
Abstract
We study the compositional and configurational heterogeneity of Greater London at the city- and neighbourhood-scale using Geographic Information System (GIS) data. Urban morphometric indicators are calculated including plan-area indices and fractal dimensions of land cover, frontal area index of buildings, evenness, and contagion. To distinguish between city-scale heterogeneity and neighbourhood-scale heterogeneity, the study area of 720 km2 is divided into 1
Introduction
The urban landscape, a patchwork of buildings, roads, pavements, gardens, parks, and water, is inherently heterogeneous. Although straightforward to understand intuitively, heterogeneity lacks a universally adopted definition, as it represents unevenness, randomness, difference, variability, complexity, and deviation from a norm. The Oxford English Dictionary defines heterogeneity as the difference or diversity in contrast with other things or being made up of things or parts differing greatly from each other (Fitch et al., 2015). Li and Reynolds (1995) define heterogeneity as ‘the complexity and/or variability of a system property in space and/or time’ (p. 280). Santos et al. (2021) distinguish between structural and functional heterogeneity. Structural heterogeneity relates to the size, quantity, and spatial configuration of different surface properties. Functional heterogeneity refers to quality and resource availability that affects ecological processes and responses, e.g., living organisms’ density and distribution. Heterogeneity also has a temporal component: the urban landscape is subject to abrupt, short-term, and long-term changes in its functional use and land-cover properties due to human activities, phenological cycles, and urbanisation of previously rural landscapes (Santos et al., 2021).
Heterogeneity in urban systems is created and maintained by many different processes across physical, biological and social realms. Physical processes involve natural progression, disturbances (e.g., fire, flood, etc.) and recovery, which set the heterogeneity of urban system at coarse scale. Biological processes refer to the interactions among organisms including humans, such as the competing for resources, resulting in the heterogeneity in population sizes and occupied locations (Pickett et al., 2000; Cadenasso et al., 2013). Social processes are related to the management, planning and design interventions by humans, modifying the physical structures and components of the urban system such as removing materials or transferring materials from one landscape to another, which leads to contrasting land covers and creates local areas differing from adjacent ones (Pastor, 2005; Pickett and Cadenasso, 2009; Cadenasso et al., 2013).
Heterogeneity of landscape properties plays an important role in the ecological processes and functioning of urban systems (Cadenasso et al., 2007, 2013). The built environment consists of a rich variety of materials and textures: common building materials are brick, stone, concrete, wood, and glass; building facades can be smooth, rough, or vegetated; roads are paved with asphalt or stones. These materials differ in their permeability, their capacity to store heat, absorb water or reflect solar radiation, and therefore influence the surface energy budget of urban environments (Oke et al., 2017). The density of buildings and street networks that run throughout a city may differ substantially for different areas. Densely built-up areas reduce the sky-view-factor and thus block the emission of thermal radiation. Continuous wide streets promote ventilation, which removes heat and air pollution from urban environments. The abundance or lack of urban vegetation and water also affect the urban energy budget on the neighbourhood scale (Zipper et al., 2017). The differences in structure and land-cover between urban and rural areas result in generally higher air temperatures in urban environments compared to the rural surroundings (Bohnenstengel et al., 2011), a phenomenon called the urban heat island (UHI; Buyantuyev and Wu, 2010; Qian et al., 2020; Stewart and Oke, 2012). The presence of the UHI has motivated research about how to assess and mitigate urban heat stress. For example, Bartesaghi Koc et al. (2020) identified different types of green infrastructure and their cooling capacity in Sydney, Australia by their morphological and spatial characteristics. As cities consist of neighbourhoods with different form and functionality, the heat island intensity varies spatially across the city, as does the distribution of air pollution (NOx, particulate matter) and anthropogenic heat from heating/cooling, industrial processes, and car engines (Allen et al., 2010; Crippa et al., 2021). Spatial heterogeneity has been a key concern for linking ecological sciences and urban design professions (Cadenasso et al., 2013; Pickett et al., 2017; Zhou et al., 2017).
Successful understanding of spatial heterogeneity in cities relies on its accurate quantification (Murwira, 2003). The quantification of urban heterogeneity not only provides a way to describe, assess and compare the morphologies of different urban landscapes, but also helps us understand how the physical characteristics of landscapes respond to urbanization or human manipulation (Cadenasso et al., 2013; Wiese et al., 2021). Heterogeneity can be quantified by measuring complexity and variability of a system property, and by measuring departure from homogeneity (Fitch et al., 2015; Li and Reynolds, 1995; Oke et al., 2017). There are numerous indices to assess heterogeneity of a landscape, each emphasizing a different aspect or property of the landscape.
Our study is motivated by providing a better representation of cities in global weather and climate models and thus the need to incorporate surface heterogeneity into atmospheric models due to the strong interaction between the land surface and the atmospheric boundary layer (Barlow, 2014; Margairaz et al., 2020; Oke et al., 2017). Indeed, the physical processes in the near-surface atmosphere are fundamentally related to urban morphology. For example, aerodynamic roughness is commonly estimated by geometric parameters including average surface element height, plan area index, and frontal area index (cf. Kent et al., 2017). Land-surface model components of atmospheric models, such as JULES (Best et al., 2011; Clark et al., 2011) and the Town-Energy-Balance model (TEB, Masson, 2000) rely on urban morphology indicators in order to make predictions of aerodynamic drag, sensible and latent heat fluxes, which characterise the influence of the surface on the atmospheric flow.
However, land-surface models use simplified representations of the urban surface and usually do not consider the spatial configuration of different surface types within the given area, even though it is known that the way the surface types are arranged within an urban area can have a profound effect on the interaction with the atmosphere (Bartesaghi Koc et al., 2020; Sützl et al., 2021a, 2021b). To improve these models, it is necessary to add information about the structural heterogeneity of the urban area to the model. This paper explores several indicators of heterogeneity that could serve this purpose, namely the fractal dimension, contagion, and evenness.
Another challenge for modelling urban climate is that heterogeneity is inherently multi-scale. An urban area may be spatially homogeneous in respect of a particular surface property at one length scale and heterogeneous at another (Oke et al., 2017). Before one can understand how the atmosphere is influenced by urban heterogeneity, it is crucial to define heterogeneity in a multi-scale context. This is particularly pertinent in the context of numerical weather prediction, where the increase in computational resources has allowed simulation at higher and higher resolution over the years (Jochem et al., 2021). For example, the UK Met Office now runs its main weather forecasting model at a grid of 1500 m (Tang et al., 2013), and experiments with resolutions even of the order of hundreds of metres (Boutle et al., 2016; Lean et al., 2019). With each increase in the resolution, part of the surface heterogeneity which was sub-grid (at scales smaller than the grid size) becomes resolved which will then affect the atmospheric flow. For an ideal model, predictions would be independent of resolution. In this paper, we develop a hierarchical decomposition at neighbourhood level that is able to quantify the effect of changes in resolution on heterogeneity.
