
Abstract
Planning and development decisions in both the government and business sectors often require small area population forecasts. Unfortunately, current methods often produce forecasts that are inaccurate, particularly for remote areas and those with smaller populations. Such inaccuracy necessitates the development and evaluation of methods to forecast and communicate forecast uncertainty, however, little research has been conducted in this domain for small area populations. In this paper, we evaluate a set of probabilistic forecasting methods which include Autoregressive integrated moving average, Exponential Smoothing, THETA, LightGBM and XGBOOST, to produce point forecasts and 80% prediction intervals for Australian SA2 small area populations. We also investigate methods to combine the intervals to produce ensemble forecasts. Our results show that individual probabilistic methods generally produce prediction intervals which underestimate forecast uncertainty. Combining forecasts improves the overall accuracy of point forecasts and the coverage of their intervals, however, coverage still tends to be less than the expected 80% for all but the most conservative combination method.
Introduction
One of the key elements of urban planning is the forecasting of local area populations. Such small area population forecasts are used widely by both governments and businesses to guide planning and development decisions. Current practices often produce forecasts which are inaccurate, particularly for areas which are remote and have small populations (Wilson and Rowe, 2011). Methods applied are generally deterministic, producing point forecasts which give users no indication of uncertainty. However, planning decisions would benefit from an understanding of the uncertainty of the predictions that are being used (Keilman, 2020). A recent review of the small area population forecasting literature found that very few projection methods incorporate any indications of forecast uncertainty (Wilson et al., 2021a). As pointed out by Keyfitz (1981), whilst demographers cannot be held responsible for providing inaccurate forecasts, they are responsible for ‘…warning one another and our public what the error of our estimates is likely to be’ (Keyfitz, 1981, p. 579). Therefore, given the extensive use of small area forecasts it is vital that methods to calculate and communicate forecast uncertainty be developed and evaluated.
Statistical agencies often communicate forecast uncertainty by applying a scenario-based approach and creating low, medium and high variants of deterministic forecasts. However, such an approach doesn’t explicitly provide uncertainty measures and it does not enable forecast users to ascertain the likelihood that a future population will fall within a certain range (Tayman, 2011). Furthermore, forecast users often give little attention to the high and low variants and focus on the medium forecast (De Beer, 1997). A more useful method is to create forecasts with prediction intervals which give a predicted range into which a future value is expected to fall, provide a better representation of uncertainty and encourage forecast users to consider a range of population outcomes in their decision-making.
Prediction intervals can be generated using probabilistic forecasting methods, empirical investigations of past forecast errors, or a combination of the two (Rayer et al., 2009). Whilst deterministic methods remain the norm, probabilistic methods are now commonly applied to generate forecasts for countries (e.g. Azose et al., 2016; Keilman et al., 2002; Okita et al., 2011; United Nations, 2019; Wilson and Bell, 2004) and large sub-national geographic areas (e.g. Setiawan et al., 2021; Tayman et al., 2007; Wilson and Bell, 2007). As we move to smaller areas such as local council areas or census tracts, probabilistic forecasts become ‘more challenging’ (Statistics New Zealand, 2016, p. 78).
Quantitative, out-of-sample evaluations of the accuracy of prediction intervals for small areas are rare and challenging. Rayer et al. (2009) generated empirical prediction intervals for US counties by examining the forecast errors produced by extrapolative models. They found that 90th percentile errors for trimmed mean forecasts of the prior period provided reasonably good estimates of 90% prediction intervals for the subsequent period. Wilson et al. (2018) generated empirical prediction intervals for Australian local area population forecasts based on past error distributions. Simpson et al. (2020) similarly created empirical prediction intervals for English local authority areas by using errors of past cohort-component forecasts for prior years and applying them to later periods. A few papers have also developed and evaluated model-based prediction intervals. Zhang and Bryant (2020) developed a Bayesian approach to estimating and forecasting internal migration for Iceland. Bryant and Graham (2013) used a Bayesian approach to estimate and forecast the components of population change, whilst Jiang et al. (2007) used an approach based on the Hidden Markov model to create point forecasts and prediction intervals for suburbs of Canberra, Australia. The literature on the application of machine learning algorithms for the probabilistic forecasting of small area populations is scarce even though such methods have previously been shown to be the most accurate approaches for creating prediction intervals in the M4 (Makridakis et al., 2018) and M5 (Makridakis and Spiliotis, 2021) forecasting competitions. These M series forecast competitions challenge forecasters to create the most accurate forecasting methods and evaluate them on a large dataset of time series (Makridakis et al., 2020).
The purpose of this research is to provide a comprehensive evaluation of probabilistic forecasting methods. We consider statistical and machine learning models, and combinations thereof, for Australian SA2 areas (Australian Bureau of Statistics, 2017a); these areas are the smallest units in the Australian Bureau of Statistics geographical hierarchy for which population statistics are regularly collected and published. This work will advance prior research by Grossman et al. (2022) which investigated combination methods for Australian SA2s but focused exclusively on deterministic forecasts and included a slightly different set of individual models. Specifically, this paper has the following objectives: 1. To identify probabilistic models that produce the most accurate forecasts with the best coverage. 2. To investigate methods to combine the interval forecasts produced by our set of probabilistic models. 3. To investigate how the results are influenced by the remoteness of the SA2 areas.
