
Abstract
Automatic image aesthetic evaluation is an attractive and challenging visual task. Recently, methods based on convolutional neural networks have achieved remarkable performance. However, semantic information, an intuitive prerequisite for evaluating image aesthetics, has not received enough attention regarding its importance in previous methods. How to efficiently extract semantic information and make better use of it to assist the aesthetic evaluation task remains unsolved. In this article, we propose to utilize the self-supervised model Auto-Encoder to extract semantic information in the form of multi-task learning. Then, a fusing module is prepended at the bottleneck layer to explicitly combine semantic information with aesthetic information in a pre-activated manner. Specifically, we implement a customized pooling operation to pool the semantic features extracted by Auto-Encoder and apply a weak constraint between the pooled semantic features and aesthetic information to realize the combination. The following regressor can complete aesthetic evaluation based on the semantic–aesthetic combined features. In addition, to enable our model to adapt to arbitrary aspect ratios of images, another pooling strategy called spatial pyramid pooling is adopted to obtain the image features of a fixed length. Our method achieves competitive performance on the public image aesthetic evaluation benchmark. Especially on the most commonly used metric Spearman rank-order correlation coefficient, the proposed model achieved the best performance compared with some state-of-the-art methods. Extensive ablation studies and visualization experiments were conducted to demonstrate the effectiveness of our method.
Introduction
Background
Image aesthetic assessment (IAA), which aims to quantify the beauty of a given image, is a meaningful vision task, as it has a large number of practical applications in our modern society. For example, with the explosive growth of Internet users, posting photos on social media platforms has already become a common demand in our daily life. Some applications with a well-designed IAA model can help users to choose the most appealing images, to sort similar images in the user’s photo libraries, or to optimize parameters for editing images.
In contrast to conventional visual tasks such as image classification,1,2 object detection,3,4 and semantic segmentation,5,6 it is nontrivial to objectively assign an aesthetic score to a given image. As illustrated in Figure 1, for the image classification task, its ground-truth label is represented as a one-hot vector. It is a binary vector, in which only one entry corresponding to the actual category is equal to 1 while all other entries are 0s. For the IAA task, its ground truth label, called aesthetic label in this article, takes the form of a distributed representation, which reflects a score distribution over the votes obtained from numerous experts. Such a kind of aesthetic label has been adopted in mainstream IAA databases like AVA. 7 In this article, we aim to devise a learning-based model that can automatically predict the distributed aesthetic score of a given image.
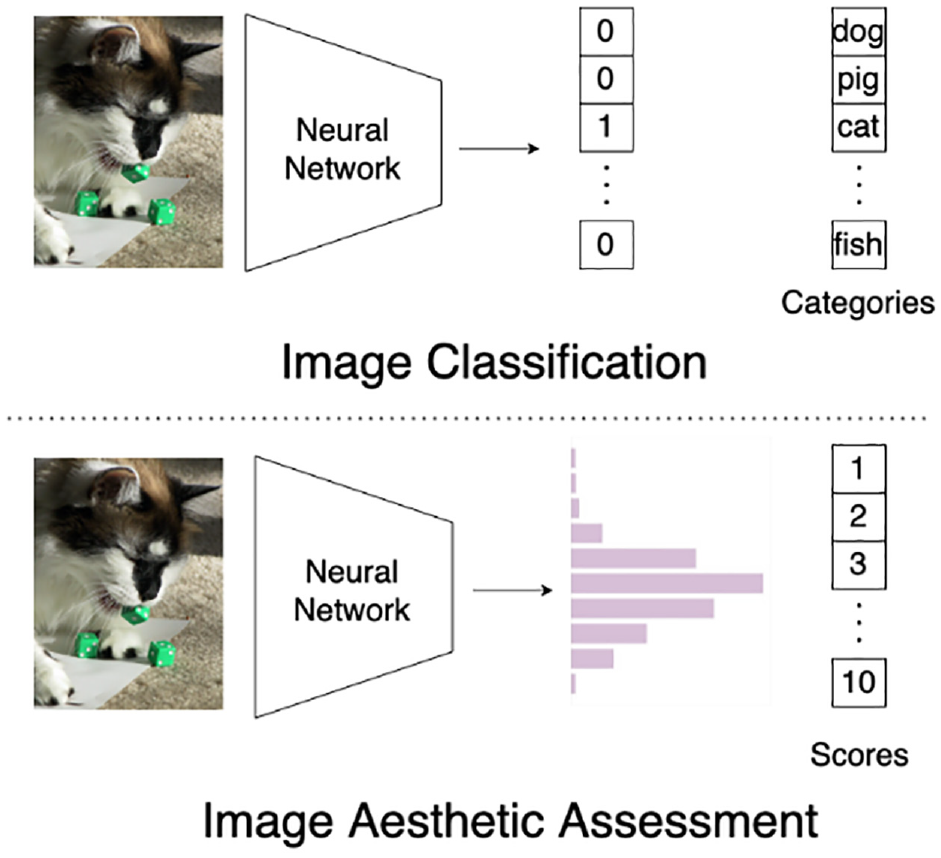
Comparison between the tasks of image classification and image aesthetic evaluation.
Researchers have paid great efforts to the IAA task. Previous methods can be roughly divided into two categories: knowledge-driven and data-driven.
Methods of the first category8–12 focus on designing a series of hand-crafted features following professional photography skills such as the rule of thirds, color harmony, and shallow depth of field. These manually designed features are fed into some universal classifier like support vector machine, 13 random forest, 14 or multilayer perceptron 15 for aesthetic classification. Although these works have achieved passable results, they still suffer from some limitations. First, implementing these methods requires professional knowledge of photography and aesthetic. Second, it is difficult even for experienced experts, due to the subjectivity and diversity of aesthetic attributes, to design a generic hand-crafted aesthetic feature suitable for all photos. Consequently, it is arduous and time-consuming to apply the knowledge-driven methods to the IAA task.
To address the above limitations, the data-driven methods16–23 resort to various deep neural networks (DNNs) for learning a hierarchy of aesthetic features geared toward the IAA task in an end-to-end manner. The data-driven methods, which are free from the help of labor-intensive feature engineering, have achieved higher accuracy in the IAA task, compared with the knowledge-driven methods.
Lu et al. 19 initiated the success of the DNN-based IAA model. They constructed a double-column CNN (Convolutional Neural Network) model to adaptively capture layout information and fine-grained details, respectively, from global and local views of an input image.
In their subsequent work, 20 a deep multi-patch aggregation network was developed to extract and aggregate aesthetic features at the patch level. Jin et al. 17 aimed to predict the distributed aesthetic score for a given image. A tailor-made loss called cumulative Jensen–Shannon (JS) divergence was used to drive the training. Recently, Talebi and Milanfar 22 stated that the traditional cross-entropy loss ignores the relationship between the buckets of a distributed aesthetic score. They solved this problem by replacing the cross-entropy loss with an Earth Mover Distance (EMD) loss.