The aim of this paper is to use high-resolution land-use data of Greater London to explore how structural heterogeneity can be defined in a multi-scale setting, making use of spatial maps of land-cover types, their spatial aggregation and fractal dimensions, distinguishing between city-scale heterogeneity and neighbourhood-scale heterogeneity. The Greater London area includes rural, suburban, and urban areas, as well as large parks and water bodies (e.g., the river Thames). Firstly, the city-scale heterogeneity is captured through land-cover and urban function categories based on a
Methodology
Study area and map sources
The study area covers most of Greater London on 24 Reclassified land-cover raster map of the study area with four categories: buildings and structures (black), impervious surface (pink), vegetation (green), and water (dark blue). A spatial reference of the area is shown in the insert map (red rectangle). National and Greater London outlines from the Boundary-Line data (Ordnance Survey (GB) 2021).
Morphometric indicators
We investigate different measurements of urban heterogeneity with the aim of providing useful additional information to models of surface-atmosphere interactions. As mentioned in the introduction, other than the basic physical representation, the heterogeneity indicators related to spatial configuration information of land types should be included to improve the urban surface representation in land-surface models. We employ several morphometric indicators to quantify the urban heterogeneity from compositional and configurational perspectives. The indicators selected must directly describe the structural heterogeneity, be present in multi-scale and measurable from data sources. The compositional heterogeneity with respect to different types of land-cover is quantified by the land-covers' plan area fractions and the evenness, and the frontal area index quantifies the compositional heterogeneity with respect to height. Contagion index and fractal dimensions of the land-cover types are used to characterise the configurational heterogeneity of the urban space in the aggregation/fragmentation and arrangement ways. The details of these morphometric indicators are described as below.
Plan area index
The plan area index of a land-cover type is expressed as (Oke et al., 2017)

Frontal area index of buildings
The frontal area index indicates the wind-facing surface area of urban elements, which relates to the height of the elements and the “porosity” of the total urban environment. This parameter is relevant to the exchange of air and heat within the urban system, hence, to the mechanisms regulating the local urban climate. The frontal area index is given by

Evenness index
The evenness index characterizes the proportions of the different land-cover types. The expression of relative evenness is

