
Abstract
Cities worldwide are commonly aspiring to transition from inefficient urban sprawl patterns to more compact and sustainable urban forms. However, urban densification efforts often face significant public resistance or skepticism, hindering at-scale implementation. There is a scarcity of empirical studies identifying the rationale and mechanisms underpinning public opposition to urban density. This study aims to bridge this gap by leveraging novel natural language processing techniques (NLP), combined with mixed-methods analysis of a unique, highly detailed public dataset on urban intensification in Hamilton. This research stands out by proposing a transferable model for rapidly generating insights from large public feedback datasets, and also unveils the polarized and complex, self-interest-driven mechanisms, including NIMBYism (Not In My Back Yard), behind public support or opposition to urban densification. NLP techniques, such as sentiment analysis, topic modeling, and ChatGPT, can be used to offer rapid insights into a large, unstructured public feedback dataset. When combined with submitters’ individual interest representation and identifies, these AI-generated summaries can offer important insights into the hidden rationales behind public opinions, and, more importantly, be used to design tailored public engagement activities to obtain community buy-in.
Introduction
Urban densification is often the focal point of contemporary planning debates (Keil, 2020). The narrative of greater density in urban areas runs in contrast to urban sprawl which has been the dominant development pattern for decades (Ehrlich et al., 2018; Nijman, 2015). Urban sprawl, with inefficient land use, is notoriously unsustainable, leading to a wide range of negative urban outcomes, such as environmental degradation, traffic congestion, housing unaffordability, and societal segregation (Addison et al., 2013; Barbour and Deakin, 2012; Ewing et al., 2008). In response, multiple key urban movements, from smart growth (Downs, 2005) and sustainable development (Dempsey et al., 2011) to the recent rise of chrono-urbanism (Allam et al., 2022), have advocated for urban densification to combat sprawl.
However, aspirations to shift the development paradigm toward greater urban density often clash with public perceptions and preferences, evoking polarized reactions (Herdt and Jonkman, 2023; Whittemore and BenDor, 2019). Those who oppose densification are often termed NIMBYs (Not In My BackYard), those who question the impacts of densification on local quality of life and personal space, preservation of local character, and capacity of existing infrastructure to support greater density (Robinson and Attuyer, 2020; Schively, 2007). Contrary to this ethos, the YIMBY (Yes In My BackYard) groups support densification in their neighborhood, citing many of the previously discussed advantages for contemporary urban living (Lake 2022). These dichotomous perspectives reflect a broader societal and generational tension between maintaining the existing status quo and the imperative need for an urban transformation.
For urban planners, understanding the underlying rationale behind public opinions on urban density is vital for obtaining community buy-ins for promoting sustainable urban development. However, this has become increasingly challenging for planners in real-world practice. On the one hand, the empirical evidence about who and why various involved communities support or oppose density is not only limited but also highly contextual to localities, thereby lacking transferable lessons (Cheshire et al., 2019). On the other hand, existing practices of manually analyzing public feedback data, collected in growing volumes through online participation platforms, are becoming increasingly time-consuming, laborious, and costly. In short, the need for rapidly understanding the local dynamics of public opinions, along with the growing data problem in this digital era, is asking for innovative approaches to assist planners and public officials in deriving informed, timely community-tailored responses.
Natural language processing (NLP), especially the latest development of large language models (LLMs), has demonstrated promising potential for analyzing the textual public feedback data at scale (Crooks and Chen, 2024). While research has proliferated in employing NLP tools to analyze large textual datasets such as social media data and planning documents (Cai, 2021; Fu, 2024), few studies focused on the actual public feedback data and how these tools can be used to text-mine public opinions systematically. This research aims to contribute to this important literature by demonstrating a methodological framework that leverages the advanced capabilities of various NLP techniques to analyze public opinions and preferences efficiently and effectively, as exemplified by using a unique public feedback dataset from Hamilton City Council (HCC), the local government for New Zealand (NZ)’s fourth-largest cities. While our proposed framework offers the needed guidance for harnessing novel NLP techniques in planning practice, we also highlight their limitations, discuss the potential implications, and provide a future research outlook.
This paper is structured as follows. The following literature review section primarily provides the academic backdrop to situate this research in the broader planning literature, with the first part focusing on the relevant literature on NIMBYism to help us contextualize the subsequent findings from text mining public feedback, and the second part emphasizing methodological studies using NLP techniques to support the development of the framework. We then detail our research methodology, including data collection, preprocessing, and the specific text mining techniques employed—namely, topic modeling, sentiment analysis, and LLMs. Results are presented in the following section, and we discuss these findings with broader N/YIMBY narratives and their implications for urban planning and policymaking. Finally, we conclude this study by highlighting key insights from our findings and elaborating the limitations of our study and then proposing areas for future research.
Literature review
NIMBYism and YIMBYism
Urban densification is situated at the nexus between NIMBYism and YIMBYism debates. NIMBYism, where residents oppose undesirable developments in their local area, has been widely observed in planning practice and across development types not limited to housing (Butterworth and Pojani, 2018; Schively, 2007). Such opposition can result in increased costs and missed opportunities for the city to develop and revitalize to meet the dynamically changing needs of residents on a larger scale (Lake, 1993). In the context of urban densification, NIMBY groups generally oppose density due to individualism, where individuals’ interests may be adversely affected despite that many community members may be better off. The NIMBY groups often claim that such development will result in decreased property value, increased competition for public resources, traffic congestion, environmental degradation, and a loss of community character (McNee and Pojani, 2022). On the contrary, YIMBYism is relatively new. These groups are especially active in cities experiencing housing crises, seeking to counter NIMBYism by arguing for urban densification as an effective solution to increase housing supply and advance social equity (McCormick, 2017).
