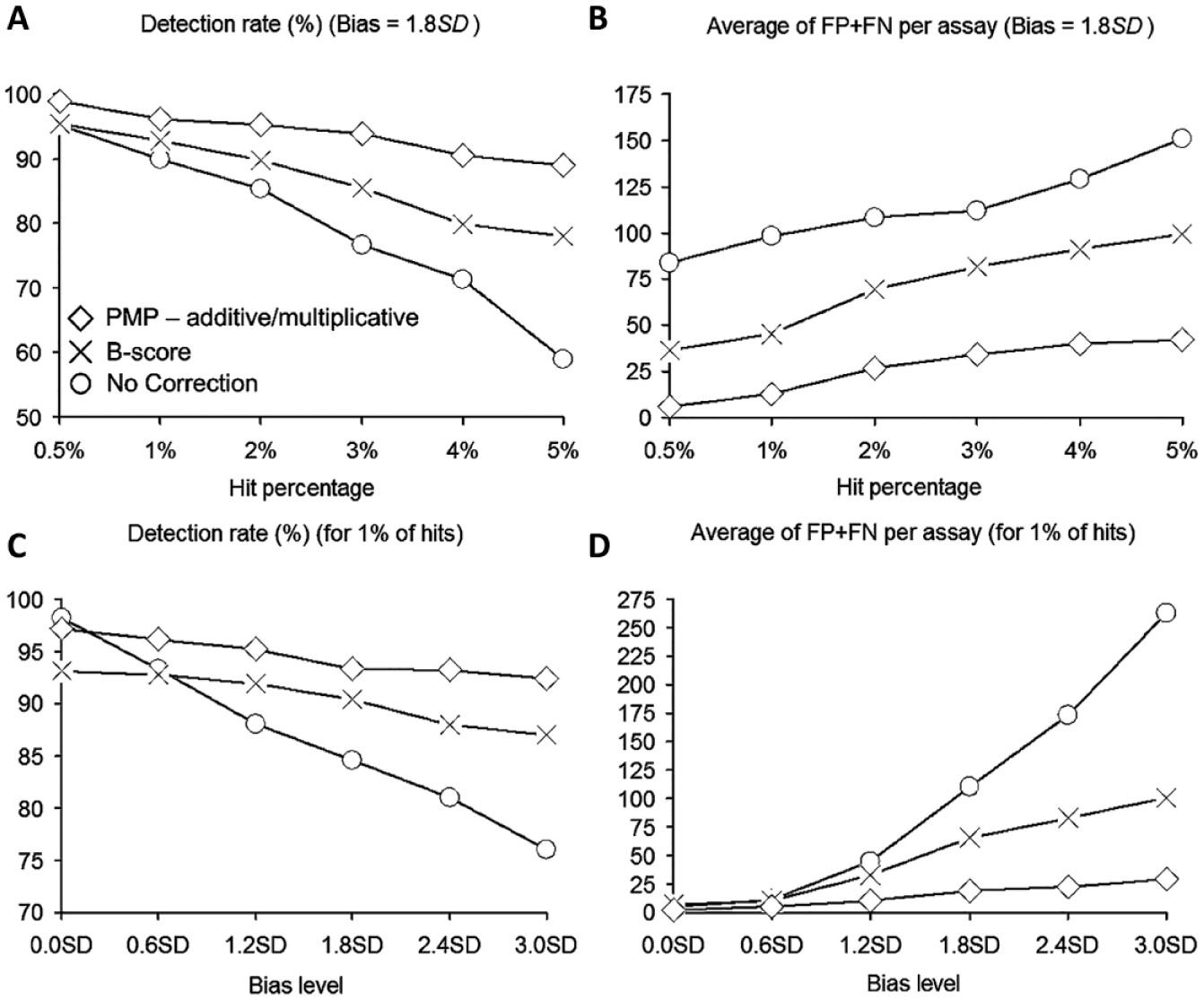
(A,C) Average true-positive rate, and (B,D) average total number of false-positive and false-negative hits per assay, obtained by using the no-correction, B-score, and partial mean polish (PMP) methods (based on Models 1–6, the nonparametric Mann–Whitney U test for bias detection, and the Anderson–Darling test for bias model selection). (A,B) The results obtained with a fixed bias level of 1.8 SD; (C,D) the results obtained with a fixed hit percentage of 1%.