Related Works
Semantic information is significant for the IAA task. This is because understanding the content of an image, namely the semantic information, is an intuitively reasonable prerequisite for evaluating the aesthetic. In this article, we propose to utilize a classic self-supervised method, called Auto-Encoder, to extract the semantic information in the form of multi-task learning.
To gear toward the IAA task, we design a fusing module, which aims to combine the extracted semantic information with image aesthetics, so as to get a better aesthetic evaluation performance. After end-to-end training, the encoder will provide an aesthetic–semantic combined feature that paves the way for evaluating the aesthetic.
In this section, we briefly review some related works from the following two aspects: (a) self-supervised learning (SSL) for IAA; (b) utilization of semantic information in IAA.
Self-Supervised Learning for IAA
Some studies attempt to incorporate SSL methods to reduce the score bias caused by the subjectivity of aesthetics. Ching et al. 16 presented an SSL-based IAA model, in which image inpainting serves as a pretext task. To some extent, inpainting an image will force the IAA model to understand the aesthetic, so as to provide a better initial state for fine-tuning. Following the SSL perspective, Sheng et al. 21 attempted to extract a set of aesthetic-aware representations from images. Specifically, they designed two pretext tasks, which are trained to identify the types and strengths of editing operations applied to images.
These SSL methods16,21 focused on designing an aesthetic-aware pretext task without using any manual annotations. Reconstruction, as a self-supervised task to extract semantic information, is trained in a multi-task manner together with aesthetic assessment in this article. This semantic information will be combined with aesthetic information of images to evaluate the image aesthetics. Auto-Encoder, which is a generative SSL architecture, 24 can leverage input data itself as supervisory signal. It is used in our model to extract the image semantic information without any additional labels.
Semantic Information in IAA
As a necessary prerequisite of image aesthetics assessment, the importance of semantic information in IAA is indisputable. Kao et al. 18 aimed to discover effective aesthetic representations with the aid of the semantic information. To this end, a multi-task network was built to accomplish the semantic recognition and the IAA task simultaneously. They further introduced a correlation item between these two tasks for learning the inter-task relationship. Zhang et al. 23 proposed a double-subnet network, in which one subnet attends aesthetic-relevant regions by encoding the holistic information, while the other one extracts fine-grained features from these attended regions. Then, a gated information fusion module adaptively combined the extracted fine-grained features at global and local levels.
Unfortunately, the extracted semantic information in literature18,23 is only used for guiding independent tasks like recognition or attention allocation. In other words, the semantic information, in these previous works,18,23 only plays an implicit role in predicting the aesthetic scores.
In contrast to the existing works,18,23 in this article, we propose to explicitly combine the semantic information with aesthetic information in a pre-activating manner. A semantic-aesthetic fusing module is designed to inject aesthetic information semantic information for their combinations. Doing so helps the model to focus on aesthetic-related semantic region, as demonstrated in the “Visualization” section. Hence, our method makes better use of semantic information to assist the task of IAA by explicitly fusing semantic and aesthetic information. The difference in the manner of using semantic information between previous methods and ours is shown in Figure 2.
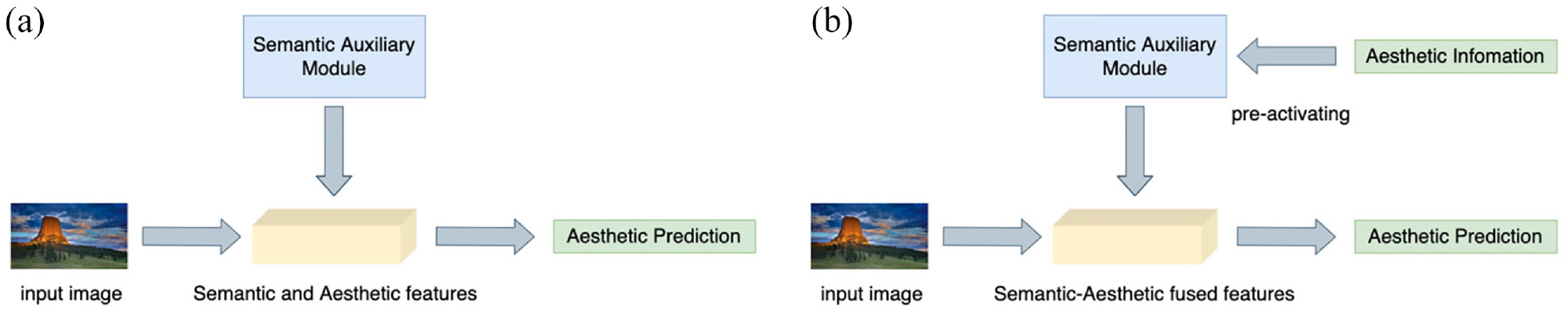
Difference in the manner of using semantic information between previous IAA methods and ours. (a) Previous methods. (b) Ours.
Contributions
Semantic information is important in IAA tasks as it is an intuitive prerequisite for evaluating the aesthetic. However, according to our investigation above, some previous works16,17,21,22 ignored this important information, while the other ones18,23 either need additional labels or are not explicit enough when utilizing semantic information. Therefore, there still exists room to improve these previous methods.
In this article, we propose a new aesthetic evaluation model that extracts and utilizes semantic information efficiently. First, a generative SSL model, that is, Auto-Encoder, is utilized to extract the semantic information without using any additional manual labels. Auto-Encoder is a classic generative self-supervised model which can use input data itself as a supervisory signal. In addition, a benefit is the ability of Auto-Encoder to maintain the complete semantic information of the image the proposed model intuitively improves the performance cross the data sets. Second, to use the semantic information more efficiently, we propose a fusing module to explicitly combine the semantic information with image aesthetics. This module is prepended at the bottleneck layer to inject the image aesthetics into the extracted semantic information. With the fusing module, there will be a relationship established between the distributed aesthetic score and pre-activated features. Thus, the combination mentioned above can be realized to assist the aesthetic evaluation. However, a conventional multi-way regressor may cause the confusion of these relationships. To address this issue, we implement a split multi-way regressor to replace the conventional one. In our experiments, the superior performance of the proposed model proves the effectiveness of our design.
Our contributions can be summarized as follows:
We propose to utilize a self-supervised model called Auto-Encoder to extract the semantic information of the images in the form of multi-task learning. This process does not require any additional manual labels.
A fusing module is designed to explicitly combine semantic information with aesthetic information in a pre-activated manner. In this module, a weak constraint is applied between the semantic features and aesthetic information to realize the combination.
The entire network is kept free of fully connected layers except for the prediction module and uses the spatial pyramid pooling layer to fix the feature dimensions before the final prediction. Therefore, our model can adapt to the image input with arbitrary aspect ratio.
Our Proposal
In this section, we first provide an overview of the proposed IAA model. Then we introduce three specific modules (i.e. auto-encoder module, semantic-aesthetic fusing module and prediction module) in detail. The loss functions that guide the process of training will also be introduced in each subsection.
Problem Definition
Let
Overview
The main insight of our method is to incorporate SSL method into the aesthetic evaluating network to extract semantic information and combine it together with aesthetic information. The model can better understand image aesthetics with the help of semantic information. Except for this, the aspect ratio of image has to be strictly maintained, because its changes can exert a great impact on the aesthetics of an image. Therefore, an IAA model needs to adapt to different aspect ratios.