Unlike what their names suggest, NIMBYism and YIMBYism are not necessarily mutually exclusive. The actual situation is far more nuanced. While NIMBYism is often connotated as a negative term in academia, it may still represent valid points against ill-advertised development projects, especially in neoliberal or authoritarian states where public scrutiny is lacking (Gerber and Debrunner, 2022; McNee and Pojani, 2022). Similarly, while YIMBYism does offer some reasonable grounds, it is not free from bias and has therefore been criticized, primarily due to the strong emphasis on neoliberalism and market-driven ideologies, such as gentrification (Tretter and Heyman, 2022). Their dynamics in the community offer invaluable insights into public perceptions and preferences for urban densification and planning processes. To this end, having a solid understanding of who and why the public opposes and supports urban densification projects is vital for planners and decision-makers to inform the development of effective and equitable local strategies (Innes and Booher, 2004).
Leveraging NLP for text mining public feedback
In recent years, planning researchers have increasingly utilized NLP techniques to process and analyze textual data (Fu et al., 2023, 2023b, 2024; Jiang et al., 2023; Ladi et al., 2022; Stich et al., 2023; Zhang et al., 2023). On one hand, many sophisticated NLP methods have been developed and proven effective for analyzing large textual datasets (Chowdhary, 2020; Khurana et al., 2023). On the other hand, the volume of available textual data from diverse sources, such as social media, public participation forums, and surveys, is growing exponentially, necessitating new tools to meet the growing needs of planners to process such voluminous data where every comment cannot be read by the same human planner or adequately coded and classified by a team (French et al., 2017). At this intersection, this research suggests that integrating NLP techniques to process and analyze textual data, such as public feedback, promises to enable a more comprehensive, and timelier understanding of public discourse on a larger scale, thereby facilitating more democratic and responsive urban planning and decision-making.
Central to this integration are NLP techniques to extract useful information from very large and often unstructured textual data. While there are plenty of NLP techniques, topic modeling and sentiment analysis are currently the two most used techniques in the planning literature (Fu, 2024). Specifically, topic modeling is a suite of statistical models that can automatically discover the commonly discussed topics from a large collection of textual documents (Jelodar et al., 2019), and sentiment analysis seeks to gauge the positive or negative orientation of any given text based on a sentiment and opinion lexicon (Wankhade et al., 2022). Both methods can be quite useful in analyzing public opinions such as mining what the public is discussing or complaining about along with overall sentiment.
However, most existing studies are primarily using these techniques on social media data. For example, Kong et al. (2022) applied sentiment analysis to analyze over 55,000 microblogs from Sina Weibo to examine public preferences for urban parks in Beijing. Other researchers used topic modeling to detect frequently discussed issues, such as assessing tourists’ perception of transport mode using public reviews from TripAdvisor (Serna and Gasparovic, 2018), and analyzing the changing themes of public discussions during 18 snowstorms using tweets within the State of Maryland (Hong et al., 2018). Additionally, numerous studies also combined topic modeling or sentiment analysis with other NLP techniques (e.g., TF-IDF and Word2Vec) to generate useful insights from similar datasets (Lock and Pettit, 2020; Su et al., 2021; Vargas-Calderón and Camargo, 2019; Zhai et al., 2020). To our knowledge, only one study used actual public feedback collected by the officials to automatically classify incoming public feedback based on a pre-trained topic model in the Seoul City of South Korea (Kim et al., 2021). Therefore, this research aims to address the existing research gap by providing and demonstrating a transferrable framework on how to leverage various NLP techniques to text-mine public opinions using a unique public feedback dataset.
Research Methodology
Research sample and context
The data used for this analysis was from public feedback in response to Hamilton City Council’s (HCC) Plan Change 12 (PC12) – Enabling Housing Supply, collected by the council between August 19 and September 30, 2022. HCC is the local government for Hamilton, the fourth-largest city in terms of population in NZ. The PC12 initiative was HCC’s local response to amend the council’s district plan (the local statutory planning document to regulate land use and development) to better align with two recent state legislations, namely, the National Policy Statement on Urban Development 2020 (NPS-UD; Ministry of the Environment, 2022a) and the Resource Management (Enabling Housing Supply and Other Matters) Amendment Act 2021 (the Act; Ministry of the Environment, 2022b), but it was not in full compliance (HCC, 2023). The central government claimed that both legislations were designed to facilitate increased housing density in urban areas by relaxing overly restrictive planning rules to improve housing availability and affordability. While the NPS-UD requested urban councils to plan for and enable greater density, the Act, enacted a year later, pushed the urban densification agenda much further by requiring major urban centers, including Hamilton NZ, to apply medium density residential standards (MDRS) across the city. This means that up to three dwellings, each up to three stories high, can be developed on each site without needing to apply for development approval, also known as resource consents in NZ, from the local council.