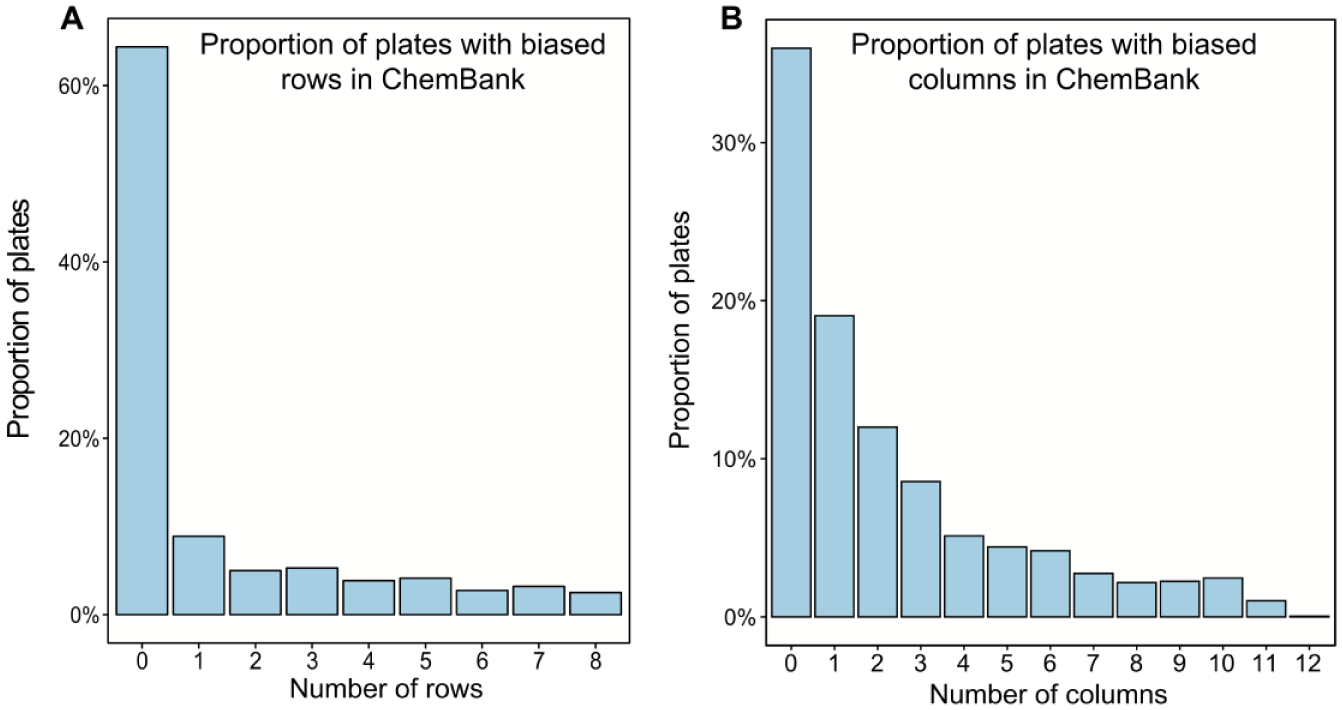
Proportion of plates with the indicated (A) number of rows affected by spatial bias and (B) number of columns affected by spatial bias. The nonparametric Mann–Whitney U test was used to detect the presence of spatial bias within each plate.