Contagion index
The contagion index describes the connectivity of land-cover types and granularity of the landscape texture by measuring the extent to which land-cover types are clumped together (Riitters et al., 1996). The adjacency state

Fractal dimension
Fractals refer to geometries that cannot be described by regular shapes such as lines, squares, or cubes (Batty and Longley, 1994; Strogatz, 2018). Urban surface form resembles a fractal by considering the spatial distribution of an urban element (for example the buildings), which can be characterised by a fractal dimension (Batty and Longley, 1994). The fractal dimension measures the complexity and irregularity of fractals. As above, we use the land-cover types to define different fractals. This study uses the box counting method (Fernández and Jelinek, 2001) to calculate the fractal dimension

Clustering algorithm
In order to explore heterogeneity on the city-scale, we use a clustering analysis of urban surface data on neighbourhood scale. The study area is divided into neighbourhood tiles of size 1 km × 1 km, which is similar to how urban surface data is processed for atmospheric models. The spatial properties of each tile are quantified using a vector of morphometric indicators introduced above. (hereafter referred to as a data point). The data are clustered using the
Results
Analysis of morphometric indicators
The spatial and frequency distributions of ten morphometric indicators at a resolution of 1 km are shown in Figure 2. The core of the city centre is densely covered by buildings accounting for about half of the land-cover, other areas have a lower building cover and average Spatial and frequency distributions of ten morphometric indicators of Greater London at a resolution of 1 km: plan area indices of (a) buildings 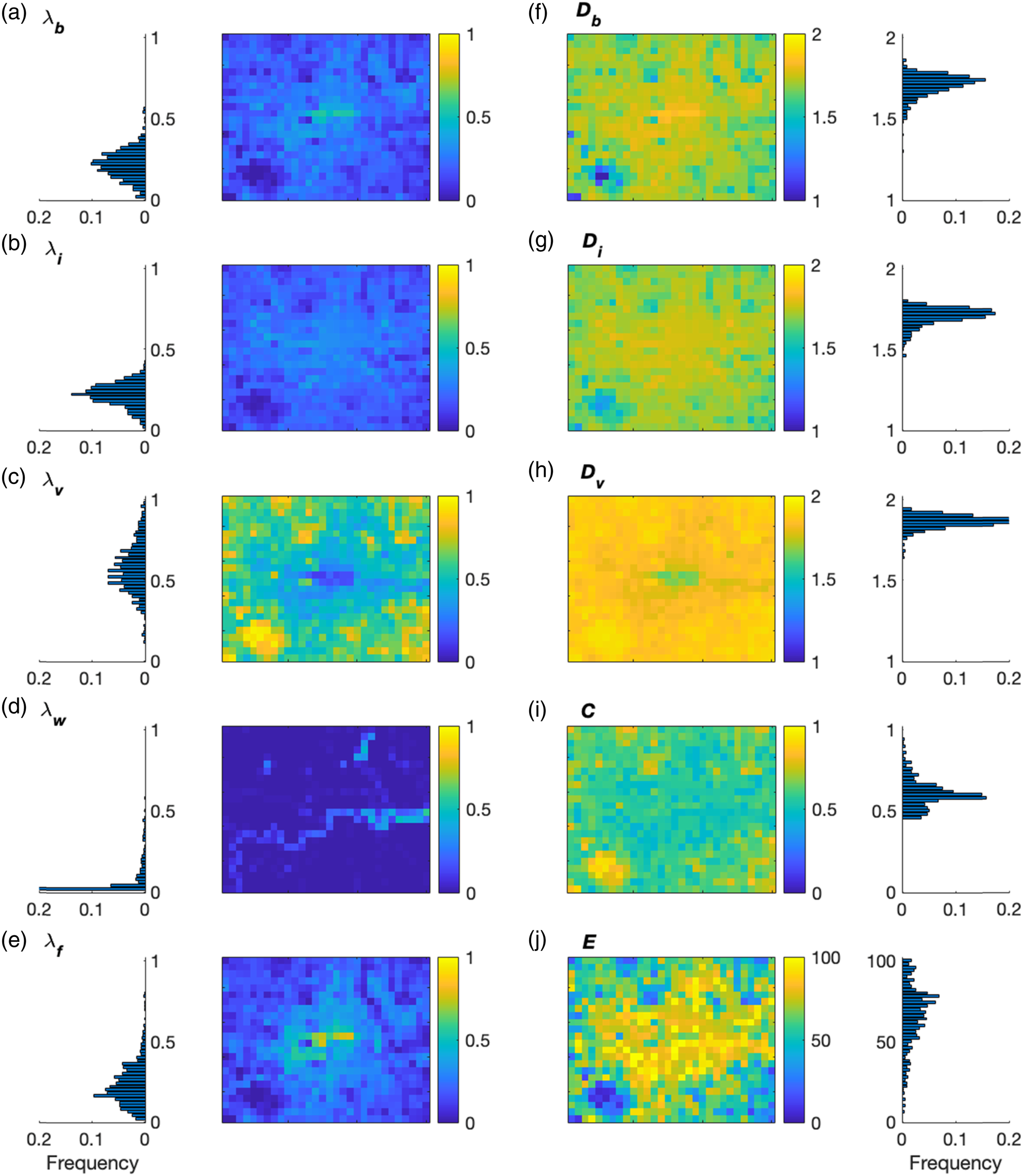
Spatial patterns between plan area index and fractal dimension of the same land-cover type are remarkably similar. This can be seen by looking at either end of the value spectrum: areas with a high plan area index
For the extent of aggregation of land-cover, most areas show weak connectivity of one land-cover type, with a contagion index
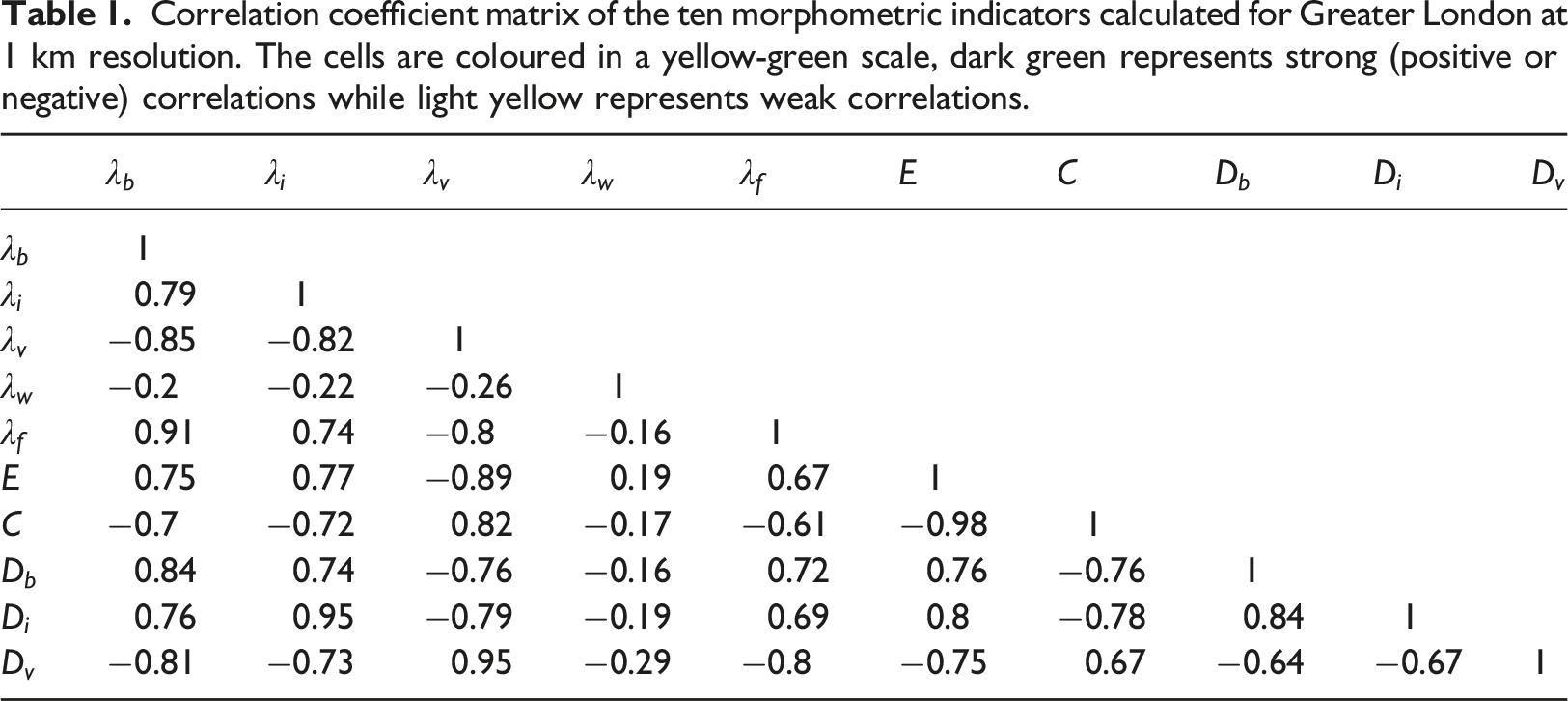
Correlation coefficient matrix of the ten morphometric indicators calculated for Greater London at 1 km resolution. The cells are coloured in a yellow-green scale, dark green represents strong (positive or negative) correlations while light yellow represents weak correlations.
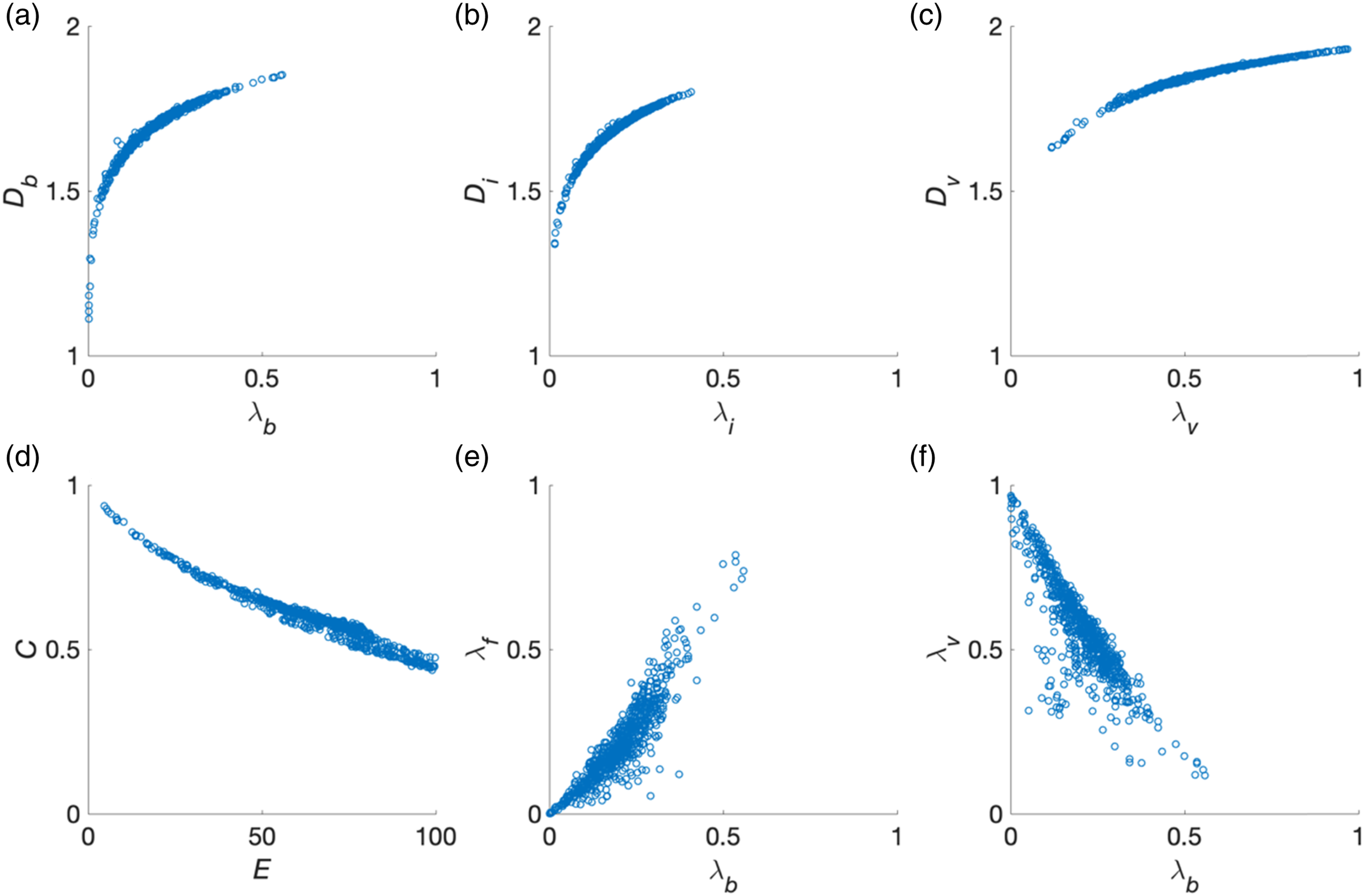
Pairwise correlations between plan area indices and fractal dimensions of (a) buildings, (b) impervious surface, and (c) vegetation, between (d) evenness and contagion, (e) plan area index and frontal area index of buildings, and (f) plan area indices of buildings and vegetation for each 1km2-tile in Greater London.