Methodology
This section describes our methodological framework in detail, broken down into two parts data preparation and data analysis (Figure 1). Specifically, we first explain how we pre-processed and prepared the raw data for the subsequent analysis. Then, we discuss the specific NLP techniques used, the reasons for choosing these techniques, along with the actual procedure. Research methodological framework.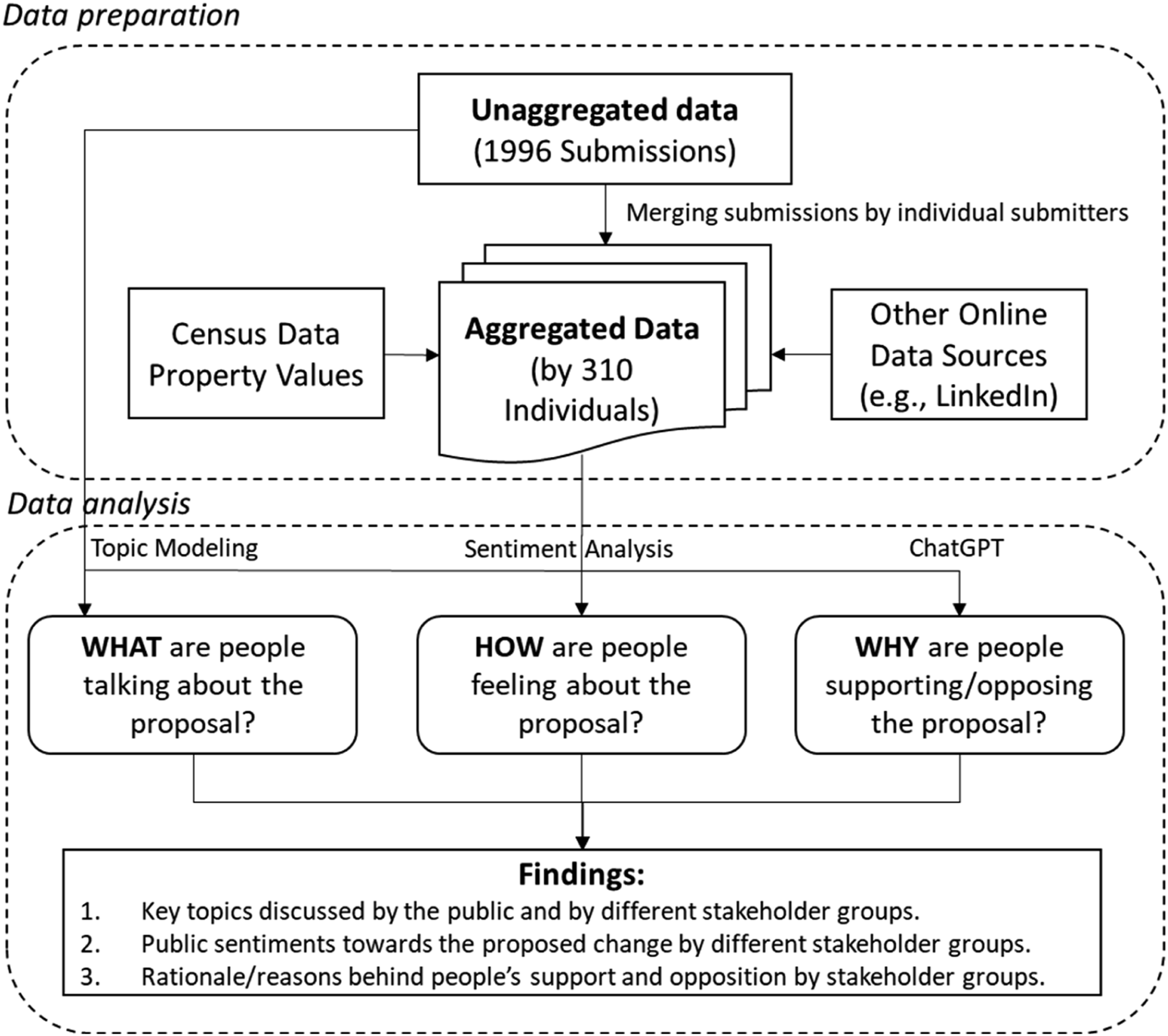
Data preparation
The raw (unaggregated) data, provided by the HCC, includes 1996 feedback entries from 310 distinct individual submitters. This is because a single submitter could submit multiple submissions, each focusing on a different aspect of the plan change, such as housing, transportation, or environment. Each submission contained information provided by the submitter regarding their personal or business identity as well as opinions on PC12, including their political stance against the proposed change, the reasons behind it, and the decisions sought. To uncover individual submitters’ opinions, we needed to consolidate the unaggregated dataset by merging the multiple submissions from each individual. This resulted in an aggregated dataset of 310 data entries by individual submitters.
Thanks to the detailed information provided about the submitters, we enriched the dataset by adding more information on each submitter to help us better understand their opinions in relation to the NIMBY/YIMBY framing. This included categorizing the submitters into their respective represented stakeholder groups, and geocoding individuals with verifiable home addresses, later combined with census data to associate them with the relevant neighborhood characteristics.
For stakeholder group categorization, we followed a systematic approach that involved: (1) for submitters with given organizations or businesses, identifying the type of their affiliations through online searches; (2) for those without affiliations provided, using Google and LinkedIn to find and identify the type of their professional representation; and (3) classifying unidentifiable submitters as the general public. Two research assistants were trained on a random subsample of 50 data entries, with discrepancies resolved by the lead researcher to ensure consistency, followed by finishing the rest of the dataset. Finally, submitters were categorized into four main categories: business (with subgroups including construction, consultancy, developers, lawyers, property management, and others), government (local and central government), (civic) organization (community groups, Māori, and professional organizations), and the general public. Next, we geocoded the dataset and verified 203 home addresses within the city (a map showing these locations can be found in Appendix Figure 1). These home addresses were then used to identify property appraisal values using Homes (Home.co.nz), and later spatially joined with census data at the Statistical Area 2 level (SA2, the most granular spatial level with rich demographic data) from Stats NZ (https://www.stats.govt.nz).