In this study, we generate population forecasts with 5 and 10 years forecast horizons for Australian small areas. The “Results” section presents the model evaluation results which are then discussed in the “Discussion” section. The aims, findings, and implications are then summarised in the “Conclusions” section.
Data and methods
Data
We prepared and evaluated probabilistic forecasts with 80% prediction intervals using the 2016 mid-year Estimated Resident population (ERP) totals for Australian SA2 areas (Australian Bureau of Statistics, 2017a). ERPs are produced by the Australian Bureau of Statistics using the place of usual residence data collected during the 5 yearly census. Data on births, deaths and migrations and administrative data are used to adjust sub-state ERPs during census years and estimate populations between census years. ERPs are revised after the subsequent census (Queensland Government Statistician’s Office, 2019). The estimates are generally good quality according to the post-enumeration survey findings, which found that for SA2s with total populations greater than 1,000, the average 2016 absolute intercensal difference was 3.5% (Australian Bureau of Statistics, 2017b).
The 2016 dataset includes population totals from 1991 to 2016, and the median across areas in 2016 was 9681. Two sets of forecasts were prepared for two different jump-off years: 10- years forecasts from 2006, and 5 years forecasts from 2011. These forecasts covered the 2066 SA2 areas whose populations remained above 100 for the duration of the base period.
Methods
In our study, we use three statistical models and two machine learning models to generate point and probabilistic forecasts. Here, the probabilistic forecasts are provided to demonstrate the uncertainty of the model forecasts, where it is expressed in the form of a probability distribution. Specifically, we provided the point forecast and 80% prediction intervals for each attested model. We implemented the three statistical models (ARIMA, ETS and THETA) using the ‘forecast’ package (Hyndman and Khandakar, 2008; Hyndman et al., 2022) in the R programming language, whereas gradient boosting based machine learning models (LGBM and XGBOOST) were developed using the packages ‘lighgbm’ (Ke et al., 2021) and ‘sklearn’ (Pedregosa et al., 2011) in Python.
We generate the prediction intervals for statistical models, assuming the residuals produced from these models are uncorrelated and normally distributed. This assumption is valid because the statistical models, that is, ETS, ARIMA and THETA are capable of capturing time series seasonalities and trends, that is, mostly the trend patterns observed in population-based datasets. In contrast to statistical models, machine learning based models produce prediction intervals based on quantile loss, independent of model residuals being uncorrelated.
The ‘forecast’ package generates the probabilistic forecasts assuming the prediction intervals are wider as the forecast horizon increases. Based on the standard deviation of the forecast distribution, the ‘forecast’ package computes the probabilistic forecasts relevant for a specific prediction interval. We use the level parameter, in the ‘forecast’ package to generate probabilistic forecasts relevant for the 80% of prediction interval. To produce probabilistic forecasts with machine learning models, we use quantile loss functions that attempt to optimise the model for a specific forecast quantile.
Autoregressive integrated moving average (ARIMA)
The Autoregressive integrated moving average (ARIMA) model is widely used for time series forecasting (Box et al., 2015). ARIMA models aim to describe autocorrelations in the time series data. An ARIMA model is a composition of differencing with autoregression (AR) and moving average (MA) components. Here, the AR component uses the lagged values of a time series in a regression model, whereas the MA component uses past forecast errors (residual errors) in a regression model. The integration (I) term represents the degree of differencing (d) applied for the time series to become stationary. A general class of an ARIMA(p,q,d) model can be defined as
Exponential smoothing (ETS)
The Exponential Smoothing (ETS) algorithm generates forecasts from a weighted average of past observations, with the weights of the past observations set to decrease exponentially as the observations get older. A simple ETS model can be defined as
THETA
THETA is a relatively simple statistical model used widely by forecasting practitioners which extrapolates the trend and the level of a series (Assimakopoulos and Nikolopoulos, 2000). The THETA model firstly decomposes a time series into a new set of series, known as Theta-lines, and afterwards applies a forecasting method to extrapolate the Theta-lines separately. Here, exponential smoothing methods are often used as the forecasting method to extrapolate the Theta-lines. The THETA model is also treated as a special case of the simple exponential smoothing with drift (SES) method (Hyndman and Billah, 2003). The final forecasts of the time series are obtained by combining the individual forecasts of Theta-lines. Compared to ETS, the THETA model is incapable of modelling seasonal patterns. However, it can capture time series trends and often deal with short time series better compared to seasonal models such as ETS and ARIMA.
The THETA model performed well for the forecasting of yearly time series in the M3 competition (Makridakis and Hibon, 2000), and it was also included as a base model in the feature-based forecast combination (FFORMA) framework that achieved the second-best results in the M4 competition (Makridakis et al., 2018). As small area populations datasets often deal with yearly, non-seasonal time series data, we have included the THETA model in our evaluation of probabilistic forecasting models for small area populations. We used the THETAf function from the package ‘forecast’ (Hyndman and Khandakar, 2008; Hyndman et al., 2022) to obtain the THETA forecasts for a given population time series.
