
Abstract
Fabric defects seriously affect the textile industry in China. Given that traditional manual detection methods have low efficiency and poor accuracy, using automatic textile defect detection methods is urgently needed. A fabric defect detection method based on an improved generative adversarial network is thus developed to address the shortage of fabric defect samples. This method learns to reconstruct the fabric image in an unsupervised manner and locates the defect areas based on the differences between the original image and the reconstruction. Afterward, the defect-related features are extracted from these areas to further recognize specific fabric defects. The central loss constraint is introduced to improve the recognition performance of this method, and lightweight processing is applied to guarantee its real-time operation in embedded systems. The application of this method is then evaluated on the publicly available Tianchi dataset. Both quantitative and qualitative results show that the proposed method can accurately detect fabric defects.
Keywords
Introduction
Given that the presence of defects seriously affects the price of fabric, 1 defect detection is critical to fabric production. Traditional defect detection methods usually involve manual detection and have the following disadvantages:
In response to these disadvantages, researchers have proposed the use of machine vision technology for the accurate and reliable detection of fabric defects. The current mainstream fabric defect detection methods include time-domain, frequency-domain, and deep learning methods.
The different grayscale values of pixels constitute the pattern and texture of fabric images. Time-domain methods, which mainly include statistics-based, texture-based, and gray co-occurrence matrix (GLCM) methods, detect defects by analyzing the grayscale distribution of fabric images. Statistics-based methods directly extract the grayscale histogram of fabric images as features and then classify these features by contrasting the grayscale histograms of normal/defective fabric images. 2 However, these methods have poor applicability, and their accuracy is easily influenced by small defect areas and changes in illumination. To extract highly robust features, texture-based methods perform defect detection by extracting texture features from fabric images. Some commonly used texture features include the edge 3 and local binary patterns.4,5 Texture filtering 6 and statistical texture transformations 7 are used to enhance the extracted texture features. However, categorizing defects based on these texture features leads to failure in recognizing specific defects. GLCM8,9 utilizes the spatial correlation properties of grayscale pixels to describe the patterns and textures of fabric images. These properties include contrast, inverse moments, entropy, and auto-correlation, all of which are sensitive to changes in fabric images and are easy to extract.
Frequency-domain methods are also widely used in fabric defect detection. Some commonly used frequency-domain methods include Fourier transform (FT), Gabor filtering (GF), and wavelet transform (WT). FT transforms an image from the space domain to the frequency domain using Fourier transform. Defect detection is then performed according to the characteristics of the defect-related high-frequency part.10,11 However, this method cannot easily position the defect areas. GF adds spatial representation to FT to achieve fabric defect localization.8,12 GF is also robust to changes in illumination, which may affect its defect detection performance. However, this method suffers from heavy computational overhead and cannot easily detect fabric defects in real-time. WT is similar to GF but has less computational overhead. However, WT achieves a higher defect detection success rate given the multi-scale property of wavelets.13,14
With the recent development of deep learning methods, many researchers have applied deep neural networks15,16 to detect fabric defects. Wei et al. 17 used Faster-RCNN to automatically detect textile defects and reported good detection results due to the robust feature learning ability of this method. Che et al. 18 enhanced the applicability of the traditional Fast-RCNN to high-resolution input images and small region defects detection. However, Faster-RCNN is a two-stage object detection scheme that is insufficient for real-time applications. Jing et al. 19 proposed an improved YOLOv3, which is a single-stage object detection method for detecting fabric defects in real time, and designed remarkable improvements based on the characteristics of fabric defects. Liu et al. 20 proposed lightweight convolutional neural networks for detecting fabric defects, and their model can be run on edge computing platforms.
Some researchers have used sparse coding technology to achieve fabric defect detection. For example, Tong et al. 21 proposed non-local sparse representation and constructed an over-complete dictionary for defect detection. Kang and Zhang 22 developed a sparse-coding-based dictionary to learn defect patterns from fabric images. Unlike the method proposed by Tong et al., 21 they designed an adaptive dictionary learning strategy to detect general fabric defects. Li et al. 23 proposed a low-rank representation method for fabric defect detection and employed the matrix decomposition method to distinguish normal textile images from defective ones.
Although the above studies have examined fabric defect detection from different perspectives, several challenges remain, including the lack of defect samples and uneven sample distribution, which may affect the training of defect detection models, especially those that are based on supervised learning methods. Moreover, while deep learning methods have demonstrated exemplary performance in fabric defect detection, they continue to show certain deficiencies, such as their significant model computation and high dependence on training data. Achieving a balance between speed and accuracy remains a non-trivial problem.
Following the above discussions, this paper proposes a fabric defect detection method based on an improved generative adversarial network (GAN). Figure 1 illustrates the pipeline of the proposed method. As shown in the figure, a difference image is obtained by calculating the difference between the input image and its reconstructed result generated by the improved GAN. Then, post-processing is used to detect the ubiquitous defect, precisely, to position the approximate defect areas based on the difference image. Afterward, the input image is fed into the specific defect detection module to recognize the puncture hole, guiding the approximate defect areas. The red dashed line indicates that the specific defect detection module utilizes partial functions of the improved GAN, specifically, the encoder part in the generator. Details of different modules will be discussed later. The main contributions of this article are as follows:
To address the problem related to the lack of defect samples, this paper proposes an improved GAN to learn the reconstruction of fabric images in an unsupervised manner. Compared with traditional fabric defect detection methods that depend on large numbers of defect samples, the improved GAN takes a large number of normal fabric images as input. Hence, it is no longer dependent on plenty of defect samples of different categories. Afterward, the approximate defect areas are positioned based on the difference between the input and reconstructed images.
To further recognize specific defects, the approximate defect areas are used to guide the extraction of defect-related features from the generator of GAN. The center loss constraint is introduced to improve recognition performance.