Data analysis
To text-mine this public feedback dataset, we employed three NLP methods, namely, topic modeling, sentiment analysis, and a novel large language model (LLM), ChatGPT (Figure 1). Specifically, we first employed sentiment analysis and topic modeling to provide a descriptive overview of how commenters felt about the proposed changes and what was also being discussed. We then leveraged the advanced reasoning ability of ChatGPT (gpt-4-1106-preview) to provide the reasons and shed light on why people from specific stakeholder groups supported or opposed PC12. All the analyses were conducted in the Python programming environment. Since the field of NLP is evolving rapidly with new techniques being developed almost daily, it should also be noted for researchers/practitioners wanting to adopt this framework that the selected techniques should be replaced by the latest or the most appropriate techniques tailored to their specific needs.
For sentiment analysis, we analyzed each submitter’s feedback using the Valence Aware Dictionary and sEntiment Reasoner tool (VADER, Hutto and Gilbert, 2014), a lexicon and rule-based technique that assigns polarity scores (−1, 0, +1 for negative, neutral, positive) to words based on a sentiment lexicon and aggregating them to determine the dominant sentiment. We chose the lexicon-based technique because of its computational efficiency, enabling analysis on larger datasets at scale, and VADER’s (python package vaderSentiment) superior performance as compared with other lexicon-based techniques (Bonta et al., 2019; Hutto and Gilbert, 2014). In addition to generating the sentiment scores, we also computed a composite opinion score 1 based on the submitters’ state political stance, as evaluated by the planners at HCC. We also conducted a correlation test between the composite opinion score and sentiment score. We found it statistically significant (p < 0.001), thereby suggesting the robustness for using the composite opinion scores to represent each submitter’s overall sentiment.
For topic modeling, we employed the Latent Dirichlet Allocation (LDA) approach using the Gensim python library. While there were various of such techniques, we chose the LDA technique due to its proven effectiveness, as evidenced by its wide adoption in the literature, as well as its ability to derive topical distribution within each data entry such that other advanced methods like BERTopic can only assign a single topic to each data entry (Egger and Yu, 2022). The topical distribution was important because we expected that the feedback would contain numerous topics, which might not be fully captured if we had used BERTopic. We first applied the LDA topic modeling to the unaggregated dataset, because we believed this would yield better results than the aggregated one that merged the multi-dimensional submissions by individual submitters. We determined the number of topics by running topic modeling over the dataset by incrementally increasing the number of topics until all the relevant topics according to HCC have been identified: 13 topics. These topics were then labeled by the researchers. Lastly, topical distributions were calculated and aggregated into individual submitters, enabling us to examine who talked about what and for how much.
Finally, the state-of-the-art LLM, ChatGPT (gpt-4-1106-preview), was employed to generate processable summaries for the extensive textual data from the actual feedback dataset through OpenAI’s API platform (python library openai). This was applied to subgroups of our dataset based on stakeholder group representation to offer insights into how varying stakeholder groups think differently about the proposed plan change and more broadly on urban densification. Based on the results, we endeavored to derive useful findings and to qualitatively support them with the assistance of ChatGPT by identifying and quoting the relevant evidence from the actual feedback dataset. In the end, we primarily centered on examining the general public’s dominant opposition against the proposed change towards greater density from a lens of NIMBYism, including identifying typologies of NIMBY and YIMBY. We also conducted further regression analysis to investigate whether specific socio-economic characteristics as implied from the neighborhoods they reside would influence their opinions. Given the insignificant results from the regression analysis, we did not present the results in this paper, but their details can be found in the Appendix.
Results
The overall opinions, as calibrated by the composite opinion scores (supporting or opposing, S/O thereafter), were opposing the plan change for enabling greater density (mean: −0.49; median: −1). Despite a high correlation with the opinion scores (p < 0.001), the sentiment analysis (SA) scores derived from the sentiment analysis appeared to be leaning towards positive sentiments (mean: 0.42; median: 0.80). This finding seems contradictory at first glance. Yet, the methodological limitation of sentiment analysis occurs because of the use of a pre-defined lexicon to compute a sentiment polarity score based on the composition of words, not based on their collective meaning (Wankhade et al., 2022). Thus, even where commenters opposed the proposal, they often couched their comments with gratitude and thanks for being heard. In sum, sentiment analysis is not a reliable nor accurate method to identify political positions such as supporting or opposing development in this case.
Varied opinions among stakeholders
The sampled dataset represents diverse public opinions with individual submitters from a range of stakeholder groups. By plotting the S/O and SA scores of stakeholders (Figure 2), we reveal the varying opinions among different stakeholder groups.