Gradient boosting models (GBM)
Gradient Boosting Models (GBM) are a popular class of machine learning algorithms based on decision trees that can be used to solve a wide range of machine learning problems. The fundamental idea of GBMs is to use an ensemble of weak decision-tree learners sequentially, where each weak learner attempts to improve on the error from the previous model. As this process is repeated sequentially, GBMs are also referred to as sequential ensemble decision-tree models. In the machine learning literature, Extreme Gradient Boosting (XGBoost) models (Chen and Guestrin, 2016) and Light Gradient Boosting (LGBM) models (Ke et al., 2017) are identified as the most popular variants of GBMs, due to their promising model accuracy and computational efficiency. The main structural difference between XGBoost and LGBM is that XGBoost uses a depth-wise algorithm to grow the decision-tree, while LGBM employs a leaf-wise algorithm.
The competitive performance of LGBMs has been recently demonstrated in the M5 Forecasting Competition, where a globally trained LGBM-based solution achieved first place in both point and uncertainty prediction tracks, followed by many other LGBM-based solutions headlining the rankings (Makridakis et al., 2022). In our study, we use both XGBoost and LGBM architectures to generate point and probabilistic forecasts for small area populations.
Total populations vary considerably between different SA2s, that is, some areas have populations in the 100s, and others in the 10,000s. Machine learning models which are trained globally across time series often require the time series within a dataset to be on the same scale for optimal performance. Thus, we first pre-processed the time series in our dataset using the recommendations of Bandara et al. (2020) and Hewamalage et al. (2021), and applied the meanscale transformation strategy, where each time series was divided by its mean value using the equation below

After normalising each time series, we applied the Moving Window (MW) transformation strategy to convert time series observations into input and output frames following the recommendations of (Hewamalage et al., 2021). The generated input and output frames were then pooled together and trained as a global model. Figure 1 shows an example of a single input and output window. Here, we assumed the size of the input window sequence {x1, x2, ..., xN} is N and the size of the output window sequence {y1, y2, ..., yM} is equivalent to M. Following the Multi-Input Multi Output (MIMO) strategy in multi-step forecasting (Hewamalage et al., 2021), we made the size of the output window M identical to the intended forecasting horizon. The MIMO is a direct forecasting strategy widely used in the forecast literature (Ben Taieb et al., 2012) that enables direct forecasts of all future values up to the intended forecasting horizon. As the default implementation of XGBoost and LGBM models are only able to train single output from a given set of inputs, we trained models separately for each forecast horizon. In other words, we train M number of models to generate forecasts for the intended forecast horizons. In our experiments, we set the value of M to 5 and 10 to generate 5-years and 10-years ahead probabilistic forecasts, respectively. As exogenous variables, we used the mean and the standard deviation of each input frame to train the XGBoost and LGBM models. The input and output window training procedure.
As discussed in Januschowski et al. (2021), GBMs can be trained with any loss function. Therefore, we use the quantile loss function to train the XGBoost and LGBM models to generate probabilistic forecasts for the required prediction intervals. Given a forecast
To implement the LGBM model, we use the lightgbm function from the Python package ‘lightgbm’ (Ke et al., 2021), whereas the GradientBoostingRegressor function from the Python package ‘sklearn’ (Pedregosa et al., 2011) is used to run the XGBoost models.
The hyper-parameter ranges used to train LGBM in our experiments.
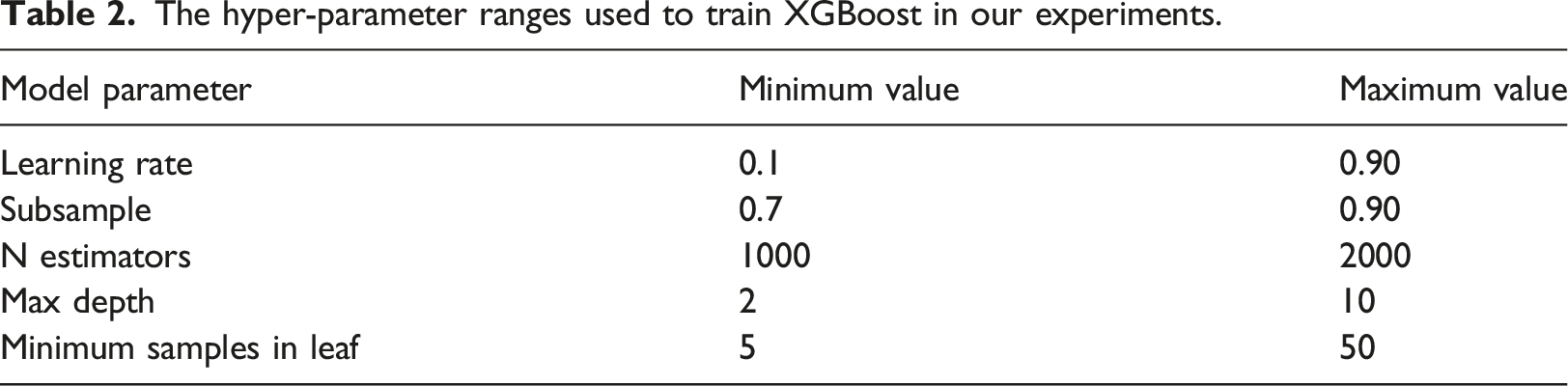
The hyper-parameter ranges used to train XGBoost in our experiments.