Pipeline of the proposed method.
Besides, the lightweight feature of the model is ensured through pruning operations and is optimized using TensorRT, which allows the model to run on NVIDIA Jetson TX2 in real-time. We argue that real-time performance is essential for fabric defect detection systems.
The proposed method is evaluated on the publicly available Tianchi AI dataset. Comparisons with other mainstream methods highlight the performance of the proposed method in detecting fabric defects. The rest of this paper is organized as follows. Section 2 introduces the related technologies. Section 3 presents the proposed method. Sections 4 and 5 present the evaluations and discussions, respectively.
Related works
Fabric defect detection methods
As we discussed before, the fabric defect detection methods mainly consist of the time-domain, frequency-domain, and deep learning methods. For a detailed review of modern fabric defect detection methods, we refer readers to the Li et al. 24 For time-domain methods, early works always adopted grayscale histograms of fabric images. 2 However, the grayscale histograms feature is not robust to disturbances like illumination changes. To improve the robustness of the fabric defect detection, many researchers designed various hand-crafted features3 –9 based on local binary patterns, GLCM, and low-rank representation. For example, Raheja et al. 8 combined GLCM and Gabor filter to detect fabric defects. Li et al. 23 performed defect detection based on fabric low-rank representations.
Since fabric defects can be taken as the noises in fabric images, defect detection can also be performed on the frequency domain. Widely used frequency-domain approaches consist of Fourier transform (FT), Gabor filtering (GF), wavelet transform (WT), and their variants. To name a few, Yapi et al. 25 designed an automatic fabric defect detection system using learning-based local textural distributions in the contourlet domain. Brad et al. 26 detected fabric defects using the combination of Fourier transform and Gabor filtering. Yang et al. 27 recognized different fabric defects based on wavelet transformation. Anandan and Sabeenian 28 used the discrete curvelet transform to discover fabric defects.
Modern fabric defect detection methods always resort to deep neural networks to automatically extract defect-related features. These methods can be divided into two categories, including supervised and unsupervised defect detection. Supervised fabric defect detection methods always leverage state-of-the-art detectors (a detailed review can be found in the next section) to detect defect regions and recognize different defects directly. For example, the two-stage Faster-RCNN 29 and the one-stage YOLO 30 are widely used in fabric defect detection systems. Liu et al. 31 utilized the single shot multi-box detector (SSD) to improve the defect detection, and the evaluation results demonstrate rationality and effectiveness. Ouyang et al. 32 presented a CNN-based algorithm for on-loom fabric defect inspection. It introduces a dynamic activation layer that utilizes the defect probability information with a pairwise potential function to a CNN. However, these supervised defect detection methods depend on many defective samples, which are hard to collect in practical conditions.
Unlike supervised defect detection methods, unsupervised fabric defect detection methods learn how to reconstruct a normal fabric image by feeding the model with plenty of normal fabric images to reduce the dependence on data. Theoretically, it cannot reconstruct a defective fabric image well, and hence defects can be found by calculating the difference between the defective input image and its reconstructed one. Typical unsupervised fabric defect detection methods are based on generators like GAN or auto-encoder. For example, Liu et al. 33 trained a multistage GAN model to generate reasonable defective samples from normal ones. Le et al. 34 utilized Wasserstein generative adversarial nets that combine transfer learning and multimodel ensembling technologies. Mei et al. 35 introduced a multi-scale convolutional denoising autoencoder network to synthesize fabric images further used to detect fabric defects. Our work is unsupervised, which mainly depends on an improved GAN to generate reasonable fabric samples.
State-of-the-art object detectors
Object detection refers to the identification of an object in an image along with its location and classification. As discussed in Section 2.1, many modern fabric defect detection methods rely on state-of-the-art object detectors, simultaneously locating the defect and recognizing its category. Hence, a brief survey of state-of-the-art object detectors based on deep learning is presented in this section.