2
There are several patterns we observed from the box plots: firstly, submitters from the general public were dominated by opponents of the plan change, with the median S/O score being −1 and the main box plot body located towards the bottom of the range. The other main sectors, however, exhibit a more diverse range of opinions, with the overall government and organization sectors leaning towards supporting and the business sector being close to the center (neutral). Boxplots of composite opinion scores (S/O) and sentiment analysis scores (SA) by various sectors and subsectors.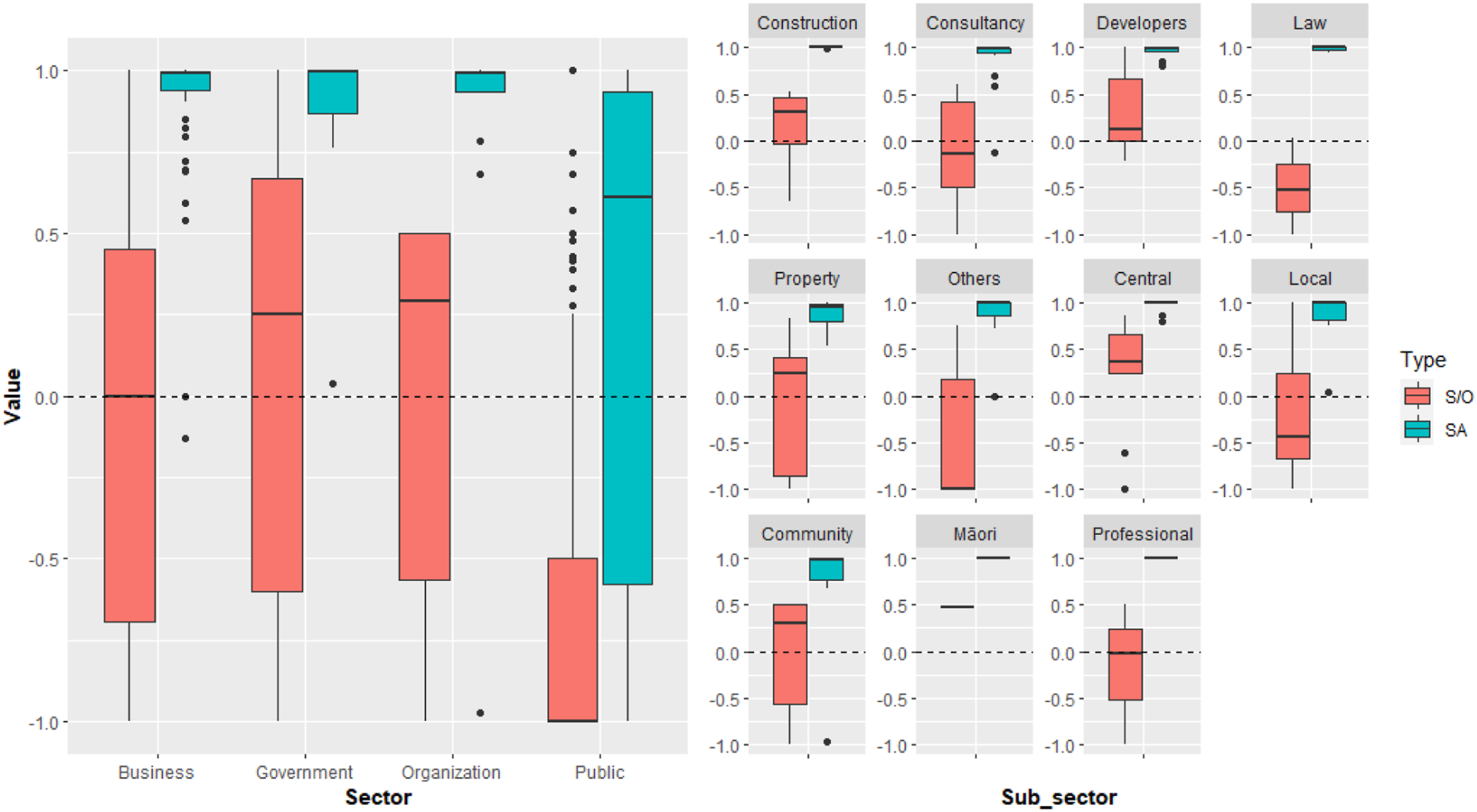
Secondly, the SA scores are generally all highly positive for the non-public sectors and subsectors, suggesting that people submitting on behalf of an institution, organization, or business were mostly using positive or neutral language, or wrote the feedback in a professional manner, even when expressing opposition, thereby rendering the sentiment analysis to yield highly positive scores. In sharp contrast, the sentiment scores for the general public have a wider range of emotions as reflected by their languages. This aligns with their overarching opposing political stance against the plan change as well as the diverse demography of the public with people from various socio-economic backgrounds and geographical locations.
Thirdly, the S/O scores among subsectors vary significantly. Specifically, within the business sector, the construction, development, and property management subsectors generally supported urban densification. This stance aligns with their assumed business interests, as densification would generate more development opportunities and be beneficial for their businesses. Interestingly, within the government sector, the central and local governments expressed contradictory stances on this plan change: the central government supported it, while the local government opposed it. We suspected that the plan change received more support from state governmental agencies because it responded to state legislation established by the central government. In contrast, local governments, possibly feeling overwhelmed by this top-down approach implemented on short notice, expressed strong opposition to the proposed changes. Finally, while the various organizations generally support the plan change, understanding the reasons behind this support, and the above-mentioned sectors and subsectors, requires further examination of the actual feedback provided. In this manner, we suggest that large-batch text processing can help tag where to start such exploratory reading.