Ensemble models
Combining forecasts often produces improved accuracy due to a reduction in model variance and bias (Schapire, 1999; Breiman, 2001). Most of the literature on combination methods focuses on point forecasts. Taking the mean of a set of point forecasts is one of the most used ensembling techniques (Timmermann, 2006; Genre et al., 2013). Investigations of methods to combine interval forecasts have been rarer, particularly in demography. Grushka-Cockayne and Jose (2020) investigated several methods for the combination of interval forecasts using the M4 competition results (Makridakis et al., 2018). Here we consider three of the methods for interval combination which performed relatively well in Grushka-Cockayne and Jose (2020) to create four ensemble models: STAT, ALLaverage, ALLenvelope and ALLinner trim. For each of these models, we produce point forecasts, upper and lower forecasts. The point forecasts of the ALL models are created using the simple mean of the mean forecasts generated by the five constituent individual models. The point forecast of the STAT model is created using the simple mean of the three statistical methods. Taking the mean of a set of forecasts has previously been shown to work well for small area population forecasts (Grossman et al., 2022). The methods to create the lower and upper forecasts are described below.
Simple mean
For the ALLaverage and STAT ensemble models the upper forecast (U
a
) is calculated as the mean of the upper 80% prediction intervals generated by the included models j
The lower interval (L
a
) is calculated as the mean of the lower intervals generated by the included models
Envelope
For the ALLenvelope ensemble model the upper interval (U
e
) is equal to the largest upper interval from the included forecasts
And the lower interval (Le) is equal to the smallest lower interval from the included forecasts
Interior trimming
For the ALLinner trim ensemble model the upper interval (Uit) is calculated by taking the average of the (n – 1) largest upper intervals, which is equal to the four largest upper intervals in our application of the model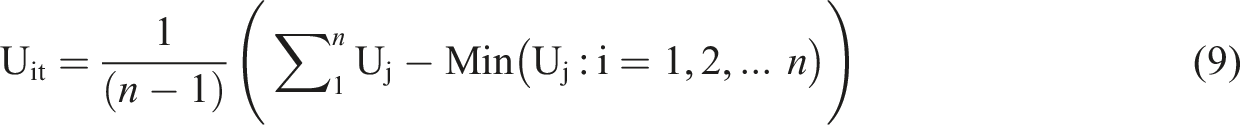
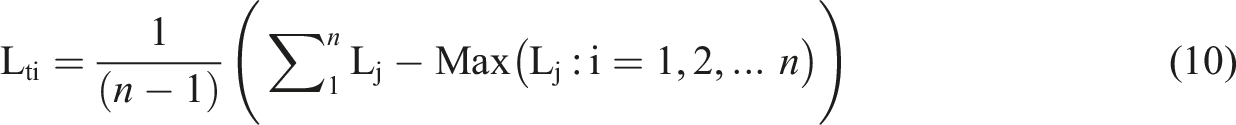
This method provides a more conservative interval than using a simple mean (Jose et al., 2013; Yaniv, 1997).
Error metrics
For each model we produce point, low and high forecasts, where the latter two represent the lower and upper bounds of the 80% prediction interval. 80% prediction intervals are commonly presented with probabilistic population forecasts, including those produced by the United Nations (e.g. United Nations, 2019). Accuracy of point forecasts is assessed using the absolute percentage error (APE), a standard metric used in population forecasting research (Rayer, 2007). At time t, the absolute percentage error (APE) equals
We use two metrics to assess the accuracy of the prediction intervals.
The formula for the MSIS at time t is presented below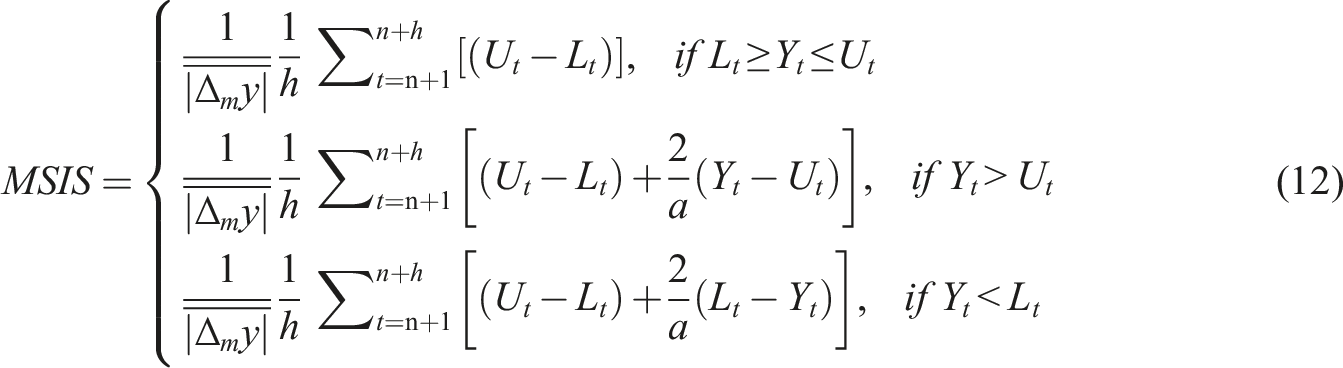
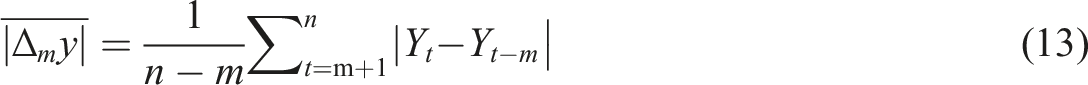
The MSIS metric penalises methods which produce large intervals. However, we suggest that large intervals are not necessarily indicative of a bad model if those intervals are accurately showing that an area’s population is difficult to predict and that forecasts for it are likely to be erroneous. To investigate this, for each model, we consider the correlation between the absolute percentage errors of the point forecasts and the half-widths of its prediction intervals (Lee and Tuljapurkar, 1994).