The bias model for each plate was selected from (1) undefined or no bias, (2) additive bias (Models 1 to 3), and (3) multiplicative bias (Models 4 to 6), with the following respective sampling probabilities: 0.274, 0.418, and 0.308, which were also estimating from the 2441 non-empty ChemBank plates considered here. In Models 1 to 6, the additive plate-specific biases were generated using the normal distribution with parameters ~N(0, C) and the multiplicative plate-specific biases using the normal distribution with parameters ~N(1, C), where parameter C was alternately set to 0, 0.6 SD, 1.2 SD, 1.8 SD, 2.4 SD, and 3 SD. Sample activity measurements affected by additive spatial bias were generated using Equations (3) to (5); and those affected by multiplicative spatial bias, using Equations (6) to (8). A random additive Gaussian noise (i.e., the parameter εijp in Equations [3] to [8]), affecting both hit and nonhit activity measurements, was generated using the normal distribution with parameters ~N(0, 0.1SD). Our PMP algorithm correcting both additive and multiplicative spatial biases was used with the Mann–Whitney U test, which was applied to identify biased rows and columns within each plate, and the AD test, which was applied to select the most appropriate bias model (for more details, see the Methods section). The significance threshold α was set to 0.01 in both of these tests.
Following the data correction, the hit selection procedure was carried out using the µp – 3σp hit selection threshold, where µp and σp were the mean and standard deviation of the measurements of plate p. The methods’ performances were measured by using the hit recovery rate (i.e., true positive rate) and the total of false positives and false negatives they returned (see also Dragiev et al. 12 ). Two simulations were conducted. In the first simulation (see Fig. 1A and 1B ), the bias level was set to 1.8 SD (fixed), whereas the hit percentage varied from 0% to 5%. In the second simulation (see Fig. 1C and 1D ), the hit percentage was set to 1% (fixed), whereas the noise level varied from 0 to 3 S.
The results of our simulations confirm that the bias correction methods should be used only when the presence of spatial bias was identified by a suitable statistical test. This is especially true for the B-score method. The obtained results suggest that the additive and multiplicative PMP algorithms, following Models 1 to 6 presented in the Methods section, provide the smallest total false-positive and false-negative hit counts as well as the best hit detection rate compared to the no-correction and B-score methods. When the hit percentage was varying from 0.5% to 5% and the bias level remained fixed at 1.8 SD ( Fig. 1A ), as well as when the bias magnitude was varying from 0.0 SD to 3.0 SD and the hit percentage remained fixed at 1% ( Fig. 1C ), the true-positive rate for all methods decreased with the increase in the hit percentage. When the hit percentage was varying from 0.5% to 5% and the bias level remained constant at 1.8 SD ( Fig. 1B ), the total count of false positives and false negatives was increasing for all methods. The PMP algorithm yielded the lowest average total counts in all cases. When the bias level ranged from 0.0 SD to 3.0 SD and the hit percentage remained constant at 1%, our method outperformed the no-correction and B-score methods in all cases, except the case of error-free data (bias = 0.0SD) when the no-correction procedure provided a slightly better hit detection rate (see Fig. 1C ). The B-score method usually coped well with the identification of true positives ( Fig. 1A and 1C ) but routinely generated a large number of false positives ( Fig. 1B and 1D ).
Results and Discussion
To assess the extent of plate-specific bias in the HTS, HCS, and SMM technologies, we examined 175 experimental assays from the ChemBank screening repository. ChemBank 16 is a public small-molecule screening database created by the Broad Institute’s Chemical Biology Program, which provides life scientists access to biomedically relevant screening data and tools. Here, we considered all eight screening categories available in ChemBank: HTS (homogeneous), HTS (microorganism), HTS (cell-based), HTS (gene expression), HCS (area), HCS (intensity), HCS (cell count), and SMM. Among the 175 examined assays were 25 assays of each HTS category, 8 assays of HCS (area: all available non-empty assays of this type in April 2017), 18 assays of HCS (intensity: all available non-empty assays of this type in April 2017), 24 assays of HCS (cell count: all available non-empty assays of this type in April 2017), and 25 assays of SMM. The ChemBank IDs of these assays are reported in Supplementary Table 1 .
First, we calculated the proportion of plates with at least one row and at least one column under- or overestimation effect (i.e., having at least one intersection of biased rows and columns). After analyzing a total of 2241 plates from the selected 175 assays, we found that plates with intersections of biased rows and columns (51.9%) were slightly more frequent than plates without such intersections (48.1%). Note that the difference between Models 1 to 3 and between Models 4 to 6 occurs only in the presence of intersections. Models 1 to 6, discussed in the Methods section, allow us to take into account the complex nature of interactions between row and column spatial biases.