Distribution of topics discussed
The topic modeling results allowed us to not only identify the major themes discussed and their relative prominence within the public feedback dataset, but also examine the distribution across different stakeholder groups (Figure 3). The intensity of the colors corresponds to the extent to which a particular topic was discussed by a stakeholder group (top chart) as well as across the entire dataset (bottom chart), with darker shapes denoting a higher frequency or coverage on that topic. Overall, submitters discussed a wide range of topics related to the urban densification proposal, with housing density, finance, infrastructure, and zoning being the most dominant. Heatmap of topic coverage (in percentage) by stakeholder groups (Top), and overall topic coverage across the entire dataset (Bottom).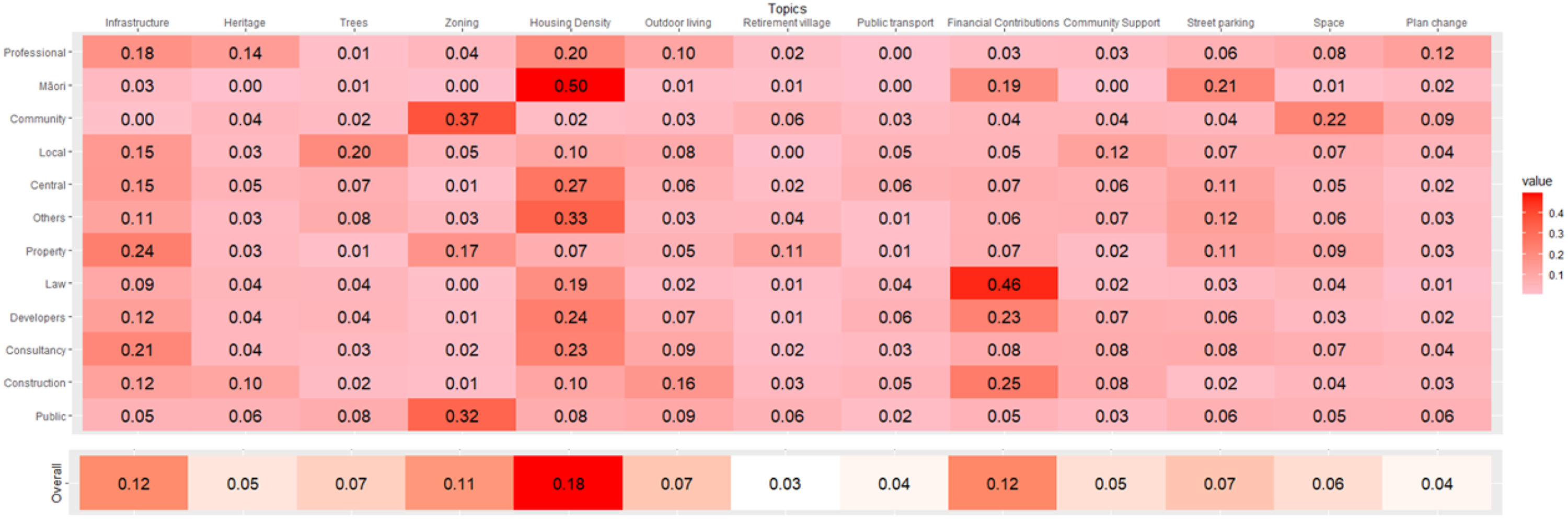
The topics discussed also varied significantly across different stakeholder groups. From the heatmap, we observed several interesting patterns. For example, the local and central governments demonstrate a relatively balanced topical distribution, but with noticeably varying attention, such as local government emphasizing “trees” and “community support” while the central government focused on “housing density.” This was because there were multiple submissions from people at the HCC, in which they reiterated and stressed the potential loss of tree canopy as one of the key counterarguments against fully complying with the state directive. Local government, being the lowest tier of the governmental body that interacts directly with communities, logically expressed numerous concerns regarding the need for community support in response to this new top-down legislation.
Furthermore, different stakeholders focused on various aspects of the urban densification proposal relevant to their interests. For instance, both local community groups and the general public demonstrated strong engagement with “zoning,” which might reflect a grassroots-level interest in the regulation of land use. The development sector, including property management, developers, and construction companies, discussed “housing density” extensively, as well as the associated “financial contributions” required for the expanding “infrastructure” needs, aligning with their business interests. It should also be noted that the Māori group had only one submitter, the Waikato Māori Tainui, yet with numerous submissions, indicating their desire to have a say in the plan proposal. Their strong focus on “housing density” and land use might be partially explained by the group’s particular interest in land stewardship, stemming from historical colonization and land confiscations by the British government during the 19th century. While topic modeling can effectively distill key information from large, unstructured text data, our interpretation of topic modeling patterns was merely based on our understanding. Hence, in the following, we aimed to contextualize and verify these findings by harnessing the advanced reasoning capabilities of a state-of-the-art LLM.
Key themes of discussions among stakeholders
Sample composition and why supporting/opposing by stakeholder groups (main groups highlighted in grey).

Additionally, the aspect of feedback largely resonates with the group’s business or professional representation. For example, the consultancy group largely discussed zoning and building standards (coverage, height, and setback) as well as the institutional sides of planning such as administration and financial contributions. This is because consultancies often work with clients on projects preparing development consents involving these matters and they also will submit these applications to and liaise with local councils to seek development approval. In addition, the Māori tribal group largely discussed the inclusion of indigenous values and the inclusion of Māori people in policy and decision-making. Furthermore, the law group mainly focused on plan change from a legal lens to ensure clarity, fairness, and legal compliance in policies, by centering discussions on term definitions, consistencies between sections, and policy vagueness. Interestingly, the law group specifically mentioned “retirement village” in the summary which seemed to be counterintuitive unless there were submissions from lawyers representing retirement village developers. By examining the actual submissions, we noticed that one of the three submitters in the law group provided feedback that included large amounts of information on retirement villages and this submission was also proportionally larger (73% of all the text in this group) than those from the other two submitters combined. These findings confirm our earlier discussions about the potential limitations of selection bias using ChatGPT and all other NLP techniques that will give larger weight to longer text and repetitive words in the data, potentially leading to biased resultant findings.
The general public’s opinion towards densification
While our regression analysis provided few statistically significant findings (detailed results can be found in the Appendix), there are still some interesting findings worth discussing. Generally, we found that key neighborhood characteristics, such as density and median household income, had little effect on submitters’ opinions towards urban densification. This suggests a uniform opposition from the public, regardless of their neighborhood’s socio-economic characteristics, likely reflecting NIMBYism. Additionally, individuals with home addresses closer to the CBD were less likely to oppose, or opposed less strongly (p < 0.05), aligning with literature that finds residents near CBDs or high-density areas are more likely to prefer and accept high-density living (Wicki et al., 2022; Wicki and Kaufmann, 2022). However, this pattern was not observed when modeling the public’s support, suggesting that those in favor are more evenly spread across the city. This comparative finding underscores the spatial nature of support for densification, as opposed to the divisive polarization between YIMBY and NIMBY perspectives.