The overall architecture of the proposed model is illustrated in Figure 3. This model is composed of three modules: (1) the auto-encoder, which is a generative SSL module, 24 aims to extract semantic information from the images without using any additional manual annotations; (2) the Semantic-Aesthetic Fusing (SAF) module is designed to inject aesthetic information into semantic features in a pre-activated manner at the bottleneck layer of our model, so as to explicitly realize the combination between the semantic and the aesthetic information; and (3) the prediction module, consisting of a Spatial Pyramid Pooling (SPP) layer 25 and a multi-way regressor, is responsible for outputting the distributed aesthetic score.
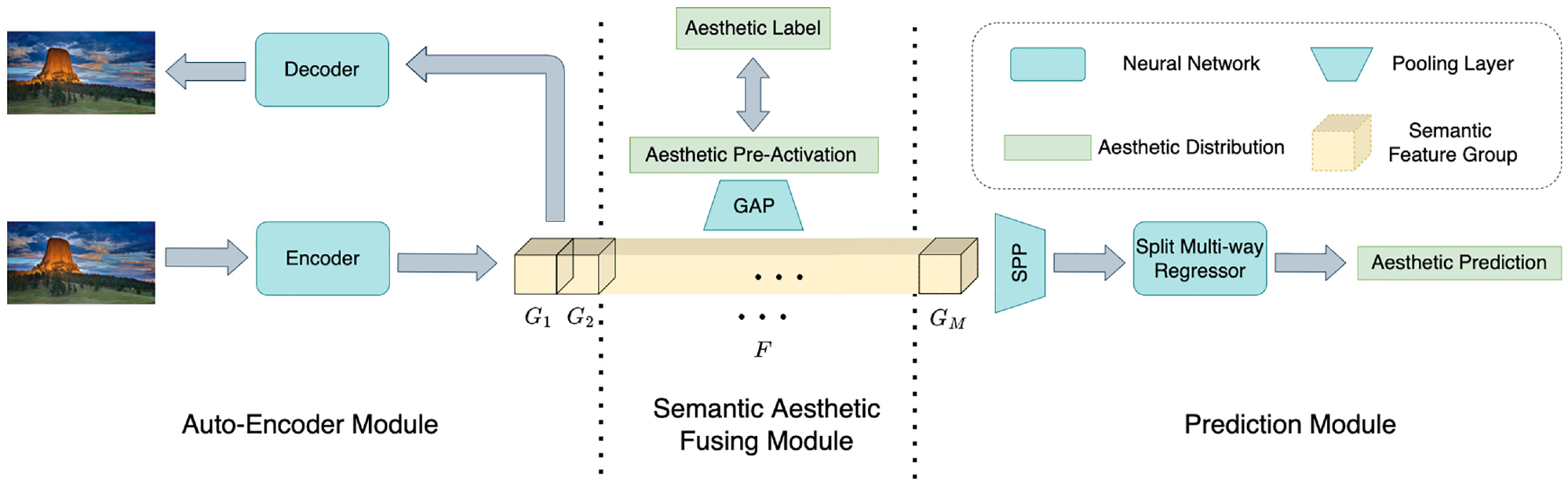
Overall architecture.
Our regressor network is composed of the fully connected layers. This is because the fully connected layer can realize a comprehensive feature integration over the spatial dimension. Thus, the features can be more accurately projected into fixed-dimensional logits.
However, the fully connected layer cannot directly adapt to input of arbitrary size. Therefore, the SPP layer is applied to pool the features by using multiple adaptive pooling layers of different sizes and concatenate their outputs to fix the feature dimension. In addition, in the whole model, the fully connected layer only exists in the regressor network. Thus, the proposed model can directly evaluate the aesthetic score of a given image regardless of its aspect ratio.
Auto-Encoder Module
Auto-encoder is a generative SSL model
24
composed of an encoder
Hereinafter, we introduce the workflow of Auto-encoder in detail. The encoder
To facilitate pre-activation operations in the subsequent SAF module, features
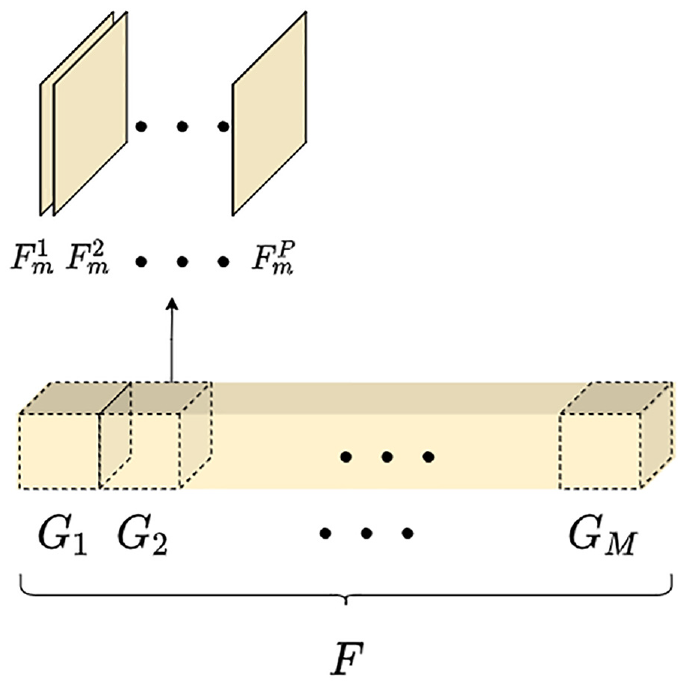
The procedure of splitting features into groups.
The decoder
Architecture of decoder.