Second, we assessed the distribution of the number of biased rows and columns in the selected set of ChemBank assays. Figure 2 shows the distribution of the number of rows ( Fig. 2A ) and columns ( Fig. 2B ) per plate affected by spatial bias, computed over the 2441 plates of the examined ChemBank assays. The Mann–Whitney U test was carried out to detect the presence of spatial bias within each plate. The presented results suggest that plates’ columns tend to be more biased than plates’ rows in experimental small-molecule screens.
Third, we carried out the correction of biased rows and columns following our algorithm described in the Methods section. Plate-specific error correction was applied on a plate-by-plate basis. It was applied only on plates in which the presence of spatial bias was detected by the Mann–Whitney U test. If the presence of spatial bias was identified within a given plate, then the detected biased measurements were corrected using the most appropriate additive or multiplicative bias correction model according to our algorithm (see the Methods section). Evidence from the AD and CVM tests was used to select the best fitting model.
Table 1 shows that the number of plates affected by additive, multiplicative, and undefined types of spatial bias differed among the three technologies, as suggested by the χ2 test of independence (χ2 (4) = 97.32; p = 5×10−4). Post-hoc tests showed that the proportion of HTS plates affected by undefined bias was significantly higher than in HCS (χ2(1) = 25.38; p = 4.7×10−7), but not in SMM (χ2 (1) = 1.38; p = 2.4×10−1), plates. The proportion of plates in SMM assays affected by undefined bias was also higher than in HCS assays (p = 6.50×10−5, χ2 =15.95). The 2×2 contingency tables were constructed by combining respective bias model and screening technologies plate counts.
Contingency table of the number of plates affected by additive, multiplicative, and undefined types of spatial bias, for the HTS, HCS, and SMM technologies.
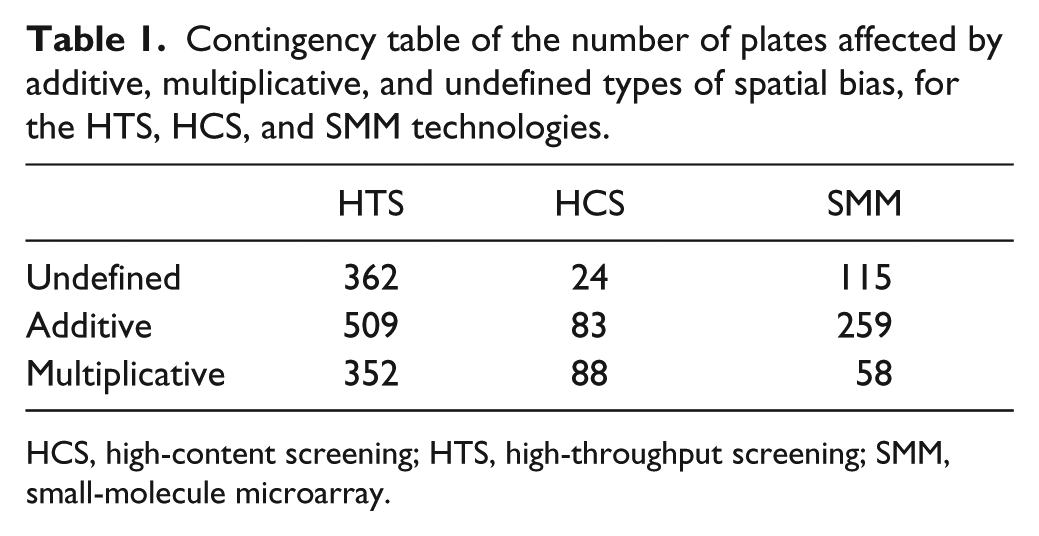
HCS, high-content screening; HTS, high-throughput screening; SMM, small-molecule microarray.