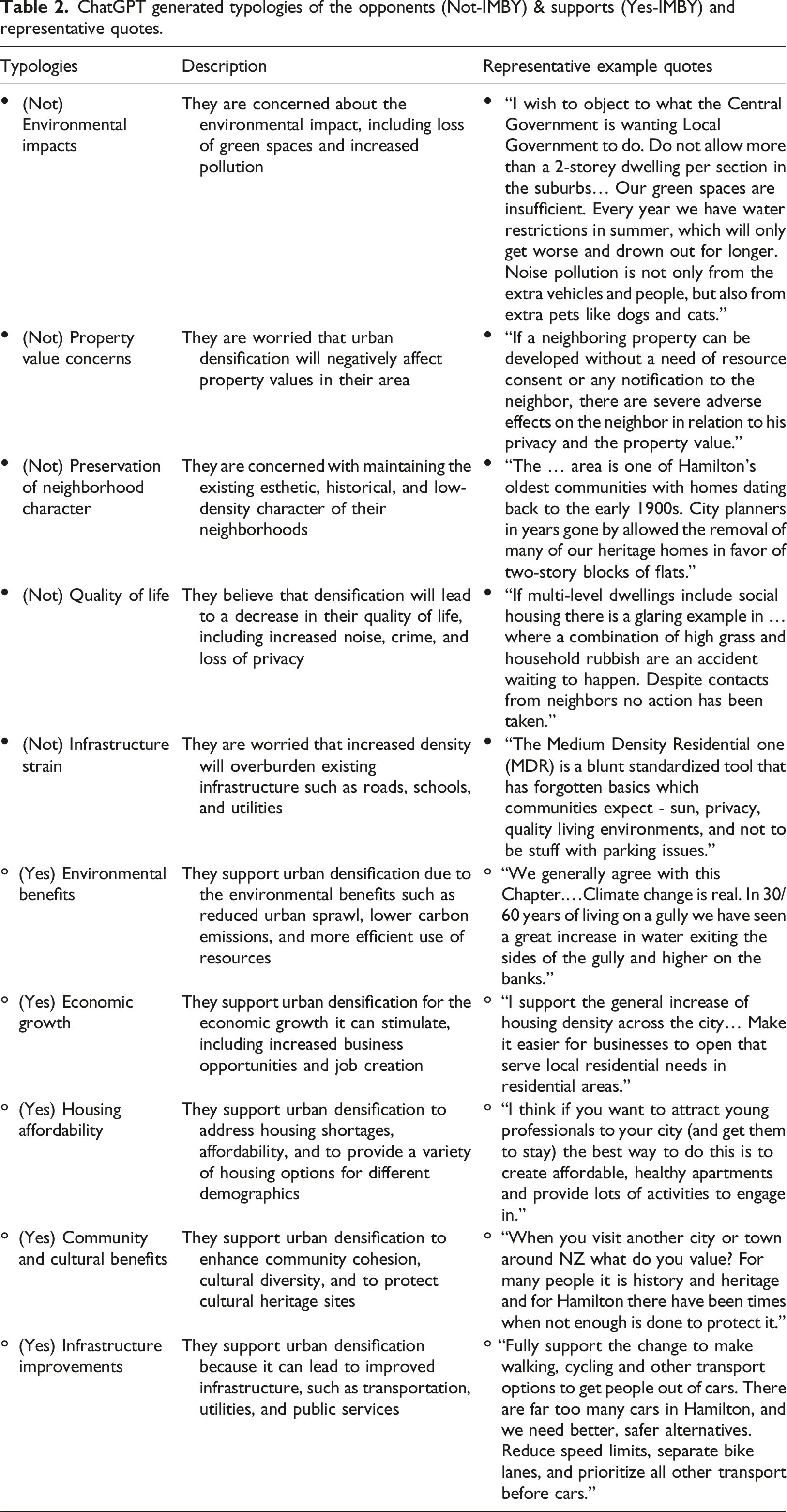
ChatGPT generated typologies of the opponents (Not-IMBY) & supports (Yes-IMBY) and representative quotes.
Discussion
This study demonstrates a transferrable framework for spatially explicit rapid large-batch text analysis using NLP techniques on public comment. We demonstrate that such analysis can provide timely, comprehensive insights into the dynamics of stakeholder opinions. Specifically, sentiment analysis can help calibrate the overall emotions hidden in the language of the provided feedback. Findings from sentiment analysis will allow planners and policymakers to address the emotions behind motivating arguments. Topic modeling can identify the range of topics discussed as well as the distribution of those topics and overlap. This analysis helps provide planners and policymakers with a shortlist of items to address that speak to public talking points. LLMs like ChatGPT can be used to interact with and provide further rapid insights into a large textual feedback dataset, including, but not limited to, summarizing the key reasons for supporting or opposing urban densification and deriving the typologies of supporters (YIMBYs) and opponents (NIMBYs). When used together, the generated results can offer useful information to better analyze the different voices to identify synergies to build upon and moderate the tensions between different stakeholder groups. For example, policymakers can report on the quantity, quality, and positionality of various arguments while making their case for constituents and the greater whole.
The scalability of this methodological framework depends on the specific NLP techniques employed, such that conventional NLP techniques like LDA and lexicon-based sentiment analysis are quite efficient algorithms that can be applied to very large datasets often from social media. But more advanced techniques such as LLMs like ChatGPT are now both computationally and monetarily expensive and are also constrained by a certain input threshold (i.e., maximum tokens the model can process per prompt) will limit the framework’s ability to be used on massive data now, but this will likely improve with the rapidly advancing technologies (e.g., quantization and small language models) into the future. In sum, our framework is applicable to datasets in the thousands, which are normally what most local councils would collect from the general public but is less feasible for analyzing social media data that are often collected in millions, particularly when using LLMs.