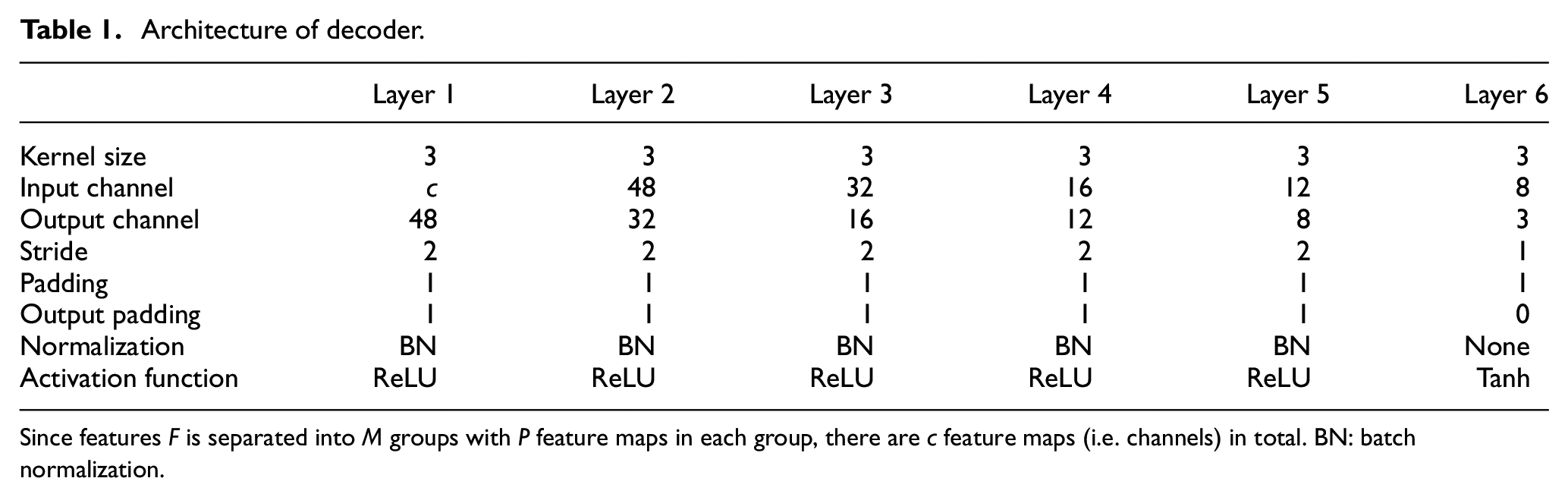
Since features F is separated into M groups with P feature maps in each group, there are c feature maps (i.e. channels) in total. BN: batch normalization.
The auto-encoder module uses the input image itself as a supervisory signal. The reconstruction loss between
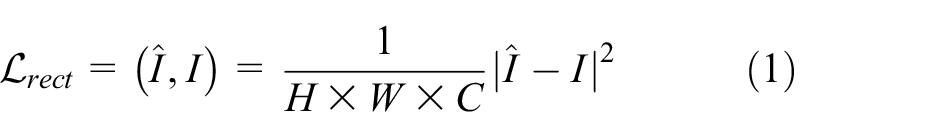
By minimizing the reconstruction loss, the auto-encoder module can effectively extract the semantic information preserved in
Semantic-Aesthetic Fusing Module
To explicitly combine the semantic information and the aesthetic information, we design a SAF module at the bottleneck layer of the proposed model. The goal of SAF module is to inject the aesthetic information into
Each component of
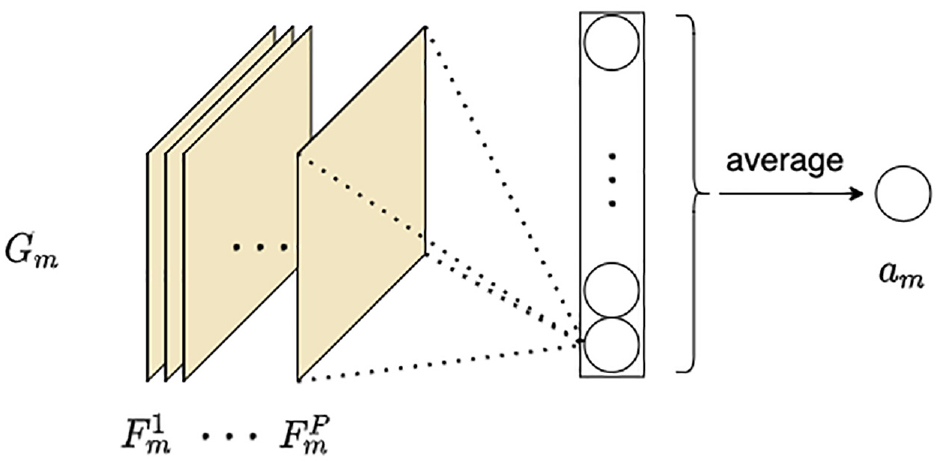
Group Average Pooling (GAP). Feature
After obtaining

where
The main idea of our SAF module is to combine the semantic information with the aesthetic information using a weak constraint. Therefore, we do not intend to apply over-strict constraints on the similarity between distributions in this phase. L1 distance calculates the sum of the absolute value of the difference between the target value and the output value. The constraint of L1 distance is for each independent scalar value, regardless of the information of distribution. Thus, it is considered as a relatively weak constraint for distribution compared with Kullback–Leibler (KL) divergence, JS divergence, and so on. To sum up, L1 distance is more suitable for our activation loss. In the “Comparative Study” section, an experiment is conducted to test different specific forms of activation loss, and the result validates the correctness of this choice.
Alternatively, the fully connected layers can be used in the SAF module to obtain
In addition, in our model, the value of
Therefore, the model needs an appropriate
Prediction Module
The prediction module is composed of an SPP (Spatial Pyramid Pooling) layer
25
and a separated multi-way regressor. The prediction module receives the extracted features
A fully connected layer is used in the regressor network to project features to
The specific process of SPP is shown in Figure 6. The SPP layer pools the features by using multiple sublayers. Each sublayer is composed of a different number of bins, and the pooling operation is performed in each bin (i.e. one value for each bin). The design of the combination of multiple sublayers with different sizes helps the model maintain multi-scale image information, since the number of bins in each sublayer is fixed regardless of the size of input features. The pooled features will be fixed to the same size. Then, these features can be handled by the regressor network.
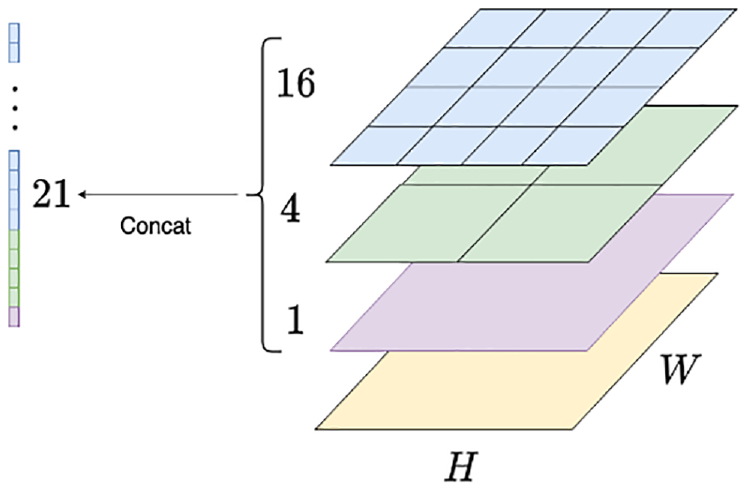
Spatial Pyramid Pooling (SPP). The SPP layer in this figure has three sublayers (purple, green, and blue), which consist of 1, 4, and 16 bins, respectively. No matter what the spatial size of the input feature map of this pooling layer is, its output is always a vector of length 21.