Remoteness
Australian SA2 areas can be classified by their remoteness as major cities, inner regional, outer regional, remote and very remote (Australian Bureau of Statistics, 2013). Here we disaggregate our forecast results by remoteness and present tables containing the MedAPE, MAPE, Coverage, MSIS, Half-Widths and correlation between APEs of the point forecasts and the half-widths of the prediction intervals, for each remoteness area.
Results
Probabilistic forecast evaluation
SA2 total population forecast errors: An evaluation of point forecasts and prediction intervals, after 5 and 10 years.
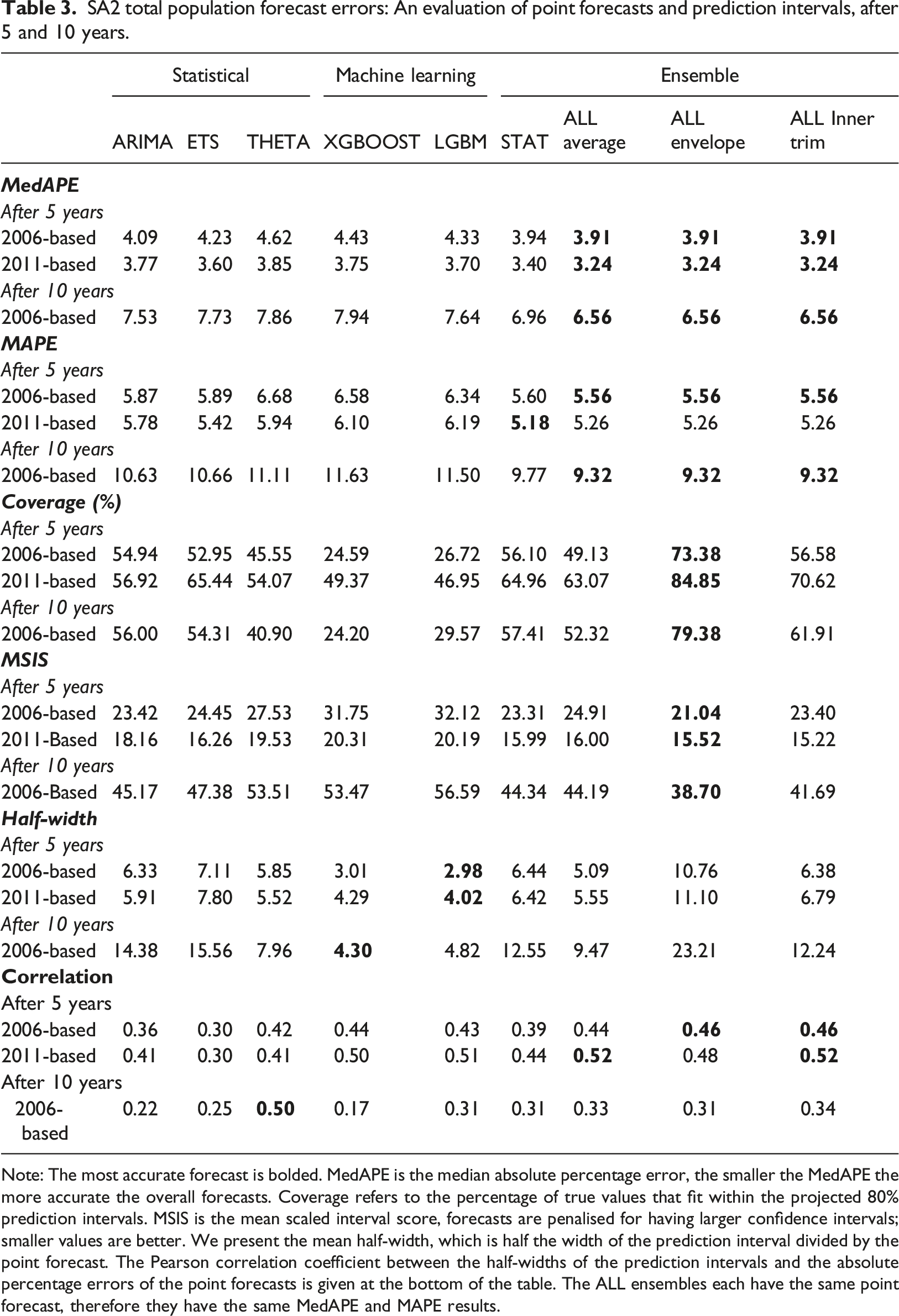
Note: The most accurate forecast is bolded. MedAPE is the median absolute percentage error, the smaller the MedAPE the more accurate the overall forecasts. Coverage refers to the percentage of true values that fit within the projected 80% prediction intervals. MSIS is the mean scaled interval score, forecasts are penalised for having larger confidence intervals; smaller values are better. We present the mean half-width, which is half the width of the prediction interval divided by the point forecast. The Pearson correlation coefficient between the half-widths of the prediction intervals and the absolute percentage errors of the point forecasts is given at the bottom of the table. The ALL ensembles each have the same point forecast, therefore they have the same MedAPE and MAPE results.