In the clustering analysis that follows, we will therefore discard the fractal dimension and the evenness indicators, as these are well represented by other indicators. We choose contagion over evenness because the correlation between contagion and the plan area indices is weaker than that between evenness and the plan area indices. Then, the remaining six indicators include the plan area indices of four land-cover types, the frontal area index of buildings, and contagion.
Clustering analysis
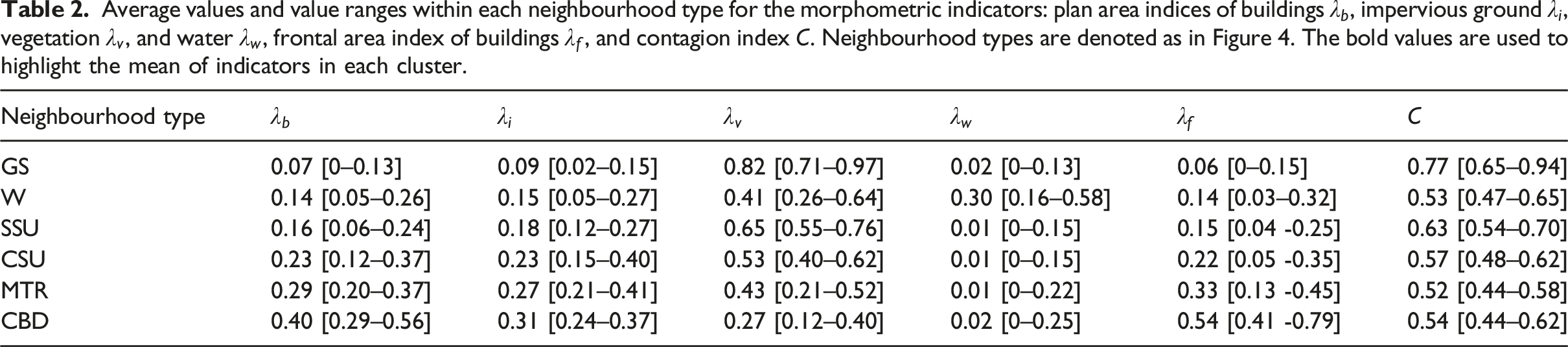
A Classification map of the study area into six neighbourhood types: greenspace (GS), water (W), sparse sub-urban (SSU), compact sub-urban (CSU), mixed-type residential (MTR), and central business district (CBD). The sample tile discussed in the hierarchical decomposition is outlined in black.
Since the morphometric indicators take values from a continuous distribution (cf. Figure 2) rather than a discrete set of values, the morphometric indicators cover a range of values within each cluster and can also partially overlap between clusters (Figure S2). To identify whether the clustering results are subject to a modifiable-areal-unit-problem (MAUP) bias, the full analysis was repeated for three other cases: two different grid resolutions (0.5 and 2 km) and a modified study domain (shifted by 0.5 km). The maps for different resolutions and shifted neighbourhoods are largely the same (Figure S3), and the elbow method also indicate that 6 clusters are optimal except for the 2 km resolution, which shows that 5 is the optimal number of categories (Figure S1). Inspection shows that the central business district cluster disappears in the 2 km case. This can be understood by realizing that these are often high-rise clusters which tend to be smaller than 2
Average values and value ranges within each neighbourhood type for the morphometric indicators: plan area indices of buildings
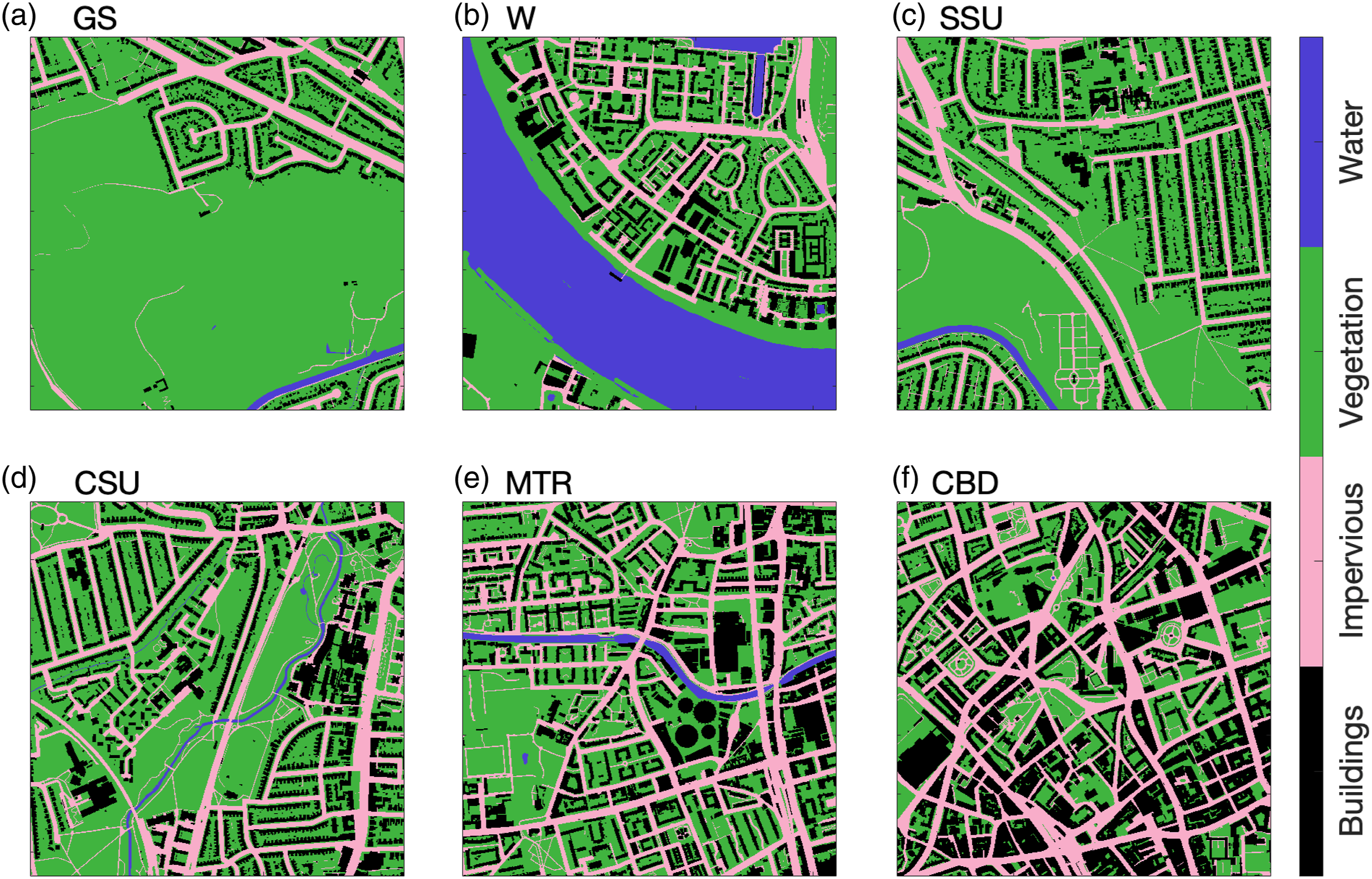
Example tiles for (a) greenspace (GS), (b) water (W), (c) sparse sub-urban (SSU), (d) compact sub-urban (CSU), (e) mixed-type residential (MTR), and (f) central business district (CBD).