The regressor predicts the distributed aesthetic score
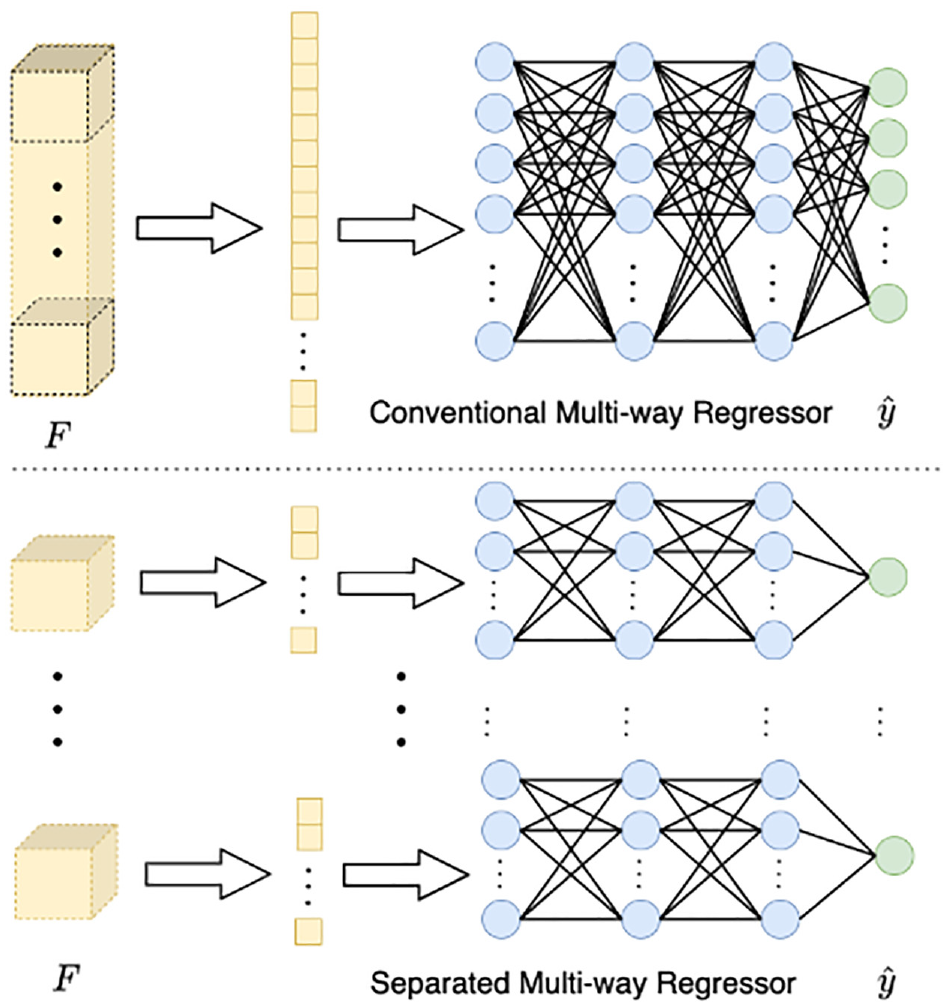
Comparison between conventional and separated multi-way regressor.
Similar to other studies,16,29,22 EMD (Earth Mover’s Distance) is chosen as the loss function between the predicted distributed aesthetic score
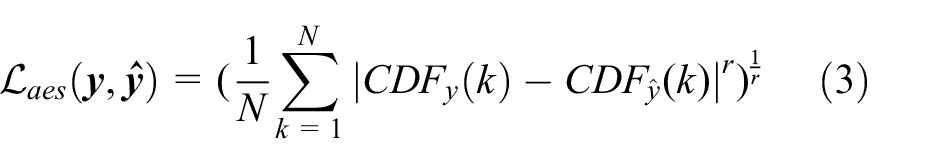
where
So far, all three loss functions of our method have been formulated. As mentioned before, our model is trained in the form of multi-task learning. The weighted sum of these three losses produces our total loss function
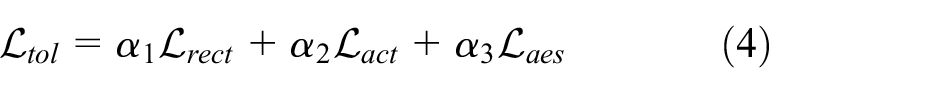
where
Experiments
In this section, we first give an introduction to the data sets used in throughout our experiments and make some necessary explanations of the details in the experiments. Then, we exhibit our quantitative results, ablation results, and visualization results, respectively.
Data Sets
Our experiments are conducted on a mainstream public data set called AVA.
7
The AVA data set has 250,000 images approximately, and each image is voted for aesthetic quality. The number of voters for each image ranges from 78 to 549, with an average of around 210. The aesthetic quality of each image in the AVA data set is denoted as a distributed aesthetic score range from 1 to 10. The distribution of the aesthetic score is normalized to the interval of [0, 1] to represent the probability of each score. One original image of the AVA data set is shown in Figure 8. On the left is an original image in the data set, and on the right is the corresponding distributed aesthetic score of this image (i.e.
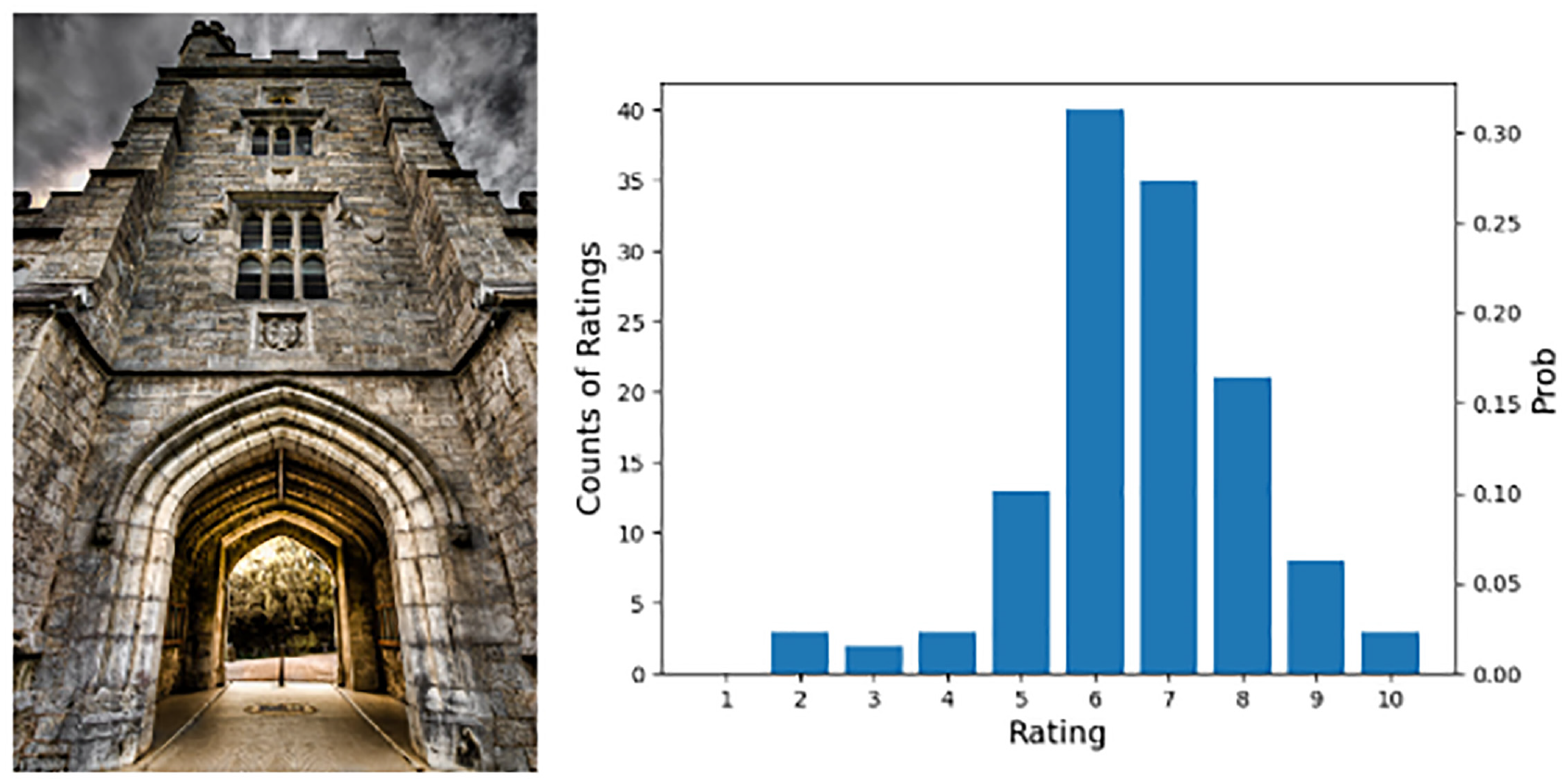
One original image in the AVA data set 7 and its corresponding distributed aesthetic score. Vertical axis at left is the counts of raters, and at right is the probability of each rating after normalizing.