The Coverage of our 80% prediction intervals is shown below MedAPE in Table 3. Coverage was less than 80% for all methods except ALLenvelope, thus for most methods the prediction intervals did not adequately forecast the range where actual populations would be. The statistical methods produced better Coverage than the GBMs. The ALLenvelope model produced the best MSIS results.
Half-widths for XGBOOST and LGBM are notably smaller than for the other methods, explaining why their Coverage is smaller despite comparable MedAPEs. As expected, the ALLenvelope model produces forecasts with the largest intervals. THETA had the narrowest intervals of the individual statistical methods.
Correlations of the absolute percentage errors of a model’s point forecasts and the size of its half widths are shown at the bottom of Table 3. THETA consistently produced correlations between 0.4 and 0.5, suggesting that the size of its intervals gives forecast users a better estimate of forecast uncertainly relative to the other models considered, however, it still isn’t able to account for most small area forecast uncertainty.
Figure 2 visualises 10 years 2006-based forecasts for the Bellingen SA2, an outer regional area in New South Wales. This visualisation indicates that methods which produce wider intervals in the first few years of a forecast may differ to those that produce wider intervals in the longer term. THETA produces relatively conservative intervals for Year one of the forecast and may be appropriate for probabilistic nowcasting (refer to Tables S1 to S6 of the Supplementary Materials for results for all forecast horizons). 2006-based 10 years forecasts for the Bellingen SA2 area. Note: Figures show forecasts with 80% prediction intervals indicated in light blue.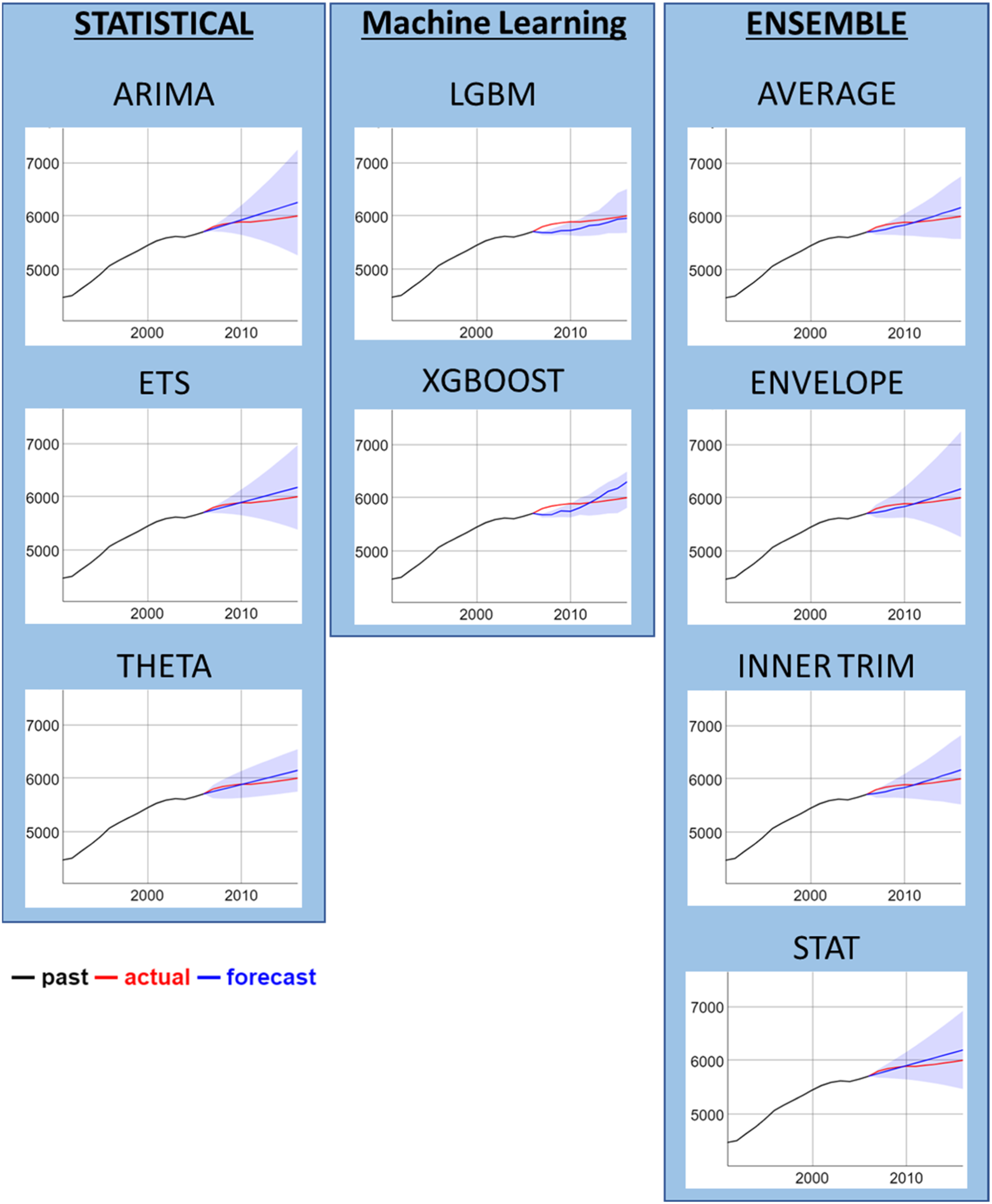
Remoteness
Previous research has shown that the accuracy of deterministic forecasts tends to be less for remote and very remote areas (Wilson and Rowe, 2011; Wilson et al., 2021b). We investigated whether remoteness influences the performance of both point forecasts and interval forecasts. These results are presented in the supplementary material, as Tables S7 to S12.
Tables S7 presents the MedAPEs for the SA2 total population point forecasts. The ensemble models tend to outperform the individual models for major cities and inner regional areas. However, the benefit of ensembling for the MedAPE score is less clear for more remote areas where individual models often perform better, particularly THETA. When we compare MedAPEs for the STAT and ALLaverage models the results indicate that the inclusion of Machine Learning models using a simple mean combination method tended to increase forecast accuracy for Major cities, however, there was no clear pattern for other remoteness areas. There is a ‘U’ shaped relationship between remoteness and forecast accuracy. Accuracy tends to be better for regional areas than for SA2s in major cities, remote areas, or very remote areas. The ‘U’ is asymmetrical, with the accuracy of forecasts for very remote areas being notably worse than for major cities. The MAPE results by remoteness are presented in Table S8. They are similar to the MEDAPE results, albeit the Remote areas have particularly high MAPEs for the 2006-based 10 years forecasts.