Figure 3 presents the model selection frequencies for our six spatial bias models (Models 1 to 6) among the eight screening categories. Here, the AD test was used to assess the goodness-of-fit of the corrected measurements to the unbiased measurements. According to the AD test, HTS data tend to contain more spatial bias than HCS or SMM data. Moreover, HTS data followed an undefined bias model more frequently than HCS or SMM data (23.7%, 5.8%, and 16.3%, respectively).
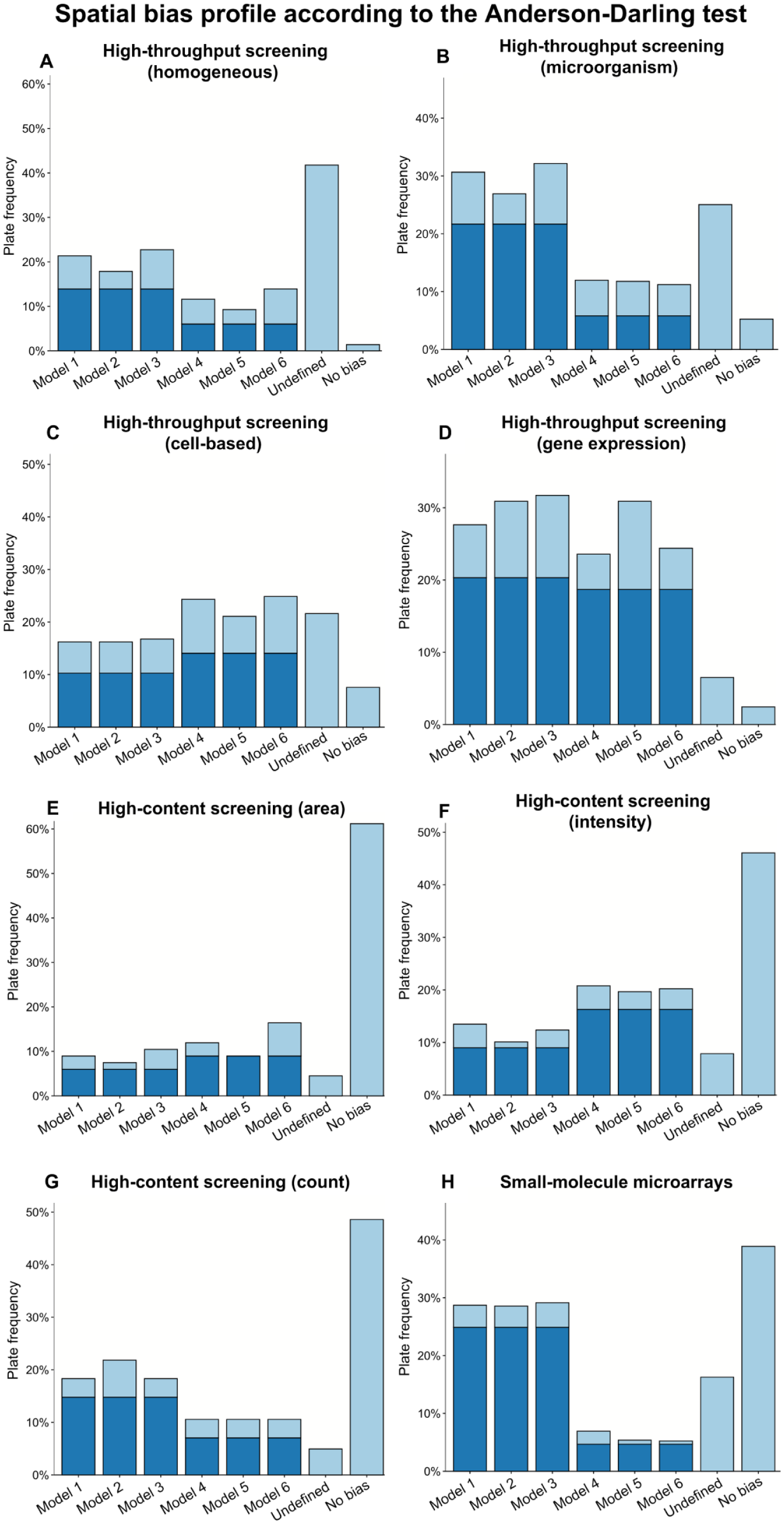
Spatial bias model frequency based on evidence obtained from the Anderson–Darling test for (A–D) high-throughput screening data, (E–G) high-content screening data, and (H) small-molecule microarray data. Control wells were excluded from all computations. Darker portions of bars account for plates without intersections of rows and columns affected by spatial bias; in this case, any additive model (Models 1–3) can be applied when spatial bias was classified as additive, and any multiplicative model (Models 4–6) can be applied when spatial bias was classified as multiplicative. Lighter portions of bars corresponding to Models 1 to 6 account for plates with intersections of rows and columns affected by spatial bias (in this case, the model yielding the largest p-value should be applied).