Implementation Details
Image Preprocessing
The original image from data set is resized to 256 on the short edge. Note that the aspect ratio of the original image during this process is not changed. The aspect ratio of image is significant in the IAA task, as the aesthetics of the image will be deteriorated when its aspect ratio is changed. Similar to other studies,20,22,29,31,32 random horizontal flip is used for data augmentation, because it will not change the aesthetics of the image.
Backbone
Any CNN-based backbones for image classification tasks, such as AlexNet, 2 VGG, 26 ResNet, 1 GoogLeNet, 27 and DenseNet, 28 can serve as the encoder. VGG16 is chosen for fair comparison with other aesthetic assessment architectures.22,33
Hyperparameters
The Stochastic Gradient Descent (SGD) optimizer with momentum is used in our experiments, in which momentum is set to 0.9. The learning rate is set to
Software and Hardware Settings
All experiments presented below were conducted with PyTorch 1.7.0 and CUDA v11.2 on a server equipped with Intel® Xeon(R) W-2150B CPU @ 3.00GHz × 20 and GeForce RTX 2080 Ti.
Metrics
The following evaluation metrics were selected for testing. The average aesthetic score

Whether the predicted average score is close to the ground-truth is an important metric to evaluate the performance of the IAA model. The standard deviation of distributed aesthetic scores can reflect the consistency of people’s aesthetic opinions on an image. It can be calculated as:

Similar to other studies,16,22,29,31 the correlations between predicted average aesthetic score and ground-truth are regarded as the most significant metrics for the IAA task. We calculate the Pearson Linear Correlation Coefficient (PLCC) as:
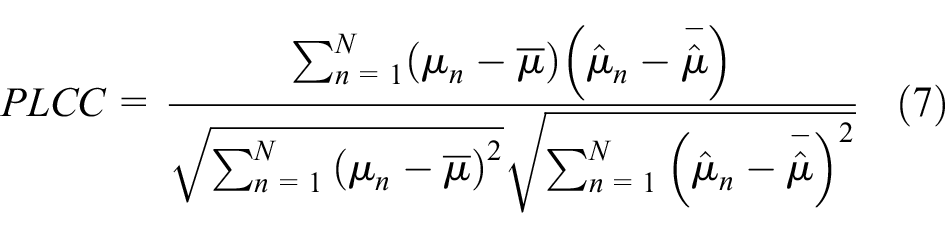
where
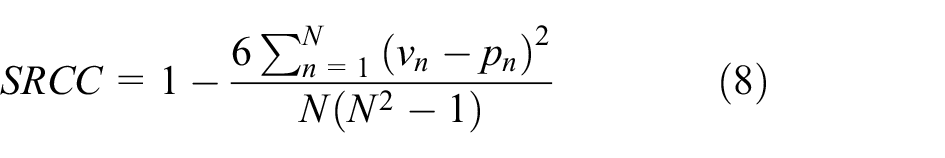
where
Besides, accuracy of binary classification is another common metric used in some early IAA works.7,20,33 According to the calculated average score

However, note that there is no explicit boundary of an image is beautiful or not in our real world. Setting an explicit threshold to directly divide images into two classes is debatable. But for comparison with previous IAA models,16,20,22,29,31,33 binary classification accuracy is also calculated in our experiments. Consistent with the previous works,16,20,22,29,31,33
Comparison with Baselines
Table 2 shows IAA performance comparisons between the proposed model and the previous methods16,20,22,29,31,33 on the metrics mentioned above. Our model achieves competitive performance with the help of efficient use of semantic information. Specifically, the proposed model outperforms all the other baselines on SRCC (mean), SRCC (SD) and PLCC (SD) and achieves second place on PLCC (mean). Our model gets relatively inferior result on accuracy of binary classification. Adaptive fractional dilated convolution (AFDC), in which the problem of the image aspect ratio is also properly solved, achieved the best performance in PLCC (mean) and accuracy of binary classification. As mentioned before, there is no explicit boundary to classify images as beautiful or ugly. It is controversial to take the accuracy of binary classification as a key metric.
Comparisons with baselines.