While we focus on urban densification using a case study in Hamilton NZ, we note that our findings can be aggregated to better understand NIMBY/YIMBY discussions globally. First, we highlight the need for a nuanced understanding of public opinions as well as the motivating rationales behind them. Further, our case study helps underscore what planners and policymakers likely already recognize: opposition to densification is not monolithic within the public discourse of their own communities. While listening and summarizing public opinion, these nuanced viewpoints within local communities can stem from a variety of concerns that are often deeply rooted in personal and community values and local knowledge that should be surfaced for decision-makers as part of the planning process. For example, the general opposition among the general public suggests the widespread concern over the implications of urban densification and the prevalent NIMBY sentiments. Such sentiment was uniformly distributed across various socio-economic backgrounds and neighborhood types, underscoring the deep-rooted nature of these concerns. However, despite the overall negative stance, the relatively positive sentiments, as indicated by the sentiment analysis, were more aligned with how politely the suggestions were couched—not necessarily in favor or not. Residents might support or support in part the concept of densification but oppose the central government’s top-down approach or HCC’s response proposed in this PC12. For example, one submitter stated: “I support a bespoke eco-density approach to how the intensification of Hamilton as a city is managed. Despite government directives I feel strongly that the City Council should be able to modify these in a way that ensures healthy, connected communities.” This finding is very important for urban planners and decision-makers because while there is prevalent resistance from the public, such opposition may have less to do with densification and more to do with the political process of how densification is implemented.
Additionally, this study also underscores the importance of engaging with diverse stakeholder groups to understand their specific concerns and motivations. This engagement is crucial for developing more targeted and effective strategies to address public apprehensions about urban densification. For instance, the machine-generated typologies of NIMBYs and YIMBYs provide important local insights from the grassroots level into reasons behind the public’s support and opposition to the proposed urban densification. More importantly, these specific typologies derived from the bottom-up uncover the nuanced local contexts and emotions underlying the public opposition against the plan change. For example, as noted in the indigenous Māori group’s submission expressing concerns over the lack of consideration for indigenous knowledge in the development processes: “(we) consider that developments and decisions associated with developments … should be required to consider Tai Tumu, … and any other iwi management plans at all times. This will assist developers/applicants with determining cultural impacts and who to engage with at the forefront of the project …” This information offers the needed evidence for planners and local officials to identify specific areas they can improve in revising the next version of the plan. If there are adequate resources to better engage the public, the council could use such information to strategically prepare resources and counterarguments tailored to the key arguments made by the public.
Conclusions
In this study, we demonstrate the effectiveness of rapid, large-batch text analysis in addressing the challenges of analyzing public dialogue for urban planning decision-making. It focuses particularly on urban densification, as exemplified in HCC’s PC12. By employing NLP techniques such as sentiment analysis, topic modeling, and ChatGPT, we have identified key areas of conversation, including opposition or support for measures, spatial distribution, local institutions, repeat commenters, and representative opinions from impacted groups. The NLP techniques provide methods for making such opaque analyses more straightforward and quantitative. The research specifically addresses a critical urban studies agenda: densification, revealing complex public attitudes influenced by factors such as economic interests and socio-economic backgrounds. These findings underscore the necessity for more focused public outreach and highlight the critical role of engaging diverse stakeholders in urban planning.
However, this study also acknowledges the limitations of current NLP tools, emphasizing the need for human oversight and the refinement of domain-specific models to ensure accuracy and reliability. The readers should always exercise caution when interpreting results either from this study or their own analysis involving similar AI tools. Human supervision and fact-checking should always be required if the machine-generated insights are to be used to inform decisions or policy making. This reflects a common challenge in AI adoption regarding the trade-offs between speed and accuracy, as well as between simplicity and complexity. Although examining the accuracy of ChatGPT’s summaries is beyond the scope of this research, what we can infer is that in practice, AI tools like ChatGPT are best used to complement human analysis, especially in cases where nuanced understanding and critical evaluation are necessary. Also, the state-of-the-art LLMs such as OpenAI’s ChatGPT, Google’s Gemini, and Meta’s Llama are all non-deterministic models, which means that they could still produce different, though slightly, outputs when given the same input prompt. Future research should examine how these models perform over time and conduct comparative analyses between them.
The rapid evolution of NLP tools like ChatGPT has promising potential in transforming public engagement and influencing decision-making in urban planning, marking an exciting frontier in the field. But we should also be concerned with the potential risks and ethical implications of using these novel technologies in practice. Such risks, even if unintentional, can lead to biased findings and potentially worsen local inequalities. This will therefore render their efficiency benefits less compelling or even counterproductive for the community planners serve. For example, ChatGPT can biasedly give greater weights to lengthier comments, omit nuanced context and detailed information, and may also potentially produce false answers or even hallucinations (note: we did not detect any hallucination issues in this research with the gpt4 model used, which was claimed to have significantly improved on this prior issue) where data outside the dataset is brought in to guide the algorithm. Future research directions can include improving NLP tools, integrating these technologies more systematically into urban planning processes, exploring the ethical implications of its application in practice, and developing platforms for real-time analysis of public feedback.
Supplemental Material
Supplemental Material - Text mining public feedback on urban densification plan change in Hamilton, New Zealand
Supplemental Material for Text mining public feedback on urban densification plan change in Hamilton, New Zealand by Xinyu Fu, Catherine Brinkley, Thomas W Sanchez, and Chaosu Li in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.