The
The different neighbourhood type (with exception of the water cluster) can also be distinguished by the proximity to the city centre: GS, SSU, CSU, MTR, and CBD (GS being furthest away and CBD being closest). Buildings, impervious surface, and frontal area indices increase as the distance from city centre decreases, implying urbanization is accompanied by the increased need to transport people and goods, while vegetation cover decreases. In addition, urbanization tends to increase the composition uniformity but promotes land fragmentation, which yields a decreasing contagion index with higher urbanization.
It is interesting to investigate how the detected neighbourhood types identified here compare to Local Climate Zones (LCZs, Stewart and Oke, 2012), which describe distinct categories of urban areas in terms of the land cover type, the height and compactness of buildings and vegetation. Each LCZ is associated with a specific range of morphology indicators (see Stewart and Oke (2012) for details). Below we determine the LCZ(s) associated with each neighbourhood type using those indicators available as within-cluster means (Table 2).
Both CSU and MTR correspond to LCZ 6 (open low-rise), and CBD corresponds to LCZ 3 (compact low-rise; see Table S2). Neither GS, W, nor SSU have a direct LCZ correspondence. These associations also change with resolution: while there are more correspondences of neighbourhood types with LCZs at 0.5 km resolution, there are almost none at 2 km (Table S2), and some mappings change with the shifted grid. We find that there is no one-to-one correspondence between the identified neighbourhood types and LCZ classes, and that the mapping between them is not robust. Mouzourides et al. (2019) similarly found that LCZ maps derived from morphometric indicators can be resolution dependent: they found 16 different LCZs in Greater London at a resolution of 100 m × 100 m, whereas at a resolution of 1.6 km × 1.6 km, the number of classes reduced to 6.
Hierarchical decomposition
In this section we explore heterogeneity within the 1 Example of coarse-grained and hierarchical maps for 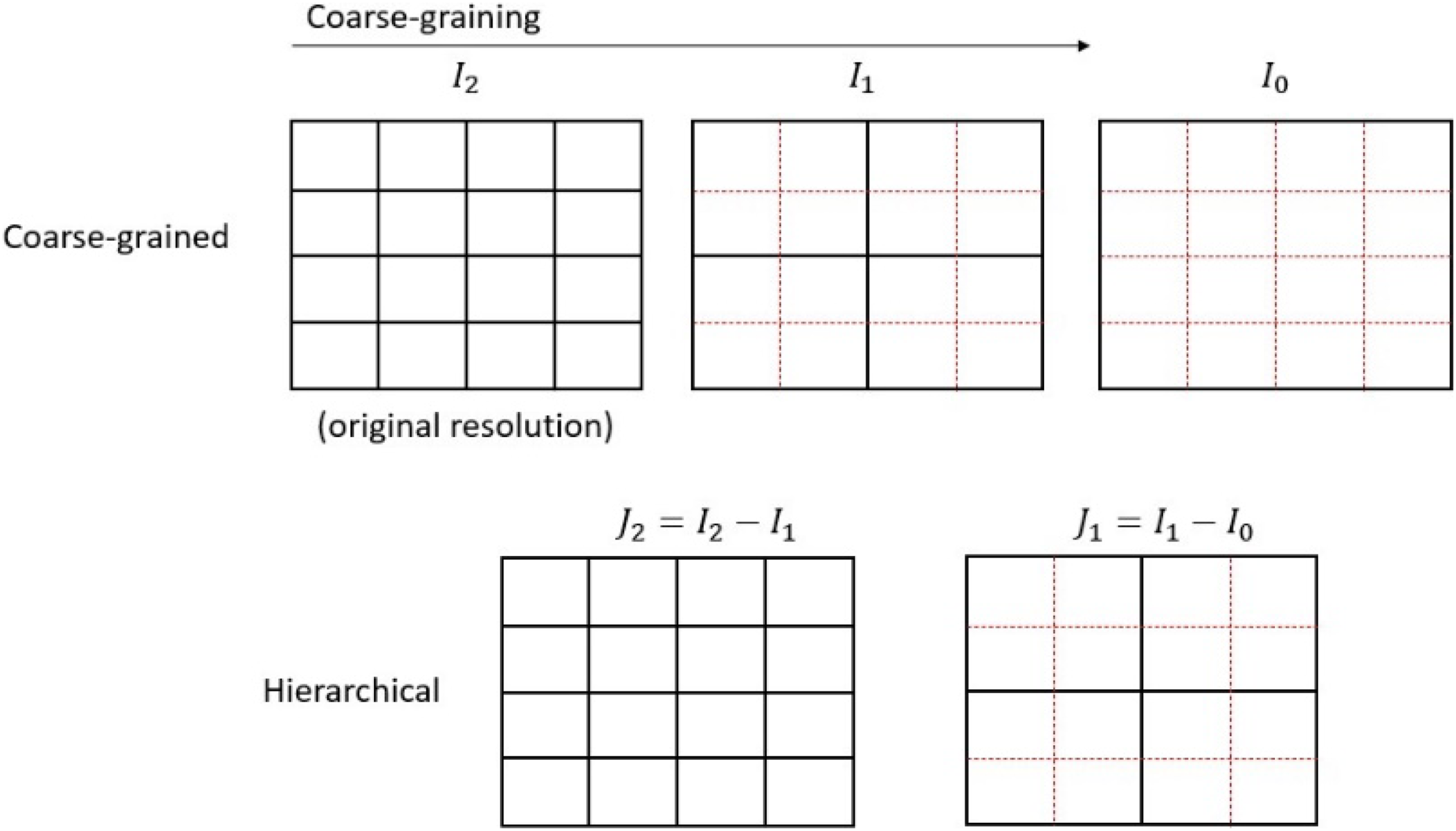
The resolution of the neighbourhood tiles is 3200 Maps 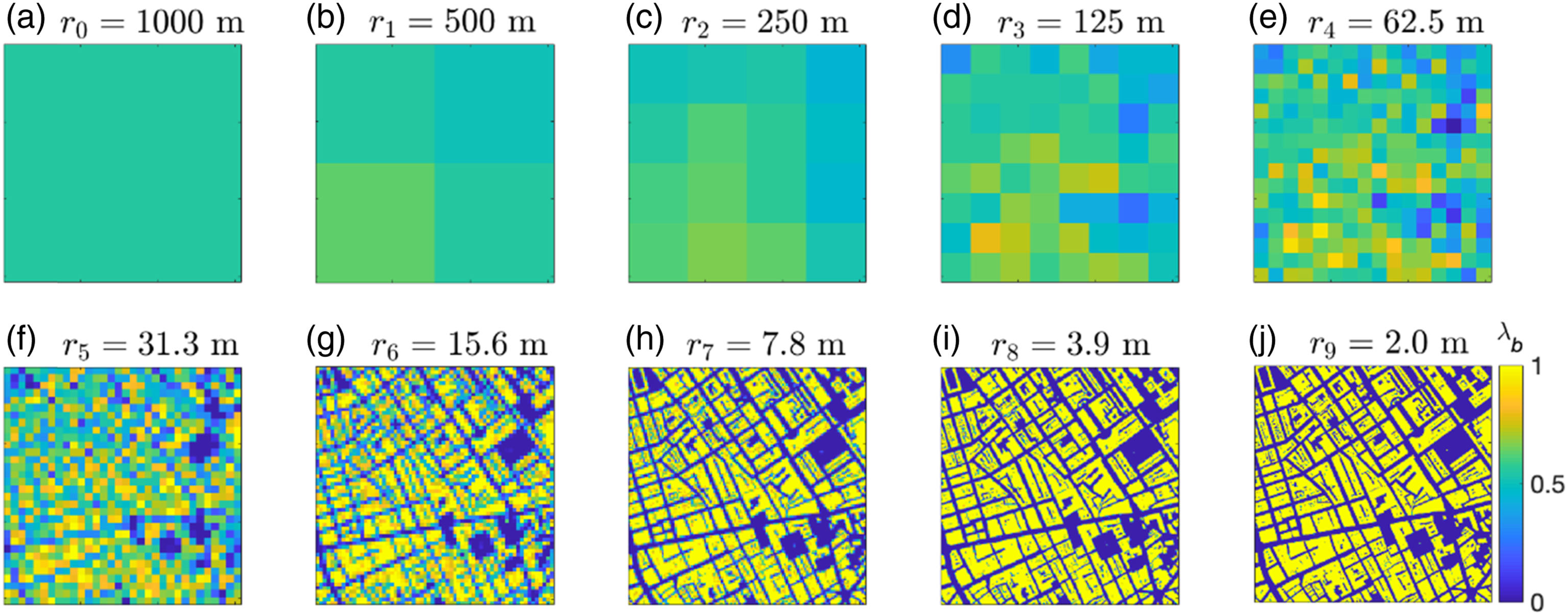
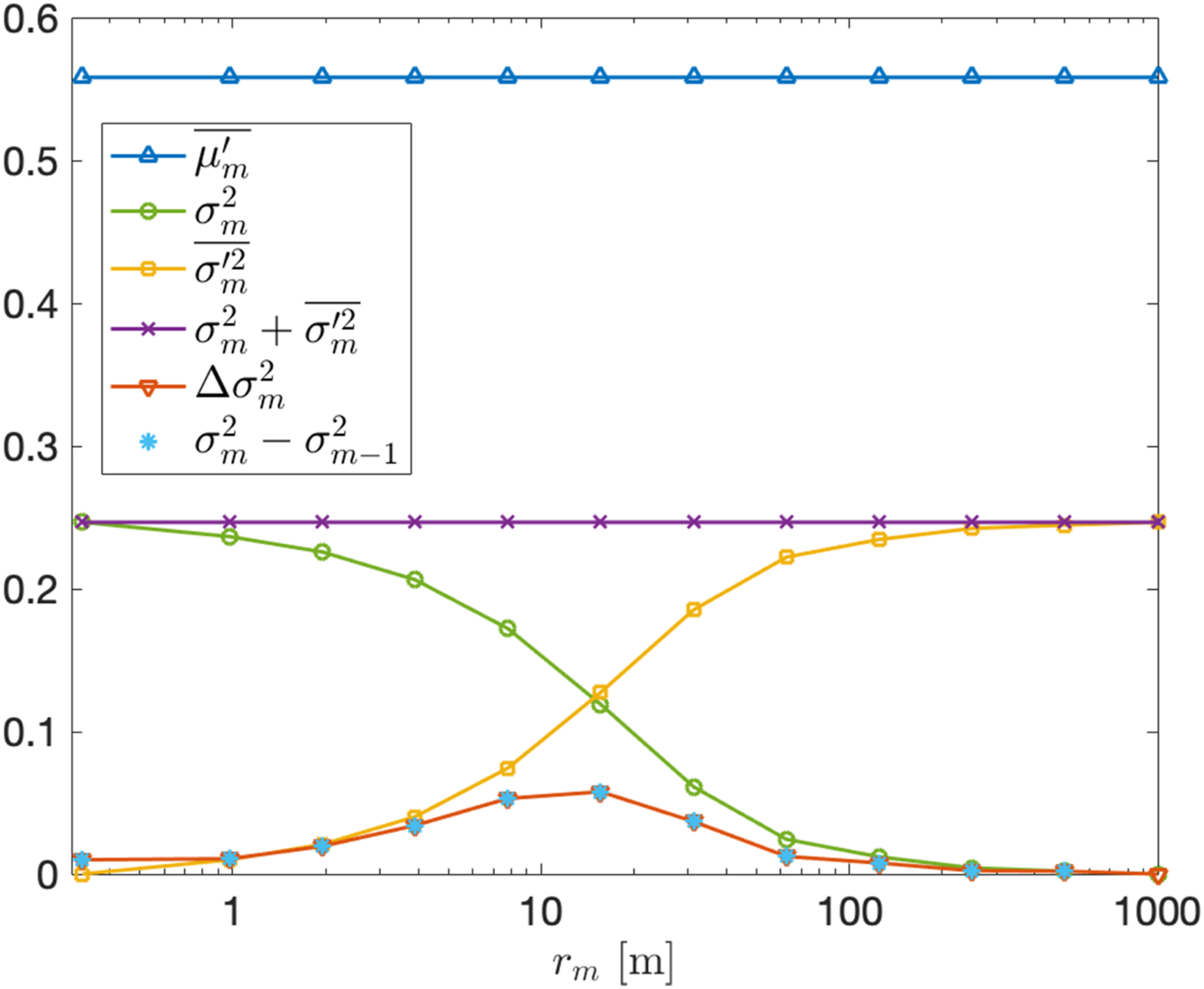
To quantify the statistical properties of each map Statistics of the sample tile (Figure 7) and its hierarchical decomposition against length scale 

We introduce a hierarchical decomposition of the data that helps to explore the heterogeneity present at different resolutions of 
Figure 9 displays the decomposition maps Hierarchical decomposition maps 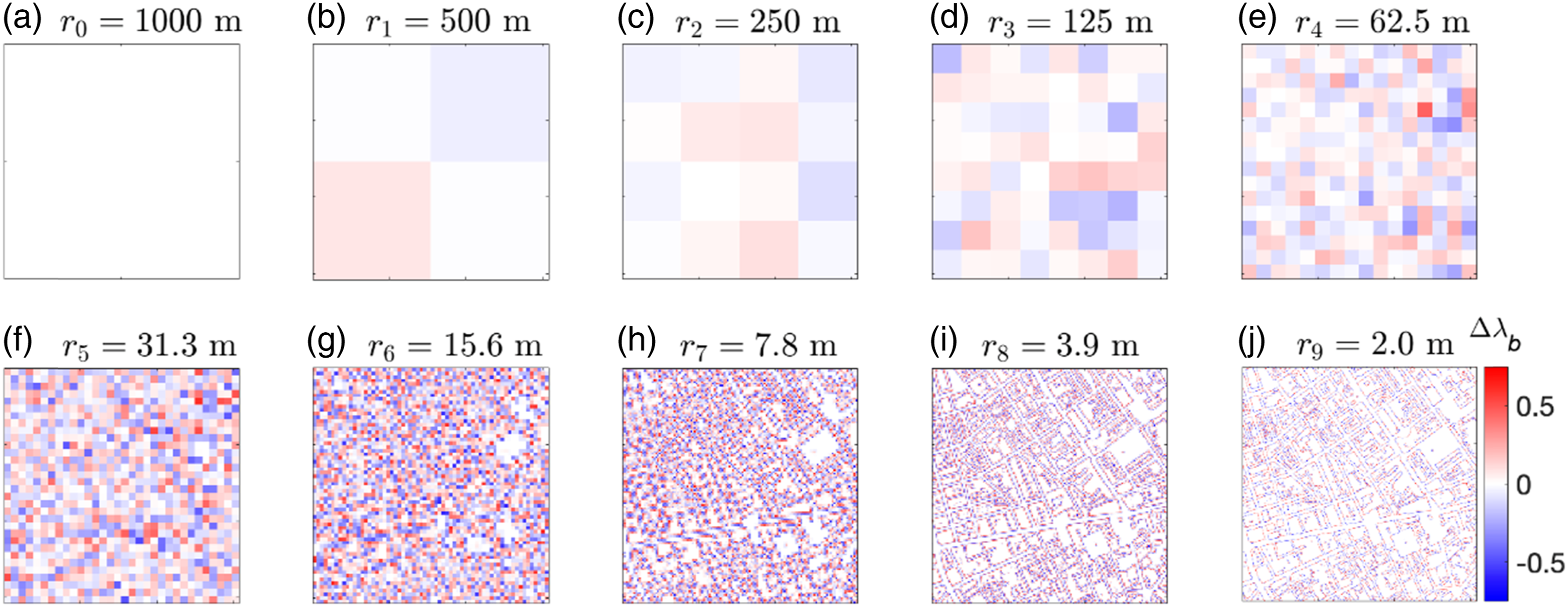
An attractive feature of the hierarchical decomposition is that the tile-based variance of a map