Figure 4 depicts the bias model selection frequencies according to the CVM test obtained for data of the eight considered screening categories. Similarly to the AD test, evidence from the CVM test indicates that HTS data tend to contain more biased plates that do not correspond to any of the six bias models presented in our study (i.e., the bias model for HTS data was classified as undefined more frequently than for HCS and SMM data). In particular, the bias model was identified as undefined in 44.3% of HTS plates (computed for the four HTS screening categories), compared to 13.5% in HCS (computed for the three HTS screening categories) and 19.5% in SMM.
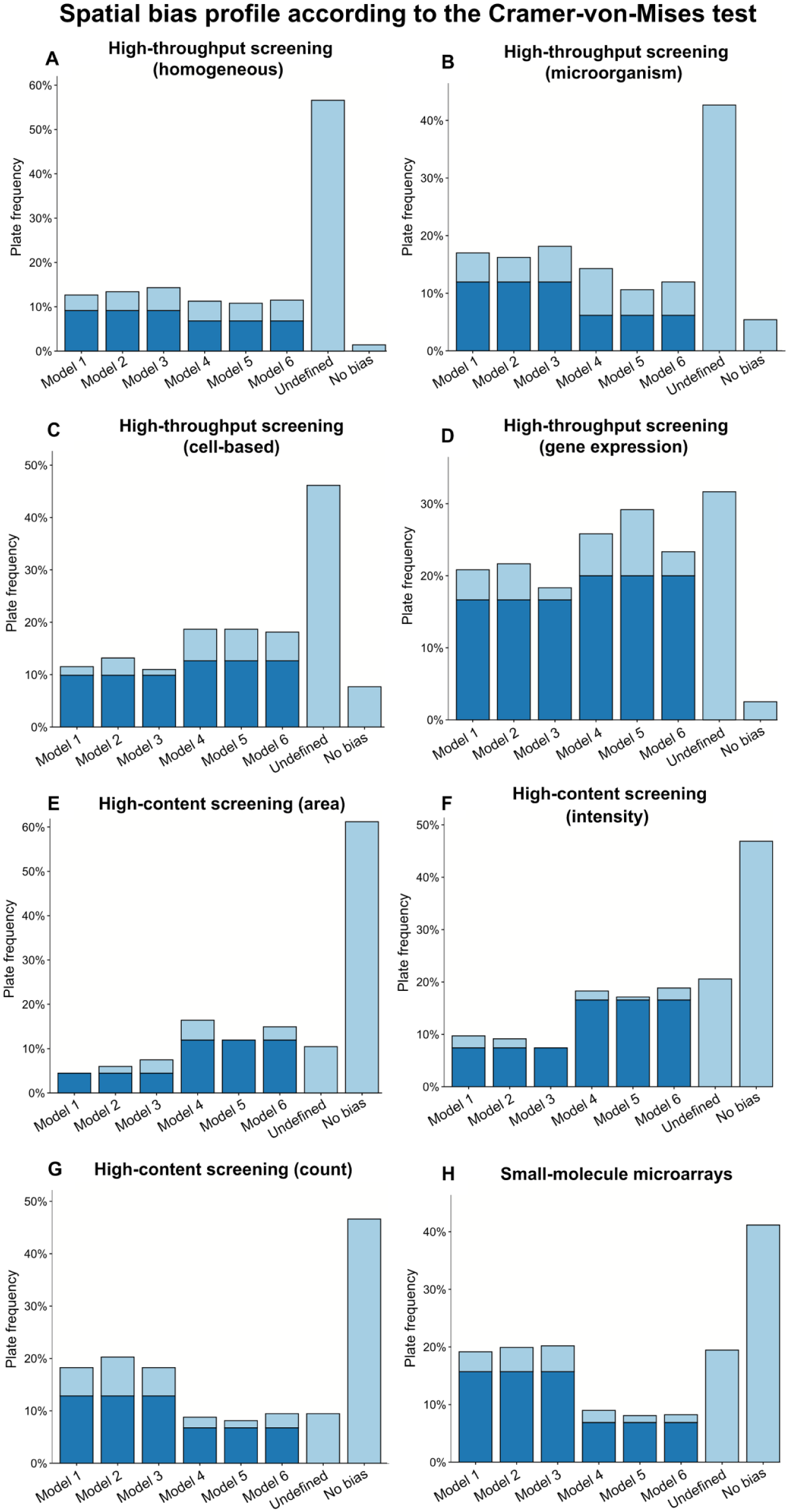
Spatial bias model frequency based on evidence obtained from the Cramer–von Mises test for (A–D) high-throughput screening data, (E–G) high-content screening data, and (H) small-molecule microarray data. Control wells were excluded from all computations. Darker portions of bars account for plates without intersections of rows and columns affected by spatial bias; in this case, any additive model (Models 1–3) can be applied when spatial bias was classified as additive, and any multiplicative model (Models 4–6) can be applied when spatial bias was classified as multiplicative. Lighter portions of bars corresponding to Models 1 to 6 account for plates with intersections of rows and columns affected by spatial bias (in this case, the model yielding the largest p-value should be applied).
Figures 3
Let us now examine in more detail the results presented in Figures 3 and 4 . The McNemar test was used to test the differences in proportions mentioned below.
- For HTS homogeneous data ( Figs. 3A and 4A ), spatial bias was found in 98.6% of plates. Here, the CVM test found the same quantity of plates corresponding to an undefined bias model as the AD test (56.6% compared to 41.8%, χ2 (1) = 0.16; p = 6.85×10−1). Both the CVM and AD tests found that both multiplicative and additive bias proportions were not different for data of the HTS homogeneous category (χ2 (1) = 2.07; p = 1.50×10−1).