The first deep neural network-based object detector is the Overfeat Network, 36 which uses convolutional neural networks along with a sliding window. Later, Girshick et al. 37 proposed Region-based Convolutional Neural Networks (RCNN), which improved nearly 30% over the previous state-of-the-art. RCNN performs object detection in a two-stage manner that firstly generates object proposals and then recognizes each proposal. Based on RCNN, Girshick further proposed Fast-RCNN, 38 Faster-RCNN, 29 and Mask-RCNN. 39 These two-stage object detectors achieve state-of-the-art performance on benchmarking databases like COCO. However, their computational complexity restricts their applications on intelligent edge equipment.
To accelerate the detection process, researchers presented a series of one-stage object detectors. The two most well-known approaches are SDD 40 and YOLO. 30 These methods generate plenty of proposals simultaneously and classify each proposal to achieve object detection. Based on YOLO, many variants are proposed. Besides, some studies are devoted to proposing novel loss functions or improving network structures. For example, Retina Net 41 proposes a Focal loss to alleviate sample imbalance. Pyramid Pooling Network 42 introduces the pyramid structure to solve the problem of scale difference.
Lightweight object detection methods
It is essential to reduce model parameters to accelerate their calculations or adopt parallel computing strategies to deploy the proposed method on computationally limited platforms. A more efficient way is designing lightweight CNN-based backbones. Unlike VGG, 43 ResNet, 44 and DenseNet, 45 there are lots of lightweight backbones, including MobileNet, 46 SqueezeNet, 47 ShuffleNet, 48 and PeleeNet. 49 Besides, several well-known strategies, for example, matrix decomposition, packet convolution, small convolutional kernels, model pruning, and model distillation, can also decrease algorithm complexity. In this work, we design a lightweight CNN-based generator, discriminator, and encoder. Details of our network will be introduced in Section 3.1.
Except for the lightweight object detection methods, studies on framework and hardware are also conducted to accelerate the modern deep learning-based methods. Specifically, TensorRT is widely used at the framework level to provide low latency and high throughput deployment inference for deep learning models. 50 It supports different deep learning frameworks, including TensorFlow, Caffe, and Pytorch. Besides, the TensorRT-based NVIDIA graphics processing unit, such as the high-performance embedding device Jetson TX2, 51 can be used to detect fabric defects with lightweight methods in real-time.
Proposed method
The proposed method is divided into two stages. The ubiquitous defects are detected at the first stage by reconstructing the input fabric images with an improved GAN. The coarse defect areas are positioned based on the difference between the input fabric images and their reconstructed versions. Specific defects recognition is performed at the second stage. The coarse defect areas are used to guide the extraction of defect-related features from the generator. The center loss constraint is introduced to improve recognition performance. Specifically, a center for deep features of each defect category is learned. Then, we jointly update the center and minimize the distances between the deep features and their corresponding class centers. With such an additional constraint, the learned deep features are more discriminative to detect specific defects. The proposed model is deployed on the NVIDIA Jetson TX2 after lightweight processing based on TensorRT.
Ubiquitous defect detection
Traditional fabric defect detection suffers from various defects and an imbalanced data distribution. Therefore, training a detection model in a supervised manner presents a challenge. An improved GAN is designed to detect ubiquitous defects in an unsupervised manner. At the training stage, GAN takes normal fabric images as input, and the network reconstructs normal fabric images after training. In this case, GAN cannot reconstruct both defect and normal images. Therefore, obvious differences can be observed between the input defect images and their reconstructed results at the test stage. On the basis of these differences, ubiquitous defects and coarse defect areas can be identified.
Figure 2 presents the structure of the improved GAN. A detailed introduction of vanilla GAN can be found in Creswell et al. 52 In this work, we directly introduce our improved GAN used to reconstruct fabric images. As shown in the figure, the network contains the generator G, discriminator D, and encoder E, where the generator G is implemented using an auto-encoder. The encoder and decoder in G are denoted by GE and GD, respectively. In this work, GE, D, and E have the same lightweight structure that contains four convolutional layers. Each is followed by a max-pooling layer, a batch normalization layer, and a P-Relu layer. All convolutional layers consist of 3 × 3 convolutional kernels, and their channel numbers are 8, 16, 32, and 64, respectively. Notably, GD has an inverted structure of GE and replaces the convolutional layer with transposed convolutional layer. Details to reconstruct fabric images with the improved GAN are as follows:

Structure of the improved GAN.
Firstly, GE takes sample x as input and outputs a latent variable z, which is subsequently fed into GD to output the reconstructed sample
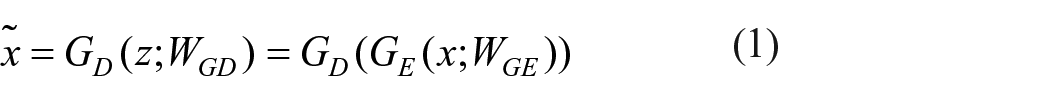
where WGD and WGE are the learnable weights of GD and GE, respectively.
Afterward, the discriminator D takes the sample x and reconstructed sample

where y represents the output of discriminator D and WD represents its learnable parameter.
Unlike a vanilla GAN, an additional encoder E is introduced to re-encode the reconstructed sample

where WE represents the learnable parameter of the decoder E, which is used to compress the image
Finally, to train the improved GAN, a joint loss function is introduced to optimize the network in a weighted manner. The loss function contains the following parts:
Adversarial loss: The adversarial loss characterizes the loss between the generator and discriminator during the game process. This loss is calculated as follows using L2 loss:

Content loss: Content loss reflects the difference between the reconstructed image

Encoding loss: The adversarial loss and content loss in the traditional GAN can enforce the generator to generate realistic and contextually sound samples. To better produce normal samples while restricting defective ones, an encoding loss 53 is used to minimize the distance between the bottleneck features of the input data and the encoded features of the generated samples. Therefore, the generator learns how to encode features of the generated image for normal samples. It will fail to minimize the distance between the input data and encoded features of the generated images for defective samples. The encoding loss is calculated as follows using L2 loss:

The joint loss function is defined as follows in a weighted manner:

where wadv, wcon, and wenc are the weighted parameters used to adjust the effect of an individual loss on the overall objective function. These parameters are set to 0.2, 0.7, and 0.1, respectively, through cross-validation on a public dataset.
After reconstructing fabric images, post-processing is used to detect ubiquitous defects and position coarse defect areas based on the input x and reconstructed

Flowchart of ubiquitous defects detection and coarse defect areas position.
Specific defect recognition
In specific defect recognition, extracting defect-related features is considered non-trivial if the defect areas are too small. Therefore, the information obtained at the ubiquitous defect detection stage is fully utilized. Specifically, the coarse defect areas guide the extraction of defect-related features from GE given that GE has learned the fabric patterns at the first stage. To improve recognition performance, the center loss constraints are introduced to enhance the discriminative ability of the learned features.
Figure 4 presents the flowchart of specific defect recognition. Given that the fabric image has ubiquitous defects at the first stage, the coarse defect areas are enlarged 1.5 times to generate fabric defect mask M, which contains probable defect areas and spatial context information. After the structure of GE and the size of the original image are fixed, the sizes of the feature maps generated by GE at different depths are determined. These feature maps contain visual features of fabric and we want to extract defect-related features from them. Therefore, we use the fabric defect mask M as a guide to extract defect-related features from Fi (i = 1, 2, . . ., L). To achieve this, M is re-sized to generate the mask sequence {Mi}, in which Mi retains the same size as Fi. Then, Mi can be used to constrain Fi as follows:

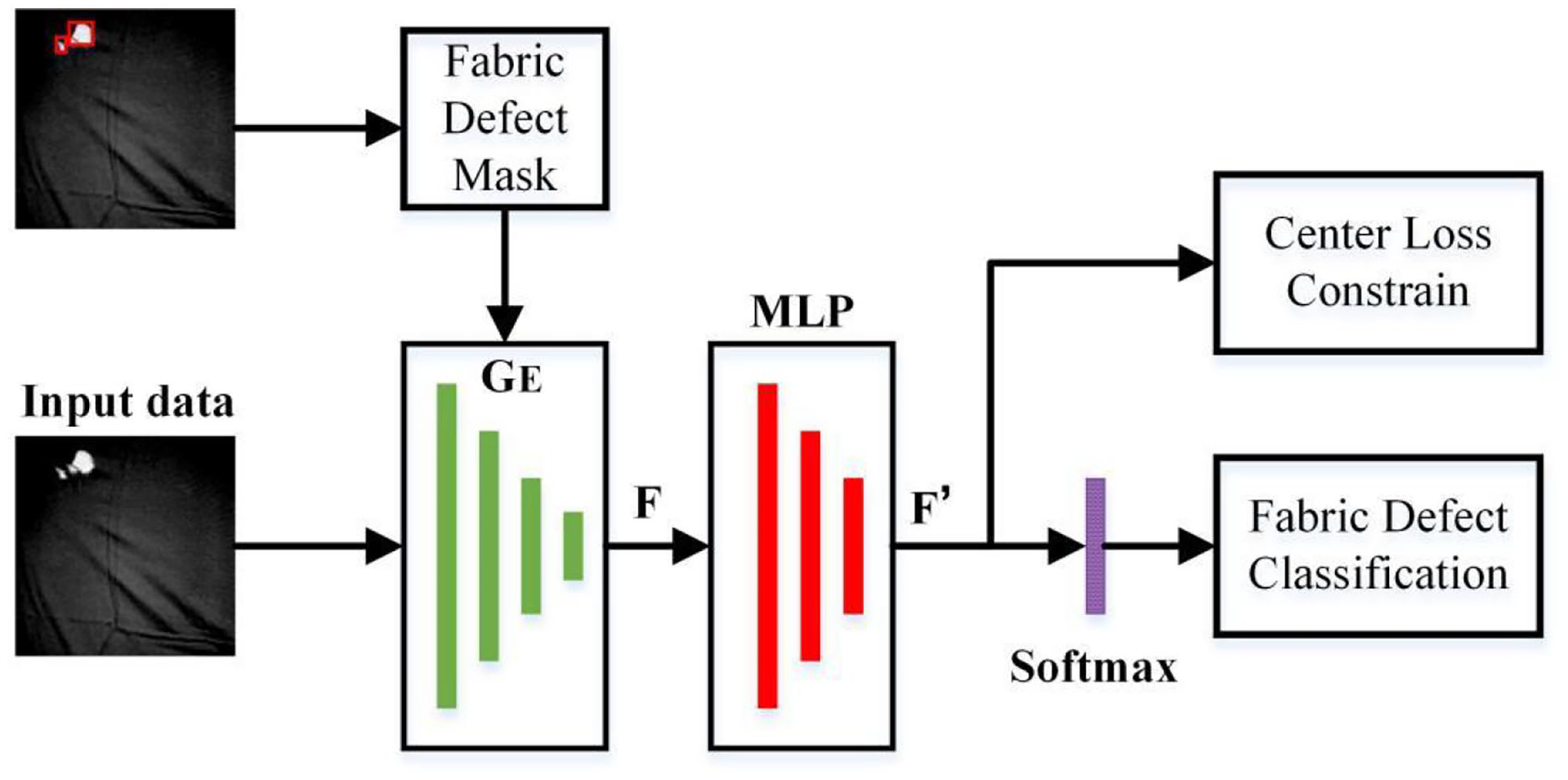
Flowchart of specific defect recognition.
where ⊙ denotes element-wise multiplication, L is the number of convolutional layers in GE, and F represents the extracted defect-related features.
A three-layer MLP (neuron numbers are 64, 32, and 16, respectively) is used to further process F and outputs F’, whose dimension is reduced from the channel number of F to the number of defect categories. To train the specific defect classifier, F’ is fed into a SoftMax activation function, and the following cross-entropy loss is used for classification:

where K represents the number of defect categories,
To enhance the discriminability of the learned deep features, the following center loss is introduced as a constraint:

Where
The joint loss function is then calculated as follows in a weighted manner:

where weights w1 and w2 are set to 0.9 and 0.1, respectively, based on the cross-validation results on a public dataset.
Model lightweight processing
The proposed method is lightweight processed to meet the real-time requirements in embedded devices. The lightweight processing is achieved by pruning the proposed model. The pruning process can be divided into two steps. First, the decoder GD in the generator, the encoder E, and the discriminator D are removed because these modules are only used in the training stage. After training, only the encoder GE is used to reconstruct the input fabric image. Afterward, the channel numbers of convolution layers in the remaining modules are reduced to decrease the computational overhead. Specifically, we employ a commonly used network optimization tool, optuna, to automatically shrink the channel numbers and fine-tune the hyper-parameters to prevent sharp performance degradation.
The Pytorch-based network is initially converted into the ONNX format for the lightweight models. Afterward, TensorRT is used to run the ONNX format model. TensorRt mainly comprises the build and deployment modules. The build module is mainly responsible for the transformation of the model, during which the module automatically completes inter-layer optimization and precision calibration. Meanwhile, the deployment module deserializes the plan files obtained in the previous step to create a running engine that enables network forward propagation. The model is eventually deployed on NVIDIA Jetson TX2.
Experimental results analysis
Dataset
The experimental data are obtained from the fabric defect detection dataset of Xuelang Tianchi AI Challenge, which contains 3331 textile images with defective positioning labels. Among these images, 2163 and 1168 are considered normal and defective, respectively. A total of 22 defects are detected, including knots, thin spinning, puncture hole, stains, and jumps. Given the data imbalance, the defect image samples are reintegrated into 10 categories, including puncture hole, knots, rubbing hole, brushed hole, thin spinning, hanging warp, lacking warp, jumps, stains, and others. These defects are common and not very complex. Notably, the proposed method can be used to detect other complex defects theoretically if enough training samples can be collected in practical conditions. The protocol proposed in 18 is adopted to ensure fair comparisons. Specifically, 70% of the dataset is used as a training set, whereas the remaining 30% is used as the test set. The samples and labels of the training data are shown in Figure 5.

Samples and their labels in the training set.
Ubiquitous defect detection
Figure 6 shows typical fabric defects in the test set. All images are transformed from RGB to grayscale to reduce computational complexity. The images from left to right and from up to down show the puncture hole, rubbing hole, knots, and thin spinning, respectively.

Typical fabric defects in the test set.
Figure 7 presents the reconstructed results of samples shown in Figure 6 using the improved GAN. At the training stage, the generator only learns knowledge from normal fabric images and is therefore unable to effectively reconstruct the defect regions.

Reconstructed results of the samples shown in Figure 6.
Figure 8 presents the differences between the test samples and their reconstructed results. Significant differences can be observed in the possible defect regions given that the generator cannot efficiently reconstruct the defective regions. As shown in the figure, the difference image contains the possible defect areas, and a binarization operation needs to be applied to detect ubiquitous defects and determine the coarse defect areas.
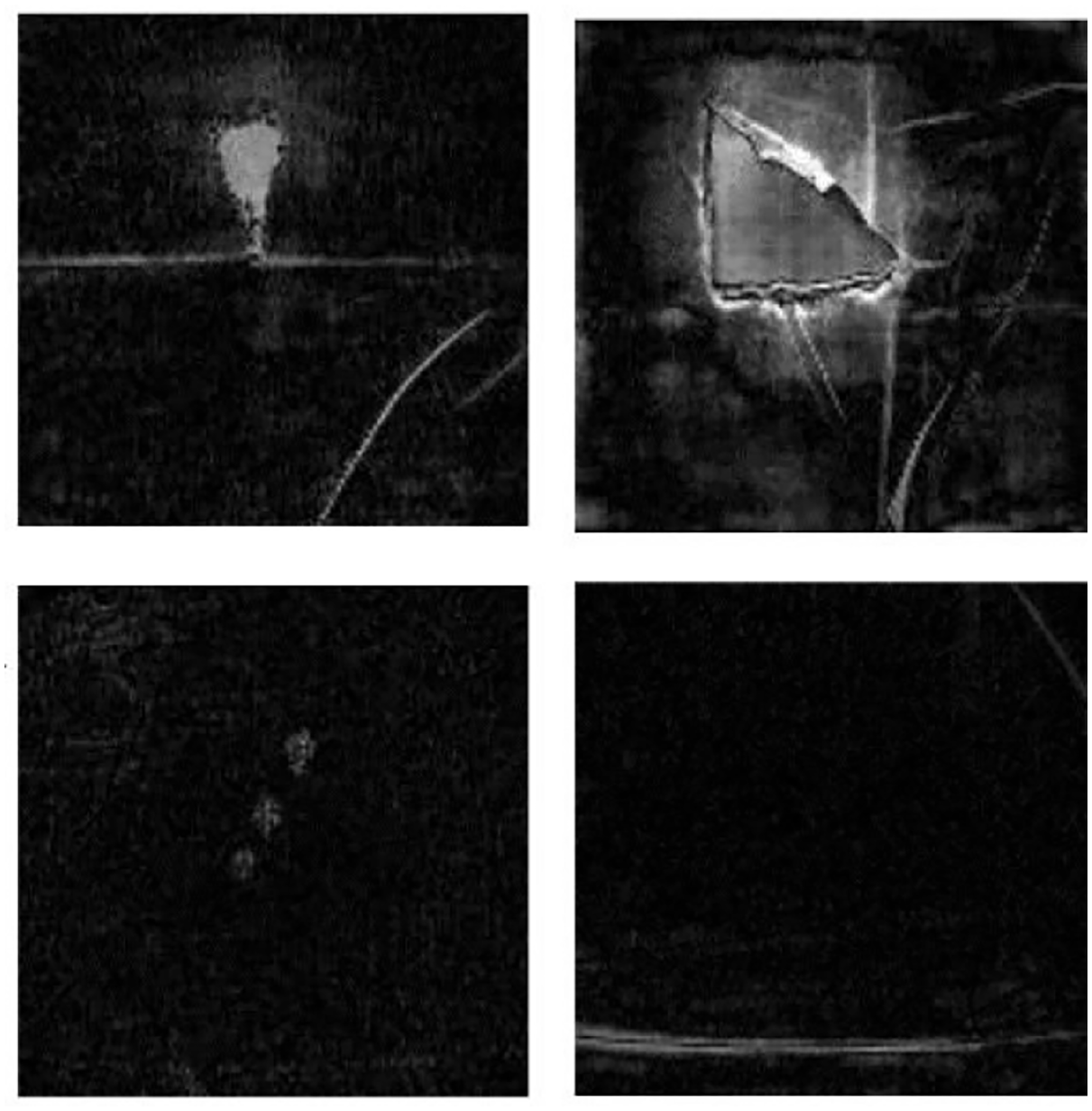
Differences between the test samples and their reconstructed results.
Figure 9 presents the binarization results of the difference images shown in Figure 8. After a series of operations, such as filtering denoising and connected domain analysis, ubiquitous defects are detected by comparing the ratio (foreground white pixels/total pixels) with a given threshold. If the ratio exceeds the threshold, the fabric image is considered a defective sample. The coarse defect areas are positioned based on the foreground white pixels.