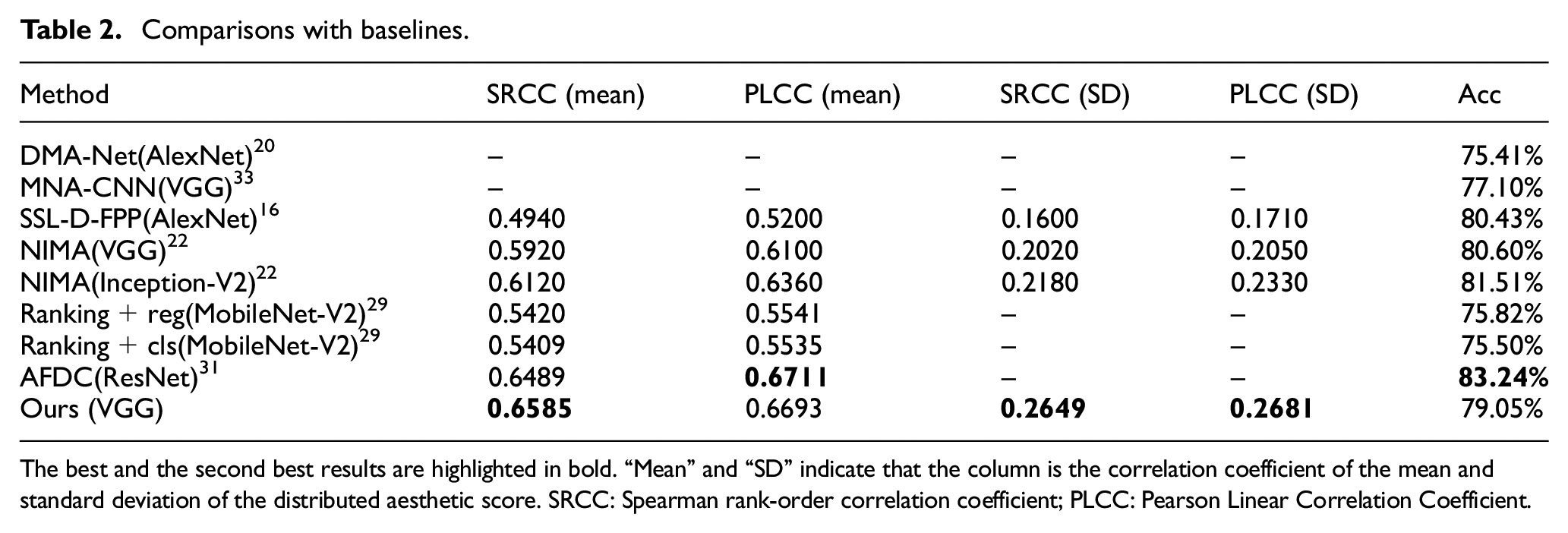
The best and the second best results are highlighted in bold. “Mean” and “SD” indicate that the column is the correlation coefficient of the mean and standard deviation of the distributed aesthetic score. SRCC: Spearman rank-order correlation coefficient; PLCC: Pearson Linear Correlation Coefficient.
Ablation Study
Ablation studies were conducted to show the specific effect of each module in the proposed model. Our ablation experiment shown in Table 3 demonstrates the effectiveness of our SAF module and the necessity of implementing the multi-way regressor in a separate manner. As shown in Table 3, the model trained without pre-activation (w/o Act) performs worst. This shows that if there is no pre-activation to explicitly combine the semantic features with the aesthetic information, the raw semantic information itself is of little help to the IAA task. This proves the effectiveness of our pre-activation design. In addition, without pre-activation, the design of the separated multi-way regressor will be meaningless; such a mismatched design may even further reduce the performance. See the third row of Table 3 for details. Instead, a joint regressor which can combine more information will get better results. As shown in the second row of Table 3, when the separated multi-way regressor is replaced by a conventional joint regressor (w/o Split), the corresponding model achieves a relatively high performance, but being slightly worse than our complete model. This is because the pre-activation can realize a better cooperation that eliminates the confusion of aesthetic information between each group.
Results of ablation studies.
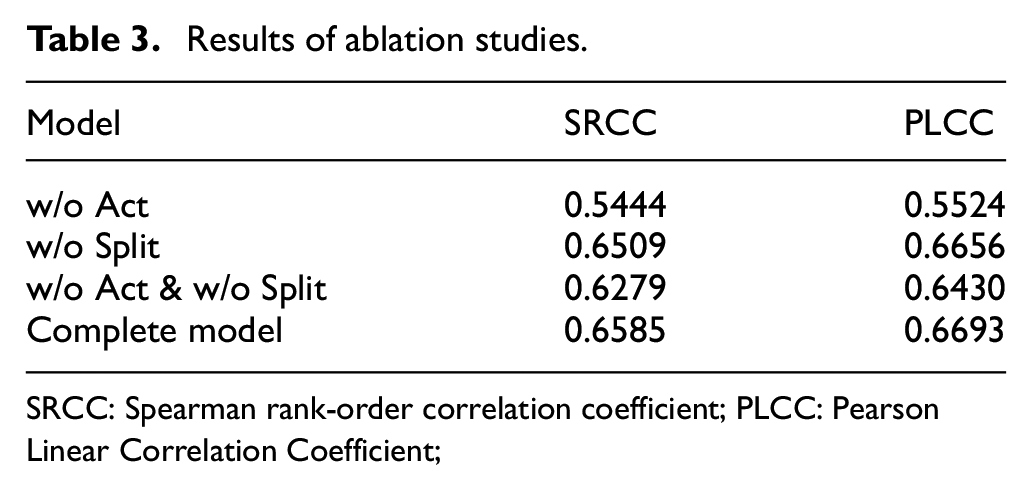
SRCC: Spearman rank-order correlation coefficient; PLCC: Pearson Linear Correlation Coefficient;
Comparative Study
In this section, we conducted comparative experiments with respect to the SAF module of the proposed method.
The Dimensions of the Features in Bottleneck Layer
The first comparative experiment is about the feature dimensions of the bottleneck layer. As mentioned before, the features
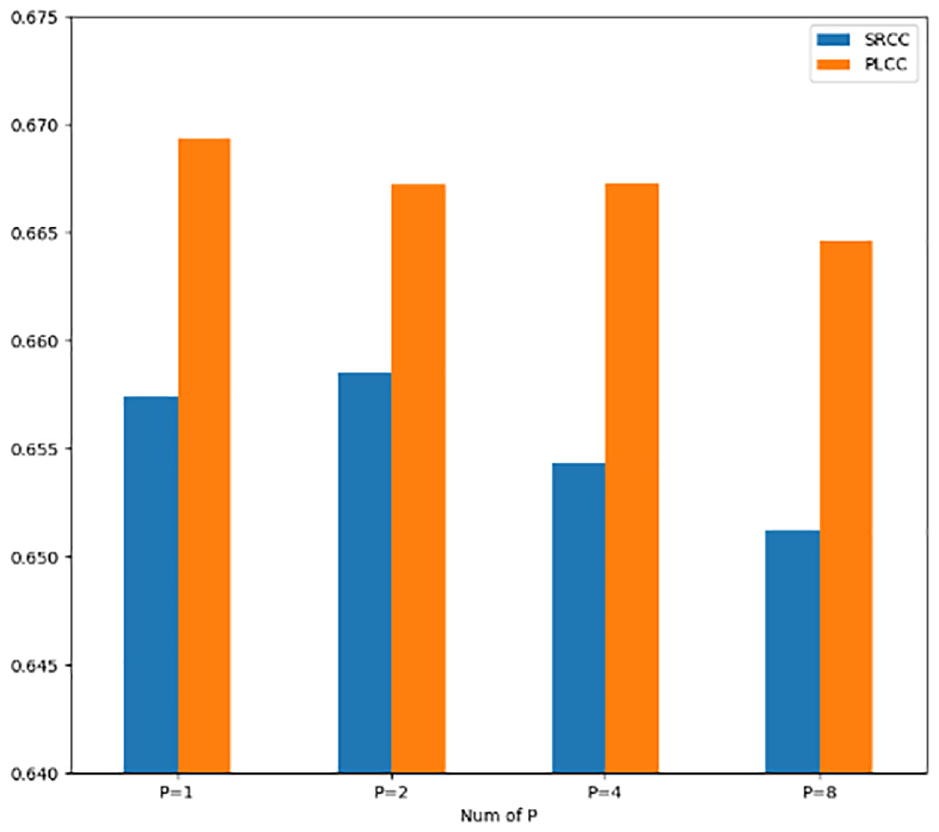
Results of comparative study for feature dimensions.