Below we conduct an analysis for the multi-scale properties of the neighbourhood types identified in the clustering analysis using the hierarchical decomposition described above. Hierarchical maps Cluster-averaged scale variance 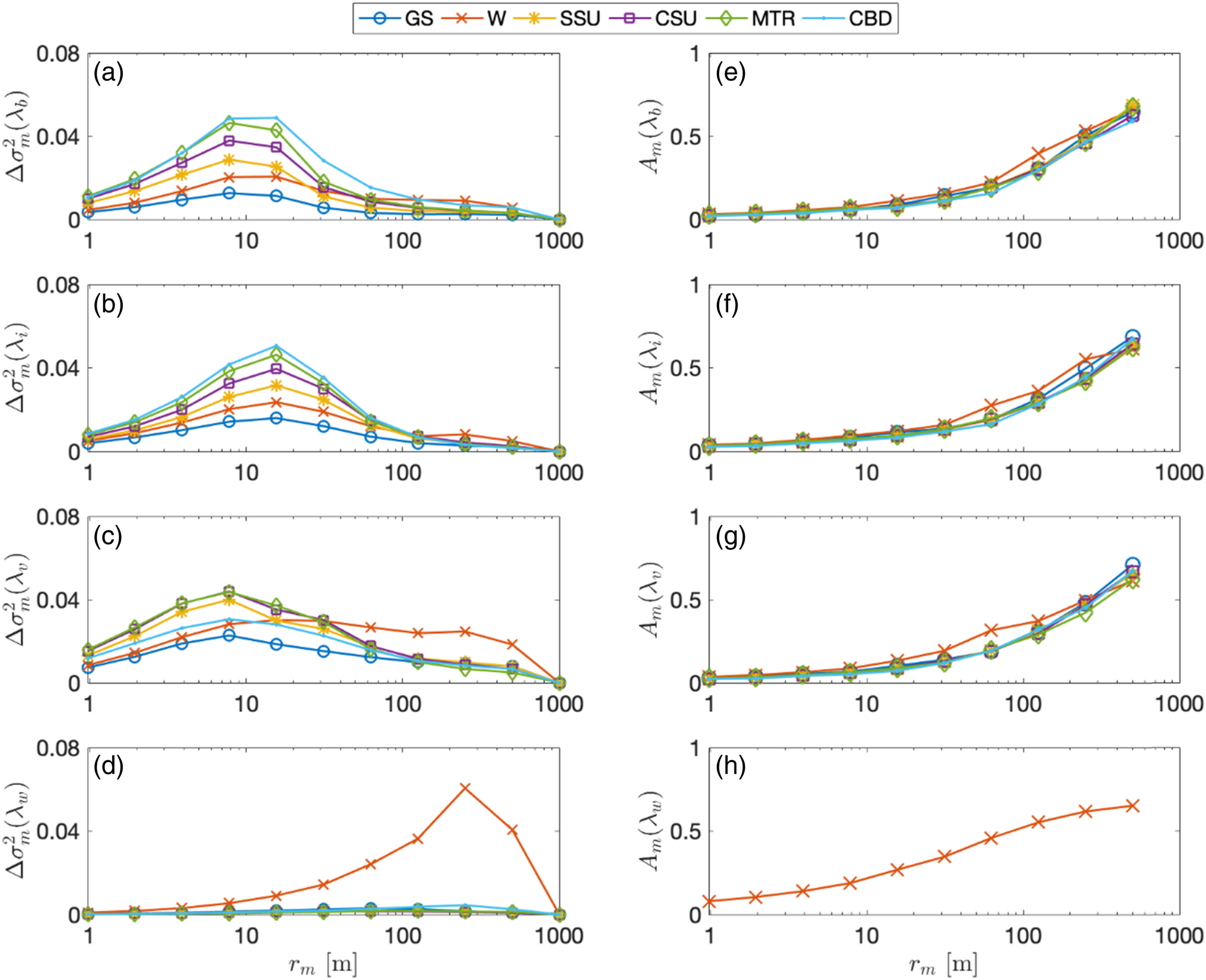
For building cover,the cluster-averaged scale variance
The scale variance of impervious ground (Figure 10(b)) exhibits a similar distribution for all neighbourhood types across the length scales with a clear maximum at a scale of 15.6 m, which is a width typical for a road. Similar to the building cover, the magnitude of the scale variance is linked to the magnitude of the plan area index, where
The scale variance of vegetation has a similar distribution for each neighbourhood type with a peak at a scale of 7.8 m, with the exception of the water neighbourhood type, in which the scale variance is nearly uniformly distributed across most length scales, suggesting that there is no dominant length scale for vegetation in the water neighbourhood type (Figure 10(c)). The peak at the maximum variance at scale 7.8 m is weaker compared to the peaks in building and impervious cover, and the relation between higher variances and higher (vegetation) land-cover is not always maintained. A typical length scale for vegetation is therefore not obvious from the data. The greenspace cluster shows least variance and a weak dependence on scale, suggesting that the tiles identified in GS indeed primarily consist of large green spaces and therefore, small changes are required upon moving to higher resolutions.