Binarization results of the difference images shown in Figure 8.
Thresholds determination
As described in Section 4.2, ubiquitous defects are detected based on the binarization results of the difference images, which are calculated between the input and reconstructed fabric images. Moreover, the ubiquitous defects are detected by comparing the ratio with a given threshold. Ideally, the reconstructed images should contain no defect for further defect detection processing. However, we must highlight that all reconstructed images generated by the proposed GAN may contain noise and ghosts, even when reconstructed from normal fabric images. Therefore, the binarization threshold T and the given threshold P are essential in ubiquitous defect detection. What makes the thresholds determination thornier is that T and P have a mutual influence. Therefore, a detailed analysis is conducted to determine these thresholds.
Small deviations are observed between the normal fabric images and their reconstructed results. Therefore, determining T and P not only ensures the detection of defective areas but also avoids judging the normal fabric images as defective. All fabric images in this work are divided into normal and defect samples. The well-trained GAN reconstructs all normal and defect samples, and the recognition rates of different T/P settings are calculated to determine the T/P values.
Table 1 shows the rates at which the normal fabric images are detected as normal when using different T/P settings. The recognition rate is used as the evaluation index, which is computed as the ratio of correctly identified samples to all test samples. Recognition rates above 0.78 (empirical threshold) are highlighted in faint yellow. These corresponding T/P settings are assumed to successfully recognize the normal fabric images.
Rates of detecting normal fabric images as normal when using different T/P settings.

Table 2 shows the rates at which defect fabric images are detected as defects when using different T/P settings. Recognition rates above 0.60 (empirical threshold) are highlighted in faint yellow. N/A indicates that the recognition rate is less than 0.5. Given that T/P values should identify the defective areas and avoid misclassification of normal images as defects, overlapping faint yellow regions are highlighted in dark yellow. In these regions, the proposed method can meet the abovementioned requirements. Following the above discussions, the highest recognition rate is achieved when the T/P values are set to 70 and 0.03. Therefore, these T/P settings are used as thresholds in the subsequent analyses.
Rates of detecting fabric defect images as defects when using different T/P settings.

Quantitative evaluations
After determining the T/P settings, the proposed method is quantitatively compared with several mainstream fabric defect detection methods on a public dataset. These methods include the AlexNet-based OurNet, 54 CNN-based defect detection method, 19 and non-local sparse representation-based defect detection method. 20 All these methods use the same data settings to ensure fair comparisons. Table 3 presents the recognition rates for each method.
Recognition rates for different methods.