Specific Forms of Activation Losses
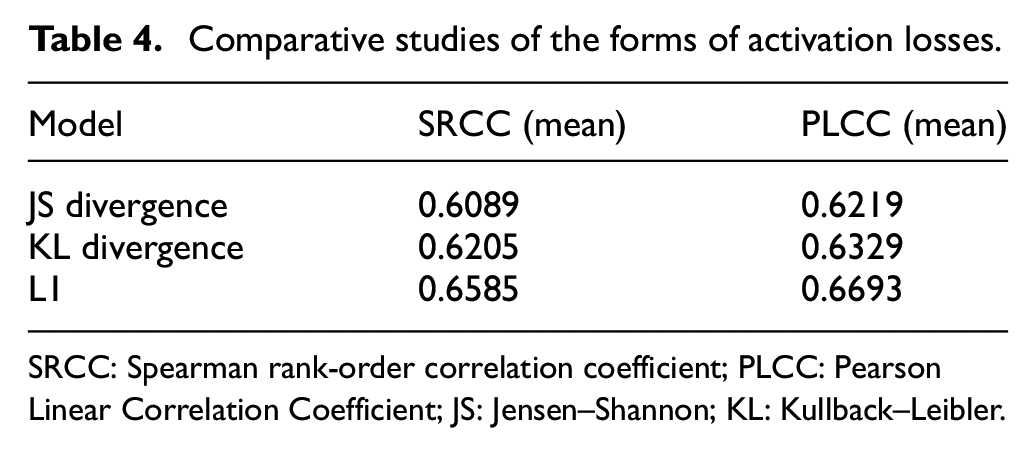
We conducted a comparative experiment to validate our choice of the specific form of activation loss. The results are shown in Table 4. It can be observed that the model performs worst when the activation function is JS divergence, and it is slightly better when the KL divergence is adopted. However, the model with these over-strict constraints on the distribution is much worse than L1 distance. The experiment results conform to our analysis in the “Our Proposal” section. It is not used to directly output the final prediction of distributed aesthetic score, but is used to explicitly combine the aesthetic information and semantic information of the image in a pre-activated manner. Therefore, compared with an over-strict distribution constraint function, a weak constraint like L1 distance is preferable here.
Comparative studies of the forms of activation losses.
SRCC: Spearman rank-order correlation coefficient; PLCC: Pearson Linear Correlation Coefficient; JS: Jensen–Shannon; KL: Kullback–Leibler.
Visualization
Visualization experiments were conducted to provide some intuitive understandings of the proposed model.
To better understand the working mechanism of pre-activation applied in the SAF module, we visualize the heatmap of

where

Grad-CAM visualization. (a) The original image in data set; (b), (c), and (d) the heatmaps added to the original image. The (b), (c) and (d) are: the vanilla Auto-Encoder, our model without activation loss, and complete model, respectively.
t-SNE Visualization
To further evaluate the effectiveness of our IAA model, we visualize the ground-truth and predicted distributed aesthetic score using t-SNE embedding.
35
Specifically, we selected

t-SNE Visualization: (a) is produced by random initialized model; (b) is produced by our model without pre-activation; (c) is produced by the complete model.
Cross Data Sets Validation
A single dataset is usually affected by the profession, personality, age, mood and etc. of raters. In other words, training on a certain dataset may mislead the trained model to fit the raters' personal factors. Thus, the ability of performing stably on different data sets of IAA model will be affected. Note that when the training data set is different from the testing data set, it is meaningless to use a specific value as the boundary of binary classification. As shown in Table 5, our method is significantly ahead of previous methods29,22 in two metrics. This is due to the reconstruction effect of the Auto-Encoder, which forces the model not only to learn the aesthetic information, but also to maintain the complete semantic information of the original image. Therefore, when there may be deviations in the aesthetic labels on different data sets, the influence of above factors of the training set can be relieved.
Cross data sets evaluation.
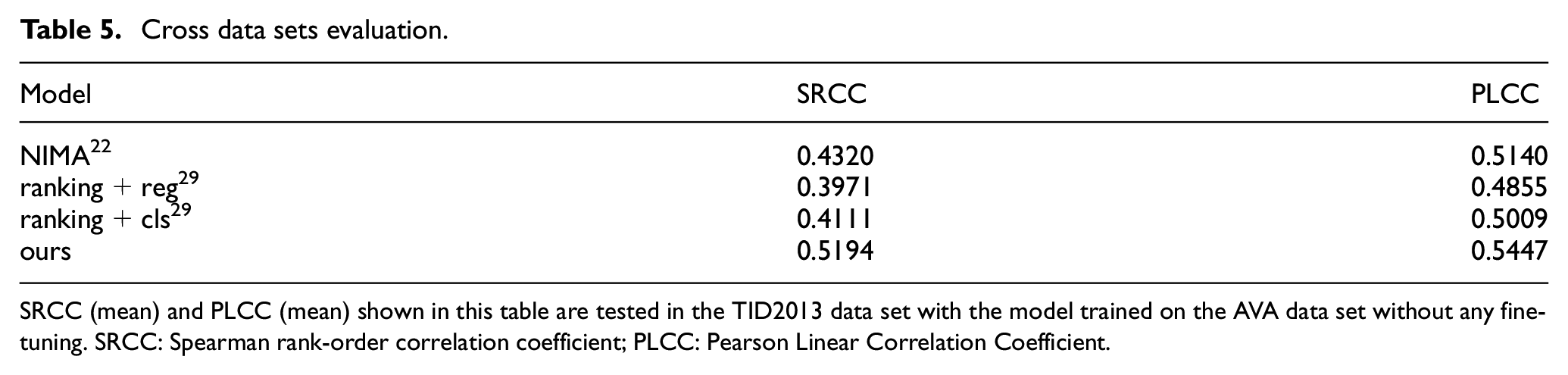
SRCC (mean) and PLCC (mean) shown in this table are tested in the TID2013 data set with the model trained on the AVA data set without any fine-tuning. SRCC: Spearman rank-order correlation coefficient; PLCC: Pearson Linear Correlation Coefficient.
Conclusion
In this article, we design a novel IAA model motivated by the utilizing the semantic information effectively by fusing it with the aesthetic information. Our model takes the self-supervised Auto-Encoder module as a branch to extract semantic information of images without using any additional manual labels. To use this semantic information efficiently, a fusing module is prepended at the bottleneck layer of our whole model. This fusing module is designed to inject image aesthetics into the semantic features using a weak constraint. To eliminate the confusion of aesthetic information caused by this fusing module, a separated multi-way regressor is implemented to replace the conventional one. In addition, we utilize the spatial pooling layer to enable our model adapt to arbitrary aspect ratio. Experimental results on the mainstream IAA data set demonstrate the effectiveness of the proposed method.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is partially supported by National Natural Science Foundation of China (62001099) and supported by the Fundamental Research Funds for the Central Universities of China (17D110408).