- For HTS microorganism data ( Figs. 3B and 4B ), spatial bias was found in 94.6% of plates. The AD test identified much fewer plates with undefined spatial bias than the CVM test (25.0% compared to 42.7%, χ2(1) = 51.51; p = 7.11×10−13). Both the AD and CVM tests suggest that the additive bias models are more appropriate than the multiplicative ones for data of the HTS microorganism category (χ2(1) = 11.73; p = 6.14×10−4).
- For HTS cell-based data ( Figs. 3C and 4C ), spatial bias was found in 92.3% of plates. The CVM test suggested that 46.2% of plates have an undefined type of bias, compared to 21.6% of plates according to the AD test (χ2(1) = 15.72; p = 7.34×10−5). Both tests found that the multiplicative spatial bias model is more adequate for plates of the HTS cell-based category than the additive one (χ2(1) = 0.53; p = 4.65×10−1).
- For HTS gene expression data ( Figs. 3D and 4D ), spatial bias was found in 97.5% of plates. Here, the AD test suggested that 6.5% of plates are affected by an undefined type of bias, compared to 31.7% of plates according to the CVM test (χ2(1) = 37.75; p = 8.03×10−10). The AD and CVM tests did not find a significant difference in proportions of HTS gene expression plates affected by multiplicative or additive types of spatial bias (χ2(1) = 2.50; p = 1.14×10−1).
- For HCS area data ( Figs. 3E and 4E ), spatial bias was found in 38.8% of plates. Both the CVM and AD tests determined that an undefined bias model is rather rare for this type of data (10.4% and 4.5%, respectively, χ2(1) = 44.17; p = 3.01×10−11). Here, both statistical tests found no significant difference between the multiplicative and additive spatial bias models (χ2(1) = 0.22; p = 6.38×10−1).