Table S9 presents Coverage by remoteness for the prediction intervals. For the 5 years forecasts, Coverage tends to be worst for more remote areas. After 10 years, the Coverage of the prediction intervals tends to be worst for major cities. Using simple mean interval combination methods did not improve coverage to desired 80% levels and the inclusion of the Machine Learning forecasts tended to decrease forecast accuracy, thus the STAT model tends to have slightly better coverage than the ALLaverage model. ALLenvelope is the only model to consistently generate prediction intervals that cover approximately 80% of actual values across remoteness levels, jump-off years and forecast horizons (range: 65.96%–90.85%). All other models always underestimate forecast uncertainty.
MSIS is presented in Table S10. The ensemble methods tended to perform better than the other statistical methods, particularly ALLenvelope. The ML methods tended to have relatively poor MSIS scores. Most models performed relatively poorly for Major Cities for the 2006-based 10 years forecasts.
Table S11 presents the mean half widths of the 80% prediction intervals by remoteness. LGBM and XGBOOST have the smallest half widths. As expected by its construction, the ALLenvelope model has the largest prediction intervals across remoteness areas. Across the models, the half-widths tend to be greatest for very remote areas and smallest for the inner regional and outer regional SA2s.
Table S12 presents the correlations between the APEs generated by the point forecasts, and the half widths of the prediction intervals, for each of the remoteness levels. The models which produce the highest correlations vary depending on the jump-off year, forecast horizon and remoteness. None of the models produce reliably high correlations across the remoteness areas.
Discussion
In this study, we have investigated and evaluated the use of probabilistic models for small area population forecasting. This context requires stochastic forecasting methods to be developed and implemented due to the high uncertainty present. We considered five individual probabilistic forecasting models and four ensemble models. Our overall results indicate that ensemble models performed better when they included both statistical models and globally trained GBMs. However, an analysis by remoteness found that whilst GBMs improved the performance of ensemble models for SA2s in major cities, they did not improve performance for remote and very remote areas. We discuss these findings below, how they addressed our aims, explore issues related to model-based prediction intervals, consider the limitations and implications of this study.