As shown in the table, OurNet has a poor defect detection performance and cannot efficiently handle small region defects because it only used an AlexNet as the backbone. Hence, it is non-trivial to recognize small region defects by directly extracting defective features from the whole image. Jing et al. 19 proposed a lightweight CNN designed according to the characteristics of fabric defects, thereby improving its defect detection performance. They proposed a lightweight variant of YOLO, named YOLO-LFD, to detect fabric defects. Multi-scale features were extracted to improve the detection ability of the proposed method for different size defects. However, its supervised training strategy restricts its detection performance. Liu et al. 20 used non-local sparse representation to characterize the fabric patterns and detect the defects. Despite its ability to describe large and middle region defects, it is struggling to characterize the patterns of small region defects. Its performance is between OurNet and YOLO-LFD. Compared with the above-mentioned methods, our method learns the fabric patterns with an improved GAN, uses the coarse defect areas to guide the extraction of defect-related features, and introduces the center loss constraint to improve the discriminability of the learned features. From these improvements, the proposed method achieves the best defect detection performance on the public dataset among the compared methods.
Lightweight processing is applied to improve the detection speed of the proposed method. The total defect detection process contains three parts, including reconstructing the fabric image with the improved GAN, localizing the defect regions from the difference between the input fabric image and the reconstructed image, and recognizing the defect category by classifying the defect-related features. These parts can be worked in a cascaded manner after training the improved GAN and classifier, respectively. Specifically, the total defect detection process spends approximately 80 ms in defect detection on the TX2 processor without lightweight processing. However, the whole process only spends 36 ms in defect detection with lightweight processing. Such improvement in detection speed meets the real-time running requirements of edge intelligent devices.
Qualitative evaluations
Qualitative evaluations are performed on a public dataset, and OurNet is used for comparison. Figure 10 shows the fabric defect detection results, where the inaccurate predictions are highlighted in red. The proposed method successfully recognizes different defect types, whereas OurNet fails to identify the hanging warp and jump defects as shown in the third line of Figure 10. Moreover, OurNet mistakes the thin spinning and stain defects for the lacking warp and hanging warp defects, respectively. The proposed method is obviously more powerful than OurNet in recognizing defects in small regions. Such superiority can be ascribed to its use of coarse defect areas to guide the extraction of defect-related features. Moreover, the center loss constraint can improve the discriminability of the learned features. Therefore, the proposed method effectively addresses the challenges in detecting small defects.

Qualitative analysis of defect detection on a public dataset.
Besides, we evaluated the proposed method on several self-collected fabric defective images to prove the generalization performance of the proposed method. Similar to the qualitative evaluations on benchmarking database, OurNet is adopted for comparison. As shown in Figure 11, the proposed method successfully detects all fabric defects, including stains, hanging warp, and knots. However, OurNet cannot detect the stains and knots defects as shown in the second line because it is not suitable to detect small region defects. The results of Figure 11 verify that the proposed method can achieve satisfactory performance in practical conditions.

Defect detection results on self-collected data.
Summary and discussion
An automatic fabric defect detection algorithm based on an improved GAN was proposed in this work. Considering the various fabric defects and imbalanced data distribution, we introduced the GAN to detect ubiquitous defects in an unsupervised manner. The GAN learned to reconstruct fabric images from normal samples in the training stage. Therefore, it could not reconstruct fabric defects because it learned nothing about them in the training stage. In contrast to the vanilla GAN, an additional encoder was introduced to re-encode the reconstructed sample. The proposed encoding loss improves the learning process of the latent vectors. Afterward, ubiquitous defect detection was achieved by calculating the difference between the input fabric images and their reconstructed results generated by the well-trained GAN. The difference images were further used to generate the coarse defect masks, which in turn were used to guide the extraction of defect-related features from the feature maps generated by the encoder in the generator (GE). An MLP processed the defect-related features, and the output of MLP was fed into the Softmax to recognize the category of specific defect. The center loss constraint was then used to improve the discriminability of the learned features. Evaluations on the publicly available dataset of Xuelang Tianchi AI Challenge verified the feasibility and accuracy of the proposed method.
This method was proven useful in achieving automatic quality detection in textile production and in improving textile production efficiency. In our future work, we aim to accurately locate the defect areas and further improve the defect detection accuracy of the proposed method.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Natural Science Foundation of China under grant number 51674265.