- For HCS intensity data ( Figs. 3F and 4F ), spatial bias was found in 92.1% of plates. The CVM test identified that the bias model was undefined for 20.6% of HCS intensity plates, compared to 7.9% found by the AD test (χ2(1) = 80.65; p = 2.70×10−19). Both the CVM and AD tests did not provide enough evidence that the additive and multiplicative bias models were present in equal proportions in plates generated by the HCS intensity technology (χ2 (1)= 0.09; p=7.69×10−1).
- For HCS count data ( Figs. 3G and 4G ), spatial bias was found in 51.4% of plates. Both the AD and CVM tests indicated that only a small proportion of plates follow an undefined spatial bias model (4.9% and 9.5%, respectively; χ2(1) = 96.64; p = 8.30×10−23). No significant difference in proportions of plates affected by additive or multiplicative bias was found here (χ2 (1) = 0.74; p = 3.88×10−1).
- For small-molecule microarray data ( Figs. 2H and 3H ), spatial bias was found in 58.8% of plates. Here, the CVM and AD tests determined that 19.5% and 16.3% of plates, respectively, follow an undefined bias model (χ2(1) = 294.35; p = 5.61×10−66). Both tests also suggested that the small-molecule microarray data tend to be affected by additive bias more frequently than by multiplicative bias (χ2 (1) = 9.1; p = 2.56×10−3).
In this article, we described the three additive and the three multiplicative spatial bias models along with a general bias detection and removal procedure. We presented evidence that all the six bias models (Models 1 to 6) considered in this study are relevant for the analysis of experimental high-throughput, high-content, and small-molecule microarray data. One of the challenges in spatial bias model selection consists of minimizing the number of plates with an undefined type of spatial bias. The AD test generally outperformed the CVM test in distinguishing between the additive and multiplicative bias models, which resulted in a lower number of plates where spatial bias was classified as undefined. Overall, the AD and CVM tests were in agreement on the spatial bias model that should be used to correct the measurements of a given plate. However, because the AD test is generally more powerful than CVM 22 and because it classifies fewer plates as being undefined, it can be recommended for analysis of modern multiwell plates. We also discovered that data generated by HTS technologies are generally more prone to spatial bias than data from HCS and SMM. Although HCS and SMM data are more likely to follow one of the six considered bias models, the bias model in HTS was more frequently classified as undefined, leaving more challenges for future investigations.
The methodology presented in this article is designed to minimize the impact of a plate-specific (additive or multiplicative) spatial bias. A plate-specific bias means that the observed bias patterns appear within a given plate only and may be different for different plates of the assay. An assay-specific bias consists of a bias pattern that appears within all plates of a given assay. A typical example of an assay-specific bias is the case in which a single well location (i.e., measurements taken among all plates of a given assay and corresponding to a fixed well position) gives a very high or a very low reading. An assay-specific bias can be removed by applying the traditional Z-score normalization, first plate-wise and then well location–wise. The traditional Z-score normalization allows one to remove both additive and multiplicative biases when applied to the measurements of a given well location. 24 Obviously, the presence of spatial bias in this well location should be primarily confirmed by an appropriate statistical test (e.g., by the Mann–Whitney U test).
The main advantage of our method, compared to the no-correction strategy and the B-score 10 method, is that it copes well with both additive and multiplicative spatial biases by taking into account complex interactions between them. This was confirmed by our simulation study. Obviously, any bias correction method has to be applied with caution. For instance, a screening practitioner should always verify that all tested samples are randomly distributed within given HTS/HCS/SMM plates. If the randomization condition does not hold, some areas of these plates can correctly give very high or very low readings. In this case, the application of bias correction methods may be rather damaging because an unwanted bias may be introduced into the data at hand.
Footnotes
Supplementary material is available online with this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Natural Sciences and Engineering Research Council of Canada (Grant no. 249644) and le Fonds Québécois de la Recherche sur la Nature et les Technologies (Grant no. 173539).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.