All neighbourhood types except for the water cluster contain almost no water (averaged
Next, we consider the isotropy of the hierarchical maps 
Conclusion
The heterogeneity of Greater London was investigated by calculating several morphometric indicators on neighbourhood-tiles of 1 km2. The clear-cut positive correlation between the plan area index and fractal dimension of land-cover types (e.g., buildings) showed that fractal properties can be inferred from the plan area index without having to explicitly calculate the fractal dimension. The data suggests that when there is little area of a specific land-cover type, it is not distributed uniformly in space. For example, buildings are more likely arranged along a twisted road in sparse sub-urban areas, which corresponds to a fractal dimension above 1 but well below 2, filling the space more than a line but much less than a surface. It is not evident a priori that this should be the case and it is likely to be a consequence of urban design decisions rather than a natural process. With larger coverage, the land-cover type tends to be more homogeneously distributed, with a fractal dimension closer to 2. Moreover, evenness is negatively correlated to contagion, which suggests that areas with uniform proportions of different land-cover types also tend to be highly fragmented into many small patches rather than having each type clumped together individually. This is an important observation for the modelling of urban surfaces within weather and climate models, as it contradicts common practise to represent different land-cover types within a grid cell by separate fractions (called “tiles”) of uniform land-cover to model their effects on the atmosphere individually.
A clustering analysis with a subset of the morphometric indicators was used to describe city-scale heterogeneity. Whilst the analysis was purely based on the morphometric indicators, the resulting neighbourhood types also distinguished the functionality of the urban ecosystems (greenspace, residential, business districts, etc.). The clustering used the contagion index because of its weaker correlation to the other indicators. However, if this index is not available, the evenness would be a good substitute which can be directly calculated from the plan area indices of the surface cover, thus enabling a clustering analysis using only the most common indicators (plan area indices of buildings, impervious ground, vegetation, water, frontal area index of buildings). The frontal-area index is required to distinguish the dense and high-rise city centres (i.e., central business districts) from other parts of the core city. This distinction is important, as high-rise buildings significantly alter air flow at the ground level, can trap short- and long-wave radiation when forming narrow and deep street canyons, and affect the mixing properties with the atmosphere. In other parts of the city, the buildings’ frontal area index is similar to the plan-area index.
The neighbourhood types identified by the clustering algorithm have only weak associations with Local Climate Zones (LCZs), as the correspondence between them is not one-to-one and varies with resolution and grid boundaries. This may partially be due to a different set of parameters used in this study and the LCZs. The clustering approach is readily usable for other city contexts. It would be interesting to explore what the clustering algorithm would define and how these would link to LCZs. The approach towards classification of urban surfaces is also complimentary: LCZs are defined by a range of urban morphometric parameter values, as a result, a region at a certain scale usually falls into one specific LCZ type. In contrast, the clustering classification is based on the relative morphological similarity/dissimilarity, consequently, the results are purely data-driven (e.g., study domain, city context). Our analysis first classified the data, and the resulting clusters were then analysed according to their parameter values. This means that the clustering analysis may not always produce the same neighbourhood types or LCZ correspondence, but identifies for each city individually which categories are relevant. This can be an advantage in several cases: for example, for cities that do not correspond well the LCZs, or for research questions where the LCZ classes are too broad, but the clustering could further distinguish the landscape within one LCZ. We also added the contagion index to represent heterogeneity, and the clustering approach is more flexible towards including further parameters should they be relevant.
Multi-scale analysis and hierarchical decomposition of land-cover maps revealed the characteristic scales of land-cover types within the neighbourhood scale. The scale variance, which is the variance from the decomposed resolutions, indicates the most energetic scales and therefore where the most information gains lie. In this study, this is between 7.8 m (for vegetation, buildings) and 15.6 m (for buildings, roads), but at 250 m for water. It was shown that below measurement scales of 62.5 m, the neighbourhood types are homogeneous. Above this scale, neighbourhoods are anisotropic. One interesting finding is that all neighbourhood types and land-cover types reach similar levels of anisotropy, indicating that anisotropy of land cover is independent of land-cover type and land-cover fraction.
While any measure of heterogeneity generally depends on measurement scale, meaning that urban surface properties which appear heterogeneous at small scales will become homogeneous as the measurement scale increases, the hierarchical decomposition introduced in this paper conserves the total variance (i.e., the sum of the between-cell resolved variance and the averaged within-cell sub-grid variance) of the land-cover map. For numerical weather modelling, this gives important insight on the representation of urban environments at different scales. For example, if the resolved variance changes little by increasing the resolution, this implies that also the sub-grid variance remains similar, which in turn implies that the urban surface properties of a grid cell at that scale can be assumed to be statistically representative (i.e., the values do not significantly change upon small increases or decreases of the considered area).
There are several opportunities for future work. First, this study was limited to Greater London and it would be interesting to study other urban areas, especially developing cities. Second, due to the large number of potential input parameters for the clustering and the option of many different clustering algorithms, the results of the clustering will therefore depend to a certain extent on these choices. Third, environmental factors such as orography, temperature, wind velocity and air pollution are not considered at this stage to link the urban spatial heterogeneity with atmospheric modelling. Fourth, it may be possible to develop new heterogeneity indicators that provide different information and identify heterogeneity indicators that are independent of plan-area indices and each other as most heterogeneity indicators are related to the proportion or arrangement of urban constituents. In our analysis, the only direct heterogeneity indicator we used was contagion which measures the arrangement of one land-cover type. Last but not least, it would be valuable to study how multi-scale heterogeneous surfaces influence urban microclimate, the atmospheric boundary and regional weather.
Supplemental Material
Supplemental Material - Urban neighbourhood classification and multi-scale heterogeneity analysis of Greater London
Supplemental Material for Urban neighbourhood classification and multi-scale heterogeneity analysis of Greater London by Tengfei Yu, Birgit S. Sützl, Maarten van Reeuwijk in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MvR is supported by the NERC highlight grant ASSURE: Across-Scale processeS in URban Environments (NE/W002868/1).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.