Our first aim was to evaluate the performance of individual probabilistic models, which included statistical models and GBMs. Of these, ARIMA and ETS produced point forecasts with the smallest MedAPEs, and 80% prediction intervals with the highest Coverage, for the 2006- and 2011- based forecasts, respectively. However, the coverage of the best performing individual methods (54%–65%) was still significantly smaller than what may be expected from 80% prediction intervals. The GBMs did not perform particularly well in our study. Whilst their point forecasts were relatively accurate, coverage was poor for their interval forecasts. Conversely, the top performing methods in the M5 uncertainty competition utilised LGBM methods (Makridakis et al., 2021). The M5 competition dataset contains daily hierarchical retail sales time series data, which are longer than the yearly time series in our small area dataset and additional explanatory variables were used to develop the models. However, the results of the M5 uncertainty competition showed that the benefit of the LGBM based methods, relative to their benchmark ARIMA model, were most evident at the higher levels of the hierarchy; the benefit was limited at the lowest levels (Makridakis et al., 2021). Thus, GBM based methods may be more useful for forecasting populations at higher geographical scales.
Our second aim was to investigate methods to combine the forecasts produced by our individual probabilistic models. The overall MedAPEs of the Ensemble models were considerably lower than those of the individual models. Indeed, the ALL ensemble produced more accurate point forecasts in terms of MedAPE than all bar one of the unconstrained results found in an evaluation of the top M4 competition methods for point forecasts of Australian SA2 small areas (Wilson et al., 2021b). Overall, the ALLaverage model performed better than the STAT model, indicating that it was advantageous to include the GBMs in the ensemble. This is in line with previous work investigating combination methods for small area population point forecasts (Grossman et al., 2022).
Our third aim was to investigate how the remoteness of small areas impacted the performance of the point forecasts and prediction intervals. Across all models, forecasts are generally more accurate and have better Coverage for regional areas than for major cities or more remote areas. Similar results were found in an evaluation of deterministic methods for Australian SA2s in Wilson et al., (2021b), however, results were different for New Zealand with Major Urban and Rural areas generally having smaller MedAPEs than Medium and Small urban areas. Whilst our overall results indicate that the addition of GBMs to ensemble models improves forecast performance, analysis by remoteness found that this is only consistently true for major cities. SA2s in major cities make up 1187 of the 2066 time series in the dataset. Conversely there were only 47 remote areas and 50 very remote areas. Therefore, it is unsurprising that the GBM forecasts are not as helpful for more remote areas, as they were not well represented by the training set.
Model-based prediction intervals routinely underestimate forecast uncertainty. This is a well-documented phenomenon, it was one of our findings, and one of the results of the M4 competition (Makridakis et al., 2018). Hyndman et al. (2002) found that the 95% Prediction intervals generated by Exponential Smoothing Methods covered between 71.1 to 87.5% of the series’ true values. The reasons for this attribute of prediction intervals relate to there being multiple sources of uncertainty that impact the performance of forecasts. Hyndman (2014) lists four: random error, parameter estimates, model choice and the uncertainty related to whether the processes which generate the data will change in the forecast period. The intervals generated by probabilistic forecasting models generally only address the uncertainty linked with the error term (Hyndman, 2014). Using an ensemble model approach can help address some of the uncertainty linked with the choice of model. Overall, our ensemble models tended to be more accurate and provided better Coverage than the individual models. ALLenvelope is the only model which achieved Coverage at the desired 80% level with relatively wide prediction intervals which had half-widths of approximately 10% of the point forecast after 5 years and 20% after 10 years. Whilst other models produced narrower intervals, this came at the cost of understating the level of uncertainty associated with their predictions. Bryant and Zhang (2016) used a Bayesian approach to create probabilistic forecasts for New Zealand small area emigration rates. Their 50% and 90% intervals covered 58% and 90.6% of the true values respectively. Their intervals were large, but they argued that this is necessary given that long-term forecasting is uncertain, and it prompts ‘users to confront the substantial uncertainty about long-term trends’ (Bryant and Zhang, 2016, p. 1337).
Conclusions
Given the inherent uncertainty in small area population forecasting, it is important to provide users with an indication of forecast uncertainty. In this study, we evaluated five individual and four ensemble models for probabilistic small area population forecasts. The individual probabilistic models produced prediction intervals that cover less than the desired 80% of true values. This is a known issue for model-based prediction intervals. We show that combination methods such as the inner trim and envelope techniques can improve Coverage. Ensemble models which included both statistical models and GBMs tended to outperform individual models for both point forecasts and prediction intervals. However, when we disaggregated the forecast results by the remoteness of the small areas, we found that the inclusion of GBMs in ensemble models was only beneficial for major cities. Practitioners using global models should consider if areas of interest are represented by the wider dataset and investigate the use of additional variables.
One of the limitations of this work is that we only evaluated our models using an Australian SA2 dataset. It is important to investigate how models perform across multiple datasets before recommendations can be made to practitioners about which probabilistic models to use. In turn, it is important for practitioners to help researchers understand what the requirements for the intervals are, and how they will be used.
Supplemental Material
Supplemental Material - Development and evaluation of probabilistic forecasting methods for small area populations
Supplemental Material for Development and evaluation of probabilistic forecasting methods for small area populations by Irina Grossman, Kasun Bandara, Tom Wilson, and Michael Kirley in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Australian Government through the through the Australian Research Council’s Discovery Projects funding scheme (Project DP200101480).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.